第9章 硬盘和显卡的访问与控制
该章节模拟操作系统加载应用程序,其中涉及的知识点:段的重定位方法、读取硬盘、控制屏幕光标等。
和主引导扇区程序一样,操作系统也位于硬盘上。
程序通常是分段的,载入内存之后,还要重新计算段地址,这叫作段的重定位。
我们把主引导扇区改造成一个程序加载器。
感觉该章节的难度瞬间就上来了,如果阅读原书籍有不太了解的地方,可以参考该篇札记。
本章代码清单
该章节提供了两个代码文件:
- 一个是加载器,就是把mbr改造成加载器;
- 另外一个就是被加载的用户程序。
程序运行结果就是:mbr加载用户程序,用户程序在页面上打印信息。参考下图:
用户程序的结构
分段、段的汇编地址和段内汇编地址
该章节介绍了NASM编译器分段的方式、align参数、段的汇编地址、获取汇编地址和vstart参数。
分段方式:NASM编译器使用汇编指令"SECTION"或者"SEGMENT"来定义段。
section 段名称
segment 段名称例如:
section header ;定义头部段
section code ;定义代码段
section data ;定义数据段分段主要是方便我们自己管理代码,处理器并不了解。
align参数 :INTEL处理器要求段在内存中的起始物理地址起码是16字节对齐 的,或者说必须是16的倍数,能被16整除。align参数用于指定多少字节对齐。
section header align=16 ;定义头部段,16字节对齐
db 0x01
section code align=16 ;定义代码段,16字节对齐
db 0x02
section data align=16 ;定义数据段,16字节对齐
db 0x03编译查看二进制文件:

下个段开始处一定是可以整除16的。
段的汇编地址 :程序编译后,每个段都位于二进制文件的特定位置,这个位置可以用它相对于文件起始处的距离来衡量,这就是段的汇编地址。段的汇编地址是段的起始位置,它也是段内第一字节的汇编地址。
如上例:
- 0x00000000 第一个段的汇编地址。
- 0x00000010 第二个段的汇编地址。
- 0x00000020 第三个段的汇编地址。
获取汇编地址 :通过 section.段名称.start 可以获取该段汇编地址。
section.header.start ;获取header段的汇编地址
section.code.start ;获取code段的汇编地址
section.data.start ;获取data段的汇编地址上面的代码加一个 test 段 ,分别获取前面3个段的汇编地址:
section header align=16 ;定义头部段,16字节对齐
db 0x01
section code align=16 ;定义代码段,16字节对齐
db 0x02
section data align=16 ;定义数据段,16字节对齐
db 0x03
section test align=16 ;定义测试段,16字节对齐
dd section.header.start ;获取header段的汇编地址
dd section.code.start ;获取code段的汇编地址
dd section.data.start ;获取data段的汇编地址编译后查看二进制文件:

vstart参数:段定义语句还可以包含"vstart="子句,用来定义段开头的地址。
例如:
section header align=16
db 0x01
section code align=16
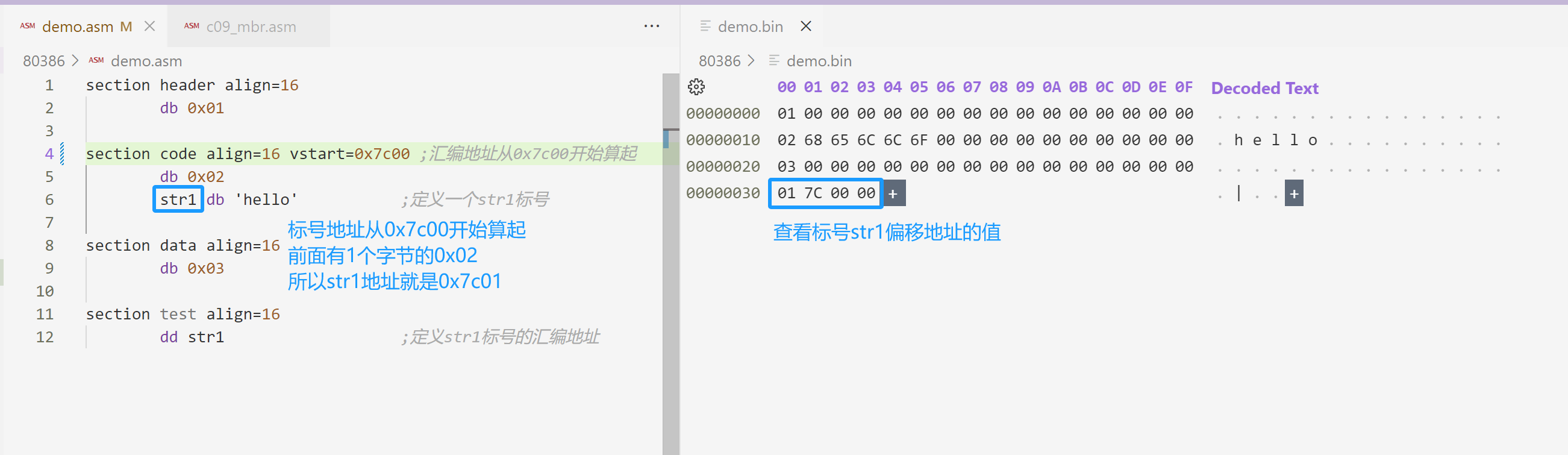
db 0x02
str1 db 'hello' ;定义一个str1标号
section data align=16
db 0x03
section test align=16
dd str1 ;定义str1标号的汇编地址编译查看二进制文件:
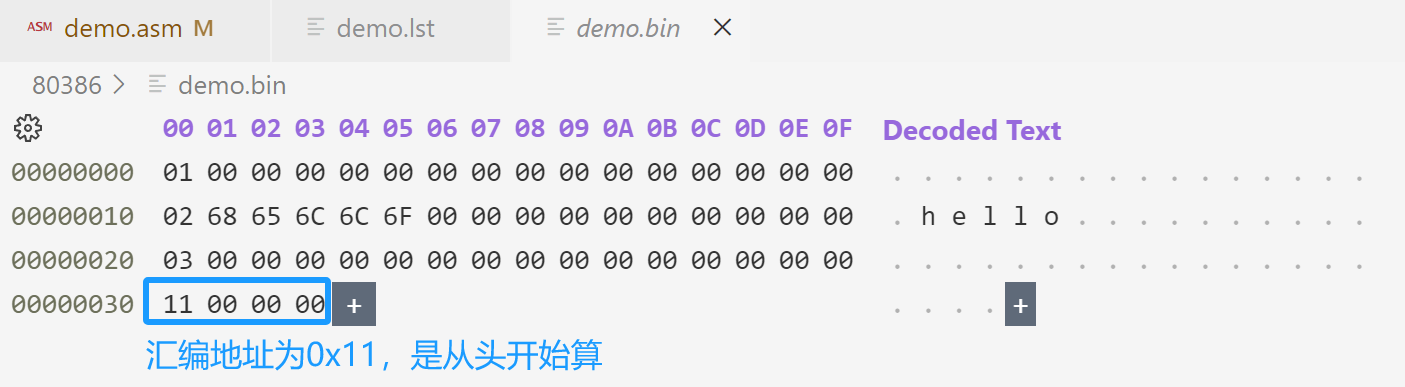
code段增加 vstart=0:
section header align=16
db 0x01
section code align=16 vstart=0 ;汇编地址从0开始算起
db 0x02
str1 db 'hello' ;定义一个str1标号
section data align=16
db 0x03
section test align=16
dd str1 ;定义str1标号的汇编地址编译后再次查看二进制文件:

用户程序头部
该章节介绍了用户程序头部信息,一种加载器知道的信息,这样加载器才能正确加载用户程序。
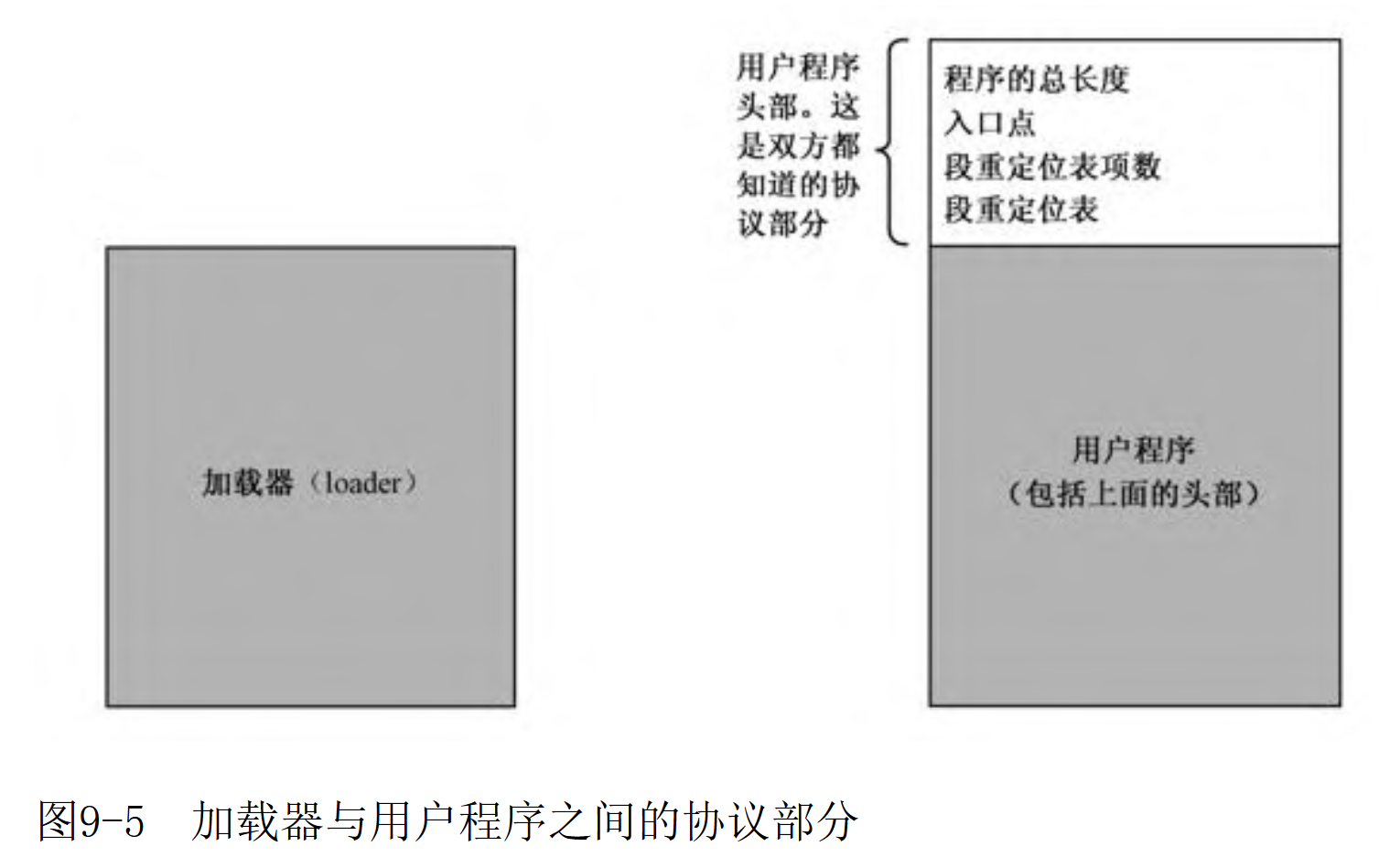
图片来源书籍
声明头部:
SECTION header vstart=0用户程序 头部要包含的信息:
- 用户程序的尺寸,即以字节为单位的大小,加载器在加载程序时,知道程序大小才能知道要读取硬盘几个扇区。在程序中就是 program_end 标号的地址。
书中的代码比较长,不方便理解,用个简单的例子就容易理解了。
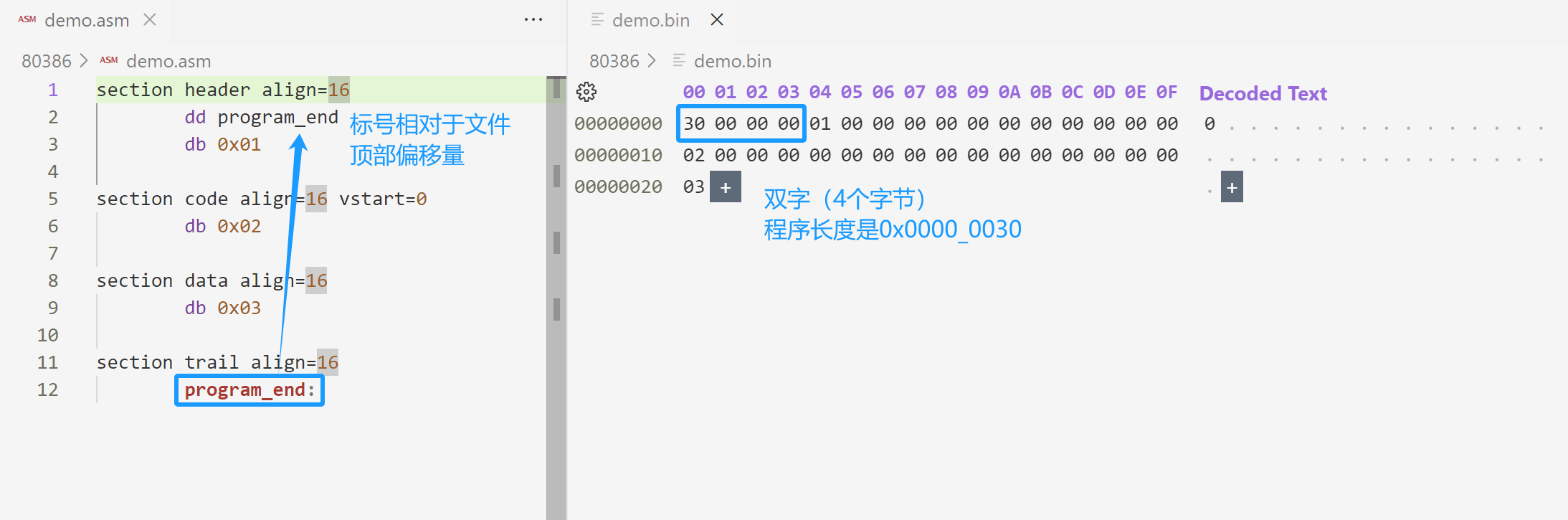
为什么长度是0x0000_0030?因为最后一个段 trail 也是16字节对齐的,汇编地址是 0x00000030 了,只是 trail 段没有内容,就一个标号 program_end,所以二进制文件就啥也看不到了。
- 应用程序的入口点,包括段地址和偏移地址。必须在头部给出第一条指令的段地址和偏移地址,这就是应用程序入口点(Entry Point)。就是程序开始执行的地方。
其实可以理解为高级语言的main函数,就是程序开始执行的地方。
通过一个更简单的示例更容易理解。
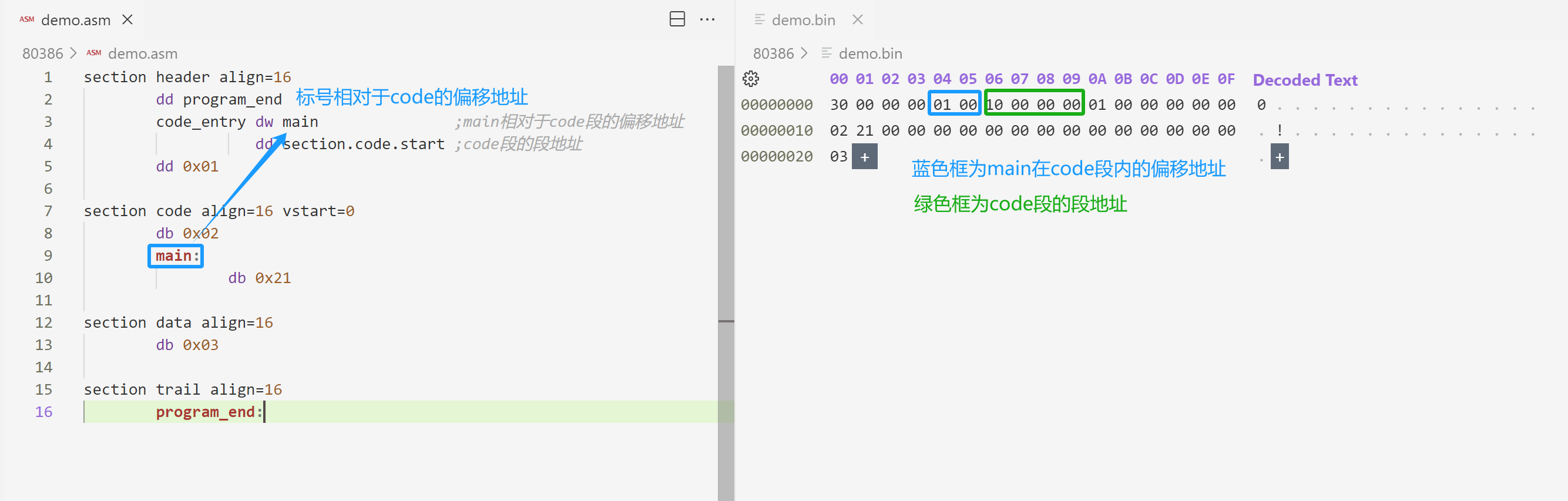
- 段重定位表:用户程序加载到内存中的位置是由加载器决定的,但是用户程序中每个段的汇编地址只有用户程序自己才清楚,所以需要一个重定位表来告知加载器每个段的汇编地址。
还是用个简单的例子说明。
计算重定位表的个数:
; 段重定位表项个数[0x0a]
realloc_tbl_len dw (header_end - code_segment) / 4 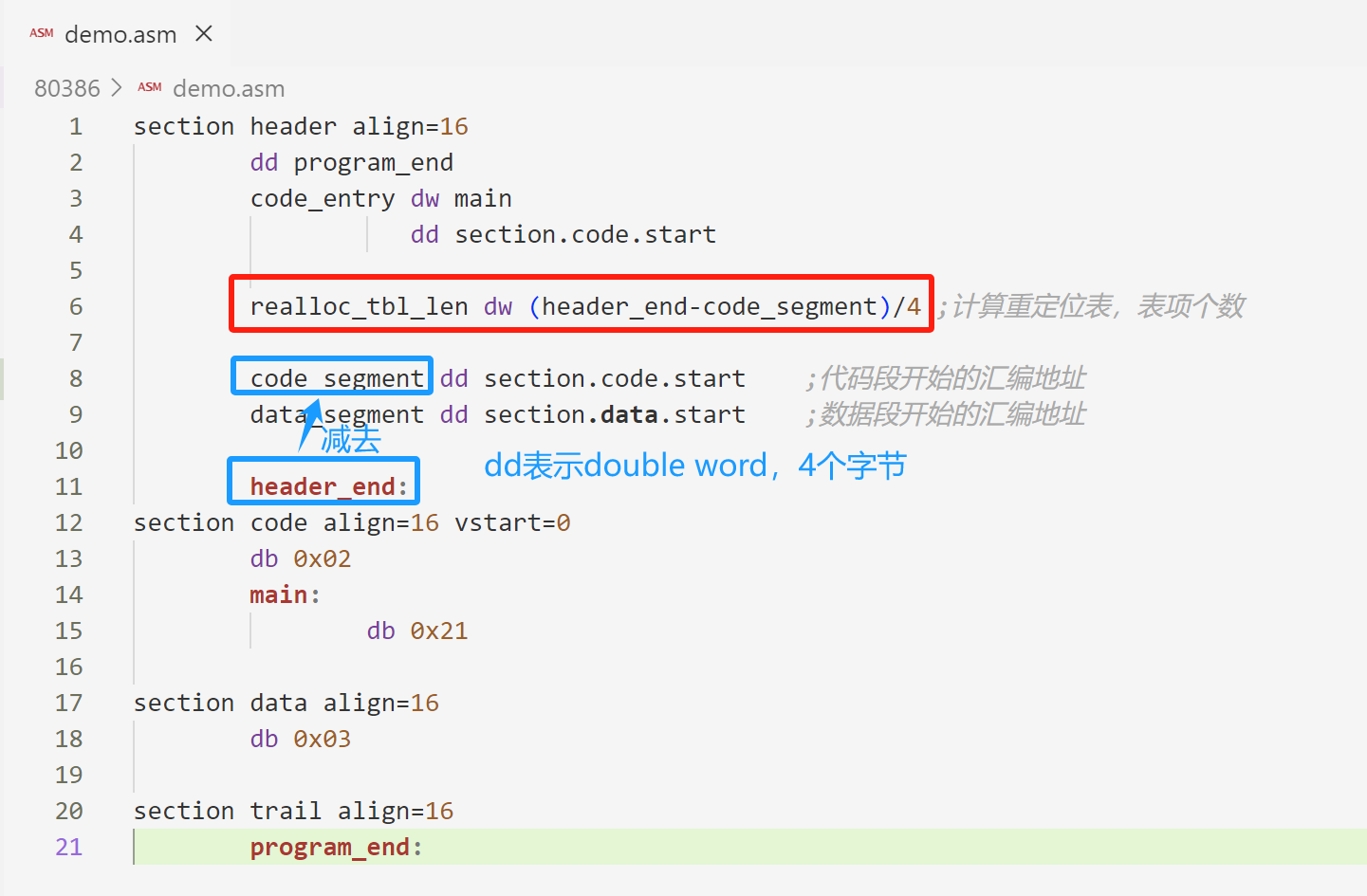
重定位表:
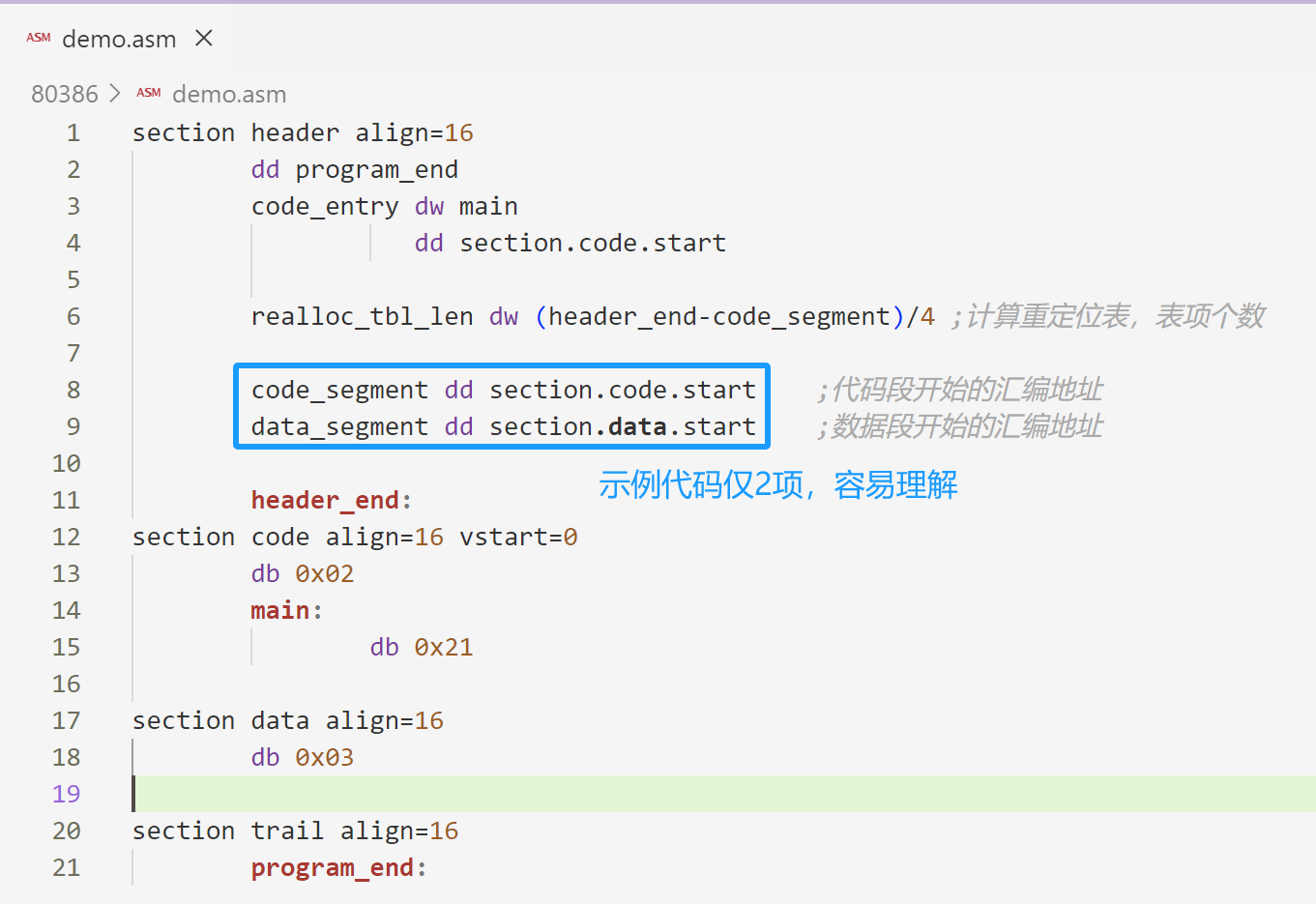
完整示例代码:
section header align=16
dd program_end
code_entry dw main
dd section.code.start
realloc_tbl_len dw (header_end-code_segment)/4 ;计算重定位表,表项个数
code_segment dd section.code.start ;代码段开始的汇编地址
data_segment dd section.data.start ;数据段开始的汇编地址
header_end:
section code align=16 vstart=0
db 0x02
main:
db 0x21
section data align=16
db 0x03
section trail align=16
program_end:加载程序(器)的工作流程
初始化和决定加载位置
加载器要加载一个用户程序,并使之开始执行,需要决定两件事。
- 看看内存中的什么地方是空闲的,即从哪个物理内存地址开始加载用户程序;
- 用户程序位于硬盘上的什么位置,它的起始逻辑扇区号是多少。
用户程序存储地址:加载器程序的一开始声明了一个常数(const)
app_lba_start equ 100 ;用户程序存储在硬盘的逻辑扇区号。其中:
- lba 全称为 Logical Block Addressing ,表示逻辑扇区号。
- equ 为 equal 的简写,表示等于的意思。
不得不再次感叹,英语好学习计算机真的很有帮助。
加载到内存哪里:加载用户程序需要确定一个内存物理地址。
phy_base dd 0x10000 ; 最低四位必须是0,能被16整除准备加载用户程序
我们将主引导扇区程序定义成一个段
SECTION mbr align=16 vstart=0x7c00书中详细说明了为什么从0x7c00开始,画一个图理解就是:
初始化栈段寄存器SS和栈指针SP
;设置堆栈段和栈指针
mov ax,0
mov ss,ax ;栈段为0x0000
mov sp,ax ;栈指针也为0x0000,push一次后则为0x0000-0x2=0xFFFE计算用于加载用户程序的逻辑段地址:
mov ax,[cs:phy_base] ; vstart=0x7c00,所以不用加了
mov dx,[cs:phy_base+0x02]因为 phy_base dd 0x10000,是一个双字(4个字节),所以需要两个寄存器进行存储。 参考下图:
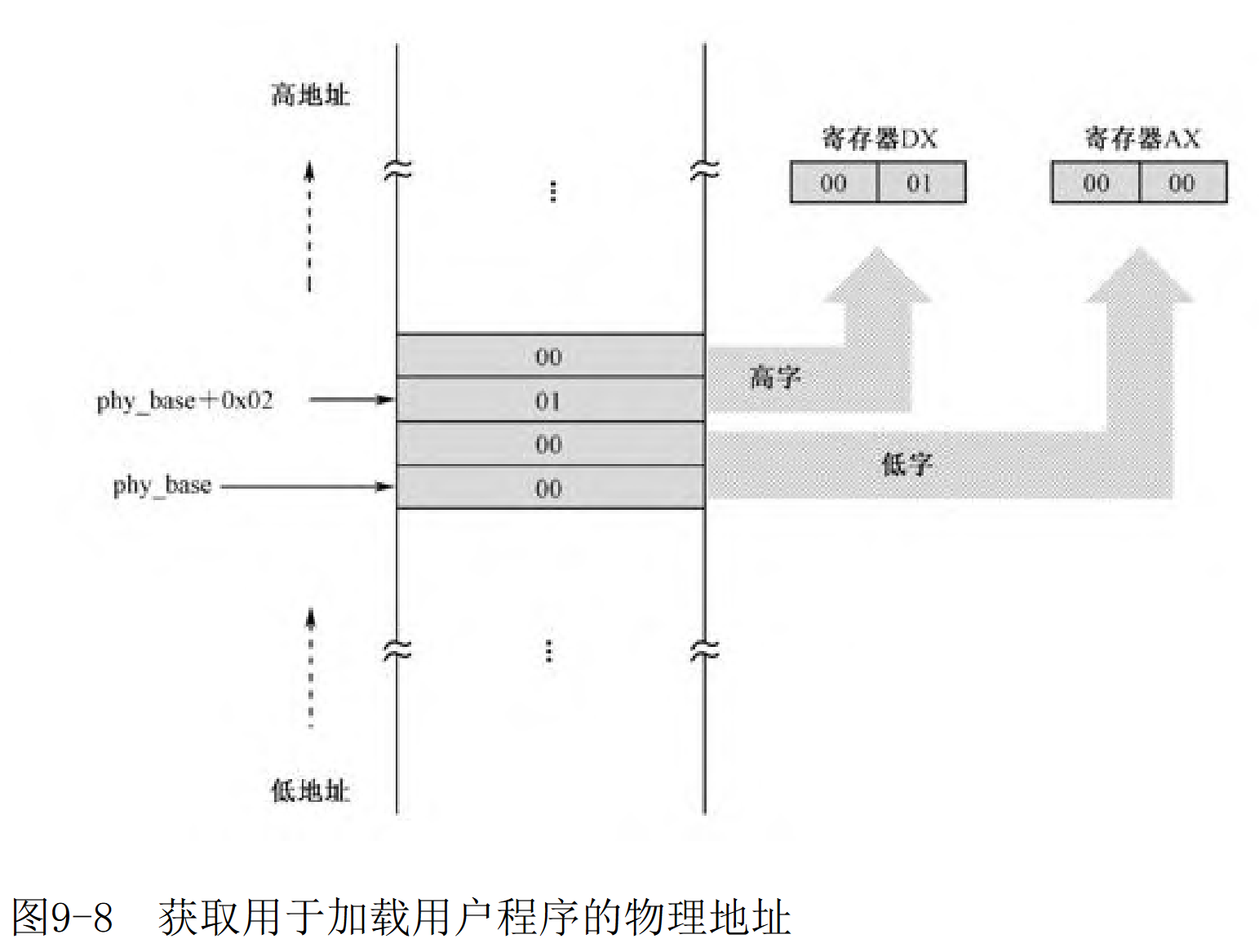
图片来源书籍
将该物理地址除以16,就是该段的段地址,并传送到数据段寄存器DS和ES。
mov bx,16 ;除以16,段地址要16字节对齐
div bx ;运行后,ax存储商,这里为 0x1000
mov ds,ax ;数据段地址
mov es,ax ;附加段地址有时候我觉得 16用0x10 表示 更容易理解,因为前后都是要用16进制,突然冒出一个十进制的,反倒有点懵逼了。
此步执行完成,内存映像为:
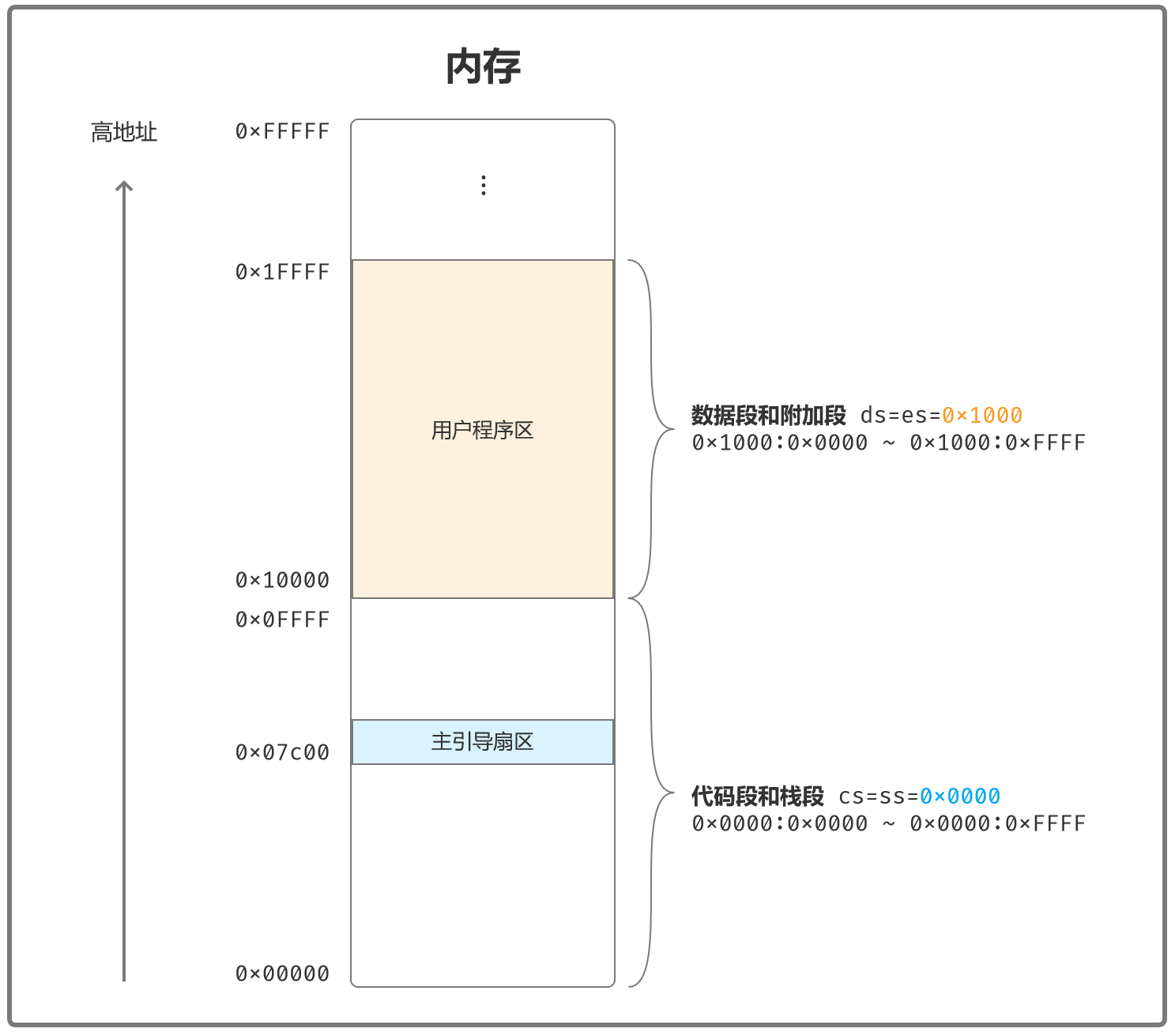
自己画一个内存映像,就可以对程序的整体结构更加清晰。
外围设备及其接口
外围设备(Peripheral Equipment):所有这些和处理器打交道的设备叫作外围设备(Peripheral Equipment)。
输入输出(Input/Output, I/O)设备:输入设备和输出设备统称输入输出设备。
- 输入设备:键盘、鼠标、麦克风、摄像头等;
- 输出设备:显示器、打印机、扬声器等。
I/O接口:每种设备都有自己的工作方式,要和处理器通信就要用到信号转换器和变速齿轮,这就是I/O接口。I/O接口可以是一个电路板,也可能是一块小芯片。
总线(Bus):采用总线技术连接所有外围设备 ,公共电线就称为总线。
输入输出控制设备集中器(I/O ControllerHub, ICH):该芯片的作用是连接不同的总线,并协调各个I/O接口对处理器的访问。在个人计算机上,这块芯片就是所谓的南桥。
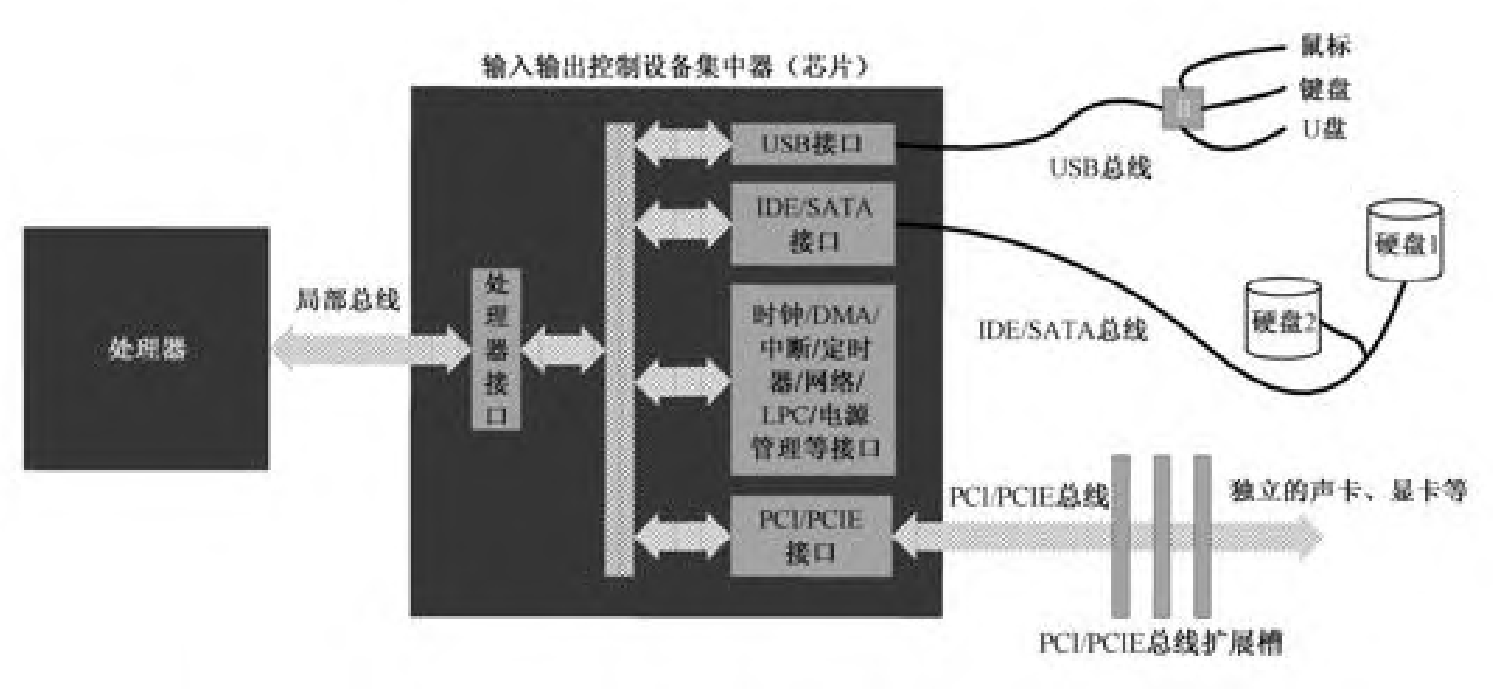
图片来源于书籍
PCI和PCI Express:主板上的扩展插槽,和ICH连接。
I/O端口和端口访问
端口(port):处理器是通过端口(Port)来和外围设备打交道的。本质上,端口就是一些寄存器,类似于处理器内部的寄存器。不同之处仅仅在于,这些叫作端口的寄存器位于I/O接口电路中。
INTEL系统端口:在INTEL的系统中,只允许65536(十进制数)个端口存在,端口号从0到65535(0x0000~0xffff)。
端口访问指令in和out:in指令从端口读,out指令用于写入端口。
in指令是从端口读,它的一般形式是
in al,dx ;从dx存储的端口读入数据,存储到al,端口为1字节。
in ax,dx ;从dx存储的端口读入数据,存储到al,端口为2字节。也可以直接指定端口号:
in al,0xf0 ;从f0端口读入数据,存储到al,端口为1字节。
in ax,0x03 ;从03端口读入数据,存储到ax,端口为2字节。out指令正好和in指令相反,目的操作数可以是8位立即数或者寄存器DX,源操作数必须是寄存器AL或者AX
out 0x37,al ;写入0x37号端口,端口为1字节。
out 0xf5,ax ;写入0xf5号端口,端口为2字节。
out dx,al ;写入dx存储的端口,端口为1字节。
out dx,ax ;写入dx存储的端口,端口为2字节。通过硬盘控制器端口读扇区数据
扇区(Sector):硬盘读写的基本单位是扇区。
CHS模式:从硬盘读写数据,最经典的方式是向硬盘控制器分别发送磁头号、柱面号和扇区号(扇区在某个柱面上的编号)。
LBA28:使用28比特来表示逻辑扇区号,从逻辑扇区0x0000000到0xFFFFFFF,共可以表示2^28=268435456个扇区。每个扇区有512字节,所以LBA28可以管理128 GB的硬盘。
列成算式就是:2^28 * 512=128GB
LBA48:同LAB28,不同之处就是采用48比特来表示逻辑扇区号。可以管理 131072 TB 的硬盘容量。
访问硬盘:书中使用 LBA28 方式访问硬盘。
第1步,设置要读取的扇区数量。这个数值要写入0x1f2端口。
mov dx,0x1f2
mov al,0x01 ;1个扇区
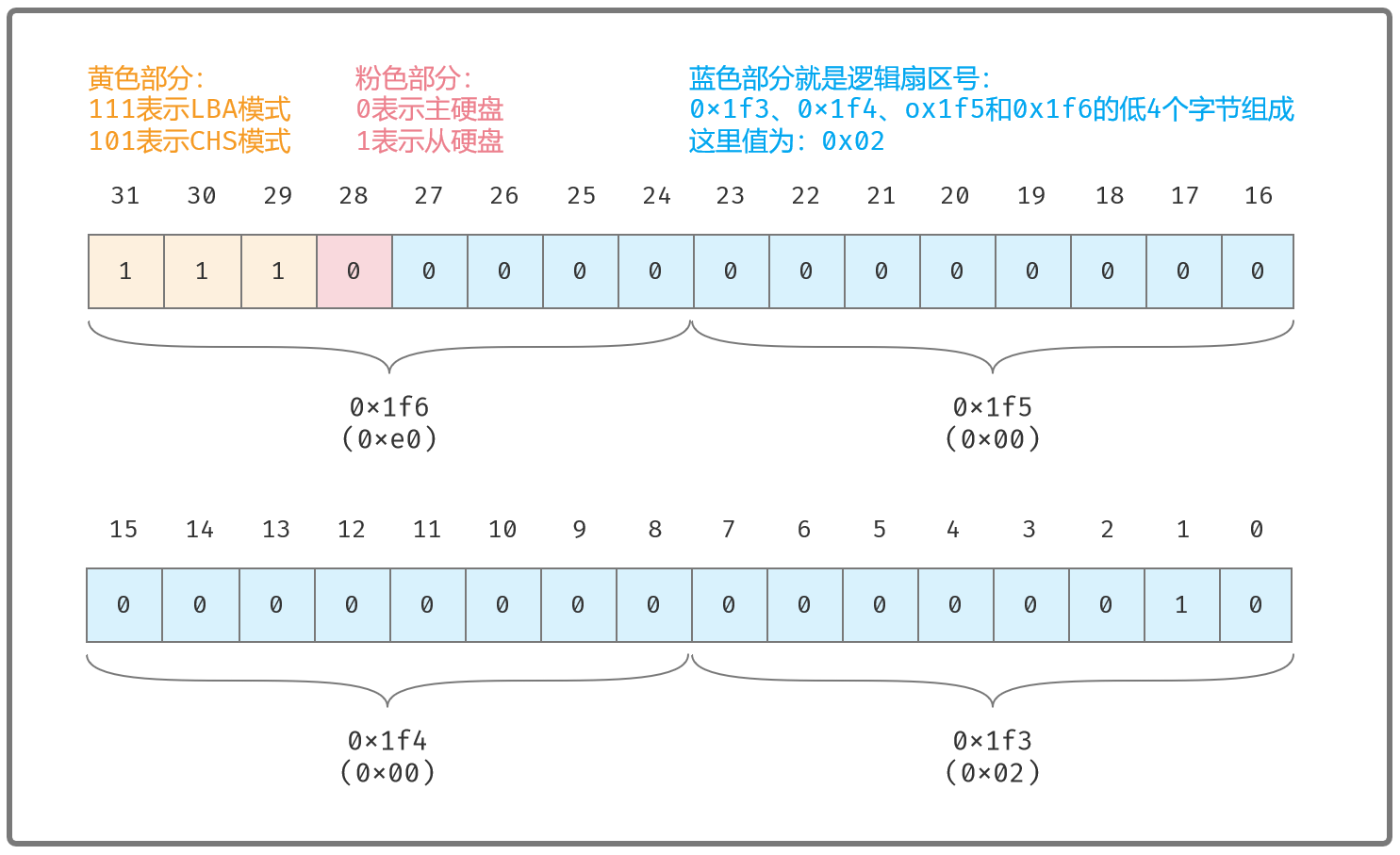
out dx,al第2步,设置起始LBA扇区号。假定我们要读写的起始逻辑扇区号为0x02,可编写代码如下:
;设置起始的LBA扇区号为0x02
mov dx,0x1f3 ;0x1f3
mov al,0x02
out dx,al ; LBA地址7~0
inc dx ; 0x1f4
mov al,0x00
out dx,al ; LBA地址15~8,将AL中的数据写入到8位端口中
inc dx ; 0x1f5
out dx,al ; LBA地址23~16
inc dx ; 0x1f6
mov al,0xe0 ; LBA模式,主硬盘,以及LBA地址27~24,1110 0000
out dx,al0x1f3~0x1f6 的端口表示画图如下:
第3步,向端口0x1f7写入0x20,请求硬盘读。
mov dx,0x1f7
mov al,0x20 ; 读命令
out dx,al第4步,等待读写操作完成。端口0x1f7既是命令端口,又是状态端口。
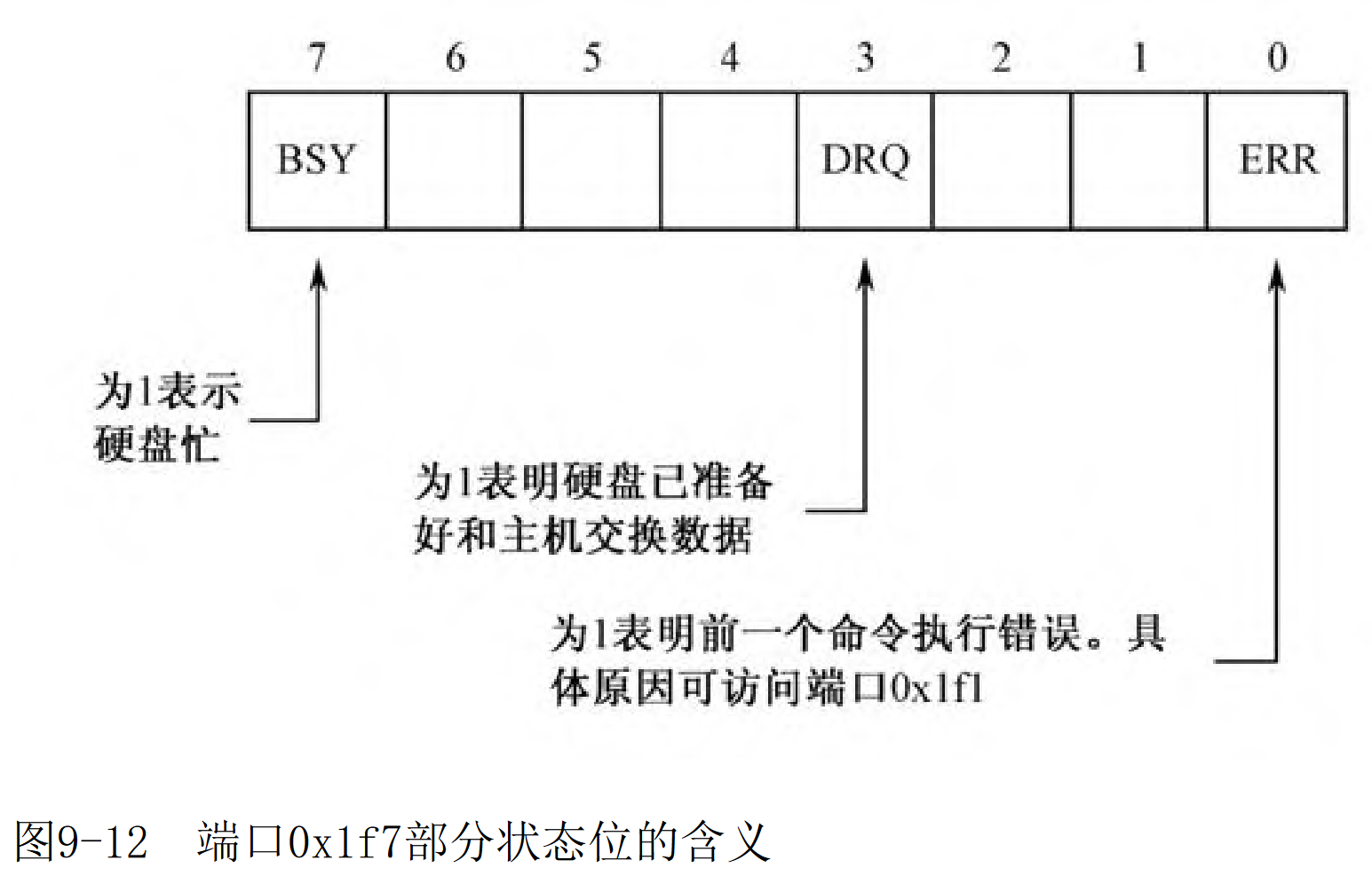
图片来源于书籍
mov dx,0x1f7
.waits:
in al,dx ;从8位I/O端口读取数据到AL
and al,0x88 ;1000_1000,将al第3和第7位除外都清0
cmp al,0x08 ;和 0000_1000 比较,如果相等则ZF=0,不相等ZF=1
jnz .waits ;如果不相等,则继续等待硬盘准备好数据第5步,连续取出数据。0x1f0是硬盘接口的数据端口,而且还是一个16位端口。
mov cx,256 ;总共要读取的字数,一次读取512个字节,总共256个字
mov dx,0x1f0 ;0x1f0端口是16位的端口,一次可以读取2个字节。
.readw:
in ax,dx ;从16位I/O端口读取数据到AX
mov [bx],ax ;存储到 ds:bx 的位置处,从代码上下文看就是0x1000:0x000位置
add bx,2 ;一次读取两个字节,所以加2
loop .readw ;继续读取下一次。第6步,排查错误。0x1f1端口是错误寄存器,包含硬盘驱动器最后一次执行命令后的状态(错误原因)。
如果出现失败,则可以通过该端口排查错误。
!!我在用 Bochs 调试的过程中,一直会处于第4步 等待读写操作完成 中,就是会一直在代码中的 .waits 循环。
查看了 0x1f1 这个端口的数据也都正常。
后来调试了很久,无意见才发现 .waits 多循环几次,读写操作就准备好了,就可以跳出 .waits 循环了。
最后总结一下in指令和out指令:
in指令:
IN AL, PortNumber ; 从8位I/O端口读取数据到AL
IN AX, PortNumber ; 从16位I/O端口读取数据到AX(在某些处理器架构中可能不支持)out指令:
OUT PortNumber, AL ; 将AL中的数据写入到8位I/O端口
OUT PortNumber, AX ; 将AX中的数据写入到16位I/O端口(在某些处理器架构中可能不支持)过程调用
过程 (Procedure)就类似高级语法的方法 或者函数,封装一次,多次调用。
汇编中过程调用通过call指令、过程返回用ret指令、参数传递使用寄存器。
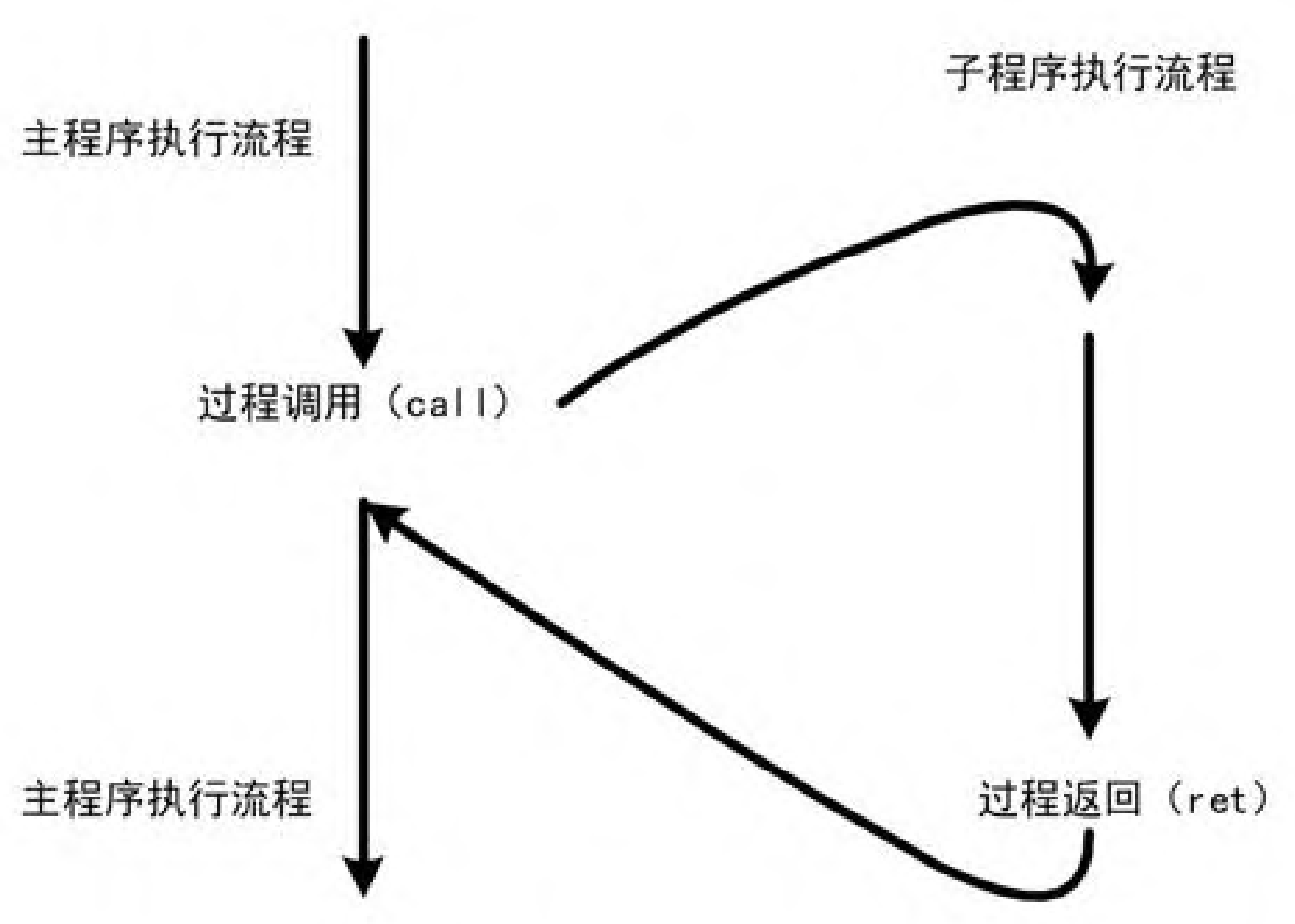
图片来源于书籍
来个简单的例子:
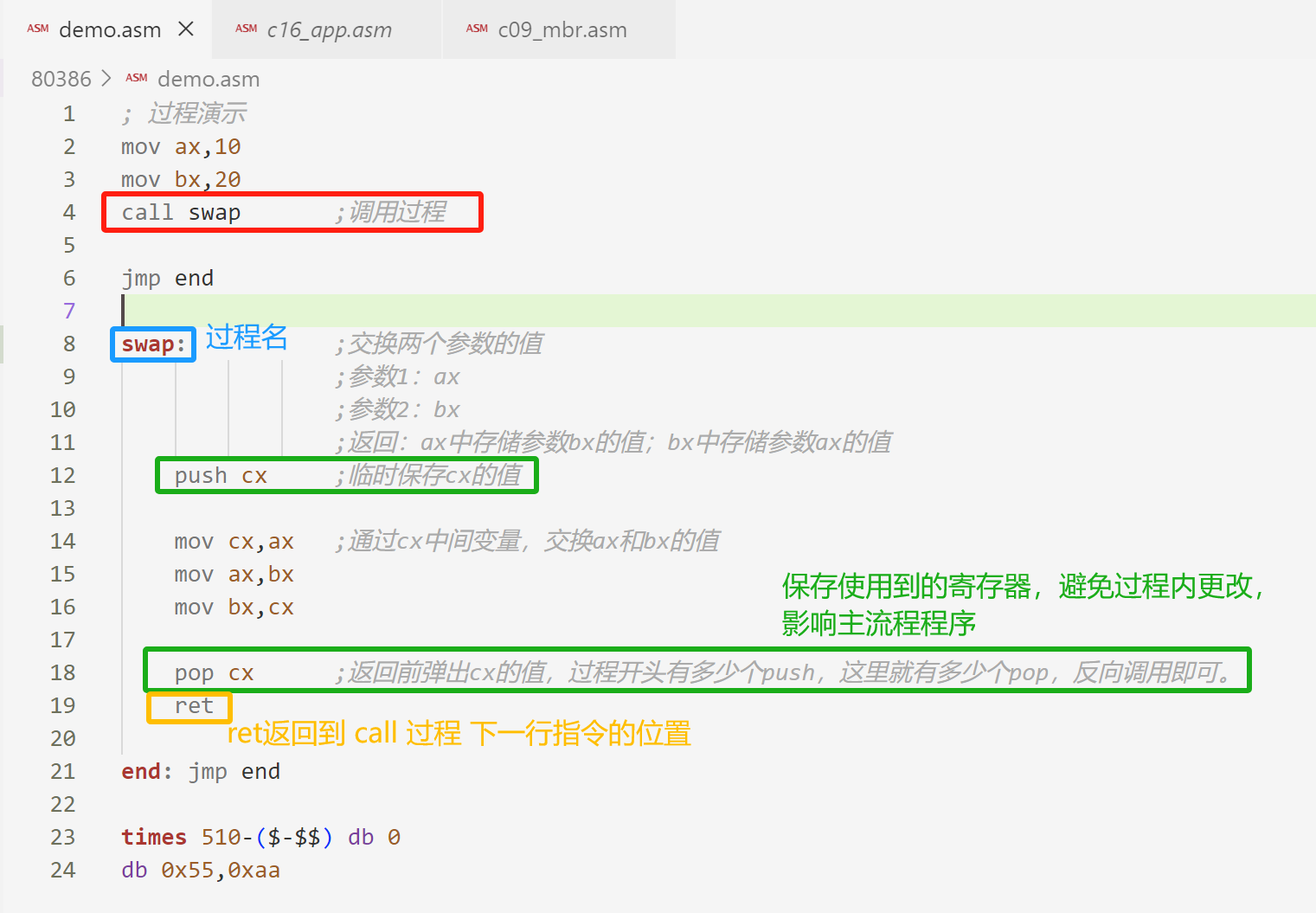
; 过程演示
mov ax,10
mov bx,20
call swap ;调用过程
jmp end
swap: ;交换两个参数的值
;参数1:ax
;参数2:bx
;返回:ax中存储参数bx的值;bx中存储参数ax的值
push cx ;临时保存cx的值
mov cx,ax ;通过cx中间变量,交换ax和bx的值
mov ax,bx
mov bx,cx
pop cx ;返回前弹出cx的值,过程开头有多少个push,这里就有多少个pop,反向调用即可。
ret
end: jmp end
times 510-($-$$) db 0
db 0x55,0xaa代码解释如下:
书中将读取硬盘封装成了一个过程,原理都是类似的。
书中还介绍了 call 指令的四种方式:相对近调用、间接绝对近调用、16位直接绝对远调用、16位间接绝对远调用。
- 相对近调用:被调用的目标过程位于当前代码段内,而非另一个不同的代码段,所以只需要得到偏移地址即可。
例如上面例子的 call swap 就是相对近调用,也可以写成 call near swap, near可以省略。
call操作数的计算规则:目标过程的汇编地址 - 调用过程的下一条指令的汇编地址
上面例子 call swap 指令操作数计算规则参考如下:
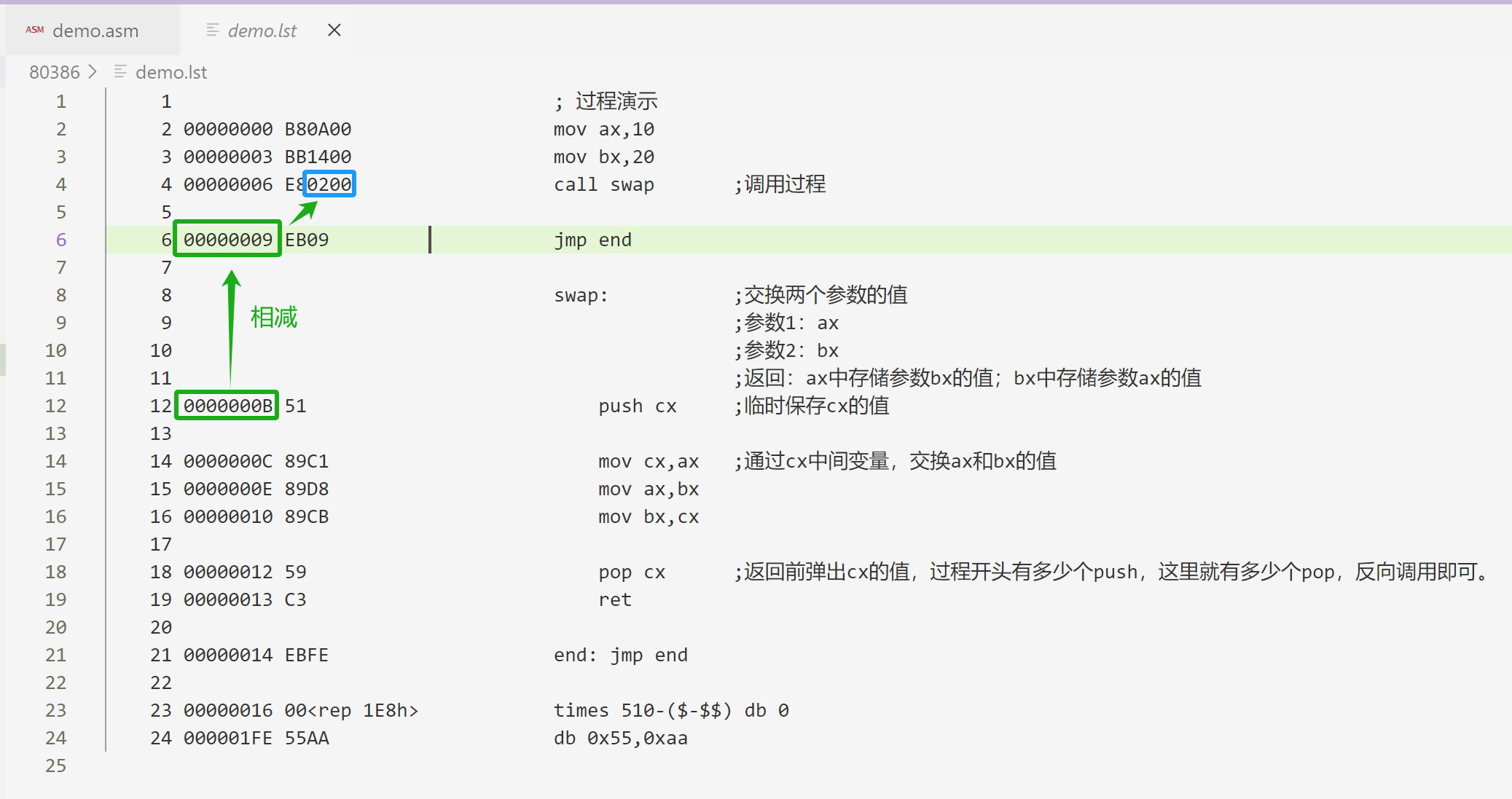
目标过程的汇编地址 - 调用过程的下一条指令的汇编地址
= 0000_000B - 0000_0009
= 0000_0002因为是16位,所以最终就保存为 0200。
程序执行流程:当使用call指令时。
- 将当前IP压入栈中。(IP指向的是下一条指令)
- (IP)=(IP)+call指令操作数。
- call执行完成后,如果有ret指令,则弹出IP,相当于从call指令的下一条指令继续执行。
从上例来看:
- IP入栈:即 0000_0009 入栈;
- (IP)=(IP)+call指令操作数:(IP)=0000_0009 + 0002 = 0000_000B ,即从swap标号处开始执行;
- ret IP出栈:(IP) = 0000_0009,即从call下一条指令 jmp end 开始执行。
-
间接绝对近调用:这种调用也是近调用,只能调用当前代码段内的过程,指令中的操作数不是偏移量,而是被调用过程的真实偏移地址,故称为绝对地址。
call cx ;目标地址在cx中。
call [0x3000] ;目标地址在ds:0x3000的一个字(2个字节)
改进上例可以清晰看到:
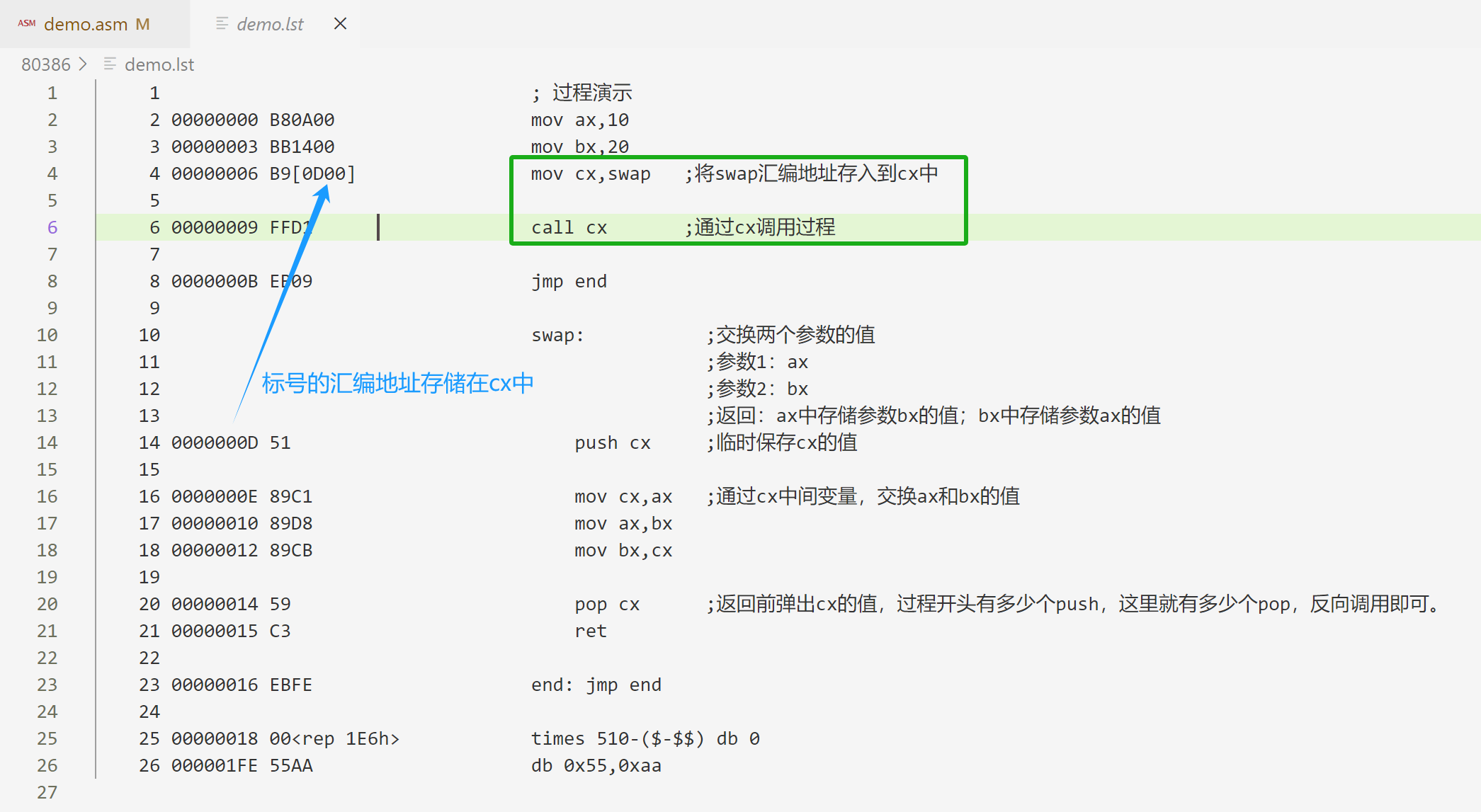
-
16位直接绝对远调用:这种调用属于段间调用,即调用另一个代码段内的过程,所以称为远调用(far call)。直接的意思就是在指令中直接给出段地址和偏移地址。
call 0x2000:0x0030 ;调用0x2000段,偏移地址0x0030的代码
程序执行流程:
- 将当前CS压入栈中。(CS就是段地址)
- 将当前IP压入栈中。(IP就是偏移地址)
- (CS)=指令操作数的段地址。
- (IP)=指令操作数的偏移地址。
- call执行完成后,如果有retf指令,则弹出IP,弹出CS。相当于从call指令的下一条指令继续执行。
-
16位间接绝对远调用:这也属于段间调用,被调用过程位于另一个代码段内,而且,被调用过程所在的段地址和偏移地址是间接给出的,需要用far关键字。
call far [0x2000] ;调用ds:0x2000存储的段地址和偏移地址。
用标号的形式:
proc_1 dw 0x0030,0x2000 ;proc_1标号处有两个字:偏移地址和段地址
......
call far [proc_1] ;通过标号proc_1获取到段地址和偏移地址4种call的方式用表格总结一下更加清晰:

加载用户程序
这边的代码初读很难理解,我绘制了一个流程图方便理解:
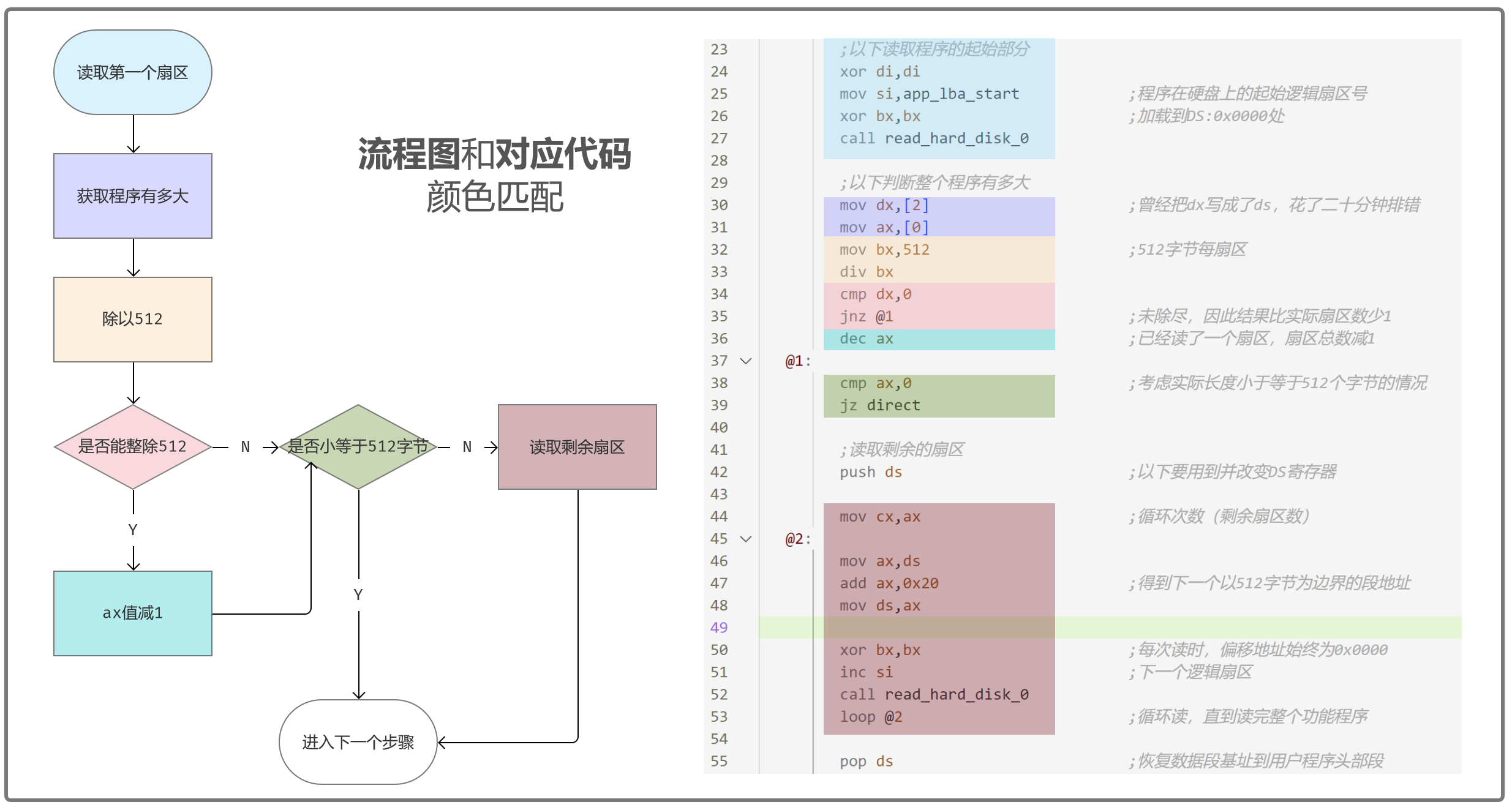
该段程序可以分为七个步骤:
- 读取第一个扇区:这个不是很难理解。
- 获取程序有多大:数据段寄存器 ds 此时已经指向了用户程序;用户程序的前面4个字节就表示程序大小;dx存储大小值的高位,ax存储大小值的低位。
- 除以512:程序读取硬盘代码,每次读取512字节;div指令后,ax保存商、dx保存余数。
- 是否能整除512:就是判断余数(dx中存储)是否为0;如果程序大小不能整除512,那么就要读取1次。
- ax值减1:可以整除512,那么ax中的值就是总读取扇区数;因为前面预读了一个扇区,所以剩余扇区数要减1。
- 是否小于512字节:ax为0表示程序小于等于512个字节,就不用再读磁盘了。
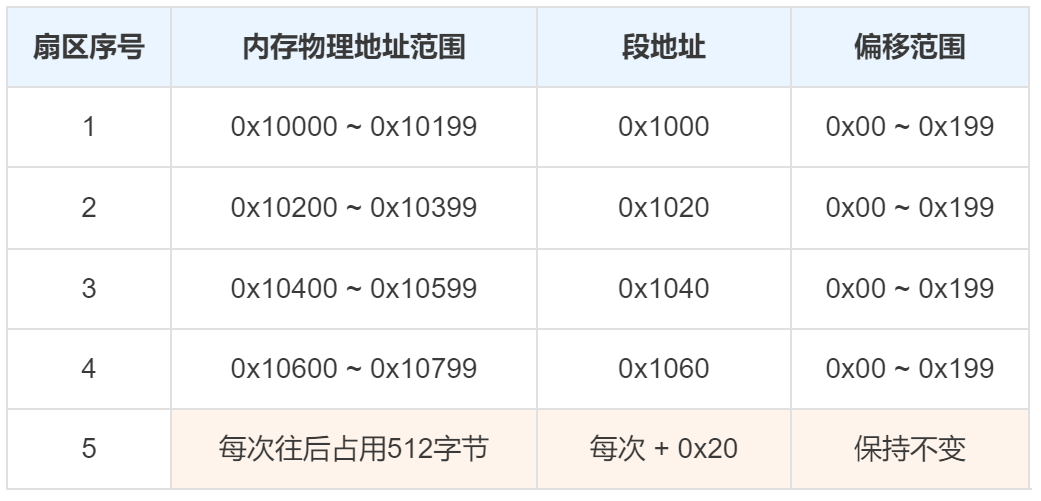
- 读取剩余扇区:程序超过512字节,那么根据还要读取的扇区数(ax中存储的值)继续读取磁盘。
读取剩余扇区这边计算段地址和偏移地址一开始也比较懵,后面多读两次就明白了。 我画了一个表格,看着也就容易理解了。
用户程序重定位
用户程序重定位实际上就是要根据用户程序实际加载到的物理内存地址,计算出用户程序入口点和各段的实际段地址。
就是下面用户程序蓝色框内的各个地址:
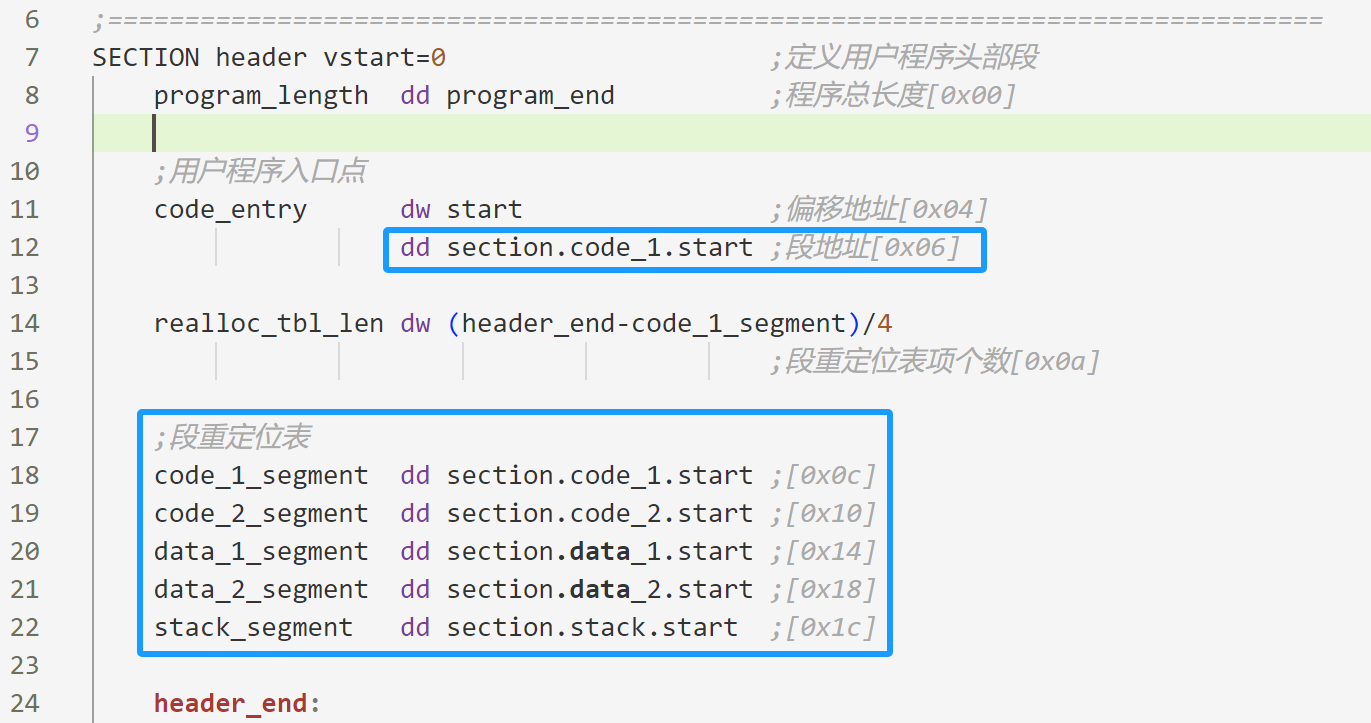
处理的代码在mbr代码中的这一块:

入口点的处理方式和重定位表的处理方式是一样的,所以弄懂1个就行了。
入口点的处理的方法主要看 calc_segment_base 这个过程:
处理的原理:
- 计算各段实际的物理地址:加载的物理起始地址 + 该段的汇编地址。
- 计算段基地址:上步得到的物理地址 除以 0x10(即16)就是各段的段基地址。
关于第1步计算各段实际的物理地址,看这个程序加载内存的映像图就容易理解了。

第2步咋一看挺迷糊的,关键有如下几点;
- 第1步计算完成后,dx保存了段开始物理地址的高位、ax保存了低位。
- 除以0x10(即16),就是右移4位。
要做的事情如下图:
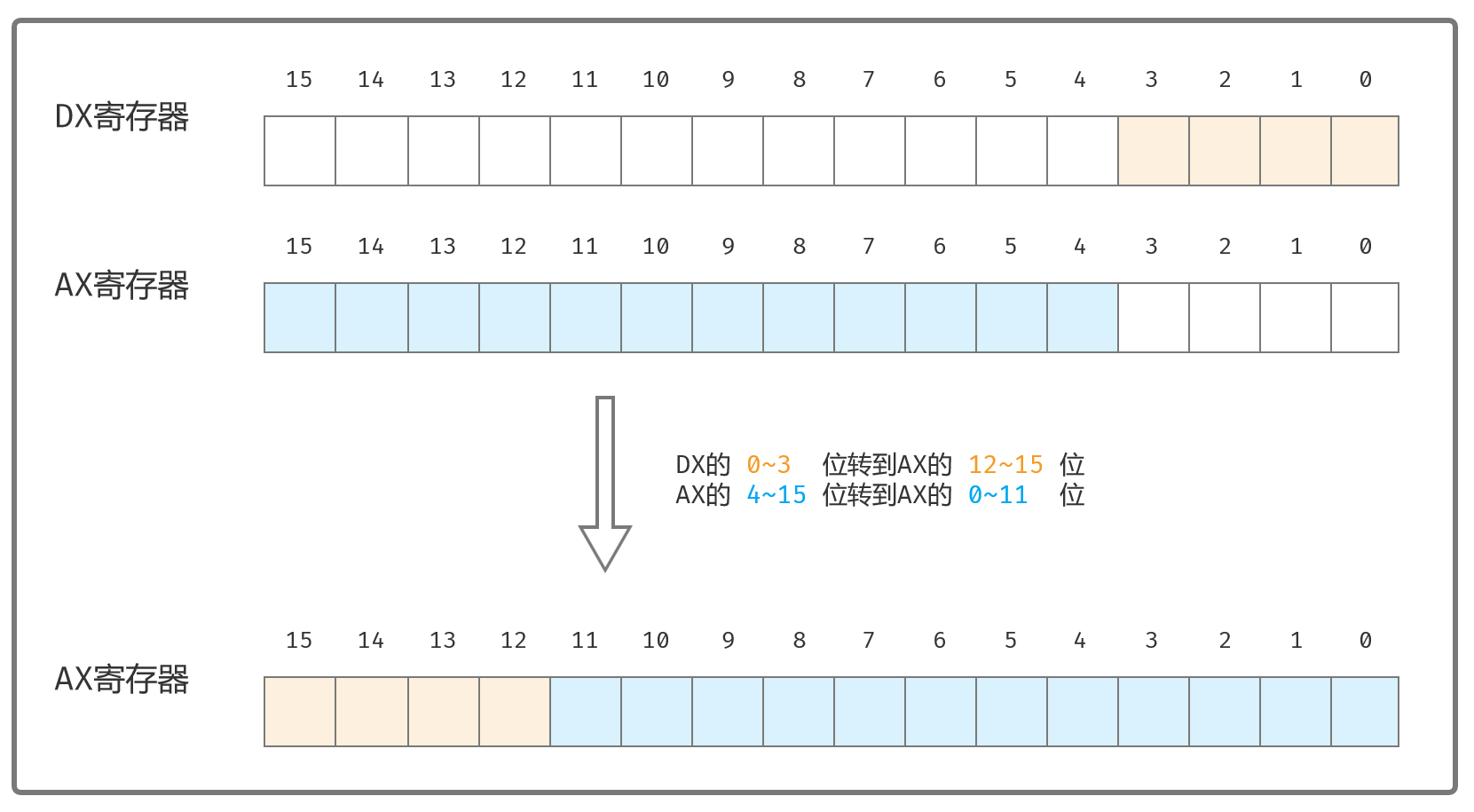
逐步进行解释一下。
处理ax先:
shr ax,4 ;ax右移4位
;shr (Shift Logical Right) 右移指令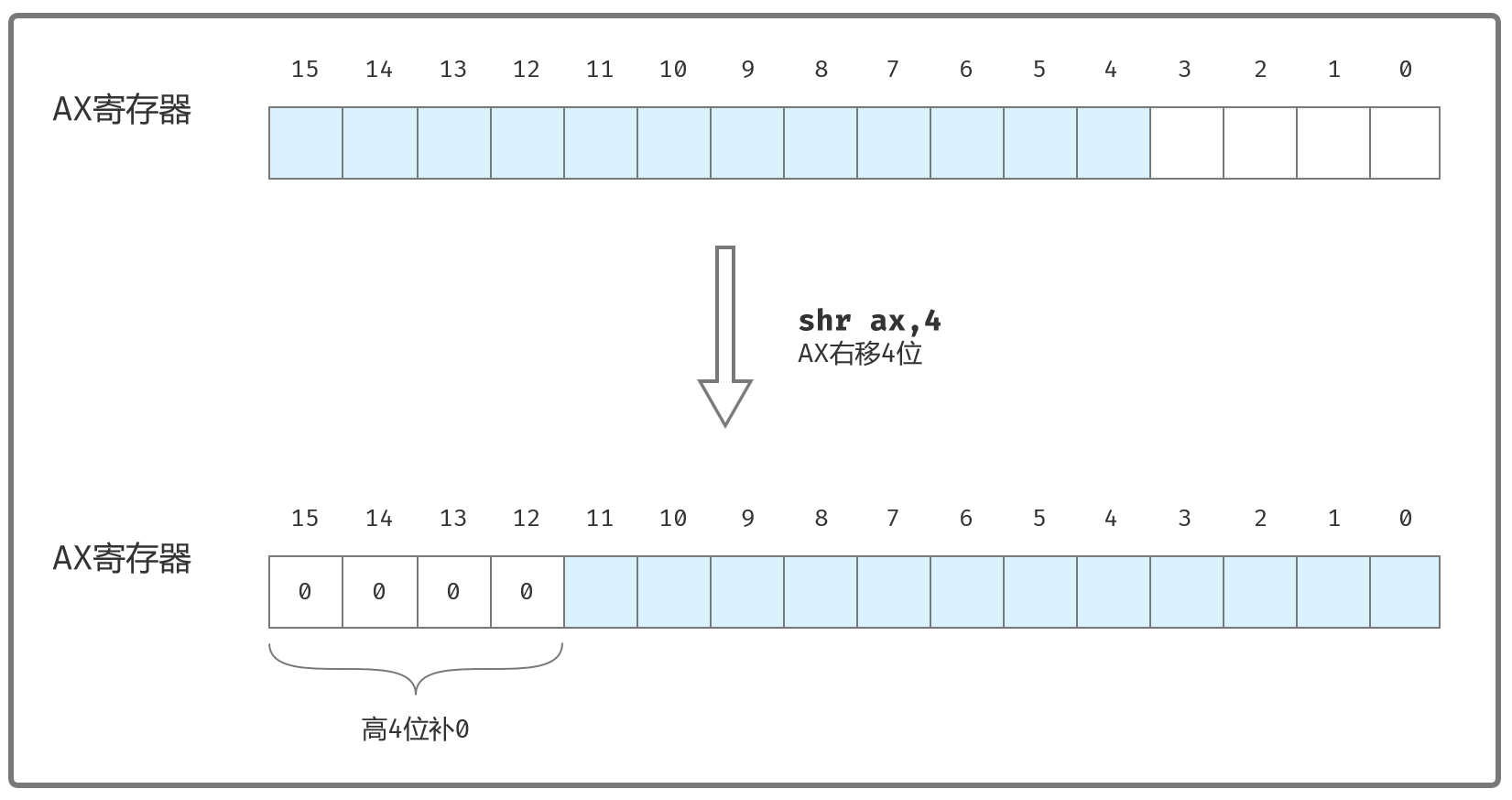
处理dx:
ror dx,4 ;dx循环右移4位。
;rof(Rotate Right)
and dx,0xf000 ;低12位清0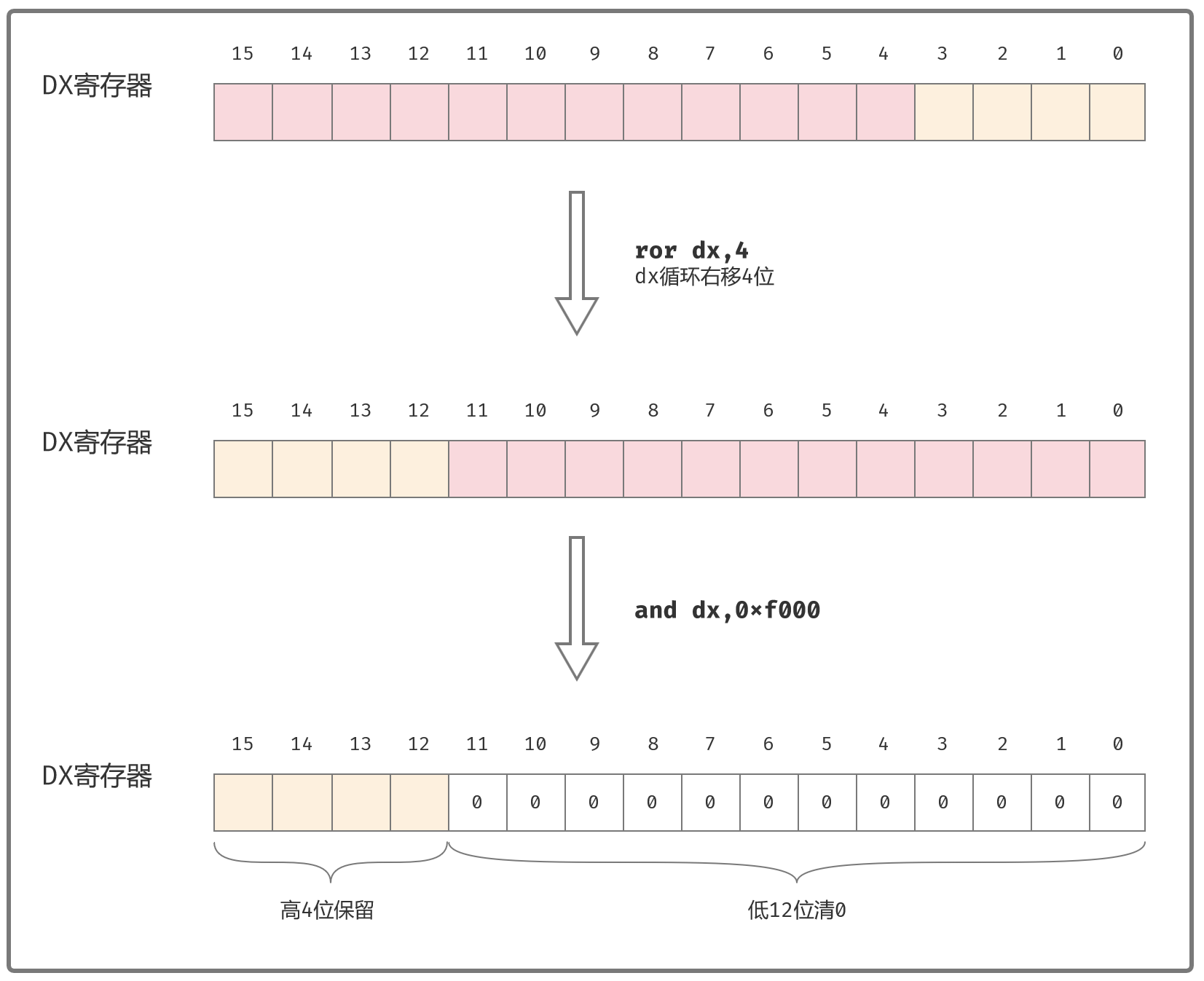
合并ax和dx,把上面处理ax和dx后的结果求异或一下:
or ax,dx ;求异或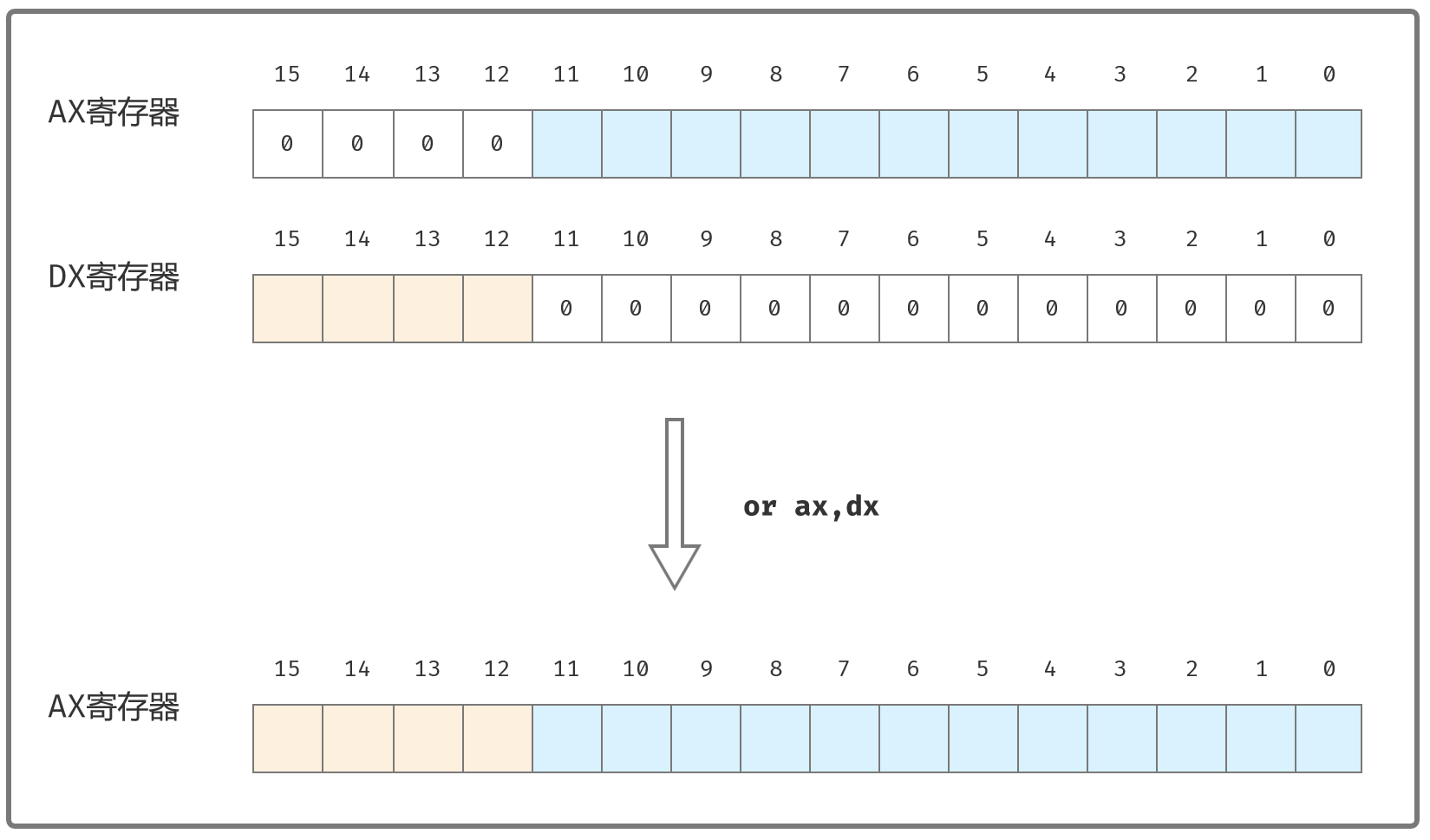
将控制权交给用户程序
跳转到用户程序入口点执行:
jmp far [0x04] ;从ds:0x04取出两个字,分别传送到CS和IP
;这里ds指向用户程序
;用户程序0x04字节存储入口的偏移地址和段地址0x04位置为code_entry,可以看下图:
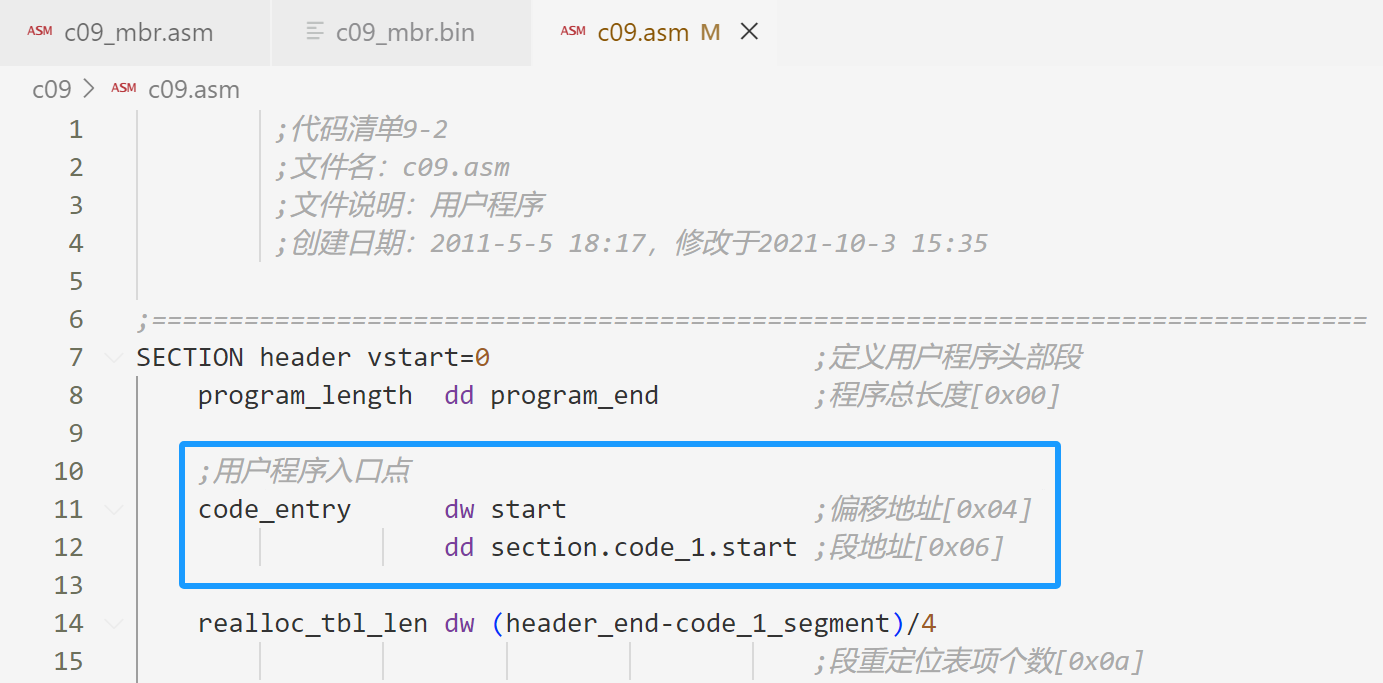
书中提到从ds:0x04取出两个字,一开始感觉有点奇怪,因为 dw start 是1个字,dd section.code_1.start 是2个字,不是应该是3个字吗?
后面才想到,前面计算段地址都是16位的(1个字),虽然这里段地址的声明 dd,但实际只用了1个字。
那么为什么声明为 dd 呢?因为用户程序一开始存储的是段的汇编地址,汇编地址是32位的(4字)。
8086处理器的无条件转移指令
- 相对短转移:jmp short,段内转移指令,只允许转移到距离当前指令-128~127字节的地方。
-
操作码为0xEB;
-
操作数是相对于目标位置的偏移量,仅1字节,是个有符号数。
jmp short infinite ;跳转到标号infinite的位置
jmp short 0x03 ;跳转到(IP)+0x03位置的地方执行
一个简单的例子:
; 相对短转移 jmp short 演示
mov ax,10
jmp short end ;跳转到end标号处执行
mov bx,20
end: jmp end ;end标号定义
times 510-($-$$) db 0
db 0x55,0xaa编译查看 .lst 文件:
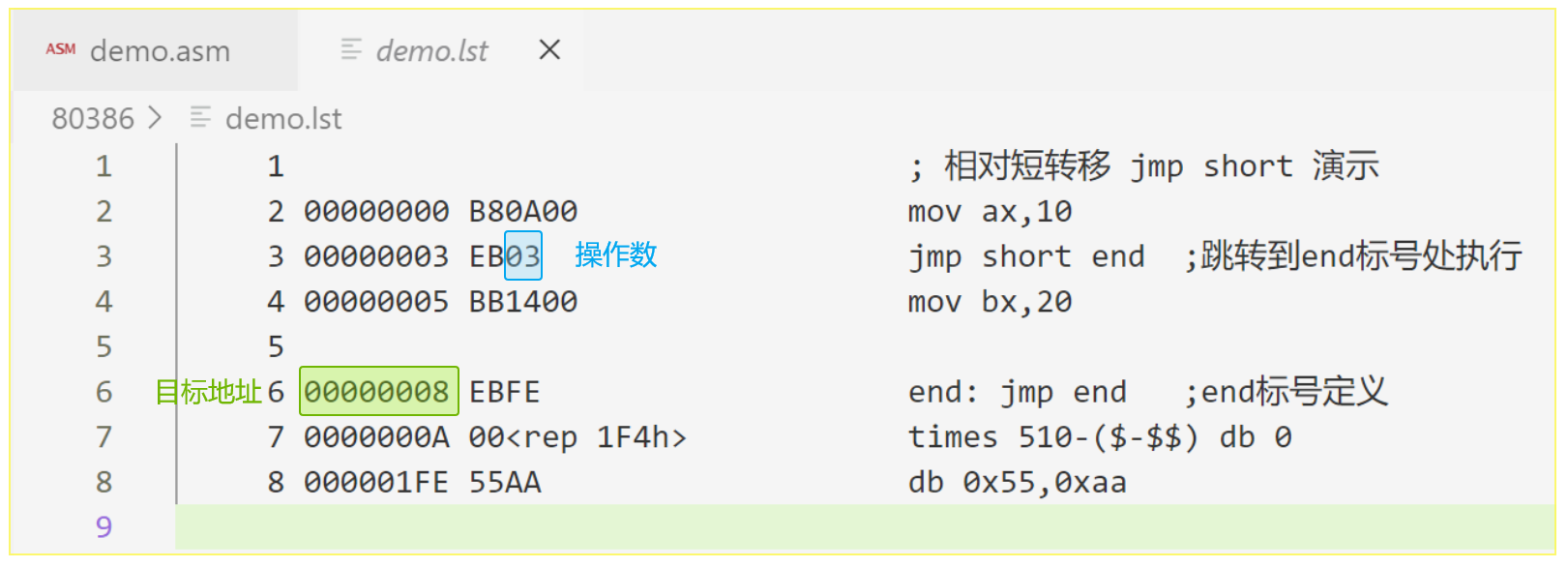
目标地址的计算方式:
(IP)+ 操作数 = 0x05 + 0x03 = 0x08- 16位相对近转移:jmp near,段内转移指令,只允许转移到距离当前指令-32768~32767字节的地方。
-
操作码为0xE9;
-
操作数是相对于目标位置的偏移量,2字节,是个有符号数。
jmp near infinite
jmp near 0x03
上例把 short 改为 near,编译查看 .lst 文件:
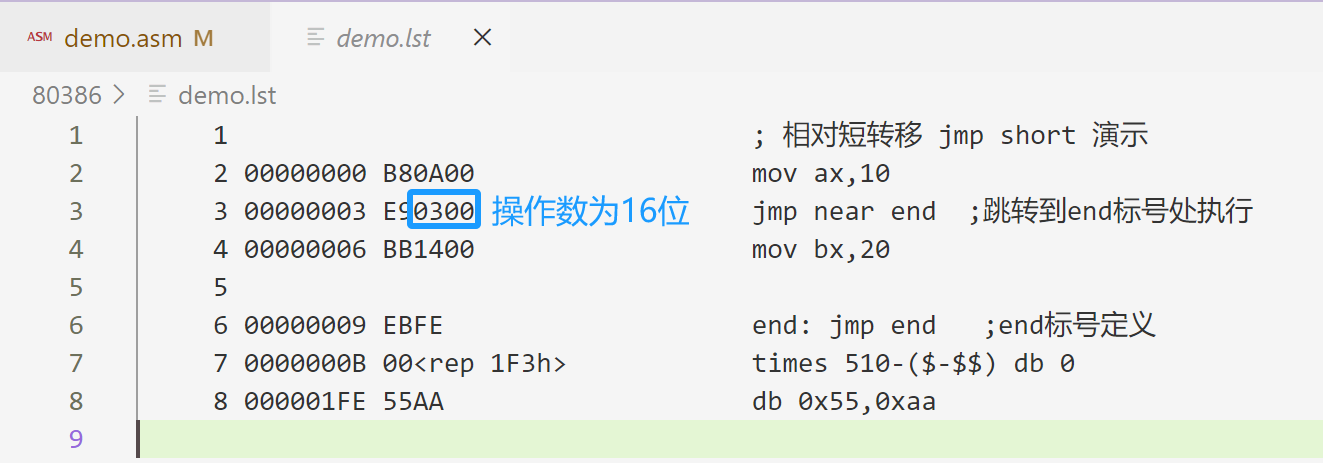
其他和相对短转移都是类似的。
-
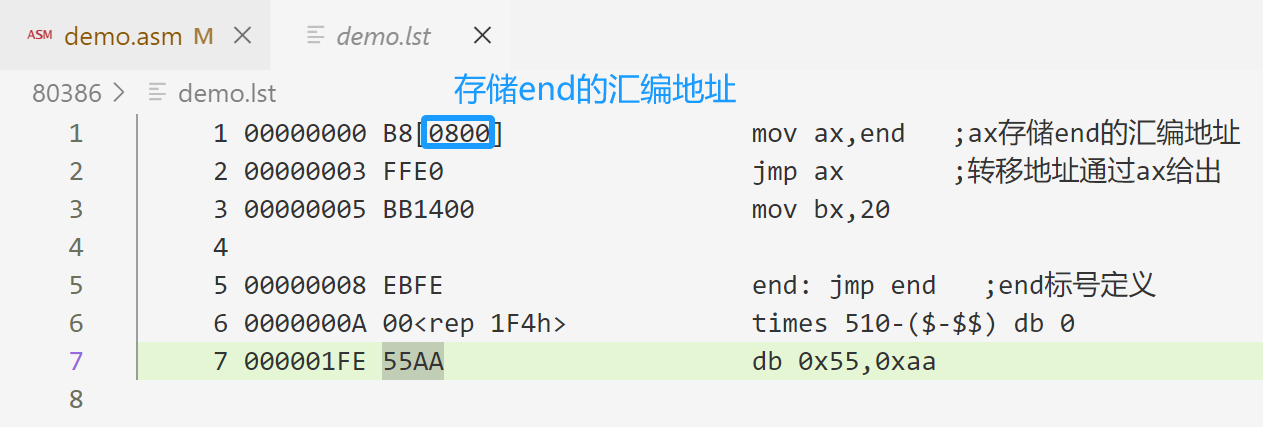
16位间接绝对近转移:段内转移,只是转移的地址用一个16位的通用寄存器或者内存地址来间接给出的。
jmp bx ;转移地址通过bx给出
jmp cx ;转移地址通过cx给出jump_dest dw 0xc000 ;声明一个jump_dest保存一个地址
jmp [jump_dest] ;转移地址通过jump_test标号指向的内存单元给出jmp [bx] ;转移地址通过位于ds:bx指向的内存单元给出
jmp [bx + si] ;转移地址通过位于ds:bx+si指向的内存单元给出
一个简单的例子:
mov ax,end ;ax存储end的汇编地址
jmp ax ;转移地址通过ax给出
mov bx,20
end: jmp end ;end标号定义
times 510-($-$$) db 0
db 0x55,0xaa编译查看 .lst 文件:
-
16位直接绝对远转移:jmp 段地址:汇编地址
jmp 0x0000:0x7c00 ;0x0000 段地址
;0x7c00 偏移地址 -
16位间接绝对远转移:jmp far 内存单元
jump_far dw 0x33c0,0xf000 ;0x33c0偏移地址;0xf000段地址
jmp far [jump_far] ;从jump_far指向的内存单元取得段地址和偏移地址。
jmp far [bx] ;从ds:bx指向的内存单元取得段地址和偏移地址。
jmp far [bx + si] ;从ds:bx+si指向的内存单元取得段地址和偏移地址。
上一个小节中,就是通过远转移指令把控制权交给用户程序的:
jmp far [0x04] ;从ds:0x04的内存单元取得段地址和偏移地址。总结一下:
该书jmp转移分了5类,是从转移的距离 和给出目的地址的方法 两个维度进行分类。
刚接触的时候有点迷糊,后面尝试从转移的距离 开始分类,再根据给出目的地址的方法 进行细分,感觉就比较清晰了,大概内容如下表格:
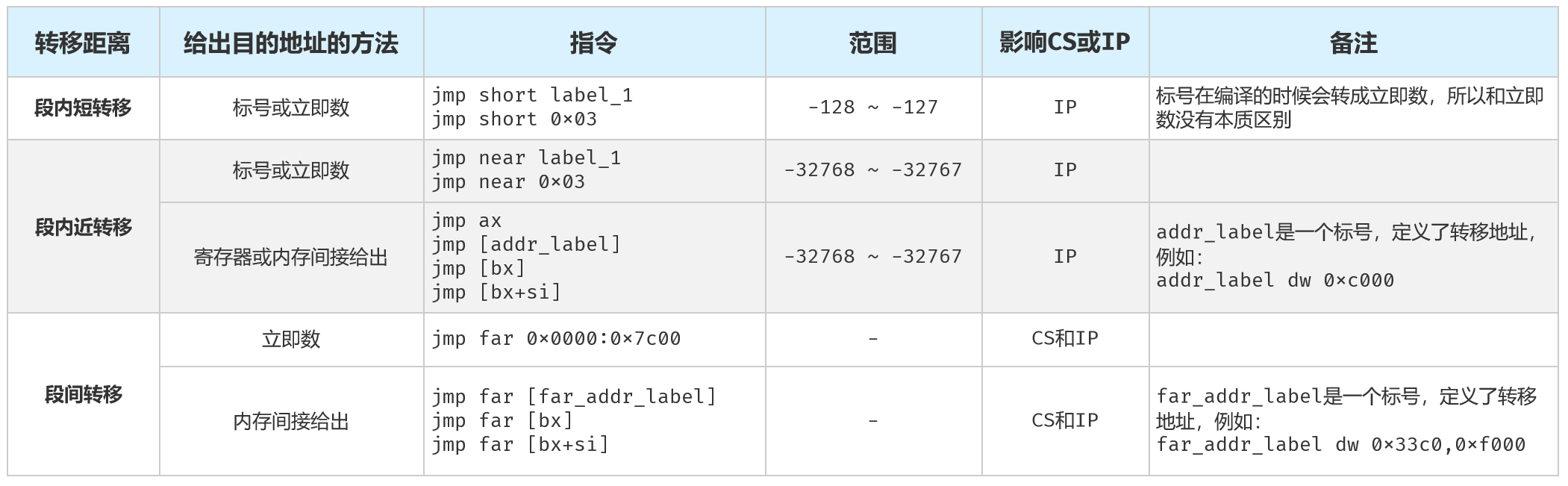
jmp指令和call指令很类似。
用户程序的工作流程
加载器加载完成后,就到用户程序的工作流程了。
初始化段寄存器和栈切换
跳转到用户程序执行后,代码段cs已经切换为code_entry指向的段地址了;附加段es指向用户程序头部。
还需要将数据段ds、栈段ss指向用户程序自己的空间。代码执行后,内存映像:
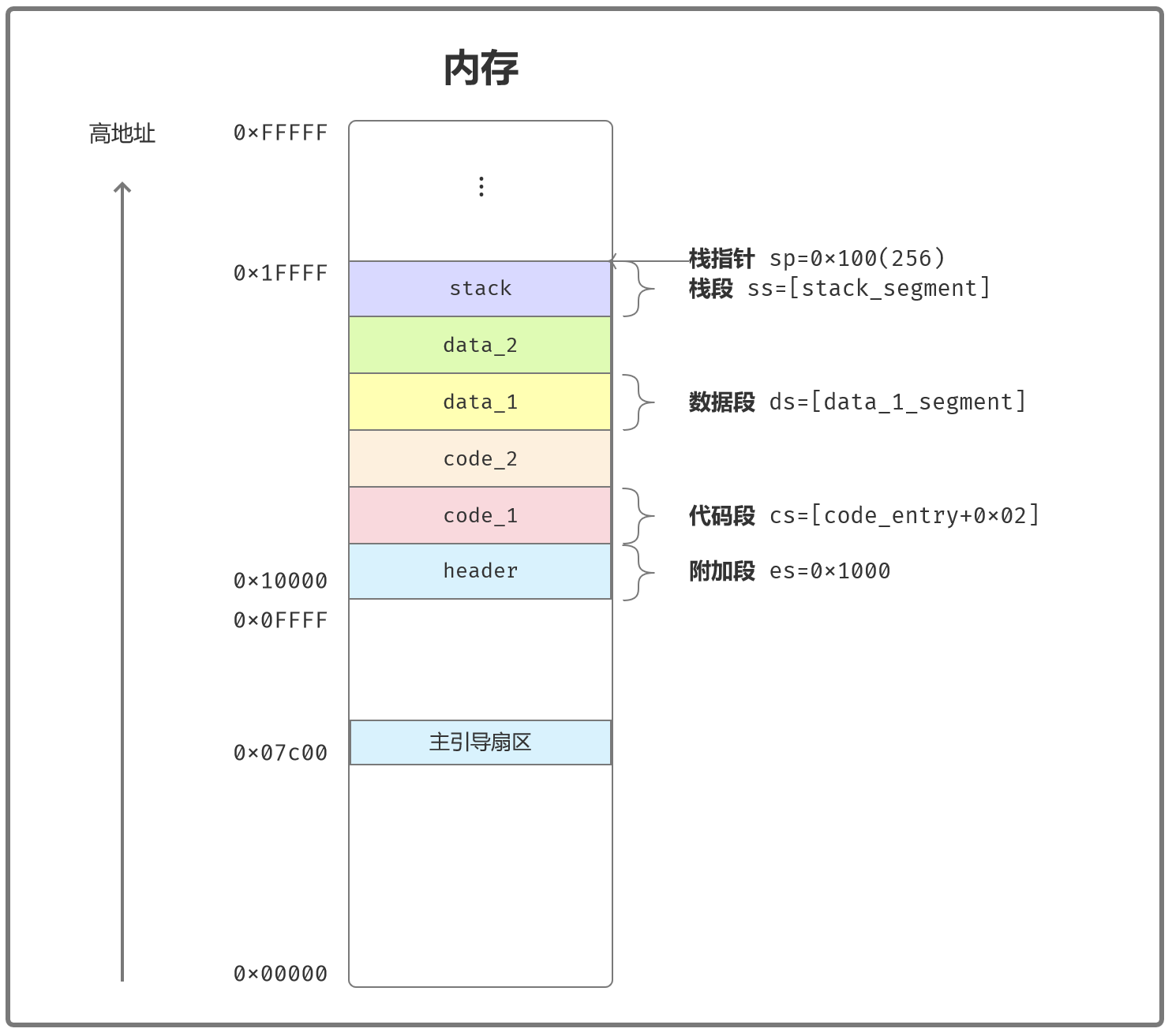
另外栈的空间初始化使用了resb指令。
resb(REServe Byte)指令:当前位置开始,保留指定数量的字节,但不初始化它们的值。
resb 256 ;保留256个字节的空间,里面内容不清楚。其实我觉得用 times 256 db 0 都初始化为0的会更好。
果然如果使用resb,编译的时候会报警:
warning: uninitialized space declared in stack section: zeroing -w+zeroing
类似的还有resw(RESever Word)和resd(RESever Double Word)指令:
resw 256 ;RESever Word, 256个字
resd 256 ;RESever Double Word,256个双字调用字符串显示例程

这里的字符串声明看起来比前面更舒服了。
声明完成后通过 call put_string 进行打印。
mov bx,msg0
call put_string ;显示第一段信息 过程的嵌套
允许在一个过程中调用另一个过程,这称为过程嵌套。
因为每次调用过程时,处理器都把返回地址压在栈中,返回时从栈中取得返回地址,所以,只要栈是安全的,嵌套的过程都能层层返回。
start过程中调用了put_string过程,后面put_string过程又调用了put_char过程等。
屏幕光标控制
光标(Cursor)是在屏幕上有规律地闪动的一条小横线,通常用于指示下一个要显示的字符位置。
光标在屏幕上的位置保存在显卡内部的两个光标寄存器中,每个寄存器是8位的,合起来形成一个16位的数值。
标准VGA文本模式:
- 0 表示光标在屏幕上第0行第0列;
- 80 表示光标在第1行第0列;
- 1999 表示光标在第25行第80列,即屏幕右下角;
取当前光标位置
显卡使用索引寄存器来访问内部相关寄存器。
- 索引寄存器的端口号是0x3d4;
- 两个8位的光标寄存器,其索引值分别是14(0x0e)和15(0x0f),分别用于提供光标位置的高8位和低8位。
- 数据端口0x3d5;
代码我额外加了一些注释:
;以下取当前光标位置
mov dx,0x3d4 ;往索引寄存器里写入0x0e
mov al,0x0e ; 表示要获取光标位置的高8位
out dx,al
mov dx,0x3d5 ;从数据端口获取数据
in al,dx ;高8位
mov ah,al ;高8位存储到ah中,后面低8位存储到al中,
;ax完整保存了光标的16位位置信息
mov dx,0x3d4 ;往索引寄存器里写入0x0f
mov al,0x0f ; 表示要获取光标位置的低8位
out dx,al
mov dx,0x3d5 ;从数据端口获取数据
in al,dx ;低8位
mov bx,ax ;BX=代表光标位置的16位数put_char过程还是挺麻烦的,涉及到换行、滚屏,幸好作者提供了put_char的流程图,方便理解。
处理回车和换行字符
遇到回车符0x0d的处理思路:
-
当前光标位置除以80,余数不要,只要商即当前行行号。
-
行号乘以80,就是当前行行首的光标数值。
;ax中存储了是光标位置的16位信息。
mov bl,80
div bl ;除以80:ax中保留了行号;dx中保留余数。
mul bl ;(ax)*80 就是当前行首的光标位置。
遇到换行符0x0a的处理思路:
-
光标位置加上80。
-
如果是最后一行,要进行滚屏操作。
add bx,80 ;光标位置加上80。
jmp .roll_screen ;roll_screen过程有检测是否需要滚屏
显示可打印字符
书中用 put_other 显示字符。我额外加了一些注释。
.put_other: ;正常显示字符
mov ax,0xb800 ;设置es为文本模式显示缓冲区段
mov es,ax
shl bx,1 ;左移1位,相当于光标位置乘以2
mov [es:bx],cl ;往缓冲区写入字符
;以下将光标位置推进一个字符
shr bx,1
add bx,1 什么要把光标位置乘以2?一开始有点迷糊,后面明白了。
因为每个字符在显示缓冲区中需要2个字节进行显示,第一个字节是字符,第二个字节是显示属性,所以需要把光标位置乘以2,从而定位到要写入的显示缓冲区。
简单理解,在25*80文本显示模式下:
- 显示缓冲区 0 ~ 3999
- 光标位置 0 ~ 1999
滚动屏幕内容
滚动屏幕的思路:
- 2~25行的内容整体往上提一行。
- 第25行填充黑底白字的空白字符。
- 光标置于最后一行行首。
代码加了一些注释:

重置光标
思路很简单,就是写法比较麻烦,要通过索引寄存器。
思路:
-
写入高位
-
写入低位
.set_cursor:
mov dx,0x3d4 ;写入高8位
mov al,0x0e
out dx,al
mov dx,0x3d5
mov al,bh ;bx存储了光标位置,bh高位、bl低位
out dx,al
mov dx,0x3d4 ;写入低8位
mov al,0x0f
out dx,al
mov dx,0x3d5
mov al,bl ;bx存储了光标位置,bh高位、bl低位
out dx,al
切换到另一个代码段中执行
这边可以理解用了一个代码技巧,使用 retf 返回的特性,跳转到 code_2.begin 执行。
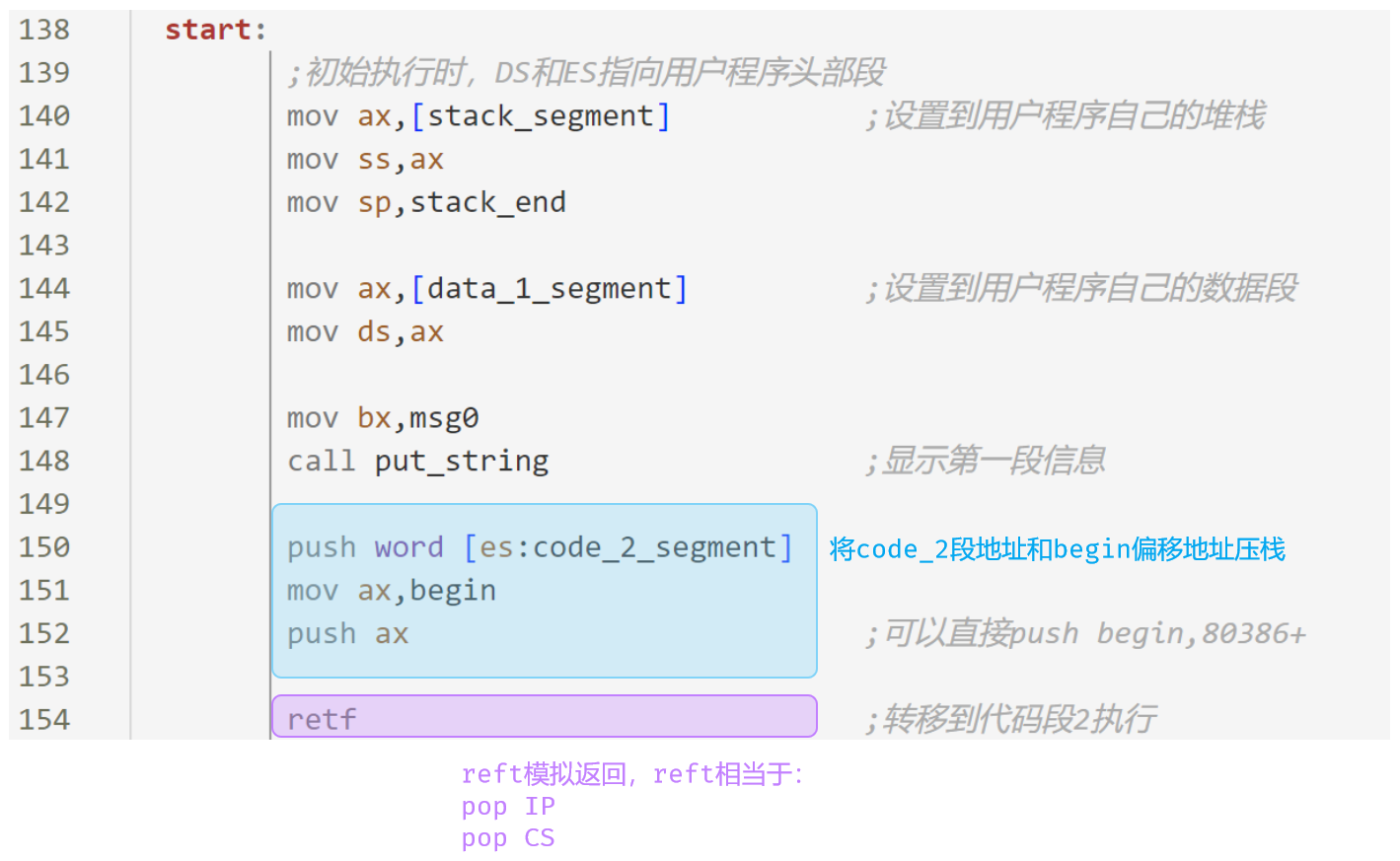
访问另一个数据段
code_2.begin 啥也没有干,又用同样的方法跳转到了 code_1.continue 执行。
code_1.continue 也容易理解,就是把数据段ds切换到 data_2,然后打印其中的msg1。
编译和运行程序并观察结果
根据书中步骤,完成作业了。
参考资料
- 王爽《汇编语言》