多线程环境下,使用Hashmap进行put操作会造成数据覆盖,应该使用支持多线程的 ConcurrentHashMap。
HashMap为什么线程不安全
put的不安全
由于多线程对HashMap进行put操作,调用了HashMap的putVal(),具体原因:
-
假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的;
- 当线程A执行完第六行由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入;
- 接着线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入;
- 最终就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
-
代码的第38行处有个++size,线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10;
- 当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU;
- 接着线程B拿到CPU后从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存;
- 接着线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存;
- 此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所有说还是由于数据覆盖又导致了线程不安全。
java
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
2 boolean evict) {
3 Node <K, V> [] tab; Node <K, V> p; int n, i;
4 if ((tab = table) == null || (n = tab.length) == 0)
5 n = (tab = resize()).length;
6 if ((p = tab[i = (n - 1) & hash]) == null) //
tab[i] = newNode(hash, key, value, null);
else {
Node < K, V > e;
K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode <K, V> ) p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0;; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
38 if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}扩容不安全
Java7中头插法扩容会导致死循环和数据丢失,Java8中将头插法改为尾插法后死循环和数据丢失已经得到解决,但仍然有数据覆盖的问题。
这是jdk7中存在的问题
java
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry <K, V> e: table) {
while (null != e) {
Entry <K, V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}transfer过程如下:
- 对索引数组中的元素遍历
- 对链表上的每一个节点遍历:用 next 取得要转移那个元素的下一个,将 e 转移到新 Hash 表的头部,使用头插法插入节点。
- 循环2,直到链表节点全部转移
- 循环1,直到所有索引数组全部转移
注意 e.next = newTablei 和newTablei = e 这两行代码,就会导致链表的顺序翻转。
扩容操作就是新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
java
Map m = Collections.synchronizedMap(new LinkedHashMap(...));ConcurrentHashMap原理?put执行流程?
回顾hashMap的put方法过程
- 计算出key的槽位
- 根据槽位类型进行操作(链表,红黑树)
- 根据槽位中成员数量进行数据转换,扩容等操作
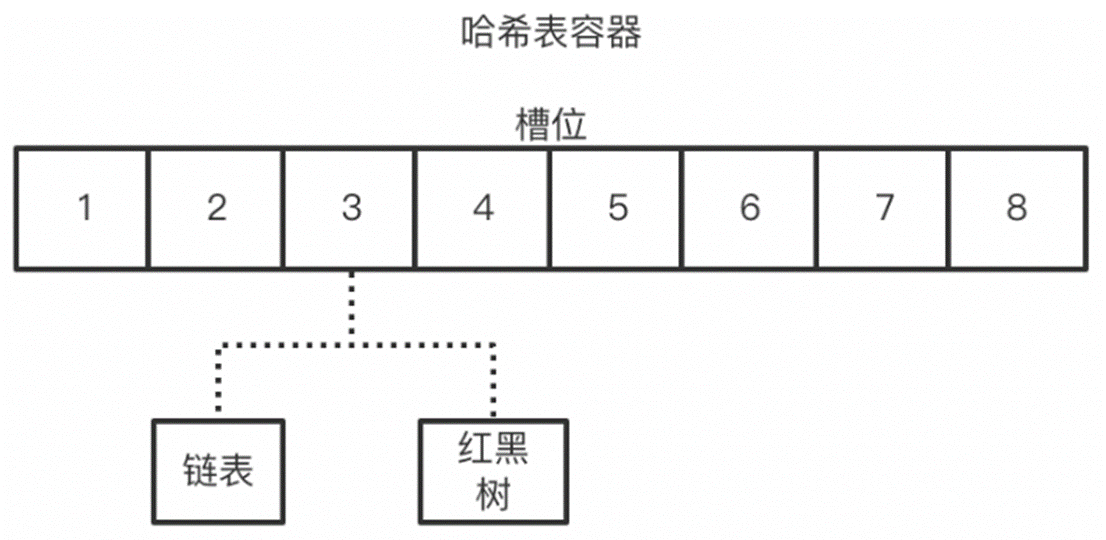
如何高效的执行并发操作:根据上面hashMap的数据结构可以直观的看到,如果以整个容器为一个资源进行锁定,那么就变为了串行操作。而根据hash表的特性,具有冲突的操作只会出现在同一槽位,而与其它槽位的操作互不影响。基于此种判断,那么就可以将资源锁粒度缩小到槽位上,这样热点一分散,冲突的概率就大大降低,并发性能就能得到很好的增强。
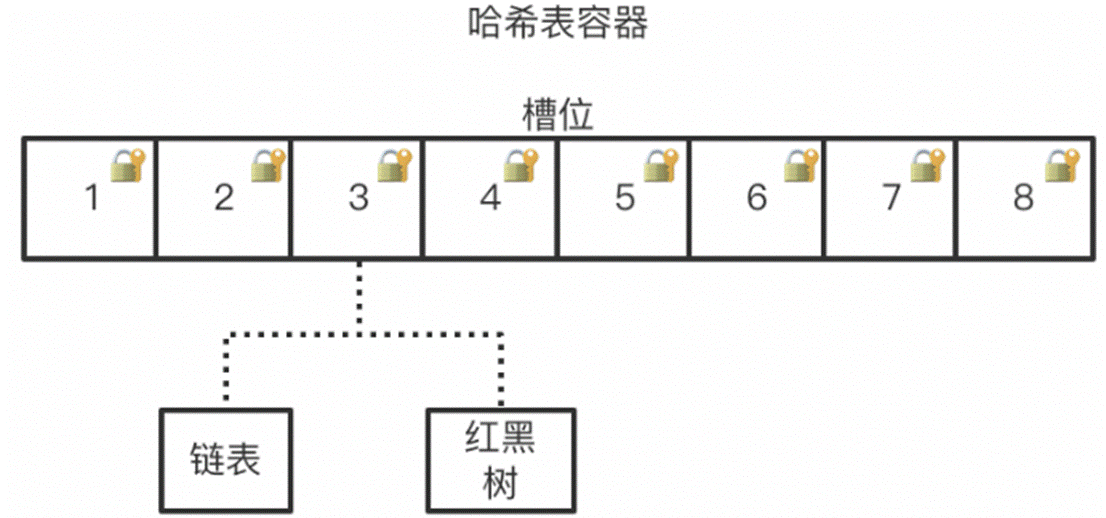
总体上来说,就是采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
ConcurrentHashMap 的get 方法是否需要加锁?
不需要加锁。
通过 volatile 关键字,concurentHashmap能够确保 get 方法的线程安全,即使在写入发生时,读取线程仍然能够获得最新的数据,不会引发并发问题
具体是通过 unsafe#getxxxvolatile 和用 volatile 来修饰节点的 val 和 next 指针来实现的。
ConcurrentHashMap 和 Hashtable 的区别?
相同点:ConcurrentHashMap 和 Hashtable 都是线程安全的,可以在多个线程同时访问它们而不需要额外的同步措施。
不同点:
- Hashtable通过使用synchronized修饰方法的方式来实现多线程同步,因此,Hashtable的同步会锁住整个数组。在高并发的情况下,性能会非常差。ConcurrentHashMap采用了使用数组+链表+红黑树数据结构和CAS原子操作实现;synchronized锁住桶,以及大量的CAS操作来保证线程安全。
- Hashtable 读写操作都加锁,ConcurrentHashMap的读操作不加锁,写操作加锁
- Hashtable默认的大小为11,当达到阈值后,每次按照下面的公式对容量进行扩充:newCapacity = oldCapacity * 2 + 1。ConcurrentHashMap默认大小是16,扩容时容量扩大为原来的2倍。
- Null 键和值: ConcurrentHashMap 不允许存储 null 键或 null 值,如果尝试存储 null 键或值,会抛出 NullPointerException。 Hashtable 也不允许存储 null 键和值。
为什么JDK8不用ReentrantLock而用synchronized
- 减少内存开销:如果使用ReentrantLock则需要节点继承AQS来获得同步支持,增加内存开销,而1.8中只有头节点需要进行同步。
- 内部优化:synchronized则是JVM直接支持的,JVM能够在运行时作出相应的优化措施:锁粗化、锁消除、锁自旋等等。
为什么key 和 value 不允许为 null
HashMap中,null可以作为键或者值都可以。而在ConcurrentHashMap中,key和value都不允许为null。
ConcurrentHashMap的作者------Doug Lea的解释如下:

主要意思就是说:
ConcurrentMap(如ConcurrentHashMap、ConcurrentSkipListMap)不允许使用null值的主要原因是,在非并发的Map中(如HashMap),是可以容忍模糊性(二义性)的,而在并发Map中是无法容忍的。
假如说,所有的Map都支持null的话,那么map.get(key)就可以返回null,但是,这时候就会存在一个不确定性,当你拿到null的时候,你是不知道他是因为本来就存了一个null进去还是说就是因为没找到而返回了null。
在HashMap中,因为它的设计就是给单线程用的,所以当我们map.get(key)返回null的时候,我们是可以通过map.contains(key)检查来进行检测的,如果它返回true,则认为是存了一个null,否则就是因为没找到而返回了null。
但是,像ConcurrentHashMap,它是为并发而生的,它是要用在并发场景中的,当我们map.get(key)返回null的时候,是没办法通过map.contains(key)(ConcurrentHashMap有这个方法,但不可靠)检查来准确的检测,因为在检测过程中可能会被其他线程锁修改,而导致检测结果并不可靠。
所以,为了让ConcurrentHashMap的语义更加准确,不存在二义性的问题,他就不支持null。
使用了ConcurrentHashMap 就能保证业务的线程安全吗?
需要知道的是,集合线程安全并不等于业务线程安全,并不是说使用了线程安全的集合 如ConcurrentHashMap 就能保证业务的线程安全。这是因为,ConcurrentHashMap只能保证put时是安全的,但是在put操作前如果还有其他的操作,那业务并不一定是线程安全的。
例如存在复合操作,也就是存在多个基本操作(如put、get、remove、containsKey等)组成的操作,例如先判断某个键是否存在containsKey(key),然后根据结果进行插入或更新put(key, value)。这种操作在执行过程中可能会被其他线程打断,导致结果不符合预期。
例如,有两个线程 A 和 B 同时对 ConcurrentHashMap 进行复合操作,如下:
java
// 线程 A
if (!map.containsKey(key)) {
map.put(key, value);
}
// 线程 B
if (!map.containsKey(key)) {
map.put(key, anotherValue);
}如果线程 A 和 B 的执行顺序是这样:
- 线程 A 判断 map 中不存在 key
- 线程 B 判断 map 中不存在 key
- 线程 B 将 (key, anotherValue) 插入 map
- 线程 A 将 (key, value) 插入 map
那么最终的结果是 (key, value),而不是预期的 (key, anotherValue)。这就是复合操作的非原子性导致的问题。
那如何保证 ConcurrentHashMap 复合操作的原子性呢?
ConcurrentHashMap 提供了一些原子性的复合操作,如 putIfAbsent、compute、computeIfAbsent 、computeIfPresent、merge等。这些方法都可以接受一个函数作为参数,根据给定的 key 和 value 来计算一个新的 value,并且将其更新到 map 中。
上面的代码可以改写为:
java
// 线程 A
map.putIfAbsent(key, value);
// 线程 B
map.putIfAbsent(key, anotherValue);或者:
java
// 线程 A
map.computeIfAbsent(key, k -> value);
// 线程 B
map.computeIfAbsent(key, k -> anotherValue);很多同学可能会说了,这种情况也能加锁同步呀!确实可以,但不建议使用加锁的同步机制,违背了使用 ConcurrentHashMap 的初衷。在使用 ConcurrentHashMap 的时候,尽量使用这些原子性的复合操作方法来保证原子性。
SynchronizedMap和ConcurrentHashMap有什么区别?
SynchronizedMap一次锁住整张表来保证线程安全,所以每次只能有一个线程来访问map。
JDK1.8 ConcurrentHashMap采用CAS和synchronized来保证并发安全。数据结构采用数组+链表/红黑二叉树。synchronized只锁定当前链表或红黑二叉树的首节点,支持并发访问、修改。
另外ConcurrentHashMap使用了一种不同的迭代方式。当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据 ,iterator完成后再将头指针替换为新的数据 ,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。