1. 背景
我就职于一家轨道交通行业公司,负责的产品之一是日志记录板卡配套软件。有一天接到了现场报告,记录软件出现通信异常,将日志数据拉回来以后,发现出现异常时,CPU使用率接近100%,记录相关软件的CPU分配被大幅降低,这说明Linux系统在CPU的调度上,就没有正常将应用软件调度执行。
记录软件是一个时间敏感型软件。当记录软件运行超时或者没有被正常调度时,就无法记录整个子系统的运行日志,造成了整个系统的可用性降低的问题。
2. 结论
记录板的 CPU 性能瓶颈本质是 SSD 垃圾回收机制与高 I/O 负载的冲突。通过定时执行trim命令,主动进行垃圾回收操作,可以有效解决高IO负载的问题。
主动垃圾回收操作,会同时带来SSD寿命降低的负面影响。受到SSD的物理特性影响,过多的垃圾回收操作,会增加硬盘擦写次数,当SSD的擦写次数达到上限时,就会导致硬盘物理损坏。需要评估寿命与IO性能之间的关系,选取合适的trim间隔,在不影响性能的前提下延长SSD使用寿命,降低使用成本。
3. 排查之路
记录板的CPU是ARM的,性能不高,只有1500Mhz左右,板卡上跑着一个精简板的linux系统。为了最大化利用CPU性能,把资源让给应用,所有很多功能都被裁剪掉了,属于是要啥没啥的状态。所以只能从零开始编译相关的软件用于分析。
3.1 工具准备
3.1.1 sysstat工具准备
本次用到的工具是sysytat,该工具是 Linux 系统中的常用工具包。它的主要用途是观察服务负载,比如CPU和内存的占用率、网络的使用率以及磁盘写入和读取速度等。
- sysstat的下载页面是:https://sysstat.github.io/
- 本次使用的版本是:sysstat-12.7.5
- 编译环境:Ubuntu 22.04.2 LTS(GNU/Linux 6.2.0-26-generic x86_64)
- 交叉编译工具链:arm-linux-gnueabihf
下载完成以后开始解压和配置:
shell
#解压
xz -d sysstat-12.7.5.tar.xz
tar xvvf sysstat-12.7.5.tar
#进入解压后的目录
cd sysstat-12.7.5/
#临时使用CC为交叉编译工具链的GCC
export CC=arm-linux-gnueabihf-gcc
#开始进行编译前的配置工作,使用CFLAGS=-static生成单个文件,不需要依赖库文件。
./configure --host=armv7-linux-gnueabihf CFLAGS=-static执行命令以后,信息如下:
text
Sysstat version: 12.7.5
Installation prefix: /usr/local
rc directory: /etc
Init directory: /etc/init.d
Systemd unit dir:
Systemd sleep dir:
Configuration file: /etc/sysconfig/sysstat
Man pages directory: ${datarootdir}/man
Compiler: arm-linux-gnueabihf-gcc
Compiler flags: -static
Linker flags: 使用make命令即可完成编译。
shell
make编译完成以后,可以查看生成了哪些文件:
shell
find . -maxdepth 1 -type f -executable结果如下:
text
$ find . -maxdepth 1 -type f -executable
./mpstat
./sa2
./sa1
./sadc
./config.status
./iostat
./iconfig
./configure
./tapestat
./sysstat
./sadf
./sar
./cifsiostat
./pidstat
./do_test3.1.2 perf工具准备
对于perf工具而言,这个工具依赖特定版本的linux源码。我们使用的linux内核版本是4.9.69,所以就需要下载这个版本的源代码。
https://ftp.sjtu.edu.cn/sites/ftp.kernel.org/pub/linux/kernel/v4.x/linux-4.9.69.tar.gz
下载完成以后,就需要解压编译了。
shell
#解压源代码
tar -zxvf linux-4.9.69.tar.gz
#进入目录
cd linux-4.9.69/tools/perf/
#指定架构为arm, 指定交叉编译链,并进行编译
make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf-
#编译完成以后,查看文件类型
file perf执行file命令以后,可以获取以下信息:
text
perf: ELF 32-bit LSB executable, ARM, EABI5 version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-armhf.so.3, for GNU/Linux 3.2.0, BuildID[sha1]=0ded60dc28cea83b24d83bfb6414da6d082741eb, with debug_info, not stripped为了查看需要的动态库,执行以下命令:
shell
objdump -p perf | grep NEEDED其结果如下:
text
NEEDED libpthread.so.0
NEEDED librt.so.1
NEEDED libm.so.6
NEEDED libdl.so.2
NEEDED libgcc_s.so.1
NEEDED libc.so.6
NEEDED ld-linux-armhf.so.3一般来说,这些库在linux系统内就有,一般不会缺。缺的话,就需要自行去网上找源码进行编译了;
3.2 排查过程
为了检测CPU波动,使用top命令在后台输出带时间戳的数据:
shell
top -b | busybox awk 'NR { printf "%s %s\n", strftime(), $0 ; fflush(stdout) }' > toplog.txt &
从产品的运行监测日志中看到,出现了CPU异常升高的情况
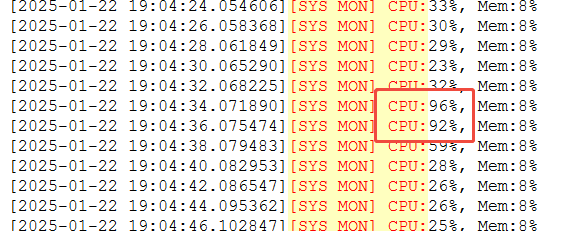
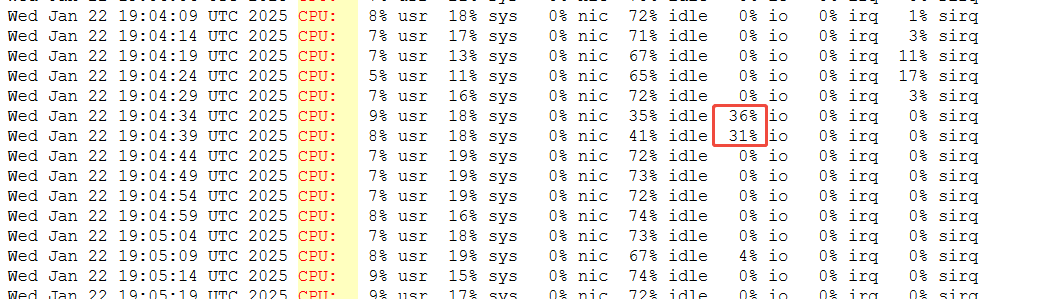
检查对应时间段的TOP信息,发现此时等待IO完成的时间占比异常升高,即可推断IO设备是引发CPU异常升高的问题点:
使用iostat检查对IO设备持续监控:
shell
./iostat 2 -d /dev/sda -t -x -k -c > iolog.txt &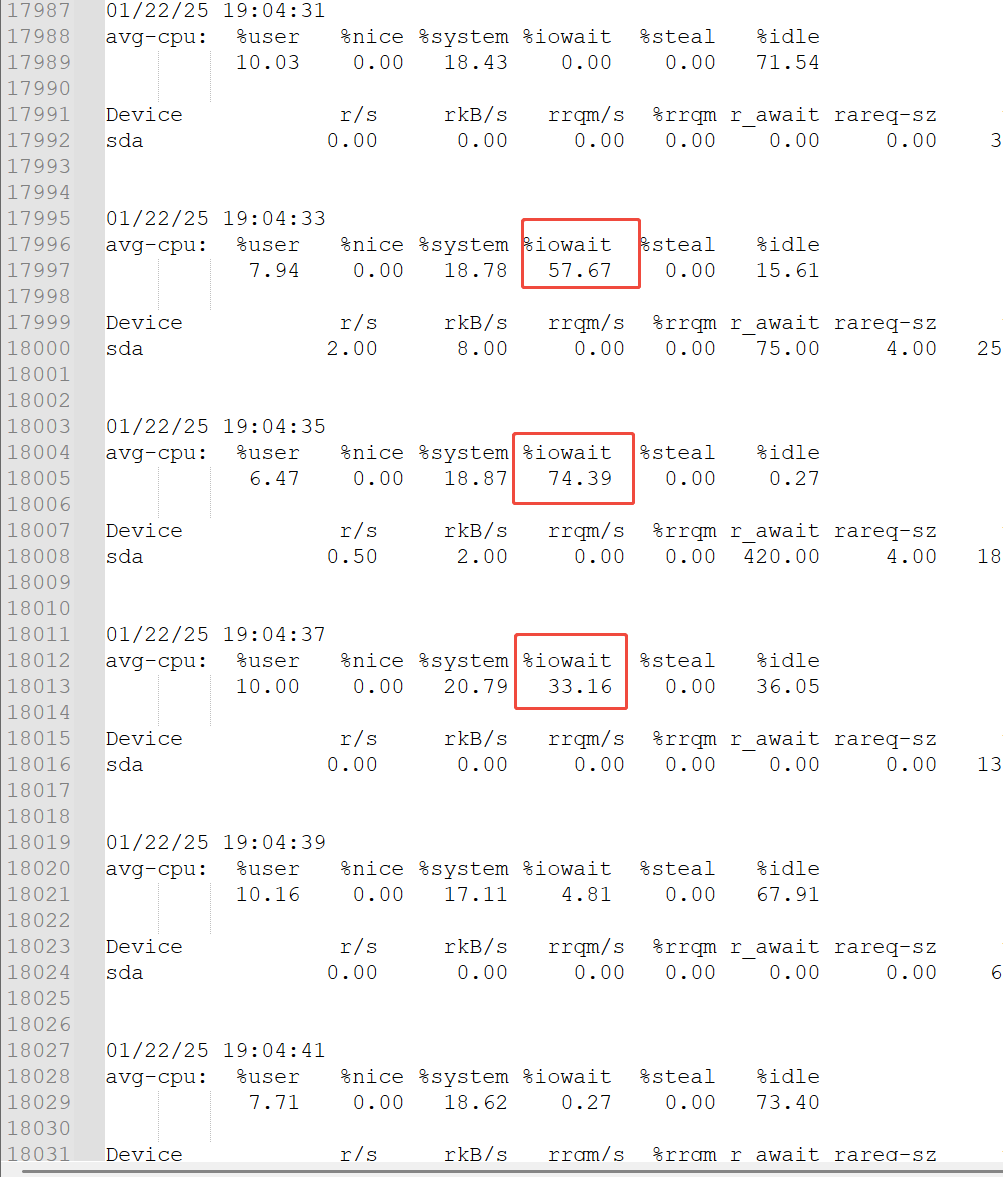
继续分析设备的信息,其中
- r/s: 每秒完成的读次数
- rkB/s: 每秒读数据量(kB为单位)
- rrqm/s: 每秒进行 merge 的读操作数目.即 delta(rmerge)/s
- wrqm/s: 每秒进行 merge 的写操作数目.即 delta(wmerge)/s
- w/s: 每秒完成的写次数
- wkB/s: 每秒写数据量(kB为单位)
- avgrq-sz:平均每次IO操作的数据量(扇区数为单位)
- avgqu-sz: 平均等待处理的IO请求队列长度
- await: 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位)
- svctm: 平均每次IO请求的处理时间(毫秒为单位)
- %util: 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率,即一秒中有百分之多少的时间用于 I/O
text
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 3.00 26.00 3.50 53.85 1.67 8.67 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 3.00 32.00 4.50 60.00 1.67 10.67 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.50
sda 2.00 8.00 0.00 0.00 75.00 4.00 25.00 5118.00 34.00 57.63 282.20 204.72 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 23.46 87.50
sda 0.50 2.00 0.00 0.00 420.00 4.00 18.00 5122.00 8.00 30.77 1806.94 284.56 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 17.86 100.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 13.00 4794.00 24.00 64.86 1046.54 368.77 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 15.28 100.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 6.50 872.00 4.50 40.91 507.69 134.15 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.24 12.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 4.50 36.00 4.50 50.00 1.11 8.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.503.2.1 推测:数据量过大
为了确认是否是因日志量过大导致的硬盘IO瓶颈,在记录板中增加获取到的数据日志大小,以及其数据的间隔时间。
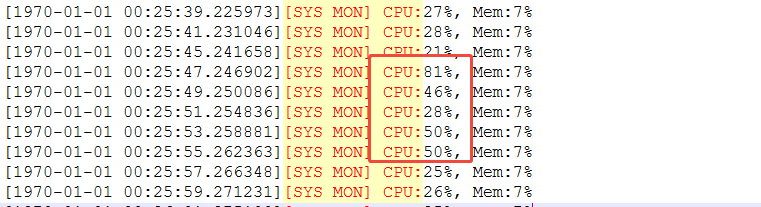
text
01/01/70 00:25:39
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 4.50 36.00 4.50 50.00 1.11 8.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 6.00 50.00 6.00 50.00 0.83 8.33 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 4.50 38.00 5.00 52.63 1.11 8.44 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.50
sda 1.00 4.00 0.00 0.00 60.00 4.00 5.50 1296.00 2.50 31.25 101.82 235.64 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.01 28.00
sda 3.00 12.00 0.00 0.00 161.67 4.00 15.50 5036.00 21.00 57.53 844.19 324.90 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16.16 100.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 7.00 936.00 3.50 33.33 797.14 133.71 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.59 19.50
sda 0.50 2.00 0.00 0.00 130.00 4.00 7.00 556.00 5.00 41.67 15.00 79.43 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.56 12.50
sda 2.00 8.00 0.00 0.00 130.00 4.00 14.00 4960.00 14.50 50.88 792.50 354.29 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 21.40 100.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 14.50 2366.00 6.00 29.27 958.28 163.17 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 3.45 48.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 5.00 52.00 4.00 44.44 7.00 10.40 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.04 3.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 4.00 36.00 4.50 52.94 2.50 9.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.04 3.50
sda 0.00 0.00 0.00 0.00 0.00 0.00 5.00 34.00 4.00 44.44 11.00 6.80 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.03 3.00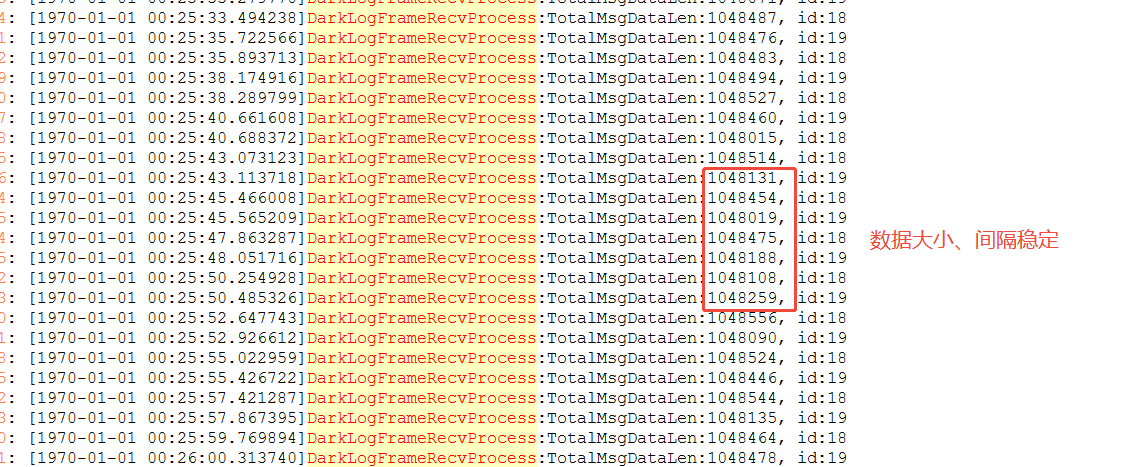
从数据看,日志收取的大小、间隔稳定,不存在跳变情况。写入到硬盘的数据的等待耗时增加,设备带宽利用率跃至100%。
根据以上数据,可以分析出日志记录量不是导致CPU飙升的原因。
3.2.2 推测:硬盘剩余空间不足
记录板的板卡硬盘空间不是很大,也就58G。但是和普通的消费级SSD不一样的是,工业级的SSD对数据的完整性、安全性、硬盘可靠性等数据要求较高。
软件内部维持了一个逻辑,保证硬盘剩余2G的空间。软件会不断的删除历史日志,保证硬盘空间足够。
为了检验是否是因为磁盘剩余空间大小的原因导致CPU异常升高,记录板目前默认保持2G剩余空间,现调整至保持8G剩余空间,再对记录板进行观察。
此时回过头来看,其实这个调整是有益的,原因是在进行垃圾回收的时候,需要有足够多的空间进行搬运。
从日志记录看,发生90%占比的概率明显下降,但是依旧存在异常升高的情况。
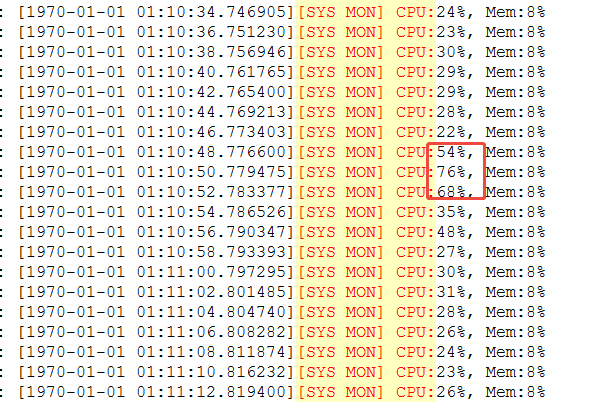
从top上看,此时IO确实存在瓶颈。
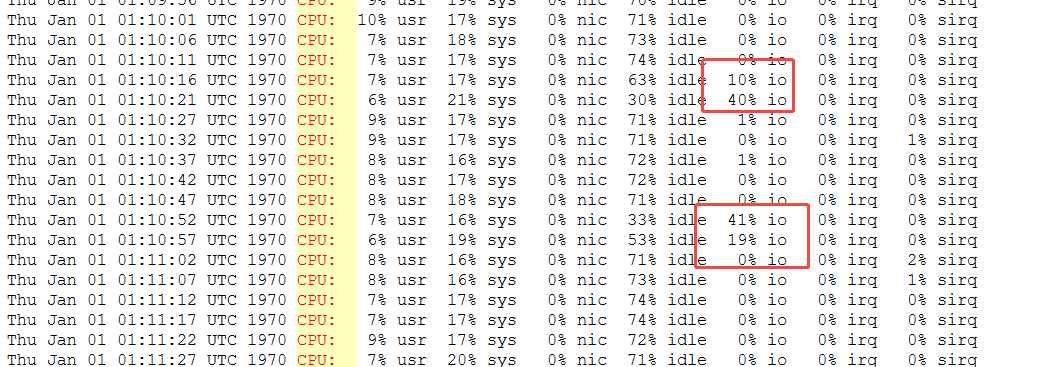
从iostat上看,此时确实存在IO耗时过长的问题。

持续运行72小时观察,对于相同环境下,分别使用2GB与8GB的调整值,对比如下:
| 比较项目 | 50G | 56G |
|---|---|---|
| 日志时长 | 72小时 | 72小时 |
| CPU在60%以上总数 | 88次 | 104次 |
| CPU在60-69之间的次数 | 56 | 57 |
| CPU在70-79之间的次数 | 9 | 26 |
| CPU在80-89之间的次数 | 16 | 12 |
| CPU在90-100之间的次数 | 7 | 9 |
| 每小时CPU在60-69之间平均次数 | 0.78 | 0.79 |
| 每小时CPU在70-79之间平均次数 | 0.13 | 0.36 |
| 每小时CPU在80-89之间平均次数 | 0.22 | 0.17 |
| 每小时CPU在90-100之间平均次数 | 0.10 | 0.13 |
根据以上日志,不能否认磁盘空间大小与CPU使用率之间存在必然的关系,从运行日志看,CPU使用率升高的频率确实降低了。
3.2.3 推测:Linux系统缓存同步时机不合适
根据运行日志,排查CPU异常升高时系统缓冲区是否在同步写入文件。
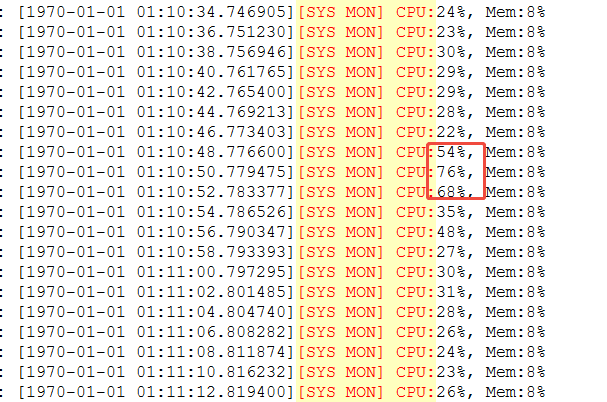
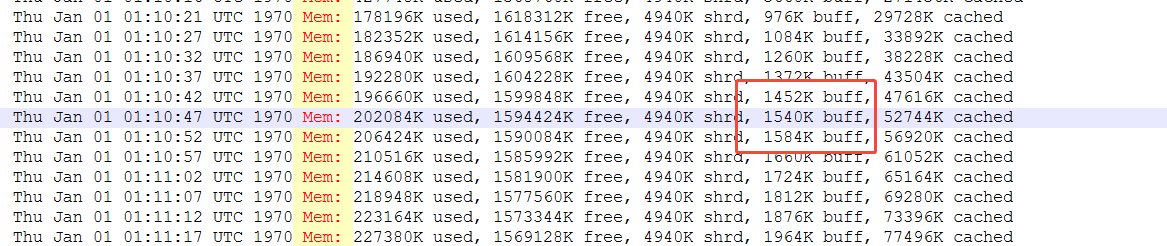
从日志上看,系统的buff也在增长过程,没有写入文件,无法得出buff和CPU升高存在必然关系。
3.2.4 推测:缓存清理存在异常
记录板会向kernel发送清理cache 的信息,清理cache可能会对IO造成影响。
停止清理cache以后,对记录板进行监测,从2月15日0点开始,至2月17日20点结束,监测了68小时。
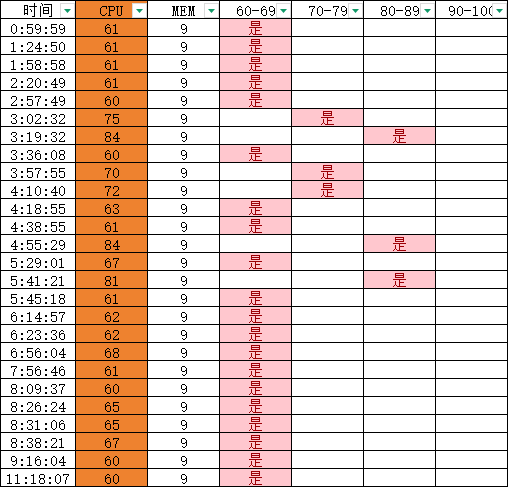
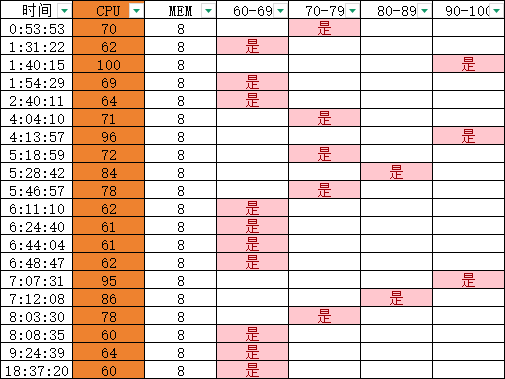
从数据统计分析看,无论是否停止清理cache,其中的差别不大,不能直接确定是cache的影响。
3.2.5 推测:文件查找过程存在高耗时行为
记录板在进行日志清理的时候,使用了find命令对系统磁盘进行查询,这个过程可能较为耗时,需要测试find命令对系统的影响。
将记录板硬盘空间清理到35G左右,保证日志记录过程不会有find命令参与。从24小时的运行结果看,CPU升高频率没有下降,故可以排除find命令参与导致的硬盘IO耗时增加。
3.2.6 推测:日志数据由CPU搬运导致IO耗时高
查询硬盘官网数据发现,硬盘支持SATA III 协议,最高6.0Gbp速率。查询系统初始化日志,发现硬盘只初始化到了3.0Gbps,故本机仅支持SATA II 协议。
text
# dmesg | grep "ata"
[ 0.000000] CPU: PIPT / VIPT nonaliasing data cache, PIPT instruction cache
[ 0.000000] Memory policy: Data cache writealloc
[ 0.000000] Memory: 1605968K/1893376K available (8192K kernel code, 411K rwdata, 2580K rodata, 2048K init, 331K bss, 98992K reserved, 188416K cma-reserved, 1213440K highmem)
[ 0.000000] .data : 0xc1000000 - 0xc1066e08 ( 412 kB)
[ 0.323529] omap_hwmod: l3_main_2 using broken dt data from ocp
[ 0.632209] omap4_sram_init:Unable to allocate sram needed to handle errata I688
[ 0.632219] omap4_sram_init:Unable to get sram pool needed to handle errata I688
[ 0.691599] libata version 3.00 loaded.
[ 1.855012] ahci 4a140000.sata: SSS flag set, parallel bus scan disabled
[ 1.861800] ahci 4a140000.sata: AHCI 0001.0300 32 slots 1 ports 3 Gbps 0x1 impl platform mode
[ 1.870408] ahci 4a140000.sata: flags: 64bit ncq sntf stag pm led clo only pmp pio slum part ccc apst
[ 1.883880] ata1: SATA max UDMA/133 mmio [mem 0x4a140000-0x4a1410ff] port 0x100 irq 325
[ 2.386170] ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 300)
[ 2.395590] ata1.00: ATA-10: XXXXXXX(保密处理), max UDMA/133
[ 2.401731] ata1.00: 125045424 sectors, multi 1: LBA48 NCQ (depth 31/32)
[ 2.424278] ata1.00: configured for UDMA/133
[ 2.698354] dmm 4e000000.dmm: workaround for errata i878 in use
[ 3.547350] EXT4-fs (mmcblk1p2): mounted filesystem with ordered data mode. Opts: (null)
[ 3.610946] EXT4-fs (mmcblk1p2): re-mounted. Opts: data=ordered
[ 4.348450] EXT4-fs (sda1): mounted filesystem with ordered data mode. Opts: (null)使用hdparm命令查看硬盘信息,发现已启用了UDMA6。
text
# hdparm -I /dev/sda
/dev/sda:
ATA device, with non-removable media
Model Number: XXXXXXX(保密处理)
Serial Number:
Firmware Revision:
Media Serial Num:
Media Manufacturer:
Standards:
Supported: 10 9 8 7
Likely used: 10
Configuration:
Logical max current
cylinders 16383 16383
heads 16 16
sectors/track 63 63
--
CHS current addressable sectors: 16514064
LBA user addressable sectors: 125045424
LBA48 user addressable sectors: 125045424
device size with M = 1024*1024: 61057 MBytes
device size with M = 1000*1000: 64023 MBytes (64 GB)
Capabilities:
LBA, IORDY(can be disabled)
Queue depth: 32
Standby timer values: spec'd by standard, no device specific minimum
R/W multiple sector transfer: Max = 1 Current = 1
DMA: mdma0 mdma1 mdma2 udma0 udma1 udma2 udma3 udma4 udma5 *udma6
Cycle time: min=120ns recommended=120ns
PIO: pio0 pio1 pio2 pio3 pio4
Cycle time: no flow control=120ns IORDY flow control=120ns
Commands/features:
Enabled Supported:
* NOP cmd
* READ BUFFER cmd
* WRITE BUFFER cmd
* Look-ahead
* Write cache
Power Management feature set
Security Mode feature set
* SMART feature set
* FLUSH CACHE EXT cmd
* Mandatory FLUSH CACHE cmd
* 48-bit Address feature set
* DOWNLOAD MICROCODE cmd
* General Purpose Logging feature set
Security:
Master password revision code = 65534
supported
not enabled
not locked
not frozen
not expired: security count
supported: enhanced erase
10min for SECURITY ERASE UNIT. 10min for ENHANCED SECURITY ERASE UNIT.
Checksum: correct从结果看,已经启用了DMA搬运数据,故在硬件上已达到最优性能。
3.2.7 推测:写文件过程导致IO性能瓶颈
推测IO性能是因为写入文件的操作导致的。为验证是否是因为写入文件导致的IO过高,我将记录板的数据清空,修改记录板软件代码,仅接收数据,不写入文件。连续运行17小时,发现记录磁盘IO不存在异常升高的问题。
CPU升高到60及以上的情况仅在创建各类文件、目录时存在,创建完毕以后立即下降。
回过头看这里,其实对文件系统的操作,本身就是一个较为耗时的操作。在这种情况下,软件内部的各种线程锁,反而在等待文件系统的反馈,这进一步加剧了软件性能损耗。
根据测试情况而言,可以确认IO瓶颈是因文件系统操作导致的。
软件内部、外部的环境因素就暂时排查到这里,还有还有一部分排查思路与这里相差的特别大,就不放出来了。
3.2.8 sched分析
之前的分析中,发现记录板存在看门狗重启现象,说明记录板软件进程未能被系统调度,为排查未被调度原因,使用技术手段对异常调时候进行sched record,分析系统当时的调度延迟原因。
自此以后,就是对linux内核相关的参数进行推测排查。
在抓取数据时,发现存在某个线程长时间阻塞的情况。
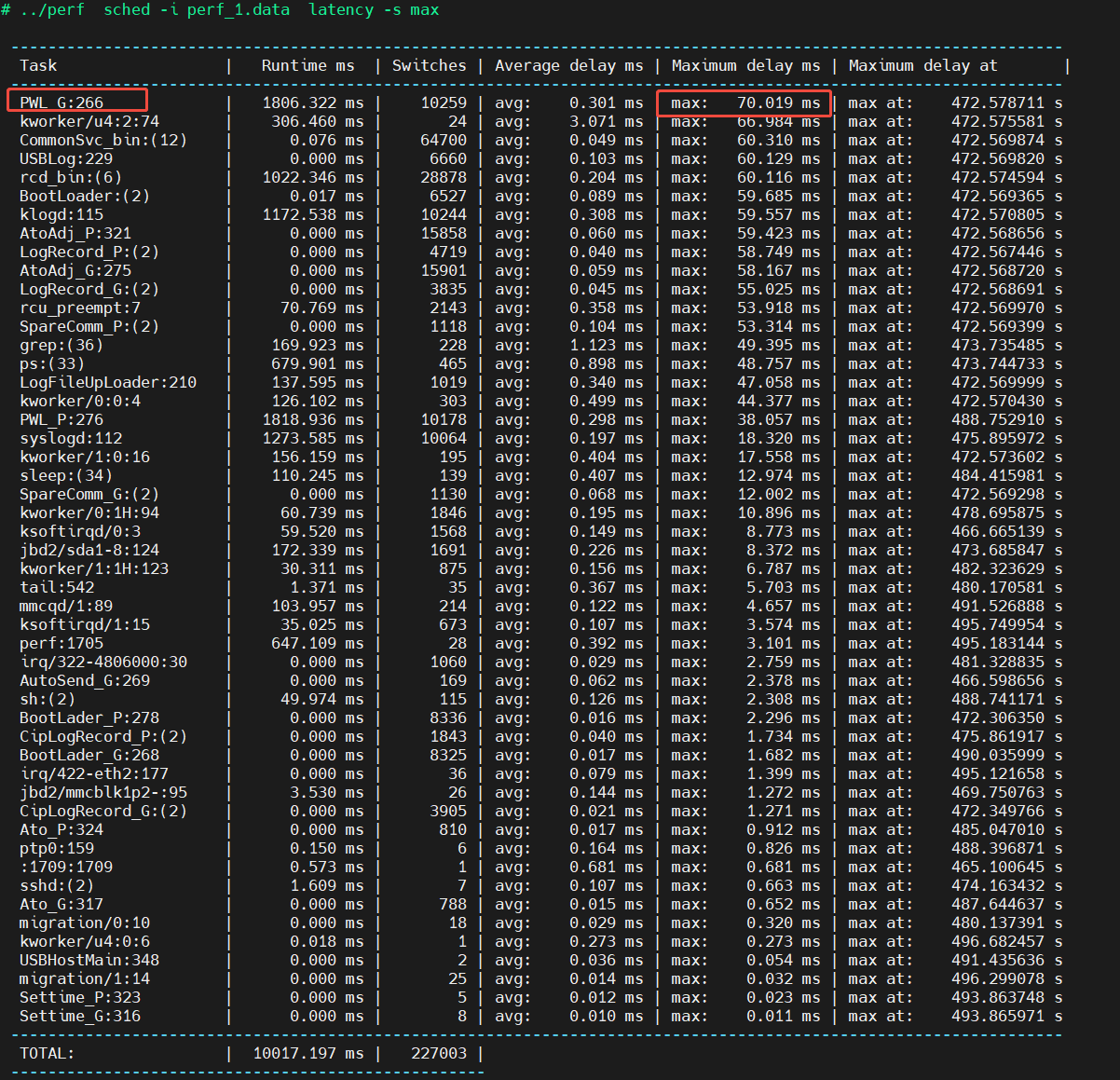
在wsl上使用perf sched -i perf.data -v script | grep -C 100 "472.578711"命令,筛选出对应时间节点的信息。
为探寻异常时的进程状态,使用相关的命令进行抓取性能数据处理:
shell
#使用TOP进行整体观测
top -b | busybox awk 'NR { printf "%s %s\n", strftime(), $0 ; fflush(stdout) }' > toplog
.txt &
#对IO进行整体观测
./iostat 2 -d /dev/sda -t -x -k -c > iolog.txt &
#使用perf对内核各项进程、cpu进行观测
./perf top -a | tee perfTmp.txt | cat -n | busybox awk 'NR { printf "%s %s\n", strftime(), $0 ; fflush(stdout) }
' > PerfTopLog.txt抓取一段时间以后,观察异常的故障时间点,针对IO进行观察。
text
03/07/25 12:08:36
avg-cpu: %user %nice %system %iowait %steal %idle
21.05 0.00 33.24 1.11 0.00 44.60
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 61.50 354.00 26.50 30.11 0.98 5.76 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.06 6.00
03/07/25 12:08:38
avg-cpu: %user %nice %system %iowait %steal %idle
12.65 0.00 27.65 29.12 0.00 30.59
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 29.50 8624.00 20.50 41.00 202.71 292.34 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 16.75 75.50
03/07/25 12:08:40
avg-cpu: %user %nice %system %iowait %steal %idle
18.52 0.00 36.18 27.35 0.00 17.95
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 32.00 3214.00 14.50 31.18 473.12 100.44 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 4.37 68.00
03/07/25 12:08:42
avg-cpu: %user %nice %system %iowait %steal %idle
20.39 0.00 34.71 2.20 0.00 42.70
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 61.50 2602.00 38.00 38.19 5.12 42.31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.32 12.50观察到以下信息:
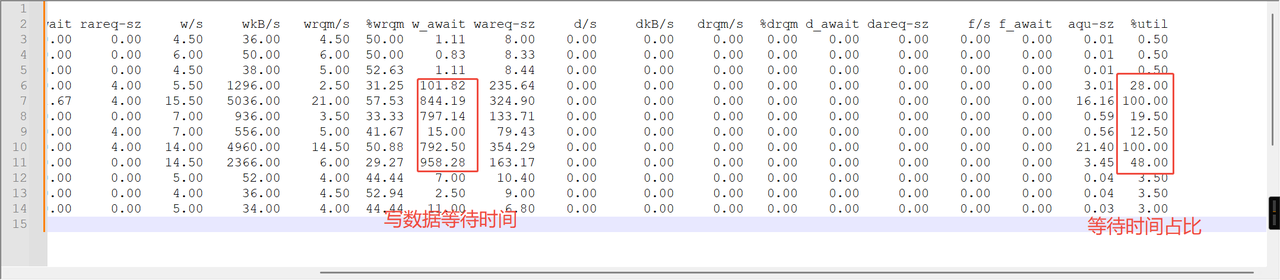
- 在 12:08:38 和 12:08:40,写操作的等待时间(w_await)分别达到 202.71ms 和 473.12ms,远高于其他时间点的 1-23ms。
- 在 12:08:38,%util 达到 75.50%,且平均队列长度(aqu-sz)飙升至 16.75。其中,%util 超过 60% 表明磁盘接近饱和。aqu-sz 表示排队中的I/O请求数,超过 1 表示请求开始堆积。磁盘无法及时处理请求,导致I/O瓶颈。
- 在 12:08:38 和 12:08:28,写入带宽(wkB/s)分别达到 8,624KB/s 和 8,808KB/s,远超其他时间点的 300-3,000KB/s。单次写请求大小(wareq-sz)也显著增大(292.34KB vs 通常的 5-100KB)。
- 在磁盘高负载时段(如 12:08:38),系统CPU使用率(%system)达到 27.65%,表明内核在处理I/O时消耗较多资源。进一步加剧系统整体负载。
3.2.9 推测:IO调度器设置
对于硬盘的数据调度而言,使用cat /sys/block/sda/queue/scheduler命令查看调度器,其结果如下
shell
# cat /sys/block/sda/queue/scheduler
noop deadline [cfq]说明当前使用的是绝对公平的调度器CFQ。尝试修改调度器为电梯式调度器noop
shell
#echo noop > /sys/block/sda/queue/scheduler运行以后,效果反而更差了。
text
03/10/25 12:03:04
avg-cpu: %user %nice %system %iowait %steal %idle
6.27 0.00 49.37 12.03 0.00 32.33
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 36.50 3564.00 15.50 29.81 59.59 97.64 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 7.83 49.00
03/10/25 12:03:06
avg-cpu: %user %nice %system %iowait %steal %idle
15.12 0.00 29.36 43.31 0.00 12.21
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.50 2.00 0.00 0.00 1680.00 4.00 14.00 5138.00 2.00 12.50 917.86 367.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 29.53 100.00
03/10/25 12:03:08
avg-cpu: %user %nice %system %iowait %steal %idle
12.83 0.00 31.49 33.82 0.00 21.87
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 11.00 4780.00 0.00 0.00 2065.00 434.55 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 27.32 100.00
03/10/25 12:03:10
avg-cpu: %user %nice %system %iowait %steal %idle
13.60 0.00 36.54 6.80 0.00 43.06
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 41.00 1354.00 37.00 47.44 687.68 33.02 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 2.09 27.50
03/10/25 12:03:12
avg-cpu: %user %nice %system %iowait %steal %idle
14.29 0.00 32.65 3.21 0.00 49.85
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 41.00 254.00 21.50 34.40 4.02 6.20 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.17 16.50尝试更换为截止时间调度器deadline。与目前一样,依旧会造成IO过高问题。
3.2.10 推测:函数内部write函数耗时过高
记录板软件会使用write函数进行数据记录。对软件的调用进行计时操作。
text
行 4907: [2025-03-10 14:28:46.854081][rec] mcpId:18, write time:2145 ms
行 4908: [2025-03-10 14:28:46.854085][rec] mcpId:19, write time:1785 ms
行 4906: [2025-03-10 14:28:46.264327][SYS MON] CPU:90%, Mem:10%
行 10012: [2025-03-10 14:30:36.610485][rec] mcpId:240, write time:1030 ms
行 10013: [2025-03-10 14:30:36.610486][rec] mcpId:241, write time:1038 ms
行 10011: [2025-03-10 14:30:36.533324][SYS MON] CPU:65%, Mem:10%
行 10038: [2025-03-10 14:30:38.307138][rec] mcpId:184, write time:1605 ms
行 10039: [2025-03-10 14:30:38.308734][rec] mcpId:240, write time:1648 ms
行 10143: [2025-03-10 14:30:38.539680][SYS MON] CPU:97%, Mem:10%从日志看,确实是write函数上下文耗时过高。write是同步型函数,其操作为阻塞式,若阻塞时间过长,会导致数据堆积。为解决wirte频次高、数据量较小的情况,使用内核缓冲区,将数据存入缓冲内,接收完数据以后即向硬盘写数据。
3.2.11 推测:降低写入频率+异步写入
为此方向编写了数据缓冲区+libaio的异步缓冲代码,发现依旧存在问题。

对系统进行检查:
shell
# cat /sys/block/sda/queue/scheduler
[noop] deadline cfq
# cat /sys/block/sda/queue/nr_requests
128
# cat /sys/block/sda/device/queue_depth
31
# cat /sys/devices/system/cpu/cpu0/cpufreq/scaling_governor
cat: can't open '/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor': No such file or directory
# cat /sys/devices/system/cpu/cpu1/cpufreq/scaling_governor
cat: can't open '/sys/devices/system/cpu/cpu1/cpufreq/scaling_governor': No such file or directory
# cat /proc/irq/325/smp_affinity
3
# dmesg | grep -i 'sata link up'
[ 2.386072] ata1: SATA link up 3.0 Gbps (SStatus 123 SControl 300)
# dmesg | grep -i 'DMA: preallocated'
[ 0.322195] DMA: preallocated 256 KiB pool for atomic coherent allocations
# cat /sys/kernel/debug/tracing/events/block/enable
cat: can't open '/sys/kernel/debug/tracing/events/block/enable': No such file or directory
# cat /sys/kernel/debug/tracing/trace_pipe
cat: can't open '/sys/kernel/debug/tracing/trace_pipe': No such file or directory- 当前I/O调度器为noop,适合SSD场景,无需调整。
- 队列深度nr_requests为128,queue_depth为31,符合SSD的NCQ深度要求,无需调整。
- CPU频率调节器系统未启用CPU频率调节器(scaling_governor不存在),大概率是由于内核未启用相关功能或硬件不支持动态调频。
- SATA中断(IRQ 325)已绑定到CPU 0和1(smp_affinity=3),无需调整。
- SATA链路速度为3.0 Gbps,符合SATA II标准,但未达到SATA III(6.0 Gbps)的峰值性能。
- DMA内存池已预分配256 KiB,符合常规配置。
3.2.12 推测:异步单次写入
使用异步批量写入的方式对数据进行写入,对数据进行60小时持续观测。异步写入核运行在A设备,标签核运行在B设备,其运行结果如下:
| CPU使用率 | 标签核(单位:次数) | 异步批量写入(单位:次数) |
|---|---|---|
| 0-59区间 | 101836(89.62%) | 100986(89.09%) |
| 60-79区间 | 11605(10.21%) | 11965(10.56%) |
| 80-100区间 | 192(0.17%) | 400(0.35%) |
| 合计 | 113633 | 113351 |
从结果看,其实差距并不大。
3.2.13 推测:虚拟内存参数存在异常
分析到可能存在虚拟内存参数不是最优的情况:
shell
# sysctl -a | grep dirty
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
vm.dirty_writeback_centisecs = 500
vm.dirtytime_expire_seconds = 43200
vm.highmem_is_dirtyable = 0- vm.dirty_background_ratio 是内存可以填充脏数据的百分比。这些脏数据稍后会写入磁盘,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。
- vm.dirty_ratio是可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。vm.dirty_background_bytes和vm.dirty_bytes是另一种指定这些参数的方法。如果设置_bytes版本,则_ratio版本将变为0,反之亦然。
- vm.dirty_expire_centisecs 指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 在运行的时候,他们会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。
- vm.dirty_writeback_centisecs 指定多长时间 pdflush/flush/kdmflush 这些进程会唤醒一次,然后检查是否有缓存需要清理
shell
# cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 3069
nr_writeback 0
nr_writeback_temp 0
nr_dirty_threshold 26435
nr_dirty_background_threshold 13201从当前情况看,目前的数据量输入稳定,基本不存在数据量快速增长的情况。目前尝试调整虚拟内存参数,减少脏页回写对I/O性能的影响。
echo 20 > /proc/sys/vm/dirty_ratio #由10提升至20
echo 5 > /proc/sys/vm/dirty_background_ratio #由10降低至5
echo 1000 > /proc/sys/vm/dirty_expire_centisecs #由500提升至1000- 当系统内存中脏页占可用内存的比例达到 20% 时,系统会强制将脏页写入磁盘。较高的值会延迟写入操作,可能提升性能,但会增加数据丢失的风险;较低的值会更快写入磁盘,减少数据丢失风险,但可能降低性能。
- 当脏页占可用内存的比例达到 5% 时,系统会在后台启动写回操作,将脏页写入磁盘。较低的值会更快启动后台写回,减少脏页积累,但可能增加 I/O 负载;较高的值会延迟写回,可能提升性能,但会增加脏页积累。
- 脏页在内存中停留超过 1000 厘秒(10 秒)后,会被标记为需要写回磁盘。较长的值会延迟写回,可能提升性能,但会增加数据丢失风险;较短的值会更快写回,减少数据丢失风险,但可能降低性能。
执行以下参数:
- 日志记录时进行批量异步IO提交
- 降低dirty_background_ratio与dirty_expire_centisecs的参数:
- dirty_background_ratio 由10降低至5
- dirty_expire_centisecs 由500降低至200
执行以下参数:
- 日志记录时进行批量异步IO提交
- 降低dirty_background_ratio与dirty_expire_centisecs的参数:
- dirty_background_ratio 由10降低至2
- dirty_expire_centisecs 由500降低至200
执行以下参数:
- 日志记录时进行批量异步IO提交
- 降低dirty_background_ratio与dirty_expire_centisecs的参数:
- dirty_background_ratio 由10降低至5
- dirty_expire_centisecs 由500降低至250

其他的参数就不再此处体现。
3.2.14 推测:日志压缩程序CPU占用过高
日志压缩程序使用7z方案中的LZMA算法。测日志压缩程序占用CPU较高,尝试对核心参数做调整。
c
typedef struct
{
int level; /* 0 <= level <= 9 */
UInt32 dictSize; /* (1 << 12) <= dictSize <= (1 << 27) for 32-bit version
(1 << 12) <= dictSize <= (3 << 29) for 64-bit version
default = (1 << 24) */
int lc; /* 0 <= lc <= 8, default = 3 */
int lp; /* 0 <= lp <= 4, default = 0 */
int pb; /* 0 <= pb <= 4, default = 2 */
int algo; /* 0 - fast, 1 - normal, default = 1 */
int fb; /* 5 <= fb <= 273, default = 32 */
int btMode; /* 0 - hashChain Mode, 1 - binTree mode - normal, default = 1 */
int numHashBytes; /* 2, 3 or 4, default = 4 */
unsigned numHashOutBits; /* default = ? */
UInt32 mc; /* 1 <= mc <= (1 << 30), default = 32 */
unsigned writeEndMark; /* 0 - do not write EOPM, 1 - write EOPM, default = 0 */
int numThreads; /* 1 or 2, default = 2 */
// int _pad;
UInt64 reduceSize; /* estimated size of data that will be compressed. default = (UInt64)(Int64)-1.
Encoder uses this value to reduce dictionary size */
UInt64 affinity;
} CLzmaEncProps;相关字段含义如下:
- level:压缩级别,控制压缩质量和速度之间的阀门。0是最低压缩质量(最快),9是最高压缩质量(最慢)。
- dictSize:字典大小决定了压缩算法可以使用的内存缓冲区大小,用于存储历史数据以寻找匹配。较大的字典可以提高压缩率,但会增加内存使用和计算复杂度。较小的字典降低内存需求,但可能牺牲压缩率。
- lc:字面上下文位数(Literal Context Bits),用于预测下一个字符的概率模型。较高的值会增加上下文敏感性,但也会增加计算复杂度。
- lp:字面位置位数(Literal Position Bits),基于当前数据在字典中的位置来调整概率模型。较高的值会增加对位置的敏感性,但也会增加计算复杂度。
- pb:位置位数(Position Bits),基于当前块的位置来调整概率模型。较高的值会增加对全局位置的敏感性。
- algo:选择压缩算法的实现方式。0是快速算法(Fast Mode),适合实时压缩场景。1是标准算法(Normal Mode),提供更高的压缩率。
- fb:快速字节数(Fast Bytes),表示匹配查找的最大长度。较大的值会尝试更长的匹配,提高压缩率,但会增加计算开销。
- btMode:匹配器模式。0是哈希链模式(Hash Chain Mode),适合快速压缩。1是叉树模式(Binary Tree Mode),适合高压缩率场景。
- numHashBytes:哈希函数使用的字节数。较大的值会提高哈希表的精度,但会增加内存使用和计算复杂度。
- numHashOutBits:哈希表输出位数,影响哈希表的大小和查找效率。默认值未明确指定,通常由库自动设置。
- mc:循环缓冲区大小(Match Cycles),用于限制匹配查找的深度。较小的值会减少计算量,但可能降低压缩率。
- writeEndMark:是否写入结束标记(End of Payload Marker, EOPM)。
- numThreads:使用的线程数。
- reduceSize:预计要压缩的数据大小,单位为字节。该值会影响字典大小的动态调整。如果实际数据小于字典大小,字典会被缩小以节省内存。
- affinity:线程亲和性设置,用于绑定线程到特定的 CPU 核心。仅在多线程模式下有效。
为了将CPU的占用率调整到最低,尝试将以下核心参数做调整:
- level:设置为0(最低级别)。代码逻辑:当小于5时会启用快速算法,降低计算复杂度。
- algo:算法指定为0,启用快速字节编码模式,跳过复杂的分支预测。
- btMode:匹配器类型设置为0,哈希链模式相比二叉树模式减少30%-50%的指令周期。
- fb:快速字节数设为32(最低有效值),原因是循环缓冲区大小会根据这个参数进行设置:p->mc = (16 + ((unsigned)p->fb >> 1)) >> (p->btMode ? 0 : 1)
- numThreads:指定线程控制为1个线程工作。
- dictSize:字典大小设置为1M,避免自动扩容,减少内存访问。
对于整体的应用程序而言,尝试降低应用程序的调度优先级亦可为新的方向。
c
pid_t pid = getpid();
int priority = 0;
/*获取优先级*/
priority = getpriority(PRIO_PROCESS, pid);
printf("[main] priority = %d\n", priority);
/*将优先级设置到最低*/
priority = 19;
setpriority(PRIO_PROCESS, pid, priority); 在A设备运行标签核,在B设备运行修改后的日志压缩核,对日志进行评估,发现并未取得明显效果,反而增加了耗时。
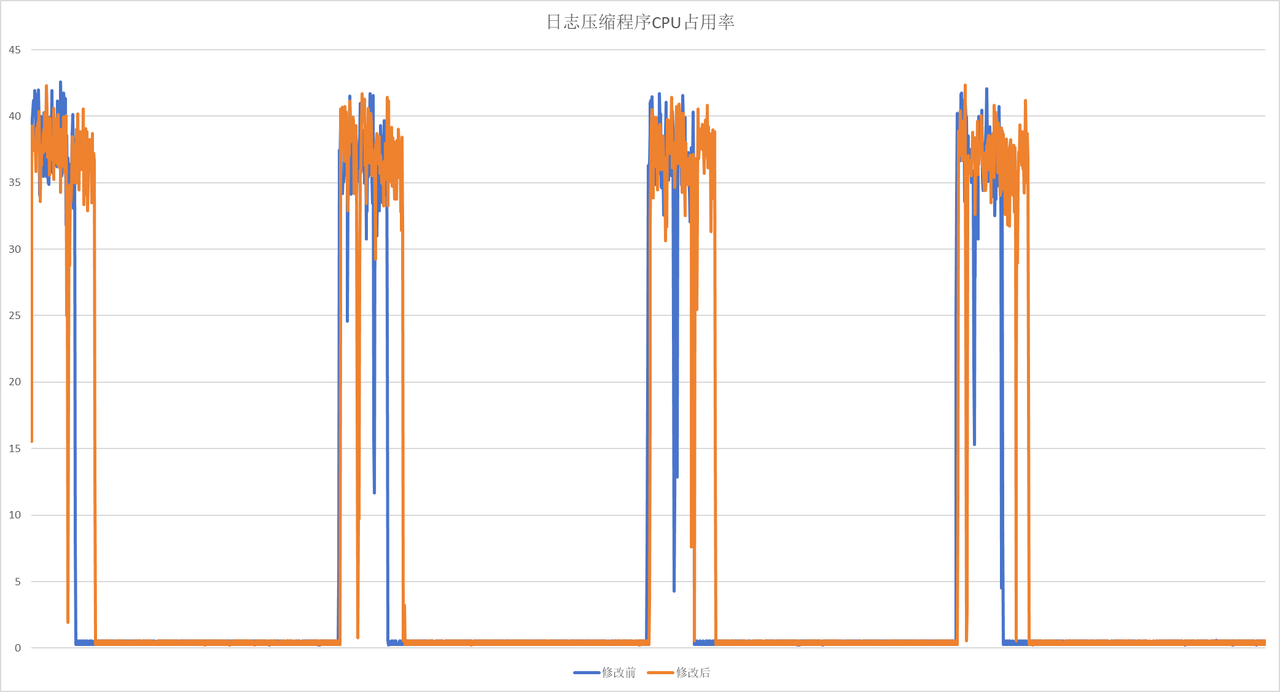
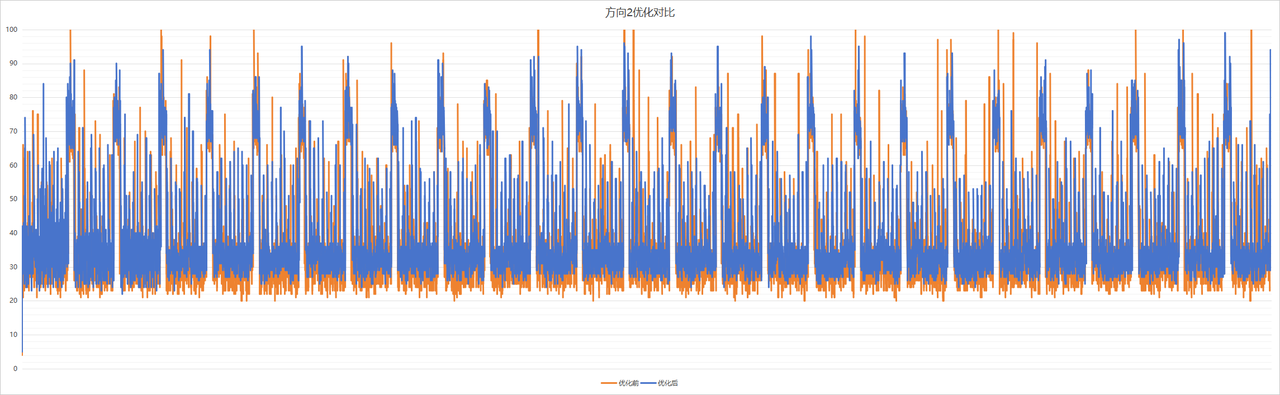
但是观察到整体的CPU占用率是呈现降低状态,修改后的日志压缩程序可能会在整体上造成影响。
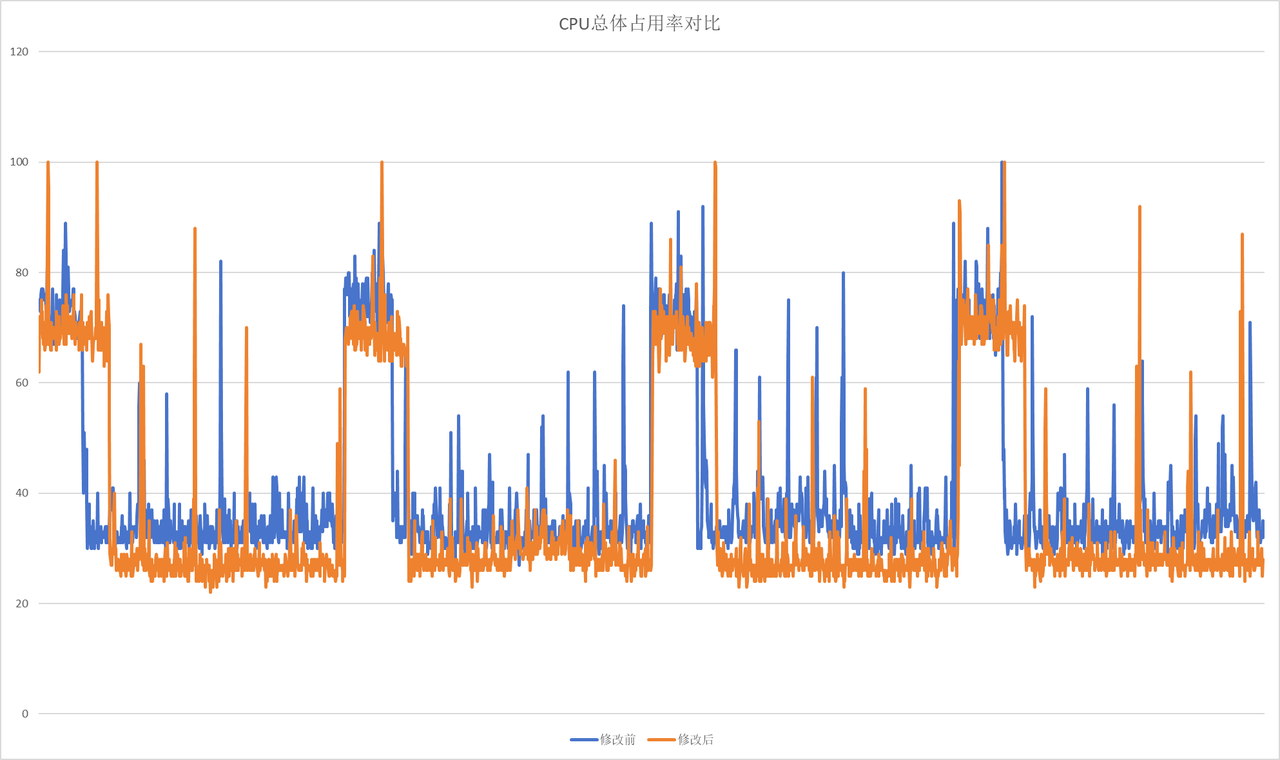
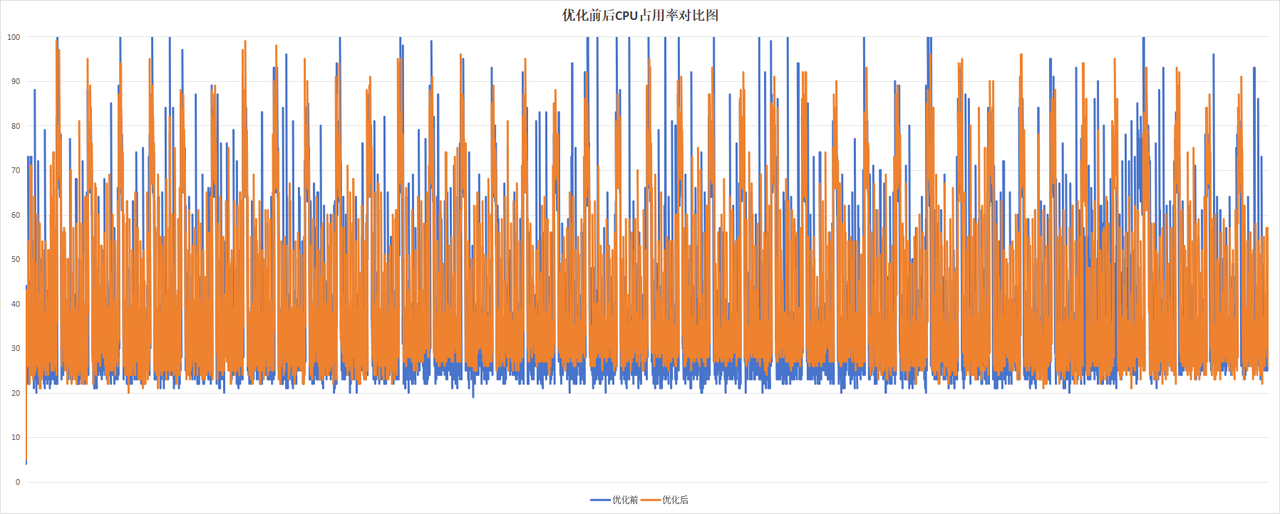
为了放大整体的影响,将上述的异步批量写入日志程序+低调度优先级的日志压缩程序共同放置,作为整体观察。
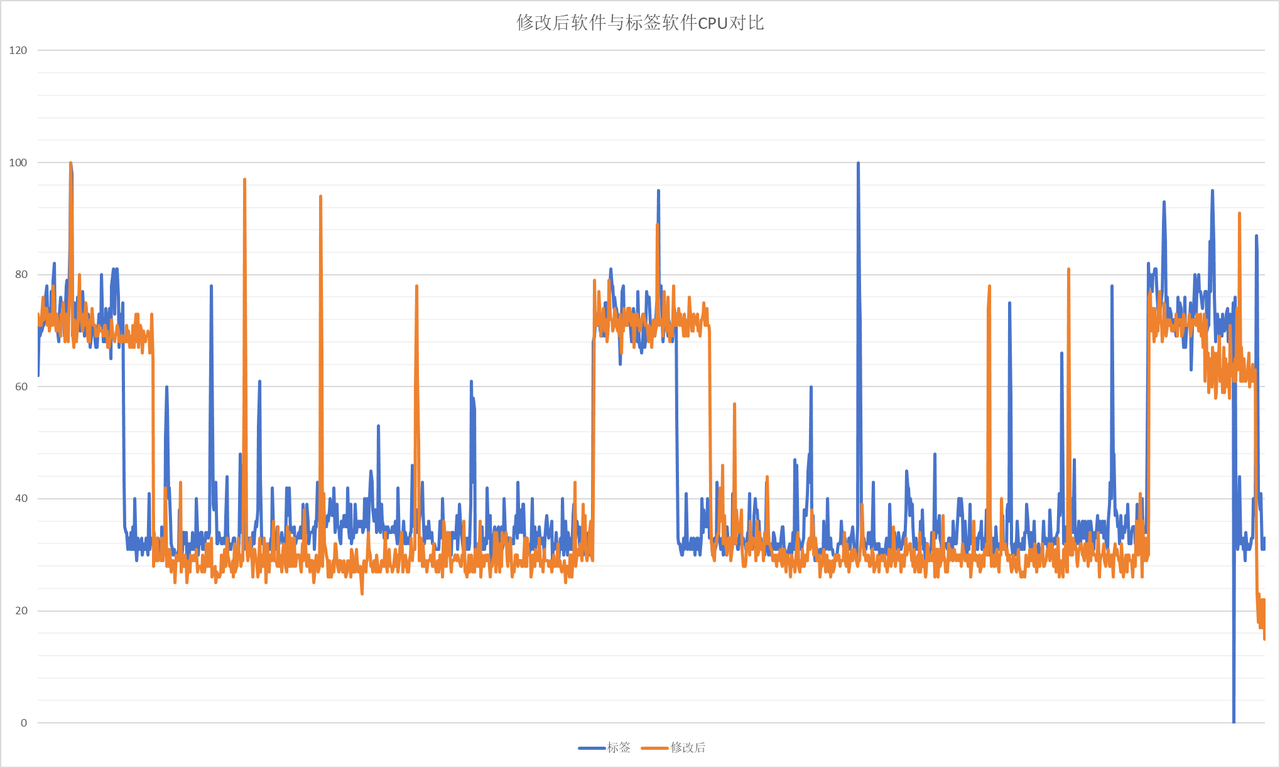
从图表可知,日志压缩压缩时,修改后软件的CPU的使用率要比标签软件的使用率更低,但是日志压缩耗时更长;常规日志记录时,修改后软件的CPU平均占比更低。
为了继续放大差异,尝试对内核参数进行同步优化:
shell
echo 5 > /proc/sys/vm/dirty_background_ratio #由10降低至5
echo 250 > /proc/sys/vm/dirty_expire_centisecs #由500降低至250 持续运行约8小时,其结果如下:
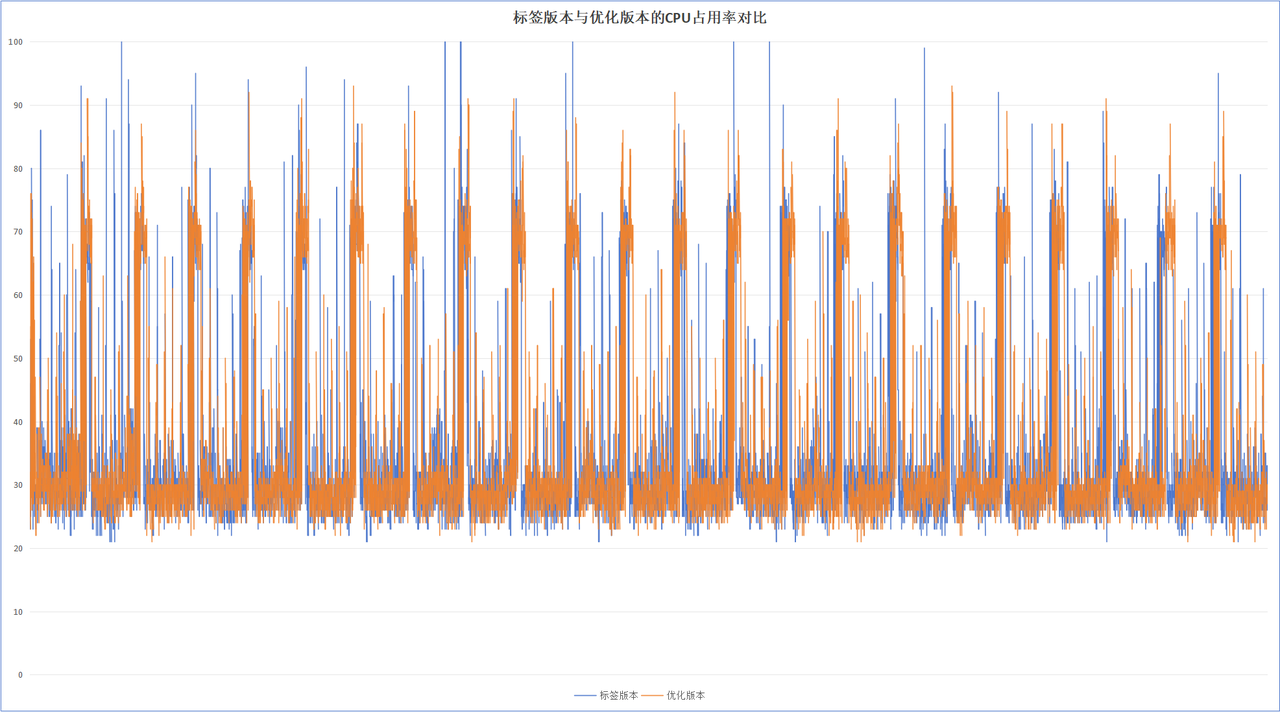
从图中可以得知:
- 整体优化以后,CPU占用率从未到达过100%
- 优化后仍然有偶发CPU升高的场景,但是要比未优化前低。
- 优化后,在未执行日志压缩时,CPU占用率基本不会超过70%
- 优化前与优化后的日志压缩CPU占用率不相上下。
整理调度耗时对比数据:
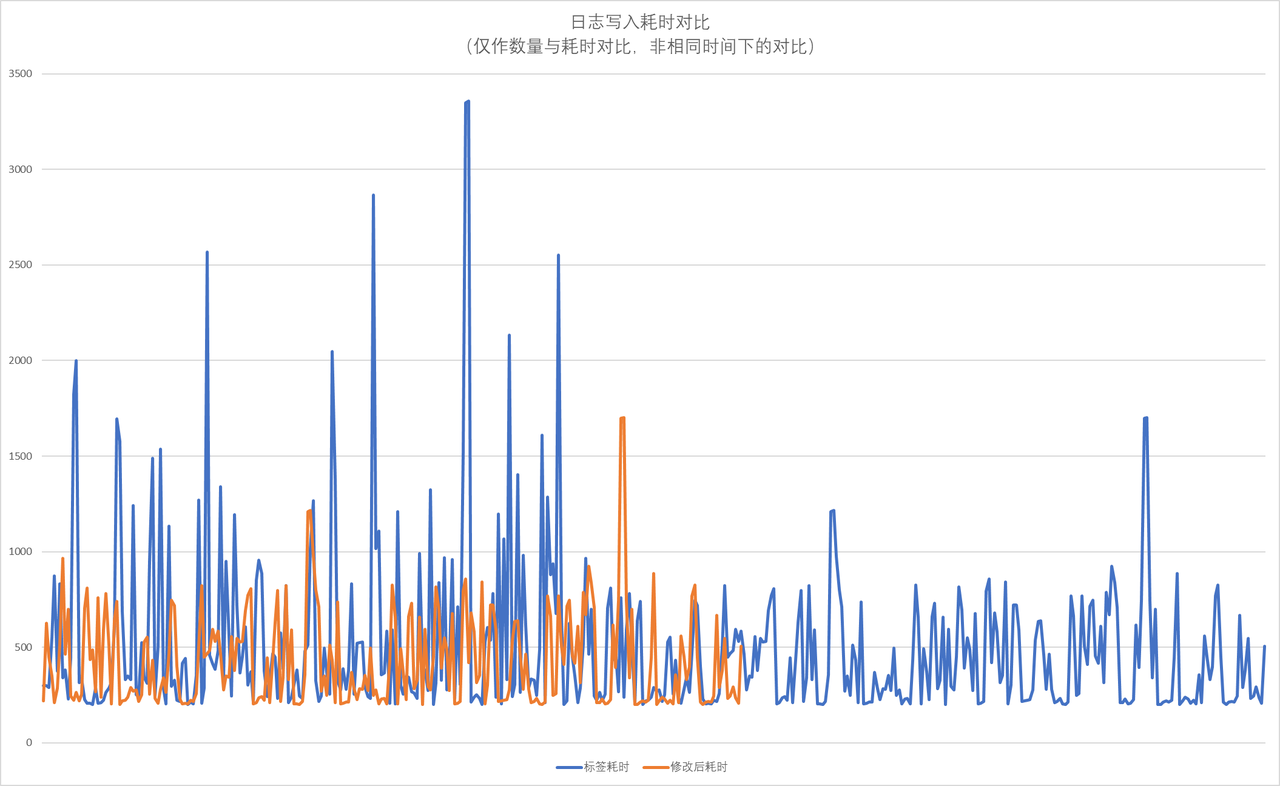
从数据看:
- 修改后的记录板软件调度耗时明显降低
- 修改后的记录板软件高于200毫秒调度次数约为标签版本的一半
3.2.15 推测:SSD在进行垃圾回收
推测记录软件写入数据量较大,SSD芯片一直在进行垃圾回收(Garbage Collection),无法响应数据写入请求,linux系统一直在等待SSD回应,而SSD忙于垃圾回收,待回收完成以后,才响应系统数据,CPU一直忙于在请求SSD,导致linux的系统CPU、IO占用过高。
对记录板软件进行trim操作,手动整理SSD的数据,从现象上看,有效降低了CPU占用耗时过高的问题。
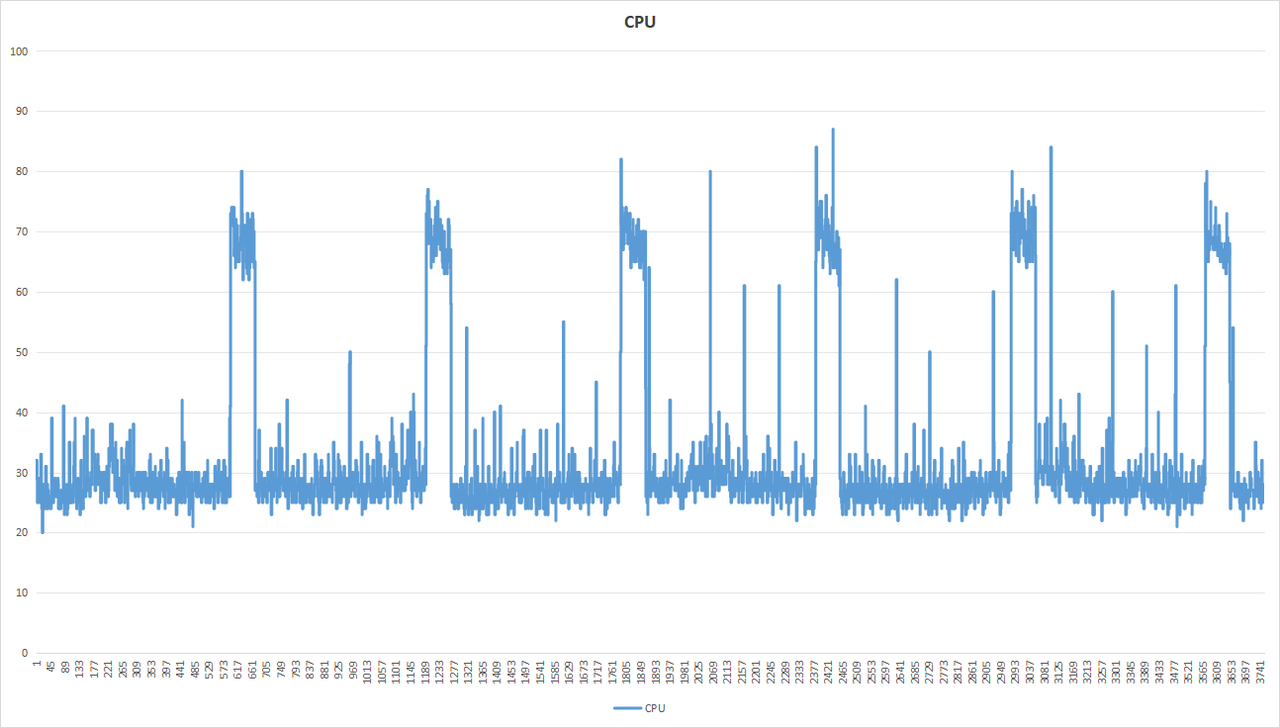
在软件中加入每隔10秒进行一次硬盘垃圾回收处理,持续运行16小时,其性能表现优秀。

4. 寿命与性能间的取舍
在上述的问题排查过程中,描述了软件、硬件存在以下性能瓶颈:
- 软件的文件关闭时耗时过长,导致线程锁耗时过长,现调整为异步关闭。
- 软件的数据写入过程较为零碎,导致write过程较长,现调整为异步IO。
- 硬盘的预留空间不足:软件设计记录板冗余空间为2G,现调整为8G。
- 硬盘的GC(垃圾回收)阈值不高,导致硬盘在写入数据时,发现硬盘空间不够用才进行垃圾回收,这导致了记录板SSD性能不足。现调整为每隔10秒进行一次Trim。
对trim原理研究以后发现,每隔10秒进行一次Trim会导致SSD的寿命显著降低,并提高了写放大系数(Write Amplification Factor),这会降低硬盘的性能。于是就对记录板Trim间隔与硬盘性能间的影响关系展开研究。
4.1 理论支持
- 2013 IEEE第21届计算机与电信系统建模、分析与仿真国际研讨会上提出了《固态磁盘写放大特性的测试与分析》的论文,讲述了对基于NAND Flash的固态硬盘(SSD)中写放大现象的测量和分析。相关论文:https://www.eng.auburn.edu/~xqin//pubs/sun_mascots13.pdf
- 在第20届USENIX文件和存储技术会议上,多伦多大学与NetApp合作,分析了线上200多万块SSD在4年内的运行数据,总结了写入速率、写入放大因子、磨损均衡及其他的相关因素,本次将重点关注写入放大因子的对小型化记录板的影响。相关论文:https://www.usenix.org/system/files/fast22-maneas.pdf
在以上论文中,确认了写放大确实会对硬盘的性能产生影响。
4.2 梯度测试
梯度测试的目的在于分析不同的Trim间隔对性能的影响,探寻SSD性能与Trim之间的关系。
使用脚本工具对数据进行收集:
shell
# 监控脚本
#!/bin/bash
INTERVAL=60 # 采集间隔(秒)
while true; do
# 记录时间戳
date +"%T" >> monitor.log
# 采集IO状态
iostat -xmd /dev/sda 1 2 | tail -n 12 >> monitor.log
sleep $INTERVAL
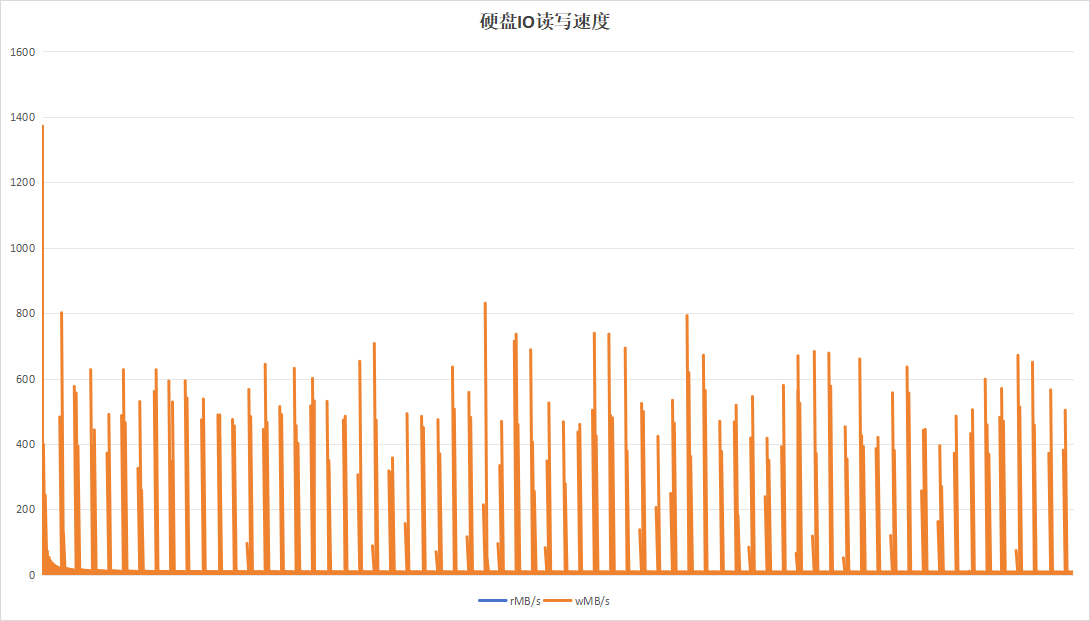
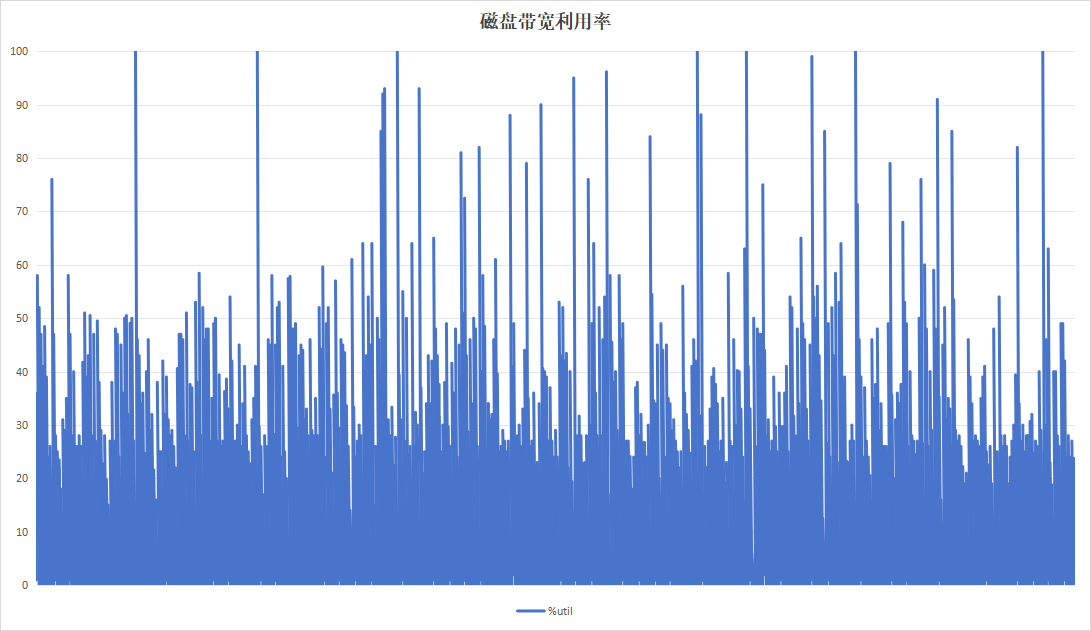
done4.2.1 10秒钟为周期(标签版本)
标签程序采用10秒为周期进行一次Trim。运行24小时的观测结果如下:
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 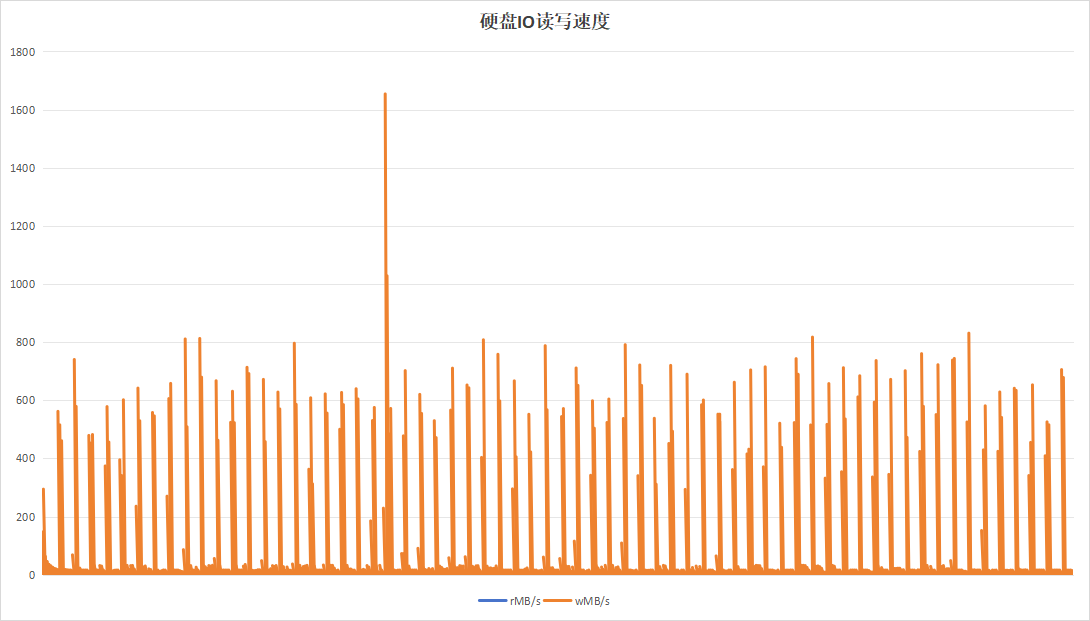 |
 |
| 读写等待耗时 | 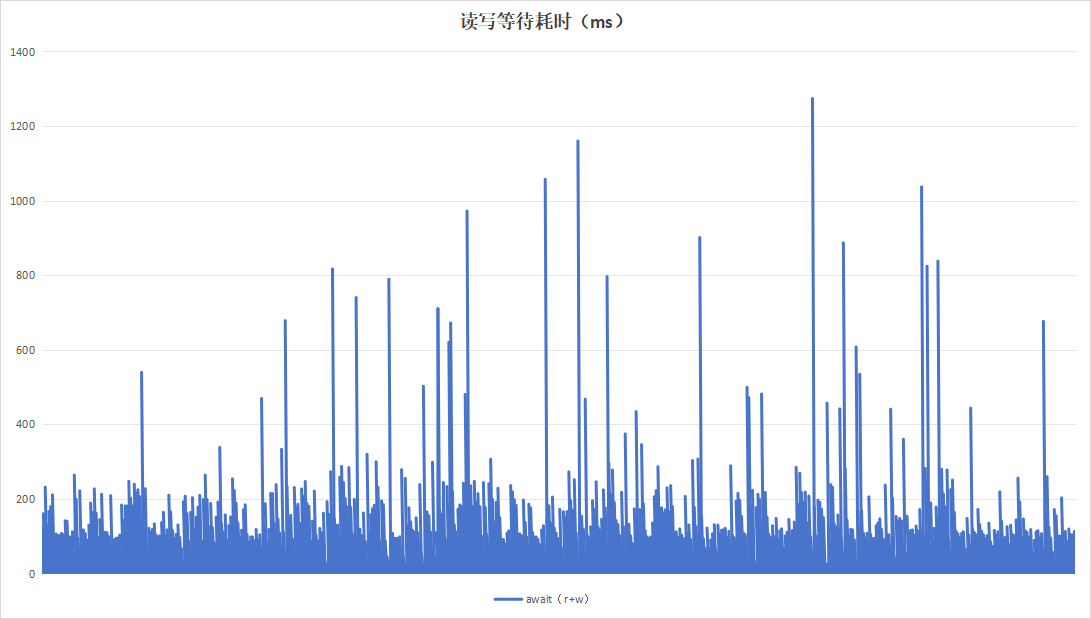 |
 |
| 硬盘带宽利用率 | 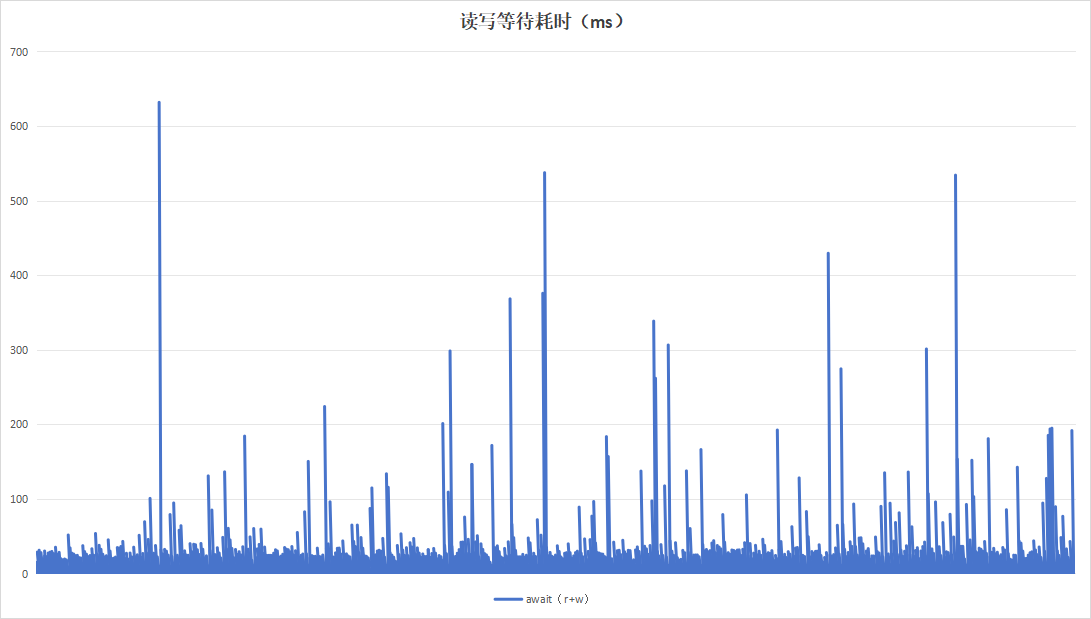 |
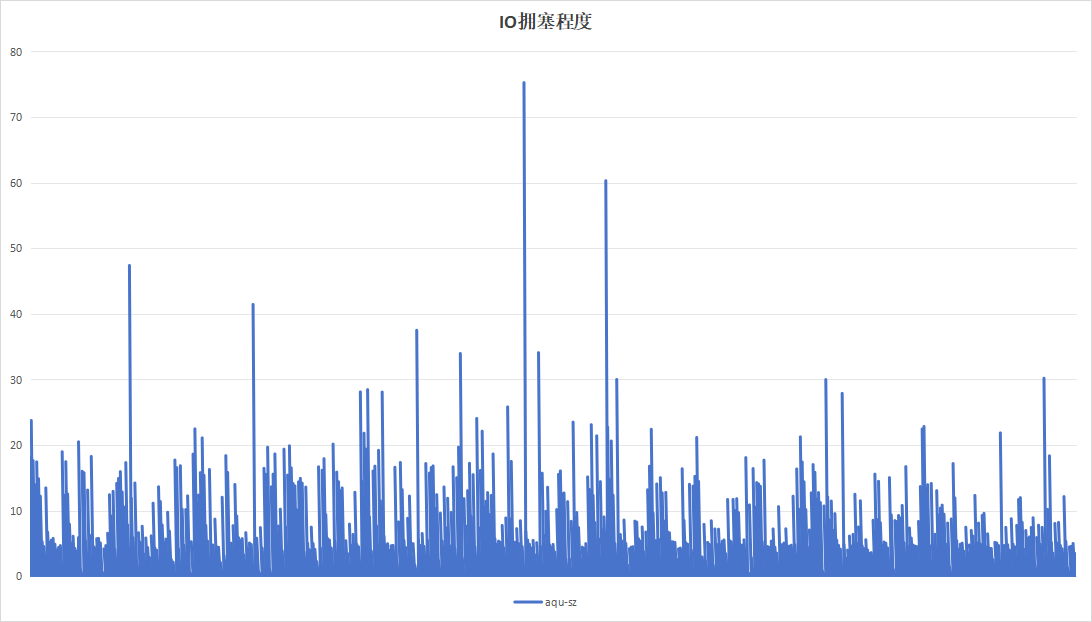 |
| IO拥塞程度 | 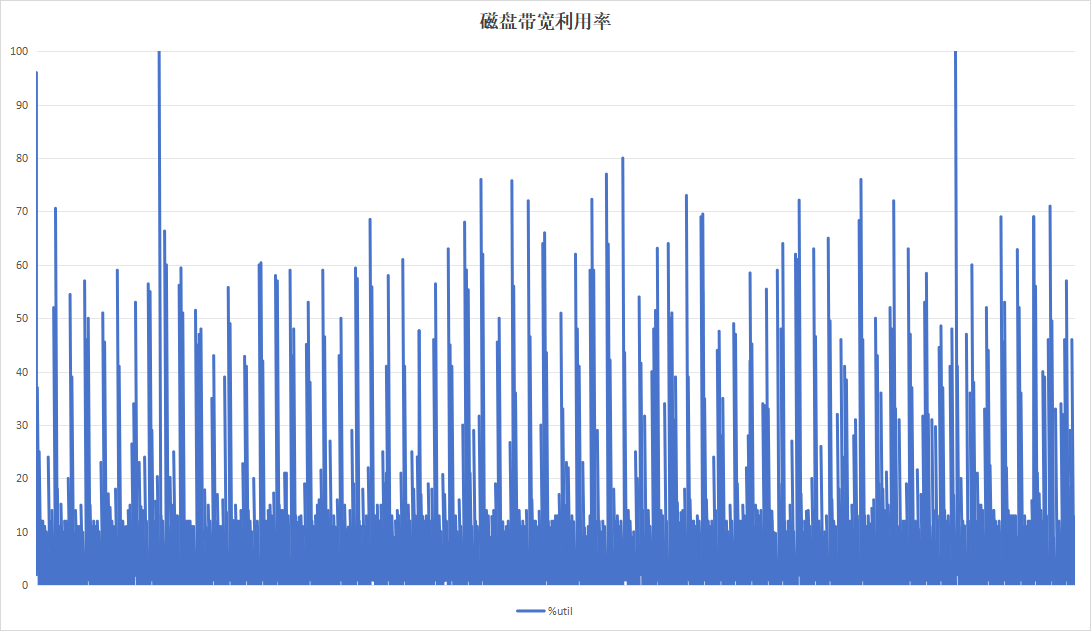 |
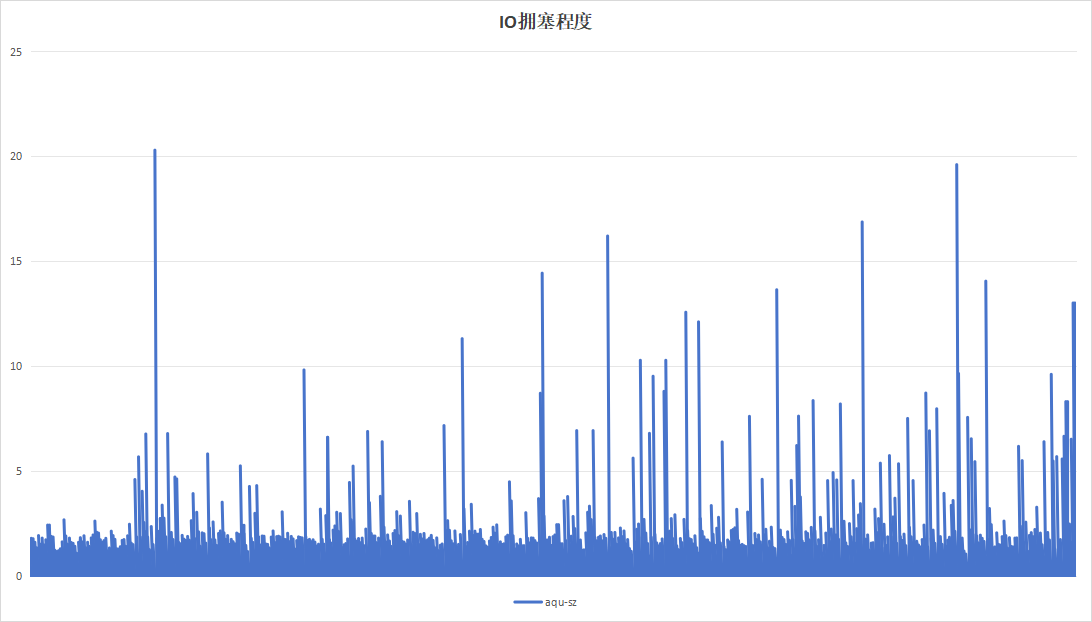 |
| 硬盘过载次数 | 89 | 3 |
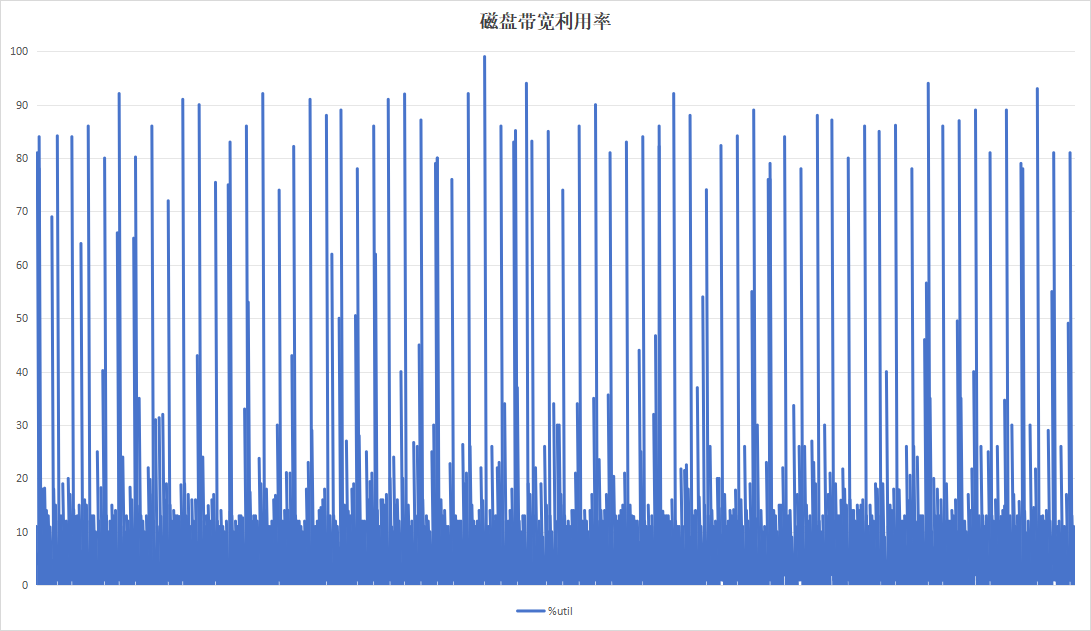
从日志以及现象看,似乎设备B的记录板的性能更好,但是这个实际上是设备B的记录板没有写满,故在性能表现上更好。设备A的记录板硬盘空间仅剩下8G左右,故对性能影响较大。
4.2.2 20分钟为周期
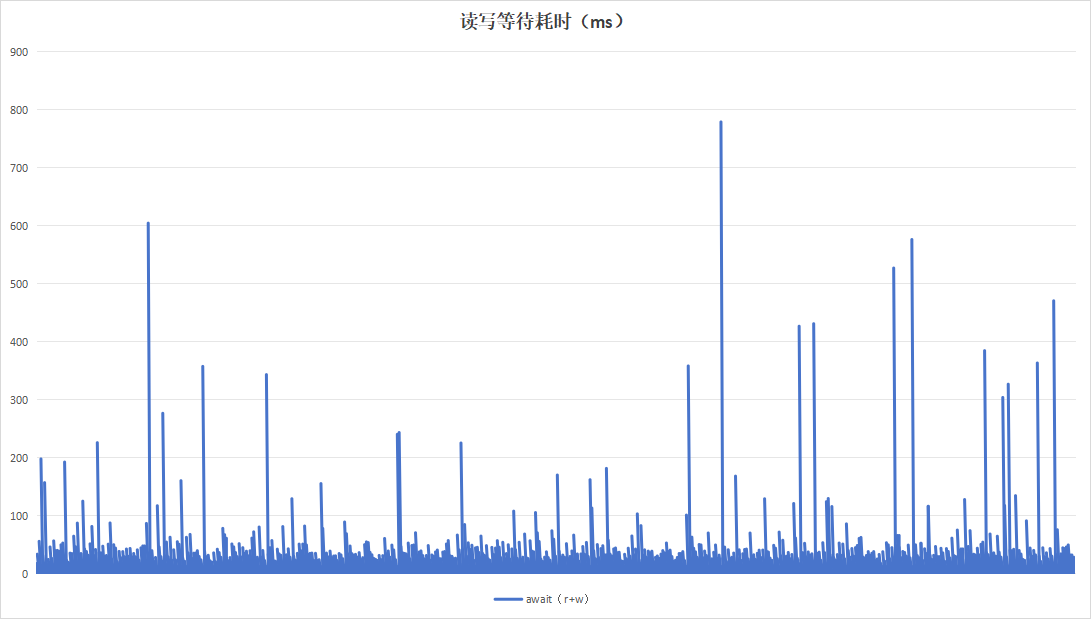
记录板应用程序以20分钟为周期运行,采用20分钟的周期进行测试,持续运行24小时。
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 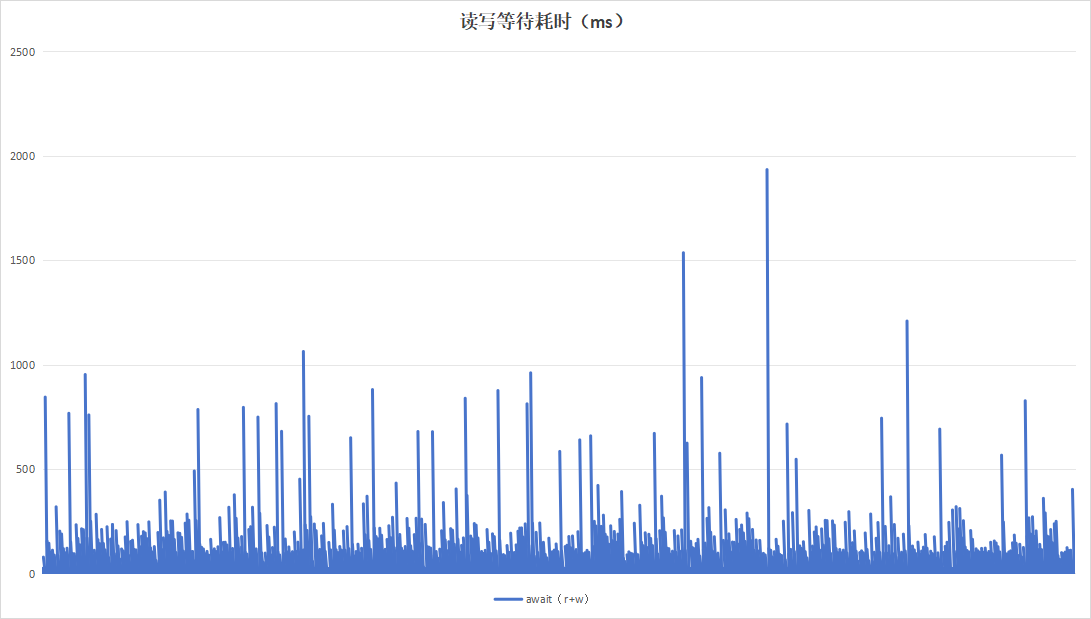 |
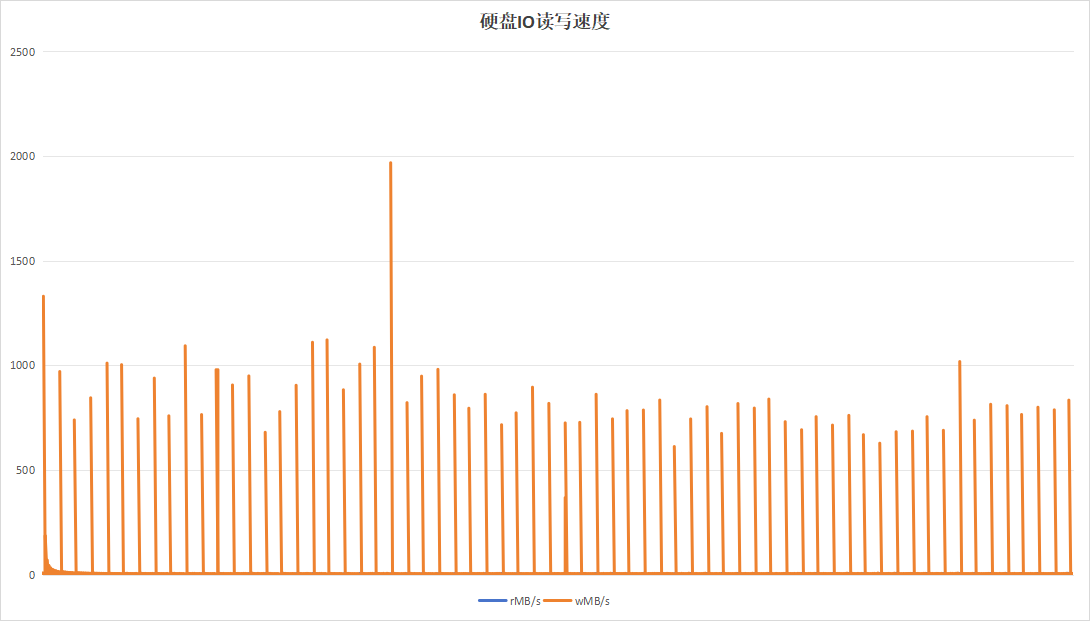 |
| 读写等待耗时 | 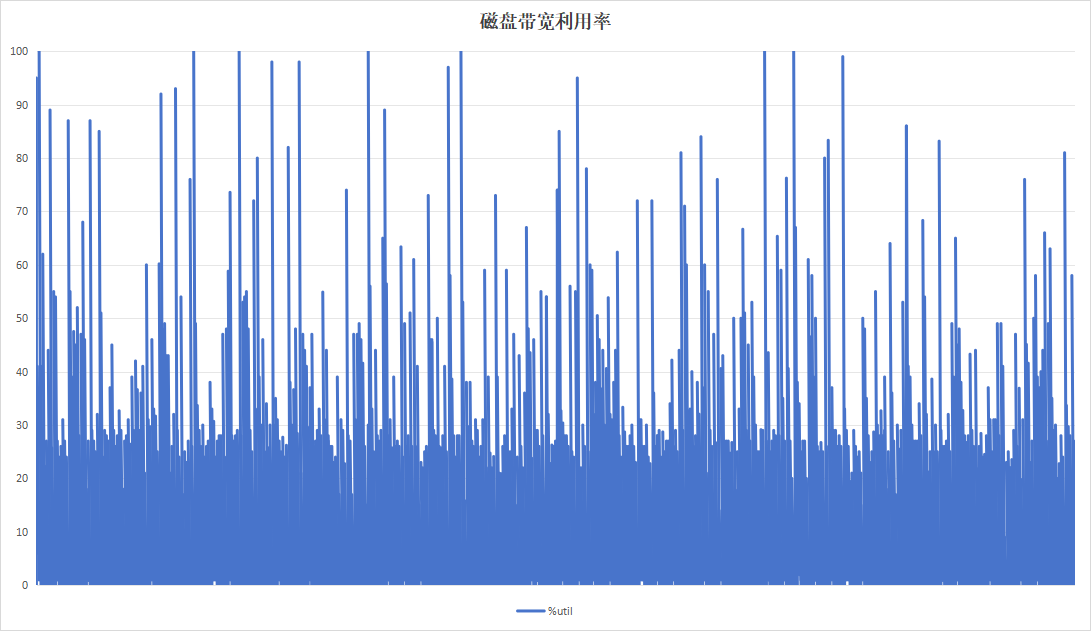 |
 |
| 硬盘带宽利用率 | 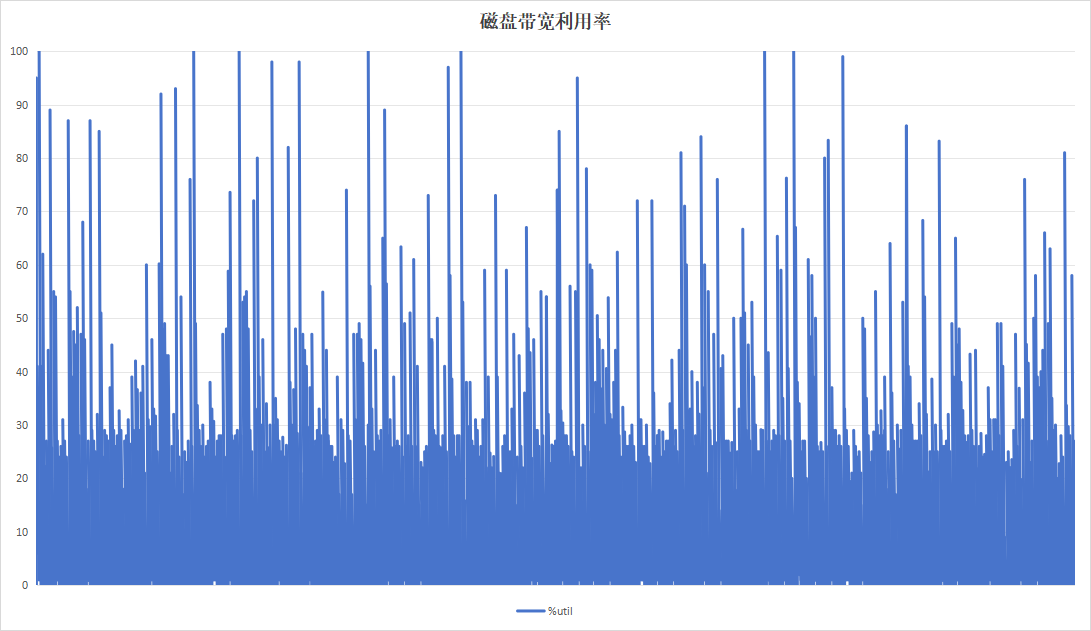 |
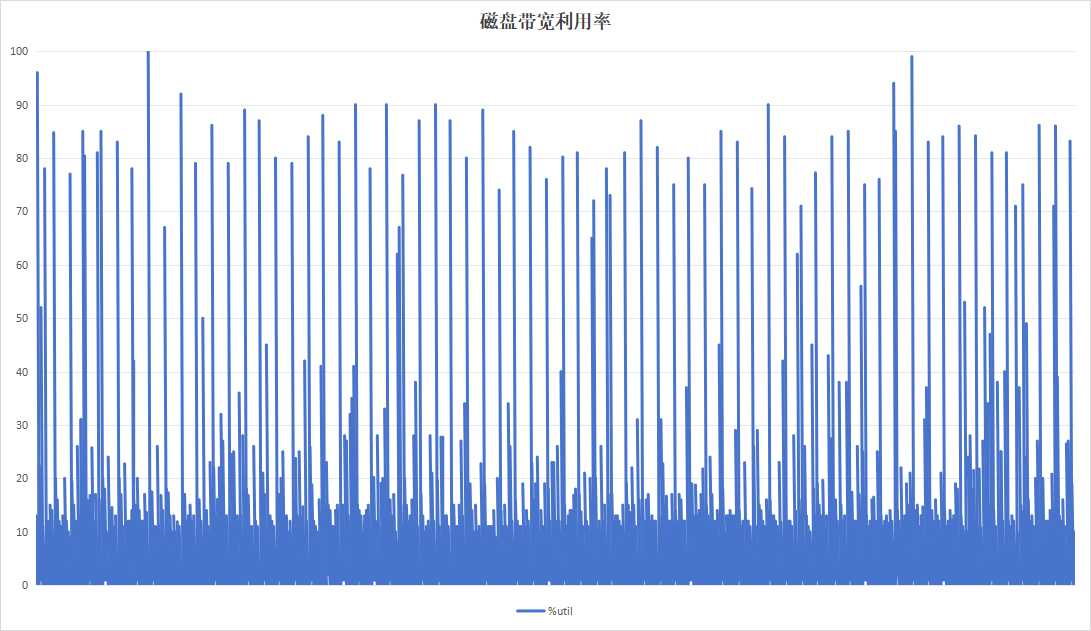 |
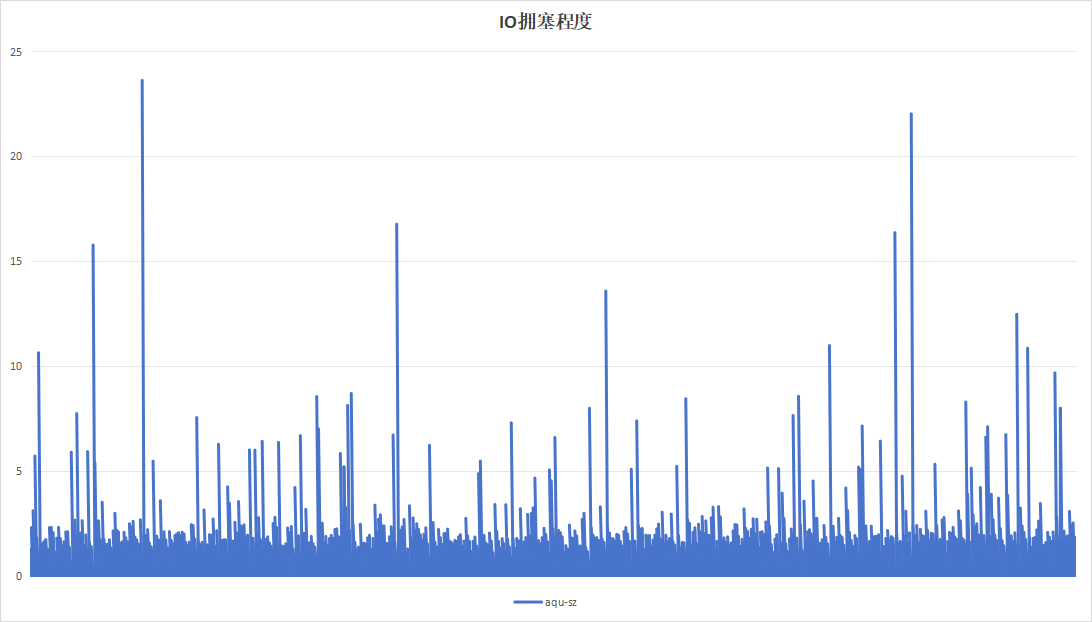
| IO拥塞程度 | 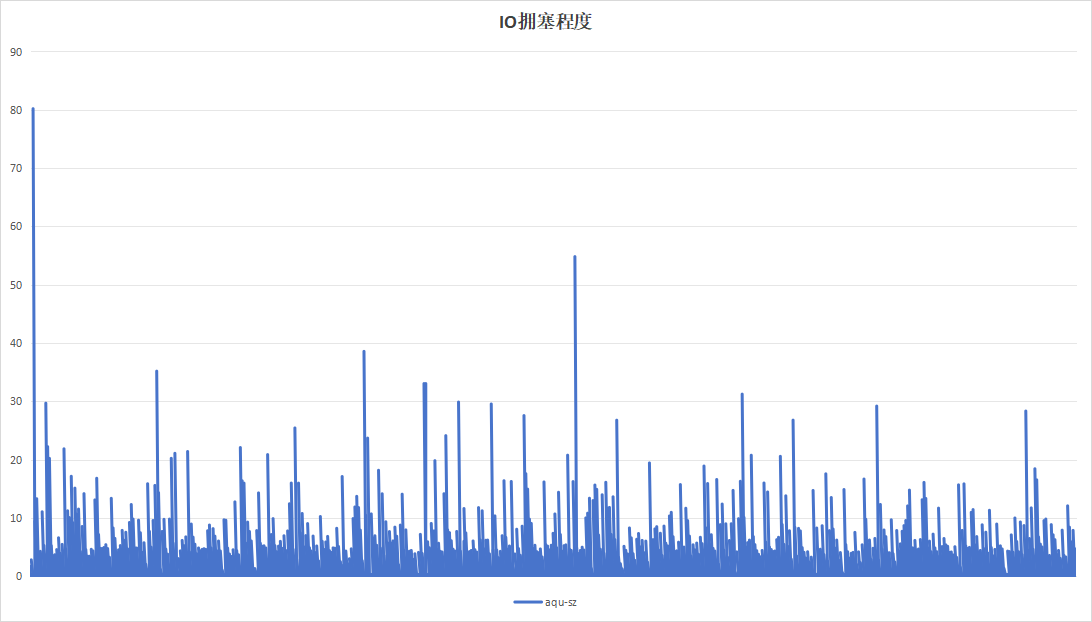 |
 |
| 硬盘过载次数 | 14 | 3 |
关注到设备B记录板磁盘带宽利用率呈现明显的间隔、高利用率现象。翻阅应时间点的日志,发现此时正在进行trim操作。硬盘带宽高利用率现象是由trim引起。
4.2.3 日志全部压缩后执行(事件驱动)
记录板日志压缩程序会在日志压缩完成以后,将原始的大文件删除。当日志压缩程序的任务列表结束时,即有任务->无任务状态时,执行trim操作。持续运行24小时:
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 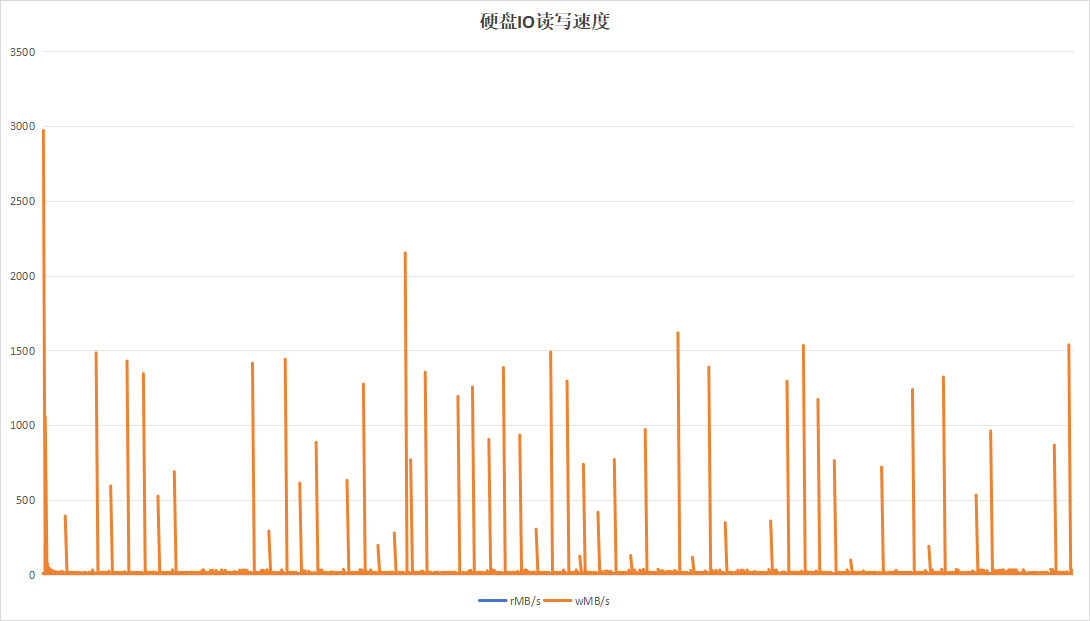 |
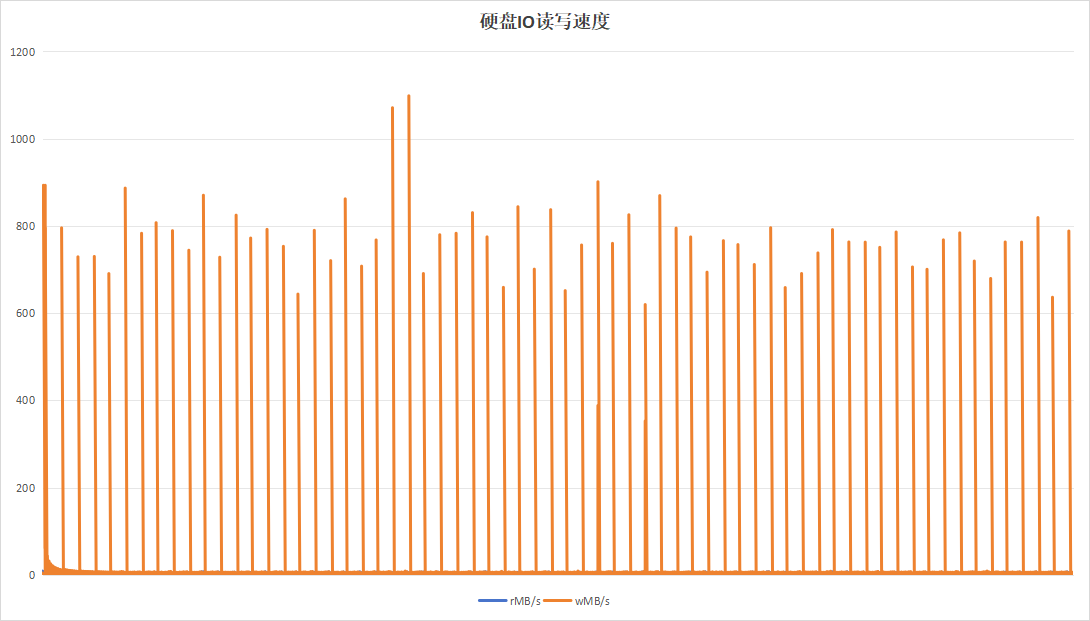 |
| 读写等待耗时 | 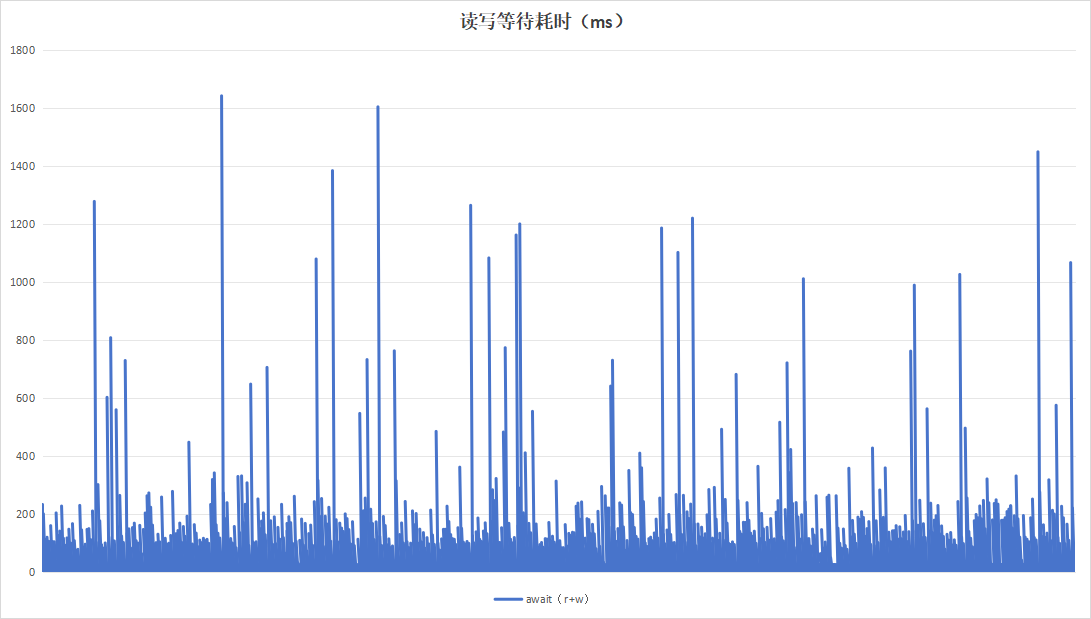 |
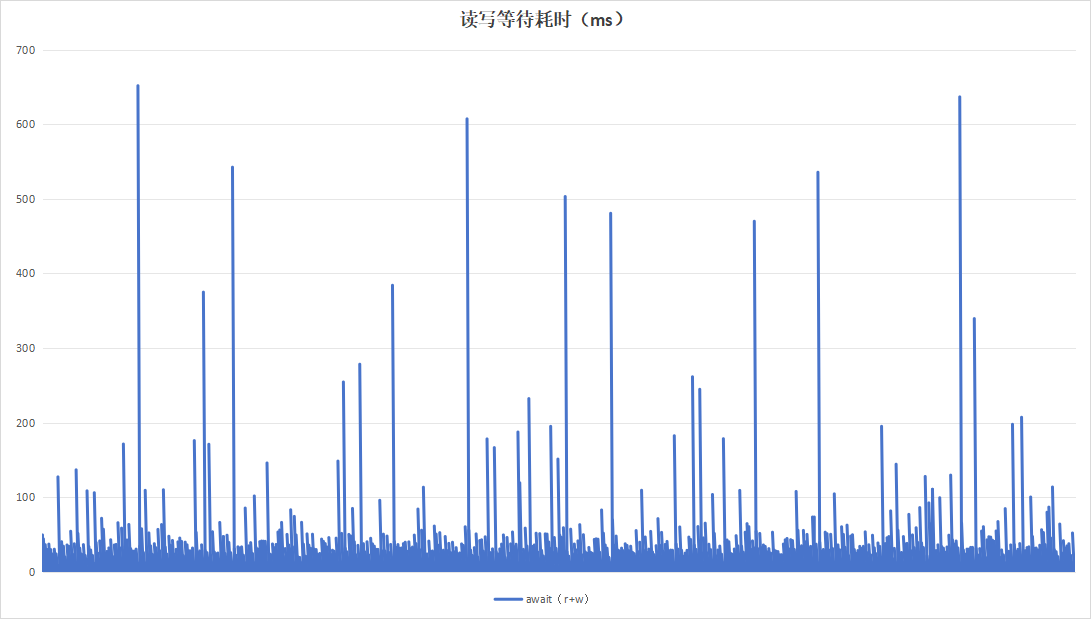 |
| 硬盘带宽利用率 | 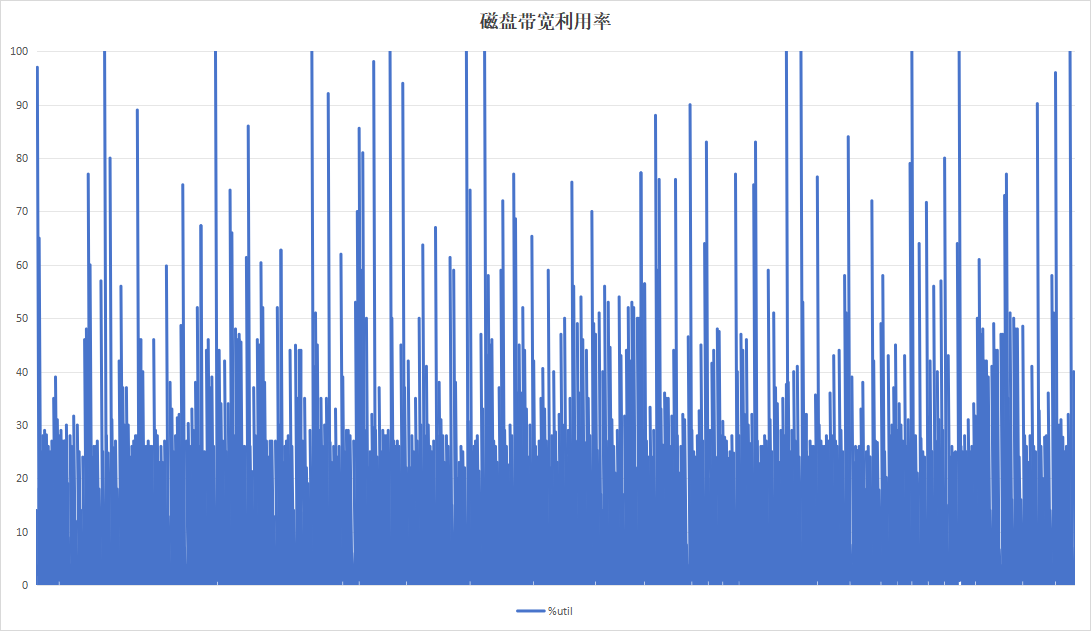 |
 |
| IO拥塞程度 | 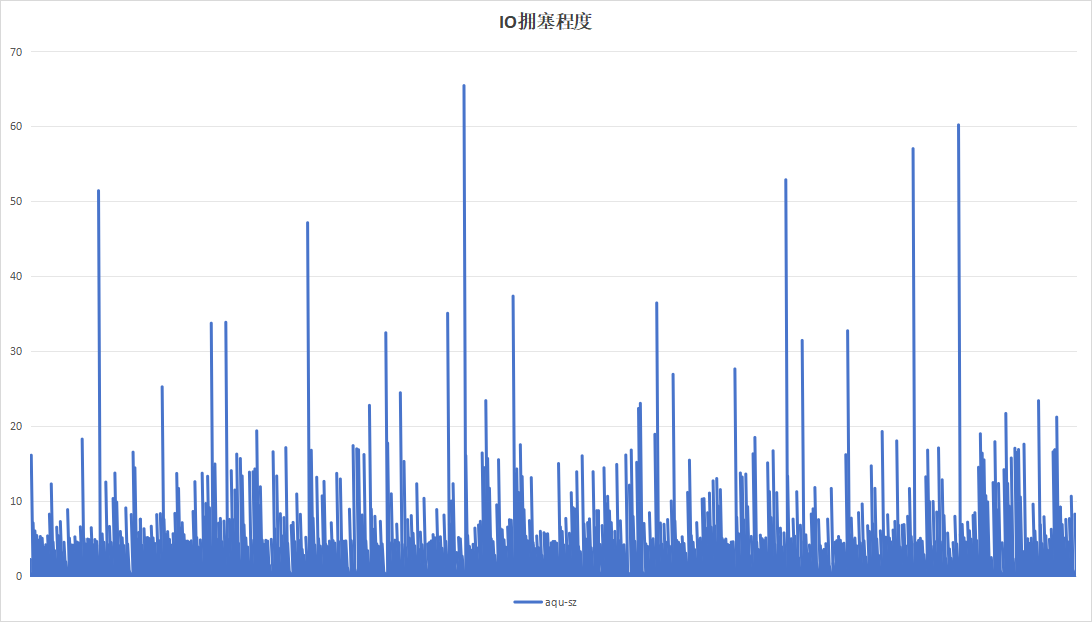 |
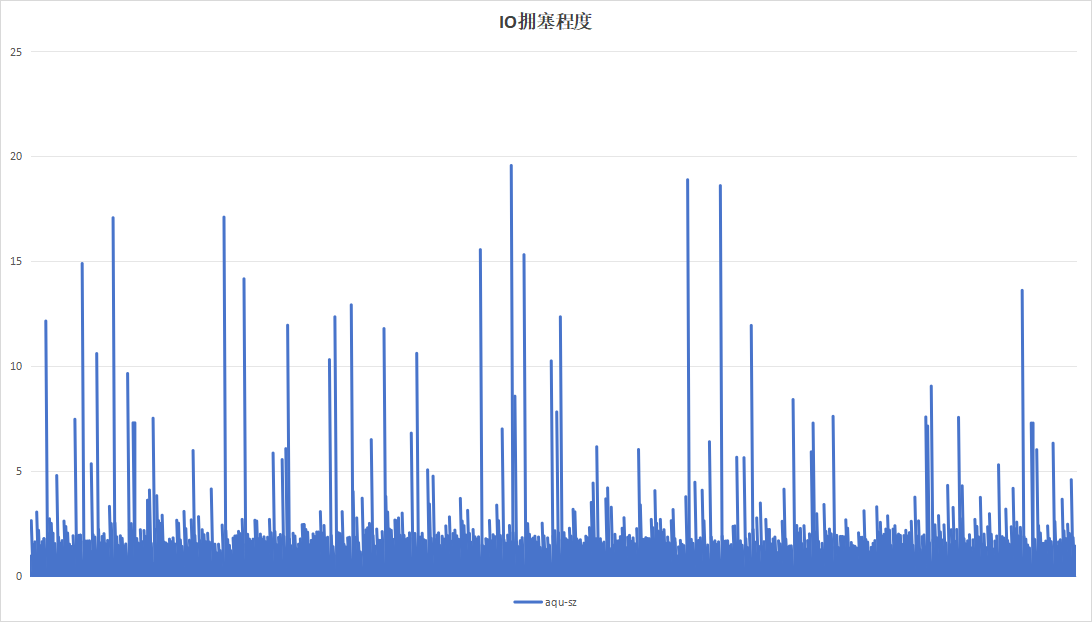 |
| 硬盘过载次数 | 17 | 2 |
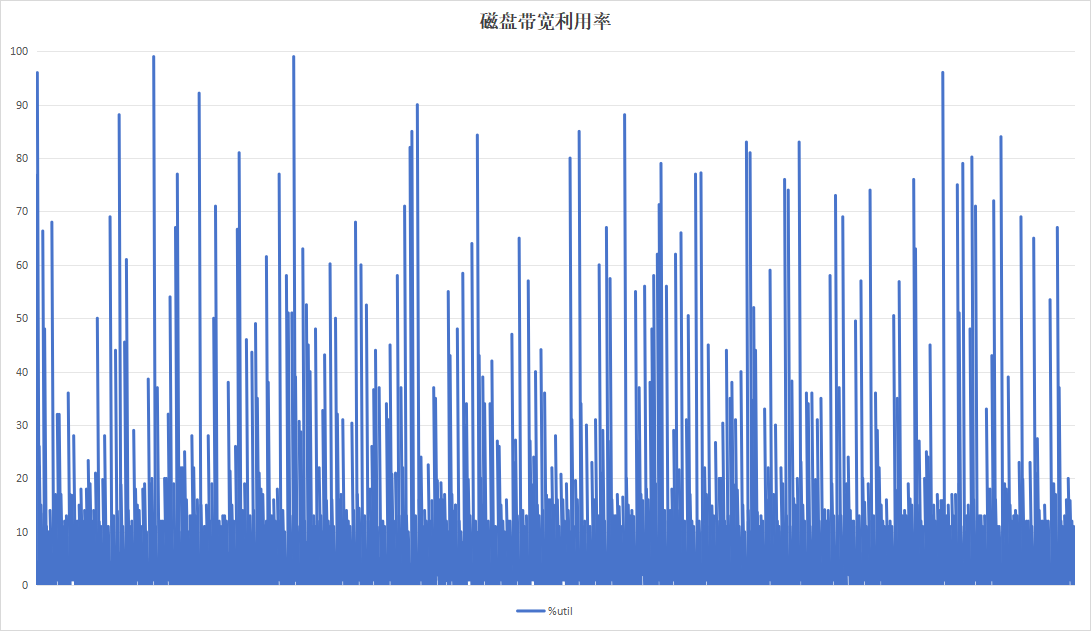
4.2.4 8小时为周期
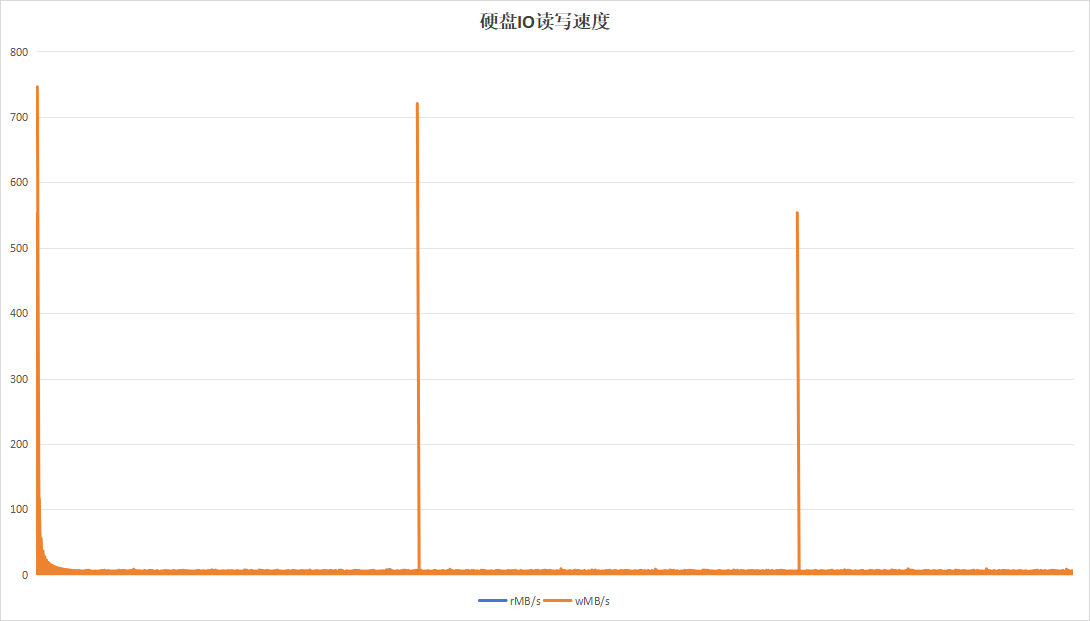
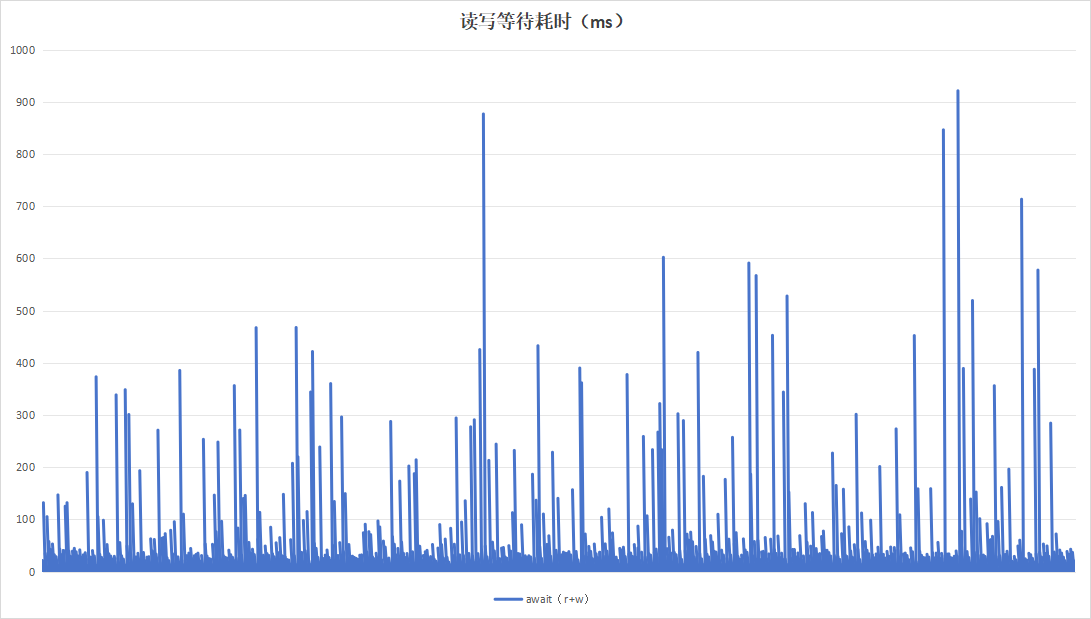
记录板应用在进行日志记录时,约16小时即可将硬盘写满,使用以8小时为周期,目的在于实验日志写入量为硬盘空间一半的情况下的性能。运行24小时效果如下:
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 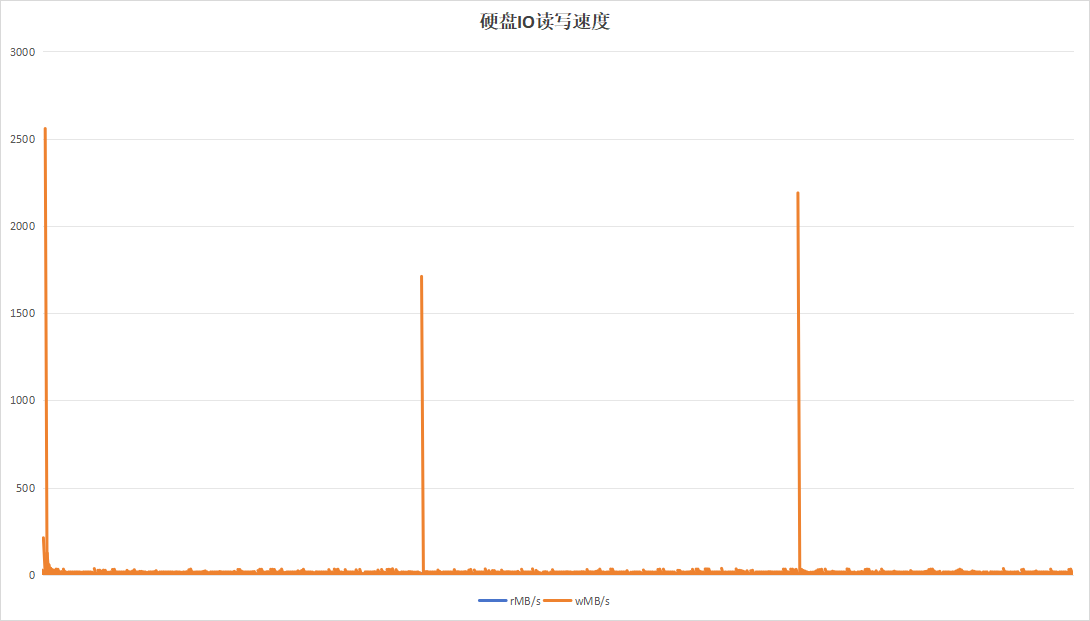 |
 |
| 读写等待耗时 | 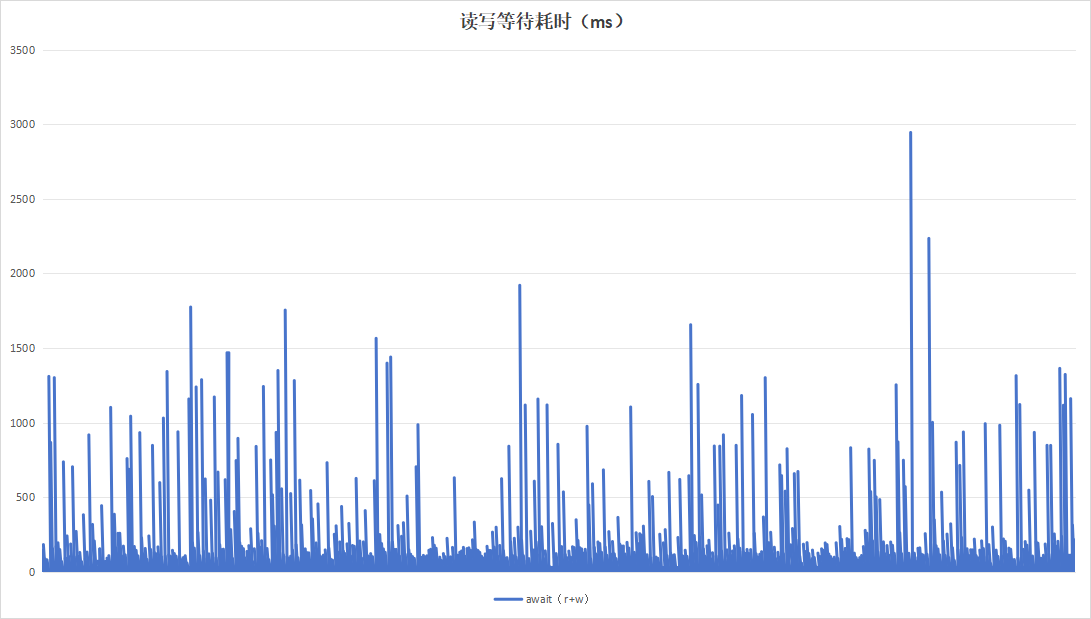 |
 |
| 硬盘带宽利用率 | 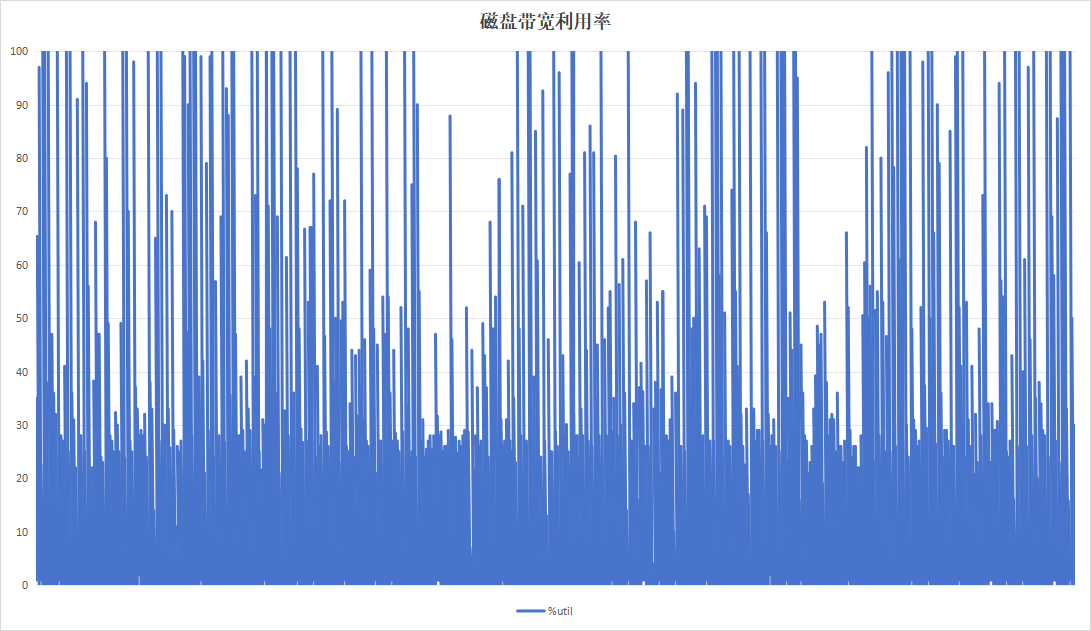 |
 |
| IO拥塞程度 | 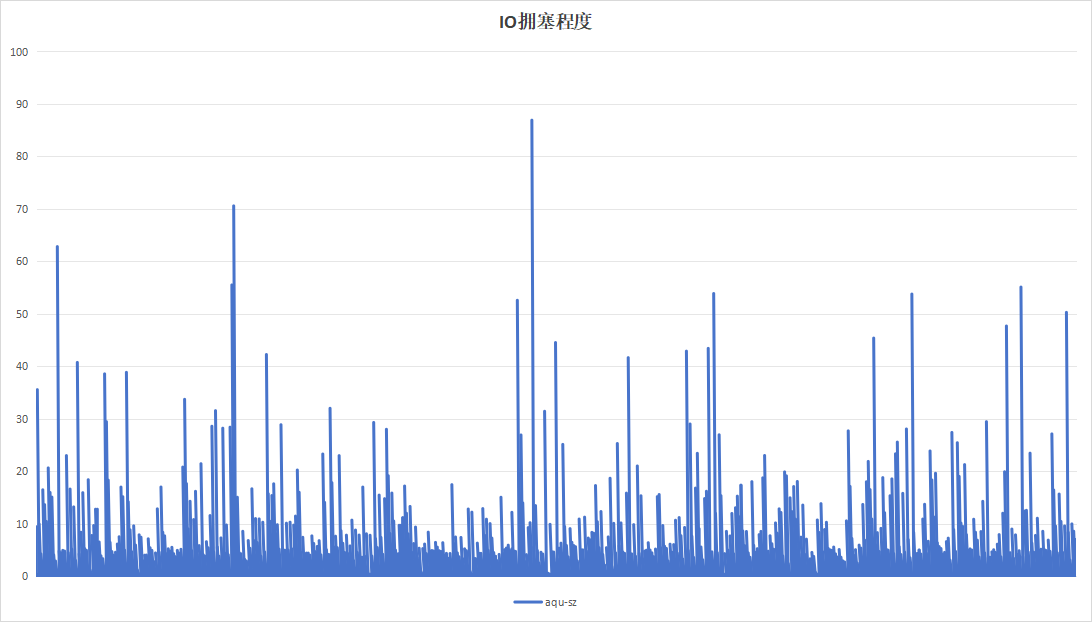 |
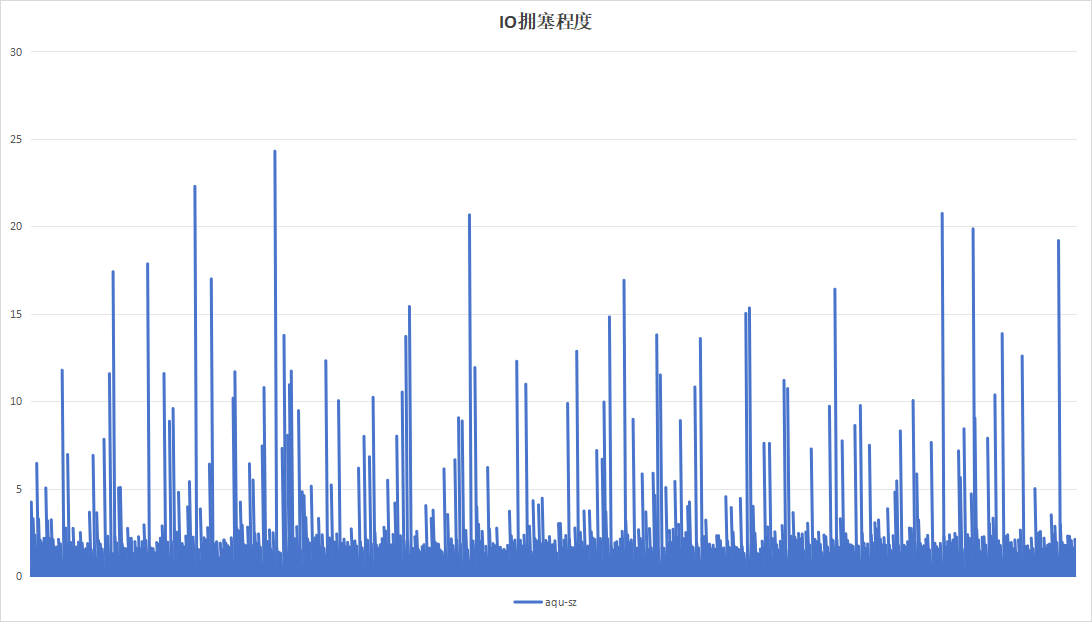 |
| 硬盘过载次数 | 104 | 4 |
4.2.5 16小时为周期
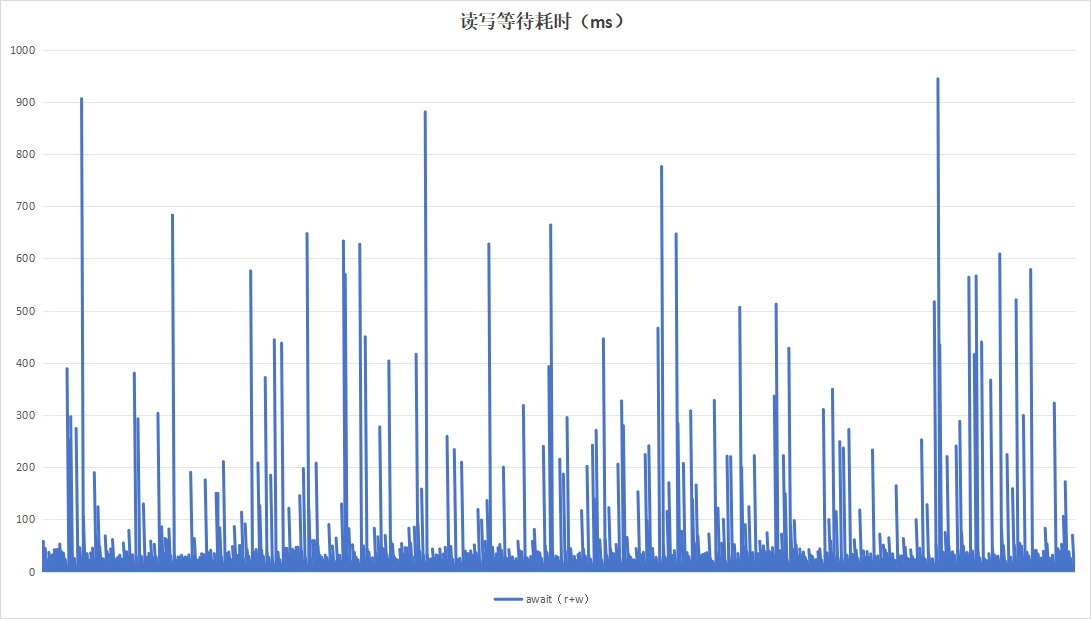
记录板应用在进行日志记录时,约16小时即可将硬盘写满,使用以16小时为周期,目的在于实验日志写入量为硬盘空间大小的时候的性能。持续运行48小时,结果如下:
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 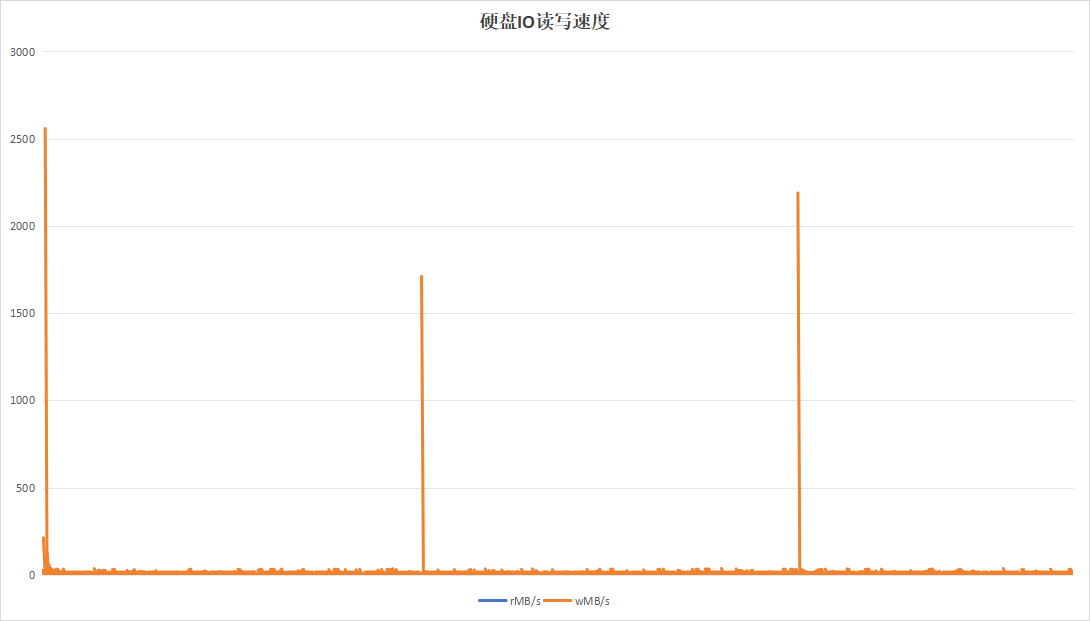 |
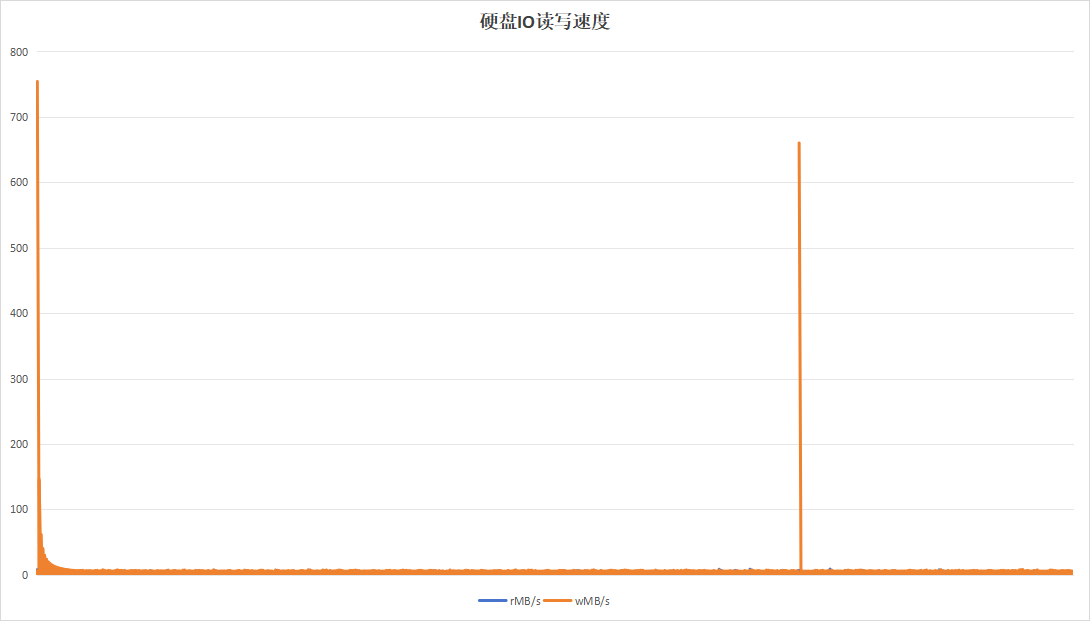 |
| 读写等待耗时 | 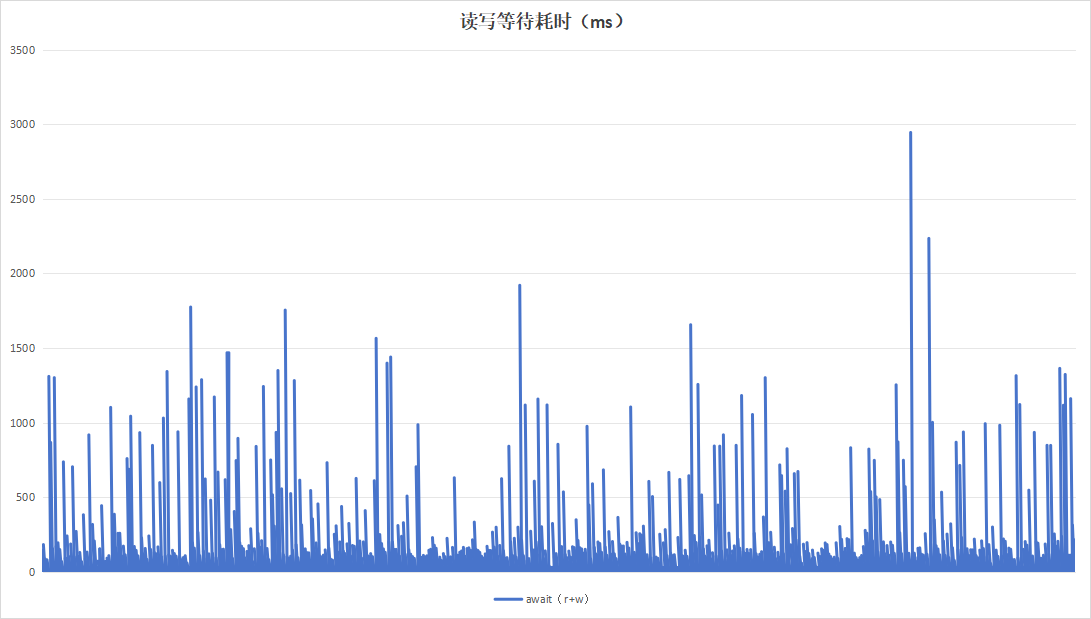 |
 |
| 硬盘带宽利用率 | 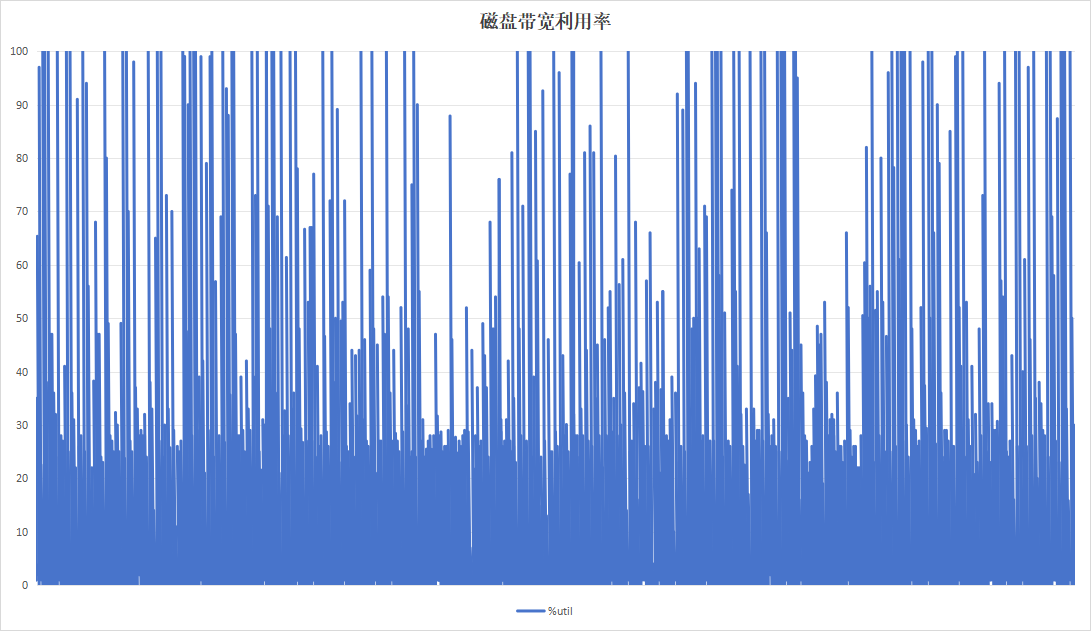 |
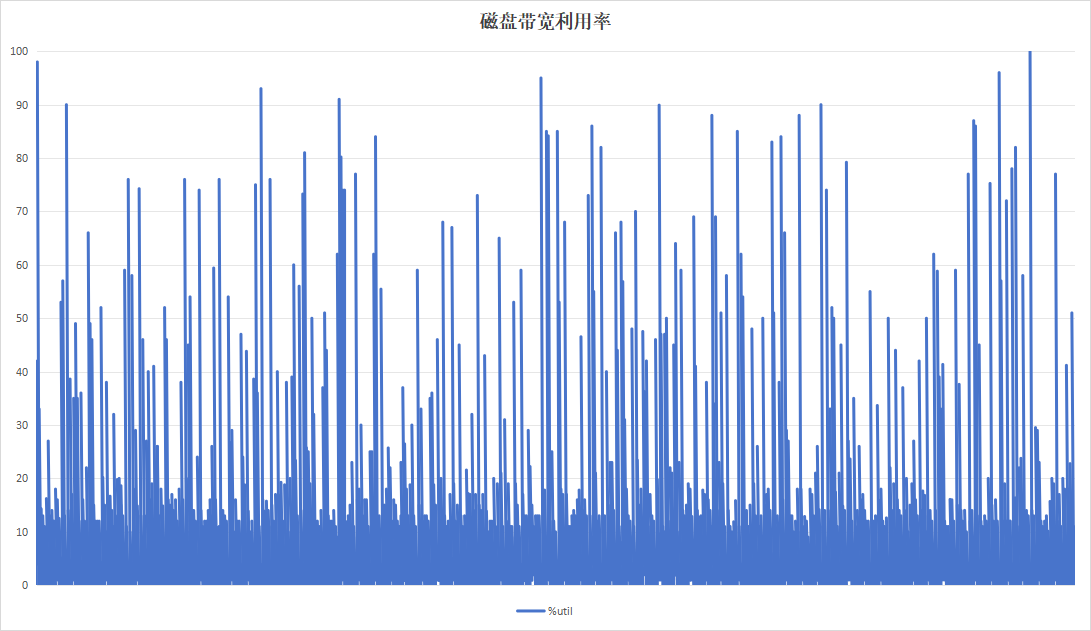 |
| IO拥塞程度 | 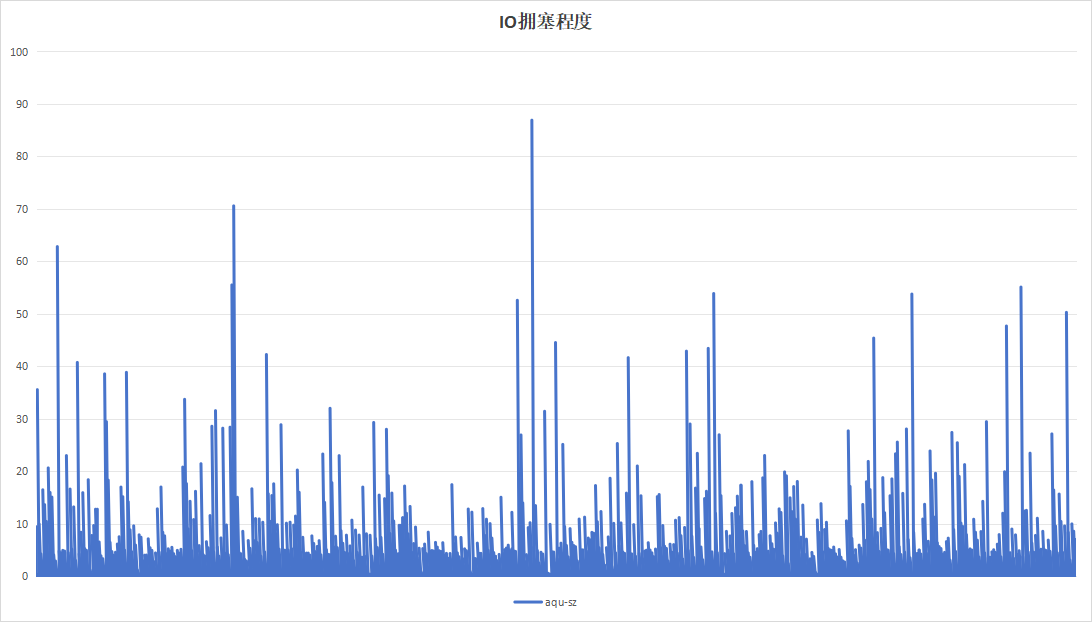 |
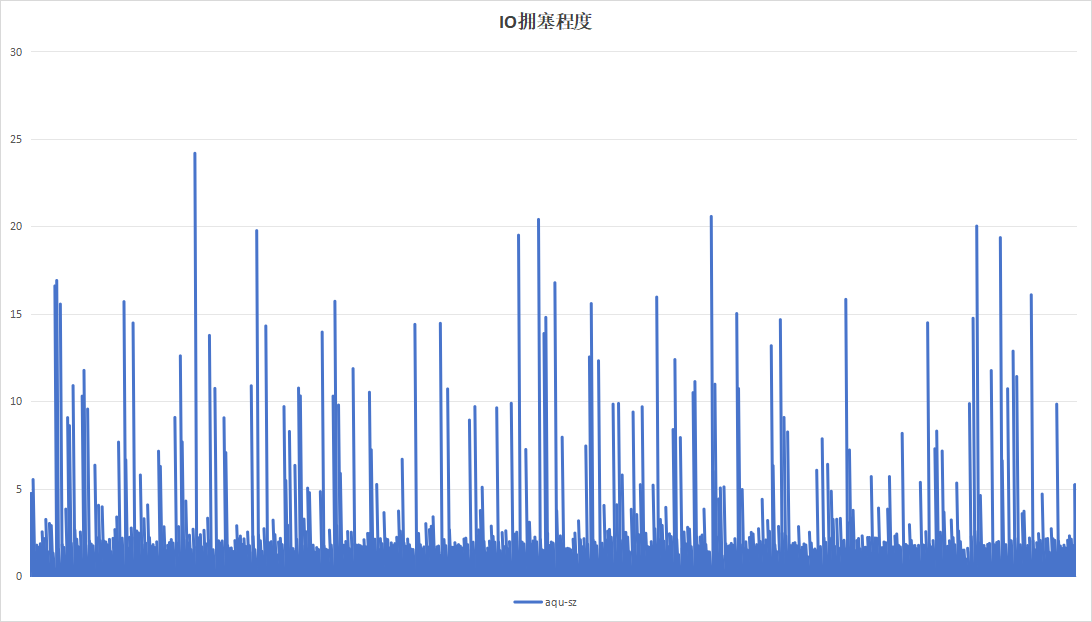 |
| 硬盘过载次数 | 365 | 12 |
4.2.6 24小时为周期
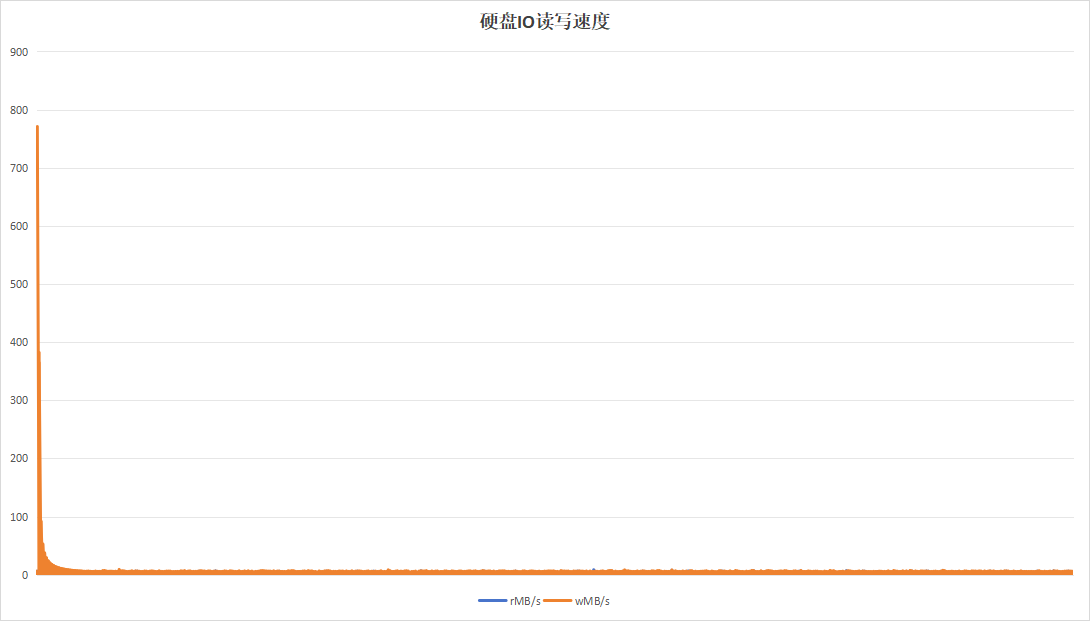
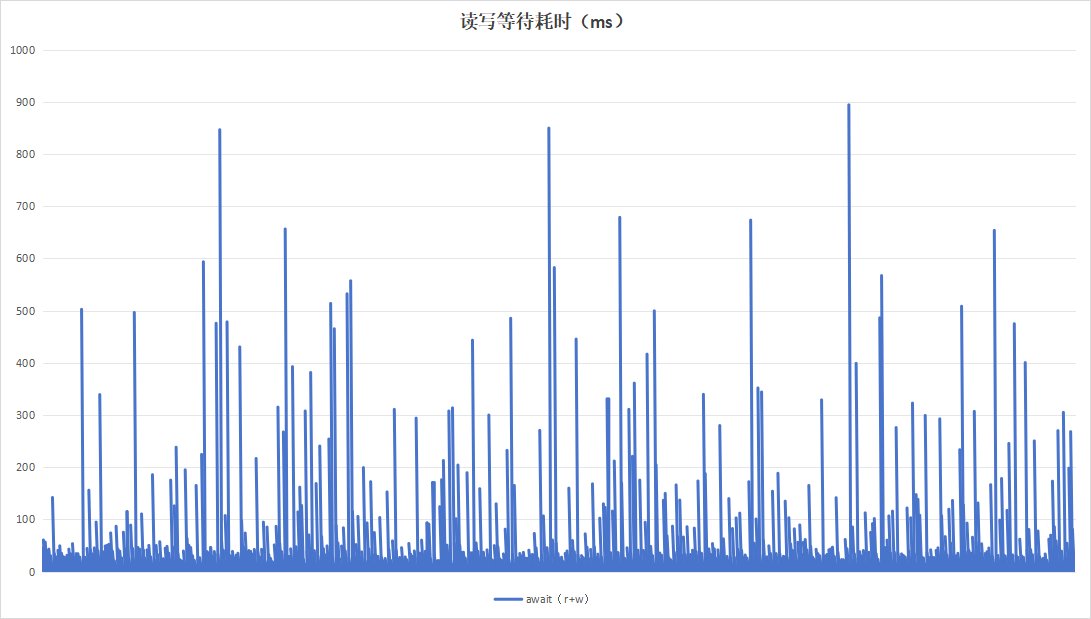
目的在于测试硬盘复写一次以后的一半数据量情况下,硬盘的性能数据情况。运行24小时结果如下:
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 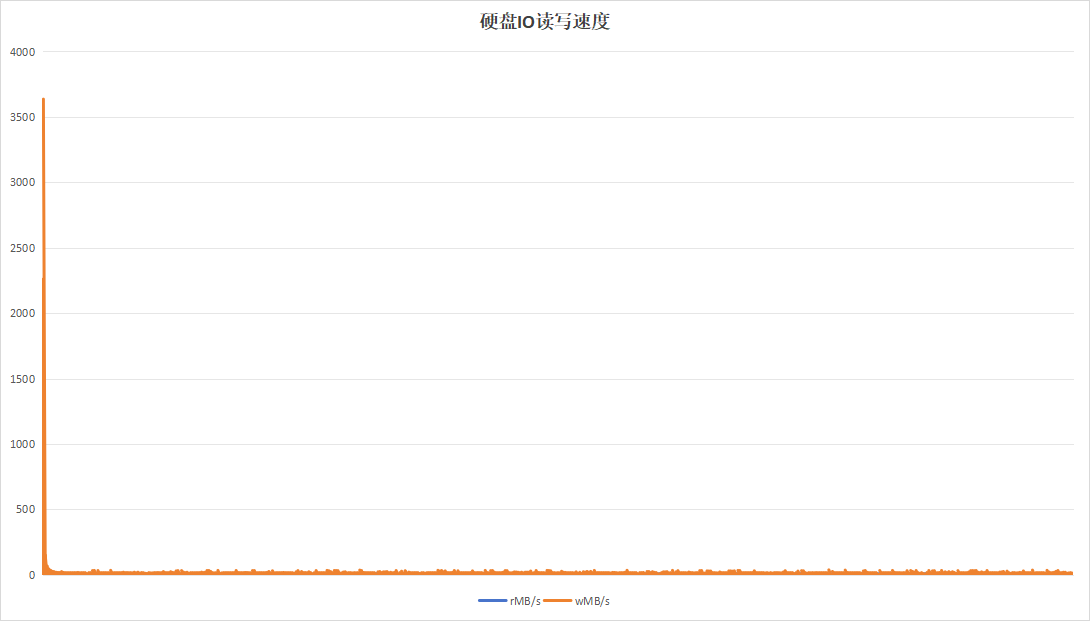 |
 |
| 读写等待耗时 | 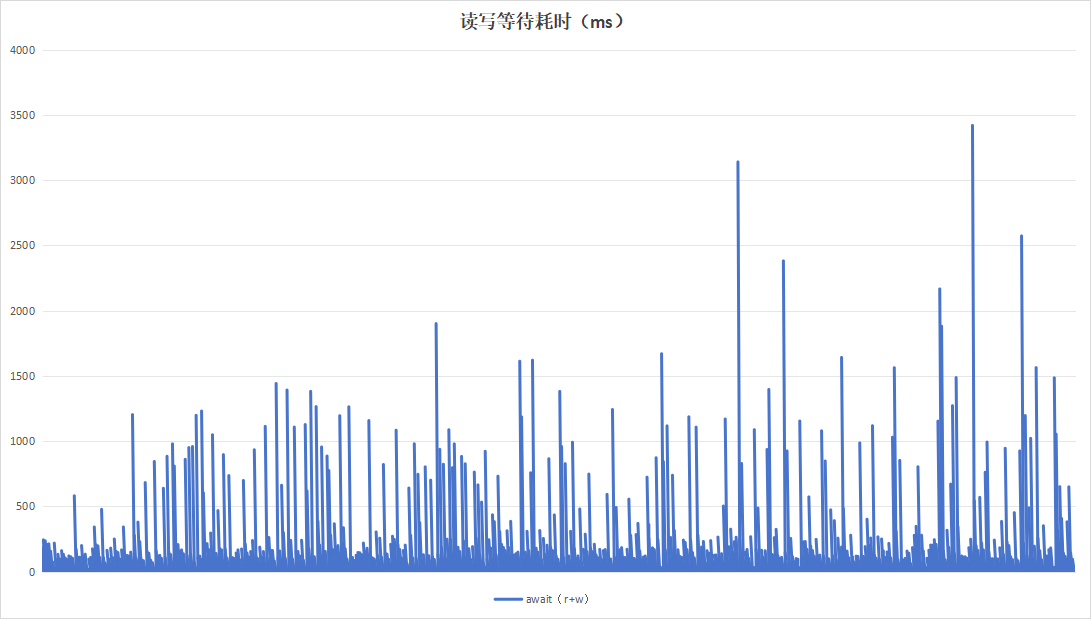 |
 |
| 硬盘带宽利用率 | 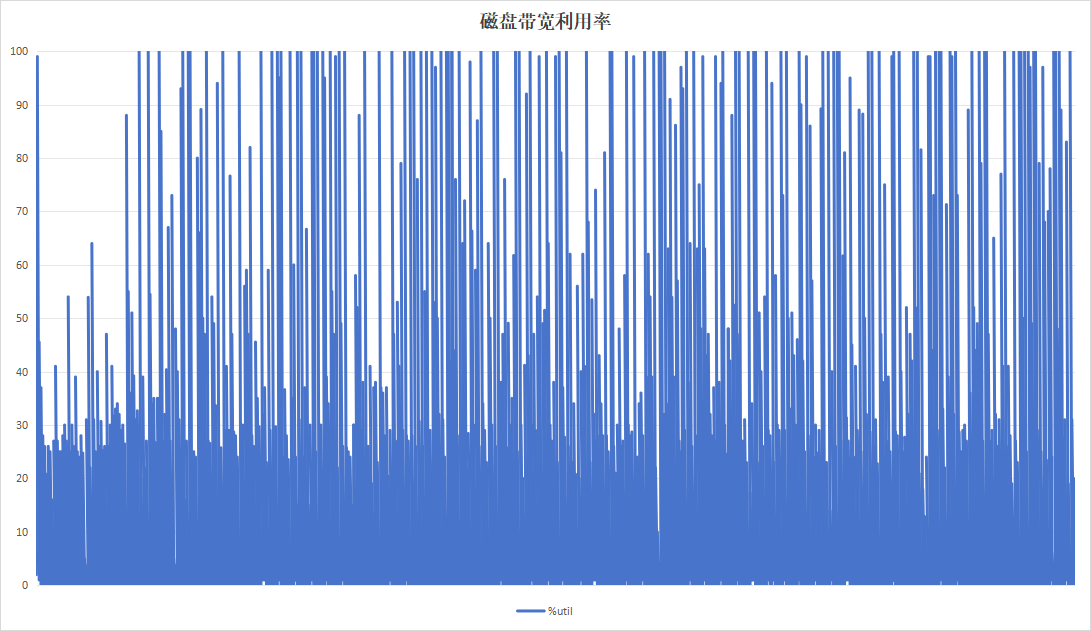 |
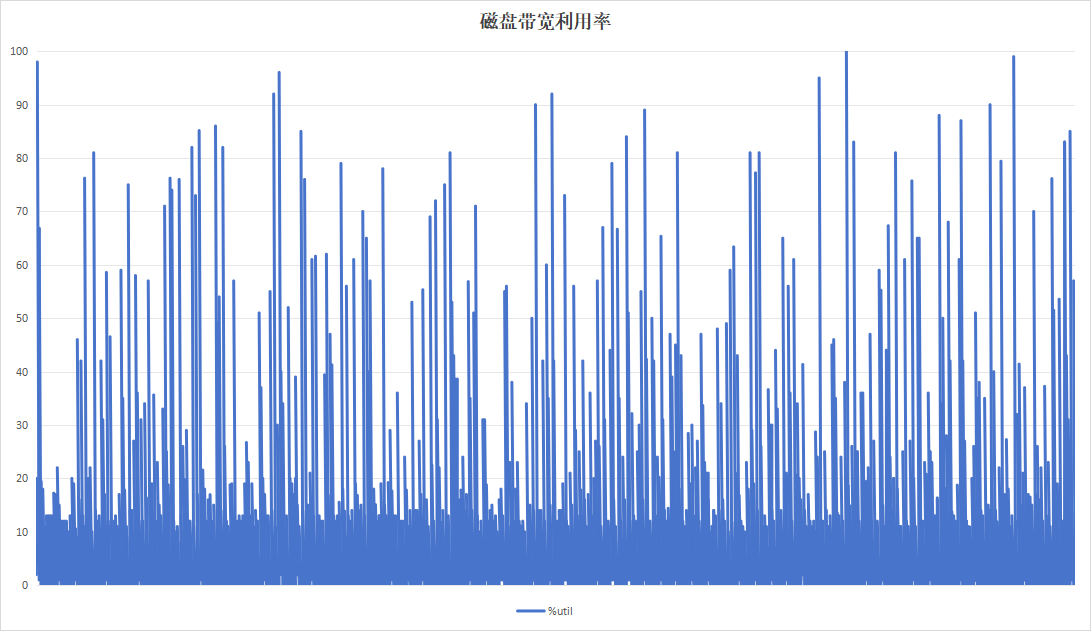 |
| IO拥塞程度 | 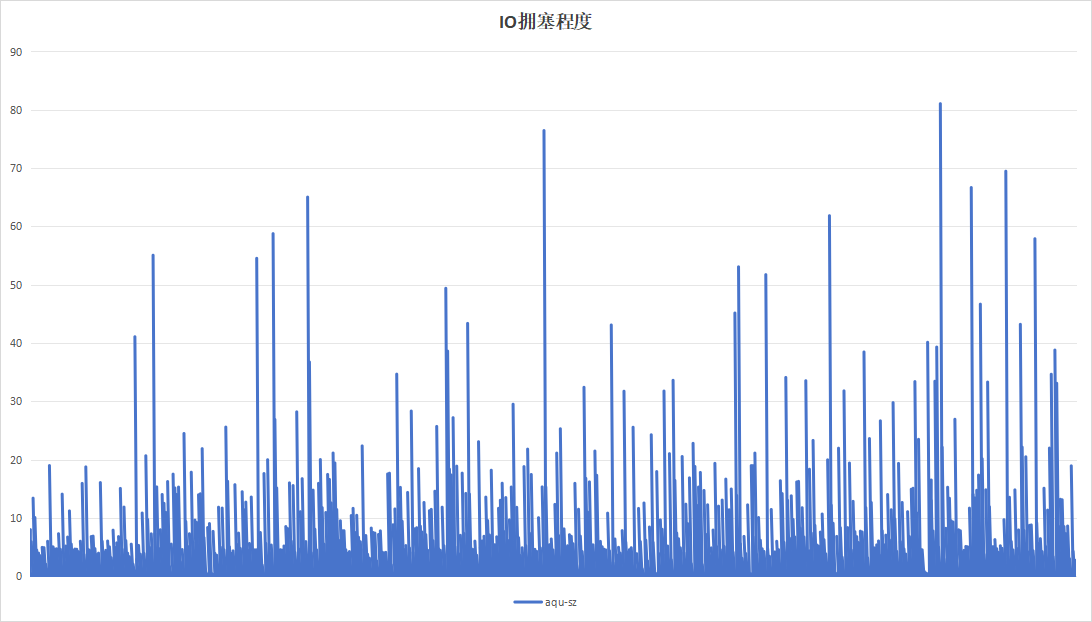 |
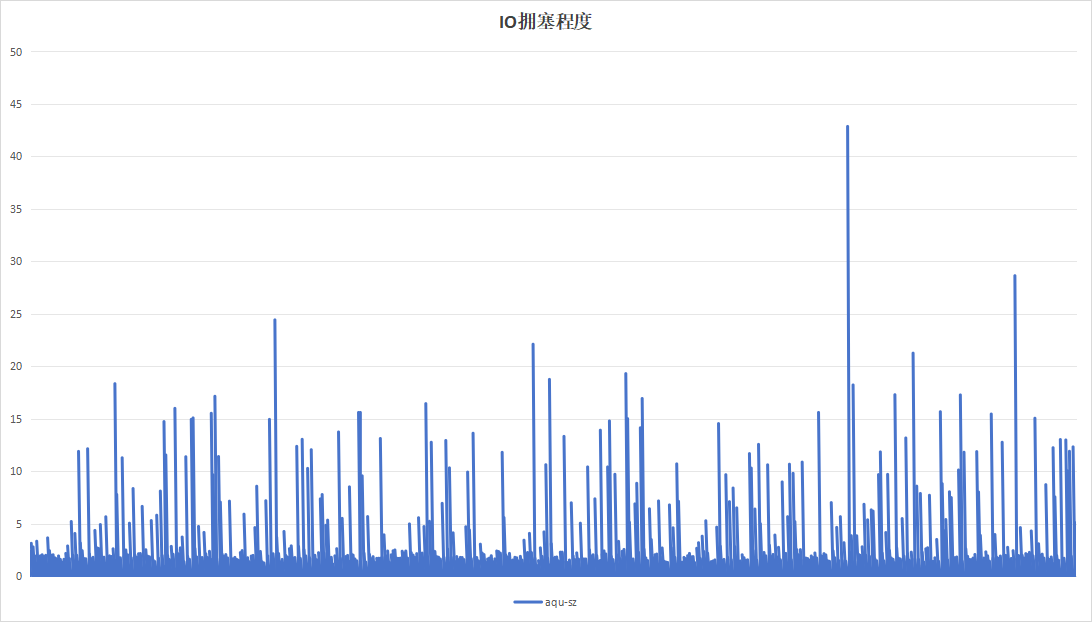 |
| 硬盘过载次数 | 141 | 8 |
4.2.7 稳定性测试-20分钟为周期
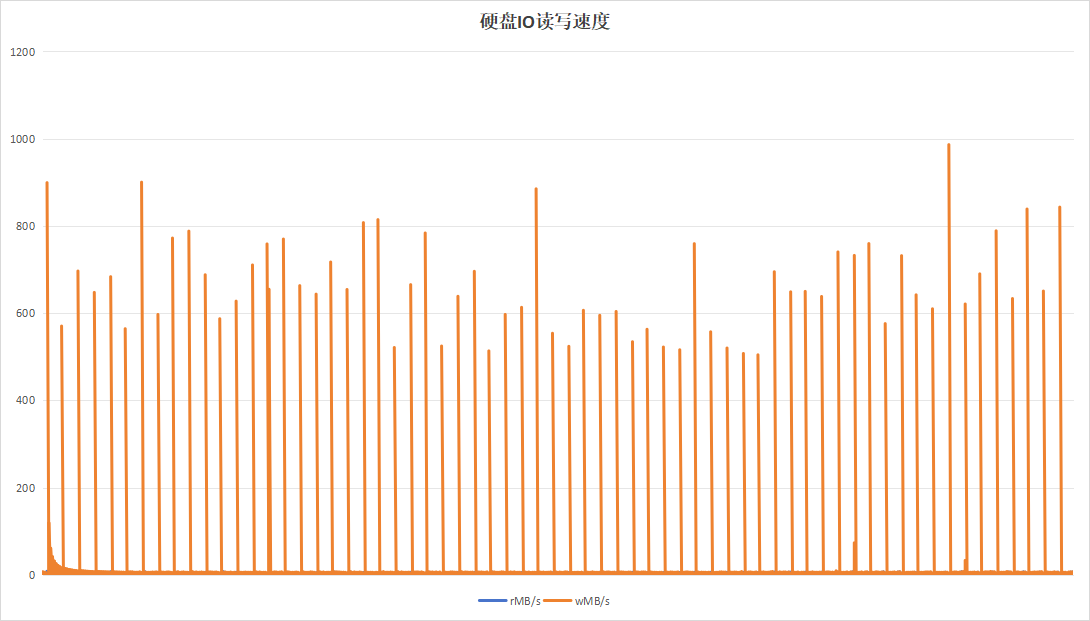
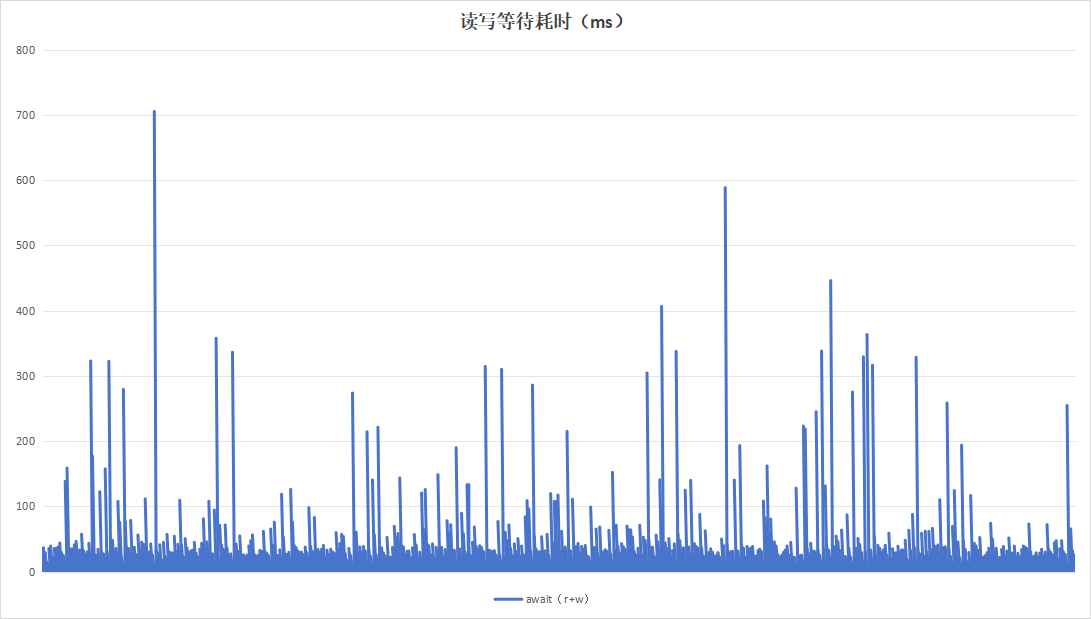
选择梯度测试阶段以20分钟为周期的参数,进行85小时不间断测试,观察稳定性指标。
| 项目 | 设备A | 设备B |
|---|---|---|
| 硬盘IO读写速度 | 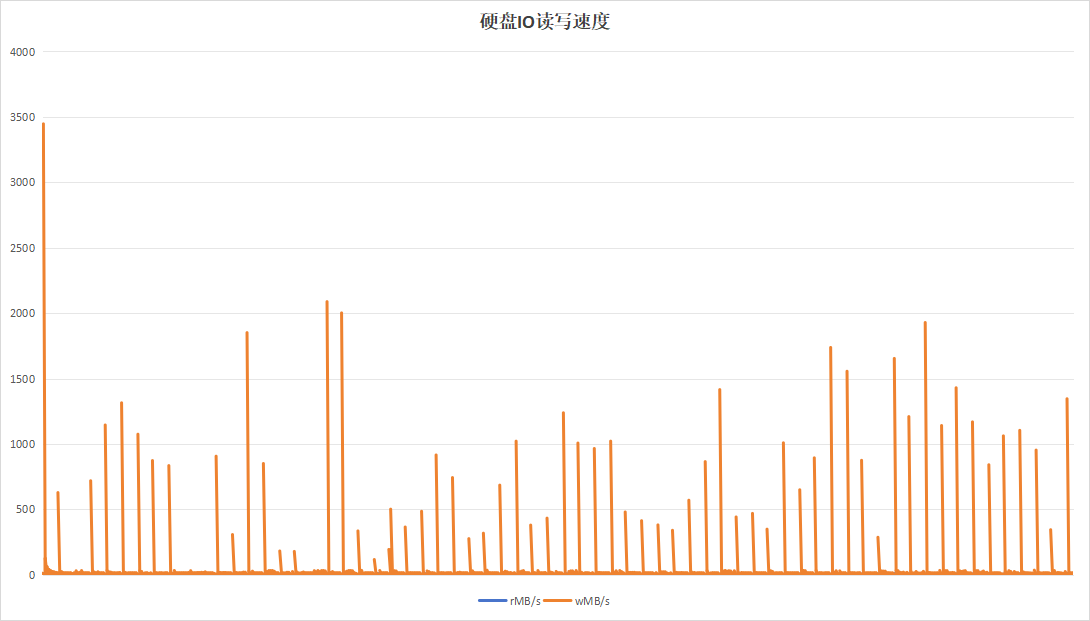 |
 |
| 读写等待耗时 | 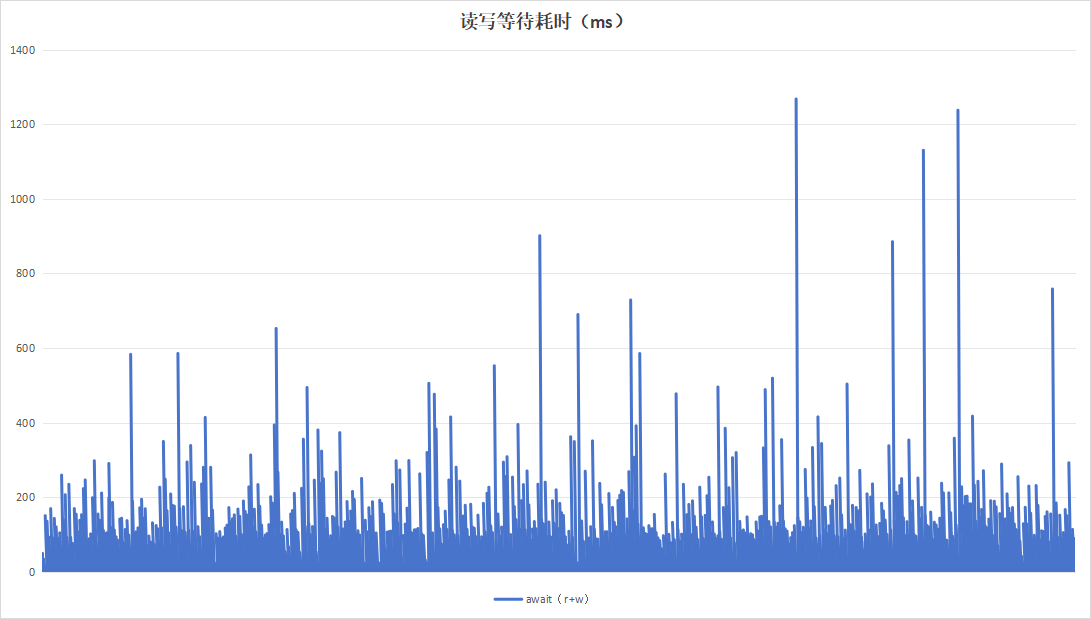 |
 |
| 硬盘带宽利用率 | 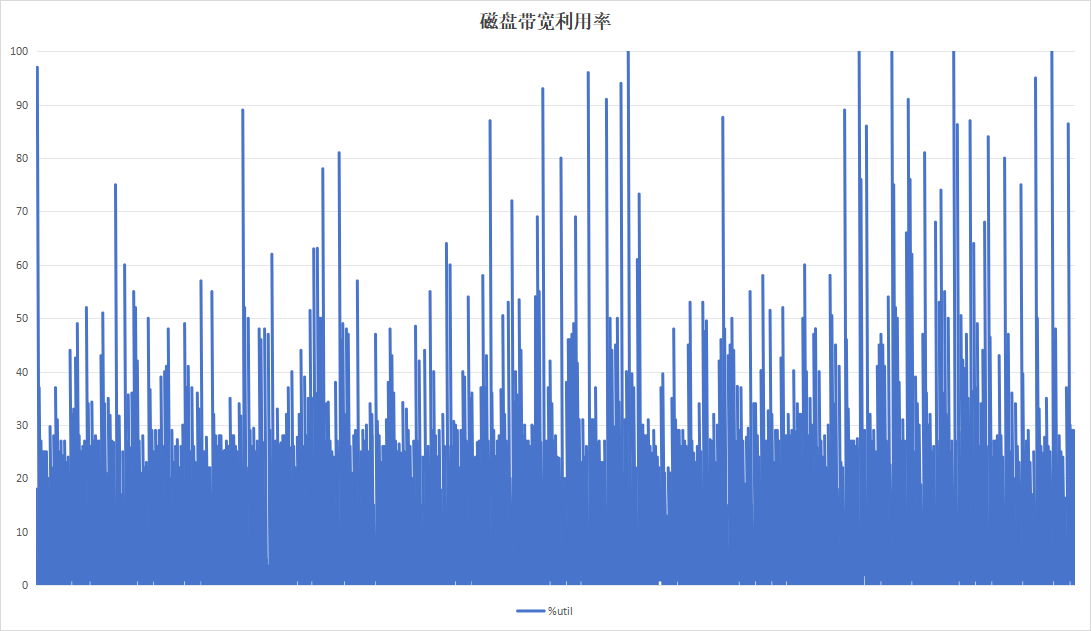 |
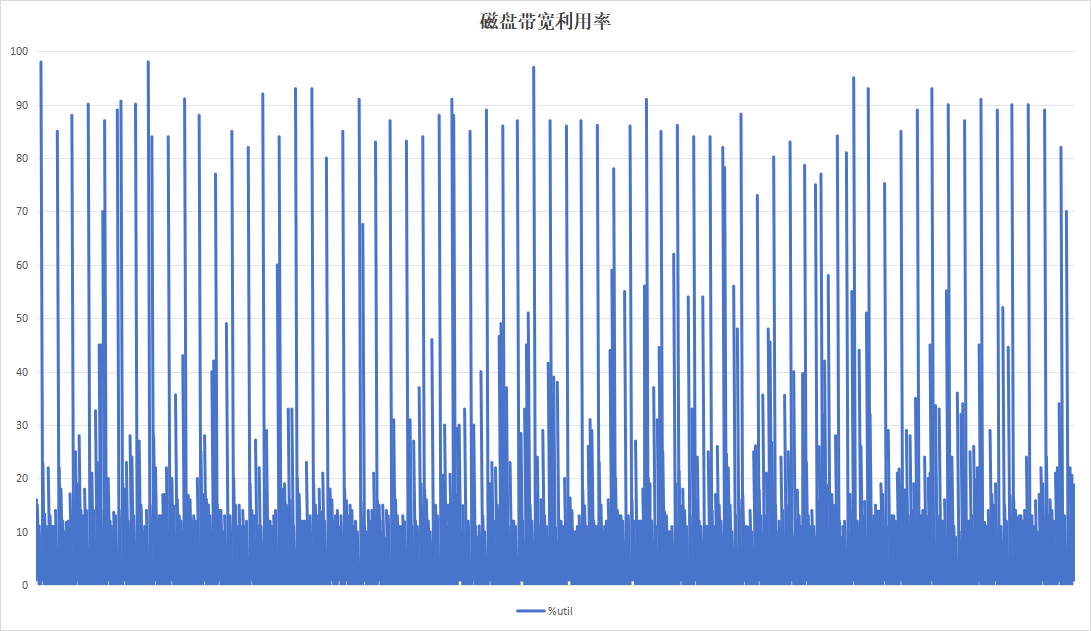 |
| IO拥塞程度 | 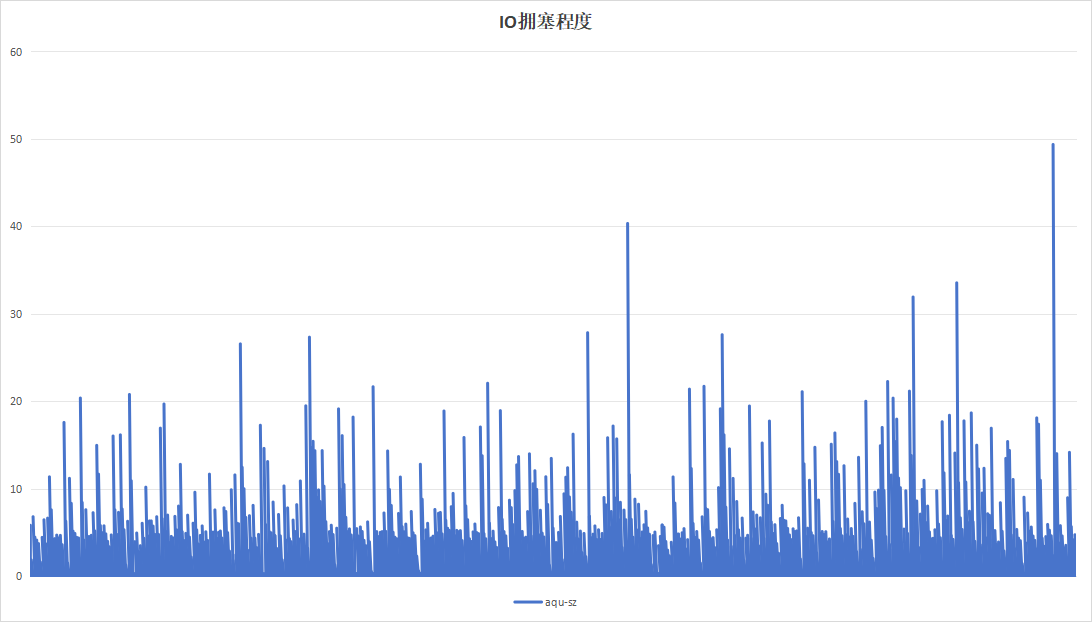 |
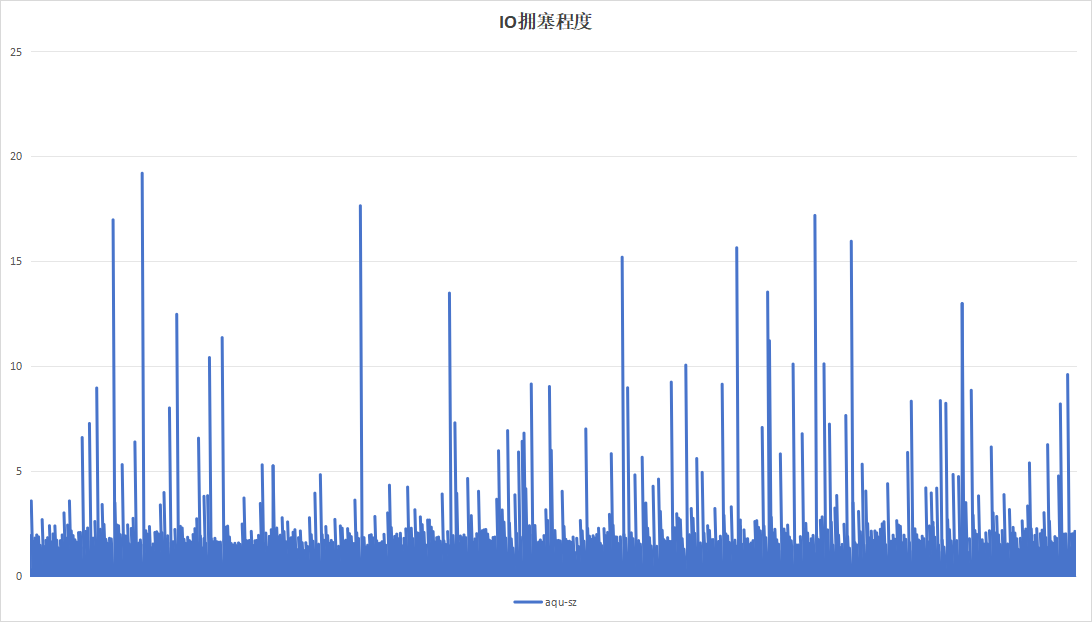 |
| 硬盘过载次数 | 58 | 8 |
4.3 SSD硬盘磨损率计算
翻阅SSD产品文档,厂家质保SSD整盘的擦写次数在3000次,按照既有的数据写入量,满负荷一直上电使用约在5年半左右,就会到达厂家的质保上限。
如果使用20分钟一次的trim间隔,可以通过smart信息进行计算。
shell
# smartctl -a /dev/sda其结果如下:
text
smartctl 7.4 (build date Sep 12 2024) [armv7l-linux-4.9.69-gd9b85500-dirty] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: XXXXXXX(保密处理)
Device Model: XXXXXXX(保密处理)
Serial Number: XXXXXXX(保密处理)
LU WWN Device Id: 5 24693e 000534688
Firmware Version: L20420
User Capacity: 64,023,257,088 bytes [64.0 GB]
Sector Size: 512 bytes logical/physical
Rotation Rate: Solid State Device
TRIM Command: Available, deterministic, zeroed
Device is: In smartctl database
ATA Version is: ACS-3 T13/2161-D revision 4
SATA Version is: SATA 3.2, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Mon Mar 10 11:24:57 2025 UTC
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x02) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Disabled.
Total time to complete Offline
data collection: ( 32) seconds.
Offline data collection
capabilities: (0x00) Offline data collection not supported.
SMART capabilities: (0x0002) Does not save SMART data before
entering power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x00) Error logging NOT supported.
General Purpose Logging supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x0000 000 000 000 Old_age Offline - 0
2 Throughput_Performance 0x0000 000 000 000 Old_age Offline - 0
5 Later_Bad_Block 0x0012 100 100 001 Old_age Always - 0
7 Seek_Error_Rate 0x0000 000 000 000 Old_age Offline - 0
8 Seek_Time_Performance 0x0000 000 000 000 Old_age Offline - 0
9 Power_On_Hours 0x0012 113 000 000 Old_age Always - 11121
10 Spin_Retry_Count 0x0000 000 000 000 Old_age Offline - 0
12 Power_Cycle_Count 0x0012 033 000 000 Old_age Always - 1825
163 Total_Bad_Block_Count 0x0000 000 000 000 Old_age Offline - 9
168 SATA_PHY_Error_Count 0x0000 000 000 000 Old_age Offline - 0
169 Remaining_Lifetime_Perc 0x0000 041 000 000 Old_age Offline - 41
175 Bad_Cluster_Table_Count 0x0000 000 000 000 Old_age Offline - 0
192 Power-Off_Retract_Count 0x0012 047 000 000 Old_age Always - 47
194 Temperature_Celsius 0x0002 037 100 000 Old_age Always - 37 (3 41 0 34 0)
197 Current_Pending_Sector 0x0000 000 000 000 Old_age Offline - 0
225 Data_Log_Write_Count 0x0000 000 000 000 Old_age Offline - 0
240 Write_Head 0x0000 000 000 000 Old_age Offline - 0
165 Max_Erase_Count 0x0012 065 000 000 Old_age Always - 2881
167 Average_Erase_Count 0x0012 251 000 000 Old_age Always - 1787
170 Spare_Block_Count 0x0013 100 100 001 Pre-fail Always - 142
171 Program_Fail_Count 0x0012 000 100 000 Old_age Always - 0
172 Erase_Fail_Count 0x0012 000 100 000 Old_age Always - 0
176 RANGE_RECORD_Count 0x0000 000 000 000 Old_age Offline - 0
184 End-to-End_Error 0x0012 000 000 000 Old_age Always - 2
187 Reported_Uncorrect 0x0012 000 000 000 Old_age Always - 500
229 Flash_ID 0x0000 100 100 000 Old_age Offline - 0x517693943a98
232 Spares_Remaining_Perc 0x0013 000 000 000 Pre-fail Always - 0
235 Later_Bad_Blk_Inf_R/W/E 0x0002 000 000 000 Old_age Always - 0 0 0
241 Host_Writes_32MiB 0x0002 100 100 000 Old_age Always - 898110
242 Host_Reads_32MiB 0x0002 100 100 000 Old_age Always - 631246
SMART Error Log not supported
SMART Self-test Log not supported
Selective Self-tests/Logging not supported
The above only provides legacy SMART information - try 'smartctl -x' for more
****只需要在测试开始前获取一次信息,测试结束后获取一次信息(比如连续运行7天),即可通过硬盘擦写次数的差值计算比例。此数据属于保密数据,故不在此展示。
思考与总结
如果要我做一个反思,我的第一反应是:"隔行如隔山"。对于SSD稍微深入了解一点,即可避免很多方向的尝试。
其次是对于个人而言,我想"学无止境"是对我这段排查经历的最好总结。
最后,送给自己的是:脚踏实地,勇攀高峰。