一、前言
记录一个简单的安装和部署过程,尽管笔者也是按照教程来的,但奈何参考了很多教程,虽然写的都非常好,但是却很散,因此笔者这里想把这些教程的精华提炼出来,汇总并且写在正文处。还是老规矩,笔者也在学习,如有错误,请在评论区及时指出!感谢!也欢迎评论区一起讨论!
二、正文
0.bashrc
不知道大家有没有发现,一些安装教程总是写着sudo gedit ~/.bashrc,然后也不告诉你为啥这么做,我这里就简单的交代一下。3
.bashrc是home目录下的一个shell文件,用于储存用户的个性化设置。在bash每次启动时都会加载.bashrc文件中的内容,并根据内容定制当前bash的配置和环境。
1.类似于?
这就类似于windows的快捷方式,不用每次进入都需要重新输入路径,这就是在bashrc文件修改后能够做到的事情之一。
环境变量就等于一个路径,这个路径由你而定。
如果我们把环境变量比作一个地址簿:
export就像把地址簿中重要的地址标记为"全家可用",每个人(子进程)都可以查阅。
快捷方式就像给某个地址做一个备忘录,任何人可以通过它找到目标,但备忘录本身不能改变目标的内容。
2.怎么用?
PATH=$PATH:路径
export PATH
export PATH=$PATH:路径最后再source ~/.bashrc一下,就是让上面你改的这些立即生效。
当然还可以自定义快捷键:
alias yyds="cd home/java/"
或者
alias ikun="conda deactivate"
等等(不小心露出只因脚了)
三、安装
0.clion远程主机(可选择,可不折腾)
实现在主机PC上使用Clion就可以在Jetson上面编程了,类似与你在ubuntu上使用VScode这种。
博客地址:参考链接
(https://blog.csdn.net/weixin_74027669/article/details/142391303 "参考链接")
(抱歉又让你跳来跳去了,不过上面文章写的超级详细!)
不过我还是更喜欢在ubuntu上直接用vscode
1.Jetpack镜像烧录
英伟达官方给Jetson开发板系列(Nano, NX, Xavier)配备了一个用于AI开发的集合包Jetpack,包含以下包:
Cuda
cuDNN
OpenCV4
TensorRT
VPI
VisionWorks
Vulkan所以你不用再傻乎乎的装什么TensorRT了啥的。。。这就是为啥叫你装系统的时候不要执着装Ubuntu新系统了,而是要去官网下载Jetpack了,因为人家把包的封装好了,哈哈哈哈。虽然JetPack也是基于ubuntu系统。。。
并且提供了已装好Jetpack的Ubuntu系统镜像官方Jetpack镜像。不过不同板子的镜像不一定能混用(部分板子架构不同)。
烧录后,可以查看Jetpack的版本:
cat /etc/nv_tegra_release出现信息:
# R32 (Release), REVISION: 6.1意思是大版本为32, 小版本为4.6.1,即v32.4.6.1,就说明没问题了
2.安装jtop(可跳过,不过尽量安装)
jtop是一个很开门的检测工具,用来查看cuda的型号、tensorRT的版本等,还能实时的看cpu和gpu的使用率等。
首先安装pip
sudo apt install python-pip python3-pip #安装Pip
pip3 install --upgrade pip #这俩哥们是来给pip进行升级的
pip install --upgrade pippip换源:请参考这篇博客 为啥换源,不还是原来的下载速度太慢了嘛。。。
安装jtop
sudo -H pip3 install jetson-stats
使用:
sudo jtop
安装成功后的结果是这个样子的:
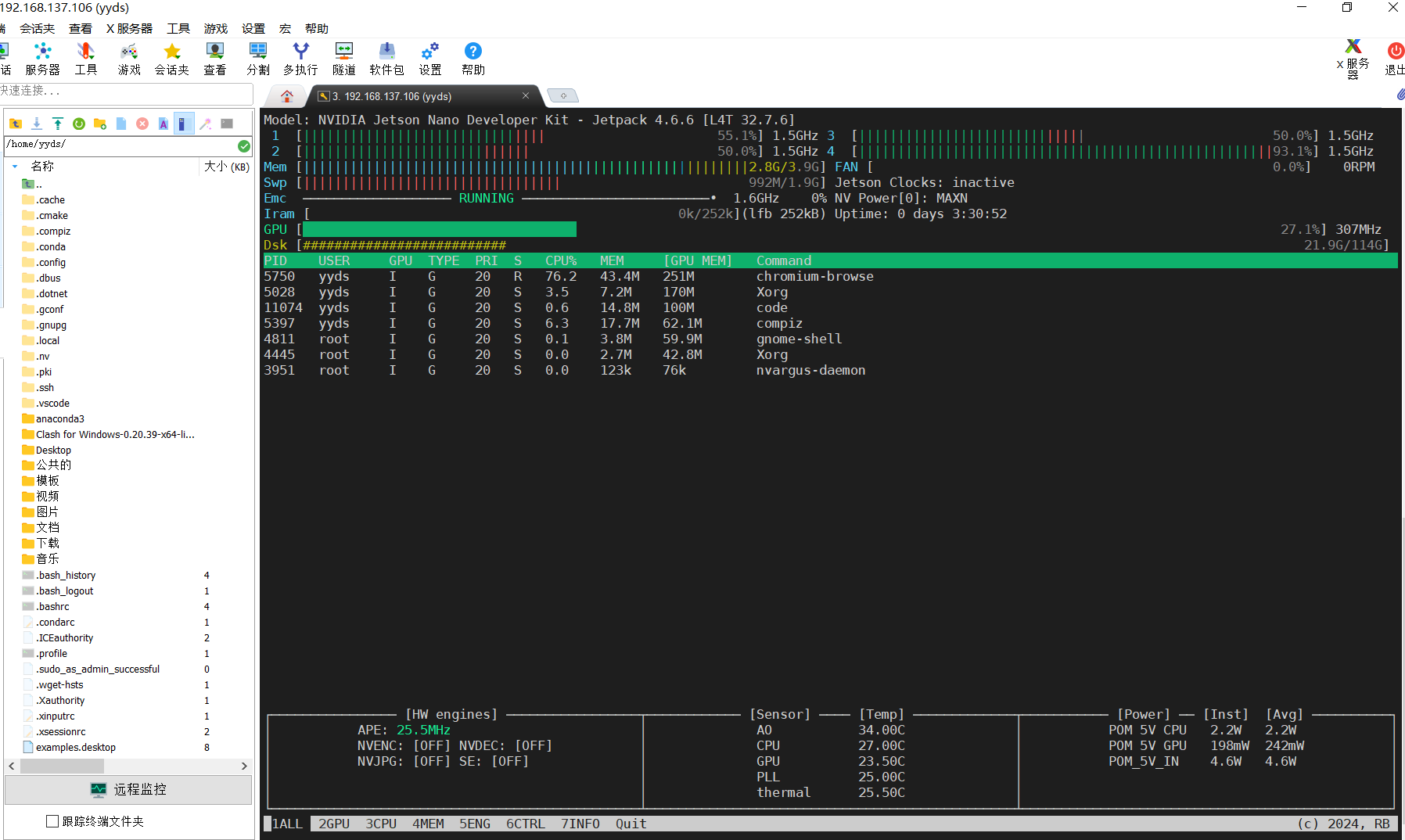
还可以查看版本的信息:
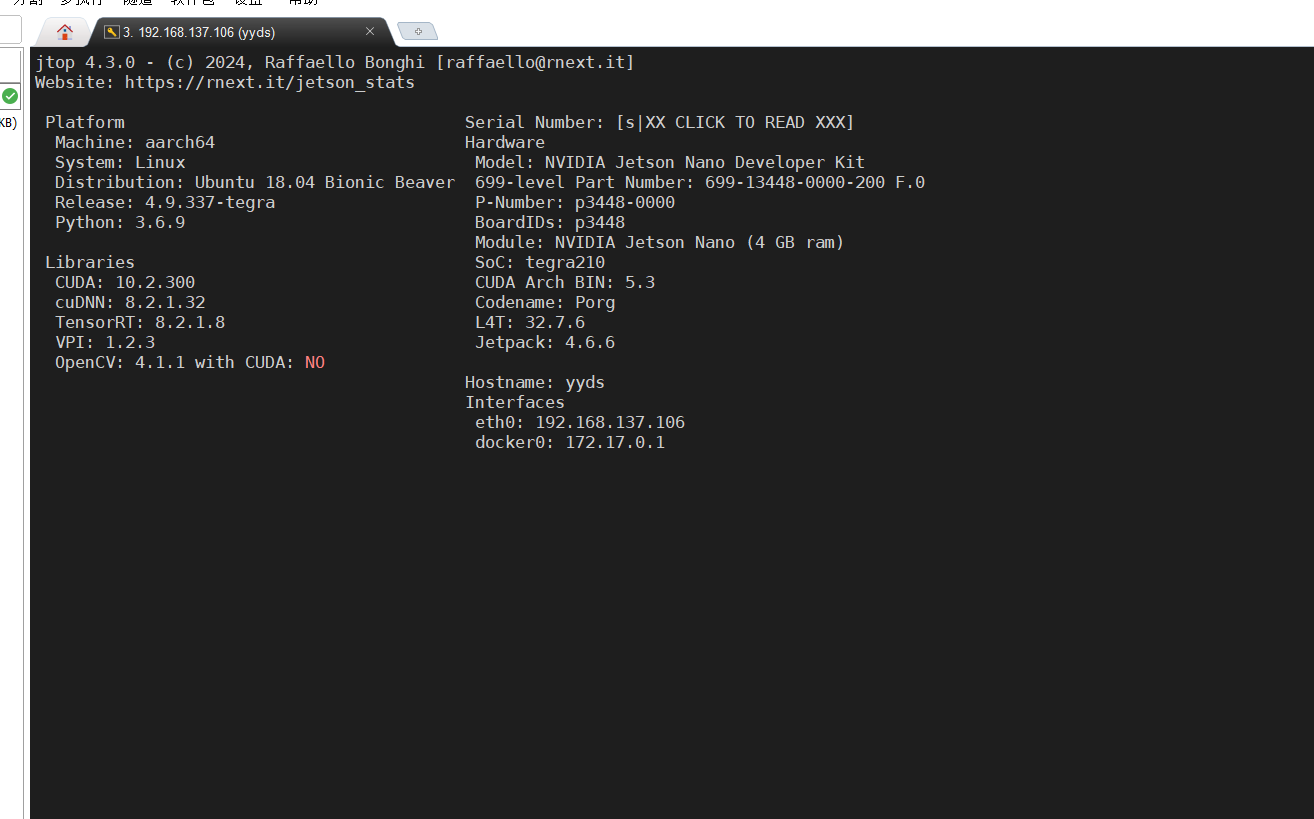
按Q退出。
也可以
free -h查看内存的使用情况,首先要知道直接从物理内存读写数据比硬盘读写数据要快的多,但是内存是有限的,所以就引出了物理内存和虚拟内存,物理内存是系统硬件提供的内存,是真正的内存,虚拟内存是为了满足物理内存不足时而提出的策略,他是利用磁盘空间虚拟出的逻辑内存,用作虚拟内存的磁盘空间被称为交换空间(swap space)
在这里很方便的就可以看到是否和指定的安装环境是否匹配了。相当开门的开源软件了。
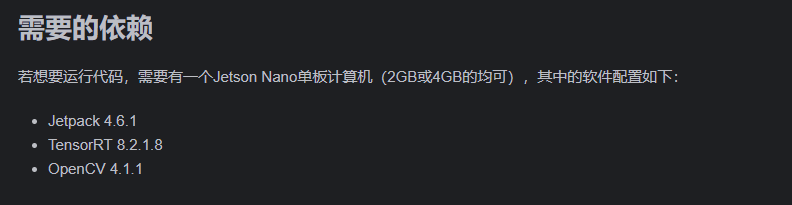
在这里其实可以看到,我已经默认安装完毕了TensorRT和OpenCV了
3..pt转换为ONNX
为了将模型部署到jetson nano当中,我们首先需要将需要转换的模型导出为onnx格式。首先,你需要下载YOLOv8的模型文件: 代码点击此处跳转
由于jetson nano的GPU计算能力较弱,在这里我使用了YOLOv8n模型,并将输入图像的尺寸缩小为原来的四分之一。转换的代码如下所示:(自己随便写个脚本,运行下就ok)
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
model.export(imgsz=320, format='onnx')这样,我们就得到了onnx格式的YOLOv8模型了。
4.ONNX转换为Engine
在 Jetson Nano 上,我们可以使用 TensorRT 对模型进行加速并部署。由于 TensorRT 对模型的优化与硬件有关,因此需要将 ONNX 模型上传至 Jetson Nano,并通过 trtexec 工具进行模型的转换。以下是模型转换的命令:
trtexec --onnx=<ONNX file> --saveEngine=<output file>
我这边用的方法是:
先切到yolo.onnx所在的目录里面,然后打开控制台:
trtexec --onnx=yolov8n.onnx --saveEngine=yolov8n.engine
通过以上操作,即可将YOLOv8模型转换为jetson nano支持的格式了。
5.导入模型,运行
这里有开源的github代码,带入即可,下面两个图我指定了在哪里进行替换,实在不会的也可以看"写在最后"部分的引用链接的原文章的教程。。
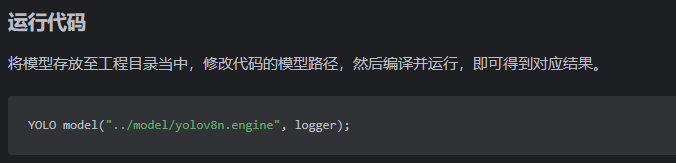
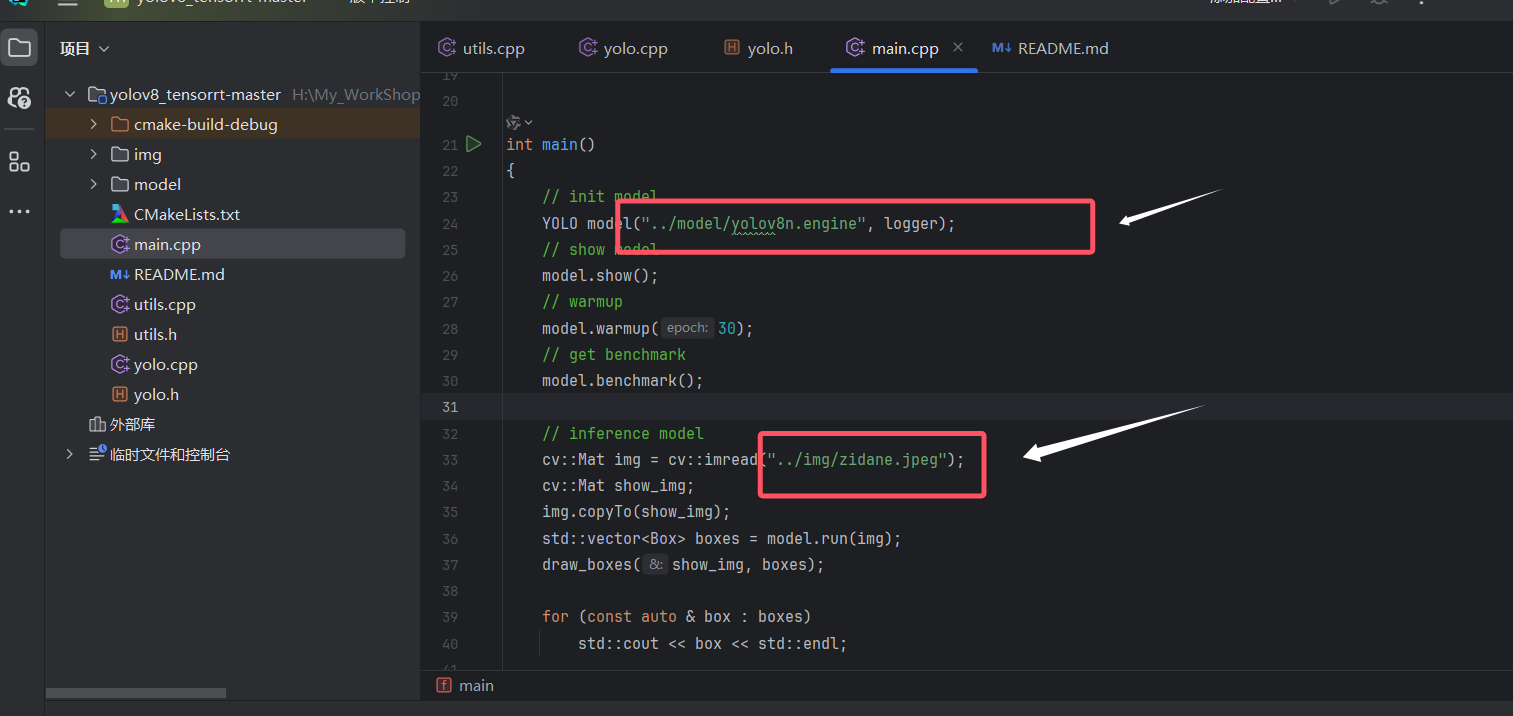
参考代码下载,里面readme写的很详细了,我这篇博客可以作为一个辅助进行参考
希望多给原作者star!
6. 什么你不会运行??简单交代下Cmake编译的原理
CMake主要是编写CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt文件转化为make所需要的makefile文件,最后用make命令编译源码生成可执行程序或共享库(so(shared object))。因此CMake的编译基本就两个步骤:
1. cmake
2. makecmake 指向CMakeLists.txt所在的目录,例如cmake ... 表示CMakeLists.txt在当前目录的上一级目录。cmake后会生成很多编译的中间文件以及makefile文件,所以一般建议新建一个新的目录,专门用来编译,例如
mkdir build
cd build
cmake ..
makemake根据生成makefile文件,编译程序。
按照下图新建build文件夹
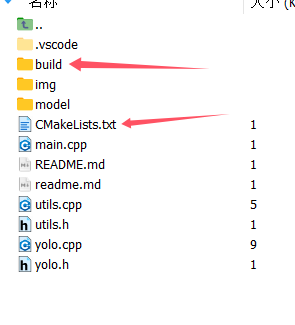
然后照我的上文进行编译,最终将生成一个可执行文件

控制台运行
./yolov8_tensorrt
文件名称对用CmakeList这个地方
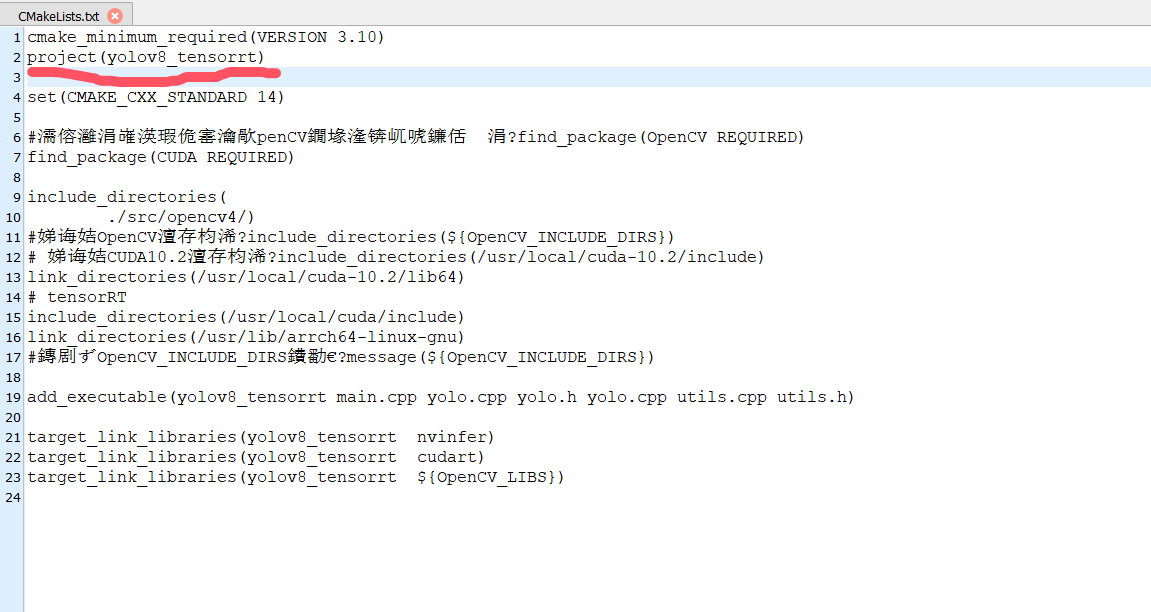
下次别再不懂了!
7.Cmakelist文件解释
简略解释以下一些关键地方的指令的含义,这里再网上找了一个例子:
cmake_minimum_required (VERSION 2.8)
project(dome CXX)
aux_source_directory(. DIR_SRC)
add_executable (demo ${DIR_SRC})(1)project中的CXX指的是C++,如果不特别指定,则支持所有语言 ;工程名称中的dome可以自由指定。
(2)aux_source_directory作用是自动搜索指定路径下的全部源文件,指定的路径由关键字提供,且与之前的"."之间有空格,表示DIR_SRC的上一级目录为指定的搜索路径。
(3)add_executable 中的第一个名字dome是我们编译后生成的可执行文件的名字,可以自由指定,不要求必须与工程同名。
四、写在最后
我按照自己的理解和原始博客没有标注的一些坑进行了我自己的总结和思考。
这篇博客只是一个过程记录以及一些知识点的总结,与其像一些教程直接把结论给你,我更想把结论为什么也给你,不但知道怎么安装的,而且还可以知道为什么这么安装。当然,只是笔者的个人总结,会有很多错误和不恰当之处,希望和读者共勉!
五、参考文献
重点参考这篇大佬的博客:
同时特此鸣谢以下参考博客!
4.关于Jetson nano系统安装前的一些需要知道的事情