LInux系统编程相关笔记
基础操作
man 帮助文档
man 是 Linux 提供的一个手册,包含了绝大部分的命令、函数使用说明。
shell
man man
1 Executable programs or shell commands
2 System calls (functions provided by the kernel)
3 Library calls (functions within program libraries)
4 Special files (usually found in /dev)
5 File formats and conventions eg /etc/passwd
6 Games
7 Miscellaneous (including macro packages and conventions), e.g.
man(7), groff(7)
8 System administration commands (usually only for root)
9 Kernel routines [Non standard]man常用功能键
| 功能键 | 功能 |
|---|---|
| 空格键 | 显示手册页的下一屏 |
| Enter键 | 一次滚动手册页的一行 |
| b | 回滚一屏 |
| f | 前滚一屏 |
| q | 退出man命令 |
| h | 列出所有功能键 |
| /word | 搜索word字符串 |
命令行常用基础命令
- less
less命令将文件内容分页显示到终端,可以自由上下浏览
| 命令 | 作用 |
|---|---|
| 回车(ctrl + n) | 显示下一行 |
| ctrl + p | 显示上一行 |
| 空格(PageDown) | 显示下一页 |
| PageUp | 显示上一页 |
| q | 退出 |
| h | 获取帮助 |
- head
head命令从文件头部开始查看前 n 行的内容。
如果没有指定行数,默认显示前10行内容。
shell
head --n[行数] 文件名- tail
从文件尾部向上查看最后 n 行的内容
shell
# 使用方式:
tail --n[行数] 文件名
# 如果没有指定行数,默认显示最后10行内容- du
du命令用于查看某个目录大小。
du命令的使用格式如下:
du 选项 目录或文件名
| 选项 | 含义 |
|---|---|
| -a | 递归显示指定目录中各文件和子目录中文件占用的数据块 |
| -s | 显示指定文件或目录占用的数据块 |
| -b | 以字节为单位显示磁盘占用情况 |
| -h | 以K,M,G为单位,提高信息的可读性 |
- df
df命令用于检测文件系统的磁盘空间占用和空余情况,可以显示所有文件系统对节点和磁盘块的使用情况。
| 选项 | 含义 |
|---|---|
| -a | 显示所有文件系统的磁盘使用情况 |
| -m | 以1024字节为单位显示 |
| -h | 以K,M,G为单位,提高信息的可读性 |
压缩包命令
- tar
tar是Unix/Linux中最常用的备份工具,此命令可以把一系列文件归档到一个大文件中,也可以把档案文件解开以恢复数据。
shell
tar [选项] 打包文件名 文件tar命令很特殊,其选项前面可以使用"-",也可以不使用。
常用参数:
| 参数 | 含义 |
|---|---|
| -c | 生成档案文件,创建打包文件 |
| -v | 列出归档解档的详细过程,显示进度 |
| -f | 指定档案文件名称,f后面一定是.tar文件,所以必须放选项最后 |
| -t | 列出档案中包含的文件 |
| -x | 解开档案文件 |
| 注意:除了f需要放在参数的最后,其它参数的顺序任意。 |
tar -cvf 创建归档文件
tar -xvf 解除归档文件(还原)
tar -tvf 查看归档文件内容
- gzip
tar与gzip命令结合使用实现文件打包、压缩。
tar只负责打包文件,但不压缩,用gzip压缩tar打包后的文件,其扩展名一般用xxxx.tar.gz。
gzip 选项 被压缩文件
常用选项:
| 选项 | 含义 |
|---|---|
| -d | 解压 |
| -r | 压缩所有子目录 |
一次性压缩多个文件: gzip后面不能跟目录
tar这个命令并没有压缩的功能,它只是一个打包的命令,但是在tar命令中增加一个选项(-z)可以调用gzip实现了一个压缩的功能,实行一个先打包后压缩的过程。
shell
# 压缩
tar cvzf 压缩包包名 文件1 文件2 ...
# 解压
tar zxvf 压缩包包名
# 解压到指定目录
tar zxvf 压缩包包名 -C ./build/- bzip2
tar与bzip2命令结合使用实现文件打包、压缩(用法和gzip一样)。
tar只负责打包文件,但不压缩,用bzip2压缩tar打包后的文件,其扩展名一般用xxxx.tar.bz2。
在tar命令中增加一个选项(-j)可以调用bzip2实现了一个压缩的功能,实行一个先打包后压缩的过程。
shell
# 压缩用法:
tar jcvf 压缩包包名 文件...(tar jcvf bk.tar.bz2 *.c)
# 解压用法:
tar jxvf 压缩包包名 (tar jxvf bk.tar.bz2)- zip和unzip
通过zip压缩文件的目标文件不需要指定扩展名,默认扩展名为zip。
shell
# 压缩文件:
zip -r 目标文件(没有扩展名) 源文件
# 解压文件:
unzip -d 解压后目录文件 压缩文件文件权限管理
用户能够控制一个给定的文件或目录的访问程度,一个文件或目录可能有读、写及执行权限。
- chmod
chmod 修改文件权限有两种使用格式:字母法与数字法。
字母法:chmod u/g/o/a +/-/= rwx 文件
| u/g/o/a | 含义 |
|---|---|
| u | user 表示该文件的所有者 |
| g | group 表示与该文件的所有者属于同一组( group )者,即用户组 |
| o | other 表示其他以外的人 |
| a | all 表示这三者皆是 |
| ±= | 含义 |
|---|---|
| + | 增加权限 |
| - | 撤销权限 |
| = | 设定权限 |
| rwx | 含义 |
|---|---|
| r | read 表示可读取,对于一个目录,如果没有r权限,那么就意味着不能通过ls查看这个目录内部的内容。 |
| w | write 表示可写入,对于一个目录,如果没有w权限,那么就意味着不能在目录下创建新的文件。 |
| x | excute 表示可执行,对于一个目录,如果没有x权限,那么就意味着不能通过cd进入这个目录。 |
shell
chmod o+w file 给文件file的其它用户增加写权限
chmod u-r file 给文件file的拥有者减去读的权限
chmod g=x file设置文件file的所属组权限为可执行,同时去除读、写权限数字法:"rwx" 这些权限也可以用数字来代替
| rwx- | 数字代号 |
|---|---|
| r | 读取权限,数字代号为 "4" |
| w | 写入权限,数字代号为 "2" |
| x | 执行权限,数字代号为 "1" |
| - | 不具任何权限,数字t代号为 "0" |
chmod 777 file:所有用户拥有读、写、执行权限
注意:如果想递归所有目录加上相同权限,需要加上参数" -R "
- chown、chgrp
1、chown用于修改文件所有者.
使用方法:chown 用户名 文件或目录名
2、chgrp用于修改文件所属组
使用方法:chgrp 用户组名 文件或目录名
进程命令相关
- ps
ps命令可以查看进程的详细状况,常用选项(选项可以不加"-")如下:
| 选项 | 含义 |
|---|---|
| -a | 显示终端上的所有进程,包括其他用户的进程 |
| -u | 显示进程的详细状态 |
| -x | 显示没有控制终端的进程 |
| -w | 显示加宽,以便显示更多的信息 |
| -r | 只显示正在运行的进程 |
shell
ps aux
ps ef
ps -a- top
top命令用来动态显示运行中的进程。top命令能够在运行后,在指定的时间间隔更新显示信息。可以在使用top命令时加上-d 来指定显示信息更新的时间间隔。
在top命令执行后,可以按下按键得到对显示的结果进行排序:
| 按键 | 含义 |
|---|---|
| M | 根据内存使用量来排序 |
| P | 根据CPU占有率来排序 |
| T | 根据进程运行时间的长短来排序 |
| U | 可以根据后面输入的用户名来筛选进程 |
| K | 可以根据后面输入的PID来杀死进程。 |
| q | 退出 |
| h | 获得帮助 |
- kill
kill命令指定进程号的进程,需要配合 ps 使用。
信号值从0到15,其中9为绝对终止,可以处理一般信号无法终止的进程。
shell
kill [-signal] pid
kill -9 3444
# 查看进程编号 kill -l (小写L)
kill -l - killall
通过进程名字杀死进程
系统函数
基础函数
C库函数
c
fopen/fclose/fread/fwrite/fgets/fputs/fscanf/fprintf/fseek/fgetc/fputc/ftell/feof/flush...- 错误处理函数
errno 是记录系统的最后一次错误代码。代码是一个int型的值,在errno.h中定义。查看错误代码errno是调试程序的一个重要方法。
当Linux C api函数发生异常时,一般会将errno全局变量赋一个整数值,不同的值表示不同的含义,可以通过查看该值推测出错的原因。
c
#include <stdio.h> //fopen
#include <errno.h> //errno
#include <string.h> //strerror(errno)
int main()
{
FILE *fp = fopen("test.txt", "r");
if (NULL == fp)
{
printf("%d\n", errno); //打印错误码
printf("%s\n", strerror(errno)); //把errno的数字转换成相应的文字
perror("fopen err"); //打印错误原因的字符串
}
return 0;
}- 虚拟地址空间
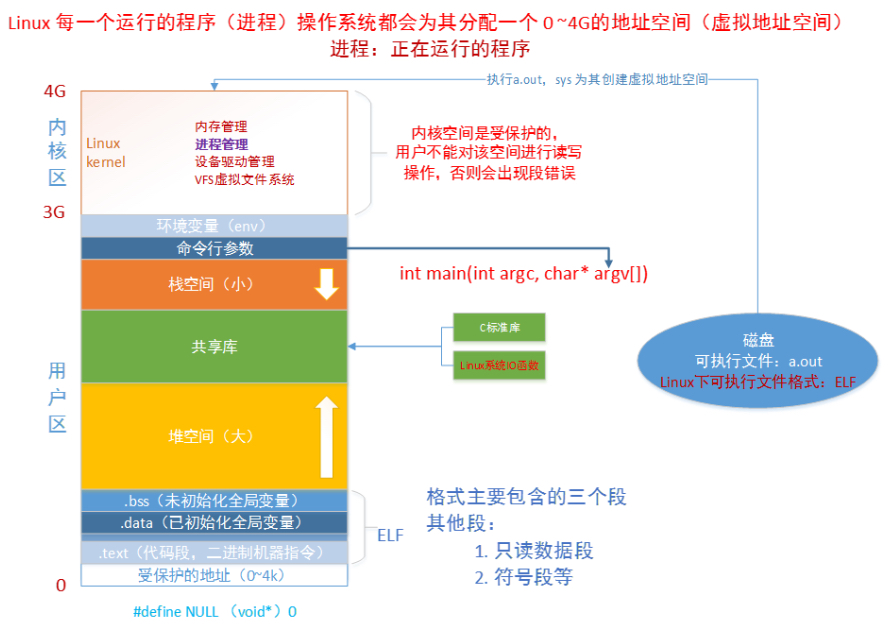
- 文件描述符
程序运行起来后(每个进程)都有一张文件描述符的表,标准输入、标准输出、标准错误输出设备文件被打开,对应的文件描述符 0、1、2 记录在表中。程序运行起来后这三个文件描述符是默认打开的。
c
#define STDIN_FILENO 0 //标准输入的文件描述符
#define STDOUT_FILENO 1 //标准输出的文件描述符
#define STDERR_FILENO 2 //标准错误的文件描述符常用文件IO函数
- open
c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 功能:
// 打开文件,如果文件不存在则可以选择创建。
// 参数:
// pathname:文件的路径及文件名
// flags:打开文件的行为标志,必选项 O_RDONLY, O_WRONLY, O_RDWR
// mode:这个参数,只有在文件不存在时有效,指新建文件时指定文件的权限
// 返回值:
// 成功:成功返回打开的文件描述符
// 失败:-1
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int fd = -1;
//1.以只读方式打开一个文件 如果文件不存在就报错
//fd = open("txt", O_RDONLY);
//2.以只写的方式打开一个文件 如果文件不存在就报错
//fd = open("txt", O_WRONLY);
//3.以只写的方式打开一个文件 如果文件不存在就创建, 如果文件存在就直接打开
//fd = open("txt", O_WRONLY | O_CREAT, 0644);
//4.以只读的方式打开一个文件 如果文件不存在就创建
//fd = open("txt", O_RDONLY | O_CREAT, 0644);
//5.以读写的方式打开文件 如果文件存在就报错, 如果文件不存在就创建
//fd = open("txt", O_RDWR | O_CREAT | O_EXCL, 0644);
//6.以读写的方式打开一个文件 如果文件不存在就创建 如果文件存在就清零
fd = open("txt", O_RDWR | O_CREAT | O_TRUNC, 0644);
if (-1 == fd)
{
perror("open");
return 1;
}- close
c
#include <unistd.h>
// 功能:
// 关闭已打开的文件
// 参数:
// fd : 文件描述符,open()的返回值
// 返回值:
// 成功:0
// 失败: -1, 并设置errno
int close(int fd);- write
c
#include <unistd.h>
// 功能:
// 把指定数目的数据写到文件(fd)
// 参数:
// fd : 文件描述符
// buf : 数据首地址
// count : 写入数据的长度(字节)
// 返回值:
// 成功:实际写入数据的字节个数
// 失败: - 1
ssize_t write(int fd, const void *buf, size_t count);
//读文件
memset(buf, 0, SIZE);
//从文件中最多读取SIZE个字节保存到buf中
ret = read(fd, buf, SIZE);
if (-1 == ret)
{
perror("read");
close(fd);
return;
}
printf("buf: %s\n", buf);- read
c
#include <unistd.h>
// 功能:
// 把指定数目的数据读到内存(缓冲区)
// 参数:
// fd : 文件描述符
// buf : 内存首地址
// count : 读取的字节个数
// 返回值:
// 成功:实际读取到的字节个数
// 失败: - 1
ssize_t read(int fd, void *buf, size_t count);
// 循环读取数据
while(1)
{
memset(buf, 0, SIZE);
//每一次从文件中读取最多SIZE个字节
ret = read(fd, buf, SIZE - 1);
if (ret < 0)
{
perror("read");
break;
}
printf("%s", buf);
//读到文件结尾
if (ret < SIZE - 1)
{
break;
}
}读常规文件是不会阻塞的,不管读多少字节,read一定会在有限的时间内返回。
从终端设备或网络读则不一定,如果从终端输入的数据没有换行符,调用read读终端设备就会阻塞,如果网络上没有接收到数据包,调用read从网络读就会阻塞,至于会阻塞多长时间也是不确定的,如果一直没有数据到达就一直阻塞在那里。
同样,写常规文件是不会阻塞的,而向终端设备或网络写则不一定.
c
#include <unistd.h> //read
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <errno.h> //EAGAIN
int main()
{
// /dev/tty --> 当前终端设备
// 以不阻塞方式(O_NONBLOCK)打开终端设备
int fd = open("/dev/tty", O_RDONLY | O_NONBLOCK);
char buf[10];
int n;
n = read(fd, buf, sizeof(buf));
if (n < 0)
{
// 如果为非阻塞,但是没有数据可读,此时全局变量 errno 被设置为 EAGAIN
if (errno != EAGAIN)
{
perror("read /dev/tty");
return -1;
}
printf("没有数据\n");
}
return 0;
}- lseek
所有打开的文件都有一个当前文件偏移量(current file offset),以下简称为 cfo。cfo 通常是一个非负整数,用于表明文件开始处到文件当前位置的字节数。
读写操作通常开始于 cfo,并且使 cfo 增大,增量为读写的字节数。文件被打开时,cfo 会被初始化为 0,除非使用了 O_APPEND 。
c
#include <sys/types.h>
#include <unistd.h>
// 功能:
// 改变文件的偏移量
// 参数:
// fd:文件描述符
// offset:根据whence来移动的位移数(偏移量),可以是正数,也可以负数,如果正数,则相对于whence往右移动,如果是负数,则相对于whence往左移动。如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过了文件末尾,再次写入时将增大文件尺寸。
// whence:其取值如下:
// SEEK_SET:从文件开头移动offset个字节
// SEEK_CUR:从当前位置移动offset个字节
// SEEK_END:从文件末尾移动offset个字节
// 返回值:
// 若lseek成功执行, 则返回新的偏移量
// 如果失败, 返回-1
off_t lseek(int fd, off_t offset, int whence);文件操作相关函数
- stat
获取文件相关信息
c
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
// 功能:
// 获取文件状态信息
// stat和lstat的区别:
// 当文件是一个符号链接时,lstat返回的是该符号链接本身的信息;
// 而stat返回的是该链接指向的文件的信息。
// 参数:
// path:文件名
// buf:保存文件信息的结构体
// 返回值:
// 成功: 0
// 失败: -1
int stat(const char *path, struct stat *buf);
int lstat(const char *pathname, struct stat *buf);
int main(void)
{
int ret = -1;
struct stat buf;
memset(&buf, 0, sizeof(buf));
//获取文件相关信息
ret = stat("txt", &buf);
if (-1 == ret)
{
perror("stat");
return 1;
}
printf("st_dev: %lu\n", buf.st_dev);
printf("st_ino: %lu\n", buf.st_ino);
printf("st_nlink: %lu\n", buf.st_nlink);
printf("st_uid: %d\n", buf.st_uid);
printf("st_gid: %d\n", buf.st_gid);
printf("st_rdev:%lu\n", buf.st_rdev);
printf("st_size: %ld\n", buf.st_size);
printf("st_blksize: %ld\n", buf.st_blksize);
printf("st_blocks: %ld\n", buf.st_blocks);
return 0;
}- access
c
#include <unistd.h>
// 功能:测试指定文件是否具有某种属性
// 参数:
// pathname:文件名
// mode:文件权限,4种权限
// R_OK: 是否有读权限
// W_OK: 是否有写权限
// X_OK: 是否有执行权限
// F_OK: 测试文件是否存在
// 返回值:
// 0: 有某种权限,或者文件存在
// -1:没有,或文件不存在
int access(const char *pathname, int mode);
//判断文件是否存在
if (access("./test", F_OK) == 0)
{
printf("文件存在...\n");
}
else
{
printf("文件不存在....\n");
}
//判断文件是否有读的权限
if (access("./test", R_OK) == 0)
{
printf("可以读\n");
}
else
{
printf("不可以读\n");
}- chmod
c
#include <sys/stat.h>
// 功能:修改文件权限
// 参数:
// filename:文件名
// mode:权限(8进制数)
// 返回值:
// 成功:0
// 失败:-1
int chmod(const char *pathname, mode_t mode);- chown
c
#include <unistd.h>
// 功能:修改文件所有者和所属组
// 参数:
// pathname:文件或目录名
// owner:文件所有者id,通过查看 /etc/passwd 得到所有者id
// group:文件所属组id,通过查看 /etc/group 得到用户组id
// 返回值:
// 成功:0
// 失败:-1
int chown(const char *pathname, uid_t owner, gid_t group);- symlink
c
#include <unistd.h>
// 功能:创建一个软链接
// 参数:
// target:源文件名字
// linkpath:软链接名字
// 返回值:
// 成功:0
// 失败:-1
int symlink(const char *target, const char *linkpath);- readlink
c
#include <unistd.h>
// 功能:读软连接对应的文件名,不是读内容(该函数只能读软链接文件)
// 参数:
// pathname:软连接名
// buf:存放软件对应的文件名
// bufsiz :缓冲区大小(第二个参数存放的最大字节数)
// 返回值:
// 成功:>0,读到buf中的字符个数
// 失败:-1
ssize_t readlink(const char *pathname, char *buf, size_t bufsiz);- unlink
c
#include <unistd.h>
// 功能:删除一个文件(软硬链接文件)
// 参数:
// pathname:删除的文件名字
// 返回值:
// 成功:0
// 失败:-1
int unlink(const char *pathname);- rename
c
#include <stdio.h>
// 功能:把oldpath的文件名改为newpath
// 参数:
// oldpath:旧文件名
// newpath:新文件名
// 返回值:
// 成功:0
// 失败:-1
int rename(const char *oldpath, const char *newpath);文件描述符相关函数
dup() 和 dup2() 是两个非常有用的系统调用,都是用来复制一个文件的描述符,使新的文件描述符也标识旧的文件描述符所标识的文件。
- dup
c
#include <unistd.h>
// 功能:
// 通过 oldfd 复制出一个新的文件描述符,新的文件描述符是调用进程文件描述符表中最小可用的文件描述符,最终 oldfd 和新的文件描述符都指向同一个文件。
// 参数:
// oldfd : 需要复制的文件描述符 oldfd
// 返回值:
// 成功:新文件描述符
// 失败: -1
int dup(int oldfd);- dup2
c
#include <unistd.h>
// 功能:
// 通过 oldfd 复制出一个新的文件描述符 newfd,如果成功,newfd 和函数返回值是同一个返回值,最终 oldfd 和新的文件描述符 newfd 都指向同一个文件。
// 参数:
// oldfd : 需要复制的文件描述符
// newfd : 新的文件描述符,这个描述符可以人为指定一个合法数字(0 - 1023),如果指定的数字已经被占用(和某个文件有关联),此函数会自动关闭 close() 断开这个数字和某个文件的关联,再来使用这个合法数字。
// 返回值:
// 成功:返回 newfd
// 失败:返回 -1
int dup2(int oldfd, int newfd);目录相关操作
- getcwd
c
#include <unistd.h>
// 功能:获取当前进程的工作目录
// 参数:
// buf : 缓冲区,存储当前的工作目录
// size : 缓冲区大小
// 返回值:
// 成功:buf中保存当前进程工作目录位置
// 失败:NULL
char *getcwd(char *buf, size_t size);- chdir
c
#include <unistd.h>
// 功能:修改当前进程(应用程序)的路径
// 参数:
// path:切换的路径
// 返回值:
// 成功:0
// 失败:-1
int chdir(const char *path);- opendir
c
#include <sys/types.h>
#include <dirent.h>
// 功能:打开一个目录
// 参数:
// name:目录名
// 返回值:
// 成功:返回指向该目录结构体指针
// 失败:NULL
DIR *opendir(const char *name);- closedir
c
#include <sys/types.h>
#include <dirent.h>
// 功能:关闭目录
// 参数:
// dirp:opendir返回的指针
// 返回值:
// 成功:0
// 失败:-1
int closedir(DIR *dirp);- readdir
c
#include <dirent.h>
// 功能:读取目录
// 参数:
// dirp:opendir的返回值
// 返回值:
// 成功:目录结构体指针
// 失败:NULL
struct dirent *readdir(DIR *dirp);时间相关函数
c
#include <time.h>
char *asctime(const struct tm *tm);
char *asctime_r(const struct tm *tm, char *buf);
char *ctime(const time_t *timep);
char *ctime_r(const time_t *timep, char *buf);
struct tm *gmtime(const time_t *timep);
struct tm *gmtime_r(const time_t *timep, struct tm *result);
struct tm *localtime(const time_t *timep);
struct tm *localtime_r(const time_t *timep, struct tm *result);
time_t mktime(struct tm *tm);进程相关
进程的状态
在三态模型中,进程状态分为三个基本状态,即运行态,就绪态,阻塞态。
在五态模型中,进程分为新建态、终止态,运行态,就绪态,阻塞态。
查看进程的状态 ps aux, 查看stat项的状态。
| 参数 | 含义 |
|---|---|
| D | 不可中断 Uninterruptible(usually IO) |
| R | 正在运行,或在队列中的进程 |
| S(大写) | 处于休眠状态 |
| T | 停止或被追踪 |
| Z | 僵尸进程 |
| W | 进入内存交换(从内核2.6开始无效) |
| X | 死掉的进程 |
| < | 高优先级 |
| N | 低优先级 |
| s | 包含子进程 |
| + | 位于前台的进程组 |
进程相关函数
每个进程都由一个进程号来标识,其类型为pid_t(整型)进程号的范围:0~32767。进程号总是唯一的,但进程号可以重用。当一个进程终止后,其进程号就可以再次使用。
进程号(PID):
标识进程的一个非负整型数。
父进程号(PPID):
任何进程( 除 init 进程)都是由另一个进程创建,该进程称为被创建进程的父进程,对应的进程号称为父进程号(PPID)。如:A 进程创建了 B 进程,A 的进程号就是 B 进程的父进程号。
进程组号(PGID):
进程组是一个或多个进程的集合。他们之间相互关联,进程组可以接收同一终端的各种信号,关联的进程有一个进程组号(PGID)。默认的情况下,当前的进程号会当做当前的进程组号。
- getpid/getppid/getpgid
c
#include <sys/types.h>
#include <unistd.h>
int main()
{
// 获取本进程号
int pid = getpid();
// 获取此函数的进程的父进程号
int ppid = getppid();
// 获取进程组号
int pgid = getpgid(pid);
printf("pid = %d ppid = %d pgid = %d\n",pid, ppid, pgid);
}- fork
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。
c
#include <sys/types.h>
#include <unistd.h>
// 功能:
// 用于从一个已存在的进程中创建一个新进程,新进程称为子进程,原进程称为父进程。
// 返回值:
// 成功:子进程中返回 0,父进程中返回子进程 ID。pid_t,为整型。
// 失败:返回-1。
// 失败的两个主要原因是:
// 1)当前的进程数已经达到了系统规定的上限,这时 errno 的值被设置为 EAGAIN。
// 2)系统内存不足,这时 errno 的值被设置为 ENOMEM。
pid_t fork();- exit进程退出函数
c
// 功能:结束调用此函数的进程。
// 参数:status:返回给父进程的参数(低 8 位有效),至于这个参数是多少根据需要来填写。
#include <stdlib.h>
void exit(int status);
#include <unistd.h>
void _exit(int status);- wait/waitpid 等待进程退出函数
父进程可以通过调用wait或waitpid得到它的退出状态同时彻底清除掉这个进程。
wait() 和 waitpid() 函数的功能一样,区别在于,wait() 函数会阻塞,waitpid() 可以设置不阻塞,waitpid() 还可以指定等待哪个子进程结束。
注意:一次wait或waitpid调用只能清理一个子进程,清理多个子进程应使用循环。
c
#include <sys/types.h>
#include <sys/wait.h>
// 功能:等待任意一个子进程结束,如果任意一个子进程结束了,此函数会回收该子进程的资源。
// 参数:status : 进程退出时的状态信息。
// 返回值:
// 成功:已经结束子进程的进程号
// 失败: -1
pid_t wait(int *status);
#include <sys/types.h>
#include <sys/wait.h>
// 功能:等待子进程终止,如果子进程终止了,此函数会回收子进程的资源。
//
// 参数:
// pid : 参数 pid 的值有以下几种类型:
// pid > 0 等待进程 ID 等于 pid 的子进程。
// pid = 0 等待同一个进程组中的任何子进程,如果子进程已经加入了别的进程组,waitpid 不会等待它。
// pid = -1 等待任一子进程,此时 waitpid 和 wait 作用一样。
// pid < -1 等待指定进程组中的任何子进程,这个进程组的 ID 等于 pid 的绝对值。
//
// status : 进程退出时的状态信息。和 wait() 用法一样。
//
// options : options 提供了一些额外的选项来控制 waitpid()。
// 0:同 wait(),阻塞父进程,等待子进程退出。
// WNOHANG:没有任何已经结束的子进程,则立即返回。
// WUNTRACED:如果子进程暂停了则此函数马上返回,并且不予以理会子进程的结束状态。(由于涉及到一些跟踪调试方面的知识,加之极少用到)
// 返回值:
// waitpid() 的返回值比 wait() 稍微复杂一些,一共有 3 种情况:
// 当正常返回的时候,waitpid() 返回收集到的已经回收子进程的进程号;
// 如果设置了选项 WNOHANG,而调用中 waitpid() 发现没有已退出的子进程可等待,则返回 0;
// 如果调用中出错,则返回-1,这时 errno 会被设置成相应的值以指示错误所在,如:当 pid 所对应的子进程不存在,或此进程存在,但不是调用进程的子进程,waitpid() 就会出错返回,这时 errno 被设置为 ECHILD;
pid_t waitpid(pid_t pid, int *status, int options);
// demo
#include<stdio.h>
#include <sys/types.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
printf("main start\n");
int pid = fork();
if (pid == 0)
{
printf("child start pid = %d\n", pid);
sleep(1);
} else {
printf("main continue pid = %d\n", pid);
int status = -1;
int wat_res = wait(&status);
printf("main wat_res = %d\n", wat_res);
if (WIFEXITED(status)) {
printf("exited, status=%d\n", WEXITSTATUS(status));
} else if (WIFSIGNALED(status)) {
printf("killed by signal %d\n", WTERMSIG(status));
} else if (WIFSTOPPED(status)) {
printf("stopped by signal %d\n", WSTOPSIG(status));
} else if (WIFCONTINUED(status)) {
printf("continued\n");
}
}
return 0;
}- 父子进程的关系
使用 fork() 函数得到的子进程是父进程的一个复制品,它从父进程处继承了整个进程的地址空间:包括进程上下文(进程执行活动全过程的静态描述)、进程堆栈、打开的文件描述符、信号控制设定、进程优先级、进程组号等。
Linux 的 fork() 使用是通过写时拷贝 (copy- on-write) 实现。
fork之后父子进程共享文件,fork产生的子进程与父进程相同的文件文件描述符指向相同的文件表,引用计数增加,共享文件文件偏移指针。
在子进程的地址空间里,子进程是从 fork() 这个函数后才开始执行代码。
孤儿进程:
父进程运行结束,但子进程还在运行(未运行结束)的子进程就称为孤儿进程(Orphan Process)。
僵尸进程:
进程终止,父进程尚未回收,子进程残留资源(PCB)存放于内核中,变成僵尸(Zombie)进程。
这样就会导致一个问题,如果进程不调用wait() 或 waitpid() 的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵尸进程,将因为没有可用的进程号而导致系统不能产生新的进程,此即为僵尸进程的危害,应当避免。
进程间通信
Linux进程间通信方式
同一主机进程间通信方式:
1、unix进程间通信方式:有名管道、无名管道、信号
2、System V进程间通讯方式:消息队列、共享内存、信号量
3、POSIX进程间通信方式:消息队列、共享内存、信号量
不同主机进程间通信:Socket
无名管道
- 理论概念
管道也叫无名管道,它是是UNIX系统IPC(进程间通信)的最古老形式,所有的UNIX系统都支持这种通信机制。
- pipe创建无名管道
c
#include <unistd.h>
// 功能:创建无名管道。
// 参数:
// pipefd : 为 int 型数组的首地址,其存放了管道的文件描述符 pipefd[0]、pipefd[1]。
// 当一个管道建立时,它会创建两个文件描述符 fd[0] 和 fd[1]。其中 fd[0] 固定用于读管道,而 fd[1] 固定用于写管道。一般文件 I/O的函数都可以用来操作管道(lseek() 除外)。
// 返回值:
// 成功:0
// 失败:-1
int pipe(int pipefd[2]);
// 示例
int main()
{
int fd_pipe[2] = { 0 };
pid_t pid;
if (pipe(fd_pipe) < 0)
{// 创建管道
perror("pipe");
}
pid = fork(); // 创建进程
if (pid == 0)
{ // 子进程
char buf[] = "write data";
// 往管道写端写数据
write(fd_pipe[1], buf, strlen(buf));
_exit(0);
}
else if (pid > 0)
{// 父进程
wait(NULL); // 等待子进程结束,回收其资源
char str[50] = { 0 };
// 从管道里读数据
read(fd_pipe[0], str, sizeof(str));
printf("str=[%s]\n", str); // 打印数据
}
return 0;
}- 特点
读管道:
管道中有数据,read返回实际读到的字节数。
管道中无数据:
管道写端被全部关闭,read返回0 (相当于读到文件结尾)
写端没有全部被关闭,read阻塞等待(不久的将来可能有数据到达,此时会让出cpu)
写管道:
管道读端全部被关闭,进程异常终止(也可使用捕捉SIGPIPE信号,使进程终止)
管道读端没有全部关闭:
管道已满,write阻塞。
管道未满,write将数据写入,并返回实际写入的字节数。
- 管道设置为非阻塞
c
//获取原来的flags
int flags = fcntl(fd[0], F_GETFL);
// 设置新的flags
flag |= O_NONBLOCK;
// flags = flags | O_NONBLOCK;
fcntl(fd[0], F_SETFL, flags);- 查看管道缓冲区
c
#include <unistd.h>
// 功能:该函数可以通过name参数查看不同的属性值
// 参数:
// fd:文件描述符
// name:
// _PC_PIPE_BUF,查看管道缓冲区大小
// _PC_NAME_MAX,文件名字字节数的上限
// 返回值:
// 成功:根据name返回的值的意义也不同。
// 失败: -1
long fpathconf(int fd, int name);
// demo
int main()
{
int fd[2];
int ret = pipe(fd);
if (ret == -1)
{
perror("pipe error");
exit(1);
}
long num = fpathconf(fd[0], _PC_PIPE_BUF);
printf("num = %ld\n", num);
return 0;
}有名管道
- 概念
管道,由于没有名字,只能用于亲缘关系的进程间通信。为了克服这个缺点,提出了命名管道(FIFO),也叫有名管道、FIFO文件。
命名管道(FIFO)不同于无名管道之处在于它提供了一个路径名与之关联,以FIFO的文件形式存在于文件系统中,这样,即使与 FIFO 的创建进程不存在亲缘关系的进程,只要可以访问该路径,就能够彼此通过FIFO相互通信,因此,通过FIFO不相关的进程也能交换数据。
命名管道(FIFO)和无名管道(pipe)有一些特点是相同的,不一样的地方在于:
1、FIFO在文件系统中作为一个特殊的文件而存在,但FIFO中的内容却存放在内存中。
2、当使用FIFO的进程退出后,FIFO文件将继续保存在文件系统中以便以后使用。
3、FIFO有名字,不相关的进程可以通过打开命名管道进行通信。
- 创建有名管道
一旦使用mkfifo创建了一个FIFO,就可以使用open打开它,常见的文件I/O函数都可用于fifo。如:close、read、write、unlink等。
FIFO严格遵循先进先出,对管道及FIFO的读总是从开始处返回数据,对它们的写则把数据添加到末尾。不支持诸如lseek()等文件定位操作。
c
#include <sys/types.h>
#include <sys/stat.h>
// 功能:命名管道的创建。
// 参数:
// pathname : 普通的路径名,也就是创建后 FIFO 的名字。
// mode : 文件的权限,与打开普通文件的 open() 函数中的 mode 参数相同。(0666)
// 返回值:
// 成功:0 状态码
// 失败:如果文件已经存在,则会出错且返回 -1。
int mkfifo(const char *pathname, mode_t mode);
// demo
int res = mkfifo("./my_fifo", 0777);
if (res == -1)
{
perror("mkfifo");
return ;
}
//进程1,写操作
int fd = open("my_fifo", O_WRONLY);
char send[100] = "Hello Mike";
write(fd, send, strlen(send));
//进程2,读操作
int fd = open("my_fifo", O_RDONLY);//等着只写
char recv[100] = { 0 };
//读数据,命名管道没数据时会阻塞,有数据时就取出来
read(fd, recv, sizeof(recv));
printf("read from my_fifo buf=[%s]\n", recv);- 注意事项
1、一个为只读而打开一个管道的进程会阻塞直到另外一个进程为只写打开该管道
2、一个为只写而打开一个管道的进程会阻塞直到另外一个进程为只读打开该管道
读管道:
管道中有数据,read返回实际读到的字节数。
管道中无数据:
管道写端被全部关闭,read返回0 (相当于读到文件结尾)
写端没有全部被关闭,read阻塞等待
写管道:
管道读端全部被关闭, 进程异常终止(也可使用捕捉SIGPIPE信号,使进程终止)
管道读端没有全部关闭:
管道已满,write阻塞。
管道未满,write将数据写入,并返回实际写入的字节数
共享存储映射
- 概念
存储映射使一个磁盘文件与存储空间中的一个缓冲区相映射。
于是当从缓冲区中取数据,就相当于读文件中的相应字节。将数据存入缓冲区,则相应的字节就自动写入文件。这样,就可在不适用read和write函数的情况下,使用地址(指针)完成I/O操作。
共享内存可以说是最有用的进程间通信方式,也是最快的IPC形式, 因为进程可以直接读写内存,而不需要任何数据的拷贝。
- 存储映射函数mmap/munmap
c
#include <sys/mman.h>
// 功能:一个文件或者其它对象映射进内存
// 参数:
// addr: 指定映射的起始地址, 通常设为NULL, 由系统指定
// length:映射到内存的文件长度
// prot: 映射区的保护方式, 最常用的:
// 读:PROT_READ
// 写:PROT_WRITE
// 读写:PROT_READ | PROT_WRITE
// flags: 映射区的特性, 可以是
// MAP_SHARED:写入映射区的数据会复制回文件, 且允许其他映射该文件的进程共享。
// MAP_PRIVATE:对映射区的写入操作会产生一个映射区的复制,对此区域所做的修改不会写回原文件。
// fd:由open返回的文件描述符, 代表要映射的文件。
// offset:以文件开始处的偏移量, 必须是4k的整数倍, 通常为0, 表示从文件头开始映射
// 返回值:
// 成功:返回创建的映射区首地址
// 失败:MAP_FAILED宏
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
// 功能:释放内存映射区
// 参数:
// addr:使用mmap函数创建的映射区的首地址
// length:映射区的大小
// 返回值:成功:0 失败:-1
int munmap(void *addr, size_t length);- 注意事项
1、创建映射区的过程中,隐含着一次对映射文件的读操作。
2、当MAP_SHARED时,要求:映射区的权限应 <=文件打开的权限(出于对映射区的保护)。而MAP_PRIVATE则无所谓,因为mmap中的权限是对内存的限制。
3、映射区的释放与文件关闭无关。只要映射建立成功,文件可以立即关闭。
4、特别注意,当映射文件大小为0时,不能创建映射区。所以,用于映射的文件必须要有实际大小。mmap使用时常常会出现总线错误,通常是由于共享文件存储空间大小引起的。
5、munmap传入的地址一定是mmap的返回地址。坚决杜绝指针++操作。
6、如果文件偏移量必须为4K的整数倍。
7、mmap创建映射区出错概率非常高,一定要检查返回值,确保映射区建立成功再进行后续操作。
c
// 1、共享映射的方式操作文件
int fd = open("xxx.txt", O_RDWR); //读写文件
int len = lseek(fd, 0, SEEK_END); //获取文件大小
//一个文件映射到内存,ptr指向此内存
void *ptr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (ptr == MAP_FAILED)
{
perror("mmap error");
exit(1);
}
close(fd); //关闭文件
char buf[4096];
printf("buf = %s\n", (char*)ptr); // 从内存中读数据,等价于从文件中读取内容
strcpy((char*)ptr, "this is a test");//写内容
int ret = munmap(ptr, len);
if (ret == -1)
{
perror("munmap error");
exit(1);
}
// 2、共享映射实现父子进程通信
int fd = open("xxx.txt", O_RDWR);// 打开一个文件
int len = lseek(fd, 0, SEEK_END);//获取文件大小
// 创建内存映射区
void *ptr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (ptr == MAP_FAILED)
{
perror("mmap error");
exit(1);
}
close(fd); //关闭文件
// 创建子进程
pid_t pid = fork();
if (pid == 0) //子进程
{
sleep(1); //演示,保证父进程先执行
// 读数据
printf("%s\n", (char*)ptr);
}
else if (pid > 0) //父进程
{
// 写数据
strcpy((char*)ptr, "i am u father!!");
// 回收子进程资源
wait(NULL);
}
// 释放内存映射区
int ret = munmap(ptr, len);
if (ret == -1)
{
perror("munmap error");
exit(1);
}匿名映射实现父子进程通信
其实Linux系统给我们提供了创建匿名映射区的方法,无需依赖一个文件即可创建映射区。同样需要借助标志位参数flags来指定。
使用MAP_ANONYMOUS (或MAP_ANON)
c
// 创建匿名内存映射区
int len = 4096;
void *ptr = mmap(NULL, len, PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANON, -1, 0);
if (ptr == MAP_FAILED)
{
perror("mmap error");
exit(1);
}
// 创建子进程
pid_t pid = fork();
if (pid > 0) //父进程
{
// 写数据
strcpy((char*)ptr, "hello mike!!");
// 回收
wait(NULL);
}
else if (pid == 0)//子进程
{
sleep(1);
// 读数据
printf("%s\n", (char*)ptr);
}
// 释放内存映射区
int ret = munmap(ptr, len);
if (ret == -1)
{
perror("munmap error");
exit(1);
}信号
- 概念
信号是 Linux 进程间通信的最古老的方式。信号是软件中断,它是在软件层次上对中断机制的一种模拟,是一种异步通信的方式 。信号可以导致一个正在运行的进程被另一个正在运行的异步进程中断,转而处理某一个突发事件。
信号的特点:简单、不能携带大量信息、满足某个特设条件才发送
信号可以直接进行用户空间进程和内核空间进程的交互,内核进程可以利用它来通知用户空间进程发生了哪些系统事件。
一个完整的信号周期包括三个部分:信号的产生,信号在进程中的注册,信号在进程中的注销,执行信号处理函数
信号的四要素:编号、名称、事件、默认处理动作
可通过man 7 signal查看帮助文档获取。
可通过kill -l(小写L)查看信号的编号。
不存在编号为0的信号。其中1-31号信号称之为常规信号(也叫普通信号或标准信号),34-64称之为实时信号,驱动编程与硬件相关。名字上区别不大。而前32个名字各不相同。
未决状态:没有被处理
递达状态:信号被处理了
阻塞信号集(信号屏蔽字):
将某些信号加入集合,对他们设置屏蔽,当屏蔽x信号后,再收到该信号,该信号的处理将推后(处理发生在解除屏蔽后)。
未决信号集:
信号产生,未决信号集中描述该信号的位立刻翻转为1,表示信号处于未决状态。当信号被处理对应位翻转回为0。这一时刻往往非常短暂。
信号产生后由于某些原因(主要是阻塞)不能抵达。这类信号的集合称之为未决信号集。在屏蔽解除前,信号一直处于未决状态。
- 常用信号产生函数
c
#include <sys/types.h>
#include <signal.h>
// 功能:给指定进程发送指定信号(不一定杀死)
// 参数:pid : 取值有 4 种情况 :
// pid > 0: 将信号传送给进程 ID 为pid的进程。
// pid = 0 : 将信号传送给当前进程所在进程组中的所有进程。
// pid = -1 : 将信号传送给系统内所有的进程。
// pid < -1 : 将信号传给指定进程组的所有进程。这个进程组号等于 pid 的绝对值。
// sig : 信号的编号,这里可以填数字编号,也可以填信号的宏定义,可以通过命令 kill - l("l" 为字母)进行相应查看。不推荐直接使用数字,应使用宏名,因为不同操作系统信号编号可能不同,但名称一致。
// 返回值:成功:0 失败:-1
int kill(pid_t pid, int sig);
// 功能:给当前进程发送指定信号(自己给自己发),等价于 kill(getpid(), sig)
// 参数:sig:信号编号
// 返回值:成功:0 失败:非0值
int raise(int sig);
#include <stdlib.h>
// 功能:给自己发送异常终止信号 SIGABRT,并产生core文件,等价于kill(getpid(), SIGABRT);
void abort(void);
#include <unistd.h>
// 功能:
// 设置定时器(闹钟)。在指定seconds后,内核会给当前进程发送SIGALRM信号。进程收到该信号,默认动作终止。每个进程都有且只有唯一的一个定时器。
// 取消定时器alarm(0),返回旧闹钟余下秒数。
// 参数:seconds:指定的时间,以秒为单位
// 返回值:返回0或剩余的秒数
unsigned int alarm(unsigned int seconds);
#include <sys/time.h>
// 功能:设置定时器(闹钟)。 可代替alarm函数。精度微秒us,可以实现周期定时。
// 参数:which:指定定时方式
// 自然定时:ITIMER_REAL → 14)SIGALRM计算自然时间
// 虚拟空间计时(用户空间):ITIMER_VIRTUAL → 26)SIGVTALRM 只计算进程占用cpu的时间
// 运行时计时(用户 + 内核):ITIMER_PROF → 27)SIGPROF计算占用cpu及执行系统调用的时间
// new_value:struct itimerval, 负责设定timeout时间
// struct itimerval {
// struct timerval it_interval; // 闹钟触发周期
// struct timerval it_value; // 闹钟触发时间
// };
// struct timeval {
// long tv_sec; // 秒
// long tv_usec; // 微秒
// }
// itimerval.it_value: 设定第一次执行function所延迟的秒数
// itimerval.it_interval: 设定以后每几秒执行function
// old_value: 存放旧的timeout值,一般指定为NULL
// 返回值:成功:0 失败:-1
int setitimer(int which, const struct itimerval *new_value, struct itimerval *old_value);
// demo
void myfunc(int sig)
{
printf("hello\n");
}
int main()
{
struct itimerval new_value;
//定时周期
new_value.it_interval.tv_sec = 1;
new_value.it_interval.tv_usec = 0;
//第一次触发的时间
new_value.it_value.tv_sec = 2;
new_value.it_value.tv_usec = 0;
signal(SIGALRM, myfunc); //信号处理
setitimer(ITIMER_REAL, &new_value, NULL); //定时器设置
while (1);
return 0;
}- 信号捕捉
一个进程收到一个信号的时候,可以用如下方法进行处理:
1、执行系统默认动作
对大多数信号来说,系统默认动作是用来终止该进程。
2、忽略此信号(丢弃)
接收到此信号后没有任何动作。
3、执行自定义信号处理函数(捕获)
用用户定义的信号处理函数处理该信号。
SIGKILL和SIGSTOP不能更改信号的处理方式,因为它们向用户提供了一种使进程终止的可靠方法。
1、signal函数
c
#include <signal.h>
// 功能:注册信号处理函数(不可用于 SIGKILL、SIGSTOP 信号),即确定收到信号后处理函数的入口地址。此函数不会阻塞。
// 参数:
// signum:信号的编号,这里可以填数字编号,也可以填信号的宏定义,可以通过命令 kill - l("l" 为字母)进行相应查看。
// handler : 取值有 3 种情况:
// SIG_IGN:忽略该信号
// SIG_DFL:执行系统默认动作
// 信号处理函数名:自定义信号处理函数,如:func
// 回调函数的定义如下:
// void func(int signo)
// {
// // signo 为触发的信号,为 signal() 第一个参数的值
// }
//
// 返回值:
// 成功:第一次返回 NULL,下一次返回此信号上一次注册的信号处理函数的地址。如果需要使用此返回值,必须在前面先声明此函数指针的类型。
// 失败:返回 SIG_ERR
typedef void(*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
// 该函数由ANSI定义,由于历史原因在不同版本的Unix和不同版本的Linux中可能有不同的行为。因此应该尽量避免使用它,取而代之使用sigaction函数
// 信号处理函数
void signal_handler(int signo)
{
if (signo == SIGINT)
{
printf("recv SIGINT\n");
}
else if (signo == SIGQUIT)
{
printf("recv SIGQUIT\n");
}
}
int main()
{
printf("wait for SIGINT OR SIGQUIT\n");
/* SIGINT: Ctrl+c ; SIGQUIT: Ctrl+\ */
// 信号注册函数
signal(SIGINT, signal_handler);
signal(SIGQUIT, signal_handler);
while (1); //不让程序结束
return 0;
}2、sigaction函数
c
#include <signal.h>
// 功能:检查或修改指定信号的设置(或同时执行这两种操作)。
// 参数:
// signum:要操作的信号。
// act: 要设置的对信号的新处理方式(传入参数)。
// oldact:原来对信号的处理方式(传出参数)。
// 如果 act 指针非空,则要改变指定信号的处理方式(设置),如果 oldact 指针非空,则系统将此前指定信号的处理方式存入 oldact。
// 返回值:成功:0 失败:-1
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
struct sigaction {
void(*sa_handler)(int); //旧的信号处理函数指针
void(*sa_sigaction)(int, siginfo_t *, void *); //新的信号处理函数指针
sigset_t sa_mask; //信号阻塞集
int sa_flags; //信号处理的方式
void(*sa_restorer)(void); //已弃用
};- SIGCHLD信号
SIGCHLD信号产生的条件
子进程终止时、子进程接收到SIGSTOP信号停止时、子进程处在停止态,接受到SIGCONT后唤醒时
如何避免僵尸进程
1、最简单的方法,父进程通过wait()和waitpid()等函数等待子进程结束,但是,这会导致父进程挂起。
2、如果父进程要处理的事情很多,不能够挂起,通过signal()函数人为处理信号SIGCHLD,只要有子进程退出自动调用指定好的回调函数,因为子进程结束后,父进程会收到该信号SIGCHLD,可以在其回调函数里调用wait()或waitpid()回收。
c
void sig_child(int signo)
{
pid_t pid;
//处理僵尸进程, -1 代表等待任意一个子进程, WNOHANG代表不阻塞
while ((pid = waitpid(-1, NULL, WNOHANG)) > 0)
{
printf("child %d terminated.\n", pid);
}
}
int main()
{
pid_t pid;
// 创建捕捉子进程退出信号
// 只要子进程退出,触发SIGCHLD,自动调用sig_child()
signal(SIGCHLD, sig_child);
pid = fork(); // 创建进程
if (pid < 0)
{ // 出错
perror("fork error:");
exit(1);
}
else if (pid == 0)
{ // 子进程
printf("I am child process,pid id %d.I am exiting.\n", getpid());
exit(0);
}
else if (pid > 0)
{ // 父进程
sleep(2); // 保证子进程先运行
printf("I am father, i am exited\n\n");
system("ps -ef | grep defunct"); // 查看有没有僵尸进程
}
return 0;
}3、如果父进程不关心子进程什么时候结束,那么可以用signal(SIGCHLD, SIG_IGN)通知内核,自己对子进程的结束不感兴趣,父进程忽略此信号,那么子进程结束后,内核会回收,并不再给父进程发送信号。
c
int main()
{
pid_t pid;
// 忽略子进程退出信号的信号
// 那么子进程结束后,内核会回收, 并不再给父进程发送信号
signal(SIGCHLD, SIG_IGN);
pid = fork(); // 创建进程
if (pid < 0)
{ // 出错
perror("fork error:");
exit(1);
}
else if (pid == 0)
{ // 子进程
printf("I am child process,pid id %d.I am exiting.\n", getpid());
exit(0);
}
else if (pid > 0)
{ // 父进程
sleep(2); // 保证子进程先运行
printf("I am father, i am exited\n\n");
system("ps -ef | grep defunct"); // 查看有没有僵尸进程
}
return 0;
}守护进程
其他操作概念
- 查看终端设备名
查看unix终端对应的设备名:终端输入tty,回车查看
- 进程组概述
每个进程都属于一个进程组。在waitpid函数和kill函数的参数中都曾使用到。操作系统设计的进程组的概念,是为了简化对多个进程的管理。
当父进程,创建子进程的时候,默认子进程与父进程属于同一进程组。进程组ID为第一个进程ID(组长进程)。所以,组长进程标识:其进程组ID为其进程ID。
组长进程可以创建一个进程组,创建该进程组中的进程,然后终止。只要进程组中有一个进程存在,进程组就存在,与组长进程是否终止无关。
进程组生存期:进程组创建到最后一个进程离开(终止或转移到另一个进程组)。
一个进程可以为自己或子进程设置进程组ID。
c
#include <unistd.h>
// 功能:获取当前进程的进程组ID 返回值:总是返回调用者的进程组ID
pid_t getpgrp(void);
// 功能:获取指定进程的进程组ID
// 参数:pid:进程号,如果pid = 0,那么该函数作用和getpgrp一样
pid_t getpgid(pid_t pid);
// 功能:改变进程默认所属的进程组。通常可用来加入一个现有的进程组或创建一个新进程组。
// 参数:将参1对应的进程,加入参2对应的进程组中
int setpgid(pid_t pid, pid_t pgid);- 会话
会话是一个或多个进程组的集合。
创建会话注意事项
1、调用进程不能是进程组组长,该进程变成新会话首进程(session header)
2、该调用进程是组长进程,则出错返回
3、该进程成为一个新进程组的组长进程
4、需有root权限(ubuntu不需要)
5、新会话丢弃原有的控制终端,该会话没有控制终端
6、建立新会话时,先调用fork, 父进程终止,子进程调用setsid
c
#include <unistd.h>
// 功能:获取进程所属的会话ID
// 参数:pid:进程号,pid为0表示查看当前进程session ID
// 返回值:成功:返回调用进程的会话ID 失败:-1
pid_t getsid(pid_t pid);
// 功能:创建一个会话,并以自己的ID设置进程组ID,同时也是新会话的ID。调用了setsid函数的进程,既是新的会长,也是新的组长。
// 返回值:成功:返回调用进程的会话ID 失败:-1
pid_t setsid(void);守护进程介绍
- 概念
守护进程(Daemon Process),也就是通常说的Daemon进程(精灵进程),是Linux中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。一般采用以d结尾的名字。
守护进程是个特殊的孤儿进程,这种进程脱离终端之所以脱离于终端是为了避免进程被任何终端所产生的信息所打断,其在执行过程中的信息也不在任何终端上显示。由于在Linux中,每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程都会依附于这个终端,这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程都会自动关闭。
- 守护进程模型
1、创建子进程,父进程退出(必须)
所有工作在子进程中进行形式上脱离了控制终端
2、在子进程中创建新会话(必须)
setsid()函数
使子进程完全独立出来,脱离控制
3、改变当前目录为根目录(不是必须)
chdir()函数
防止占用可卸载的文件系统
也可以换成其它路径
4、重设文件权限掩码(不是必须)
umask()函数
防止继承的文件创建屏蔽字拒绝某些权限
增加守护进程灵活性
5、关闭文件描述符(不是必须)
继承的打开文件不会用到,浪费系统资源,无法卸载
6、开始执行守护进程核心工作(必须)
守护进程退出处理程序模型
- 守护进程示例
c
// 写一个守护进程, 每隔2s获取一次系统时间, 将这个时间写入到磁盘文件
/*
* time_t rawtime;
* time ( &rawtime ); --- 获取时间,以秒计,从1970年1月一日起算,存于rawtime
* localtime ( &rawtime ); //转为当地时间,tm 时间结构
* asctime() // 转为标准ASCII时间格式:
*/
void write_time(int num)
{
time_t rawtime;
struct tm * timeinfo;
// 获取时间
time(&rawtime);
#if 0
// 转为本地时间
timeinfo = localtime(&rawtime);
// 转为标准ASCII时间格式
char *cur = asctime(timeinfo);
#else
char* cur = ctime(&rawtime);
#endif
// 将得到的时间写入文件中
int fd = open("/home/timelog.txt", O_RDWR | O_CREAT | O_APPEND, 0664);
if (fd == -1)
{
perror("open error");
exit(1);
}
// 写文件
int ret = write(fd, cur, strlen(cur) + 1);
if (ret == -1)
{
perror("write error");
exit(1);
}
// 关闭文件
close(fd);
}
int main(int argc, const char* argv[])
{
pid_t pid = fork();
if (pid == -1)
{
perror("fork error");
exit(1);
}
if (pid > 0)
{
// 父进程退出
exit(1);
}
else if (pid == 0)
{
// 子进程
// 提升为会长,同时也是新进程组的组长
setsid();
// 更改进程的执行目录
chdir("/home/edu");
// 更改掩码
umask(0022);
// 关闭文件描述符
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
// 注册信号捕捉函数
// 先注册,再定时
struct sigaction sigact;
sigact.sa_flags = 0;
sigemptyset(&sigact.sa_mask);
sigact.sa_handler = write_time;
sigaction(SIGALRM, &sigact, NULL);
// 设置定时器
struct itimerval act;
// 定时周期
act.it_interval.tv_sec = 2;
act.it_interval.tv_usec = 0;
// 设置第一次触发定时器时间
act.it_value.tv_sec = 2;
act.it_value.tv_usec = 0;
// 开始计时
setitimer(ITIMER_REAL, &act, NULL);
// 防止子进程退出
while (1);
}
return 0;
}多线程相关
线程相关函数
- 线程id相关
c
// 线程函数的程序在 pthread 库中,故链接时要加上参数 -lpthread
#include <pthread.h>
// 功能:获取线程号。
// 返回值调用线程的线程 ID
pthread_t pthread_self(void);
// 功能: 判断线程号 t1 和 t2 是否相等。为了方便移植,尽量使用函数来比较线程 ID。
// 参数: t1,t2:待判断的线程号。
// 返回值: 相等: 非 0 不相等:0
int pthread_equal(pthread_t t1, pthread_t t2);
int main()
{
pthread_t thread_id = pthread_self(); // 返回调用线程的线程ID
printf("Thread ID = %lu \n", thread_id);
if (0 != pthread_equal(thread_id, pthread_self()))
{
printf("Equal!\n");
}
else
{
printf("Not equal!\n");
}
return 0;
}- 线程的创建和回收
c
#include <pthread.h>
// 功能:创建一个线程。
// 参数:
// thread:线程标识符地址。
// attr:线程属性结构体地址,通常设置为 NULL。
// start_routine:线程函数的入口地址。
// arg:传给线程函数的参数。
// 返回值:成功:0 失败:非 0
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void *),
void *arg );
// 功能: 等待线程结束(此函数会阻塞),并回收线程资源,类似进程的 wait() 函数。如果线程已经结束,那么该函数会立即返回。
// 参数:
// thread:被等待的线程号。
// retval:用来存储线程退出状态的指针的地址。
// 返回值: 成功:0 失败:非 0
int pthread_join(pthread_t thread, void **retval);
void *thead(void *arg)
{
static int num = 123; //静态变量
printf("after 2 seceonds, thread will return\n");
sleep(2);
return #
}
int main()
{
pthread_t tid;
int ret = 0;
void *value = NULL;
// 创建线程
pthread_create(&tid, NULL, thead, NULL);
// 等待线程号为 tid 的线程,如果此线程结束就回收其资源
// &value保存线程退出的返回值
pthread_join(tid, &value);
printf("value = %d\n", *((int *)value));
return 0;
}
// 调用该函数的线程将挂起等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join得到的终止状态是不同的,总结如下:
// 1、如果thread线程通过return返回,retval所指向的单元里存放的是thread线程函数的返回值。
// 2、如果thread线程被别的线程调用pthread_cancel异常终止掉,retval所指向的单元里存放的是常数PTHREAD_CANCELED。
// 3、如果thread线程是自己调用pthread_exit终止的,retval所指向的单元存放的是传给pthread_exit的参数。
// 注意的一点是,如果设置一个线程为分离线程,而这个线程运行又非常快,它很可能在pthread_create函数返回之前就终止了,它终止以后就可能将线程号和系统资源移交给其他的线程使用,这样调用pthread_create的线程就得到了错误的线程号。
// 要避免这种情况可以采取一定的同步措施,最简单的方法之一是可以在被创建的线程里调用pthread_cond_timedwait函数,让这个线程等待一会儿,留出足够的时间让函数pthread_create返回。- 线程分离
不能对一个已经处于detach状态的线程调用pthread_join,这样的调用将返回EINVAL错误。也就是说,如果已经对一个线程调用了pthread_detach就不能再调用pthread_join了。
c
#include <pthread.h>
// 功能:使调用线程与当前进程分离,分离后不代表此线程不依赖与当前进程,线程分离的目的是将线程资源的回收工作交由系统自动来完成,也就是说当被分离的线程结束之后,系统会自动回收它的资源。所以,此函数不会阻塞。
// 参数:thread:线程号。
// 返回值:成功:0 失败:非0
int pthread_detach(pthread_t thread);
// 功能:杀死(取消)线程
// 参数:thread : 目标线程ID。
// 返回值:成功:0 失败:出错编号
int pthread_cancel(pthread_t thread);
// 注意:线程的取消并不是实时的,而又一定的延时。需要等待线程到达某个取消点(检查点)。
// 杀死线程也不是立刻就能完成,必须要到达取消点。- 线程属性相关
属性值不能直接设置,须使用相关函数进行操作,初始化的函数为pthread_attr_init,这个函数必须在pthread_create函数之前调用。之后须用pthread_attr_destroy函数来释放资源。
c
typedef struct
{
int etachstate; //线程的分离状态
int schedpolicy; //线程调度策略
struct sched_param schedparam; //线程的调度参数
int inheritsched; //线程的继承性
int scope; //线程的作用域
size_t guardsize; //线程栈末尾的警戒缓冲区大小
int stackaddr_set; //线程的栈设置
void* stackaddr; //线程栈的位置
size_t stacksize; //线程栈的大小
} pthread_attr_t;
#include <pthread.h>
// 功能:初始化线程属性函数,注意:应先初始化线程属性,再pthread_create创建线程
// 参数:attr:线程属性结构体
// 返回值:成功:0 失败:错误号
int pthread_attr_init(pthread_attr_t *attr);
// 功能:销毁线程属性所占用的资源函数
// 参数:attr:线程属性结构体
// 返回值:成功:0 失败:错误号
int pthread_attr_destroy(pthread_attr_t *attr);
// 功能:设置线程分离状态
// 参数:
// attr:已初始化的线程属性
// detachstate: 分离状态
// PTHREAD_CREATE_DETACHED(分离线程)
// PTHREAD_CREATE_JOINABLE(非分离线程)
// 返回值:成功:0 失败:非0
int pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate);
// 功能:获取线程分离状态
// 参数:
// attr:已初始化的线程属性
// detachstate: 分离状态
// PTHREAD_CREATE_DETACHED(分离线程)
// PTHREAD _CREATE_JOINABLE(非分离线程)
// 返回值:成功:0 失败:非0
int pthread_attr_getdetachstate(const pthread_attr_t *attr, int *detachstate);
// 当系统中有很多线程时,可能需要减小每个线程栈的默认大小,防止进程的地址空间不够用,当线程调用的函数会分配很大的局部变量或者函数调用层次很深时,可能需要增大线程栈的默认大小
// 功能:设置线程的栈大小
// 参数:
// attr:指向一个线程属性的指针
// stacksize:线程的堆栈大小
// 返回值:成功:0 失败:错误号
int pthread_attr_setstacksize(pthread_attr_t *attr, size_t stacksize);
// 功能:获取线程的栈大小
// 参数:
// attr:指向一个线程属性的指针
// stacksize:返回线程的堆栈大小
// 返回值:成功:0 失败:错误号
int pthread_attr_getstacksize(const pthread_attr_t *attr, size_t *stacksize);- 线程使用注意事项
1、主线程退出其他线程不退出,主线程应调用pthread_exit
2、避免僵尸线程
a、pthread_join
b、pthread_detach
c、pthread_create指定分离属性
被join线程可能在join函数返回前就释放完自己的所有内存资源,所以不应当返回被回收线程栈中的值;
3、malloc和mmap申请的内存可以被其他线程释放
4、应避免在多线程模型中调用fork,除非马上exec,子进程中只有调用fork的线程存在,其他线程t在子进程中均pthread_exit
5、信号的复杂语义很难和多线程共存,应避免在多线程引入信号机制
锁相关
- 互斥锁Mutex函数
c
#include <pthread.h>
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);
// 功能:初始化一个互斥锁。
// 参数:
// mutex:互斥锁地址。类型是 pthread_mutex_t 。
// attr:设置互斥量的属性,通常可采用默认属性,即可将 attr 设为 NULL。
// 可以使用宏 PTHREAD_MUTEX_INITIALIZER 静态初始化互斥锁,比如:
// pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// 这种方法等价于使用 NULL 指定的 attr 参数调用 pthread_mutex_init() 来完成动态初始化,不同之处在于 PTHREAD_MUTEX_INITIALIZER 宏不进行错误检查。
// 返回值:成功:0,成功申请的锁默认是打开的。失败:非 0 错误码
int pthread_mutex_destroy(pthread_mutex_t *mutex);
// 功能:销毁指定的一个互斥锁。互斥锁在使用完毕后,必须要对互斥锁进行销毁,以释放资源。
// 参数:mutex:互斥锁地址。
// 返回值:成功:0 失败:非 0 错误码
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 功能:对互斥锁上锁,若互斥锁已经上锁,则调用者阻塞,直到互斥锁解锁后再上锁。
// 参数: mutex:互斥锁地址。
// 返回值:成功:0 失败:非 0 错误码
int pthread_mutex_trylock(pthread_mutex_t *mutex);
// 调用该函数时,若互斥锁未加锁,则上锁,返回 0;
// 若互斥锁已加锁,则函数直接返回失败,即 EBUSY。
int pthread_mutex_unlock(pthread_mutex_t *mutex);
// 功能:对指定的互斥锁解锁。
// 参数:mutex:互斥锁地址。
// 返回值:成功:0 失败:非0错误码- 读写锁相关
读写锁的特点:
1、如果有其它线程读数据,则允许其它线程执行读操作,但不允许写操作。
2、如果有其它线程写数据,则其它线程都不允许读、写操作。
如果某线程申请了读锁,其它线程可以再申请读锁,但不能申请写锁。
如果某线程申请了写锁,其它线程不能申请读锁,也不能申请写锁。
c
#include <pthread.h>
int pthread_rwlock_init(pthread_rwlock_t *restrict rwlock, const pthread_rwlockattr_t *restrict attr);
// 功能:用来初始化 rwlock 所指向的读写锁。
//
// 参数:
// rwlock:指向要初始化的读写锁指针。
// attr:读写锁的属性指针。如果attr为NULL则会使用默认的属性初始化读写锁,否则使用指定的attr初始化读写锁。
//
// 可以使用宏 PTHREAD_RWLOCK_INITIALIZER 静态初始化读写锁,比如:
// pthread_rwlock_t my_rwlock = PTHREAD_RWLOCK_INITIALIZER;
//
// 这种方法等价于使用NULL指定的attr参数调用pthread_rwlock_init()来完成动态初始化,不同之处在于PTHREAD_RWLOCK_INITIALIZER 宏不进行错误检查。
//
// 返回值:成功:0,读写锁的状态将成为已初始化和已解锁。 失败:非 0 错误码。
int pthread_rwlock_destroy(pthread_rwlock_t *rwlock);
// 功能:用于销毁一个读写锁,并释放所有相关联的资源(所谓的所有指的是由 pthread_rwlock_init() 自动申请的资源) 。
// 参数:rwlock:读写锁指针。
// 返回值:成功:0 失败:非 0 错误码
int pthread_rwlock_rdlock(pthread_rwlock_t *rwlock);
// 功能:
// 以阻塞方式在读写锁上获取读锁(读锁定)。
// 如果没有写者持有该锁,并且没有写者阻塞在该锁上,则调用线程会获取读锁。
// 如果调用线程未获取读锁,则它将阻塞直到它获取了该锁。一个线程可以在一个读写锁上多次执行读锁定。
// 线程可以成功调用 pthread_rwlock_rdlock() 函数 n 次,但是之后该线程必须调用 pthread_rwlock_unlock() 函数 n 次才能解除锁定。
// 参数:rwlock:读写锁指针。
// 返回值:成功:0 失败:非 0 错误码
int pthread_rwlock_tryrdlock(pthread_rwlock_t *rwlock);
// 用于尝试以非阻塞的方式来在读写锁上获取读锁。
// 如果有任何的写者持有该锁或有写者阻塞在该读写锁上,则立即失败返回。
int pthread_rwlock_wrlock(pthread_rwlock_t *rwlock);
// 功能:
// 在读写锁上获取写锁(写锁定)。
// 如果没有写者持有该锁,并且没有写者读者持有该锁,则调用线程会获取写锁。
// 如果调用线程未获取写锁,则它将阻塞直到它获取了该锁。
// 参数:
// rwlock:读写锁指针。
// 返回值:成功:0 失败:非 0 错误码
int pthread_rwlock_trywrlock(pthread_rwlock_t *rwlock);
// 用于尝试以非阻塞的方式来在读写锁上获取写锁。
// 如果有任何的读者或写者持有该锁,则立即失败返回。
int pthread_rwlock_unlock(pthread_rwlock_t *rwlock);
// 功能:无论是读锁或写锁,都可以通过此函数解锁。
// 参数:rwlock:读写锁指针。
// 返回值:成功:0 失败:非 0 错误码- 条件变量
与互斥锁不同,条件变量是用来等待而不是用来上锁的,条件变量本身不是锁!
条件变量用来自动阻塞一个线程,直到某特殊情况发生为止。通常条件变量和互斥锁同时使用。
条件变量的两个动作:
条件不满, 阻塞线程
当条件满足, 通知阻塞的线程开始工作
c
#include <pthread.h>
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);
// 功能:初始化一个条件变量
// 参数:
// cond:指向要初始化的条件变量指针。
// attr:条件变量属性,通常为默认值,传NULL即可
// 也可以使用静态初始化的方法,初始化条件变量:
// pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
// 返回值:成功:0 失败:非0错误号
int pthread_cond_destroy(pthread_cond_t *cond);
// 功能:销毁一个条件变量
// 参数:cond:指向要初始化的条件变量指针
// 返回值:成功:0 失败:非0错误号
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
// 功能:阻塞等待一个条件变量
// a、阻塞等待条件变量cond(参1)满足
// b、释放已掌握的互斥锁(解锁互斥量)相当于pthread_mutex_unlock(&mutex); ab两步为一个原子操作。
// c、当被唤醒,pthread_cond_wait函数返回时,解除阻塞并重新申请获取互斥锁pthread_mutex_lock(&mutex);
// 参数:
// cond:指向要初始化的条件变量指针
// mutex:互斥锁
// 返回值:成功:0 失败:非0错误号
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
// 功能:限时等待一个条件变量
// 参数:
// cond:指向要初始化的条件变量指针
// mutex:互斥锁
// abstime:绝对时间
// 返回值:成功:0 失败:非0错误号
int pthread_cond_signal(pthread_cond_t *cond);
// 功能:唤醒至少一个阻塞在条件变量上的线程
// 参数:cond:指向要初始化的条件变量指针
// 返回值:成功:0 失败:非0错误号
int pthread_cond_broadcast(pthread_cond_t *cond);
// 功能:唤醒全部阻塞在条件变量上的线程
// 参数:cond:指向要初始化的条件变量指针
// 返回值:成功:0 失败:非0错误号条件变量使用示例
c
// 节点结构
typedef struct node
{
int data;
struct node* next;
}Node;
// 永远指向链表头部的指针
Node* head = NULL;
// 线程同步 - 互斥锁
pthread_mutex_t mutex;
// 阻塞线程 - 条件变量类型的变量
pthread_cond_t cond;
// 生产者
void* producer(void* arg)
{
while (1)
{
// 创建一个链表的节点
Node* pnew = (Node*)malloc(sizeof(Node));
// 节点的初始化
pnew->data = rand() % 1000; // 0-999
// 使用互斥锁保护共享数据
pthread_mutex_lock(&mutex);
// 指针域
pnew->next = head;
head = pnew;
printf("====== produce: %lu, %d\n", pthread_self(), pnew->data);
pthread_mutex_unlock(&mutex);
// 通知阻塞的消费者线程,解除阻塞
pthread_cond_signal(&cond);
sleep(rand() % 3);
}
return NULL;
}
void* customer(void* arg)
{
while (1)
{
pthread_mutex_lock(&mutex);
// 判断链表是否为空
if (head == NULL)
{
// 线程阻塞
// 该函数会对互斥锁解锁
pthread_cond_wait(&cond, &mutex);
// 解除阻塞之后,对互斥锁做加锁操作
}
// 链表不为空 - 删掉一个节点 - 删除头结点
Node* pdel = head;
head = head->next;
printf("------ customer: %lu, %d\n", pthread_self(), pdel->data);
free(pdel);
pthread_mutex_unlock(&mutex);
}
return NULL;
}
int main(int argc, const char* argv[])
{
pthread_t p1, p2;
// init
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond, NULL);
// 创建生产者线程
pthread_create(&p1, NULL, producer, NULL);
// 创建消费者线程
pthread_create(&p2, NULL, customer, NULL);
// 阻塞回收子线程
pthread_join(p1, NULL);
pthread_join(p2, NULL);
pthread_mutex_destroy(&mutex);
pthread_cond_destroy(&cond);
return 0;
}优缺点:
相较于mutex而言,条件变量可以减少竞争。
如直接使用mutex,除了生产者、消费者之间要竞争互斥量以外,消费者之间也需要竞争互斥量,但如果汇聚(链表)中没有数据,消费者之间竞争互斥锁是无意义的。
有了条件变量机制以后,只有生产者完成生产,才会引起消费者之间的竞争。提高了程序效率
- 信号量
信号量广泛用于进程或线程间的同步和互斥,信号量本质上是一个非负的整数计数器,它被用来控制对公共资源的访问。
编程时可根据操作信号量值的结果判断是否对公共资源具有访问的权限,当信号量值大于0时,则可以访问,否则将阻塞。
PV原语是对信号量的操作,一次P操作使信号量减1,一次V操作使信号量加1。
信号量主要用于进程或线程间的同步和互斥这两种典型情况
c
#include <semaphore.h>
// 功能:创建一个信号量并初始化它的值。一个无名信号量在被使用前必须先初始化。
// 参数:
// sem:信号量的地址。
// pshared:等于 0,信号量在线程间共享(常用);不等于0,信号量在进程间共享。
// value:信号量的初始值。
// 返回值:成功:0 失败: - 1
int sem_init(sem_t *sem, int pshared, unsigned int value);
// 功能:删除 sem 标识的信号量。
// 参数:sem:信号量地址。
// 返回值: 成功:0 失败: - 1
int sem_destroy(sem_t *sem);
// 功能:将信号量的值减 1。操作前,先检查信号量(sem)的值是否为 0,若信号量为 0,此函数会阻塞,直到信号量大于 0 时才进行减 1 操作。
// 参数:sem:信号量的地址。
// 返回值:成功:0 失败: - 1
int sem_wait(sem_t *sem);
// 以非阻塞的方式来对信号量进行减 1 操作。
// 若操作前,信号量的值等于 0,则对信号量的操作失败,函数立即返回。
int sem_trywait(sem_t *sem);
// 限时尝试将信号量的值减 1
// abs_timeout:绝对时间
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
// 功能:将信号量的值加 1 并发出信号唤醒等待线程(sem_wait())。
// 参数:sem:信号量的地址。
// 返回值:成功:0 失败:-1
int sem_post(sem_t *sem);
// 功能:获取 sem 标识的信号量的值,保存在 sval 中。
// 参数:sem:信号量地址。sval:保存信号量值的地址。
// 返回值:成功:0 失败:-1
int sem_getvalue(sem_t *sem, int *sval);信号量示例
c
sem_t sem; //信号量
void printer(char *str)
{
sem_wait(&sem);//减一
while (*str)
{
putchar(*str);
fflush(stdout);
str++;
sleep(1);
}
printf("\n");
sem_post(&sem);//加一
}
void *thread_fun1(void *arg)
{
char *str1 = "hello";
printer(str1);
}
void *thread_fun2(void *arg)
{
char *str2 = "world";
printer(str2);
}
int main(void)
{
pthread_t tid1, tid2;
sem_init(&sem, 0, 1); //初始化信号量,初始值为 1
//创建 2 个线程
pthread_create(&tid1, NULL, thread_fun1, NULL);
pthread_create(&tid2, NULL, thread_fun2, NULL);
//等待线程结束,回收其资源
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
sem_destroy(&sem); //销毁信号量
return 0;
}