伙伴们,很奇怪~ 关于LLM的开源与闭源模型的竞争又开始愈发激烈。
众所周知,开源模型以其开放性和社区驱动的特点受到一部分用户的青睐,而闭源模型则因其专业性和性能优化被广泛应用于商业领域。由于大模型最近2年的突然兴起,开源社区对"开源"有了重新定义。终于开放源代码倡议(OSI)于10月2日首次发布了开源 AI 定义的暂行版本 1.0,其中Meta 和 Google等作为其重要参与者,为LLaMA等披上了"开源"的外衣,为什么这么说呢。于是这次专门写个文章主要想通过技术、商业等层面的比较,一起探讨下开源、假装开源和闭源这件事。
(: 主要是网上吵的太厉害。。谈谈鄙人浅薄的看法吧。。


到底啥是开源、假装开源和闭源?
在讨论开源与闭源模型的优劣之前,我们首先要明确两者的定义。开源模型 指的是那些源代码、数据集、训练过程等对公众开放,允许自由使用、修改和分发的模型。假装开源 就比如LLaMA等大部分目前所谓的开源模型,因为它们只开源了模型参数而已。而闭源模型则是这些要素不公开,通常由单一实体控制,使用受限的模型。开源模型因其透明性和社区参与度高而受到一部分开发者的喜爱;假装开源模型则可以让我们感觉到自我认为我们能掌控该模型的所有;但闭源模型在性能优化、安全性和专业性服务方面可能更具优势。
开源模型的最大特点是其开放性,这使得全球的开发者都可以参与到模型的改进和创新中来。然而,这种开放性也带来了一定的风险,比如安全漏洞和隐私泄露。相比之下,闭源模型由于其源代码和数据集的不公开,能够提供更好的安全性和隐私保护,同时,专业的团队也能够对模型进行更深入的优化。
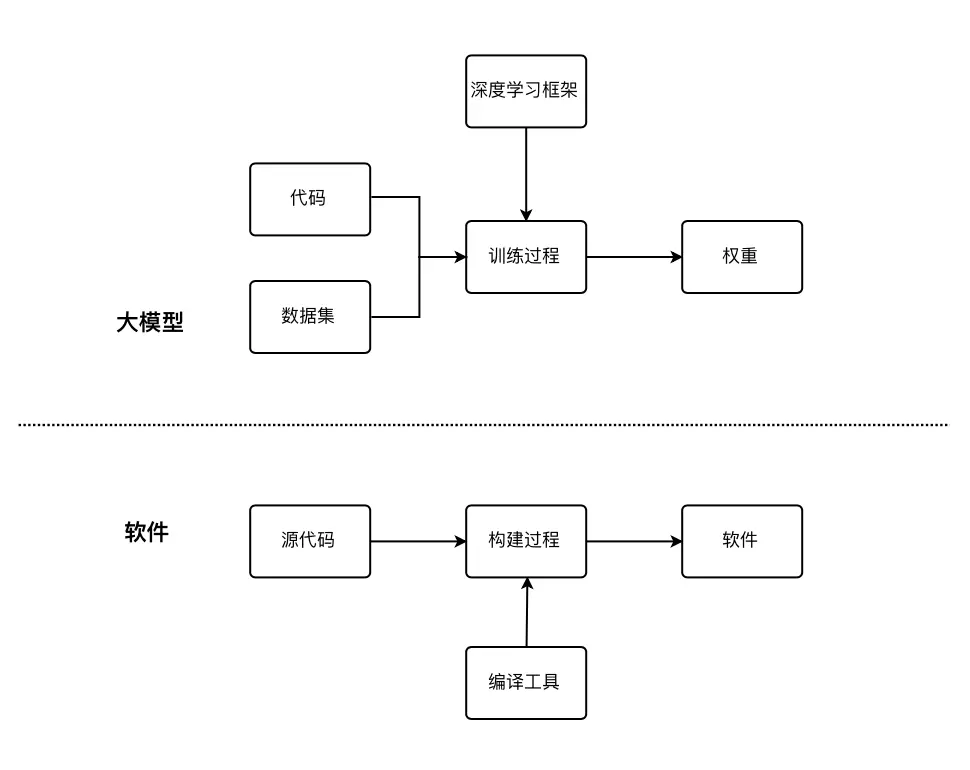
大家可能会搞混淆的另一个概念是软件开源,这俩的区分是:软件开源主要针对应用程序和工具,开源的资源需求较低,而大语言模型的开源则涉及大量计算资源、训练细节、高质量数据和最终的模型参数,并且可能有更多使用限制。
技术层面的比较
在性能与优化方面,闭源模型通常由专业团队进行优化,能够针对特定的应用场景进行定制和调整,因此在性能上可能更优。假装开源模型因为不开源优化细节trick等非常核心的部分,导致大家无法复现其完全公布的性能,只能接近;而开源模型能够快速集成社区的创新,但其优化速度和效果往往受限于社区的活跃度和技术能力。
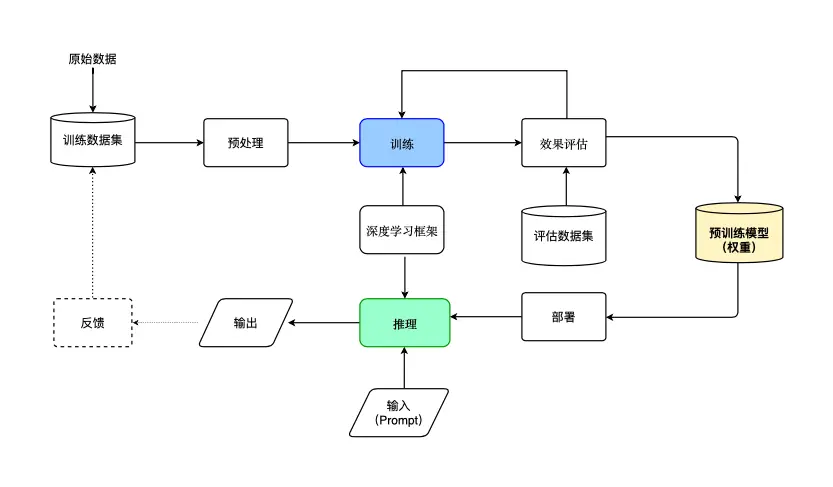
数据集与训练过程也是衡量模型优劣的重要指标。闭源模型可能使用更高质量或更大规模的数据集进行训练(默认闭源都是公司级别主导的);假装开源模型则不公开数据集和具体训练过程,只能让你用训好的模型,但无法改进,在不这样的情况下train或者sft模型直接会影响了模型的准确性和鲁棒性的...;而开源模型的数据集和训练过程可能不够完善。
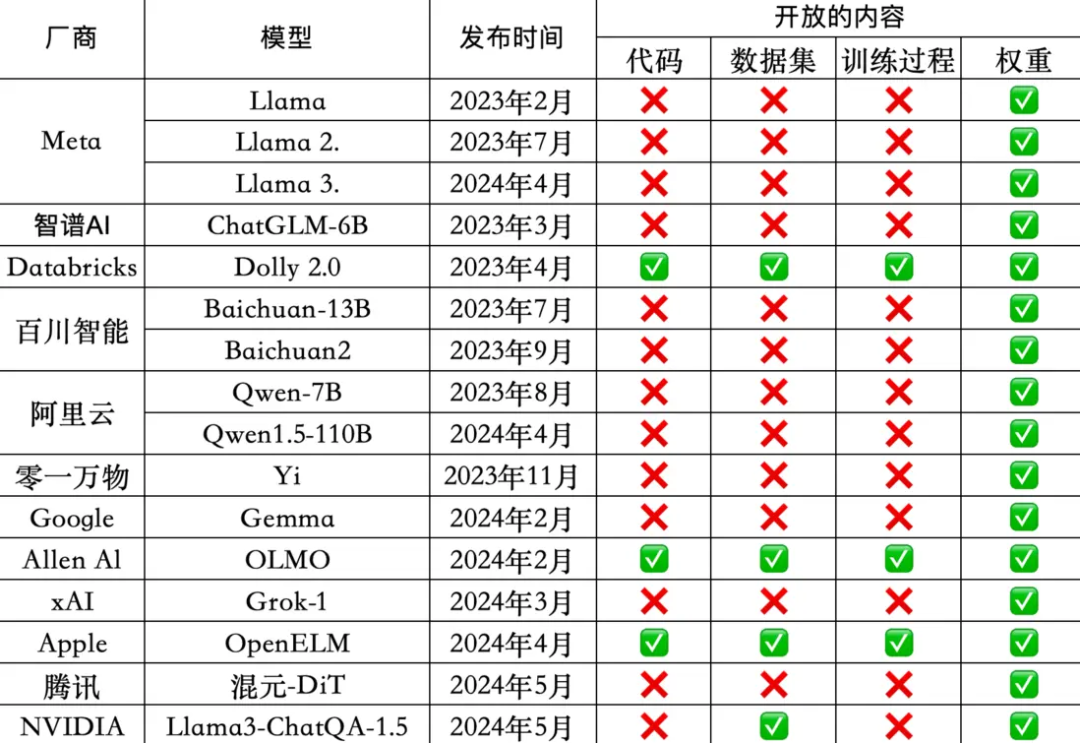
是的。。真正完全开源的基本都是你没听说过得。。
在安全性与隐私方面,闭源模型由于其不公开的特性,能够更好地控制数据的使用和流动,从而提供更好的安全性和隐私保护(意思就是你看不到我数据,无法直接发现我的漏洞)。假装开源模型可以直接让大家通过各种后门攻击来直接测试漏洞是否存在,很危险。而开源模型必然也可能存在安全漏洞和隐私泄露的风险,尤其是在数据集和训练过程中,但是能够和黑客进行攻防战,在不涉及难以挽回的场景下,可以不断优化安全领域的研究工作~
易用性与支持也是用户选择模型时考虑的重要因素。闭源模型通常提供专业的技术支持和客户服务,易用性较高。而假装开源和开源模型一样了,虽然社区活跃,但支持可能不及时或不专业,这对于需要快速解决问题的用户来说可能是一个缺点。
实际案例分析
以Meta的LLaMA模型为例,尽管LLaMA模型开源,但其使用条款中存在一定的限制,比如对于拥有超过7亿用户的应用程序的商业用途限制,以及不提供对训练数据的访问,这导致其不符合开放源代码促进会(OSI)的开源标准。这表明即使是开源模型,也可能存在使用上的限制,并不总是能够满足用户的需求。

另一方面,OpenAI的ChatGPT(o1-mini/o1-preview/GPT-4o等)以及国内百度的ERNIE模型作为闭源模型,虽然也被诟病不开源啥的,在实际应用当中表现出了更高的性能和易用性(难以想象吧~)。通过对少量数据的精调和后预训练,ERNIE模型在AI续写等场景中的表现优于同等参数规模的开源模型,这证明了闭源模型在特定业务场景下的优势。
商业与市场角度

从商业模式的角度来看,开源模型可能依赖于社区和广告收入,其商业模式可能不如闭源模型明确。闭源模型通过订阅服务和专业技术支持创造收入,商业模式更为成熟和稳定~
哎,还是钱钱钱~ 没办法~
在市场竞争力方面,闭源模型因其专业性和性能优化,在专业领域和高端市场中更具竞争力。而开源模型则在教育和非盈利领域更受欢迎,因其开放性和低成本的特点。
结论

综上所述,开源模型并不一定比闭源模型好。现在突然想到了某度老板曾说过:开源模型会越来越落后。当初不以为然,现在深层考虑下,好吧,或许说得也有些道理。
选择模型时应考虑具体的业务需求、技术条件以及市场环境。开源模型的开放性和社区驱动的特点在某些场景下具有优势,而闭源模型在性能优化、安全性和专业性服务方面可能更胜一筹。因此,用户在选择模型时,应根据自身的需求和条件,做出最合适的选择。
但是对于咱们普通人来说,随便玩玩模型,当时我必站队开源啊,否则我咋发论文?科学咋进步?嘿嘿~
公司那种高端服务,对于准确率和成本还要求特别严格的,还是踏踏实实选择闭源的服务吧。开源你玩不起,成本你都hold不住,谁让它们假装开源!给你400+B的我看你finetune到啥时候才能商用~
说到这吧,下课~