⭐️基础链接导航⭐️
服务器 → ☁️ 阿里云活动地址
看样例 → 🐟 摸鱼小网站地址
学代码 → 💻 源码库地址
一、前言
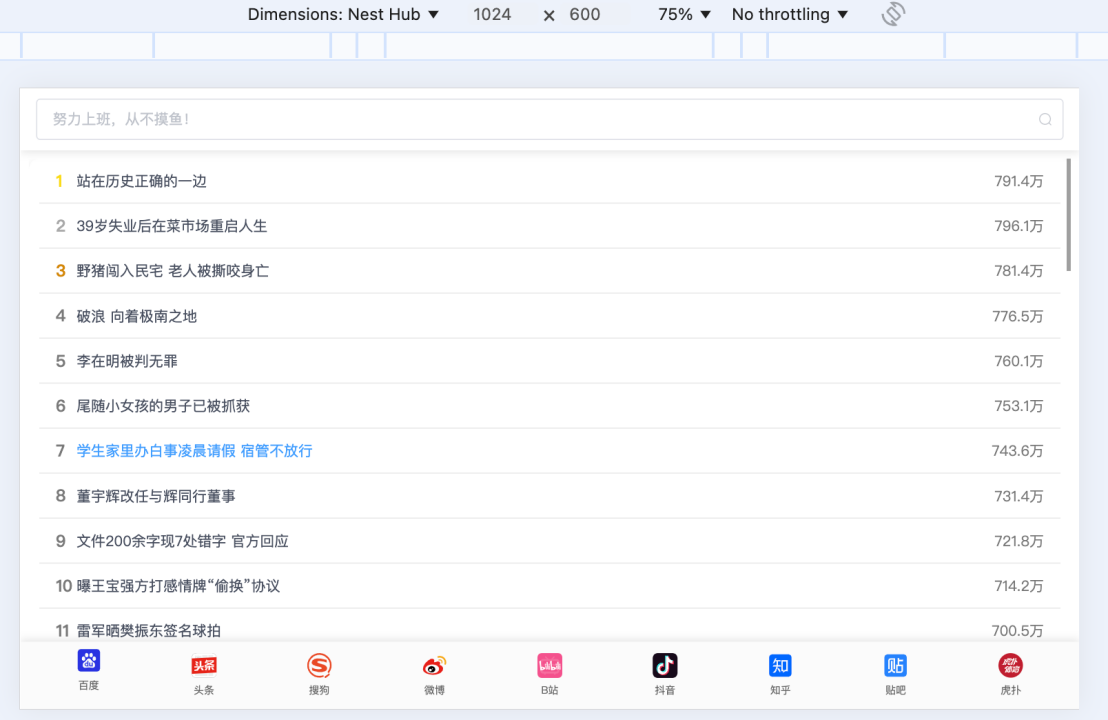
大家好呀,我是summo,小网站一直有个问题,就是PC端的样式和移动端的样式是两套,并且不能根据显示屏的大小进行动态化布局,如果PC端屏幕非常小就是这样:
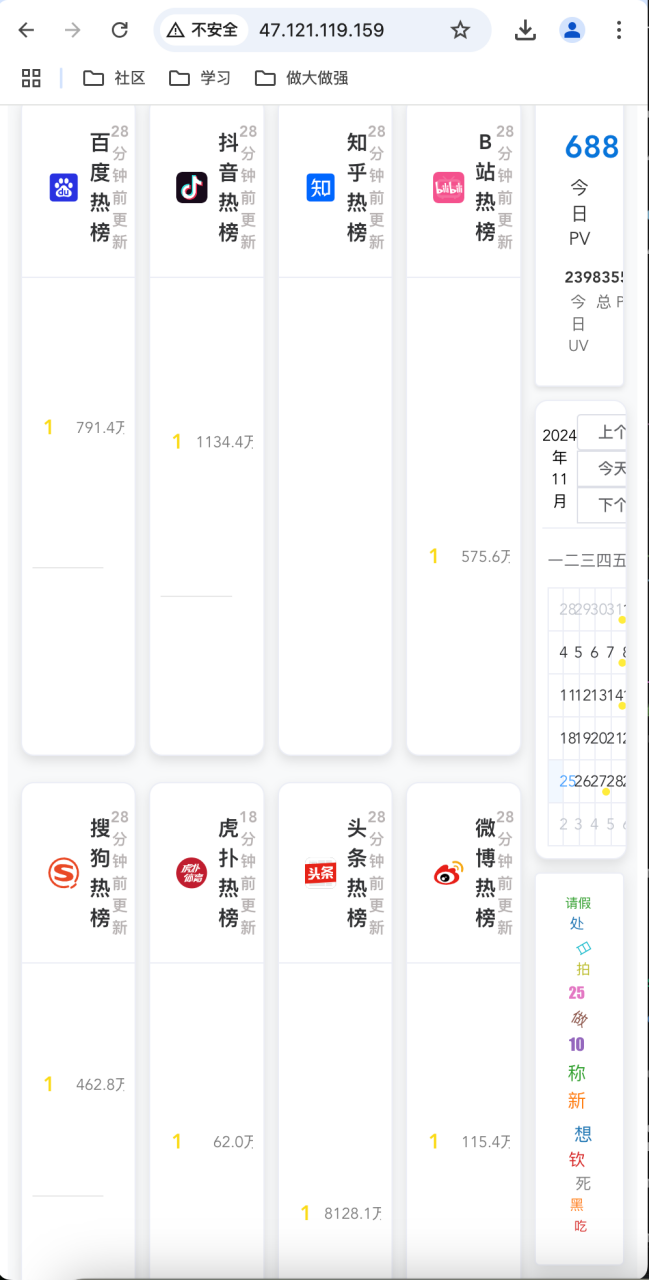
如果移动端屏幕非常大就是这样:
总之,这样的效果不是我想要的,我想要是下面这样的:
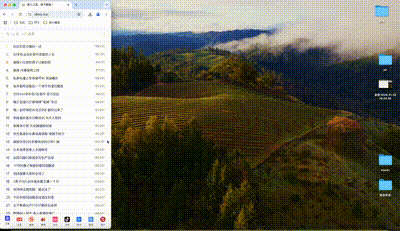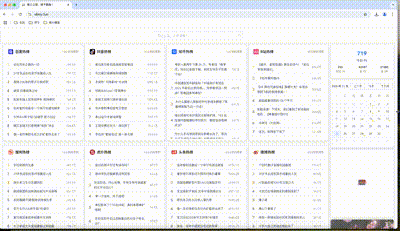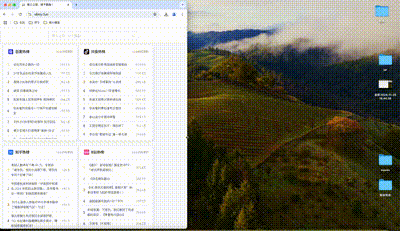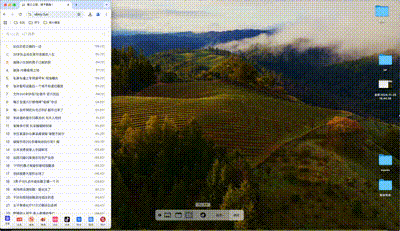
这个功能我本来以为会很麻烦,实际上还好,已经发布上线了,代码也提交到Gitee了,下面介绍一下我是怎么实现这个响应式布局功能的。
二、响应式布局
响应式布局是同一页面在不同的屏幕上有不同的布局,即只需要一套代码使页面适应不同的屏幕。 这个听起来很牛逼,但是小网站想要实现这个功能却很容易,因为小网站的前端是基于ElementUI实现的,而ElementUI本身就支持响应式布局。
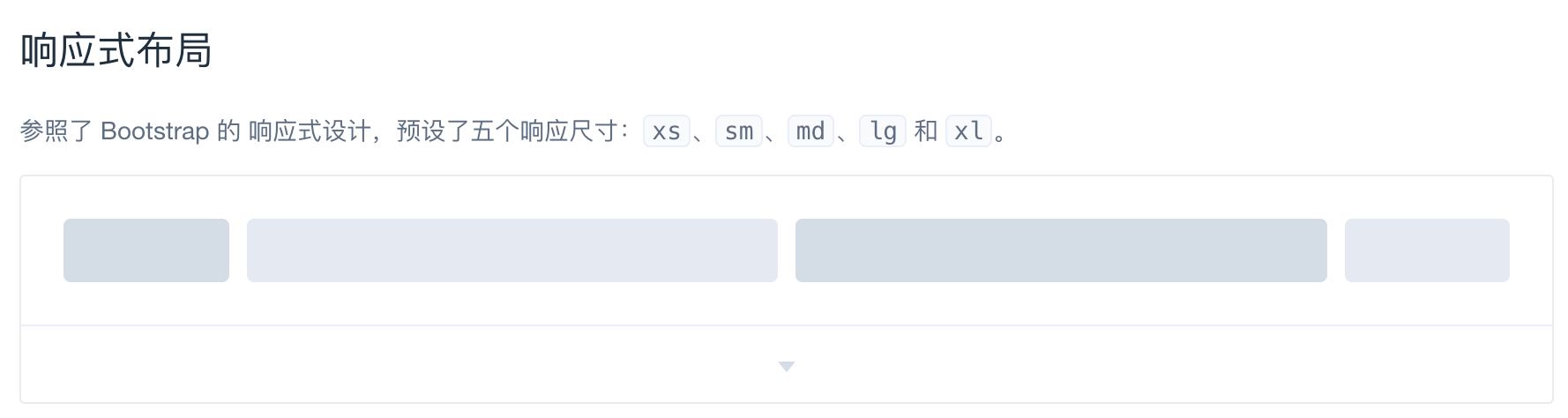
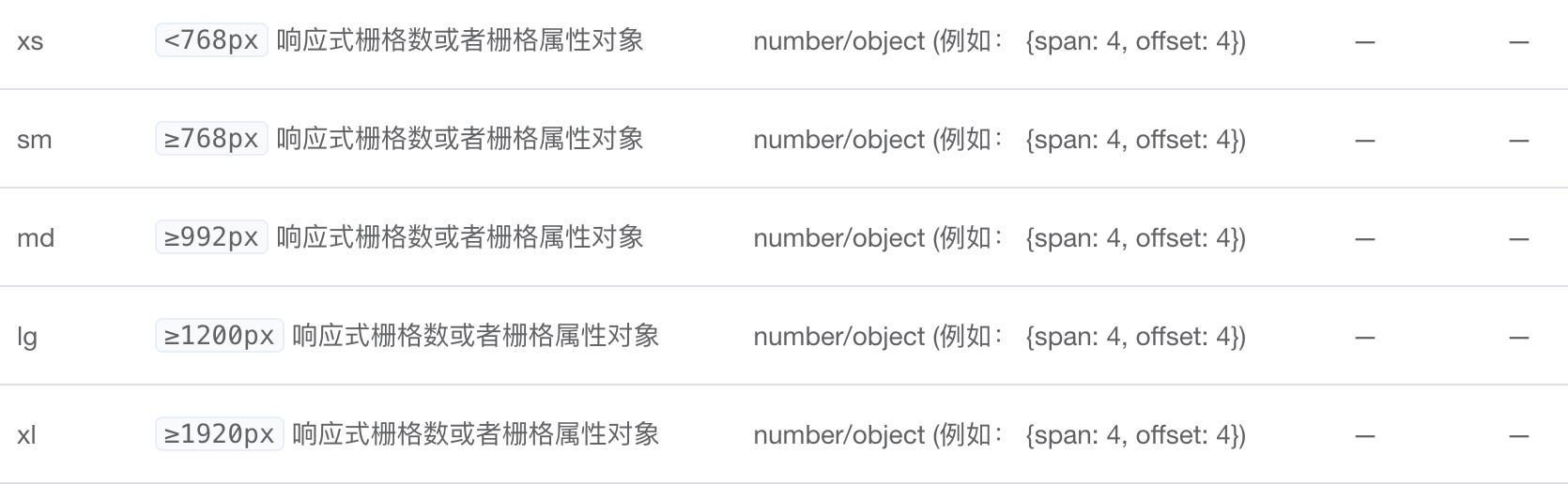
也就是说我们只要利用ElementUI的这个特性就可以实现响应式布局。
这是小网站的main区域修改后的代码
html
<el-main>
<el-row :gutter="10">
<el-col :sm="24" :md="20" :lg="20" :xl="20">
<el-row :gutter="10">
<el-col
v-for="(board, index) in hotBoards"
:key="index"
:xs="24"
:sm="10"
:md="8"
:lg="6"
:xl="6">
<hot-search-board
:title="board.title"
:icon="board.icon"
:fetch-url="board.fetchUrl"
:type="board.type"
/>
</el-col>
</el-row>
</el-col>
<el-col :xs="0" :sm="4" :md="4" :lg="4" :xl="4">
<visitor-log />
<holiday-calendar />
<word-cloud />
<poetry />
<camera-player />
</el-col>
</el-row>
</el-main>从代码上可以看到,在内容区域和侧边栏区域设置了响应式布局属性,正常情况下两块区域的比例分配是20:4 ,但由于侧边栏在页面宽度很小时会出现样式混乱的问题,所以可以通过设置
:xs="0"直接隐藏。第二部分就是内容区域里面的热搜组件,由于每行展示的热搜组件个数需要根据页面宽度来动态调整,所以这里也是使用了响应式布局属性,核心逻辑就是随着页面宽度的减少,单个热搜组件的占比增加,最终增加到24,占满整个屏幕。
三、PC端和移动端样式替换
本来我以为这个功能会很复杂,但实际上这个反而是最简单的,我先上代码:
html
<template>
<div v-if="!isSmallScreen">
<pc-app />
</div>
<div v-else>
<mp-app />
</div>
</template>
<script>
import PcApp from "@/PCApp.vue";
import MpApp from "@/MpApp.vue";
export default {
components: { PcApp, MpApp },
data() {
return {
// 用于标识是否为小屏幕
isSmallScreen: false,
};
},
created() {
// 根据初始屏幕宽度设置isSmallScreen的值
this.checkScreenSize();
},
methods: {
checkScreenSize() {
const screenWidth = window.innerWidth;
this.isSmallScreen = screenWidth < 768;
},
},
mounted() {
// 监听窗口大小变化事件
window.addEventListener("resize", this.checkScreenSize);
},
beforeDestroy() {
// 移除窗口大小变化事件监听器
window.removeEventListener("resize", this.checkScreenSize);
},
};
</script>
<style scope></style>核心逻辑就是,我将PC端和移动端分为了两个组件,然后利用
isSmallScreen属性来判断当前屏幕是否需要进行PC端和移动端切换,非常简单。
四、小结一下
小网站的功能一直都不是很全,很多都只有最初始的版本,优化的点很多,但我前面确实对前端技术不是怎么熟悉就没有做。不过最近好好重新学了一下,感觉自己前端功力大涨,后续我会尝试增加一些新功能,让小网站的功能更加丰富。
番外:虎扑恋爱区热搜爬虫
1. 爬虫方案评估
虎扑恋爱区一直都是大家最爱看的热搜板块,今天我讲一下这个热搜数据是怎么获取到的。这个板块的核心接口是https://bbs.hupu.com/love-hot,返回的是HTML页面,所以又得用上我们的老朋友 Jsoup了,核心代码在第二段。
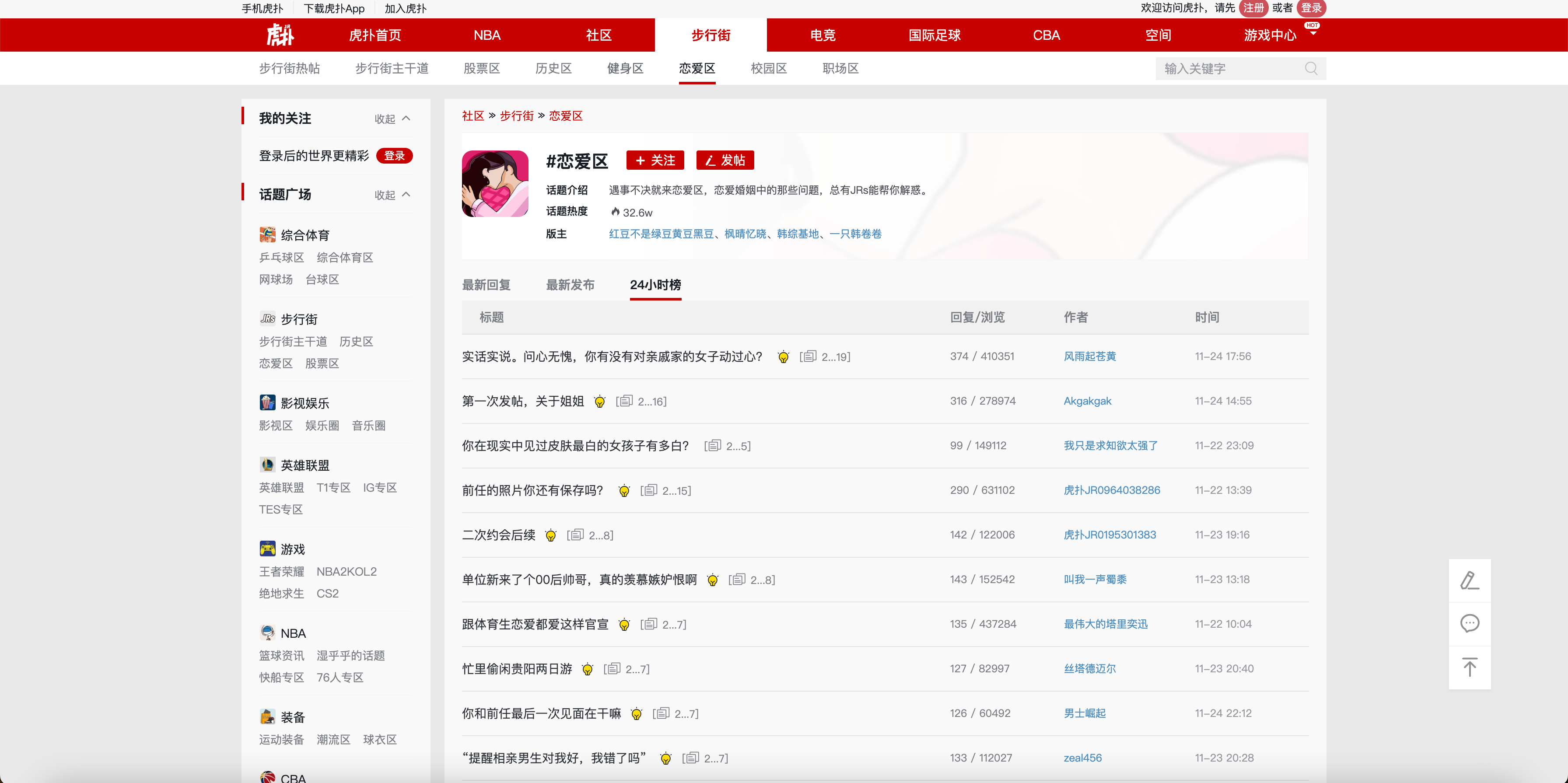
2. 网页解析代码
HupuHotSearchJob.java
java
package com.summo.sbmy.job.hupu;
import com.summo.sbmy.common.model.dto.HotSearchDetailDTO;
import com.summo.sbmy.dao.entity.SbmyHotSearchDO;
import com.summo.sbmy.service.SbmyHotSearchService;
import com.summo.sbmy.service.convert.HotSearchConvert;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;
import static com.summo.sbmy.cache.hotSearch.HotSearchCacheManager.CACHE_MAP;
import static com.summo.sbmy.common.enums.HotSearchEnum.HUPU;
/**
* @author summo
* @version HupuHotSearchJob.java, 1.0.0
* @description 虎扑热搜Java爬虫代码
* @date 2024年08月09
*/
@Component
@Slf4j
public class HupuHotSearchJob {
@Autowired
private SbmyHotSearchService sbmyHotSearchService;
@XxlJob("hupuHotSearchJob")
public ReturnT<String> hotSearch(String param) throws IOException {
log.info("虎扑热搜爬虫任务开始");
try {
String url = "https://bbs.hupu.com/love-hot";
List<SbmyHotSearchDO> sbmyHotSearchDOList = new ArrayList<>();
Document doc = Jsoup.connect(url).get();
//元素列表
Elements elements = doc.select(".p-title");
for (int i = 0; i < elements.size(); i++) {
SbmyHotSearchDO sbmyHotSearchDO = SbmyHotSearchDO.builder().hotSearchResource(HUPU.getCode()).build();
//设置文章标题
sbmyHotSearchDO.setHotSearchTitle(elements.get(i).text().trim());
//设置虎扑三方ID
sbmyHotSearchDO.setHotSearchId(getHashId(HUPU.getCode() + sbmyHotSearchDO.getHotSearchTitle()));
//设置文章连接
sbmyHotSearchDO.setHotSearchUrl("https://bbs.hupu.com/" + doc.select(".p-title").get(i).attr("href"));
//设置热搜热度
sbmyHotSearchDO.setHotSearchHeat(doc.select(".post-datum").get(i).text().split("/")[1].trim());
//设置热搜作者
sbmyHotSearchDO.setHotSearchAuthor(doc.select(".post-auth").get(i).text());
//按顺序排名
sbmyHotSearchDOList.add(sbmyHotSearchDO);
}
AtomicInteger count = new AtomicInteger(1);
sbmyHotSearchDOList = sbmyHotSearchDOList.stream().sorted(Comparator.comparingInt((SbmyHotSearchDO hotSearch) -> Integer.parseInt(hotSearch.getHotSearchHeat())).reversed()).map(sbmyHotSearchDO -> {
sbmyHotSearchDO.setHotSearchOrder(count.getAndIncrement());
return sbmyHotSearchDO;
}).collect(Collectors.toList());
if (CollectionUtils.isEmpty(sbmyHotSearchDOList)) {
return ReturnT.SUCCESS;
}
//数据加到缓存中
CACHE_MAP.put(HUPU.getCode(), HotSearchDetailDTO.builder()
//热搜数据
.hotSearchDTOList(sbmyHotSearchDOList.stream().map(HotSearchConvert::toDTOWhenQuery).collect(Collectors.toList()))
//更新时间
.updateTime(Calendar.getInstance().getTime()).build());
//数据持久化
sbmyHotSearchService.saveCache2DB(sbmyHotSearchDOList);
log.info("虎扑热搜爬虫任务结束");
} catch (IOException e) {
log.error("获取虎扑数据异常", e);
}
return ReturnT.SUCCESS;
}
/**
* 根据文章标题获取一个唯一ID
*
* @param title 文章标题
* @return 唯一ID
*/
private String getHashId(String title) {
long seed = title.hashCode();
Random rnd = new Random(seed);
return new UUID(rnd.nextLong(), rnd.nextLong()).toString();
}
@PostConstruct
public void init() {
// 启动运行爬虫一次
try {
hotSearch(null);
} catch (IOException e) {
log.error("启动爬虫脚本失败",e);
}
}
}