目录
哨兵
导读
- Redis Sentinel是Redis的高可用实现方案:故障发现、故障自动转移、配置中心、客户端通知
- Redis Sentinel从Redis2.8版本开始才正式生产可用,之前版本生产不可用
- 尽可能在不同物理机上部署Redis Sentinel所有节点
- Redis Sentinel中的Sentinel节点个数应该为大于等于3且最好为奇数
- Redis Sentinel中的数据节点与普通数据节点没有区别
- 客户端初始化时连接的是Sentinel节点集合,不再是具体的Redis节点,但Sentinel只是配置中心不是代理
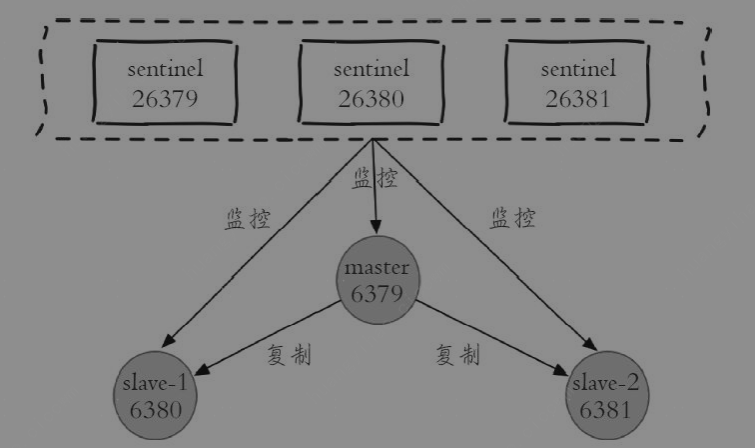
- Redis Sentinel通过三个定时任务实现了Sentinel节点对于主节点、从节点、其余Sentinel节点的监控
- Redis Sentinel在对节点做失败判定时分为主观下线和客观下线
- 看懂Redis Sentinel故障转移日志对于Redis Sentnel以及问题排查非常有帮助
- Redis Sentinel实现读写分离高可用可以依赖Sentinel节点的消息通知,获取Redis数据节点的状态变化
基本概念
| 名词 | 逻辑结构 | 物理结构 |
|---|---|---|
| 主节点(master) | Redis 主服务 / 数据库 | 一个独立的 Redis 进程 |
| 从节点(slave) | Redis 从服务 / 数据库 | 一个独立的 Redis 进程 |
| Redis 数据节点 | 主节点和从节点 | 主节点和从节点的进程 |
| Sentinel 节点 | 监控 Redis 数据节点 | 一个独立的 Sentinel 进程 |
| Sentinel 节点集合 | 若干 Sentinel 节点的抽象组合 | 若干 Sentinel 节点进程 |
| Redis Sentinel | Redis 高可用实现方案 | Sentinel 节点集合和 Redis 数据节点进程 |
| 应用方 | 泛指一个或多个客户端 | 一个或者多个客户端进程或者线程 |
主从复制问题
优点:
作为主节点的一个备份,一旦主节点出了故障不可达的情况,从节点可以作为后备"顶"上来,并且保证数据尽量不丢失(主从复制是最终一致性)
从节点可以扩展主节点的读能力
缺点:
一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预-->Redis高可用问题
主节点的写能力、存储能力受到单机的限制-->Redis分布式问题
Redis Sentinel的高可用性
高可用:
- 判断节点不可达的机制
- 怎样保证只有一个被晋升为主节点
- 通知客户端新的主节点机制是否足够健壮
当主节点出现故障时,Redis Sentinel能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用
Redis Sentinel是一个分布式架构,其中包含若干个Sentinel节点和Redis数据节点,每个Sentinel节点会对数据节点和其余Sentinel节点进行监控,
当它发现节点不可达时,会对节点做下线标识。如果被标识的是主节点,它还会和其他Sentinel节点进行"协商",
当大多数Sentinel节点都认为主节点不可达时,它们会选举出一个Sentinel节点来完成自动故障转移的工作,同时会将这个变化实时通知给Redis应用方。
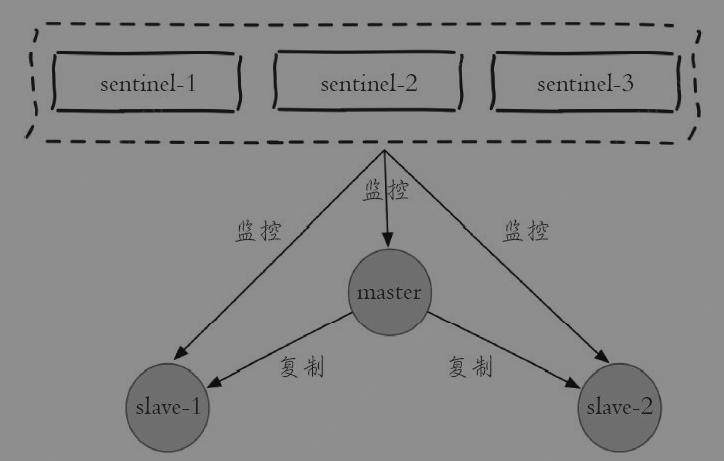
1主2从3哨兵
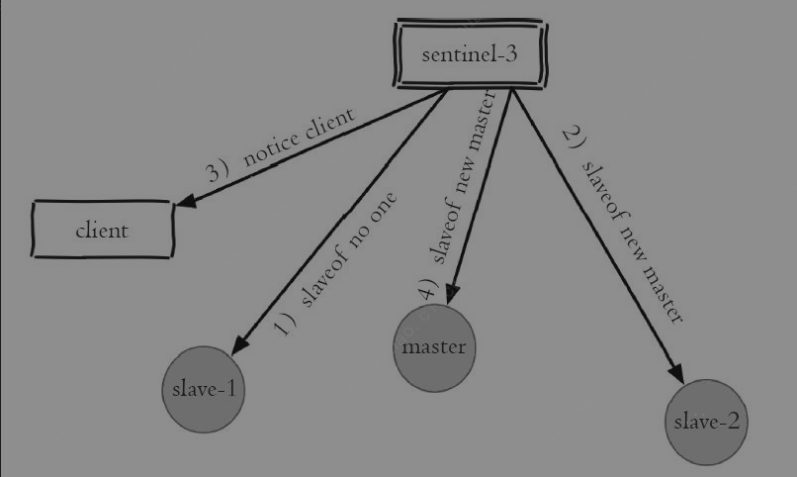
- 主节点出现故障,此时两个从节点与主节点失去连接,主从复制失败。
- 每个Sentinel节点通过定期监控发现主节点出现了故障
- Sentinel节点对主节点的故障达成一致,选举出sentinel-3节点作为领导者负责故障转移
- 对其执行slaveof no one命令使其成为新的主节点
- 原来的从节点(slave-1)成为新的主节点后,更新应用方的主节点信息,重新启动应用方
- 客户端命令另一个从节点(slave-2)去复制新的主节点(new-master)
- 待原来的主节点恢复后,让它去复制新的主节点。
- Sentinel领导者节点执行了故障转移
故障>协商>从节点1--slaveof no one--升主>通知client>从节点2复制新的主节点>原来的主节点恢复后复制新的主节点
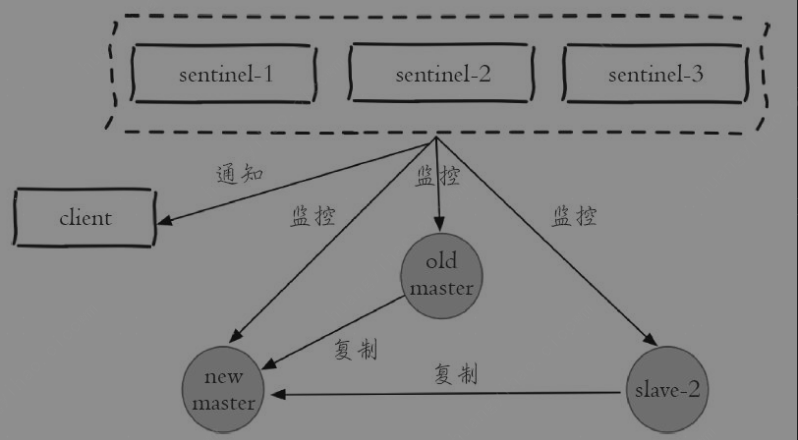
Redis Sentinel具有以下几个功能:
- 监控(Monitoring):Sentinel节点会定期检测Redis数据节点的状态
- 通知(Notification):Sentinel节点会将故障转移后的结果通知给应用方
- 故障转移(Failover):实现自动的故障转移
- 配置中心(Configuration):在Redis Sentinel架构中,客户端连接的是Sentinel节点集合而不是直接连接的Redis数据节点
安装和部署
| 角色 | ip | port | 别名(为了后文中方便) |
|---|---|---|---|
| master | 127.0.0.1 | 6379 | 主节点或者 6379 节点 |
| slave - 1 | 127.0.0.1 | 6380 | slave - 1 节点或者 6380 节点 |
| slave - 2 | 127.0.0.1 | 6381 | slave - 2 节点或者 6381 节点 |
| sentinel - 1 | 127.0.0.1 | 26379 | sentinel - 1 节点或者 26379 节点 |
| sentinel - 2 | 127.0.0.1 | 26380 | sentinel - 2 节点或者 26380 节点 |
| sentinel - 3 | 127.0.0.1 | 26381 | sentinel - 3 节点或者 26381 节点 |
部署数据节点
- 主节点
bash
vi redis-6379.conf
port 6379
daemonize yes
logfile "/var/log/redis-6379.log"
dbfilename "dump-6379.rdb"
dir "/var/redis/data/"- daemonize yes # 后台运行
- logfile "/var/log/redis-6379.log" # 日志文件
- dbfilename "dump-6379.rdb" # 持久化文件名
- dir "/var/redis/data/" # 持久化文件存放目录
redis-server redis-6379.conf
- 从节点
bash
vi redis-6380.conf
port 6380
daemonize yes
logfile "/var/log/redis-6380.log"
dbfilename "dump-6380.rdb"
dir "/var/redis/data/"
slaveof 127.0.0.1 6379
bash
vi redis-6381.conf
port 6381
daemonize yes
logfile "/var/log/redis-6381.log"
dbfilename "dump-6381.rdb"
dir "/var/redis/data/"
slaveof 127.0.0.1 6379- slaveof 127.0.0.1 6379 # 从节点复制主节点的地址和端口
redis-server redis-6380.conf
redis-server redis-6381.conf
bash
redis-cli -p 6379 info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=491,lag=0
slave1:ip=127.0.0.1,port=6381,state=online,offset=491,lag=1
master_repl_offset:491
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:2
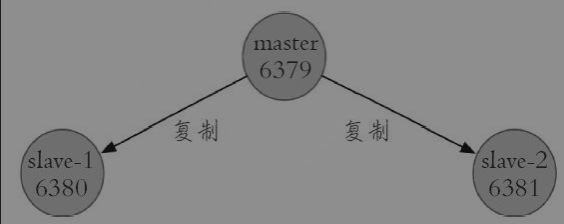
repl_backlog_histlen:490此时拓扑如下:
部署Sentinel节点
bash
vi redis-sentinel-26379.conf # 26379、26380、26381的配置文件类似,只是端口不同
port 26379
daemonize yes
logfile "/var/log/26379.log"
dir /var/redis/data/
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 30000
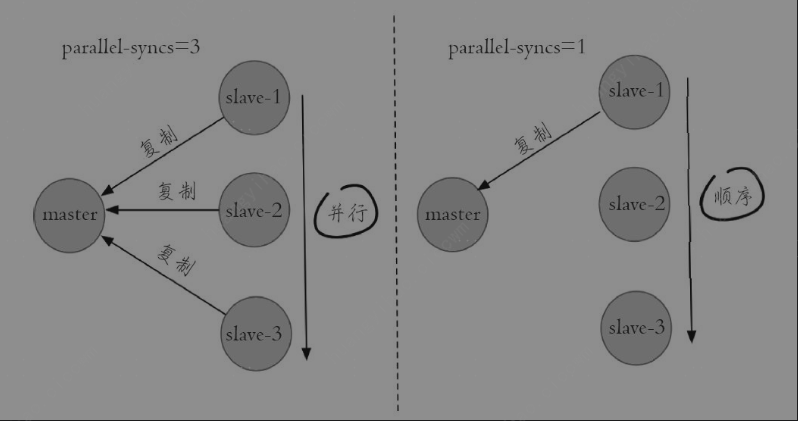
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 180000Sentinel节点的默认端口是26379
sentinel monitor mymaster 127.0.0.1 63792
sentinel-1节点需要监控127.0.0.1:6379这个主节点,
2代表判断主节点失败至少需要2个Sentinel节点同意,
mymaster是主节点的别名
超过了down-after-milliseconds 配置的时间且没有有效的回复,则判定节点不可达
parallel-syncs 就是用来限制在一次故障转移之后,每次向新的主节点发起复制操作的从节点个数
sentinel failover-timeout mymaster 180000 # 故障转移超时时间
sentinel auth-pass mymaster mypassword # 认证密码
sentinel notification-script mymaster /var/redis/notify.sh # 故障通知脚本,当故障转移发生时,会执行这个脚本
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh # 客户端重新配置脚本,当故障转移发生时,会执行这个脚本
启动:
redis-sentinel redis-sentinel-26379.conf
redis-server redis-sentinel-26379.conf --sentinel
bash
redis-cli -p 26379 info sentinel
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
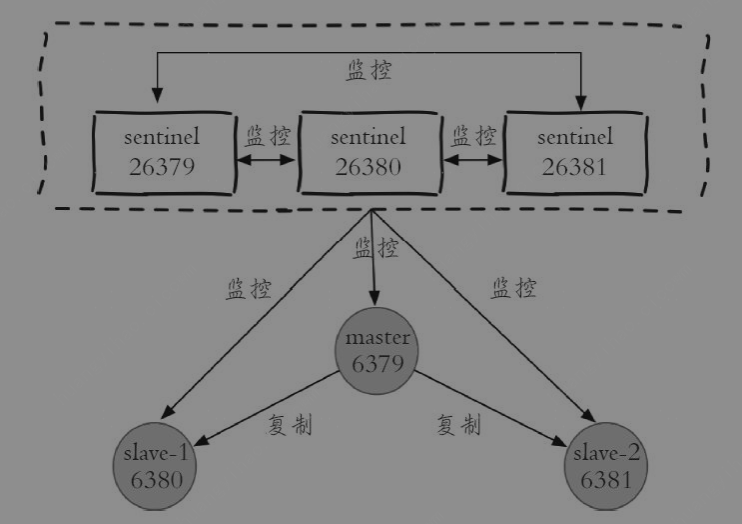
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=3此时拓扑如下:
Seninel配置优化
Redis安装目录下有一个sentinel.conf,是默认的Sentinel节点配置文件
bash
port 26381
daemonize yes
logfile "/var/log/26381.log"
dir "/var/redis/data"
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
sentinel known-slave mymaster 127.0.0.1 6380
# Generated by CONFIG REWRITE
sentinel known-slave mymaster 127.0.0.1 6381
sentinel known-sentinel mymaster 127.0.0.1 26380 187ef7cee830e5728fdcf913682f8acc69bca9f6
sentinel known-sentinel mymaster 127.0.0.1 26379 131c66c696c7d604728d2102475dfce8b37d15b2
sentinel current-epoch 0- 部署技巧
- Sentinel节点不应该部署在一台物理"机器"上
- 部署至少三个且奇数个的Sentinel节点
3个以上是通过增加Sentinel节点的个数提高对于故障判定的准确性,因为领导者选举需要至少一半加1个节点,奇数个节点可以在满足该条件的基础上节省一个节点
sentinel API
Sentinel节点是一个特殊的Redis节点,它有自己专属的API
bash
sentinel masters # 查看所有被监控的主节点信息
sentinel master mymaster # 查看指定主节点的详细信息
sentinel slaves mymaster # 查看指定主节点的所有从节点信息
sentinel sentinels mymaster # 查看指定主节点的所有Sentinel节点信息
sentinel get-master-addr-by-name mymaster # 查看指定主节点的地址和端口
sentinel reset mymaster # 清除 Sentinel 内部关于 mymaster 的所有状态信息、重新发现并注册 mymaster 的从节点和哨兵节点(通过向主节点发送 ROLE 命令获取拓扑信息)
sentinel failover mymaster # 手动触发故障转移
sentinel ckquorum mymaster # 检查 Sentinel 集群是否可以就故障转移达成共识
sentinel flushconfig # 将Sentinel节点的配置强制刷到磁盘上,通常用于磁盘损坏导致配置丢失
sentinel remove mymaster # 移除监控的主节点
sentinel monitor mymaster 127.0.0.1 6379 2 # 添加监控的主节点,和配置文件的一致实现原理
三个定时任务
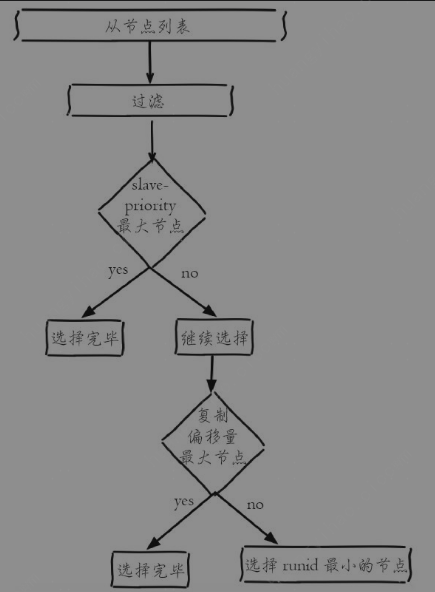
Redis Sentinel通过三个定时监控任务完成对各个节点发现和监控
- 每隔10秒,每个Sentinel节点会向主节点和从节点发送info replication 命令获取最新的拓扑结构-->master、slave
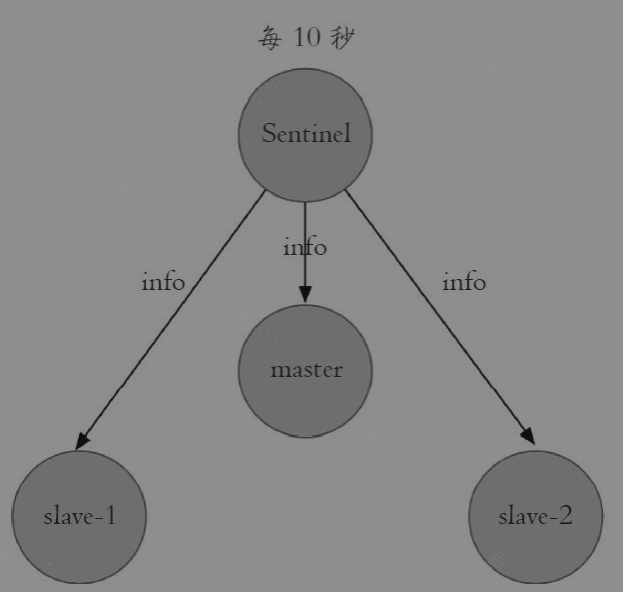
- 每隔1秒,每个Sentinel节点会向主节点、从节点以及其他Sentinel节点发送ping命令做一次心跳检测
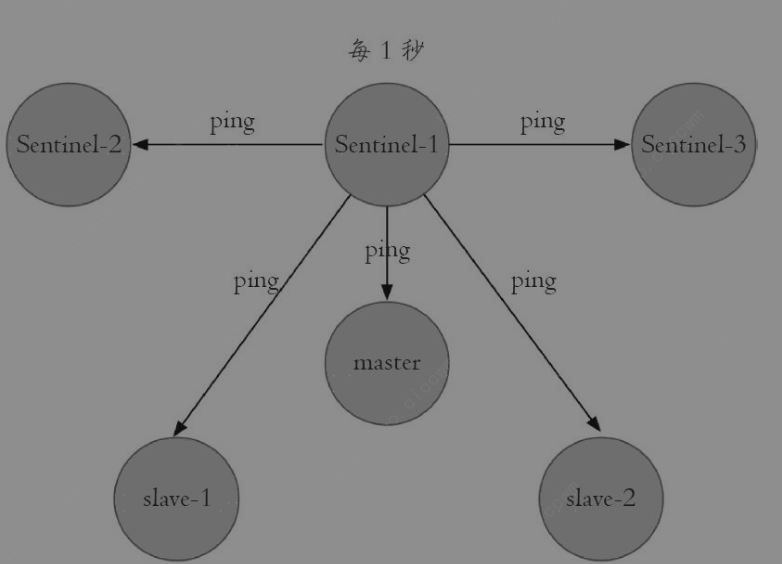
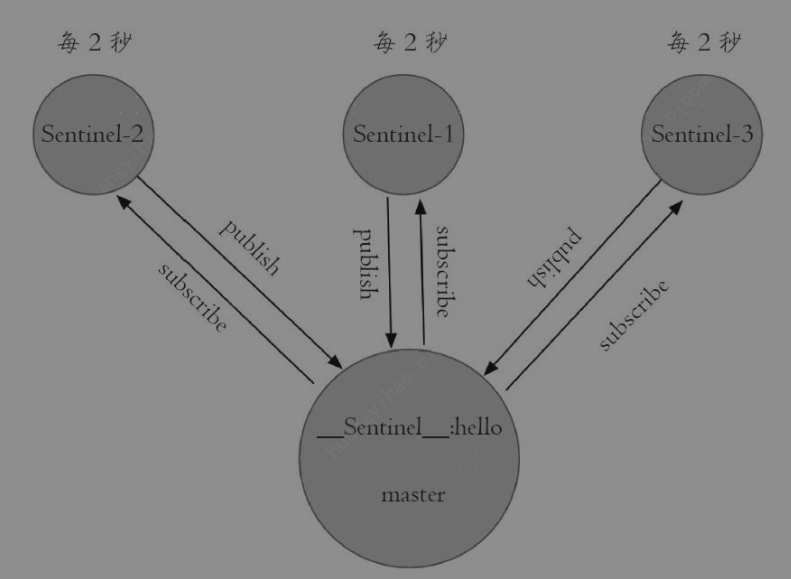
- 每隔2秒,每个Sentinel节点会向Redis数据节点的__sentinel__:hello频道上发送该Sentinel节点对于主节点的判断以及当前Sentinel节点的信息
bash
简单的说,就两个作用
1. 了解其他的Sentinel节点信息
2. 了解其他Sentinel节点对于主节点的状态判断
具体细节:
每个 Sentinel 节点既是消息的发布者,也是订阅者。
Sentinel 会向所有已知的数据节点(master 和 slave)发送发布 / 订阅命令
Sentinel 启动时:
向所有已知的 master 和 slave 节点发送 SUBSCRIBE __sentinel__:hello 命令,订阅该频道。
定时任务触发时:
向所有已知的 master 和 slave 节点发送 PUBLISH __sentinel__:hello "消息内容" 命令,发布自身状态和主节点判断。
消息传递逻辑:
无论消息发布到 master 还是 slave,只要节点在线,订阅该频道的其他 Sentinel 都能收到消息(因为 Redis 的 Pub/Sub 是节点级别的,不依赖数据同步)。主观下线和客观下线
-
主观下线
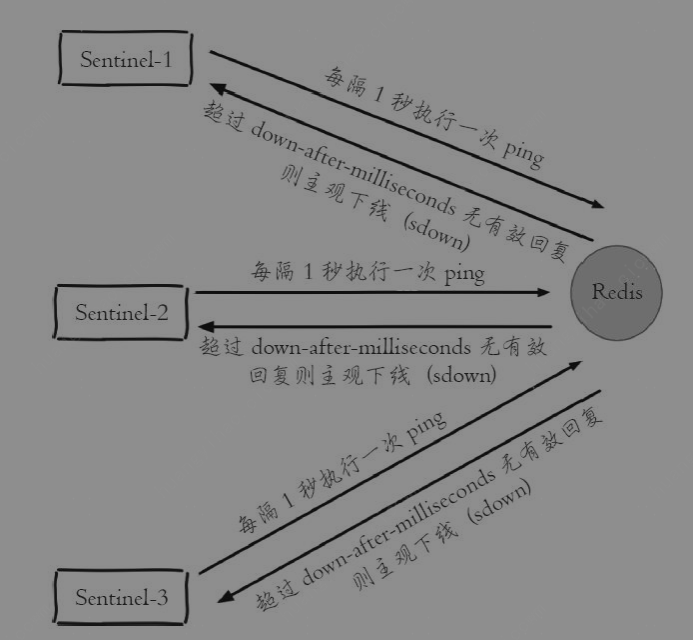
-
客观下线
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel is-master-down-by-addr 命令向其他Sentinel节点询问对主节点的判断
当超过 个数的Sentinel节点认为主节点确实有问题,这时该Sentinel节点会做出客观下线的决定,这样客观下线的含义是比较明显了,也就是大部分Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观的
例如sentinel-1节点对主节点做主观下线后,会向其余Sentinel节点发送该命令:
sentinel is-master-down-by-addr 127.0.0.1 6379 0 *
日志分析
先kill掉主节点,然后启动原主节点
bash
2793:X 18 Jun 13:39:34.452 # +sdown master mymaster 127.0.0.1 6379 # Sentinel(进程 ID 2793)主观认为 mymaster 主节点(127.0.0.1:6379)下线(不可达)
2793:X 18 Jun 13:39:34.536 # +new-epoch 6 # 开启一个新的选举纪元(Epoch 6)
2793:X 18 Jun 13:39:34.539 # +vote-for-leader 187ef7cee830e5728fdcf913682f8acc69bca9f6 6 # # 当前 Sentinel 投票给节点 187ef7...(另一个 Sentinel)作为领导者
2793:X 18 Jun 13:39:34.539 # +odown master mymaster 127.0.0.1 6379 #quorum 2/2 # Sentinel 集群达成共识,认为 mymaster 客观下线。
2793:X 18 Jun 13:39:34.539 # Next failover delay: I will not start a failover before Wed Jun 18 13:45:34 2025 # 此次故障转移后,6分钟内不会再次发起故障转移
2793:X 18 Jun 13:39:35.616 # +config-update-from sentinel 127.0.0.1:26380 127.0.0.1 26380 @ mymaster 127.0.0.1 6379 # 从 Sentinel 节点 127.0.0.1:26380 接收新的配置信息。
2793:X 18 Jun 13:39:35.616 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 # 故障转移成功,新主节点切换为 127.0.0.1:6381。
2793:X 18 Jun 13:39:35.616 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 # 新主节点(6381)开始管理从节点。
2793:X 18 Jun 13:39:35.616 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 # 新主节点(6381)开始管理从节点。
2793:X 18 Jun 13:40:05.696 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 # Sentinel 认为从节点(6379)下线。
2797:X 18 Jun 13:39:34.455 # +sdown master mymaster 127.0.0.1 6379 # +sdown:主观下线
2797:X 18 Jun 13:39:34.532 # +odown master mymaster 127.0.0.1 6379 #quorum 3/2 # +odown:Sentinel 集群达成共识,确认主节点客观下线
2797:X 18 Jun 13:39:34.532 # +new-epoch 6 # +new-epoch 6:开启一个新的选举纪元(Epoch),用于区分不同轮次的故障转移。
2797:X 18 Jun 13:39:34.532 # +try-failover master mymaster 127.0.0.1 6379 # +try-failover:尝试发起故障转移,但不立即执行。需要等待领导者选举完成。
2797:X 18 Jun 13:39:34.533 # +vote-for-leader 187ef7cee830e5728fdcf913682f8acc69bca9f6 6 # +vote-for-leader:投票给领导者
2797:X 18 Jun 13:39:34.538 # 127.0.0.1:26381 voted for 187ef7cee830e5728fdcf913682f8acc69bca9f6 6 # 其他 Sentinel 节点(127.0.0.1:26381 和 26379)也投票给 187ef7...
2797:X 18 Jun 13:39:34.540 # 127.0.0.1:26379 voted for 187ef7cee830e5728fdcf913682f8acc69bca9f6 6 # 其他 Sentinel 节点(127.0.0.1:26381 和 26379)也投票给 187ef7...
2797:X 18 Jun 13:39:34.605 # +elected-leader master mymaster 127.0.0.1 6379 # +elected-leader:获得多数票,当选为故障转移领导者
2797:X 18 Jun 13:39:34.605 # +failover-state-select-slave master mymaster 127.0.0.1 6379 # +failover-state-select-slave:领导者开始选择从节点作为新的主节点候选者。
2797:X 18 Jun 13:39:34.706 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # +selected-slave:选中从节点 127.0.0.1:6381 作为新主节点。
2797:X 18 Jun 13:39:34.706 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # +failover-state-send-slaveof-noone:向选中的从节点(6381)发送 SLAVEOF NO ONE 命令,使其成为独立主节点。
2797:X 18 Jun 13:39:34.783 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # +failover-state-wait-promotion:等待从节点(6381)完成主节点晋升
2797:X 18 Jun 13:39:35.543 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6379 # +promoted-slave:从节点(6381)成功晋升为新主节点。
2797:X 18 Jun 13:39:35.543 # +failover-state-reconf-slaves master mymaster 127.0.0.1 6379 # +failover-state-reconf-slaves:开始重新配置其他从节点,使其复制新主节点(6381)。--127.0.0.1 6379:原主节点的 IP 和端口(故障转移后,该节点将作为从节点存在)。
2797:X 18 Jun 13:39:35.614 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 # +slave-reconf-sent:向从节点(6380)发送 SLAVEOF 命令,使其复制新主节点。
2797:X 18 Jun 13:39:36.622 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 # +slave-reconf-inprog:从节点(6380)正在与新主节点(6381)建立复制连接。
2797:X 18 Jun 13:39:36.623 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379 # +slave-reconf-done:从节点(6380)完成配置,开始复制新主节点。
2797:X 18 Jun 13:39:36.678 # -odown master mymaster 127.0.0.1 6379 # -odown:取消原主节点(6379)的客观下线状态(但此时它仍是下线的)。
2797:X 18 Jun 13:39:36.678 # +failover-end master mymaster 127.0.0.1 6379 # +failover-end:故障转移流程结束
2797:X 18 Jun 13:39:36.678 # +switch-master mymaster 127.0.0.1 6379 127.0.0.1 6381 # +switch-master:主节点已从 127.0.0.1:6379 切换为 127.0.0.1:6381。
2797:X 18 Jun 13:39:36.679 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381 # +slave:记录新的从节点列表
2797:X 18 Jun 13:39:36.679 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 # +slave:记录新的从节点列表
2797:X 18 Jun 13:40:06.697 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ mymaster 127.0.0.1 6381 # +sdown:原主节点(6379)作为从节点暂时不可达。- 故障检测:Sentinel 先主观判断主节点下线(+sdown),后通过法定人数达成客观下线共识(+odown)。
- 领导者选举:Sentinel 通过投票选出负责故障转移的领导者(+elected-leader)。
- 新主选择与晋升:从从节点中选出最优节点(6381),并将其提升为新主(+promoted-slave)。
- 集群重组:通知其他从节点(6380、6379)复制新主(+slave-reconf-done)。
- 故障转移完成:更新集群拓扑(+switch-master),恢复服务可用性。
- 故障转移