在计算机世界中,文件是数据的抽象集合,它为用户提供了一种直观的方式来处理数据。而这些文件的数据最终必须存储在具体的物理设备上,例如HDD、SSD 或是 USB。这些存储设备通过设备控制器将他们的物理介质映射为一个巨大的、可随机寻址的地址空间,我们可以将其看作一个超大的数组。一个设备可以储存多个文件,那么,如何将多个抽象的文件映射到这一巨大空间上,就是一个非常重要的问题。文件系统的设计在这里起着至关重要的作用,它必须以合理的方式将文件分布到物理存储介质上,以确保存储和访问的高效性。本文将为您介绍几种经典的文件分配方式及其优缺点。
物理存储的基本概念:块与簇
当硬盘经过设备控制器抽象为一个超大的数组后,对于设备来说,块(block) 通常是存储介质的最小单元。每个块有固定的大小,例如 4KB,由存储介质本身决定。这些块是存储设备的最小分配和管理单位。而为了更好地利用空间并减少管理开销,在系统中,块可以进一步组合成更大的存储单位,称为簇(cluster),通常簇由几个连续的块组成。通常在格式化时可以指定簇大小,之后就不再改变,一簇至少包含一个块,也可以设定为包含多个块。在格式化完成后,簇就成为文件系统视角下的最小分配单位。
簇的大小直接影响到存储效率和文件系统的性能。大簇(如32KB或64KB)意味着每个簇可以容纳更多数据,从而减少文件系统管理这些簇的开销,管理更容易且读写性能高,但会导致即使是 1 字节的文件也会占用一簇,造成小文件占用过多空间的情况,导致内部碎片(internal fragmentation)。反之,小簇(如512字节或4KB)可以减少内部碎片,但会增加管理簇的复杂性和处理开销。因此,簇大小的选择是权衡存储效率与管理开销的重要决策。
连续分配:最简单却难以扩展的方案
存储器已经划分为以簇编址的巨大数组,而文件也被划分为几簇,接下来我们要考虑怎样为他们安排位置。
连续分配(Contiguous Allocation) 是文件系统中最简单的物理分配方式。它将文件存储在一组连续的簇中。在文件记录中,只需要存储文件的起始位置 和长度 ,这样在访问文件时,只需要从起始位置开始,读取指定长度的数据即可。由于连续分配的文件在物理磁盘上是紧密排列的,因此它非常适合随机访问(random access),尤其是对大文件的顺序访问时,性能表现十分优秀。当新增文件时,直接找到可容纳下文件的连续块插入即可。
然而,连续分配也有许多致命缺点:
- 外部碎片(External Fragmentation):随着文件不断地创建和删除,磁盘空间会被割裂为许多不连续的小块,导致碎片化,最终可能出现虽然总空间足够,但无法找到足够连续空间分配给新文件的情况。
- 文件大小固定:由于文件必须存储在连续的空间中,因此文件的大小在创建时就需要确定,且不能动态扩展。如果文件需要增长,就可能会覆盖其他文件的数据。
- 频繁的数据移动 :如果文件需要扩展而当前空间不足,就可能需要将文件移动到其他更大的连续区域,这将导致大量的数据移动(data movement),耗费性能。
这些缺点使得连续分配在现代操作系统中很少使用,尤其是在面对高频率的文件操作时。然而,在某些特定情况下,例如对于磁带这样的顺序访问存储介质(sequential access storage medium),连续分配仍然是有效的选择。
简单链表分配:解决碎片问题的尝试
为了解决外部碎片的问题,一种改进的方法是链表分配(Linked Allocation)。在链表分配中,文件被分为多个块,每个块通过一个指针链接到下一个块,从而形成一个链表。文件记录只需要存储文件的第一个块的地址(以及可能的最后一个块地址),其余的块通过链表指针进行访问。这样离散的分配方式也就不再有外部碎片。
然而,链表分配也有明显的缺点:
- 无法随机访问 :由于块之间通过指针链接,无法直接跳转到某个特定块,因此只能**顺序访问(sequential access)**文件的内容。如果需要访问文件的某个特定位置,必须从头开始遍历整个链表。
- 可靠性问题:由于每个块都通过指针链接,一旦某个块的指针损坏,就会导致整个文件的剩余部分无法访问。
- 存储开销:每个块需要额外存储一个指针,这增加了存储开销,文件越小,这种额外开销带来的浪费越显著。
链表分配解决了外部碎片的问题,但由于无法随机访问和存储开销大的缺点,使得它在现代操作系统中的应用也较为有限。
显式链表分配:文件分配表 (FAT)
在链表分配的基础上,另一种改进方式是显式链表分配(Explicit Linked Allocation) ,即将每个块的指针信息集(即下一块)中存储在一个专门的表中(而非储存到每个块中),这就是文件分配表(File Allocation Table, FAT)。FAT 是一种将每一个簇和其后续簇的位置关系集中存储的结构,通过查找文件的起始簇,可以逐步找到文件的所有簇。
在 FAT 结构下,文件记录仍只需要存储文件的起始块位置,然后通过 FAT 来找到其他块的位置。这样的设计使得在文件内进行块间跳转变得更加方便,虽然 FAT 仍然不能真正实现随机访问,但跳转速度相较于简单链表分配要快得多。为了提高访问速度,操作系统通常将 FAT 缓存在内存中,从而在文件访问时减少对磁盘的频繁读取。
FAT 结构具有如下特点:
- 集中管理链表信息:通过将所有簇的信息集中管理,FAT 使得文件的管理更加简单,整个文件系统只需要一张表,特别是在进行空间分配和回收时,能有效追踪哪些簇是空闲的。
- 提高访问效率:由于 FAT 可以被缓存到内存中,文件访问的速度显著提高,尤其是在文件内部跳转时。
- 文件限制:簇大小和指针位数决定了单文件大小的上限。假设一个 FAT 文件系统使用 16 位指针来表示每个簇的位置,并且簇的大小为 4KB,那么可以表示的最大簇数是 2^16 = 65536 个簇。因此,该文件系统支持的最大文件大小为 65536 * 4KB = 256MB。
FAT 系列文件系统最早设计于 1977 年,历经多次演化,至今仍有应用,特别是在嵌入式设备和闪存设备(如 USB 闪存)中。FAT 系列文件系统(如 FAT16、FAT32)由于其简单性和广泛兼容性,成为了很多嵌入式设备的首选。exFAT 是微软在 2006 年引入的一种新的文件系统,专为闪存设备设计,主要目的是在 FAT32 的基础上克服其局限性,相比上面介绍的原始版本拓展了很多功能,同时保持兼容性。
索引分配:真正实现随机访问
在离散存储的基础上,显然不一定要使用链表可以在文件记录中以变长数组记录每个块的位置,这样就可以实现真正的随机访问(random access) 。这种数组叫做索引(index) ,这种分配方式称为索引分配(Indexed Allocation)。在索引分配中,文件系统会为在每个文件的文件记录里维护其索引块,索引块中存储了文件各个数据块的物理位置。通过查找这个索引块,操作系统可以直接定位到文件的任意块,从而实现快速的随机访问。简单来说,索引用数组实现就可以,也可以选择二叉树或哈希表,这就不是本文的重点了。
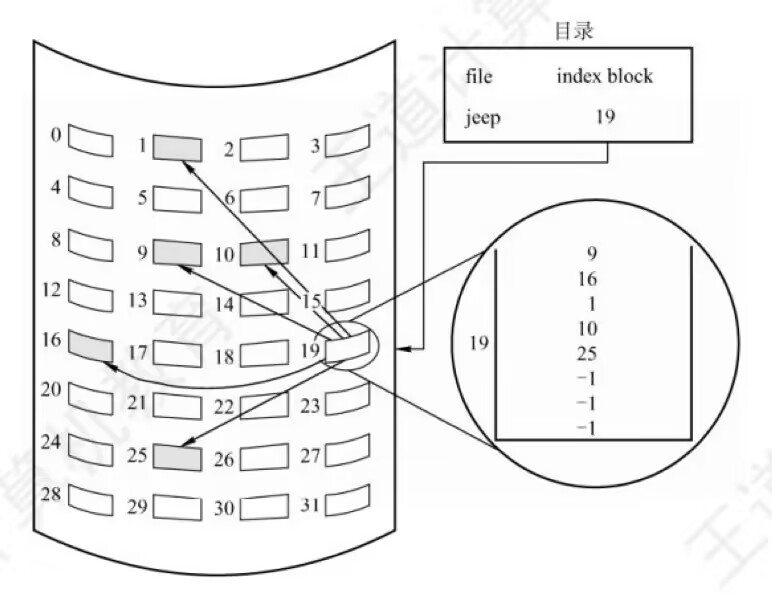
**单级索引(Single-Level Index)**是最简单的一种索引分配方式,其中每个文件都有一个单独的索引块,记录文件的所有数据块位置。这使得文件的访问变得非常灵活,特别是对于需要频繁随机访问的场景,索引分配具有显著的优势。此外,由于索引块集中存储了所有的块位置,文件的增删也变得更加容易,只需更新索引块即可,无需对物理块进行复杂的移动操作。
例如,假设一个单级索引系统,每个索引块的大小为 4KB,且每个指针占用 4 字节,那么一个索引块最多可以容纳 4KB / 4B = 1024 个指针。如果每个数据块的大小也是 4KB,那么这个文件系统支持的最大文件大小为 1024 * 4KB = 4MB。
由此可以看出,单级索引适用于中小型文件。然而,索引块的大小是有限的,这意味着单级索引的文件大小上限很低,只能用于较小的文件。对于非常大的文件,则需要使用其他的多级索引方案。
多级索引
由于文件记录的大小通常是有限的,因此文件系统引入了多级索引(Multi-Level Indexing) 的概念,也叫间接索引。多级索引通过使用多个层次的索引块来管理文件的数据块位置。例如,**两级索引(Two-Level Indexing)**使用一个一级索引块指向多个二级索引块,而二级索引块则记录文件的数据块位置。这种设计使得文件系统可以存储比单级索引更大的文件。
以二级索引为例子,文件记录中储存的索引是一级索引,一级索引中指向的块并非文件本身,而是其他索引块,叫做二级索引,由二级索引记录文件簇的物理位置。
混合索引:现代文件系统的主流
多级索引提高了单文件大小的上限,但是,如果文件记录中全部使用多级索引,即使只有 1 字节的文件,也至少需要占用多级索引中每一级索引块各一个。文件越小,索引本身带来的开销越大。

现代文件系统为了平衡小型文件和大型文件的存储需求,引入了**混合索引(Hybrid Indexing)**的方式。混合索引结合了直接索引、间接索引和多级索引的优点。例如,在某些文件系统中,文件记录中包含了一些直接指向数据块的指针(适用于小文件),以及间接指向索引块的指针(适用于较大的文件)。这种设计使得文件系统能够高效地处理各种不同大小的文件,既能减少小文件的管理开销,又能支持大型文件的高效存取。
例如,假设一个文件系统使用混合索引的方式,每个 inode 包含 12 个直接指针、1 个一级间接指针、1 个二级间接指针以及 1 个三级间接指针。假设每个数据块大小为 4KB,每个指针占用 4 字节。则:
- 直接指针:可以直接指向 12 个数据块,存储大小为 12 * 4KB = 48KB。即 48 KB 以下的文件只需要单级索引。
- 一级间接指针:指向一个索引块,该索引块包含 4KB / 4B = 1024 个指针,每个指针指向一个数据块,因此可以存储 1024 * 4KB = 4MB 的数据。即 4 MB + 48 KB 以下的文件只需要前两级索引。
- 二级间接指针:指向一个索引块,该索引块中的每个指针又指向另一个索引块,这样可以指向 1024 * 1024 个数据块,共计 1024 * 1024 * 4KB = 4GB 的数据。
- 三级间接指针:同样道理,可以指向 1024 * 1024 * 1024 个数据块,共计 1024 * 1024 * 1024 * 4KB = 4TB 的数据。
因此,该混合索引结构支持的最大文件大小约为 48KB + 4MB + 4GB + 4TB。由此可以看出,混合索引的设计使得文件系统既能够高效地处理小型文件,又可以支持非常大的文件。
混合索引方式被广泛应用于现代绝大多数文件系统中,例如:
- NTFS(New Technology File System):是 Windows 操作系统的默认文件系统,使用了混合索引结构来实现对文件的灵活管理。
- HFS+(Hierarchical File System Plus):是 macOS 中曾经使用的文件系统,通过索引节点和混合索引来管理文件。
- APFS(Apple File System):是苹果公司为 macOS、iOS 等设备开发的新一代文件系统,同样使用了混合索引来提高文件访问的效率和灵活性。
- ext4(Fourth Extended File System):是 Linux 操作系统中的默认文件系统,使用了混合索引结构,并通过扩展的多级索引和日志机制来提高文件的管理效率和可靠性。
混合索引结构的优势在于其对小型文件和大型文件的适应性,使得文件系统能够在各种应用场景下提供高效的存储和访问性能。因此,混合索引成为了现代文件系统设计的主流选择。通过这种方式,文件系统不仅能够高效管理存储空间,还能够提供灵活的随机访问能力,以满足不同用户和应用程序的需求。