Hive 技术及应用介绍
参考资料
Apache Hive 是基于 Hadoop 构建的数据仓库工具,它为海量结构化数据提供类 SQL 的查询能力,并将查询翻译为 MapReduce、Tez 或 Spark 作业执行。Hive 简化了大数据批量分析的使用门槛,让熟悉 SQL 的开发者能够在 Hadoop 生态上轻松进行 ETL、OLAP 和 BI 分析。
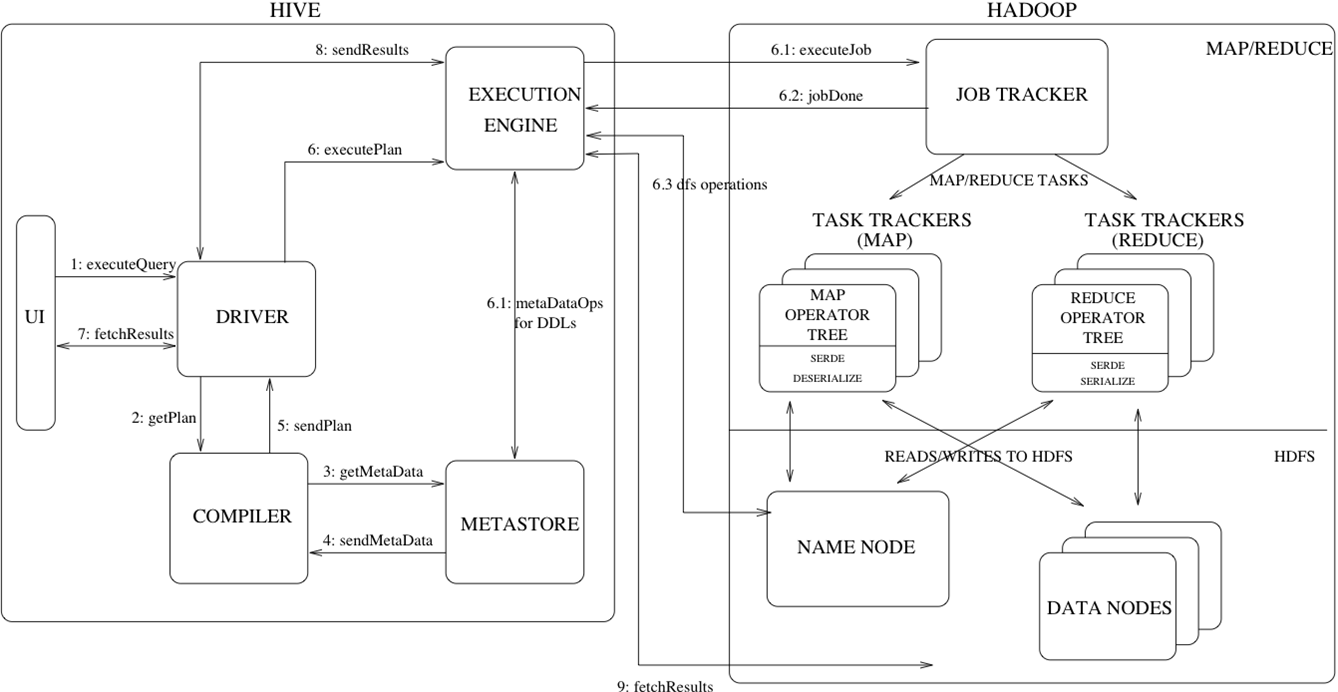
Hive 的执行流程
Hive 的背景与定位
- 背景:随着大数据时代到来,Hadoop 分布式文件系统(HDFS)与 MapReduce 为存储与计算提供了高吞吐的能力,但原生 MapReduce 编程复杂、开发成本高。
- 定位:Hive 通过 HiveQL(类似 SQL 的查询语言)屏蔽 MapReduce/Tez/Spark 的底层细节,将查询语句编译为执行计划并自动运行,适合批量离线分析,主要面向 ETL、数据聚合与多维分析。
Hive 在 Hadoop 生态系统中的位置

Hive 的运行深度依赖于 Hadoop 的核心生态,包括其分布式文件系统 HDFS、计算框架 MapReduce 以及资源调度器 YARN,因此可以将 Hive 理解为一种构建在 Hadoop 之上的 "SQL on Hadoop" 应用。其核心工作机制是将用户输入的类 SQL 查询语句转换为底层的 MapReduce 任务来执行,也正是因为多了这一步从 SQL 到 MapReduce 的转化开销,所以在同等条件下,Hive 查询的执行效率通常会低于直接编写原生 MapReduce 程序。
Hive 体系结构
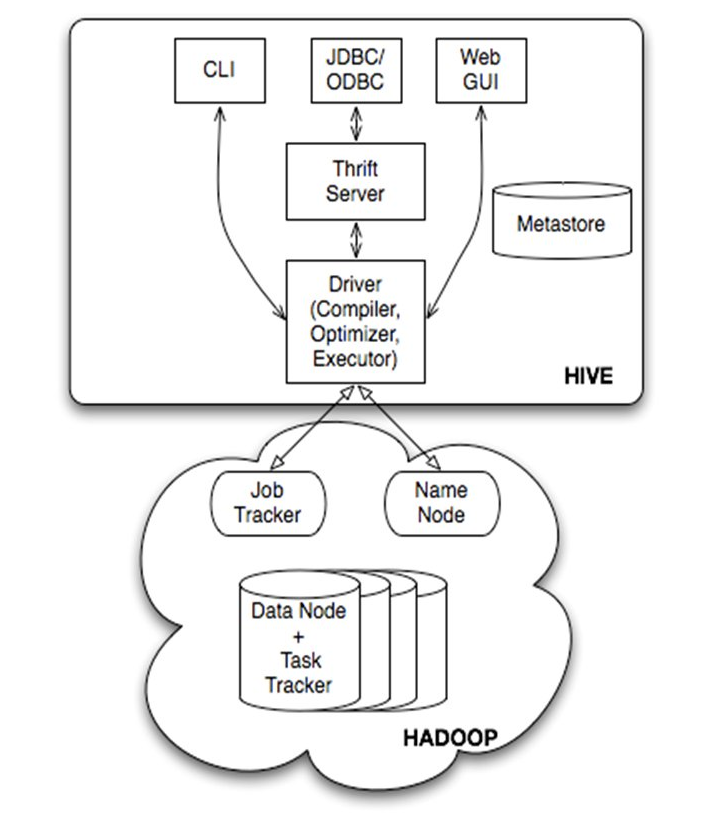
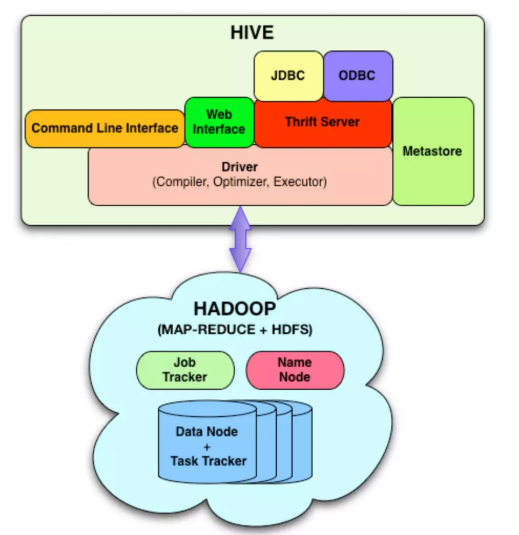
Hive 的核心组件包括:
-
Hive 客户端(CLI、Beeline、JDBC/ODBC)
- 支持交互式提交 HiveQL,或通过 JDBC/ODBC 接入 BI 工具(如 Tableau、Power BI)。
-
Driver
- 接收并解析 HiveQL,生成抽象语法树(AST),再进行优化和编译,生成执行计划(Execution Plan)。
-
Compiler / Optimizer
- 将 AST 转为逻辑计划,应用谓词下推、列裁剪等优化,再生成物理计划,拆分为一个或多个 MapReduce/Tez/Spark 任务。
-
Execution Engine
- 将物理计划提交给底层执行框架(MapReduce、Tez 或 Spark),监控任务状态并返回结果。
-
Metastore
- 存储表结构、分区信息、列类型、SerDe、统计信息等元数据,通常使用 MySQL、PostgreSQL 或 Derby。
数据模型与存储格式
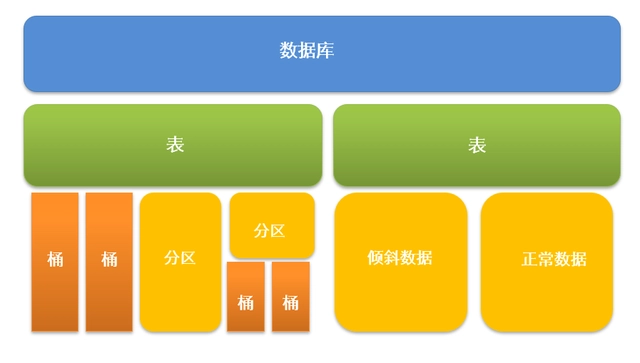
- 表与分区
- Hive 将 HDFS 文件组织为表(Table)、分区(Partition)和桶(Bucket)。分区通常按日期、地域等字段维度存储,减少查询扫描量。
数据库:创建表时如果不指定数据库,则默认为 default 数据库。
表:物理概念,实际对应 HDFS 上的一个目录。
分区:对应所在表所在目录下的一个子目录。
桶:对应表或分区所在路径的一个文件
- 文件格式
- 支持文本(Text)、SequenceFile、ORC、Parquet、Avro 等列式与行式格式。列式格式(ORC、Parquet)通过压缩和列裁剪大幅提升查询性能。
sql
-- 创建按日期分区的 ORC 表
CREATE EXTERNAL TABLE logs (
user_id BIGINT,
action STRING,
ts TIMESTAMP
)
PARTITIONED BY (dt STRING)
STORED AS ORC
LOCATION '/data/logs/';- SerDe(序列化/反序列化)
- 通过自定义 SerDe,Hive 能解析任意复杂格式(JSON、CSV、XML 等)。
HiveQL 基本用法
数据操作
创建表
sql
CREATE TABLE IF NOT EXISTS example.employee(
Id INT COMMENT 'employeeid',
Company STRING COMMENT 'your company',
Money FLOAT COMMENT 'work money',)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;可以发现就是对应的 SQL 语句
查询
sql
SELECT id, name FROM employee WHERE salary >= 10000;
SELECT department, avg(salary) FROM employee GROUP BY department;
SELECT id, salary, date FROM employee_a UNION ALL
SELECT id, salary, date FROM employee_b;
sql
-- 加载数据到表(分区)
ALTER TABLE logs ADD PARTITION (dt='2025-06-01');
LOAD DATA INPATH '/raw/logs/2025-06-01/*.log'
INTO TABLE logs PARTITION (dt='2025-06-01');
-- 简单查询
SELECT user_id, COUNT(*) AS cnt
FROM logs
WHERE dt='2025-06-01'
GROUP BY user_id
ORDER BY cnt DESC
LIMIT 10;窗口函数与高级特性
sql
-- 统计每个用户每天的前 3 次操作
SELECT dt, user_id, action, ts,
ROW_NUMBER() OVER (PARTITION BY dt, user_id ORDER BY ts) AS rn
FROM logs
WHERE dt >= '2025-06-01' AND dt <= '2025-06-07'
AND rn <= 3;与 Spark 集成
在 Hive on Spark 模式下,HiveQL 会被提交到 Spark 引擎执行,兼享 Spark 的低延迟与丰富算子。
bash
-- 启动 Hive 使用 Spark 执行引擎
set hive.execution.engine=spark;典型应用场景
-
ETL 批量处理
- 定时从日志系统、关系库导入数据,清洗、聚合后写入 Hive 数据仓库,用于下游 BI 报表。
-
多维 OLAP 分析
- 基于 Hive 的 HiveCube 或第三方 OLAP 引擎(如 Apache Kylin)实现大规模多维分析。
-
数据探索与报表
- 数据分析师通过 Beeline 或 BI 工具(Tableau、Power BI)直接查询 Hive 表。
-
机器学习特征工程
- 使用 HiveQL 快速统计用户行为特征,然后将结果导出到 HDFS,再由 Spark/MLlib 训练模型。
性能优化要点
-
合理分区
- 按查询高频过滤字段分区(如按日期、地域),减少文件扫描。
-
使用列式存储
- ORC/Parquet 格式支持列裁剪、矢量化读取和压缩。
-
开启成本模型优化
sql
SET hive.cbo.enable=true;-
利用 Tez/Spark
- 将执行引擎换为 Tez 或 Spark,降低 MapReduce 的启动开销与 I/O 序列化成本。
-
小文件合并
- 小文件过多会导致任务过多,建议合并或使用 HDFS 合并工具。
示例:用户次日留存率统计
sql
-- 1. 计算用户首次活跃日期
CREATE TABLE user_first (
user_id BIGINT,
first_dt STRING
)
STORED AS ORC
AS
SELECT user_id, MIN(dt) AS first_dt
FROM logs
GROUP BY user_id;
-- 2. 次日留存:join 当天活跃用户与第一天活跃日期后一天
SELECT f.first_dt AS reg_dt,
l.dt AS act_dt,
COUNT(DISTINCT f.user_id) AS reg_users,
COUNT(DISTINCT l.user_id) AS retained_users,
ROUND(COUNT(DISTINCT l.user_id) / COUNT(DISTINCT f.user_id), 4) AS retention_rate
FROM user_first f
JOIN logs l
ON f.user_id = l.user_id
AND l.dt = date_add(f.first_dt, 1)
GROUP BY f.first_dt, l.dt
ORDER BY f.first_dt;优缺点
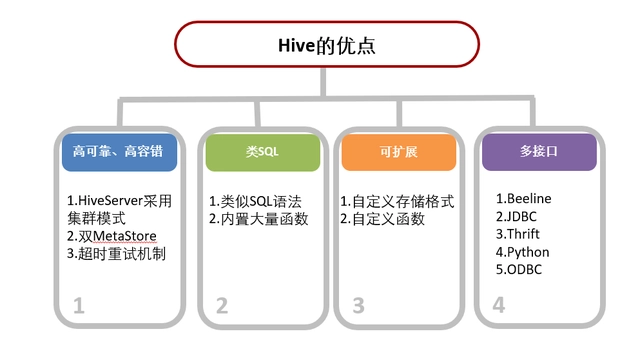
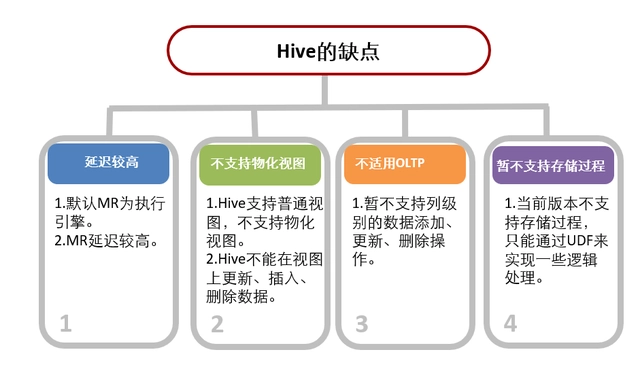
总结
- Hive 以 SQL 友好的方式在 Hadoop 集群上实现批量离线分析,适用于 ETL、OLAP、报表和特征工程。
- 通过 Metastore 管理元数据,通过多种文件格式和执行引擎(MapReduce/Tez/Spark)兼顾兼容性与性能。
- 合理分区、列式存储和成本模型优化可显著提升查询性能。
- Hive 与 Spark、Flink、Presto 等工具生态配合,为大数据平台提供灵活多样的计算选择。