1、概述
大型语言模型(LLM)的输出行为可以通过多种配置参数进行精细控制。这些参数共同决定了模型生成文本的质量、风格和多样性。理解这些配置选项及其相互作用对于有效使用LLM至关重要。
2、输出长度 (Output length)
一个重要的配置设置是响应中要生成的令牌数量。生成更多令牌需要 LLM 进行更多计算,导致更高的能耗、可能更慢的响应时间以及更高的成本。
减少 LLM 的输出长度并不会使 LLM 在其创建的输出中变得风格或文本上更简洁,它只是导致 LLM 在达到限制时停止预测更多令牌。 如果需求需要较短的输出长度,可能还需要相应地设计提示以适应。需要明确的是:通过配置限制令牌数量 (max_tokens) 是一种强制截断,它本身并不能促使模型生成简洁的内容。实现简洁通常需要在提示本身中给出具体指令(例如,"用一句话总结") 。
对于某些 LLM 提示技术(如 ReAct),输出长度限制尤为重要,因为在获得所需响应后,LLM 可能会继续发出无用的令牌 。
3、采样控制 (Sampling controls)
** LLM 并非正式地预测单个令牌。相反,LLM 预测下一个令牌可能是什么的概率,LLM 词汇表中的每个令牌都会获得一个概率。然后对这些令牌概率进行采样,以确定将生成的下一个令牌。**温度(Temperature)、Top-K 和 Top-P 是最常见的配置设置,它们决定了如何处理预测的令牌概率以选择单个输出令牌 。
3.1 温度 (Temperature)
温度控制令牌选择中的随机程度。较低的温度适用于期望更确定性响应的提示,而较高的温度可能导致更多样化或意想不到的结果。温度为 0(贪婪解码)是确定性的:始终选择概率最高的令牌(但请注意,如果两个令牌具有相同的最高预测概率,根据平局处理方式的不同,温度为 0 时可能不总是得到相同的输出)。
接近最大值的温度倾向于产生更随机的输出。随着温度越来越高,所有令牌成为下一个预测令牌的可能性变得均等。温度参数提供了一个在可预测性/事实准确性(低温)与创造性/多样性(高温)之间的基本权衡。为不同任务选择合适的温度至关重要------事实问答需要低温,而故事生成可能受益于高温。
Gemini 的温度控制可以类似于机器学习中使用的 softmax 函数来理解。低温度设置类似于低 softmax 温度 (T),强调具有高确定性的单个首选温度。较高的 Gemini 温度设置类似于高 softmax 温度,使得所选设置周围更宽范围的温度变得更可接受。这种增加的不确定性适应了那些不需要严格精确温度的场景,例如在尝试创意输出时。
Temperature 参数默认为 1.0,建议根据如下表格,按使用场景设置 temperature:
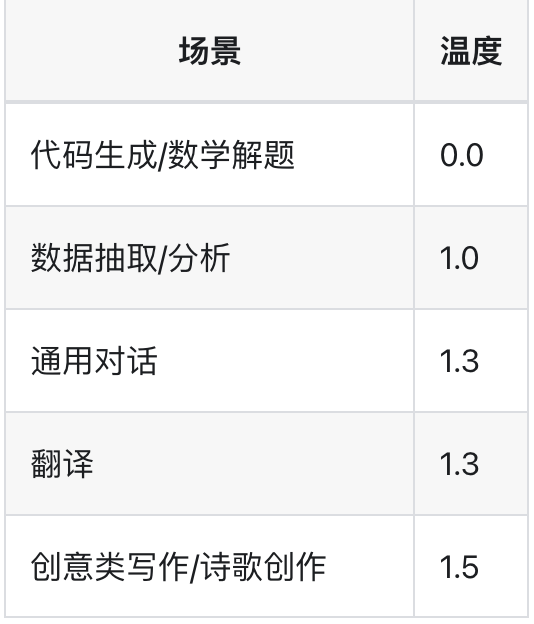
3.2 Top-K 和 Top-P (Top-K and top-P)
Top-K 和 Top-P(也称为核采样)是 LLM 中使用的两种采样设置,用于将预测的下一个令牌限制为来自具有最高预测概率的令牌。与温度类似,这些采样设置控制生成文本的随机性和多样性 。
-
Top-K 采样从模型预测的分布中选择概率最高的 K 个令牌。Top-K 值越高,模型的输出越具创造性和多样性;Top-K 值越低,模型的输出越受限制和基于事实。Top-K 为 1 等同于贪婪解码。
-
Top-P 采样选择累积概率不超过某个值 (P) 的最高概率令牌。P 的值范围从 0(贪婪解码)到 1(LLM 词汇表中的所有令牌)。
Top-K 和 Top-P 提供了补充温度控制的不同方式来塑造采样前的概率分布。Top-K 限制了选择的数量,而 Top-P 基于累积概率质量进行限制。Top-K 设置了考虑令牌数量的硬限制(例如,只看前 40 个)。Top-P 设置了基于概率总和的限制(例如,考虑令牌直到它们的概率加起来达到 0.95)。这些是不同的机制。理解这种差异允许比单独使用温度更精细地控制输出多样性。选择 Top-K 还是 Top-P 的最佳方法是同时(或一起)试验这两种方法,看看哪种能产生您所寻找的结果。
3.3 综合运用 (Putting it all together)
在 Top-K、Top-P、温度和要生成的令牌数量之间进行选择,取决于具体的应用和期望的结果,并且这些设置相互影响 1。理解所选模型如何组合不同的采样设置也很重要。
如果温度、Top-K 和 Top-P 都可用,则同时满足 Top-K 和 Top-P 标准的令牌成为下一个预测令牌的候选者,然后应用温度从通过 Top-K 和 Top-P 标准的令牌中进行采样。如果只有 Top-K 或 Top-P 可用,行为相同,但只使用一个 Top-K 或 P 设置。
如果温度不可用,则从满足 Top-K 和/或 Top-P 标准的令牌中随机选择一个,以产生单个下一个预测令牌。
在某个采样配置值的极端设置下,该采样设置要么抵消其他配置设置,要么变得无关紧要:
-
如果将温度设置为 0,Top-K 和 Top-P 将变得无关紧要------概率最高的令牌成为下一个预测的令牌。如果将温度设置得极高(高于 1------通常在 10 的量级),温度将变得无关紧要,通过 Top-K 和/或 Top-P 标准的任何令牌随后将被随机采样以选择下一个预测令牌。
-
如果将 Top-K 设置为 1,温度和 Top-P 将变得无关紧要。只有一个令牌通过 Top-K 标准,该令牌就是下一个预测的令牌。如果将 Top-K 设置得极高,例如达到 LLM 词汇表的大小,任何具有非零概率成为下一个令牌的令牌都将满足 Top-K 标准,没有令牌被筛选掉。
-
如果将 Top-P 设置为 0(或一个非常小的值),大多数 LLM 采样实现将只考虑概率最高的令牌来满足 Top-P 标准,使得温度和 Top-K 无关紧要。如果将 Top-P 设置为 1,任何具有非零概率成为下一个令牌的令牌都将满足 Top-P 标准,没有令牌被筛选掉。
这些配置参数并非独立运作。它们的相互作用很复杂,某些设置可以主导或抵消其他设置。理解这些相互作用对于可预测的控制至关重要。例如,将温度设为 0 或 Top-K 设为 1 会使其他采样参数失效。有效的配置需要全局视角 1。
作为一般的起点,温度为 0.2、Top-P 为 0.95、Top-K 为 30 将给出相对连贯的结果,可以具有创造性但不过度。如果想要特别有创意的结果,可以尝试从温度 0.9、Top-P 0.99 和 Top-K 40 开始。如果想要较少创意的结果,可以尝试从温度 0.1、Top-P 0.9 和 Top-K 20 开始。 最后,如果任务总是只有一个正确答案(例如,回答数学问题),则从温度 0 开始 1。提供针对不同任务类型(连贯、创意、事实)的具体起始值,为实践提供了宝贵的指导。这承认了寻找最优设置需要实验,但可以通过启发式方法来指导,减少了初始搜索空间 1。
** 注意: 自由度越高(温度、Top-K、Top-P 和输出令牌越高),LLM 可能生成相关性较低的文本。**
4、总结
大型语言模型(LLM)的输出可通过关键参数控制:max_tokens限制长度,Temperature调节随机性(低值稳定/高值创意),Top-K和 Top-P筛选候选词。实际应用中需平衡这些参数------事实任务用低温+严格筛选,创意任务用高温+宽松采样,并通过测试优化配置。