来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: VL4AD: Vision-Language Models Improve Pixel-wise Anomaly Detection

创新性
- 提出
VL4AD模型用于解决语义分割网络难以检测来自未知语义类别的异常的问题,避免额外的数据收集和模型训练。 VL4AD将视觉-语言(VL)编码器纳入现有的异常检测器,利用语义广泛的VL预训练来增强对离群样本的感知,还加入max-logit提示集成和类别合并策略用于丰富类别描述。- 提出了一种新的评分函数,可通过文本提示实现无数据和无训练的离群样本监督。
VL4AD
视觉文本编码器
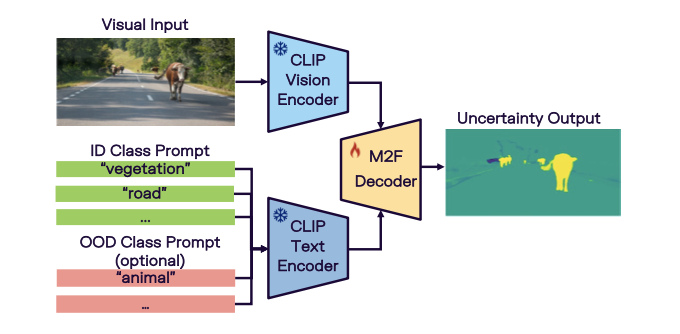
视觉编码器 \(\mathcal{E}\text{vision, vis-lang}\) 是与文本编码器 \(\mathcal{E}\text{text}\) 共同预训练,解码器 \(\mathcal{D}_\text{vis-lang}\) 处理多尺度的视觉和文本嵌入,生成两种类型的输出:掩码预测分数 \(\mathbf{s} \in 0, 1^{N\times H\times W}\) 和掩码分类分数 \(\mathbf{c} \in 0, 1^{N\times K}\) ,其中 \(N\) 表示对象查询的数量。
对象查询是可学习的嵌入,类似于目标检测网络中的先验框。掩码预测分数以类别无关的方式识别物体,而掩码分类分数计算掩码属于特定语义类别的概率。
基于编码后的视觉嵌入 \(\mathbf{v}_i\) ( \(i=1, \dots, N\) )和ID类别文本嵌入 \(\mathbf{t}_j\) ( \(j=1, \dots, K\) )之间的余弦相似性计算掩码分类分数:
\\\begin{equation} \\mathbf{c}_{i} = \\text{softmax}\\Big(1/T \\begin{bmatrix} \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_1), \& \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_2), \& \\ldots, \& \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_{K}) \\end{bmatrix} \\Big) \\end{equation} \\
在架构上, \(\mathcal{E}\text{vision, vis-only}\) 和 \(\mathcal{E}\text{vision, vis-lang}\) ,以及 \(\mathcal{D}\text{vis-only}\) 和 \(\mathcal{D}\text{vis-lang}\) 是相当相似的,区别在于 \(\mathcal{E}\text{vision, vis-lang}\) 在预训练后保持不变,仅对视觉-语言解码器 \(\mathcal{D}\text{vis-lang}\) 进行微调。通过这种方式,将零样本CLIP在图像级别的竞争性OOD检测性能转移到像素级任务中。
Max-Logit提示集成于类合并
优化ID类文本嵌入可以使其更好地与相应的ID视觉嵌入对齐,提高ID和OOD类别之间的可分离性,但盲目地微调文本编码器可能导致灾难性遗忘。
为此,论文通过max-logit提示集成在文本提示中引入概念词汇多样性和具体化,显著提高模型对OOD输入的敏感性。词汇多样性包括同义词和复数形式,而具体化涉及更好地与CLIP预训练对齐的分解概念。例如,使用概念{vegetation, tree, trees, palm tree, bushes}来表示类vegetation。
max-logit集成考虑给定类 \(k\) 的所有替代概念,替换内容为视觉嵌入 \(\mathbf{v}_i\) 与所有 \(l\) 个替代文本嵌入 \(\\mathbf{t}_{k}\^{1}, \\ldots, \\mathbf{t}_{k}\^{l}\) 的最大余弦相似度:
\\\begin{equation} \\max\\Big( \\begin{bmatrix} \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_{k}\^{1}), \& \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_{k}\^{2}), \& \\ldots, \& \\text{cos}(\\mathbf{v}_i, \\mathbf{t}_{k}\^{l}) \\end{bmatrix}\\Big). \\end{equation} \\
此外,单靠在 \(K\) 类维度上的最大像素级得分可能导致次优性能,因为在两个ID类之间的边缘像素的不确定性较高,尤其是当类别数量增加时。
为了解决这个问题,将相关的ID类合并为超类。通过在测试期间将各个语义类的文本提示作为不同的替代概念连接到超类中来实现,而无需重新训练。然后,可以使用max-logit方法获得超类的不确定性。
通过OOD提示实现无数据、无训练异常监督
通过视觉-语言预训练,通常能够很好地检测到与ID类不同的语义OOD类(远OOD类)。但当OOD类与ID类非常相似的情况(近OOD类),则更具挑战性。例如,在CityScapes类别中,OOD类大篷车在城市驾驶场景中可能在视觉上与ID类卡车相似。
利用视觉-语言模型的开放词汇能力,论文引入了一种新的评分函数,旨在更好地检测这些近OOD类,而不需要额外的训练或数据准备。
为了在测试时整合 \(Q\) 个新的OOD概念,需要通过 \(Q\) 个额外的项 \(\text{cos}(\mathbf{v}i, \mathbf{t}{K+1}), \ldots, \text{cos}(\mathbf{v}i, \mathbf{t}{K+Q})\) 扩展公式1中的掩码分类得分 \(\mathbf{c}_i\) 。遵循公式2,即通过将 \(\mathbf{c} \in \left0, 1\\right^{N\times (K+Q)}\) 的前 \(K\) 个通道与掩码预测得分 \(\mathbf{s} \in \left0, 1\\right^{N\times H\times W}\) 进行组合,获得最终的不确定性得分 \(\mathbf{u} \in \mathbb{R}^{H\times W}\) :
\\\begin{equation} \\mathbf{u}_{h,w} = -\\max_{k}\\sum_{i=1}\^{N} \\mathbf{s}_{i, h, w} \\cdot \\mathbf{c}_{i, k}\\ \\ . \\end{equation} \\
通过这一整合, \(Q\) 类中的OOD对象将(在大多数情况下)正确分配到其相应的类别。如果没有这一整合,它们可能会被错误地分配到与其实际OOD类别相似的ID类。相反,如果输入中不存在OOD对象,额外的 \(Q\) 类的影响将保持微不足道。
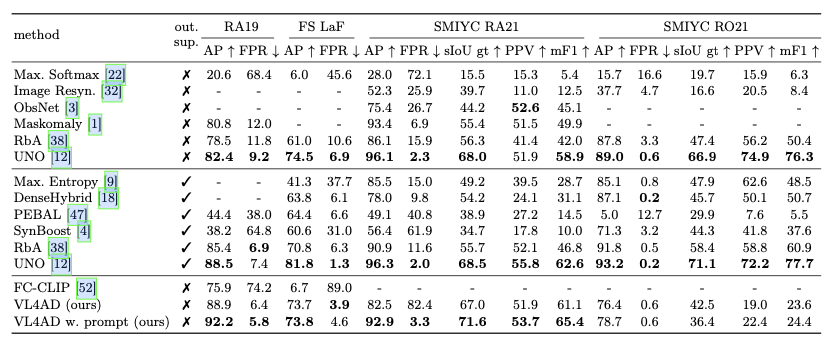
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
