作者:来自 Elastic Brad Deam 及 Christos Argyropoulos

了解 Elastic SRE 团队如何发现并解决 Azure Kubernetes Service (AKS) 中意外的数据包丢失问题,该问题影响了 Elastic Cloud Serverless 的性能。
发现总结
Elastic 的站点可靠性工程团队(SRE)在运行于 Azure Kubernetes Service (AKS) 上的 Elastic Cloud Serverless 中观察到吞吐量不稳定和数据包丢失。经调查,主要原因是 SR-IOV 接口的 RX 环形缓冲区溢出和内核输入队列饱和。为此,我们增大了 RX 缓冲区大小并调整了 netdev backlog,显著提升了网络稳定性。
背景介绍
Elastic Cloud Serverless 是一款完全托管的解决方案,允许你部署并使用 Elastic,而无需管理底层基础设施。基于 Kubernetes 构建,它改变了你与 Elasticsearch 交互的方式。你无需管理集群、节点、数据层和扩展,只需创建由 Elastic 全自动管理和扩展的无服务器项目。这种基础设施抽象让你专注于从数据中获取价值和洞察。
Elastic Cloud Serverless 已在 AWS、GCP 上正式发布(GA),目前在 Azure 上处于技术预览阶段。为准备 Azure 上的正式发布,我们进行了广泛的性能和扩展性测试,以确保用户获得稳定可靠的体验。
本文将带你深入了解一项针对 Azure Kubernetes 集群中 Serverless Elasticsearch 令人意外的性能问题的技术调查。起初,网络似乎是最不可能出现问题的地方,尤其是在主机拥有高速 100 Gb/s 接口的情况下。但在 Microsoft Azure 团队的协助下,调查深入后,问题正是出在这里。
意外结果!
尽管主要云供应商的架构和系统设计模式通常类似,但具体实现不同,这些差异对系统性能影响巨大。
不同云供应商间最大的差异之一是虚拟机的底层虚拟机监控软件和服务器硬件可能有显著差异,甚至同一供应商的不同实例系列间也存在差异。
硬件无法完全被应用层抽象掉。Elasticsearch 的性能本质上取决于物理服务器的 CPU、内存、磁盘和网络接口。为准备 Azure 上 Elastic Cloud Serverless 正式发布,Elasticsearch 性能团队启动了针对运行于 Azure Kubernetes Service (AKS) 上的 Serverless Elasticsearch 项目的大规模负载测试,使用了 ARM 架构的虚拟机(我们非常喜欢!)。在此过程中,团队大量依赖 Elastic 工具分析系统行为、识别瓶颈,并验证负载下的性能。
性能团队使用 Rally(一款开源基准测试工具)来衡量 Elasticsearch 集群性能。此次测试使用了 GitHub Archive Track。Rally 通过官方 Python 客户端发送测试遥测数据到一个运行 Elastic Observability 的 Elasticsearch 集群,使团队能够通过 Kibana 实时监控和分析测试过程。
测试结果显示,Serverless 项目的索引速率(每秒文档数)不仅远低于硬件预期,而且吞吐量极不稳定,出现峰谷交替和频繁错误,而我们原本期待的是稳定的索引速率。
这些测试旨在将系统推向极限,因此暴露出了索引吞吐量不稳定和间歇性错误的异常行为。正是我们希望在正式发布前发现的问题,让我们有机会与 Azure 紧密合作解决。
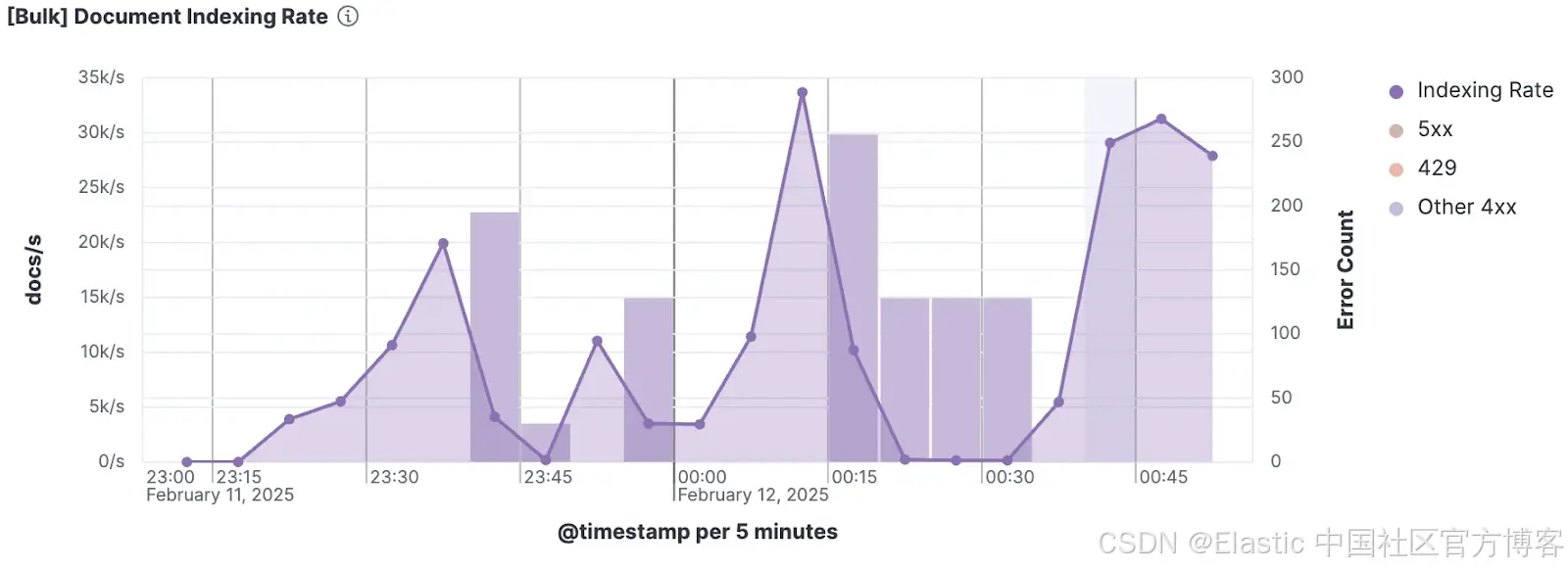 Kibana 中的 Rally 遥测可视化,显示 Elasticsearch 索引速率波动,同时伴随 5xx 和 4xx HTTP 错误响应的峰值。
Kibana 中的 Rally 遥测可视化,显示 Elasticsearch 索引速率波动,同时伴随 5xx 和 4xx HTTP 错误响应的峰值。
调试!
调试性能问题有点像在 "飓风中找蝴蝶",所以采用系统化的方法分析应用和系统性能非常关键。
使用方法论能让你更有条理、更全面地调试,避免遗漏。我们从利用率、饱和度和错误(USE)方法开始,检查客户端和服务器端,找出系统中的明显瓶颈。
Elastic 的站点可靠性工程师(SRE)维护了一套自定义的 Elastic Observability 仪表盘,用于可视化从各种 Elastic 集成中收集的数据。这些仪表盘能深入了解 Elastic Cloud 基础设施和系统的健康状况与性能。
此次调查中,我们利用了一个基于 System 和 Linux 集成的指标和日志数据构建的自定义仪表盘:
 这是 SRE 团队构建和维护的众多 Elastic Observability 仪表盘之一。
这是 SRE 团队构建和维护的众多 Elastic Observability 仪表盘之一。
按照 USE 方法,这些仪表盘突出显示了我们系统中的资源利用率、饱和度和错误。在它们的帮助下,我们迅速发现承载测试中 Elasticsearch pod 的 AKS 节点每秒丢失了数千个数据包。
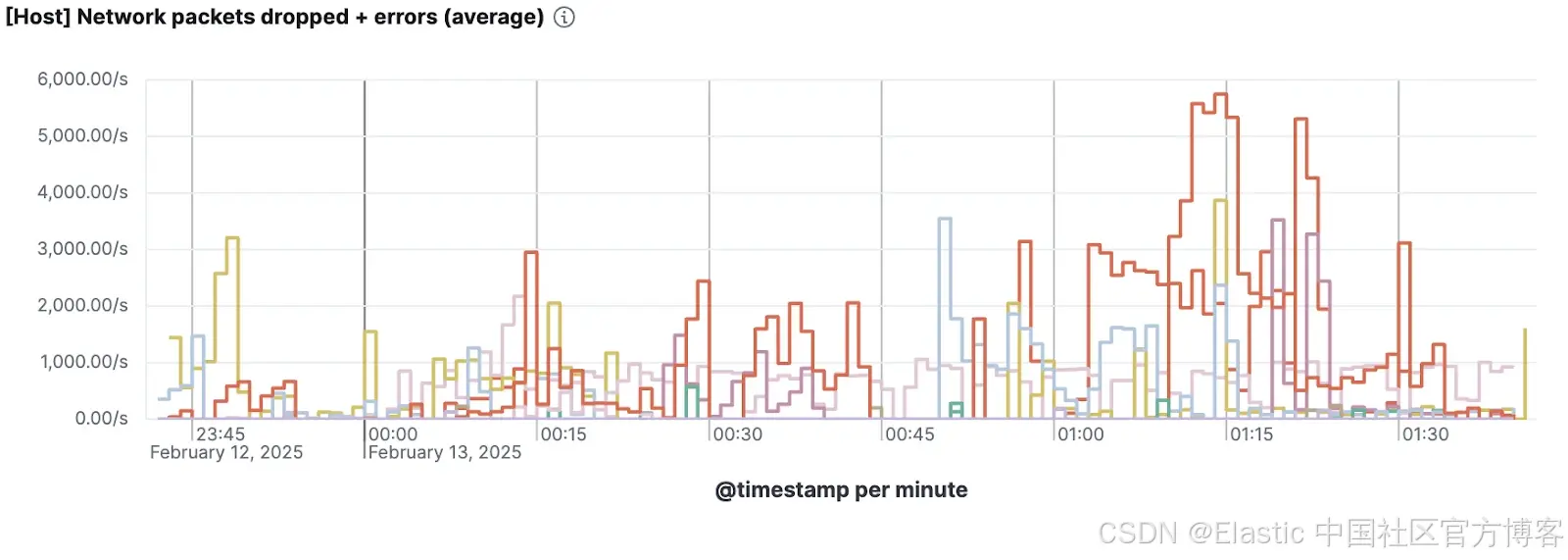 Kibana 中 Elastic Agent 的 System Integration 可视化,显示 AKS 节点每秒的数据包丢失率。
Kibana 中 Elastic Agent 的 System Integration 可视化,显示 AKS 节点每秒的数据包丢失率。
数据包丢失会迫使可靠协议(如 TCP)重传丢失的数据包。重传会引入显著延迟,严重影响吞吐量,尤其是在客户端请求仅在上一个请求完成后才触发(称为闭环系统)的情况下。
为进一步调查,我们登录到其中一个出现数据包丢失的 AKS 节点,检查基础情况。首先,我们想确定丢包或错误的类型;是针对特定的 pod,还是整个主机?
root@aks-k8s-node-1:~# ip -s link show
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 7c:1e:52:be:ce:5e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped missed mcast
373507935420 134292481 0 0 0 15
TX: bytes packets errors dropped carrier collsns
644247778936 303191014 0 0 0 0
3: enP42266s1: <BROADCAST,MULTICAST,SLAVE,UP,LOWER_UP> mtu 1500 qdisc mq master eth0 state UP mode DEFAULT group default qlen 1000
link/ether 7c:1e:52:be:ce:5e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped missed mcast
386782548951 307000571 0 0 5321081 0
TX: bytes packets errors dropped carrier collsns
655758630548 477594747 0 0 0 0
altname enP42266p0s2
15: lxc0ca0ec41ecd2@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether f6:f5:5e:c9:4e:fb brd ff:ff:ff:ff:ff:ff link-netns cni-3f90ab53-df66-cac5-bd19-9cea4a68c29b
RX: bytes packets errors dropped missed mcast
627954576078 54297550 0 1600 0 0
TX: bytes packets errors dropped carrier collsns
372155326349 133538064 0 3927 0 0在这个输出中,你可以看到 enP42266s1 接口在 missed 列显示了大量的数据包。这很有意思,但 missed 实际上代表什么?enP42266s1 又是什么?
要理解这些,我们先大致了解数据包到达网卡(NIC)时发生的过程:
-
数据包从网络到达 NIC。
-
NIC 使用 DMA(直接内存访问)将数据包放入由内核分配、映射供 NIC 使用的接收环形缓冲区。由于我们的 NIC 支持多个硬件队列,每个队列都有自己的专用环形缓冲区、中断请求(IRQ)和 NAPI 上下文。
-
NIC 触发硬件中断(IRQ),通知 CPU 有数据包准备好。
-
CPU 执行 NIC 驱动的 IRQ 处理程序。驱动安排 NAPI(新 API)轮询,将数据包处理延后到软中断(softirq)上下文。这是 Linux 内核中一种机制,用于将工作推迟到硬中断上下文之外执行,以便更好地批处理和提高 CPU 效率,从而提升可扩展性。
-
NAPI 轮询函数在软中断上下文(NET_RX_SOFTIRQ)中执行,从环形缓冲区获取数据包。轮询会持续,直到驱动的数据包预算耗尽(net.core.netdev_budget)或时间限制到达(net.core.netdev_budget_usecs)。
-
每个数据包被封装在 sk_buff(socket buffer)结构中,包含协议头、时间戳和接口标识等元数据。
-
如果网络栈处理速度慢于 NAPI 获取数据包的速度,多余的数据包会排入每个 CPU 的后备队列(通过 enqueue_to_backlog)。该队列最大大小由 net.core.netdev_max_backlog sysctl 控制。
-
数据包随后交给内核网络栈进行路由、过滤和协议特定处理(如 TCP、UDP)。
-
最后,数据包进入对应的套接字接收缓冲区,供用户空间应用程序消费。
用图示来看,大致是这样的:
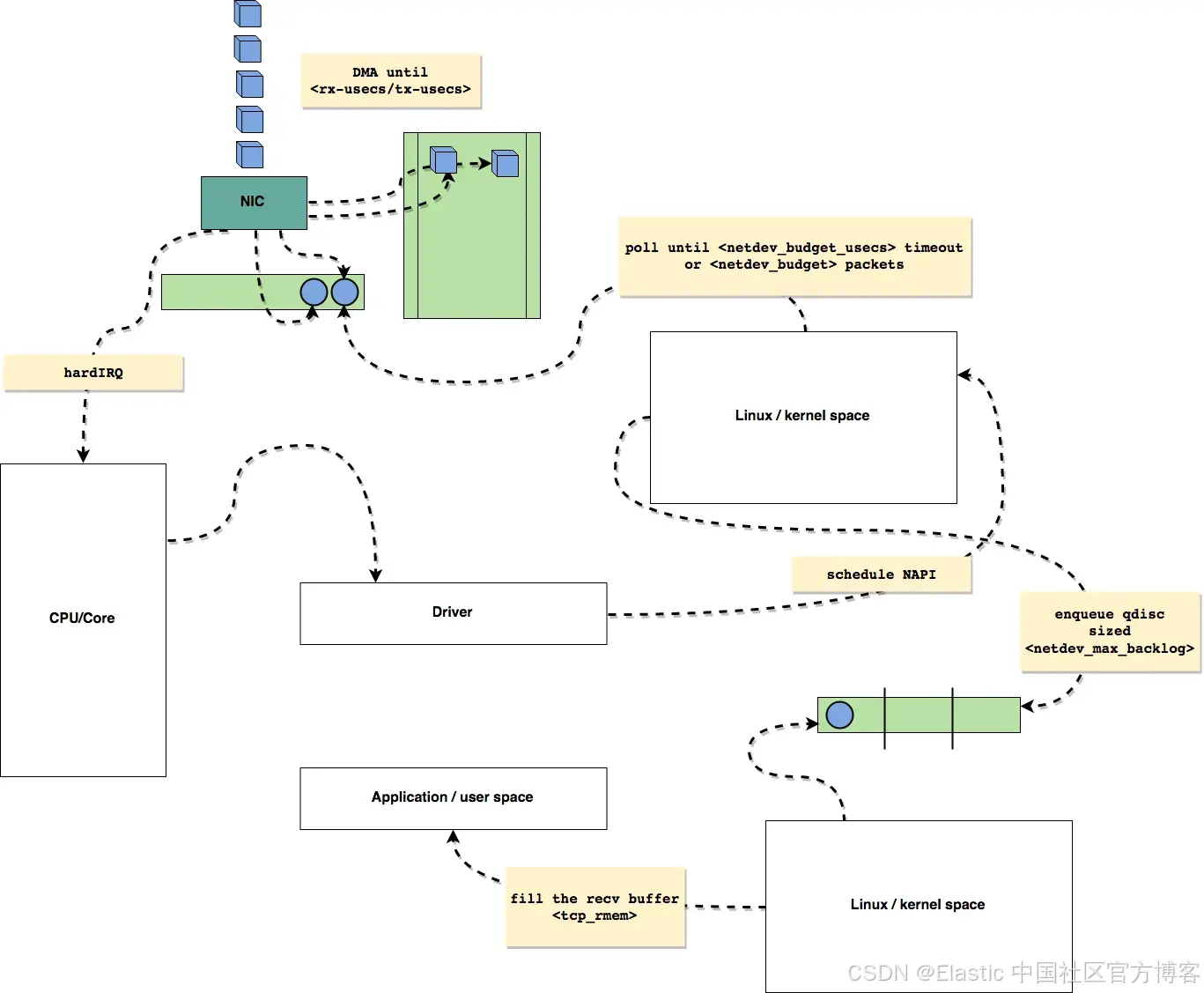 Leandro Moreira。根据 BSD 3-Clause 许可证使用。来源:GitHub 仓库。
Leandro Moreira。根据 BSD 3-Clause 许可证使用。来源:GitHub 仓库。
当 NIC 试图通过 DMA 将数据包放入已满的环形缓冲区时,missed 计数器会增加。NIC 实际上 "错过" 了将数据包传递到虚拟机内存的机会。不过,有趣的是,这个计数器在虚拟机上很少增加。这是因为虚拟网卡通常通过虚拟机管理程序(hypervisor)以软件方式实现,虚拟机管理程序的内存管理更灵活,可以减少环形缓冲区溢出的可能性。
之前提到,我们是在 Azure 的 AKS 服务上构建 Azure Elasticsearch Serverless,这很重要,因为我们所有的 AKS 节点都使用了 Azure 的一个功能,叫做加速网络(Accelerated Networking)。在这种配置下,网络流量直接传递到虚拟机的网络接口,绕过了虚拟机管理程序。这是通过单根 I/O 虚拟化(SR-IOV)实现的,它比传统虚拟机网络提供更低的延迟和更高的吞吐量。每个节点物理连接到一个 100 Gb/s 的网络接口,但暴露给虚拟机的 SR-IOV 虚拟功能(VF)通常只提供总带宽的一小部分。
尽管虚拟机只有 100 Gb/s 带宽的一小部分,微突发流量依然很可能发生。这些物理接口速度极快,能在纳秒内发送和接收多个数据包,远远超过大多数缓冲区或处理队列的吸收能力。在这样的时间尺度内,即使是短暂的流量突发也会让接收端不堪重负,导致数据包丢失和不可预测的延迟。
直接访问 SR-IOV 接口意味着我们的虚拟机必须及时处理由 NIC 触发的硬件中断。如果处理硬件中断有延迟(比如被虚拟机管理程序调度 CPU 时等待),网络数据包就可能会丢失!
首先 ------ 网卡级别调优
既然我们确认了虚拟机使用的是 SR-IOV,我们发现 enP42266s1 和 eth0 接口是绑定在一起的,作为一个单一接口使用。基于这个认知,我们认为可以通过 ethtool 直接调整环形缓冲区的值。
root@aks-k8s-node-1:~# ethtool -g enP42266s1
Ring parameters for enP42266s1:
Pre-set maximums:
RX: 8192
RX Mini: n/a
RX Jumbo: n/a
TX: 8192
Current hardware settings:
RX: 1024
RX Mini: n/a
RX Jumbo: n/a
TX: 1024在上面的输出中,我们只用了可用环形缓冲区描述符的八分之一。这些值是由操作系统默认设置的,通常旨在平衡性能和资源使用。设置过低,会在负载下导致数据包丢失;设置过高,则可能导致不必要的内存消耗。我们知道虚拟机使用的是直接连接的 100 Gb/s 网络接口划分出来的虚拟功能,速度足够快,能够产生容易让小缓冲区不堪重负的微突发流量。为了更好地吸收这些短暂且高强度的流量突发,我们将网卡的 RX 环形缓冲区大小从 1024 增加到 8192。通过一个特权 DaemonSet,我们在所有 AKS 节点上推送了这个更改,安装了一个 udev 规则来自动增加缓冲区大小:
# Match Mellanox ConnectX network cards and run ethtool to update the ring buffer settings
ENV{INTERFACE}=="en*", ENV{ID_NET_DRIVER}=="mlx5_core", RUN+="/sbin/ethtool -G %k rx ${CONFIG_AZURE_MLX_RING_BUFFER_SIZE} tx ${CONFIG_AZURE_MLX_RING_BUFFER_SIZE}"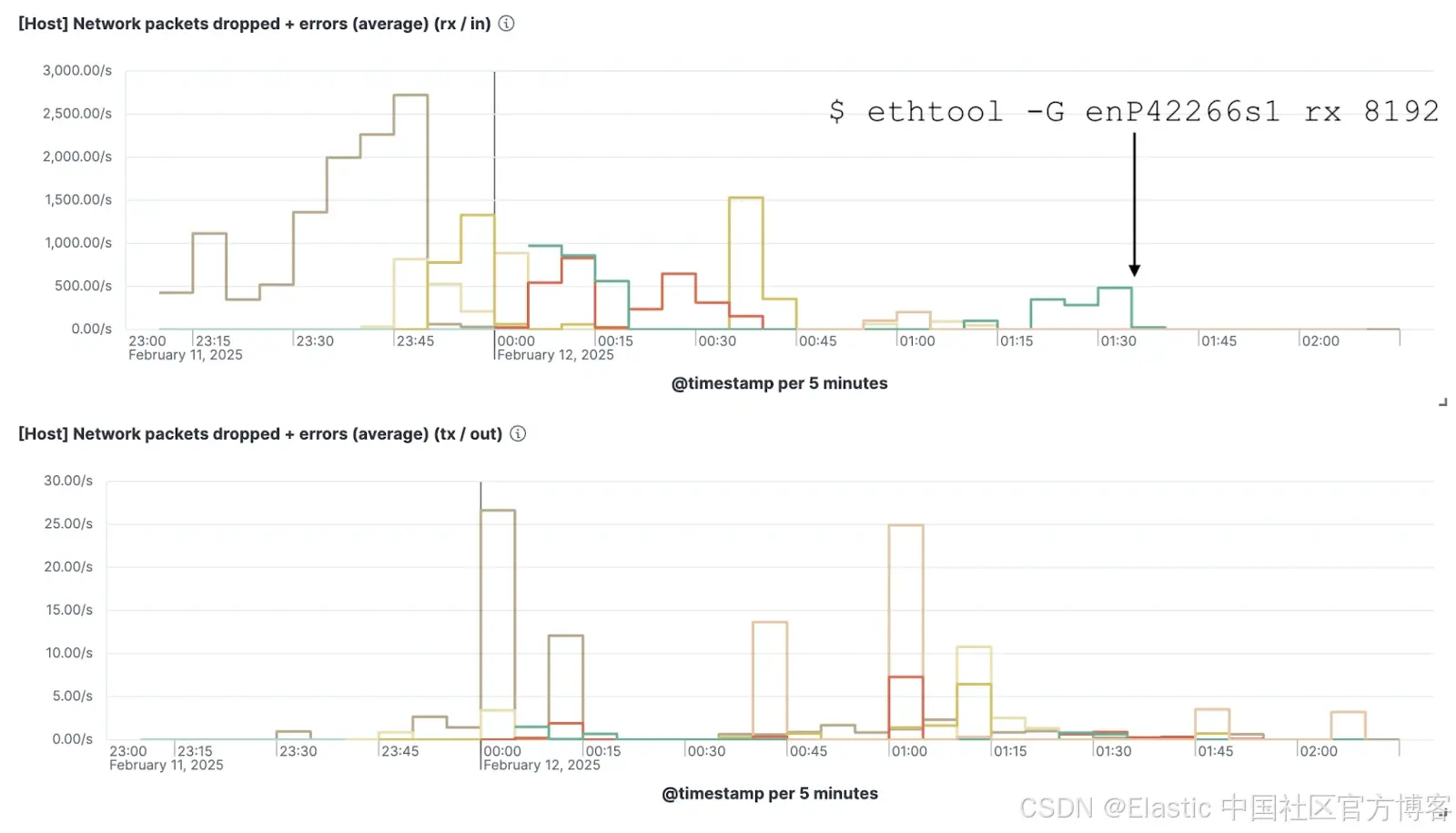 Kibana 可视化图表,显示 Elastic Agent 的系统集成数据,在增加网卡 RX 环形缓冲区值后,数据包丢失减少了约 99%。
Kibana 可视化图表,显示 Elastic Agent 的系统集成数据,在增加网卡 RX 环形缓冲区值后,数据包丢失减少了约 99%。
一旦这个更改应用到所有 AKS 节点,我们就不再 "丢失" 接收的数据包了!太棒了!由于这个简单的更改,我们观察到了索引吞吐量和稳定性的显著提升。
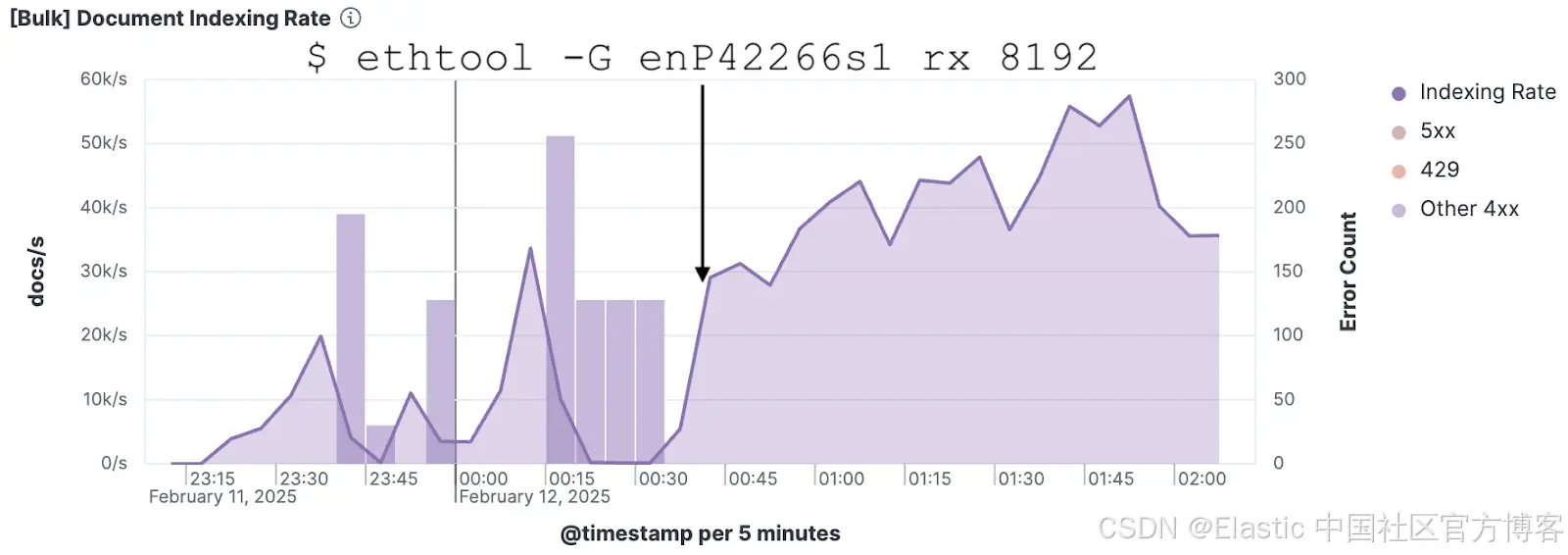 Kibana 可视化图表,显示在增加 RX 环形缓冲区大小后,Rally 远程遥测数据中 Elasticsearch 索引速率稳定且提升。
Kibana 可视化图表,显示在增加 RX 环形缓冲区大小后,Rally 远程遥测数据中 Elasticsearch 索引速率稳定且提升。
工作完成了,对吗?还没完全。
进一步改进 ------ 内核级调优
细心的读者可能注意到两点:
-
在之前的截图中,尽管调整了物理 RX 环形缓冲区的值,我们仍然在 TX 端观察到少量数据包丢失。
-
在最初的 ip link -s show 输出中,Elasticsearch pod 使用的其中一个 "逻辑" 接口在 TX 和 RX 两端都有数据包丢失。
15: lxc0ca0ec41ecd2@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether f6:f5:5e:c9:4e:fb brd ff:ff:ff:ff:ff:ff link-netns cni-3f90ab53-df66-cac5-bd19-9cea4a68c29b
RX: bytes packets errors dropped missed mcast
627954576078 54297550 0 1600 0 0
TX: bytes packets errors dropped carrier collsns
372155326349 133538064 0 3927 0 0
于是,我们继续深入调查。我们已经消除了约 99% 的数据包丢失,剩下的丢包率虽然没有最初那么严重,但我们仍想弄清楚为什么在调整了网卡的 RX 环形缓冲区大小后,丢包问题仍然存在。
那么,dropped 表示什么?lxc0ca0ec41ecd2 这个接口又是什么?dropped 类似于 missed,但它只在数据包被内核或网络接口主动丢弃时发生。关键是,它并不会告诉你数据包被丢弃的具体原因。至于 lxc0ca0ec41ecd2 接口,我们使用 Azure CNI Powered by Cilium 为 AKS 集群提供网络功能。任何在 AKS 节点上启动的 pod 都会有一个 "逻辑" 接口,这是一个虚拟以太网(veth)对,用来连接 pod 的网络命名空间和宿主机的网络命名空间。数据包就是在这里被丢弃的。
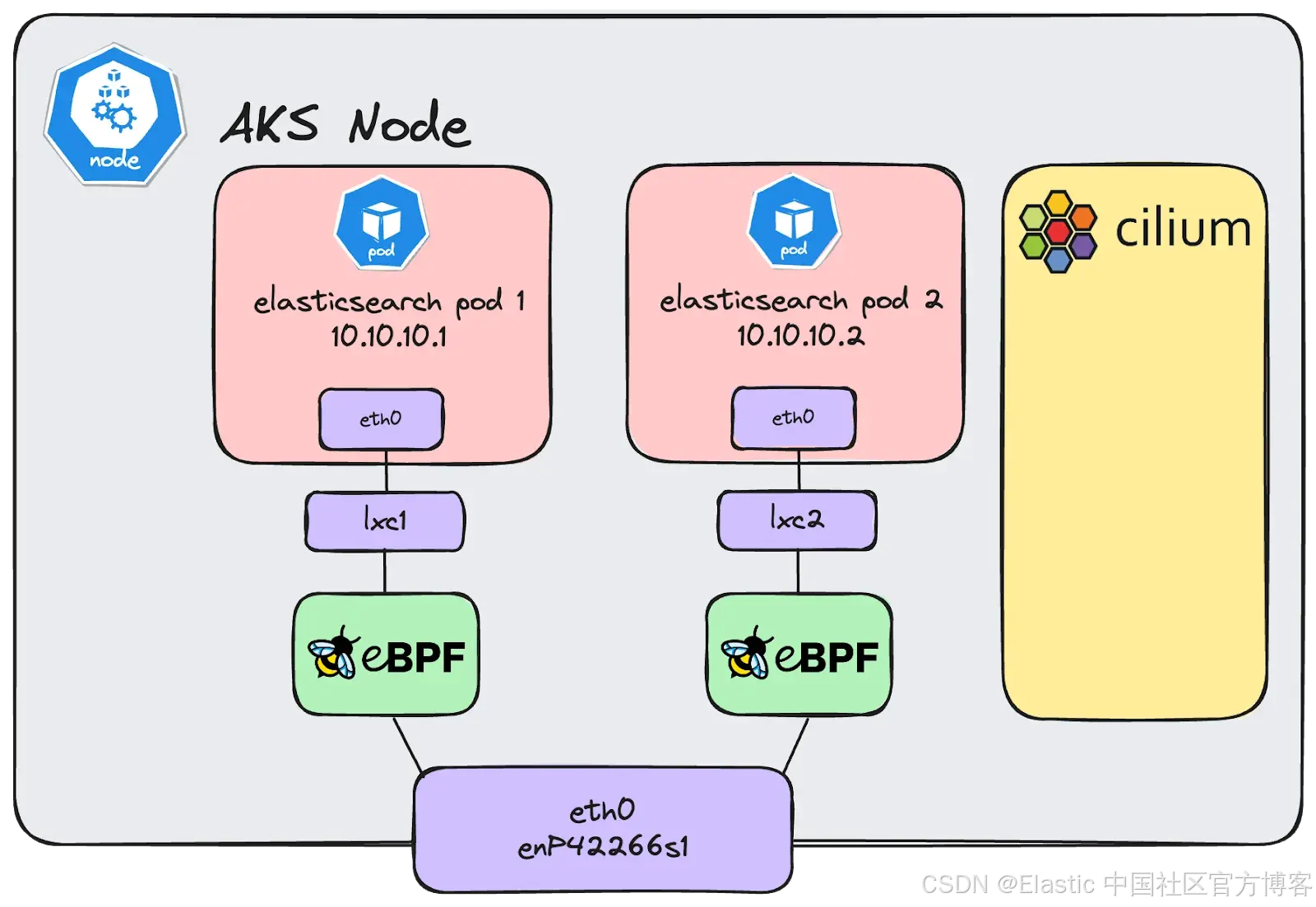
根据我们的经验,这一层发生的数据包丢失比较少见,所以我们开始深入挖掘丢包的原因。调试数据包为什么被丢弃有很多方法,其中一个最简单的是使用 perf attach 到 skb:kfree_skb 跟踪点。"socket buffer"(skb)是 Linux 内核中表示网络数据包的主要数据结构。当数据包被丢弃时,其对应的 socket buffer 通常会被释放,触发 kfree_skb 跟踪点。使用 perf 附加到这个事件,可以捕获调用栈,从而分析丢包的原因。
# perf record -g -a -e skb:kfree_skb我们让它运行了大约 10 分钟,以捕获尽可能多的丢包,然后 "深受 Ivan Babrou 的这个 GitHub Gist 启发",将调用栈转换成了更 "易读" 的火焰图(Flamegraphs):
# perf script | sed -e 's/skb:kfree_skb:.*reason:\(.*\)/\n\tfffff \1 (unknown)/' -e 's/^\(\w\+\)\s\+/kernel /' > stacks.txt
cat stacks.txt | stackcollapse-perf.pl --all | perl -pe 's/.*?;//' | sed -e 's/.*irq_exit_rcu_\[k\];/irq_exit_rcu_[k];/' | flamegraph.pl --colors=java --hash --title=aks-k8s-node-1 --width=1440 --minwidth=0.005 > aks-k8s-node-1.svg 火焰图显示了数据包丢失的各种调用栈来源。
火焰图显示了数据包丢失的各种调用栈来源。
火焰图显示了不同函数在数据包丢失的调用栈中出现的频率。每个框代表一个函数调用,框越宽表示该函数在调用栈中出现得越频繁。调用栈从底部的早期调用向上构建,到顶部是后续调用。
首先,我们很快发现遗憾的是 skb_drop_reason 枚举是在内核 5.17 中新增的(而当时 Azure 的节点镜像使用的是 5.15)。这意味着没有单一的可读消息告诉我们数据包为什么被丢弃,取而代之的是显示为 NOT_SPECIFIED。为了弄清丢包原因,我们需要通过调用栈追踪,推断数据包丢弃时执行了哪些代码路径。
从上面的火焰图可以看到,许多调用栈包含 veth 驱动函数调用(例如 veth_xmit),且许多调用栈都以 enqueue_to_backlog 函数调用突然结束。当许多调用栈都在同一个函数(如 enqueue_to_backlog)结束时,说明该函数是数据包丢弃的常见位置。回顾之前对数据包到达 NIC 时的解释,你会发现第 7 步中提到:
7. If the networking stack is slower than the rate at which NAPI fetches packets, excess packets are queued in a per-CPU backlog queue (via enqueue_to_backlog). The maximum size of this backlog is controlled by the net.core.netdev_max_backlog sysctl.
使用同样的特权 DaemonSet 方法调整 RX 环形缓冲区后,我们将可调内核参数 net.core.netdev_max_backlog 的值从 1000 设置为 32768:
/usr/sbin/sysctl -w net.core.netdev_max_backlog=32768这个值是基于我们知道主机使用的是 100 Gb/s 的 SR-IOV NIC,即使 VM 只被允许使用总带宽的一小部分。我们承认未来值得重新评估这个值,看看是否可以更好地优化以避免浪费多余的内存,但当时 "perfect 是 good 的敌人"。
我们重新运行了负载测试,并比较了到目前为止收集的三组结果。
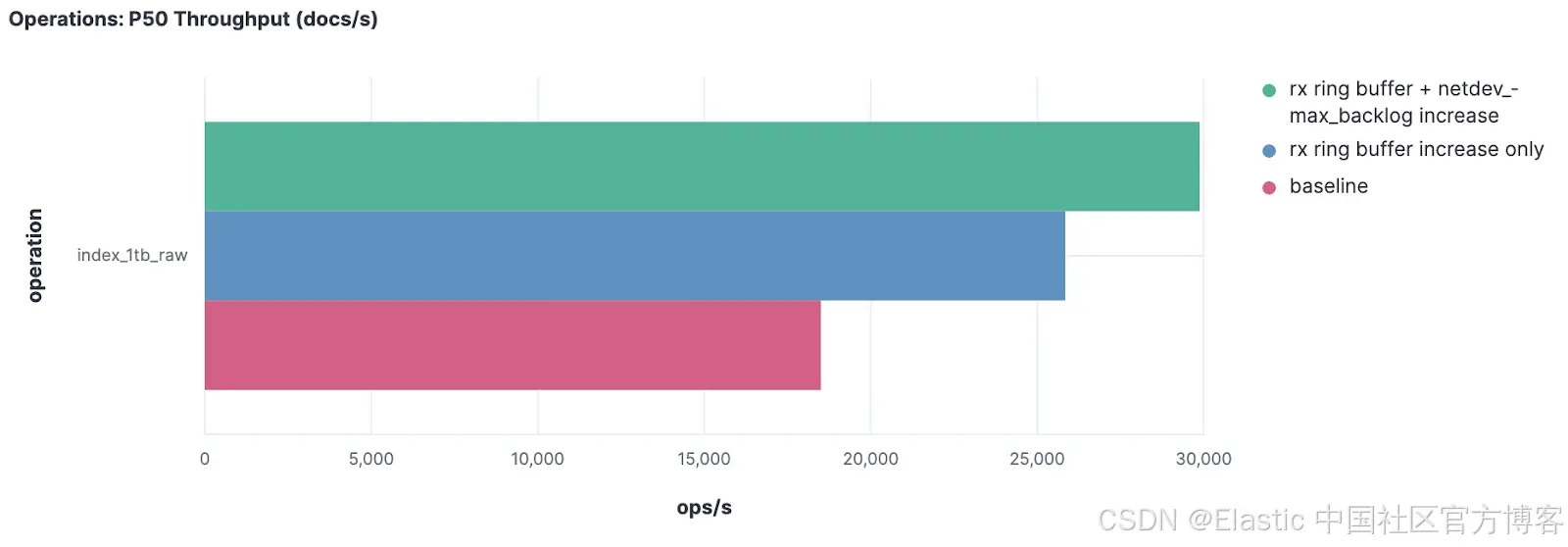 一个 Kibana 可视化图,比较了每次配置更改后对中位吞吐量的影响。
一个 Kibana 可视化图,比较了每次配置更改后对中位吞吐量的影响。
| Tuning Step | Packet Loss | Median indexing throughput |
|---|---|---|
| Baseline | High | ~18,000 docs/s |
| +RX Buffer | ~99% drop ↓ | ~26,000 (+ ~40% from baseline) |
| +Backlog & +RX Buffer | Near zero | ~29,000 (+ ~60% from baseline) |
这里可以看到在数小时的负载测试中,文档每秒吞吐量的 P50(中位数)变化。与基线相比,仅调整 RX 环形缓冲区大小就带来了约 40% 的吞吐量提升,而同时调整 RX 环形缓冲区和内核 backlog 参数后,吞吐量提升约 50% 到 60%!太棒了!
这是一个非常好的结果,也是我们不断优化 Serverless Elasticsearch 性能的重要一步。
与 Azure 的合作
虽然我们快速发现并缓解了大部分丢包问题,但由于我们使用的是 AKS 和 AKS 节点镜像,因此与 Azure 团队合作,理解为何默认配置不适合我们的负载非常有必要。
我们向 Azure 团队详细介绍了调查过程、缓解措施和结果,并请求他们帮忙验证。Azure 工程师确认主机网卡没有丢包,说明所有到达主机的流量都成功传递给了主机上的虚拟机监控程序(Hypervisor)。进一步调查确认 Azure 网络底层和 Hypervisor 内部没有任何丢包,这让我们把重点转向了来宾操作系统(Guest OS)内核为何在从 enP* SR-IOV 接口读取数据包时表现缓慢。
为了更好地定位问题,我们还开发了一个简化版的复现测试,使用 iperf3 工具,专门提供给 Azure 进行分析。这在 Elastic Observability 和 Rally 的监控基础上,进一步增强了对丢包问题的分析。
Azure 确认了我们观测到的丢包和 missed 包计数的增加,并认可了增加 RX 环形缓冲区和 netdev_max_backlog 参数的缓解方案。
总结
云服务商虽然提供了诸多抽象和管理便利,但底层硬件最终决定了应用的性能和稳定性。高性能硬件往往需要操作系统层面的调优,远超默认配置。
在像 AKS 这样的托管 Kubernetes 服务中,Azure 控制节点镜像和基础设施,低层配置(比如网络设备环形缓冲区大小和 net.core.netdev_max_backlog)容易被忽视,但却对性能有显著影响。
我们这次经历表明,不能因为 SR-IOV 直连的高速 100 Gb/s 网卡就假设网络不会成为瓶颈。事实证明,适当的系统级调优是必不可少的。
及早与 Azure 合作非常重要,他们提供了底层基础设施的深度视角,并协助我们调优关键参数。配合全面的负载和扩展测试,以及基于 Elastic Observability 的强大可观测性,我们成功提前发现并解决了问题,确保了用户体验的稳定和高性能。
原文:Debugging Azure Networking for Elastic Cloud Serverless --- Elastic Observability Labs