DRL
总体的大致过程:
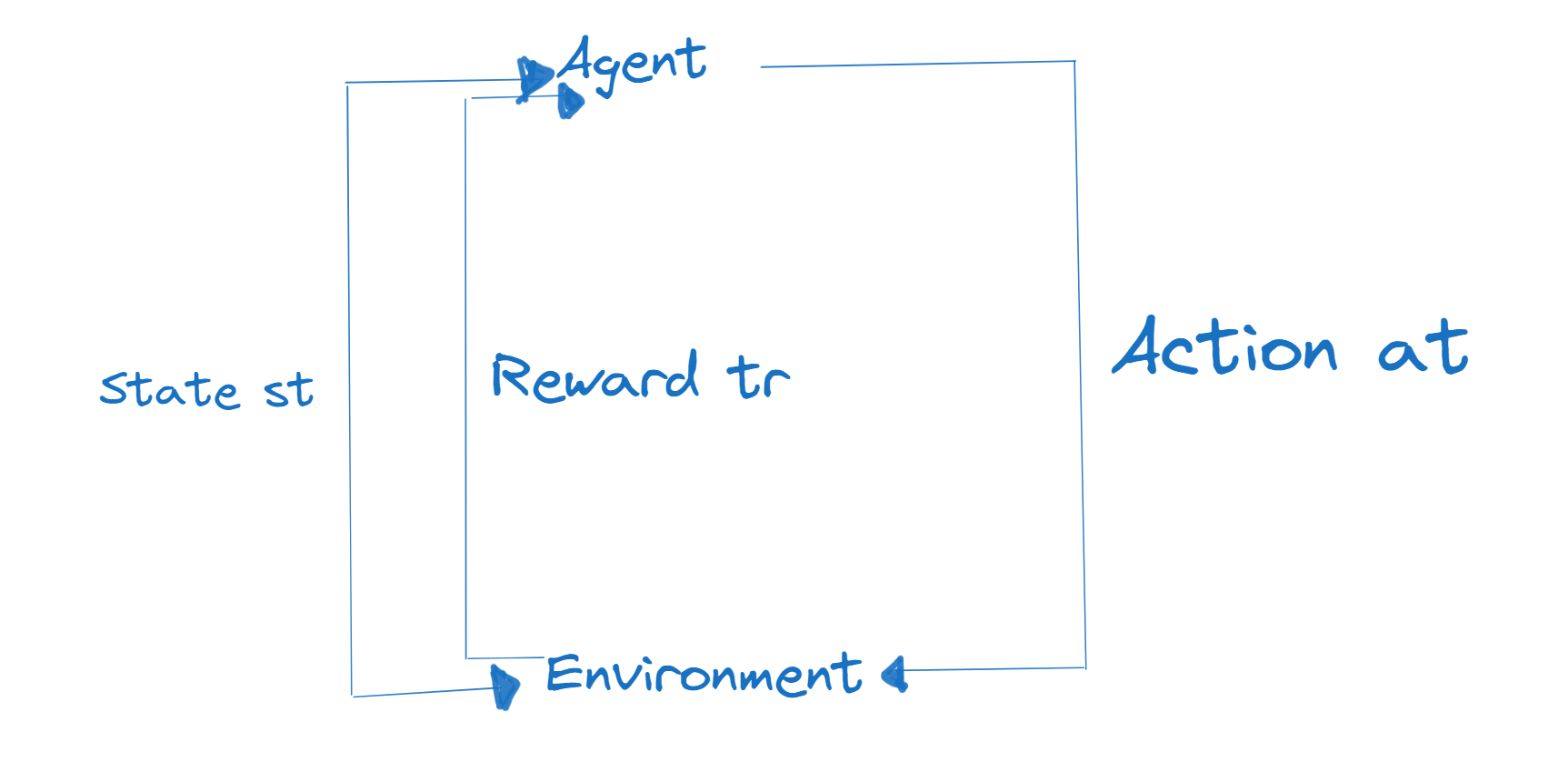
基础知识点扫盲---专业术语 Terminologies
-
Agent 智能体:相当于主角,智能体是与环境交互的主体。它通过执行 动作(action) 来影响环境,并从环境中接收反馈(奖励/惩罚(reward))。
-
Environment 环境:环境是智能体所处的外部世界。它包含了 智能体(agent) 可以观察到的 状态(state),并根据 智能体(agent) 的动作,同时给予智能体 奖励(reward)。
-
State s 状态:状态是环境在某一时刻的描述。它是智能体需要考虑的信息,以便决定采取什么动作。
-
Action a 动作:动作是智能体在某一状态下可以执行的行为。智能体通过执行动作来影响环境。
-
Reward r 奖励:奖励是智能体在执行动作后从环境中获得的反馈。它通常是一个数值,用来表示动作的好坏。智能体的目标是最大化累积奖励。
-
Policy π(a∣s) 策略/派:策略是智能体决定在给定状态下采取什么动作的规则或函数。它定义了智能体的行为策略。
-
State transition p(s′∣s,a):状态转移概率描述了在给定当前状态 s 和动作 a 的情况下,转移到下一个状态 s′ 的概率
Return and Value(回报和价值)
- Return(回报) :
- 回报是智能体在某一时刻 t 之后获得的所有未来奖励的总和,通常表示为
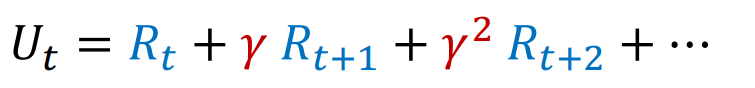 其中 γ 是折扣因子,用于权衡未来奖励的重要性。
其中 γ 是折扣因子,用于权衡未来奖励的重要性。
- 回报是智能体在某一时刻 t 之后获得的所有未来奖励的总和,通常表示为
- Action-value function(动作价值函数) :
- 动作价值函数
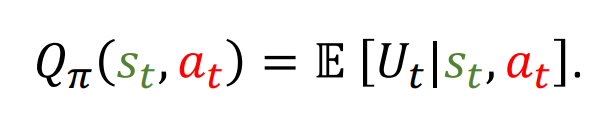 表示在策略 π 下,从状态 st 执行动作 at 后所能获得的期望回报。
表示在策略 π 下,从状态 st 执行动作 at 后所能获得的期望回报。
- 动作价值函数
- Optimal action-value function(最优动作价值函数) :
- 最优动作价值函数
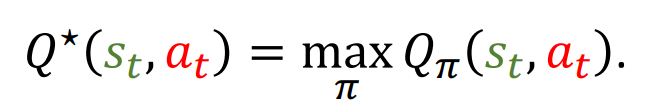 是在所有可能的策略中,对于给定状态和动作,所能获得的最大期望回报。
是在所有可能的策略中,对于给定状态和动作,所能获得的最大期望回报。
- 最优动作价值函数
- State-value function(状态价值函数) :
- 状态价值函数
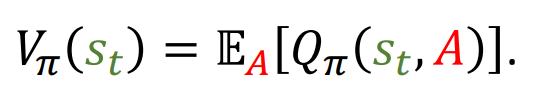 表示在策略 π 下,从状态 st 开始所能获得的期望回报。其中 A 是动作。
表示在策略 π 下,从状态 st 开始所能获得的期望回报。其中 A 是动作。
- 状态价值函数
总体流程:
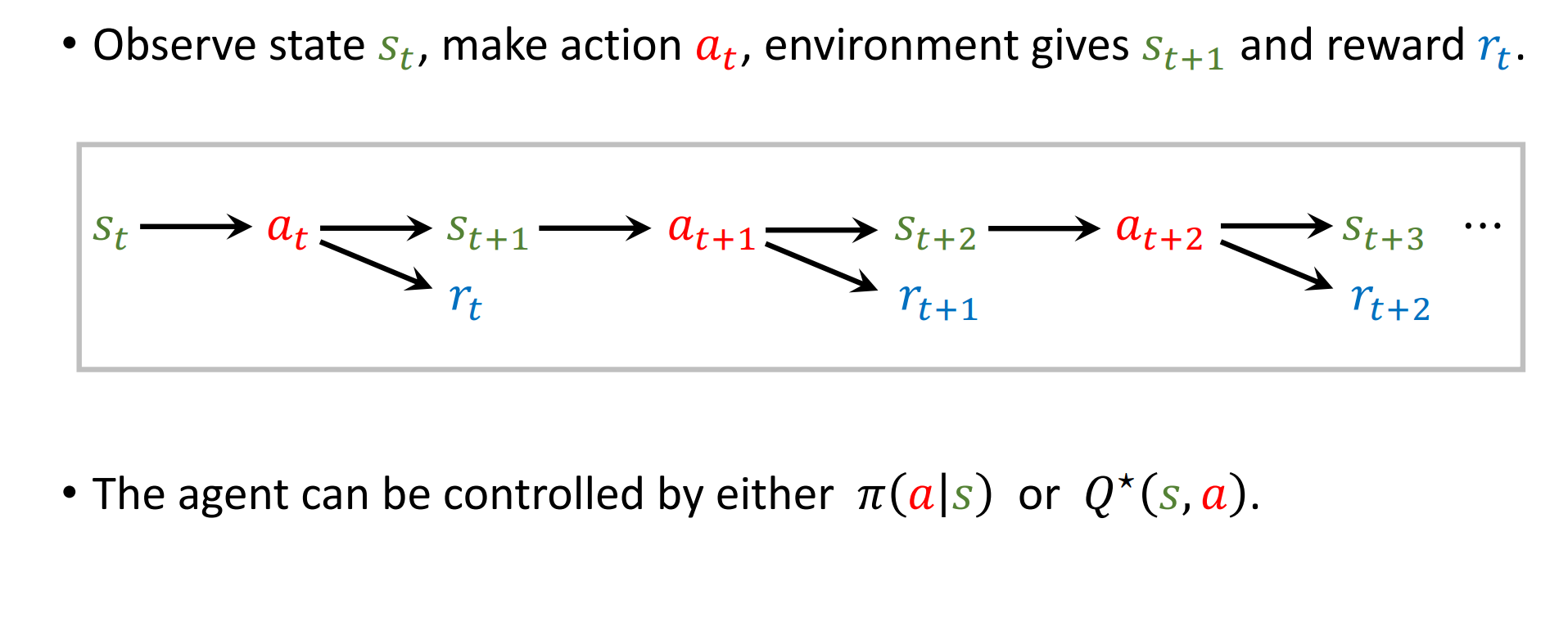
- 观察状态 st :
- 智能体首先观察当前的环境状态 st。状态是环境在某一时刻的完整描述,智能体需要根据这个状态来决定下一步的动作。
- 做出动作 at :
- 智能体根据当前观察到的状态 st ,选择并执行一个动作 at 。这个动作是根据智能体的策略 π (a ∣s) 来选择的,策略是智能体决定在给定状态下采取什么动作的规则。
- 环境给出新状态 st+1 和奖励 rt :
- 环境接收到智能体的动作 at 后,会转移到一个新的状态 st +1,并给智能体一个奖励 rt。奖励是环境对智能体动作的反馈,用于评价动作的好坏。奖励可以是正的(表示动作是有益的),也可以是负的(表示动作是有害的)。
- 智能体可以由策略 π(a∣s) 或最优动作价值函数 Q∗(s,a) 控制 :
- 智能体的行为可以由两种方式控制:
- 策略 π(a∣s):这是智能体在给定状态下选择动作的概率分布。智能体根据这个策略来选择动作。
- 最优动作价值函数 Q∗(s,a) :这是在所有可能的策略中,对于给定状态和动作,所能获得的最大期望回报。智能体可以选择使 Q ∗(s ,a) 最大化的动作。
- 智能体的行为可以由两种方式控制:
- 重复过程 :
- 这个过程会不断重复。在每个时间步 t ,智能体会观察新的状态 s**t +1,然后基于这个状态选择新的动作 at +1,环境会再次给出新的状态 st +2 和奖励 rt+1,以此类推。