引言
AI阅读器作为一种新型的内容消费工具,正在改变人们获取和处理信息的方式。本文将介绍Saga Reader项目中如何利用大型语言模型(LLM)进行网页内容抓取、智能优化和富文本渲染,特别是如何通过精心设计的提示词(prompt)引导LLM生成样式丰富的HTML内容,提升用户阅读体验。
关于Saga Reader
基于Tauri开发的著名开源AI驱动的智库式阅读器(前端部分使用Web框架),能根据用户指定的主题和偏好关键词自动从互联网上检索信息。它使用云端或本地大型模型进行总结和提供指导,并包括一个AI驱动的互动阅读伴读功能,你可以与AI讨论和交换阅读内容的想法。
Github - Saga Reader,完全开源 ,可外部服务0依赖 ,可纯本地 电脑运行的AI项目。欢迎大家关注分享。🧑💻码农🧑💻开源不易,各位好人路过请给个小星星💗Star💗。
核心技术栈 :Rust + Tauri(跨平台)+ Svelte(前端)+ LLM(大语言模型集成),支持本地 / 云端双模式
关键词:端智能,边缘大模型;Tauri 2.0;桌面端安装包 < 5MB,内存占用 < 20MB。
运行截图

系统架构概述
Saga Reader的内容处理流程主要包含以下几个关键步骤:
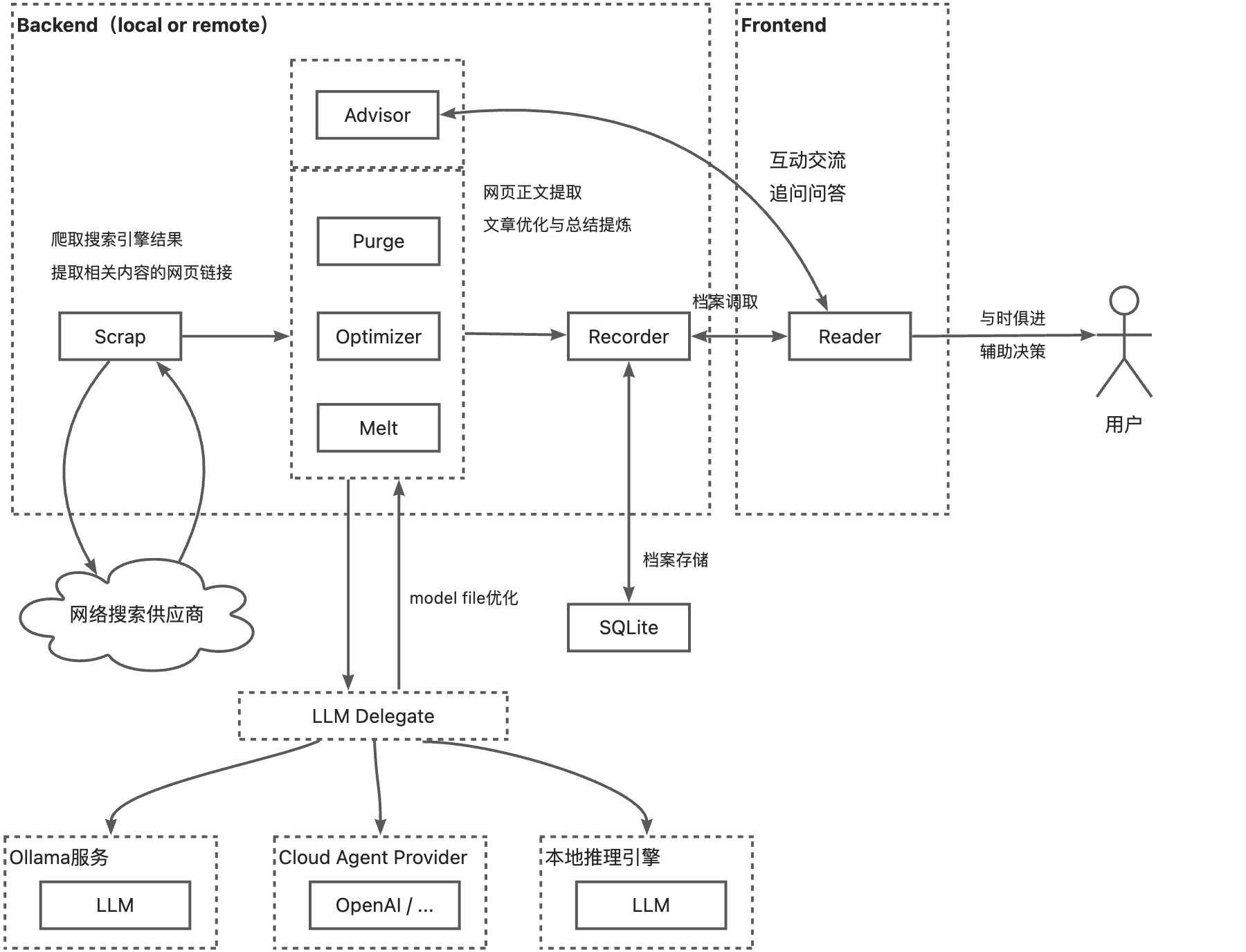
- 内容抓取:通过爬虫或RSS获取原始网页内容
- 内容净化(Purge):清理原始HTML中的无关元素
- 内容优化(Optimize):将净化后的内容转换为富文本格式
- 内容摘要(Melt):生成文章摘要
- 内容渲染:在前端展示优化后的内容
这些步骤形成了一个完整的内容处理管道,每个环节都由专门的处理器负责。
基于LLM的文章处理器
在Saga Reader中,文章处理的核心是ArticleLLMProcessor类,它实现了IArticleProcessor接口,负责调用LLM进行内容转换:
rust:crates/intelligent/src/article_processor/llm_processor.rs
/// 基于LLM的文章处理器。
pub struct ArticleLLMProcessor {
/// Agent化的生成式服务实例。
agent: CompletionAgent,
/// 用于与Agent交互的user prompt。
user_prompt_command: String,
}
impl IArticleProcessor for ArticleLLMProcessor {
async fn process(&self, input: &Article) -> anyhow::Result<Article> {
let mut output = input.clone();
let content = output.content.as_ref().unwrap();
let mut chat = format!(r#"## 原内容\n"{}"\n"#, content);
chat.push_str(self.user_prompt_command.as_str());
let content = self.agent.completion(chat).await?;
output.content.replace(content);
Ok(output)
}
}这个处理器的工作方式很直观:它接收一篇文章,将文章内容与预设的提示词组合,发送给LLM,然后用LLM的输出替换原始内容。
优化器(Optimizer)的实现
在内容处理管道中,优化器(Optimizer)是将净化后的内容转换为富文本格式的关键组件:
rust:crates/intelligent/src/article_processor/optimizer.rs
pub struct Optimizer {}
impl IPresetArticleLLMProcessor for Optimizer {
fn new_processor(llm_section: LLMSection) -> anyhow::Result<ArticleLLMProcessor> {
let options = AITargetOption {
temperature: Some(0.1),
..Default::default()
};
ArticleLLMProcessor::new(llm_section, SYSTEM_PROMPT.into(), USER_PROMPT_COMMAND_OPTIMIZE.into(), options)
}
}优化器使用较低的temperature值(0.1),这有助于生成更加确定性的输出,确保HTML结构的一致性和稳定性。
从Markdown到富HTML的转变
最近的一项重要升级是将LLM的输出从简单的Markdown转变为样式丰富的HTML。这一转变的核心在于系统提示词(System Prompt)的设计。
系统提示词设计
新的系统提示词将LLM定位为"专业内容设计师",要求它生成"视觉现代化的HTML电子邮件片段":
html:crates/intelligent/src/article_processor/prompts/optimizer_sys.prompt
You are to act as a professional Content Designer. Your task is to convert the provided article into **visually modern HTML email snippets** that render well in modern email clients like Hotmail.Few-shot示例约束
提示词中包含了多种HTML组件的模板,作为few-shot示例,引导LLM按照特定的样式生成内容:
- 标准段落:用于介绍、结论和过渡文本
- 要点列表:用于组织多个核心观点
- 强调文本:用于突出关键词或短语
- 引用块:用于突出重要观点或原文引用
- 图片块:用于嵌入文章中的图片
例如,要点列表的模板如下:
html:crates/intelligent/src/article_processor/prompts/optimizer_sys.prompt
<ul style="margin:20px 0; padding-left:0; list-style-type:none;">
<li style="position:relative; margin-bottom:12px; padding-left:28px; font-family:'Google Sans',Roboto,Arial,sans-serif; font-size:15px; line-height:1.6" class="text-surface-700-300">
<span class="preset-filled-primary-500" style="position:absolute; left:0; top:0; width:18px; height:18px; border-radius:50%; color:white; text-align:center; line-height:18px; font-size:12px;">1</span>
Description of the first key point
</li>
</ul>输出要求
提示词还详细规定了输出的要求,包括:
- 美观优雅的设计,和谐的配色方案
- 一致的视觉风格
- 将Markdown图片链接转换为HTML img标签
- 使用多种视觉元素增强可读性
- 移除与正文无关的操作性信息
- 翻译为中文
- 使用过渡文本连接各个组件
- 适当引用重要的原文片段
- 使用高亮样式标记关键点
前端渲染实现
在前端,ArticleRenderWidget.svelte组件负责渲染优化后的内容:
svelte:app/src/lib/widgets/ArticleRenderWidget.svelte
<script lang="ts">
/** eslint-disable svelte/no-at-html-tags */
import type { ArticleRenderProps, ArticleRenderType } from './types';
import Markdown from './Markdown.svelte';
import { removeCodeBlockWrapper } from '$lib/utils/text';
import { featuresApi } from '$lib/hybrid-apis/feed/impl';
import { onMount } from 'svelte';
const { value }: ArticleRenderProps = $props();
const purgedHtml = $derived(removeCodeBlockWrapper(value));
const renderType: ArticleRenderType = $derived(purgedHtml[0] === '<' ? 'html' : 'markdown');
let htmlContainer: HTMLDivElement | null = $state(null);
onMount(() => {
if (!htmlContainer) return;
const anchorClickInterceptor = (event: MouseEvent) => {
// 检查点击的元素是否是一个链接
const target = event.target as HTMLElement;
if (target?.tagName === 'A') {
// 阻止默认的链接跳转行为
event.preventDefault();
// 获取链接的 href 属性
const url = (target as HTMLAnchorElement).href;
// 调用特定函数来处理链接
featuresApi.open_article_external(url);
}
};
(htmlContainer as HTMLDivElement).addEventListener('click', anchorClickInterceptor);
return () => {
(htmlContainer as HTMLDivElement).removeEventListener('click', anchorClickInterceptor);
};
});
</script>
{#if renderType === 'html'}
<div bind:this={htmlContainer} class="p-6 preset-filled-surface-50-950">{@html purgedHtml}</div>
{:else}
<Markdown {value} />
{/if}该组件能够智能判断内容类型,对HTML和Markdown分别采用不同的渲染方式:
- 对于HTML内容,直接使用Svelte的
{@html}指令渲染 - 对于Markdown内容,使用
Markdown.svelte组件渲染
此外,组件还实现了链接点击拦截,确保外部链接在适当的环境中打开。
内容处理流水线
在FeaturesAPIImpl中,我们可以看到完整的内容处理流水线:
rust:crates/feed_api_rs/src/features/impl_default.rs
async fn process_article_pipelines(
&self,
article: &mut Article,
purge: &ArticleLLMProcessor,
optimizer: &ArticleLLMProcessor,
melt: &ArticleLLMProcessor,
) -> anyhow::Result<(Article, Article, Article)> {
let out_purged_article = purge.process(article).await?;
info!(
"article purged, title = {}, source_link = {}, optimizing",
article.title, article.source_link
);
let out_optimized_article = optimizer.process(&out_purged_article).await?;
info!(
"purged article optimized, title = {}, melting",
out_purged_article.title
);
if let Some(optimized_content) = out_optimized_article.content.clone() {
if optimized_content.contains("QINO-AGENTIC-EXECUTION-FAILURE") {
return Err(anyhow::Error::msg("QINO-AGENTIC-EXECUTION-FAILURE"));
}
}
let out_melted_article = melt.process(&out_optimized_article).await?;
info!(
"optimized article melted, title = {}, recording",
out_melted_article.title
);
Ok((
out_purged_article,
out_optimized_article,
out_melted_article,
))
}这个方法依次调用三个处理器:
purge:清理原始HTMLoptimizer:将净化后的内容转换为富文本melt:生成文章摘要
处理完成后,返回三个版本的文章,分别对应处理流程的三个阶段。
技术亮点与创新
1. 基于Few-shot的HTML样式约束
通过在系统提示词中提供HTML组件的模板,我们实现了对LLM输出的精确控制。这种few-shot示例约束的方法,使LLM能够生成符合预期样式的HTML内容,而不是简单的文本或基础Markdown。
2. 多模态内容处理管道
Saga Reader实现了一个完整的内容处理管道,从原始网页到富文本展示,每个环节都由专门的处理器负责。这种模块化设计使系统易于维护和扩展。
3. 智能渲染适配
前端组件能够智能判断内容类型,对HTML和Markdown分别采用不同的渲染方式,确保最佳的展示效果。
结论
Saga Reader项目通过精心设计的提示词和完整的内容处理管道,成功地将大型语言模型应用于文本转换与富文本渲染优化。这种方法不仅提升了用户阅读体验,也为AI辅助内容处理提供了一个可行的实践范例。
未来,我们可以进一步探索更多的视觉元素和交互方式,使AI生成的内容更加丰富多样,更好地满足用户的阅读需求。同时,随着大型语言模型能力的不断提升,我们也可以期待更加智能和个性化的内容处理方案。
📝 Saga Reader系列技术文章
- 开源我的一款自用AI阅读器,引流Web前端、Rust、Tauri、AI应用开发
- 【实战】深入浅出 Rust 并发:RwLock 与 Mutex 在 Tauri 项目中的实践
- 【实战】Rust与前端协同开发:基于Tauri的跨平台AI阅读器实践
- 揭秘 Saga Reader 智能核心:灵活的多 LLM Provider 集成实践 (Ollama, GLM, Mistral 等)
- Svelte 5 在跨平台 AI 阅读助手中的实践:轻量化前端架构的极致性能优化
- Svelte 5状态管理实战:基于Tauri框架的AI阅读器Saga Reader开发实践
- Svelte 5 状态管理全解析:从响应式核心到项目实战
- 【实战】基于 Tauri 和 Rust 实现基于无头浏览器的高可用网页抓取