1.简介
随着网页的复杂性和动态性的增加,自动化测试变得越来越重要。Playwright作为一款强大的无头浏览器测试库,提供了多种元素定位方式,使得我们能够轻松地对网页进行自动化操作。在基础的定位方式如通过id、class name和tag name等之外,Playwright还提供了更高级的定位技巧,如nth()、first、last和filter()等。本文将对这些高级定位方式进行深入探讨,帮助读者更好地理解和应用这些技术。
2.nth():基于索引的元素定位
在网页中,有时我们会遇到多个具有相同属性或文本的元素,这时我们就需要通过索引来选择特定的元素。Playwright的nth()方法正是为此而生。nth()方法接受一个索引参数,从0开始计数,返回指定索引位置的元素。根据元素索引来选择元素,当符合定位信息的元素有多个时,我们通常要挑选出我们需要的元素,可以使用 nth()来进行挑选我们需要的是哪一个元素。索引是从 0 开始的。例如,如果我们想选择页面上第二个"公司名称"文本的元素,可以这样写:
const element = await page.get_by_text('公司名称', { exact: true }).nth(1);3.first和last:选择第一个和最后一个元素
根据名称我们就可以知道,这是定位的第一个和最后一个元素,这两个是作为类属性使用的,使用时不需要加()在某些情况下,我们可能只关心一组元素中的第一个或最后一个。Playwright提供了first和last这两个类属性,用于快速选择第一个和最后一个元素。这两个属性无需加括号,直接作为方法调用即可。例如,如果我们想选择页面上第一个名为"确定"的按钮,可以这样写:
const button = await page.get_by_role('button', { name: '确定' }).first();4.filter():二次筛选元素
根据名称我们就可以知道,这个是用来做筛选的。他的作用主要是在元素定位后,进行二次筛选。有利于在复杂的页面当中,过滤出我们需要的元素。主要用到的参数有两个,has_text: 包含的文本信息 has_not_text: 不包含的文本信息。
在复杂的网页中,有时我们需要通过多个条件来筛选元素。Playwright的filter()方法允许我们在元素定位后进行二次筛选。这使得我们能够在已经定位到的元素集合中,根据特定条件过滤出我们真正需要的元素。例如,如果我们想选择页面上所有带有"active"类的按钮中的第一个,可以这样写:
const activeButton = await page.get_by_role('button').filter(button => button.hasClass('active')).first();5.链式选择器
我们先来认识一下链式选择器中的两个符号,常用的是 >>
1.>: 定位子元素,定位和父级元素相邻的元素,只能定位"亲儿子"
2.>>:定位后代元素,定位父级元素下的所有元素,只要位于父元素下,都可以定位
链式选择器用来根据多个 css 样式定位元素。当元素没有 id 并且 css 样式又繁多的时候,我们可以通过使用链式选择器,来根据多个 css 样式进行元素定位。例如,如果我们想定位 van-popover__wrapper 样式下样式为 MPMicon 的元素,可以这样写:
const = await page.locator('.van-popover__wrapper >> .MPMicon');6.正则表达式
我们在根据文本信息进行元素定位时,有文本的部分内容会发生变化的情况,我们可以通过正则表达式,来根据某些固定的内容,进行元素定位。首先需要先了解一下正则表达式的知识 例如,如果我们想定位名称由1-9数字开头和" 个 进行中" 文字结尾的按钮,可以这样写:
const = await page.get_by_role("button", name=re.compile(r"[1-9]\d* 个 进行中$"));7.XPath
XPath 是一种用于在 XML 文档中定位和选择节点的语言。它可以通过使用路径表达式来指定节点的位置,并支持使用各种条件进行过滤和匹配。以下是一些常见的 XPath 高阶定位方法:
- 使用逻辑运算符,如 and、or、not,将多个条件组合起来进行定位。
- 使用轴定位,通过预定义的轴(如子节点、父节点、兄弟节点等)来获取相对于当前节点的其他节点集合。
- 使用谓词,查找特定节点或包含特定值的节点,谓词嵌入方括号中。
- 使用内置函数,执行一些复杂的操作,如字符串处理、数值计算等。
7.1包含-contains()
- Xpath 表达式中的一个函数,contains 会匹配符合某属性中包含 xx 字符串的元素。例如//*contains(@text,"hogwarts")则会匹配text属性的属性值中包含hogwarts的元素
- contains()函数的使用格式
//*[contains(@属性,"属性值")]- 特点
- contains() 函数定位的元素很容易为 list
- contains() 函数内的属性名需要用 @ 开始
7.2XPath 轴
XPath 轴是 XPath 语言中的一个重要概念,它可以根据节点之间的关系来选择节点。XPath 轴定义了节点的一个集合,这个集合由满足特定条件的节点组成。
可以通过过定位一个节点,定位到当前的节点的兄弟节点、父节点、爷爷节点、祖先节点等等。
7.3XPath 运算符
7.3.1 AND
AND 表示可以在 XPath 表达式中同时具备 2 个条件,在 AND 两个条件都应该为真的情况下,即该元素既有 条件A 又有 条件B 。AND 定位取到的是交集。
示例:定位如下图页面中的红框所框出来的元素。demo网站:https://sahitest.com/demo/formTest.htm
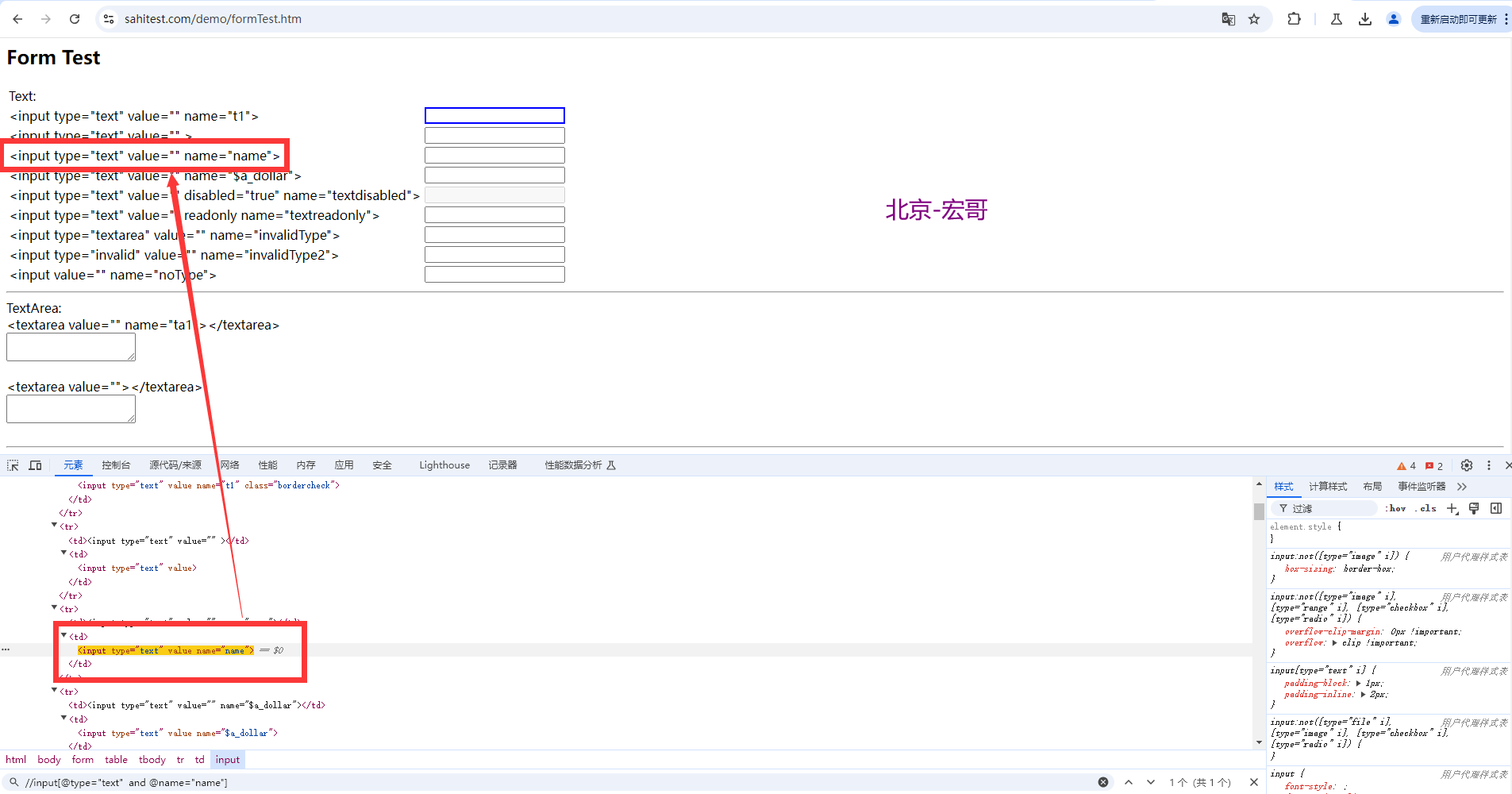
1.使用 type 属性进行定位时,会定位到多个元素(从图中看到定位到8个),如下图所示:
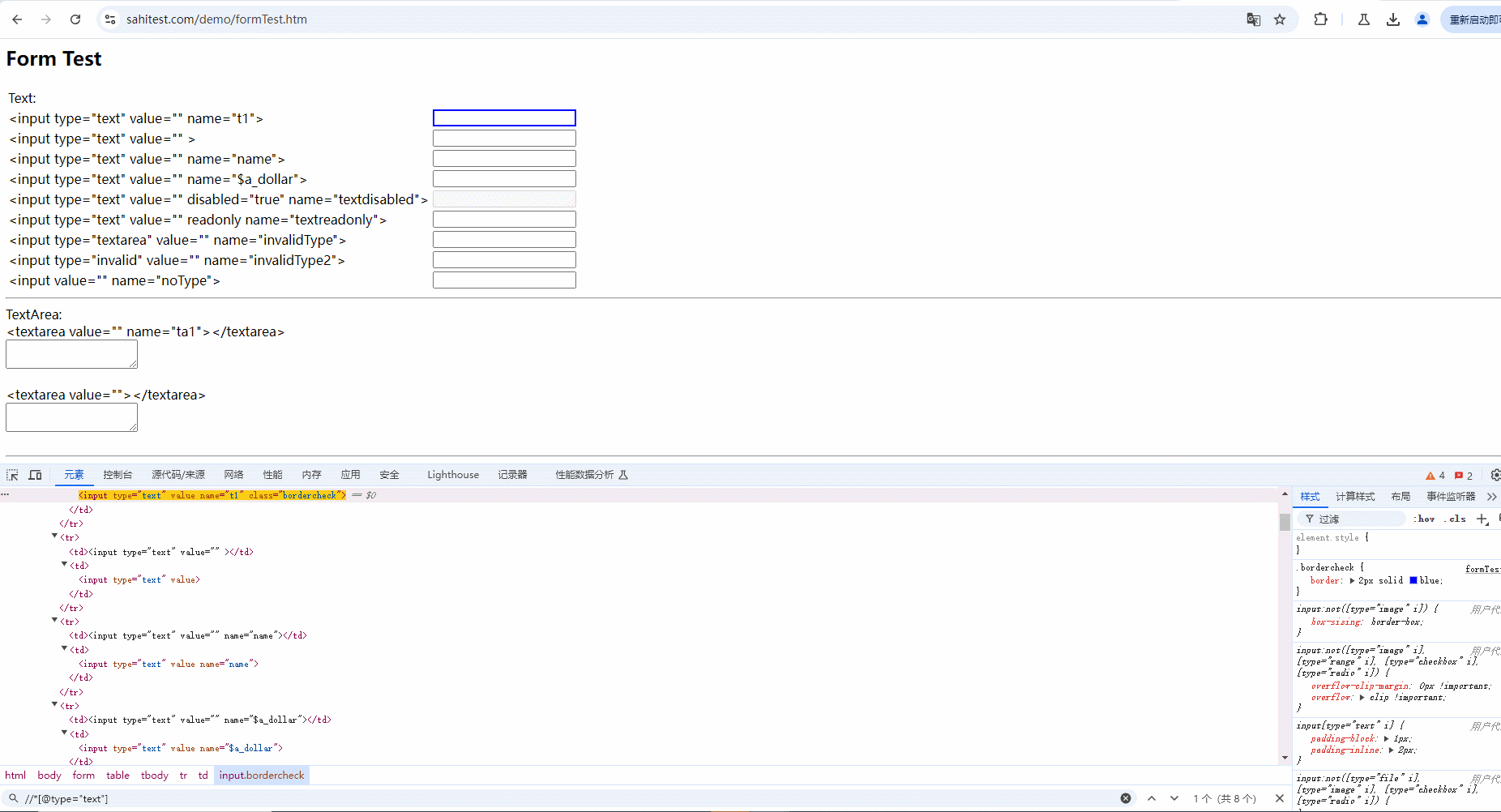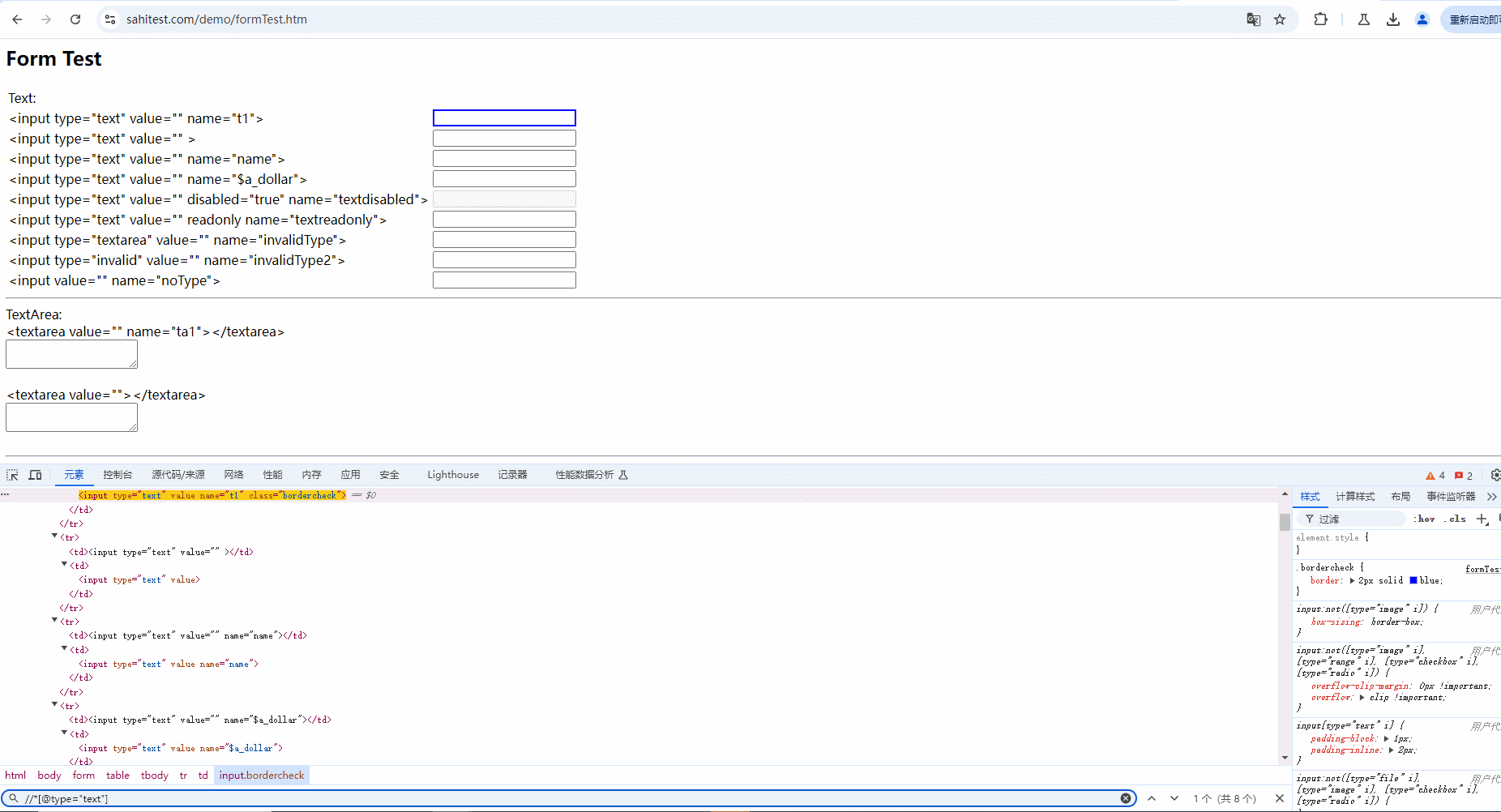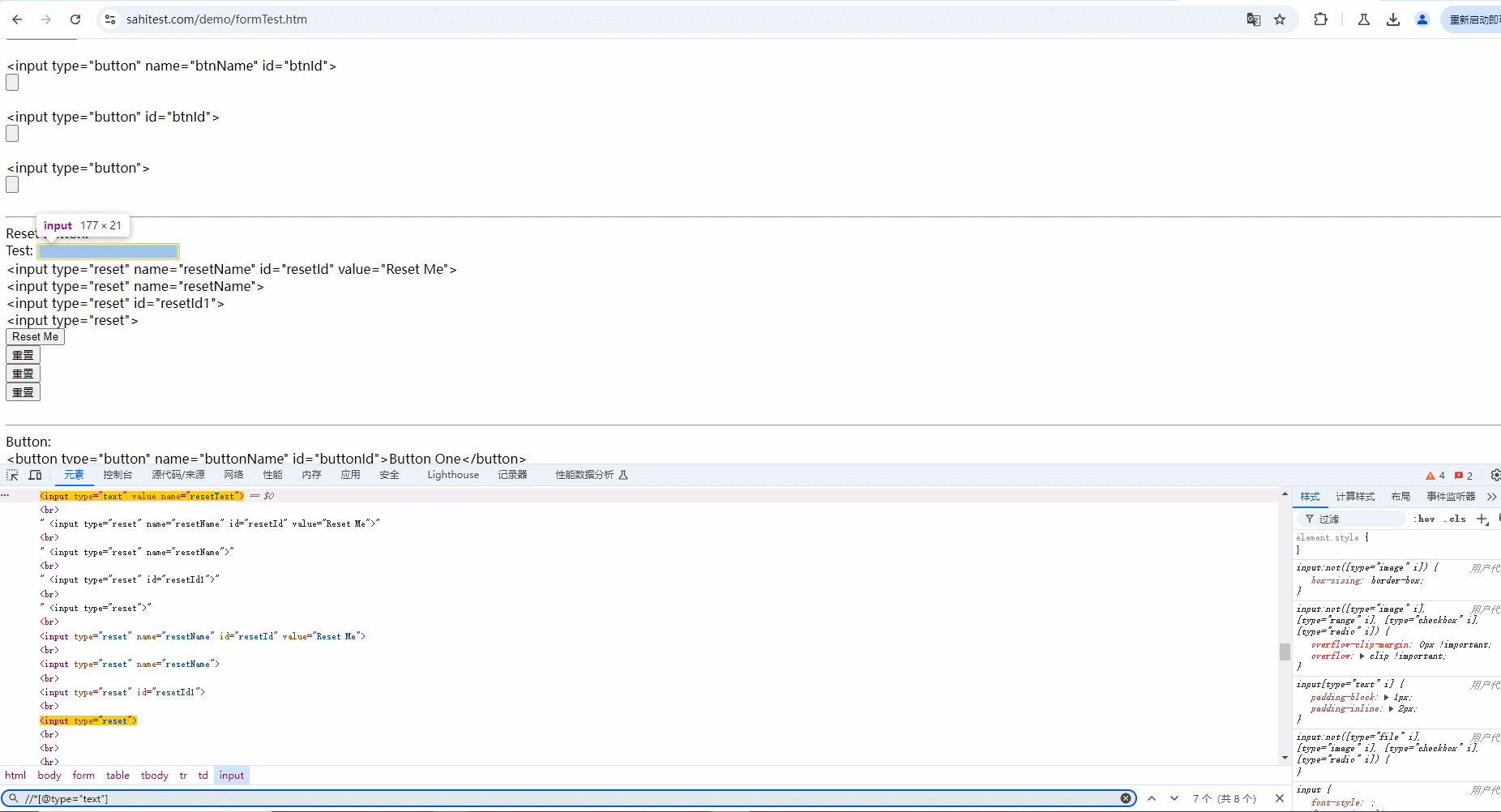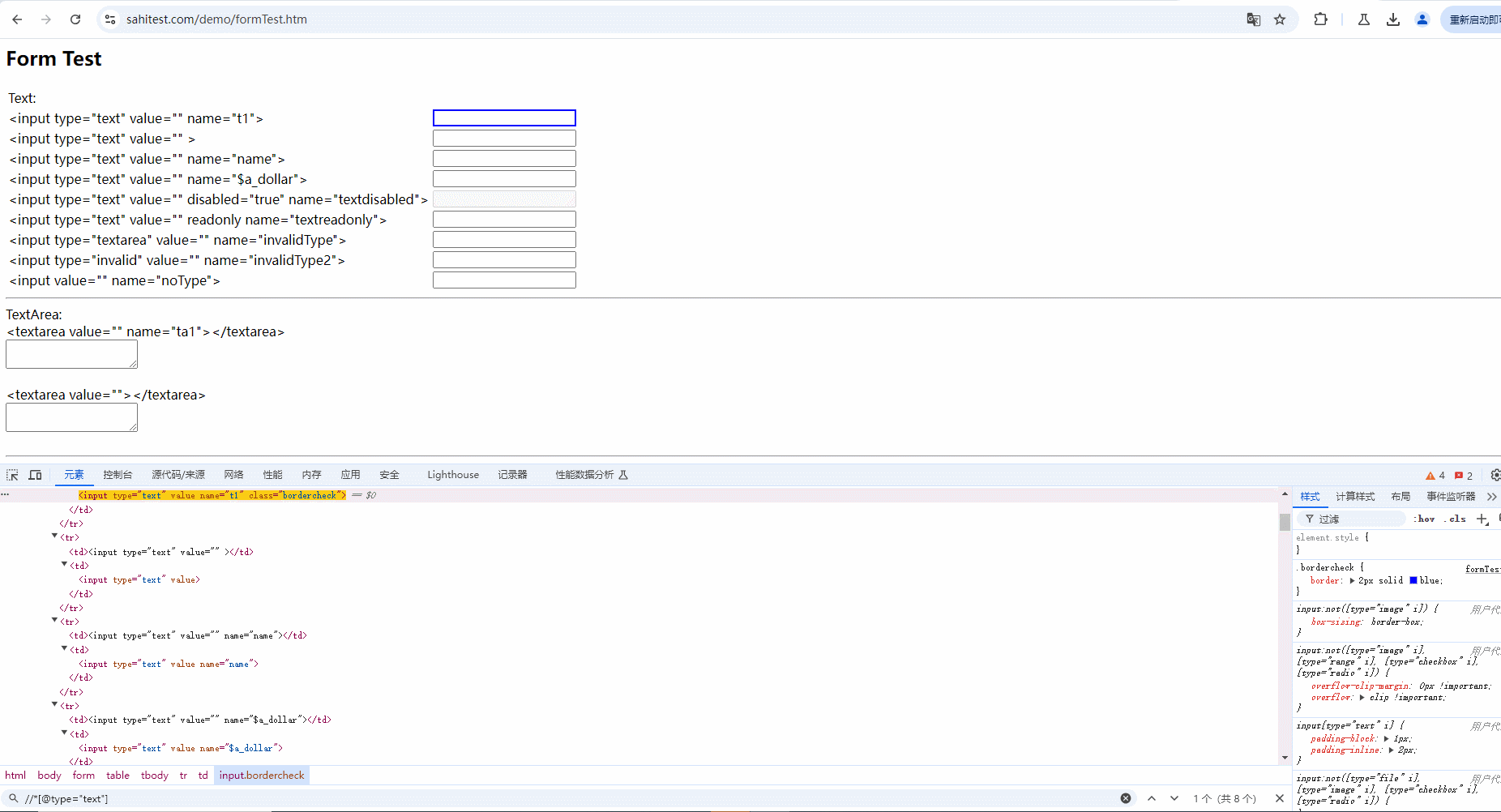
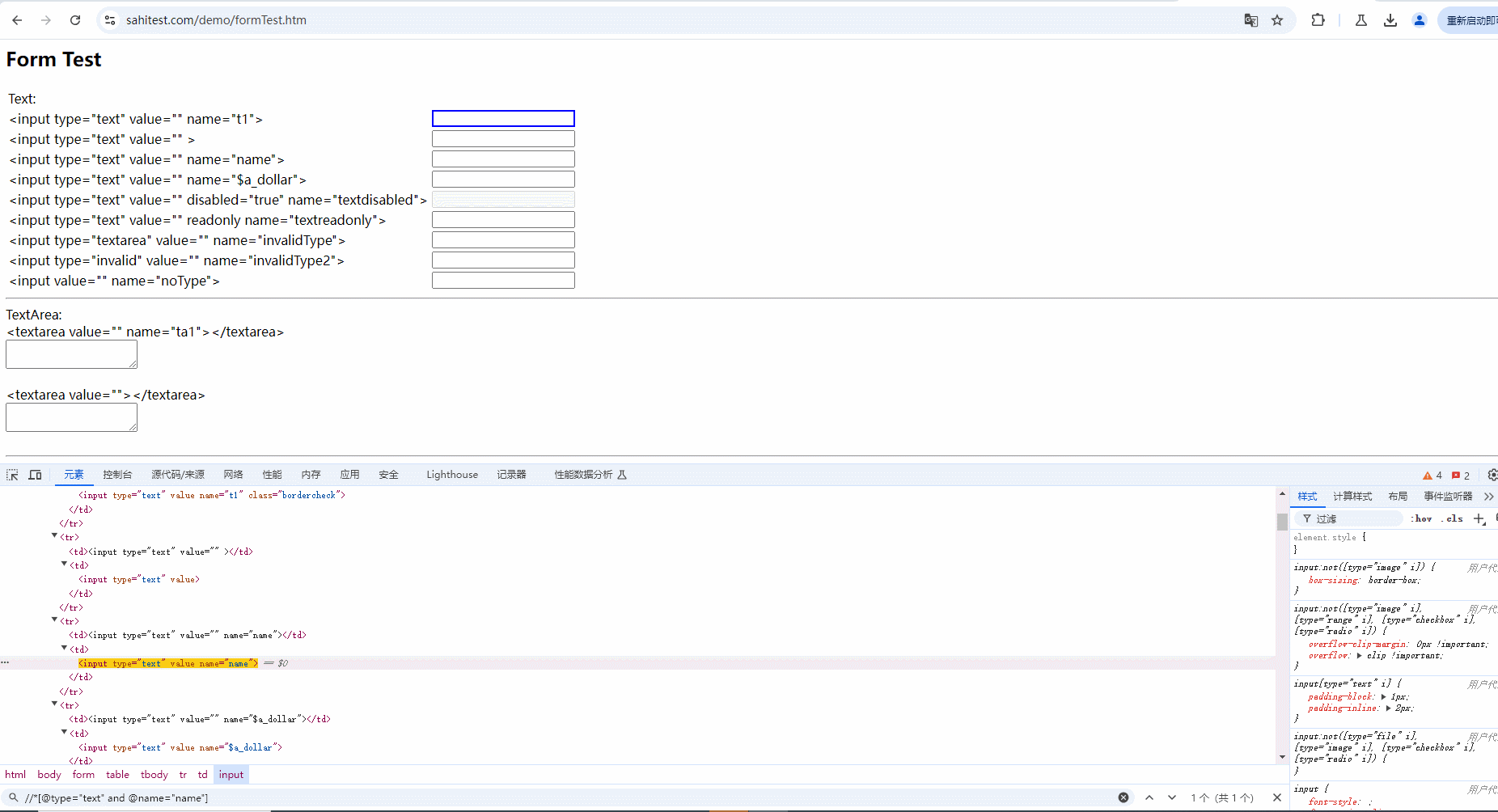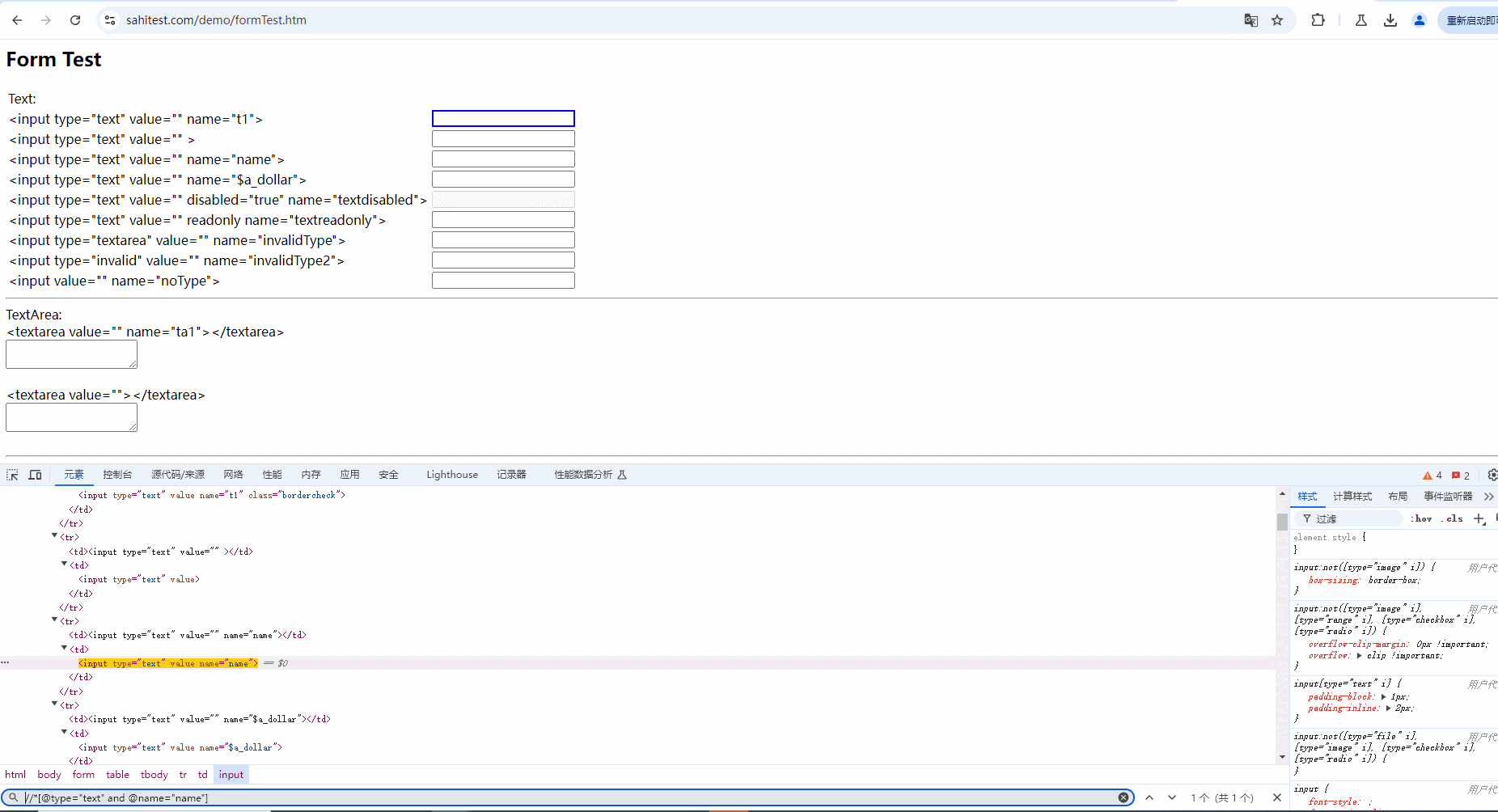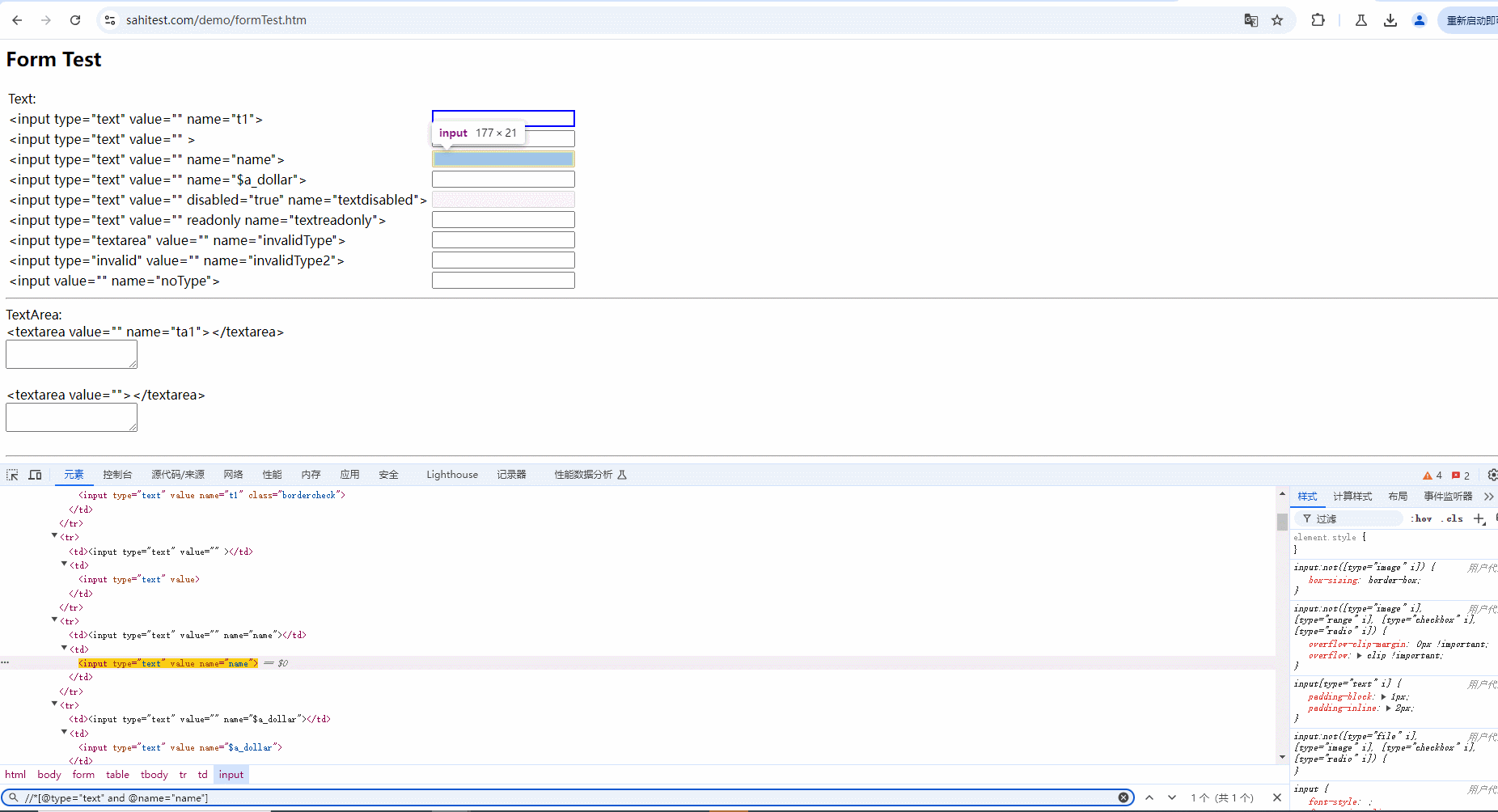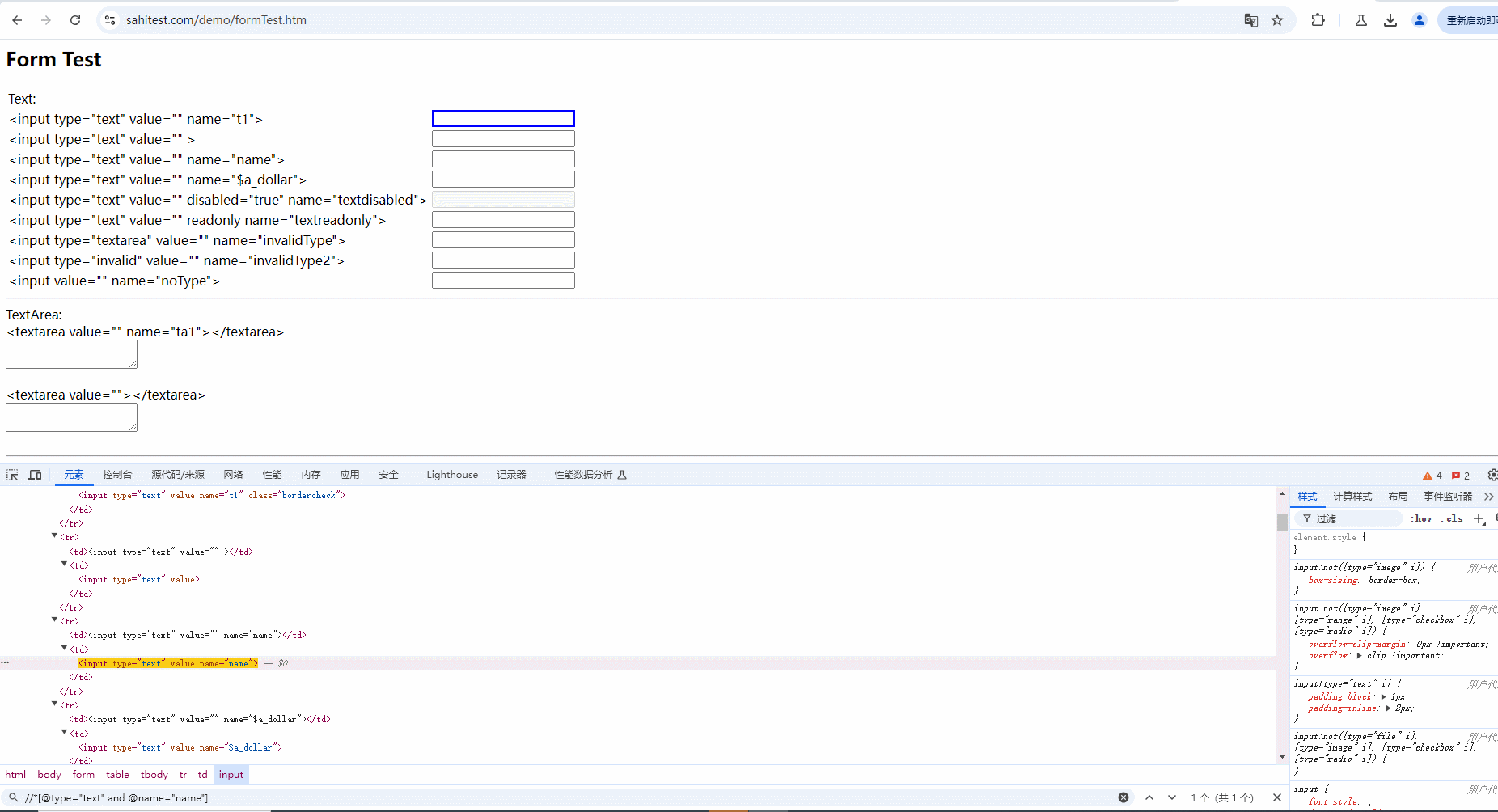
2.使用and运算符增加筛选条件进行过滤,需要满足符合 type 属性 ,且 name 内容为 name 的元素。只有两个条件都符合时才会被选中,如下图所示:
7.3.2 OR
OR 表示可以在 XPath 表达式中放置 2 个条件,在 OR 的情况下,两个条件中的任何一个为真,就可定位到该元素。OR 定位获取的是并集。
示例:定位当前页面中 type 为 text 或 name为 q 的元素,也就是下面 5 个元素。demo网站:https://sahitest.com/demo/strict_visible.htm
Xpath语法:
//*[@type="text" or @name="q"]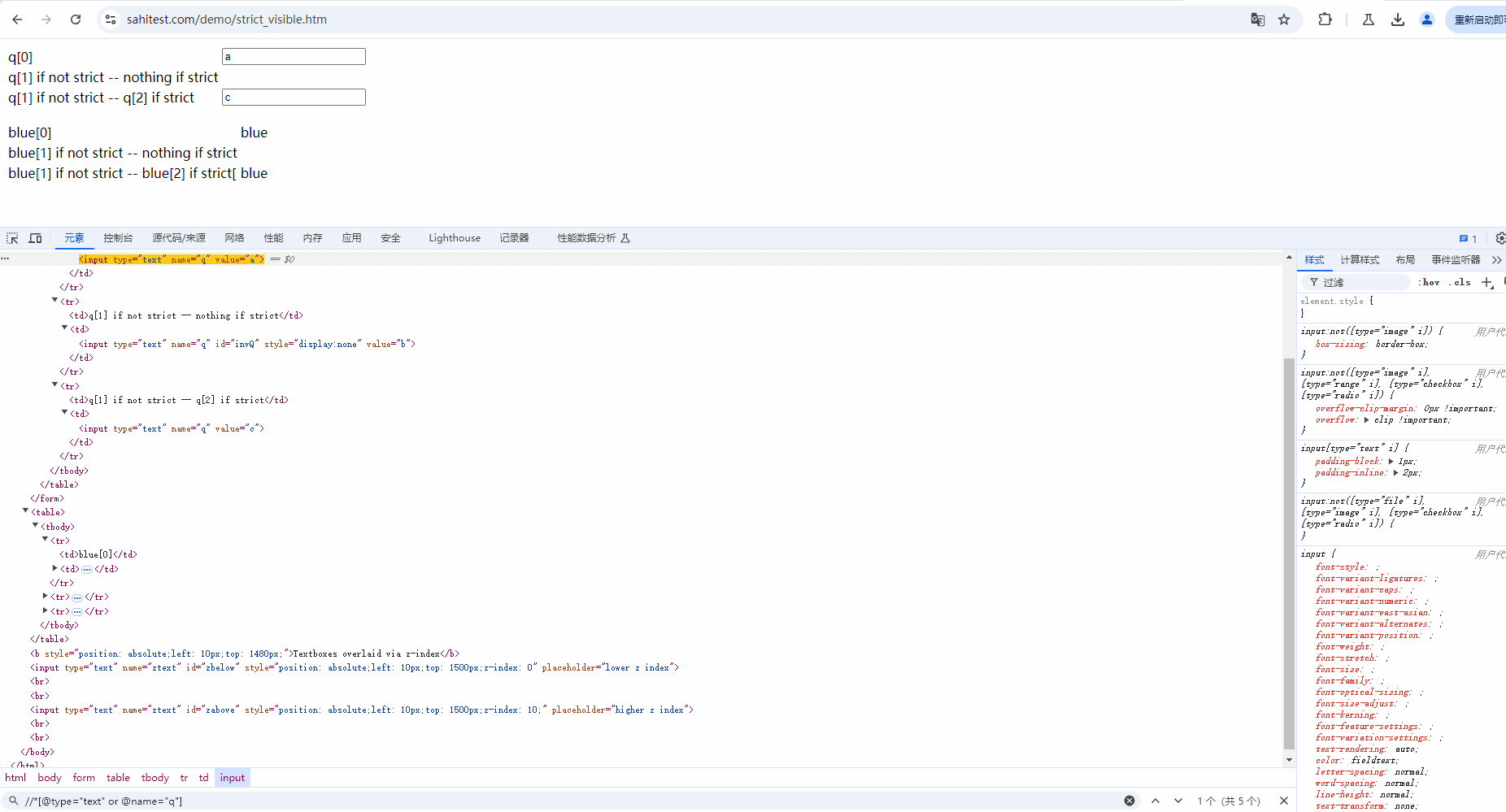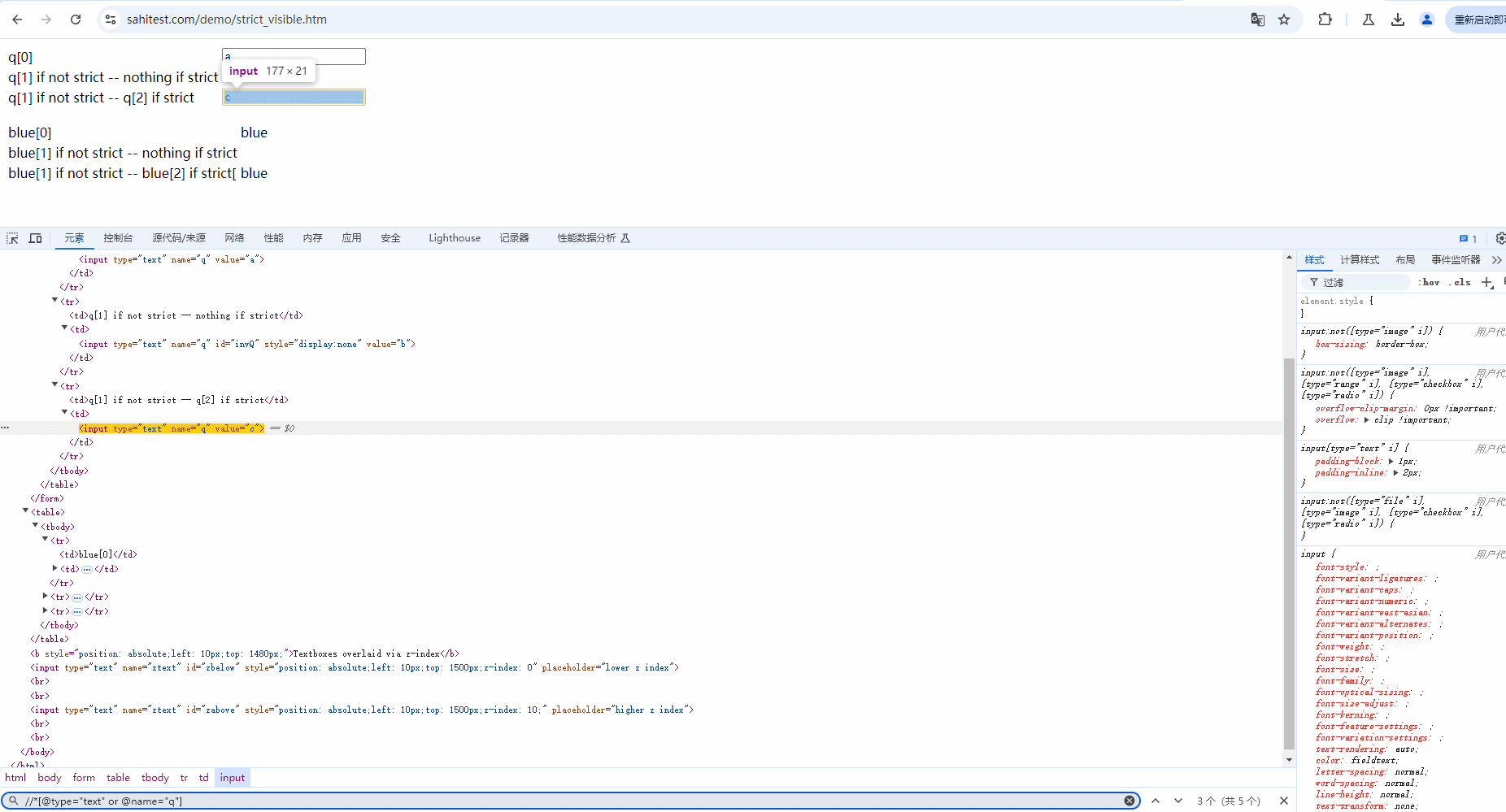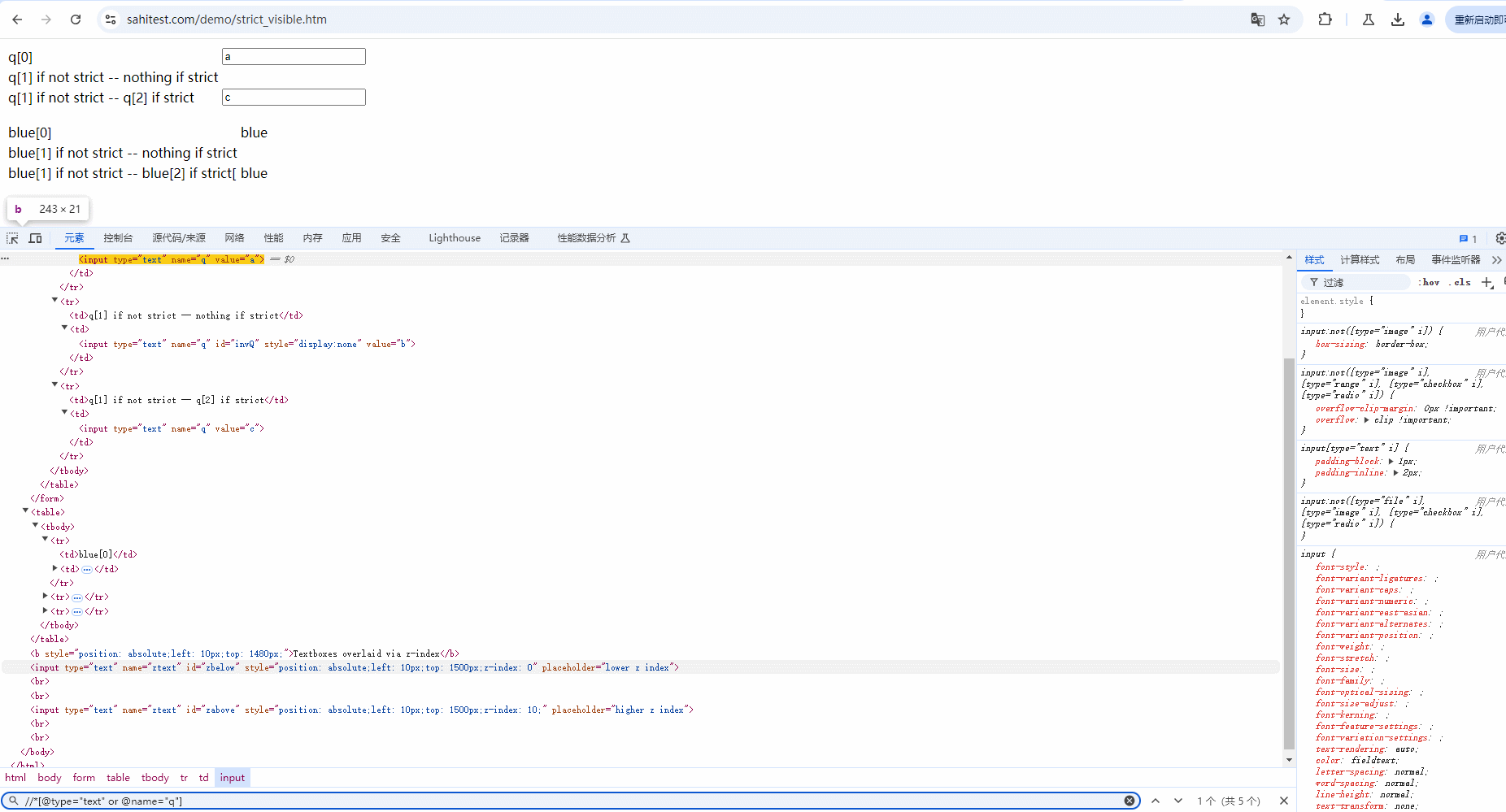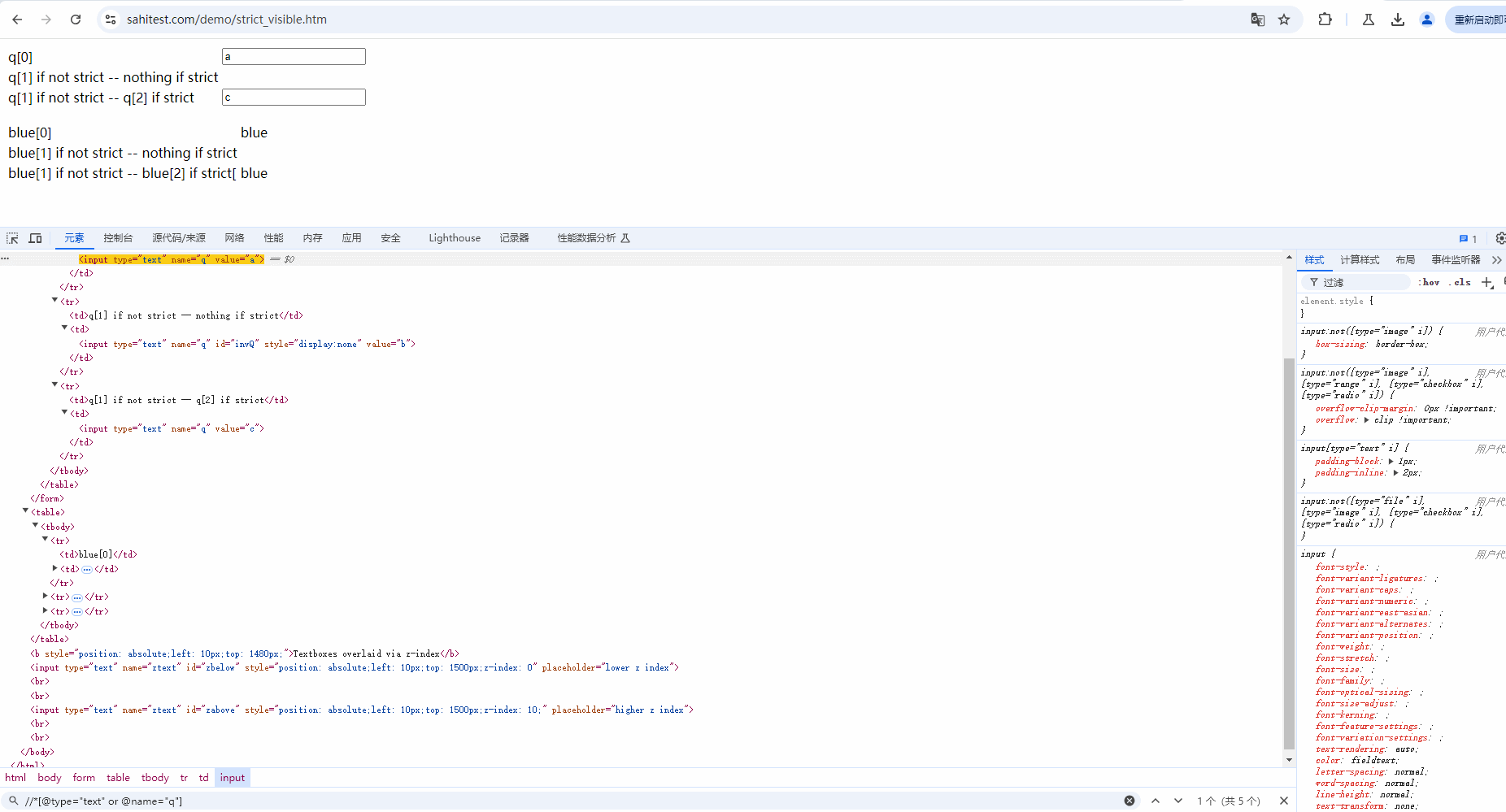
7.4Xpath 混合使用
特性就是管道符|的使用,在XPath中可指定多个选择器。它将匹配该列表中的选择器之一可以选择的所有元素。
示例:定位当前页面中 type 为 text 或 name为 q 的元素,也就是下面 5 个元素。demo网站:https://sahitest.com/demo/strict_visible.htm
Xpath语法:
//*[@type="text"] | //*[@name="q"]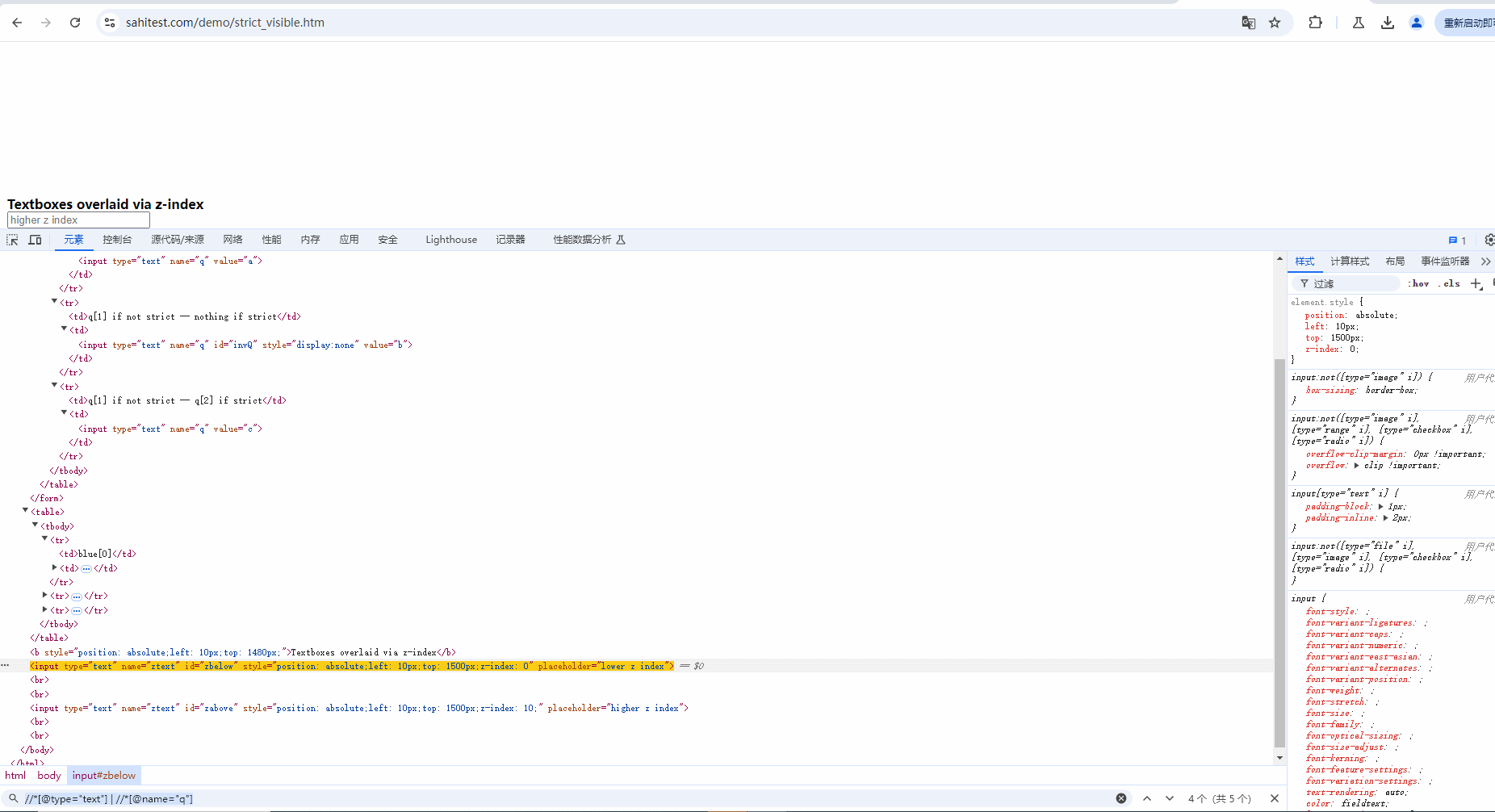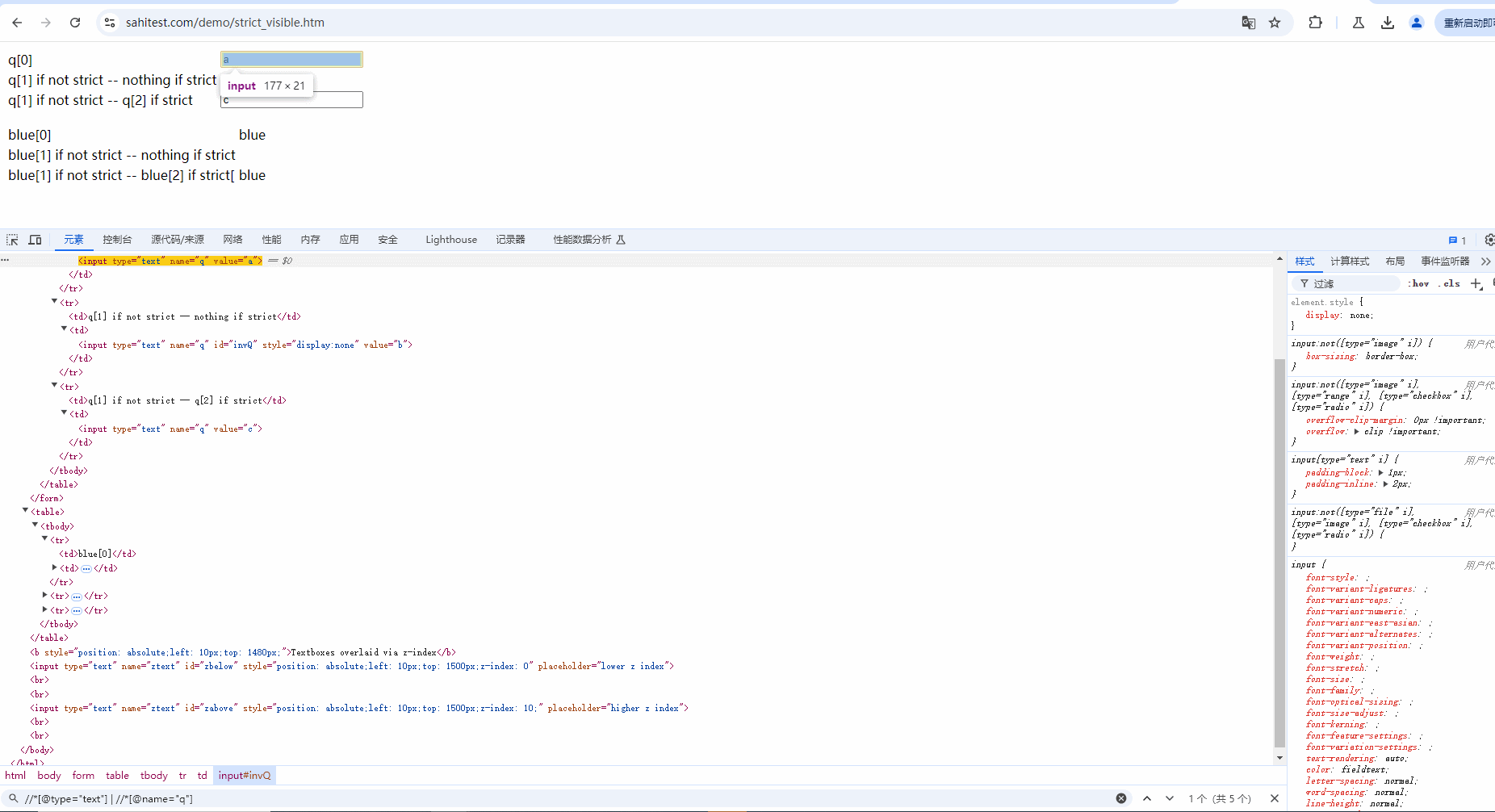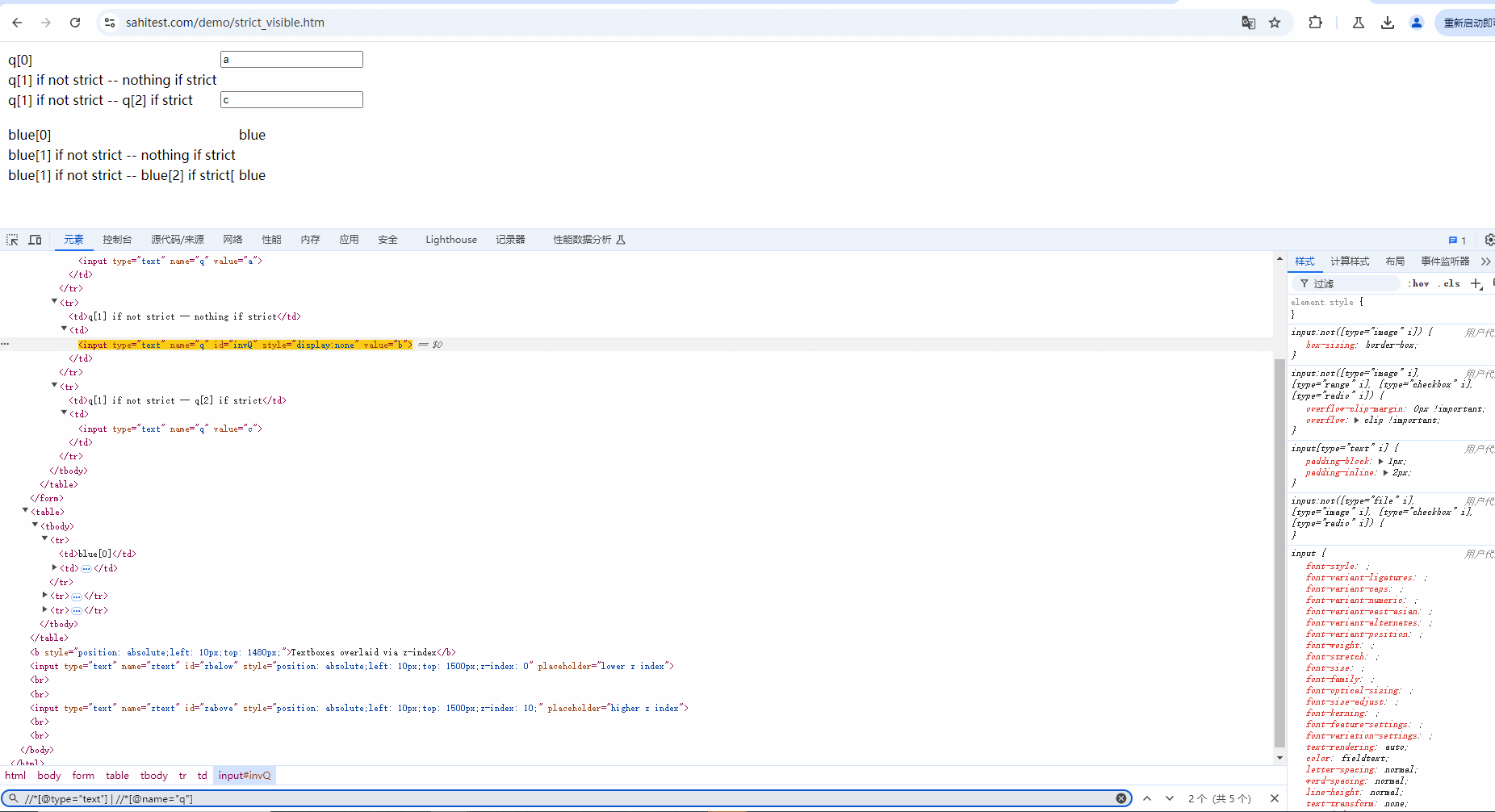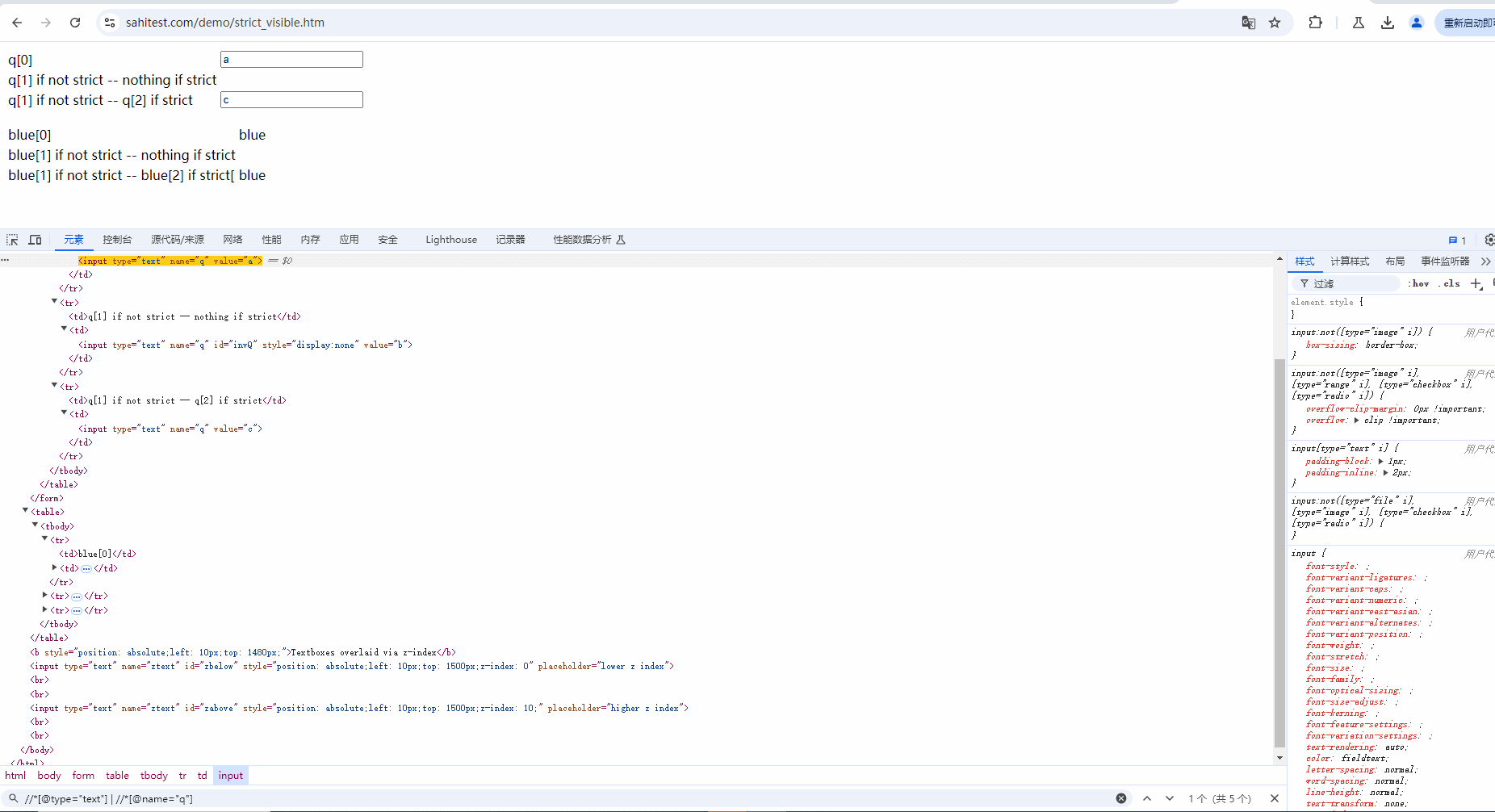
7.5属性与逻辑定位
在前面我们介绍到使用属性定位 ,但是如若使用一个属性定位不到怎么办 ? 你就可以是用两个属性或者多个属性同时定位 。
这里就不得不说的一个逻辑运算符 ,and(逻辑与) . 它的意思是并且,大白话就是两者都要求满足 。比如 属性1 and 属性2 ,代表这两个属性都要同时都满足 。
所以 ,如果你一个属性定位不到的话 ,再加一个属性就可以进一步缩小范围,从而提高定位准确率 。
而这种写法也正好是xpath语言中所支持的,它的编写格式为 ://标签@属性1='值1' and @属性2='值2' 。
举例 :
- xpath两个属性的编写格式 :
//input[@class='text_cmu' and @name='username'] - selenium xpath方法编写格式 :
find_element_by_xpath("//input[@class='text_cmu' and @name='username']")
以上的定位虽然使用到了and逻辑运算符 ,但是xpath中,其实并不仅仅支持这一个逻辑运算符 。以下的都可以使用 :
- 算术运算符 : = ,!= , < , <= , >, >=
- 逻辑运算符 : or , and
只是以上运算符中,用在定位上的可能只有and比较有用 。
7.6路径与属性结合定位
如果你使用了上面的各种方法 ,依然定位不到元素 ,那这个时候 ,你就可以考虑把路径加进来 。
一般原则是先加它的父路径 ,然后再加上当前路径 ,结合使用 。
具体格式为 :
//*[@id='um']/input: 父路径属性 + 子标签//bookstore/[@price='30']: 父路径标签 + 子属性//div[@class='login_bnt']/a[@class='J-login-submit': 父路径属性 + 子属性
不管咋写 ,只要能确定元素的唯一性 ,就都可以 ,不过这种写法很明显是逼不得已 ,因为你可能使用其它方法都无效的情况下 ,才会使用这种方法 。
8.趁热打铁
需求:
使用Java语言通过playwright完成对百度搜索的"北京-宏哥"的操作,具体如下 :
1.使用xpath属性定位百度首页输入框 ,并输入搜索内容:北京-宏哥,
2.使用路径与属性结合定位"百度一下"按钮,并点击 。
8.1代码设计
8.2参考代码
package com.bjhg.playwright;
import com.microsoft.playwright.Browser;
import com.microsoft.playwright.BrowserContext;
import com.microsoft.playwright.BrowserType;
import com.microsoft.playwright.Locator;
import com.microsoft.playwright.Page;
import com.microsoft.playwright.Playwright;
/**
* @author 北京-宏哥
*
* @公众号:北京宏哥(微信搜索,关注宏哥,提前解锁更多测试干货)
*
* 《刚刚问世》系列初窥篇-Java+Playwright自动化测试-8- 元素高级定位技巧(详细教程)
*
* 2024年8月10日
*/
public class Test_Search {
public static void main(String[] args) {
try (Playwright playwright = Playwright.create()) {
//使用chromium浏览器,# 浏览器配置,设置以GUI模式启动Chrome浏览器(要查看浏览器UI,在启动浏览器时传递 headless=false 标志。您还可以使用 slowMo 来减慢执行速度。
Browser browser = playwright.chromium().launch(new BrowserType.LaunchOptions().setHeadless(false).setSlowMo(500));
BrowserContext context = browser.newContext();
//创建page
Page page = context.newPage();
//浏览器打开百度
page.navigate("https://www.baidu.com/");
//判断title是不是 百度一下,你就知道
try{
String baidu_title = "百度一下,你就知道";
assert baidu_title == page.title();
System.out.println("Test Pass");
}catch(Exception e){
e.printStackTrace();
}
//使用xpath属性定位百度首页输入框 ,并输入搜索内容:北京-宏哥
page.locator("//*[@id='kw']").type("北京-宏哥");
//使用路径与属性结合定位"百度一下"按钮,并点击 。
page.locator("//span/input[@id='su']").click();
//关闭page
page.close();
//关闭browser
browser.close();
}
}
}8.3运行代码
1.运行代码,右键Run'Test',就可以看到控制台输出,如下图所示:
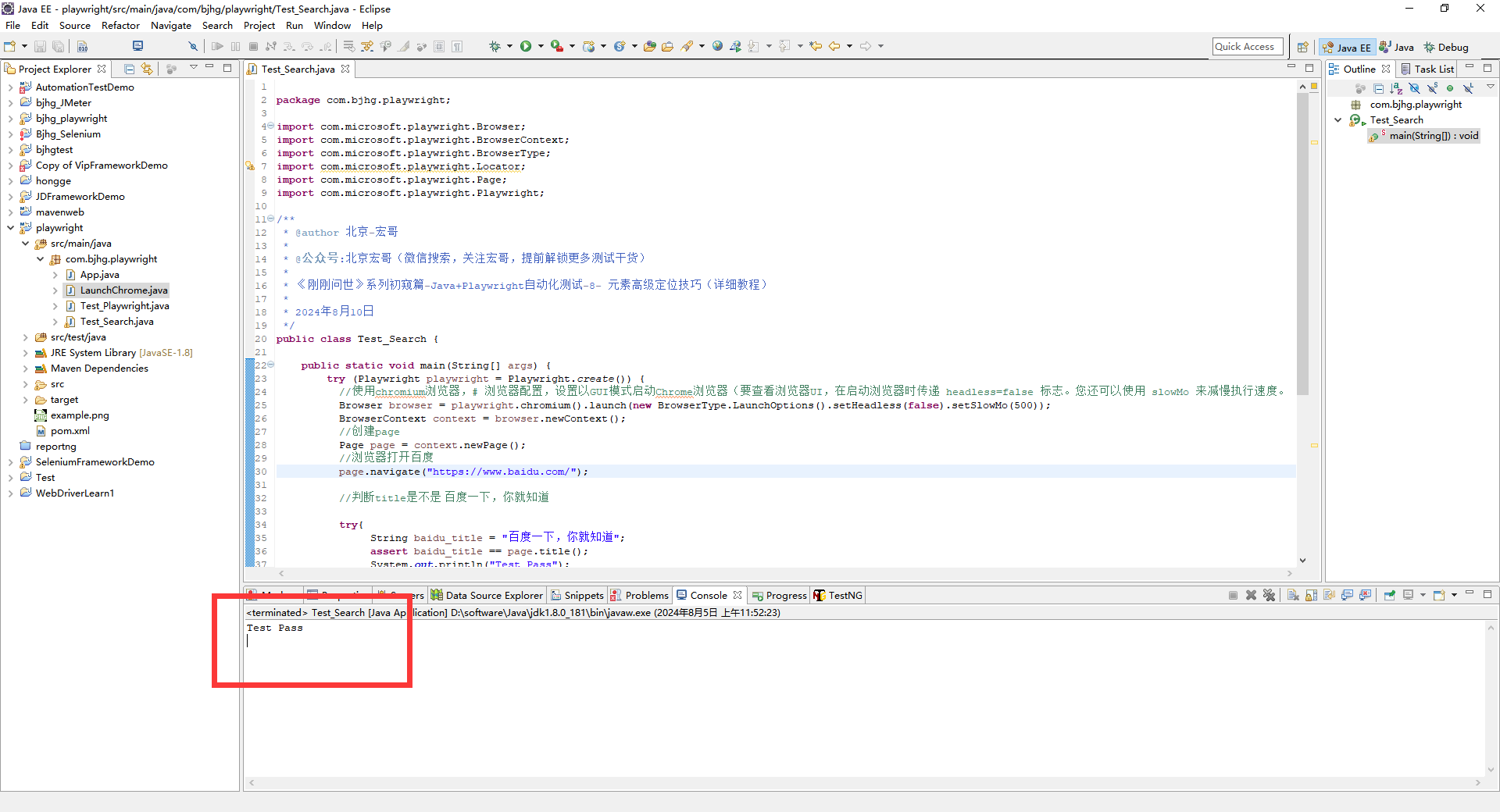
2.运行代码后电脑端的浏览器的动作。如下图所示:

9.小结
9.1Xpath定位总结
我们将Xpath所有方法(基础+高级)总结为,可以使用以下的几种方法进行定位 。
| 定位方式 | xpath |
|---|---|
| id属性定位 | //*@id='值' |
| class属性定位 | //*@class='值' |
| 属性定位 | //*@属性名='值' |
| 标签+属性定位 | //标签@属性名='值' |
| 逻辑+属性定位 | //标签@属性名='值' and @属性名1='值1' |
| 路径定位+属性定位 | //标签@属性名='值'/标签@属性名='值' |
Playwright提供了丰富多样的元素定位方式,无论是基础定位还是高级定位技巧,都能满足我们在自动化测试中的需求。掌握这些定位方式,将使我们能够更加灵活、高效地进行网页自动化测试。希望本文能够帮助读者更好地理解和应用Playwright的元素定位技术。
好了,今天时间也不早了,宏哥就讲解和分享到这里,感谢您耐心的阅读,希望对您有所帮助。
最后,首先宏哥要拉一下票,希望喜欢宏哥的支持一下,投下你宝贵的6票,投票完成还可以抽奖哦,灰常感谢!!!掘金2024年度人气创作者打榜中,快来帮我打榜吧~ activity.juejin.cn/rank/2024/w...