本文将带领大家入门 dotnet 的 SourceGenerator 源代码生成器技术,期待大家阅读完本文能够看懂理解和编写源代码生成器和分析器
恭喜你看到了本文,进入到 C# dotnet 的深水区。如果你还是在浅水玩耍的小鲜肉,推荐你点击右上方的关闭按钮,避免受到过于深入的知识的污染
我所在的团队在 Rosyln 刚出来没两年就开始玩了,那时候还没有现在这么多机制。我之前很多关于 Rosyln 的博客都涉及到了很底层的玩法,导致入门门槛过高。随着 dotnet 生态的不断建设,渐渐有了源代码生成技术、增量源代码生成技术等等。这次我打算综合之前的经验和知识,根据现在的 dotnet 的生态技术,编写这篇入门博客,让大家更好地入门源代码生成器和分析器,降低入门门槛。本文将尽量使用比较缓的知识爬坡方式编写,以便让大家更舒适地进入到源代码生成器和分析器的世界
在开始之前期望大家已经了解基础的 dotnet C# 基础知识,了解基础的概念和项目组织结构
在阅读本文过程中,发现本文有任何错误或不足之处,欢迎大家在评论区留言或发送邮件给我,我会尽快修正。如果大家有任何问题或疑问,也欢迎大家在评论区留言或发送邮件给我,我会尽快回复
本文内容比较长,知识量比较多,推荐先点收藏
项目搭建
本文先从项目搭建开始告诉大家如何创建一个源代码生成器项目。本文后续的内容将会在这个项目中进行演示。本文的编写顺序是先搭建项目,然后再讲解一些基础的概念和用法,再到如何进行调试,最后提供一些实际的演练给到大家。基础知识部分也放在演练里面,先做演练再讲基础知识,防止一口气拍出大量基础知识劝退大家
本文的推荐打开方式是一边阅读本文,一边打开 Visual Studio 2022 或更高版本,对照本文的内容进行操作。照着本文的内容对照着编写代码,可以让大家更好地理解本文的内容,照着过一遍预计就能掌握基础的源代码生成器和分析器的知识,入门源代码生成器和分析器的编写
本文过程中会添加一些外部链接文档,这些外部链接文档都是可选阅读内容,只供大家感兴趣时扩展阅读。本文的核心内容是在本文中编写的,不需要阅读外部链接文档也能够掌握本文的内容。作为入门博客,我担心自己编写过程中存在高手盲区问题,于是尽可能将更多细节写出来,尽管这样会导致一些重复的表述
先新建一个控制台项目,新建完成之后在 Visual Studio 2022 或更高版本中打开项目,双击 csproj 项目文件,即可进行编辑项目文件
本文这里新建了一个名为 DercelgefarKarhelchaye.Analyzer 的控制台项目。也许细心的伙伴发现了这个项目使用了 Analyzer 作为后缀,这是因为在 dotnet 中源代码生成器和分析器是一体的,按照历史原因的惯性,依然将其命名为分析器项目。在 Visual Studio 2022 的每个项目依赖项里面,大家都会看到如下图的一个名为分析器的项,而没有专门一个名为源代码生成器的项,其原因也是如此
如果在这一步就开始卡住了也不用慌,本文在整个过程中都会给出示例代码。我整个代码仓库比较庞大,使用本文各个部分提供的拉取源代码的命令行代码,可以减少拉取的数据,提升拉取的速度,且能够确保切换到正确的 commit 代码
创建之后,在 Visual Studio 的解决方案里的界面大概如下
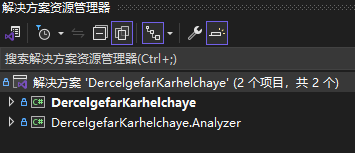
编辑名为 DercelgefarKarhelchaye.Analyzer 的控制台项目的 csproj 项目文件,将其 TargetFramework 降级到 netstandard2.0 版本,且按照 dotnet 的惯例,使用 NuGet 添加必要的组件。编辑之后的 csproj 项目文件的内容如下
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<LangVersion>latest</LangVersion>
<EnforceExtendedAnalyzerRules>true</EnforceExtendedAnalyzerRules>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.Analyzers" Version="3.11.0" PrivateAssets="all" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.12.0" PrivateAssets="all" />
</ItemGroup>
</Project>为什么需要降级为 netstandard2.0 版本?这是为了让此分析器项目能够同时在 dotnet CLI 和 Visual Studio 2022 里面使用。在 Visual Studio 2022 里,当前依然使用的是 .NET Framework 的版本。于是求最小公倍数,选择了 netstandard2.0 版本。预计后续版本才能使用到最新的 dotnet 框架版本
以上的 <LangVersion>latest</LangVersion> 只是为了方便让咱使用最新的语言特性。前面选择的 netstandard2.0 会导致语言特性默认开得比较低,这里设置为 latest 可以让我们使用最新的语言特性,让代码编写更加方便。这里需要再次提醒,在 dotnet 里面,语言和框架是分开的。使用低版本框架也能使用高版本语言。如果对语言和框架的关系依然有所疑惑,推荐先了解一下 dotnet 的基础知识,不要着急往下看。编写源代码生成器和分析器需要对 dotnet 有一定的了解,否则写着就开始混淆概念了
以上的 <EnforceExtendedAnalyzerRules>true</EnforceExtendedAnalyzerRules> 的作用是强制执行扩展分析器规则。这个属性是为了让我们在编写分析器的时候能够更加严格,让我们的代码更加规范。这里大家不需要细致了解,如有兴趣,请参阅 Roslyn 分析器 EnforceExtendedAnalyzerRules 属性的作用
以上的 Microsoft.CodeAnalysis.Analyzers 和 Microsoft.CodeAnalysis.CSharp 是必须的组件。Microsoft.CodeAnalysis.Analyzers 是分析器的基础组件,Microsoft.CodeAnalysis.CSharp 是 C# 的基础组件。这两个组件是必须的,没有这两个组件,我们就无法编写分析器和源代码生成器
通过以上的步骤也可以让大家看到,其实 dotnet 分析器项目也没什么特殊的,依然可以通过一个简单的控制台项目修改而来。其核心关键仅仅只是安装了 Microsoft.CodeAnalysis.Analyzers 和 Microsoft.CodeAnalysis.CSharp 两个组件而已
现在只是有了一个空的分析器项目,但是还不知道这个项目的效果。为了让分析器项目工作,那就需要有一个被分析的项目。为此咱就再次新建一个控制台项目,让这个控制台项目成为被分析项目
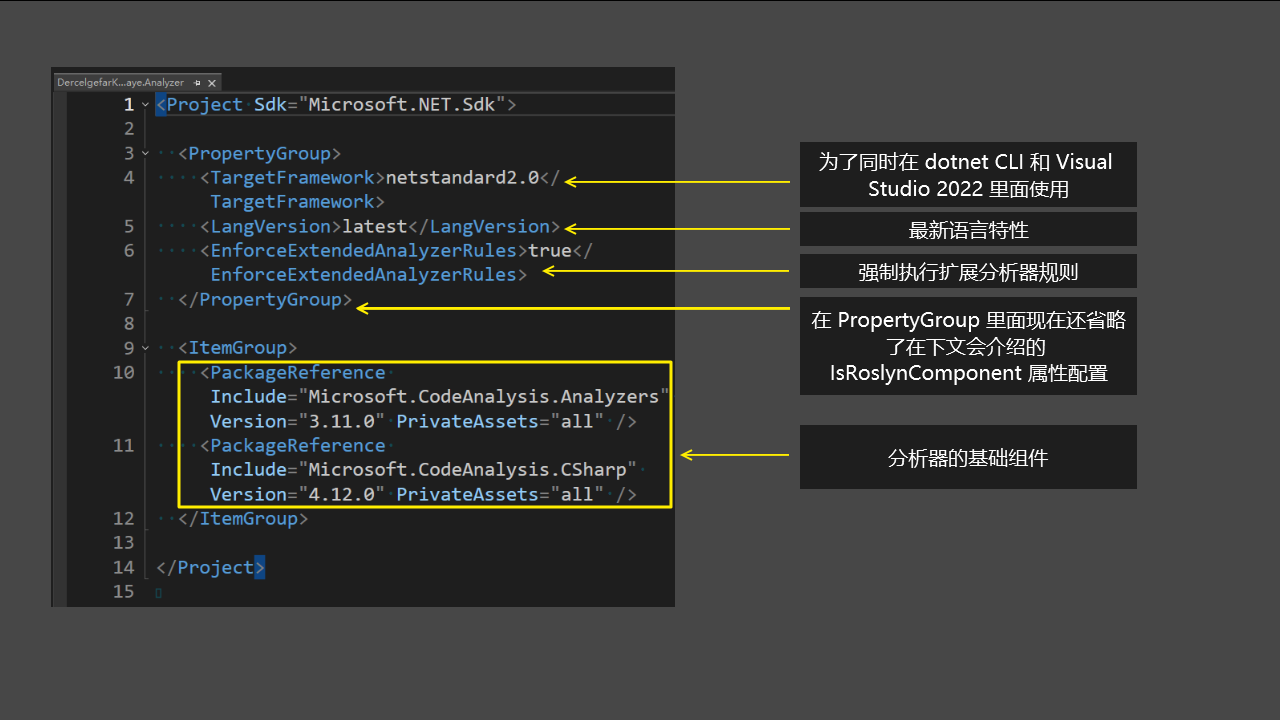
我这里新建了一个名为 DercelgefarKarhelchaye 的控制台项目。编辑 DercelgefarKarhelchaye 的 csproj 项目文件,让其引用 DercelgefarKarhelchaye.Analyzer 项目,且设置 DercelgefarKarhelchaye.Analyzer 为分析器。编辑之后的 csproj 项目文件的内容如下
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net9.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\DercelgefarKarhelchaye.Analyzer\DercelgefarKarhelchaye.Analyzer.csproj" OutputItemType="Analyzer" ReferenceOutputAssembly="false"/>
</ItemGroup>
</Project>可以看到以上的 csproj 项目文件和正常的控制台项目的差别仅仅只有在对 DercelgefarKarhelchaye.Analyzer.csproj 的引用上。且和正常的引用项目的方式不同的是,这里额外添加了 OutputItemType="Analyzer" ReferenceOutputAssembly="false" 两个配置。这两个配置的作用如下:
- 以上的
OutputItemType="Analyzer"是告诉 dotnet 这个引用项目是一个分析器项目。这个配置是必须的,没有这个配置,dotnet 就不知道这个项目是一个分析器项目。通过这个配置是告诉 dotnet 这个项目是一个分析器项目,才能让 dotnet 在编译的时候能够正确地当成分析器处理这个项目 - 以上的
ReferenceOutputAssembly="false"是告诉 dotnet 不要引用这个项目的输出程序集。正常的项目是不应该引用分析器项目的程序集的,分析器项目的作用仅仅只是作为分析器,而不是提供程序集给其他项目引用。这个配置是为了让 dotnet 在编译的时候不要引用这个项目的输出程序集,避免引用错误或导致不小心用了不应该使用的类型
对于正常的项目引用来说,一旦存在项目引用,那被引用的项目的输出程序集就会被引用。此时项目上就可以使用被引用项目的公开类型,以及获取 NuGet 包依赖传递等。但是对于分析器项目来说,这些都是不应该的,正常就不能让项目引用分析器项目的输出程序集。这就是为什么会额外添加 ReferenceOutputAssembly="false" 配置的原因
在这里,咱接触到了非常多次的 csproj 项目文件,如果大家对 csproj 项目文件格式感兴趣,请参阅 理解 C# 项目 csproj 文件格式的本质和编译流程 - walterlv
以上的步骤完成之后,最简单的分析器项目和被分析的项目就搭建完成了。这也是分析器的基础,大部分的带分析器的代码都是如此方式搭建的。但也有其他部分是通过 NuGet 带出去的分析器,被 NuGet 带出去的分析器能够更好做到开箱即用,不需要让分析器尝试构建。在后文将会讲解如何将分析器通过 NuGet 带出去,即如何进行分发分析器
现在的分析器项目还没有任何源代码生成和分析的功能,接下来咱将编写简单的源代码生成的代码,让大家看到源代码生成器的效果
编写源代码生成器
在 DercelgefarKarhelchaye.Analyzer 项目中新建一个名为 IncrementalGenerator 的源代码生成器类。编辑 IncrementalGenerator 类,让其继承 IIncrementalGenerator 接口,实现 Initialize 方法,且标记 [Generator(LanguageNames.CSharp)] 特性。编辑之后的 HelloWorldGenerator 类的内容如下
csharp
using Microsoft.CodeAnalysis;
namespace DercelgefarKarhelchaye.Analyzer;
[Generator(LanguageNames.CSharp)]
public class IncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
... // 忽略其他代码
}
}本文这里直接就是和大家介绍 IIncrementalGenerator 增量 Source Generator 源代码生成器技术,不再介绍 ISourceGenerator 源代码生成器技术。其原因是在 2022 之后,官方大力推荐的是使用 IIncrementalGenerator 增量源代码生成器技术。从业务上讲,仅仅只是 IIncrementalGenerator 多了增量的功能,在进行源代码生成逻辑处理中没有太大的差别。功能上 IIncrementalGenerator 也能完全代替 ISourceGenerator 的功能。但是在性能上,IIncrementalGenerator 要比 ISourceGenerator 更加高效,更加快速,更加能够防止原本已经很卡的 Visual Studio 更加卡
整个 IIncrementalGenerator 的入口都在 Initialize 方法里面,从 IncrementalGeneratorInitializationContext 参数里可以点出来非常多有用的方法。咱这里先不展开讲解这些方法,先让大家看到一个简单的源代码生成器的效果
在 Initialize 方法里面,咱可以通过 context.RegisterPostInitializationOutput 方法注册一个源代码输出。如以下代码所示,将输出一个名为 GeneratedCode 的代码
csharp
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(initializationContext =>
{
initializationContext.AddSource("GeneratedCode.cs",
"""
using System;
namespace DercelgefarKarhelchaye
{
public static class GeneratedCode
{
public static void Print()
{
Console.WriteLine("Hello from generated code!");
}
}
}
""");
});
}预期此时能够将生成的 GeneratedCode 类型注入到被分析的项目中。在被分析的项目中,可以通过 GeneratedCode.Print() 方法输出 Hello from generated code! 字符串
好的,进入到 DercelgefarKarhelchaye 项目中,编辑 Program 类,调用 GeneratedCode.Print() 方法。编辑之后的 Program 类的内容如下
csharp
using DercelgefarKarhelchaye;
GeneratedCode.Print();尝试运行一下 DercelgefarKarhelchaye 项目,可以看到控制台输出了 Hello from generated code! 字符串。这就是源代码生成器的效果,通过源代码生成器生成的代码,注入到被分析的项目中,让被分析的项目能够使用生成的代码
如此证明了在 DercelgefarKarhelchaye.Analyzer 分析器项目中编写的源代码生成器生效了。这就是源代码生成器的基硋,通过源代码生成器生成的代码,注入到被分析的项目中,让被分析的项目能够使用生成的代码
以上代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin 95c14524130238b2d6fbca97ca35b89dc921536b以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin 95c14524130238b2d6fbca97ca35b89dc921536b获取代码之后,进入 Roslyn/DercelgefarKarhelchaye 文件夹,即可获取到源代码
分析和生成入门
在上文中,和大家介绍了如何生成静态的固定的代码内容。在 RegisterPostInitializationOutput 方法里面,只允许传递静态固定的代码,不能依据当前项目状态或配置进行动态生成代码。这是因为 RegisterPostInitializationOutput 方法的定义上就是用于提供分析器开始分析工作之前的初始化代码。这部分代码由于可不用运行分析过程,可以非常快给到 IDE 层,一般用于提供一些类型定义,可以给到开发者直接快速使用,而不会在使用过程中飘红
上文的代码只是让大家粗略熟悉了一下 IIncrementalGenerator 的 API 调用方法。接下来我将带大家开始入门分析器的分析和生成功能
分析和生成很多时候都是不分离的,生成的代码需要依赖分析的结果。为了能让大家更好理解分析器的入门知识,我尝试布置一个任务,接下来让咱根据布置的任务来入门分析和生成功能
任务
咱来实现一个经典的需求任务,将项目里面的标记了某个 Attribute 特性的类型全收集起来,最后生成一个代码,让生成的代码输出有哪些类型标记了这个 Attribute 特性,将这些类型的名称输出到控制台
进一步分解任务需求,咱需要有一个源代码生成器。源代码生成器生成两部分代码,第一部分就是 FooAttribute 特性,第二部分就是收集所有标记了 FooAttribute 特性的类型,生成将这些类型的名称输出到控制台的代码。要求全程没有反射参与,全程都是通过 Roslyn 分析和生成完成
使用 ForAttributeWithMetadataName 快速分析代码
从工程上进行分析发现,非常大量的分析生成任务都有一个特点,这个特点就是需要找到标记了某个 Attribute 特性的类型或方法或属性等,然后再做某个事情。这个特点其实源自于 dotnet C# 对于 Attribute 特性的设计。Attribute 特性是一种元数据,可以标记在类型、方法、属性等上面,用于描述这个类型、方法、属性等的特性。也常常用于标记给 IDE 和编译器看的,用于告诉 IDE 和编译器这个类型、方法、属性等的特性。比如常用的 ObsoleteAttribute 、CallerMemberNameAttribute 、DebuggerDisplayAttribute 等等
在 IIncrementalGenerator 增量 Source Generator 源代码生成器中,提供了 ForAttributeWithMetadataName 工具方法。如此方法名所述,这个方法是用于找到标记了某个 Attribute 特性的类型、方法、属性等。这个方法的使用非常简单,只需要传递一个 Attribute 特性的完整名称,就可以找到标记了这个 Attribute 特性的类型、方法、属性等
在上文的任务中,咱需要找到标记了某个 Attribute 特性的类型,然后将这些类型的名称输出到控制台。这个任务非常适合使用 ForAttributeWithMetadataName 方法来实现。接下来咱就来实现这个任务
依然是新建两个项目,其中一个作为分析器项目,另一个作为被分析的项目。大家既可以在上文现有的项目中继续编写,也可以新建两个项目。这里我新建了一个名为 NinahajawhuLairfoheahurcee.Analyzer 的分析器项目,和一个名为 NinahajawhuLairfoheahurcee 的被分析项目。本文内容里面只给出关键代码片段,如需要全部的项目文件,可在下文找到所有代码的下载方法。如果自己编写的代码构建不通过或运行输出不符合预期,也推荐大家拉取本文的代码进行阅读
先来完成任务需求分解中的第一部分,编写 FooAttribute 特性代码的生成。由于 FooAttribute 特性的代码不依赖任何分析结果,因此可以使用 RegisterPostInitializationOutput 方法生成。修改上文的 RegisterPostInitializationOutput 注册 GeneratedCode.cs 的代码,将其替换为 FooAttribute.cs 的生成代码,如下所示
csharp
[Generator(LanguageNames.CSharp)]
public class IncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
// 先注册一个特性给到业务方使用
context.RegisterPostInitializationOutput(initializationContext =>
{
initializationContext.AddSource("FooAttribute.cs",
"""
namespace Lindexi;
public class FooAttribute : Attribute
{
}
""");
});
}
}完成这一步之后,即可在业务端编写类型,将类型标记上 FooAttribute 特性。回到名为 NinahajawhuLairfoheahurcee 的被分析项目,在 NinahajawhuLairfoheahurcee 控制台项目里面添加两个类型,让这两个类型标记上 FooAttribute 特性,用于后续测试类型被收集
csharp
using Lindexi;
namespace NinahajawhuLairfoheahurcee;
[Foo]
public class F1
{
}
[Foo]
public class F2
{
}在 IIncrementalGenerator 增量 Source Generator 源代码生成,可在 IncrementalGeneratorInitializationContext 里面的 SyntaxProvider 属性,通过 ForAttributeWithMetadataName 快速收集标记了某个特性的类型、属性、方法等等
基本写法格式如下
csharp
var provider =
context.SyntaxProvider.ForAttributeWithMetadataName
(
"特性名",
(SyntaxNode node, CancellationToken token) => 语法判断条件,
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken token) => 语义处理和获取返回值
);第一个参数是特性名,记得带上特性的命名空间,以及写明特性的全名。在正常的 C# 代码里面,都会忽略 Attribute 后缀,但是在这里需要带上 Attribute 后缀。第二个参数是语法判断条件,用于判断当前节点是否符合条件。第三个参数是语义处理和获取返回值,用于处理当前节点的语义,获取返回值
那什么是语法,什么是语义呢? 在 Roslyn 里面,将初步的代码分析的语法层面内容称为 Syntax 语法。语法是非常贴近编写出来的代码直接的内存映射的样子,这个过程里面只做片面考虑,即不考虑代码之间的引用关系,只考虑代码语法本身。语法分析过程是最早的过程,也是损耗极小的过程,也是可以并行化执行的过程。一般来说,进行语法分析都可以将写出来的代码分为一个个 SyntaxTree 语法树,每个代码或代码片都可以转换为一个 SyntaxNode 语法节点
对应于 Syntax 语法的概念,语义 Semantic 则是包含了代码的含义,不仅仅只是语法层面上,语义 Semantic 包含了代码之间的引用关系,包含了各个符号的信息。语义分析过程是在语法分析之后的过程,执行过程中有所损耗,且存在多个代码文件和程序集之间的引用关联关系,这就是为什么在 IIncrementalGenerator 增量 Source Generator 源代码生成设计中是先做语法分析,判断结果通过,再做语义分析的原因
再简单理解可以是如 C# 里面有分部类的概念,进行语法分析的时候,只能一次一个文件一个文件的分析,难以或无法直接分部类的其他分部在哪。但是进行语义分析的时候,可以将所有分部类的信息都收集起来,然后再进行分析,这样就能够找到所有分部类的信息。且在语义分析过程中,能够非常明确知道某个符号的确切含义
语法和语义有比较庞大的知识,我将在后文的专门章节里面详细介绍。这里只是让大家粗略了解一下语法和语义的概念,以便大家能够更好理解后续的内容。本章内容也不会涉及多少的语法和语义知识,不需要对语法和语义有太多的了解,只需要知道这两个概念的存在即可
粗略了解了一点语法和语义的概念,接下来咱就来实现 ForAttributeWithMetadataName 方法的使用。在 NinahajawhuLairfoheahurcee.Analyzer 分析器项目中,修改 IncrementalGenerator 类的 Initialize 方法,添加 ForAttributeWithMetadataName 方法的使用,如下所示
csharp
IncrementalValuesProvider<string> targetClassNameProvider = context.SyntaxProvider.ForAttributeWithMetadataName("Lindexi.FooAttribute",
// 进一步判断
(SyntaxNode node, CancellationToken token) => node.IsKind(SyntaxKind.ClassDeclaration),
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken token) => syntaxContext.TargetSymbol.Name);如上面代码所示,第一个参数传入特性名,即 "Lindexi.FooAttribute" 字符串。此时将进入预设逻辑,增量的寻找所有标记了名为 "Lindexi.FooAttribute" 特性的类型或属性或方法等等代码。一旦找到了标记了 "Lindexi.FooAttribute" 特性的代码,将会进入第二个参数的语法判断条件,即 (SyntaxNode node, CancellationToken token) => node.IsKind(SyntaxKind.ClassDeclaration) 代码块。此时将进入进一步判断,只有当找到的代码是类声明的时候,才是符合咱的任务需求的代码,即满足感兴趣的条件。这里的 SyntaxNode.IsKind 方法是判断当前传入的 SyntaxNode 是什么。前面步骤只是找到了标记了 "Lindexi.FooAttribute" 特性的代码,这里进一步判断找到的代码是不是类声明。满足前两个步骤,则证明这是一个在类型上面标记了名为 "Lindexi.FooAttribute" 特性的代码,可以进入最后一个参数里面进行进一步的语义处理
进一步的语义处理是 (GeneratorAttributeSyntaxContext syntaxContext, CancellationToken token) => syntaxContext.TargetSymbol.Name 代码块。这里的 GeneratorAttributeSyntaxContext.TargetSymbol 属性是当前找到的代码的符号,即当前找到的代码的语义信息。这里的 TargetSymbol.Name 属性是当前找到的代码的名称,即当前找到的代码的类型名称。这里的代码块返回的是当前找到的代码的类型名称,即当前找到的代码的名称
将其返回的内容是类似 Linq 的查询结果,即 IncrementalValuesProvider<string> 类型。这个类型是一个增量的值提供者,而不是立刻就返回一次所有满足条件的代码。在 Visual Studio 里面的执行逻辑上,大家可以认为是每更改、新增一次代码,就会执行一次这个查询逻辑,整个查询逻辑是源源不断执行的,不是一次性的,也不是瞬时全跑的,而是增量的逐步执行的
执行过程也是一级级执行的,先通过了第一个参数的特性名,快速判断是否满足参数条件,再经过第二个参数进行语法判断。经过前面两个参数判断就可以快速过滤掉大量的代码,如此的方式可以极大减少计算工作量
现在拿到了 IncrementalValuesProvider<string> 返回值,能够从这里源源不断取出一个个类型出来。但按照咱的任务需求,咱是需要一口气收集所有类型的,不能一个个慢慢取。为此咱需要将 IncrementalValuesProvider<string> 给收集起来,成为一个集合数组。这里可以使用 Collect 方法进行收集,如下所示
csharp
IncrementalValueProvider<ImmutableArray<string>> targetClassNameArrayProvider = targetClassNameProvider
.Collect();可以看到此时返回值就从 IncrementalValuesProvider<string> 类型转换为 IncrementalValueProvider<ImmutableArray<string>> 类型。核心不同在于 string 和 ImmutableArray<string> 不可变数组的差异而已。在整个 Roslyn 设计里面,大量采用不可变思想,这里的返回值就是不可变思想的一个体现。细心的伙伴可以看到 IncrementalValuesProvider 和 IncrementalValueProvider 这两个单词的差别,没错,核心在于 Values 和 Value 的差别。在增量源代码生成器里面,使用 IncrementalValuesProvider 表示多值提供器,使用 IncrementalValueProvider 表示单值提供器,两者差异只是值提供器里面提供的数据是多项还是单项。使用 Collect 方法可以将一个多值提供器的内容收集起来,收集为一个不可变集合,从而转换为一个单值提供器,这个单值提供器里面只有一项,且这一项是一个不可变数组。这部分细节内容将在下文和大家详细介绍,在本章节里面就不过多描述
最后一步就是将 IncrementalValueProvider<ImmutableArray<string>> 返回值注册到输出源代码中。在 IncrementalGenerator 类的 Initialize 方法里面,使用 context.RegisterSourceOutput 方法注册输出源代码,如下所示
csharp
context.RegisterSourceOutput(targetClassNameArrayProvider, (productionContext, classNameArray) =>
{
productionContext.AddSource("GeneratedCode.cs",
$$"""
using System;
namespace NinahajawhuLairfoheahurcee
{
public static class GeneratedCode
{
public static void Print()
{
Console.WriteLine("标记了 Foo 特性的类型有: {{string.Join(",", classNameArray)}}");
}
}
}
""");
});尝试运行控制台项目,可见此时能够输出以下内容到控制台
标记了 Foo 特性的类型有: F1,F2尝试展开 Visual Studio 的 依赖项->分析器,如下图所示
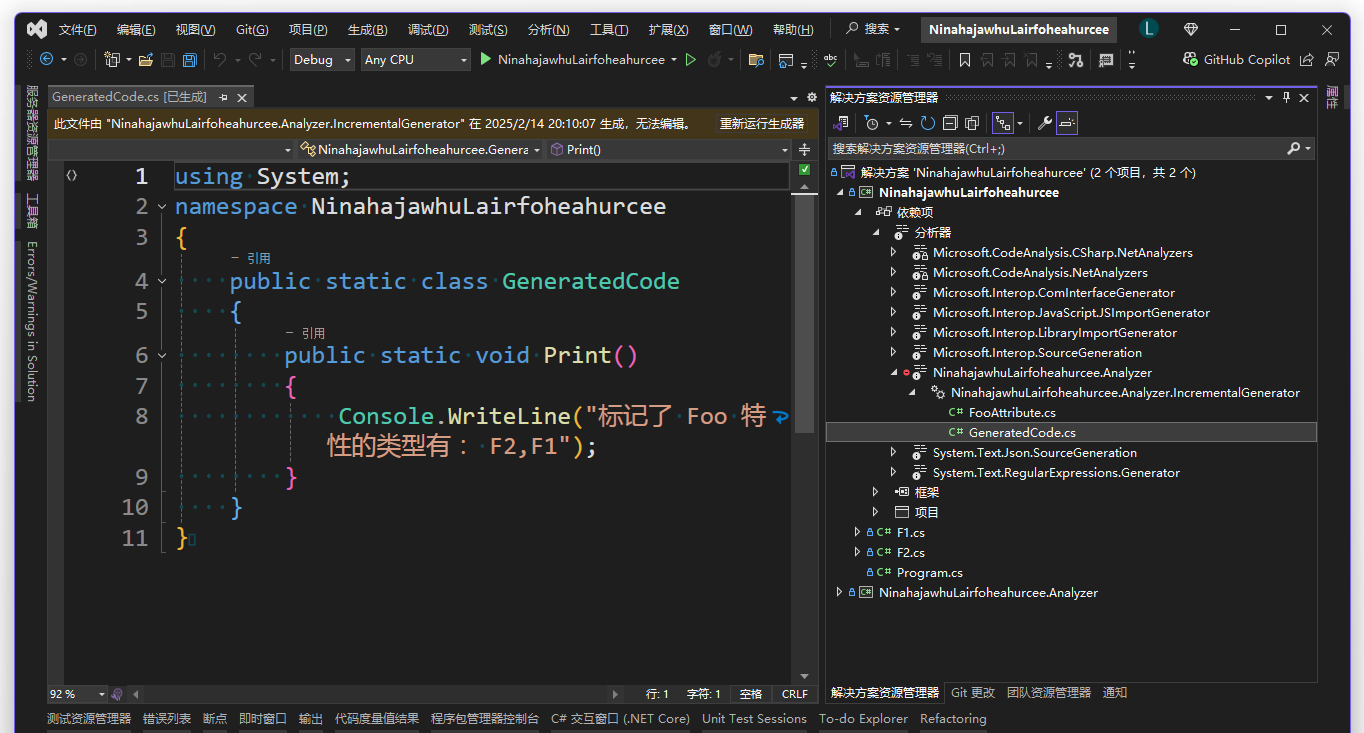
可以看到生成的代码如下
csharp
using System;
namespace NinahajawhuLairfoheahurcee
{
public static class GeneratedCode
{
public static void Print()
{
Console.WriteLine("标记了 Foo 特性的类型有: F2,F1");
}
}
}如此以来,对比传统的反射的方法,源代码生成的方式可以将耗时完全放在开发编译过程,不会占用用户端的执行时间。且这个过程都是完完全全的直接代码,也方便运行时的 JIT 进行优化,大大提升了运行时间。完完全全的直接代码也带来了静态分析的友好,可以作为代码裁剪和 AOT 的底层支持
喜欢点点的伙伴也许在准备写 RegisterSourceOutput 的时候,就发现了还有一个名为 RegisterImplementationSourceOutput 方法,那 RegisterSourceOutput 和 RegisterImplementationSourceOutput 的差别是什么?这两个方法对最终生成的代码是没有影响的,核心差别是 RegisterImplementationSourceOutput 是用来注册具体实现生成的代码,这部分输入的代码会被 IDE 作为可选分析项。如 RegisterImplementationSourceOutput 命名所述,这是一个用来注册"具体实现"的代码,在代码里面,咱可以强行将代码分为"定义代码"和"实现代码",比如说方法签名是定义代码,方法体是实现代码。从 IDE 的分析角度来看,只对"定义代码"而跳过"实现代码",可以更大程度的减少分析压力,提升分析速度。通过 RegisterImplementationSourceOutput 方法注册的代码,会被 IDE 作为可选分析项,不会因为生成了大量代码导致 IDE 过于卡顿。但带来的问题是这部分生成代码可能不被加入 IDE 分析,导致业务方调用时飘红。因此通过 RegisterImplementationSourceOutput 生成的代码,基本要求是不会被业务方直接调用。常用的套路是先通过 RegisterSourceOutput 或甚至是 RegisterPostInitializationOutput 生成分部类或分部方法,然后再慢慢在 RegisterImplementationSourceOutput 里面填充实现代码。如果感觉对 RegisterSourceOutput 和 RegisterImplementationSourceOutput 的差别还是很混乱,没关系,咱将在后文通过实践来让大家更好地理解两者的差别
以上就是通过 ForAttributeWithMetadataName 开始入门编写分析和收集和生成的简单例子,如果对 ForAttributeWithMetadataName 使用方法感兴趣,扩展阅读部分请参阅 使用 ForAttributeWithMetadataName 提高 IIncrementalGenerator 增量 Source Generator 源代码生成开发效率和性能
如果大家照着以上的例子编写不出来能构建通过的代码,或者是运行代码不符合预期,欢迎拉取我的示例代码进行阅读
同样的,以上代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin b8c036de9d9d7c4b1a3d329054086d6566d14dc4以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin b8c036de9d9d7c4b1a3d329054086d6566d14dc4获取代码之后,进入 Roslyn/NinahajawhuLairfoheahurcee 文件夹,即可获取到源代码
更底层的收集分析和生成
阅读到这里,也许大家会感慨,使用 ForAttributeWithMetadataName 还是有很大的限制。比如我的需求任务是分析任意的继承了 IFoo 接口的代码,而没有任何的标记,那应该如何做呢?只通过 ForAttributeWithMetadataName 是无法实现的。这个时候就需要更底层的收集分析和生成技术
本文会和大家介绍 ForAttributeWithMetadataName 仅仅只是因为 ForAttributeWithMetadataName 方法使用简单,且使用频率高。不代表只能通过 ForAttributeWithMetadataName 方法进行分析和生成。实际上,ForAttributeWithMetadataName 方法只是对更底层的收集分析和生成技术的封装,更底层的收集分析和生成技术是可以实现更多的需求任务的
在 IIncrementalGenerator 增量 Source Generator 源代码生成里面提供了众多数据源入口,比如整个的配置、引用的程序集、源代码等等。最核心也是用最多的就是通过提供的源代码数据源进行收集分析
按照官方的设计,将会分为三个步骤完成增量代码生成:
- 告诉框架层需要关注哪些文件或内容或配置的变更
- 在有对应的文件等的变更情况下,才会触发后续步骤。如此就是增量代码生成的关键
- 告诉框架层从变更的文件里面感兴趣什么数据,对数据预先进行处理
- 预先处理过程中,是会不断进行过滤处理的,确保只有感兴趣的数据才会进入后续步骤
- 其中第一步和第二步可以合在一起
- 使用给出的数据进行处理源代码生成逻辑
- 这一步的逻辑和普通的 Source Generator 是相同的,只是输入的参数不同
按照以上的步骤,咱来开始重新实现上文的使用 ForAttributeWithMetadataName 实现的任务需求。这次咱将不使用 ForAttributeWithMetadataName 方法,而是使用更底层的收集分析和生成技术。在这个实现过程中,大家也能感受到使用 ForAttributeWithMetadataName 方法的便捷性
为了方便大家后续拉取代码方便,防止多个版本之间的代码误导。我这里重新新建了两个项目,分别是名为 BegalllalhereCilaywhonerdem.Analyzer 的分析器项目,和一个名为 BegalllalhereCilaywhonerdem 的被分析项目。本文内容里面只给出关键代码片段,如需要全部的项目文件,可在下文找到所有代码的下载方法。如果自己编写的代码构建不通过或运行输出不符合预期,也推荐大家拉取本文的代码进行阅读
先完全按照上文的方式进行项目组织,甚至是完全的代码拷贝。因为接下来咱简要替换的部分只是将原本的 ForAttributeWithMetadataName 相关代码进行替换而已,其他逻辑依然保持不变
删掉原本的 ForAttributeWithMetadataName 相关代码,即删掉如下代码
csharp
IncrementalValuesProvider<string> targetClassNameProvider = context.SyntaxProvider.ForAttributeWithMetadataName("Lindexi.FooAttribute",
// 进一步判断
(SyntaxNode node, CancellationToken token) => node.IsKind(SyntaxKind.ClassDeclaration),
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken token) => syntaxContext.TargetSymbol.Name);
IncrementalValueProvider<ImmutableArray<string>> targetClassNameArrayProvider = targetClassNameProvider
.Collect();接下来咱将使用更底层的收集分析和生成技术,即从 context.SyntaxProvider.CreateSyntaxProvider 方法开始
在 context.SyntaxProvider.CreateSyntaxProvider 方法里面包含两个参数,第一个参数是一个进行语法判断的过程,第二个参数是进行语义进一步判断和加工处理的逻辑。也就是说 CreateSyntaxProvider 方法就包含了上文所述的"告诉框架层需要关注哪些文件或内容或配置的变更"和"告诉框架层从变更的文件里面感兴趣什么数据,对数据预先进行处理"两个步骤
在 CreateSyntaxProvider 方法里面,第一步的语法判断是判断当前传入的是否类型定义。如果是类型定义,则读取其标记的特性,判断特性满足 Lindexi.FooAttribute 的特征时,则算语法判断通过,让数据走到下面的语义判断处理上。其代码大概如下
csharp
IncrementalValueProvider<ImmutableArray<string>> targetClassNameArrayProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
if (node is not ClassDeclarationSyntax classDeclarationSyntax)
{
return false;
}
// 为什么这里是 Attribute List 的集合?原因是可以写出这样的语法
// ```csharp
// [A1Attribute, A2Attribute]
// [A3Attribute]
// private void Foo()
// {
// }
// ```
foreach (AttributeListSyntax attributeListSyntax in classDeclarationSyntax.AttributeLists)
{
foreach (AttributeSyntax attributeSyntax in attributeListSyntax.Attributes)
{
NameSyntax name = attributeSyntax.Name;
string nameText = name.ToFullString();
if (nameText == "Foo")
{
return true;
}
if (nameText == "FooAttribute")
{
return true;
}
// 可能还有 global::Lindexi.FooAttribute 的情况
if (nameText.EndsWith("Lindexi.FooAttribute"))
{
return true;
}
if (nameText.EndsWith("Lindexi.Foo"))
{
return true;
}
}
}
return false;
}, (syntaxContext, _) =>
{
// 先忽略语义处理过程代码
}).Collect();如上述的代码所示,首先是经过 if (node is not ClassDeclarationSyntax classDeclarationSyntax) 判断,过滤掉非类型定义部分的代码。此时就可以确保大量的代码都不会进入到后续分支。毕竟对于正常的代码逻辑来说,类型的定义还是少数哈。接着的逻辑编写就有些考大家对于 C# 的基础语法知识了,先获取特性列表。这里获取到的是列表的集合,为什么呢?因为在 C# 代码里面允许以下的写法,如上文代码注释所述
csharp
[A1Attribute, A2Attribute]
[A3Attribute]
private void Foo()
{
}以上代码里面的 [A1Attribute, A2Attribute] 就是一个特性列表,而 [A1Attribute, A2Attribute] 和 A3Attribute 三个特性构成了特性列表的集合,如此才能保证能够获取到所有的特性且不丢失语法上的特征。即可能某些特性是和其他的特性写在一起的特征才不会被丢失。这就是为什么需要有两层的 foreach 循环才能遍历所有的特性的原因
在语法层面上,是不能完全判断一个特性是否真的是某个指定类型的特性的,比如说对以下代码的分析
csharp
[Foo]
public class F1
{
}在语法层面上只能知道 F1 类型标记了 [Foo] 特性,但不知道这个 [Foo] 特性是否真的是 Lindexi.FooAttribute 特性。需要在语义分析过程中,进一步判断是否真的是 Lindexi.FooAttribute 特性。语法层面上只能知道写下去的是什么代码,完全字面量。这也就是为什么上面代码的判断逻辑会额外多了那么多判断的原因。当然了,如果大家图省事,那直接判断是否包含 Foo 字符串也可以的
上面代码使用了对 NameSyntax 调用 ToFullString 方法获取到所标记的名,再通过字符串判断逻辑,判断是否可能是标记了 Lindexi.FooAttribute 特性
csharp
NameSyntax name = attributeSyntax.Name;
string nameText = name.ToFullString();
if (nameText == "Foo")
{
return true;
}
if (nameText == "FooAttribute")
{
return true;
}
// 可能还有 global::Lindexi.FooAttribute 的情况
if (nameText.EndsWith("Lindexi.FooAttribute"))
{
return true;
}
if (nameText.EndsWith("Lindexi.Foo"))
{
return true;
}如果大家对以上的 NameSyntax 的 ToFullString 感兴趣,请参阅 Roslyn NameSyntax 的 ToString 和 ToFullString 的区别
虽然上文判断逻辑看起来写的很多,但也不代表能通过语法判断逻辑的,就一定是标记了 Lindexi.FooAttribute 特性。在语义部分进行进一步处理,代码如下
csharp
context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
// 忽略语法处理部分代码
}, (syntaxContext, _) =>
{
ISymbol declaredSymbol = syntaxContext.SemanticModel.GetDeclaredSymbol(syntaxContext.Node);
if (declaredSymbol is not INamedTypeSymbol namedTypeSymbol)
{
return (string) null;
}
ImmutableArray<AttributeData> attributeDataArray = namedTypeSymbol.GetAttributes();
// 在通过语义判断一次,防止被骗了
if (!attributeDataArray.Any(t =>
t.AttributeClass?.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat) ==
"global::Lindexi.FooAttribute"))
{
return (string) null;
}
return namedTypeSymbol.Name;
})由于在语法分析过程中,只能知道标记了名为 Foo 的特性,不知道是否真的是特性。需要在语义分析过程中,进一步判断是否真的是特性。进一步判断的方法就是通过 GetAttributes 方法获取标记在类型上面的特性,此时和语法不同的是,可以拿到分部类上面标记的特性,不单单只是某个类型文件而已。接着使用 ToDisplayString 方法获取标记的特性的全名,判断全名是否为 global::Lindexi.FooAttribute 从而确保类型符合预期。当然了,这个过程里面,咱是省略了判断 global::Lindexi.FooAttribute 特性是属于哪个程序集的。正常的分析器项目里面也不会真的去判断某个全名的类型属于哪个程序集的。这个方法即是缺陷也是功能,方便很多开发者只要写出来"鸭子"类型即可的行为。这里说的"鸭子"行为就是只要一个类型的命名空间和名字符合约定即可,至于这个类型是放在哪个程序集和用什么方式的可访问描述都不重要。许多的 C# 高版本语法也是这么定义出来的,如 init 或 ValueTuple 等等。因为通过这样的设计,可以更好的让 C# 语言和具体的框架分离,这也是 C# dotnet 的设计基本原则
在通过了语义判断逻辑之后,即可决定返回值是 (string) null 还是 namedTypeSymbol.Name 的值。返回值这一步就对应着 "告诉框架层从变更的文件里面感兴趣什么数据,对数据预先进行处理"步骤
合起来的代码实现如下
csharp
IncrementalValueProvider<ImmutableArray<string>> targetClassNameArrayProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
if (node is not ClassDeclarationSyntax classDeclarationSyntax)
{
return false;
}
// 为什么这里是 Attribute List 的集合?原因是可以写出这样的语法
// ```csharp
// [A1Attribute, A2Attribute]
// [A3Attribute]
// private void Foo()
// {
// }
// ```
foreach (AttributeListSyntax attributeListSyntax in classDeclarationSyntax.AttributeLists)
{
foreach (AttributeSyntax attributeSyntax in attributeListSyntax.Attributes)
{
NameSyntax name = attributeSyntax.Name;
string nameText = name.ToFullString();
if (nameText == "Foo")
{
return true;
}
if (nameText == "FooAttribute")
{
return true;
}
// 可能还有 global::Lindexi.FooAttribute 的情况
if (nameText.EndsWith("Lindexi.FooAttribute"))
{
return true;
}
if (nameText.EndsWith("Lindexi.Foo"))
{
return true;
}
}
}
return false;
}, (syntaxContext, _) =>
{
ISymbol declaredSymbol = syntaxContext.SemanticModel.GetDeclaredSymbol(syntaxContext.Node);
if (declaredSymbol is not INamedTypeSymbol namedTypeSymbol)
{
return (string) null;
}
ImmutableArray<AttributeData> attributeDataArray = namedTypeSymbol.GetAttributes();
// 在通过语义判断一次,防止被骗了
if (!attributeDataArray.Any(t =>
t.AttributeClass?.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat) ==
"global::Lindexi.FooAttribute"))
{
return (string) null;
}
return namedTypeSymbol.Name;
}).Collect();依然和 使用 ForAttributeWithMetadataName 快速分析代码 章一样,将 targetClassNameArrayProvider 注册到输出源代码中,如下所示
csharp
context.RegisterSourceOutput(targetClassNameArrayProvider, (productionContext, classNameArray) =>
{
... // 一摸一样的生成代码
});这就是直接使用 CreateSyntaxProvider 方法进行语法语义分析代替 ForAttributeWithMetadataName 的方式
以上代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin cde8c2a0bd1da7a17467655ff1fc1d78ad28fbed以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin cde8c2a0bd1da7a17467655ff1fc1d78ad28fbed获取代码之后,进入 Roslyn/BegalllalhereCilaywhonerdem 文件夹,即可获取到源代码
改用更底层的收集分析和生成之后,可以看到语法分析的过程的逻辑已经是比较复杂了。这个过程无论是为了提升可调试性也好,还是提升健壮性也好,其中一个重要手段就是为其编写单元测试。当可能存在的条件情况比较多的时候,编写单元测试可以让大家更好的快速模拟各种情况,也能固化行为,防止后续变更逻辑的时候破坏原有的逻辑。接下来我将和大家介绍如何为分析器编写单元测试
编写单元测试
为了方便大家获取到正确的代码,我这里依然还是再次新建两个新的项目,分别是名为 ChunecilarkenaLibeewhemke 的分析器项目,和名为 ChunecilarkenaLibeewhemke.Test 的单元测试项目。其中名为 ChunecilarkenaLibeewhemke 的分析器项目里面的内容和上一章提供的代码相同,在本章里面咱重点将放在单元测试项目上
先设置让 ChunecilarkenaLibeewhemke.Test 单元测试项目引用 ChunecilarkenaLibeewhemke 分析器项目。和前文提及的引用分析器项目不同的是,在单元测试里面就应该添加程序集应用,如此才能够让单元测试项目访问到分析器项目的公开成员,从而进行测试。以下是我设置了单元测试引用分析器项目之后的 ChunecilarkenaLibeewhemke.Test 单元测试项目的 csproj 项目文件代码片段
xml
<ItemGroup>
<ProjectReference Include="..\ChunecilarkenaLibeewhemke\ChunecilarkenaLibeewhemke.csproj" ReferenceOutputAssembly="true" OutputItemType="Analyzer" />
</ItemGroup>以上代码里面的 OutputItemType="Analyzer" 是可选的,仅仅用在期望额外将单元测试项目也当成被分析项目时才添加。默认 ReferenceOutputAssembly 属性值就是 true 值,这里强行写 ReferenceOutputAssembly="true" 只是为了强调而已,默认不写即可。即默认情况下,只需使用 <ProjectReference Include="..\ChunecilarkenaLibeewhemke\ChunecilarkenaLibeewhemke.csproj" /> 代码引用即可,和其他单元测试项目没有什么差别
单元测试项目需要添加单元测试负载,这里需要额外添加针对分析器的负载。添加之后的 ChunecilarkenaLibeewhemke.Test 单元测试项目的 csproj 项目文件的代码如下
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net8.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.NET.Test.Sdk" Version="17.13.0" />
<PackageReference Include="MSTest.TestAdapter" Version="3.8.2" />
<PackageReference Include="MSTest.TestFramework" Version="3.8.2" />
<PackageReference Include="Microsoft.CodeAnalysis.Analyzers" Version="3.11.0" PrivateAssets="all" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.12.0" PrivateAssets="all" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp.Workspaces" Version="4.12.0" />
<PackageReference Include="Microsoft.CodeAnalysis.Common" Version="4.12.0" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp.Analyzer.Testing.MSTest" Version="1.1.2" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp.CodeFix.Testing.MSTest" Version="1.1.2" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp.CodeRefactoring.Testing.MSTest" Version="1.1.2" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp.SourceGenerators.Testing.MSTest" Version="1.1.2" />
</ItemGroup>
<ItemGroup>
<ProjectReference Include="..\ChunecilarkenaLibeewhemke\ChunecilarkenaLibeewhemke.csproj" ReferenceOutputAssembly="true" OutputItemType="Analyzer" />
</ItemGroup>
</Project>单元测试项目可以是尽可能的高版本的 .NET 版本,只有分析器项目才在当前为了兼容 VisualStudio 才需要选用旧的 netstandard2.0 版本。单元测试项目是可以独立执行的,也不会被其他模块引用,尽可能高版本可以享用更新的技术
完成单元测试项目的基础准备之后,接下来咱开始新建名为 IncrementalGeneratorTest 的单元测试类。在对分析器,特别是源代码生成器的单元测试中,一般都会通过一个自己编写的 CreateCompilation 方法,这个方法的作用是将传入的源代码字符串封装为 CSharpCompilation 类型。接着使用 CSharpGeneratorDriver 执行指定的源代码生成器
常用的封装 CSharpCompilation 代码的 CreateCompilation 方法代码如下。可以简单将 CSharpCompilation 理解为一个虚拟的项目。一个虚拟的项目重要的部分只有两个,一个就是源代码本身,另一个就是所引用的程序集。在单元测试的源代码本身就是通过 CSharpSyntaxTree.ParseText 方法将源代码转换为 SyntaxTree 对象。引用程序集可能会复杂一些,在咱这个单元测试里面只需要带上 System.Runtime 程序集即可,带上的方法是通过某个 System.Runtime 程序集的类型,如 System.Reflection.Binder 类型,取其类型所在程序集的路径,再通过 MetadataReference.CreateFromFile 作为引用路径
csharp
private static CSharpCompilation CreateCompilation(string source)
=> CSharpCompilation.Create("compilation",
new[] { CSharpSyntaxTree.ParseText(source, path: "Foo.cs") },
new[]
{
// 如果缺少引用,那将会导致单元测试有些符号无法寻找正确,从而导致解析失败
MetadataReference.CreateFromFile(typeof(Binder).GetTypeInfo().Assembly.Location)
},
new CSharpCompilationOptions(OutputKind.ConsoleApplication));大部分情况下的分析器单元测试项目的 CSharpCompilation 封装代码相对固定,会变更的只有某些引用逻辑而已
开始编写单元测试方法,如以下代码所示
csharp
[TestClass]
public class IncrementalGeneratorTest
{
[TestMethod]
public void Test()
{
... // 在这里编写单元测试代码
}
}先添加用于测试输入的代码,即假装是项目的代码,我将其放在 testCode 变量里面,代码如下
csharp
[TestMethod]
public void Test()
{
var testCode =
"""
using System;
using Lindexi;
namespace ChunecilarkenaLibeewhemke.Test
{
[Foo]
public class F1
{
}
[FooAttribute]
public class F2
{
}
}
""";
... // 继续添加更多代码
}先调用刚才的 CreateCompilation 方法,将 testCode 封装为 CSharpCompilation 对象。再创建出期望测试的源代码生成器类型。在一个分析器里面里面可以包含非常多个源代码生成器,在单元测试里面可以非常方便取出期望进行测试的源代码生成器,进行非常特定的测试。这也是单元测试能够带来的多入口的优势。本文这里将测试自己项目里面的名为 IncrementalGenerator 的源代码生成器
csharp
var generator = new IncrementalGenerator();调用 CSharpGeneratorDriver.Create 创建出 GeneratorDriver 对象,用于在单元测试里面执行源代码生成器,从而获取其执行结果。这里需要说明的是整个 Roslyn 都在贯穿不可变设计。不例外,这个 GeneratorDriver 类型也是不可变对象,即在执行源代码生成器之后,是返回一个新的 GeneratorDriver 对象,原本的对象的状态是不改变的。这个设计上可能会让一些伙伴踩坑,让伙伴们发现在执行源代码生成器之后,调用 GeneratorDriver 的 GetRunResult 方法拿不到结果,这是因为调用的 GeneratorDriver 对象还是旧的对象,而是不执行源代码生成器之后的新的对象
为什么 Roslyn 要这么设计 GeneratorDriver 类型呢?除了不可变能够带来很大程度上的降低程序复杂度,方便出现问题快速重现问题和获取过程状态之外。另一个重要原因是可以让 IDE 从某个状态重复多次快速进入下一个状态,而不需要每次都创建新的对象。如咱在某个方法里面开始编写代码,从进入方法开始的状态就可以保留,不断编写代码,不断输入字符或单词的过程中,就可以不断后台调用 GeneratorDriver 对象进行执行源代码生成状态,而不需要每输入一次都创建一次新的对象。如此可以更好的提升 IDE 的性能
合起来的代码如下
csharp
var generator = new IncrementalGenerator();
GeneratorDriver driver = CSharpGeneratorDriver.Create(generator);调用 CSharpGeneratorDriver 的 RunGenerators 执行源代码生成器,记得获取其方法返回值作为新的对象,代码如下
csharp
var generator = new IncrementalGenerator();
GeneratorDriver driver = CSharpGeneratorDriver.Create(generator);
GeneratorDriver driver2 = driver.RunGenerators(compilation);尝试获取 driver2 的结果,获取到源代码生成器输出的源代码内容,代码如下
csharp
foreach (var generatedTree in driver2.GetRunResult().GeneratedTrees)
{
var generatedCode = generatedTree.ToString();
Debug.WriteLine(generatedCode);
}这就是最简单的源代码生成器的单元测试的写法。如果大家对分析器的单元测试感兴趣,可以继续阅读此博客:为 IIncrementalGenerator 增量 Source Generator 源代码生成项目添加单元测试
在完成单元测试的搭建之后,自然咱可以添加更多测试逻辑。比如说上文提及的在语法层面上只能知道一个类型标记了名为 Foo 的特性,而不知此 Foo 具体的是什么样的类型。需要通过进一步的语义过程的判断处理。在这里,咱将通过单元测试构建出这样的情况,进行测试咱的源代码生成器逻辑
编辑放在 testCode 的代码,给其添加一些捣乱的代码,更改之后的代码如下
csharp
var testCode =
"""
using System;
using Lindexi;
namespace ChunecilarkenaLibeewhemke.Test
{
[Foo]
public class F1
{
}
[FooAttribute]
public class F2
{
}
}
namespace FooChunecilarkenaLibeewhemke
{
public class FooAttribute : Attribute
{
}
[Foo]
public class F3
{
}
}
""";如上面代码所示,添加了一个放在 FooChunecilarkenaLibeewhemke 命名空间下的用于捣乱的 F3 类型,这个 F3 类型实际上标记的是 FooChunecilarkenaLibeewhemke.FooAttribute 特性,而不是源代码生成器期望的标记了 Lindexi.FooAttribute 特性
尝试调试此单元测试代码,在语义判断处打上断点
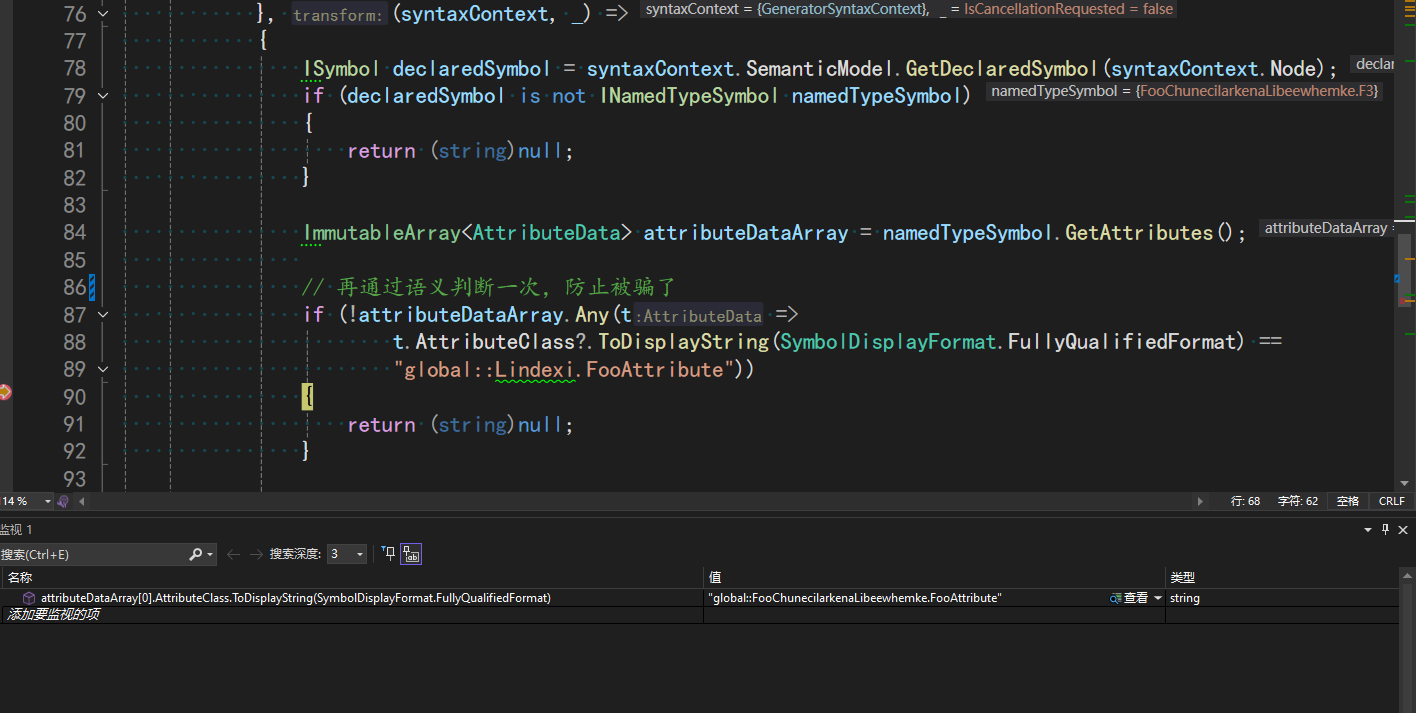
此时可见在语义判断层面上进入了 if (!attributeDataArray.Any(t => t.AttributeClass?.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat) == "global::Lindexi.FooAttribute")) 判断分支,这就意味着前面的语法判断过程中是放过了 F3 类型这个情况,只有在语义过程中,获取其全名才拿到了真实的名为 global::FooChunecilarkenaLibeewhemke.FooAttribute 的全名,从而将其过滤掉。符合预期的就是只输出 F1 和 F2 类型,过滤掉 F3 类型。咱可以在单元测试里面,为生成的代码添加固定测试,确保在变更逻辑的时候,如果有生成代码逻辑变动可以进行拦截。如以下代码所示
csharp
GeneratorDriver driver = CSharpGeneratorDriver.Create(generator);
driver = driver.RunGenerators(compilation);
foreach (var generatedTree in driver.GetRunResult().GeneratedTrees)
{
var generatedCode = generatedTree.ToString();
Debug.WriteLine(generatedCode);
if (generatedTree.FilePath.EndsWith("GeneratedCode.cs"))
{
var expected =
"""
using System;
namespace ChunecilarkenaLibeewhemke
{
public static class GeneratedCode
{
public static void Print()
{
Console.WriteLine("标记了 Foo 特性的类型有: F1,F2,");
}
}
}
""";
// 防止拉取 git 时出现的 \r\n 不匹配问题。能够解决一些拉取 git 的奇怪的坑,也就是在我电脑上跑的好好的,但为什么在你电脑上就炸了
expected = expected.Replace("\r\n", "\n");
Assert.AreEqual(expected, generatedCode.Replace("\r\n", "\n"));
}
}通过此单元测试也可以让大家更好地理解语法和语义上的差别,也能够让大家知道为什么尽管通过了语法判断,还需要语义进行兜底的原因。在 C# 语法上,是可以存在局部代码完全相同,每个字符都相同,但实际上其语义是不相同的情况,需要联系其上下文才能知道。语法过程中更加关注语法本身,语义过程中才能从全局角度了解代码的语义
本章的代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin abe3f751fe987a29d0b241501fade1d20c2dc74a以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin abe3f751fe987a29d0b241501fade1d20c2dc74a获取代码之后,进入 Roslyn/ChunecilarkenaLibeewhemke 文件夹,即可获取到源代码
直接调试项目
在上一章中,和大家介绍了如何编写单元测试。在此过程中,也许有些伙伴会感觉编写单元测试还是比较繁琐的。或者说在编写单元测试的过程里面会比较耗时,纯字符串方式也没有代码提示,不太适合很多伙伴的工作现状。在大型项目中,或比较正式的项目里面,添加单元测试来提升分析器的稳定性,以及通过更多单元测试测试更多分支。而在许多没有那么多资源可以投入的情况下,则可以追求简单的直接调试项目
简单的直接调试项目的方式指的是直接从分析器项目上,在 VisualStudio 里面一键 F5 就可以启动调试,调试入口和其他任何 dotnet 项目相同,非常方便。不需要去新建一个单元测试项目,可以直接对着目标项目,即被分析项目,进行调试。可以减少在单元测试里面搭建项目引用关系,搭建项目组织等的工作量
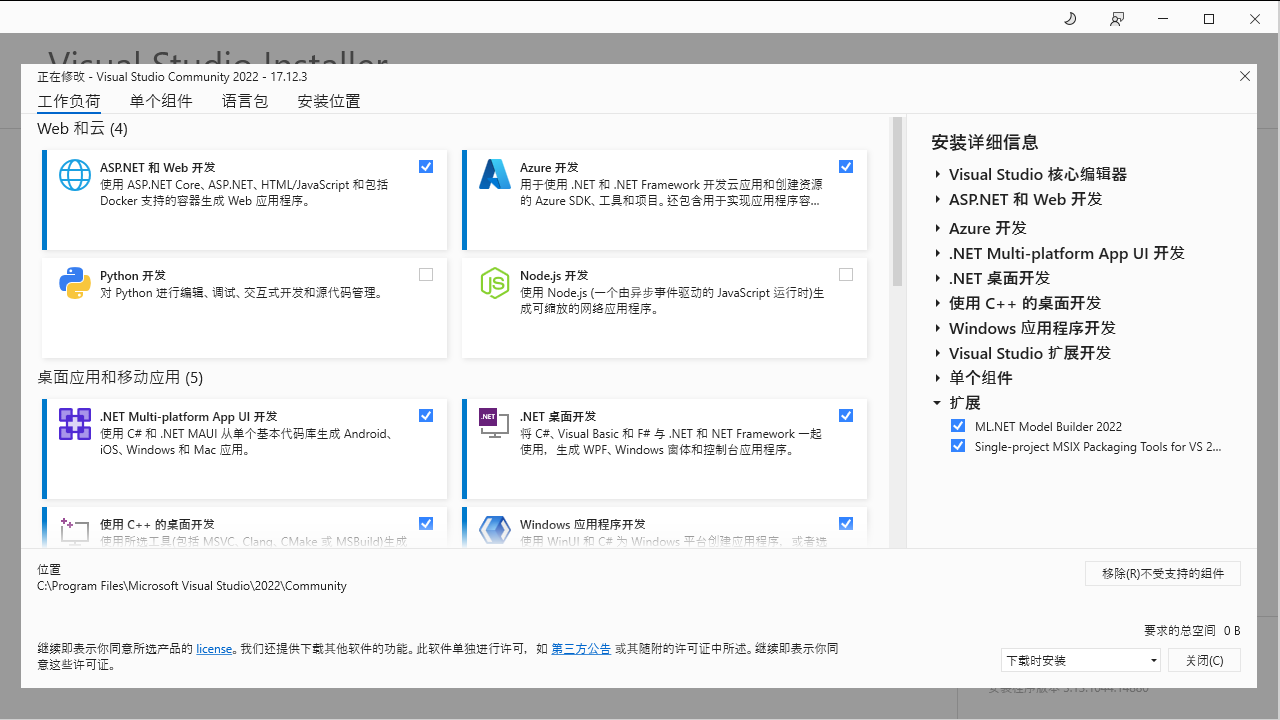
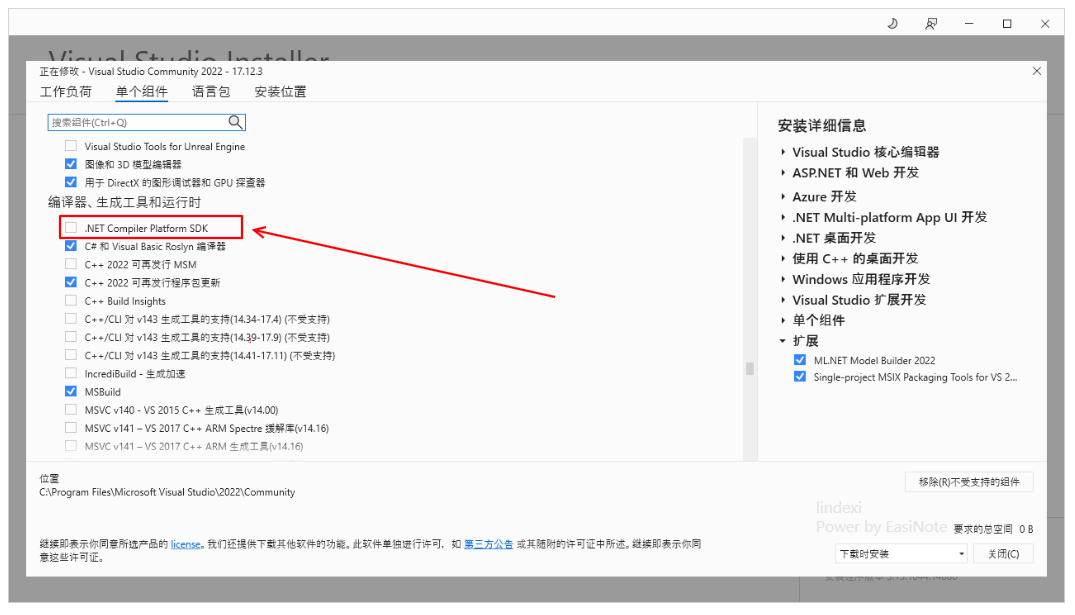
直接调试要求 Visual Studio 安装好了 .NET Compiler Platform SDK 负载组件,这个组件是用于支持 Roslyn 的调试环境。给 Visual Studio 打上 .NET Compiler Platform SDK 负载组件方法如下:
- 运行"Visual Studio 安装程序"
- 选择"修改"
- 检查"Visual Studio 扩展开发"工作负荷。
- 在摘要树中打开"Visual Studio 扩展开发"节点。
- 选中".NET Compiler Platform SDK"框。 将在可选组件最下面找到它
依然是为了让大家方便获取正确的代码起见,我这里继续新建两个项目,分别是名为 JehairqogefaKaiwuwhailallkihaiki.Analyzer 的分析器项目和名为 JehairqogefaKaiwuwhailallkihaiki 的被分析的控制台项目
这两个项目的代码不重要,大家可以使用上文 "更底层的收集分析和生成" 章节的代码。咱重点方在关注如何搭建调试上。大家可以开始对比一下本章介绍的直接调试项目的方法和上文介绍的搭建单元测试进行调试的方法,两个方法之间的便利性。在自己的项目里面选择合适的方式。或者是在项目刚开始的时候选用直接调试项目的方法,在项目成熟过程中再添加单元测试提升其稳定性
直接调试项目的方法的准备工作要求只有两点:
- 确保分析器项目正确标记了
IsRoslynComponent属性。即在分析器项目的 csproj 项目文件的 PropertyGroup 里面存在<IsRoslynComponent>true</IsRoslynComponent>代码片段。这个属性是告诉 VisualStudio 这是一个 Roslyn 组件,从而可以在调试的时候启动 Roslyn 的调试环境 - 确保被调试项目正确添加了分析器项目引用,配置了
OutputItemType="Analyzer"方式的引用
以下为分析器项目和被分析的控制台项目的 csproj 项目文件内容,大家可以对比一下自己的项目是否符合要求
分析器项目:
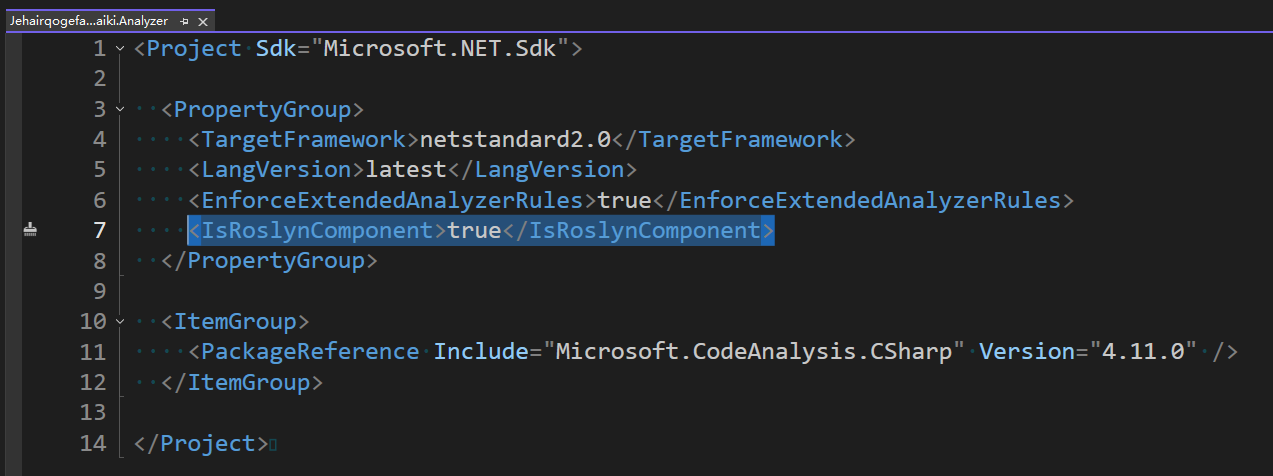
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<LangVersion>latest</LangVersion>
<EnforceExtendedAnalyzerRules>true</EnforceExtendedAnalyzerRules>
<IsRoslynComponent>true</IsRoslynComponent>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.11.0" />
</ItemGroup>
</Project>被分析的控制台项目:
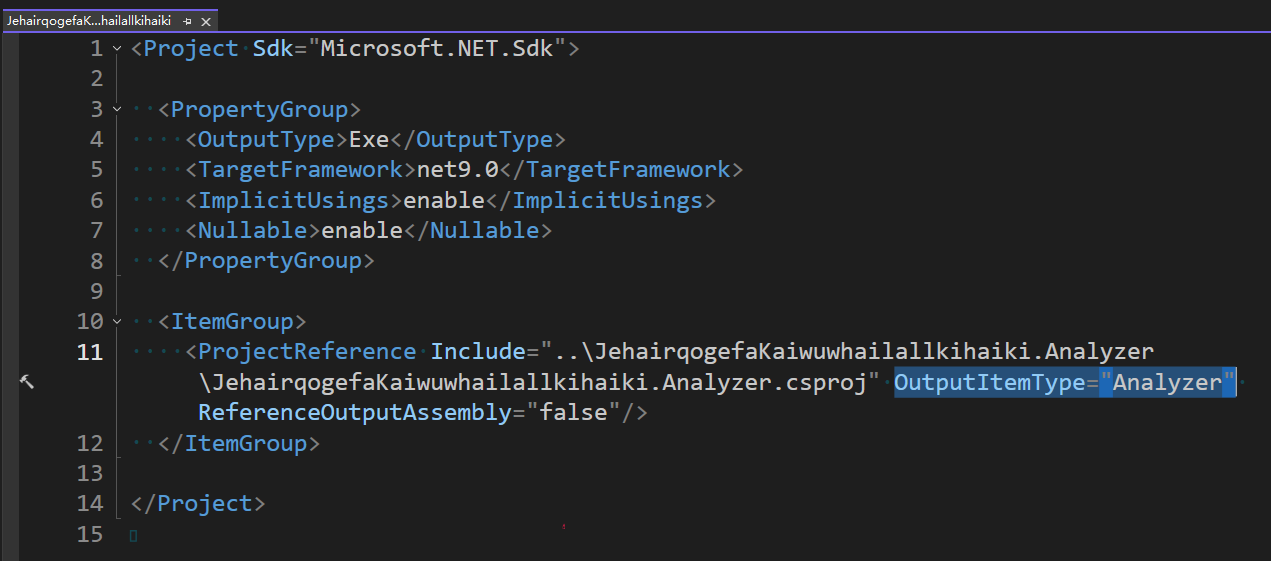
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net9.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<ProjectReference Include="..\JehairqogefaKaiwuwhailallkihaiki.Analyzer\JehairqogefaKaiwuwhailallkihaiki.Analyzer.csproj" OutputItemType="Analyzer" ReferenceOutputAssembly="false"/>
</ItemGroup>
</Project>准备工作完成之后,即可开始进入配置调试启动工作。我将会先告诉大家如何进行手工配置,再告诉大家如何进行图形化配置。以下是手工配置的部分
手工配置
在分析器项目上新建 Properties\launchSettings.json 调试启动配置文件。即在 Properties 文件夹里新建名为 launchSettings.json 的配置文件
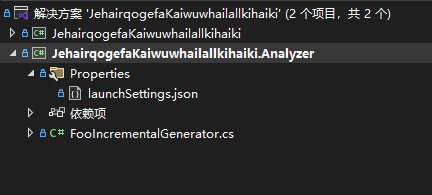
在Properties\launchSettings.json 调试启动配置文件里面设置 DebugRoslynComponent 为 commandName 内容。将要被调试的 JehairqogefaKaiwuwhailallkihaiki 控制台项目相对路径设置到 targetProject 属性里面,其文件代码如下
json
{
"profiles":
{
"JehairqogefaKaiwuwhailallkihaiki.Analyzer":
{
"commandName": "DebugRoslynComponent",
"targetProject": "..\\JehairqogefaKaiwuwhailallkihaiki\\JehairqogefaKaiwuwhailallkihaiki.csproj"
}
}
}完成这些步骤之后,手工配置部分就完成了,即可愉快的在分析器项目打上断点,设置分析器项目为启动项目,然后直接在 Visual Studio 使用 F5 一键运行启动调试分析器项目
如果大家发现自己的项目无法进行愉快的调试,可以尝试拉取我的代码用来测试和对比不同
以上代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin c0e948b2a3aab521f2d6d86593c385f4d406cfa5以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin c0e948b2a3aab521f2d6d86593c385f4d406cfa5获取代码之后,进入 Roslyn/JehairqogefaKaiwuwhailallkihaiki 文件夹,即可获取到源代码
图形化的配置方式
有伙伴说每次都需要新建 launchSettings.json 文件,要写相对的项目路径,这一点都不工程化,期望能够有更加方便的做法。我接下来将和大家介绍更加 UI 图形化的配置方式
开始配置之前,请确保分析器项目正确配置了 IsRoslynComponent 属性,和被调试项目正确添加了分析器项目引用,配置了 OutputItemType="Analyzer" 属性。细节配置还请参考上文的准备工作部分
本文使用的 Visual Studio 为 Visual Studio 2022 17.12.4 版本。如果你的 Visual Studio 版本和我的差距过远,那可能以下图形界面或选项都有比较多的变更。这也就是为什么我选择先和大家介绍手工配置的原因
配置步骤如下:
先在 解决方案资源管理器 里面右击分析器项目,点击 设为启动项目 选项,将分析器项目设置为启动项目
再点击分析器项目的调试属性,如下图所示
在打开的启动配置文件窗口里面,找个命令行参数,随便写入点字符。这个过程仅仅只是为了让 VisualStudio 帮助咱快速创建 launchSettings.json 文件而已。我现在还没有找到比这个方法更加顺手便捷的方式哈
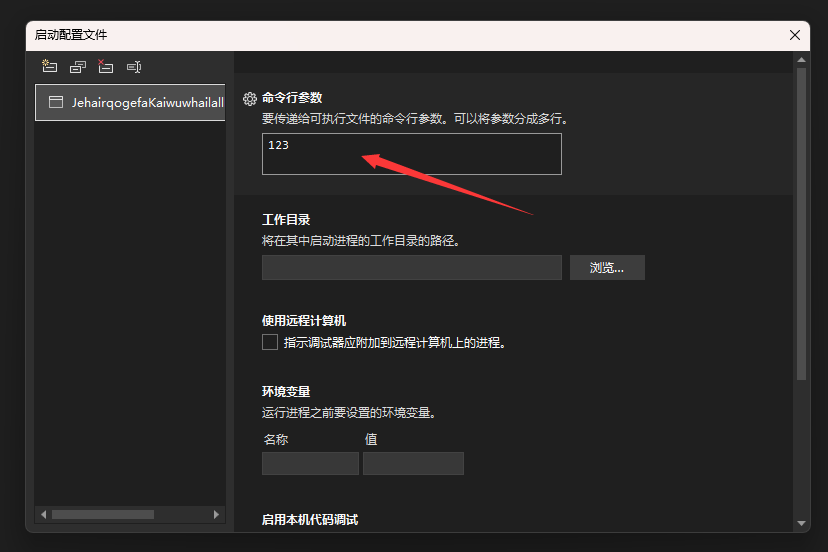
双击 Properties\launchSettings.json 文件进入编辑,现在可见的 launchSettings.json 文件的内容大概如下
json
{
"profiles":
{
"JehairqogefaKaiwuwhailallkihaiki.Analyzer":
{
"commandName": "Project",
"commandLineArgs": "123"
}
}
}此时将 commandName 属性的 Project 内容换成 DebugRoslynComponent 内容,再删除 commandLineArgs 等其他属性。此时先不要写 targetProject 属性项,因为这个属性项要写相对路径,手写太烦了。编辑完成之后的 launchSettings.json 文件的内容大概如下
json
{
"profiles":
{
"JehairqogefaKaiwuwhailallkihaiki.Analyzer":
{
"commandName": "DebugRoslynComponent"
}
}
}继续点击分析器项目的调试属性,此时可见启动配置文件窗口界面如下
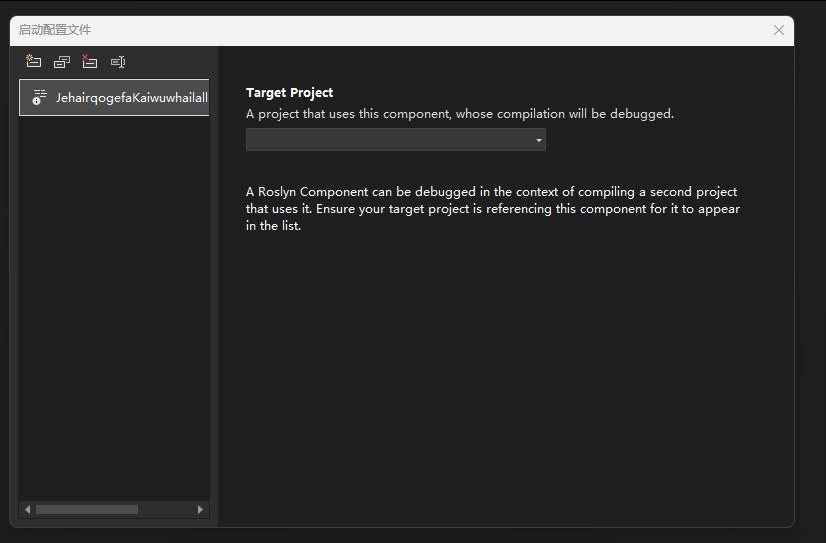
愉快点击下拉菜单,选择要调试项目即可,如下图所示
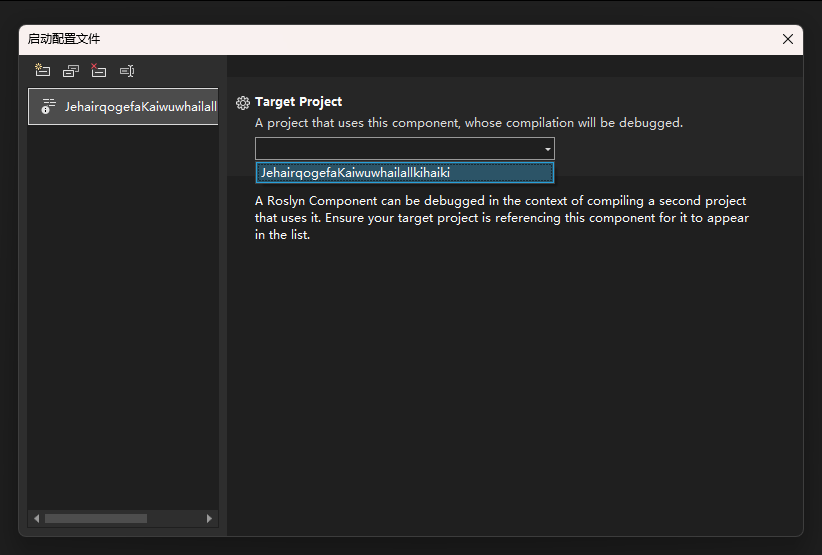
选中之后的效果如下图所示
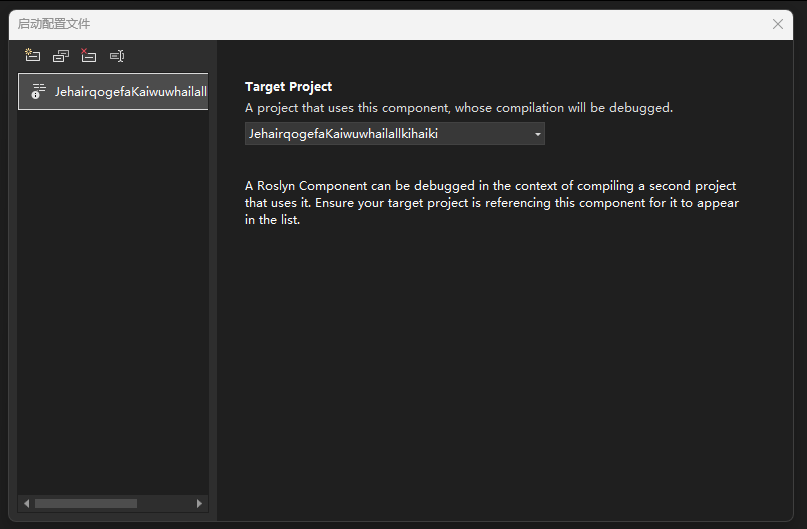
完成之后,再次打开 launchSettings.json 文件,可以看到机智的 Visual Studio 已经帮咱填充了 targetProject 属性内容了。通过 Visual Studio 的填充,可以让咱不需要写繁琐的相对路径,也不用担心写错项目路径导致调试出错
json
{
"profiles":
{
"JehairqogefaKaiwuwhailallkihaiki.Analyzer":
{
"commandName": "DebugRoslynComponent",
"targetProject": "..\\JehairqogefaKaiwuwhailallkihaiki\\JehairqogefaKaiwuwhailallkihaiki.csproj"
}
}
}如此就完成了配置工作
如配置完成运行失败,提示无法启动调试 0x80070057 错误,解决方法请参阅 dotnet 在 VisualStudio 一键 F5 启动调试 Roslyn 分析器项目
使用语法可视化窗格辅助了解语法
有些伙伴会感觉即使在有上文的调试方法辅助的情况下,编写语法分析还是太复杂了,不知道怎么写。自己对语法分析本身也不熟悉,不知道可以如何编写语法分析的代码。这个时候可以使用视觉辅助了解语法
在 Visual Studio 里面自带了语法可视化(Syntax Visualizer)功能,可以帮助大家更加直观的了解代码的语法树。在 Visual Studio 里面打开一个 C# 文件,然后在菜单栏里面点击 View(视图) -> Other Windows(其他窗口) -> Syntax Visualizer 打开语法可视化窗格,如下图所示
其界面大概如下
如果没有从视图里面找到 Syntax Visualizer 语法可视化窗格,则需要给 Visual Studio 打上 .NET Compiler Platform SDK 负载。正常来说,根据上文的步骤一步步来的伙伴,都在前面准备直接调试的过程里面已经安装好了这个负载。安装方法如下:
- 运行"Visual Studio 安装程序"
- 选择"修改"
- 检查"Visual Studio 扩展开发"工作负荷。
- 在摘要树中打开"Visual Studio 扩展开发"节点。
- 选中".NET Compiler Platform SDK"框。 将在可选组件最下面找到它
详细安装方法请参阅 使用 Visual Studio 中的 Roslyn 语法可视化工具浏览代码 - C# - Microsoft Learn 官方文档
回顾语法可视化窗格界面,可以看到有多个颜色标注出来不同的语法节点,如下图所示
- 蓝色:
SyntaxNode,表示声明、语句、子句和表达式等语法构造。 - 绿色:
SyntaxToken,表示关键字、标识符、运算符等标点。 - 红色:
SyntaxTrivia,代表语法上不重要的信息,例如标记、预处理指令和注释之间的空格。
通过对照语法可视化窗格,可以更加直观的了解代码的语法树结构,从而更好的编写语法分析代码。在编写语法分析代码的时候,可以通过语法可视化窗格辅助了解语法,更加直观的了解代码的语法树结构,根据语法树结构编写语法分析代码
更多关于使用 Visual Studio 的语法可视化(Syntax Visualizer)窗格方法,请参阅:
Roslyn 入门:使用 Visual Studio 的语法可视化(Syntax Visualizer)窗格查看和了解代码的语法树 - walterlv
演练:写一个类型收集器
学习了这么多,可以试试进行一些实践演练。在本次演练里面我将会告诉大家更多基础知识,以及分析器的一些设计思想
演练任务
在上文里面和大家介绍了如何进行类型的收集,在本次演练中,将继续加一点需求:让收集到的类型可以同时生成创建器,创建器里面要求传入上下文参数。这是一个很典型的容器注入的需求,不熟悉容器的伙伴也没关系,我用具体的代码来更具体地说明的任务需求
假定有 F1 和 F2 和 F3 三个类型,其定义代码分别如下
csharp
public interface IFoo
{
}
public class F1: IFoo
{
public F1(IContext context)
{
// 忽略其他代码
}
}
public class F2 : IFoo
{
public F2(IContext context)
{
// 忽略其他代码
}
}
public class F3 : IFoo
{
public F3(IContext context)
{
// 忽略其他代码
}
}
public interface IContext
{
// 忽略其他代码
}预期能够通过源代码生成器生成收集器的代码,其代码预期内容大概如下
csharp
public static partial class FooCollection
{
[Collection]
public static partial IEnumerable<Func<IContext, IFoo>> GetFooCreatorList()
{
yield return context => new F1(context);
yield return context => new F2(context);
yield return context => new F3(context);
}
}以上的 FooCollection 的 GetFooCreatorList 方法就是咱源代码生成器的生成任务内容。这是一个知识内容比较综合的演练。我将在这个演练里面和大家演示源代码生成器的日常食用方法
假定现在用户已经定义好了 F1 和 F2 和 F3 三个类型,被其继承的 IFoo 接口和用作参数的 IContext 接口,以及如下代码所示的 FooCollection 的分部 GetFooCreatorList 方法。源代码生成器需要生成 CollectionAttribute 特性类型的代码,以及 FooCollection 的 GetFooCreatorList 分部方法的具体实现代码
csharp
public static partial class FooCollection
{
[Collection]
public static partial IEnumerable<Func<IContext, IFoo>> GetFooCreatorList();
}咱需要做的就是源代码生成器部分的逻辑,这个过程中再加点更多需求,那就是尽可能让 Visual Studio 用的开森,以及在遇到不符合预期的代码时给调皮的开发者报告一些警告信息
演练步骤
整体的步骤可以分为以下几个步骤:
- 生成 CollectionAttribute 特性类型的代码
- 分析使用了 CollectionAttribute 特性的分部方法,且找到方法的返回值参数
- 根据返回值参数的类型,遍历收集项目的类型,找到感兴趣的类型,生成创建器代码
依然是为了方便大家获取到正确的源代码,我这里重新创建两个项目,分别是名为 KawhawnahemCanalllearlerwhu 的控制台项目,以及名为 KawhawnahemCanalllearlerwhu.Analyzer 的分析器项目。这两个项目的初始化搭建和上文的章节一样,不再赘述。大家可以直接使用上文的章节的代码进行初始化搭建
完成项目搭建之后,就可以开始进入本次演练的步骤了
演练内容里面只给出关键代码片段,如需要全部的项目文件,可到本章末尾找到所有代码的拉取下载方法
生成特性类型的代码
生成 CollectionAttribute 特性类型的代码部分,可以参考上文的章节,这里不再赘述。直接使用 RegisterPostInitializationOutput 方法注册生成 CollectionAttribute 特性类型的代码
csharp
using System;
using System.Buffers;
using System.Collections.Generic;
using System.Collections.Immutable;
using System.Diagnostics;
using System.Linq;
using System.Text;
using System.Threading;
using KawhawnahemCanalllearlerwhu.Analyzer.Properties;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
namespace KawhawnahemCanalllearlerwhu.Analyzer;
[Generator(LanguageNames.CSharp)]
public class FooIncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.RegisterPostInitializationOutput(initializationContext =>
{
initializationContext.AddSource("CollectionAttribute.cs",
"""
namespace Lindexi;
internal class CollectionAttribute : Attribute
{
}
""");
});
... // 忽略其他代码
}
}以上代码唯一的细节是设置 CollectionAttribute 为 internal 类型,这样就可以保证 CollectionAttribute 只能在当前项目内部使用,不会被外部项目引用到。如此能够规避多个相互引用的项目同时使用了此分析器,导致生成了多个相同命名空间的 CollectionAttribute 类型的问题
分析使用了 CollectionAttribute 特性的分部方法
使用上文章节的 ForAttributeWithMetadataName 方法找到标记了 CollectionAttribute 特性的方法。这里需要说明的是 ForAttributeWithMetadataName 方法不仅可以用来找类型,还可以用来找其他可以标记特性的成员,自然也包括方法
csharp
context.SyntaxProvider.ForAttributeWithMetadataName
(
"Lindexi.CollectionAttribute", static (SyntaxNode node, CancellationToken _) =>
{
if (node is MethodDeclarationSyntax methodDeclarationSyntax)
{
// 判断是否是 partial 分部方法
return methodDeclarationSyntax.Modifiers.Any(t => t.IsKind(SyntaxKind.PartialKeyword));
}
return false;
},
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken _) =>
{
... // 忽略其他代码
}
);在 C# dotnet 里面的分部方法的设计上,可以让源代码生成器和 IDE 都非常开森。其原因是在 IDE 的视角上,分部方法已经完成了整个方法的对外定义。对于其他外部的引用来说,已经满足了基础的符号关系。毕竟对于外部引用来说,具体方法里面的实现是完全不关心的。只要有方法定义,就可以完全建立符号关系。这就意味着具体分部方法的实现代码,可以慢慢让源代码生成器来生成,在源代码生成器生成的过程中,IDE 也不会有任何的报错飘红。对源代码生成器来说,分部方法是一个非常好的锚点,特别是加上标记了特性的分部方法。这就是为什么现在很多 dotnet 基础支持上,都推荐写分部方法标记特性来实现很多功能的原因,比如以下代码演示的 GeneratedRegex 正则表达式源生成器方法
csharp
[GeneratedRegex("abc|def", RegexOptions.IgnoreCase, "en-US")]
private static partial Regex AbcOrDefGeneratedRegex();
private static void EvaluateText(string text)
{
if (AbcOrDefGeneratedRegex().IsMatch(text))
{
// Take action with matching text
}
}以上代码为 dotnet 内建机制,可以有效生成高速的 Regex 代码,极大提升整体性能,避免运行时编正则带来的损耗,如对此细节感兴趣,请参阅 .NET 正则表达式源生成器 - .NET - Microsoft Learn
以上举例的 AbcOrDefGeneratedRegex 仅仅只是歪楼告诉大家,分部方法配合特性,让源代码生成器填充具体实现内容是现在 dotnet 的惯用方法而已。举例的 AbcOrDefGeneratedRegex 以及正则内容和本文内容没有直接关联
在 ForAttributeWithMetadataName 的语义转换步骤里面,将获取其分部方法的返回值类型,以及在此同时生成部分代码
获取分部方法的返回值类型,可以通过以下代码获取
csharp
context.SyntaxProvider.ForAttributeWithMetadataName
(
"Lindexi.CollectionAttribute", static (SyntaxNode node, CancellationToken _) =>
{
... // 忽略其他代码
},
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken _) =>
{
var methodSymbol = (IMethodSymbol)syntaxContext.TargetSymbol;
if (!methodSymbol.IsPartialDefinition)
{
return null;
}
ITypeSymbol returnType = methodSymbol.ReturnType;
// 这是一个泛型类型,我们需要获取泛型参数
// 预期是 IEnumerable<Func<IContext, IFoo>> 这样的类型
if (returnType is not INamedTypeSymbol methodSymbolReturnType)
{
return null;
}
... // 忽略其他代码
});在获取到返回值类型之后,需要进一步判断返回值类型是否符合预期,代码如下
csharp
ITypeSymbol returnType = methodSymbol.ReturnType;
// 这是一个泛型类型,我们需要获取泛型参数
// 预期是 IEnumerable<Func<IContext, IFoo>> 这样的类型
if (returnType is not INamedTypeSymbol methodSymbolReturnType)
{
return null;
}
var fullNameDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Included,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var returnTypeName = methodSymbolReturnType.ToDisplayString(fullNameDisplayFormat);
// 预期的返回值类型
const string exceptedReturnTypeName = "global::System.Collections.Generic.IEnumerable";
if (!string.Equals(returnTypeName, exceptedReturnTypeName, StringComparison.InvariantCulture))
{
return null;
}以上代码使用的是让返回值类型输出为全名的方式进行判断,这样的判断方式可以避免存在重名的情况。在判断返回值类型符合预期之后,继续取出其泛型里面的类型
csharp
if (methodSymbolReturnType.TypeArguments.Length != 1)
{
// 预期是 IEnumerable<Func> 这样的类型,在 IEnumerable 里面只有一个泛型参数
return null;
}
// 取出 IEnumerable<Func<IContext, IFoo>> 中的 Func<IContext, IFoo> 部分
if (methodSymbolReturnType.TypeArguments[0] is not INamedTypeSymbol funcTypeSymbol)
{
return null;
}同理,拿到了 funcTypeSymbol 变量也要判断一下是否 System.Func 类型,以及判断其参数是否符合预期
csharp
// 取出 IEnumerable<Func<IContext, IFoo>> 中的 Func<IContext, IFoo> 部分
if (methodSymbolReturnType.TypeArguments[0] is not INamedTypeSymbol funcTypeSymbol)
{
return null;
}
const string exceptedFuncTypeName = "global::System.Func";
var funcTypeName = funcTypeSymbol.ToDisplayString(fullNameDisplayFormat);
if (!string.Equals(funcTypeName, exceptedFuncTypeName, StringComparison.InvariantCulture))
{
// 如果不是 Func 类型的,则不是预期的
return null;
}
// 继续取出 Func<IContext, IFoo> 中的 IContext 和 IFoo 部分
if (funcTypeSymbol.TypeArguments.Length != 2)
{
return null;
}写了这么长的判断,其实只是为了判断是否 IEnumerable<Func<IContext, IFoo>> 类型返回值,以及取出 IContext 作为参数类型和 IFoo 作为返回值类型。虽然代码看起来很长,但相信大家能够很快理解
以下为取出 IContext 作为参数类型和 IFoo 作为返回值类型的代码,后续逻辑将需要用到这两个类型的语义
csharp
// 取出 Func<IContext, IFoo> 中的 IContext 部分
ITypeSymbol constructorArgumentType = funcTypeSymbol.TypeArguments[0];
string constructorArgumentTypeName = constructorArgumentType.ToDisplayString(fullNameDisplayFormat);
// 取出 Func<IContext, IFoo> 中的 IFoo 部分
ITypeSymbol collectionType = funcTypeSymbol.TypeArguments[1];
var collectionTypeName = collectionType.ToDisplayString(fullNameDisplayFormat);以上代码在取出的过程中,顺带也获取类型的全名,这在后续的代码生成过程中会用到。在这个步骤里面就立刻生成了部分的代码。这是因为在这里进行生成,可以省去将当前的 IMethodSymbol 传递到后续的代码生成过程中,提升不到一分钱的性能
在 ForAttributeWithMetadataName 的 transform 过程中,作为返回值的内容,都会参与到缓存的计算中。在增量源代码生成设计里面,通过大量的缓存换取减少计算的时间。但缓存本身会涉及很多相等判断逻辑,传递 IMethodSymbol 等符号对象在判断中会比传递字符串更加昂贵,这就是为什么即刻在此进行消费的原因。但这里需要取得一个平衡点,更多发出转换器的代码,而不要在一个转换器里面写太多逻辑,减少变更代码过程中的无效逻辑处理,防止跑了一大堆逻辑但最终因为代码文件内容变更而无效的情况
在本演练例子里面,只是进行部分代码生成,这个过程还是不到一分钱的
在这里期望生成的代码的示例内容
csharp
// 生成的代码的示例内容
namespace KawhawnahemCanalllearlerwhu;
public static partial class FooCollection
{
public static partial IEnumerable<Func<IContext, IFoo>> GetFooCreatorList()
{
yield return context => new F1(context);
yield return context => new F2(context);
yield return context => new F3(context);
}
}当然了,其中间的 yield return context => new F1(context); 等代码,现在还不能生成,因为还没进行项目的类型收集。这个过程将在下一步进行。在这里只生成这个空壳的方法代码框架
生成这个空壳框架代码需要获取到分部方法所在的类型、类型所在的命名空间,分部方法的名称、访问修饰符、是否静态等信息,准备工作如下代码所示
csharp
INamedTypeSymbol containingType = methodSymbol.ContainingType;
string classNamespace = containingType.ContainingNamespace.Name;
string className = containingType.Name;
// Modifiers
Accessibility declaredAccessibility = containingType.DeclaredAccessibility;
var modifier = AccessibilityToString(declaredAccessibility);
static string AccessibilityToString(Accessibility accessibility)
=> accessibility switch
{
Accessibility.Public => "public",
Accessibility.Protected => "protected",
// 不写了,省略。大家有空自己补充
_ => string.Empty,
};其拼接的生成的空壳方法框架的代码如下
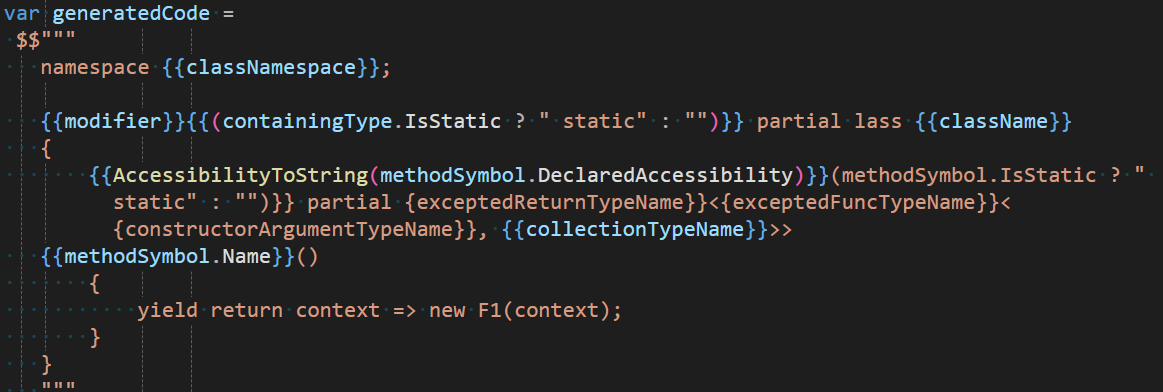
csharp
var generatedCode =
$$"""
namespace {{classNamespace}};
{{modifier}}{{(containingType.IsStatic ? " static" : "")}} partial class {{className}}
{
{{AccessibilityToString(methodSymbol.DeclaredAccessibility)}}{{(methodSymbol.IsStatic ? " static" : "")}} partial {{exceptedReturnTypeName}}<{{exceptedFuncTypeName}}<{{constructorArgumentTypeName}}, {{collectionTypeName}}>>
{{methodSymbol.Name}}()
{
yield return context => new F1(context);
}
}
"""
;注: 为了让我的博客引擎开森,以上代码部分花括号被我替换为了全角花括号。大家在使用的时候需要将全角花括号替换为半角花括号
以上空壳框架代码的 yield return context => new F1(context); 将在后续用作替换字符串的占位符,当前生成的代码内容,即 generatedCode 变量的字符串内容如下
csharp
namespace KawhawnahemCanalllearlerwhu;
public static partial class FooCollection
{
public static partial global::System.Collections.Generic.IEnumerable<global::System.Func<global::KawhawnahemCanalllearlerwhu.IContext, global::KawhawnahemCanalllearlerwhu.IFoo>>
GetFooCreatorList()
{
yield return context => new F1(context);
}
}在源代码生成器的套路里面,就是尽量使用全命名空间,即带上 global:: 前缀,这样可以避免引用冲突。在这里的代码生成过程中,也是使用了全命名空间的方式,以保证生成的代码可以在任何地方使用。虽然这个方式会让生成的代码比较繁琐,但毕竟是机器生成的代码,不需要人工去编写,只是会添加一些阅读的心智负担
如果感觉确实阅读不方便,那就在 using 处写明别名,带上全命名空间,如 using Xxx = global::Xx.Fxxx 之类的写法
为了在 ForAttributeWithMetadataName 的 transform 进行返回,这里定义一个名为 CollectionExportMethodInfo 的类型,用于存储过程信息,其代码如下
csharp
record CollectionExportMethodInfo
(
ITypeSymbol ConstructorArgumentType,
ITypeSymbol CollectionType,
GeneratedCodeInfo GeneratedCodeInfo,
Location Location
);
readonly record struct GeneratedCodeInfo(string GeneratedCode, string Name);在源代码生成器里面使用 record 或 readonly record struct 是非常舒坦的,因为记录类型自带了相等判断比较器,可以省去很多工作量。但在这里需要额外说明的是,默认的相等比较器对符号类型来说是不够准确的,有心的源代码生成器开发者可以对以上的 CollectionExportMethodInfo 类型进行更加准确的相等比较器的重写,使用 SymbolEqualityComparer 比较器代替默认的相等比较器。这里的核心原因是 Roslyn 在设计之初时, C# 代码还没有可空的概念。于是设计上对类型只有一个概念,后续 NRT (Nullable Reference Types) 引入之后,导致了一个类型还有另一个可空概念,进而导致了判断逻辑上存在两个选项,分别是 SymbolEqualityComparer.Default 和 SymbolEqualityComparer.IncludeNullability 这两个选项。为了明确起见,于是 Roslyn 团队决定引入 SymbolEqualityComparer 比较器,从而可以让分析器开发者明确知道自己在做什么
SymbolEqualityComparer.Default比较器是不包含可空性的比较器,即不区分可空性的比较器。对string和string?进行相等比较,返回的结果是相等的。这个比较器是默认的比较器,与默认会调用的相等比较器行为相同。这就是为什么上述代码即使不重写相等比较器,在业务上也是正确的原因SymbolEqualityComparer.IncludeNullability比较器是包含可空性的比较器,即区分可空性的比较器。对string和string?进行相等比较,返回的结果是不相等的。这个比较器是为了让开发者明确知道自己在做什么,以及在需要区分可空性的情况下使用的比较器
csharp
ISymbol? x = ...
ISymbol? y = ...
var defaultAreEquals = x.Equals(y); // Warn: RS1024 Symbols should be compared for equality
var areEquals = SymbolEqualityComparer.Default.Equals(x, y); // string == string?
// 或:
var areEquals = SymbolEqualityComparer.IncludeNullability.Equals(x, y); // string != string?注: 更多关于 SymbolEqualityComparer 比较器与默认比较器的差别,请参阅此帖子: https://github.com/dotnet/roslyn-analyzers/issues/3427
完成 CollectionExportMethodInfo 的定义之后,将其作为返回值返回
csharp
// 获取代码的位置,用于生成警告和错误。即告诉 Visual Studio 应该在哪里飘红
var location = syntaxContext.TargetNode.GetLocation();
// 使用 record 类型自带的相等判断,能够省心很多
return new CollectionExportMethodInfo(constructorArgumentType, collectionType,
new GeneratedCodeInfo(generatedCode, $"{className}.{methodSymbol.Name}"), location);返回时,从 TargetNode 里面调用 GetLocation 获取到 Location 位置信息。此 Location 信息可用于后续生成警告和错误信息,即告诉 Visual Studio 应该在哪里飘红。拿到的 Location 就是对应的代码的位置信息,如是哪个文件,哪个行号,从哪列到哪列等信息
由于在 ForAttributeWithMetadataName 语义分析过程中,还包含了一些过滤条件,将不满足条件的,都使用 null 进行返回。于是在 ForAttributeWithMetadataName 方法完成返回时,再叠加 Where 条件,用于过滤掉不符合条件的情况。其代码如下
csharp
var provider = context
.SyntaxProvider.ForAttributeWithMetadataName
(
"Lindexi.CollectionAttribute", static (SyntaxNode node, CancellationToken _) =>
{
... // 忽略其他代码
},
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken _) =>
{
... // 忽略其他代码
}
)
// 过滤掉不符合条件的情况
.Where(t => t != null);回顾本次演练的任务,在当前步骤里面收集到的是一个个的标记了 CollectionAttribute 特性的分部方法,以及这些方法的返回值类型。敲黑板,这里收集到的是一个个的。这就意味着如果直接拿这一个个去与后续的全项目所有类型进行处理,则其处理次数会是 m * n 的量,这里的 m 是标记了 CollectionAttribute 特性的分部方法的数量,n 是全项目所有类型的数量。且这个触发不止一次,而是每次有代码变更都会触发。在 Roslyn 源代码生成器里面禁止此行为,只允许将 IncrementalValuesProvider 多值提供器与 IncrementalValueProvider 单值提供器进行 Combine 组合。禁止将 IncrementalValuesProvider 多值提供器与 IncrementalValuesProvider 多值提供器进行组合
这里有一个容易混淆的点,多值提供器与单值提供器,其类型分别如下:
IncrementalValuesProvider<T>多值提供器IncrementalValueProvider<T>单值提供器
两者差异只是一个是 Values 而另一个是 Value 而已,即多了 s 的差别而已,两个单词比较好混哦
为了能够和后续的全项目类型收集进行 Combine 合并组合处理,这里在 Where 之后,再调用 Collect 方法,将其收集起来,成为 IncrementalValueProvider<ImmutableArray<CollectionExportMethodInfo>> 单值提供器,代码如下
csharp
IncrementalValueProvider<ImmutableArray<CollectionExportMethodInfo>> collectionMethodInfoProvider = context
.SyntaxProvider.ForAttributeWithMetadataName(
"Lindexi.CollectionAttribute", static (SyntaxNode node, CancellationToken _) =>
{
... // 忽略其他代码
},
(GeneratorAttributeSyntaxContext syntaxContext, CancellationToken _) =>
{
... // 忽略其他代码
})
// 过滤掉不符合条件的情况
.Where(t => t != null)
.Collect()!;大家是否好奇,似乎这里的 IncrementalValueProvider<ImmutableArray<T>> 单值提供器也是骗人的,里面明明就是一个不可变数组,也就是里面就是一个集合。为什么这样也能称为单值提供器?因为多值和单值是从源代码生成器的缓存角度来说的。即数据提供器里面提供的是多个值还是单个值。这里的 IncrementalValueProvider<ImmutableArray<T>> 单值提供器,其提供的是一个集合,即一个值,所以称为单值提供器。核心差异在于如代码变更的时候,应该刷新的范围是多大。对于 IncrementalValueProvider<ImmutableArray<T>> 来说,只要有一个标记了 CollectionAttribute 的符合条件的分部方法发生了变更,就会触发整个集合的刷新,即 collectionMethodInfoProvider 将会重新提供值
但对于 IncrementalValuesProvider<T> 多值提供器来说,里面的每一项都是独立的,其中一项的变更,只有触发其对应的一次,而不会影响其他项的触发。这也就是为什么 Collect 的设计上不允许多值提供器与多值提供器进行组合的原因。因为多值提供器与多值提供器组合,将会在某一项值变更的时候,其触发条件是比较震荡的,复杂度比较高,不仅人类程序猿顶不住,机器也顶不住
换句话说就是只要任意一个标记了 CollectionAttribute 的符合条件的分部方法发生了变更,就会触发整个 ImmutableArray 集合的刷新。但任意一个标记了 CollectionAttribute 的符合条件的分部方法发生了变更,走到 Where 处的变更也就只有这一个分部方法而已,只不过后续的 ImmutableArray 集合的刷新是靠 Collect 触发的。因为到 Where 处还是多值提供器,只有到 Collect 处才会变成单值提供器
以上代码就完成了对标记了 CollectionAttribute 特性的分部方法的收集,分析使用了 CollectionAttribute 特性的分部方法,且找到方法的返回值参数,生成 CollectionAttribute 特性类型的代码。接下来将会在下一步根据返回值参数的类型,遍历收集全项目的类型,找到感兴趣的类型,生成创建器代码
遍历收集全项目的类型,生成创建器代码
全项目类型收集过程里面将不能使用 ForAttributeWithMetadataName 方法,而是需要使用上文介绍的高度定制支持的更底层的收集分析的 CreateSyntaxProvider 方法。在语法层面,先判断是类型即可通过,本身就需要遍历全项目的类型的,自然判断语法是类型即可
csharp
IncrementalValuesProvider<INamedTypeSymbol> wholeAssemblyClassTypeProvider = context.SyntaxProvider.CreateSyntaxProvider(
static (SyntaxNode node, CancellationToken _) => node.IsKind(SyntaxKind.ClassDeclaration),
(GeneratorSyntaxContext syntaxContext, CancellationToken _) =>
{
... // 忽略其他代码
});语义层面上,由于现在还没有和对标记了 CollectionAttribute 特性的分部方法的收集的合并,在语义层面上也就没啥好判断的。最多只判断要求类型不能是抽象的,毕竟按照咱的需求任务来说,要的就是创建出对象,抽象类型就不能被直接创建啦,自然就可以被过滤掉
csharp
// 全项目里面的类型
IncrementalValuesProvider<INamedTypeSymbol> wholeAssemblyClassTypeProvider
= context.SyntaxProvider
.CreateSyntaxProvider(
static (SyntaxNode node, CancellationToken _) => node.IsKind(SyntaxKind.ClassDeclaration),
static (GeneratorSyntaxContext generatorSyntaxContext, CancellationToken token) =>
{
var classDeclarationSyntax = (ClassDeclarationSyntax) generatorSyntaxContext.Node;
INamedTypeSymbol? assemblyClassTypeSymbol =
generatorSyntaxContext.SemanticModel.GetDeclaredSymbol(classDeclarationSyntax, token);
if (assemblyClassTypeSymbol is not null && !assemblyClassTypeSymbol.IsAbstract)
{
return assemblyClassTypeSymbol;
}
return null;
})
.Where(t => t != null)!;完成了全项目类型的收集之后,就可以和收集了标记了 CollectionAttribute 特性的分部方法的 collectionMethodInfoProvider 进行合并,其代码如下
csharp
wholeAssemblyClassTypeProvider
.Combine(collectionMethodInfoProvider)调用 Combine 之后返回的类型是一个元组,为 IncrementalValuesProvider<(INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right)> 类型。即左边 Left 是多值提供器里面的每一个值,即项目里面的每个类型,右边是单值提供器里面的值
继续处理,带上 Select 方法,判断各自类型是否满足标记了 CollectionAttribute 特性的分部方法的感兴趣条件
csharp
wholeAssemblyClassTypeProvider
.Combine(collectionMethodInfoProvider)
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
INamedTypeSymbol assemblyClassTypeSymbol = tuple.Left;
var exportMethodReturnTypeCollectionResultArray = tuple.Right;
... // 忽略其他代码
})在这一步里面,咱可以激进一些,直接就干到生成了对应的项的代码里面,即生成如 yield return context => new Foo(context); 的代码。为了表示此返回类型,这里再次定义一个名为 ItemGeneratedCodeResult 的新的类型
csharp
readonly record struct ItemGeneratedCodeResult
(
string ItemGeneratedCode,
GeneratedCodeInfo ExportMethodGeneratedCodeInfo
)
{
public Diagnostic? Diagnostic { get; init; }
}这个新的 ItemGeneratedCodeResult 类型采用的是 readonly record struct 的设计,这会让分析器更加开森。我感觉 readonly record struct 是非常舒坦的设计,不会担心这样的类型在大量使用中,会造成大量的堆对象分配,也不会担心其分配成本和 GC 压力。使用值类型的设计是在分析器官方里面所推荐的,如以下的官方文档所示
Use value types where possible: Value types are more amenable to caching and usually have well defined and easy to understand comparison semantics.
以上的 ItemGeneratedCodeResult 类型包含了 Diagnostic 类型的 Diagnostic 属性,这是用于在进行源代码生成过程中,发现某些代码不符合预期,进行的分析警告或错误信息。从这里也可以看出来源代码生成器本身也带有分析器的功能,这部分的具体使用将在下文介绍
由于 Right 是 ImmutableArray<CollectionExportMethodInfo> 类型,表示的所有的标记了 CollectionAttribute 的分部方法收集信息。因此这里咱也需要对应的创建一个列表,用于建立多对多的关系,即一个类型可能存在对应多个分部方法的关系
csharp
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
INamedTypeSymbol assemblyClassTypeSymbol = tuple.Left;
var exportMethodReturnTypeCollectionResultArray = tuple.Right;
// 慢点创建列表,因为这里是每个类型都会进入一次的,进入次数很多。但大部分类型都不满足条件。因此不提前创建列表能减少很多对象的创建
List<ItemGeneratedCodeResult>? result = null;
... // 忽略其他代码
})这里的 List<ItemGeneratedCodeResult>? result 我选择不要一开始就创建,因为现在收集到的类型不一定会满足任何一个分部方法的要求,即这将是一个被忽略的类型。慢点创建可以减少浪费
遍历分部方法收集 ImmutableArray<CollectionExportMethodInfo> 数组,判断类型是否落在某个分部方法感兴趣条件里面,代码如下
csharp
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
INamedTypeSymbol assemblyClassTypeSymbol = tuple.Left;
var exportMethodReturnTypeCollectionResultArray = tuple.Right;
// 慢点创建列表,因为这里是每个类型都会进入一次的,进入次数很多。但大部分类型都不满足条件。因此不提前创建列表能减少很多对象的创建
List<ItemGeneratedCodeResult>? result = null;
foreach (CollectionExportMethodInfo exportMethodInfo in exportMethodReturnTypeCollectionResultArray)
{
// 一般进入循环的时候,都会加上这个判断。这个判断逻辑的作用是如开发者在 IDE 里面进行编辑文件的时候,那此文件对应的类型就需要重新处理,即类型对应的 token 将会被激活。此时在循环跑的逻辑就是浪费的,逻辑需要重跑,因此需要判断 token 是否被取消,减少循环里面的不必要的逻辑损耗
// check for cancellation so we don't hang the host
token.ThrowIfCancellationRequested();
... // 忽略其他代码
}
})按照 Roslyn 的设计,在进入大循环等逻辑时,应该多判断一下令牌。这个原因是开发者可能不断在 IDE 里面进行编辑文件,源代码生成器执行过程中对应的文件已经被更改了,本次处理是无效的,此时对此文件涉及的相关类型的处理就应该无效掉,等待重新进入。预先多加令牌判断,可以减少无用处理,减少损耗,避免原本就很卡的 Visual Studio 更加卡顿
在 foreach 里面判断当前的 assemblyClassTypeSymbol 类型是否继承自分部方法要求的返回类型,如以下代码所示
csharp
foreach (CollectionExportMethodInfo exportMethodInfo in exportMethodReturnTypeCollectionResultArray)
{
token.ThrowIfCancellationRequested();
// 判断当前的类型是否是我们需要的类型
if (!IsInherit(assemblyClassTypeSymbol, exportMethodInfo.CollectionType))
{
continue;
}
... // 忽略其他代码
}以上的 IsInherit 方法的实现如下
csharp
/// <summary>
/// 判断类型继承关系
/// </summary>
/// <param name="currentType">当前的类型</param>
/// <param name="requiredType">需要继承的类型</param>
/// <returns></returns>
public static bool IsInherit(ITypeSymbol currentType, ITypeSymbol requiredType)
{
var baseType = currentType.BaseType;
while (baseType is not null)
{
if (SymbolEqualityComparer.Default.Equals(baseType, requiredType))
{
// 如果基类型是的话
return true;
}
// 否则继续找基类型
baseType = baseType.BaseType;
}
foreach (var currentInheritInterfaceType in currentType.AllInterfaces)
{
if (SymbolEqualityComparer.Default.Equals(currentInheritInterfaceType, requiredType))
{
// 如果继承的类型是的话
return true;
}
}
return false;
}继承条件判断里面是无视引用对象可空情况的,直接使用 SymbolEqualityComparer.Default 判断即可,不用或不该用 SymbolEqualityComparer.IncludeNullability 进行判断。以上的 IsInherit 是一个我常写的工具方法,可以用来判断给定类型是否被继承,包括基类型和接口类型
在真实项目里面,通过 IsInherit 即可过滤大量类型,毕竟能够满足条件的,预期还是少数。再下一步就是寻找构造函数了。在 C# 语法里面,只能做到 new T() 泛型,做不到构造函数里面带参数的情况。源代码生成器里面可以轻易做到这一点,通过这个演练也能让大家看到源代码生成器的威力。在很多通用创建器、工厂模式等,可以打破泛型 T 只能创建无参构造函数的限制,过程中也不用任何反射,都是最直接的代码,对裁剪和 AOT 友好
如果类型满足继承条件,则继续寻找构造函数。感兴趣的构造函数的特征是有且只有一个参数,参数类型等于分部方法传入的 context 类型。我这里就完全限定参数类型相等,而不是说其 context 的基类型也可以,这仅仅只是为了简单演示而已
csharp
// 判断当前的类型是否是我们需要的类型
if (!IsInherit(assemblyClassTypeSymbol, exportMethodInfo.CollectionType))
{
continue;
}
// 遍历其构造函数,找到感兴趣的构造函数
IMethodSymbol? candidateConstructorMethodSymbol = null;
foreach (IMethodSymbol constructorMethodSymbol in ssemblyClassTypeSymbol.Constructors)
{
if (constructorMethodSymbol.Parameters.Length != 1)
{
// 根据需求任务可知,感兴趣的构造函数的特征是有且只有一个参数
// 如果参数数量不等于 1 则不满足条件
continue;
}
// 判断参数的类型是否符合预期
IParameterSymbol parameterSymbol = constructorMethodSymbol.Parameters[0]; // 前面判断限定有且只有一个参数,这里可以放心使用下标访问获取首个参数
var parameterType = parameterSymbol.Type;
// 以下忽略是否可空的判断,因此业务上传入时都是有值的,因此无视可空情况。直接使用 SymbolEqualityComparer.Default 判断即可
if (SymbolEqualityComparer.Default.Equals(parameterType,
exportMethodInfo.ConstructorArgumentType))
{
// 如果参数类型满足条件,则这就是感兴趣的构造函数
candidateConstructorMethodSymbol = constructorMethodSymbol;
// 为什么直接 Break 了,不继续找找?继续找找也找不到的,因为不可能存在两个构造函数有相同的参数签名,即不存在两个构造函数的参数数量只有一个且参数类型相同的情况。不信的话,自己写写看就明白了,写任意类型包含两个构造函数,这两个构造函数的参数数量只有一个且参数类型相同
// 当然,如果前面判断条件开放为判断满足 `exportMethodInfo.ConstructorArgumentType` 的基类型条件,那自然这里也许就可能会有多个构造函数的情况,也就需要排优先级了哈。不排也可以,毕竟生成出来的代码都是一样的,但不排的话,语义层面则是不正确的。为了简单演示,这里就直接限制要求类型相同而不是判断继承关系
break;
}
}能够进入到这一步的,才开始创建列表用于作为返回值
csharp
result ??= new List<ItemGeneratedCodeResult>();判断是否存在满足条件的构造函数,如满足条件,则开始生成代码
csharp
result ??= new List<ItemGeneratedCodeResult>();
if (candidateConstructorMethodSymbol is not null)
{
var fullNameDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Included,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var className = assemblyClassTypeSymbol.ToDisplayString(fullNameDisplayFormat);
// context => new F1(context)
var generatedCode = $"context => new {className}(context)";
result.Add(new ItemGeneratedCodeResult(generatedCode, exportMethodInfo.GeneratedCodeInfo));
}那如果没有存在满足条件的构造函数呢?此时就可以报告一条分析报告信息了
csharp
if (candidateConstructorMethodSymbol is not null)
{
... // 忽略其他代码
}
else
{
// 找不到满足条件的构造函数,给出分析警告
Diagnostic diagnostic = ...
result.Add(default(ItemGeneratedCodeResult) with
{
Diagnostic = diagnostic,
});
}分析警告警告内容也有点知识量,也比较独立,我准备在下文独立和大家介绍,这里就一笔略过。大家在这里只需知道在源代码生成器过程中,如果分析到某些代码难以开展后续的生成工作,可以在此创建分析警告或错误,用于提示开发者
最后,将 result 列表返回即可
csharp
return result?.ToImmutableArray() ?? ImmutableArray<ItemGeneratedCodeResult>.Empty;以上代码将 List<ItemGeneratedCodeResult> 转换为不可变的数组进行返回,如此可以更好的符合分析器的设计。整个寻找整个项目的感兴趣的类型和生成部分代码的过程的代码如下
csharp
IncrementalValuesProvider<ImmutableArray<ItemGeneratedCodeResult>> itemGeneratedCodeResultProvider =
wholeAssemblyClassTypeProvider
.Combine(collectionMethodInfoProvider)
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
INamedTypeSymbol assemblyClassTypeSymbol = tuple.Left;
var exportMethodReturnTypeCollectionResultArray = tuple.Right;
// 慢点创建列表,因为这里是每个类型都会进入一次的,进入次数很多。但大部分类型都不满足条件。因此不提前创建列表能减少很多对象的创建
List<ItemGeneratedCodeResult>? result = null;
foreach (CollectionExportMethodInfo exportMethodInfo in exportMethodReturnTypeCollectionResultArray)
{
// 一般进入循环的时候,都会加上这个判断。这个判断逻辑的作用是如开发者在 IDE 里面进行编辑文件的时候,那此文件对应的类型就需要重新处理,即类型对应的 token 将会被激活。此时在循环跑的逻辑就是浪费的,逻辑需要重跑,因此需要判断 token 是否被取消,减少循环里面的不必要的逻辑损耗
// check for cancellation so we don't hang the host
token.ThrowIfCancellationRequested();
// 判断当前的类型是否是我们需要的类型
if (!IsInherit(assemblyClassTypeSymbol, exportMethodInfo.CollectionType))
{
continue;
}
// 遍历其构造函数,找到感兴趣的构造函数
IMethodSymbol? candidateConstructorMethodSymbol = null;
foreach (IMethodSymbol constructorMethodSymbol in assemblyClassTypeSymbol.Constructors)
{
if (constructorMethodSymbol.Parameters.Length != 1)
{
continue;
}
// 判断参数的类型是否符合预期
IParameterSymbol parameterSymbol = constructorMethodSymbol.Parameters[0];
var parameterType = parameterSymbol.Type;
if (SymbolEqualityComparer.Default.Equals(parameterType,
exportMethodInfo.ConstructorArgumentType))
{
candidateConstructorMethodSymbol = constructorMethodSymbol;
break;
}
}
result ??= new List<ItemGeneratedCodeResult>();
var fullNameDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Included,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var className = assemblyClassTypeSymbol.ToDisplayString(fullNameDisplayFormat);
if (candidateConstructorMethodSymbol is not null)
{
// context => new F1(context)
var generatedCode = $"context => new {className}(context)";
result.Add(new ItemGeneratedCodeResult(generatedCode, exportMethodInfo.GeneratedCodeInfo));
}
else
{
// 找不到满足条件的构造函数,给出分析警告
Diagnostic diagnostic = ...
result.Add(default(ItemGeneratedCodeResult) with
{
Diagnostic = diagnostic,
});
}
}
return result?.ToImmutableArray() ?? ImmutableArray<ItemGeneratedCodeResult>.Empty;
});为了能够在后续步骤更好地聚焦处理,这里也同样在 itemGeneratedCodeResultProvider 叠加一个 Where 进行过滤,去掉空集,代码如下
csharp
IncrementalValuesProvider<ImmutableArray<ItemGeneratedCodeResult>> itemGeneratedCodeResultProvider =
wholeAssemblyClassTypeProvider
.Combine(collectionMethodInfoProvider)
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
... // 忽略其他代码
})
.Where(t => t != ImmutableArray<ItemGeneratedCodeResult>.Empty);如此即可确保后续步骤拿到的 itemGeneratedCodeResultProvider 提供的值都不会是空集
在这里,大家看到了很多熟悉的类似 Linq 里面的 Where 和 Select 方法。这些方法只是命名上和 Linq 相同,实际上不是原来的 Linq 的方法。但从方法的用途上和设计上,可以看到在 IIncrementalGenerator 这部分设计里面是非常靠近 Linq 的设计的。在更底层的设计上,所期望的就是让数据可以和 Linq 的数据流设计一样,能够一级级传递,且过程中是 Lazy 的和带缓存的。核心目的就是减少计算压力,充分利用 Roslyn 的不可变性带来的缓存机制,减少分析过程的计算压力,不让原本就很卡的 Visual Studio 更加卡。我将在下文基础知识部分和大家详细解析 Where 和 Select 和 Combine 等这几个基础 IIncrementalGenerator 增量源代码生成器的专有方法
通过以上的步骤,就完成了收集各个感兴趣类型的构造函数的过程,且生成了对应的创建器委托代码。接下来就可以进行组装最终的代码了
以上是逐个类型跑出来的,需要将其组装起来,生成最终的代码。这里采用的方法是先用 Collect 将其聚合为一个大数组,再使用 SelectMany 将其散开。为什么需要做合分的处理?原因是 itemGeneratedCodeResultProvider 提供的数组是一个类型对应在多个分部方法里面的生成代码,而最终需要生成的是单个分部方法包含多个类型的代码,且期望各个分部方法独立生成。于是就需要先调用 Collect 将其聚合为一个大数组,如此才能让各个分部方法拿到所有感兴趣的类型的生成代码,再调用 SelectMany 方法让每个分部方法独立输出,代码如下
csharp
itemGeneratedCodeResultProvider
.Collect()
.SelectMany((ImmutableArray<ImmutableArray<ItemGeneratedCodeResult>> array, CancellationToken oken) =>
{
... // 忽略其他代码
});原本 itemGeneratedCodeResultProvider 就是一个多值提供器,提供的每个值都是 ImmutableArray<ItemGeneratedCodeResult> 类型。调用 Collect 之后,就转换成了 ImmutableArray<ImmutableArray<ItemGeneratedCodeResult>> 类型,套了两层数组。在 SelectMany 里面,需要先将其拆散,按照 ItemGeneratedCodeResult 里面的 ExportMethodGeneratedCodeInfo 进行分组。这时候采用 Linq 来写就非常简单,代码如下
csharp
itemGeneratedCodeResultProvider
.Collect()
.SelectMany((ImmutableArray<ImmutableArray<ItemGeneratedCodeResult>> array, CancellationTokentoken) =>
{
IEnumerable<IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult>> group = array
.SelectMany(t => t)
// 如果 Diagnostic 不是空,则证明这条是用来报告的,忽略
.Where(t => t.Diagnostic is null)
.GroupBy(t => t.ExportMethodGeneratedCodeInfo);
... // 忽略其他代码
});这里拿到的 IEnumerable<IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult>> group 看似很长,其实含义非常明了,表示的是多个组。每个组的领导就是 GeneratedCodeInfo 类型,实际含义是分部方法。简单来说可以看成 IEnumerable<分部方法组> 类型,细分 分部方法组 就包含了分部方法的信息本身,以及各个满足条件的类型和其生成代码。每个 分部方法组 就可以组成一个最终生成代码
将 IEnumerable<IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult>> group 进行遍历,每一项都可生成一个独立的分部方法的实现代码
csharp
IEnumerable<IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult>> group = array
.SelectMany(t => t)
// 这条是用来报告的,忽略
.Where(t => t.Diagnostic is null)
.GroupBy(t => t.ExportMethodGeneratedCodeInfo);
var generatedCodeList = new List<GeneratedCodeInfo>();
foreach (IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult> temp in group)
{
// 在这里就是可以组装出各个标记了 CollectionAttribute 特性的分部方法的实现代码
... // 忽略其他代码
}以下就是组装标记了 CollectionAttribute 特性的分部方法的实现代码,先将各个满足条件的类型的生成代码放入到 StringBuilder 里面,转换为方法体核心内容,代码如下
csharp
var generatedCodeList = new List<GeneratedCodeInfo>();
foreach (IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult> temp in group)
{
// 进行组装生成代码。在 Select 系列方法组装会比在 RegisterSourceOutput 更好,在这里更加便被打断
var stringBuilder = new StringBuilder();
foreach (ItemGeneratedCodeResult itemGeneratedCodeResult in temp)
{
token.ThrowIfCancellationRequested();
// yield return context => new F1(context);
stringBuilder.AppendLine($" yield return itemGeneratedCodeResult.ItemGeneratedCode};");
}
// 严谨一些,添加 break 语句。顺带解决收集不到任何一个类型的情况
stringBuilder.AppendLine(" yield break;");
}在以上生成代码里面,还在最后添加了 yield break; 代码,如此可以顺带解决收集不到任何一个类型的情况,即使收集不到一个类型,也能返回空集,而不会让构建炸掉
再根据上文提供的 yield return context => new F1(context); 用于被替换的预置内容,将其进行替换,即可完成分部方法实现方法体的内容
csharp
// 这是用来替换的代码
var replacedCode = " yield return context => new F1(context);";
GeneratedCodeInfo generatedCodeInfo = temp.Key;
var generatedCode = generatedCodeInfo.GeneratedCode.Replace(replacedCode, stringBuilder.ToString());当前的 generatedCode 变量的内容大概如下,即以下代码内容就是最终的分部方法生成的方法体内容示例
csharp
namespace KawhawnahemCanalllearlerwhu;
public static partial class FooCollection
{
public static partial global::System.Collections.Generic.IEnumerable<global::System.Func<global::KawhawnahemCanalllearlerwhu.IContext, global::KawhawnahemCanalllearlerwhu.IFoo>>
GetFooCreatorList()
{
yield return context => new global::KawhawnahemCanalllearlerwhu.F1(context);
yield return context => new global::KawhawnahemCanalllearlerwhu.F2(context);
yield break;
}
}生成最终代码之后,将其加入到 generatedCodeList 列表里面,如以下代码所示
csharp
generatedCodeList.Add(new GeneratedCodeInfo(generatedCode, generatedCodeInfo.Name));最后,将 generatedCodeList 列表返回即可
csharp
IncrementalValuesProvider<GeneratedCodeInfo> generatedCodeInfoProvider = itemGeneratedCodeResultProvider
.Collect()
.SelectMany((ImmutableArray<ImmutableArray<ItemGeneratedCodeResult>> array, CancellationToken token) =>
{
IEnumerable<IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult>> group = array
.SelectMany(t => t)
// 这条是用来报告的,忽略
.Where(t => t.Diagnostic is null)
.GroupBy(t => t.ExportMethodGeneratedCodeInfo);
var generatedCodeList = new List<GeneratedCodeInfo>();
foreach (IGrouping<GeneratedCodeInfo, ItemGeneratedCodeResult> temp in group)
{
var generatedCode = ... // 最终生成的分部方法的方法体
generatedCodeList.Add(new GeneratedCodeInfo(generatedCode, generatedCodeInfo.Name));
}
return generatedCodeList;
});是否大家好奇为什么 generatedCodeInfoProvider 是 IncrementalValuesProvider<GeneratedCodeInfo> 类型?明明最后返回的是 List<GeneratedCodeInfo> generatedCodeList 列表?这是因为当前调用的就是 SelectMany 方法,其功能和 Linq 的 SelectMany 方法一样,都是将返回的列表进行拆散
最后一步就是将生成的代码进行注入,这里调用的是 RegisterImplementationSourceOutput 方法。回顾一下几个注入生成代码的方法的差别,其中 RegisterImplementationSourceOutput 的作用是注册具体的实现部分的生成代码。这个方法的调用可以让 IDE 进行充分的优化,因为具体的实现的内容不影响外部的语法语义分析,外部的语法语义分析靠定义部分即可完成,因此对于实现的内容部分可以尽量慢点调用和减少调用频次。刚好在本演练里面,生成的代码就是具体的实现部分,调用 RegisterImplementationSourceOutput 方法是非常合适的
csharp
context.RegisterImplementationSourceOutput(generatedCodeInfoProvider,
(SourceProductionContext productionContext, GeneratedCodeInfo generatedCodeInfo) =>
{
productionContext.AddSource($"{generatedCodeInfo.Name}.cs", generatedCodeInfo.GeneratedCode);
});按照源代码生成器的最佳实践来说,在 RegisterImplementationSourceOutput 等注册代码步骤里面,应该接近没有逻辑。即在值提供器步骤时,就将代码生成完成,到 RegisterXxx 方法里面只做注册而已。这样就比较方便在前面步骤进行打断,以及缓存复用
报告 Diagnostic 信息
认真阅读文章的伙伴也许还记得上文部分提到了 Diagnostic 信息。在源代码生成器的过程中,如果发现某些代码不符合预期,可以通过报告 Diagnostic 信息,用于提示开发者。在上文的代码里面,如果找不到满足条件的构造函数,就会报告一条分析警告。这里就来详细介绍如何报告 Diagnostic 信息
回到 itemGeneratedCodeResultProvider 变量的赋值部分代码,即使对全项目的类型 wholeAssemblyClassTypeProvider 进行"遍历"的时候,如果一个类型满足分部方法收集条件,但不存在任何一个满足条件的构造函数时,应该给出分析警告。如本演练给出的 F3 测试类型的定义如下
csharp
public class F3 : IFoo
{
public F3()
{
// 忽略其他代码
}
}对应的分部方法的定义如下
csharp
public static partial class FooCollection
{
[Collection]
public static partial IEnumerable<Func<IContext, IFoo>> GetFooCreatorList();
}可以明显看出给出的 F3 测试类型是歪楼的,没有构造函数满足 GetFooCreatorList 收集条件。于是在 wholeAssemblyClassTypeProvider 进行遍历的过程中,应该对这些歪楼的类型给出警告
csharp
IncrementalValuesProvider<INamedTypeSymbol> wholeAssemblyClassTypeProvider = ...
wholeAssemblyClassTypeProvider
.Combine(collectionMethodInfoProvider)
.Select(static ((INamedTypeSymbol Left, ImmutableArray<CollectionExportMethodInfo> Right) tuple,
CancellationToken token) =>
{
INamedTypeSymbol assemblyClassTypeSymbol = tuple.Left;
var exportMethodReturnTypeCollectionResultArray = tuple.Right;
List<ItemGeneratedCodeResult>? result = null;
foreach (CollectionExportMethodInfo exportMethodInfo inexportMethodReturnTypeCollectionResultArray)
{
... // 忽略其他代码
// 遍历其构造函数,找到感兴趣的构造函数
IMethodSymbol? candidateConstructorMethodSymbol = null;
... // 尝试获取满足条件的构造函数
if (candidateConstructorMethodSymbol is not null)
{
}
else
{
Diagnostic diagnostic = ...
result.Add(default(ItemGeneratedCodeResult) with
{
Diagnostic = diagnostic,
});
}
}
return result?.ToImmutableArray() ?? ImmutableArray<ItemGeneratedCodeResult>.Empty;
})现在咱来开始填补 Diagnostic diagnostic = ... 这句代码的具体内容。首先需要创建一个 DiagnosticDescriptor 对象,用于描述这个 Diagnostic 信息的基本信息,如 ID、Title、MessageFormat、Category 等。这是因为大部分的 Diagnostic 基本信息都是固定的,唯一不同的就是具体的 Message 提示消息内容的一些参数不同,以及代码 Location 的不同而已。再加上为了让分析器能够提供给全球的开发者使用,自然要照顾多语言问题,这部分就可以独立出来定义,不用每次报告都重复生成。当然了,为了演示方便,我这里就在每次循环里面,每找到一次不满足条件的构造函数就创建一个 DiagnosticDescriptor 对象,实际项目中应该是提前定义好的,不用每次循环都创建,甚至作为静态的字段都是合理的
csharp
// 找不到满足条件的构造函数,给出分析警告
var diagnosticDescriptor = new DiagnosticDescriptor
(
id: nameof(Resources.Kaw001),
title: Localize(nameof(Resources.Kaw001)),
messageFormat: Localize(nameof(Resources.Kaw001_Message)),
category: "FooCompiler",
DiagnosticSeverity.Warning,
isEnabledByDefault: true
);大家可以发现,以上代码写了 Resources.Kaw001 资源定义,这部分是依靠在分析器项目里面建立 Resources.resx 资源而被生成的属性。通过建立 Resources.resx 文件,可以复用原本 dotnet 内建的多语言机制,生成多语言程序集等方式提供多语言包。本文这里不过多介绍多语言的创建方式,大家感兴趣还请自行了解
具体做法就是创建 Resources.resx 文件,确保在 csproj 项目里面里面设置为 ResXFileCodeGenerator 生成方式或其他的生成方式
xml
<ItemGroup>
<Compile Update="Properties\Resources.Designer.cs">
<DesignTime>True</DesignTime>
<AutoGen>True</AutoGen>
<DependentUpon>Resources.resx</DependentUpon>
</Compile>
</ItemGroup>
<ItemGroup>
<EmbeddedResource Update="Properties\Resources.resx">
<Generator>ResXFileCodeGenerator</Generator>
<LastGenOutput>Resources.Designer.cs</LastGenOutput>
</EmbeddedResource>
</ItemGroup>
在 Resources.resx 文件里面添加两项,内容分别如下
Kaw001: 找不到符合预期的构造函数Kaw001_Message: 无法从 {0} 类型中找到构造函数,期望构造函数的只有一个参数,且参数为 {1} 类型
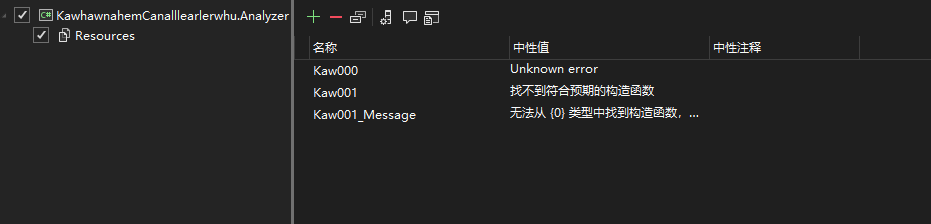
如上文代码,可见 Kaw001 将被当成标题,而 Kaw001_Message 被作为具体警告内容。其中 Kaw001_Message 添加了 {0} 和 {1} 内容,用于分别替换为具体警告信息内容的具体类型
为了作为警告内容,在 DiagnosticDescriptor 需要将 DiagnosticSeverity 设置为 Warning 等级。如期望作为错误,则需要设置为 Error 才可以。可用选项如下所示
csharp
/// <summary>Describes how severe a diagnostic is.</summary>
public enum DiagnosticSeverity
{
/// <summary>
/// Something that is an issue, as determined by some authority,
/// but is not surfaced through normal means.
/// There may be different mechanisms that act on these issues.
/// </summary>
Hidden,
/// <summary>
/// Information that does not indicate a problem (i.e. not prescriptive).
/// </summary>
Info,
/// <summary>Something suspicious but allowed.</summary>
Warning,
/// <summary>
/// Something not allowed by the rules of the language or other authority.
/// </summary>
Error,
}以上 category 分类是自己分析器内自定义的,这部分没有做要求,只要自己分类好就可以了。在我所在的团队的 https://github.com/dotnet-campus/dotnetCampus.MSBuildUtils 开源项目里面就内建了一些常用的分类,大家如果没有思路可以参考
上文代码中的 DiagnosticDescriptor 构造函数参数的 Localize 方法的实现如下,其作用是返回支持语言文化的 LocalizableString 类型而不是具体字符串
csharp
public static LocalizableString Localize(string key) =>
new LocalizableResourceString(key, Resources.ResourceManager, typeof(Resources));上文代码里面选用的 Kaw001 也是有约束的,即这是一个 C# 的标识符,使用前缀加数字形式,长度小于 15 个字符,确保唯一性。详细约束请参阅 https://learn.microsoft.com/en-us/dotnet/csharp/roslyn-sdk/choosing-diagnostic-ids
完成了对 DiagnosticDescriptor 的定义之后,接下来就可以开始创建 Diagnostic 对象。也如 DiagnosticDescriptor 的构造函数可以看到,其实基本信息都全了,剩下的就是填充具体警告信息的参数内容,即 {0} 和 {1} 参数内容,以及可选的警告的代码 Location 在哪信息而已
csharp
var fullNameDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Included,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var className = assemblyClassTypeSymbol.ToDisplayString(fullNameDisplayFormat);
// 无法从 {0} 类型中找到构造函数,期望构造函数的只有一个参数,且参数类型为 {1}
Diagnostic diagnostic = Diagnostic.Create(diagnosticDescriptor, exportMethodInfo.Location,
messageArgs:
[
className,
exportMethodInfo.ConstructorArgumentType.ToDisplayString(fullNameDisplayFormat)
]);如以上代码,可见警告飘红就在分部方法的定义上,内容就是当前的类型和分部方法构成的警告信息。按照本演练的例子,输出信息大概如下
csharp
C:\lindexi\Code\Roslyn\KawhawnahemCanalllearlerwhu\KawhawnahemCanalllearlerwhu\Foo.cs(40,5,41,81): warning Kaw001: 无法从 global::KawhawnahemCanalllearlerwhu.F3 类型中找到构造函数,期望构造函数的只有一个参数,且参数为 global::KawhawnahemCanalllearlerwhu.IContext 类型
这个过程中可以看到似乎有分析器的影子在里面了,报告 Diagnostic 过程本身也就是分析器的一个部分,大部分分析器的功能都是和源代码生成器相互重叠的,比如都需要进行语法语义的分析。不同点只是源代码生成器多了一个生成代码的过程
不过这里演示的还不是专用分析器的功能,在下文将会告诉大家如何写一个专用分析器。专用的分析器有更多好用的方法,其核心在于分析要尽量不影响用户编写代码,有各个时机可以选。但源代码生成器是如果没有生成,可能就影响到了用户写代码了,可选时机少了很多
以上就是本演练的全部实现内容。期望能够让大家了解到一个比较全面的源代码生成器的各个方面内容。大家也不要被此吓到,这是我专门找到的能够覆盖源代码生成器所用大部分技术的例子。大部分源代码生成器都不会用到涉及这么全面的技术内容的。以上的例子是我按照我所在的团队的可产品化的开源项目简化的内容,更多细节和产品化处理逻辑,可以去参考开源项目
使用了本演练介绍的技术的可产品化使用的开源项目: https://github.com/dotnet-campus/Telescope
代码
本章的代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin 7799af7403b6408b1e30151e144b2273c86433c7以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin 7799af7403b6408b1e30151e144b2273c86433c7获取代码之后,进入 Roslyn/KawhawnahemCanalllearlerwhu 文件夹,即可获取到源代码
生成的源代码保存到本地文件
在本演练里面生成的代码还算简单,也不知道大家是否在一开始就在好奇生成的代码是什么样子的。接下来我将告诉大家如何将生成的源代码保存到本地文件
对于比较复杂的生成代码而言,有时候会导致项目构建不通过。这个技术在实际开发中非常有用,默认的生成代码只能在 VisualStudio 里面的分析器里面一项项展开查看,没有具体的文件路径,对于源代码生成器作者的调试分析不够友好,也不方便将生成的代码发送给其他开发者辅助调试。将生成的源代码保存到本地文件,可以更好的辅助大家进行阅读和调试,以及采用第三方工具辅助分析生成的代码内容
将生成的源代码保存到本地文件只需在 csproj 项目文件里面设置 EmitCompilerGeneratedFiles 属性即可,设置完成之后,默认的生成源代码将会存放到 $(IntermediateOutputPath)\generated 文件夹里面,这里的 $(IntermediateOutputPath) 由 obj\$(Configuration)\$(TargetFramework.ToLowerInvariant())\ 构成,调试下的输出大概是 obj\Debug\net9.0\ 等类似的文件夹里
xml
<PropertyGroup>
<EmitCompilerGeneratedFiles>true</EmitCompilerGeneratedFiles>
</PropertyGroup>如果期望自己指定保存的文件夹,可以自行设置 EmitCompilerGeneratedFiles 属性,如以下代码
xml
<PropertyGroup>
<CompilerGeneratedFilesOutputPath>Generated\$(TargetFramework)</CompilerGeneratedFilesOutputPath>
</PropertyGroup>以上代码之所以拼接上 TargetFramework 是因为期望默认处理多框架的文件冲突问题,源代码生成器会在多框架下分别执行,为每个框架生成独立的代码。如果在多框架项目下没有配置加上 TargetFramework 将会造成生成的源代码存放的文件冲突
更多请参阅 将 Source Generator 生成的源代码保存到本地文件
基础知识
在上文介绍了基础 IIncrementalGenerator 增量源代码生成器的专有方法,如 Where 和 Select 和 Combine 等,这里将详细介绍这几个方法的用法和设计
开始之前重新介绍两个类型的值提供器,分别是 IncrementalValuesProvider 多值提供器和 IncrementalValueProvider 单值提供器。这两个类型的值提供器是源代码生成器的核心,用于提供源代码生成器的输入源
对于 IncrementalValuesProvider 多值提供器来说,里面的每一项都是独立的。比如以下代码
csharp
IncrementalValuesProvider<Foo> provider = ...
var t = provider.Select(...);当某个 Foo 项变更的时候,那么 Select 方法里面的代码就会重新执行,且只执行一次。其他没有变更的 Foo 项则不会触发 Select 方法里面的委托执行。通过类似的方式可以应用缓存,减少计算工作量
有些伙伴会感谢增量源代码生成器这部分 API 比较复杂。确实是比较复杂。但大家需要明确的是,咱现在正在编写的是和编译器相关的代码,所有和编译器沾边的,其难度都不低。在 Roslyn 以及其周边的设施的设计上,都追求性能、编写的复杂度、可维护性等多方面的平衡。如果没有源代码生成的 API 封装,直接面对最裸的编译器相关实现逻辑,那其开发难度和入门门槛可想而知的高
在性能追求方面上,性能优化常用套路里面就是减少计算量。除了语言层面能够提升之外,减少计算工作量能达到算法级的优化,这才是真正的优化。尽管 Roslyn 在发布之初就强调了性能,但即使单次构建足够快,架不住次数多。比如一个代码文件压到 1 毫秒,但我的项目有 2000 个文件,我假设无时不刻都在修改代码,那么每次构建就是 2000 毫秒,也就是 2 秒。这个时间对于一个大型项目来说,还是比较可观的。但事实上,绝大部分的代码我都没有动到,只有少部分的代码在修改。这时候就需要增量构建,只处理修改的代码,这样就能大大减少构建时间。这就是增量构建的优势所在
为了达成增量构建,就需要引入缓存不可变机制。引入缓存不可变机制,在一定程度上能够降低整体逻辑复杂度,不需要让程序猿去内耗对象是否被变更等问题。也方便底层设施搭建者进行复现问题,即方便重现问题,各个部件都是不可变的,方法都是无副作用的,自然重现步骤就简单了
在多方平衡之下,就有了现在大家所看到的 IIncrementalGenerator 增量源代码生成器的各个方法了。虽然看起来复杂,但只要想想原本的开发难度和复杂度,能够被降低到这个程度,就不会觉得这个 API 复杂了
对于 IncrementalValueProvider 单值提供器来说,里面只提供一个值,有时候这个值是一个数组集合,有时候里面就真的是一个值,比如下文会和大家介绍到的配置内容。在 IIncrementalGenerator 增量源代码生成器里面就充满了聚合和散开的逻辑,也推荐这么干,这样的逻辑更底层的思想是实现细颗粒度管控,能够更好地利用缓存,减少计算工作量
无论是 IncrementalValuesProvider 多值提供器还是 IncrementalValueProvider 单值提供器,整体设计都是采用管线方式,走数据流的方式,让数据一步步往下走。在每一步的输出里面都进行缓存检查,如果命中缓存,即没有更改,则不会触发后续的计算。这也就是 IIncrementalGenerator 增量源代码生成器命名的由来,即增量构建,只处理变更的部分。而 Linq 刚好就是数据流的一个现有实践,在增量源代码生成器里面复用了这部分的设计思想,只是 API 实现和行为略微不同,接下来我将逐一和大家介绍这几个方法的用法和设计
本章以下的介绍顺序保持和 https://github.com/dotnet/roslyn/blob/main/docs/features/incremental-generators.md 官方文档相同的顺序,对应的代码附图来源于此官方文档
Select
方法签名:
csharp
public static partial class IncrementalValueSourceExtensions
{
// 1 => 1 transform
// 1 对 1 的转换,从 TSource 转换为 TResult 类型的输出
// 为了简单表述,我使用 `IncrementalValue[s]Provider` 代表 `IncrementalValuesProvider` 和 `IncrementalValueProvider` 两个类型的值提供器都适用的情况
public static IncrementalValue[s]Provider<TResult> Select<TSource, TResult>(this IncrementalValue[s]Provider<TSource> source, Func<TSource, CancellationToken, TResult> selector);
}这是一个最常用的转换逻辑,用于从当前提供的数据转换为新的数据进行输出,可同时在 IncrementalValuesProvider 多值提供器和 IncrementalValueProvider 单值提供器
为了简单表述,我使用 IncrementalValue[s]Provider 代表 IncrementalValuesProvider 和 IncrementalValueProvider 两个类型的值提供器都适用的情况
如以下代码所示,从 FooInfo1 数据转换为 FooInfo2 数据
csharp
IncrementalValuesProvider<FooInfo1> foo1ValuesProvider = ...
IncrementalValuesProvider<FooInfo2> foo2ValuesProvider = foo1ValuesProvider.Select((FooInfo1 info1, CancellationToken token) => new FooInfo2());转换过程中,支持分叉和链式转换。分叉转换,即从一个 IncrementalValuesProvider 分叉为多条不同的转换分支,如下面代码所示
csharp
IncrementalValuesProvider<FooInfo1> foo1ValuesProvider = ...
IncrementalValuesProvider<FooInfo2> foo2ValuesProvider = foo1ValuesProvider.Select((FooInfo1 info1, CancellationToken token) => new FooInfo2());
IncrementalValuesProvider<FooInfo3> foo3ValuesProvider = foo1ValuesProvider.Select((FooInfo1 info1, CancellationToken token) => new FooInfo3());可见 foo2ValuesProvider 和 foo3ValuesProvider 来源于共同的 foo1ValuesProvider 数据源。这在多个不同的业务逻辑存在共有转换时非常有用,可以更多程度地进行复用计算
链式转换即一级级进行转换
csharp
IncrementalValuesProvider<FooInfo1> foo1ValuesProvider = ...
IncrementalValuesProvider<FooInfo2> foo2ValuesProvider = foo1ValuesProvider.Select((FooInfo1 info1, CancellationToken token) => new FooInfo2());
IncrementalValuesProvider<FooInfo3> foo3ValuesProvider = foo2ValuesProvider.Select((FooInfo2 info2, CancellationToken token) => new FooInfo3());
Select Many
方法签名:
csharp
// 1 转 多
// 多 转 多
public static IncrementalValuesProvider<TResult> SelectMany<TSource, TResult>(this IncrementalValue[s]Provider<TSource> source, Func<TSource, CancellationToken, IEnumerable<TResult>> selector);如以下代码所示,先从 IncrementalValueProvider<FooInfo1> 单值提供器,调用 SelectMany 进行单转多,获取到 IncrementalValuesProvider<FooInfo2> 多值提供器。再继续对 IncrementalValuesProvider<FooInfo2> 多值提供器调用 SelectMany 进行多转多获取到 IncrementalValuesProvider<FooInfo3> 多值提供器
csharp
IncrementalValueProvider<FooInfo1> foo1ValueProvider = ...
IncrementalValuesProvider<FooInfo2> foo2ValuesProvider = foo1ValueProvider.SelectMany
(
(FooInfo1 info1, CancellationToken token) =>
{
var n = info1.Number;
var list = new List<FooInfo2>();
for (int i = 0; i < n; i++)
{
list.Add(new FooInfo2());
}
return list;
}
);
IncrementalValuesProvider<FooInfo3> foo3ValuesProvider = foo2ValuesProvider.SelectMany
(
(FooInfo2 info2, CancellationToken token) =>
{
var list = new List<FooInfo3>();
for (int i = 0; i < info2.Count; i++)
{
list.Add(new FooInfo3());
}
return list;
}
);假定 FooInfo1 的 Number 的是 3 的值。每个 FooInfo2 的 Count 也是 3 的值,则经过以上转换之后,可获取带有 3x3=9 个元素的 IncrementalValuesProvider<FooInfo3> 多值提供器
从 IncrementalValueProvider<FooInfo1> 单值提供器,调用 SelectMany 进行单转多,获取到 IncrementalValuesProvider<FooInfo2> 多值提供器的过程是 1 转多的过程,相对来说很是清晰
对 IncrementalValuesProvider<FooInfo2> 多值提供器调用 SelectMany 进行多转多获取到 IncrementalValuesProvider<FooInfo3> 多值提供器的过程,相对来说就比较复杂,如以下的官方附图,每项都可转换为不定数量集合输出
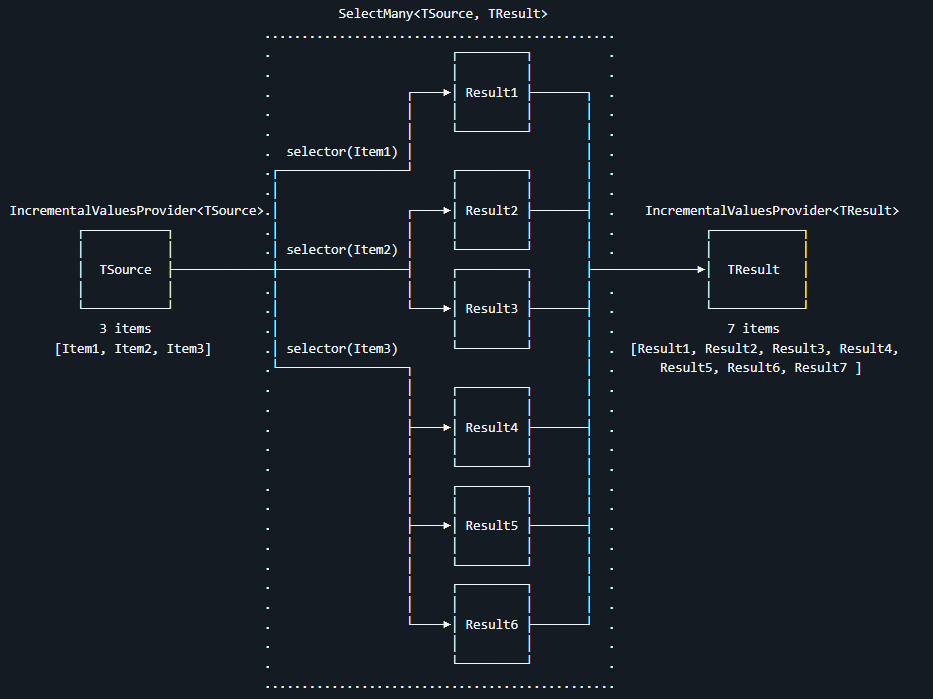
敲黑板,使用 SelectMany 的过程中,也可以附带过滤的作用。如上文所述,每项都可转换为不定数量集合输出,不定数量就意味着也可以返回 0 项。在 SelectMany 执行过滤作用的做法就是将不满足条件的直接过滤掉,甚至返回空集合。因此比较少见 SelectMany(...).Where(...) 的组合,直接就是在 SelectMany 里面内置了 Where 的活了
常见于将 SelectMany 和下文介绍的 Collect 混用,达成合和分的效果
Where
方法签名:
csharp
public static IncrementalValuesProvider<TSource> Where<TSource>(this IncrementalValuesProvider<TSource> source, Func<TSource, bool> predicate);没错,只有多值提供器才有 Where 方法。通过 Where 方法可用来过滤输入源里面符合条件的元素,将符合条件的元素作为输出源内容
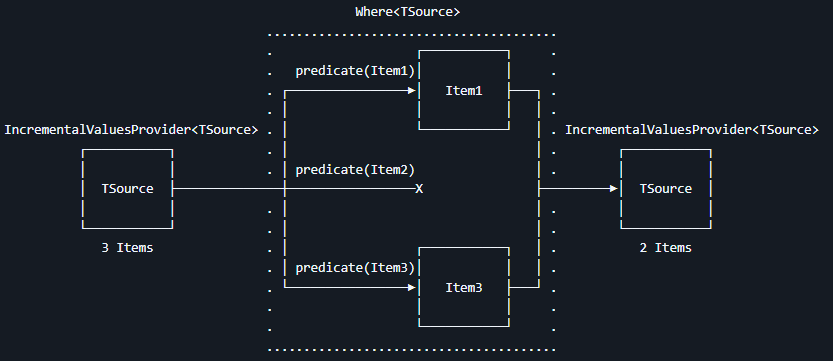
如上图官方附图所示,假定输入源有三个,中间一个不满足条件,也就是上面打了叉叉的 Item2 项,则最终只有 Item1 和 Item3 才能流向输出源里
正如大家所熟悉的 Linq 里面的 Select 和 Where 配合一样,在增量源代码生成器这里对这两个的用法和设计实现也都和 Linq 的相同
Collect
方法签名:
csharp
IncrementalValueProvider<ImmutableArray<TSource>> Collect<TSource>(this IncrementalValuesProvider<TSource> source);这是一个不用附带任何条件和转换器的方法。用于将一个多值提供器的内容,转换为单值提供器。这个过程中,一旦输入源有任何一项变动,则会重新输出整个新的不可变集合
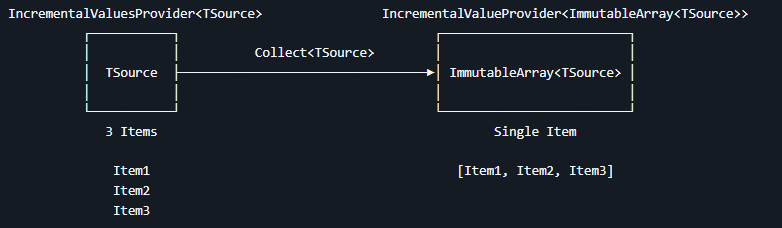
如以上官方附图所示,通过 Collect 方法将一个多值提供器转换为一个单值提供器,且这个单值提供器提供的单个值就是一个集合
这个 Collect 过程可以认为和 SelectMany 是互逆的过程,即可以从 Collect 由多值提供器转换为一个单值提供器,再从 SelectMany 由单值提供器转换为多值提供器。如以下代码所示
csharp
IncrementalValuesProvider<FooInfo1> foo1ValuesProvider = ...;
IncrementalValueProvider<ImmutableArray<FooInfo1>> foo1ArrayValueProvider = foo1ValuesProvider.Collect();
IncrementalValuesProvider<FooInfo1> backToValuesProvider = foo1ArrayValueProvider.SelectMany((ImmutableArray<FooInfo1> array, CancellationToken token) => array);
foo1ValuesProvider = backToValuesProvider;以上代码先使用 Collect 方法,从 IncrementalValuesProvider<FooInfo1> 多值提供器,转换为带不可变集合的 IncrementalValueProvider<ImmutableArray<FooInfo1>> 单值提供器
再调用 SelectMany 方法,重新将 IncrementalValueProvider<ImmutableArray<FooInfo1>> 单值提供器转换为原来的 IncrementalValuesProvider<FooInfo1> 多值提供器。从以上代码最后一行可以看到,经过 SelectMany 转换回来的 backToValuesProvider 的类型是完全和 foo1ValuesProvider 一样的,相互赋值都能通过构建
Split
准确来说这只是一个用法,不是一个 API 方法。表示的就是分叉调用,多分支调用。如在 Select 一节中和大家介绍,允许进行分叉转换。事实上,在以上介绍的每个内容里面,每个值提供器,无论是多值提供器还是单值提供器,都可以被多次调用各个方法作为输入源进行消费。这和 Linq 里面的固有印象有所不同,在 Linq 里面,枚举 IEnumerable<TSource> 是不支持多次重复消费的,多次消费将获取不可控结果。但在源代码生成器这里面,数据源的提供依靠的是缓存失效来驱动,或者称为数据变更驱动。一旦有数据变更,缓存失效,则会一条链路进行传递
咱所编写的对各个值提供器的各种转换逻辑,只是用于写入记录转换链路而已。当数据变更的时候,将会重新开始跑整个链路。在跑的过程中,引入了大量缓存判定,从而最大程度减少执行逻辑量
在演练中,咱也用到了 Split 的功能,即在拿到 IncrementalValuesProvider<ImmutableArray<ItemGeneratedCodeResult>> itemGeneratedCodeResultProvider 数据源时,一路作为 Diagnostic 报告输出,一路作为最终源代码生成的输出
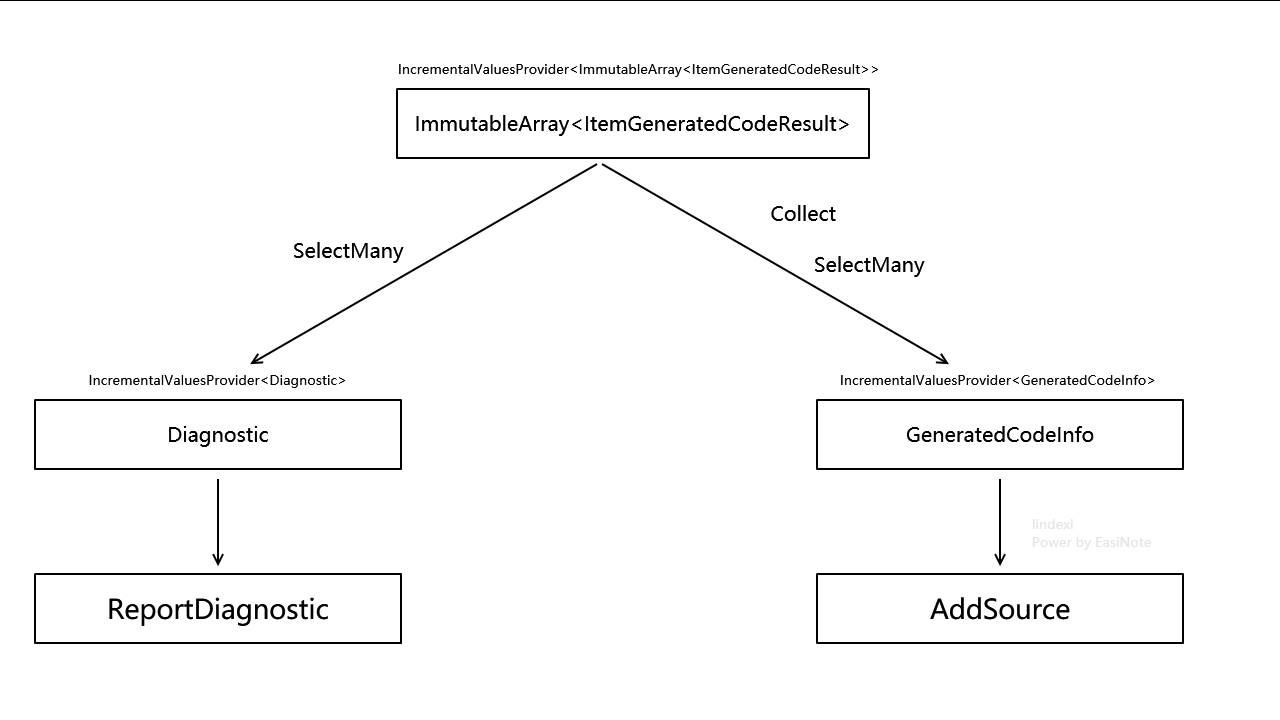
Combine
方法签名:
csharp
// 1 对 1 合并
IncrementalValueProvider<(TLeft Left, TRight Right)> Combine<TLeft, TRight>(this IncrementalValueProvider<TLeft> provider1, IncrementalValueProvider<TRight> provider2);
// 多对 1 合并
IncrementalValuesProvider<(TLeft Left, TRight Right)> Combine<TLeft, TRight>(this IncrementalValuesProvider<TLeft> provider1, IncrementalValueProvider<TRight> provider2);和以上的分叉相对,以上的 Split 分叉是将一条值提供器作为多个数据提供源,将一个数据链路拆分为多个数据链路。而 Combine 则是将两个数据链路合并到一个链路。能够支持的合并方式是两个单值提供器的合并,以及一个多值提供器和一个单值提供器的合并
两个单值提供器的合并:
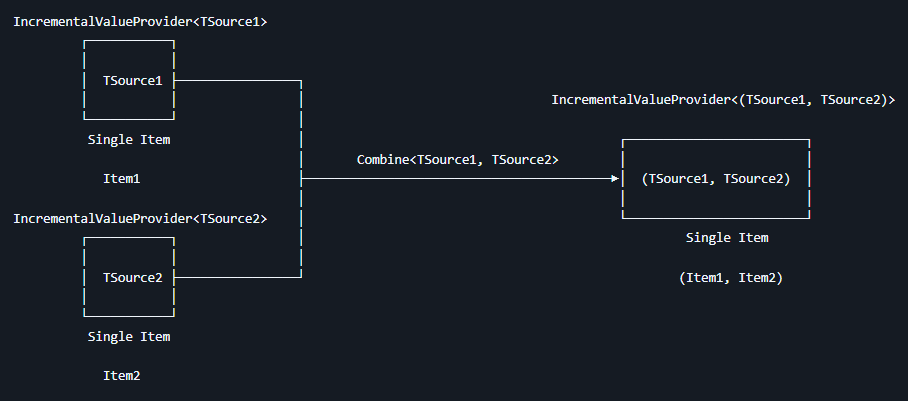
如以上的官方附图,将两个单值提供器的合并,返回结果依然是一个单值提供器。只是返回的输出源里面包含的是一个元组,其中左右值就是所 Combine 顺序的左右值。如以下代码所示
csharp
IncrementalValueProvider<FooInfo1> foo1ValueProvider = ...;
IncrementalValueProvider<FooInfo2> foo2ValueProvider = ...;
IncrementalValueProvider<(FooInfo1 Left, FooInfo2 Right)> foo1AndFoo2CombineValueProvider = foo1ValueProvider.Combine(foo2ValueProvider);以上代码分别将 IncrementalValueProvider<FooInfo1> 和 IncrementalValueProvider<FooInfo2> 两个单值提供器进行合并。合并之后获得了 IncrementalValueProvider<(FooInfo1 Left, FooInfo2 Right)> 的单值提供器
一个多值提供器和一个单值提供器的合并:
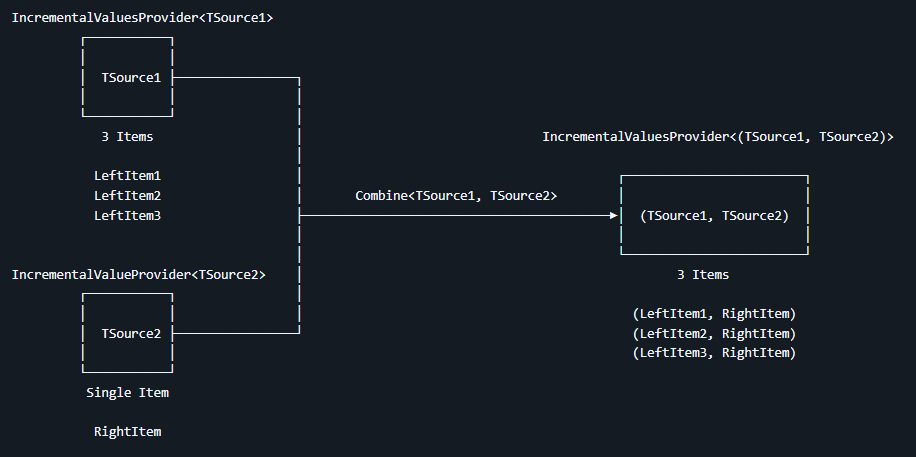
如以上的官方附图,最终输出源里面是多值提供器里面的每一项都带着单值提供器里面的内容。即输出源里面的元组的左侧是多值提供器里面的每一项,右侧都是相同的单值提供器里面的元素
那两个多值提供器的合并呢?
敲黑板,在 Combine 方法里面不支持两个多值提供器的合并。因为一旦两个多值提供器进行合并,则一旦出现任何一方某个元素的缓存失效问题,将会有笛卡尔积次的执行风险。只提供一个多值提供器和一个单值提供器的合并,则可以明确让源代码生成器开发者决定其优化方向,即将哪方作为单值提供器
那假定我的业务上就是有两个多值提供器,我确实下一步的逻辑就需要两个多值提供器提供的数据才能完成工作。那此时应该如何开展呢?相信会灵活运用所学知识的伙伴已经想到了方法了。没错,就是将其中一个多值提供器调用 Collect 方法,将其转换为单值提供器,于是就可以继续愉快地调用 Combine 进行一个多值提供器和一个单值提供器的合并。这个过程中,源代码生成器开发者可选用两个多值提供器中量小、变化次数少的一方调用 Collect 转换为单值提供器,从而提供更多的优化效果
以上就是增量源代码生成器的专有基础知识,合理运用好以上的几个数据源处理方法,即可实现对复杂的数据处理的同时,减少计算量
演练:源代码专有 Interceptor 技术
经过了上文的介绍,大家是否对源代码生成器的基础知识有了一定的了解。是否会存在一个错觉,认为源代码生成器最多只是减轻人类程序猿的工作量,但并不能轻易突破人类程序猿难以做到的事情?接下来我将介绍源代码生成器的专有技术 Interceptor 拦截器技术,这是一种源代码生成器专有的技术,可以在构建过程中执行额外的逻辑实现拦截现有代码的功能
或许换个叫法大家会更熟悉这一类型的技术,即 AOP 面向切面编程。核心差别在于源代码生成器方式的 AOP 是发生在编译阶段,可以做到零反射。且过程中是可以实现到完全的调用转发。即大家进行静态代码阅读的时候,看到的是调用了 A 方法,然而实际构建出来的代码是调用了 B 方法。这种技术在实际开发中非常有用,比如在构建过程中进行日志记录、性能监控、权限控制等等
现在直接使用 Interceptor 技术的就有 ASP.NET Core 的配置和部分日志的等模块功能,详细请参阅 Compile-time configuration source generation - .NET - Microsoft Learn
在本演练中,我将和大家介绍如何在源代码生成器里面使用 Interceptor 技术,实现对现有代码的拦截调用转发。将原本调用 Foo 类型的 WriteLine 方法,转发到调用源代码新生成的代码里面。比如有以下的代码,大家猜猜在本演练里面,执行代码将会输出什么内容
csharp
class Program
{
static void Main()
{
var c = new Foo();
c.WriteLine(1);
c.WriteLine(2);
c.WriteLine(3);
}
}
class Foo
{
public void WriteLine(int message)
{
Console.WriteLine($"Foo: {message}");
}
}想必大家一看就知道,执行代码将会输出以下内容
csharp
Foo: 1
Foo: 2
Foo: 3然而我告诉大家,以上代码执行的输出将会看我在源代码生成器里面的生成代码怎么写,静态阅读代码是看不出来的。接下来我将和大家介绍如何实现这个功能
为了方便大家拉取代码,我依然是新建两个项目,分别是名为 JuqawhicaqarLairciwholeni 的控制台项目,和名为 JuqawhicaqarLairciwholeni.Analyzer 的分析器项目。项目搭建方式和上文介绍的一样,不再赘述
在本演练任务里面,咱需要拦截所有对 Foo 类型的 WriteLine 方法的调用,将其转换为源代码生成器所生成的新的代码
开始之前先介绍一下 C# 12 引入的 Interceptor 拦截器技术,拦截器技术的核心是通过一个 InterceptsLocationAttribute 特性标记一个方法。被标记的方法可以拦截在 InterceptsLocationAttribute 特性上所设置的所要拦截的代码的调用。如以下代码所示,在名为 FooInterceptor 类型的 InterceptorMethod1 方法上,标记了 InterceptsLocationAttribute 特性,注明了拦截 Program.cs 文件上的某行代码
csharp
static partial class FooInterceptor
{
// C:\lindexi\Code\JuqawhicaqarLairciwholeni\JuqawhicaqarLairciwholeni\Program.cs(8,11)
[InterceptsLocation(version: 1, data: "PSnZx2mpBdT444AVZJmMJX8AAABQcm9ncmFtLmNz")]
public static void InterceptorMethod1(this global::JuqawhicaqarLairciwholeni.Foo foo, int param)
{
Console.WriteLine($"Interceptor1: lindexi is doubi");
}
}这里能够看到的是在 InterceptsLocationAttribute 特性上标记了人类难懂的 PSnZx2mpBdT444AVZJmMJX8AAABQcm9ncmFtLmNz 字符串内容。这其实是对 C:\lindexi\Code\JuqawhicaqarLairciwholeni\JuqawhicaqarLairciwholeni\Program.cs(8,11) 的一个标识,这个标识是由源代码生成器里面的 SemanticModel 的 GetInterceptableLocation 方法提供的
假定 C:\lindexi\Code\JuqawhicaqarLairciwholeni\JuqawhicaqarLairciwholeni\Program.cs(8,11) 对应的代码就是 c.WriteLine(1); 这一行代码。那么在执行代码的时候,将会输出以下内容
csharp
Interceptor1: lindexi is doubi而不是原本预期的 Foo: 1 的输出内容。这就是 Interceptor 拦截器技术的核心,通过拦截器技术,可以在构建过程中执行额外的逻辑实现拦截现有代码的功能

简单了解了 Interceptor 拦截器技术的核心,在本演练中将开始和大家介绍如何实现这个功能,将原本调用 Foo 类型的 WriteLine 方法,转发到调用源代码新生成的代码里面。以下是我的实现效果,将原本代码里面对 Foo 类型的 WriteLine 方法的三个调用,分别转发到源代码生成器所生成的三个不同的方法里面,如下图所示
通过本演练的源代码生成器所处理之后,通过 ILSpy 工具查看生成的 dll 文件,可见最终的生成代码是调用了 FooInterceptor 的三个生成的方法,完全不是静态代码所见的调用 Foo 类型的 WriteLine 方法
即在这个过程里面,所发生的所有科技都在构建之中完成,不会在运行时发生任何额外的调用
在 JuqawhicaqarLairciwholeni.Analyzer 项目里面新建名为 FooIncrementalGenerator 的继承 IIncrementalGenerator 的类型,其代码如下
csharp
[Generator(LanguageNames.CSharp)]
public class FooIncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
...
}
}为了分析所有对 Foo 类型的 WriteLine 方法的调用,需要找到所有 InvocationExpressionSyntax 类型的语法点。这些语法点就是各个代码里面调用方法等的地方了,再进一步判断调用的是不是名为 WriteLine 的方法,语法判断部分的工作就完成了。也许有伙伴读到这里会有疑问,为什么只是判断调用的是不是名为 WriteLine 的方法,而不再继续判断是不是 Foo 类型的 WriteLine 方法。这是因为在语法判断里面,我们是无法直接访问到调用的具体类型的,语法层面上只能猜,而猜不如放到语义过程进行准确判断
csharp
[Generator(LanguageNames.CSharp)]
public class FooIncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
context.SyntaxProvider.CreateSyntaxProvider(
(node, _) =>
{
if (node is InvocationExpressionSyntax invocationExpressionSyntax)
{
if (invocationExpressionSyntax.Expression is MemberAccessExpressionSyntax memberAccessExpressionSyntax)
{
// 这是一个调用名为 WriteLine 的方法代码,但就不知道具体是谁的 WriteLine 了。语法过程中是无法知道具体的类型是哪个的
// 比如 Foo a = ...; a.WriteLine(...);
// 或 Foo b = ...; b.WriteLine(...);
// 此时最多在语法层面只判断出是 WriteLine 方法,进一步判断就交给语义过程了
return memberAccessExpressionSyntax.Name.Identifier.Text == "WriteLine";
}
}
return false;
},
(syntaxContext, _) =>
{
...
});
...
}
}在语义转换里面,进一步判断所调用的是不是 Foo 类型的 WriteLine 方法,即判断当前调用的 WriteLine 方法是不是在 Foo 类型上面定义的。这里使用 SemanticModel 的 GetSymbolInfo 方法获取到调用的方法的符号信息,接着判断方法符号所在的类型是不是 Foo 类型
csharp
context.SyntaxProvider.CreateSyntaxProvider(
(node, _) =>
{
...
},
(syntaxContext, _) =>
{
var symbolInfo = syntaxContext.SemanticModel.GetSymbolInfo(syntaxContext.Node);
if (symbolInfo.Symbol is not IMethodSymbol methodSymbol
// 以下这句判断纯属多余,因为语法过程中已经判断了是 WriteLine 方法
|| methodSymbol.Name != "WriteLine")
{
return default;
}
// 语义过程继续判断具体是否 Foo 类型的 WriteLine 方法
var className = methodSymbol.ContainingType.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat);
if (className != "global::JuqawhicaqarLairciwholeni.Foo")
{
return default;
}
...
})为了调用 SemanticModel 的 GetInterceptableLocation 方法获取传入到 InterceptsLocationAttribute 特性的必要参数,这里通过 syntaxContext.Node 属性拿到当前正在发起方法调用的 InvocationExpressionSyntax 语法节点。接着调用 GetInterceptableLocation 方法获取到拦截器的位置信息
csharp
...
var invocationExpressionSyntax = (InvocationExpressionSyntax) syntaxContext.Node;
...现在 SemanticModel 的 GetInterceptableLocation 方法还被标记了实验性,调用此方法之前需要使用 #pragma warning disable RSEXPERIMENTAL002 开启实验性功能
csharp
var invocationExpressionSyntax = (InvocationExpressionSyntax) syntaxContext.Node;
#pragma warning disable RSEXPERIMENTAL002 // 实验性警告,忽略即可
InterceptableLocation interceptableLocation = syntaxContext.SemanticModel.GetInterceptableLocation(invocationExpressionSyntax)!;此时拿到的 InterceptableLocation 对象就是包含了将要拦截的代码的具体信息,包括具体是哪个文件的哪行哪列代码,且这个过程里面还包含了代码文件的摘要信息,确保将要拦截替换的代码是符合源代码生成器在生成过程中所预期的。如以下代码尝试拿到 DisplayLocation 字符串信息内容
csharp
var displayLocation = interceptableLocation.DisplayLocation;这里的 displayLocation 字符串的大概内容是对应的代码的路径和所在行列信息,如以下代码所示
csharp
C:\lindexi\Code\JuqawhicaqarLairciwholeni\JuqawhicaqarLairciwholeni\Program.cs(9,11)为了演示效果,我这里还尝试使用语法语义方式读取在 Program.cs 里面调用 WriteLine 方法的参数值,即调用 WriteLine 方法的参数值是多少。这里使用 invocationExpressionSyntax.ArgumentList.Arguments 属性获取到所有的参数列表,再取其首个参数。最后配合语义获取传入的常量值
csharp
ArgumentSyntax argumentSyntax = invocationExpressionSyntax.ArgumentList.Arguments.First();
var argument = (int)syntaxContext.SemanticModel.GetConstantValue(argumentSyntax.Expression).Value!;以上代码仅仅用于演示哈,因为这要求原本的代码里面传入参数确实就是常量值。在实际的代码里面,传入的参数可能是变量、表达式等等,不能像本演练里面这样直接获取到常量值
完成准备工作之后,就可以开始来生成代码啦
依然是为了让我的博客引擎开森,我将以下代码的两个连在一起的花括号替换为全角的花括号
csharp
var generatedCode =
$$"""
using System.Runtime.CompilerServices;
namespace Foo_JuqawhicaqarLairciwholeni
{
static partial class FooInterceptor
{
// {{displayLocation}}
[InterceptsLocation(version: {{interceptableLocation.Version}}, data: "{{interceptableLocation.Data}}")]
public static void InterceptorMethod{{argument}}(this {{className}} foo, int param)
{
Console.WriteLine($"Interceptor{{argument}}: lindexi is doubi");
}
}
}
namespace System.Runtime.CompilerServices
{
[AttributeUsage(AttributeTargets.Method, AllowMultiple = true)]
file sealed class InterceptsLocationAttribute : Attribute
{
public InterceptsLocationAttribute(int version, string data)
{
_ = version;
_ = data;
}
}
}
""";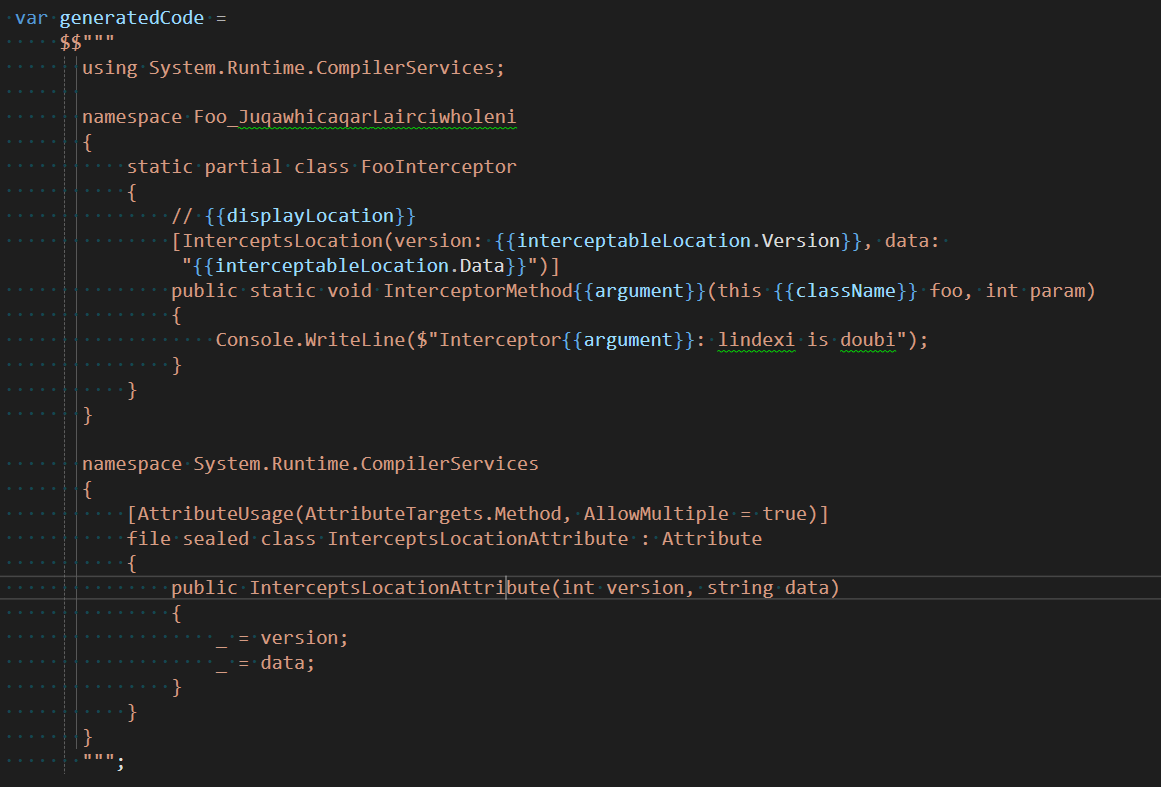
如以上代码所示,可以看到将 displayLocation 作为注释放在拦截方法上方,如此即可在阅读源代码生成器所生成的代码的时候,可以看到被拦截的代码的位置信息。接着再将读取到的传入参数信息拼接成为拦截方法的方法名以及作为拦截方法的输出内容
由于 InterceptsLocationAttribute 本身也只是一个给编译器看的特性,不在 Runtime 里面定义,且编译器也不关心这个类型的可见性,编译器只关心特性的全名,即命名空间和类型名符合要求即可。那就直接开森地使用 file 关键字进行修饰,放入到对应的生成的代码所在文件里面。这样也可以防止定义的 InterceptsLocationAttribute 特性去污染其他源代码生成器或项目里面的代码
完成了生成代码的拼接,为了将其进行返回,这里再定义一个名为 GeneratedCodeInfo 的结构体,代码如下
csharp
readonly record struct GeneratedCodeInfo(string GeneratedCode, string Name);将其作为返回值返回,且再叠加一个 Where 方法过滤掉不符合条件的情况
csharp
IncrementalValuesProvider<GeneratedCodeInfo> sourceProvider = context.SyntaxProvider.CreateSyntaxProvider(
(node, _) =>
{
...
},
(syntaxContext, _) =>
{
var invocationExpressionSyntax = (InvocationExpressionSyntax) syntaxContext.Node;
ArgumentSyntax argumentSyntax = invocationExpressionSyntax.ArgumentList.Arguments.First();
var argument = (int) syntaxContext.SemanticModel.GetConstantValue(argumentSyntax.Expression).Value!;
var generatedCode = ...
return new GeneratedCodeInfo(generatedCode, $"FooInterceptor{argument}.cs");
})
.Where(t => t != default);最后将 sourceProvider 值提供器注册到 RegisterImplementationSourceOutput 方法上即可。为什么是注册到 RegisterImplementationSourceOutput 方法上呢?因为这里面只是包含了具体的实现逻辑,没有任何可以参与语法分析的定义部分,也不会被外部所访问,放入到 RegisterImplementationSourceOutput 方法上十分合适
csharp
context.RegisterImplementationSourceOutput(sourceProvider,
(productionContext, provider) =>
{
productionContext.AddSource(provider.Name, provider.GeneratedCode);
});通过以上的源代码生成器的代码,即可实现本演练中的拦截效果。最后尝试运行一下 JuqawhicaqarLairciwholeni 控制台项目,可看到输出内容是
csharp
Interceptor1: lindexi is doubi
Interceptor2: lindexi is doubi
Interceptor3: lindexi is doubi这项 Interceptor 拦截器技术的介绍就到这里,拦截器技术现在还是有很多争议的,核心一点是破坏原本的静态代码阅读能力。静态阅读代码,不运行不构建时,所见的代码认为的运行效果不等于最终执行效果。这将会给很多开发者带来困惑,甚至可能被用于恶意代码的隐藏。但是在某些场景下,拦截器技术是非常有用的,比如在构建过程中进行日志记录、性能监控、权限控制等等,将原本影响性能的代码使用拦截器重新实现生成,不破坏原本代码结构等等
整个使用 Interceptor 拦截器的源代码生成器的代码如下,同样是为了让我的博客引擎开森,我将以下代码的两个连在一起的花括号替换为全角的花括号
csharp
[Generator(LanguageNames.CSharp)]
public class FooIncrementalGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
IncrementalValuesProvider<GeneratedCodeInfo> sourceProvider = context.SyntaxProvider.CreateSyntaxProvider(
(node, _) =>
{
if (node is InvocationExpressionSyntax invocationExpressionSyntax)
{
if (invocationExpressionSyntax.Expression is MemberAccessExpressionSyntax memberAccessExpressionSyntax)
{
// 这是一个调用名为 WriteLine 的方法代码,但就不知道具体是谁的 WriteLine 了。语法过程中是无法知道具体的类型是哪个的
// 比如 Foo a = ...; a.WriteLine(...);
// 或 Foo b = ...; b.WriteLine(...);
// 此时最多在语法层面只判断出是 WriteLine 方法,进一步判断就交给语义过程了
return memberAccessExpressionSyntax.Name.Identifier.Text == "WriteLine";
}
}
return false;
},
(syntaxContext, _) =>
{
var symbolInfo = syntaxContext.SemanticModel.GetSymbolInfo(syntaxContext.Node);
if (symbolInfo.Symbol is not IMethodSymbol methodSymbol
// 以下这句判断纯属多余,因为语法过程中已经判断了是 WriteLine 方法
|| methodSymbol.Name != "WriteLine")
{
return default(GeneratedCodeInfo);
}
// 语义过程继续判断具体是否 Foo 类型的 WriteLine 方法
var className = methodSymbol.ContainingType.ToDisplayString(SymbolDisplayFormat.FullyQualifiedFormat);
if (className != "global::JuqawhicaqarLairciwholeni.Foo")
{
return default(GeneratedCodeInfo);
}
/*
class Foo
{
public void WriteLine(int message)
{
Console.WriteLine($"Foo: {message}");
}
}
*/
var invocationExpressionSyntax = (InvocationExpressionSyntax) syntaxContext.Node;
ArgumentSyntax argumentSyntax = invocationExpressionSyntax.ArgumentList.Arguments.First();
var argument = (int)syntaxContext.SemanticModel.GetConstantValue(argumentSyntax.Expression).Value!;
#pragma warning disable RSEXPERIMENTAL002 // 实验性警告,忽略即可
var interceptableLocation = syntaxContext.SemanticModel.GetInterceptableLocation(invocationExpressionSyntax)!;
var displayLocation = interceptableLocation.GetDisplayLocation();
var generatedCode =
$$"""
using System.Runtime.CompilerServices;
namespace Foo_JuqawhicaqarLairciwholeni
{
static partial class FooInterceptor
{
// {{displayLocation}}
[InterceptsLocation(version: {{interceptableLocation.Version}}, data: "{{interceptableLocation.Data}}")]
public static void InterceptorMethod{{argument}}(this {{className}} foo, int param)
{
Console.WriteLine($"Interceptor{{argument}}: lindexi is doubi");
}
}
}
namespace System.Runtime.CompilerServices
{
[AttributeUsage(AttributeTargets.Method, AllowMultiple = true)]
file sealed class InterceptsLocationAttribute : Attribute
{
public InterceptsLocationAttribute(int version, string data)
{
_ = version;
_ = data;
}
}
}
""";
return new GeneratedCodeInfo(generatedCode, $"FooInterceptor{argument}.cs");
})
.Where(t => t != default);
context.RegisterImplementationSourceOutput(sourceProvider,
(productionContext, provider) =>
{
productionContext.AddSource(provider.Name, provider.GeneratedCode);
});
}
}
readonly record struct GeneratedCodeInfo(string GeneratedCode, string Name);更多拦截器技术的介绍请参阅: Interceptors document
本演练代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin f242a711c0f2fb65a01406a36042d87fc314cb51以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin f242a711c0f2fb65a01406a36042d87fc314cb51获取代码之后,进入 Roslyn/JuqawhicaqarLairciwholeni 文件夹,即可获取到源代码
以上介绍的都是从代码入手,通过对现有的代码进行分析而生成新的代码。大家是否好奇其输入源还有没有其他方式。接下来将通过演练的方式和大家分别介绍从 csproj 等项目属性配置以及通过其他非代码文件的方式进行源代码生成
演练:将构建时间和自定义配置写入源代码
本次演练的任务是将构建时间和自定义配置写入源代码。这个任务的背景是,有时候我们想要直接从代码里面读取一些构建时的信息,比如构建时间呀、一些自定义配置呀等等。这个任务的目的是让大家了解如何从 csproj 项目文件里面读取属性配置,以及如何将这些属性配置写入源代码
再细化一下,我期望的是能够在源代码里面写出以下代码
csharp
Console.WriteLine($"BuildAt={BuildInformation.BuildAt}");
Console.WriteLine($"Platform={BuildInformation.Platform}");
Console.WriteLine($"Configuration={BuildInformation.Configuration}");运行的输出内容大概如下
csharp
BuildAt=2025/3/9 13:41:29
Platform=AnyCpu
Configuration=Release以上的 BuildInformation 类型就是一个由源代码生成器生成的类,里面包含了构建时间、平台和配置信息
在源代码生成器里面,不需要直接碰触 csproj 项目文件的读取,取而代之的是从 CompilationProvider 值提供器里面获取到项目的编译信息
这里也能和大家证明的是,作为源代码生成器的输入源,不仅仅是代码,还可以是其他的一些信息。这里的信息是编译信息,也可以是其他的一些信息,比如额外的文件等等信息
此演练的核心实现方法如下,首先是从 CompilationProvider 值提供器里面获取到项目的编译信息,接着就可以愉快地写入生成的代码啦,非常简单。这里我就跳过了项目创建的步骤,直接到核心代码的实现
csharp
[Generator(LanguageNames.CSharp)]
public class FooGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var compilerOptions = context.CompilationProvider.Select((s, _) => s.Options);
}
}以上的 compilerOptions 就包含了构建配置信息,如 Platform 和 Configuration 等信息。当然了以上的这句 Select 纯属卖萌,没有挑拣出任何有用信息,也没有做转换,不符合最佳实践,只能作为演示
接下来就直接将 compilerOptions 放入到 RegisterSourceOutput 方法里面,进行生成源代码,如以下代码
csharp
context.RegisterSourceOutput(compilerOptions, static (productionContext, options) =>
{
var code = $@"
using System;
using System.Globalization;
public static class BuildInformation
{{
/// <summary>
/// Returns the build date (UTC).
/// </summary>
public static readonly DateTime BuildAt = DateTime.ParseExact(""{DateTime.UtcNow:O}"", ""O"", CultureInfo.InvariantCulture, DateTimeStyles.RoundtripKind);
/// <summary>
/// Returns the platform.
/// </summary>
public const string Platform = ""{options.Platform}"";
/// <summary>
/// Returns the configuration.
/// </summary>
public const string Configuration = ""{options.OptimizationLevel}"";
}}
";
productionContext.AddSource("LinkDotNet.BuildInformation.g", code);
});同样地,为了让我的博客引擎开森,以上代码部分花括号被我替换为了全角花括号。大家在使用的时候需要将全角花括号替换为半角花括号
这就完成了生成了一个名为 BuildInformation 的静态类,且此静态类还没有包含在任何的命名空间里面
大家如果对更多细节感兴趣,还请参阅 IIncrementalGenerator 增量 Source Generator 生成代码应用 将构建时间写入源代码
以上就是采用 CompilationProvider 间接读取 csproj 项目文件的属性配置,将自定义配置内容写入源代码的过程。接下来将继续通过演练的方式,告诉大家如何在分析器项目里面读取其他非代码文件的内容
演练:写一个 禁用API调用 分析器
前面介绍的都是围绕着编写源代码生成器展开的,本章将介绍使用专用分析器技术编写一个纯分析器。这个过程中也会介绍如何读取其他非代码文件的内容作为输入源的方式
在前面的章节有和大家演示过调用 ReportDiagnostic 给出分析报告的方法。在源代码生成器里面给出的分析报告的步骤是进行语法和语义的分析,判断符合某个条件,则给出分析报告的结果。整个过程是非常公式化的。只不过在源代码生成器步骤里面更加侧重如何进行生成代码,从而需要许多细节的分析语法和语义的过程。专用的分析器则可以更大程度地省略掉这些琐碎的步骤,让大家可以使用根据方便的高级的 API 进行快速的分析语法语义
为了能够更好地介绍专用分析器,在本章演练过程中,咱将带着这样的一个任务开始:编写一个禁用API调用分析器
具体的任务需求细节是根据配置的禁用 API 调用文件里面记录的禁用列表,扫描整个项目里面,如果有哪个代码访问了在禁用 API 调用文件记录的禁用方法列表,则给出错误提示
这个需求任务可以强行拆分为两步,第一步是获取到禁用 API 调用文件里面记录的禁用列表,第二步的扫描分析代码调用关系
先不着急建立分析器项目,为了能够让大家更好地理解本演练的内容,这里选择先搭建好一个用于测试的项目,我这里创建名为 NelbecarballReanallyerhohe 的控制台项目,在控制台项目里面存放一个名为 BanList.txt 的文件。这个文件只是一个默认的文本文件,里面存放了一条禁用 API 调用的记录,如以下内容,禁用的是控制台输出的 WriteLine 方法
txt
System.Console.WriteLine其含义就是如果在当前项目里面,一旦有代码调用了 System.Console.WriteLine 方法,就会给出错误提示
在 Program.cs 里面保持原样的 Console.WriteLine("Hello, World!"); 输出。尝试构建项目,要求给出错误提示,告诉开发者不能调用被禁用的 System.Console.WriteLine 方法,如输出以下错误内容
error Ban01: 不能调用禁用的 API 哦,WriteLine 被 BanList.txt 标记禁用以上就是整个演练的任务需求,这是一个非常经典的分析器任务。也适用于在真实项目里面做 API 约束。比如现在咱正在编写的分析器项目的 EnforceExtendedAnalyzerRules 限制属性,其实现原理也和本章将要介绍的具体技术十分接近。如果大家忘了 EnforceExtendedAnalyzerRules 属性,还请向前翻翻,或参阅 Roslyn 分析器 EnforceExtendedAnalyzerRules 属性的作用
开始编写专用分析器。搭建项目的方式和上文介绍的源代码生成器一样,也如上文所述,源代码生成器和分析器本身就一体的。在一个项目里面同时存在专用分析器和源代码生成器是完全被允许的,也是被推荐的做法。这里就不再详细展开项目的创建方法了,如需整个项目代码,可在本章末尾找到本章所有代码的下载拉取方法
在分析器项目里面创建一个名为 BanAPIAnalyzer 的类型,让其继承自 Microsoft.CodeAnalysis.Diagnostics.DiagnosticAnalyzer 类型。如此即可让 BanAPIAnalyzer 成为专用分析器。继承之后,就需要实现 DiagnosticAnalyzer 抽象类型的 SupportedDiagnostics 属性和 Initialize 方法
在专用分析器的设计里面,要求实现 SupportedDiagnostics 属性,告诉框架层当前这个专用分析器类型支持哪些 Diagnostic 内容。一旦 IDE 等配置某些 Diagnostic 被禁用时,如果当前的这个专用分析器的所有 Diagnostic 内容都被禁用,则此专用分析器将不会被启用。另一个作用则是可以在 VisualStudio 的分析器列表里面枚举查看信息,方便配置。比如通过 .editorconfig 文件,将原本是错误等级的 Diagnostic 设置为警告等级
# 演示在 .editorconfig 文件将原本是 error 等级的 Ban01 设置为 warning 等级
dotnet_diagnostic.Ban01.severity = warning在本演练这里,只添加一个 DiagnosticDescriptor 到 SupportedDiagnostics 属性。如任务需求所述,本演练这里只有一个禁用 API 调用的分析。创建 DiagnosticDescriptor 的方法在上文已经有详细介绍了,上文介绍的是支持多语言的创建方式,相对来说比较繁琐,但也正式。我在这里和大家介绍另一个方式,就是只有单个语言的固定字符串方式,当然了,这样的方式适用范围肯定更小了,难以全球化使用
csharp
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class BanAPIAnalyzer : DiagnosticAnalyzer
{
... // 忽略其他代码
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics { get; } = new[]
{
new DiagnosticDescriptor("Ban01", "CallBanAPI", "不能调用禁用的 API 哦,{0} 被 {1} 标记禁用", category: "Error",
DiagnosticSeverity.Error, isEnabledByDefault: true)
}.ToImmutableArray();
}和源代码生成器一样,核心的代码实现放在 Initialize 方法里面。这两个 Initialize 不同点在于其方法参数上,以下是专用分析器的 Initialize 方法的签名
csharp
public override void Initialize(AnalysisContext context)
{
... // 忽略其他代码
}通常的专用分析器在 Initialize 的第一句话是调用 AnalysisContext 的 EnableConcurrentExecution 方法。这句话的作用是告诉框架层,当前的专用分析器是线程安全的,可以多线程并发执行。这样可以提高分析器的执行效率,但也要求开发者在编写专用分析器的时候要保证线程安全。不过在调试过程中,却通常将其注释掉,防止多线程进入让调试困难
csharp
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class BanAPIAnalyzer : DiagnosticAnalyzer
{
public override void Initialize(AnalysisContext context)
{
context.EnableConcurrentExecution();
... // 忽略其他代码
}
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics { get; } = new[]
{
new DiagnosticDescriptor("Ban01", "CallBanAPI", "不能调用禁用的 API 哦,{0} 被 {1} 标记禁用", category: "Error",
DiagnosticSeverity.Error, isEnabledByDefault: false)
}.ToImmutableArray();
}在 Initialize 的第二句话通常是配置是否对源代码生成器生成的源代码进行分析,默认咱选 None 即可,如以下代码
csharp
public override void Initialize(AnalysisContext context)
{
context.EnableConcurrentExecution();
context.ConfigureGeneratedCodeAnalysis(GeneratedCodeAnalysisFlags.None);
... // 忽略其他代码
}这两句话的调用时机没有约束,换句话说就是顺序倒过来也毫无影响
喜欢点点点的伙伴也许看到了在 AnalysisContext 类型里面充满了各种 RegisterXxxAction 的方法。这些方法的作用都是寻找一个注入点,即在什么时机进行分析、在什么范围内进行分析。越是靠后的时机,能够拿到的信息越多,但其分析提示可能就不够及时。具体选用什么时机进行分析,如果把握不准的话,大家可以先选一个比较靠后的时机,调试成功之后再逐渐选择比较靠前的时机。这里的靠前和靠后相对的是构建时机。在本演练里面,为了演示方便,就选用了很是靠后的 RegisterCompilationStartAction 时机,在这里能够拿到完全的 AdditionalFile 附加文件,即 BanList.txt 文件
现在开始这个专用分析器实现的第一步,获取到禁用 API 调用文件里面记录的禁用列表。在咱这个专用分析器里面,比较灵活,允许开发者设置哪个文件记录的就是禁用 API 列表的文件。如在控制台项目(敲黑板,非分析器项目,是那个被分析的项目)里面的 csproj 项目文件通过如下代码指定 BanList.txt 就是记录禁用 API 列表的文件
xml
<PropertyGroup>
<BanAPIFileName>BanList.txt</BanAPIFileName>
</PropertyGroup>一般的分析器项目都在分发的时候带上 $(PackageId).targets 和 $(PackageId).props 文件。但咱这里没有通过 NuGet 进行分发,因此一些可以放在 $(PackageId).targets 和 $(PackageId).props 文件的杂活就需要放入到被分析的项目里面。详细关于如何打包 NuGet 进行分发,我将在下文详细和大家介绍
为什么会提到 $(PackageId).targets 和 $(PackageId).props 文件的杂活呢?这是因为咱在被分析的控制台项目的 csproj 项目文件配置的 BanAPIFileName 属性内容,默认情况下是无法直接被分析器项目感知到的,添加的 BanList.txt 文件也无法被分析器直接感知到。为了让分析器能够拿到配置的 BanAPIFileName 属性,以及 BanList.txt 文件,就需要在被分析的控制台项目的 csproj 项目文件里面添加额外的配置
- CompilerVisibleProperty : 用于标记有哪些 Property 可以被分析器感知到
- AdditionalFiles : 添加用于让分析器项目使用的附加文件,官方翻译为
分析器其他文件或C# 分析器其他文件
按照以上描述可以了解到,咱需要通过 CompilerVisibleProperty 标记 BanAPIFileName 属性,使用 AdditionalFiles 添加 BanList.txt 文件,即让 BanList.txt 使用 C# 分析器其他文件 生成方式,如下图所示
修改之后的被分析的控制台项目的 csproj 项目文件内容大概如下
xml
<PropertyGroup>
<BanAPIFileName>BanList.txt</BanAPIFileName>
</PropertyGroup>
<ItemGroup>
<CompilerVisibleProperty Include="BanAPIFileName" />
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="BanList.txt" />
</ItemGroup>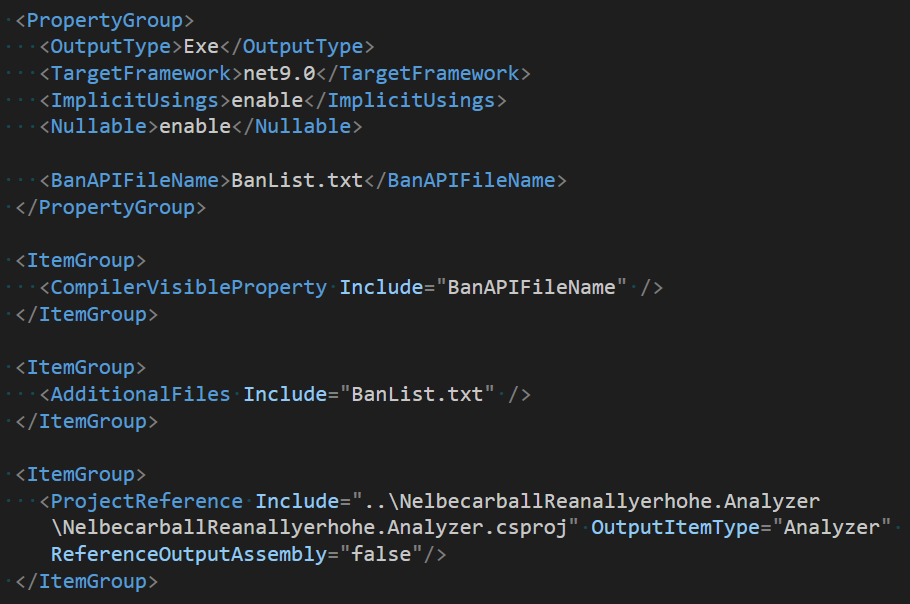
对于一个通过 NuGet 分发的分析器项目,则是会在 $(PackageId).props 文件里面存放 <CompilerVisibleProperty Include="BanAPIFileName" /> 和 <AdditionalFiles Include="BanList.txt" /> 这两个配置,而不需要被分析项目添加这些杂活
以上介绍的 CompilerVisibleProperty 和 AdditionalFiles 是对整个分析器生效,即无论是专用分析器还是源代码生成器,这部分知识内容都完全相同
如对在分析器项目里面读取 PropertyGroup 里面的 Property 感兴趣,还请参阅 读取 csproj 项目文件的属性配置方法
完成被分析的控制台项目的 csproj 项目文件配置之后,就可以在 RegisterCompilationStartAction 方法内通过 BanAPIFileName 属性了解到哪个 AdditionalFiles 就是标记禁用列表的文件,其代码如下
csharp
public override void Initialize(AnalysisContext context)
{
context.EnableConcurrentExecution();
context.ConfigureGeneratedCodeAnalysis(GeneratedCodeAnalysisFlags.None);
context.RegisterCompilationStartAction((CompilationStartAnalysisContext analysisContext) =>
{
if (analysisContext.Options.AnalyzerConfigOptionsProvider.GlobalOptions.TryGetValue(
"build_property.BanAPIFileName", out var fileName))
{
... // 忽略其他代码
}
});
}再遍历 AdditionalFiles 找到记录禁用 API 列表的文件,代码如下
csharp
context.RegisterCompilationStartAction(analysisContext =>
{
if (analysisContext.Options.AnalyzerConfigOptionsProvider.GlobalOptions.TryGetValue(
"build_property.BanAPIFileName", out var fileName))
{
AdditionalText? file = analysisContext.Options.AdditionalFiles.FirstOrDefault(t =>
Path.GetFileName(t.Path) == fileName);
if (file != null)
{
... // 忽略其他代码
}
}
});也许有伙伴表示,这样的实现方法需要两步,第一步是读取 Property 属性,第二步是遍历 AdditionalFiles 文件,相对来说比较麻烦。能否直接在 AdditionalFiles 里面标记配置呢?即如以下的写法
xml
<PropertyGroup>
<!-- 不要 BanAPIFileName 属性,直接在文件标记 -->
<!-- <BanAPIFileName>BanList.txt</BanAPIFileName> -->
</PropertyGroup>
<ItemGroup>
<!-- 不要 BanAPIFileName 属性,自然也就不要 CompilerVisibleProperty 配置 -->
<!-- <CompilerVisibleProperty Include="BanAPIFileName" /> -->
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="BanList.txt" IsBanAPIFileName="True"/>
</ItemGroup>这当然是完全可以的啦,只不过其读取方法需要更改一下,按照 Roslyn 分析器 读取 csproj 项目文件的 AdditionalFiles Item 的 Metadata 配置 进行更改。一般情况下不会这么写的,因为在有 NuGet 分发的帮助下,将杂活放入到 props 文件里面,整个实际的被分析项目只有编写 <BanAPIFileName>BanList.txt</BanAPIFileName> 这一句配置,相对来说会比写 <AdditionalFiles Include="BanList.txt" IsBanAPIFileName="True"/> 更加方便
获取到了配置禁用 API 列表的文件之后,即可通过 AdditionalText.GetText 方法获取到文件内容,代码如下
csharp
AdditionalText file = ...;
SourceText sourceText = file.GetText(analysisContext.CancellationToken);这里依然和源代码生成器一样,将令牌传入到调用 AdditionalText.GetText 方法里面,避免读取文件过程中被分析的内容变更导致白白读取内容进行空等
进一步的,直接获取 SourceText 的 Lines 属性,即可拿到一行一个禁用 API 的列表。为了后续判断方便,咱将其转换为哈希集合,合起来的代码如下
csharp
var file = analysisContext.Options.AdditionalFiles.FirstOrDefault(t =>
Path.GetFileName(t.Path) == fileName);
if (file != null)
{
ImmutableHashSet<string> banSet =
file.GetText()?.Lines.Select(t => t.ToString()).ToImmutableHashSet) ??
ImmutableHashSet<string>.Empty;
... // 忽略其他代码
}以上代码就是获取到了禁用 API 列表的文件内容,接下来就是扫描分析代码调用关系,进入到这个专用分析器实现的第二步。这个过程和源代码生成器的分析过程类似,只不过这里不需要生成代码,而是给出分析报告。只是给出分析结果,咱有更多便捷的方法可用,不再和源代码生成器的分析一样逐个爬语法树或者语义树的节点,而是直接使用 RegisterSyntaxNodeAction 方法,给定感兴趣的分析内容点
在咱本次演练内容里面,核心就是判断调用的方法是否在禁用列表里面。即感兴趣的分析内容点就是代码里面方法调用,即 SyntaxKind.InvocationExpression 内容。于是在调用 RegisterSyntaxNodeAction 方法过程,将 SyntaxKind.InvocationExpression 作为第二个参数传入,代码如下
csharp
ImmutableHashSet<string> banSet =
file.GetText()?.Lines.Select(t => t.ToString()).ToImmutableHashSet() ??
ImmutableHashSet<string>.Empty;
analysisContext.RegisterSyntaxNodeAction((SyntaxNodeAnalysisContext nodeAnalysisContext) =>
{
... // 忽略其他代码
}, SyntaxKind.InvocationExpression);由于在 RegisterSyntaxNodeAction 参数要求了是 InvocationExpression 类型,在 RegisterSyntaxNodeAction 的委托里面,就可以使用强转方式将 nodeAnalysisContext.Node 转换为 InvocationExpressionSyntax 类型,代码如下
csharp
analysisContext.RegisterSyntaxNodeAction(nodeAnalysisContext =>
{
var invocationExpression = (InvocationExpressionSyntax) nodeAnalysisContext.Node;
... // 忽略其他代码
}, SyntaxKind.InvocationExpression);分析调用的 API 离不开语义的辅助,从全语法层面是难以或无法知道具体调用的 API 是哪个的。通过 SemanticModel 获取语义符号,即可知道调用的 API 是哪个
csharp
analysisContext.RegisterSyntaxNodeAction(nodeAnalysisContext =>
{
var invocationExpression = (InvocationExpressionSyntax) nodeAnalysisContext.Node;
var symbolInfo = nodeAnalysisContext.SemanticModel.GetSymbolInfo(invocationExpression);
if (symbolInfo.Symbol is not IMethodSymbol symbol)
{
return;
}
... // 忽略其他代码
}, SyntaxKind.InvocationExpression);理论上这里拿到的 Symbol 必然是 IMethodSymbol 且不是空的
拿到方法符号之后,再获取这个方法所在的类型是哪一个,代码如下
csharp
analysisContext.RegisterSyntaxNodeAction(nodeAnalysisContext =>
{
var invocationExpression = (InvocationExpressionSyntax) nodeAnalysisContext.Node;
var symbolInfo = nodeAnalysisContext.SemanticModel.GetSymbolInfo(invocationExpression);
if (symbolInfo.Symbol is not IMethodSymbol symbol)
{
return;
}
var containingType = symbol.ContainingType;
... // 忽略其他代码
}, SyntaxKind.InvocationExpression);既然已经拿到被调用的方法和被调用的方法所在的类型,那就可以简单使用字符串匹配的方式判断方法是否在禁用列表里面。即先取出其带命名空间的全名,拼接带命名空间的类型名和方法名即可用于判断,代码如下
csharp
var containingType = symbol.ContainingType;
var symbolDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Omitted,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var containingTypeName = containingType.ToDisplayString(symbolDisplayFormat);
var name = symbol.Name;
var methodName = $"{containingTypeName}.{name}";如此即可拿到方法全名,即 命名空间.类型.方法名 的格式。再进入 banSet 集合判断一下即可了解当前的调用方法是否在禁用了集合中
csharp
var methodName = $"{containingTypeName}.{name}";
if (banSet.Contains(methodName))
{
... // 当前调用的方法在禁用列表中
}一旦判断当前调用的方法在禁用集合内,则给出错误信息。给出错误信息时,可选列出代码所在的文件、第几行第几列的 Location 信息。从 SyntaxNodeAnalysisContext.Node 创建出 Location 对象,代码如下
csharp
var location = Location.Create(nodeAnalysisContext.Node.SyntaxTree, nodeAnalysisContext.Node.FullSpan);再将符号名,即方法名,和记录禁用 API 列表的文件名传入到方法列表里面,用于填充错误详细信息的 "不能调用禁用的 API 哦,{0} 被 {1} 标记禁用" 里面的 {0} 和 {1} 内容,代码如下
csharp
nodeAnalysisContext.ReportDiagnostic(Diagnostic.Create(SupportedDiagnostics[0],
location,
messageArgs: new object[] { symbol.Name, fileName }));如此即可完成本演练的禁止调用禁用列表的 API 的分析器,整个 BanAPIAnalyzer 类的代码如下,可以看到使用很少的代码量就能实现此功能
csharp
[DiagnosticAnalyzer(LanguageNames.CSharp)]
public class BanAPIAnalyzer : DiagnosticAnalyzer
{
public override void Initialize(AnalysisContext context)
{
context.EnableConcurrentExecution();
context.ConfigureGeneratedCodeAnalysis(GeneratedCodeAnalysisFlags.None);
context.RegisterCompilationStartAction(analysisContext =>
{
if (analysisContext.Options.AnalyzerConfigOptionsProvider.GlobalOptions.TryGetValue(
"build_property.BanAPIFileName", out var fileName))
{
var file = analysisContext.Options.AdditionalFiles.FirstOrDefault(t =>
Path.GetFileName(t.Path) == fileName);
if (file != null)
{
ImmutableHashSet<string> banSet =
file.GetText()?.Lines.Select(t => t.ToString()).ToImmutableHashSet() ??
ImmutableHashSet<string>.Empty;
analysisContext.RegisterSyntaxNodeAction(nodeAnalysisContext =>
{
var invocationExpression = (InvocationExpressionSyntax) nodeAnalysisContext.Node;
var symbolInfo = nodeAnalysisContext.SemanticModel.GetSymbolInfo(invocationExpression);
if (symbolInfo.Symbol is not IMethodSymbol symbol)
{
return;
}
var containingType = symbol.ContainingType;
var symbolDisplayFormat = new SymbolDisplayFormat
(
// 带上命名空间和类型名
SymbolDisplayGlobalNamespaceStyle.Omitted,
// 命名空间之前加上 global 防止冲突
SymbolDisplayTypeQualificationStyle
.NameAndContainingTypesAndNamespaces
);
var containingTypeName = containingType.ToDisplayString(symbolDisplayFormat);
var name = symbol.Name;
var methodName = $"{containingTypeName}.{name}";
if (banSet.Contains(methodName))
{
var location = Location.Create(nodeAnalysisContext.Node.SyntaxTree, nodeAnalysisContext.Node.FullSpan);
nodeAnalysisContext.ReportDiagnostic(Diagnostic.Create(SupportedDiagnostics[0],
location,
messageArgs: new object[] { symbol.Name, fileName }));
}
}, SyntaxKind.InvocationExpression);
}
}
});
}
public override ImmutableArray<DiagnosticDescriptor> SupportedDiagnostics { get; } = new[]
{
new DiagnosticDescriptor("Ban01", "CallBanAPI", "不能调用禁用的 API 哦,{0} 被 {1} 标记禁用", "Error",
DiagnosticSeverity.Error, true)
}.ToImmutableArray();
}以上代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin ed27dcda954d4baed58c74b9c1e355468c7135fc以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin ed27dcda954d4baed58c74b9c1e355468c7135fc获取代码之后,进入 Roslyn/NelbecarballReanallyerhohe 文件夹,即可获取到源代码
既然有了分析器,可以给开发者报告出一些警告或错误信息,那是否还能自动帮助开发者修复这些问题呢?这就需要用到超过本文范围的 代码修改器 知识了。编写代码修改器是另外的故事了,这里就不展开了,如果大家对此感兴趣,可以参阅 使用 Roslyn 分析代码注释,给 TODO 类型的注释添加负责人、截止日期和 issue 链接跟踪 - walterlv
演练:用源代码生成技术实现中文编程语言
自然而然,大家了解到了从任意的其他非代码文件也能作为输入源,那么是不是可以实现中文编程语言呢?也就是说能否实现从一个包含中文编程语言的文件里面,读取其内容,根据其内容生成对应的代码,通过此方式实现中文编程语言
开始之前,先给大家看看效果
如果大家感觉这个效果很酷,那请参阅 dotnet 用 SourceGenerator 源代码生成技术实现中文编程语言 文章,里面详细介绍了如何通过源代码生成技术实现中文编程语言
打包 NuGet 包进行分发
学习了很多源代码生成器和分析器的知识,相信此时大家也很想编写和发布一个自己的源代码生成器或分析器。按照 dotnet 里面的惯例,各种产物都会通过 NuGet 的形式进行发布,自然也包括源代码生成器和分析器。接下来我将和大家介绍如何将自己编写的源代码生成器分析器打包成 NuGet 包进行分发
和其他基础库的打包过程非常先进,单独分析器项目本身就可以打出 NuGet 包,只不过需要一些额外的配置。核心配置如下
xml
<!--
配置为无依赖。即避免带上 TargetFramework=netstandard2.0 的限制
配合 IncludeBuildOutput=false 即可让任意项目引用,无视目标框架
-->
<SuppressDependenciesWhenPacking>true</SuppressDependenciesWhenPacking>
<!-- 不要将输出文件放入到 nuget 的 lib 文件夹下 -->
<IncludeBuildOutput>false</IncludeBuildOutput>
<!-- 不要警告 lib 下没内容 -->
<NoPackageAnalysis>true</NoPackageAnalysis>其中核心为 IncludeBuildOutput 属性,表示不要将分析器输出程序集放入到 NuGet 包的 lib 文件夹下。一旦被放入到 NuGet 包的 lib 文件夹下,将会让安装了此 NuGet 包的项目引用了分析器程序集,而不会将分析器程序集作为分析器运行
现在如果就直接打出来 NuGet 包,则会看到 NuGet 包是一个空包,什么有用的内容都没有包含。这是因为分析器项目的输出程序集还没被作为分析器内容打入到 NuGet 包里面。再添加以下代码,将分析器项目的输出程序集放入到 NuGet 包的 analyzers/dotnet/cs 文件夹下,这样就可以让其他项目在安装到本 NuGet 包的时候,按照 NuGet 的约定,从 analyzers/dotnet/cs 文件夹里加载上分析器
xml
<Target Name="AddOutputDllToNuGetAnalyzerFolder" BeforeTargets="_GetPackageFiles">
<!--
以下这句 ItemGroup 不能放在 Target 外面。否则首次构建之前 $(OutputPath)\$(AssemblyName).dll 是不存在的
这里需要选用在 _GetPackageFiles 之前,确保在 NuGet 收集文件之前,标记将输出的 dll 放入到 NuGet 的 analyzers 文件夹下
-->
<ItemGroup>
<None Include="$(OutputPath)\$(AssemblyName).dll"
Pack="true"
PackagePath="analyzers/dotnet/cs"
Visible="false" />
</ItemGroup>
</Target>大家可以看到,这里使用了 BeforeTargets="_GetPackageFiles" 属性,表示在 NuGet 收集文件之前,将输出的 dll 放入到 NuGet 的 analyzers 文件夹下。为什么不能直接在 Project 下的一级 ItemGroup 里面添加呢?这是因为首次构建之前 $(OutputPath)\$(AssemblyName).dll 是不存在的,直接打包将会输出空包。于是选定在 Build 构建之后,收集文件之前的时机,此最佳时机就是在 _GetPackageFiles 之前
如果选用直接在 Project 下的一级 ItemGroup 里面添加 $(OutputPath)\$(AssemblyName).dll 则不能一次构建出包,此时最推荐的是先做一次 dotnet build 再做一次 dotnet pack --no-build 打包。由于这个命令过程需要拆分为两步,可能会漏掉导致行为不符合预期,因此我在本文里面就特意使用了 Target 的方式进行收集
如果大家对于在 csproj 里面编写 Target 等逻辑不熟悉,还请参阅 如何编写基于 Microsoft.NET.Sdk 的跨平台的 MSBuild Target(附各种自带的 Task) - walterlv
整体修改之后的分析器项目的 csproj 项目文件内容大概如下
xml
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>netstandard2.0</TargetFramework>
<LangVersion>latest</LangVersion>
<EnforceExtendedAnalyzerRules>true</EnforceExtendedAnalyzerRules>
<IsRoslynComponent>true</IsRoslynComponent>
<Nullable>enable</Nullable>
<Version>1.0.0</Version>
</PropertyGroup>
<PropertyGroup>
<!-- [dotnet 打包 NuGet 的配置属性大全整理](https://blog.lindexi.com/post/dotnet-%E6%89%93%E5%8C%85-NuGet-%E7%9A%84%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%A4%A7%E5%85%A8%E6%95%B4%E7%90%86.html ) -->
<Copyright>Copyright (c) lindexi 2020-$([System.DateTime]::Now.ToString(`yyyy`))</Copyright>
<PackageLicenseExpression>MIT</PackageLicenseExpression>
<PackageReadmeFile>README.md</PackageReadmeFile>
<Description>这里填写描述信息</Description>
<!--
配置为无依赖。即避免带上 TargetFramework=netstandard2.0 的限制
配合 IncludeBuildOutput=false 即可让任意项目引用,无视目标框架
-->
<SuppressDependenciesWhenPacking>true</SuppressDependenciesWhenPacking>
<!-- 不要将输出文件放入到 nuget 的 lib 文件夹下 -->
<IncludeBuildOutput>false</IncludeBuildOutput>
<!-- 不要警告 lib 下没内容 -->
<NoPackageAnalysis>true</NoPackageAnalysis>
</PropertyGroup>
<ItemGroup>
<None Include="..\..\..\README.md" Link="README.md" Pack="True" PackagePath="\"/>
</ItemGroup>
<ItemGroup>
<PackageReference Include="dotnetCampus.LatestCSharpFeatures" Version="12.0.1" PrivateAssets="all" />
<PackageReference Include="Microsoft.CodeAnalysis.CSharp" Version="4.11.0" PrivateAssets="all" />
</ItemGroup>
<ItemGroup>
<Compile Update="Properties\Resources.Designer.cs">
<DesignTime>True</DesignTime>
<AutoGen>True</AutoGen>
<DependentUpon>Resources.resx</DependentUpon>
</Compile>
</ItemGroup>
<ItemGroup>
<EmbeddedResource Update="Properties\Resources.resx">
<Generator>ResXFileCodeGenerator</Generator>
<LastGenOutput>Resources.Designer.cs</LastGenOutput>
</EmbeddedResource>
</ItemGroup>
<Target Name="AddOutputDllToNuGetAnalyzerFolder" BeforeTargets="_GetPackageFiles">
<!--
以下这句 ItemGroup 不能放在 Target 外面。否则首次构建之前 $(OutputPath)\$(AssemblyName).dll 是不存在的
这里需要选用在 _GetPackageFiles 之前,确保在 NuGet 收集文件之前,标记将输出的 dll 放入到 NuGet 的 analyzers 文件夹下
-->
<ItemGroup>
<None Include="$(OutputPath)\$(AssemblyName).dll"
Pack="true"
PackagePath="analyzers/dotnet/cs"
Visible="false" />
</ItemGroup>
</Target>
</Project>第一个 PropertyGroup 块为分析器固有信息,其中的 <Version>1.0.0</Version> 版本号被程序集和 NuGet 包版本号所共用。如果只为指定 NuGet 的包版本号而不影响程序集的版本号,可使用专用的 PackageVersion 属性
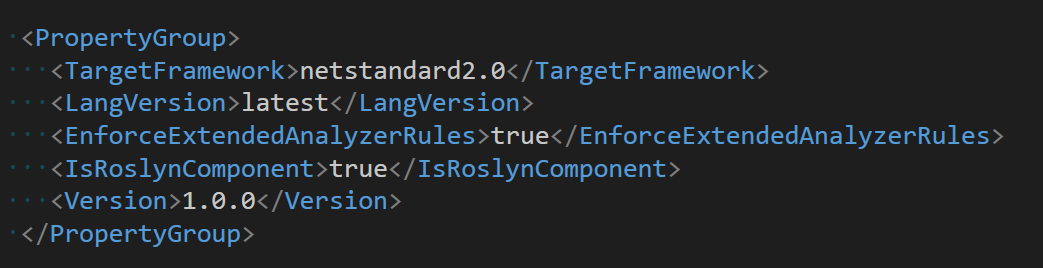
第二个 PropertyGroup 块为 NuGet 包的信息。其中的 <Description>这里填写描述信息</Description> 为 NuGet 包的描述信息,这个描述信息可以在 NuGet Package Explorer 里面直接看到,如下图所示,直接使用 NuGet Package Explorer 打开 NuGet 包,即可看到描述信息
而 ReadMe 文件记录则是需要与下方的 <None Include="..\..\..\README.md" Link="README.md" Pack="True" PackagePath="\"/> 配合才能完成,用于放入识别的 README.md 文件,帮助开发者入门使用此分析器 NuGet 包
版权 Copyright 信息里面,我使用了 $([System.DateTime]::Now.ToString(yyyy)) 语法,用于获取当前年份。这样可以保证每年都会更新版权信息,不需要手动修改,只需要在新年的时候重新打包即可
再往下是 SuppressDependenciesWhenPacking 配置无依赖和 IncludeBuildOutput 配置不要将输出文件放入到 nuget 的 lib 文件夹等信息,这部分上文有描述,这里就不再赘述
以上内容里面用到了很多 NuGet 打包相关属性,如对此感兴趣,还请参阅 dotnet 打包 NuGet 的配置属性大全整理
如果大家打不出来正确的 NuGet 包,可以拉取我的代码进行对比参考
本章以上的代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin 7ee17551c750a643593f6f5e4a0d03f89456b393以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin 7ee17551c750a643593f6f5e4a0d03f89456b393获取代码之后,进入 Roslyn/NayijainawNerkanekajawi 文件夹,即可获取到源代码
以上是十分简单地将分析器打成 NuGet 包。如编写一个 禁用API调用 的分析器演练章节中所述,在制作 NuGet 包的过程可以附带 props 文件和 targets 文件,用于在安装 NuGet 包的时候,自动添加一些配置。这样就可以让分析器的使用更加方便,不需要安装了分析器的项目手动添加配置
回顾一下原本在 禁用API调用 的分析器章节中的引用分析器的 NelbecarballReanallyerhohe 控制台项目的 csproj 文件内容
xml
<PropertyGroup>
<BanAPIFileName>BanList.txt</BanAPIFileName>
</PropertyGroup>
<ItemGroup>
<CompilerVisibleProperty Include="BanAPIFileName" />
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="BanList.txt" />
</ItemGroup>以上内容里面的 <CompilerVisibleProperty Include="BanAPIFileName" /> 和 <AdditionalFiles Include="BanList.txt" /> 都是固定配置内容。完全可以放入到分析器 NuGet 包里面,不需要每个安装了分析器的项目都手动添加这些重复的配置内容
在分析器的 NuGet 包里面存放 props 文件和 targets 文件,将分析器所需配置放入到这两个文件里面,即可在安装完 NuGet 包之后,应用这两个文件里面的配置,避免安装分析器的项目需要添加固定配置内容
依然是为了方便大家获取源代码,我这里重新拷贝 禁用API调用 的分析器演练章节的项目里面的代码,重新新建了名为 JabeehuharKekajerlurlaw.Analyzer 的分析器项目和名为 JabeehuharKekajerlurlaw 控制台项目
首先在分析器项目里面新建一个名为 Assets 的文件夹。这个 Assets 文件夹名仅仅只是我的喜好,大家可以根据自己的喜好换成其他的文件夹名。再在 Assets 文件夹里面新建两个文件,分别是 Package.props 和 Package.targets 文件。这两个文件的内容如下
Package.props 文件内容如下
xml
<Project>
</Project>Package.targets 文件内容如下
xml
<Project>
<ItemGroup>
<CompilerVisibleProperty Include="BanAPIFileName" />
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="$(BanAPIFileName)" />
</ItemGroup>
</Project>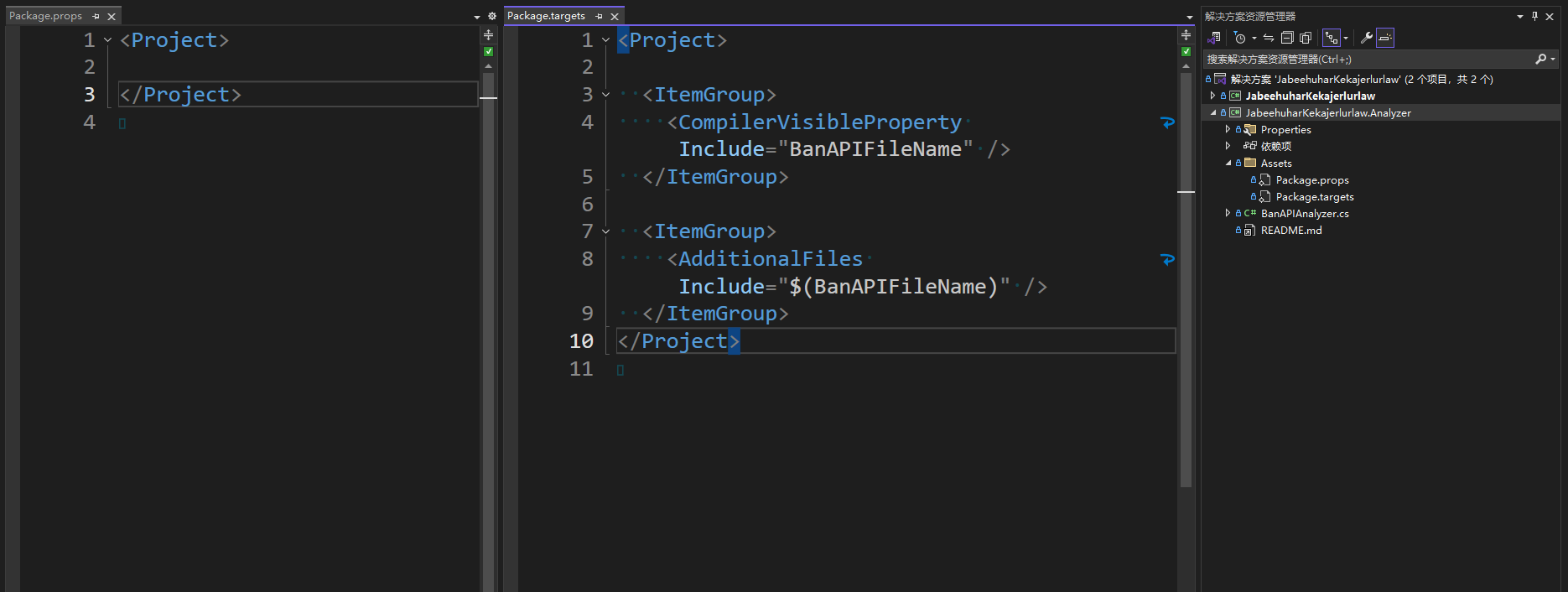
针对上文的 禁用API调用 的分析器演练的需求,完全将配置的信息写入到 Package.targets 文件里面,确保顺序足够靠后,在对应的安装了分析器的项目里面完成配置之后,再设置加入到 AdditionalFiles 文件里面
完成 Package.props 和 Package.targets 文件的创建之后,将这两个文件按照 Roslyn 打包自定义的文件到 NuGet 包 博客的方法,将这两个文件打包到 NuGet 包的 build 文件夹下
xml
<ItemGroup>
<None Include="Assets\Package.targets" Pack="True" PackagePath="\build\$(PackageId).targets" />
<None Include="Assets\Package.props" Pack="True" PackagePath="\build\$(PackageId).props" />
</ItemGroup>放入到 NuGet 包里面的 build 文件夹下,这样安装了分析器的项目就会自动引入这两个文件,依靠这两个文件提供的配置,不需要手动添加配置。以下是从原本项目引用方式分析器,更改为引用分析器 NuGet 包的方式之后,控制台项目的 csproj 文件里的配置内容发生的变更
原来的引用分析器项目:
xml
<PropertyGroup>
<BanAPIFileName>BanList.txt</BanAPIFileName>
</PropertyGroup>
<ItemGroup>
<CompilerVisibleProperty Include="BanAPIFileName" />
</ItemGroup>
<ItemGroup>
<AdditionalFiles Include="BanList.txt" />
</ItemGroup>改用分析器 NuGet 包之后:
xml
<PropertyGroup>
<BanAPIFileName>BanList.txt</BanAPIFileName>
</PropertyGroup>可以看到,引用分析器 NuGet 包之后,不需要再手动添加 <CompilerVisibleProperty Include="BanAPIFileName" /> 和 <AdditionalFiles Include="BanList.txt" /> 这两个配置内容,这两个配置内容已经被分析器 NuGet 包的 Package.targets 文件提供了。整个项目看起来更加简洁
以上在分析器 NuGet 包里面存放 props 和 targets 的全部项目代码放在 github 和 gitee 上,可以使用如下命令行拉取代码。我整个代码仓库比较庞大,使用以下命令行可以进行部分拉取,拉取速度比较快
先创建一个空文件夹,接着使用命令行 cd 命令进入此空文件夹,在命令行里面输入以下代码,即可获取到本文的代码
git init
git remote add origin https://gitee.com/lindexi/lindexi_gd.git
git pull origin fb40665eacad9578d14bf799969bb0e9ac6f0b89以上使用的是国内的 gitee 的源,如果 gitee 不能访问,请替换为 github 的源。请在命令行继续输入以下代码,将 gitee 源换成 github 源进行拉取代码。如果依然拉取不到代码,可以发邮件向我要代码
git remote remove origin
git remote add origin https://github.com/lindexi/lindexi_gd.git
git pull origin fb40665eacad9578d14bf799969bb0e9ac6f0b89获取代码之后,进入 Roslyn/JabeehuharKekajerlurlaw 文件夹,即可获取到源代码
以上就是 dotnet 的源代码生成器、分析器的入门介绍,希望能够帮助大家更好的了解源代码生成器、分析器的使用方法。在使用过程中,可能以上介绍的内容还不够满足大家的需求。我将在下文给出一些常用方法,供大家参考
常用方法
以下是我记录的一些零碎的常用方法和做法,供大家参考,期望能够解决大家一些使用上的问题
获取配置
IIncrementalGenerator 增量 Source Generator 生成代码入门 读取 csproj 项目文件的属性配置
Roslyn 分析器 读取 csproj 项目文件的 AdditionalFiles Item 的 Metadata 配置
获取文件的实际本地路径
Roslyn 源代码生成器 SourceGenerator 获取代码文件的本地绝对路径
获取引用程序集的所有类型
IIncrementalGenerator 增量 Source Generator 生成代码入门 获取引用程序集的所有类型
判断程序集之间的 InternalsVisibleTo 关系
IIncrementalGenerator 增量 Source Generator 生成代码入门 判断程序集之间的 InternalsVisibleTo 关系
判断程序集的引用关系
IIncrementalGenerator 增量 Source Generator 生成代码入门 判断程序集的引用关系
获取项目默认命名空间
IIncrementalGenerator 增量 Source Generator 生成代码入门 获取项目默认命名空间
参考文档
从零开始学习 dotnet 编译过程和 Roslyn 源码分析 - walterlv
更多编译器、代码分析、代码生成相关博客,请参阅我的 博客导航