探秘Transformer系列之(27)--- MQA & GQA
目录
- [探秘Transformer系列之(27)--- MQA & GQA](#探秘Transformer系列之(27)--- MQA & GQA)
- [0x00 概述](#0x00 概述)
- [0x01 MHA](#0x01 MHA)
- [1.1 概念](#1.1 概念)
- [1.2 实现](#1.2 实现)
- [1.2.1 哈佛](#1.2.1 哈佛)
- [1.2.2 llm-foundry](#1.2.2 llm-foundry)
- [1.3 资源占用](#1.3 资源占用)
- [0x02 MQA](#0x02 MQA)
- [2.1 概念](#2.1 概念)
- [2.2 实现](#2.2 实现)
- [1.2.1 精简版](#1.2.1 精简版)
- [1.2.2 完整版](#1.2.2 完整版)
- [2.3 效果](#2.3 效果)
- [2.3.1 内存](#2.3.1 内存)
- [2.3.2 速度](#2.3.2 速度)
- [2.3.3 表征能力](#2.3.3 表征能力)
- [2.3.3 通信](#2.3.3 通信)
- [0x03 GQA](#0x03 GQA)
- [3.1 概念](#3.1 概念)
- [3.2 架构比对](#3.2 架构比对)
- [3.3 实现](#3.3 实现)
- [3.3.1 精简版](#3.3.1 精简版)
- [3.3.2 完整版](#3.3.2 完整版)
- [3.4 效果](#3.4 效果)
- [3.4.1 内存](#3.4.1 内存)
- [3.4.2 速度](#3.4.2 速度)
- [3.4.3 表征能力](#3.4.3 表征能力)
- [3.5 转换](#3.5 转换)
- [3.6 优化](#3.6 优化)
- [0xFF 参考](#0xFF 参考)
0x00 概述
在前文"优化KV Cache"中我们提到过,在"减少注意力头的数量"这个维度上,目前主要的相关工作有 MQA和GQA。MQA 和 GQA 是在缓存多少数量KV的思路上进行优化:直觉是如果缓存的KV个数少一些,显存就占用少一些,大模型能力的降低可以通过进一步的训练或者增加FFN/GLU的规模来弥补。
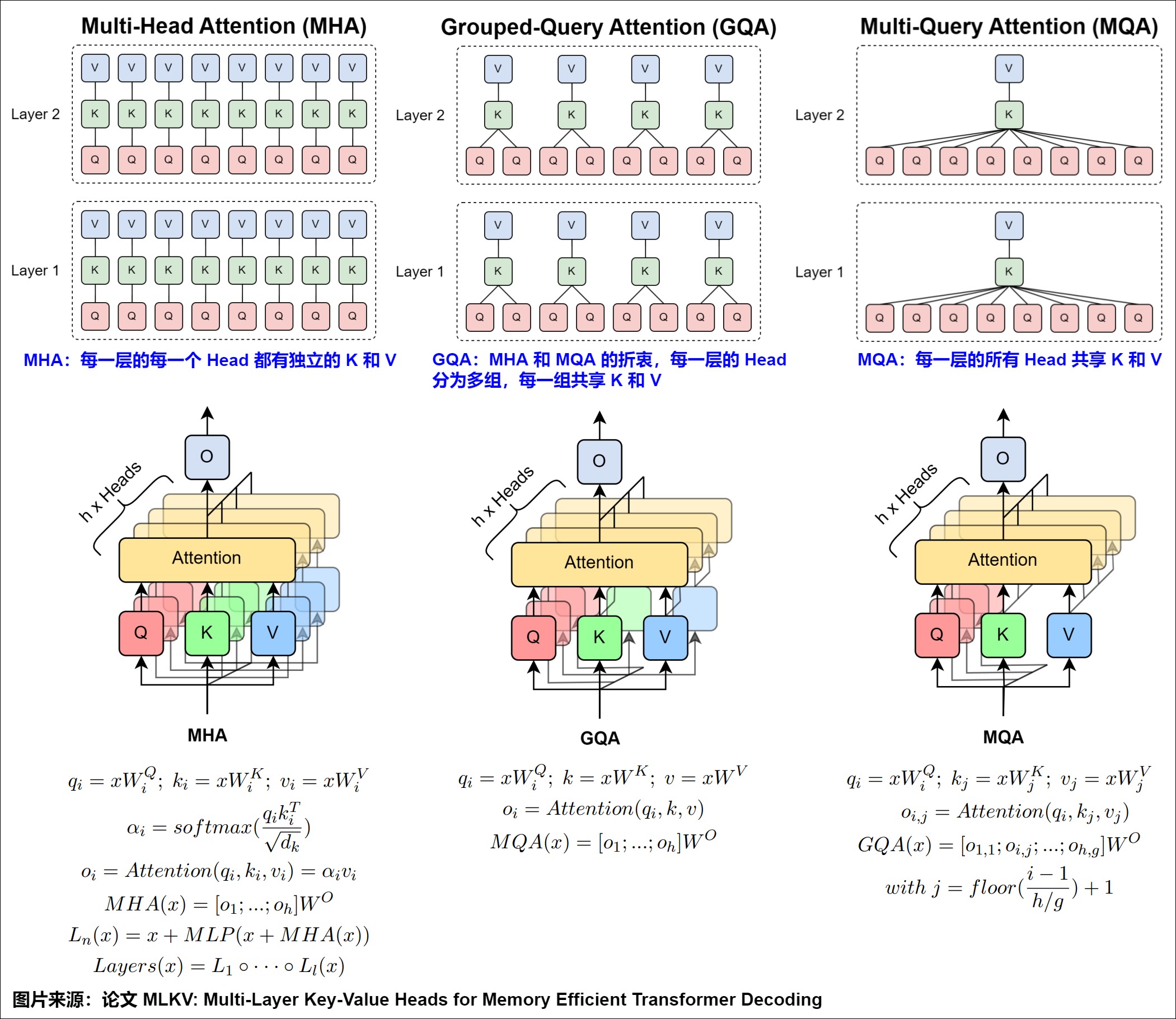
因为MQA和GQA是基于MHA进行改进,所以我们用下图展示了三者的区别。可以看到,通过缩减注意力头数目,MQA/GQA会降低KV Cache存储,让不同的注意力头或者同一组的注意力头共享一个K和V的集合,因为只单独保留了一份(或者几份)查询参数。因此K和V的矩阵仅有一份(或者几份),这大幅度减少了显存占用,使其更高效。另外,传统的基于MHA的Attention算子过于卡访存带宽,MQA和GQA,乃至后续的MLA都可以提计算访存比,这样也是对性能的极大提升。
注:
- 全部文章列表在这里,估计最终在35篇左右,后续每发一篇文章,会修改此文章列表。cnblogs 探秘Transformer系列之文章列表
- 本系列是对论文、博客和代码的学习和解读,借鉴了很多网上朋友的文章,在此表示感谢,并且会在参考中列出。因为本系列参考文章太多,可能有漏给出处的现象。如果原作者发现,还请指出,我在参考文献中进行增补。
0x01 MHA
因为MQA,GQA是基于MHA进行修改,所以我们有必要先回顾下MHA。
1.1 概念
MHA(即多头注意力机制)在2017年就随着Transformer原始论文"Attention Is All You Need"一起提出,其主要工作是:把原来一个注意力计算拆成多个小份的注意力头,即把Q、K、V分别拆分成多份,每个注意力头使用独立的Q、K、V进行计算。而多个头可以并行计算,分别得出结果,最后再合回原来的维度。
我们通过下图来看看MHA的流程,这里设 𝑑 表示词嵌入的维度, \(𝑛_ℎ\) 表示注意力头的数量, \(𝑑_ℎ\) 表示每一个头的维度, \(ℎ_𝑡\in𝑅^𝑑\) 表示第 𝑡 个token在一个注意力层的输入, \(𝑊^𝑂∈𝑅^{𝑑×𝑑_ℎ𝑛_ℎ}\) 表示输出映射矩阵。则MHA可以分为以下四步:
- 通过3个参数矩阵 \(𝑊^𝑄,𝑊^𝐾,𝑊^𝑉∈𝑅^{𝑑_ℎ𝑛_h\times d}\) 就可以得到 \(𝑞_𝑡,𝑘_𝑡,𝑣_𝑡∈𝑅^{𝑑_ℎ𝑛_h}\) 。
- \(𝑞_𝑡,𝑘_𝑡,𝑣_𝑡\) 会分割成 \(𝑛_ℎ\) 个向量,\(𝑞_{𝑡,𝑖},𝑘_{𝑡,𝑖},𝑣_{𝑡,𝑖}∈𝑅^{𝑑_ℎ}\) 分别表示Q、K和V的第 𝑖 个向量,这些拆分后的向量我们后续称之为Q头,K头和V头。
- 每个注意力头会利用自己获得的Q、K、V向量进行注意力计算。
- 利用\(W^O\)对多头注意力计算结果进行合并。

1.2 实现
1.2.1 哈佛
我们回顾下"The Annotated Transformer"中MHA代码的实现
python
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
'''
h: head number
'''
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d
self.d = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d)
return self.linears[-1](x)1.2.2 llm-foundry
作为对比,我们看看工业界的产品。
python
class MultiheadAttention(nn.Module):
"""Multi-head self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = 'triton',
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
self.attn_dropout_p = attn_pdrop
self.Wqkv = nn.Linear(self.d_model, 3 * self.d_model, device=device)
# for param init fn; enables shape based init of fused layers
fuse_splits = (d_model, 2 * d_model)
self.Wqkv._fused = (0, fuse_splits) # type: ignore
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(self.d_model, device=device)
self.k_ln = layernorm_class(self.d_model, device=device)
if self.attn_impl == 'flash':
self.attn_fn = flash_attn_fn
elif self.attn_impl == 'triton':
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == 'torch':
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f'{attn_impl=} is an invalid setting.')
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True # type: ignore
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
query, key, value = qkv.chunk(3, dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
# Applying layernorm to qk
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
context, attn_weights, past_key_value = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
)
return self.out_proj(context), attn_weights, past_key_valuescaled_multihead_dot_product_attention()代码如下。
python
def scaled_multihead_dot_product_attention(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads)
kv_n_heads = 1 if multiquery else n_heads
k = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads)
v = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads)
if past_key_value is not None:
if len(past_key_value) != 0:
k = torch.cat([past_key_value[0], k], dim=3)
v = torch.cat([past_key_value[1], v], dim=2)
past_key_value = (k, v)
b, _, s_q, d = q.shape
s_k = k.size(-1)
if softmax_scale is None:
softmax_scale = 1 / math.sqrt(d)
attn_weight = q.matmul(k) * softmax_scale
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - s_q)
_s_k = max(0, attn_bias.size(3) - s_k)
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
attn_weight = attn_weight + attn_bias
min_val = torch.finfo(q.dtype).min
if key_padding_mask is not None:
attn_weight = attn_weight.masked_fill(
~key_padding_mask.view((b, 1, 1, s_k)), min_val)
if is_causal and (not q.size(2) == 1):
s = max(s_q, s_k)
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float16)
causal_mask = causal_mask.tril()
causal_mask = causal_mask.to(torch.bool)
causal_mask = ~causal_mask
causal_mask = causal_mask[-s_q:, -s_k:]
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k),
min_val)
attn_weight = torch.softmax(attn_weight, dim=-1)
if dropout_p:
attn_weight = torch.nn.functional.dropout(attn_weight,
p=dropout_p,
training=training,
inplace=True)
out = attn_weight.matmul(v)
out = rearrange(out, 'b h s d -> b s (h d)')
if needs_weights:
return out, attn_weight, past_key_value
return out, None, past_key_value1.3 资源占用
如果模型结构是MHA,在推理时,KV Cache对于每个token需要缓存的参数有 \(2𝑛_ℎ𝑑_ℎ𝑙\)(𝑙 表示网络层数)。当模型层数加深和头数变多后,注意力计算所涉及的算力、IO和内存都会快速增加。但是对这些资源却利用得不好。
就下图而言,d 表示 hidden size,h 表示 Head 个数,l 表示当前输入序列一共有 l 个 Token。
-
当 Batch Size 为 1 时,图中红色、绿色、蓝色虚线圈处的乘法全部为矩阵乘向量,是明显的 Memory Bound,算术强度不到 1。
-
当 Batch Size 大于 1 时(比如 Continuous Batching):
-
- 红色和蓝色部分:线性层计算是权重乘以激活,不同请求之间可以共享权重,因此是矩阵乘矩阵,并且 Batch Size 越大,算术强度越大,越趋近于计算密集型(FFN 层也类似)。
- 绿色部分:注意力计算是激活乘以激活。因为不同的请求之间没有任何相关性,即使 Batching,此处也是 Batched 矩阵乘向量,并且因为序列长度可能不同,这里不同请求的矩阵乘向量是不规则的。即,这里算术强度始终不到 1,是明显的 Memory Bound。
-
因此,绿色部分难以优化,输入序列越长,此处的瓶颈就越大。

为了缓解这些资源占用,同时也可以更好的利用资源,相继出现了MQA(Multi-Query Attention) 和GQA(Grouped-Query Attention )等方法,这些方法都是围绕"如何减少资源占用且尽可能地保证效果"这个主题发展而来的产物。
0x02 MQA
目前的基本假设是,在头维度上存在非常高的稀疏性,我们可以把头的数量缩减到相当小的数目。在这些注意力头中,有一些头部专门用于检索和长上下文相关能力,因此应该保留这些检索头并修剪其他头。需要注意的是,头部修剪通常发生在预填充之后,这意味着它们只会改善解码、并发性和上下文切换,但并没有改善预填充阶段。
2.1 概念
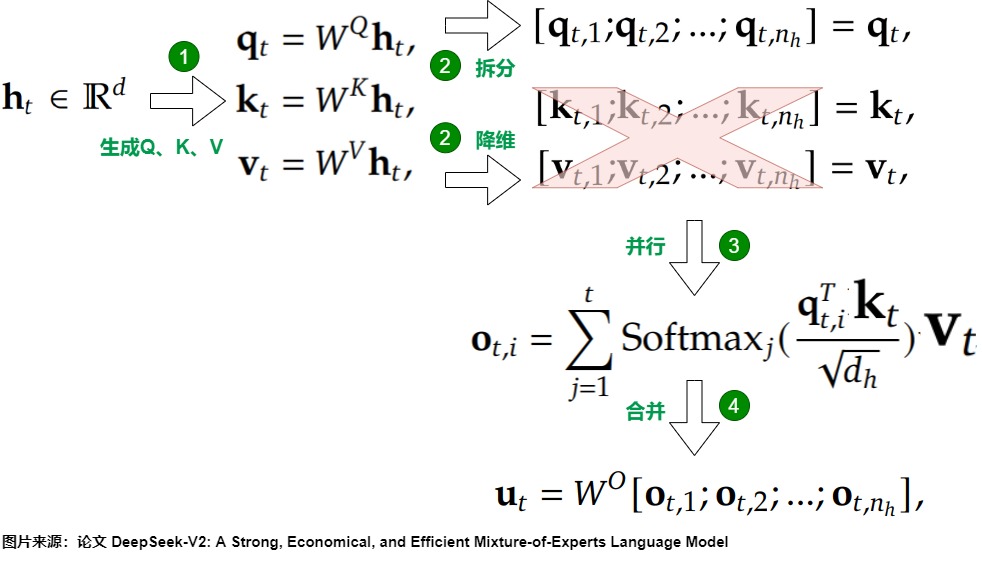
MQA(Multi Queries Attention)出自论文 [2019 Fast Transformer Decoding: One Write-Head is All You Need](https://arxiv.org/pdf/1911.02150.pdf)。在MQA中,保留query的多头性质,所有查询头共享相同的单一键和值头,这用可以减少Key和Value矩阵的数量,从而降低计算和存储开销。这相当于把不同Head的注意力差异,全部都放在了Query上,需要模型仅从不同的Query Heads上就能够关注到输入hidden states不同方面的信息。
MQA的具体特点如下。
- Q 仍然保持原来的头数,即线性变换之后,依然对Q进行切分(像MHA一样),每个注意力头单独保留了自己的Q向量。
- K 和 V 只有一个头,具体是在线性变换时直接把K和V的维度降到了\(d_{head}\),而不是做切分变小。
- 所有的 Q 头共享这个K 和 V 头,或者可以认为是 k, v矩阵参数共享。实现上,就是改一下线性变换矩阵,然后把 K、V 的处理从切分变成复制。
- 所有Q头都使用这个相同的K头计算它们的注意力分数,并且所有头的输出都使用相同的V头计算(但注意力分数不同)。
- 最后将每个头计算的结果拼接起来。
2.2 实现
我们还是以llm-foundry为例来进行分析。
1.2.1 精简版
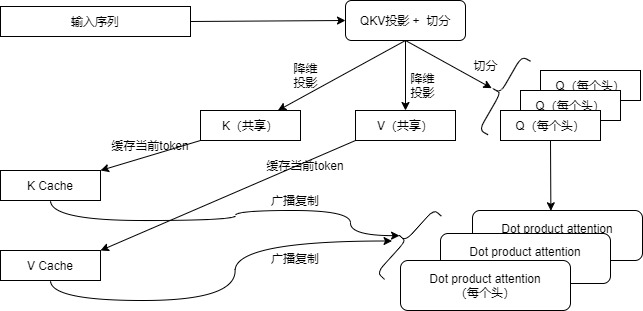
我们先给出MHA和MQA的精简版对比。这里假设 x (tensor): (batch, hidden_state, d_model) ,比如 (1, 512, 768) 。可以看到,两者主要不同在于:
- W矩阵的维度不同。
- QKV切分方式不同。

从代码中可以看到,对于MQA来说,所有头之间共享一份 key 和 value 的参数,但是如何将这 1 份参数同时让 8 个头都使用呢?在scaled_multihead_dot_product_attention()函数的代码会使用矩阵乘法 matmul来广播,使得每个头都乘以这同一个张量,以此来实现参数共享。

MQA的总体流程可以参见下图。
1.2.2 完整版
我们再给出完整版本代码。
python
class MultiQueryAttention(nn.Module):
"""Multi-Query self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = 'triton',
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.head_dim)
self.attn_dropout_p = attn_pdrop
# NOTE: if we ever want to make attn TensorParallel, I'm pretty sure we'll
# want to split Wqkv into Wq and Wkv where Wq can be TensorParallel but
# Wkv shouldn't be TensorParallel
# - vchiley
self.Wqkv = nn.Linear(
d_model,
d_model + 2 * self.head_dim,
device=device,
)
# for param init fn; enables shape based init of fused layers
fuse_splits = (d_model, d_model + self.head_dim)
self.Wqkv._fused = (0, fuse_splits) # type: ignore
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(d_model, device=device)
self.k_ln = layernorm_class(self.head_dim, device=device)
if self.attn_impl == 'flash':
self.attn_fn = flash_attn_fn
elif self.attn_impl == 'triton':
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == 'torch':
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f'{attn_impl=} is an invalid setting.')
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True # type: ignore
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
query, key, value = qkv.split(
[self.d_model, self.head_dim, self.head_dim], dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
# Applying layernorm to qk
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
context, attn_weights, past_key_value = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
multiquery=True,
)
return self.out_proj(context), attn_weights, past_key_value2.3 效果
2.3.1 内存
MQA需要缓存的 K、V 值从所有头变成一个头,因此直接将KV Cache减少到了原来的1/ℎ。MHA的单个Token需要保存的KV数( \(2∗𝑙∗𝑛_ℎ\) ),而MQA减少到了( 2×𝑙 )个,即每一层共享使用一个 𝑘 向量和一个 𝑣 向量。
2.3.2 速度
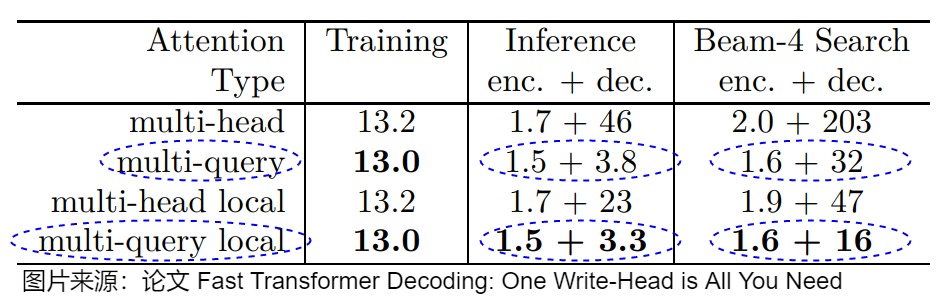
论文作者做了一系列测试,具体参见上表(数值是平均生成每个token所需要的毫秒数)。需要注意的几个点是:
- 训练速度几乎没有变化。
- 推理时间和Beam search时间都显著缩短。
- 推理速度中,encoder的推理速度基本不变,decoder的推理快了很多。
虽然MQA只有一组KV头,但实际上MQA是读取这组KV头之后,复制给所有Q头使用,因此按照道理来说,MQA只能降低显存的使用,运算量并没有减少,为啥速度能提高这么多?其实主要收益是因为降低了KV Cache而带来计算量的减少,具体如下:
- KV-Cache空间占用降低。因为头数量的减少,所以需要存储在GPU内存中的张量也减少了(假设之前要存储32个头的KV Cache,目前只需要存储1个头的KV Cache)。节省的空间可以用来增加批次大小,提升吞吐,从而提高效率(虽然单条请求的总时延会增加,但服务的总吞吐量是明显增加)。
- 降低内存读取模型权重的时间开销。因为头数量的减少,所以减少了从显存中读取的数据量,减少了计算单元的等待时间,从内存密集型趋近于计算密集型。另外,同一个 Request 中的不同 Head 可以共享,这就提升了 Q、K 和 V 的 Attention 计算的算术强度。
2.3.3 表征能力
因为目前只有一个共享的KV头,所以原先多QKV头带来的注意力差异都需要仅仅依靠多个Q头完成,这样限制了模型的表征能力,因此MQA虽然能好地支持推理加速,但是在效果上比MHA略差。为了弥补共享KV带来的参数量减少,人们往往会相应地增大FFN/GLU的规模,以此来维持模型总参数量的不变,进而弥补一部分效果损失。
另外需要注意的是,由于MQA和GQA改变了注意力机制的结构,因此模型通常需要从训练开始就支持 MQA或者GQA 。如果模型已经训练好了,将KV Cache强行换成这两个方法,效果会很差,因此需要需要借助微调来弥补。有研究表明需要约 5% 的原始训练数据量就可以达到不错的效果。
2.3.3 通信
在多卡并行情况下,MQA减少了访存,但是增加了并行通信开销。因为K和V张量在所有头部之间共享,每个GPU上都需要有自己的备份。与下图(a)中MHA并行策略相比,MQA需要使用all-to-all对进行输入输出激活张量resharding,从而产生额外的通信成本。具体如下图(b)所示。另外,因为每个卡上都有备份,这可能会导致MQA的内存成本节省将会丧失。
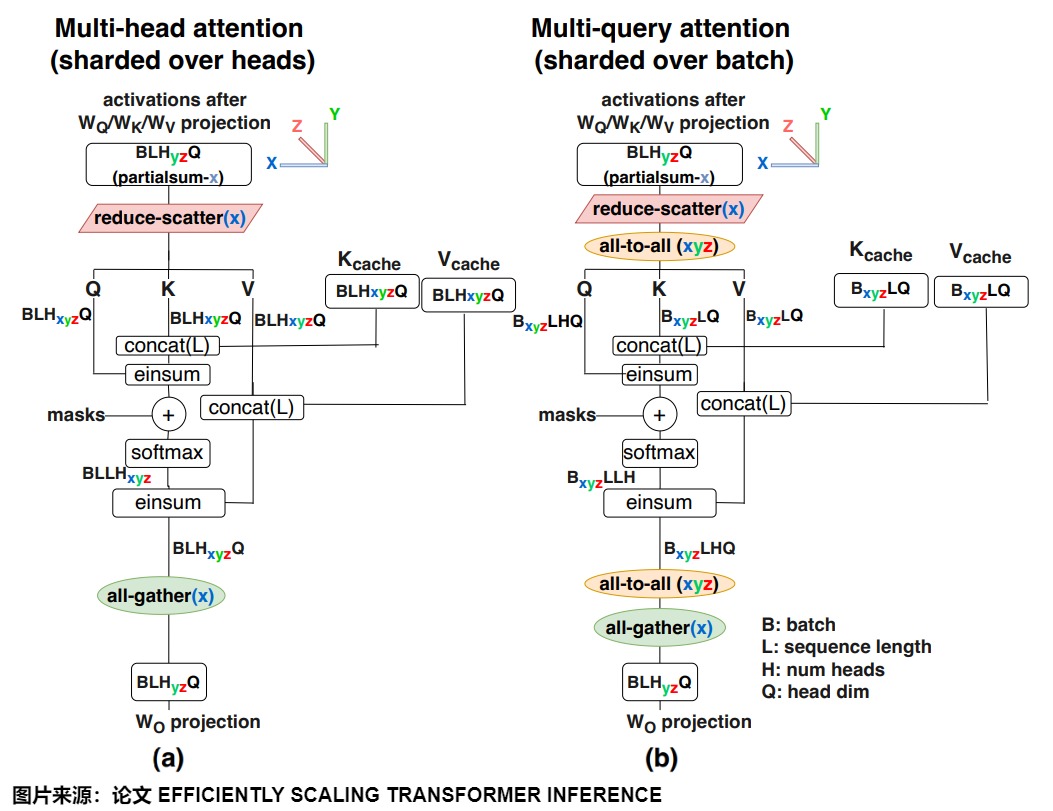
0x03 GQA
对于更大的模型而言,彻底剥离所有头过于激进。例如,相比从32减少到1,将头数从64减少到1在模型的表征能力上是一个更大的削减。而且根据GQA论文的实验说,MQA虽然"drastically"提升了decoder中的推理性能,但这样做会带来生成质量的显著下降以及导致训练不稳定。所以为了在牺牲更小性能前提下加速,GQA应运而生。
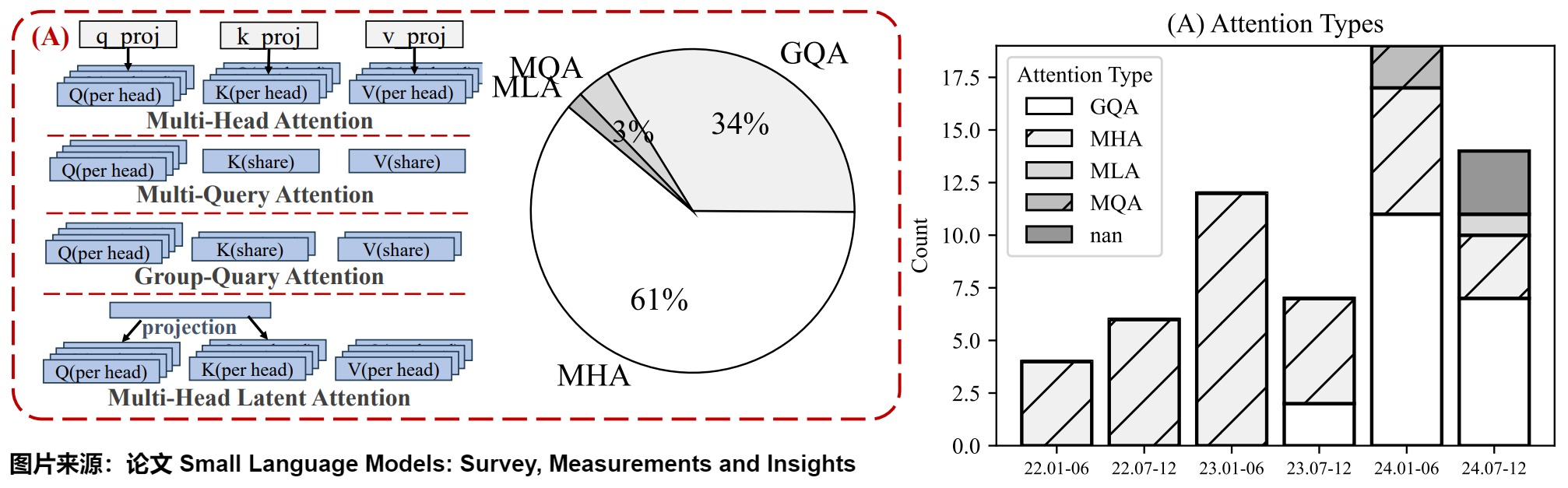
上图显示了从2022年到2024年期间自注意力机制的演变趋势。可以看出,MHA 正在逐步淘汰,并被 GQA 所取代。
3.1 概念
GQA(Grouped Query Attention/分组查询注意力机制)由论文"GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints"提出,它通过分组查询的方式来提高信息处理的效率和效果。GQA的核心改进点在于:让 多个 Query 共享少量的 Key 和 Value,减少计算开销,并通过 分组机制(Grouping Mechanism) 进行更高效的计算。
GQA是MHA和MQA 之间的泛化,或者说是介于MHA和MQA之间的折中方案。MHA 有 H 个 query、key 和 value 头。MQA 在所有 query 头中共享单个 key 和 value 头。而GQA不再让所有查询头共享相同的唯一KV头,而是将所有的Q头分成g组,同一组的Q头共享一个K头(Key Head)和一个V头(Value Head)。
下图中4个Q头(Query Heads)被分成2组,每个组包含2个Q头,每组又对应一个K头,一个V头。图上标号1为一组,标号2为另外一组。
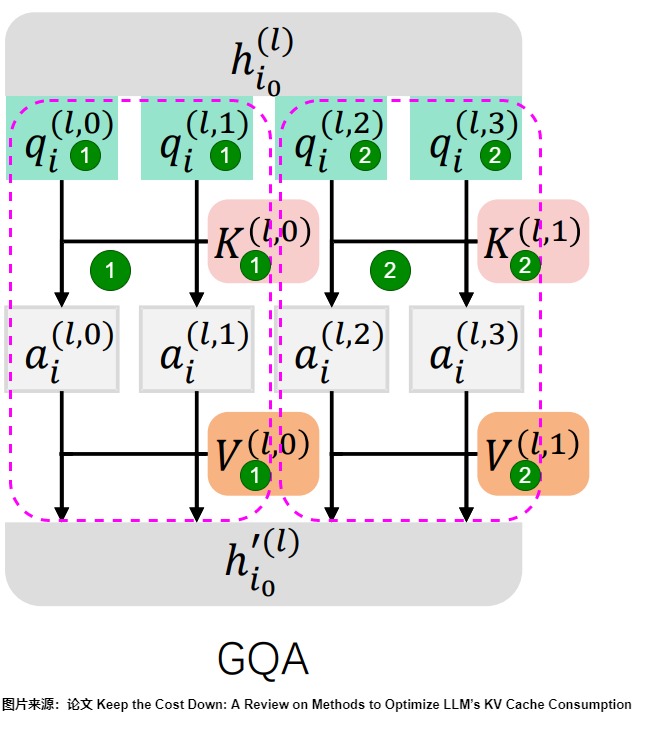
下图是GQA的公式和流程。

苏神则指出,GQA其实是一个\(x_i\)的低秩投影。

3.2 架构比对
GQA巧妙地结合了MHA和MQA的元素,创造了一种更有效的注意力机制。GQA是在MHA和MQA之间进行插值,将KV头的数量从\(n\_heads\)减少到\(1<g<n\_heads\),而不是将头数从\(n\_heads\)减少到1个KV头。这个新参数g可以这么表达:
\g = \\frac{注意力头数}{KV头数} \\
引入这个参数g之后,GQA就构成了一个统一视角。在这个视角下,MHA和MQA都是GQA的特殊情况(分别对应于g=1和 g=\(n\_heads\))。
- g = 1:相当于MQA,即在所有 N 个头中使用共享的键和值投影。
- g = 注意力头数:相当于MHA。
GQA能更顺畅地在模型准确性/KV缓存大小(与时延和吞吐量有关),和MHA以及MQA这两个极端用例间进行权衡。或者说,GQA每个组内是一个小型的MQA,而组间是传统的MHA。
大型模型的MHA会将单个键和值头复制到模型分区的数量,MQA代表了内存带宽和容量的更大幅度的削减,而GQA 使我们能够随着模型大小的增加保持带宽和容量的相同比例下降,可以为较大的模型提供特别好的权衡。GQA 消除了这种分片带来的浪费。因此,我们预计 GQA 将为较大的模型提供特别好的权衡。
下图则给出了三者架构上的区别。
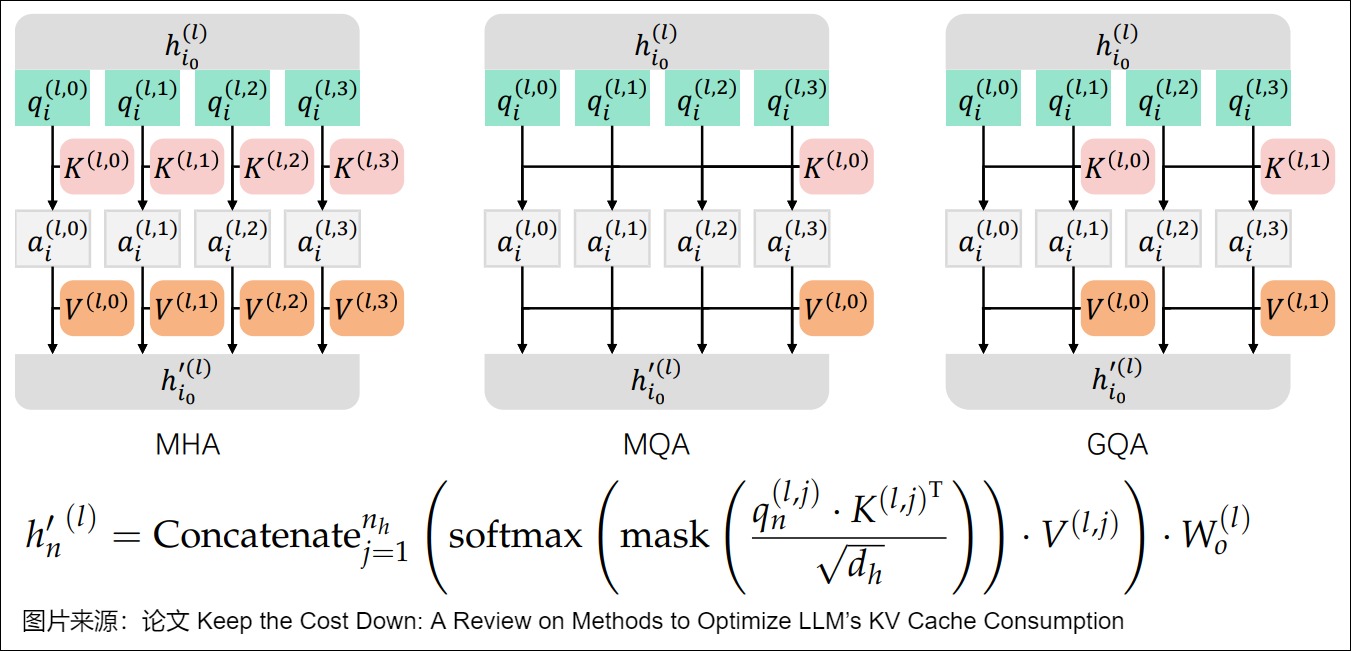
3.3 实现
在目前大部分主流训推框架或算法,都已经支持MQA/GQA,比如FlashAttention中,也支持MQA和GQA。对于MQA和GQA的情形,FlashAttention采用Indexing的方式,而不是直接复制多份KV Head的内容到显存然后再进行计算。Indexing,即通过传入KV/KV Head索引到Kernel中,然后计算内存地址,直接从内存中读取KV。

顺带一提,GQA 不应用于编码器自注意力层,编码器表示是并行计算的,因此内存带宽通常不是主要瓶颈。
我们使用llama3的代码来进行分析。首先给出利于学习的精简版,然后给出完整版。
3.3.1 精简版
为了更好的分析,我们给出精简版代码如下。
本来 MHA 中 Query, Key, Value 的矩阵的大小为 (batch_size, n_head, seq_length, hidden_size)。而 GQA 中 Query 的大小保持不变,Key, Value 的矩阵的大小变为 (batch_size, n_head / group_size, seq_length, hidden_size)。即,在GQA中,key和value都要比query小group倍。为了在后续做矩阵乘法,一般有两种做法:
-
利于广播机制把QKV的形状进行调整,即Query : (batch_size, n_head / group_size, group_size, seq_length, hidden_size),Key : (batch_size, n_head / group_size, 1, seq_length, hidden_size),Value : (batch_size, n_head / group_size, 1, seq_length, hidden_size)。但是这样需要做广播和最终合并的处理,要对 MHA 的代码进行多处修改。
-
把GQA拓展到MHA再进行计算,即先把
key和value的head利用expand扩展张量到和query相同的维度,然后进行计算。
python
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads # 设定组数目
self.head_dim = args.dim // args.n_heads
# 用self.n_kv_heads * self.head_dim初始化,当n_kv_heads小于n_heads时,参数量变少
self.wq = ColumnParallelLinear(args.dim, args.n_heads * self.head_dim,)
self.wk = ColumnParallelLinear(args.dim, self.n_kv_heads * self.head_dim,)
self.wv = ColumnParallelLinear(args.dim, self.n_kv_heads * self.head_dim,)
self.wo = RowParallelLinear(args.n_heads * self.head_dim, args.dim,)
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len,
self.n_local_kv_heads, self.head_dim,)).cuda()
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len,
self.n_local_kv_heads, self.head_dim,)).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
'''
self.n_rep = q_heads // kv_heads
query头数大于KV的头数,一对KV对应多个query,需要把每个KV复制n_rep份,这样第2个维度就和q一样了
即,num_key_value_heads就是q_heads // kv_heads
repeat_kv方法将hidden states从(batch, num_key_value_heads, seqlen, head_dim) 变成 (batch, num_attention_heads, seqlen, head_dim),相当于是复制了self.num_key_value_groups份
'''
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)repeat_kv()函数代码如下。为什么要用expand之后再reshape而不能直接用tensor自带的repeat?因为使用expand()函数可以在运算的时候节省很多显存。
expand方法用于对张量进行扩展,但不实际分配新的内存。它返回的张量与原始张量共享相同的数据repeat方法通过实际复制数据来扩展张量。它返回的新张量不与原始张量共享数据,扩展后的张量占用了更多的内存。
python
# 定义输入x, n_rep是需要重复的次数,在这里一般是组数
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
# 第4维进行扩维,扩展成5维
x[:, :, :, None, :]
# first we expand x to (bs, seq_len, head, group, head_dim),即第4维从1扩展为n_rep
.expand(bs, slen, n_kv_heads, n_rep, head_dim) # 进行广播,k,v向量共享
# reshape make head -> head * group,缩成4维,即把第3维从n_kv_heads扩展n_rep份
# 这样第3个维度就和q一样了
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)3.3.2 完整版
完整版代码如下。
python
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(
keys, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(
values, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(
1, 2
) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)另外,对于MQA和GQA的解码阶段,一种常用的优化技巧是把共用一个KV头的所有QO头,与query的行数融合(因为他们需要跟相同的KV-Cache做Attention计算)。这样的效果是增加了有效的行数,增加了算子密度,自回归解码阶段虽然说查询的长度是1,但是经过Head Group融合之后,有效行数增大到 \(H_{QO}/H_{KV}\)。
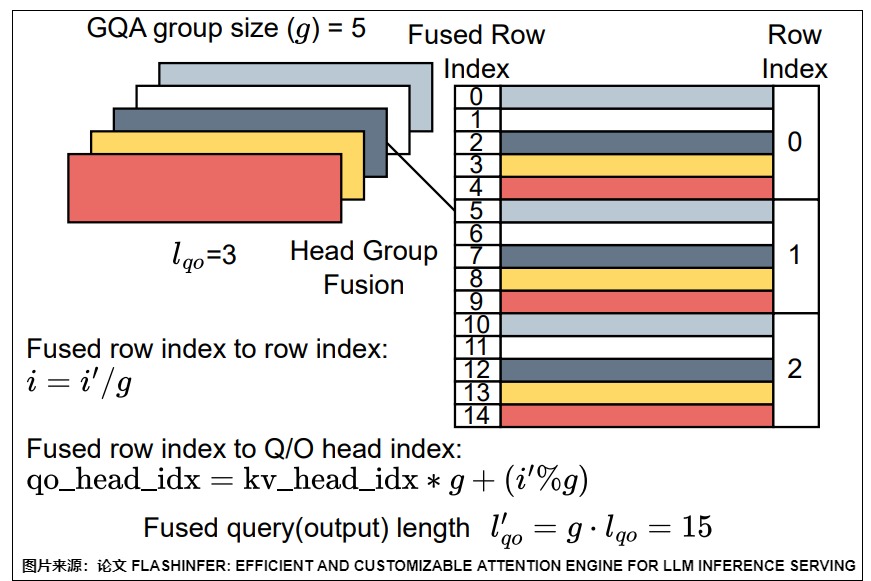
3.4 效果
3.4.1 内存
GQA在推理阶段可以显著降低 KV Cache 的大小,为更大的 Batch Size 提供了空间,可以进一步提升吞吐。
在MHA下,对于所有输入批次和序列中的每个token,KV缓存的总大小可以用以下公式表示:
\2 \\times B \\times L \\times H \\times D \\times N \\
- B代表batch size,
- L代表总序列长度,sequence length(输入序列+输出序列,或者说是提示 + 完成部分),
- H代表number of head,
- D代表size of head,每个head的维度。
- N代表层数
在MQA下,每个token的对应为:
\2 \\times B \\times L\\times D \\times N \\
在GQA下,每个token的对应为:
\2 \\times B \\times L\\times G \\times D\\times N \\
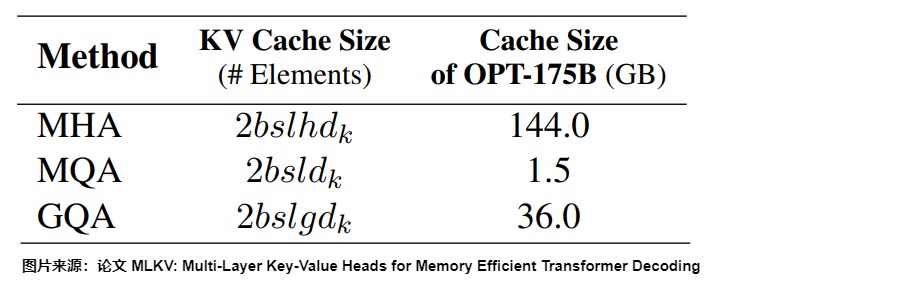
具体比对也可以参考下图,其中 g 是KV头的组数(\(𝑛_ℎ/𝑔\)个Head 共享一个KV),h 是查询的头数 ,\(d_k\)是头维度,l 是层数,s 是序列长度,b 是batch size。
GQA和MQA在GPU 上的实现带来的收益来主要自于KV cache 的减少,从而能放下更多的token。但是,GQA和MQA的性能容易受到并行策略的影响。如果GQA kernel在Q head维度做并行(一个Q head是一个block),则会导致共享一个KV head 的block 被调度在不同的SM上,每个SM 都会对同一份KV head 做重复加载。则内存减少的收益会大大降低。另外,加载 KV 是MHA 和 GQA 的瓶颈。因此需要减少Q head的并行度。
3.4.2 速度
GQA并没有降低Attention的计算量(FLOPs),因为Key、Value映射矩阵会以广播变量的形式拓展到和MHA和一样,因此计算量不变,只是Key、Value参数共享。但是,因为GQA 将查询矩阵 Q 分成多个组,每个组分别计算注意力分数和加权求和。这样一来,每个注意力头只需要计算一部分查询的注意力分数,从而降低了计算复杂度,特别是在处理长序列时。所以,虽然GQA 的 QKV 计算量没有减少,但是速度得到了很大提高,速度提高的原因和MQA相同。
3.4.3 表征能力
GQA既保留了多头注意力的一定表达能力,又通过减少内存访问压力来加速推理速度。
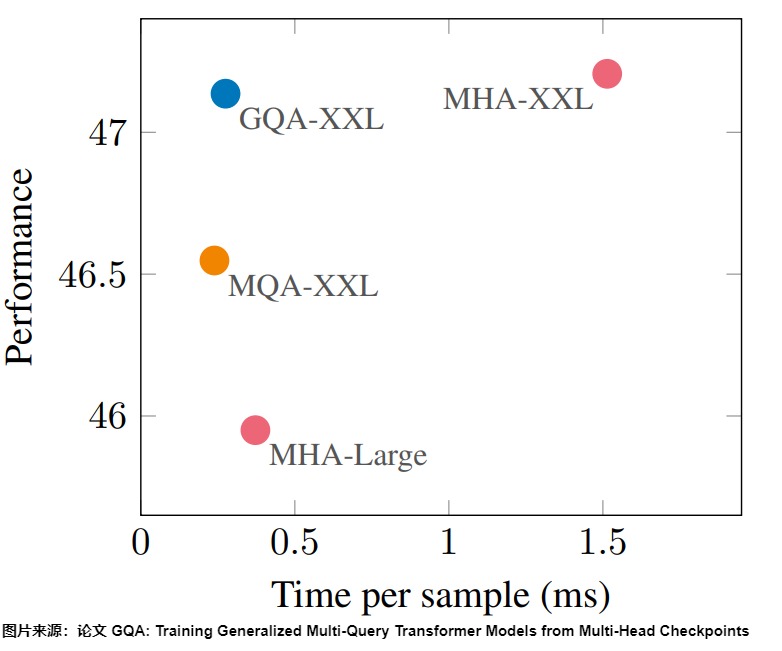
论文"GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints"研究了模型的精度和推理效率。论文作者采用T5模型作为研究对象,模型版本采用T5-Large和T5-XXL。下图中,横轴代表平均每条样本的推理耗时,越大代表延迟越大,纵轴代表在众多数据集上的评价得分,越大代表得分越高。
下图表明,MQA略微损失了模型精度,但是确实能够大幅降低推理开销,而如果选择了合适的分组数,GQA能够两者皆得。GQA的表征能力显著高于MQA,几乎跟MHA一致(GQA还是有可能导致精度的损失),而且推理速度上GQA跟MQA的区别不大,比起MHA依旧有显著提升。其中,GQA的分组数是一个超参数,组数越大越接近MHA,推理延迟越大,同时模型精度也越高。另外,也可以增加模型深度来缓解模型效果的下降。
3.5 转换
虽然最新的模型基本都在预训练阶段默认采用 GQA,我们也可以思考下,如何将已经训练好的MHA结构的模型转换成MQA或者GQA?
3.5.1 平均池化
如果是从已有的 multi-head model 开始继续训练 multi-query model (Uptraining),我们可以对MHA的头进行分组,通过对该组中所有原始头进行平均池化(mean pool)来构建每个组的键和值头,然后继续进行预训练即可。实验证明mean pool的映射效果好于选则第一个head或者任意初始化。人们把这个训练过程叫做uptraining。
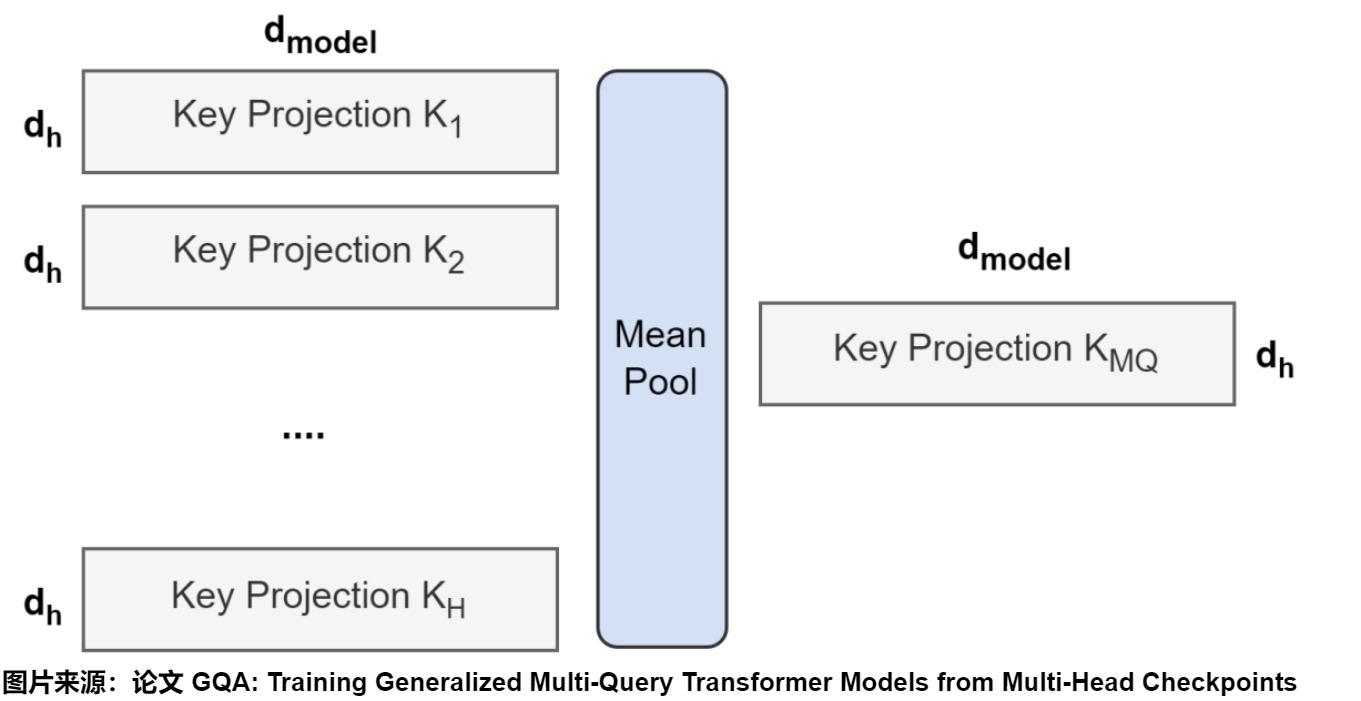
具体参考代码如下。
python
import torch.nn as nn
n_heads=4
n_kv_heads=2
hidden_size=3
group = n_heads // n_kv_heads
k_proj = nn.Linear(hidden_size, n_heads)
# mean pool操作
k_proj_4d = k_proj.weight.data.unsqueeze(dim=0).unsqueeze(dim=0)
pool=nn.AvgPool2d(kernel_size=(group,1))
pool_out = pool(k_proj_4d).squeeze(dim=0).squeeze(dim=0)
k_proj_gaq = nn.Linear(hidden_size, n_kv_heads)
k_proj_gaq.weight.data = pool_out3.5.2 基于掩码
论文"Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA"提出了一种低成本方法,可将 MHA 模型按任意 KV Head 压缩比修剪为 GQA 模型。该方法基于 \(L_0\) 掩码逐步剔除冗余参数。此外,在不改变模型的前提下,对注意力头施加正交变换,以在修剪训练前提升 Attention Head 间的相似度,从而进一步优化模型性能。
具体方案分为如下几步:网络转换;进行分组;剪枝训练。
网络转换
这一步是在剪枝训练之前,对模型进行转换。具体的过程大概为:
- 使用部分 C4 的训练集来收集相应的 KV Cache,这样才能对KV Cache进行更有效的分析。
- 基于余弦相似性或者欧氏距离,计算最优的正交矩阵。

- 将计算得到的正交矩阵融合到对应的 Q、K、V 投影矩阵中,保证计算不变性。因为RoPE的原因,所以对于 Q 和 K 的投影矩阵,分别在子空间应用正交变换。
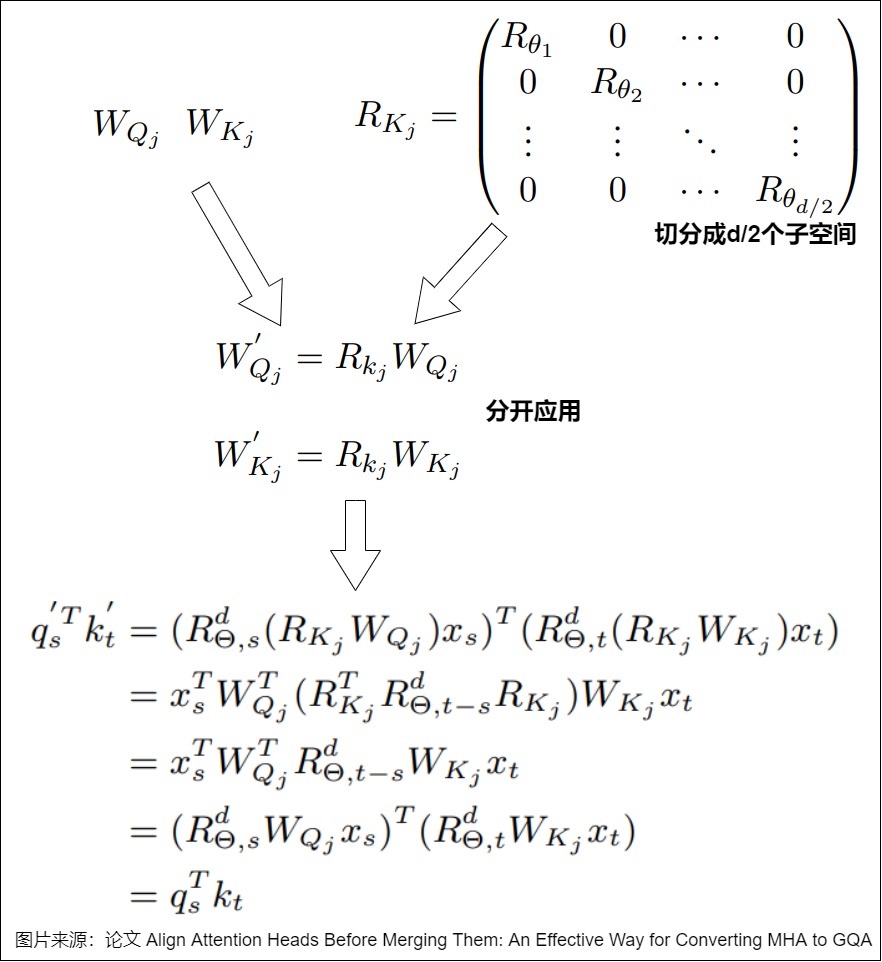
通过正交变换,可以使得同一组内不同 Attention Head 在特征空间中更加接近,从而在后续的剪枝训练过程中更容易找到合适的参数共享方式,提高模型的压缩效果和性能。
找到更好的分组方法
在获取了每对 Attention Head 之间的相似度评分后,可依据这些评分对 Attention Head 进行重新分组。单个组的相似度评分是该组内每对 Attention Head 之间相似度评分的总和,而每种分组结果的总相似度评分则是所有组相似度评分的累加。算法的目标是找到得分最高的分组方法。
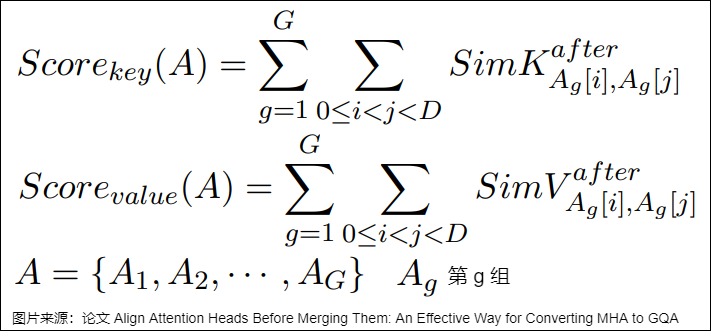
合理的分组方式可以使得同一组内的 Attention Head 在特征空间中更加相似,从而在剪枝时更容易找到合适的参数共享方式,提高模型的压缩效果和性能。
剪枝训练
此步骤会通过剪枝训练,逐步将原始的 KV Head 转移到新的 KV Head 上,同时保持模型性能。如下图 所示,具体过程包括:
- 添加新的投影矩阵:在每组内使用 Mean Pooling 初始化新的投影矩阵。
- 应用 \(L_0\) 掩码:引入 \(L_0\) 掩码来控制原始 KV Head 和新 KV Head 之间的转换。初始时,掩码值为 1,表示使用原始 KV Head;在剪枝过程中,逐步将掩码值约束为 0(表示使用新的 KV Head)。
- 知识蒸馏:使用 KL 损失和 BiLD 损失,鼓励学生模型与教师模型的输出对齐,从而保持模型性能。
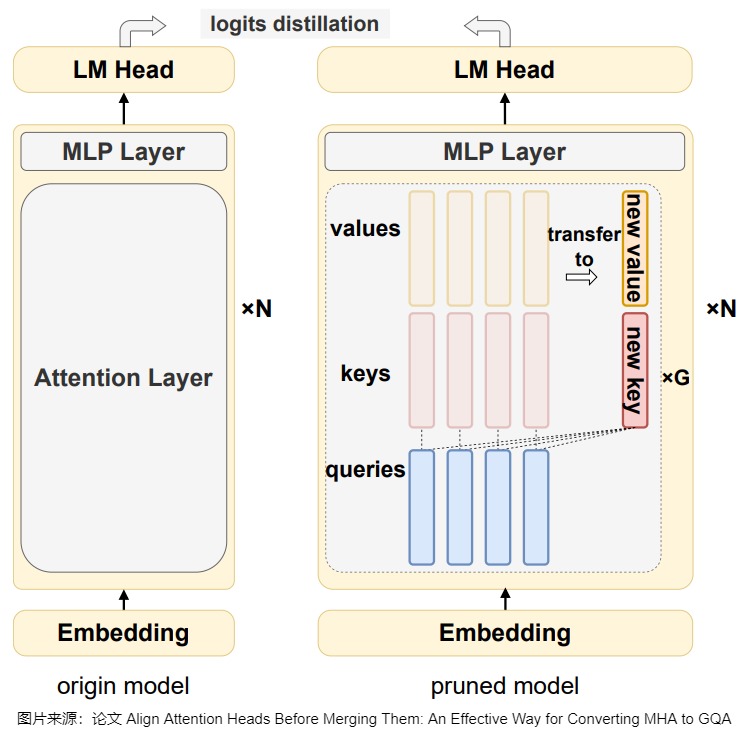
3.6 优化
论文"A Survey on Large Language Model Acceleration based on KV Cache Management"给出了MQA、GQA以及其改进方案的总结,具体参见下图。
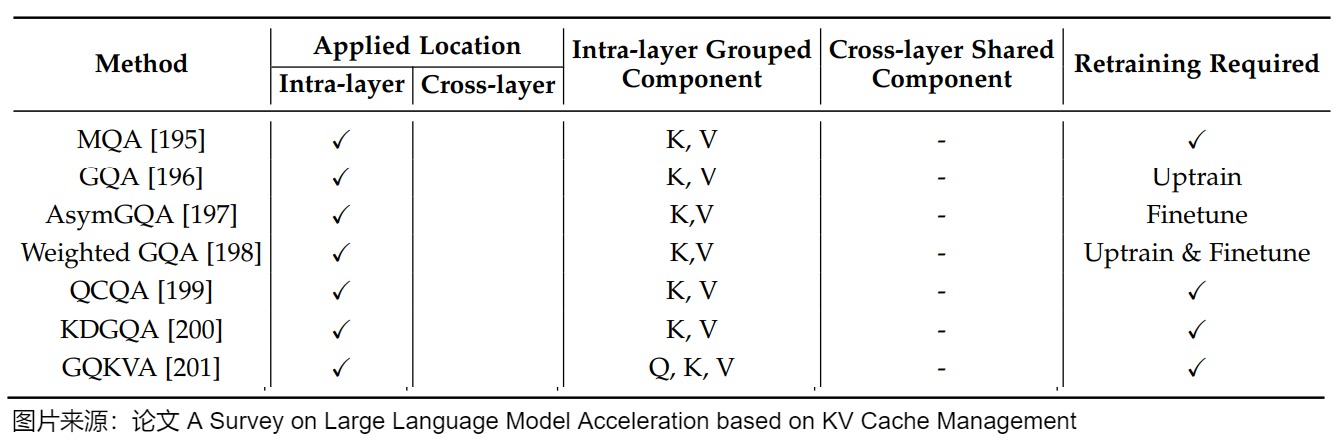
几种改进方案具体如下。
- 加权GQA(Weighted GQA)为每个键和值头引入了额外的可训练权重,这些权重可以无缝集成到现有的GQA模型中。通过在训练过程中调整权重,它可以在不增加额外推理开销的情况下提高模型的性能。

- AsymGQA通过提出激活通知合并策略(activationinformed merging strategy)来扩展GQA。AsymGQA不是通过统一聚类(uniform clustering)对头进行分组,而是根据训练过程中的激活相似性来动态确定如何分组,并构建不对称的组,从而实现更好的优化和泛化。
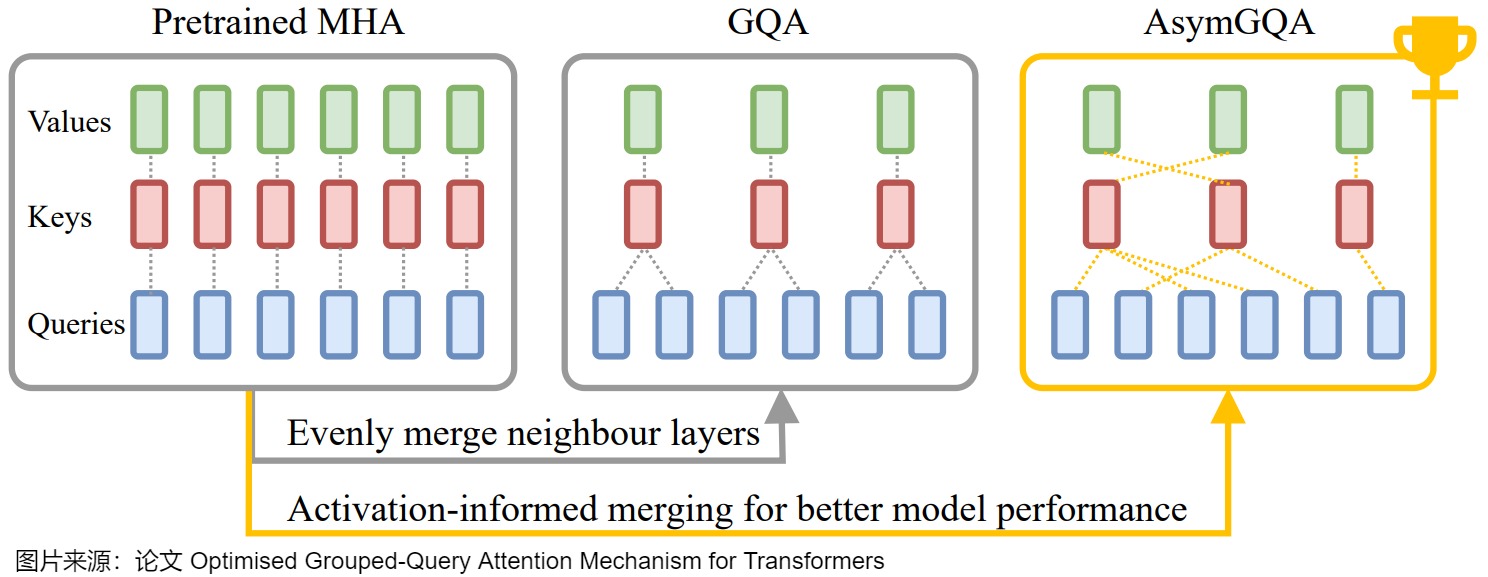
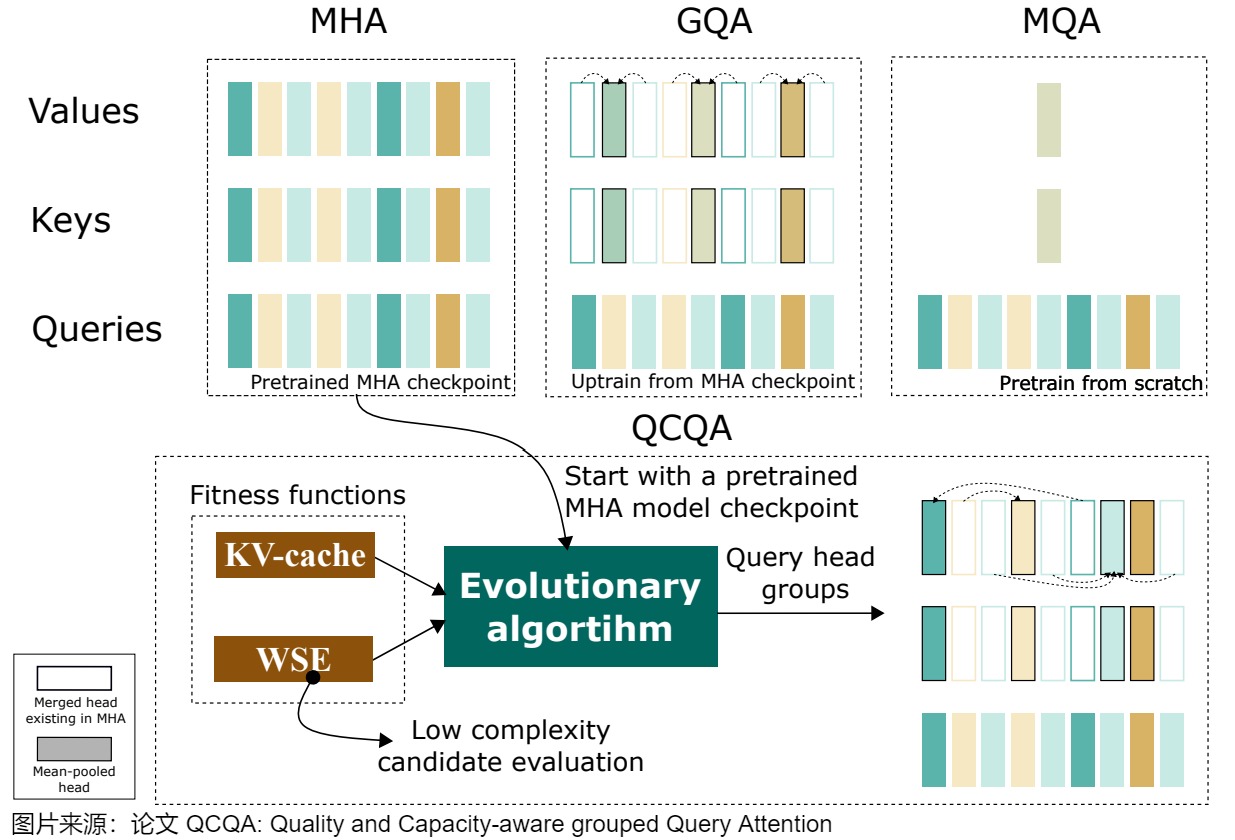
- QCQA利用进化(evolutionary)算法来识别GQA的最佳查询头分组,该算法由一个计算高效的适应度(computationally efficient fitness)函数指导,该函数利用权重共享(weight-sharing)误差和KV缓存来评估文本生成质量和内存容量。
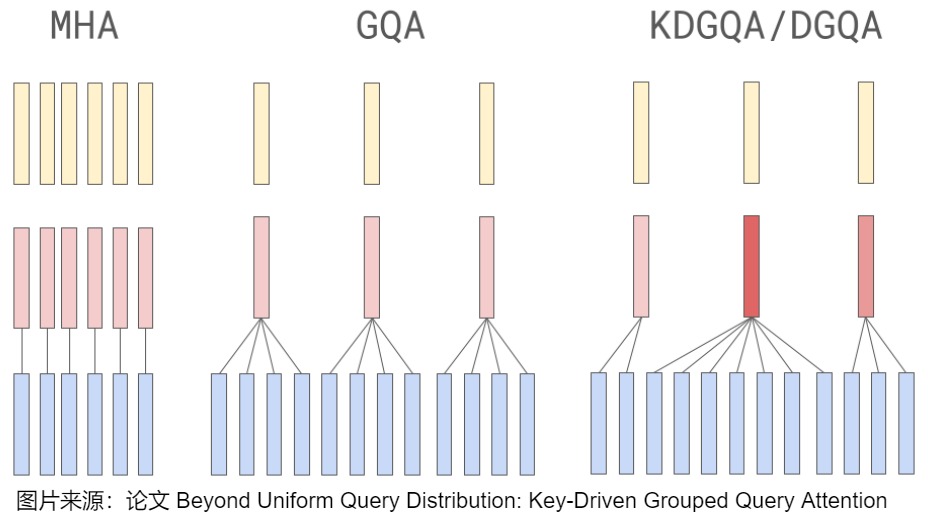
- KDGQA认为,GQA的许多变体采用固定的分组策略,因此缺乏对训练过程中键值交互演变的动态适应性。他们的Dynamic Key-Driven GQA通过在训练过程中使用key head norms自适应地分组来解决这些问题,从而产生了一种灵活的策略来将查询头分组并提高性能。
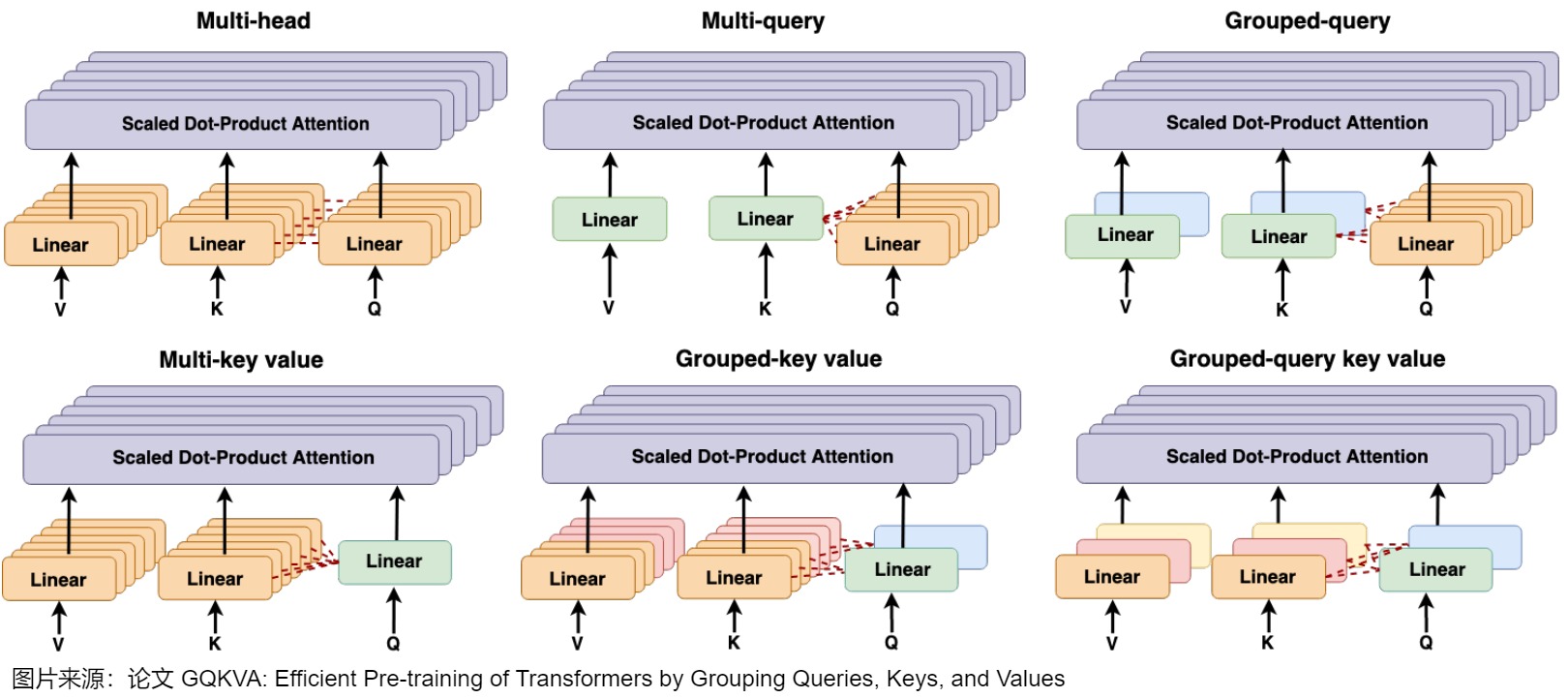
- GQKVA提出了分组策略,并提出了一种通用的查询、键和值分组机制。它首先介绍了MKVA和GKVA,其中键和值被分组以共享同一个查询。在此基础上,该论文提出使用GQKVA将查询和键值对分开分组。通常,查询被划分为\(g_q\)组,键值被划分为\(g_{kv}\)组,查询和键值对的每个组合都会使用点积注意力进行交互。这导致\(g_q×g_{kv}\)产生不同的输出。GQKVA在查询、键和值上推广了不同的组策略,并保持了良好的计算效率和与MHA相当的性能。下图展示了在注意力机制中对查询、键和值进行分组的各种策略,包括Vanilla MHA、MQA、GQA、MKVA、GKVA和GQKVA。
0xFF 参考
【LLM 加速技巧】Muti Query Attention 和 Attention with Linear Bias(附源码) 何枝
https://github.com/meta-llama/llama3
2万字长文!一文了解Attention,从MHA到DeepSeek MLA,大量图解,非常详细! ShuYini AINLPer(javascript:void(0)😉
阿里一面代码题:"实现一下 GQA" 看图学 看图学(javascript:void(0)😉
MHA -> GQA:提升 LLM 推理效率 AI闲谈 AI闲谈(javascript:void(0)😉
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA
FLASHINFER: EFFICIENT AND CUSTOMIZABLE ATTENTION ENGINE FOR LLM INFERENCE SERVING
FlashInfer中DeepSeek MLA的内核设计 yzh119
大模型并行推理的太祖长拳:解读Jeff Dean署名MLSys 23杰出论文 方佳瑞
由GQA性能数据异常引发的对MHA,GQA,MQA 在GPU上的感性分析 代码搬运工
MHA->MQA->GQA->MLA的演进之路 假如给我一只AI
Y. Chen, C. Zhang, X. Gao, R. D. Mullins, G. A. Constantinides, and Y. Zhao, "Optimised Grouped-Query Attention Mechanism for Transformers," in Workshop on Efficient Systems for Foundation Models II @ ICML2024, Jul. 2024. Online. Available: https://openreview.net/forum?id=13MMghY6Kh
S. S. Chinnakonduru and A. Mohapatra, "Weighted Grouped Query Attention in Transformers," Jul. 2024. Online. Available: http://arxiv.org/abs/2407.10855
V. Joshi, P. Laddha, S. Sinha, O. J. Omer, and S. Subramoney, "QCQA: Quality and Capacity-aware grouped Query Attention," Jun. 2024. Online. Available: http://arxiv.org/abs/2406.10247
Z. Khan, M. Khaquan, O. Tafveez, B. Samiwala, and A. A. Raza, "Beyond Uniform Query Distribution: Key-Driven Grouped Query Attention," Aug. 2024. Online. Available: http://arxiv.org/abs/2408.08454
F. Javadi, W. Ahmed, H. Hajimolahoseini, F. Ataiefard, M. Hassanpour, S. Asani, A. Wen, O. M. Awad, K. Liu, and Y. Liu, "GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values," Dec. 2023. Online. Available: http://arxiv.org/abs/2311.03426