
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈PySpark大数据分析与应用 ⌋ ⌋ ⌋ PySpark作为Apache Spark的Python API,融合Python工具与Spark分布式计算能力,专为大数据处理设计。支持批处理、流计算、机器学习和图计算,通过内存计算与弹性数据集RDD优化性能,利用DataFrame API和SQL接口简化数据操作。可跨Hadoop/云平台部署,适用于ETL、日志分析、实时推荐等场景,兼顾高效分析与易用性。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/PySpark_Data_Analysis。
文章目录
-
- 前言
- 一、安装JDK
- 二、安装Anaconda
- 三、安装Hadoop
- 四、安装MySQL
- 五、安装Hive
- 六、配置PySpark模块
- [七、运行Jupyter Notebook](#七、运行Jupyter Notebook)
前言
本文主要帮助初学者在Windows系统上搭建一个可以运行PySpark程序的开发环境。单机模式的搭建步骤相对于分布式模式更加简单、易操作,且搭建的环境能够满足Spark应用程序的开发和测试工作,对初学者而言是非常有益的。
在Windows操作系统上搭建一个可以运行PySpark程序的开发环境,需要准备如表1所示的安装包。
表1 单机模式的PySpark开发环境安装包
| 安装包 | 版本 | 备注 |
|---|---|---|
| JDK | jdk-8u281 | Java运行环境,Spark的运行需要JDK的支持 |
| Anaconda | Anaconda3-2020.11 | Python的包管理器和环境管理器 |
| Hadoop | 3.2.2 | 提供HDFS分布式文件系统支持,Hive运行环境支持 |
| Hive | 3.1.1 / 1.22 | Hive运行环境,其中3.1.1为运行版本,1.22版本提供在Windows下运行时工具 |
| MySQL | 8 | Hive元数据存储服务 |
| MySQL Connector | 8.0.21 | Hive数据库连接工具包 |
本文中所用到的安装包和安装工具网盘下载链接:
链接:https://pan.quark.cn/s/9d3531f9fa20(提取码:4jFp)
一、安装JDK
由于Hadoop、Hive和Spark是由Java编写而成的,运行环境需要Java支持,所以需要下载安装Java开发工具包JDK。在Java官方网站下载版本为jdk-8u281的JDK。在Windows系统下安装JDK可参考安装中的文字提示完成JDK的安装。
JDK安装包链接:jdk-8u281-windows-x64
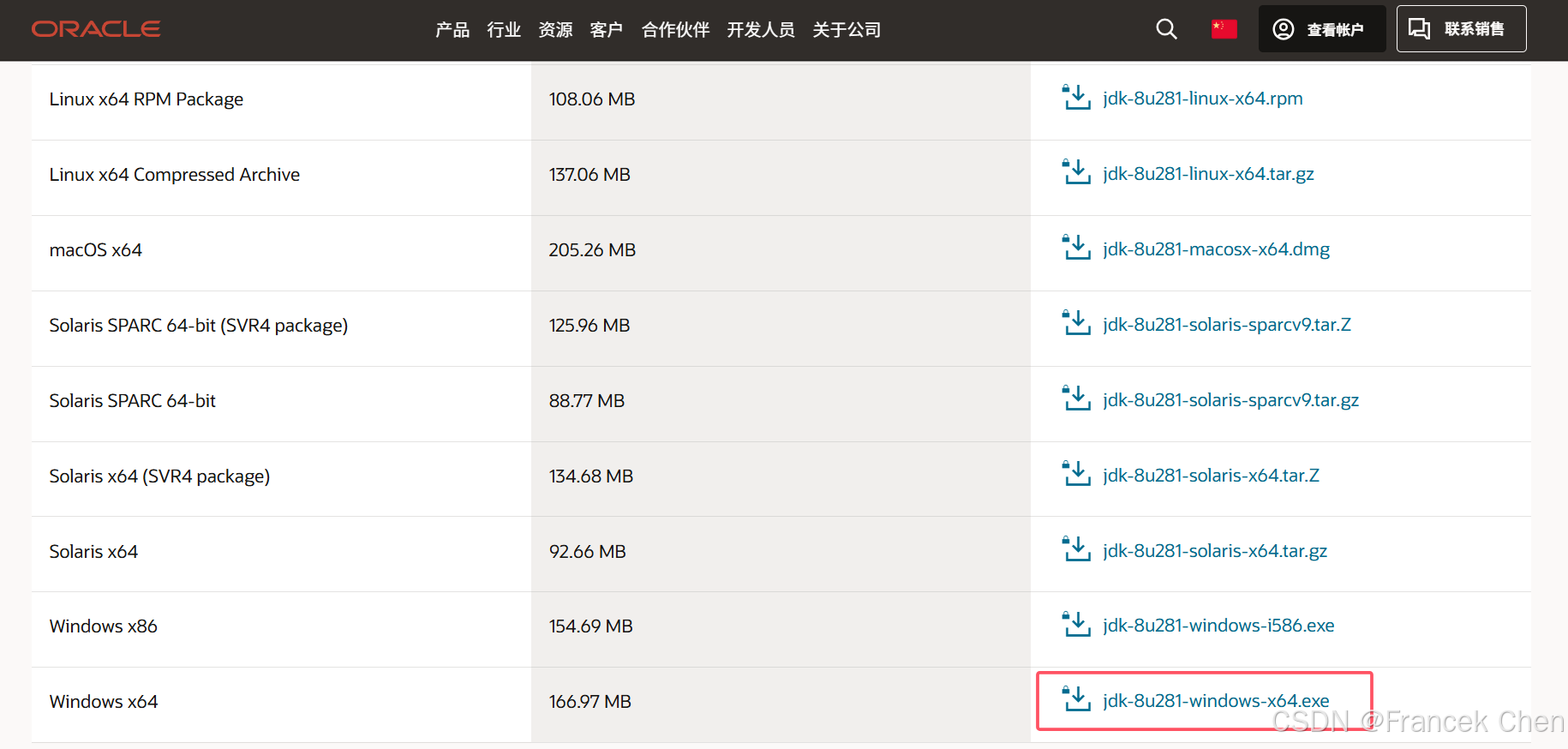
图1 下载jdk-8u281-windows-x64
JDK安装完成,还需要配置Java环境变量。以Windows 10为例,右键单击"此电脑"图标,选择"属性"选项,在弹出的窗口中选择"系统属性"选项,在弹出的对话框中,选择"高级"选项卡,可看到Windows环境变量设置入口,单击"环境变量(N)..."按钮进入,如图2所示。
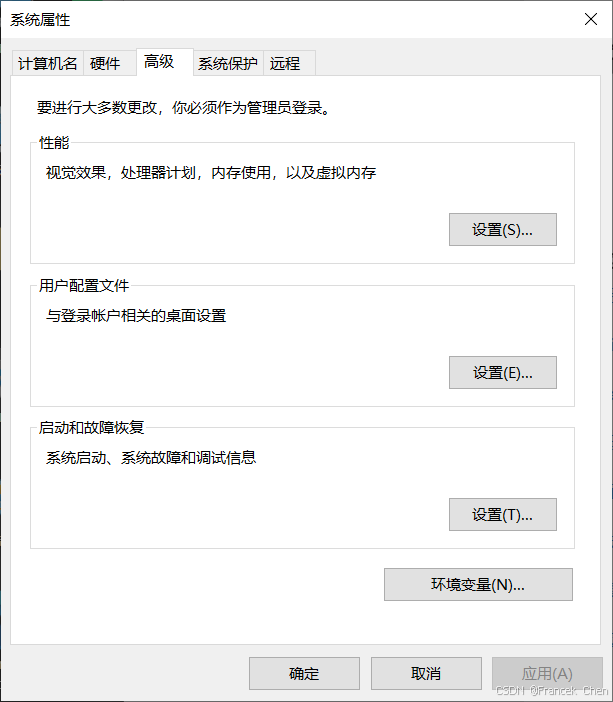
图2 Windows环境变量设置入口
在环境变量对话框中,配置Java环境变量。配置环境包括:
- 新建JAVA_HOME系统环境变量,指定Java目录(即JDK安装包解压目录),如图3。
- 编辑Path变量,指定JDK安装包解压目录的bin目录和jre目录,如图4。
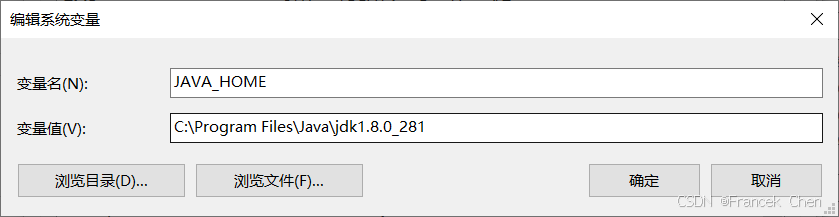
图3 设置JAVA_HOME环境变量

图4 设置JDK的PATH环境变量
回到"环境变量"界面,新建一个"系统变量"命名"CLASSPATH"设置变量值:
text
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar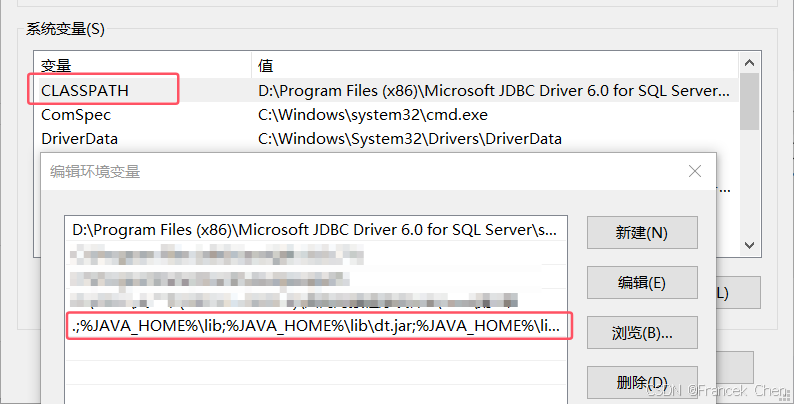
图5 设置JDK的CLASSPATH环境变量
最后在"环境变量"对话框也点击"确定"按钮,至此环境变量配置完成。点击快捷键Win+R,输入"cmd",回车,打开命令行窗口。输入java -version命令,查看Java版本,验证Java是否安装成功。
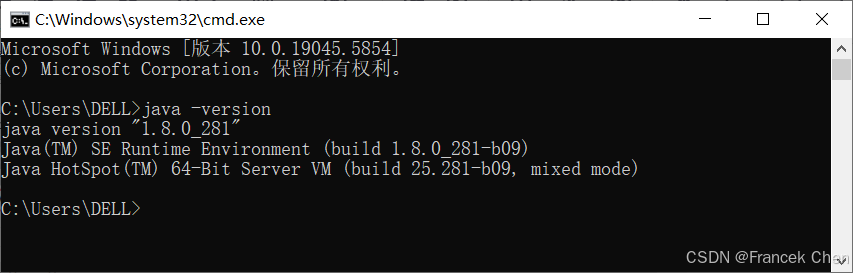
图6 验证Java版本
二、安装Anaconda
Anaconda是Python的包管理器和环境管理器,包含了大量的Python科学包及其依赖项。Anaconda可以便捷获取包且对包进行管理,同时也可以对Python环境统一管理。Anaconda的安装可以通过官方网站或清华大学开源软件镜像站下载Windows版本的安装包进行安装。这里的安装版本是Anaconda3-2020.11-Windows-x86_64。
- Anaconda官方网站:https://www.anaconda.com/
图7 Anaconda官方网站
图8 清华大学开源软件镜像站
在Windows"开始"菜单中,选择"Anaconda3(64-bit)",单机"Anaconda Navigator(Anaconda3)"打开Anaconda管理器,出现"Anaconda Navigator"窗口,如图9所示。

图9 "Anaconda Navigator"窗口
Anaconda默认使用Jupyter Notebook作为Python语言的的编辑器,在左侧导航栏选择"Environments"选项,单机"Create"按钮可以创建指定版本的Python运行环境,如图10所示。
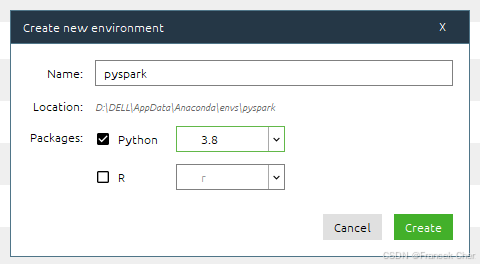
图10 在Anaconda种创建Python运行环境
在Anaconda中,默认安装3种Python集成开发环境(Integreted Development Environment,IDE),如表2所示。
表2 Anaconda中的Python IDE
| IDE | 备注 |
|---|---|
| Jupyter Notebook | 基于Web环境的交互式Python编辑运行环境,对IPython的功能进行了扩展 |
| Spyder | 开源跨平台的Python IDE,Spyder既可以跨平台,也可以使用附加组件扩充,自带交互式工具以处理数据 |
| IPython | Python的交互式Shell,基于命令行方式编写代码。从4.0版本开始IPython集中精力只做交互式Shell,使其变得轻量化,用户可从Windows系统的开始菜单启动Anaconda Prompt并进入IPython。其他Notebook格式和Notebook Web应用等均从IPython分离出来并统一命名为Jupyter Notebook |
安装好Anaconda后,通过Windows系统的"开始"菜单,启动Jupyter Notebook,如图11所示。
图11 在Windows"开始"菜单中选择并启动Jupyter Notebook
注意,这里也要将Anaconda的安装目录添加到系统环境变量中,我的路径如下:
D:\DELL\AppData\Anaconda
D:\DELL\AppData\Anaconda\Scripts
D:\DELL\AppData\Anaconda\Library\bin
D:\DELL\AppData\Anaconda\Library\mingw-w64\bin
三、安装Hadoop
为了向Spark提供存储支持,需要安装Hive,Hive需要Hadoop运行环境,因此需要在Windows系统上搭建Hadoop单机运行环境。
(一)下载Hadoop安装包并配置环境变量
从Apache Hadoop官方网站下载Hadoop安装包,并将安装包解压缩至文件夹中(如"D:\Hadoop",下文将该文件夹所在路径称之为HADOOP_HOME路径)。我这里下载的是hadoop-3.2.2.tar.gz版本。
图12 从Apache Hadoop官网下载Hadoop安装包
为方便在命令行中执行Hadoop命令,需要设置Windows中的环境变量。在环境变量对话框中,配置Hadoop环境变量。配置环境包括:
- 新建HADOOP_HOME系统环境变量,指定Hadoop家目录(即Hadoop安装包解压目录),如图13。
- 编辑Path变量,指定Hadoop中可执行程序的路径(即Hadoop安装包解压目录的bin目录和sbin目录,如图14。
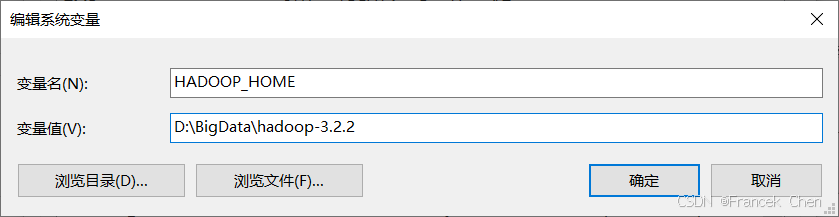
图13 设置HADOOP_HOME环境变量
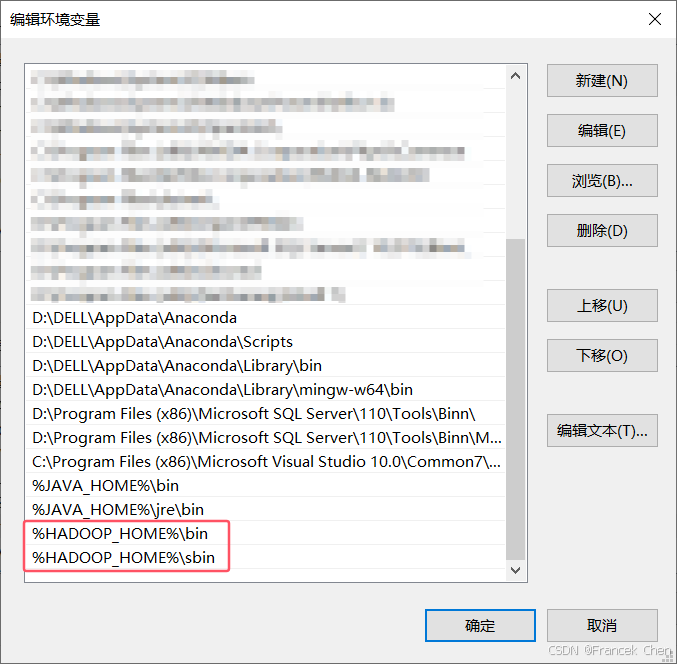
图14 设置Hadoop的PATH环境变量
(二)修改Hadoop配置文件
完成Hadoop的环境变量配置后,需要修改Hadoop的配置文件,以便Hadoop可以正常运行。Hadoop主要的配置文件如表3所示。这些配置文件在该路径下:D:\BigData\hadoop-3.2.2\etc\hadoop(配置项中的路径替换为实际路径)。
表3 Hadoop主要的配置文件
| 文件名 | 文件描述 |
|---|---|
| hadoop-env.cmd | 记录Hadoop要使用的环境变量 |
| hdfs-site.xml | HDFS守护进程配置文件,包括NameNode,DataNode配置 |
| core-site.xml | Hadoop Core配置文件,包括HDFS和MapReduce常用的I/O设置 |
| mapred-site.xml | MapReduce守护进程配置文件 |
| yarn-site.xml | YARN资源管理器配置文件 |
1. 修改hadoop-env.cmd文件
在hadoop-env.cmd文件末尾添加Java环境变量,将JAVA_HOME对应的Java路径更改为实际的路径。本文JDK的安装路径是"C:\Program Files\Java\jdk1.8.0_281"。
sh
set JAVA_HOME="C:\Program Files\Java\jdk1.8.0_281"由于路径中带有空格,为了避免执行时出现问题,可采用"8.3"命名方式,用6位字母,然后添加"~"符号和1个数字。
sh
set JAVA_HOME=C:\Progra~1\Java\jdk1.8.0_2812. 修改hdfs-site.xml文件
修改hdfs-site.xml文件内容,配置如下参数(配置项中的路径替换为实际路径):
- dfs.replication配置项设置了HDFS中文件副本数为1;
- dfs.namenode.name.dir配置项设置了HDFS中NameNode的元数据存储的本地文件路径;
- dfs.datanode.data.dir配置项设置了DataNode存储数据的本地文件路径。
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/BigData/hadoop-3.2.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/BigData/hadoop-3.2.2/data/datanode</value>
</property>
</configuration>3. 修改core-site.xml文件
修改core-site.xml文件内容。hadoop.tmp.dir定义Hadoop使用的临时存储目录。设置HDFS服务主机名和端口,fs.defaultFS配置项配置HDFS服务的主机名和端口号,主机名localhost即为本机。
xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/BigData/hadoop-3.2.2/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>4. 修改mapred-site.xml文件
修改mapred-site.xml文件内容,配置MapReduce执行框架为YARN。mapreduce.framework.name配置项配置MapReduce执行框架为YARN。
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. 修改yarn-site.xml文件
修改yarn-site.xml文件内容,配置NodeManager上运行的服务和配置mapreduce_shuffle的实现类:
- yarn.nodemanager.aux-services配置项需将NodeManager上运行的附属服务配置成mapreduce_shuffle,后续才可以运行MapReduce程序;
- yarn.nodemanager.aux-services.mapreduce.shuffle.class配置项配置mapreduce_shuffle的实现类,即org.apache.hadoop.mapred.ShuffleHandler。
xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>6. 配置文件存储路径
在hdfs-site.xml文件中,配置了NameNode和DataNode的数据存储的本地文件路径,需要按照对应路径创建文件夹。dfs.namenode.name.dir配置的路径为"D:/BigData/hadoop-3.2.2/data/namenode",因此需要在"D:/BigData/hadoop-3.2.2/data"路径下创建文件夹namenode。按照相同方法在dfs.datanode.data.dir指定的路径下创建datanode文件夹。如图15所示。
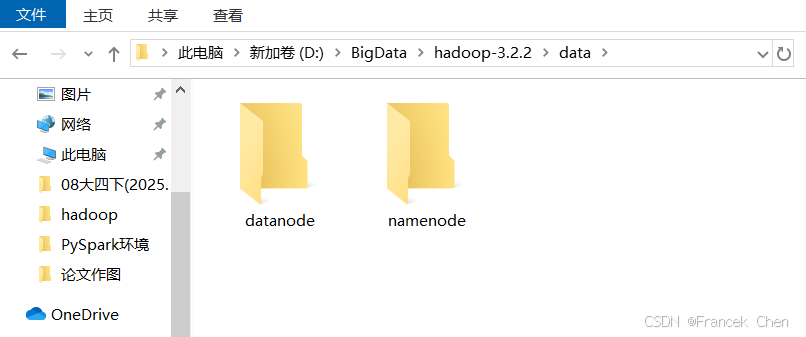
图15 创建namenode和datanode文件夹
在修改core-site.xml文件中,hadoop.tmp.dir定义了Hadoop使用的临时存储目录"/D:/BigData/hadoop-3.2.2/tmp",因此需要创建tmp文件夹。如图16所示。
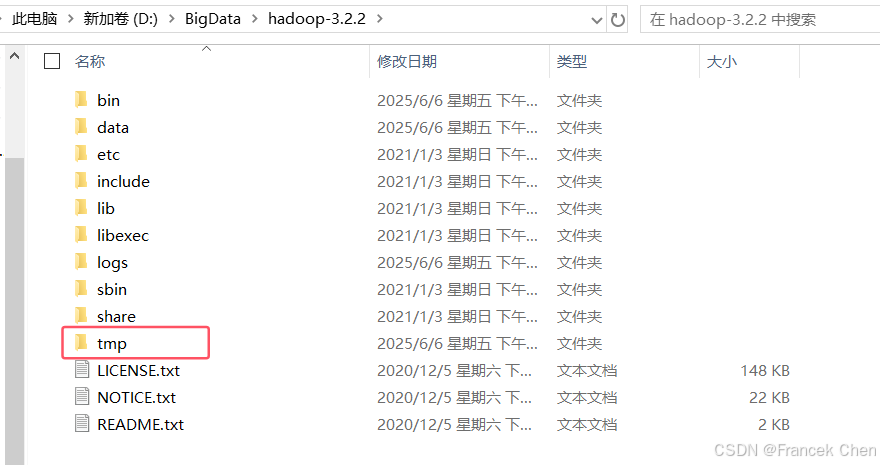
图16 创建tmp文件夹
(三)复制工具文件
在Windows中运行Hadoop,需要下载两个额外的工具文件winutils.exe和hadoop.dll(需要和Hadoop安装包的版本保持一致),并将这两个文件复制至"C:\Windows\System32"和"D:\BigData\hadoop-3.2.2\bin"目录中。

图17 工具文件hadoop.dll和winutils.exe
(四)格式化NameNode
先输入命令hadoop version验证Hadoop版本。
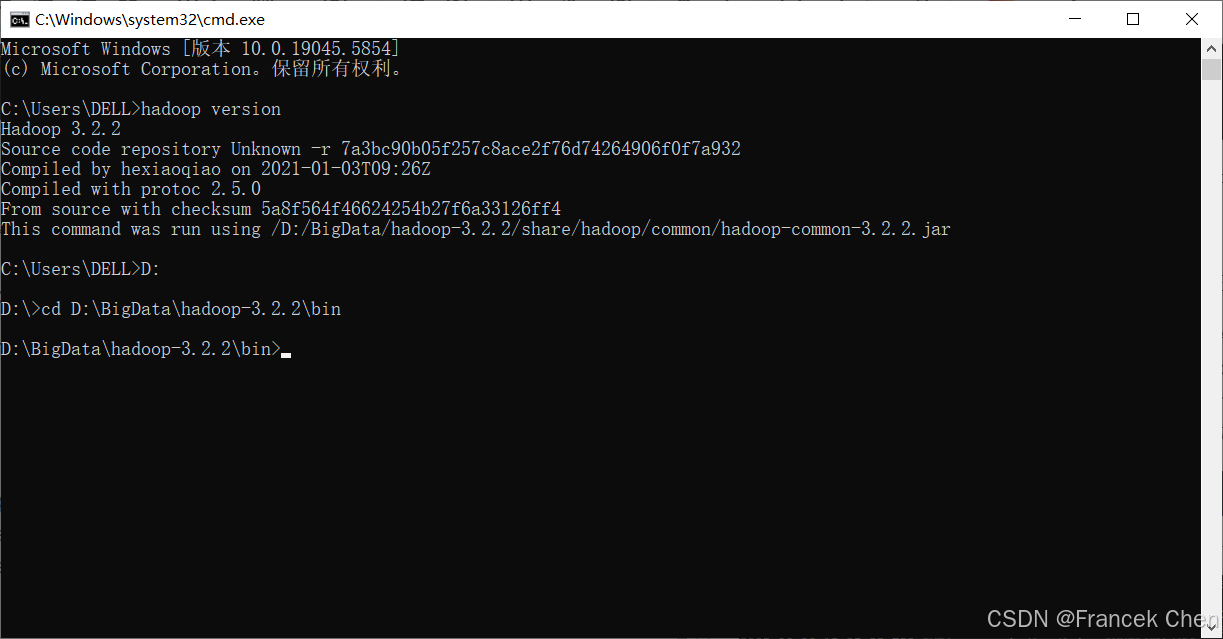
图18 验证Hadoop版本
在第一次启动Hadoop前,必须先将HDFS格式化,打开cmd命令提示符,执行命令格式化HDFS。
bash
hdfs namenode -format出现如图19所示信息表示格式化成功。
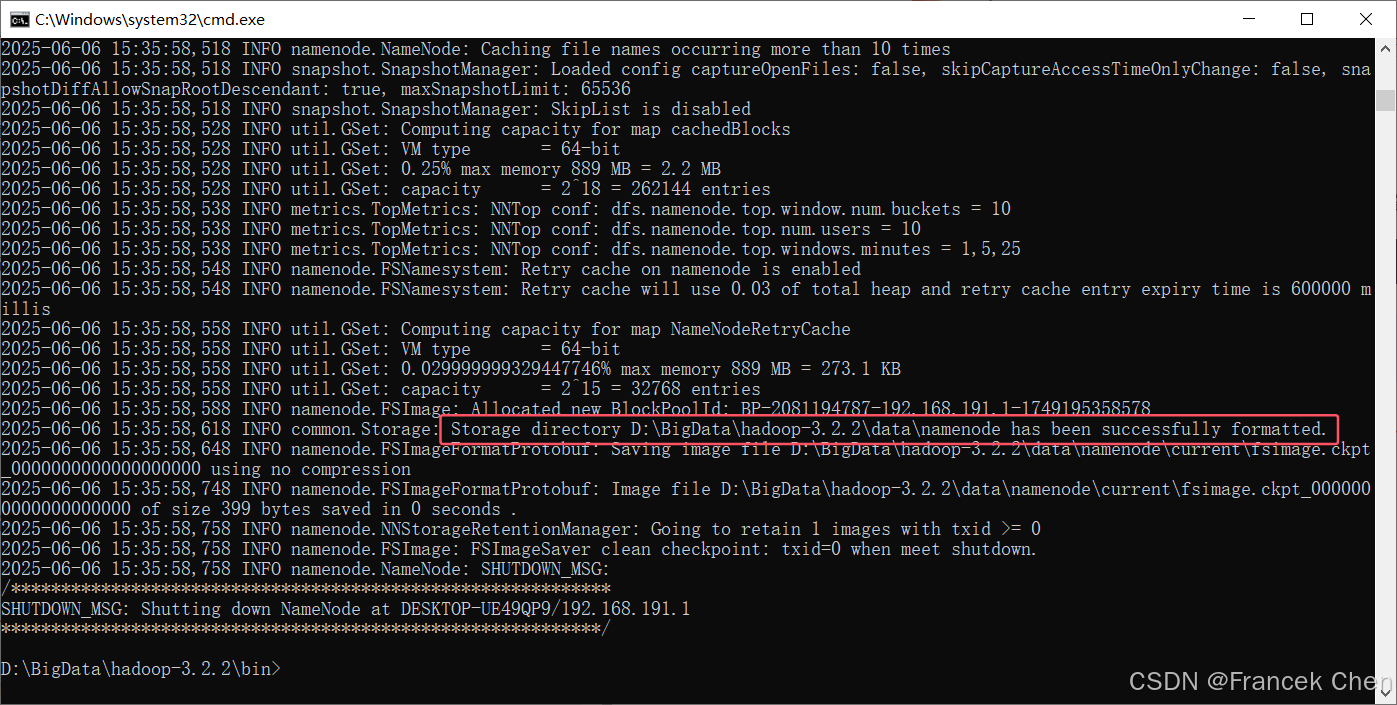
图19 格式化NameNode成功
(五)启动Hadoop
格式化HDFS后,便可以启动Hadoop。在Hadoop家目录的sbin目录中执行start-all.cmd脚本文件,如图20。执行命令启动Hadoop后,将弹出4个窗口,分别是Apache Hadoop Distribution - hadoop namenode、Apache Hadoop Distribution - hadoop datenode、Apache Hadoop Distribution - yarn resourcemanager、Apache Hadoop Distribution - yarn nodemanager,Hadoop启动后打开的窗口,如图21。
bash
start-all.cmd
图20 启动Hadoop集群
图21 Hadoop启动后打开的窗口
(六)验证Hadoop是否安装成功
打开浏览器,在地址栏输入"http://localhost:9870"网址,该页面为Hadoop的Web UI界面,如下图,正常显示该页面内容即表示Hadoop配置正确且正常运行。
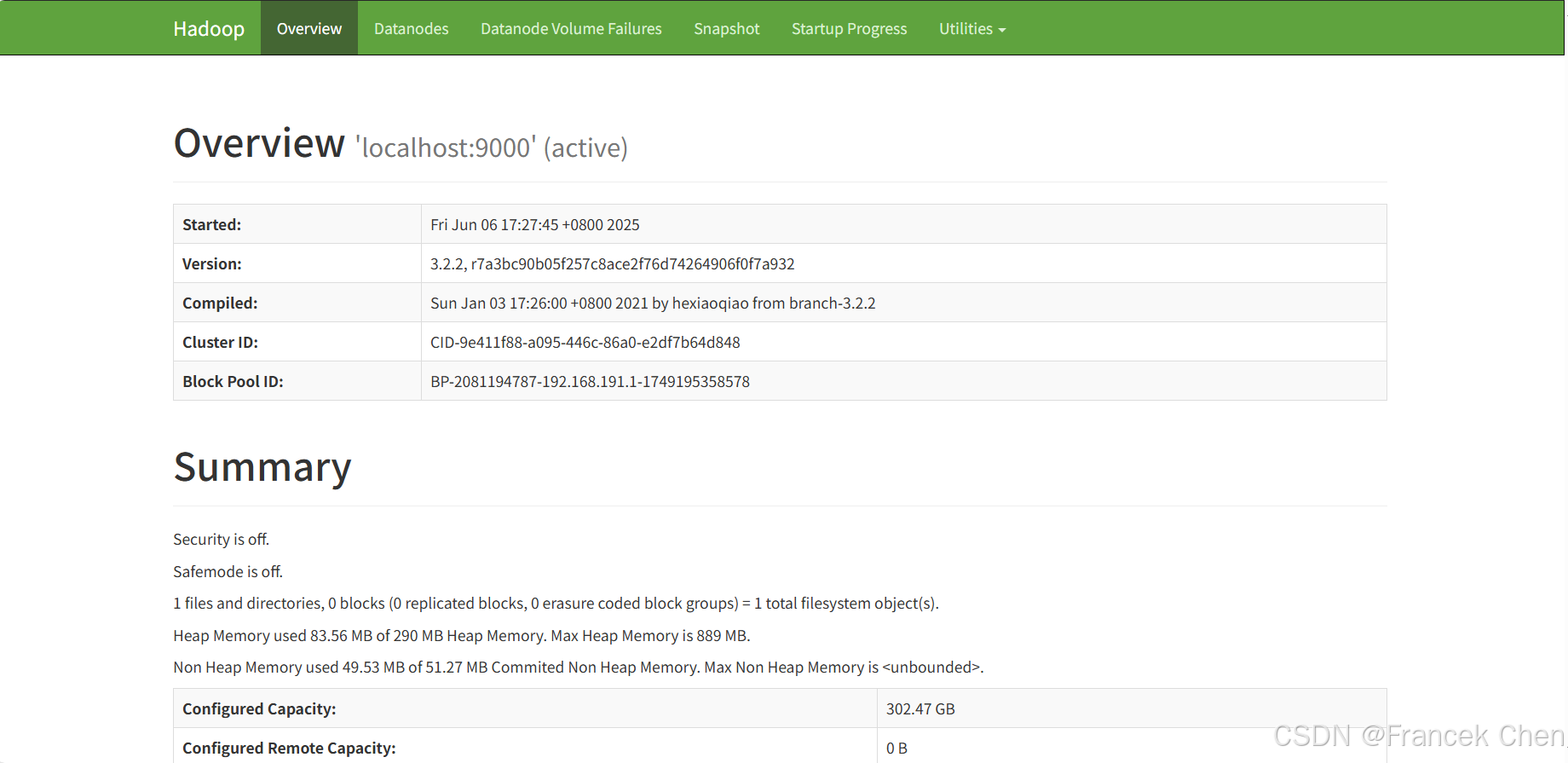
图22 Hadoop的Web UI界面
关闭Hadoop服务,直接×掉,或者使用如下命令:stop-all.cmd
四、安装MySQL
数据仓库Hive在运行时,需要数据库系统为Hive提供元数据存储服务,需要安装数据库管理系统。
MySQL下载链接为:https://dev.mysql.com/downloads/installer/,我这里使用的版本是mysql-installer-community-8.0.21.0.msi。
这里建议选择这两种安装模式:
- Developer Default:开发者默认选择,安装比较简便也是大多数人的选择。不过唯一的缺点,安装在C盘。 如果不打算安装在C盘,不要选择。安装mysql服务器以及开发mysql应用所需的工具。
- Custom:自定义安装,如果想安装在D盘请选择。
我选择的是自定义安装。如图23所示。
图23 自定义安装MySQL
建议每个都点开看看,然后再开始选择设置的位置。比如在D盘的某个位置建立MySQL和MySQLData两个文件夹。将所有MySQL的组件安装在MySQL下,将数据部分安装在MySQLData下。也就是路径上带Data的放在MySQLData,不带的放置在MySQL下。
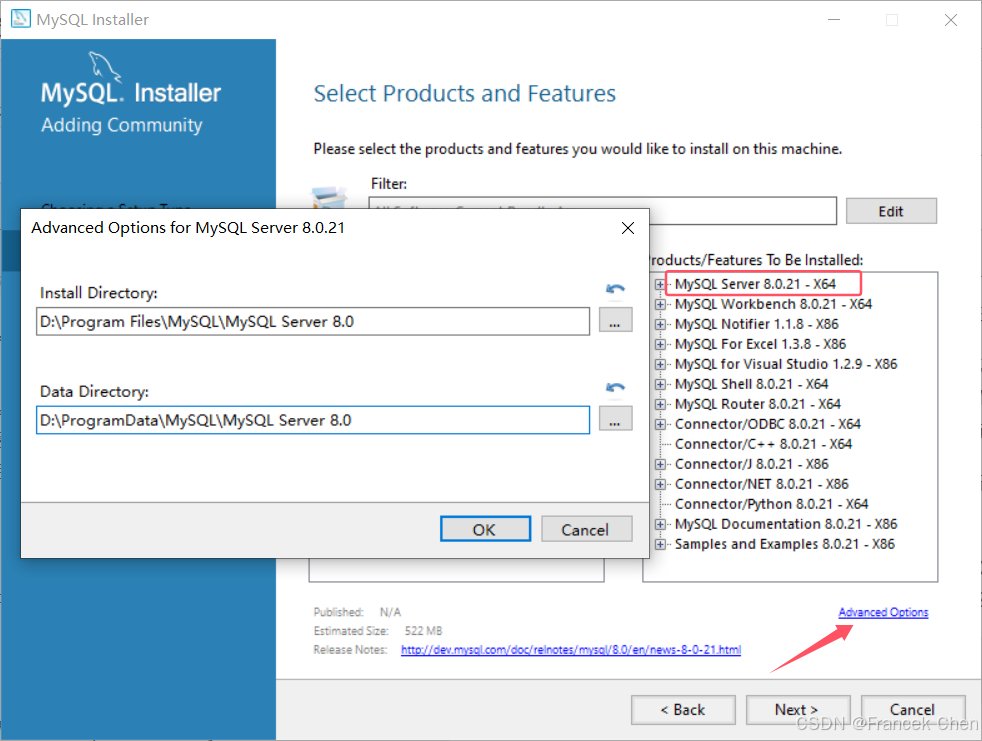
图24 自定义MySQL安装目录
点击"Execute"开始安装MySQL。
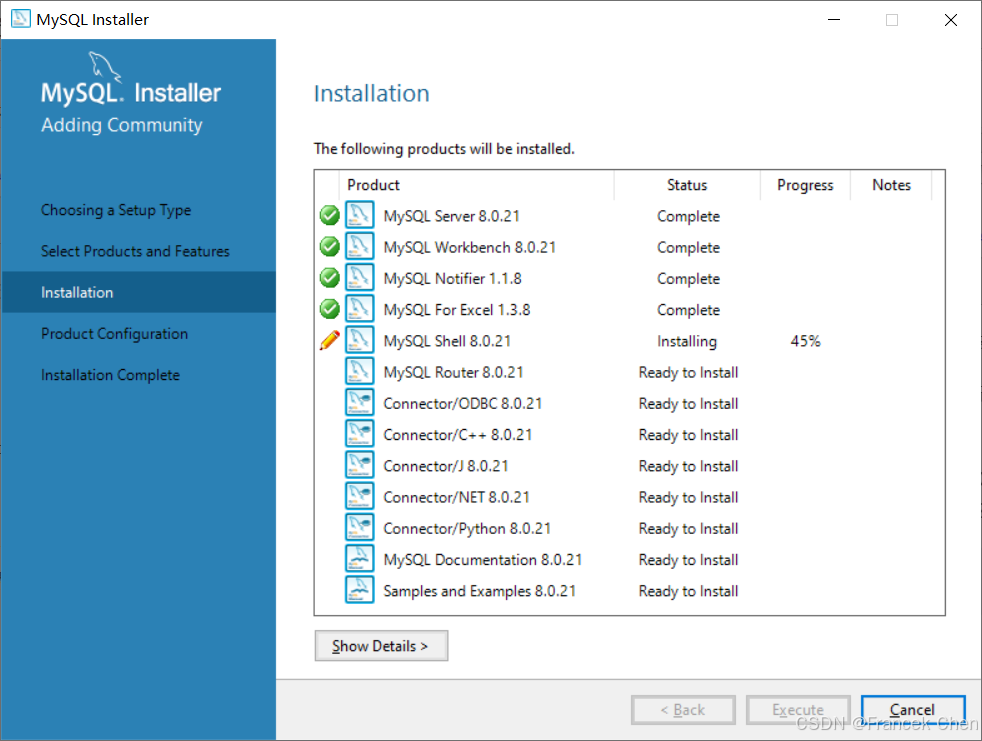
图25 正在安装MySQL
在Windows系统下安装MySQL可参考安装中的文字提示完成MySQL数据库的安装,其中设置用户名为root,密码为123456。
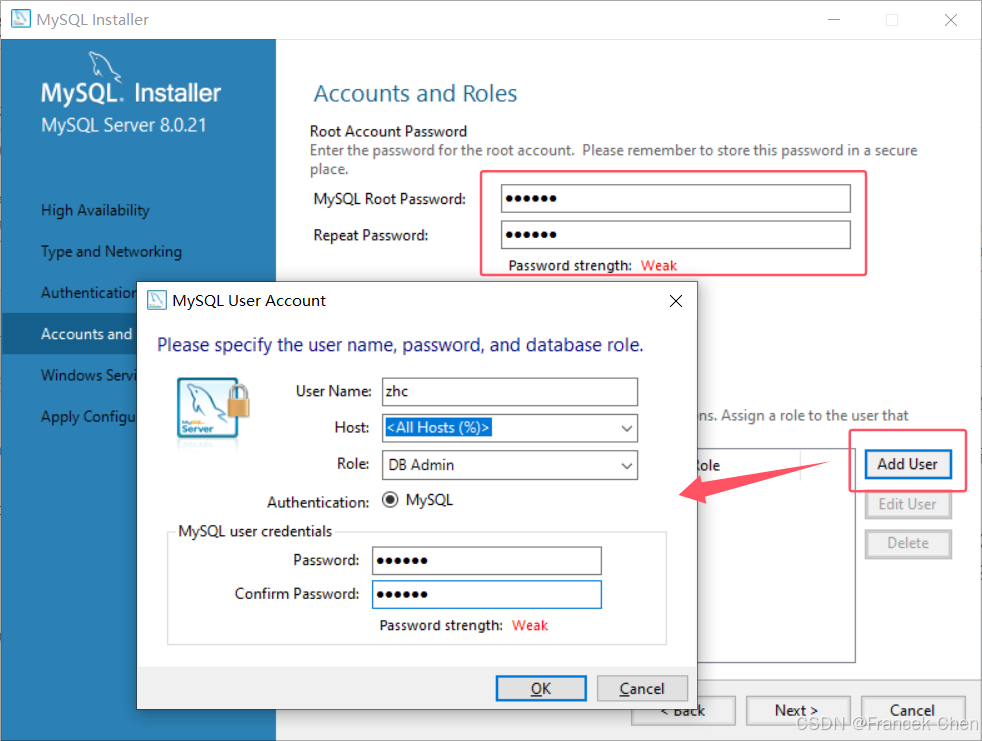
图26 设置MySQL用户名和密码
安装完成后,在Windows开始菜单中,依次选择"MySQL"→"MySQL 8.0 Commnad Line Client"。
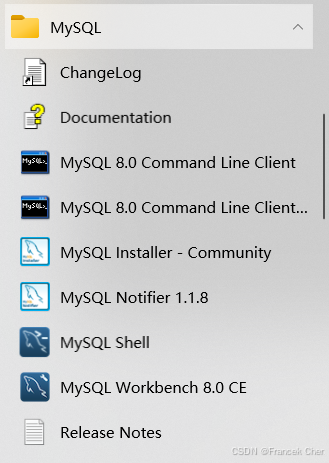
图27 在Windows开始菜单中选择并启动MySQL
在启动的窗口中,输入root用户的密码(本文设置为"123456")即可登录MySQL客户端。
图28 登录MySQL客户端
输入"quit"即可退出客户端。
还要在系统变量中添加Path环境变量,我的路径如图29所示。
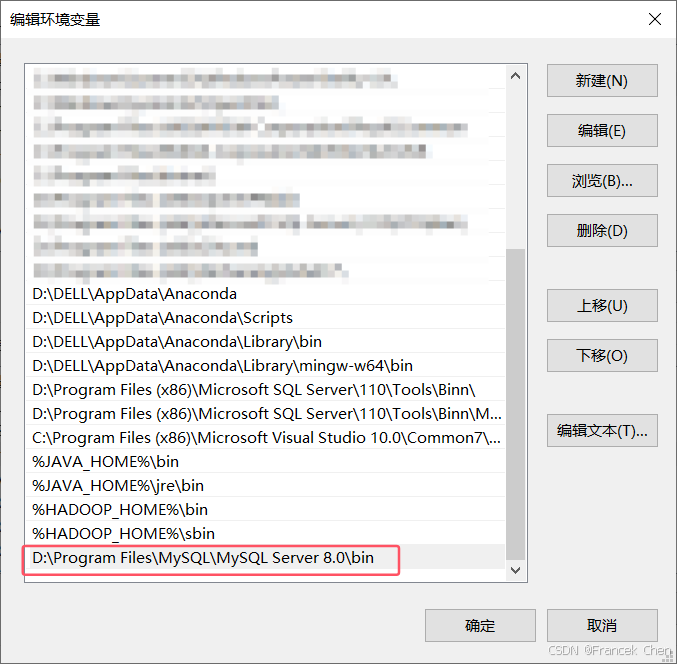
图29 添加MySQL环境变量
最后,Win+R输入cmd,再输入mysql -u root -p,看能否输入密码登录mysql。如果成功,恭喜配置完成。
图30 成功配置MySQL环境变量
五、安装Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能,可为PySpark提供数据存储服务。
(一)安装Hive并配置环境变量
在官网下载Hive安装包,并将Hive的安装包解压至本地文件路径中(如"D:\BigData\hive-3.1.1",下文将其称为HIVE_HOME路径)。我这里下载的是hive-3.1.1版本。
配置环境包括:
- 新建HIVE_HOME环境变量,指定Hive家目录(即Hive安装包解压目录),如图31。
- 编辑Path环境变量,指定Hive中可执行程序的路径(即Hive安装包解压目录的bin目录),如图32。
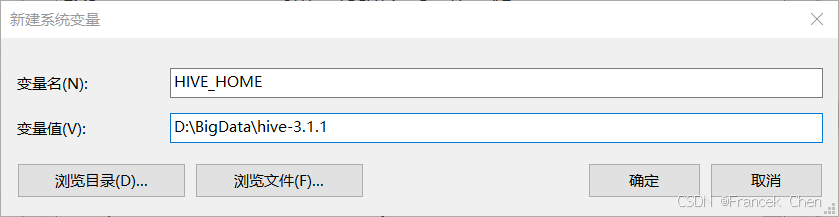
图31 设置HIVE_HOME环境变量
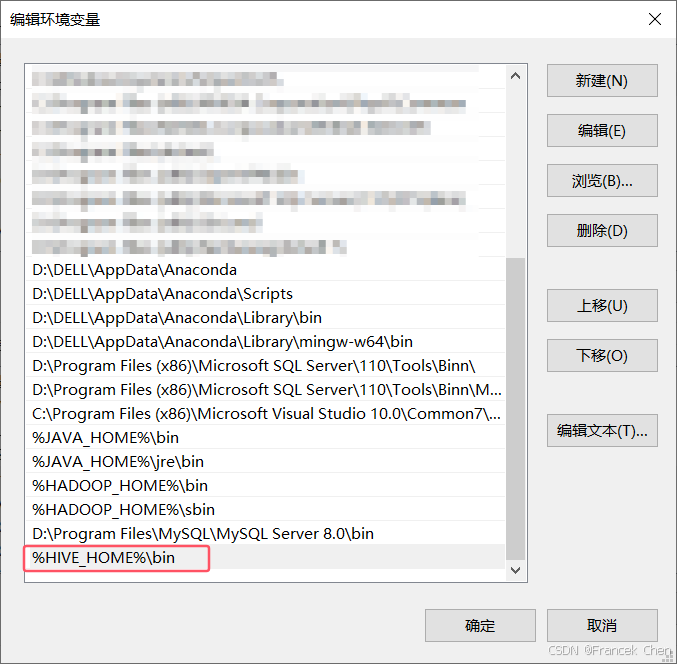
图32 编辑Path环境变量
(二)配置MySQL驱动
Hive需要将元数据存储至数据库中,本文使用MySQL作为Hive元数据存储数据库。Hive需要访问MySQL数据库,则需要为Hive提供MySQL的JDBC驱动JAR包(mysql-connector-java-8.0.21.jar),将该JAR包复制至HIVE_HOME\lib目录下,否则Hive不能成功连接MySQL数据库。
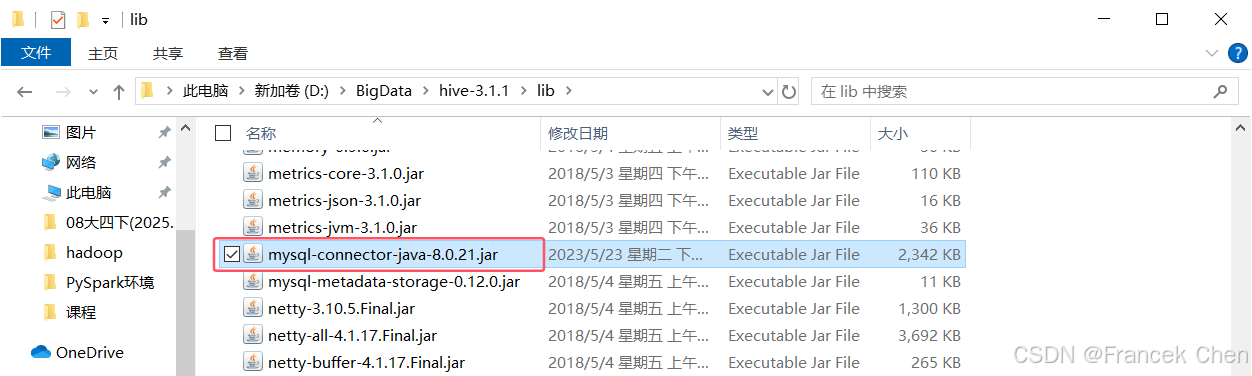
图33 配置Hive的MySQL驱动
(三)在HDFS文件系统中创建目录
Hive将表中的数据是以文件形式存储在HDFS文件系统中的,因此需要在HDFS中为Hive创建存储目录。打开cmd命令提示符,进入命令执行界面。在HDFS文件系统中创建tmp目录,user目录及其子目录,并设置组可写权限(在HDFS文件系统中创建目录前需要先启动Hadoop)。如图34所示。
bash
hadoop fs -mkdir /tmp
hadoop fs -chmod g+w /tmp
hadoop fs -mkdir -p /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod g+w /user/hive/warehouse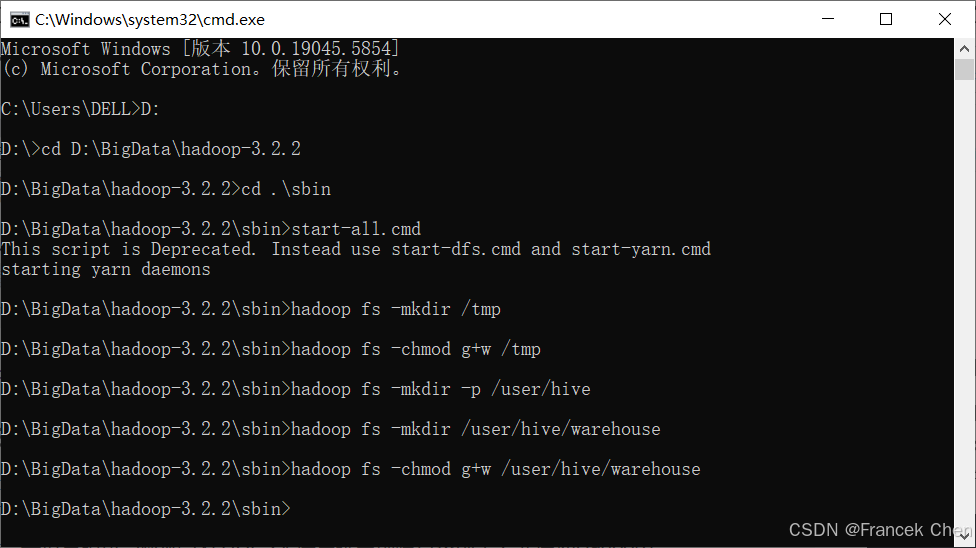
图34 在HDFS中创建Hive存储目录
(四)创建data目录及其子目录
在HIVE_HOME对应的路径中,创建本地data目录。在data目录创建operation_logs、querylog、resources、scratch子目录用于存储Hive本地日志内容,如图35所示。
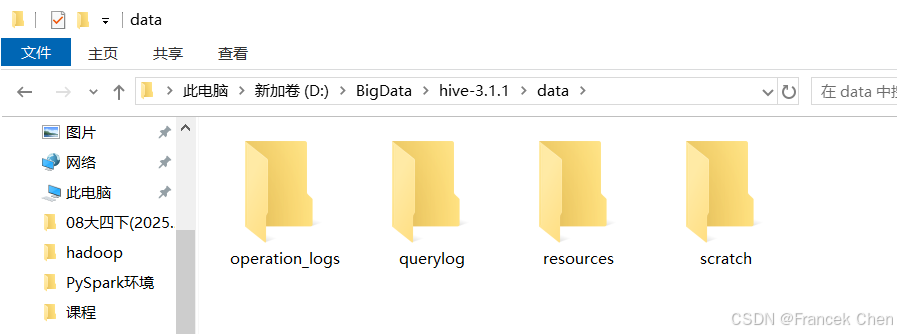
图35 在data目录中创建子目录
(五)修改hive-site.xml文件
复制HIVE_HOME目录的conf目录下的hive-default.xml.template文件并重命名为hive-site.xml,并修改文件内容(注意将配置文件中的路径替换成实际路径)。该文件休要修改的内容比较多。
xml
<configuration>
<!-- scratch 本地目录 -->
<property>
<name>hive.exec.local.scratch.dir</name>
<value>D:/BigData/hive-3.1.1/data/scratch</value>
<description>Local scratch space for Hive jobs</description>
</property>
<!-- resources_dir 本地目录 -->
<property>
<name>hive.downloaded.resources.dir</name>
<value>D:/BigData/hive-3.1.1/data/resources</value>
<description>Temporary local directory for added resources in the remotefile system.</description>
</property>
<!-- querylog 本地目录 -->
<property>
<name>hive.querylog.location</name>
<value>D:/BigData/hive-3.1.1/data/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
<!-- operation_logs 本地目录 -->
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>D:/BigData/hive-3.1.1/data/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>
<!-- 数据库连接地址配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=TRUE&serverTimezone=GMT&characterEncoding=UTF-8&allowPublicKeyRetrieval=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore.</description>
</property>
<!-- 数据库驱动配置 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!-- 数据库用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>
<!-- 数据库访问密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<!-- 解决 Caused by: MetaException(message:Version information not found in metastore. ) -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
<!-- 自动创建全部 -->
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<!-- HIVE 3.1.1 hive-site.xml 3210行 description有错误,删除 -->
<description>
Ensures commands with OVERWRITE (such as INSERT OVERWRITE) acquire Exclusive locks for transactional tables. This ensures that inserts (w/o overwrite) running concurrently are not hidden by the INSERT OVERWRITE.
</description>
</configuration>(六)修改hive-env.sh
复制HIVE_HOME目录的conf目录下的hive-env.sh.template文件并重命名为hive-env.sh,修改文件内容,配置Hive所需要的环境变量信息。
sh
HADOOP_HOME=D:\BigData\hadoop-3.2.2
export HIVE_CONF_DIR=D:\BigData\hive-3.1.1\conf
export HIVE_AUX_JARS_PATH=D:\BigData\hive-3.1.1\lib(七)复制Hive运行文件
Hive1.2以后版本不再提供Windows下的命令行工具,无法通过命令行工具访问Hive数据仓库。该工具可以在hive.1.2.2-src源码包中找到,复制hive.1.2.2-src安装包中的bin目录至Hive的家目录中,覆盖Hive家目录原有的bin目录。执行后,Hive的bin目录文件如图36所示,其中,hive.cmd为Windows系统下的Hive命令行工具。
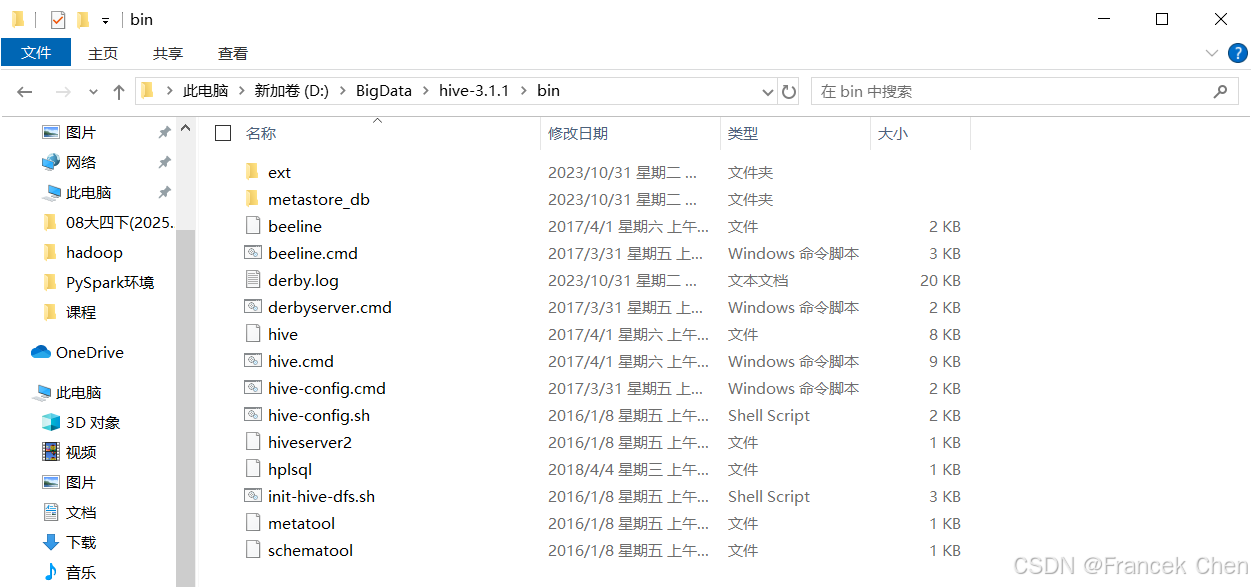
图36 Hive的bin目录文件
(八)初始化Hive元数据
Hive将元数据存储在MySQL数据库中,运行Hive前,需要初始化Hive元数据库,创建存储Hive元数据的数据表。打开cmd命令提示符,输入cd D:\BigData\hive-3.1.1\bin命令,切换工作目录至"D:\BigData\hive-3.1.1\bin",输入hive --service schematool -dbType mysql -initSchema命令初始化Hive元数据库,执行成功后显示"Initialization script completed schemaTool completed"信息。
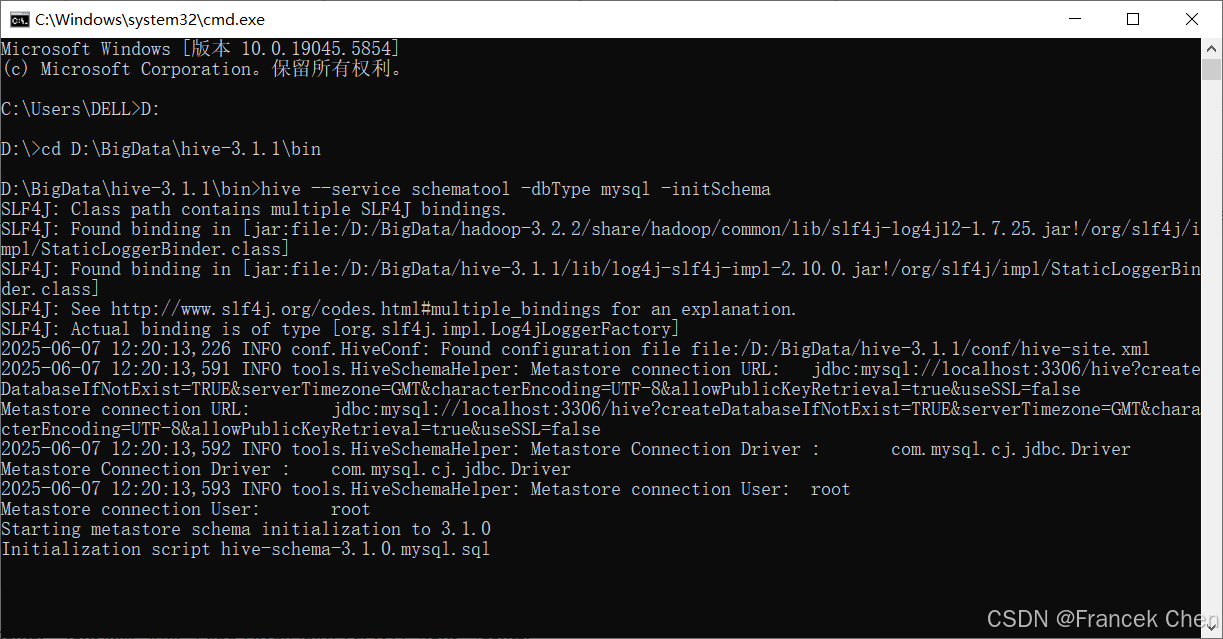
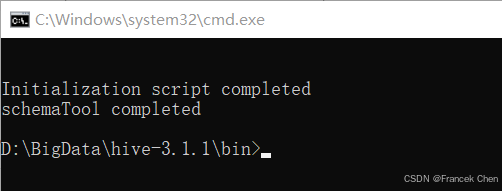
图37 元数据库初始化成功后显示信息
在cmd命令提示符窗口中,输入并执行hive --service schematool -dbType mysql -info命令,查看元数据库初始化信息,如图38所示。
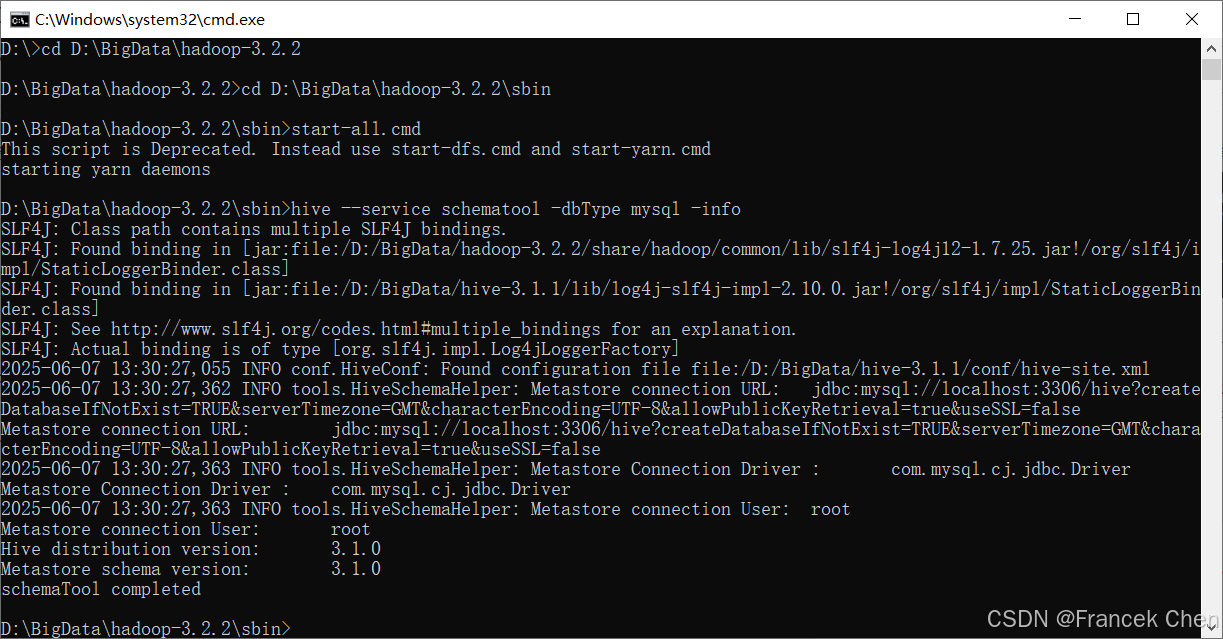
图38 查看元数据库初始化信息
(九)启动Hive
打开cmd命令提示符,切换工作目录至"D:\BigData\hive-3.1.1\bin",执行bin目录中的Hive.cmd文件,执行成功后,会出现"hive> "提示符,表示Hive运行成功,如图39所示。
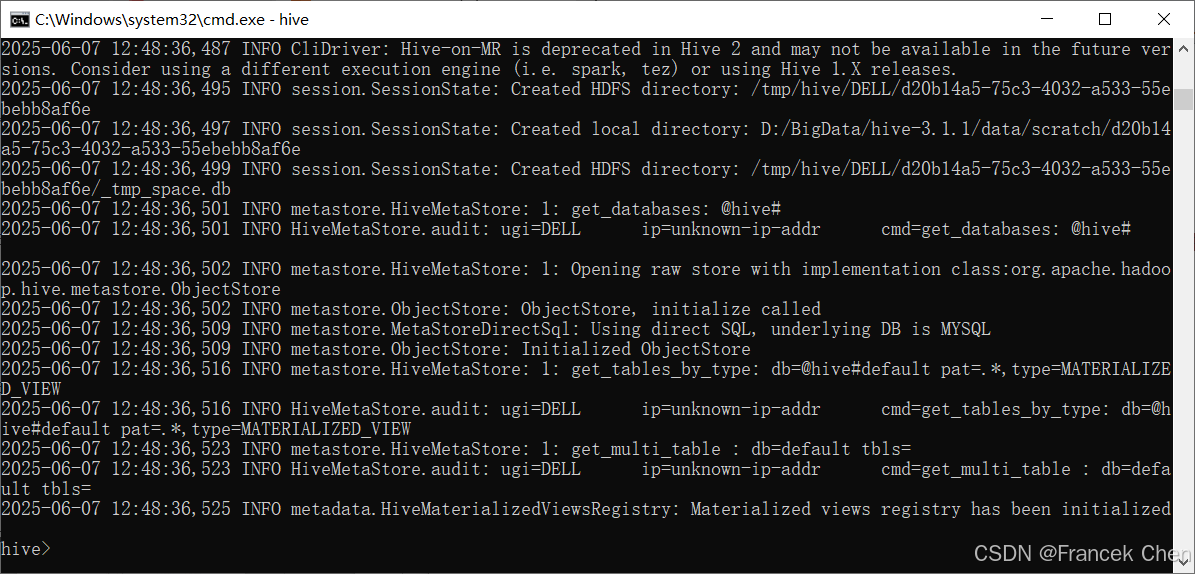
图39 Hive运行界面
输入命令quit;即可退出hive。
注意,启动Hive之前,要确保MySQL服务已启动!
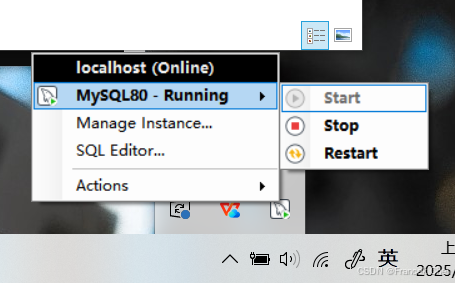
图40 MySQL服务已启动
六、配置PySpark模块
(一)安装pyspark模块
PySpark模块实现调用Spark功能的Python接口,可以使用Anaconda包管理器安装PySpark模块。打开Anaconda Navigator,在左侧导航栏依次选择"Environments"→"pyspark"选项,在右边窗口中的下拉框选择"ALL",并在搜索框搜索"pyspark",选中后单击"Apply"按钮安装pyspark模块。
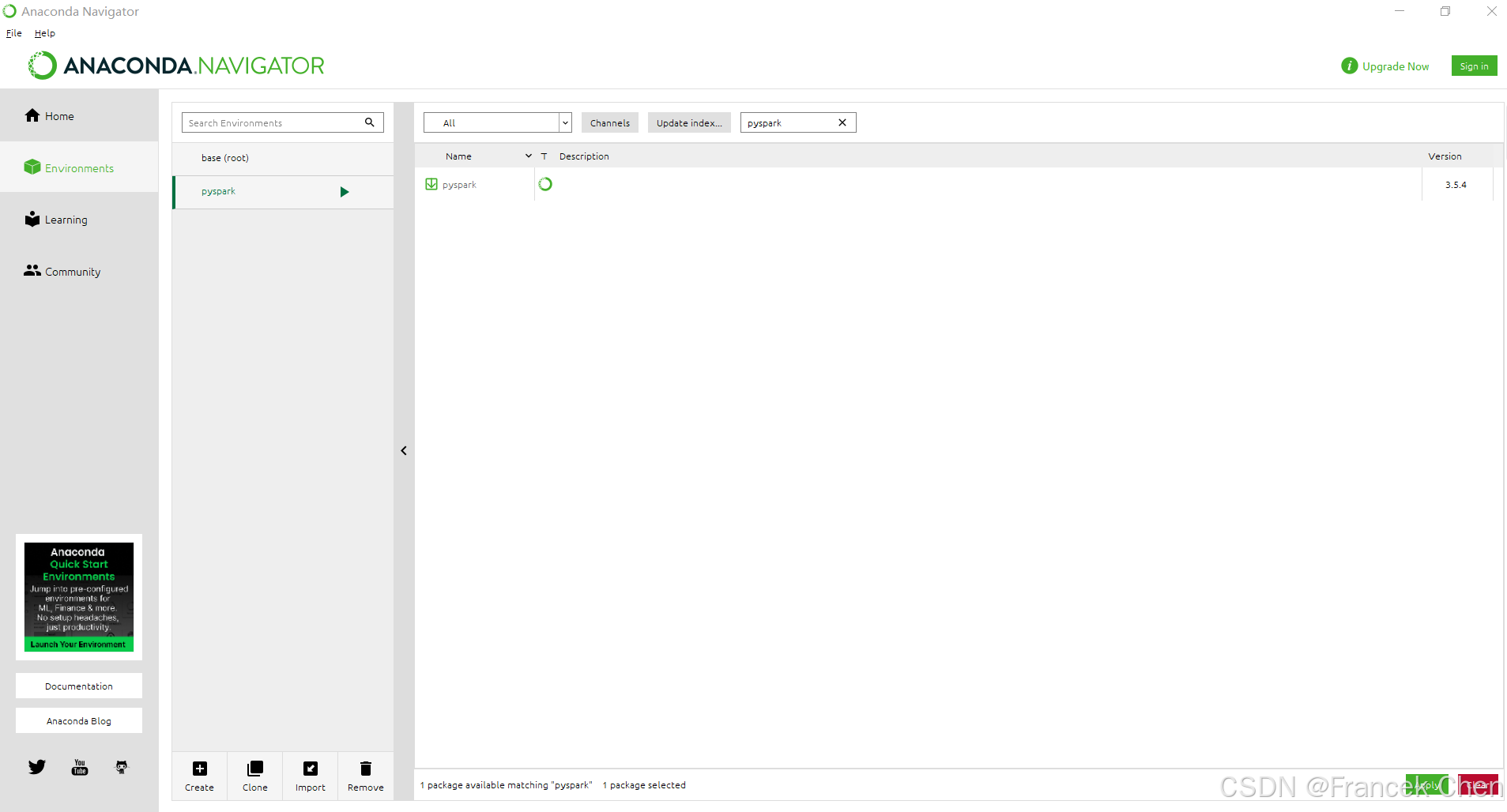
图41 在Anaconda中安装PySpark模块
安装成功后,将Hive的配置文件hive-site.xml复制到PySpark的配置文件夹中(即路径ANACONDA_HOME\env环境名称Lib\site-packages\pyspark\conf),本文的路径为"D:\DELL\AppData\Anaconda\envs\pyspark\Lib\site-packages\pyspark\conf",conf文件夹需手动创建。
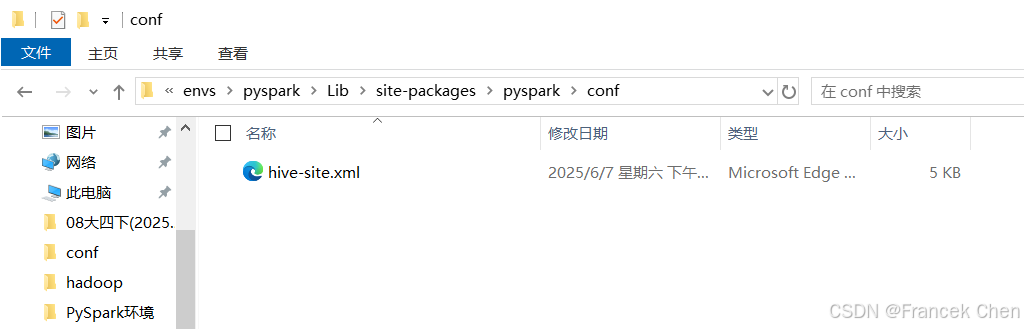
图42 复制hive-site.xml到PySpark的配置文件夹conf
(二)配置MySQL驱动
Anaconda中的pyspark环境也需要连接MySQL数据库,要将MySQL数据库驱动程序JAR包(mysql-connector-java-8.0.21.jar)复制到Anaconda\envs\pyspark\Lib\site-packages\jar目录下,我的路径为"D:\DELL\AppData\Anaconda\envs\pyspark\Lib\site-packages\jar"。(jar文件夹没有的话自己新建)
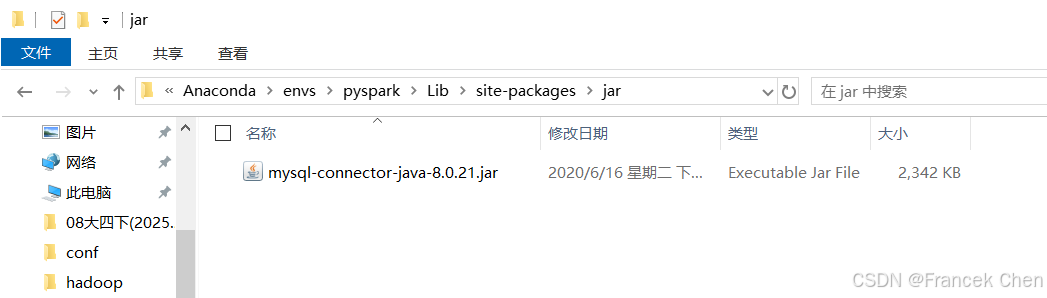
图43 配置Anaconda中pyspark环境的MySQL驱动
为了让PySpark能够顺利连接MySQL数据库,还需要MySQL数据库驱动程序。将MySQL的JDBC驱动JAR包(mysql-connector-java-8.0.21.jar)复制至pyspark\Lib\site-packages\pyspark\jars目录下,否则PySpark不能成功连接MySQL数据库。(我的路径为"D:\DELL\AppData\Anaconda\envs\pyspark\Lib\site-packages\pyspark\jars")
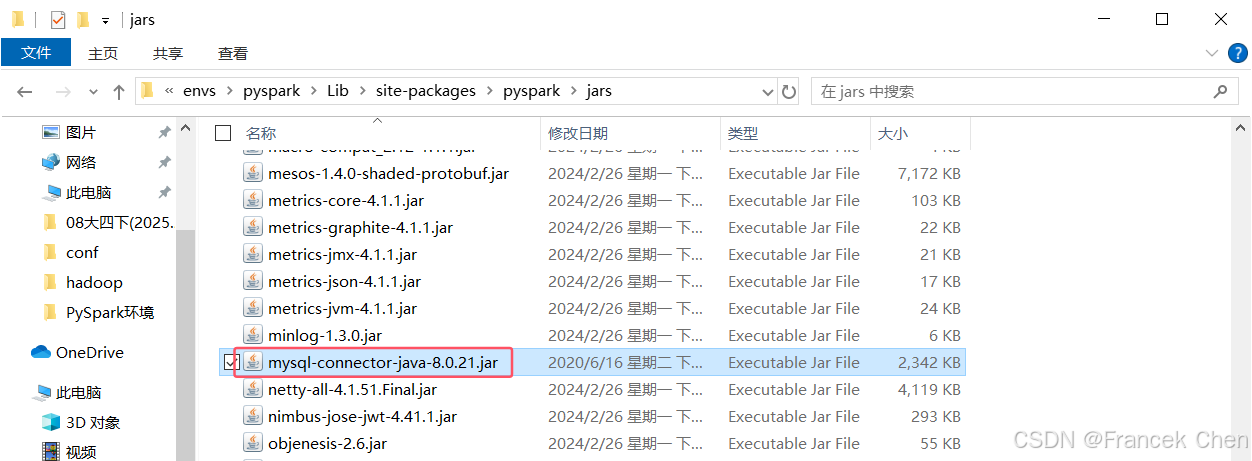
图44 配置pyspark库的MySQL驱动
(三)配置环境变量
在电脑环境变量中添加Python解释器路径,其中变量名为PYSPARK_PYTHON,变量值为创建的PySpark环境中的python.exe,本文设置为"D:\DELL\AppData\Anaconda\envs\pyspark\python.exe"。
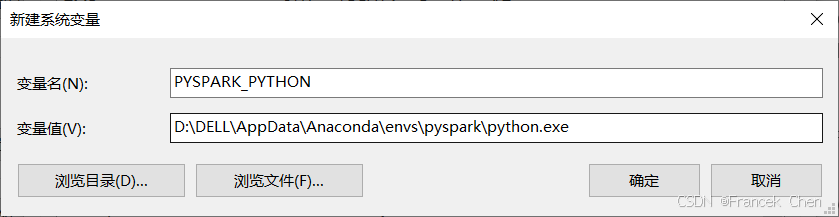
图45 添加PYSPARK_PYTHON环境变量
七、运行Jupyter Notebook
打开Anaconda Navigator,在Home页面的"Applications on"选择pyspark,单击运行Jupyter Notebook,Anaconda将会打开浏览器,并连接到Jupyter Notebook。为了验证PySpark单机运行环境是否搭建成功,可以在Jupyter Notebook新建一个Python3的笔记本,在单元格中编写程序进行测试(注意运行代码前需要先启动Hadoop和Hive服务)。
python
import sys
print(sys.version)
print(sys.executable)
python
from pyspark.sql import SparkSession
spark = SparkSession.builder.enableHiveSupport().getOrCreate()
spark
python
spark.sql("create table test(id int);")
spark.sql("show tables;").show()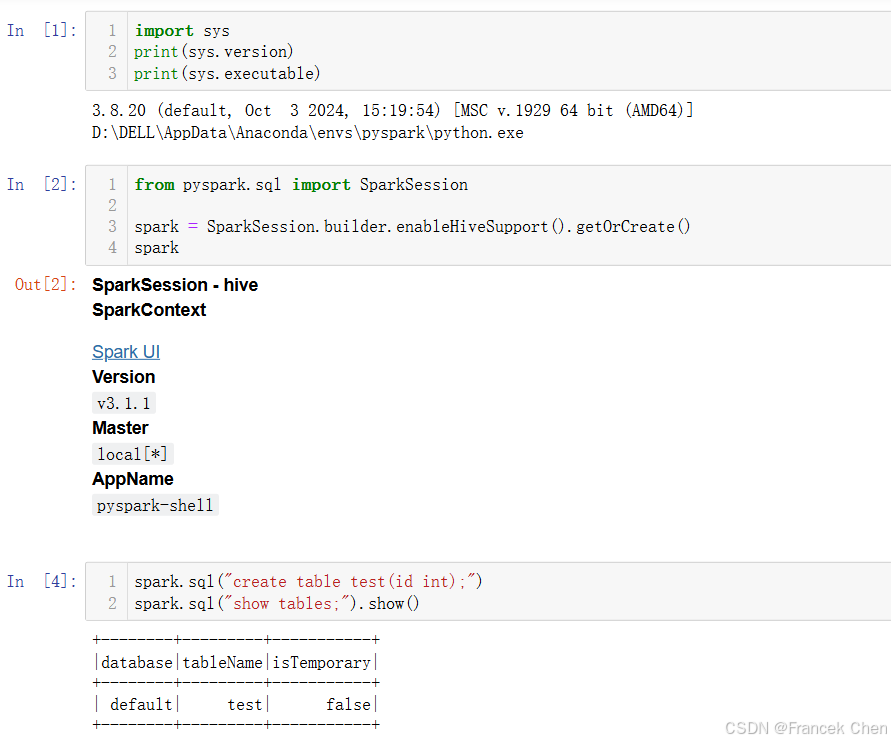
至此,单机模式的PySpark开发环境搭建完成。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
