本地缓存带来的挑战
分布式缓存相比于本地缓存,在实现层面需要关注的点有哪些不同。梳理如下:
| 维度 | 本地缓存 | 集中式缓存 |
|---|---|---|
| 缓存量 | 受限于单机内存大小,存储数据有限 | 需要提供给分布式系统里面所有节点共同使用,对于大型系统而言,对集中式缓存的容量诉求非常的大,远超单机内存的容量大小。 |
| 可靠性 | 影响有限,只有本进程使用,不会影响其他进程的可靠性。 | 作为整个系统扛压屏障,系统内所有节点共同依赖的通用服务,一旦集中式缓存出问题,会影响与其对接的所有业务节点,对系统的影响是致命性的。 |
| 承压性 | 承载单机节点的压力,请求量有限 | 承载整个分布式集群所有节点的流量,系统内业务分布式节点部署数量越多、业务体量越大,会导致集中缓存要承载的压力就越大,甚至是上不封顶的。 |
从上述几个维度的对比可以发现,同样是缓存,但集中式缓存 所承担的使命是完全不一样的,业务对集中式缓存的存储容量、可靠性、承压性等方面的诉求也是天壤之别,不可等同视之。以Redis为例:
- 如何打破redis缓存容量受限于机器单机内存大小的问题?
- 如何使得redis能够扛住多方过来的请求压力?
- 如何保证redis不会成为单点故障源?
其实答案很简单,加机器!通过多台机器的叠加使用,达到比单机更优的效果 ------ 现在业务系统的集群化部署,也都是采用的这个思路。Redis的分布式之路亦是如此,但相比于常规的业务系统分布式集群化构建更加复杂:
- 很多业务实现集群化部署会很简单,因为每个业务进程节点都是无状态的,只需要部署下然后通过负载均衡的方式对外提供请求应答即可。
- Redis作为一个集中式缓存数据库,它是有状态的,不仅需要将进程分别部署在多个节点上,还需要将数据也分散存储在各个节点上,同时还得保证整个Redis集群对外是一个统一整体。
所以对于一个集中式缓存的分布式能力构建,必须要额外提供一些机制,来保障数据在各个节点上的安全与一致性,还需要将分散在各个节点上的数据都组成一个逻辑上的整体。
主从复制简介
主从复制是什么
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点,而对于redis来说,一主两从是比较常见的搭配。
主从模式按照读写分离的策略来提升整体的请求处理能力:
- 主节点(Master)同时对外提供读和写操作
- 从节点(Slave)通过
replicate同步的方式,从主节点复制数据,保持自身数据与主节点一致 - 从节点只能对外提供读操作
当然,对于读多写少类的操作,为了提升整体读请求的处理能力,可以采用一主多从的方式。所有的从节点都从主节点进行数据同步,这样会导致主节点的同步处理压力过大而成为瓶颈。为了解决这个问题,redis还支持了从slave节点分发的能力,也就是从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个主从链。这样可以分摊主服务器压力。
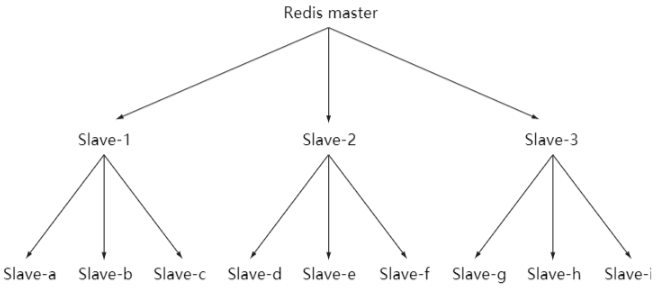
主从复制的作用
- 数据备份:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复。
- 读写分离:由主节点提供写服务,由从节点提供读服务,提高Redis服务器的并发量。
主从复制流程
全量复制
在第一次同步时会进行全量复制(但并非只有第一次同步时全量复制,其他情况看后文)
第一次同步时流程:

第一阶段:建立链接、协商同步
从服务器向主服务器发送PSYNC ? -1 命令,主动请求进行完整重同步
psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
- runID,每个 Redis 服务器在启动时都会自动生产一个随机的 ID 来唯一标识自己。当从服务器和主服务器第一次同步时,因为不知道主服务器的 run ID,所以将其设置为 "?"。
- offset,表示复制的进度,(也叫复制偏移量),主要为增量复制服务,这里因为是全量复制,所以使用-1表示。
主服务器收到 psync 命令后,会向从服务器发送FULLRESYNC响应命令并带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
第二阶段:主服务器同步数据给从服务器
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器(数据持久化)。
从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。这是因为从服务器在通过 replicaof 命令开始和主服务器同步前,可能保存了其他数据。为了避免之前数据的影响,从服务器需要先把当前数据库清空。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
就像RDB文件生成过程中Redis不停止提供服务一样,从服务器在接收并载入RDB文件的过程中,主服务器仍然可以写入数据,那怎么将这部分数据传给从服务器呢?
第三阶段:主服务器发送新写操作命令给从服务器
为了保证主从服务器的数据一致性,主服务器为每个连接进来的从服务器准备了一个replication buffer缓冲区,这段时间内写入的数据都会被存入这个replication buffer中,从服务器完成 RDB 的载入后,会回复一个确认消息给主服务器。主服务器就将replication buffer中的数据推送过去。
长连接传播
主从服务器在完成第一次同步后,双方之间就会维护一个 TCP 连接,这个TCP连接是长连接
之后就会基于这个长连接进行命令传播。通过这种方式来保证第一次同步后的主从服务器的数据一致性。
增量复制
实际上,生成RDB文件是比较耗费资源的,同时,主服务器传输 RDB 文件给从服务器,这个操作会耗费主从服务器大量的网络资源,并对主服务器响应时延产生影响。而对从服务器而言,载入 RDB 文件期间,会阻塞其他命令请求,这也会导致响应效率的降低。并且,当从服务器断开后重新连接,主从数据不一致,在数据少量不一致的情况下,也不需要全量复制。因此,就提供了增量复制
复制偏移量(replication offset)
主服务器和从服务器会分别维护一个复制偏移量。如果主从服务器的复制偏移量相同,则说明二者的数据库状态一致;反之,则说明二者的数据库状态不一致,此时从服务器需要使用增量复制来同步缺失的这一部分数据。

复制积压缓冲区(replication backlog)
主服务器的写命令,除了传给从服务器后,还会写入replication backlog(全局唯一),这是一个固定长度的先进先出(FIFO)队列,默认大小为 1MB。其在内存中是一个环形结构。


- 主服务器按照顺时针方向写命令,主服务器最新写入的位置即为上文提到的主服务器的偏移量,这里叫master offset。
- 假设从服务器在set key2 2后断开连接,也就是上图中slave offset的位置,当它重连时,再次给主服务器发送psync指令时,会带上自己的offset(注意和全量复制的区别,全量复制时offset设置为-1,此时是从服务器真实的offset值)。
- 接着,主服务器发现从服务器的偏移量与自己不一致,需要进行增量复制。此时主服务器会计算出master offset与slave offset之间的指令,并发送给该为从服务器准备的replication buffer中,进而发送给从服务器。
- 从服务器进行写入后便又恢复到和主服务器一致的状态。
断开重连并不一定总是增量复制
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
- 整个replication backlog是个环形结构,也就是说最新的写命令会将最老的写命令覆盖。换句话说,如果从服务器断开时间太久,环形缓冲区被主服务器的写命令覆盖了,那么从服务器连上主服务器后只能通过全量复制 来获取数据了。所以replication backlog配置要尽量大一些,可以降低主从断开后全量复制的概率。
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
- 上文中有提到每个实例有自己的RunID,这个值在服务器启动时自动生成,由 40 个随机的十六进制字符组成。从服务器断开重连时会将之前主服务器的RunID一起发送过去(这里注意和第一次连接的区别,第一次连接时发送的RunID是"?"),主服务器会判断这个RunID是否为自己,如果不是(比如出现脑裂,出现两个主服务器),则会和全量复制时一样返回FULLRESYNC响应命令,告知从服务器需要进行全量复制。
总结
主从服务器第一次同步的时候,就是采用全量复制。
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
如果遇到网络断开,就需要进行增量复制(当然不一定是增量复制,具体还需要看replication backlog的大小,以及对应的主服务器RunID)。
面试题专栏
Java面试题专栏已上线,欢迎访问。
- 如果你不知道简历怎么写,简历项目不知道怎么包装;
- 如果简历中有些内容你不知道该不该写上去;
- 如果有些综合性问题你不知道怎么答;
那么可以私信我,我会尽我所能帮助你。