在一些中小型项目开发中,我们通常会使用自增 ID 来作为主键的生成策略,但随着时间的推移,数据库的信息也会越来越多,尤其是使用自增 ID 作为日志表的主键生成策略时,可能很快就会遇到 ID 被用完的情况,那么如果发生了这种情况,MySQL 又会怎样执行呢?
PS:当然,在分库分表的场景中,我们通常会使用雪花算法来替代自增 ID,但中小型项目开发中,使用自增 ID 的场景还是比较多的。
1.自增ID
在 MySQL 中,如果字段的数据类型为整数类型(如 INT、BIGINT 等),则可以通过关键字"AUTO_INCREMENT"来设置让当前的字段实现自增,例如以下 SQL:
sql
CREATE TABLE example_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(128)
);1.1 优点分析
自增 ID 的优点如下:
- 简单方便,能自动为每行数据分配唯一的标识。
- 对于按顺序插入的数据,能很好地反映数据插入的先后顺序。
1.2 缺点分析
自增 ID 的缺点如下:
- 在数据进行迁移或分库分表时,可能会出现问题,需要特殊处理。
- 如果数据量非常大,可能会达到自增 ID 的上限。
- 存在安全性问题,比如通过自增 ID 可能会推测出一些业务信息。例如,一个电商订单表使用自增 ID 作为主键,可能会被竞争对手通过订单号大致推测出业务量等信息。
2.自增ID用完会怎样?
自增 ID 分为以下两种情况:
一种是主键自增 ID 用完后的情况,另一种是 InnoDB 引擎中未设置主键时使用 row_id 用完后的场景,它们的情况是不一样的,所以我们分开来聊。
2.1 主键自增ID用完
当主键自增 ID 达到上限后,再新增下一条数据时,它的 ID 不会变(还是最大的值),只是此时再添加数据时,因为主键约束的原因,ID 是不允许重复的,所以就会报错提示主键冲突。
我们可以使用以下 SQL 来测试:
sql
CREATE TABLE t (
id INT AUTO_INCREMENT PRIMARY KEY,
`name` VARCHAR(128)
) auto_increment=2147483647;
insert into t(id,`name`) values(null,'javacn.site');
select * from t;
insert into t(id,`name`) values(null,'www.javacn.site');以上 SQL 是创建了一个表 t,并且给 t 表的主键 id 设置自增 ID,之后再将表的自增 ID 初始化为 INT(有符号)的最大值 2147483647,然后再添加两条数据。
以上 SQL 的执行结果如下:
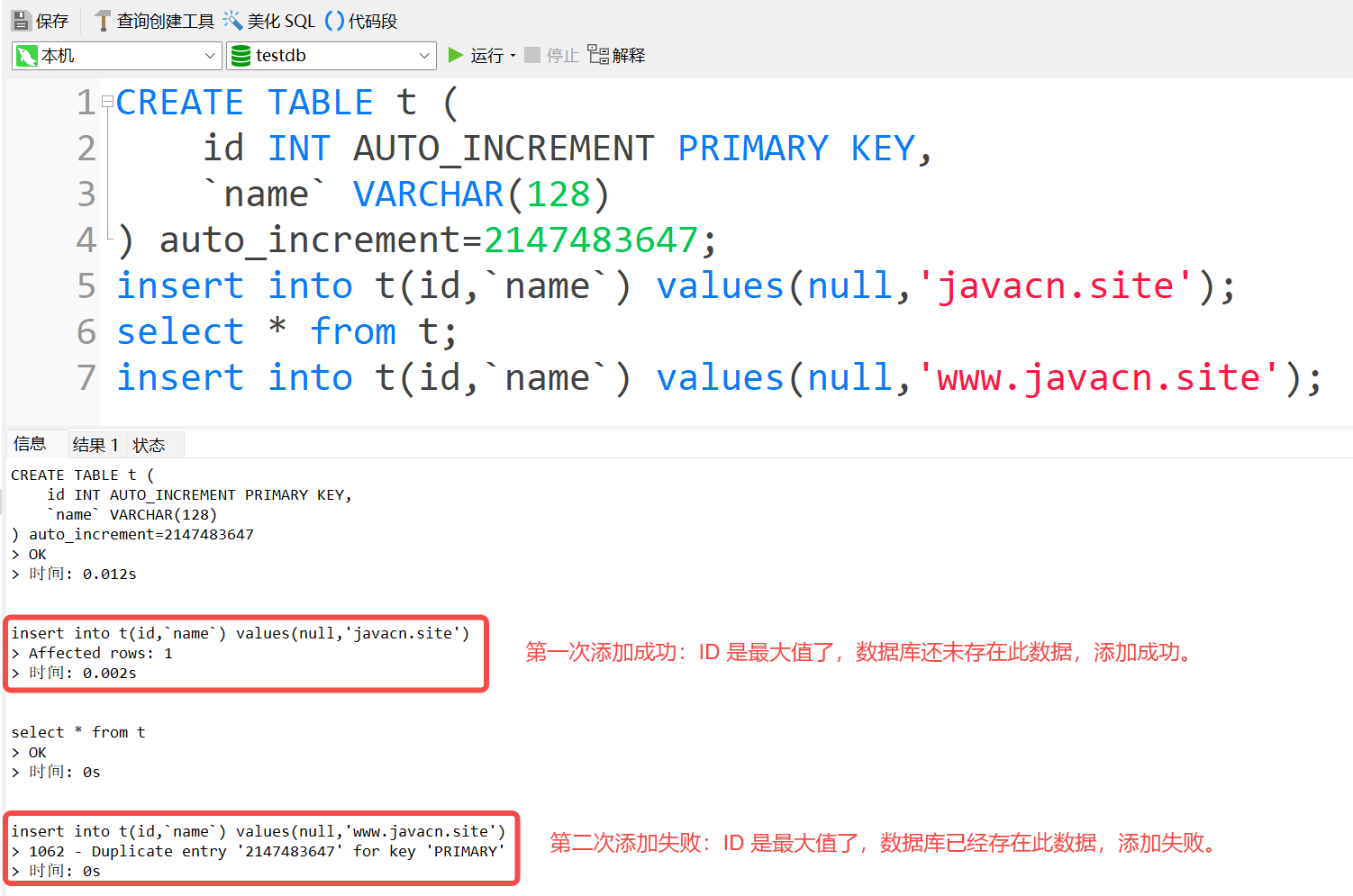
从上面的执行结果可以看出:当主键自增 ID 达到上限后,再新增下一条数据时,它的 ID 不会变(还是最大的值),只是此时再添加数据时,因为主键约束的原因,ID 是不允许重复的,所以就会报错提示主键冲突。
2.2 row_id用完
如果表没有设置主键,InnoDB 会自动创建一个全局隐藏的 row_id,其长度为 6 个字节,当 row_id 达到上限后,它的执行流程和主键 ID 不同,它是再次归零,然后重新递增,如果出现相同的 row_id,后面的数据会覆盖之前的数据。
课后思考
如何验证 row_id 用完后归零覆盖原数据的情况?
本文已收录到我的面试小站 www.javacn.site,其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、设计模式、消息队列等模块。