探秘Transformer系列之(13)--- FFN
目录
- [探秘Transformer系列之(13)--- FFN](#探秘Transformer系列之(13)--- FFN)
- [0x00 概述](#0x00 概述)
- [0x01 网络结构](#0x01 网络结构)
- [0x02 实现](#0x02 实现)
- [2.1 哈佛代码](#2.1 哈佛代码)
- [2.2 llama3](#2.2 llama3)
- [0x03 FFN的作用](#0x03 FFN的作用)
- [3.1 提取更多语义信息](#3.1 提取更多语义信息)
- [3.2 增加表达能力](#3.2 增加表达能力)
- [3.3 存储知识](#3.3 存储知识)
- [3.4 增加参数量](#3.4 增加参数量)
- [3.5 小结](#3.5 小结)
- [0x04 知识利用](#0x04 知识利用)
- [0x05 优化与演进](#0x05 优化与演进)
- [0xFF 参考](#0xFF 参考)
0x00 概述
Transformer抽取"序列信息"并加工的方法包含两个环节:以原始Transformer结构的编码器为例,每一层包含multi-head self-attention block(MHSA)和一个FFN(前馈神经网络/Feed Forward Network),即在自注意力层之后,编码器还有一个FFN。
FFN是一个包含两个线性变换和一个激活函数的简单网络(linear + relu + linear),考虑注意力机制可能对复杂过程的拟合程度不够,Transformer作者通过增加两层网络来增强模型加模型的容量和非线性。

0x01 网络结构

前馈网络可以分为两种主要类型:标准 FFN 和门限 FFN。
- 标准 FFN:这是神经网络中常用的结构,网络由两层组成,利用一个激活函数。
- 门限 FFN(gated FFN):在标准方法之外进一步采用了门限层,这个层增强了网络控制和调节信息流的能力。
随着时间的推移,人们对这些前馈神经网络类型的偏好也发生了变化。上图的右侧显示了2022年至2024年SLM使用的前馈网络类型的趋势,标准的 FFN 正在逐步被门限 FFN 所取代。本篇我们主要介绍标准FFN,就是Transformer论文的实现。
1.1 数学表示
FFN层是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,在两个线性变换之间除了 ReLu 还使用了一个 Dropout。
\FFN(x) = max(0,xW_1+b_1)W_2+b_2 \\
- 第一个线性层。其输入\(X∈R^{d_{input} \times d_{model}}\)是多头注意力的输出,可以看作是由每个输入位置( \(d_{input}\) 行)的注意力结果( \(d_{model}\) 列)堆叠而成。第一个线性层通常会扩展输入的维度。例如,如果输入维度是 512,输出维度可能是 2048。这样做是为了使模型能够学习更复杂的函数,也是为了更好的融合前面多头注意力机制的输出内容。
- ReLU 激活: 这是一个非线性激活函数。此函数相对简单,如果输入是负数,则返回 0;如果输入是正数,则返回输入本身。ReLU激活使得模型能够学习非线性化能力,也可以理解为引入非线性对向量进行筛选。其数学表达为\(max(0,xW_1+b_1)\)。
- 第二个线性层。这是第一个线性层的逆操作,将维度降低回原始维度。FFN最终得到的输出矩阵维度与输入X的维度一致。
上述结构对输入X的每一行进行相同的信息变换(行与行之间无交错,即"separately and identically"),这个线性变换在不同的位置都表现相同,只是在不同的层之间使用不同的参数,即每行(每个token)之间共享参数,但是在不同层中,学习到的参数矩阵又是不同的。我们可以将上述结构表示如下,其中,d是embedding size(Transformer中为512),\(d_{ffn}\)是FFN的隐藏层维度(Transformer中为2048)。

最终,FFN的权重体现在这两个线性层上。注意力机制是在同一特征空间内,对不同的实体进行整合,强调了不同实体之间的重要性。而FFN完成对实体从特征空间A到特征空间B的映射。二者比较的粒度不相同。另外,从T5 开始,很多模型在FFN层都不用偏置了。
1.2 中间层比率
FFN的中间比率是指中间层维数与隐含层维数之间的比值。简单而言,它决定了中间层相对于整个网络的大小。标准 FFN通常设置中间比率为4。这意味着中间层通常比隐藏层小四倍。另一方面,门限 FFN 在中间比值上表现出更大的灵活性,比如可以是从2到8的任何范围,依据模型特点进行选择。
如果中间比率调得过小,会导致模型参数变少,性能变差。如果调节过大,则会造成峰值内存过高,因此需要综合考虑。下面图提供了从2022年到2024年不同前馈网络中间比率的趋势变化。

1.3 position-wise
论文中给这个 FNN 取名为 Position-wise feed-forward networks。"position-wise"表示对序列中的每个元素(每个位置)分别采用相同的线性变换。作者强调"position-wise"是因为FFN有如下特点(此处也会和注意力机制进行一定的比对):
-
建模只考虑单独位置。FFN层对输入矩阵每行(每个token,即每个position)对应的单个token的信息表征进行独立的非线性变换(从矩阵运算角度可以理解为变换和平移)。因为FFN是对序列中每个位置的token向量分别进行相同的操作,所以每个时刻的全连接层是可以独立并行计算的,可以提高训练和推理的速度。
-
不会进行元素间的信息交换。Transformer已经利用注意力机制来考虑单词在不同位置的语义和依赖关系,在每个位置上把序列中的信息做了一次全局的汇聚。因为信息当到达FFN时,每个token就包括了在token层面其感兴趣的信息,序列中的上下文已经被汇聚完成,所以不需要在FFN处再进行交互(元素间的互动完全靠自注意力)。FFN所做的是在注意力层进行元素间的信息交换之后,让每个元素消化整合自己的信息,为下一层再次通过自注意力交换信息做好准备。
-
计算颗粒度是 token 内的维度。注意力机制可以捕捉序列中的上下文关系,是对不同位置的 token 混合,其计算是以token为颗粒度。而FFN在处理序列数据时只考虑单个位置的信息,是对每个 token 不同维度上的特征进行混合(各个token之间没有进行交互),是在token内部完成特征映射。
-
精细再加工。MHA允许模型在不同的表示子空间中学习信息,FFN则允许模型利用注意力机制生成的上下文信息,并进一步转化这些信息,从而捕捉数据中更复杂的关系。所以,在FFN中,矩阵的每一行都是独立运算,把每个token的上下文信息加工成最终需要的的语义空间向量。

另外,也可以从卷积的角度解释。关于矩阵 \(W_1∈R^{d_{input} \times d_{model}}\) 和\(W_2∈R^{d_{input} \times d_{model}}\) 的维度倒置,Transformer作者认为可以将其理解为"two convolutions with kernel size 1",即Position-wise FFN等价于kernel_size=1的卷积,这样每个position(token)都是独立运算的。为何要指定kernel大小为1?因为如果大于1,则相邻位置之间就具有依赖性了就不能叫做position-wise了。
综上所述,FFN的本质就是一个position-wise的"升维-过激活-降回原来维度"的MLP。
1.4 激活函数
激活函数是神经网络中的非线性函数,用于在神经元之间引入非线性关系,从而使模型能够学习和表示复杂的数据模。如果没有激活函数,神经网络无论有多少层,都只能表示输入和输出之间的线性关系,这大大限制了网络处理复杂问题的能力。
常见函数
在前馈神经网络(FFN)中,有几种常用的激活函数:
- ReLU(Rectified Linear Unit):ReLU 就像一个开关,打开或关闭的信息流,它应用广泛。
- GELU(Gaussian Error Linear Unit):GELU 是一种在平滑零值和正值之间转换的激活函数
- SiLU(Sigmoid Linear Unit):SiLU 是一个结合了 Sigmoid 函数和线性函数特性的激活函数,其实就是\(\beta\)为1时的Swish激活函数。
这些激活函数在论文"GLU Variants Improve Transformer"中有具体论述,该论文提出使用GLU的变种(将GLU中原始的Sigmoid激活函数替换为其他的激活函数)来改进Transformer的FFN层,并列举了替换为ReLU,GELU和SwiGLU的三种变体。命名上将激活函数的缩写加在GLU前面作为前缀。论文用这种GLU变体替换FFN中的第一层全连接和激活函数,并且去除了GLU中偏置项bias。具体公式如下。

下图是常见大模型的信息,从中可以看到对激活函数的使用情况。

随着时间的推移,这些激活函数的使用发生了变化。在2022年,ReLU成为许多 FFN 的首选激活函数。然而,进入2023年,过渡到使用 GELU 及其变体GELU Tanh。到2024年,SiLU成为激活函数的主要选择。具体如下图所示。

ReLU
ReLU函数是修正线性单元函数,由Vinod Nair和 Geoffrey Hinton在论文"Rectified Linear Units Improve Restricted Boltzmann Machines"提出,它的公式为:
\\\text{ReLU}(x) = \\max(0, x) \\
ReLU函数在输入大于0时输出等于输入,否则输出为0。ReLU函数的优点是计算简单,收敛速度快。相比于Sigmoid和Tanh函数,ReLU在正区间的梯度为常数1,有助于缓解梯度消失问题,使得深层网络更容易训练。但它也存在一个问题,就是在输入小于0时,梯度为0,这会导致神经元无法更新权重,从而出现"神经元死亡"的问题。
GLU
论文GLU Variants Improve Transformer 提出,可以利用门控线形单元 ------ GLU(Gated Linear Units)对激活函数进行改进。GLU激活则提出于2016年发表的论文"language modeling with gated convolutional networks"中。GLU其实不算是一种激活函数,而是一种神经网络层。它是一个线性变换后面接门控机制的结构。其中门控机制是一个sigmoid函数用来控制信息能够通过多少。其公式如下:\(GLU(x, W, V, b, c) = (xW + b) ⊗ \sigma(xV + c)\)。其中 ⊗ 表示逐元素乘法,\(X\) 是输入,\(W\) 和 \(V\) 是权重矩阵,\(b\) 和 \(c\) 是偏置项。注,有论文对将GLU的门控放在了权重W的部分,即\(GLU(x, W, V, b, c) = \sigma(xW + b) ⊗ (xV + c)\)。
GELU
论文"Gaussian Error Linear Units(GELUs)"提出了GELU(Gaussian Error Linear Unit,高斯误差线性单元)函数,这是ReLU的平滑版本。GELU通过高斯误差函数(标准正态分布的累积分布函数)对输入进行平滑处理,从而提高模型的性能。GELU函数的数学表达式为\(\text{GELU}(x) = x \cdot \Phi(x)\)$。其中:
- \(x\) 是输入。
- \(\Phi(x)\) 是标准正态分布的累积分布函数,定义为:\(\Phi(x) = \frac{1}{2} \left( 1 + \text{erf}\left( \frac{x}{\sqrt{2}} \right) \right)\) 。\(\text{erf}(x)\) 是误差函数。
之前由于计算成本较高,因此论文提供了两个初等函数作为近似计算,目前很多框架已经可以精确计算。

SwiGLU
SwiGLU(Swish-Gated Linear Unit)是一种结合了Swish和GLU(Gated Linear Unit)特点的激活函数。SwiGLU其实就是采用Swish作为激活函数,且去掉偏置的GLU变体。与ReLU相比,SwiGLU可以提升模型的性能。两者的核心差异在于:
- ReLU 函数会将所有负数输入直接归零,而正数输入则保持不变。
- SwiGLU 函数含有一个可学习的参数 \(\beta\),能够调节函数的插值程度。随着 \(\beta\) 值的增大,SwiGLU 的行为将逐渐接近 ReLU。
Swish函数
Swish函数由Google团队在2017年在论文"Searching for Activation Functions"中提出,其公式和效果如下图所示。Swish函数的曲线是平滑的,并且函数在所有点上都是可微的。这在模型优化过程中很有帮助,被认为是 Swish 优于 ReLU 的原因之一。
Swish函数的数学表达式为:\(\text{Swish}(x) = x \cdot \sigma(\beta x)\),其中\(\sigma\)为激活函数Sigmoid,定义为 \(\sigma(x) = \frac{1}{1 + e^{-x}}\)。输入x和\(\sigma\)相乘使得Swish类似LSTM中的门机制,因此Swish也被成为self-gated激活函数,只需要一个标量输入即可完成门控操作。
\(\beta\) 是一个可学习的参数,控制函数的形状,通常为一个常数或者让模型自适应学习得到。当\(\beta=0\) 时,Swish退化为一个线性函数,当\(\beta\) 趋近于无穷大时,Swish就变成了ReLU。在大多数情况下,\(\beta\) 被设置为1,从而简化为\\text{Swish}(x) = x \\cdot \\sigma(x),也叫SiLU( Sigmoid Gated Linear Unit)。

SwiGLU激活函数
SwiGLU的数学表达式为 f(X) = (X ∗ W + b) ⊗ Swish(X ∗ V + c) \\(,\\)\\otimes 表示逐元素乘法(Hadamard乘积)。此公式也可以转换为:\\text{SwiGLU}(a, b) = \\text{Swish}(a) \\otimes \\sigma(b),其中,\(a\) 和 \(b\) 是输入张量。\(\sigma(x) = \frac{1}{1 + e^{-x}}\) 是Sigmoid激活函数。\(\text{Swish}(x) = x \cdot \sigma(x)\) 是Swish激活函数。
SwiGLU本质上是对Transformer的FFN前馈传播层的第一层全连接和ReLU进行替换。在原生的FFN中采用两层全连接,第一层升维,第二层降维回归到输入维度,两层之间使用ReLE激活函数。SwiGLU也是全连接配合激活函数的形式,不同的是SwiGLU采用两个权重矩阵和输入分别变换,再配合Swish激活函数做哈达马积的操作,因为FFN本身还有第二层全连接,所以带有SwiGLU激活函数的FFN模块一共有三个权重矩阵,其中W1,V为SwiGLU模块的两个权重矩阵,W2为原始FFN的第二层全连接权重矩阵,Swish为激活函数。

由于SwiGLU的原因,FFN从2个权重矩阵变成3个权重矩阵,为了使得模型的参数量大体保持不变,研究人员通常会对隐藏层的大小做一个缩放,比如把中间层维度缩减为原来的2/3,每个矩阵的形状应该是 (ℎ,8ℎ/3)。进一步为了使得中间层是256的整数倍,也会做取模再还原的操作。
实现
我们使用LlamaMLP的代码来看看。在LLaMA中采用常数\(\beta\) =1,此时Swish简化为\\text{Swish}(x) = x \\cdot \\sigma(x),SwiGLU就是使用了nn.SiLU。
python
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj从ACT2CLS可以看出来,使用了nn.SiLU。
python
ACT2CLS = {
"gelu": GELUActivation,
"gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}),
"gelu_fast": FastGELUActivation,
"gelu_new": NewGELUActivation,
"gelu_python": (GELUActivation, {"use_gelu_python": True}),
"gelu_pytorch_tanh": PytorchGELUTanh,
"gelu_accurate": AccurateGELUActivation,
"laplace": LaplaceActivation,
"leaky_relu": nn.LeakyReLU,
"linear": LinearActivation,
"mish": MishActivation,
"quick_gelu": QuickGELUActivation,
"relu": nn.ReLU,
"relu2": ReLUSquaredActivation,
"relu6": nn.ReLU6,
"sigmoid": nn.Sigmoid,
"silu": nn.SiLU,
"swish": nn.SiLU,
"tanh": nn.Tanh,
}
ACT2FN = ClassInstantier(ACT2CLS)dReLU
研究人员一直没有停止优化的脚步,比如,因为激活稀疏性可以在不影响性能的情况下显著加速大型语言模型的推理过程,所以论文 Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters 提出了一种新的dReLU函数,该函数旨在提高LLM激活稀疏性(实现了接近90%的稀疏性)。dReLU公式和效果如下。

0x02 实现
2.1 哈佛代码
两个线性层的特点如下,其中B为batch_size,L是seq长度,D是特征维度。
| 名称 | 算子类型 | 输入形状 | 权重形状 | 输出形状 | 其他说明 |
|---|---|---|---|---|---|
| FFN expansion | dense | (B, L, D) | (D, 4D) | (B, L, 4D) | 维度扩增到4D |
| FFN contraction | dense | (B, L, 4D) | (4D, D) | (B, L, D) | 维度缩减回D |
代码实现非常简单:
python
# 定义一个继承自nn.Module,名为PositionwiseFeedForward的类来实现前馈全连接层
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
"""
d_model:线性层的输入维度也是第二个线性层的输出维度
d_ff:隐层的神经元数量。是第二个线性层的输入维度和第一个线性层的输出维度
dropout:置0比率
"""
super(PositionwiseFeedForward, self).__init__()
# 使用nn.Linear实例化了两个线性层对象,self.w1和self.w2
self.w_1 = nn.Linear(d_model, d_ff) # 第一个全连接层,输入维度为d_model,输出维度为d_ff
self.w_2 = nn.Linear(d_ff, d_model) # 第二个全连接层,输入维度为d_ff,输出维度为d_model
self.dropout = nn.Dropout(dropout) # 定义一个dropout层,dropout概率为传入的dropout参数
# 前向传播方法
def forward(self, x):
"""输入参数为x,代表来自上一层的输出"""
"""
操作如下:
1. 经过第一个线性层
2. 使用Funtional中relu函数进行激活,公式中的max(0, xW+b)其实就是ReLU的公式
3. 使用dropout进行随机置0
4. 通过第二个线性层w2,返回最终结果
"""
return self.w_2(self.dropout(self.w_1(x).relu()))2.2 llama3
llama3的实现如下,其使用ColumnParallelLinear和RowParallelLinear这样分布式线性层。从llama的源码中可以看到,其有三个w参数需要训练。
python
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))0x03 FFN的作用
论文"Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth"中发现,如果不加残差和FFN,堆叠再多层自注意力,整个模型的秩也会很快坍缩,也即所有表征趋于一个向量,模型都会变得不可用。因此,Attention, FFN, ResNet 可以被认为是 Transformers 架构的三驾马车,各司其职、缺一不可。了解了FFN的重要性,我们再来看FFN的几个作用:
- 提取更多语义信息。
- 增加表达能力。
- 存储知识。
我们接下来一一进行分析。
3.1 提取更多语义信息
我们再来看看一个问题,为什么FFN要先升维后降维?具体分析如下:
LLM在自己构造的高维语言空间中,通过预训练,记录了人类海量的语言实例,从中提取了无数的结构与关联信息。我们可以把这个高维的语言空间,加上训练提取的结构与关联信息,理解为LLM的脑。而FFN就是提取信息的关键模块。FFN在把输入的词向量映射到输出的词向量的过程中,将多头注意力学到的东西进行一波混合操作,以提取更丰富的语意信息,混合操作具体分为两步:
- 升维。其主要作用是拟合一个更高维的映射空间,从而提升模型的表达能力和拟合精度。
- 第一个线性层及激活函数组合,可以看作是在学习一组基函数,每个神经元可以视作一个简单的分类器,用以近似输入数据的高维映射。升维操作有效扩展了网络的自由度,使得模型能够学习更多的特征表示,从而提升模型的拟合能力。从一维卷积的角度看,升维可以提取更多的特征,以哈佛代码为例,就是使用了2048个1, 512的卷积核来提取特征。
- 升维把输入的词向量映射到一个更大维度的特征空间。FFN并非简单的直接在输入维度这个嵌入空间上进行建模,而是通过一系列线性变换来拟合一个高维的映射空间。若仅使用线性基,理论上我们只需使用等同于输入维度的基数量。然而,所有可能的平滑映射组成的空间是无限维的,因而需要通过升维来完整表示这一空间。
- 降维。其主要作用是还原维度,限制计算复杂度。
- 降维可以将维度还原,让下一层能够继续计算,从而保证encoder layer和decoder layer能够堆叠。
- 降维可以浓缩特征,防止过拟合。尽管升维带来更多的特征表示,但隐藏维度(或键值对数量)并非越大越好。过多的隐藏维度可能导致信息瓶颈和过拟合,甚至使模型难以有效传递信息。
- 降维可以限制计算复杂度。尽管升维有助于捕捉更多的信息,但理论上需要无限多的自由度来表达完整的光滑映射。然而,实践中我们不可能拥有无限的计算资源,因此必须通过降维来控制网络的规模和计算复杂度。降维操作通过将高维表示映射回较低维空间,有效地控制了模型的复杂度。
3.2 增加表达能力
Transformer架构中的非线性特征对Transformer模型的能力有重大影响。增强非线性可以有效地缓解特征坍塌的问题,并提高Transformer模型的表达能力。
注意力机制本质上是对Value的线性变换。虽然变换的权重是通过非线性的softmax计算得到,但是对于 value 来说,并没有任何的非线性变换。每一次 Attention 的计算相当于是对 value 代表的向量进行了加权平均,即使堆叠多个 Self Attention,依然只是对 value 向量的加权平均而已,无法处理一些非线性的特征。因此,无论堆叠多少层,都是最开始输入 x 的一个线性变换,其整体运算仍然是线性的,和单层变化没有本质区别,则其假设空间受限,无法充分利用多层表示的优势。
FFN中的激活函数是一个主要的能提供非线性变换的单元。通过它可以增加特征学习能力。非线性激活函数的引入打破了线性模型的限制,使得模型可以对数据进行更复杂的变换。降维操作将升维后的结果映射回原始维度,从而将这些非线性特征组合到最终的输出中。这种操作增强了模型的表达能力,使其能够表示更加复杂的函数关系。这就是 FFN 必须要存在的原因,或者说 FFN 提供了最简单的非线性变换。
3.3 存储知识
大型语言模型的强大能力离不开其对知识的记忆:比如模型想要回答"中国的首都是哪座城市?",就必须在某种意义上记住"中国的首都是北京"。Transformer并没有外接显式的数据库,记忆只能隐式地表达在参数当中。而记忆可以通过两个基本能力实现普遍计算:递归状态维护和可靠的历史访问。
真正学到的知识或者信息大多都存储在 FFN 中。从某个角度来看,FFN可以类比为一种键值对存储结构。第一个线性层生成"键",即为每个token计算一组召回权重。第二个线性层则计算"值",并与召回权重进行加权求和。这种方式类似于通过大规模的记忆存储(升维)来提升网络的长期记忆能力。
但是,FFN这种存储是分布式的,或者说是多义的,即面对看似不相关的输入,神经元都会做出反应。特征与输出结果有因果关系,但特征与神经元并不对应。关于多义性的成因,有一种理论称为叠加假说(superposition):神经网络通过存储多个特征的线性组合的方式来表示比其神经元更多的独立的特征。如果我们将每个特征视为一个神经元对应的向量,那么这些特征组成了激活空间上的一组过完备基。对模型性能有帮助的特征,如果其在训练数据中的频率是稀疏的,那么在神经网络训练过程中会自然出现叠加现象。与压缩感知一样,给定任意的激活空间中的向量,稀疏性允许模型消除叠加现象带来的歧义。另外,根据交叉熵损失训练的模型通常更倾向于用多义表示更多特征,而不是单义表示较少的 "真实特征",即使在稀疏性约束使得叠加不可能的情况下也是如此。
既然FFN是存储知识的模块,那就意味着其难以压缩和加速,因为:如果FFN变小,则意味着模型容量变小,从而导致模型性能变差。而且FFN中间的激活难以看出低秩,没法加速。
3.4 增加参数量
大模型的涌现现象是一个复杂且引人入胜的话题。其产生原因主要与参数量有关。当大模型的训练参数达到一定规模时,模型内部各组件之间的相互作用开始显现。这种相互作用随着参数数量的增加而逐渐增强,最终可能导致模型整体性能的显著提升,即涌现现象。因此,参数量对于大模型至关重要。语言模型中的参数数量决定了语言模型在训练期间学习和存储信息的能力。更多的参数通常允许模型覆盖更多知识维度,捕获更复杂的模式和细微差别,从而提高语言任务的性能。
使用FNN替代RNN有个好处就是可以避免参数稀疏化,我们都知道CNN和RNN都是具备参数共享功能的,这种参数共享在处理简单任务的时候,可能具备一定的好处,但是在处理复杂任务的时候,参数的共享可能不会带来优势,反而是稠密连接的FNN有更大的优势,稠密连接意味着参数量的增加,而参数量的增加,至少可以让模型可承载的信息量变大。
不考虑词嵌入层,一个transformer架构的模型里,FFN 和 Attention 参数占据了模型参数的绝大部分,基本上超过了 90%。其中 FFN 和 Attention 参数量比例接近 2:1。或者可以说,前馈层占了模型大约三分之二的参数量。我们可以使用PyTorch快速获得答案。
python
import torch.nn as nn
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
d_model = 512
n_heads = 8
multi_head_attention = nn.MultiheadAttention(embed_dim=d_model, num_heads=n_heads)
print(count_parameters(multi_head_attention)) # 1050624
print(4 * (d_model * d_model + d_model)) # 10506243.5 小结
最后,我们总结一下在Transformer模型中,为何要区分MHA和MLP?其原因就是这两个核心组件各有分工又彼此配合。Transformer用embedding解决无法定义的概念,用MHA+FFN来解决不能用已有运算符来表达的计算和变化。
- MHA考虑单词在不同位置的语义和依赖关系,并使用这些信息来捕捉句子的内部结构和表示,MHA是Transformer中最靓的仔。
- FFN 允许模型利用注意力机制生成的上下文信息,并进一步整合和转化这些信息,从而捕捉数据中更复杂的关系,为学习过程提供了深度和复杂性。同时FFN也提供了存储知识的场所。FFN是Transformer模型中的无名英雄。
这两者共同工作以提高模型的性能。
0x04 知识利用
既然提到了FFN是用来存储知识的,我们就来做进一步的分析。
知识被定义为对事实、概念等的认知和理解。掌握知识一直是人工智能系统发展的核心追求。在人工智能快速发展的今天,LLM展现出了令人惊叹的能力,经常被视为支撑知识导向任务的虚拟知识库,或者说,Transformer 的出色表现一定程度上要归功于其海量参数中存储的丰富信息,包括但不限于语言学知识、常识、算术知识以及世界知识等。然而,在这些表面性能的背后,LLM学习、存储、利用知识以及知识的动态演化规律依然是未解之谜。比如,针对"刘翔出生在哪个城市?"之类的问题,我们无法判断模型是真正理解它所处理的概念,并且基于内部知识和逻辑推理得到的答案,还是单纯因为该问题在训练集中出现过而依据表层的统计模式匹配之后输出答案。因此,我们需要探寻语言模型中概念形成、对齐及其认知机制的内在规律,需要探寻 LLMs 存储和管理事实知识的机制。
另外,尽管 LLMs 具有巨大的潜力,但直接将它们视作新一代知识库仍然存在某些局限,通常表现为实际应用中输出不准确或者错误的结果。而一个理想的知识库,不仅能够存储大量信息,还允许对其中的信息进行高效且有针对性的更新,以纠正这些错误并提高准确性。为了弥补这一差距,针对 LLMs 的知识编辑领域应运而生。这种方法旨在在保持模型处理通用输入的总体性能的同时,高效地改进 LLM 在特定领域的表现。
我们接下来从几个角度来学习下模型如何在 Transformer 的复杂架构中有效地检索、处理和运用已学习的信息,即如何更好的利用知识,具体包括。
- 记忆,指模型如何存储知识。
- 定位,指模型如何回忆基本知识。
- 修改,指模型如何修改存储的某个知识。
4.1 提取步骤
我们首先看看知识提取的步骤,不同论文提出了不同思路和方案。
论文"Dissecting Recall of Factual Associations in Auto-Regressive Language Models"通过对信息流的分析,揭示了一个属性提取的内部机制。我们用实例进行说明,假设输入的prompt是"Beat music is owned by",LLM返回的正确答案应该是"apple"。和很多方案一样,此论文也把知识抽象成如下三元组 (𝑠, 𝑟, 𝑜),s代表头部实体(主语𝑠),尾部实体(对象,𝑜),以及它们之间的关系r。我们首先确定关键点:关系和实体。这个例子里,"Beat music"是个实体,"is owned by "是关系,"Apple"是这个实体对应的某个属性。然后,通过分析这些点的信息,可以确定属性提取的三步如下:
- 融入信息。经过早期的多层MLP处理之后,最后一个主语位置的表示(Music)会融入很多与主语相关的属性,比如融入Beats的信息。
- 传播关系。模型的最初几层会把所查询的关系 r 的信息传播到整个输入的最后一个 token 位置(by)上。
- 属性提取。最后一个位置(by)已经集成了单词"own"的信息,此时通过注意力机制(使用关系r)把"beats music"对应的属性"apple"提取出来。

论文"A mechanism for solving relational tasks in transformer language models" 则将语言模型完成事实回忆任务的过程分为两个阶段:
- 形成参数:当我们问模型"法国的首都是",在残差流中解码出来的答案会首先形成被查询的国家,即"法国"。可以将这个过程比作模型形成了类似于"get_capital(x)"的隐式函数,将残差流逐渐形成"法国"信息的过程比喻成模型正在形成隐式函数的参数。
- 应用函数:随着层数继续加深,残差流中解码出的高概率token会由国家过渡到首都名字,即"巴黎"。可以将这个变化比喻成模型应用了"get_capital(x)"隐式函数。
这些观察提供了很有价值的研究基础,但是仍有很多问题没有被回答,这些问题对于进一步理解语言模型中的事实回忆机制至关重要:
- 模型如何完成"传参"?
- 隐式函数到底是怎么被应用的?MLP在这个过程中是怎么工作的?
- 论文主要关注了one-shot设定,zero-shot或者few-shot情况下模型的工作机制如何?
论文"Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models"做了进一步研究,其将语言模型在zero-shot场景下完成事实回忆任务的过程总结为以下几步:
- 注意力头对"隐式函数"传参。首先,在浅层形成的任务语义会激活一些中至深层的特定任务的注意力头。 这些注意力头具有对与特定主语(例如国家名称)相关的token敏感的QK矩阵。 它们关注这些主语token并将它们移动到残差流的末尾位置。 这种机制使得模型能够从上下文中提取"参数"并将其传递给"隐式函数"。 此外,一些注意力头的OV矩阵可以直接将"参数"映射到所需的输出,而无需通过后续的MLP进一步处理。 这种映射可以看作是完成了部分"函数应用"。
- MLP是注意力头输出的"激活函数"。注意力头之后的MLP充当了每个头输出的"激活函数",使得特定任务头传递的"参数"会在残差流中脱颖而出。鉴于所有注意力头的输出在添加到残差流之前被等权地相加在一起, 该MLP可以通过使用生成与头输出方向相一致或相反的向量来擦除或放大各个头的输出。
- 参数应用即" \(b+r_{mid}\) "。MLP的输出中,一个"任务相关"的分量,即这里的截距项,在与残差流相加的时候,完成了"函数应用",将残差流引导向MLP认为正确的输出的方向。我们可以从MLP的输出中分解出一个任务感知的分量,这个分量在与残差流相加的时候会完成对残差流方向的操控,MLP可以通过这个分量将残差流引导向目标答案的unembedding vector的方向。这个分量与残差流相加的操作可以被认为是"函数应用"的基本实现。
- 另外,模型最后一层普遍存在Anti-overconfidence机制。无论是模型最后一层的注意力头,还是MLP,都是在将模型的输出向"高频"或者换句话说"安全"的方向引导,这样即使模型预测错了,从整个训练集来看,获得的loss的期望还是比较小的。
下图给出了基于Transformer的语言模型所采用的事实回忆的关键机制。
- 图上(1)展示,特定任务相关的注意力头\(𝐴^{𝑙,1}\)将主语实体(即"法国")移动到残差流的最终位置。
- 图上(2)展示,MLP将"France"作为隐式函数"get_capital(X)"的参数。其输出将残差流重定向到其预期答案的方向,即本例中的"Paris"。
- 图上(3)展示,MLP的输出会擦除或放大残留流中单个磁头的输出。在这种情况下,\(𝐴^{𝑙,1}\)的"法国"输出被放大,而其他磁头的输出被擦除。

4.2 知识记忆
知识记忆的目的是记忆和回忆知识,例如具体术语、语法和概念等,王坚院士称:"记忆就是重塑神经元之间的连接,记忆的偏好,就是神经元之间相互链接的关系改变了。而对于今天的大语言模型来讲,就是权重发生了变化"。现有大量研究工作致力于揭示 LLMs 的行为机制,特别是 LLMs 中的知识存储模式,下图是一个简要的汇总。

我们首先看看一些典型的思考和研究。目前的工作中,有两个方向的尝试比较重要:
- 键值对。该方向认为事实以键值对的形式存储在mlp中,在这个基础上人们使用知识编辑(knowledge editing),遗忘学习(machine unlearning),祛毒(detoxification)等方法对模型的mlp层修改,以缓解修复模型的缺陷。
- 知识回路。该方向认为知识不是单独的存储在某一区域的,而是由不同的组件共同构成的。
键值对形式
下图展示了键值对的概念,我们接下来看看这个领域内的几篇重要论文。

记忆网络
2015年,论文"End-To-End Memory Networks"提出了记忆网络的概念,这是一种 Key-Value Memory 的结构,借此可以在神经网络中添加记忆模块。该论文将需要存储的信息分别映射为key向量与value向量,然后以向量内积的指数形式建模键(key)对于输入(x)的条件概率,进而得到记忆网络的整体是对每个键值对的加权求和。模型的架构如下图所示。每个文本都会分别映射成向量\(c_i\)和\(m_i\),query也被编码成一个内部状态u。在嵌入的空间中,模型通过计算u和\(m_i\)的内积以及一个softmax 来得到计算u和mi之间的交互关系\(p_i\)。最终输出向量O是用\(c_i\)和\(p_i\) 计算得到。

我们对模型结构做进一步抽象,给定输入x和键k,我们有 \(x,k_i ∈R^d\),则记忆网络的结构为\(MemoryNet(x)=softmax(x⋅K^⊤)⋅V\),具体细节如下图所示。

我们已经知道FFN 的公式为\(FFN(H)=f(H⋅W_1)W_2\),这里 \(f\) 是 ReLU 激活函数。因此可以发现,记忆网络和注意力机制很类似,而FFN几乎与记忆网络的key-value memory相同。唯一的区别在于:记忆网络使用 softmax 进行归一化,FFN的采用 ReLU 进行筛选,并不要求归一化。假设FFN层是一个key-value memory,每一个key向量 \(𝑘_𝑖\) 可以捕获输入序列的模式,\(𝑘_𝑖\)对应的value向量 \(v_𝑖\) 可以表示遵循该模式的token分布。
Key-Value
基于上述信息,"Transformer Feed-Forward Layers Are Key-Value Memories"和"Knowledge Neurons in Pretrained Transformers"这两篇论文也做了深入研究,发现FFN 确实将一些 pattern 或者知识记忆和存储起来了,其中一些相关论点如下:
- Transformer 架构下的FFN在形式上高度类似于记忆神经网络,都是一个双层 Key-Value 记忆网络。并且FFN第一层前馈网络权重 \(𝑊_{𝑓𝑐}^{(𝑙)}\)对应记忆网络里键值对(KEY-VALUE)的KEY,而第二层前馈网络权重 \(𝑊_{𝑝𝑟𝑜𝑗}^{(𝑙)}\) 对应着VALUE。中间层维度对应memory token数量(或许是中间层维度需要较大的一种解释)。
- FFN 学到的记忆有一定的可解释性。前馈网络的KEY捕捉了输入的某种模式,或者说,每个KEY至少与一个人类可理解的输入模式高度相关。储存的模式来源于训练数据。
- 每个KEY神经元都会触发人类可理解的浅输入模式,相应的VALUE 神经元存储下一个词的输出概率。
- VALUE 可以基于KEY捕获的模式,预测下一个输出词的分布。或者说,VALUE对应的KEY所关联的模式句子的下一个词会以高概率值出现在该分布中。
- 每层的输出相当于合并了数以千百计的激活记忆分布,最后形成全新的分布。该分布的预测会随着每层里的残差链接被不断校正、细化,直到最后一层。最终产生模型的预测结果。FFN 的最终输出可以理解为激活值的加权和。
- 浅层倾向于检测出浅层模式,高层倾向于检测语义模式。
下面是论文中推导出的FFN的KV详细结构,FFN的第一层可以认为是KEY,第二层可以认为是VALUE。

在下图上可以看到由模式到VALUE的流程。

我们接下来详细分析下这些论点。
Key模式
关于key的模式,"Transformer Feed-Forward Layers Are Key-Value Memories"也做了研究。论文作者标注了一批键值对应的句子,要求模式必须满足:重复三次以上,可描述,并且包含浅表模式(重复词句n-gram)或者语义模式(多次重复的主语)。通过实验,作者发现每个键向量至少对应一种人类可解读的模式。低层键向量趋向于捕捉浅显的模式,比如一些通用 pattern(比如以某某结尾),而高层的 Key 趋向于捕捉抽象的语义模式(比如句子的分类)。这个发现类似于CNN里,底层趋向于捕捉显示的图像特征,而高层趋向于捕捉抽象的特征。也类似于ELMO等论文在NLP学界的发现。
另外,论文作者针对移去尾部词和移去头部词的效果做了实验,相较于高层键值来说,底层的浅表模式的记忆系数对"移去尾部词"的影响更敏感。这佐证了高层和底层关注的模式抽象层次不同的结论。

值向量表示的是分布
记忆网络的值向量表示的是输出词汇的分布,其倾向于补全对应key的prefix的下一个词,具体特点如下:
- 每一个key \(k_i^l\)对应的value \(v_i^l\),即FF层第二个参数矩阵的第 𝑖 行,可以视为输出词表的一个分布,同时可以作为 \(k_i^l\)所捕获的模式的一种补充。
- 直接将 \(v_i^l\) 和输出词表的embedding矩阵E(假设模型每一层都使用的是同一个词表矩阵)进行相乘,然后进行softmax,即 \(p_i^l=𝑠𝑜𝑓𝑡𝑚𝑎𝑥(v_i^l⋅𝐸)\) ,就可以将values转换为输出词表的分布。这个 \(p_i^l\) 没有被校准,不是一个真正的词表分布。因为FF包含了两个参数矩阵,第一个参数矩阵会得到记忆系数 \(𝑚_𝑖^𝑙=𝑓(𝑥⋅𝑘_𝑖)\) ,该系数会与第二个参数矩阵相乘,得到 \(m_i^l \cdot v_i^l\) ,而这里直接使用 \(v_i^l\) 得到词表分布。
- 对于每一层,根据 \(𝑎𝑟𝑔𝑚𝑎𝑥(𝑝_𝑖^𝑙)\) 得到 top-ranked 的token,然后该token和 \(w_i^l\)进行比较。 \(w_i^l\)是分数最高的\(m_i^l\)所触发前缀序列的下一个token,即通过value得到的词表分布遵循了key捕获的模式。
分布式存储和记忆聚合
截至目前,我们讨论的依然是某个特定的键值对。但我们知道一个记忆网络是所有值向量的加权(记忆系数)求和(并加上偏置项)。如果值向量表示的是在词空间的分布,那么这些信息是如何聚合到一个最终分布的呢?
有研究表明,大脑中所有只是不会只存储在一个地方,也不是像全息图一样在任何地方存储所有东西。关于一个物体的知识会分布在成千上万根皮质柱中。比如,卡尔·拉什利(Karl Lashley)在20世纪早期就给出了一个非定位结论:大脑中没有专门的记忆器官,信息根本不是存储在特定的文件柜中,而是分布在神经元中。这一结论被后来改进的实验方案证明是基本正确的。
和人脑类似,FFN中对于某个知识也是分布存储的,用以存储一个特定模式的权重会分布的存于不同层。FFN不单是激活一个key及其value,而是多个value的加权和。每一层的输出又进一步是FFN的输出与残差的组合。
知识回路
论文"Knowledge Circuits in Pretrained Transformers"发现了Transformer架构中的知识回路(Knowledge Circuits)。知识回路将语言模型看作一个由组件(input,output,attention_head,mlp)为节点,连接组件的边(残差流),共同组成的一个计算图,信息在这些组件中流动。相对于知识编辑关注知识的存储区域,知识回路更关注信息的流动。
下图为模型回答"The official language of France is "这个问题时,所经过回路。对于下图的回路来说,基于一个事实三元组"(Franch, official language, French)" ,让模型补全"The official language of France is "这句话,从而预测出客体是French。在回路中,MLP14类似的点代表着第14层的MLP层;L18H14代表着第18层的第14个注意力头,点之间的褐色连线代表这他们之间的信息流动。通过消融节点(即参数置为0)之间的边就可以判断出某个边对于知识是否为关键边,通过保留重要的边就可以构造出关于这个事实的回路。

论文做了一些实验,把每一层的中间输出解码,然后观察其预测结果。针对"The official language of France is French"这一事实,下图给出了在最后一个主语(subject )token位置和最后一个token位置上,目标实体的排名和概率。图上几个标志的说明如下:
- Target Entity at Last Position表示"French"这个词在"is"位置时输出logits的预测排名。数值越低,排名越高。
- Target Entity at Subject Position表示"French"这个词在"France"位置时输出logits的预测排名。数值越低,排名越高。
- Prob. of Entity表示实体的可能性,数值越高,实体的可能性越大。

从上图可以看出,在MLP17层以后,目标实体的可能性开始渐渐上升。从再上面的的网络图可以看到,连接MLP17的边是(L14H13 → MLP17), (L14H7 → MLP17)和(L15H0 → MLP17) ,因此,该论文判断,不同的注意力头起不同的作用。
- 注意力头L14H13是一个关系头(relation head),它更关注上下文中的关系(relation)token。这个头部的输出是与关系相关的token,如"language"和"Language"。
- 注意力头L14H7是一个移动(mover )头,它将信息从主语位置"France"移动到最后一个token。
- MLP17层则是结合之前组件提供的信息,提升目标token的最高rank。
注意力模块
另外,注意力模块在存储关系知识方面也发挥了重要作用。这表明在分析和修改LLMs中的知识时,不能仅仅关注MLP层,还需要考虑注意力机制的作用。比如,论文"EXBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models"解释了每个注意头所学习到的知识。具体来说,注意头会存储明显的语言特征、位置信息等。此外,事实信息和偏见也会通过注意力头传递。

上图展示了在预训练模型BERTbase和不同语料库下,不同注意力头的效果。
- (a)显示,注意力头5-3通过助动词(AUX)"to"来预测掩码的单词应该是一个动词。
- (b显示,注意力头7-5找到了输入句子中介词(PREP)与其宾语(POBJ)之间的关系。
- (c)显示,注意力头5-5学习到了关于实体关系的的共同参考(co-reference),因为因为"she"和"her"都明确指向"Kim"。
4.3 知识的定位
除了知识存储之外,其实已经开始有一些研究从网络架构或者注意力机制的角度探究知识的检索以及利用的问题。
事实的定位
事实知识的定位可以分为两步:知识归因 (Knowledge Attribution)、精炼神经元 (Knowledge Neuron Refining)。
知识归因 (Knowledge Attribution)
论文"Axiomatic Attribution for Deep Networks" 提出可以使用积分梯度法(Integrated Gradients)来计算每一个特征对输出的归因,以此来解释模型预测和输入特征之间的关系。
积分梯度法有个重要的性质,那就是所有的归因加起来就是f(x)和f(x')的差值。公式如下,其中函数F表示神经网络。如果F(x')=0, F(x)=1,那么每个特征的归因可以认为是对该样本属于label=1的贡献。

深度网络归因定义如下图所示:假设函数F表示一个深度网络,该网络输入为x,另有一个基线输入x'。 则x相较x'的归因是一个向量\(A_F(x,x')\),其中\(a_i\)就是输入\(x_i\)对于预测结果F(x)的贡献。

精炼神经元 (Knowledge Neuron Refining)
我们可以通过一种精炼策略去更准确地定位事实知识。虽然在经过初筛的神经元集合中,很多"true-positive"知识神经元会对最后的输出做主要贡献,但是集合中还有很多"false-positive"知识神经元,它们表示其他知识(比如句法信息和词法信息,即它们代表的是附属信息或者上下文信息)。所以,我们需要过滤掉这些"false-positive"知识神经元来提升定位效果。

如何过滤?我们先看看"false-positive"神经元的特点。比如由若干描述李世民的prompts,因为它们之间有着各种各样的句法,词汇信息,所以它们的"false-positive"知识神经元会不同。但是它们都有相同的事实信息:李世民。所以,我们能通过提炼出不同 prompts 之间共享的神经元,从而定位出那些普遍的事实信息。具体来说,给定一个关系事实,识别其知识神经元的完整过程描述如下:
- 构建 n 个不同的 prompts 去表达这个事实。
- 对于每个提示,计算神经元的知识归因得分。
- 对于每个提示,保留归因得分大于归因阈值 t 的神经元,获得粗略的知识神经元集。
- 设置一个共享阈值 p%(是否被多个 prompt 共享)。
- 将所有的粗略的知识神经元集聚合在一起,只保留达到这个阈值的神经元。
以下图为例,对于一个关系和它的激活神经元,我们输入 10 个 prompts(包含 head 和 tail 实体)来获取知识神经元的平均激活。然后,我们对这些 prompts 进行排序,保留 top-2(activation 最高的),bottom-2(activation 最低的)。我们发现,top-2 总是表示相应的关系事实,而 bottom-2 尽管包含相同的 head 和 tail 实体,但没有表示相应的关系。这个发现表明,知识神经元可以捕获关系事实的语义模式,并且再一次验证了知识神经元是由知识探测 prompt 激活的。

关系的定位
前面主要从实体的角度调查 LLMs 中的知识。如果我们从关系的角度来处理相同的知识,可能会得到完全不同的观察结果。理论上,一条知识包括实体和它们之间的关系,缺少任何一个,知识就是不完整的。因此,在这种情况下,实体和关系应该是等价的,这也是当前许多模型编辑工作的前提,因为需要在模型参数中修改知识。
论文"Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models" 研究了实体和关系之间的差异,具体是通过修改实体或关系知识来确定这些变化是否会产生一致的结果,并从两个角度观察效果。理想情况下,这些效果应该是相同的,因为编辑的知识涉及同一条信息。

研究者提出了以下研究问题:
- 关系知识存储在哪里?它是否像实体知识一样存储在 MLPs 中?
- 无论存储位置如何,关系和实体知识在知识三元组中是否同等重要?
论文针对两个问题的回答如下:
-
实体和关系知识可能以不同的方式存储和表示。
- 实体和关系知识并不简单地存储在相同的位置或以相同的方式表示,而应该是分开存储的。
- 注意力模块在存储关系知识方面也发挥了重要作用。关系知识与较高的 MLP 层和中上层注意力层密切相关。
-
实体知识和关系知识是可互换的。基于这一假设,研究者认为通过改变关系知识来修改实体知识在理论上是可能的。但是编辑实体知识和关系知识并不完全等价。
字典学习和稀疏自编码器
我们首先看看几个概念。
-
线性表示假设(linear representation hypothesis):这个假设认为神经网络将有意义的概念(称为特征)表示为其激活空间中的方向。简单来说,就是模型对于某个概念的理解和表示,可以被看作是在一个多维空间中的一种方向。更改这个方向,即改变特征的值,就可以改变模型对于这个概念的理解和处理。
-
叠加假设(superposition hypothesis):从上面假设进一步拓展,神经网络利用高维空间中几乎正交方向的存在,来表示比维数更多的特征。这意味着,即使我们的模型只有有限的维度,但是通过在不同的方向上叠加和组合这些维度,我们可以表示和理解更多的特征和概念。
-
字典学习:字典学习是一种常用的特征提取方法,通过学习一个字典,可以把高维数据表示为字典中元素的线性组合。该技术借鉴了经典机器学习,分离了在许多不同背景下反复出现的神经元激活模式,将神经元激活模式(称为特征)与人类可解释的概念进行匹配。对于上下文,字典学习的目标是将 LLM 神经元内部的激活解开为一小组可解释的特征。然后,我们可以查看这些特征来检查模型在处理给定上下文时内部发生的情况。
-
稀疏自编码器是一种特殊的字典学习方法,它通过限制字典元素的数量和它们的线性组合的稀疏性,可以有效地提取出数据的关键特征。
基于这些概念,论文"Towards Monosemanticity: Decomposing Language Models With Dictionary Learning"从另一个角度为我们拓展了LLM中知识的可解释性。其核心是:使用稀疏自编码器能从单层transformer模型中提取大量可解释的特征。
从某种意义上说,下图是最简单的人无法理解的语言模型。论文的目标是将它的 MLP 激活向量并分解到各个特征。这是通过在MLP的activation后接上一个过完备的autoencoder来完成的,即autoencoder是用来解释模型内在激活(MLP层后的激活)的。autoencoder分解后的特征数量多于神经元数量,隐状态的每一个维度都可以作为一个抽象出的特征,并且具有很强的可解释性。这是因为我们认为 MLP 层很可能使用叠加来表示比它的神经元更多的特征(当然,不只是发生了叠加,还对特征进行了非线性的映射)。

这样就可以通过在多维空间中找到表示不同概念的"方向",并通过在这些方向上进行叠加和组合,来理解和处理复杂的数据和概念。通过字典学习和稀疏自编码器,我们可以有效地提取出这些方向,从而更好地理解和控制模型的行为。
下图给出了Transformer和稀疏自编码器的对比。


论文中的一些有趣的结论如下。
- 稀疏自编码器能提取相对单一的语义特征。
- 稀疏自编码器能产生可解释的特征,而这些特征在神经元中实际上是不可见的。
- 稀疏自编码器特征可用于干预和引导transformer的内容生成。
- 稀疏自编码器能产生相对通用的特征。
- 增加自编码器的大小时,特征会 "分裂"。
- 仅 512 个神经元就能表示数以万计的特征。尽管 MLP 层非常小,但随着稀疏自编码器的规模扩大,我们仍能不断发现新的特征。
- 这些功能在类似于 "有限状态自动机 "的系统中相互连接,从而实现复杂的行为。例如,我们可以找到共同生成有效 HTML 的特征。
4.3 修改知识
LLM在理解和生成自然语言方面表现出了非凡的能力。然而,由于巨量参数的存在,其训练过程中需要大量算力。现实世界在不断发展变化,因此需要频繁地更新 LLM 以移除过时信息或者整合新的知识。这使得对于算力的挑战变得愈发严峻。除了为了保证 LLM 能够进行持续学习而需要对其频繁更新参数外,许多应用也需要在训练后不断调整模型,以解决预训练模型存在的不足或不良行为。
因此,越来越多的工作尝试提出能够实时修改模型的高效、轻量级方法。近年来,作为这类方法的代表性技术路线---知识编辑技术,在LLM 领域取得了突破性进展。该技术通过对 LLMs 快速准确的修改,使它们生成更准确、更相关的输出结果。这样一来,就有望弥补当前 LLMs 存在的不足,从而充分发挥它们作为动态、准确的知识库在各种下游应用中的潜力。
相关路线
下图展示了一些与知识编辑相关的几条技术路线,包括参数高效的微调(parameter-efficient fine-tuning)、知识增强(knowledge augmentation)、持续学习(continue learning)以及机器遗忘)(machine unlearning)。

符号✔ 表示技术中存在特定特征,而✗表示不存在,+表示LLM能力的增强,-表示模型中某些能力的减少或删除。
如上图所示,知识编辑与其它技术相互交叉、博采众家之长。知识编辑技术针对性地定位 LLMs 内嵌的知识,并利用这些模型中固有的知识机制。这不仅仅是将已知技术应用到新模型中,而是更关乎理解和操纵 LLMs 微妙的知识存储和处理能力。此外,知识编辑代表了一种更精确、更细粒度的模型操纵形式,因为它涉及到选择性地改变或增强模型知识库的特定方面,而不是重新训练或微调整个模型。因此,与简单地对现有方法进行修改不同,知识编辑需要更深入地理解 LLMs 的功能。这些特点使得知识编辑可能成为更新和优化 LLMs 以适应特定任务或应用的更有效且高效的技术路线。
功能
作为一个理想的知识库,针对 LLMs 的知识编辑必须能实现以下三个基本功能:知识插入、知识修改和知识擦除。
-
知识插入。随着各个新兴领域和实体的涌现与发展,赋予 LLMs 吸收新知识的能力至关重要。知识插入通过赋予 LLMs 现有范围之外的新知识来实现这一点:即 𝜃′=𝐹(𝜃,{∅}→{𝑘}) 。
-
知识修改。知识修改则是指改变 LLMs 中已存储的知识:𝜃′=𝐹(𝜃,{𝑘}→{𝑘′}) ,具体可分为两类:
- 知识修正 - 旨在纠正 LLMs 中的不准确信息,以确保其能够传递准确的信息。作为庞大的知识库,LLMs 中容易存在过时或错误的信息。知识修正旨在纠正这些谬误,确保模型始终产生准确的、与时俱进的信息。
- 知识干扰 - 修改 LLMs 以回答反事实或存在排印错误(非故意造成的谬误)的问题输入。这是一件更难的事情。现有工作表明,与事实性知识相比,反事实观念在 LLMs 中得分很低,导致被生成的概率远低于事实性知识,因此需要进行更有针对的修改。
-
知识擦除。知识擦除是在模型中移除已有的知识,主要是为了重置事实、关系或属性:𝜃′=𝐹(𝜃,{𝑘}→{∅}) 。实施知识擦除对于消除有偏见的以及有害的知识至关重要,且有助于限制对机密或私人数据的回放,从而形成负责任的、值得信赖的人工智能应用。
总而言之,知识插入、修改和擦除之间的相互作用构成了针对 LLMs 的知识编辑技术的基本框架。当这些技术结合在一起时,它们能够赋予 LLMs 在必要时进行自我转换、自我纠正和道德适应的能力。

分类
面向 LLMs 的知识编辑主要分为以下几类,其对应了人类知识获取的三个不同阶段:识别、关联和掌握。
- 外部知识依赖。代表方案是提示工程和知识检索,具体发生在知识识别阶段。这种方法类似于人类认知过程中的识别阶段,需要在相关背景下接触新知识,就像人们第一次接触新信息一样。例如,可以给大模型提供具有事实更新的示范语句,从而实现大模型对待编辑知识的初步识别。或者通过检索来校验LLM的回答,一旦检索的事实与 LLM 的输出冲突,则更新 LLM 的回答;反之则沿用 LLM 的输出作为最终答案。
- 外部知识注入。代表方案是增加参数、替换输出,具体发生在知识关联阶段。这种方法与人类认知过程中的关联阶段非常相似,让新知识和模型中现有知识之间形成联系。此类方法一般会使用一套习得的知识表示来对大模型的输出或中间结果进行增强或替换。总体而言,我们可以统一表示这些方法为:\(ℎ_{final} =ℎ+ℎ_{know}\) 。然而,这些方法将新知识与原始模型相结合,使得不同来源的知识的加权成为一个需要考虑的关键参数。其实,外部知识依赖和外部知识注入都算是保留权重方法。即通过引入外部模型、利用上下文学习或改变LLM的表示空间来实现这种保留。也可以叫做基于记忆的方法。
- 内在知识编辑。这种方法类似于人类认知过程中的掌握阶段,通过修改大模型权重并利用这些权重来让大模型完全整合知识。
下表汇总了 LLMs 知识编辑领域的代表性方法。No Training 表示不需要额外训练的方法;Batch Edit 意味着这些方法是否能在支持一次同时编辑多个案例。Edit Area 是指使用模型组件的位置;Editor #Params 表示编辑时需要更新的参数数目。𝐿 表示需要更新的层数。𝑑_ℎ \\(表示 Transformers 中隐藏层的维数。\\)𝑑_𝑚 是指在上投影和下投影之间的中间维数。𝑁 表示在每个单独层中进行更新的神经元总数。表中方法对应的具体论文请参考论文"A Comprehensive Study of Knowledge Editing for Large Language Models"。

内在知识编辑
尽管外部知识依赖和外部知识注入这两类方法在不同任务上表现良好,但我们仍然面临着模型如何存储知识以及如何利用和表达知识的问题。因此,我们来到了发生在掌握阶段的内在知识编辑(更新参数)。在掌握阶段,模型需要学习关于它自身参数的知识,并自主掌握这些知识。
微调模型是编辑内在知识最直接的方式。然而,前面我们也提到,训练整个模型需要大量的计算资源,而且耗时较长。同时,微调技术通常容易出现灾难性遗忘和过拟合现象。目前,属于掌握阶段的研究大多在使用专门针对特定知识的方法来对模型参数进行更新。这些方法可以分为两类:元学习(meta-learning)和定位-编辑。
元学习并非直接更新模型权重,而是训练一个超网络来学习模型权重的变化 Δ𝑊,比如可以直接使用新知识的表示来训练超网络。或者引入一个新的训练目标,考虑顺序、局部和泛化模型更新,用以保证在使用超网络更新内在相关知识的同时,保持其他知识不变。
定位-编辑则是首先定位到知识存储在大模型中的位置,然后通过修改这些特定区域来进行知识编辑。
FFN
论文"Knowledge Neurons in Pretrained Transformers."提出了一种通过计算梯度变化敏感性的知识归因方法用以定位知识存储的位置。既然可以定位到对某些事实或者知识影响较大的神经元,于是论文作者直接使用目标知识的嵌入来修改相应的值槽,具体包括以下:
- 对这些神经元内的数值进行增强或者抑制,从而让Transformers 对这些事实或者知识的回答效果也会变好或者变差。
- 将这些神经元删掉,从而让 Transformers 完全忘记了这些知识。比如当识别到和这个知识有关的所有知识神经元之后。设置一个阈值 m=5,然后通过将这m个神经元设置为 UNK来删除这些神经元。
下图上方给出了把第二列修改为第三列,所需要修改的神经元数目。下方说明通过修改与知识神经元对应的几个值槽,可以擦除部分知识。也给出了知识擦除前后四种关系的缺失实体预测准确性。

这种对模型中的FFN层的值矩阵进行编辑的方案可能会引起遗忘和其他的副作用。因此,论文"WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models"参考人类学习的方式---即人类不断的渐进的获取新的知识,然后遗忘旧的知识---设计了一种终身学习的模型编辑方法,既可以实现模型高效的更新,又能避免灾难性遗忘等知识变价的副作用。终生学习编辑的目的是确保大模型经历数百上千次编辑之后,能够对齐人类的期望并且维持以前的知识和能力。为了达到这个目的,该论文引入了两个组件辅助记忆模块和知识分片和合并机制。
- 辅助记忆设计。该组件将模型中的值矩阵复制一份作为辅助记忆,进而在辅助记忆上进行编辑,从而绕过了这些缺陷。而在推理过程中,通过一个路由机制来判断是否使用辅助记忆。如果给定查询在之前的编辑范围内,辅助记忆会被使用;否则,使用主要记忆。
- 知识分片与合并。为了实现终生学习编辑,需要在参数空间进行数百甚至上千次编辑,最终一定会引起编辑知识冲突,最终造成灾难性遗忘。为了避免在一个参数空间中进行多次编辑,该论文提出将将辅助记忆复制k次,然后将n次编辑应用到k个分片中,从而实现持续的编辑。对于多个辅助记忆分片,存在着重叠的元素和不相交的元素。该论文采用Ties-Merge的合并方法,把重叠的部分当作锚点,最终将多个记忆分片合并为一个记忆。

注意力头
上述将的是对FFN进行知识编辑。除了在 FFN 区域进行知识编辑外,论文"PMET: Precise Model Editing in a Transformer"还对注意力头进行了编辑,如下图所示:

这篇文章分别对 MHSA 的输出与 FFN 的输出进行处理,更新的时候还是只处理 FFN 对应的输出。
研究者们观察到MHSA部分包含的知识比FFN部分有更多的变化和动态性。这种观察可能意味着MHSA在捕捉和编码输入数据中的某些模式或关系时,其内部表示和权重需要更频繁的调整。基于这种观察以及对现有研究的回顾,研究者们进一步提出了一个新的假设,即MHSA可以视为一个"知识提取器"。它不仅能够识别输入数据中的模式和关系,而且还能够存储一些通用的知识提取模式,这些模式可以帮助模型更好地从数据中提取和理解有价值的信息或知识。
基于这种新的理解和假设,研究者们提出了一种新的优化策略。他们认为,可以通过对MHSA的隐藏状态(或称为Transformer组件的隐藏状态)进行优化来扩展其功能空间,从而使其能够更好地提取和存储知识。而且,这种优化可以在不更新MHSA权重的情况下实现。
ROME
最后,我们看看论文"Locating and Editing Factual Associations in GPT"。该论文主要提出了一种LLM的编辑方法,作者通过知识三元组(s,r,o)来完成模型编辑。首先,作者通过实验发现在subject的最后一个token中,MLP发挥了主要的中介作用,因此,作者假设这个位置的中间层MLP存储了事实之间的关联信息。即 \(w_{fc}\)存储subject信息,\(w_{proj}\)存储事实之间的关联信息。作者将 \(w_{fc}\)看作key,\(w_{proj}\)看作value,通过编辑键值对来修改LLM中的事实信息,从而达到模型编辑,提高模型泛化能力和可移植性的目的。

论文将每个事实表示为一个知识三元组 𝑡=(s,r,𝑜) ,其中包含主语 s、客体 o 以及连接两者的关系 r。然后,提供了描述 (s,r) 的自然语言提示 𝑝 并检查模型对 𝑜 的预测。论文将 𝑊_{𝑝r𝑜𝑗}\^{(𝑙)} 视为线性联想记忆(linear associative memory)。从这个角度来看,通过求解 WK≈V,任何线性运算 𝑊 都可以作为一组向量键 K=k1\|k2\|... 和相应的向量值 𝑉=v1\|v2\|... 的键值存储。通过求解约束最小二乘问题,论文在全连接层中得出一个封闭形式的解,如上图标号1。一旦计算出 (k∗,v∗) ,我们就可以直接插入任何事实。于是我们来看看如何找合适的 k∗ 和 v∗ 。具体步骤如下:
-
步骤1:选择 k∗ 来选择主语。基于 MLP 输入在最终主语token中的决定性作用,我们将选择代表主语的最后一个token的输入作为查找键 k∗ 。具体来说,我们通过收集激活来计算 k∗ :将包含主语 s 的文本 𝑥 传递给语言模型 𝐺 ;然后在 𝑙∗ 层中最后一个主语token索引 𝑖 处,我们读取 MLP 内部非线性层之后的数值。因为状态会根据文本中 s 之前的token而变化,所以我们将 k∗ 设置为以主语 s 结尾的一小组文本的平均值。见上图标号2。
-
步骤 2:选择 v∗ 来回忆事实。接下来,我们希望选择一些向量值 v∗ ,将新关系 (r,𝑜∗) 编码为 s 的属性。我们的具体处理如下,如上图标号3。
第一项(方程 a)寻找一个向量 z,当用 z 替换掉主语末尾token i 的 MLP 输出时,模型对于提示 p 将会预测出目标对象 o * 。
第二项(方程 b)的作用是,对于未更改模型和提示 p'(形式为"{subject} is a"),此项会最小化 KL 散度(该优化不会直接改变模型权重),这有助于保持模型对主语本质的理解。方程 b 会识别出 v∗ 的向量表示,如果目标 MLP 模块输出 v∗,就说明 v∗ 是主语 s 的新属性 (r, o*)。
-
步骤 3:插入事实。一旦我们计算出代表完整事实 (s,r,𝑜∗) 的对 (k∗,v∗) ,我们就应用上图标号1的方程,通过直接插入新的键值关联的rank one更新来更新 MLP 权重 𝑊_{𝑝r𝑜𝑗}\^{(𝑙)}。
下图给出了完整流程。

4.4 学习知识
我们接下来回头看看学习知识的过程中,Transformer内部是如何调整或者修改的。
前向传播
现有的方法主要集中在研究前向传播的隐状态和权重的映射上。例如,Logit Lens 是一种用于分析和解释大型语言模型内部机制的方法,其通过将 LM 的隐状态转换为词汇概率来展示了模型在生成过程中的表现。这种投影有助于理解 LM 在生成过程中逐渐构建输出的模式。
Logit Lens的原理非常简单。解码新token的过程是先把隐向量用线性层变换,然后经过softmax转换为词典的概率分布。那么对中间每一层的这个流程进行破解,就能获取中间层的token了。具体到某一层,Logit Lens通过直接将特定神经元或层的输出与unembedding矩阵相乘,然后通过观察得到的top tokens来定位模型中存储的信息,排在前面的tokens说明这个neuron/layer output存储了这些tokens的信息。
下图是一个实例。

另外,论文"Physics of Language Models"指出,LLM对知识的存储能力符合 2 bit / param 的线性scaling law,前提是该知识在预训练阶段被充分训练,充分训练的标准大致是一个知识要在训练语料中出现1000次以上(相同语义的不同表达都可以算作是多次出现)。该能力只与模型参数量有关,而与模型结构、深度、训练超参数等都无关,甚至即使去掉MLP层也是如此。
但如果知识的训练不够充分(例如出现次数降低到100次),其存储能力大概会降低到 1 bit / param。在这种情况下,不同模型架构的差异开始显现:Llama和Mistral的架构表现要比GPT-2差大约1.3倍。
- 将GPT-2的MLP层缩减到1/4,其存储能力没有太明显的损失,但如果完全移除MLP层,则会有显著的损失。
- 如果把Llama的结构中GatedMLP换成标准的MLP,其存储能力将恢复到与GPT-2一致。
这里的bit是语义意义上的,即数据集中的语义相同但措辞可能不同的数据条目的模板都算做相同的信息,指对其中填入的不同数值/内容进行信息计量,即只考虑语义上不同的信息。该实验是在针对单问题数据集上训练和测试的。
反向传播
论文"Backward Lens: Projecting Language Model Gradients into the Vocabulary Space"扩展了现有的可解释性方法,尤其是将其应用于 LM 的反向传播过程。通过分析反向传播中的梯度矩阵,我们能够更全面地理解信息在模型中的流动。此外,论文还提出了一种新的思路,通过将梯度矩阵映射到词汇空间来揭示 LM 在学习新知识时的内在机制。通过这一方法,研究者希望能够明确地理解模型如何在多层次上进行信息存储和记忆。
反向传播算法通过计算每一层的梯度,更新模型中的权重。这一机制不仅使模型能够学习新的信息,也为研究人员提供了解释模型行为的机会。近期的可解释性研究已提出了多种方法,试图通过可视化权重和隐藏状态来解读语言模型的内部运作,尤其是在前向传播阶段。然而,关于反向传递的梯度如何影响模型学习和知识存储的探讨仍然较为稀缺。
下图展示了梯度在 MLP 层前向与反向过程中对模型更新的影响,具体表现为梯度(以绿色表示)和权重(以蓝色表示)之间的相互作用。论文主要关注如何将这些梯度信息有效地应用于模型的知识更新与编辑中。

论文作者通过将Logit Lens应用于梯度矩阵,提出了一种称为"印记与偏移"(imprint and shift)的方法,该方法可以揭示信息储在MLP中的机制。
每个 MLP 层的梯度可以表示为正向传递的输入向量和反向传递的 VJP(向量雅可比乘积)的组合。具体而言,梯度在更新过程中的表现可以表示为:
\\\frac{\\partial L}{\\partial W}= x_i\^\\top \\cdot \\delta_i \\
在这个表达式中, \(x_i\)是前向传播的输入,\(\delta_i\)而 是相应的 VJP。当使用反向传播更新 LM 的 MLP 层时,会发生以下两个主要阶段的变化:
- 印记(imprint)阶段:在这一阶段,输入 \(x_i\)被加入或减去到 \(FF_1\) 的神经元中,从而调整每个对应的 \(FF_2\)神经元的激活程度。这个过程赋予了 MLP 层对于给定输入的"印记"。这相当于对最有可能的词汇进行强化。
- 偏移(shift)阶段:此阶段涉及调整或者改变 \(FF_2\)的输出,因此叫做偏移。具体表现为从 \(FF_2\)的神经元中减去 VJP \(\delta_i\),以放大在启用 VJP 值后输出的影响。这相当于将之前概率较低的词汇提升为可能性更高的目标。
此"印记与偏移"机制可以用在知识更新过程中:给定层的原始输入和新目标,该过程通过更新\(FF_1\)来强化类似的输入,随后将\(FF_2\)的输出移向新目标。这种方法的优势是:只依靠单次的前向传播就能在 MLP 层中有效地存储和调整信息。

0x05 优化与演进
我们接下来看看对FFN的优化与演进方案。
5.1 MoE
在这个领域,许多研究都集中在将混合专家(MoE)技术集成到LLM中,以提高其性能,同时保持计算成本。MoE的核心思想是动态地将不同的计算预算分配给不同的输入令牌。在基于MoE的Transformers中,多个FFN(即专家)与可训练的路由模块一起使用。在推理过程中,该模型有选择地为路由模块控制的每个令牌激活特定的专家。
下图为论文"A Survey on Efficient Inference for Large"给出了FFN高效设计的方法,可以看到,大多数方案是与MoE相关的。

我们会在后续文章中对MoE进行学习。
5.2 MemoryFormer
大型语言模型具有卓越的语境理解和融合新信息能力。然而,由于有效上下文长度的限制,这种方法的潜力常常受到约束。解决这个问题的一个方法是通过让注意力层访问外部存储器,包含有 (key, value) 对。
论文"MemoryFormer: Minimize Transformer Computation by Removing Fully-Connected Layers"提出了一种名为 MemoryFormer 的新型 Transformer 架构。该架构用创新的 Memory Layer 设计来替代了传统 Transformer 中计算成本高昂的全连接层,显著降低了计算复杂度和资源需求,同时保持了模型的性能和灵活性。
动机与挑战
虽然多头注意力机制在捕捉序列数据的内在关系方面表现出色,但全连接层在计算负载中占据主导地位。随着模型规模的扩大,全连接层的计算复杂度和内存需求呈指数级增长,这使得模型的训练和推理成本急剧上升。尽管已有方法尝试优化 Transformer 的计算效率,例如模型剪枝、权重量化以及重新设计注意力机制(如线性注意力和闪光注意力),但这些方法大多忽视了全连接层的计算瓶颈,导致整体优化效果有限。为应对上述挑战,MemoryFormer 提出了全新的解决方案,通过引入内存层替代全连接层,从根本上减少计算复杂度和资源消耗。
原理与创新
下图左侧给出了 Memory Layer 的示意图,右侧给出了MemoryFormer的一个组成部分。

MemoryFormer 的核心在于其 Memory Layer 设计,该层通过内存查找表和局部敏感哈希(LSH)算法取代传统的全连接层。以下是其关键技术细节:
内存层的设计与工作原理
Memory Layer 的主要功能是通过内存检索预计算的向量表示来替代传统的矩阵乘法。具体而言,输入嵌入首先通过局部敏感哈希算法进行哈希处理,将相似的嵌入映射到相同的内存位置。然后,模型从内存中检索预存储的向量,这些向量能够近似矩阵乘法的结果。
这种设计的优势在于:
- 降低计算复杂度:通过预计算和内存查找,避免了传统全连接层中高昂的矩阵运算。
- 减少内存需求:输入嵌入被划分为更小的块并独立处理,从而显著降低了内存占用。
- 支持端到端训练:内存层中的哈希表整合了可学习向量,允许模型通过反向传播进行优化。
局部敏感哈希(LSH)算法的应用
局部敏感哈希是一种高效的近似最近邻搜索算法,其核心思想是通过哈希函数将高维数据投影到低维空间,从而快速定位相似数据。在 MemoryFormer 中,LSH 算法用于将输入嵌入映射到内存中的特定位置。这种映射方式确保了哈希表中存储的特征能够不断适应输入数据,并在推理阶段根据输入特征的相似性高效检索出近似的输出结果,实现全连接层所需的特征变换功能。
可扩展的内存查找表
MemoryFormer 的内存查找表设计支持动态扩展,能够根据任务需求灵活调整存储容量和检索精度。此外,通过引入可学习的向量,查找表可以在训练过程中不断优化,从而提高模型的整体性能。此外,MemoryFormer通过多表分块和向量分段的方式来控制哈希表的存储规模,使得内存需求不会因哈希表的引入而暴增。其推导过程如下。

5.3 Memory Layers at Scale
预训练语言模型通常在其参数中编码大量信息,并且随着规模的增加,它们可以更准确地回忆和使用这些信息。对于主要将信息编码为线性矩阵变换权重的密集深度神经网络来说,参数大小的扩展直接与计算和能量需求的增加相关。语言模型需要学习的一个重要信息子集是简单关联。虽然前馈网络原则上(给定足够的规模)可以学习任何函数,但使用联想记忆(associative memory)会更高效。
记忆层(memory layers)使用可训练的键值查找机制向模型添加额外的参数,而不会增加 FLOP。从概念上讲,稀疏激活的记忆层补充了计算量大的密集前馈层,提供了廉价地存储和检索信息的专用容量。
论文"Memory Layers at Scale"使记忆层超越了概念验证阶段,通过用记忆层替换一个或多个 transformer 层的前馈网络(FFN)来实现这一点(保持其他层不变)。这证明了记忆层在大型语言模型(LLM)扩展中的实用性。该研究将键-值对的数量扩展到数百万。
可训练的记忆层类似于注意力机制。给定一个查询,一组键,以及值。可训练的记忆层会输出值的软组合,该组合是根据 q 和相应键之间的相似性进行加权的。在使用时,记忆层与注意力层之间存在两个区别。
- 首先,记忆层中的键和值是可训练参数,而不是激活参数;
- 其次,记忆层在键和值的数量方面通常具有更大的规模,因此稀疏查询和更新是必需的。
一个简单的记忆层可以用下面的等式来描述:

扩展记忆层
扩展记忆层时面临的一个瓶颈是「查询 - 键」检索机制。简单的最近邻搜索需要比较每一对查询 - 键,这对于大型记忆来说很快就变得不可行。虽然可以使用近似向量相似性技术,但当键正在不断训练并需要重新索引时,将它们整合起来是一个挑战。相反,本文采用了可训练的「product-quantized」键。
并行记忆
记忆层是记忆密集型的,主要是由于可训练参数和相关优化器状态的数量庞大导致的。该研究在多个 GPU 上并行化嵌入查找和聚合,记忆值在嵌入维度上进行分片。在每个步骤中,索引都从进程组中收集,每个 worker 进行查找,然后将嵌入的部分聚合到分片中。此后,每个 worker 收集与其自身索引部分相对应的部分嵌入。该过程如图 所示。

共享记忆
深度网络在不同层上以不同的抽象级别对信息进行编码。向多个层添加记忆可能有助于模型以更通用的方式使用其记忆。与以前的工作相比,该研究在所有记忆层中使用共享记忆参数池,从而保持参数数量相同并最大化参数共享。

该研究通过引入具有 silu 非线性的输入相关门控来提高记忆层的训练性能。
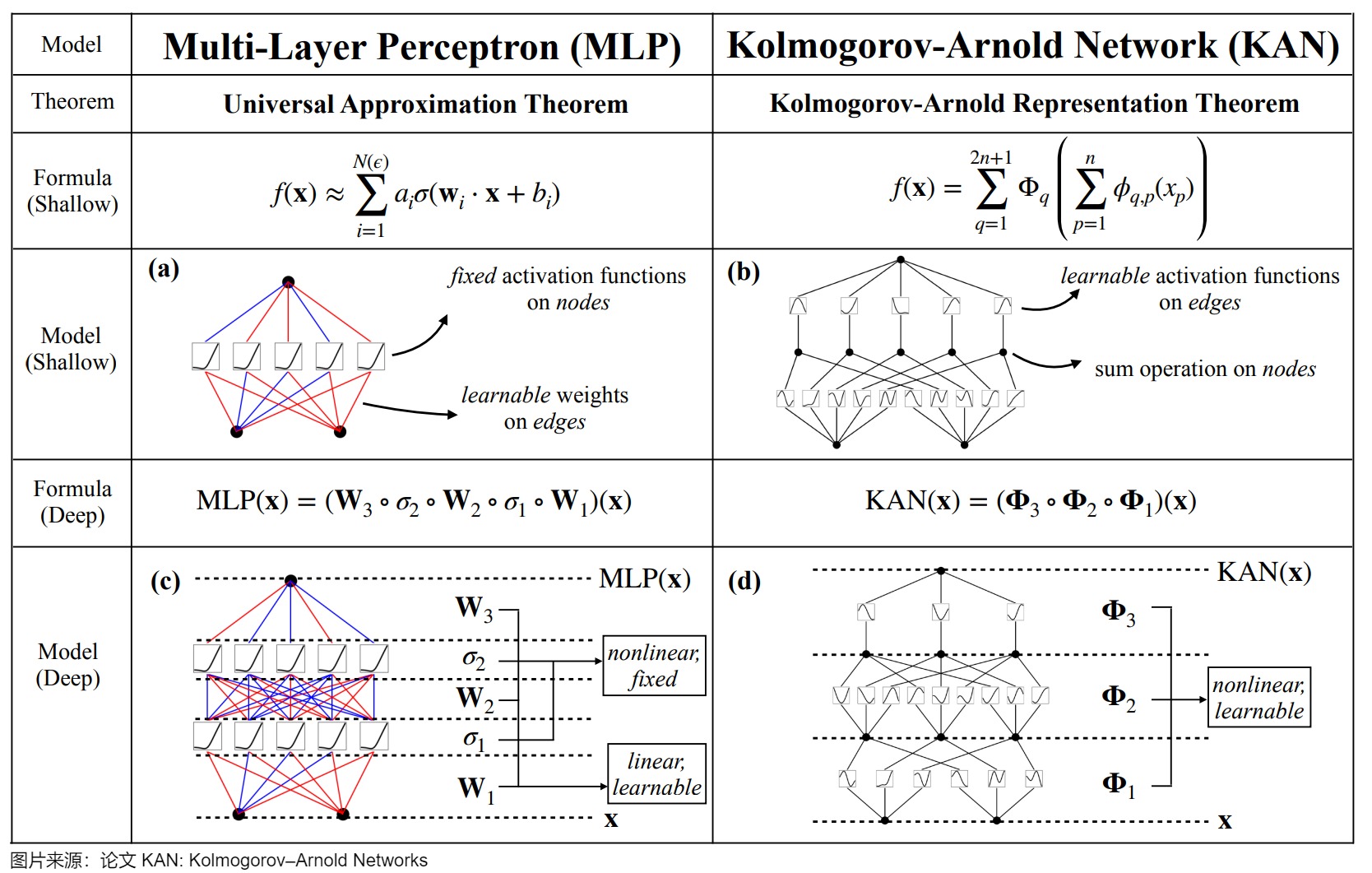
5.4 KAN
论文"KAN: Kolmogorov--Arnold Networks"的作者认为MLPs是当今神经网络的基础构建模块,但并非最优解,存在一些缺点,因此提出了一种新的神经网络架构KAN(Kolmogorov--Arnold Networks)。作者选择用参数样条函数替代参数+激活函数的组合,并宣称KAN是MLPs的有力替代者,其在准确性和可解释性方面超越了传统的多层感知器(MLPs),为进一步改进当前严重依赖MLPs的深度学习模型提供了新的可能性(更快的神经缩放规律)。
论文主要观点如下:
- KANs的设计灵感来源于Kolmogorov-Arnold表示定理,而不是MLPs所依据的通用逼近定理,通过其独特的结构设计和权重表示方式(可学习的激活函数,表示为样条曲线),能够在保持高效计算的同时,实现比传统MLPs更高的模型性能,展示了KANs在资源受限环境中作为高效非线性逼近器的潜力。
- KANs的主要特点是去掉了线性权重和固定的激活函数,将权重替换为可学习的激活函数,这些激活函数是用单变量样条函数来表示的(单变量输入,多参数,可以控制该函数在不同区间形状不同,用于生成一条平滑曲线)。
- 作者认为KANs是样条(splines)和多层感知机(MLPs)的组合,它们各自发挥优势并避免各自的弱点(样条函数在低维函数上非常准确,存在严重的维数灾难问题;LPs由于其特征学习能力而较少受到维数灾难的影响,但在低维情况下,它们不如样条准确)。在外层有MLPs来学习特征,在内层有样条来优化这些学习的特征以达到高准确性,这使得KANs在处理高维函数时既能学习组合结构,又能很好地逼近单变量函数。
- 作者强调了使用Kolmogorov-Arnold表示定理来构建神经网络(即KANs)的潜力,之前已经有使用Kolmogorov-Arnold表示定理来构建神经网络的研究,但大多数工作都局限于原始的深度为2、宽度为(2n + 1)的表示形式,这些研究并没有充分利用现代技术(如反向传播)来训练网络。作者将原始的Kolmogorov-Arnold表示定理推广到了任意宽度和深度,使其更加适应于当今深度学习的环境。
0xFF 参考
Axiomatic Attribution for Deep Networks
NeurIPS 2024 MemoryFormer:华为提出存储代替计算的Transformer新架构,推理计算量减小10倍 王云鹤
[语言模型的物理学 3.1:知识存储和提取](http://www.banxian-w.com/article/2023/12/14/2667.html)(http://www.banxian-w.com/article/2023/12/14/2667.html) Digital Garden | 王半仙
ACL 2020 | 最佳主题论文奖" 迈向NLU:关于数据时代的意义、形式和理解" 学术头条
Analyzing Memorization in Large Language Models through the Lens of Model Attribution
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Efficient softmax approximation for GPUs
EMNLP 2024 | 大语言模型的知识机理:综述和观点 ZJUKG
EMNLP 2024最佳论文:从反向传播矩阵来理解Transformer的运作机制 PaperWeekly
Focused Transformer: Contrastive Training for Context Scaling
In-The-Wild可解释性:GPT-2 Small 中的间接目标识别电路 Hao Bai
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
KAN: Kolmogorov--Arnold Networks
Knowledge Circuits in Pretrained Transformers
Knowledge Neurons in Pretrained Transformer
Memory-Based Model Editing at Scale Fred
MemoryFormer:一种新颖的高效且可扩展的大型语言模型架构 袁焱 顿数AI
Meta探索大模型记忆层,扩展至1280亿个参数,优于MoE 机器之心
PMET: Precise Model Editing in a Transformer
ROME: Locating and Editing Factual Associations in GPT Hao Bai
Transformer Circuits的数学框架 Hao Bai
Transformer Feed-Forward Layers Are Key-Value Memories
Transformer Feed-Forward Layers Are Key-Value Memories pureDemon
Transformer是否真正理解了自然语言的语义信息,还是单纯的模式识别 中森
【模型编辑技术】论文阅读笔记(一)PMET: Precise Model Editing in a Transformer [
从数学到神经网络(二)计算篇:从计算到构建 大象Alpha
北京大学 & 微软:预训练模型(Transformer)中的知识神经元 机器学习社区
可解释性之积分梯度算法(Integrated Gradients) Shepherd
大型语言模型系列解读(二):Transformer中FFN的记忆功能 丁稼宇
大型语言模型记忆机制分析与干预研究综述 可可 顿数AI
大模型中的知识存储,到底是怎么回事 芝士AI吃鱼
大模型承重墙,去掉了就开始摆烂!苹果给出了「超级权重」 机器之心
打开AI黑箱的新视角,LMs概念对齐:揭示LLM的认知机制 | 普林斯顿大学 AI修猫Prompt
机器阅读理解之推理网络(一)End-To-End Memory Networks全文翻译 低级炼丹师
模型可解释性:Axiomatic Attribution for Deep Networks knight
模型解释新方向!浙大揭秘LLM隐层之间的知识流动! bhn 深度学习自然语言处理
看图学大模型:Transformers 的前生今世(中) 看图学
算法冷知识第1期-大模型的FFN有什么变化? Sam多吃青菜
聊一聊Transformer中的FFN 潘梓正 青稞AI
论文笔记:Dissecting Recall of Factual Associations in Auto-Regressive Language Models Vicle
论文解读:Physics of Language Models(面向应用层读者)【2024.7】 原创 孔某人 孔某人的低维认知
语言模型完成事实回忆任务使用到的若干重要机制 GSAI-ALOHA
读论文 LINEARITY OF RELATION DECODING IN TRANSFORMER LANGUAGE MODELS Fred
读论文《Locating and Editing Factual Associations in GPT》 Fred
迈向单义性:通过字典学习分解语言模型 Hao Bai
面向大语言模型的知识编辑:(一) 前言与背景知识 长颈鹿骑着鲨鱼
面向大语言模型的知识编辑:(三) 知识编辑任务定义及方法分类 长颈鹿骑着鲨鱼
https://arxiv.org/abs/2411.12992
https://zhuanlan.zhihu.com/p/409287967
https://zhuanlan.zhihu.com/p/432553711
https://zhuanlan.zhihu.com/p/558937247
https://zhuanlan.zhihu.com/p/604739354
Rectified Linear Units Improve Restricted Boltzmann Machines
Rectifier Nonlinearities Improve Neural Network Acoustic Models
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
Language Modeling with Gated Convolutional Networks
Searching for Activation Functions
Self-Normalizing Neural Networks
Gaussian Error Linear Units (GELUs)
Mish: A Self Regularized Non-Monotonic Neural Activation Function