📚 目录(快速跳转)
- 选择题(上午题)(每题1分,共75分)
-
- [一、 计算机系统基础知识 🖥️](#一、 计算机系统基础知识 🖥️)
-
- [💻 题目1:计算机组成原理 - 系统总线](#💻 题目1:计算机组成原理 - 系统总线)
- [🖥️ 题目2:计算机组成原理 - 存储体系与DMA](#🖥️ 题目2:计算机组成原理 - 存储体系与DMA)
- [🔍题目3:计算机组成原理 - 海明码校验位计算](#🔍题目3:计算机组成原理 - 海明码校验位计算)
- [⚡ 题目4:计算机组成原理 - 中断向量](#⚡ 题目4:计算机组成原理 - 中断向量)
- [🔢 题目5:计算机组成原理 - 补码表示](#🔢 题目5:计算机组成原理 - 补码表示)
- [⏱️题目6:计算机体系结构 - 指令流水线时间计算](#⏱️题目6:计算机体系结构 - 指令流水线时间计算)
- [🌐 题目7:计算机网络 - OSI模型表示层](#🌐 题目7:计算机网络 - OSI模型表示层)
- [🔍 题目20:编程基础 - 布尔表达式短路计算](#🔍 题目20:编程基础 - 布尔表达式短路计算)
- [🔤 题目21:形式语言与自动机 - 正规式特征分析](#🔤 题目21:形式语言与自动机 - 正规式特征分析)
- [🖥️ 题目22:程序设计 - 参数传递方式分析](#🖥️ 题目22:程序设计 - 参数传递方式分析)
- [💾 题目23:操作系统 - 位示图大小计算](#💾 题目23:操作系统 - 位示图大小计算)
- [💽 题目24:操作系统 - 磁盘调度算法](#💽 题目24:操作系统 - 磁盘调度算法)
- [🧵 题目25:操作系统 - 多线程资源共享](#🧵 题目25:操作系统 - 多线程资源共享)
- [🔄 题目26-28:操作系统 - PV操作与进程同步](#🔄 题目26-28:操作系统 - PV操作与进程同步)
- [🐍 题目48:程序设计语言 - Python对象类型获取type()函数](#🐍 题目48:程序设计语言 - Python对象类型获取type()函数)
- [🐍 题目49:程序设计语言 - Python元组定义](#🐍 题目49:程序设计语言 - Python元组定义)
- [🐍 题目50:程序设计语言 - Python语法特性](#🐍 题目50:程序设计语言 - Python语法特性)
- [🗃️ 题目51:数据库设计 - 数据库三级模式结构](#🗃️ 题目51:数据库设计 - 数据库三级模式结构)
- [🔍 题目52:数据库设计 - 数据库理论](#🔍 题目52:数据库设计 - 数据库理论)
- [🗃️ 题目53-54:关系数据库设计 - 候选键与主属性分析](#🗃️ 题目53-54:关系数据库设计 - 候选键与主属性分析)
- [🔐 题目55-56:数据库设计 - SQL权限管理](#🔐 题目55-56:数据库设计 - SQL权限管理)
- [🧮 题目57:数据结构与算法 - 栈的应用](#🧮 题目57:数据结构与算法 - 栈的应用)
- [🌳 题目58:数据结构与算法 - 哈夫曼编码合法性判断](#🌳 题目58:数据结构与算法 - 哈夫曼编码合法性判断)
- [🕸️ 题目59:数据结构与算法 - 图的广度优先搜索(BFS)时间复杂度分析](#🕸️ 题目59:数据结构与算法 - 图的广度优先搜索(BFS)时间复杂度分析)
- [🔍 题目60:数据结构与算法 - 折半查找(二分查找)的关键字序列分析](#🔍 题目60:数据结构与算法 - 折半查找(二分查找)的关键字序列分析)
- [🌲 题目61:数据结构与算法 - 森林转换为二叉树的结构分析](#🌲 题目61:数据结构与算法 - 森林转换为二叉树的结构分析)
- [🔢 题目62-63:数据结构与算法 - 排序算法特性选择](#🔢 题目62-63:数据结构与算法 - 排序算法特性选择)
- [🌳 题目64-65:数据结构与算法 - Kruskal算法与最小生成树](#🌳 题目64-65:数据结构与算法 - Kruskal算法与最小生成树)
- [🌐 题目66:计算机网络 - WWW控制协议](#🌐 题目66:计算机网络 - WWW控制协议)
- [🐧 题目67-68:计算机系统 - Linux Web服务器配置](#🐧 题目67-68:计算机系统 - Linux Web服务器配置)
- [📡 题目69:计算机网络 - SNMP传输协议](#📡 题目69:计算机网络 - SNMP传输协议)
- [二、 系统开发和运行知识 🗃️](#二、 系统开发和运行知识 🗃️)
-
- [📊 题目15:软件工程 - 数据流图加工规格说明](#📊 题目15:软件工程 - 数据流图加工规格说明)
- [🏗️ 题目16:软件工程 - 优秀设计原则](#🏗️ 题目16:软件工程 - 优秀设计原则)
- [🗺️ 题目17-18:软件工程 - 关键路径分析](#🗺️ 题目17-18:软件工程 - 关键路径分析)
- [🗣️ 题目19:软件工程 - 团队沟通路径计算](#🗣️ 题目19:软件工程 - 团队沟通路径计算)
- [🛠️题目29:系统开发模型 - 增量模型特性](#🛠️题目29:系统开发模型 - 增量模型特性)
- [🏃 题目30:敏捷开发方法 - Scrum框架](#🏃 题目30:敏捷开发方法 - Scrum框架)
- [🔗 题目31:软件工程 - 模块耦合类型](#🔗 题目31:软件工程 - 模块耦合类型)
- [💻 题目32:软件设计 - 可移植性设计原则](#💻 题目32:软件设计 - 可移植性设计原则)
- [🛠️ 题目33:软件体系结构 - 管道过滤器风格](#🛠️ 题目33:软件体系结构 - 管道过滤器风格)
- [🔍题目34-35:软件测试 - McCabe复杂度分析](#🔍题目34-35:软件测试 - McCabe复杂度分析)
- [🛠️ 题目36:系统设计 - 改善性维护](#🛠️ 题目36:系统设计 - 改善性维护)
- [三、 面向对象基础知识 🧩](#三、 面向对象基础知识 🧩)
-
- [🧩 题目37-38:面向对象程序设计基础](#🧩 题目37-38:面向对象程序设计基础)
- [🧪 题目39:面向对象 - 方法测试归属](#🧪 题目39:面向对象 - 方法测试归属)
- [🧩 题目40:面向对象设计原则 - 共同重用原则](#🧩 题目40:面向对象设计原则 - 共同重用原则)
- [📊 题目41-42:面向对象设计 - UML序列图解析](#📊 题目41-42:面向对象设计 - UML序列图解析)
- [📦 题目43:UML包图 - 元素所有权规则](#📦 题目43:UML包图 - 元素所有权规则)
- [🧬 题目44-45:设计模式 - 原型模式解析](#🧬 题目44-45:设计模式 - 原型模式解析)
- [💰 题目46-47:设计模式 - 策略模式解析](#💰 题目46-47:设计模式 - 策略模式解析)
- [四、 网络与信息安全知识 🌐](#四、 网络与信息安全知识 🌐)
-
- [🔐 题目8-9:网络安全 - HTTPS加密与证书撤销](#🔐 题目8-9:网络安全 - HTTPS加密与证书撤销)
- [🛡️ 题目10:网络安全 - 入侵防御系统(IPS)功能](#🛡️ 题目10:网络安全 - 入侵防御系统(IPS)功能)
- [🛡️ 题目11:网络安全 - Web应用防火墙(WAF)防护范围](#🛡️ 题目11:网络安全 - Web应用防火墙(WAF)防护范围)
- [🌐 题目70:网络故障诊断 - DNS问题定位](#🌐 题目70:网络故障诊断 - DNS问题定位)
- [五、 标准化、信息化和知识产权基础知识 🛠️](#五、 标准化、信息化和知识产权基础知识 🛠️)
-
- [📜 题目12:知识产权 - 著作权保护期限](#📜 题目12:知识产权 - 著作权保护期限)
- [🌍 题目13:知识产权 - 国际软件保护方式](#🌍 题目13:知识产权 - 国际软件保护方式)
- [📜 题目14:知识产权 - 软件著作权继承规则](#📜 题目14:知识产权 - 软件著作权继承规则)
- [六、 计算机英语 🐧](#六、 计算机英语 🐧)
-
- [📊 题目71-75:计算机英语](#📊 题目71-75:计算机英语)
选择题(上午题)(每题1分,共75分)
2023年上午题试卷:百度云盘
💡 注意:文章按照知识点顺序总结,未按真题顺序
一、 计算机系统基础知识 🖥️
💻 题目1:计算机组成原理 - 系统总线
计算机中,系统总线用于 (1) 连接。
(1)
A. 接口和外设
B. 运算器、控制器和寄存器
C. CPU、主存及外设部件 ✅D. DMA 控制器和中断控制器
📌 正确答案:C
🔍 详细解析
系统总线(System Bus) 是计算机内部各核心部件之间进行 数据传输 和 控制信号交换 的公共通道,主要连接:
-
CPU(中央处理器)
-
主存(内存)
-
外设部件(如硬盘、显卡、USB设备等)
💡 知识点分析
-
系统总线的组成:
-
数据总线(Data Bus):传输数据(双向)。
-
地址总线(Address Bus):指定内存或外设地址(单向,CPU→外设)。
-
控制总线(Control Bus):传输控制信号(如读写、中断请求)。
-
-
其他选项分析:
-
A. 接口和外设 ❌
- 外设通常通过 I/O总线(如PCIe、USB) 连接,而不是直接连系统总线。
-
B. 运算器、控制器和寄存器 ❌
- 这些是 CPU内部组件,通过 内部总线 通信,不涉及系统总线。
-
D. DMA 控制器和中断控制器 ❌
- 它们属于 外设管理模块 ,通常通过 局部总线 连接CPU,而非系统总线。
-
-
扩展概念:
-
DMA(直接内存访问) :允许外设 不经过CPU 直接访问内存,但仍需总线仲裁。
-
北桥 vs 南桥:
-
北桥(传统架构)负责 CPU、内存、显卡(高速总线)。
-
南桥负责 硬盘、USB等外设(低速总线)。
-
-
🖥️ 题目2:计算机组成原理 - 存储体系与DMA
在由高速缓存、主存和硬盘构成的三级存储体系中,CPU执行指令时需要读取数据,那么DMA控制器和中断控制器发出的数据地址是(2)。
(2)
A. 高速缓存地址
B. 主存物理地址 ✅C. 硬盘的扇区地址
D. 虚拟地址
📌 正确答案:B
🔍 详细解析
-
DMA(直接内存访问)的核心作用:
-
DMA控制器允许外设(如硬盘、网卡)绕过CPU,直接与主存(物理内存)交换数据。
-
因此,DMA操作的地址必须是主存的物理地址(CPU不参与,无需虚拟地址转换)。
-
-
中断控制器的角色:
- 中断控制器管理外设的中断请求,但数据最终仍需通过主存传递(例如:硬盘读取的数据先存入内存,再被CPU处理)。
-
其他选项排除:
-
A. 高速缓存地址 ❌
- 缓存地址对CPU透明,由硬件自动管理,DMA不直接访问缓存。
-
C. 硬盘扇区地址 ❌
- DMA传输的是内存目标地址,而非硬盘原始地址(硬盘驱动会转换扇区地址到内存地址)。
-
D. 虚拟地址 ❌
- DMA操作的是物理内存,虚拟地址需经MMU转换,但DMA不依赖CPU的MMU单元。
-
💡 核心知识点
- 三级存储体系
| 层级 | 存储介质 | 特点 | 访问权限 |
|---|---|---|---|
| 高速缓存 | SRAM | 速度快,容量小 | CPU直接访问 |
| 主存 | DRAM | 速度中等,容量较大 | CPU、DMA均可访问 |
| 硬盘 | 磁盘/SSD | 速度慢,容量大 | 需通过DMA/中断调入主存 |
-
DMA工作流程
-
外设发起请求 → DMA控制器接管总线。
-
直接读写主存 → 数据按物理地址传输。
-
传输完成 → DMA通知CPU(中断)。
-
-
虚拟地址 vs 物理地址
-
虚拟地址:CPU生成的逻辑地址(需MMU转换)。
-
物理地址:实际内存硬件地址(DMA直接使用)。
-
🔍题目3:计算机组成原理 - 海明码校验位计算
设信息位是8位,用海明码来发现并纠正1位出错的情况,则校验位的位数至少为(3)。
(3)
A. 1
B. 2
C. 4 ✅D. 8
📌 正确答案:C
🔍 详细解析
海明码的校验位数k必须满足:
2 k ≥ n + k + 1 2^k \geq n + k + 1 2k≥n+k+1
其中:
- n = 信息位数(本题n=8)
- k = 校验位数
所以,最大信息位数:对于k位校验位,最多可保护:
n ≤ 2 k − k − 1 n \leq 2^k - k - 1 n≤2k−k−1
如k=4时,最大n=11(但本题n=8)
拓展:纠正 2 位错误
纠正 2 位同时出错 需要更强的纠错能力。此时需满足:
2 k ≥ ( n 0 ) + ( n 1 ) + ( n 2 ) = 1 + n + n ( n − 1 ) 2 \begin{align} 2^k &\geq \binom{n}{0} + \binom{n}{1} + \binom{n}{2} \\ &= 1 + n + \frac{n(n-1)}{2} \end{align} 2k≥(0n)+(1n)+(2n)=1+n+2n(n−1)
校验位 ( k ) 需满足:
2 k ≥ 1 + n + n ( n − 1 ) 2 , 其中 n = n + k = 8 + k \begin{align} 2^k &\geq 1 + n + \frac{n(n-1)}{2}, \\ \text{其中 } n &= n + k = 8 + k \end{align} 2k其中 n≥1+n+2n(n−1),=n+k=8+k
解得最小 k = 7
| 纠错能力 | 最小校验位数 ( r ) | 总码长 ( n ) |
|---|---|---|
| 1 位 | 4 | 12 |
| 2 位 | 7 | 15 |
后面以此类推
📝 计算过程
- 代入
n=8:
2 k ≥ 8 + k + 1 2^k \geq 8 + k + 1 2k≥8+k+1
- 尝试k值:
-
k=3 → 2³-1=7 ≥ 8+3=11 ❌(7≥11不成立)
-
k=4 → 2⁴-1=15 ≥ 8+4=12 ✅(15≥12成立)
💡 海明码核心知识点
举个例子来说明,海明码工作原理
- 选择数据位
假设我们有4位数据需要传输:1011。
- 确定校验位数量
根据上面公式,n = 4 ,需要 k=3位校验位
- 决定数据位和校验位的位置
我们将校验位放在2的幂次( 2 i 2^i 2i ,其中i = 0,1,2,3...)位置(1,2,4,......),数据位放在其他位置:
| 第1位 | 第2位 | 第3位 | 第4位 | 第5位 | 第6位 | 第7位 |
|---|---|---|---|---|---|---|
| 校验位 P1 | 校验位 P2 | 数据位 D1 | 校验位 P3 | 数据位 D2 | 数据位 D3 | 数据位 D4 |
所以,位置应该是:_ _ D1 _ D2 D3 D4。
- 插入数据位
将数据位(1011)插入相应位置:
| 第1位 | 第2位 | 第3位 | 第4位 | 第5位 | 第6位 | 第7位 |
|---|---|---|---|---|---|---|
| 校验位 P1 | 校验位 P2 | 1 | 校验位 P3 | 0 | 1 | 1 |
- 计算校验位覆盖范围
先将位置用二进制表示
| 位置 | 二进制表示 | 说明 |
|---|---|---|
| 1 | 0001 | P1 |
| 2 | 0010 | P2 |
| 3 | 0011 | D1 |
| 4 | 0100 | P3 |
| 5 | 0101 | D2 |
| 6 | 0110 | D3 |
| 7 | 0111 | D4 |
P1 (0001)需要覆盖所有位置的二进制表示中第1位为1的位。
- 位置1(二进制:000
1),第1位为1。 - 位置3(二进制:001
1),第1位为1。 - 位置5(二进制:010
1),第1位为1。 - 位置7(二进制:011
1),第1位为1。
所以,P1 覆盖位置1, 3, 5, 7。
类似地,校验位 P2 (0010)覆盖所有位置的二进制表示中第2位为1的位:
位置2(二进制:0010),第2位为1。
位置3(二进制:0011),第2位为1。
位置6(二进制:0110),第2位为1。
位置7(二进制:0111),第2位为1。
- 计算校验位
校验位的计算涉及到覆盖特定位的奇偶校验(异或运算):
首先来解释一下什么是异或运算:
-
当符号两边为一样的时后,结果为0,当两边不一样的时候,结果为1。
- 1 ⊕ 1 = 0
- 0 ⊕ 0 = 0
- 1 ⊕ 0 = 1
- 0 ⊕ 1 = 1
-
P1 覆盖位置 1, 3, 5, 7:
- P1 = D1 ⊕ D2 ⊕ D4 = 1 ⊕ 0 ⊕ 1 = 0
-
P2 覆盖位置 2, 3, 6, 7:
- P2 = D1 ⊕ D3 ⊕ D4 = 1 ⊕ 1 ⊕ 1 = 1
-
P3 覆盖位置 4, 5, 6, 7:
- P3 = D2 ⊕ D3 ⊕ D4 = 0 ⊕ 1 ⊕ 1 = 0
- 插入校验位
将计算得到的校验位插入相应位置:
| 第1位 | 第2位 | 第3位 | 第4位 | 第5位 | 第6位 | 第7位 |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 0 | 0 | 1 | 1 |
最终得到的海明码为:0110011
- 检测和纠正错误
假设传输过程中接收到的码是:0110011
我们重新计算校验位来检测错误:
-
检查 P1 :
- 位置 1, 3, 5, 7: 0 ⊕ 1 ⊕ 0 ⊕ 1 = 0(正确)
-
检查 P2 :
- 位置 2, 3, 6, 7: 1 ⊕ 1 ⊕ 1⊕ 1 = 0(正确)
-
检查 P3 :
- 位置 4, 5, 6, 7: 0 ⊕ 0 ⊕ 1 ⊕ 1 = 0(正确)
⚡ 题目4:计算机组成原理 - 中断向量
中断向量提供的是(4)。
(4)
A. 中断源的设备地址
B. 中断服务程序的入口地址 ✅C. 传递数据的起始地址
D. 主程序的断点地址
📌 正确答案:B
🔍 详细解析
-
中断向量的本质:
-
中断向量是中断服务程序(ISR)的入口地址 的存储位置,相当于一个
导航坐标。 -
当CPU接收到中断请求时,通过查询中断向量表,直接跳转到对应的ISR执行。
-
-
中断处理流程:

-
其他选项排除:
-
A. 中断源设备地址 ❌
- 设备地址由I/O端口或内存映射管理,与中断向量无关。
-
C. 数据起始地址 ❌
- 数据传输地址由DMA或程序指令指定。
-
D. 主程序断点地址 ❌
- 断点地址由CPU的
程序计数器(PC)自动保存到栈中。
- 断点地址由CPU的
💡 核心知识点
- 中断向量表(IVT)
| 中断号 | 内存地址(示例) | 对应的ISR入口 |
|---|---|---|
| 0 | (除法错误) | 0x0000 |
| 1 | (键盘中断) | 0x0004 |
| ... | ... | ... |
-
📌 关键特性:
-
每个中断号对应固定内存位置 (如x86实模式中,中断号n对应地址4*n)。
-
现代系统使用IDT(中断描述符表),支持更复杂的权限控制。
-
- 相关概念对比
| 术语 | 作用 | 存储位置 |
|---|---|---|
| 中断向量 | ISR入口地址 | 内存(向量表) |
| 断点地址 | 主程序返回地址 | CPU栈 |
| 设备地址 | 外设寄存器位置 | I/O空间 |
- 硬件支持
-
中断控制器(如8259A):管理多个中断源的优先级和屏蔽。
-
CPU的EFLAGS寄存器:IF标志位控制全局中断开关。
🔢 题目5:计算机组成原理 - 补码表示
计算机系统中,定点数常采用补码表示,以下关于补码表示的叙述中,错误的是(5)。
(5)
A. 补码零的表示是唯一的
B.可以将减法运算转化为加法运算
C. 符号位可以与数值位一起参加运算
D. 与真值的对应关系简单且直观 ✅
📌 正确答案:D
🔍 详细解析
补码的核心特性及其对应的选项分析:
| 特性 | 选项 | 正确性 |
|---|---|---|
| 零的唯一性 | A | ✅ +0=0000, -0在补码中也是0000 |
| 减法变加法 | B | ✅ a-b = a+(-b)的补码 |
| 符号位参与运算 | C | ✅ 无需单独处理符号位 |
| 真值转换复杂度 | D | ❌ 负数补码需取反+1,不直观 |
💡 核心知识点
- 补码转换规则
-
对于 正数 (符号位 0):
- 原码 = 反码 = 补码
(直接按二进制表示,符号位为 0,数值位不变)
- 原码 = 反码 = 补码
-
对于 负数 (符号位 1):
-
原码:符号位为 1,数值位直接表示绝对值的二进制。
-
反码:原码符号位不变,数值位按位取反(0→1,1→0)。
-
补码:反码 + 1(进位到符号位时丢弃)。
-
| 真值 | 原码 | 反码 | 补码 |
|---|---|---|---|
| +5 | 00000101 | 00000101 | 00000101 |
| -5 | 10000101 | 11111010 | 11111011 |
- 补码运算示例
例如:计算 7 - 5:
7的补码 = 00000111
-5的补码 = 11111011
相加结果 = 00000010 → 真值2(自动溢出位丢弃)
- 与其他编码对比
| 编码类型 | 零的表示 | 减法处理 | 硬件复杂度 |
|---|---|---|---|
| 原码 | +0/-0 | 需单独处理符号 | 高 |
| 反码 | +0/-0 | 需循环进位 | 中 |
| 补码 | 唯一零 | 直接相加 | 低 |
⏱️题目6:计算机体系结构 - 指令流水线时间计算
设指令流水线将一条指令的执行分为取指、分析、执行三段,已知取指时间是2ns,分析时间是2ns,执行时间是1ns,则执行完1000条指令所需的时间为(6)。
(6)
A. 1004ns
B. 1998ns
C. 2003ns ✅D. 2008ns
📌 正确答案:C
🔍 详细解析
📌 流水线执行时间公式
对于k段流水线执行n条指令:
java
总时间 = 流水线建立时间 + (n-1) × 最长段耗时
(所有段耗时之和) (流水线周期)📝 计算步骤
-
各段耗时:
-
取指:2ns(最长段)
-
分析:2ns(最长段)
-
执行:1ns
-
-
计算参数:
-
流水线建立时间 = 2 + 2 + 1 = 5ns
-
最长段耗时 = m a x ( 2 , 2 , 1 ) max(2,2,1) max(2,2,1) = 2ns
-
指令数n = 1000
-
-
总时间:
java
总时间 = 5ns + (1000-1) × 2ns
= 5 + 1998
= 2003ns🌰 直观示例(前5条指令)
| 时间(ns) | 取指 | 分析 | 执行 |
|---|---|---|---|
| 0-2 | 指令1 | ||
| 2-4 | 指令2 | 指令1 | |
| 4-5 | 指令1 | ||
| 4-6 | 指令3 | 指令2 | |
| 5-6 | 指令2 | ||
| 6-8 | 指令4 | 指令3 | |
| ... | ... | ... | ... |
| t-3 - t-1 | 指令n | ||
| t-1 - t | 指令n |
从第5ns开始,每2ns完成一条指令(由最长段2ns决定)。
💡 核心知识点
- 流水线加速比
加速比 = 顺序执行时间 / 流水线执行时间
= ( n × S ) / k × Δ t + ( n − 1 ) × Δ t (n×S) / k×Δt + (n-1)×Δt (n×S)/k×Δt+(n−1)×Δt
-
本题若顺序执行:1000×5ns = 5000ns
-
加速比 ≈ 5000/2003 ≈ 2.5倍
- 吞吐率计算
java
吞吐率 = n / 总时间
= 1000/2003 ≈ 0.499 条/ns- 流水线冲突类型
| 冲突类型 | 原因 | 解决方案 |
|---|---|---|
| 结构冲突 | 硬件资源竞争 | 增加资源 |
| 数据冲突 | 数据依赖 | 转发/暂停 |
| 控制冲突 | 分支指令 | 分支预测 |
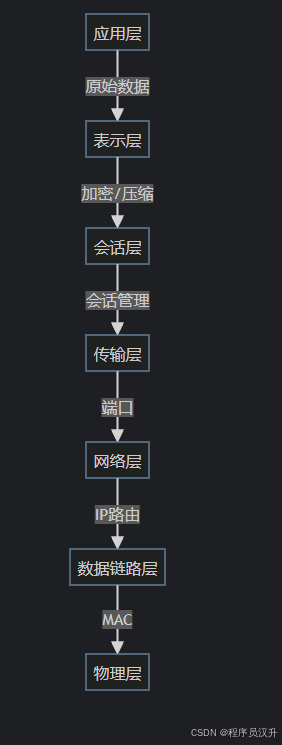
🌐 题目7:计算机网络 - OSI模型表示层
在OSI参考模型中,负责对应用层消息进行压缩、加密功能的层次为(7)。
(7)
A. 传输层
B. 会话层
C. 表示层 ✅D. 应用层
📌 正确答案:C
🔍 详细解析
表示层(Presentation Layer)的核心职责:
| 功能 | 具体实现 |
|---|---|
| 数据压缩 | ZIP、JPEG等编码 |
| 数据加密 | SSL/TLS(早期)、AES、DES |
| 数据格式转换 | ASCII ↔ Unicode,字节序转换 |
⚡ 其他选项排除
| 层级 | 主要功能 | 排除原因 |
|---|---|---|
| A. 传输层 | 端到端可靠性(TCP/UDP) | ❌ 只管传输不管内容 |
| B. 会话层 | 建立/维护/终止会话(RPC) | ❌ 不涉及数据变形 |
| D. 应用层 | HTTP/FTP/SMTP等协议 | ❌ 原始数据生成层 |
💡 核心知识点
OSI七层模型速记
🔍 题目20:编程基础 - 布尔表达式短路计算
对布尔表达式"a or ((b < c) and d)"求值时,当(20)时可进行短路计算。
(20)
A. a 为 true ✅B. b 为 true
C. c 为 true
D. d 为 true
📌 正确答案:A
🔍 详细解析
短路计算(Short-circuit Evaluation)规则:
| 表达式 | 短路条件 | 后续计算 |
|---|---|---|
| X or Y | X为true | 跳过Y |
| X and Y | X为false | 跳过Y |
应用到本题:
java
a or ((b < c) and d)-
若
a == true:-
整个表达式必为
true(or的特性) -
立即短路,不再计算
(b < c) and d
-
-
若
a == false:- 需继续计算
(b < c) and d
- 需继续计算
💡 核心知识点
- 短路计算原理

- 编程语言支持
| 语言 | 运算符 | 典型应用场景 |
|---|---|---|
| C/Java | && |
避免空指针异常:if (obj != null && obj.value > 0) |
| Python | or / and | 默认支持短路 |
| SQL | OR / AND | WHERE条件优化 |
🔤 题目21:形式语言与自动机 - 正规式特征分析
设有正规式 s = (0 | 10)*,则其所描述正规集中字符串的特点是(21)。
(21)
A. 长度必须是偶数
B. 长度必须是奇数
C. 0 不能连续出现
D. 1 不能连续出现 ✅
📌 正确答案:D
🔍 详细解析
正规式 s = (0 | 10)表示的正规集为{0, 10},s = (0 | 10)*表示的正规集为{ ε , 0, 10, 00, 010, 100, 1010, 000, 0010, 0100, 01010, 1000, 10010, 10100, 101010, ... },用自然语言描述其正规式特点就是 0 可以连续出现,1 不能连续出现,长度没有必须是奇数或偶数的特点。
正规式 (0 | 10)* 的生成规则:
-
基本单元:
-
0 :单个0
-
10 :1后必须跟0
-
-
重复特性:
-
*表示可以重复任意次(包括0次) -
关键限制 :1后面必须紧跟0,因此1永远不会连续出现
-
🌰 合法 vs 非法字符串示例
| 合法字符串 | 非法字符串 | 原因 |
|---|---|---|
| ε (空串) | 11 | 1连续 |
| 0 | 101 | 最后一个1无0跟随 |
| 010 | 1001 | 最后两个1连续 |
🖥️ 题目22:程序设计 - 参数传递方式分析
设函数 foo() 和 hoo() 的定义如下所示,在函数 foo() 中调用函数 hoo() 时,hoo()的第一个参数采用传引用方式(call by reference),第二个参数采用传值方式(call by value),那么函数 foo中的 print(a, b) 将输出(22)。
(22)
A. 8, 5
B. 39, 5 ✅C. 8, 40
D. 39, 40

📌 正确答案:B
🔍 详细解析
代码执行流程分析
cpp
// 原始代码逻辑
int a = 8, b = 5;
hoo(a, b); // 传引用调用x=a,传值调用m=b
// hoo函数内部操作:
m = x * m; // m = 8 * 5 = 40(局部变量m改变)
x = m - 1; // x = 40 - 1 = 39(修改了外部a的值)
// 返回后:a=39(引用修改),b保持原值5(传值保护)⚡ 关键点说明
| 参数 | 传递方式 | 函数内外变量关系 |
|---|---|---|
| x (对应a) | 传引用 | 函数内修改直接影响外部a |
| m (对应b) | 传值 | 函数内操作不影响外部b |
🌰 内存变化示意
| 步骤 | 外部变量 | hoo内变量 |
|---|---|---|
| 调用前 | a=8, b=5 | x→a, m=5 |
| 执行后 | a=39, b=5 | m=40(丢弃) |
💡 核心知识点
参数传递方式对比
| 方式 | 内存操作 | 典型语言 | 性能影响 |
|---|---|---|---|
| 传值 | 创建副本 | C++默认 | 大对象复制开销高 |
| 传引用 | 操作原变量 | C++的& |
高效但可能意外修改 |
💾 题目23:操作系统 - 位示图大小计算
某文件管理系统采用位示图(bitmap)来记录磁盘的使用情况,若计算机系统的字长为64位,磁盘容量为512GB,物理块的大小为4MB,那么位示图的大小为(23)个字。
(23)
A. 1024
B. 2048 ✅C. 4096
D. 9600
📌 正确答案:B
🔍 详细解析
计算步骤详解
-
计算物理块总数:
物理块数 = 磁盘容量 块大小 = 512 GB 4 MB = 512 × 1024 MB 4 MB = 131072 块 \text{物理块数} = \frac{\text{磁盘容量}}{\text{块大小}} = \frac{512 \text{ GB}}{4 \text{ MB}} = \frac{512 \times 1024 \text{ MB}}{4 \text{ MB}} = 131072 \text{ 块} 物理块数=块大小磁盘容量=4 MB512 GB=4 MB512×1024 MB=131072 块
-
计算位示图所需字数:
- 每个字(64位)可记录64个块的状态
字数 = ⌈ 物理块数 字长 ⌉ = ⌈ 131072 64 ⌉ = 2048 字 \text{字数} = \lceil \frac{\text{物理块数}}{\text{字长}} \rceil = \lceil \frac{131072}{64} \rceil = 2048 \text{ 字} 字数=⌈字长物理块数⌉=⌈64131072⌉=2048 字
⚡ 关键点说明
| 参数 | 值 | 计算逻辑 |
|---|---|---|
| 磁盘容量 | 512GB | 需转换为MB(1GB=1024MB) |
| 块大小 | 4MB | 直接作为分母 |
| 字长 | 64位 | 1字=64bit=64块信息 |
💡 核心知识点
位示图原理
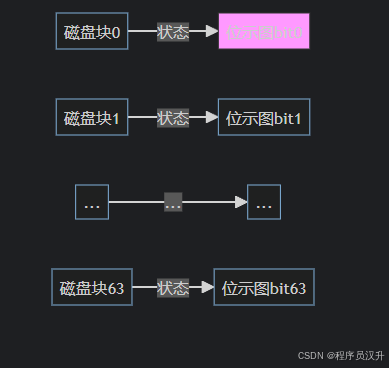
-
每个bit对应一个物理块的使用状态(0=空闲,1=占用)
-
空间优化:相比链表法,节省存储开销
💽 题目24:操作系统 - 磁盘调度算法
磁盘调度分为移臂调度和旋转调度两类,在移臂调度的算法中,(24)算法可能会随时改变移动臂的运行方向。
(24)
A. 单向扫描和先来先服务
B. 电梯调度和最短寻道时间优先
C. 电梯调度和最短寻道时间优先
D. 先来先服务和最短寻道时间优先 ✅
📌 正确答案:D
🔍 详细解析
磁盘调度算法特性对比:
| 算法 | 移动方向 | 特点 | 方向可变性 |
|---|---|---|---|
| 先来先服务(FCFS) | 无规律 | 按请求顺序处理 | ✅ 可能频繁转向 |
| 最短寻道时间优先(SSTF) | 动态调整 | 总是选择最近的磁道 | ✅ 可能来回摆动 |
| 电梯调度(SCAN) | 单向到边界 | 类似电梯运行 | ❌ 到边界才反向 |
| 单向扫描(C-SCAN) | 单向循环 | 只单向移动 | ❌ 严格单向 |
🌰 实例说明
-
FCFS:请求序列为 98, 183, 37, 122 → 磁头从50出发的移动路径:50→98→183→37→122(多次转向)
-
SSTF:请求序列为 98, 183, 37, 122 → 可能路径:50→37→98→122→183(中间可能反转)
💡 核心知识点
- 算法动态演示

- 性能影响
| 算法 | 平均寻道时间 | 公平性 | 适用场景 |
|---|---|---|---|
| FCFS | 最长 | 高 | 请求稀疏时 |
| SSTF | 较短 | 低 | 负载较轻时 |
| SCAN | 中等 | 中 | 负载均衡时 |
-
现代扩展算法
-
LOOK:电梯调度的改进版(不到物理边界就反向) -
N-Step-SCAN:解决SSTF的"饥饿"问题
-
🧵 题目25:操作系统 - 多线程资源共享
在支持多线程的操作系统中,假设进程P创建了T1、T2、T3线程,那么(25)。
(25)
A. 该进程的代码段不能被T1、T2、T3共享
B. 该进程的全局变量只能被T1共享
C. 该进程中T1、T2、T3的栈指针不能被共享 ✅D. 该进程中T1的栈指针可以被T2、T3共享
📌 正确答案:C
🔍 详细解析
多线程内存模型关键特性:
| 资源类型 | 是否共享 | 说明 |
|---|---|---|
| 代码段 | ✔️ 共享 | 所有线程执行相同指令 |
| 全局变量 | ✔️ 共享 | 需同步机制(如互斥锁) |
| 堆内存 | ✔️ 共享 | 动态分配的区域 |
| 栈空间 | ❌ 不共享 | 每个线程有独立栈(保存局部变量/返回地址) |
🌰 实例说明
java
import java.util.concurrent.atomic.AtomicInteger;
public class ThreadExample {
private static final AtomicInteger global = new AtomicInteger(0); // 共享变量(线程安全)
static class MyThread implements Runnable {
private final int local; // 局部变量
public MyThread(int local) {
this.local = local;
}
@Override
public void run() {
int globalValue = global.incrementAndGet(); // 线程安全地增加 global
System.out.println("Thread " + local + ": local=" + local + ", global=" + globalValue);
}
}
public static void main(String[] args) {
Thread t1 = new Thread(new MyThread(1));
Thread t2 = new Thread(new MyThread(2));
t1.start();
t2.start();
}
}💡 核心知识点
- 线程私有与共享资源

- 栈空间独立性
| 线程 | 栈指针 | 存储内容 |
|---|---|---|
| T1 | ESP1 | 局部变量、函数调用链 |
| T2 | ESP2 | 与T1完全隔离 |
| T3 | ESP3 | 无法访问ESP1/ESP2 |
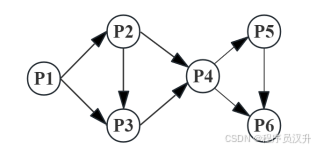
🔄 题目26-28:操作系统 - PV操作与进程同步
进程 P1、P2、P3、P4、P5 和 P6 的前趋图如下所示。
若用 PV 操作控制进程 P1、P2、P3、P4、P5 和 P6 并发执行的过程,需要设置信号量 S1、S2、S3、S4、S5、S6、S7和 S8,且信号量 S1~S8 的初值都等于零。下面 P1~P6 的进程执行过程中,空①和空②处应分别为 (26) ,空③和空④处应分别为 (27) ,空⑤和空⑥处应分别为(28) 。
(26)
A. P(S1)P(S2)和 V(S3)V(S4)
B. P(S1)P(S2)和 V(S1)V(S2)
C.V(S3)V(S4)和 P(S1)P(S2)
D. V(S3)V(S4)和 P(S2)P(S3) ✅(27)
A. V(S5)和 P(S4)P(S5) ✅B. V(S3)和 P(S4)V(S5)
C. P(S5)和 V(S4)V(S5)
D. P(S3)和 P(S4)P(S5)
(28)
A. V(S6)和 V(S8)
B. P(S6)和 P(S7)
C. P(S6)和 V(S8) ✅D. P(S8)和 P(S8)

📌 正确答案:(26)D,(27)A,(28)C
🔍 深度解析
什么是 PV 操作?
PV 操作(P - Wait, V - Signal) 是 进程同步 的基本操作,使用 信号量(Semaphore) 来协调进程执行的顺序,防止资源竞争或死锁。
-
P(S)操作**(Wait/Semaphore -1)**等待信号量
S > 0,如果S = 0,进程就会 阻塞 ,直到S变成正数。 -
V(S)操作**(Signal/Semaphore +1)**释放信号量
S,通知其他进程该资源可用。
进程同步图解
有 6 个进程:P1, P2, P3, P4, P5, P6,使用 8 个信号量(S1-S8) 来控制它们的执行顺序。
| 信号量 | 作用 | 相关进程 |
|---|---|---|
| S1 | 控制 P2 何时执行,P1 释放 | P1 → P2 |
| S2 | 控制 P3 何时执行,P1 释放 | P1 → P3 |
| S3 | 控制 P3 何时执行,P2 释放 | P2 → P3 |
| S4 | 控制 P4 何时执行,P2 释放 | P2 → P4 |
| S5 | 控制 P4 何时执行,P3 释放 | P3 → P4 |
| S6 | 控制 P5 何时执行,P4 释放 | P4 → P5 |
| S7 | 控制 P6 何时执行,P4 释放 | P4 → P6 |
| S8 | 控制 P6 何时执行,P5 释放 | P5 → P6 |
前趋图与PV操作映射
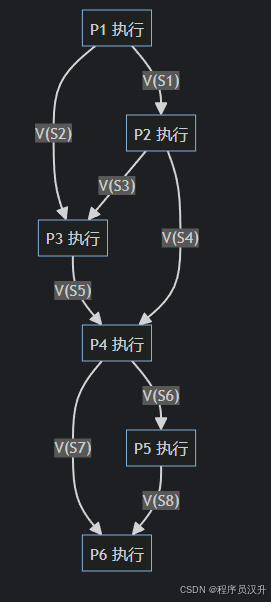
详细流程:
-
P1先执行,释放S1和S2:-
P2需要S1,所以P2可以执行。 -
P3需要S2但还需要S3,所以P3要等待P2释放S3。题中②是 P(S2) 和 P(S3)
-
-
P2运行完后,释放S3和S4:题中①是 V(S3) 和 V(S4)-
P3现在有S2和S3,所以P3可以执行。 -
P4需要S4(来自P2)和S5(来自P3),所以P4必须等待P3释放S5。题中④是 P(S4)和 P(S5)
-
-
P3运行完后,释放S5:题中③是 V(S5)- P4 现在有 S5(P2 释放的)和 S4(P3 释放的),所以 P4 可以执行。
-
P4运行完后,释放S6和S7:-
P5需要S6,所以P5可以执行。题中⑤为P(S6) -
P6需要S7和S8,但S8需要P5释放,所以P6仍需等待。
-
-
P5运行完后,释放S8:题中⑥为V(S8)P6现在有S7(P4释放的)和S8(P5释放的),所以P6可以执行。
🐍 题目48:程序设计语言 - Python对象类型获取type()函数
Python中采用(48)方法来获取一个对象的类型。
(48)
A. str()
B. type() ✅C. id()
D. object()
📌 正确答案:(48)C
🔍 深度解析
Python类型查询方法对比
| 方法 | 作用 | 示例输出 | 题目适用性 |
|---|---|---|---|
| type() | 返回对象类型 | <class 'int'> | ✅ 精准匹配 |
| str() | 对象转字符串 | "123" | ❌ 不涉及类型 |
| id() | 返回内存地址 | 140736823984 | ❌ 标识符非类型 |
| object() | 创建基类对象 | <object at 0x...> | ❌ 构造函数 |
💡 type()的高级用法
-
动态类型检查:
pythonif type(var) == list: print("这是一个列表") -
与isinstance()区别:
pythonclass Parent: pass class Child(Parent): pass print(type(Child()) == Parent) # False print(isinstance(Child(), Parent)) # True
⚡ 相关函数性能对比
| 操作 | 时间复杂度 | 适用场景 |
|---|---|---|
type(x) |
O(1) | 精确类型判断 |
isinstance(x, T) |
O(1) | 继承关系判断 |
callable(x) |
O(1) | 可调用对象检测 |
🐍 题目49:程序设计语言 - Python元组定义
在Python中,语句x = (49)不能定义一个元组。
(49)
A. (1, 2, 1, 2)
B. 1, 2, 1, 2
C. tuple()
D. (1) ✅
📌 正确答案:(49)D
🔍 深度解析
Python元组定义方式对比
| 写法 | 类型 | 说明 | 题目判断 |
|---|---|---|---|
| (1,2,1,2) | tuple | 标准多元素元组 | ✅ 是元组 |
| 1,2,1,2 | tuple | 省略括号的元组 | ✅ 是元组 |
| tuple() | tuple | 空元组构造函数 | ✅ 是元组 |
| (1) | int | 括号表达式 | ❌ 不是元组 |
💡 单元素元组的正确写法
python
x = (1,) # 必须加逗号
print(type(x)) # <class 'tuple'>⚡ 元组特性速记
| 特性 | 示例 | 注意点 |
|---|---|---|
| 不可变性 | t[0] = 1 会报错 |
与列表核心区别 |
| 解包赋值 | a, b = (1, 2) |
元素数量需匹配 |
| 省略括号 | return 1, 2 返回元组 |
函数返回常用 |
🚀 考试技巧
-
逗号决定论:
- 元组的本质是逗号分隔,括号仅辅助可读性
-
快速验证法:
python
>>> type((1)) # <class 'int'>
>>> type((1,)) # <class 'tuple'>-
特殊场景:
- 空元组必须用
tuple()或()
- 空元组必须用
🐍 题目50:程序设计语言 - Python语法特性
关于Python语言的叙述中,不正确的是(50)。
(50)
A. for语句可以用在序列(如列表、元组和字符串)上进行迭代访问
B. 循环结构如for和while后可以加else语句
C. 可以用if...else和switch...case语句表示选择结构 ✅D. 支持嵌套循环
📌 正确答案:(50)C
🔍 深度解析
Python选择结构的特殊性
| 特性 | 说明 | 题目对应性 |
|---|---|---|
| if-elif-else | Python唯一原生选择结构 | ❌ 无switch-case |
| 模式匹配 | Python 3.10+引入match-case | 非传统switch |
| 字典分发 | 用字典模拟switch效果 | 需手动实现 |
💡 各选项验证
| 选项 | 验证代码 | 正确性 |
|---|---|---|
| A | for x in 1,2: print(x) | ✅ |
| B | while False:... else:... | ✅ |
| C | switch(1){case 1:...} | ❌ 语法错误 |
| D | for i in range(3): for j in... | ✅ |
⚡ Python 3.10的match-case
虽然Python没有switch,但3.10版本后可用match替代:
python
match status:
case 400:
print("Bad request")
case 404:
print("Not found")
case _: # 默认case
print("Other error")🗃️ 题目51:数据库设计 - 数据库三级模式结构
在数据库应用系统开发中,关于抽象层次的叙述错误的是(51)。
(51)
A. 视图层是最高层次的抽象
B. 逻辑层是比视图层更低一层的抽象
C. 物理层是最低层次的抽象
D. 物理层是比逻辑层更高一层的抽象 ✅
📌 正确答案:(51)D
🔍 深度解析
数据库三级模式结构
| 层级 | 别名 | 抽象级别 | 描述 | 错误点 |
|---|---|---|---|---|
| 视图层 | 外模式 | 最高 | 用户可见的数据视图 | - |
| 逻辑层 | 概念模式 | 中间 | 全局数据结构定义 | - |
| 物理层 | 内模式 | 最低 | 数据物理存储方式 | D选项颠倒层级 |
各层核心功能对比
| 层级 | 典型操作 | 变化影响 |
|---|---|---|
| 视图层 | CREATE VIEW | 不影响逻辑结构 |
| 逻辑层 | CREATE TABLE | 需调整视图映射 |
| 物理层 | 索引/分区设计 | 对用户透明 |
sql
-- 视图层示例
CREATE VIEW student_view AS
SELECT name, score FROM students WHERE class='A';
-- 逻辑层示例
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50),
score FLOAT
);
-- 物理层示例(MySQL)
ALTER TABLE students ADD INDEX idx_score (score);🔍 题目52:数据库设计 - 数据库理论
给定关系模式 R(U, F),其中 U 为属性集,F 是 U 上的一组函数,属于自反律的是 (52) 。
(52)
A. 若 Y∈X∈U,则 X→Y 为 F 所蕴含 ✅B. 若 X→Y,Y→Z,则 X→Z 为 F 所蕴含
C. 若X→Y,Z∈Y,则 X→Z 为 F 所蕴含
D. 若 X→Y,X→Z,则 X→YZ 为 F 所蕴含
📌 正确答案:(51)A
🔍 深度解析
Armstrong公理系统三大定律
| 定律 | 形式化表示 | 通俗理解 | 题目对应 |
|---|---|---|---|
| 自反律 | 若 Y∈X,则 X→Y | "属性集总能决定自己的子集" | A选项 |
| 增广律 | 若 X→Y,则 XZ→YZ | "两边同时增加相同属性" | - |
| 传递律 | 若 X→Y且Y→Z,则 X→Z | "函数依赖的连锁反应" | B选项 |
其他选项分析
| 选项 | 对应的公理/规则 | 非自反律原因 |
|---|---|---|
| B | 传递律 | 需要两个依赖关系 |
| C | 分解规则 | 从X→Y分解出X→Z |
| D | 合并规则 | 合并多个右部属性 |
⚡ 自反律的典型应用
平凡函数依赖:
-
{学号,姓名} → {学号} -
{A,B,C} → {B}
💡 核心知识点
关系模式 R(U, F) 详解
关系模型(Relational Model)是数据库设计的理论基础,关系模式 R(U, F) 是关系模型的数学化定义,用于描述表的结构和约束条件。
-
关系模型的核心概念
-
关系(Relation)
- 对应数据库中的一张表(Table)。
- 例如:学生表
Student(ID, Name, Age)。
-
属性(Attribute)
-
表中的
列名(字段),表示数据的某一特征。 -
例如:
ID、Name、Age。
-
-
元组(Tuple)
-
表中的一行数据,表示一个具体实例。
-
例如:
(1, "Alice", 20)。
-
-
域(Domain)
-
属性的取值范围(数据类型)。
-
例如:
Age的域是整数 ≥ 0。
-
-
-
关系模式 R(U, F) 的定义
关系模式是关系的抽象描述,形式化表示为:
R(U, F)-
R:关系名(表名)。
-
U:属性的集合(所有字段)。
-
F :属性间的函数依赖集(约束规则)。
示例
学生选课系统的关系模式:
javaStudent_Course(学号, 姓名, 课程号, 课程名, 成绩)-
U = {学号, 姓名, 课程号, 课程名, 成绩}
-
F = {
{学号} → {姓名},
{课程号} → {课程名},
{学号, 课程号} → {成绩}
}
-
-
函数依赖(Functional Dependency, F)
函数依赖是关系模式中属性间的约束关系 ,定义为:
若对于属性集 X 的任意两个元组,若 X 相同,则 Y 必须相同,记作 X → Y。
-
完全函数依赖
-
X → Y,且
X的任意真子集X'都不能决定Y。 -
示例:
{学号, 课程号} → {成绩}
(单独学号或课程号不能决定成绩)。
-
-
部分函数依赖
-
X → Y,但X的某个真子集X'也能决定Y。 -
示例:
{学号, 课程号} → {姓名}
(因为 {学号} → {姓名} 已存在)。
-
-
传递函数依赖
-
若
X → Y且Y → Z,但Y ↛ X,则X → Z是传递依赖。 -
示例:
{学号} → {院系},{院系} → {院长} ⇒ {学号} → {院长}。
-
-
🗃️ 题目53-54:关系数据库设计 - 候选键与主属性分析
给定关系模式R(U, F),U = {A,B,C,D},函数依赖集F = {AB→C, CD→B}。 关系模式R(53), 主属性和非主属性个数分别是(54)?
(53)
A. 只有1个候选关键字ACB
B. 只有1个候选关键字BCD
C. 有2个候选关键字ABD和ACD ✅D. 有2个候选关键字ACB和BCD
(54)
A. 4和0 ✅B. 3和1
C. 2和2
D. 1和3
📌 正确答案:(53)C,(54)A
🔍 深度解析
候选键求解步骤
-
确定必选属性:
-
D不出现在任何FD右部→必须包含在所有候选键中
-
A不出现在任何FD右部→必须包含在所有候选键中
-
-
闭包计算验证:
-
(ABD)⁺ = ABD + C(AB→C) = ABCD ✅
-
(ACD)⁺ = ACD + B(CD→B) = ABCD ✅
-
-
最小性检查:
-
ABD的子集(如AD)的闭包≠U
-
ACD的子集(如AD)的闭包≠U
-
💡 主属性判定
| 属性 | 是否在候选键中 | 分类 |
|---|---|---|
| A | ABD/ACD均包含 | 主属性 |
| B | ABD包含 | 主属性 |
| C | ACD包含 | 主属性 |
| D | ABD/ACD均包含 | 主属性 |
📚 闭包(Closure)计算详解
闭包(记作 X + X^+ X+)是关系数据库中函数依赖理论 的核心概念,用于确定给定属性集 X 能推导出的所有属性。
-
闭包的定义
给定关系模式 R(U,F)和属性集 X⊆U, X + X^+ X+表示:
- 所有能通过
F中的函数依赖从X推导出的属性集合。 - 即: X + = A ∈ U ∣ X → A 可由 F 推导 X^+ = {A ∈ U | X → A 可由 F 推导} X+=A∈U∣X→A可由F推导。
- 所有能通过
-
闭包的计算步骤
闭包的计算是一个迭代过程,具体步骤如下:
-
初始化
- X + = X X^+ = X X+=X(开始时闭包等于自身)。
-
迭代扩展
- 遍历 F 中的每一个函数依赖 Y→Z,检查是否满足 Y⊆ X + X^+ X+(即 Y 的所有属性已在当前闭包中)。
-
如果满足,则将 Z 加入 X + X^+ X+(即 X + X^+ X+ = X + ∪ Z X^+ ∪Z X+∪Z)。
-
重复此过程,直到闭包不再变化。
-
- 遍历 F 中的每一个函数依赖 Y→Z,检查是否满足 Y⊆ X + X^+ X+(即 Y 的所有属性已在当前闭包中)。
-
终止条件:
- 遍历完所有函数依赖且闭包不再扩大时,算法结束。
-
-
示例解析
示例 1:计算 ( A B D ) + (ABD)^+ (ABD)+
假设函数依赖集 F={AB→C,CD→B},求 ( A B D ) + (ABD)^+ (ABD)+ 。
步骤:
-
初始化: X + X^+ X+ =ABD。
-
检查 AB→C:
-
AB⊆ABD(A 和 B 都在闭包中),因此将 C 加入闭包。
-
更新: X + X^+ X+=ABCD。
-
-
检查 CD→B:
- CD⊆ABCD,但 B 已在闭包中,无需新增。
-
闭包不再变化,最终结果:
- ( A B D ) + (ABD)^+ (ABD)+ =ABCD ✅
示例 2:计算 ( A C D ) + (ACD)^+ (ACD)+
同样基于 F={AB→C,CD→B},求 ( A C D ) + (ACD)^+ (ACD)+ 。
步骤:
-
初始化: X + X^+ X+ =ACD。
-
检查 AB→C:
- A B ⊈ A C D AB \nsubseteq ACD AB⊈ACD(缺少 B),跳过。。
-
检查 CD→B:
-
CD⊆ACD,因此将 B 加入闭包。
-
更新: X + X^+ X+=ABCD。
-
-
检查 AB→C:
- AB⊆ABCD,但 C 已在闭包中,无需新增。
-
闭包不再变化,最终结果:
- ( A C D ) + (ACD)^+ (ACD)+ =ABCD ✅
-
🔐 题目55-56:数据库设计 - SQL权限管理
将Students表的插入权限赋予User1,并允许其将该权限授予他人,正确的SQL语句是: GRANT (55) TABLE Students TO User1 (56)
(55)
A. INSERT
B. INSERT ON ✅C. UPDATE
D. UPDATE ON
(56)
A. FOR ALL
B. PUBLIC
C. WITH GRANT OPTION ✅D. WITH CHECK OPTION
📌 正确答案:(55)B,(56)C
🔍 深度解析
GRANT语句标准语法
sql
GRANT 权限 ON 对象 TO 用户 [WITH GRANT OPTION];各选项对比
| 部分 | 正确写法 | 错误示例 | 说明 |
|---|---|---|---|
| 权限 | INSERT ON | INSERT | 必须带ON指定对象 |
| 权限传递 | WITH GRANT OPTION | FOR ALL | 唯一正确的权限传递选项 |
sql
-- 正确授权语句
GRANT INSERT ON Students TO User1 WITH GRANT OPTION;
-- 错误示例1(缺少ON)
GRANT INSERT Students TO User1; -- 语法错误
-- 错误示例2(错误权限传递)
GRANT INSERT ON Students TO User1 WITH CHECK OPTION; -- 校验约束非权限传递⚡拓展
收回User1对Students表的插入权限,需使用?
sql
REVOKE INSERT ON Students FROM User1🧮 题目57:数据结构与算法 - 栈的应用
利用栈计算表达式10*(40-30/5)+20时,操作数栈的最小容量需求是(57)。
(57)
A. 2
B. 3
C. 4 ✅D. 5
📌 正确答案:(57)C
🔍 深度解析
算过程模拟(操作数栈变化)
| 步骤 | 当前字符 | 操作数栈内容 | 栈深度 | 操作 |
|---|---|---|---|---|
| 1 | 10 | 10 | 1 | 压入 |
| 2 | 40 | 10, 40 | 2 | 压入 |
| 3 | 30 | 10, 40, 30 | 3 | 压入 |
| 4 | 5 | 10, 40, 30, 5 | 4 | 压入 |
| 5 | / | 10, 40, 6 | 3 | 弹出30,5 → 30/5=6 → 压入6 |
| 6 | - | 10, 34 | 2 | 弹出40,6 → 40-6=34 → 压入34 |
| 7 | * | 340 | 1 | 弹出10,34 → 10*34=340 → 压入340 |
| 8 | 20 | 340, 20 | 2 | 压入 |
| 9 | + | 360 | 1 | 弹出340,20 → 340+20=360 → 压入360 |
💡 关键峰值时刻
-
步骤4 :扫描到
5时,栈中暂存[10,40,30,5],达到最大深度4 -
后续运算会减少栈深度
⚡ 后缀表达式视角
java
10 40 30 5 / - * 20 + # 后缀表达式-
压入:10 → 40 → 30 → 5 (栈深=4)
-
遇到
/:弹出5,30 → 计算30/5=6 → 压入6 -
后续操作栈深均≤4
逆波兰表示法(后缀表达式)详解
逆波兰表示法(Reverse Polish Notation, RPN)是一种不需要括号就能明确运算顺序的数学表达式表示方法,其核心特点是运算符位于操作数之后。
-
无括号:运算顺序由运算符位置唯一确定
java中缀:(3 + 4) × 5 → 后缀:3 4 + 5 × -
操作数顺序不变:与原始表达式顺序一致
-
适合栈式计算:可通过简单的栈操作实现高效求值
算法步骤:
-
初始化:
-
运算符栈 stack
-
输出队列 output
-
-
处理规则:
| 当前元素 | 操作 |
|---|---|
| 数字 | 直接加入输出队列 |
( |
压入栈 |
) |
弹出栈顶元素加入输出队列,直到遇到((弹出但不输出() |
| 运算符 | 弹出栈顶优先级≥当前运算符的所有元素,再将当前运算符压栈 |
- 收尾:将栈内剩余运算符全部弹出
示例转换过程(A+B*(C-D)):
| 当前元素 | 栈 | 输出队列 | 说明 |
|---|---|---|---|
| A | \[\] | A | 数字直接输出 |
| + | + | A | 栈空直接压栈 |
| B | + | A, B | 数字直接输出 |
| * | +, \* | A, B | *优先级>+,直接压栈 |
| ( | +, \*, ( | A, B | 左括号直接压栈 |
| C | +, \*, ( | A, B, C | 数字直接输出 |
| - | +, \*, (, - | A, B, C | 栈顶是(,直接压栈 |
| D | +, \*, (, - | A, B, C, D | 数字直接输出 |
| ) | +, \* | A, B, C, D, - | 弹出到(,丢弃( |
| 结束 | \[\] | [A, B, C, D, -, *, +] |
弹出剩余运算符 |
🌳 题目58:数据结构与算法 - 哈夫曼编码合法性判断
设有5个字符,以下哈夫曼编码方案中(58)是不可能的。
(58)
A. {111, 110, 101, 100, 0}
B. {0000, 0001, 001, 01, 1}
C. {11, 10, 01, 001, 000}
D. {11, 10, 011, 010, 000}✅
📌 正确答案:(58)D
🔍 深度解析
哈夫曼编码核心规则
-
前缀特性 :任何编码都不是其他编码的前缀
-
长度分配:高频字符编码短,低频字符编码长
-
二叉树结构:只有叶子节点存放字符,内部节点无编码
💡 选项D的问题分析
| 编码 | 问题点 |
|---|---|
| 11 | 是011和010的前缀 |
| 10 | 合法 |
| 011 | 与11冲突 |
| 010 | 与11冲突 |
| 000 | 合法 |
冲突示例:
- 接收
11011时无法判断是11+011还是110+11
🕸️ 题目59:数据结构与算法 - 图的广度优先搜索(BFS)时间复杂度分析
设有向图G具有n个顶点、e条弧,采用邻接表存储,完成广度优先遍历的时间复杂度为(59)。
(59)
A. O(n + e) ✅B. O(n²)
C. O(e²)
D. O(n*e)
📌 正确答案:(59)A
🔍 深度解析
BFS算法的执行过程
-
初始化阶段:
-
为所有顶点设置未访问标记:O(n)时间
-
初始化队列:O(1)时间
-
-
遍历阶段:
-
每个顶点入队和出队各一次:O(n)操作
-
每条边被检查一次:O(e)操作
-
💡 邻接表存储的特性
c
// 邻接表数据结构示例
struct AdjListNode {
int dest; // 目标顶点
struct AdjListNode* next; // 下一条边
};
struct Graph {
struct AdjList* array; // 顶点数组
int V; // 顶点数
};⚡ 时间复杂度组成
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 顶点访问 | O(n) | 每个顶点处理一次 |
| 边检查 | O(e) | 每条边检查一次 |
| 总计 | O(n + e) |
线性复杂度 |
🔍 题目60:数据结构与算法 - 折半查找(二分查找)的关键字序列分析
对有序顺序表进行折半查找(二分查找)时,进行比较的关键字序列不可能是(60)。
(60)
A. 42, 61, 90, 85, 77
B. 42, 90, 85, 61, 77
C. 90, 85, 61, 77, 42 ✅D. 90, 85, 77, 61, 42
📌 正确答案:(60)C
🔍 深度解析
折半查找的核心规则
-
有序性:必须在有序序列中进行
-
区间折半:每次比较后搜索区间减半
-
路径唯一:查找路径由目标值唯一确定
💡 选项C的非法性分析
| 步骤 | 当前mid值 | 合法区间 | 问题 |
|---|---|---|---|
| 1 | 90 | min, max | 合法起点 |
| 2 | 85 | min, 89 | 需在90左侧 |
| 3 | 61 | min, 84 | 需在85左侧 |
| 4 | 77 | 62, 84 | 61右侧应>61 |
| 5 | 42 | 62, 76 | 42不在区间内 |
✅ 用选项A体现一下合法性
| 步骤 | 当前mid值 | 合法区间 | 问题 |
|---|---|---|---|
| 1 | 42 | min, max | 合法起点 |
| 2 | 61 | 43, max | 需在42右侧 |
| 3 | 90 | 62, max | 需在61右侧 |
| 4 | 85 | 62, 89 | 90左侧 |
| 5 | 77 | 62, 89 | 77确实在62, 89区间内,故合法 |
🌲 题目61:数据结构与算法 - 森林转换为二叉树的结构分析
由三棵树构成的森林(结点数分别为n1,n2,n3)转换为二叉树后,该二叉树的右子树包含(61)个结点。
(61)
A. n1
B. n1 + n2
C. n3
D. n2 + n3 ✅
📌 正确答案:(61)D
🔍 深度解析
森林转二叉树的规则
-
孩子-兄弟表示法:
-
节点的左指针指向第一个孩子
-
节点的右指针指向下一个兄弟
-
-
森林转换步骤:
-
将每棵树单独转为二叉树
-
将第i+1棵树作为第i棵树根节点的右子树
-
-
三棵树的关系
java
二叉树的根:T₁的根
\
T₂的根(右子树)
\
T₃的根(右子树)
/
T₃的子结构所以T1的右子树等于n2结点+n3节点
💡 核心知识点
- 原始森林结构
java
森林包含3棵树:
T1: T1根
/ \
T1B T1C
T2: T2根
/
T2B
T3: T3根
/
T3B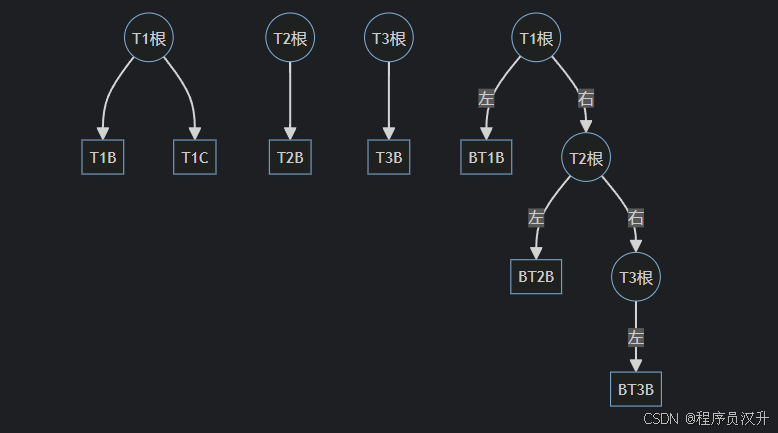
- 转换规则(核心)
-
左指针:指向节点的第一个子节点(最左孩子)
-
右指针:指向节点的相邻兄弟节点(右侧兄弟)
-
转换步骤
-
处理T1树:
-
T1根的左指针 → T1B(第一个孩子)
-
T1B的右指针 → T1C(兄弟)
-
-
连接T1和T2:
- T1根的右指针 → T2根(T1的"兄弟"是下一棵树的根)
-
处理T2树:
-
T2根的左指针 → T2B(第一个孩子)
-
T2B没有兄弟,故右指针为空
-
-
连接T2和T3:
- T2根的右指针 → T3根(T2的"兄弟"是T3根)
-
处理T3树:
-
T3根的左指针 → T3B(第一个孩子)
-
T3B没有兄弟,故右指针为空
-
-
🔢 题目62-63:数据结构与算法 - 排序算法特性选择
对一组数据进行排序,要求排序算法的时间复杂度为 O(nlgn),且要求排序是稳定的,则可采用(62)算法。若要求排序算法的时间复杂度为O(nlgn),且在原数据上进行,即空间复杂度为 O(1),则可以采用(63)算法。
(62)
A. 直接插入排序
B. 堆排序
C. 快速排序
D. 归并排序 ✅(63)
A. 直接插入排序
B. 堆排序 ✅C. 快速排序
D. 归并排序
📌 正确答案:(62)D,(63)B
🔍 深度解析
| 算法 | 时间复杂度 | 稳定性 | 空间复杂度 |
|---|---|---|---|
| 归并排序 | O(nlogn) | ✔️ 稳定 | O(n) |
| 堆排序 | O(nlogn) | ❌ 不稳定 | O(1) |
| 快速排序 | O(nlogn)~O(n²) | ❌ 不稳定 | O(logn)递归栈 |
| 直接插入排序 | O(n²) | ✔️ 稳定 | O(1) |
结论:
- 唯一同时满足
O(nlogn)和稳定的算法是归并排序。 - 堆排序是唯一严格满足
O(nlogn)时间复杂度和O(1)空间复杂度的算法(尽管不稳定)。
🌳 题目64-65:数据结构与算法 - Kruskal算法与最小生成树
采用 Kruskal 算法求解下图的最小生成树,采用的算法设计策略是 (64) 。该最小生成树的权值是 (65) 。
(64)
A. 分治法
B. 动态规划
C. 贪心法 ✅D. 回溯法
(65)
A. 14 ✅B. 16
C. 20
D. 32

📌 正确答案:(64)C,(65)A
🔍 深度解析
Kruskal算法的贪心特性:
-
局部最优选择:每次选择当前权值最小的边
-
全局最优解:最终得到最小生成树(MST)
-
关键操作:
-
按边权排序(贪心选择)
-
并查集检测环(保证无环)
-
| 算法策略 | 适用场景 | Kruskal符合性 |
|---|---|---|
| 贪心法 | 最优子结构 | ✔️ 每次选最小边 |
| 分治法 | 问题可分割 | ❌ 不分割问题 |
| 动态规划 | 重叠子问题 | ❌ 无重复计算 |
| 回溯法 | 试错搜索 | ❌ 无回退步骤 |
边选择顺序与权值:
-
选AC(权1)
-
选DF(权2)
-
选BE(权3)
-
选CE(权4)
-
选CF(权4)
- 总权值:1 + 2 + 3 + 4 + 4 = 14
💡 核心知识点
最小树详解:
-
假设有一个加权无向图:
javaA---1---B / \ / \ 3 2 4 6 / \ / \ C---5---D---7---E-
A 和 B 之间有一条边,权重为 1:A-B: 1
-
A 和 C 之间有一条边,权重为 3:A-C: 3
-
A 和 D 之间有一条边,权重为 2:A-D: 2
-
B 和 D 之间有一条边,权重为 4:B-D: 4
-
B 和 E 之间有一条边,权重为 6:B-E: 6
-
C 和 D 之间有一条边,权重为 5:C-D: 5
-
D 和 E 之间有一条边,权重为 7:D-E: 7
-
-
确认所有顶点
顶点有:
A, B, C, D, E ------ 共 5 个顶点。 -
最小生成树的性质
最小生成树(MST)是一个连通无向图的生成树,其所有边的权重之和最小。
对于有 n 个顶点的连通图,其生成树有 n-1 条边。因此,我们需要选择 5 - 1 =
4 条边,连接所有顶点,且无环,总权重最小。 -
寻找最小生成树
常用的算法有 Kruskal 和 Prim。这里我尝试用 Kruskal 算法:
-
将所有边按权重从小到大排序。
-
按顺序选择边,如果加入该边不形成环,则加入;否则跳过。
-
直到选中 n-1 条边。
边排序:
1 (A-B), 2 (A-D), 3 (A-C), 4 (B-D), 5 (C-D), 6 (B-E), 7 (D-E)
步骤:
-
选 A-B: 1,边集合 {A-B},连通分量 {A,B}, {C}, {D}, {E}
-
选 A-D: 2,边集合 {A-B, A-D},连通分量 {A,B,D}, {C}, {E}
-
选 A-C: 3,边集合 {A-B, A-D, A-C},连通分量 {A,B,D,C}, {E}
-
下一个是 B-D: 4,但 B 和 D 已经在同一个连通分量(会形成环 A-B-D-A),跳过。
-
下一个是 C-D: 5,C 和 D 已经在同一个连通分量(A-B-D-C),跳过。
-
选 B-E: 6,边集合 {A-B, A-D, A-C, B-E},连通分量 {A,B,D,C,E} ------ 已连接所有顶点。
此时已经选了
4条边,停止。总权重:1 + 2 + 3 + 6 = 12
-
🌐 题目66:计算机网络 - WWW控制协议
www 的控制协议是 (66) 。
(66)
A. FTP
B. HTTP ✅C. SSL
D. DNS
📌 正确答案:(66)B
🔍 深度解析
HTTP(超文本传输协议)的核心角色:
| 特性 | 说明 |
|---|---|
| 应用层协议 | 负责Web浏览器与服务器间的通信 |
| 请求/响应模型 | 客户端发送请求,服务器返回HTML/CSS/JS等资源 |
| 默认端口 | 80(HTTP)、443(HTTPS) |
⚡ 其他协议对比
| 协议 | 全称 | 主要功能 | 与WWW的关系 |
|---|---|---|---|
| FTP | 文件传输协议 | 文件上传/下载 | 非Web核心协议 |
| SSL | 安全套接层 | 加密通信 | HTTPS=HTTP+SSL |
| DNS | 域名系统 | 域名→IP转换 | 前置寻址服务 |
🐧 题目67-68:计算机系统 - Linux Web服务器配置
在 Linux 操作系统中通常使用 (67) 。作为 Web 服务器,其默认的 Web 目录为 (68) 。
(67)
A. IIS
B. Apache ✅C. NFS
D. MYSQL
(68)
A. /etc/httpd
B. /var/log/httpd
C. /etc/home
D. /home/httpd✅
📌 正确答案:(67)B,(68)B
🔍 深度解析
| 软件 | 类型 | 主要用途 | Linux适配性 |
|---|---|---|---|
| Apache | Web服务器 | 托管网站 | ✔️ 原生支持,最流行 |
| IIS | Web服务器 | Windows专用 | ❌ 不兼容Linux |
| NFS | 网络文件系统 | 文件共享 | ❌ 非Web服务 |
| MySQL | 数据库 | 数据存储 | ❌ 非Web服务器 |
关键点:
-
Apache是Linux平台最传统的Web服务器(尽管Nginx近年更流行)
-
名称源自"a patchy server"(补丁服务器)的谐音
目录结构对比
| 路径 | 用途 | 典型内容 |
|---|---|---|
/home/httpd |
传统默认站点根目录 | HTML/PHP文件 |
| /var/www/html | 现代常见默认目录 | index.html等 |
| /var/log/httpd | 日志文件 | access_log, error_log |
| /etc/httpd | 配置文件 | httpd.conf |
注意:
-
不同Linux发行版可能略有差异:
-
RHEL/CentOS:
/var/www/html -
较旧系统:
/home/httpd(如题目所述)
-
📡 题目69:计算机网络 - SNMP传输协议
SNMP 的传输层协议是 (69) 。
(69)
A. UDP ✅B. TCP
C. IP
D. ICMP
📌 正确答案:(69)A
🔍 深度解析
SNMP协议设计选择:
| 特性 | UDP适配性 | TCP对比 |
|---|---|---|
| 实时性 | ✔️ 无连接快速响应 | ❌ 三次握手延迟 |
| 开销 | ✔️ 头部仅8字节 | ❌ 至少20字节 |
| 可靠性 | ❌ 无重传机制 | ✔️ 保证送达 |
| 典型端口 | 161(请求)/162(Trap) | 不适用 |
🌰 典型SNMP报文流
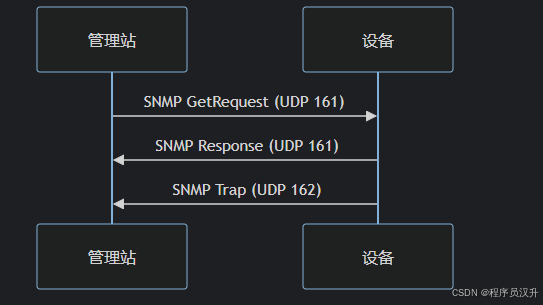
💡 核心知识点
-
SNMP协议栈
层级 协议 应用层 SNMP 传输层 UDP 网络层 IP 数据链路层 Ethernet/Wi-Fi等 -
UDP端口分配
端口 用途 161 Agent处理请求 162 Manager接收Trap
二、 系统开发和运行知识 🗃️
📊 题目15:软件工程 - 数据流图加工规格说明
以下关于数据流图基本加工的叙述中,不正确的是(15)。
(15)
A. 对每一个基本加工,必须有一个加工规格说明
B. 加工规格说明必须描述把输入数据流变换为输出数据流的加工规则
C. 加工规格说明需要给出实现加工的细节 ✅D. 决策树、决策表可以用来表示加工规格说明
📌 正确答案:C
🔍 详细解析
数据流图(DFD)分层设计原则:
| 层级 | 描述重点 | 是否含实现细节 |
|---|---|---|
| 上下文图 | 系统边界 | ❌ |
| 0层图 | 主要功能模块 | ❌ |
| 基本加工 | 输入→输出规则 | ❌ |
| 程序设计 | 具体算法/代码 | ✅ |
加工规格说明的核心要求:
-
抽象性:只描述"做什么",不规定"怎么做"
-
表示工具:
-
决策表(复杂条件组合)
-
判定树(分支逻辑可视化)
-
结构化语言(伪代码)
-
-
分层设计规范
| 阶段 | 产物 | 抽象级别 |
|---|---|---|
| 需求分析 | DFD | 逻辑模型 |
| 概要设计 | 模块图 | 系统架构 |
| 详细设计 | 流程图 | 实现细节 |
⚡ 错误选项分析
- C选项陷阱 :
"实现细节"属于详细设计阶段 任务(如伪代码),与DFD的逻辑建模定位冲突
🏗️ 题目16:软件工程 - 优秀设计原则
以下关于好的软件设计原则的叙述中,不正确的是(16)。
(16)
A. 模块化
B. 提高模块独立性
C. 集中化 ✅D. 提高抽象层次
📌 正确答案:C
🔍 详细解析
优秀设计原则 vs 反模式对比:
| 设计原则 | 核心思想 | 集中化的问题 |
|---|---|---|
| 模块化 | 分而治之 | 集中化导致功能堆积 |
| 高内聚低耦合 | 模块独立 | 集中化增加依赖 |
| 抽象层次 | 隐藏细节 | 集中化暴露实现 |
集中化的典型弊端:
-
单点故障风险:如所有功能集中在单一服务器
-
扩展困难:修改会影响全局系统
-
团队协作障碍:代码冲突概率增加
🗺️ 题目17-18:软件工程 - 关键路径分析
下图是一个软件项目的活动图,其中顶点表示项目里程碑,连接顶点的边表示包含的活动,则里程碑(17)在关键路径上,关键路径长度为(18)。
(17)
A. B
B. E ✅C. G
D. I
(18)
A. 15
B. 17
C. 19
D. 23 ✅
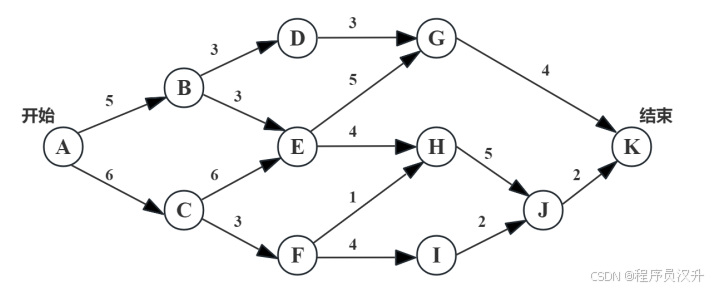
📌 正确答案:(17)B,(18)D
🔍 深度解析
📌 关键路径确定步骤
- 列出所有路径及长度,从 A(开始) 到 K(结束) 的所有可能路径:
| 路径序号 | 路径 | 总长度 |
|---|---|---|
| 路径1 | A → B → D → G → K | 5+3+3+4 = 15 |
| 路径2 | A → B → E → G → K | 5+3+5+4 = 17 |
| 路径3 | A → B → E → H →J→ K | 5+3+4+5+2 = 19 |
| 路径4 | A → C → E → H →J→ K | 6+6+4+5+2 = 23 |
| 路径5 | A → C → F → H →J→ K | 6+3+1+5+2 = 17 |
| 路径6 | A → C → F → I →J→K | 6+3+4+2+2 = 17 |
-
关键路径特征:
-
最长路径(决定项目总工期)
-
里程碑E在最长路径上
-
🗣️ 题目19:软件工程 - 团队沟通路径计算
由8位成员组成的开发团队中,一共有(19)条沟通路径。
(19)
A. 64
B. 56
C. 32
D. 28 ✅
📌 正确答案:D
🔍 深度解析
沟通路径计算公式:
沟通路径数 = n ( n − 1 ) / 2 ( n 为团队成员数) 沟通路径数 = n(n-1)/2 (n为团队成员数) 沟通路径数=n(n−1)/2(n为团队成员数)
计算过程:
8 位成员的沟通路径 = 8 × ( 8 − 1 ) / 2 = 28 条 8位成员的沟通路径 = 8×(8-1)/2 = 28条 8位成员的沟通路径=8×(8−1)/2=28条
🌰 直观示例(小团队验证)
| 成员数 | 沟通路径 | 计算公式 |
|---|---|---|
| 2人 | 1条 | 2×1/2=1 |
| 3人 | 3条 | 3×2/2=3 |
| 4人 | 6条 | 4×3/2=6 |
| ... | ... | ... |
🛠️题目29:系统开发模型 - 增量模型特性
以下关于增量模型优点的叙述中,不正确的是(29)。
(29)
A. 能够在较短的时间提交一个可用的产品系统
B. 可以尽早让用户熟悉系统
C. 优先级高的功能首先交付,这些功能将接受更多的测试
D. 系统的设计更加容易 ✅
📌 正确答案:D
🔍 深度解析
增量模型的本质特征与选项对比:
| 特性 | 选项 | 正确性 | 说明 |
|---|---|---|---|
| 快速交付MVP | A | ✅ | 首个增量即可提供核心功能 |
| 早期用户反馈 | B | ✅ | 每个增量都可收集用户意见 |
| 优先级驱动 | C | ✅ | 高优先级功能优先开发测试 |
| 设计复杂性 | D | ❌ | 需提前规划全周期架构,设计反而更复杂 |
增量模型 vs 其他模型
| 模型 | 设计难度 | 用户参与 | 适用场景 |
|---|---|---|---|
| 瀑布模型 | 一次性完成 | 晚期介入 | 需求明确的项目 |
| 增量模型 | 需全周期规划 | 早期介入 | 核心需求明确,细节可迭代 |
| 敏捷模型 | 持续演进 | 全程参与 | 需求变化快的项目 |
⚡经典案例
银行系统开发:
-
首个增量:账户登录/余额查询(高优先级)
-
后续增量:转账、理财、贷款功能
-
设计难点:需提前设计统一账户体系和安全协议
🏃 题目30:敏捷开发方法 - Scrum框架
以下敏捷开发方法中,(30)使用迭代的方法,把一段短的时间(如30天)的迭代称为一个冲刺,并按照需求优先级来实现产品。
(30)
A. 极限编程(XP)
B. 水晶法(Crystal)
C. 并列争求法(Scrum) ✅D. 自适应软件开发(ASD)
📌 正确答案:C
🔍 深度解析
Scrum的核心特征
| 关键词 | 说明 | 对应题目描述 |
|---|---|---|
| 冲刺(Sprint) | 固定周期(通常2-4周)的迭代开发 | "30天的迭代称为冲刺" |
| 产品待办列表 | 按优先级排序的需求池 | "按需求优先级实现" |
| 每日站会 | 15分钟同步进度/障碍 | 快速反馈机制 |
| 评审会&回顾会 | 每个冲刺结束后的改进会议 | 持续优化流程 |
其他敏捷方法对比
| 方法 | 核心特点 | 区别点 |
|---|---|---|
| XP(极限编程) | 结对编程、测试驱动开发 | 强调工程实践而非固定迭代 |
| 水晶法 | 根据项目规模灵活调整 | 无固定"Sprint"概念 |
| ASD | 需求驱动、自适应调整 | 更关注需求变化响应 |
🔗 题目31:软件工程 - 模块耦合类型
若模块A通过控制参数来传递信息给模块B,从而确定执行模块B中的哪部分语句。则这两个模块的耦合类型是(31)耦合。
(31)
A. 数据
B. 标记
C. 控制 ✅D. 公共
📌 正确答案:C
🔍 深度解析
控制耦合的核心特征:
| 场景 | 示例 | 题目对应点 |
|---|---|---|
| 通过参数控制逻辑流 | moduleB(operation="sort") | "确定执行哪部分语句" |
| 调用方影响被调用方行为 | 传递标志位/指令码 | "控制参数传递信息" |
🆚 耦合类型对比
| 耦合类型 | 特点 | 题目排除原因 |
|---|---|---|
| 数据耦合 | 仅传递必要数据(如add(x,y)) | ❌ 不涉及逻辑控制 |
| 标记耦合 | 共享数据结构的部分字段(如传递整个学生对象但只用学号) | ❌ 无数据结构传递 |
| 公共耦合 | 共享全局变量(如全局配置表) | ❌ 无全局数据依赖 |
| 控制耦合 | 传递控制信号(如flag=1执行分支A) | ✅ 完全匹配 |
💻 题目32:软件设计 - 可移植性设计原则
在设计中实现可移植性设计的规则不包括(32)。
(32)
A. 将设备相关程序和设备无关程序分开设计
B. 可使用特定环境的专用功能 ✅C. 采用平台无关的程序设计语言
D. 不使用依赖于某一平台的类库
📌 正确答案:B
🔍 深度解析
可移植性设计的核心原则与选项对比:
| 原则 | 正确性 | 反例说明 |
|---|---|---|
| 分层设计(A) | ✅ | 如操作系统硬件抽象层(HAL) |
| 使用环境专用功能(B) | ❌ | 直接调用Win32 API会绑定Windows平台 |
| 跨平台语言(C) | ✅ | Java/Python的"一次编写,到处运行" |
| 避免平台类库(D) | ✅ | 如.NET Framework仅限Windows |
🛠️ 题目33:软件体系结构 - 管道过滤器风格
以下关于管道-过滤器软件体系结构风格优点的叙述中,不正确的是(33)。
(33)
A. 构件具有良好的高内聚、低耦合的特点
B. 支持软件复用
C. 支持并行执行
D. 适合交互处理应用 ✅
📌 正确答案:D
🔍 深度解析
管道过滤器核心特性
| 特性 | 说明 | 题目对应性 |
|---|---|---|
| 高内聚低耦合 | 过滤器独立处理数据流 | A正确 |
| 软件复用 | 过滤器可像积木一样重组 | B正确 |
| 并行执行 | 多个过滤器可同时工作 | C正确 |
| 交互处理 | 不适合实时交互 | D错误 |
💡为什么D不正确?
-
批处理导向:
-
管道过滤器设计用于线性数据流(如编译器:词法分析→语法分析→语义分析)
-
交互式应用需要事件驱动(如GUI点击立即响应)
-
-
典型非交互用例:
- 从日志文件中提取所有包含
"error"的行,排序后去重,并将结果保存到新文件
bash# Unix管道(典型批处理) cat log.txt | grep "error" | sort | uniq > result.txt - 从日志文件中提取所有包含
🔍题目34-35:软件测试 - McCabe复杂度分析
以下流程图中,至少需要 (34) 个测试用例才能覆盖所有路径。采用 McCabe 方法计算程序复杂度为 (35) 。
(34) A. 3 B. 4 ✅ C. 5 D. 6
(35) A. 2 B. 3 C. 4 ✅ D. 5
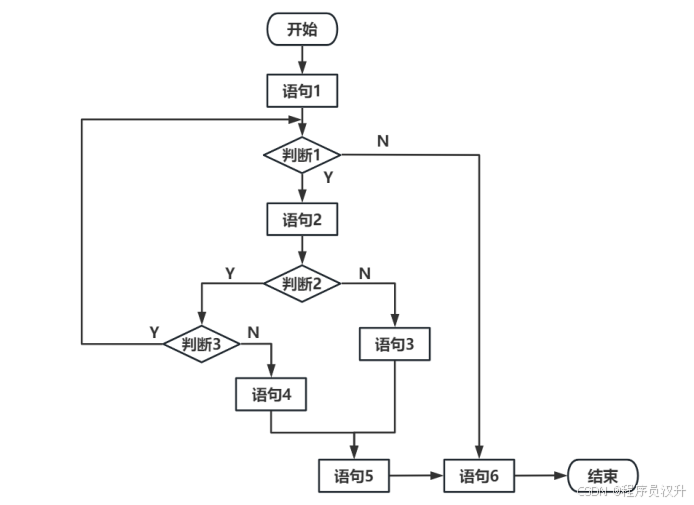
📌 正确答案:(34)B,(35)C
🔍 深度解析
独立路径覆盖
-
路径1 :判断1→N
开始 → 语句1 → 判断1(N) → 语句6 → 结束 -
路径2 :判断1→Y → 判断2→N
开始 → 语句1 → 判断1(Y)→语句2→判断2(N)→语句3→语句5→语句6→结束 -
路径3 :判断1→Y → 判断2→Y → 判断3→N
开始 → 语句1 → 判断1(Y)→语句2→判断2(Y)→判断3(N)→语句4→语句5→语句6→结束 -
路径4 :判断1→Y → 判断2→Y → 判断3→Y(循环)
开始 → 语句1 → 判断1(Y)→语句2→判断2(Y)→判断3(Y)→[循环回判断1]...
McCabe环路复杂度
公式:
java
V(G) = E - N + 2P
或
V(G) = 判断节点数 + 1计算过程:
-
判断节点:判断1、判断2、判断3 → 3个
-
复杂度:3 + 1 = 4
💡 核心知识点
-
快速计算McCabe复杂度:
- 数流程图中的
if/while/for节点数+1
- 数流程图中的
-
路径覆盖策略:
- 每个新判断节点指数级增加路径数(n个二分支判断→最多2ⁿ条路径)
-
简化技巧:
- 遇到循环结构,至少需要
2个用例(进入循环vs跳过循环)
- 遇到循环结构,至少需要
🛠️ 题目36:系统设计 - 改善性维护
在软件系统交付后,为了使用户界面更友好而改进图形输出的行为属于(36)维护。
(36)
A. 改正性
B. 适应性
C. 改善性 ✅D. 预防性
📌 正确答案:(36)C
🔍 深度解析
四种维护类型对比
| 维护类型 | 触发原因 | 典型场景 | 本题匹配性 |
|---|---|---|---|
| 改正性 | 修复缺陷 | 修复系统崩溃bug | ❌ 无错误修复 |
| 适应性 | 环境变化 | 适配新操作系统 | ❌ 无环境变更 |
| 改善性 | 优化体验 | 改进UI/性能 | ✅ 界面友好化 |
| 预防性 | 防止故障 | 重构高风险代码 | ❌ 非预防行为 |
💡 改善性维护的典型场景
-
UI/UX优化:
- 调整界面布局、增加动画效果
-
功能增强:
- 新增数据可视化图表
-
性能提升:
- 缩短页面加载时间
三、 面向对象基础知识 🧩
🧩 题目37-38:面向对象程序设计基础
采用面向对象方法开发学生成绩管理系统,学生的姓名、性别、出生日期、期末考试成绩、查看成绩操作均被 (37)在学生对象中。系统中定义不同类,不同类的对象之间通过 (38) 进行通信。
(37)
A. 封装 ✅B. 继承
C. 多态
D. 信息
(38)
A. 继承
B. 多态
C. 消息 ✅D. 重载
📌 正确答案:(37)A,(38)C
🔍 深度解析
学生类设计示例
java
// 封装学生数据和行为(对应37题)
class Student {
// 属性封装
private String name;
private String gender;
private Date birthday;
private double score;
// 方法封装
public void viewScore() {
System.out.println(this.score);
}
}
// 对象间消息通信(对应38题)
class Teacher {
public void queryScore(Student s) {
s.viewScore(); // 发送"消息"请求查看成绩
}
}面向对象四大特性应用
| 特性 | 本题体现 | 反例说明 |
|---|---|---|
| 封装(37) | 将学生属性和方法包装成类 | 若选继承→混淆代码复用与数据组织 |
| 消息(38) | 对象间通过方法调用交互 | 若选多态→混淆通信方式与行为多样性 |
⚡易混淆概念对比
| 概念 | 定义 | 典型应用场景 |
|---|---|---|
| 封装 | 隐藏实现细节,暴露接口 | 类的私有字段+公有方法 |
| 继承 | 子类复用父类特性 | Teacher extends Person |
| 多态 | 同一接口不同实现 | 方法重写+父类引用指向子类对象 |
| 消息 | 对象间的请求调用 | obj.method() |
🧪 题目39:面向对象 - 方法测试归属
对面向对象系统测试时,测试类中定义的每个方法属于(39)层。
(39)
A. 算法 ✅B. 类
C. 模板
D. 系统
📌 正确答案:(39)A
🔍 深度解析
测试层次与面向对象特性
| 测试层次 | 测试对象 | 本题关联性 |
|---|---|---|
| 算法层 | 方法内部的逻辑实现 | ✅ 方法即算法载体 |
| 类层 | 类的整体行为(含多个方法交互) | ❌ 题目明确"每个方法" |
| 模板层 | 非标准测试层次(C++模板特化等) | ❌ 无关选项 |
| 系统层 | 整个系统的集成功能 | ❌ 粒度太大 |
💡 为什么是算法层?
-
方法本质:
-
类中的每个方法本质上是独立算法单元
-
例如:
Student.calculateGPA()包含GPA计算算法
-
-
测试实践:
java// 测试方法内部的算法逻辑 @Test void testCalculateGPA() { Student s = new Student(); s.addGrade("A"); assertEquals(4.0, s.calculateGPA()); // 验证算法正确性 }
⚡ 面向对象测试金字塔
🧩 题目40:面向对象设计原则 - 共同重用原则
在面向对象系统设计中,若重用某个包中的类就必须重用该包所有类,这属于(40)原则。
(40)
A. 共同封闭
B. 共同重用 ✅C. 开放-封闭
D. 接口分离
📌 正确答案:(40)B
🔍 深度解析
共同重用原则(Common Reuse Principle, CRP)
| 维度 | 说明 | 题目对应性 |
|---|---|---|
| 定义 | 包中的类应被共同重用,不存在部分重用情况 | ✅ 强制全包重用 |
| 目的 | 减少不必要的依赖,提高模块内聚性 | 避免"牵一发而动全身" |
| 反例 | 若包中仅部分类被重用,说明包设计不合理 | 如只重用Logger却被迫引入DBConnector |
💡 六大包原则对比
| 原则 | 核心思想 | 记忆口诀 |
|---|---|---|
| 共同重用(CRP) | 要重用就全重用 | "同生共死" |
| 共同封闭(CCP) | 相同变化的类放同包 | "变则同变" |
| 开放-封闭(OCP) | 对扩展开放,对修改关闭 | "可扩展不修改" |
| 接口隔离(ISP) | 客户端不应依赖不需要的接口 | "按需取用" |
📊 题目41-42:面向对象设计 - UML序列图解析
以下关于 UML 序列图的描述是(41),下图所示 UML 图中消息可能执行的顺序是(42)。
(41)
A. 系统在它的周边环境的语境中所提供的外部可见服务
B. 某一时刻一组对象以及它们之间的关系
C. 系统内从一个活动到另一个活动的流程
D. 以时间顺序组织的对象之间的交互活动 ✅(42)
A. a→b→c→a→b
B. c
C. a→b→a→b→c ✅D. a→b→c→a→b→c

📌 正确答案:(41)D,(42)C
🔍 深度解析
序列图(Sequence Diagram)的核心特征:
-
时间轴纵向延伸:消息按时间顺序从上到下排列
-
对象间交互:展示对象如何通过消息协作
-
控制结构:包含循环(loop)、条件(alt)等片段
消息执行顺序
-
循环体
(a→b)执行1到2次,loop[1..2]表示至少1次,至多2次 -
循环结束后执行c
可能顺序:
-
循环2次:a→b→a→b→c
-
其他选项问题:
-
A/D:循环后再次执行a/b(错误)
-
B:未执行循环(错误)
-
💡 UML序列图核心知识点
- 序列图组成要素
| 元素 | 说明 | 图示示例 |
|---|---|---|
| 生命线 | 对象垂直线 | │A│ |
| 消息箭头 | 对象间交互 | ─→ |
| 循环片段 | loop[min..max] |
虚线框标注 |
- 交互片段类型
| 片段 | 含义 | 示例 |
|---|---|---|
| loop | 循环执行 | loop[1..3] 表示至少1次,至多3次 |
| alt | 条件分支 | alt条件 |
| opt | 可选执行 | opt登录成功 |
📦 题目43:UML包图 - 元素所有权规则
关于UML包图的叙述中,不正确的是(43)。
(43)
A. 可以拥有类、接口构件、结点
B. 一个元素可以被多个包拥有 ✅C. 一个包可以嵌套其他包
D. 一个包内元素不能重名
📌 正确答案:(43)B
🔍 深度解析
UML包图核心规则
| 特性 | 正确描述 | 题目对应性 |
|---|---|---|
| 元素类型 | 可包含类/接口/构件/嵌套包等 | A正确 |
| 元素所有权 | 一个元素只能属于一个包 | B错误 |
| 嵌套结构 | 包内可嵌套子包 | C正确 |
| 命名空间 | 同包内同类元素不能重名 | D正确 |
java
// 包声明示例(Java)
package com.ecommerce.order; // Order类只能属于此包
public class Order {...}🧬 题目44-45:设计模式 - 原型模式解析
在某招聘系统中,要求实现求职简历自动生成功能。简历的基本内容包括求职者的姓名、性别、年龄及工作经历等。希望每份简历中的工作经历有所不同,并尽量减少程序中的重复代码。针对此需求,设计如下所示的类图。该设计采用了(44) 模式,由 Cloneable 示例指定创建对象的种类,声明一个复制自身的接口,并且通过复制这些Resume,WorkExperience 的对象来创建新的对象。该模式属于 (45) 模式。
(44)
A. 单例(Singleton)
B. 抽象工厂(Abstract Factory)
C. 生成器(Builder)
D. 原型(Prototype) ✅(45)
A. 混合型
B. 行为型
C. 结构型
D. 创建型✅
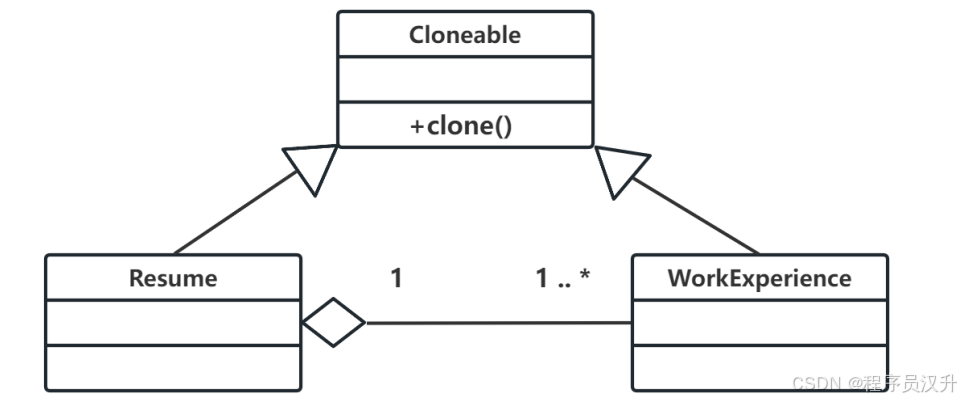
📌 正确答案:(44)D,(45)D
🔍 深度解析
具体23种设计模式见文章《软考中级-软件设计师 23种设计模式(内含详细解析)》
原型模型详解见文章《23种设计模式-原型(Prototype)设计模式》
代码实现:
java
// 原型接口
interface Cloneable {
Object clone();
}
// 具体原型类
class Resume implements Cloneable {
private String name;
private List<WorkExperience> works;
@Override
public Resume clone() {
Resume cloned = new Resume();
cloned.works = new ArrayList<>(this.works); // 深拷贝工作经历
return cloned;
}
}💰 题目46-47:设计模式 - 策略模式解析
某旅游公司需根据季节/节假日动态调整定价策略(如淡季打折、一口价等),适合采用(46)模式,该模式的主要意图是(47)。
(46)
A. 策略模式(Strategy) ✅
B. 状态(State)
C. 观察者(Observer)
D. 命令(Command)
(47)
A. 请求封装为对象
B. 状态变更通知
C. 状态改变行为
D. 定义系列算法,可相互替换 ✅
📌 正确答案:(46)A,(47)D
🔍 深度解析
具体23种设计模式见文章《软考中级-软件设计师 23种设计模式(内含详细解析)》
原型模型详解见文章《23种设计模式-策略(Strategy)设计模式》
策略模式核心机制
| 要素 | 说明 | 题目对应点 |
|---|---|---|
| 策略接口 | 定义算法族(如PricingStrategy) | "不同定价策略" |
| 具体策略 | 实现具体算法(淡季/节假日策略) | "淡季打折、一口价" |
| 上下文类 | 持有策略引用并可动态切换 | 旅游定价系统 |
代码实现:
java
// 策略接口
interface PricingStrategy {
double calculatePrice(double basePrice);
}
// 具体策略
class OffSeasonStrategy implements PricingStrategy {
public double calculatePrice(double basePrice) {
return basePrice * 0.7; // 淡季7折
}
}
// 上下文
class TravelPackage {
private PricingStrategy strategy;
public void setStrategy(PricingStrategy s) {
this.strategy = s;
}
public double getFinalPrice(double basePrice) {
return strategy.calculatePrice(basePrice);
}
}四、 网络与信息安全知识 🌐
🔐 题目8-9:网络安全 - HTTPS加密与证书撤销
在 PKI 体系中,由 SSL / TSL 实现 HTTPS 应用。浏览器和服务器之间用于加密HTTP消息的方式是(8),如果服务器证书被撤销那么所产生的后果是 (9) 。
(8)
A. 对方公钥+公钥加密
B. 本方公钥+公钥加密
C. 会话密钥+公钥加密
D. 会话密钥+对称加密 ✅(9)
A. 服务器不能执行加解密
B. 服务器不能执行签名
C. 客户端无法再信任服务器 ✅D. 客户端无法发送加密信息给服务器
📌 正确答案:(8)D,(9)C
🔍 深度解析
HTTPS 采用 混合加密 方式,即结合 非对称加密 和 对称加密 进行安全通信。整个握手过程中,服务器和客户端通过 非对称加密算法 进行身份认证,确认彼此身份后,再生成一个会话密钥 ,随后使用对称加密算法 对后续的通信数据进行加密传输。因此,浏览器和服务器之间用于加密 HTTP 消息的方式是:会话密钥 + 对称加密(选项 D)
HTTPS混合加密流程

关键点对比
| 阶段 | 加密 | 类型 | 用途 | 性能 |
|---|---|---|---|---|
| 握手阶段 | 非对称加密 | (RSA/ECDH) | 交换会话密钥 | 慢 |
| 数据传输 | 对称加密 | (AES/ChaCha20) | 加密HTTP数据 | 快 |
证书撤销机制
| 机制 | 描述 | 实时性 |
|---|---|---|
| CRL(证书吊销列表) | CA定期发布的撤销证书列表 | 低 |
| OCSP(在线证书状态协议) | 实时查询证书状态 | 高 |
撤销后的影响
-
客户端行为:
-
浏览器会检查证书的OCSP状态或CRL
-
发现撤销后弹出安全警告(如Chrome的"NET::ERR_CERT_REVOKED")
-
-
技术后果:
-
信任链断裂(证书虽有效但不可信)
-
HTTPS连接终止(除非用户手动忽略警告)
-
💡 核心知识点
- HTTPS握手细节
-
会话密钥生成:
-
RSA:客户端生成密钥并用服务器公钥加密
-
ECDH:双方协商生成密钥(前向保密)
-
-
证书生命周期

🛡️ 题目10:网络安全 - 入侵防御系统(IPS)功能
以下关于入侵防御系统功能的描述中,不正确的是(10)。
(10)
A. 监测并分析用户和系统的网络活动
B. 匹配特征库识别已知的网络攻击行为
C. 联动入侵检测系统使其阻断网络攻击行为 ✅D. 检测僵尸网络、木马控制等僵尸主机行为
📌 正确答案:C
🔍 深度解析
入侵防御系统(IPS)的核心特性:
| 功能 | 描述 | 正误 |
|---|---|---|
| 主动阻断 | IPS能独立检测并实时阻断攻击 |
✅ |
| 无需联动 | IPS本身已集成检测+阻断能力 | ❌(选项C错误) |
| 检测范围 | 覆盖已知攻击(特征库)和异常行为(启发式) | ✅ |
IPS vs IDS 关键区别
| 系统类型 | 检测能力 | 阻断能力 | 部署位置 |
|---|---|---|---|
| IDS (入侵检测系统) | ✔️ | ❌ | 旁路监听 |
| IPS (入侵防御系统) | ✔️ | ✔️ | 串联部署 |
📌 选项C的陷阱:
-
IPS本身具备阻断功能,不需要依赖IDS来阻断攻击
-
实际中可能存在IDS+IPS联动,但这不是IPS的核心功能定义
💡 核心知识点
- IPS工作原理

- 典型检测技术
| 技术 | 原理 | 示例 |
|---|---|---|
| 特征匹配 | 比对攻击签名 | SQL注入特征OR 1=1 -- |
| 异常检测 | 偏离基线行为 | 突发高频SSH登录 |
| 协议分析 | 违反RFC规范 | HTTP请求头注入 |
🛡️ 题目11:网络安全 - Web应用防火墙(WAF)防护范围
Web应用防火墙无法有效防护(11)。
(11)
A. 登录口令暴力破解
B. 恶意注册
C. 抢票机器人
D. 流氓软件 ✅
📌 正确答案:D
🔍 深度解析
WAF工作原理

流氓软件的特点
-
传播途径:
- 捆绑安装/钓鱼邮件/恶意广告(非Web应用层流量)
-
攻击阶段:
- 已突破网络边界,在用户终端执行
-
防护工具:
- 终端防护软件(如EDR)、沙箱技术
💡 核心知识点
- WAF防护范围
| 防护层级 | 示例攻击 |
|---|---|
| 应用层 | SQL注入、XSS、CSRF |
| 会话层 | Cookie篡改、会话固定 |
| 业务逻辑层 | 薅羊毛、抢购机器人 |
- 流氓软件常见类型
| 类型 | 危害 |
|---|---|
| 广告软件 | 弹窗广告、隐私窃取 |
| 间谍软件 | 键盘记录、屏幕截图 |
| 勒索软件 | 文件加密勒索 |
- 综合防御体系
🌐 题目70:网络故障诊断 - DNS问题定位
某电脑无法打开任意网页,但是互联网即时聊天软件使用正常。造成该故障的原因可能是(70)。
(70)
A. IP地址配置错误
B. DNS配置错误 ✅C. 网卡故障
D. 链路故障
📌 正确答案:(70)B
🔍 深度解析
现象与DNS故障的关联性:
| 现象 | DNS故障解释 | 其他选项排除 |
|---|---|---|
| 网页打不开 | 域名无法解析为IP | IP正确(聊天软件正常) |
| 聊天软件正常 | 直接使用IP连接服务器 | 网卡/链路正常(有基础连接) |
快速诊断命令
| 命令 | 用途 |
|---|---|
| nslookup example.com | 手动测试DNS解析 |
| ping 8.8.8.8 | 验证基础网络连通性 |
| tracert www.baidu.com | 检查路由与解析 |
五、 标准化、信息化和知识产权基础知识 🛠️
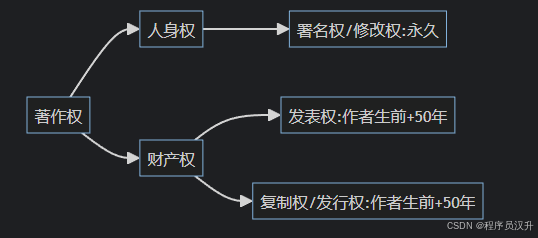
📜 题目12:知识产权 - 著作权保护期限
著作权中(12)的保护期不受限制。
(12)
A. 发表权
B. 发行权
C. 展览权
D. 署名权 ✅
📌 正确答案:D
🔍 深度解析
《中华人民共和国著作权法》第二十二条规定:
作者的署名权、修改权、保护作品完整权的保护期不受限制。
著作人身权 vs 财产权对比:
| 权利类型 | 具体权利 | 保护期限 | 示例 |
|---|---|---|---|
| 人身权 | 署名权 | 永久 | 鲁迅作品的"鲁迅"署名 |
| 修改权 | 永久 | 禁止他人篡改作品 | |
| 保护作品完整权 | 永久 | 禁止歪曲《红楼梦》原著 | |
| 财产权 | 发表权 | 作者终生+50年 | 卡夫卡遗作出版 |
| 发行权/展览权 | 作者终生+50年 | 梵高画作展览 |
著作权保护期限规则
🌍 题目13:知识产权 - 国际软件保护方式
国际上为保护计算机软件知识产权不受侵犯所采用的主要方式是实施(13)。
(13)
A. 合同法
B. 物权法
C. 版权法 ✅D. 刑法
📌 正确答案:C
🔍 深度解析
国际通行的软件保护体系:
| 保护方式 | 适用场景 | 软件保护案例 |
|---|---|---|
| 版权法(著作权法) | 主要方式 | 代码作为文字作品自动受保护(无需登记) |
| 专利法 | 少数创新算法/流程 | Amazon一键下单专利 |
| 合同法 | 软件许可协议 | 微软Windows EULA |
| 商业秘密法 | 未公开代码 | 可口可乐配方式保护 |
📜 题目14:知识产权 - 软件著作权继承规则
以下关于计算机软件著作权的叙述中,不正确的是(14)。
(14)
A. 软件著作权人可以许可他人行使其软件著作权,并有权获得报酬
B. 软件著作权人可以全部或者部分转让其软件著作权,并有权获得报酬
C. 软件著作权属于自然人的,该自然人死亡后,在软件著作权的保护期内,继承人能继承软件著作权的所有权利 ✅D. 为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等使用软件的,可以不经软件著作权人许可,不向其支付报酬
📌 正确答案:C
🔍 深度解析
《计算机软件保护条例》第十五条明确规定:
软件著作权属于自然人的,该自然人死亡后,在软件著作权的保护期内:
-
继承人可继承复制权、发行权、出租权等财产权
-
署名权等人身权不可继承(由继承人保护其不受侵犯)
关键区别:
| 权利类型 | 是否可继承 | 法律依据 |
|---|---|---|
| 财产权(复制/发行/改编等) | ✔️ 可继承 | 条例第十五条 |
| 人身权(署名/修改/保护完整权) | ❌ 不可继承 | 条例第八条 |
六、 计算机英语 🐧
📊 题目71-75:计算机英语
Low-code and no code software development solutions have emerged as viable and convenient alternatives to the traditional development process.
Low-code is a rapid application development (RAD) approach that enables automated code generation through(71)building blocks like drag-and-drop and pull-down menu interfaces. This(72) allows low-code users to focus on the differentiator rather than the common denominator of programming. Low-code is a balanced middle ground between manual coding and no-code as its users can still add code over auto-generated code.
No-code is also a RAD approach and is often treated as a subset of the modular plug-and-play, lowcode development approach. While in low-code there is some handholding done by developers in the form of scripting or manual coding, no-code has a completely (73) approach, with 100% dependence on visual tools.
A low-code application platform (LCAP) --- also called a low-code development platform (LCDP) --- contains an integrated development environment (IDE) with (74)features like APIs, code templates, reusable plug-in modules and graphical connectors to automate a significant percentage of the application development process. LCAPs are typically available as cloud-based Platform-as-a-Service (PaaS) solutions.
A low-code platform works on the principle of lowering complexity by using visual tools and techniques like process modeling, where users employ visual tools to define workflows, business rules, user interfaces and the like. Behind the scenes, the complete workflow is automatically converted into code. LCAPs are used predominantly by professional developers to automate the generic aspects of coding to redirect effort on the last mile of (75).
(71)
A. visual ✅B. component-based
C. object-oriented
D. structural
(72)
A. block
B.automation ✅C. function
D. method
(73)
A. medern
B. hands-off✅C. generic
D. labor-free
(74)
A. reusable
B. built-in ✅C. existed
D. well-konwn
(75)
A. delivery
B. automation
C. development ✅D. success
📌 正确答案:(71)A,(72)B,(73)B,(74)B,(75)C
参考译文:
低代码和无代码软件开发解决方案已成为传统开发过程的可行且方便的替代品。
低代码是一种快速应用程序开发(RAD)方法,通过拖放和下拉菜单界面等可视化构建块实现自动代码生成。这种自动化允许低代码用户专注于差异而不是编程的公分母。低代码是手动编码和无代码之间的平衡中景,因为它的用户仍然可以在自动生成的代码上添加代码。
无代码也是一种 RAD 方法,通常被视为模块化即插即用、低代码开发方法的一个子集。虽然在低代码中,开发人员以脚本或手动编码的形式进行了一些手动操作,但无代码具有完全不干涉的方法,100%依赖于可视化工具。
低代码应用平台(LCAP)------也称为低代码开发平台(LCDP)------包含一个集成开发环境(IDE),该环境具有 API、代码模板、可重用插件模块和图形连接器等内置功能,可自动化很大一部分应用程序开发过程。LCAP 通常作为基于云的平台即服务(PaaS)解决方案提供。
低代码平台的工作原理是通过使用可视化工具和流程建模等技术来降低复杂性。在流程建模中,用户使用可视化工具来定义工作流、业务规则、用户界面等。在幕后,完整的工作流会自动转换为代码。专业开发人员主要使用 LCAP 来自动化编码的一般方面,以重新引导开发的最后一英里。

码字不易,写完发现4万多字。如果有收获不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️
