1. Reactor 对比
1.1 Reactor 线程模型
Reactor 线程模型就是通过 单个线程 使用 Java NIO 包中的 Selector 的 select()方法,进行监听。当获取到事件(如 accept、read 等)后,就会分配(dispatch)事件进行相应的事件处理(handle)。
如果要给 Reactor 线程模型 下一个更明确的定义,应该是:
java
Reactor线程模式 = Reactor(I/O多路复用)+ 线程池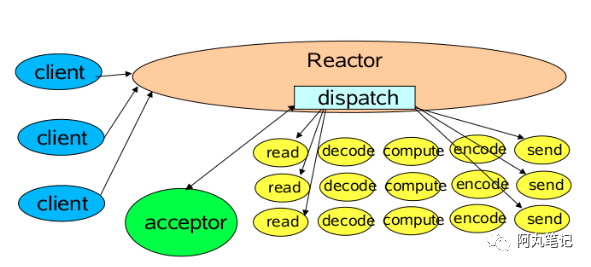
Netty、Redis 使用了此模型,主要是解决 C10K 问题
C10K 问题:服务器如何支持 10K 个并发连接
1.2 Spring Reactor
Reactor 是 JVM 完全非阻塞的响应式编程基础,响应式编程是一种关注数据流和变化传播的异步编程范式。这意味着可以通过所采用的编程语言轻松地表达静态(例如数组)或动态(例如事件发射器)数据流。
java
Mono<List<String>> cartInfoMono = Mono.just( "songjiyang" )
.map( UserService::findUserByName )
.map( UserService::findUserShoppingCart );
String user = UserService.findUserByName( "songjiyang" );
List<String> userShoppingCart = UserService.findUserShoppingCart( user );1.3 区别和联系
联系:
- 两者都是使用异步的手段来提高系统的性能
区别:
- Reactor 模型主要异步的处理新连接、连接和读写,而 Spring Reactor 在更高的代码级别提供了异步框架
或者反过来说,新连接、连接和读写等事件触发了 Netty Reactor 的某些管道处理器流程,某些事件触发了 Spring Reactor 的执行流程,这也是 Reactor(反应器)名称的由来
2. Java 中的异步
上面我们一直在讲异步,异步其实是针对调用者的,也就是调用者调用完方法之后就可以做的别的事情了,Java 中实现异步就两种方式:
- 回调
- 多线程
2.1 回调
回调其实就是把当前的事情完成之后,后面需要做的事当成函数传进行,等完成之后调用就行
java
public static void main( String[] args ){
doA( ( next ) -> {
log.info( "doB" );
next.run();
}, () -> log.info( "doC" ) );
}
public static void doA( Consumer<Runnable> next, Runnable nextNext ){
log.info( "doA" );
next.accept( nextNext );
}
// output
15:06:52.818 [main] INFO concurrent.CompleteTest - doA
15:06:52.820 [main] INFO concurrent.CompleteTest - doB
15:06:52.820 [main] INFO concurrent.CompleteTest - doC回调是在一个线程中来完成的,很容易理解,但问题是回调太多代码就变的很复杂,有回调地域的问题
回调只是一种异步的编程方式,本身实现异步其实还是需要多线程,例如单独起一个监听线程来执行回调函数,例如 EventListener
如果执行的任务不考虑线程安全问题的话,可以使用 CompletableFuture 来解决,会更加易于阅读
java
CompletableFuture
.runAsync( ()-> log.info("doA") )
.thenRunAsync( ()-> log.info("doB") )
.thenRunAsync( ()->log.info("doC") )
.get();
// output
15:08:04.407 [ForkJoinPool.commonPool-worker-1] INFO concurrent.CompleteTest - doA
15:08:04.410 [ForkJoinPool.commonPool-worker-1] INFO concurrent.CompleteTest - doB
15:08:04.410 [ForkJoinPool.commonPool-worker-1] INFO concurrent.CompleteTest - doCCompletableFuture 的 thenRunAsync 也是基于回调,每个任务 Class 会有一个 next, 多个任务组成一个回调链
java
Mono.just("")
.doOnNext( (x)-> log.info("doA") )
.doOnNext( (x)-> log.info("doB") )
.doOnNext( (x)-> log.info("doC") )
.block();
15:12:56.160 [main] INFO concurrent.CompleteTest - doA
15:12:56.160 [main] INFO concurrent.CompleteTest - doB
15:12:56.161 [main] INFO concurrent.CompleteTest - doC2.2 多线程
多线程的方式,大家应该都很熟悉
- Thread
- ExecutorService 线程池
- CompletionService 带结果队列的线程池
- CompletableFuture 用于任务编排
- Runable、Callable、Future、CompletableFuture
3. Spring Reactor
从上面可以看到一些使用 Reactor 的代码中,都可以在原生 JDK 中找到替换,那我们为什么还需要它呢?
- 可组合和可读性
- 丰富的操作
- 订阅之前什么都不会发生
- 背压
下面是 Java9 中 Flow 类的类图,SpringReactor 也是使用这四个类,在 Java9 中已经成了规范
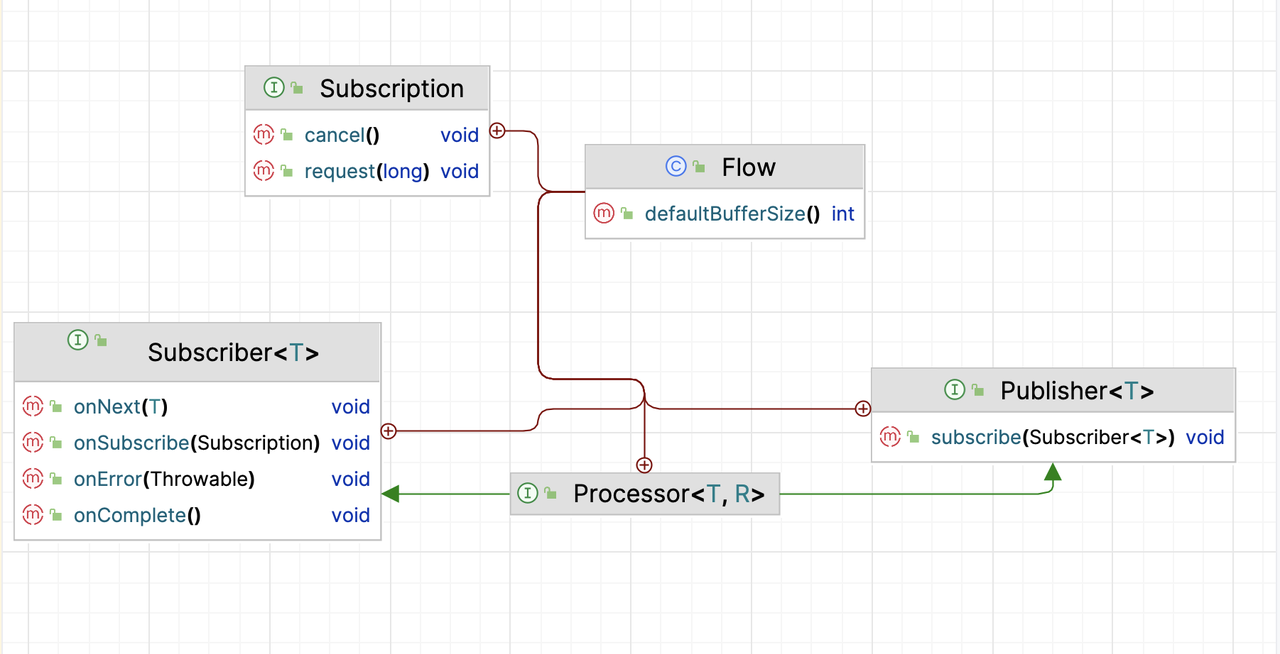
3.1 Publisher
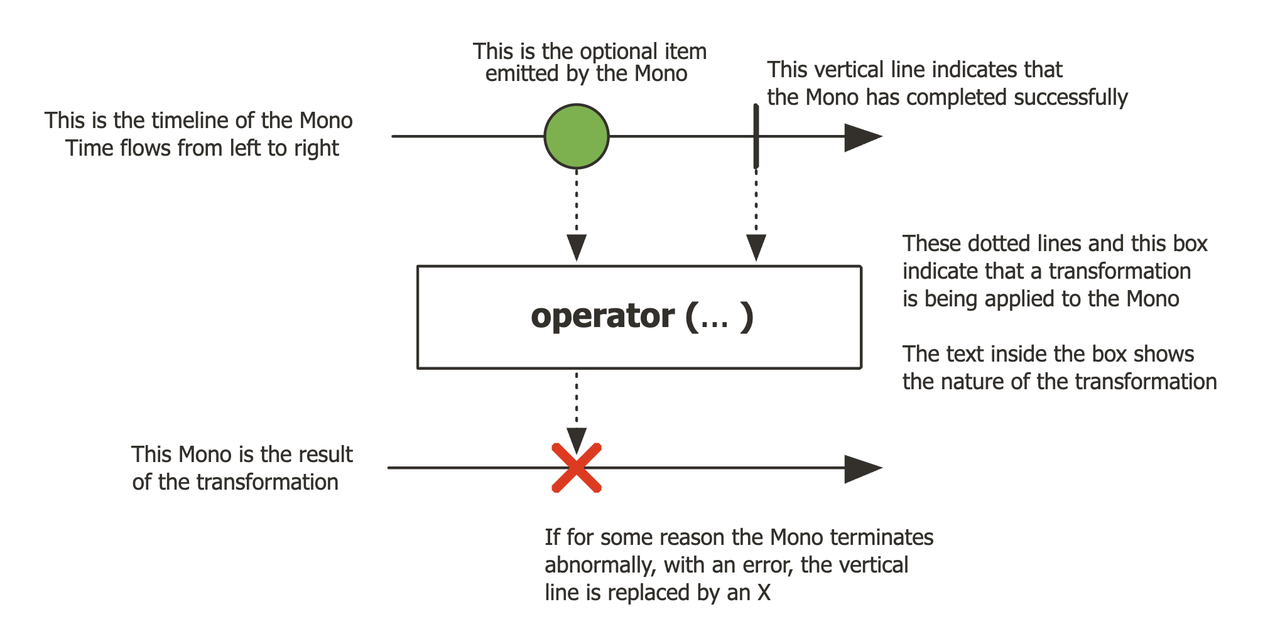
- Mono,提供 0 到 1 个 Item
- Flux,提供 0 到 N 个 Item
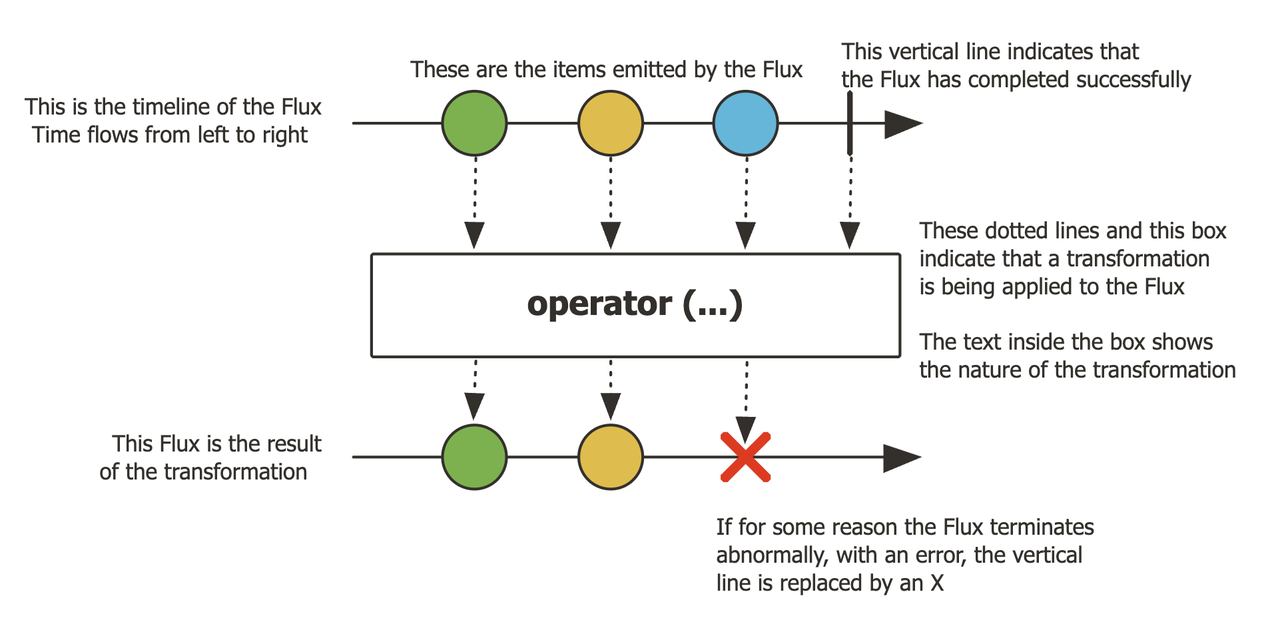
发布者提供 n 个 Item, 经过一些 operator(数据处理操作),完成或者异常中止
核心方法:
- subscribe
3.1.1 创建
java
Mono<String> noData = Mono.empty();
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3);
Mono.fromSupplier( ()->1 );
Mono.fromFuture( CompletableFuture.runAsync( ()-> {} ) );
Flux.create((sink)->{
for( int i = 0; i < 5; i++ ){
sink.next( i ) ;
}
sink.complete();
});3.1.2 处理
下面这些都称为 operator,可以很灵活处理其中的 Item
- 转化 map、flatMap、
- 消费 doOnNext、doNextError、doOnCancel
- 过滤 filter、distinct、take
- 错误处理 onErrorReturn、onErrorComplete、onErrorResume、doFinally
- 时间相关 timeout、interval、delay
- 分隔 window、buffer
- 转同步 block、toStream
3.1.3 订阅
订阅然后消费发布者的内容
java
subscribe();
subscribe(Consumer<? super T> consumer); 订阅之后的返回值是**Disposable****,**可以使用这个对象来取消订阅,会告诉发布者停止生产对象,但不保证会立即终止
- 当然可以给 subscribe 传递参数,自定义 complete 或者 error 时需要做的时
- 同时可以使用 BaseSubscriber 类来实现订阅,可以控制消费的数量
3.2 Subscriber
消费者一般不用手动创建,通过 subscribe 传进 Consumer 函数后,会自动生成一个 LambdaSubscriber,核心方法:
- onSubscribe
- onNext
- onError
- onComplete
3.3 Processor
既是发布者,又是订阅者
3.4 Subscription
订阅,消费者调用 subscribe 方法之后可以在 onSubscribe 回调中获取,可以请求下一个 Item 或者取消订阅
- request
- cancel
3.5 Thread 和 Scheduler
没有指定的情况下:
- 当前的 operator 使用上一个 operator 的线程,最先的 operator 使用调用 subscribe 的线程来执行
Reactor 中使用 Scheduler 来执行流程,类似 ExecutorService
- subscribeOn 可以指定订阅时使用的线程,这样可以不阻塞的订阅
- publishOn 指定发布时使用的线程
4. Spring Reactor 优化案例
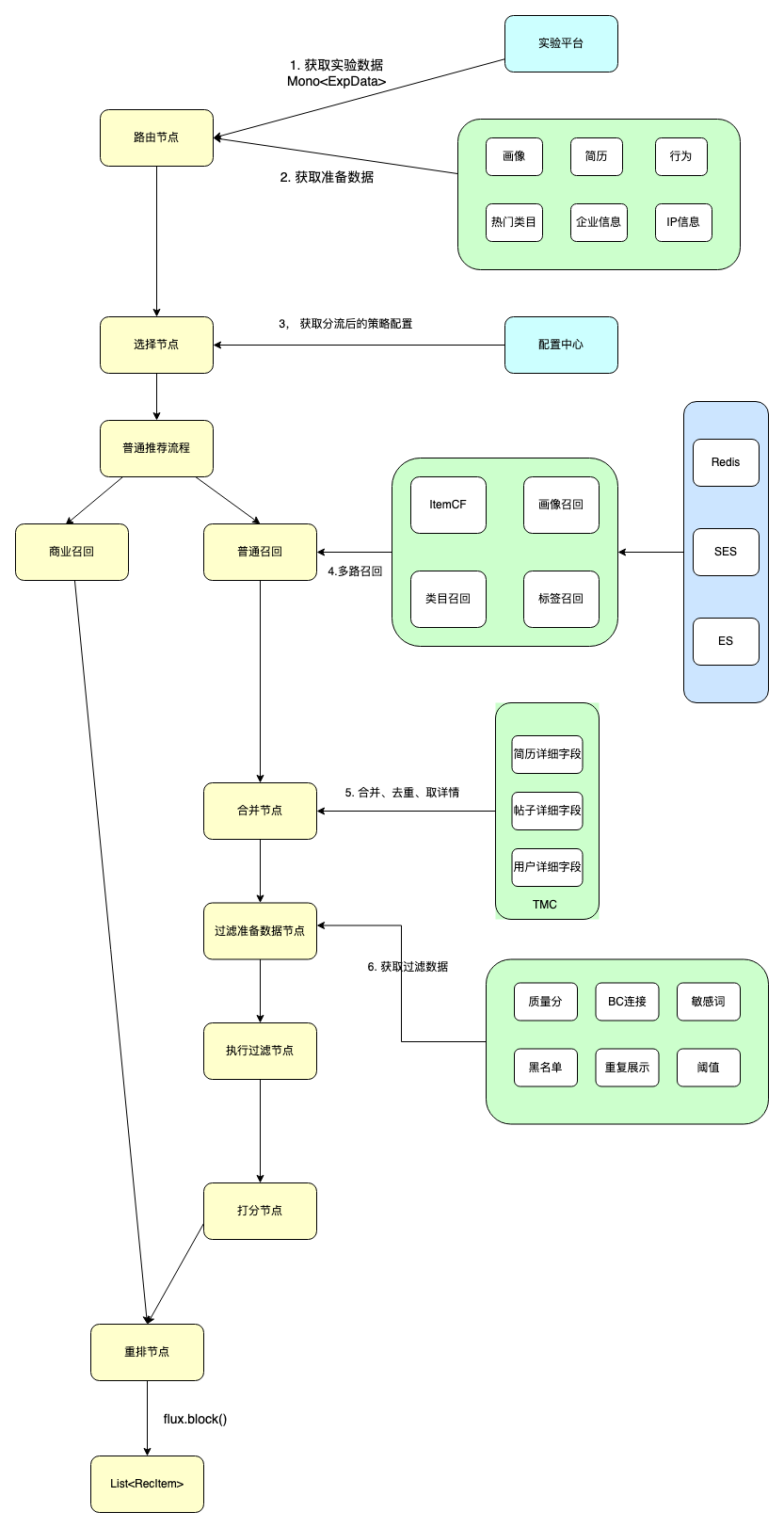
流程中可以优化的点:
- 准备数据可以异步,等需要用的时候在去阻塞获取,相当于一个 Future
- 召回可以完成之后就去等正排数据,新的问题,如何去重?本来拿一次正排数据,现在拿 N 个召回次数据,请求量是不是会变大,耗时是不是也会增加
- 过滤的准备数据也可以异步,也就是说某个过滤策略的数据准备好了,就可以去执行过滤了,而且还存在很多不需要依赖数据的过滤策略也需要等
- 一般粗排只需要 1000 条数据,过滤时已经拿够了 1000 条就可以跳过了
我们上面所说的异步,其实就是说流程中某些节点是在同时执行的,不必等一个节点完成后再执行另外一个,这其实一个统筹学的问题
4.1 解决方法对比
| 问题 | Java 原生 | Reactor |
|---|---|---|
| 准备数据异步 | Future,缺点:1. 需要调用方处理异常 2. 不能编排后续流程,eg: 拿完企业信息后继续拿企业治理信息,Future 需要 get 阻塞 | Mono, 使用 onErrorResume 处理异常,使用 map 编排后续流程 |
| 召回完成拿正排 | 需要一个阻塞队列,召回把结果往里面 push,另外一个线程从队列里面拿同时去取正排数据,需要自己维护 map 来去重,需要循环等待到达批次后去取正排 | Flux ,召回使用 sink.next 把结果放进去合并节点订阅,使用 distinct 来去重,使用 buffer 来实现批次数据 |
| 过滤准备数据异步 | 需要阻塞队列 | Flux , 在依赖任务中把准备好的过滤策略放进去,过滤节点订阅 Flux 并过滤 |
| 粗排取 1000 条 | 异步执行过滤,把过滤结果放到一个容器中,粗排节点不断查看这个容器的结果是否够 1000 条,够了就可以执行粗排了 | Flux , 使用 take(1000) |
java
for (StrategyConfig filterConfig : filterConfigList) {
doStrategyFilter(filterChainContext, recommendContext, recRequest, filterConfig, allFilters, partitionContext, partitionTrace);
}
readyStrategyFlux.publishOn(ExecutorServiceHolder.scheduler).doOnNext((readyStrategyName) -> {
try {
List<StrategyConfig> strategyConfigs = strategyNameToConfigs.get(readyStrategyName);
for (StrategyConfig strategyConfig : strategyConfigs) {
doStrategyFilter(filterChainContext, recommendContext, recRequest, strategyConfig, allFilters, partitionContext, partitionTrace);
}
} catch (Exception e) {
LOGGER.error("doOnNext filter error", e);
}
}).blockLast();这里的 blockLast 又回到了同步世界,可以很好的和已有的代码兼容
下面是 20240629 到 20240702 某个场景优化过滤阶段的耗时对比
| pv | qps | tp99 | avg | |
|---|---|---|---|---|
| 实验组 | 4051865 | 46.90 | 369.00 | 230.88 |
| 对照组 | 4054074 | 46.92 | 397.00 | 251.55 |
业务指标对比
无明显波动
5. 总结
Spring Reactor 是一个响应式编程框架,非常适合类似 MXN 这样的流程编排系统,也是 Java 中异步编程的一种补充,但也会有一些其他的问题,例如潜在的线程安全问题,已有框架的冲突 ThreadLocal 等