X-Stream论文 :《X-Stream: Edge-centric Graph Processing using Streaming Partitions》
前面通过文章《论文图谱当如是:Awesome-Graphs用200篇图系统论文打个样》向大家介绍了论文图谱项目Awesome-Graphs,并分享了Google的Pregel以及OSDI 2012上的PowerGraph。这次向大家分享发表在SOSP 2013上的另一篇经典图计算框架论文X-Stream,构建了单机上基于外存的Scatter-Gather图处理框架。
对图计算技术感兴趣的同学可以多做了解,也非常欢迎大家关注和参与论文图谱的开源项目:
- Awesome-Graphs:https://github.com/TuGraph-family/Awesome-Graphs
- OSGraph:https://github.com/TuGraph-family/OSGraph
提前感谢给项目点Star的小伙伴,接下来我们直接进入正文!
摘要
- X-Stream是一个单机共享内存的既可以处理内存图也可以处理外存图的图处理系统。
- 特点:
- 以边为中心的计算模型。
- 流式访问无序边,而不是随机访问。
1. 介绍
传统的以点为中心的处理:
- scatter函数将点状态传播给邻居点。
- gather函数累计更新,并重新计算点状态。

顺序/随机访问不同存储介质的性能差异:
- 磁盘:500x
- SSD:30x
- 内存:1.8x - 4.6x
X-Stream的以边为中心的处理:
- scatter/gather在边/更新上迭代,而不是在点上迭代。
- 使用流式分区缓解点集的随机访问。
- 将边和源点划分到同一个分区。

X-Stream主要贡献:
- 边中心处理模型。
- 流式分区。
- 不同存储介质上的良好扩展性。
- 高性能。
2. X-Stream处理模型
API设计:
- Scatter:根据边和源点,计算目标点更新。
- Gather:根据目标点收到更新,重新计算目标点状态。
2.1 流
X-Stream使用流的方式执行Scatter+Gather。边和更新是顺序访问的,但是点是随机访问的。
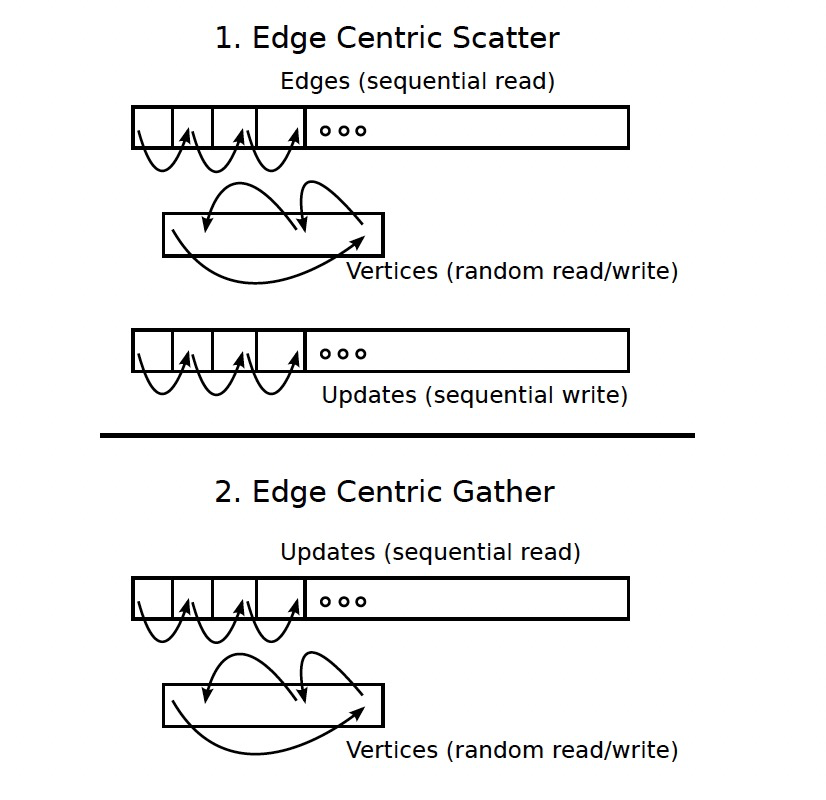
2.2 流式分区
流式分区包含:
- 点集:分区上的点子集。
- 边列表:源点的边。
- 更新列表:目标点的更新。
2.3 分区上的Scatter-Gather
Scatter + Shuffle + Gather:

2.4 分区的大小和数量
- 一方面为了让点集合尽量加载到快存储,分区数不能太小。
- 另一方面为了最大化利用慢存储的顺序读写能力,分区数不能太大。
- 通过固定分区点集合大小的方式进行分区。
2.5 API限制和扩展
- 虽然不能遍历点上的所有边,但是可以对所有的点进行迭代,并提供自定义的点函数。
- 不仅限于支持scatter-gather模型,也可以支持semi-streaming、W-Stream模型等。
3. 基于外存的流式引擎
每个流式分区维护三个磁盘文件:点文件、边文件、更新文件。
难点在于实现shuffle节点的顺序访问,通过合并scatter+shuffle阶段,更新写入到内存buffer,buffer满时执行内存shuffle追加到目标分区磁盘文件。
3.1 内存数据结构
stream buffer设计:
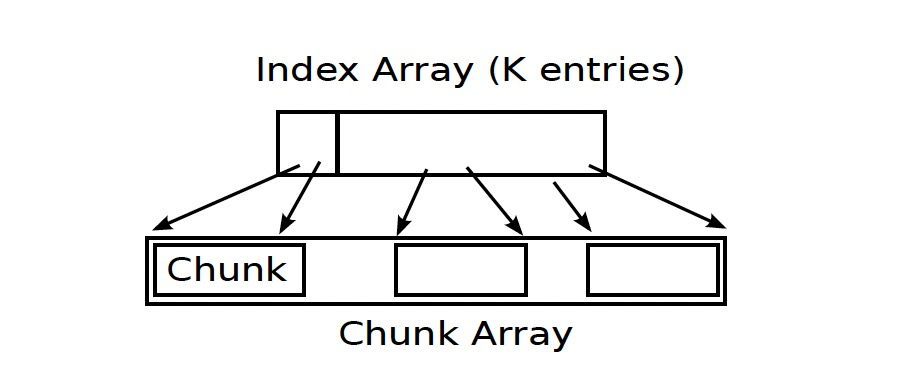
基于stream buffer,一个buffer用于存储scatter的更新,另一个存储内存shuffle的结果。
3.2 操作
初始化边分区可以使用内存shuffle方式实现。

3.3 磁盘IO
- X-Stream的stream buffer采用异步Direct I/O,而不是OS页面缓存(4K)。
- 预读和块写提高磁盘利用率,但是需要额外的stream buffer。
- 使用RAID实现读写分离。
- 使用SSD存储TRIM操作实现truncate。
3.4 分区数量
假设分区的更新满足均匀分布,则有如下内存公式:
- N:点集合内存总量。
- S:最大带宽IO请求包大小。
- K:分区数。
- M:内存总量。
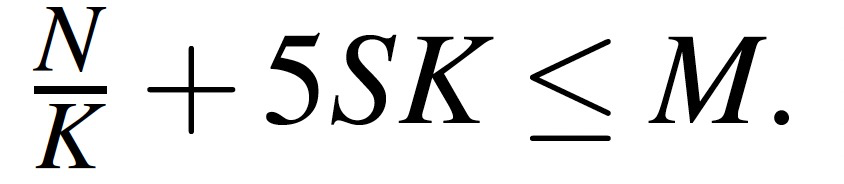
4. 基于内存的流式引擎
4.1 并行Scatter-Gather
- 每个线程写自由缓存,再统一flush到贡献的输出数据块。
- 通过worker stealing避免倾斜。
4.2 并行多阶段shuffle
- 将分区使用树形结构组织起来,分支因子F(扇出度大小),树的每一层对应一步shuffle。
- 因此对于K个分区,一共需要logFK步shuffle。
- 使用两个stream buffer轮换输入输出角色实现shuffle。
- 论文将F设置为CPU cache的可用行数。
4.3 磁盘流的分层
内存引擎逻辑上在外存引擎上层,外存引擎可以自由选择使用内存引擎处理的分区数量,以最大化利用内存和计算资源。
5. 评估
- 256M内存cache大小,在16core时达到最大内存带宽25GB/s。
- 16M IO请求包大小。