专业级语义搜索优化:利用 Cohere AI、BGE Re-Ranker 及 Jina Reranker 实现精准结果重排
1. 简介
1.1 RAG
在说重排工具之前,我们要先了解一下 RAG。
检索增强生成(RAG)是一种新兴的 AI 技术栈,通过为大型语言模型(LLM)提供额外的 "最新知识" 来增强其能力。
基本的 RAG 应用包括四个关键技术组成部分:
- Embedding 模型:用于将外部文档和用户查询转换成 Embedding 向量
- 向量数据库:用于存储 Embedding 向量和执行向量相似性检索(检索出最相关的 Top-K 个信息)
- 提示词工程(Prompt engineering):用于将用户的问题和检索到的上下文组合成大模型的输入
- 大语言模型(LLM):用于生成回答
上述的基础 RAG 架构可以有效解决 LLM 产生 "幻觉"、生成内容不可靠的问题。但是,一些企业用户对上下文相关性和问答准确度提出了更高要求,需要更为复杂的架构。一个行之有效且较为流行的做法就是在 RAG 应用中集成 Reranker。
语义搜索提供基于文本段落的上下文含义的搜索功能。它解决了替代方法(关键字搜索)的局限性。
例如我们来查询:"吃饭的地方"。使用语义搜索模型就能够自动将其与 "餐馆" 联系起来,因为它们的含义相似。而通过关键字搜索却无法做到这一点,因为搜索结果将局限于 "地点"、"去" 和"吃"等关键字。
这就像是与搜索引擎进行一场对话,它不仅理解你询问的内容,还理解你为什么要询问。这正是自然语言处理、人工智能和机器学习的魅力所在。它们共同努力理解用户的查询、查询的上下文以及用户的意图。语义搜索研究单词之间的关系或单词的含义,以提供比传统关键词搜索更准确、更相关的搜索结果。
1.2 Reranker
Reranker 是信息检索(IR)生态系统中的一个重要组成部分,用于评估搜索结果,并进行重新排序,从而提升查询结果相关性。 在 RAG 应用中,主要在拿到向量查询(ANN)的结果后使用 Reranker,能够更有效地确定文档和查询之间的语义相关性,更精细地对结果重排,最终提高搜索质量。
目前,Reranker 类型主要有两种------基于统计和基于深度学习模型的 Reranker:
- 基于统计的 Reranker 会汇总多个来源的候选结果列表,使用多路召回的加权得分或倒数排名融合(RRF)算法来为所有结果重新算分,统一将候选结果重排。这种类型的 Reranker 的优势是计算不复杂,效率高,因此广泛用于对延迟较敏感的传统搜索系统中。
- 基于深度学习模型的 Reranker,通常被称为 Cross-encoder Reranker。由于深度学习的特性,一些经过特殊训练的神经网络可以非常好地分析问题和文档之间的相关性。这类 Reranker 可以为问题和文档之间的语义的相似度进行打分。因为打分一般只取决于问题和文档的文本内容,不取决于文档在召回结果中的打分或者相对位置,这种 Reranker 既适用于单路召回也适用于多路召回。
1.3 Reranker 在 RAG 中的作用
将 Reranker 整合到 RAG 应用中可以显著提高生成答案的精确度,因为 Reranker 能够在单路或多路的召回结果中挑选出和问题最接近的文档。此外,扩大检索结果的丰富度(例如多路召回)配合精细化筛选最相关结果(Reranker)还能进一步提升最终结果质量。使用 Reranker 可以排除掉第一层召回中和问题关系不大的内容,将输入给大模型的上下文范围进一步缩小到最相关的一小部分文档中。通过缩短上下文, LLM 能够更 "关注" 上下文中的所有内容,避免忽略重点内容,还能节省推理成本。

上图为增加了 Reranker 的 RAG 应用架构。可以看出,这个检索系统包含两个阶段:
- 在向量数据库中检索出 Top-K 相关文档,同时也可以配合 Sparse embedding(稀疏向量模型)覆盖全文检索能力。
- Reranker 根据这些检索出来的文档与查询的相关性进行打分和重排。重排后挑选最靠前的结果作为 Prompt 中的 Context 传入 LLM,最终生成质量更高、相关性更强的答案。
但是需要注意,相比于只进行向量检索的基础架构的 RAG,增加 Reranker 也会带来一些挑战,增加使用成本。
1.4. 使用 Reranker 的成本
在使用 Reranker 提升检索相关性的同时需要着重关注它的成本。这个成本包括两方面,增加延迟对于业务的影响、增加计算量对服务成本的增加。我们建议根据自己的业务需求,在检索质量、搜索延迟、使用成本之间进行权衡,合理评估是否需要使用 Reranker。
- Reranker 会显著增加搜索延迟
未使用 Reranker 的情况下,RAG 应用只需执行低延迟的向量近似最近邻 (ANN) 搜索,从而获取 Top-K 相关文档。例如 Milvus 向量数据库实现了 HNSW 等高效的向量索引,可实现毫秒级的搜索延迟。如果使用 Zilliz Cloud,还能借助更加强大的 Cardinal 索引进一步提升搜索性能。
但如果增加了 Reranker,尤其是 Cross-encoder Reranker 后,RAG 应用需要通过深度学习模型处理所有向量检索返回的文档,这会导致延时显著增加。相比于向量检索的毫秒级延迟,取决于模型大小和硬件性能,延迟可能提高到几百毫秒甚至到几秒!
- Reranker 会大幅度提高计算成本
在基础架构的 RAG 中,向量检索虽然需要预先使用深度学习模型处理文档,但这一较为复杂的计算被巧妙设计在离线状态下进行。通过离线索引(Embedding 模型推理),每次在线查询过程只需要付出极低计算成本的向量检索即可。与之相反,使用 Reranker 会大大增加每次在线查询的计算成本。这是因为重排过程需要对每个候选文档进行高成本的模型推理,不同于前者可以每次查询都复用离线索引的结果,使用 Reranker 需要每次在线查询都进行推理,结果无法复用,带来重复的开销。这对于网页搜索、电商搜索等高流量的信息检索系统非常不适用。
让我们简单算一笔账,看看使用 Reranker 的成本。
根据 VectorDBBench 的数据,一个能负担每秒钟 200 次 查询请求的向量数据库使用成本仅为每月 100 美元,平摊下来相当于每次查询成本仅为 0.0000002 美元。如果使用 Reranker,假设第一阶段向量检索返回 top-100 个文档,重排这些文档的成本高达 0.001 美元。也就是增加 Reranker 比单独执行向量搜索的成本高出了 5000 倍。
虽然很多实际情况中可能只针对少量结果进行重排(例如 10 到 20 个),但是使用 Cross-encoder reranker 的费用仍然远高于单纯执行向量搜索的费用。
从另一个角度来看,使用 Reranker 相当于在查询时负担相当于离线索引的高昂成本,也就是模型推理的计算量。推理成本与输入大小(文本的 Token 数)和模型本身的大小有关。一般 Embedding 和 Reranker 模型大小在几百 MB 到几个 GB 不等。我们假设两种模型尺寸接近,因为查询的文档一般远大于查询的问题,对问题进行推理成本忽略不计,如果每次查询需要重排 top-10 个文档,这就相当于 10 倍对于单个文档离线计算 Embedding 的成本。如果在高查询负载的情况下,计算和使用成本可能是无法承受的。对于低负载的场景,例如企业内部高价值低频率的知识库问答,这一成本则可能完全可以接受。
1.5 成本比较:向量检索 v.s. Cross-encoder Reranker v.s. 大模型生成
虽然 Reranker 的使用成本远高于单纯使用向量检索的成本,但它仍然比使用 LLM 为同等数量文档生成答案的成本要低。 在 RAG 架构中,Reranker 可以筛选向量搜索的初步结果,丢弃掉与查询相关性低的文档,从而有效防止 LLM 处理无关信息,相比于将向量搜索返回的结果全部送进 LLM 可大大减少生成部分的耗时和成本。
举一个贴近实际的例子:第一阶段检索中,向量搜索引擎可以在数百万个向量中快速筛选出语义近似度最高的 20 个文档,但这些文档的相对顺序还可以使用 Reranker 进一步优化。虽然会产生一定的成本,但 Reranker 可以在 top-20 个结果进一步挑出最好的 top-5 个结果。那么,相对更加昂贵的 LLM 只需要分析这 top-5 个结果即可,免去了处理 20 个文档带来的更高成本和注意力 "涣散" 的问题。这样一来,我们就可以通过这种复合方案平衡延迟、回答质量和使用成本。
1.6. Reranker 使用场景
追求回答高精度和高相关性的场景中特别适合使用 Reranker,例如专业知识库或者 客服系统等应用。因为这些应用中的查询都具有很高的商业价值,提升回答准确性的优先级远高于系统性能和控制成本。使用 Reranker 能够生成更准确的答案,有效提升用户体验。
但是在网页搜索、电商搜索 这类场景中,响应速度和成本至关重要,因此不太适合使用代价高昂的 Cross-Encoder Reranker。此类应用场景更适合选用向量检索搭配更轻量的 Score-based Reranker,从而确保响应速度,在提升搜索质量的同时降低开销。
相比于单独使用向量检索,搭配 Reranker 可以通过对第一层检索结果的进一步精细化排序提高检索增强生成(RAG)和搜索系统中答案的准确性和相关性。但是使用 Reranker 会增加延时和提高使用成本,因此不适合高频高并发的应用。考虑是否使用 Reranker 时,需要在回答准确性、响应速度、使用成本间做出权衡。
重排器在提高检索相关性的同时,也会增加延迟和计算成本。因此,在检索质量、搜索延迟、使用成本之间进行权衡之后,当前可选择的重排工具并不多,下面介绍三款:Cohere Rerank 、 BGE Re-Ranker、Jina Reranker。
2.Cohere AI
- 公司介绍
Aidan Gomez(首席执行官)、Nick Frosst 和 Ivan Zhu 于 2019 年创立了 Cohere。
其中 Aidan Gomez 于 2017 年 6 月与人合著论文《Attention Is All You Need》,这个的分量大家都知道,在此不赘述。 2023 年初,YouTube 前首席财务官 Martin Kon(总裁兼首席运营官)加入团队。
- 目标:构建大模型基础设施
Gomes : "刚开始时,我们并不真正知道我们想要构建什么产品... 我们只是专注于构建基础设施,以使用我们可以获得的任何计算在超级计算机上训练大型语言模型。很快在我们启动 Cohere 后,GPT-3 出现了,这是一个巨大的突破时刻,非常有效,并给了我们 一个指示,表明我们正在走上正确的道路。"
2.1 产品功能
Cohere 为各种阅读和写作任务训练大型语言模型 (LLMs),例如摘要、内容创建和情感分析。
其语言模型针对三个主要用例进行了优化:
- 检索文本(retrieving text)
- Embed(嵌入)
- Semantic Search(语义搜索)
- Rerank(重新排名)
- 生成文本(generating text)
- Summarize(总结)
- Generate(生成)
- Command Model:遵循业务应用程序的用户命令
- 分类文本(classifying text)

根据您的隐私 / 安全要求,有多种方式可以访问 Cohere:
- Cohere 的 API:这是最简单的选择,只需从仪表板中获取一个 API 键,并开始使用 Cohere 托管的模型。
- 云人工智能平台:此选项提供了易用性和安全性的平衡。您可以在各种云人工智能平台上访问 Cohere,如 Oracle 的 GenAI 服务、AWS 的 Bedrock 和 Sagemaker 平台、谷歌云和 Azure 的 AML 服务。
- 私有云部署:Cohere 的模型可以在大多数虚拟私有云(VPC)环境中进行私有部署,提供增强的安全性和最高程度的定制。有关信息,请联系销售人员。

2.2 商业模式
Cohere 承担着构建每个模型的大量前期成本和持续的推理成本。
它通过基于使用量的定价来收回成本,并提供三种不同的定价等级:
- 免费:访问所有 Cohere API 端点,并限速使用,用于学习和原型设计。
- 产品:增加对所有 Coheres API 端点的访问速率限制、增强客户支持以及根据提供的数据训练自定义模型的能力。
Cohere 根据其所有 API 端点的 Token 数量(Token 基本上是数字、字母或符号)进行收费,端点的价格各不相同,从每个 Token 0.0000004 美元(嵌入)到 0.001 美元(重新排序)不等。 - 企业:专用模型实例、最高级别的支持和自定义部署选项。企业级的定价未公开。
2.3 Cohere Rerank 3
Cohere Rerank 是在业界被广泛使用的重排工具,它通常集成在 LangChain 和 LlamaIndex 框架中,使用相对简单。
其背后公司 Cohere 的来头不简单。Cohere 成立于 2019 年,由曾在 Google Brain 和 Cortex 工作的研究人员和工程师创立,其联合创始人之一 Aidan Gomez,是 Transformers 架构的作者之一。
根据不完全统计,Cohere 累计融资已经超过 4.45 亿美元。今年 3 月,还爆出 Cohere 的新一轮融资已进入后期谈判阶段,筹集超 5 亿美元资金,估值有望达到 50 亿美元。
今年 4 月, Cohere 发布了 Rerank 3,各方面都提升了不少,包括:
-
4k 上下文长度可显著提高较长文档的搜索质量
-
能够搜索多方面和半结构化数据,如电子邮件、发票、JSON 文档、代码和表格
-
覆盖 100 多种语言
-
改善延迟并降低总体拥有成本 (TCO)
不过,它是商业闭源的。原本每 1000 次搜索,用户需要花费 1 美元,在升级到 Rerank 3 之后,每 1000 次搜索,需要 2 美元。
2.4 Cohere 使用
Cohere 为各种阅读和写作任务训练大型语言模型 (LLMs),例如摘要、内容创建和情感分析。其语言模型针对三个主要用例进行了优化:检索文本(retrieving text)、生成文本(generating text)和分类文本(classifying text)。
Cohere 为企业提供 API 端点,以利用其 LLMs 和许多部署选项,使企业能够通过 AWS 等云合作伙伴或 Cohere 的托管云安全地存储数据。为了更高效地帮助其 LLMs 客户,Cohere 还提供定制模型培训服务。
- 官网 : https://cohere.com
- github : https://github.com/cohere-ai/cohere-python
- 文档:https://docs.cohere.com
基于 Cohere AI 实现语义搜索
准备
1、安装库
pip install cohere2、获取 秘钥
import cohere
import numpy as np
import re
import pandas as pd
from tqdm import tqdm
from datasets import load_dataset
import umap
import altair as alt
from sklearn.metrics.pairwise import cosine_similarity
from annoy import AnnoyIndex
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_colwidth', None)
api_key = ''
co = cohere.Client(api_key)-
获取问题分类数据集
这里将使用 trec 数据集来演示,trec 数据集由问题及其类别组成。
# 获取数据集 dataset = load_dataset("trec", split="train") # 将其导入到pandas的dataframe中,只取前1000行 df = pd.DataFrame(dataset)[:1000] # 预览数据以确保已正确加载 df.head(10) -
文档嵌入
可以使用 Cohere 对问题文本进行嵌入。
使用 Cohere 库的 embed 函数对问题进行嵌入。生成一千个这样长度的嵌入大约需要 15 秒钟。
# 获取嵌入 embeds = co.embed(texts=list(df['text']), model="large", truncate="RIGHT").embeddings # 检查嵌入的维度 embeds = np.array(embeds) embeds.shape -
使用索引和最近邻搜索进行搜索
使用 annoy 库的 AnnoyIndex 函数,一种优化快速搜索的方式存储嵌入。
在给定集合中找到距离给定点最近(或最相似)的点的优化问题被称为最近邻搜索。
这种方法适用于大量的文本(其他选项包括 Faiss、ScaNN 和 PyNNDescent)。
构建索引后,我们可以使用它来检索现有问题的最近邻,或者嵌入新问题并找到它们的最近邻。
# 创建搜索索引,传入嵌入的大小 search_index = AnnoyIndex(embeds.shape[1], 'angular') # 将所有向量添加到搜索索引中 for i in range(len(embeds)): search_index.add_item(i, embeds[i]) search_index.build(10) # 10 trees search_index.save('test.ann') -
查找数据集中示例的邻居
如果我们只对数据集中的问题之间的距离感兴趣(没有外部查询),一种简单的方法是计算我们拥有的每对嵌入之间的相似性。
# 选择一个示例(我们将检索与之相似的其他示例) example_id = 7 # 检索最近的邻居 similar_item_ids = search_index.get_nns_by_item(example_id,10, include_distances=True) # 格式化并打印文本和距离 results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'], 'distance': similar_item_ids[1]}).drop(example_id) print(f"问题:'{df.iloc[example_id]['text']}'\n最近的邻居:") results -
查找用户查询的邻居
我们可以使用诸如嵌入之类的技术来找到用户查询的最近邻居。
通过嵌入查询,我们可以衡量它与数据集中项目的相似性,并确定最近的邻居。
query = "世界上最高的山是什么?" # 获取查询的嵌入 query_embed = co.embed(texts=[query], model="large", truncate="RIGHT").embeddings # 检索最近的邻居 similar_item_ids = search_index.get_nns_by_vector(query_embed[0],10, include_distances=True) # 格式化结果 results = pd.DataFrame(data={'texts': df.iloc[similar_item_ids[0]]['text'], 'distance': similar_item_ids[1]}) print(f"问题:'{query}'\n最近的邻居:") results
参考链接:
-
硅谷科技评论:Cohere,为企业提供大模型
https://mp.weixin.qq.com/s/H-FNecz6rhfVkWg_ayoKKg -
如何使用 Cohere AI 文本嵌入技术实现语义搜索
https://mp.weixin.qq.com/s/wWeYopgO3t6vyjHlA85sBQ -
每个人都能做 NLP 开发:cohere 及开源平替测试
https://www.bilibili.com/video/BV1ov4y1U7Au/
3.BGE Re-Ranker v2.0

近日,智源团队再度推出新一代检索排序模型 BGE Re-Ranker v2.0,同时扩展向量模型 BGE 的 "文本 + 图片" 混合检索能力。
-
BGE Re-Ranker v2.0 支持更多语言,更长文本长度,并在英文检索基准 MTEB、中文检索基准 C-MTEB、多语言检索基准 MIRACL、LLaMA-Index Evaluation 等主流基准上取得了 state-of-the-art 的结果。
-
BGE Re-Ranker v2.0 借助分层自蒸馏策略进一步优化推理效率,适度的开销即可换取显著的性能收益。
-
BGE-v1.5、BGE-M3 以融入 visual token 的方式进一步新增 "文本 + 图片" 混合检索能力,同时保持优异的文本检索性能。
上述模型现已通过 Hugging Face、Github 等平台发布,采用免费、商用许可的开源协议:
https://github.com/FlagOpen/FlagEmbedding
3.1 技术亮点
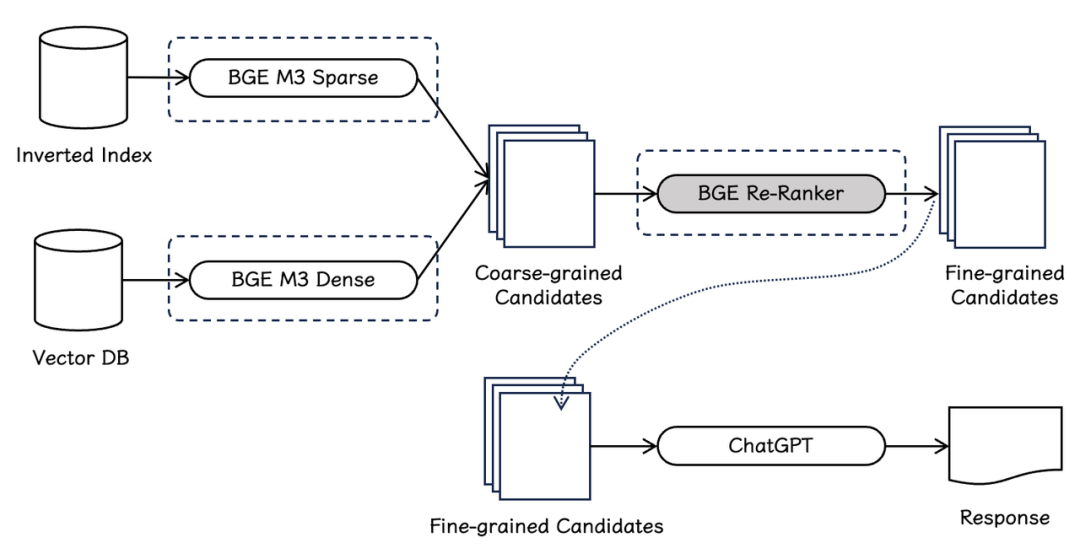
图 1 RAG pipline如图 1 所示,检索排序模型是信息检索及 RAG pipeline 中的重要组成部分。与向量模型与稀疏检索模型相比,检索排序模型会利用更加复杂的判定函数以获得更加精细的相关关系。通常,系统会首先借助向量模型(BGE-M3-Dense)与稀疏检索模型(BGE-M3-Sparse)分别从向量数据库与倒排索引中初步获取粗力度的候选文档(coarse-grained candidates)。紧接着,系统会进一步利用排序模型(BGE Re-Ranker)进一步过滤候选集,并最终获得精细的文档集(fine-grained candidates),以支持下游大语言模型完成检索增强任务(RAG)。
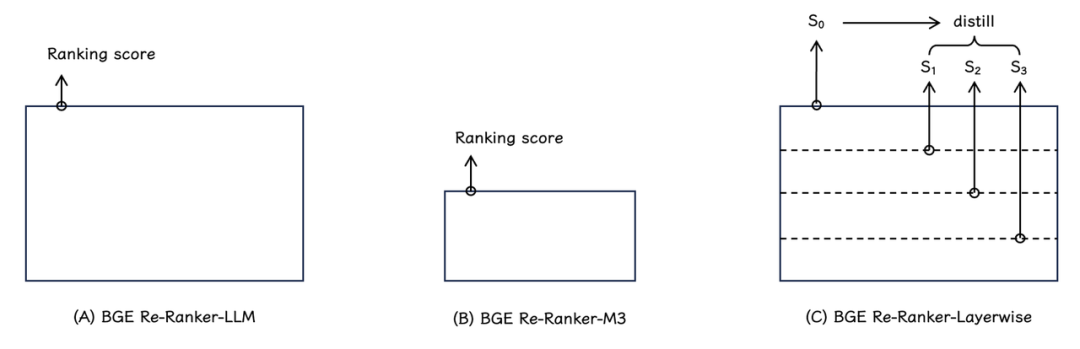
图 2-
BGE Re-Ranker v2.0 系列排序模型采用了两种不同尺寸的模型基座:
-
BGE Re-Ranker v2-LLM(如图 2A):基于 MiniCPM-2B,Gemma-2B 等性能卓越的轻量化大语言模型。
-
BGE Re-Ranker v2-M3(如图 2B) :基于性能出色、参数量更小的 BGE-M3-0.5B 速度更快。
-
所有模型均通过多语言数据训练产生,具备多语言检索的能力 。例如:BGE Re-Ranker v2-MiniCPM-2B 大幅提升了中英文检索能力,而 BGE Re-Ranker v2-Gemma-2B 与 BGE Re-Ranker v2-M3 则在多语言检索任务中取得了最佳的检索效果(注:BGE Re-ranker v2.0 系列模型训练数据配比见 GitHub 仓库说明)。
-
为了进一步提升模型推理效率,BGE Re-Ranker v2.0 采取了分层自蒸馏训练策略(如图 2C) 。具体而言,模型最终排序得分(S(0))被用作教师信号,利用知识蒸馏的方式,模型的各中间层也被学习并赋予了排序能力。在实际应用中,用户可以基于具体场景的算力条件及时延限制灵活选择排序模型的层数。
-
BGE 系列向量模型扩展 "文本 + 图片" 混合检索功能 。通过引入由 CLIP 模型所生成的 visual token,BGE 得以获得 "文本 + 图片" 混合建模能力。值得注意的是,扩增 visual token 的训练仅仅作用在 visual tokenizer 之上,而原本的 BGE 模型(BGE v1.5,BGE M3)参数保持不变。因此,在获得混合建模能力的同时,BGE 模型出色的文本检索能力得以完全保持。
3.2 性能评测
BGE Re-Ranker v2.0 系列模型在英文、中文、多语言主流基准的检索性能评测结果如下:
1. 英文检索评测基准
英文评测 MTEB/Retrival 结果如下(表 1):
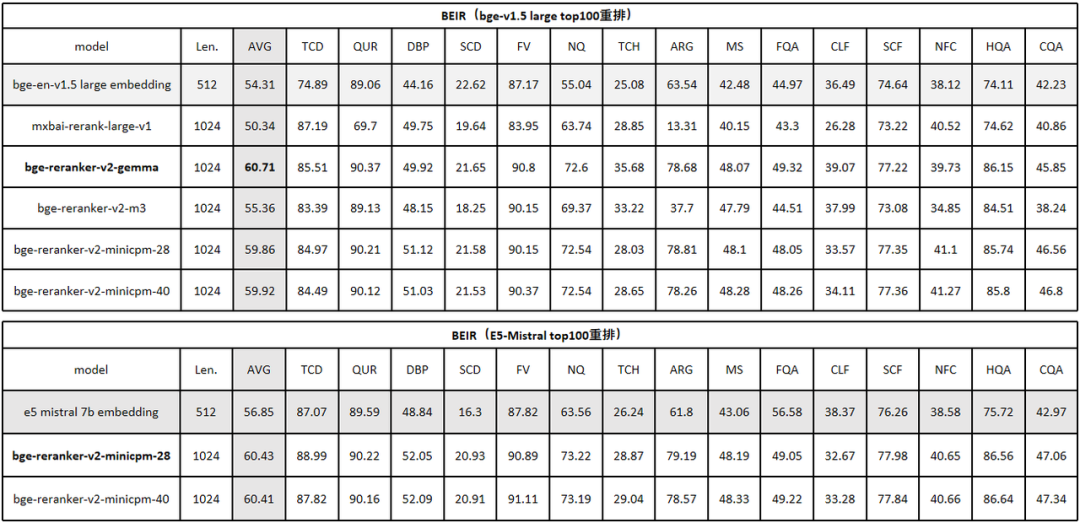
BGE Re-Ranker v2 首先对 BGE-v1.5-large 的 top-100 候选集进行重排。实验结果显示,BGE Re-Ranker v2-Gemma-2B 取得了最为出色的效果,检索精度得以大幅提升 6% 。与此同时,通过分层自蒸馏策略获得的中间层排序结果(BGE Re-Ranker v2-MiniCPM-28 vs. BGE Re-Ranker v2-MiniCPM-40)很好的保持了最终层的检索精度。此外,在切换至性能更为出色的向量模型 E5-Mistral-7B 之后(仍旧重拍其 top-100),检索精度获得了进一步提升,平均检索等分(NGCG@10)达到了 60.4,相较原本的 embedding-only 的结果 56.85 提升了近 4%,这一结果也是目前 BEIR 基准上的最佳评测结果。12。
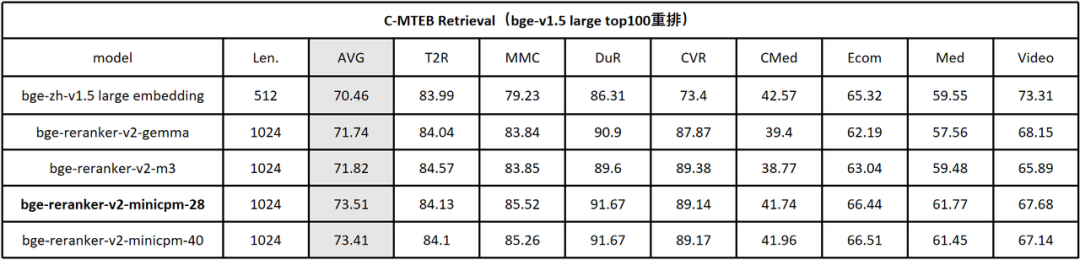
2. 中文检索评测基准
在中文评测 C-MTEB/Retrival 中,BGE Re-Ranker v2 同样对 BGE- v1.5-large 的 top-100 候选集进行重排。与英文结果相类似,BGE Re-Ranker v2-MiniCPM-2B 取得了最优检索质量,且中间层排序结果(BGE Re-Ranker v2-MiniCPM-2B-layer 28)仍旧充分保持最终层的检索精度。
3. 多语言检索评测基准
在多语言评测 MIRACL 中(表 3),BGE Re-Ranker v2 对 BGE-M3 的 top-100 候选集进行重排。与先前结果不同的是,BGE Re-Ranker v2-Gemma-2B 综合效果位居首位,而 BGE Re-Ranker v2-M3 则以较小的模型尺寸(0.5B)取得了与之相近的效果。上述结果也反映了各个预训练模型基座在不同语言下的性能差异。

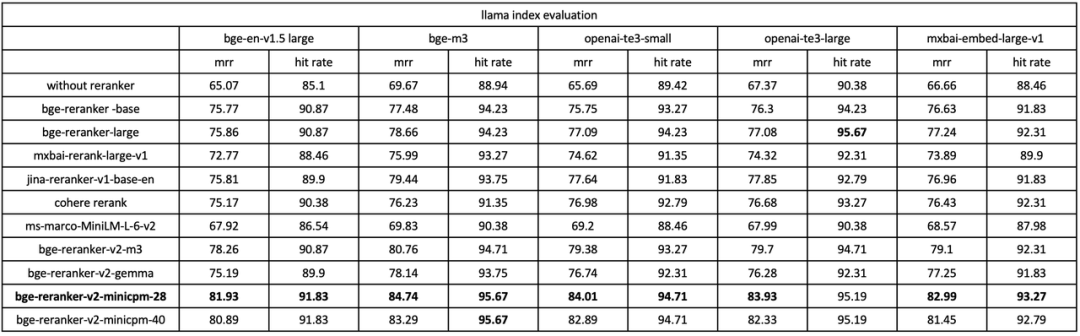
4. RAG 评测基准
在 Llama Index 所提供的 RAG 评测基准中 3,我们使用 BGE Re-Ranker v2 及多种 baseline re-ranker 对不同的 embedding 模型 (bge v1.5 large, bge-m3, openai-te3, mxbai-embedding) 的召回结果进行重排。如下表所示(表 4),BGE Re-Ranker v2 可以大幅提升各个 embedding model 在 RAG 场景下的精度。同时,BGE Re-Ranker v2 搭配 bge-m3 可以获得最佳的端到端检索质量。
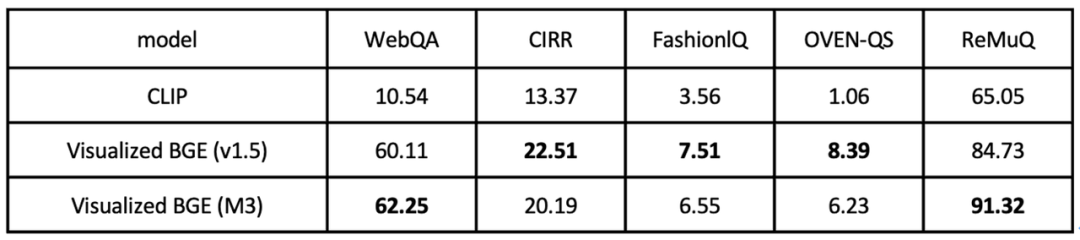
5. "文本 + 图片" 混合评测基准
最后,在 "文本 + 图片" 混合检索的任务中(表 4),Visualized BGE 在 WebQA、CIRR、FashionlQ、OVEN-QS、ReMuQ 等五个常用评测基准上取得了对比 CLIP baseline 的显著优势。
3.3 BGE 社区生态
得益于 BGE 出色的性能与良好的通用性,行业内主流的向量数据库纷纷跟进 BGE 的各个模型版本。此前备受欢迎的 BGE-M3 模型已被 Vespa、Milvus 等框架集成,为社区用户快速搭建 "三位一体的"(稠密检索、稀疏检索、重排序)检索流水线带来的极大便利。
1. Vespa 使用示例(详见 4)

2. Milvus 使用示例(详见 5)

参考资料:
1 MTEB Leaderboard, https://huggingface.co/spaces/mteb/leaderboard
2 SFR-Embedding-Mistral, https://blog.salesforceairesearch.com/sfr-embedded-mistral/
3 Llama-Index Evaluation, https://docs.llamaindex.ai/en/latest/optimizing/evaluation/evaluation.html
4 Vespa for BGE M3, https://github.com/vespa-engine/pyvespa/blob/master/docs/sphinx/source/examples/mother-of-all-embedding-models-cloud.ipynb
5 Zilliz for BGE, https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3
4.Jina Reranker
Jina Reranker 是由神经搜索公司 Jina AI 开发。2022 年,Jina AI 完成 A 轮融资,融资总额已经超过 2 亿人民币。其开发的神经搜索框架 Jina 多次登上 GitHub 全球 Trending 排行榜第一名。
Jina Reranker v2 在今年 6 月发布,在速度、多语言支持和功能上都有显著提升,尤其适用于检索增强生成(RAG)场景。

4.1Jina Reranker v2 的主要优势:
-
多语言支持:在 100 多种语言中提供更相关的搜索结果,性能超过 bge-reranker-v2-m3;
-
代理能力:具备最先进的函数调用和文本到 SQL 转换能力,适用于代理 RAG 场景。
-
代码检索:在代码检索任务上表现最佳;
-
极速:推理速度比上一代产品快 6 倍,比同类产品 bge-reranker-v2-m3 快 15 倍。

不同 Reranker 模型在 ToolBench 数据集上的 Recall@3 分数报告。如图所示,Jina Reranker v2 基本达到了最先进的性能水平,并且模型体积减半,速度提升了近 15 倍。
4.2 Jina Reranker v2 的特性:
-
创新需求:弥补嵌入模型在检索精度上的不足。
-
多语言支持:在 MKQA、BEIR 和 AirBench 等基准测试中表现优异。
-
应用场景:在结构化数据查询、函数调用和代码检索方面的应用。
-
推理速度:模型尺寸更小、采用了 Flash Attention 2 技术。
-
训练过程:分四个阶段进行,包括使用英语数据预训练、添加跨语言数据、微调等。
4.3 Jina Reranker v2 的应用方式:
-
通过 Reranker API:使用 Jina Reranker v2 最快捷的方式是通过其 API,无需部署模型,就能轻松提升搜索的相关性和 RAG 的准确性。
-
通过 RAG/LLM 框架集成:Jina Reranker 与现有的 LLM 和 RAG 编排框架集成,只需使用模型名称即可快速集成。
-
Huggingface:Jina AI 开放了(在 CC-BY-NC-4.0 下)对 Hugging Face 上的 jina-reranker-v2-base-multilingual 模型的访问,以用于研究和评估目的。
-
私有云部署:Jina Reranker v2 的预构建私有部署包即将在 AWS Marketplace 和 Azure Marketplace 上线,方便 AWS 和 Azure 用户部署。
Jina Reranker 也是收费的,不过前 100 万个 token 可以免费。10 亿 个 token 是 20 美元,110 亿个 token 要 200 美元。
4.4 Jina Reranker 快速使用
a. 通过 Reranker API
使用 Jina Reranker v2 最快捷的方式是通过其 API,无需部署模型,就能轻松提升搜索的相关性和 RAG 的准确性。
示例 1:对函数调用进行排名
要对最相关的外部函数或工具进行排序,按以下格式组织查询和文档(函数架构)。
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'预期结果如下:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}- 示例 2:对 SQL 查询进行排名
要获取用户查询与数据库表结构的相关性得分,可以使用以下 API 调用示例。
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'预期的响应是:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}b. 通过 RAG/LLM 框架集成
Jina Reranker 与现有的 LLM 和 RAG 编排框架集成,只需使用模型名称即可快速集成。详情请访问各自的文档页面了解如何集成 Jina Reranker v2:jina-reranker-v2-base-multilingual。
Haystack by deepset :在 Haystack 中,可以使用 JinaRanker 类集成 Jina Reranker v2: https://docs.haystack.deepset.ai/docs/jinaranker
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)LlamaIndex :Jina Reranker v2 可作为 JinaRerank 节点后处理器模块使用。https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/JinaRerank/
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)Langchain :利用 JinaRerank 模块,在现有应用程序中集成 Jina Reranker 2,需要使用正确的模型名称来初始化 JinaRerank 模块。具体参考:https://python.langchain.com/v0.2/docs/integrations/document_transformers/jina_rerank/
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")Huggingface
我们还开放了(在 CC-BY-NC-4.0 下)对 Hugging Face 上的 jina-reranker-v2-base-multilingual 模型的访问,以用于研究和评估目的。
要从 Hugging Face 下载并运行模型,请安装 transformers 和 einops:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation使用 Hugging Face token 登录到您的 Hugging Face 帐户:
huggingface-cli login --token <"HF-Access-Token">
下载预训练模型:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # or 'cpu' if no GPU is available
model.eval()定义查询和要重新排序的文档:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]构建句子对并计算相关性分数:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)所得的得分将以浮点数列表形式呈现,每个数值对应着一个文档与查询间的相关性程度,数值越大,表明相关性越强。
rerank 能够将长文本分解为若干小部分,对每个部分与查询的匹配度进行单独评分,最后,将各部分的得分综合起来,形成完整的重排序输出。在这个过程中,max_query_length 和 max_length 参数用于控制文本分割的长度和细度。
results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)该函数不仅返回每个文档的相关性分数,还返回它们的内容和在原始文档列表中的位置。