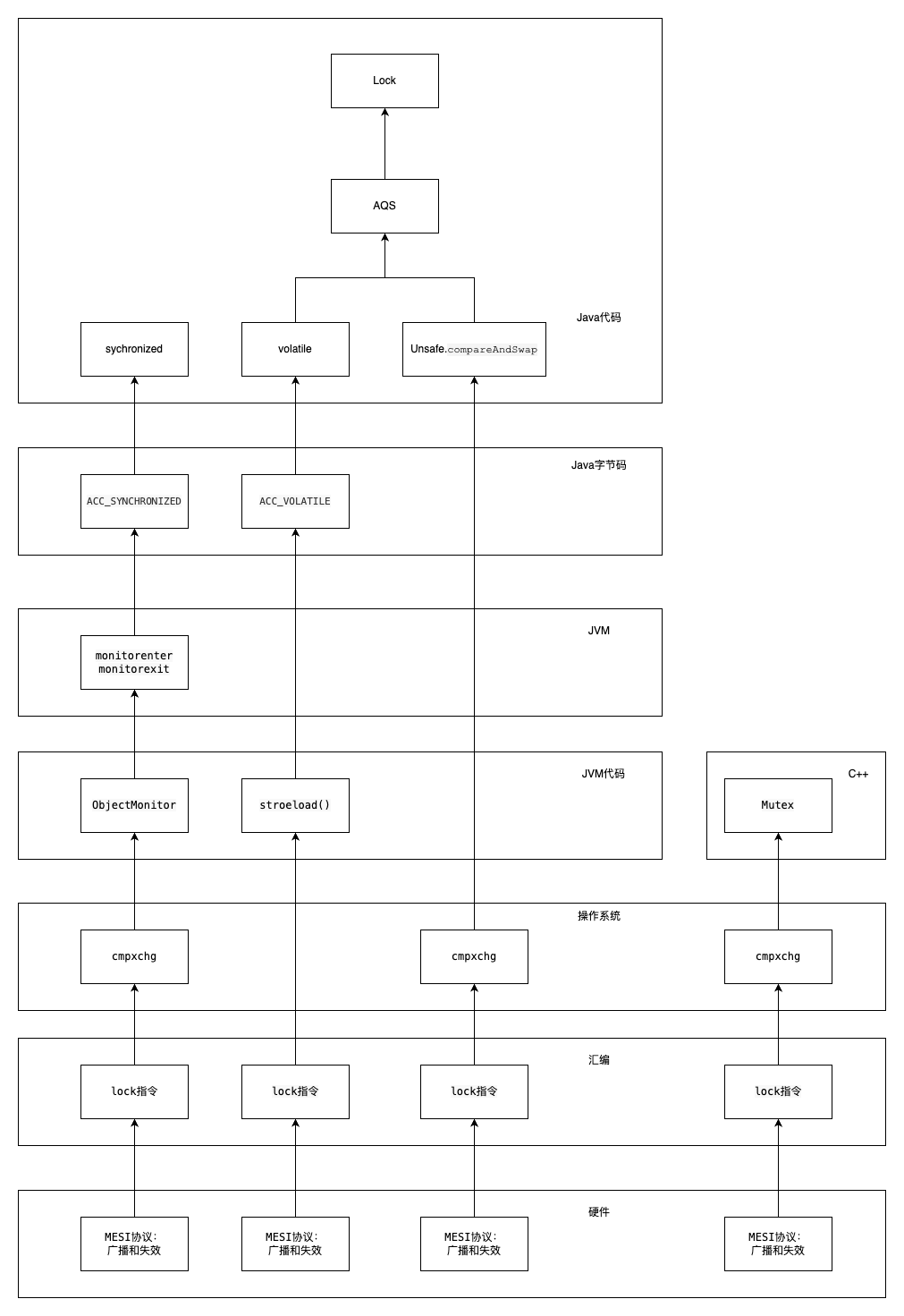
1. 概览
从Java代码级别到硬件级别各层都是如何实现的
2. Synchronized
2.1 字节码层面
使用javap -verbose <class文件>可以查看到字节码信息,其中synchronized方法会有flags:ACC_SYNCHRONIZED,此时字节码中不会包含monitorenter和moniotrexit,JVM会自动加
java
public synchronized void syncMethod();
flags: ACC_PUBLIC, ACC_SYNCHRONIZED使用``javap -verbose <class文件>`编译一个带synchronized块的代码可以看到字节码中的monitorenter和moniotrexit
java
0: new #2 // 创建一个新的Object实例
3: dup
4: invokespecial #1 // 调用Object的构造函数
7: astore_1 // 将引用存储到局部变量1(lock)
8: aload_1 // 将局部变量1(lock)加载到操作数栈
9: monitorenter // 进入monitor
10: ... // 同步块体的字节码
: aload_1
: monitorexit // 退出monitor
: ...2.2 JVM层面
源码可以在Github上面查看
monitorenter底层是由JVM的代码ObjectMonitor来实现的
c++
ObjectMonitor() {
// 多线程竞争锁进入时的单向链表
ObjectWaiter * volatile _cxq;
//处于等待锁block状态的线程,会被加入到该列表
ObjectWaiter * volatile _EntryList;
// _header是一个markOop类型,markOop就是对象头中的Mark Word
volatile markOop _header;
// 抢占该锁的线程数,约等于WaitSet.size + EntryList.size
volatile intptr_t _count;
// 等待线程数
volatile intptr_t _waiters;
// 锁的重入次数
volatile intptr_ _recursions;
// 监视器锁寄生的对象,锁是寄托存储于对象中
void* volatile _object;
// 指向持有ObjectMonitor对象的线程
void* volatile _owner;
// 处于wait状态的线程,会被加入到_WaitSet
ObjectWaiter * volatile _WaitSet;
// 操作WaitSet链表的锁
volatile int _WaitSetLock;
// 嵌套加锁次数,最外层锁的_recursions属性为0
volatile intptr_t _recursions;
}2.2.1 enter方法
整个方法比较长,但我们了解的无锁、偏向锁、轻量级锁、重量级锁都可以看到,核心方法是Atomic::cmpxchg_ptr,这个是CAS操作
| 锁 | 方法 | 描述 |
|---|---|---|
| 偏向锁 | Atomic::cmpxchg_ptr | 将owner替换为当前线程,成功则获取到锁 |
| 轻量级锁 | TrySpin->Atomic::cmpxchg_ptr | 不断自旋将owner替换为当前线程,成功则获取到锁 |
| 重量级锁 | EnterI>Atomic::cmpxchg_ptr | park然后将owner替换为当前线程,成功则获取到锁 |
c++
void ATTR ObjectMonitor::enter(TRAPS) {
// The following code is ordered to check the most common cases first
// and to reduce RTS->RTO cache line upgrades on SPARC and IA32 processors.
Thread * const Self = THREAD ;
void * cur ;
// 无锁CAS 转为 偏向锁
cur = Atomic::cmpxchg_ptr (Self, &_owner, NULL) ;
if (cur == NULL) {
// Either ASSERT _recursions == 0 or explicitly set _recursions = 0.
assert (_recursions == 0 , "invariant") ;
assert (_owner == Self, "invariant") ;
// CONSIDER: set or assert OwnerIsThread == 1
return ;
}
// 可重入锁
if (cur == Self) {
// TODO-FIXME: check for integer overflow! BUGID 6557169.
_recursions ++ ;
return ;
}
if (Self->is_lock_owned ((address)cur)) {
assert (_recursions == 0, "internal state error");
_recursions = 1 ;
// Commute owner from a thread-specific on-stack BasicLockObject address to
// a full-fledged "Thread *".
_owner = Self ;
OwnerIsThread = 1 ;
return ;
}
// We've encountered genuine contention.
assert (Self->_Stalled == 0, "invariant") ;
Self->_Stalled = intptr_t(this) ;
// Try one round of spinning *before* enqueueing Self
// and before going through the awkward and expensive state
// transitions. The following spin is strictly optional ...
// Note that if we acquire the monitor from an initial spin
// we forgo posting JVMTI events and firing DTRACE probes.
// 自旋获取锁
if (Knob_SpinEarly && TrySpin (Self) > 0) {
assert (_owner == Self , "invariant") ;
assert (_recursions == 0 , "invariant") ;
assert (((oop)(object()))->mark() == markOopDesc::encode(this), "invariant") ;
Self->_Stalled = 0 ;
return ;
}
assert (_owner != Self , "invariant") ;
assert (_succ != Self , "invariant") ;
assert (Self->is_Java_thread() , "invariant") ;
JavaThread * jt = (JavaThread *) Self ;
assert (!SafepointSynchronize::is_at_safepoint(), "invariant") ;
assert (jt->thread_state() != _thread_blocked , "invariant") ;
assert (this->object() != NULL , "invariant") ;
assert (_count >= 0, "invariant") ;
// Prevent deflation at STW-time. See deflate_idle_monitors() and is_busy().
// Ensure the object-monitor relationship remains stable while there's contention.
Atomic::inc_ptr(&_count);
EventJavaMonitorEnter event;
{ // Change java thread status to indicate blocked on monitor enter.
JavaThreadBlockedOnMonitorEnterState jtbmes(jt, this);
DTRACE_MONITOR_PROBE(contended__enter, this, object(), jt);
if (JvmtiExport::should_post_monitor_contended_enter()) {
JvmtiExport::post_monitor_contended_enter(jt, this);
}
OSThreadContendState osts(Self->osthread());
ThreadBlockInVM tbivm(jt);
Self->set_current_pending_monitor(this);
// TODO-FIXME: change the following for(;;) loop to straight-line code.
for (;;) {
jt->set_suspend_equivalent();
// cleared by handle_special_suspend_equivalent_condition()
// or java_suspend_self()
// 重量级锁
EnterI (THREAD) ;
省略.......
}2.2.2 cmpxchg_ptr
上面的锁都用了这个方法cmpxchg_ptr,这个和java中的cas是类似的,那它又是怎么实现的呢
其中cmpxchg是Linux操作系统的函数,执行了一段汇编指令,并且有lock前缀
c++
// 多核心多cpu前面就要加lock
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
inline intptr_t Atomic::cmpxchg_ptr(intptr_t exchange_value, volatile intptr_t* dest, intptr_t compare_value) {
return (intptr_t)cmpxchg((jlong)exchange_value, (volatile jlong*)dest, (jlong)compare_value);
}
inline jlong Atomic::cmpxchg (jlong exchange_value, volatile jlong* dest, jlong compare_value) {
bool mp = os::is_MP();
__asm__ __volatile__ (LOCK_IF_MP(%4) "cmpxchgq %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}3. Volatile
3.1 字节码层面
java
static volatile int greaterThanSevenCnt;
descriptor: I
flags: ACC_STATIC, ACC_VOLATILE3.2 JVM层面
可以看到判断是否是volatile字段,是的话最后会有OrderAccess::storeload(); , 就是就是storeload屏障
c++
CASE(_putfield):
CASE(_putstatic):
{
// .... 省略若干行
// ....
// Now store the result 现在要开始存储结果了
// ConstantPoolCacheEntry* cache; -- cache是常量池缓存实例
// cache->is_volatile() -- 判断是否有volatile访问标志修饰
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) { // ****重点判断逻辑****
// volatile变量的赋值逻辑
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {// 对象类型赋值
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {// byte类型赋值
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {// long类型赋值
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {// char类型赋值
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {// short类型赋值
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {// float类型赋值
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {// double类型赋值
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
// *** 写完值后的storeload屏障 ***
OrderAccess::storeload();
} else {
// 非volatile变量的赋值逻辑
if (tos_type == itos) {
obj->int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->double_field_put(field_offset, STACK_DOUBLE(-1));
}
}
UPDATE_PC_AND_TOS_AND_CONTINUE(3, count);
}进入OrderAccess源码可以看到,直接执行了一段汇编指令,并且有lock前缀
c++
inline void OrderAccess::storeload() { fence(); }
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}4. lock指令
在上面的分析中,最底层都设计到汇编层面的lock指令,这个指令有什么作用呢?
根据汇编参考文档IA-32 Assembly Language Reference Manual
The LOCK # signal is asserted during execution of the instruction following the lock prefix. This signal can be used in a multiprocessor system to ensure exclusive use of shared memory while LOCK # is asserted. The bts instruction is the read-modify-write sequence used to implement test-and-run. The lock prefix works only with the instructions listed here. If a lock prefix is used with any other instructions, an undefined opcode trap is generated.
Lock是一个指令前缀,用于多核处理器系统不使用共享内存
那么它又是怎么让其他核心不访问共享内存,有两种方法
- 锁内存总线,也就是说执行这条指令的时候,其他的核心都不能在访问内存了
- 锁缓存行,现在CPU本身是有多级缓存的,而这些缓存是如何保持一致的,由MESI来支持,MESI协议可以保证其他核心不使用内存,或者换一种说法,可以使用,但被修改的内容会失效
5. MESI协议
现代CPU多核架构中为了协调快速的CPU运算和相对较慢的内存读写速度之间的矛盾,在CPU和内存之间引入了CPU cache:
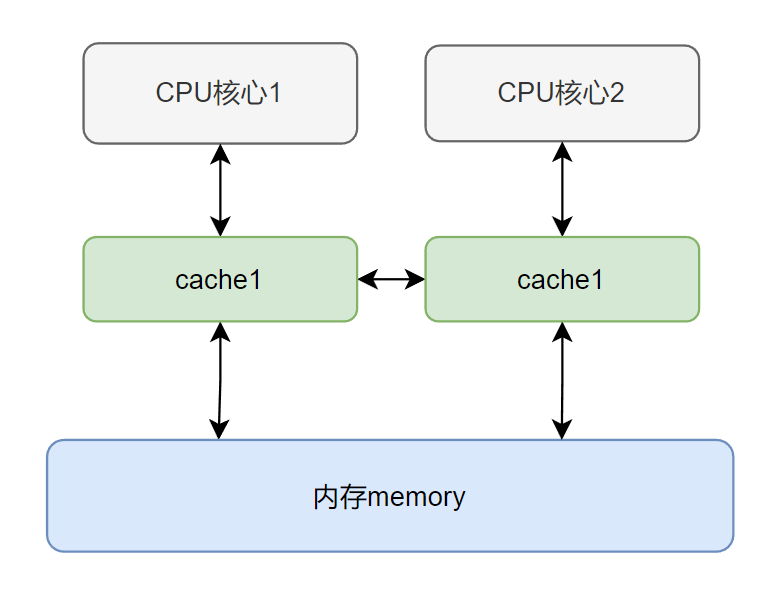
MESI协议下,缓存行(cache line)有四种状态来保证缓存的一致性
- 已修改Modified (M) 缓存行是脏的,与主存的值不同。如果别的CPU内核要读主存这块数据,该缓存行必须回写到主存,状态变为共享(S)
- 独占Exclusive (E) 缓存行只在当前缓存中,但是干净的(clean)--缓存数据同于主存数据。当别的缓存读取它时,状态变为共享;当前写数据时,变为已修改状态。
- 共享Shared (S) 缓存行也存在于其它缓存中且是干净的。缓存行可以在任意时刻抛弃。
- 无效Invalid (I) 缓存行是无效的,需要从主内存中读取最新值
每次要修改缓存,如果缓存行状态为 S 的话都要先发一个 invalidate 的广播,再等其他 CPU 将缓存行设置为无效后返回 invalidate ack 才能写到 Cache 中,因为这样才能保证缓存的一致性
但是如果 CPU 频繁地修改数据,就会不断地发送广播消息,CPU 只能被动同步地等待其他 CPU 的消息,显然会对执行效率产生影响
为了解决此问题,工程师在 CPU 和 cache 之间又加了一个 store buffer,同时在cache和总线之间添加了Invalidate Queue
这个buffer可以让广播和收广播的处理异步化,效率当然会变高,但强一致性变为了最终一致性
lock指令是CPU硬件工程师给程序员留的一个口子,把对MESI协议的优化(store buffer, invalidate queue)禁用,暂时以同步方式工作,使得对于该关键字的MESI协议退回强一致性状态
6. 总结
分析到此:
所有的并发问题可以概括为,多个核心同时修改内存数据,导致结果不符合预期
解决并发问题的方法可以概括为,同一时间只能让一个核心修改内存,但有多种手段,例如锁总线、或者广播让其他核心失效
7. 其他问题
-
既然sychronized的和volatile底层实现是一样的,那么volatile为什么没有原子性呢?
在于锁定的范围,volatile修饰的是一个字段,只能保证读和写是原子性的,但读出来、在计算、写入分为三步则不是原子性的。
sychronized底层也用了volatile的,但它的锁定范围是程序员指定的,这个范围之间的代码是原子的
cas volatile变量开始锁定 任意程序代码 cas volatile变量释放锁定 -
现在一般推荐使用Java的Atomic类,他是通过CAS来实现的,它和sychronized的区别是什么?
cas不能单独使用,需要加自旋操作,本身是一个乐观锁
sychronized本身结合了乐观锁和悲观锁,悲观锁会让线程park然后重试,不会消耗CPU,而乐观锁但不断消耗cpu
8. 对比
在阅读ObjectMonitor代码时,发现有很熟悉的感觉
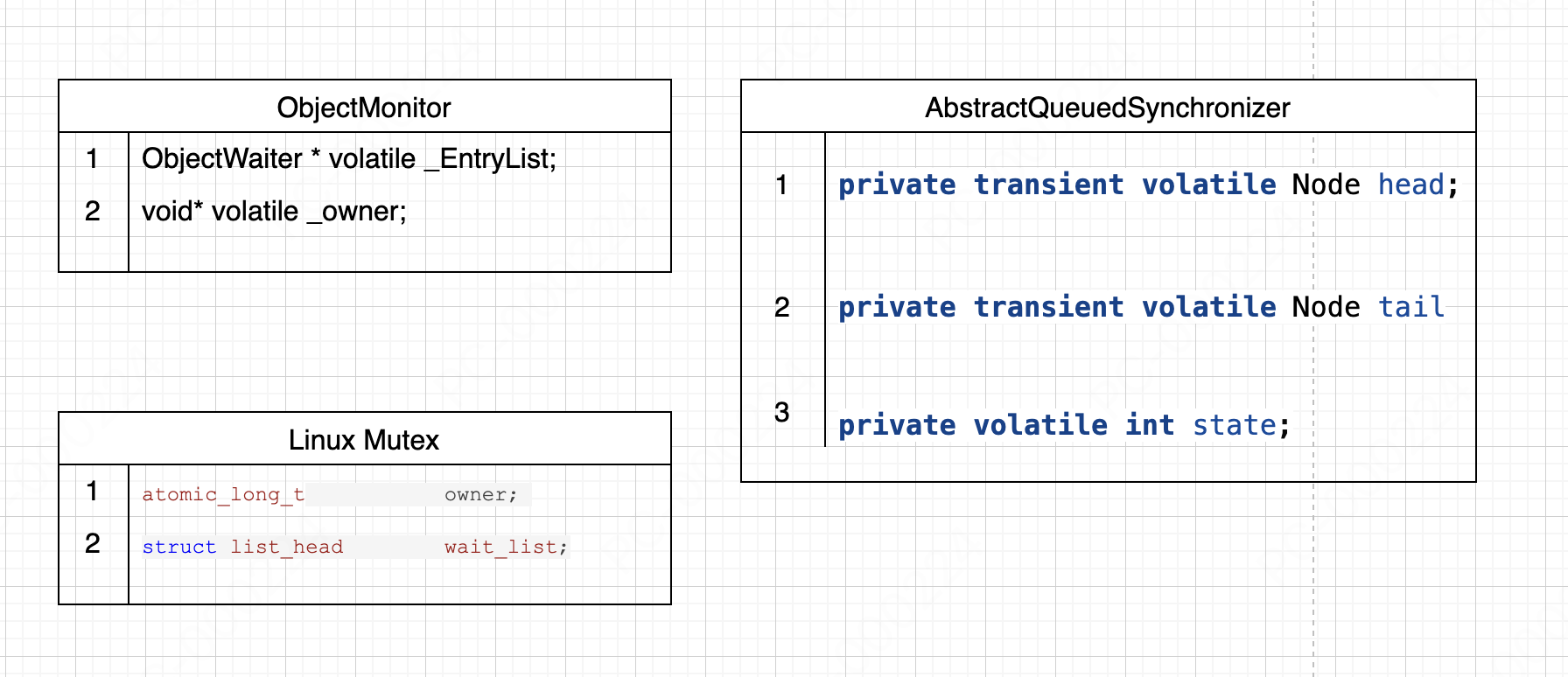
发现这些锁的数据结果都是类似的,一个volatile变量加一个等待队列
参考
【2】Java多线程:objectMonitor源码解读(3)
【4】聊聊CPU的LOCK指令
【5】12 张图看懂 CPU 缓存一致性与 MESI 协议,真的一致吗?
【8】浅析mutex实现原理
【9】CAS你以为你真的懂?
【10】x86 LOCK 指令前缀
【11】Linux Mutex机制分析