1.简介
在日常的自动化测试工作中进行断言的时候,我们可能经常遇到的场景。从一个字符串中找出一组数字或者其中的某些关键字,而不是将这一串字符串作为结果进行断言。这个时候就需要我们对字符串进行操作,宏哥这里介绍两种方法:正则和字符串切片函数split()。
2.测试场景
宏哥在这里说一下,自己的胡诌的测试场景哈,仅供学习和参考。然后按照宏哥说的进行自动化测试,测试场景:在度娘或者其他搜索引擎中搜索"北京宏哥",然后搜索完毕,会返回搜索结果,告诉你搜索到多少个"北京宏哥"。宏哥这里分别用搜狗和必应搜索,然后对比她俩谁所搜到的"北京宏哥"多,然后通过对比说明谁的搜索能力强大(搜索结果多说明搜索能力强大)。
3.字符串切片操作
关于这个字符串切片的这个概念宏哥就在这里赘述一下或许不是很全面,有兴趣的也可以自己查一下。但是宏哥上边说的测试场景就需要用到这一操作。
在python中,我们定义好一个字符串,如下所示。

在python中定义个字符串然后把它赋值给一个变量。我们可以通过下标访问单个的字符,跟所有的语言一样,下标从0开始。这个时候呢,我们可以通过切片的方式来截取出我们定义的字符串的一部分。使用切片的时候我们有两种方式:
1.没有步长的简单切片
语法格式是这样的:
- 首先定义一格字符串,比如叫s,然后给它赋值
- 截取字符串中的一部分,我们用的语法是 s start : stop
注意一下: 在这里呢,start表示的是字符串要截取的开始下标,stop 表示终止的字符串结束的前一个位置。
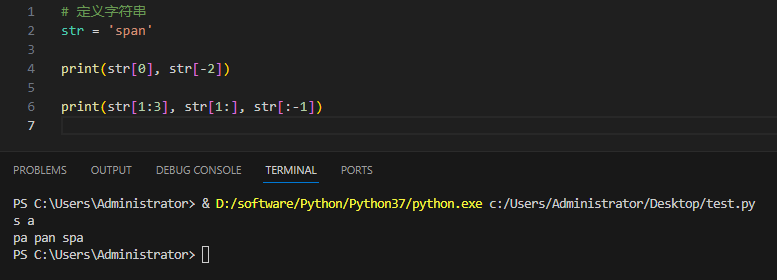
从上面我们可以知道,如果从开头截取到某个特定的位置可以用 : a来表示

如果从某一位开始截取到最后一位可以用 a : 来表示
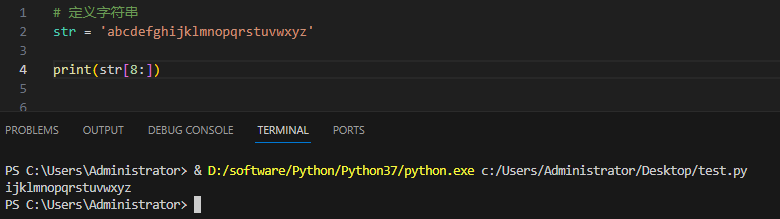
这里有一点要说明, 在 pyhton中的字符串的索引序号可以是正数也可以是负数,从-1开始算:
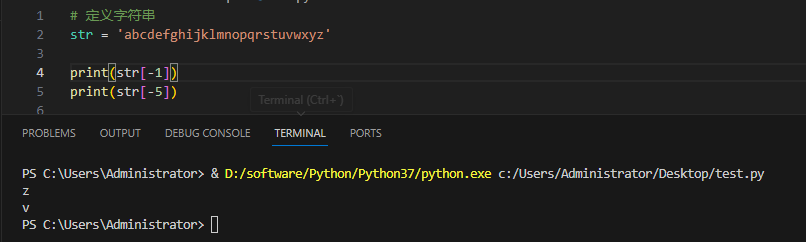
所以我们还可以这么玩:
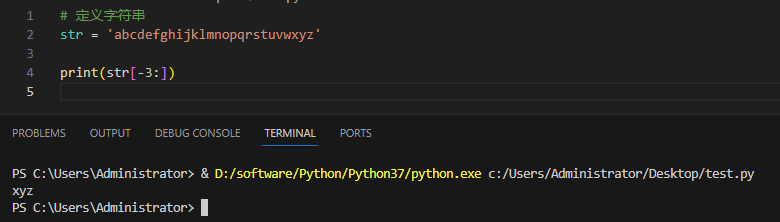
2.有步长的切片方式
另外的一种切片方式就是,首先还是定义一格字符串的变量,然后间隔的取出我们的字符串中的字符。
语法格式:

同样这里取出来的字符串的结束字符是stop结束的前一个字符
stride表示的是间隔的取出字符串
下面来看几个例子:
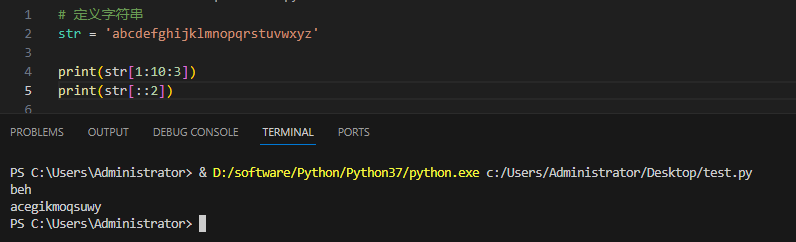
这个时候我们可以还可以反转字符串
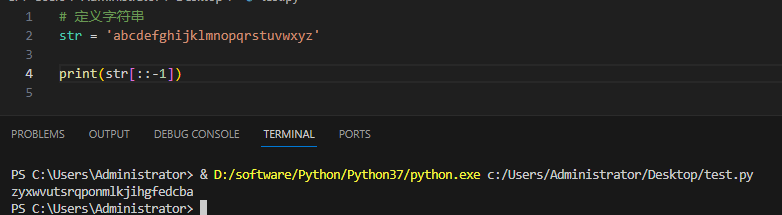
间隔逆向的取出字符串:
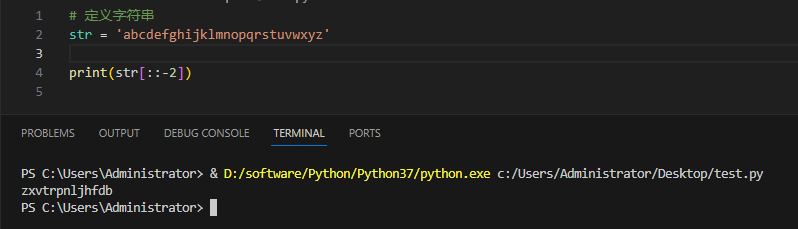
反方向的截取部分的字符串:
这个时候我们将步长的那个地方设置为负数,表示从右向左取字符串,步长的绝对值大于1表示间隔的取数。
开始的部分那个截取下标也要从负数计算,或者start必须大于结束的下标,因为它是从右开始的截取的。
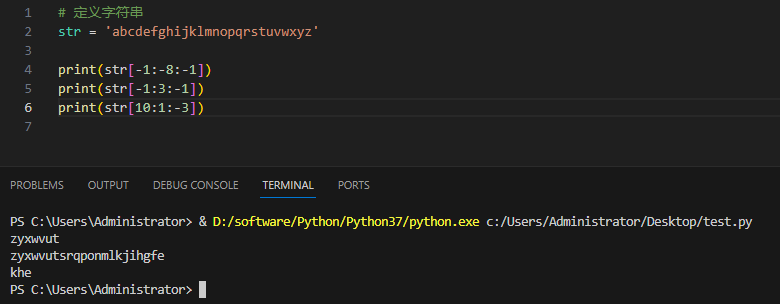
python的字符串切片就是这个样子的。好了就介绍这么多差不多够用了。
4.项目实战
4.1测试用例
首先宏哥根据测试场景进行测试用例的设计,如下:
1.分别在搜狗和必应搜索框"北京宏哥"
2.分别点击查询,观察查询结果
3.分别将查询结果取到
4.提取结果中的数字,保存在变量中
5.对比两个数字的大小
4.2代码设计
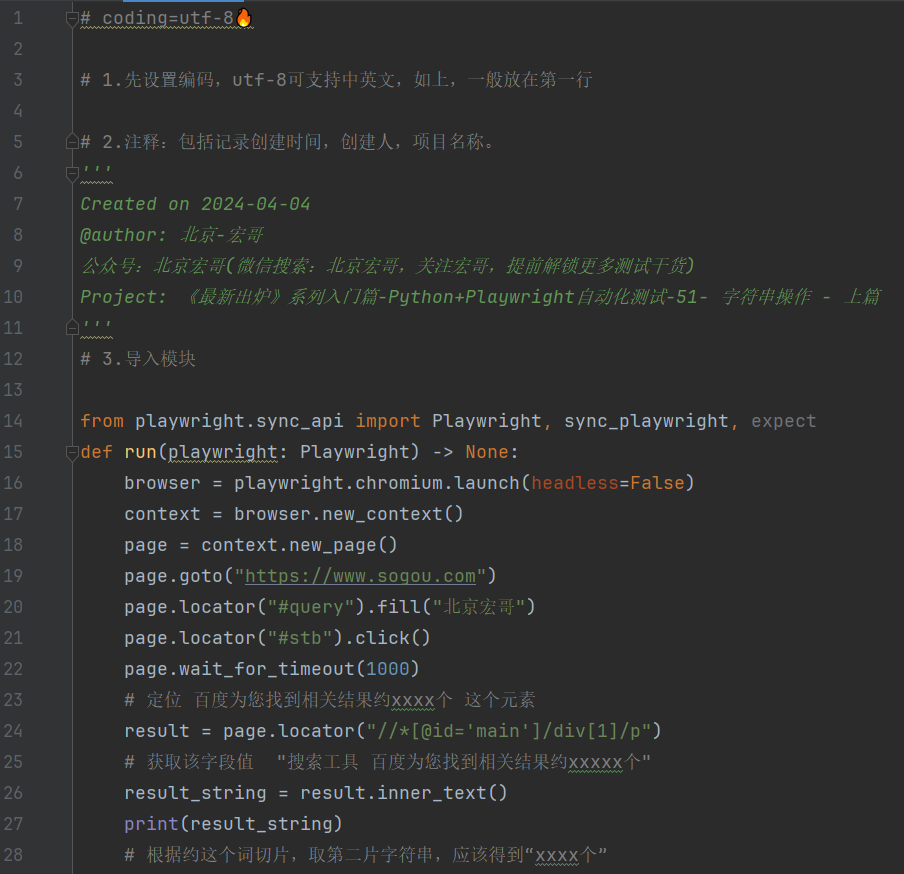
4.3参考代码
# coding=utf-8🔥
# 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行
# 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2024-04-04
@author: 北京-宏哥
公众号:北京宏哥(微信搜索:北京宏哥,关注宏哥,提前解锁更多测试干货)
Project: 《最新出炉》系列入门篇-Python+Playwright自动化测试-51- 字符串操作 - 上篇
'''
# 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.sogou.com")
page.locator("#query").fill("北京宏哥")
page.locator("#stb").click()
page.wait_for_timeout(1000)
# 定位 搜狗为您找到相关结果约xxxx个 这个元素
result = page.locator("//*[@id='main']/div[1]/p")
# 获取该字段值 "搜索工具 搜狗为您找到相关结果约xxxxx个"
result_string = result.inner_text()
print(result_string)
# 根据约这个词切片,取第二片字符串,应该得到"xxxx个"
st1 = result_string.split("约")[1]
print(st1)
# 再切一次,去除条,得到我们想要的数字结果数
search_number = st1.split("条")[0]
# 去掉字符串中的逗号,方便转换成int
search_number1 = search_number.replace(",", "")
print(search_number1)
page.goto("https://cn.bing.com")
page.locator("#sb_form_q").fill("北京宏哥")
page.locator("#search_icon").click()
page.wait_for_timeout(1000)
# 定位 必应为xxxx条结果 这个元素
result1 = page.locator("//*[@id='b_tween_searchResults']/span")
# 获取该字段值 "约 xxx 个结果"
result_string1 = result1.inner_text()
print(result_string1)
st2 = result_string1.split("约")[1]
print(st2)
# 再切一次,去除个,得到我们想要的数字结果,根据个这个词切片,取第一片字符串,应该得到"273,000 "
st2 = st2.split("个")[0]
# 去掉字符串中的逗号和空格,方便转换成int
st3 = st2.strip().replace(",", "")
print(st3)
# 首先将两个数都转换为int 数据
a_N = int(search_number1)
b_N = int(st3)
# 搜狗和必应的搜索结果对比
if (a_N > b_N):
print("搜狗牛逼,搜狗威武!!!")
else:
print("必应牛逼,必应威武!!!");
page.wait_for_timeout(20000)
page.close()
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)4.4运行代码
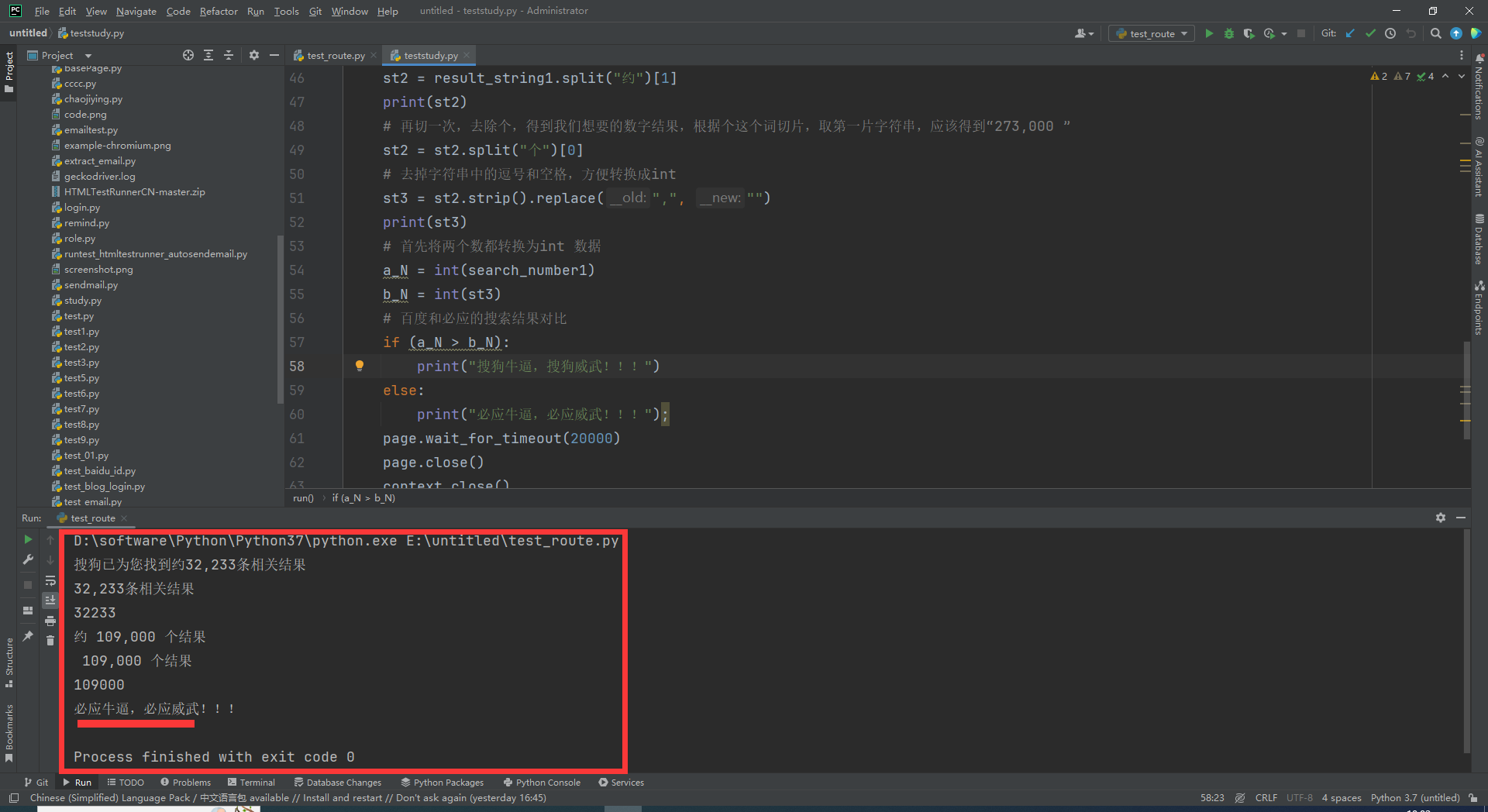
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
2.运行代码后电脑端的浏览器的动作。如下图所示:
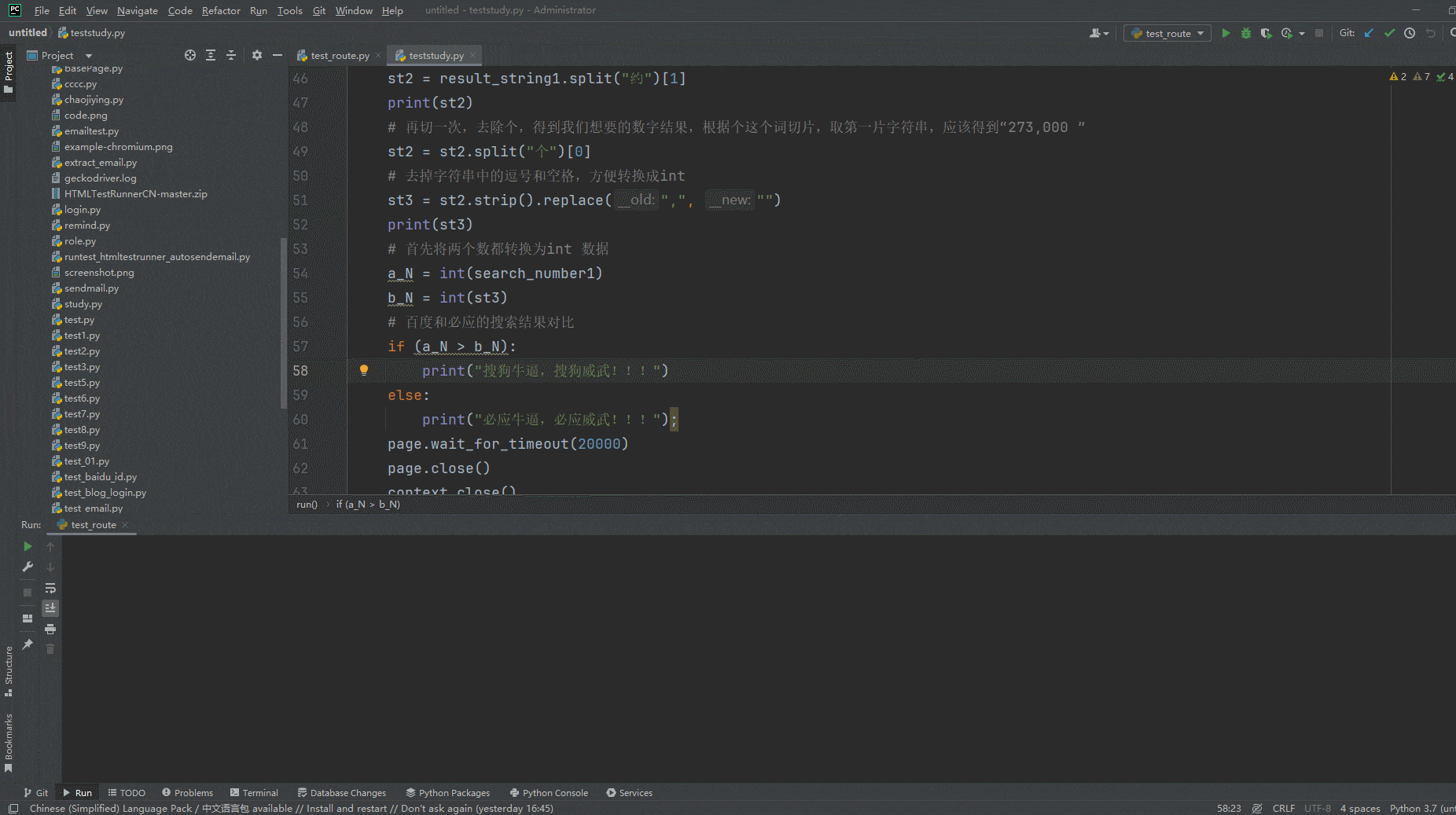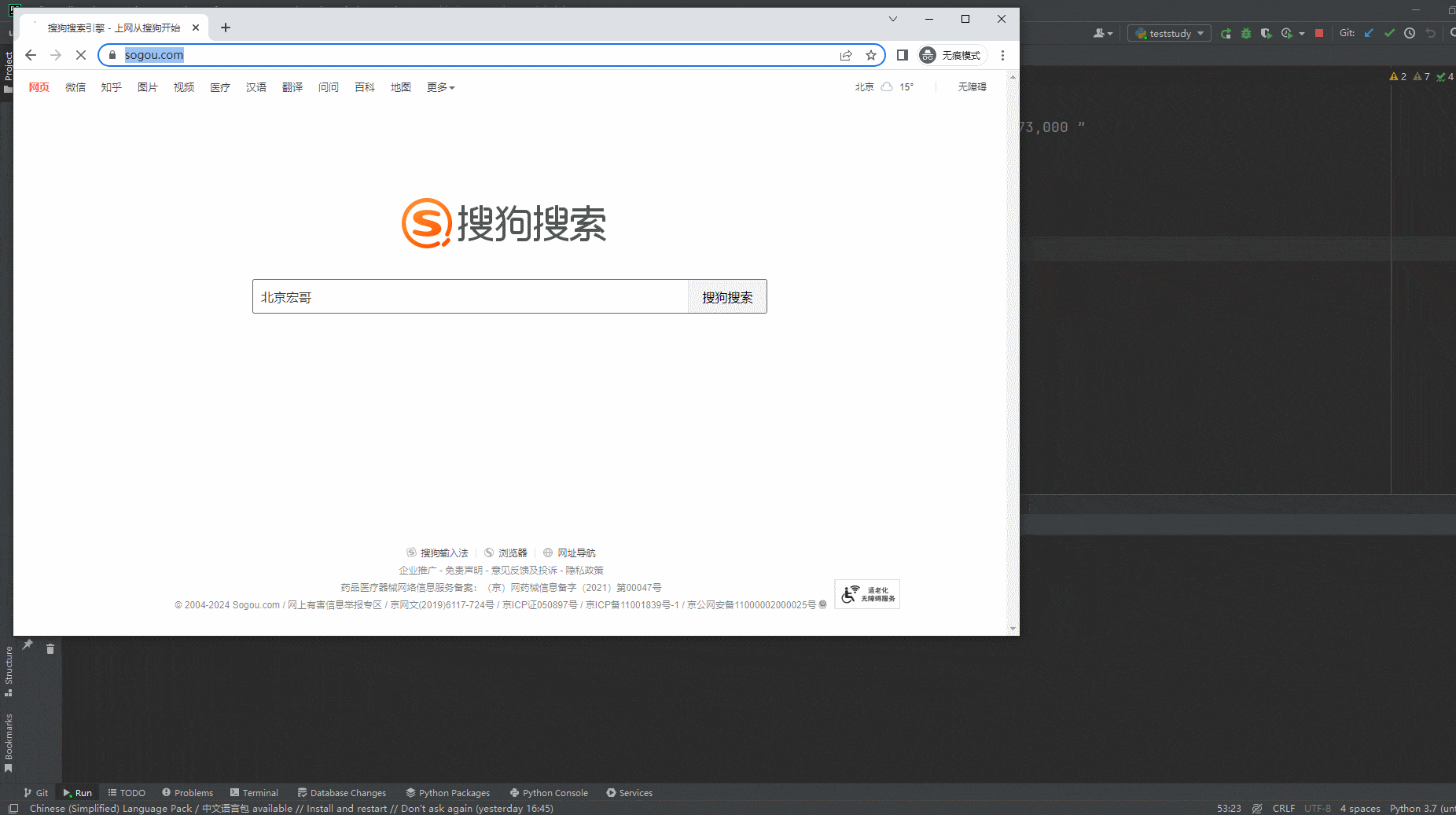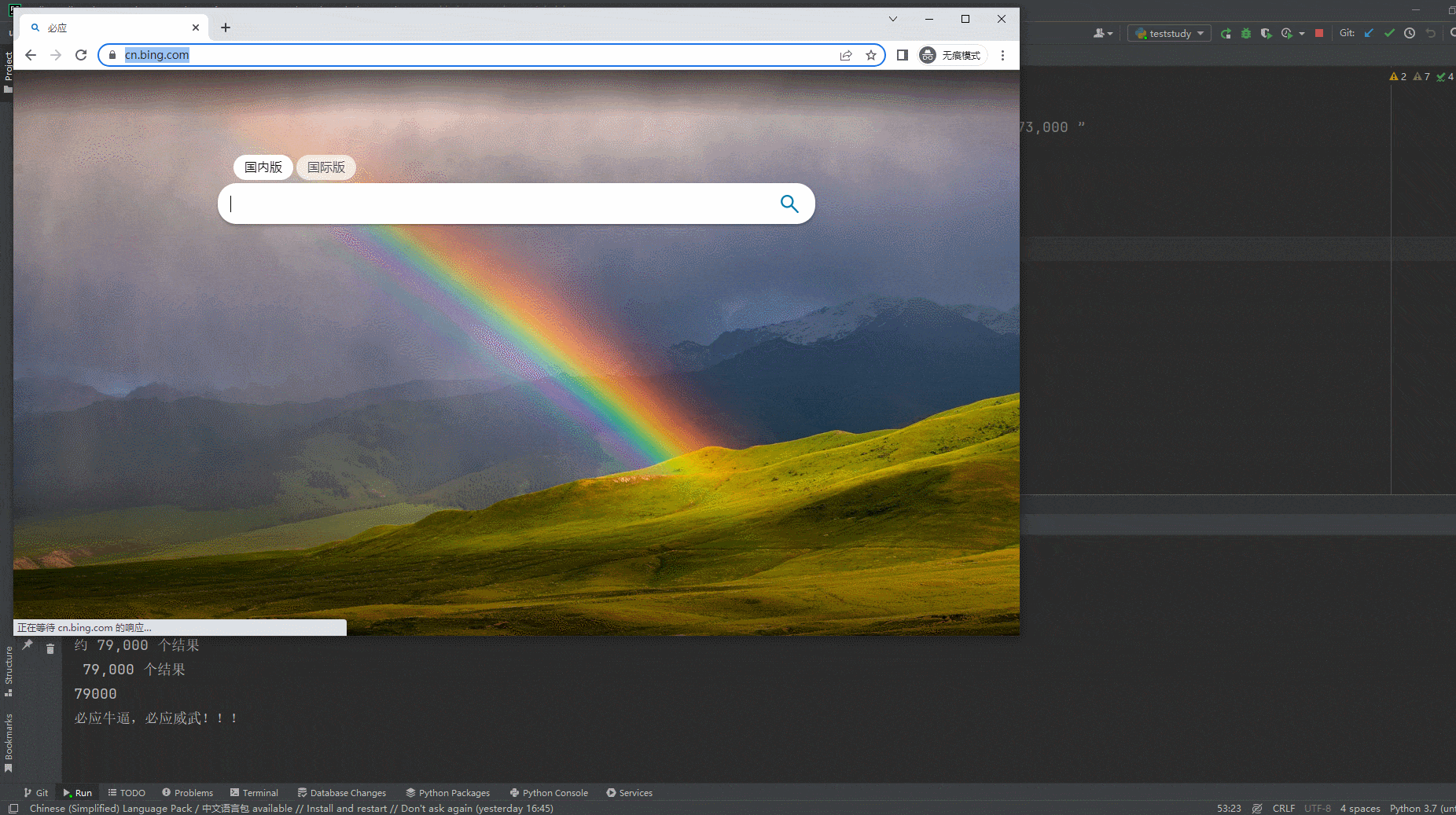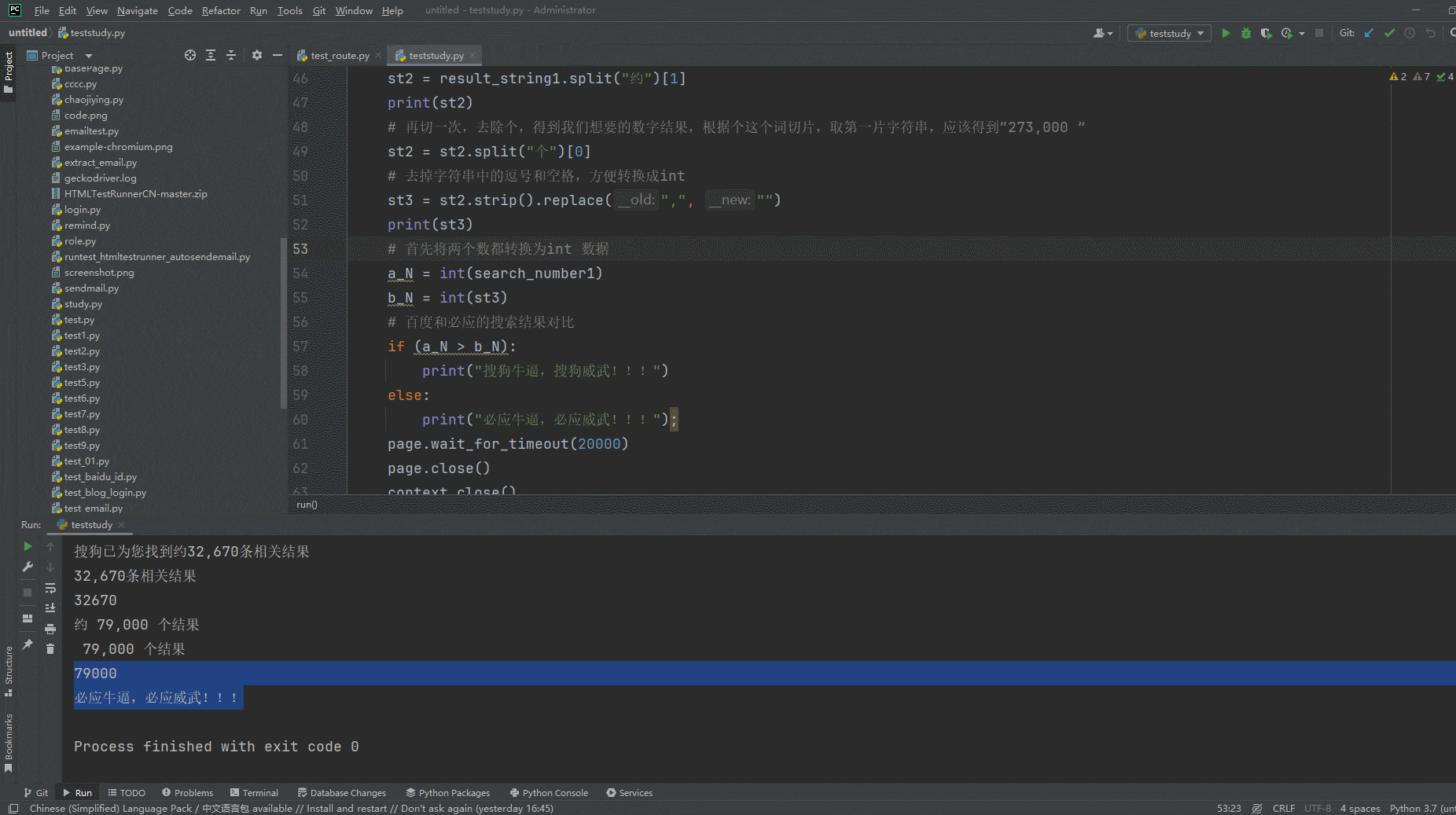
5.小结
1.注意切片取到字符串数字中,带有逗号,转成成int的数字会报错,因此需要将逗号去掉,但是必应的逗号去掉后,数字中带有空格,转换成int的数字也会报错,因此也需要去掉。
2.宏哥这里去掉逗号比较简单,但是如果字符串中带有的逗号多了,这种方法不适用,你需要自己写一个方法,进行替换。
好了,时间不早了,今天就分享和讲解到这里。