一、需求背景
有好几种报告文件,目前是人肉找报告信息填到Excel上生成统计信息
跟用户交流了下需求和提供的几个文件,发现都是html文件
其实所谓的报告的文件,就是一些本地可打开的静态资源,里面也有js、img等等
二、方案选型
前面老板一直说是文档解析,我寻思这不就是写爬虫吗....
因为是在现有系统上加新功能实现,现有系统还是Java做后端服务,所以之前学的Python就不想用了
写Python还需要单独起个服务部署起来,Java有JSOUP能用,没Python那么好用就是...
三、落地实现
1、JSOUP依赖坐标:
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.18.1</version>
</dependency>2、文件读取问题
我发现每种类型的报告文件的存放方式都不一样
第一种单HTML文件:
这种相对简单,只需要读取路径后直接访问文件内容即可
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxx.html";
String htmlContent = new String(Files.readAllBytes(Paths.get(reportFilePath)), StandardCharsets.UTF_8);
Document doc = Jsoup.parse(htmlContent); 第二种单Zip压缩文件:
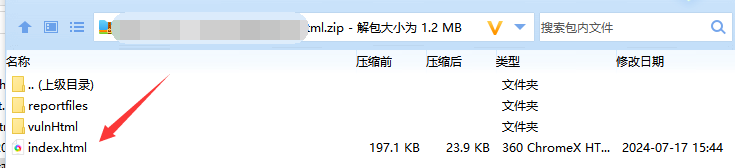
单层压缩,可以通过zipFile的API访问,取出压缩条目一个个用条目名称进行判断
再通过zipFile打开读取流对该条目进行读取
String targetFile = "index.html";
ZipEntry targetEntry = null;
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xxxhtml.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> zipEntries = zipFile.entries();
while (zipEntries.hasMoreElements()) {
ZipEntry zipEntry = zipEntries.nextElement();
boolean isDirectory = zipEntry.isDirectory();
if (isDirectory) continue;
String name = zipEntry.getName();
if (targetFile.equals(name)) {
targetEntry = zipEntry;
break;
}
}
boolean hasFind = Objects.nonNull(targetEntry);
if (!hasFind) return; /* 没有可读取的目标文件 */
InputStream inputStream = zipFile.getInputStream(targetEntry);
String htmlCode = IoUtil.readUtf8(inputStream);
Document doc = Jsoup.parse(htmlCode);执行完成后记得要释放资源:
/* 资源释放 */
inputStream.close();
zipFile.close();
第三种多Zip嵌套压缩文件:
文件被压缩了两次,要解压两边才可以访问
1、读取内嵌的Zip文件时发现MALFORM报错,需要根据操作系统设置读取编码...
https://blog.csdn.net/qq_25112523/article/details/136060946 然后在创建ZipFile对象的API加了一个操作系统的判断
public static boolean isWinSys() {
String property = System.getProperty("os.name");
return property.contains("win") || property.contains("Win");
}2、ZipFile只对单层压缩有用,如果是嵌套的压缩文件就不支持了
这个报告文件的情况是第一层只有一个条目,所以上传上来的文件我只关心里面只有一个内嵌的压缩文件就行
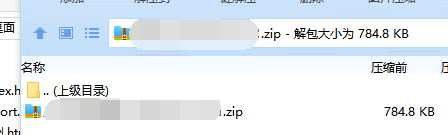
当匹配这个条件交给ZipFile读取输入流,转换成Zip输入流,否则不处理
可以在下面代码看到,对被压缩的文件进行inputStream读取后,要改用ZipInputStream读取
zipInputStream 等效 zipFile + zipEntries的合体,包含了条目迭代信息
但是只有一个getNextEntry方法,只能写While循环不断判断下一个条目是否还存在
文件名叫report.html,判断条目名是否匹配后结束循环
再利用IO工具类直接读取ZipInputStream即可 (getNextEntry方法就是让ZipInputStream不断切换到当前条目的引用)
如果要处理复杂情况要在While里面才能实现的,建议每个条目结束之后调用closeEntry方法
String targetSuffix = ".zip";
String targetFile = "report.html";
String reportFilePath = "C:/Users/Administrator/Desktop/report-type/xx_20240729153751.zip";
ZipFile zipFile = isWinSys() ? new ZipFile(new File(reportFilePath), ZipFile.OPEN_READ, Charset.forName("GBK")) : new ZipFile(reportFilePath);
Enumeration<? extends ZipEntry> enumeration = zipFile.entries();
/* 转换成集合条目,迭代条目不能判断size */
List<ZipEntry> zipEntrieList = new ArrayList<>();
while (enumeration.hasMoreElements()) {
ZipEntry zipEntry = enumeration.nextElement();
zipEntrieList.add(zipEntry);
}
/* 只有1个zip压缩文件时才处理 */
if (CollectionUtils.isEmpty(zipEntrieList)) return;
boolean isOnlyOneEntry = zipEntrieList.size() == 1;
boolean anyMatch = zipEntrieList.stream().anyMatch(ze -> ze.getName().endsWith(targetSuffix));
if (!isOnlyOneEntry || !anyMatch) return;
ZipEntry zipEntry = zipEntrieList.get(0);
/* 通过ZipInputStream不断切换条目找到目标文件 */
InputStream inputStream = zipFile.getInputStream(zipEntry);
ZipInputStream zipInputStream = new ZipInputStream(inputStream);
/* 在内层中寻找目标文件 */
ZipEntry reportEntry = zipInputStream.getNextEntry();
while (Objects.nonNull(reportEntry)) {
String name = reportEntry.getName();
if (targetFile.equals(name)) break;
reportEntry = zipInputStream.getNextEntry();
}
String htmlCode = IoUtil.readUtf8(zipInputStream);
Document doc = Jsoup.parse(htmlCode);同样这里也需要释放资源:
/* 资源释放 */
zipInputStream.close();
inputStream.close();
zipFile.close();
3、常见查询API使用
一、常见API方法
下班到家才反应过来ownText是元素自己的文本内容,过滤掉其他嵌套的元素文本

也可以直接使用cssQuery
doc.select("table.y-report-ui-report-info-grid")
二、使用兄弟元素查找对应关系
有一个特殊的情况就是有些元素按文档结构应该是一个逐层关联的结构
先有A,然后B在A里面,C又在B里面这样
但是这个是摊开来的结构,A -> B -> C -> D,元素id和类名也没用直接关系,这样是很难构建关联的
只能通过元素的顺序推断结构:
1、获取当前ip标题元素和下一个ip标题元素的兄弟元素下标值
2、将idp元素的兄弟元素下标值取出
3、比较idp元素是否在两者之间,如果为是表示idp元素属于第一个ip标题元素
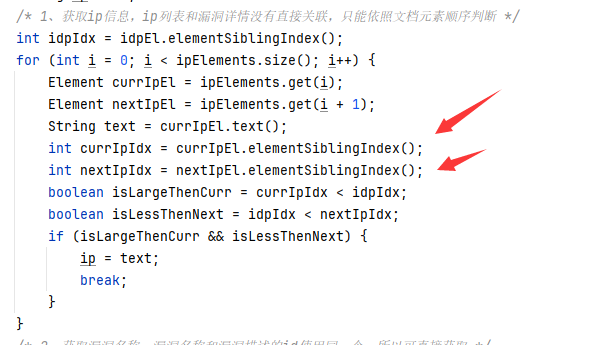
三、父子元素操作获取兄弟元素
/* 2、读取【漏洞分布】信息 *//* 2、读取【漏洞分布】信息 */
Element vulnTable = doc.getElementById("vuln_distribution");
Element vulnTableBody = vulnTable.child(1);
Elements allTrList = vulnTableBody.children();
Elements vulnTitleTrList = vulnTable.select("tr[style='cursor:pointer;']");
for (Element vrTr : vulnTitleTrList) {
/* 2-1、漏洞名称 */
String vt = vrTr.child(1).text();
int vrTrIdx = allTrList.indexOf(vrTr);
Element vrDetailTr = allTrList.get(vrTrIdx + 1);
Element vrDetailTableBody = vrDetailTr.child(1).child(0).child(0);
/* 2-2、漏洞主机 */
String ipHosts = vrDetailTableBody.child(0).child(1).text();
ipHosts = ipHosts.replaceAll(" ", "").replaceAll(" 点击查看详情;", "");
/* 2-3、漏洞描述 */
String vulnDesc = vrDetailTableBody.child(1).child(1).text();
/* 2-4、威胁分值 */
String vulnTag = vrDetailTableBody.child(3).child(1).text();
String format = StrFormatter.format("reportTime: {}, ip: {}, name: {}, tag: {} desc: {}, ", date, ipHosts, vt, vulnTag, vulnDesc);
System.out.println(format);
}
Element vulnTable = doc.getElementById("vuln_distribution"); Element vulnTableBody = vulnTable.child(1); Elements allTrList = vulnTableBody.children(); Elements vulnTitleTrList = vulnTable.select("tr[style='cursor:pointer;']"); for (Element vrTr : vulnTitleTrList) { /* 2-1、漏洞名称 */ String vt = vrTr.child(1).text(); int vrTrIdx = allTrList.indexOf(vrTr); Element vrDetailTr = allTrList.get(vrTrIdx + 1); Element vrDetailTableBody = vrDetailTr.child(1).child(0).child(0); /* 2-2、漏洞主机 */ String ipHosts = vrDetailTableBody.child(0).child(1).text(); ipHosts = ipHosts.replaceAll(" ", "").replaceAll(" 点击查看详情;", ""); /* 2-3、漏洞描述 */ String vulnDesc = vrDetailTableBody.child(1).child(1).text(); /* 2-4、威胁分值 */ String vulnTag = vrDetailTableBody.child(3).child(1).text(); String format = StrFormatter.format("reportTime: {}, ip: {}, name: {}, tag: {} desc: {}, ", date, ipHosts, vt, vulnTag, vulnDesc); System.out.println(format); }