大浪淘沙,2024 年的今天,市面上很多监控系统慢慢淡出了大家的视野,而一些新的监控系统也逐渐崭露头角。今天我们就来看看 2024 年的当下,哪些 IT 运维监控系统最值得关注。
Prometheus
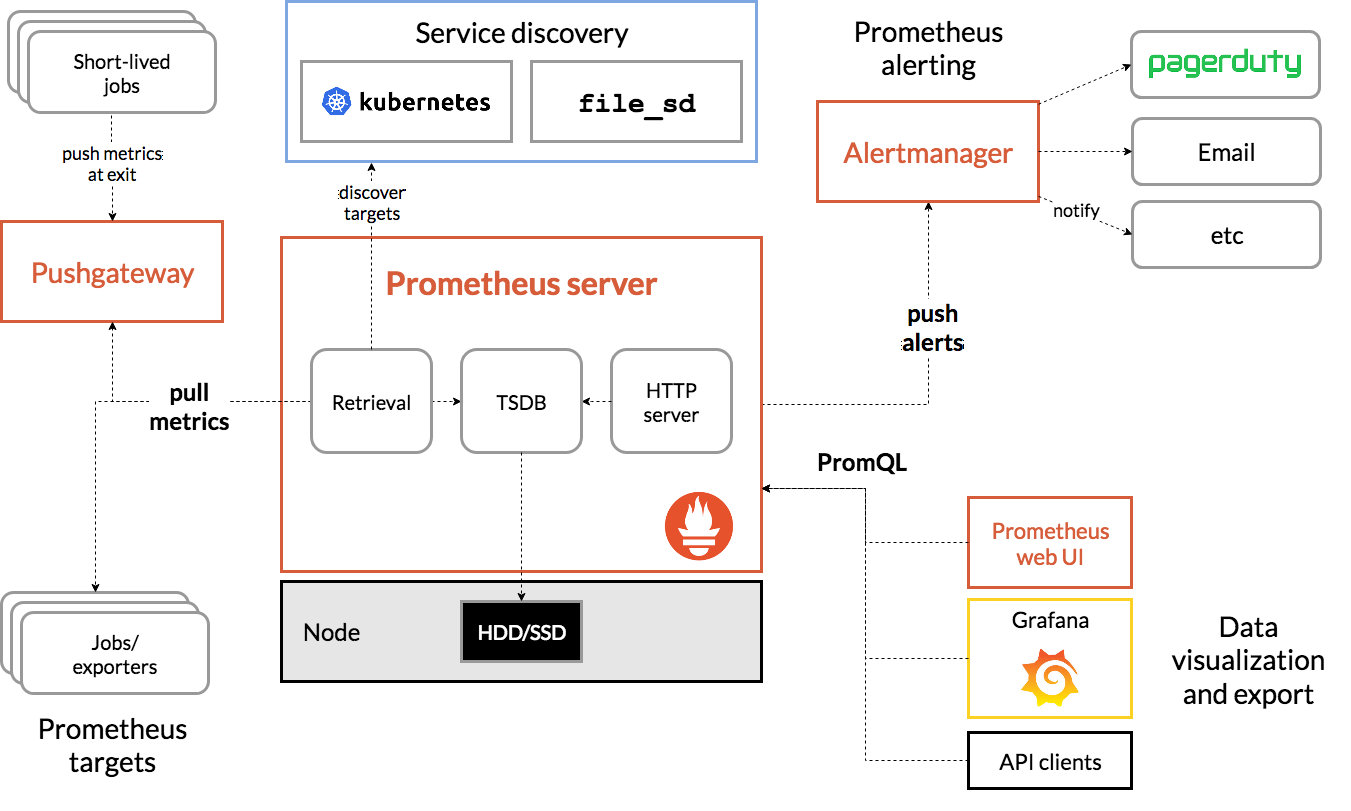
毫无疑问,Prometheus 是最值得关注的监控系统,因为 Prometheus 的规范和生态都非常厉害,很多中间件、数据库,直接就内置支持了 Prometheus,比如 ETCD、Kubernetes、RabbitMQ、Nginx VTS 等等,这个势能是非常强大的。
尤其是在容器和微服务监控场景,Prometheus 生态是不二之选,因为:
- 由于资源的生命周期比较短,通常是基于服务发现来发现监控目标,而不是资产管理式(Zabbix就是资产管理式)。
- 多维度筛选的需求强烈,比如通过标签聚合、过滤、分组等。需要一个针对性的 Query Language。PromQL 就是为此而生。
当然,这里我们说的是 Prometheus 生态,至于是否真的使用 Prometheus 二进制倒不一定,因为 Prometheus 本身的存储和查询性能并不是很好,所以很多公司会选择使用 Prometheus 的兼容产品,比如 VictoriaMetrics、Thanos 等。
Grafana
Prometheus 可以搞定数据采集、存储问题,并提供查询接口、查询语言,但是对于数据的展示,Prometheus 本身并不是很强大,通常大家会选择使用 Grafana 作为展示工具。
Grafana 不仅仅为 Prometheus 提供了很多的 Dashboard 模板,而且还支持多种数据源,比如 InfluxDB、Elasticsearch、Loki、MySQL、PostgreSQL、CloudWatch、Zabbix 等等。Grafana 的可视化能力,基本就是开源领域的标杆甚至事实标准了。
Nightingale
很多公司有多套 Prometheus,我在社区里见过一个公司有 200 多套 Prometheus,四五套、八九套的更是比比皆是,此时,大家就很想统一管理,比如公司有 8 套 Kubernetes,每套 Kubernetes 都有一个 Prometheus,这些 Prometheus 的数据类似,告警规则通用,每次修改一个告警规则,要修改 8 套 Prometheus,这就很麻烦了。另外,监控能力作为基础能力,通常是开放给公司所有业务研发团队,需要一些权限管控、知识沉淀的能力,Nightingale 可以帮助你解决这些问题。
Nightingale 的核心是做一个告警引擎,支持对接 Prometheus、VictoriaMetrics、Thanos、M3DB、Loki 等多种数据源,统一管理告警规则。而且考虑了边缘机房网络割裂的场景,即便是边缘机房和中心机房之间的网络坏掉了,边缘机房内部也可以自闭环生成、发送告警。
Zabbix
Zabbix 相对比较老了,擅长服务器、网络设备的监控,不擅长 Kubernetes、微服务的监控,由于越来越多的公司采用公有云,公有云自然搞定了硬件、网络设备的监控,所以 Zabbix 的市场份额在逐渐下降。
国内很多公司在使用 Zabbix,社区较为活跃,很多公司基于 Zabbix 封装了商业化产品,如果你是网工或系统运维,Zabbix 还是值得关注的。
其他
当然,还有一些其他的监控系统,比如:Cacti、Nagios,都太老了,不推荐使用。Cacti 在网工圈子里还是有一定的市场份额,Nagios 基本销声匿迹了。
监控作为稳定性保障的重要手段,涉及到的内容非常驳杂,如果您找乙方协助构建监控、可观测性方案,欢迎联系我们做产品技术交流:https://flashcat.cloud/contact/。