摘要:
语音情感识别 (SER) 技术可帮助计算机理解语音中的人类情感,这在推进人机交互和心理健康诊断方面占据了关键地位。本研究的主要目标是通过创新的深度学习模型提高 SER 的准确性和泛化性。尽管它在人机交互和心理健康诊断等各个领域都很重要,但由于说话者、口音和背景噪音的差异,从语音中准确识别情绪可能具有挑战性。这项工作提出了两种创新的深度学习模型来提高 SER 准确性:CNN-LSTM 模型和注意力增强 CNN-LSTM 模型。这些模型在 2015 年至 2018 年间收集的瑞尔森情感言语和歌曲视听数据库 (RAVDESS) 上进行了测试,该数据库包括 1440 个男性和女性演员表达八种情绪的音频文件。这两个模型在将情绪分为八类方面都取得了令人印象深刻的超过 96% 的准确率。通过比较 CNN-LSTM 和注意力增强 CNN-LSTM 模型,本研究提供了对建模技术的比较见解,有助于开发更有效的情绪识别系统,并为医疗保健和客户服务中的实时应用提供实际意义。
关键词:
语音情感识别;CNN-LSTM;注意力机制;深度学习;音频处理;爵士
1. 引言
语音信号是人类最自然、最实用的交流形式。它们不仅传达语言信息,还传达大量非语言线索,包括面部表情和情绪。在过去的十年中,语音情感识别 (SER) 已成为一个前景广阔的研究领域,使计算机能够理解语音中的情感细微差别 [1,2](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1,2")。SER 检查副语言语音质量线索(副语言学是指交流的非语言元素,例如语气、音调、音量和面部表情,它们传达了超越语言的含义),例如音高、语调、节奏和语速,以了解说话者的情绪状态。SER 的应用扩展到医疗保健和教育,系统可以监测情绪健康并提供个性化支持,例如量身定制的治疗课程或自适应学习环境。随着技术的不断发展,SER 具有增强人机交互 (HCI) 和加深我们对人类通信的理解的潜力。
从语音信号中识别情绪是一项复杂的任务,原因有几个。主要挑战之一是缺乏准确和平衡的语音情感数据集,这限制了 SER 系统的开发和评估 [2](https://www.mdpi.com/2624-6120/6/2/22#B2-signals-06-00022 "2")。创建高质量的语音情感数据库需要大量的精力和时间,因为它们必须包括不同性别、年龄、语言、文化和情感表达的广泛说话者。此外,情绪通常通过句子而不是单个单词来传达,这使得从语音信号中识别情绪变得更加困难。由于需要考虑情感表达中的文化和语言差异(例如,不同语言的语气或表达方式的变化)以及情绪的主观性质(即个体如何以不同的方式感知和表达情感),这些挑战变得更加复杂。所有这些因素在塑造 SER 系统的开发和性能方面都起着至关重要的作用 [1](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1")。
然而,研究人员正在积极努力克服这些挑战,旨在提高语音信号中情感识别的准确性和效率。他们的努力旨在增强机器对口语中复杂情感线索(例如,语气或语速的细微变化)的理解。除了传达的单词和信息外,语音信号还带有说话者的隐含情绪状态(例如,快乐或沮丧) [1](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1")。高效的 SER 系统通过分离声学成分有效地反映说话者的情绪,为更有效的 HCI 奠定了基础。SER 系统不仅是必不可少的,而且在健康、人机交互以及行为分析和客户支持等其他各个领域也具有重要的科学价值。这些系统在增强语言障碍者或非语言线索至关重要的环境中的沟通方面的潜力进一步凸显了它们在通过辅助技术或虚拟助手等替代渠道解释和促进情感表达方面的重要性。
本研究的主要目的是开发和比较两种用于 SER 的深度学习模型,解决以下研究问题:CNN-LSTM 和注意力增强 CNN-LSTM 模型在情绪识别的准确性和泛化方面有何不同?我们开发了这些模型来识别 RAVDESS 数据集中的情绪 [3](https://www.mdpi.com/2624-6120/6/2/22#B3-signals-06-00022 "3")。本研究包括 SER 的简要文献综述。主要目的是比较两种不同的深度学习模型:一种使用 2D CNN 和 LSTM,另一种结合双向 LSTM 和注意力层。我们详细介绍了从头开始创建和使用这些模型的方法,包括通过添加 AWGN 来改进模型泛化的技术。本文通过对这些高级模型进行全面比较,证明它们在情感识别中的有效性,并深入了解它们在实际场景中的实际实施和潜在应用,为该领域做出了贡献。
2. 文献综述
传统上,SER 中的机器学习模型依赖于手工制作的特征,例如信号能量、语音音调、熵、交叉率、梅尔频率倒谱系数 (MFCC) 4,5,6,7 和基于色度的特征 [8](https://www.mdpi.com/2624-6120/6/2/22#B8-signals-06-00022 "8")。然而,这些模型的有效性通常取决于所选的特定特征,从而导致其性能的不确定性(例如,数据集之间的准确性不一致)。正在进行的研究探索了旨在捕捉反映人类情感的特征序列的复杂动态的新特征和算法。然而,挑战仍然存在于识别与不同情绪最密切相关的属性,以促进准确预测。
自 2015 年以来,深度学习技术的重大进步和处理能力的提高导致了更高效的端到端 SER 系统的发展。这些系统可以从频谱图或原始波形中快速提取信息 [9,10](https://www.mdpi.com/2624-6120/6/2/22#B10-signals-06-00022 "9,10"),无需手动提取特征。许多研究表明,采用基于频谱图和原始波形的深度学习(CNN 和 RNN)模型可以提高 SER 性能 [11,12,13](https://www.mdpi.com/2624-6120/6/2/22#B12-signals-06-00022 "11,12,13")。Tocoglu et al. (2019) 使用 Tweepy Python 模块分析了 205,000 条土耳其推文,发现 CNN 的准确率达到了 87% [14](https://www.mdpi.com/2624-6120/6/2/22#B14-signals-06-00022 "14")。Kamyab et al. (2021) 提出了一种基于注意力的 CNN 和 Bi-LSTM 模型用于情感分析,结合 TF-IDF 和 GloVe 词嵌入,在多个数据集中实现超过 90% 的准确率 [15](https://www.mdpi.com/2624-6120/6/2/22#B15-signals-06-00022 "15")。以前在音频情感识别方面的工作表现较低。 [16](https://www.mdpi.com/2624-6120/6/2/22#B16-signals-06-00022 "16") 中的作者提出了混合 MFCCT-CNN 特征,这些特征在最近的研究中表现出卓越的准确性。使用 ResNets 和门机制的多任务深度神经网络在 SER 任务中显示出潜力,在 RAVDESS 数据集上以 64.68% 的准确率 [17](https://www.mdpi.com/2624-6120/6/2/22#B17-signals-06-00022 "17")。此外, [18](https://www.mdpi.com/2624-6120/6/2/22#B18-signals-06-00022 "18") 还调查了基于隐马尔可夫的 SER 技术,每种技术都解决了情绪识别中的不同挑战。将 CNN 与 LSTM 相结合的混合模型用于 RAVDESS 的情感分析达到了 90% 的准确率 [19](https://www.mdpi.com/2624-6120/6/2/22#B19-signals-06-00022 "19"),而 BERT 模型 [20](https://www.mdpi.com/2624-6120/6/2/22#B20-signals-06-00022 "20") 在文本中的情感检测方面表现出色,准确率为 92%。还探索了创新方法,如将 DNN 与 GNN 相结合进行音频信号情感识别和多模态情感分析 [21](https://www.mdpi.com/2624-6120/6/2/22#B21-signals-06-00022 "21")。针对实时情感识别进行了优化的轻量级神经网络 [22](https://www.mdpi.com/2624-6120/6/2/22#B22-signals-06-00022 "22") 实现了 80% 的准确率。其他几项研究 3,23,24,25,26,27,28,29,30,31 也做出了重大贡献。然而,这些研究通常缺乏对同一数据集的直接比较或详细的消融研究,从而限制了他们对模型泛化的见解。创建复杂的 SER 系统并非易事,因为它需要大量的标记训练数据。如果没有足够的数据,模型可能无法准确捕捉语音情感的细微差别,而缺乏数据会导致模型变得过于专业化,从而限制其更广泛的适用性。
本研究的主要目的是使用 RAVDESS 数据集训练和评估两个混合模型,重点是实现尽可能高的准确性,同时确保在不同条件下的稳健泛化。我们的主要贡献在于通过新颖的架构和噪声增强来改进模型泛化和提高准确性。此外,我们的目标是对模型在各种训练技术和参数下的性能进行全面比较,以丰富对其功效和多功能性的见解,通过验证 RAVDESS 和部分 SAVEE 的泛化以实现跨数据集洞察并与主流方法进行比较,从而解决先前工作中的差距( 表 1).本研究旨在加强这两个模型的优化策略和对 SER 系统的更广泛理解。然而,这项研究不仅推进了 SER 的技术方面,还探讨了负责任地使用技术的道德影响和最佳实践。
**表 1.**语音情感识别 (SER) 的重要研究概述。
Table 1. Overview of significant studies in Speech Emotion Recognition (SER).
| Study Ref. | Technique | Data Used | Key Findings | Accuracy |
|---|---|---|---|---|
| [9](https://www.mdpi.com/2624-6120/6/2/22#B9-signals-06-00022 "9"),[10](https://www.mdpi.com/2624-6120/6/2/22#B10-signals-06-00022 "10") | End-to-end SER | Various | Swift information extraction; no manual features | - |
| [11](https://www.mdpi.com/2624-6120/6/2/22#B11-signals-06-00022 "11"),[12](https://www.mdpi.com/2624-6120/6/2/22#B12-signals-06-00022 "12"),[13](https://www.mdpi.com/2624-6120/6/2/22#B13-signals-06-00022 "13") | CNN-LSTM, others | Various | Enhanced SER performance | - |
| [14](https://www.mdpi.com/2624-6120/6/2/22#B14-signals-06-00022 "14") | CNN | Turkish tweets | Excelling in text analysis | 87% |
| [15](https://www.mdpi.com/2624-6120/6/2/22#B15-signals-06-00022 "15") | LSTM, CNN | Various | Improved sentiment analysis | 94% |
| [16](https://www.mdpi.com/2624-6120/6/2/22#B16-signals-06-00022 "16") | CNN | Audio | Novel approach; modest success | 63% |
| [17](https://www.mdpi.com/2624-6120/6/2/22#B17-signals-06-00022 "17") | ResNets | Various | Promising in SER tasks | 70+% |
| [19](https://www.mdpi.com/2624-6120/6/2/22#B19-signals-06-00022 "19") | CNN-LSTM | RAVDESS | High accuracy in sentiment analysis | 90% |
| [20](https://www.mdpi.com/2624-6120/6/2/22#B20-signals-06-00022 "20") | BERT | Text emotion | Excellent in text-based detection | 92+% |
| [21](https://www.mdpi.com/2624-6120/6/2/22#B21-signals-06-00022 "21") | DNN, GNN | Audio, multimodal | Innovative in audio signal recognition | 70--88% |
| [22](https://www.mdpi.com/2624-6120/6/2/22#B22-signals-06-00022 "22") | NN | RAVDESS | Real-time emotion recognition | 80% |
3. 方法
本节介绍了本研究中使用的方法,包括数据收集、预处理和模型开发。每个步骤都详细说明了研究过程,以确保研究结果的可靠性。
3.1. 数据集
本研究选择了公开的 Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) 数据集,因为它提供了音频和视频格式的广泛情绪表达 [3](https://www.mdpi.com/2624-6120/6/2/22#B3-signals-06-00022 "3")。RAVDESS 收集于 2015 年至 2018 年间,包括来自 24 位专业演员(12 位男性和 12 位女性)的 1440 个音频文件,表达了八种情绪:中性、平静、快乐、悲伤、愤怒、恐惧、厌恶和惊讶。每种情绪都以两个强度级别(正常和强烈)记录,中性除外,增强了其对 SER 的适用性。它的优势包括高质量的录音和平衡的性别代表,尽管它仅限于英语和受控设置,可能会减少现实世界的可变性。在这项研究中,只使用了音频数据,这些数据是通过从多模态数据集中分离语音组件来提取的,忽略了视频元素。图 1 显示了每个类的示例。

**图 1.**RAVDESS 数据集。
3.2. 预处理
本小节概述了为 SER 模型准备 RAVDESS 音频数据的预处理步骤。神经网络在处理图像时产生有效的结果,而 CNN 算法构成了这项研究的支柱。虽然 RAVDESS 包含音频文件,但要利用 CNN 功能,必须将这些音频文件处理成图像。在将数据直接提供给模型之前,数据集最初会转换为适合模型处理的形式。预处理是一个非常重要的步骤,因为它将数据转换为合适的格式。每个音频信号都经过处理,以使用数学变换创建称为梅尔频谱图的图像表示。为了减轻来自多模态数据的噪声(例如,背景声音或演员可变性),音频被标准化为 16 kHz 采样率,并修剪了静音片段。首先,使用称为窗口的过程将音频信号分成短的重叠片段,该过程的窗口为 25 毫秒,重叠时间为 10 毫秒。每个段都经过傅里叶变换以将其转换为频域,其中它表示为频率频谱。然后,这些频谱被转换为 Mel 量表,它近似于人类对音高的感知。这种转换有助于强调音频中感知相关的特征。生成的梅尔频谱图本质上是一个 2D 图像,其中时间在横轴上表示,频率在纵轴上表示。此外,图像中的颜色强度或亮度对应于每个频率分量的幅度。 图 2 显示了预处理后生成的 Mel 频谱图样本。

**图 2.**Mel Spectrogram 音频信号的表示形式。
将音频转换为 Mel Spectrograms将音频转换为频谱图的数学原理如下:

预处理阶段通过调整采样率和采用噪声调制技术(详见第 3.3 节)来优化 SER 模型的数据,以确保所提出的模型暴露在真实且具有挑战性的音频输入阵列中,从而增强它们在各种条件下概括和准确识别情绪的能力,例如嘈杂的真实世界环境。
3.3. 模型描述
所提出的模型集成了卷积和递归神经网络,以有效地处理和分类音频数据中的情绪。数据被分成 80% 的训练集、10% 的验证集和 10% 的测试集,并进行时间分离(早期记录用于训练,后期用于测试)以避免过度拟合。以下是对这两种模型如何工作的全面解释,并有数学背景和特定参数的支持,并通过共享配置确保了它们的可重复性。
3.3.1. 时间分布的二维 CNN-LSTM 模型
以下步骤表示第一个模型的结构。堆栈时间是指对时间分布的数据(例如 Mel 频谱图块)进行顺序处理,以捕获时间依赖性 [13](https://www.mdpi.com/2624-6120/6/2/22#B13-signals-06-00022 "13")。
我们设计了如图 3 所示的模型。该模型从六个时间分布的 2D CNN 块开始,这些块处理分段的 Mel 频谱图块,这些块是预处理后获得的语音音频文件的频谱。前两个卷积块应用步幅为 1 且填充为 2 的 5 × 5 内核,而其余四个使用填充为 1 的 3 × 3 内核。此配置可确保在大多数卷积运算中保留空间维度。每个块中的初始卷积层从输入频谱图中提取局部特征。批量归一化遵循每个卷积以稳定和加速训练,如公式 (4) 中所述。
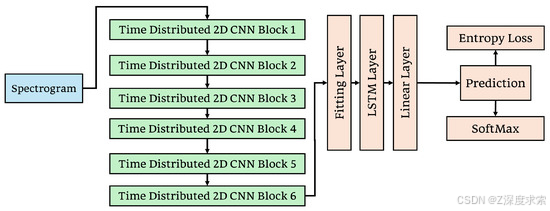
**图 3.**模型 1:建议的系统架构显示 2D CNN-LSTM 架构。
整个模型中使用的激活函数是 ELU (Exponential Linear Unit),在归一化后应用,以引入非线性并改进复杂模式的学习(使用方程 (5))。每次激活后,都会应用最大池化。前三个卷积块使用步幅为 2 的 2 × 2 核,而后三个使用步幅为 4 的 4 × 4 核(方程 (6))。在每个池化层之后以 0.2 的概率应用 Dropout (公式 (7)) 以防止过拟合。
卷积块按以下顺序逐步增加过滤器的数量:8、16、32、64、128 和 256。这使模型能够从 Mel 频谱图中学习越来越复杂和抽象的特征,从而捕获与语音中不同情绪表达相关的变化。
在卷积层之后,输出被展平并传递到完全连接的密集层。在特征被转发到最终的 softmax 分类器之前,这个密集层充当降维器和特征组合器。输出层使用线性变换(方程 (8))后跟 softmax 激活函数(方程 (9))来生成每个情绪类别的概率。
例如,考虑这样一个场景:其中有一个某人愉快地说话的音频剪辑。该音频首先转换为 Mel 频谱图,突出语音的独特频率和时间特性。时间分布的 CNN 层分析此频谱图,提取表示幸福的重要特征,例如强度和音高变化。然后,这些经过处理的特征通过密集层,将情绪准确地归类为快乐。

first_page
下载 PDF
设置
订购文章重印本
Open Access Article
Speech Emotion Recognition: Comparative Analysis of CNN-LSTM and Attention-Enhanced CNN-LSTM Models
by
Jamsher Bhanbhro
1,*  ,
,
Asif Aziz Memon
2 ,
Bharat Lal
1 ,
Shahnawaz Talpur
3 and
Madeha Memon
3
1
DIMES Department, University of Calabria, 87036 Rende, Italy
2
Computer Science Department, Dawood University of Engineering and Technology, Karachi 75300, Pakistan
3
Computer Systems Engineering Department, Mehran University of Engineering and Technology, Jamshoro 76062, Pakistan
*
Author to whom correspondence should be addressed.
Signals 2025 , 6 (2), 22; https://doi.org/10.3390/signals6020022
Submission received: 28 February 2025 / Revised: 10 April 2025 / Accepted: 25 April 2025 / Published: 9 May 2025
Downloadkeyboard_arrow_down
Browse Figures
Versions Notes
Abstract
Speech Emotion Recognition (SER) technology helps computers understand human emotions in speech, which fills a critical niche in advancing human--computer interaction and mental health diagnostics. The primary objective of this study is to enhance SER accuracy and generalization through innovative deep learning models. Despite its importance in various fields like human--computer interaction and mental health diagnosis, accurately identifying emotions from speech can be challenging due to differences in speakers, accents, and background noise. The work proposes two innovative deep learning models to improve SER accuracy: a CNN-LSTM model and an Attention-Enhanced CNN-LSTM model. These models were tested on the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS), collected between 2015 and 2018, which comprises 1440 audio files of male and female actors expressing eight emotions. Both models achieved impressive accuracy rates of over 96% in classifying emotions into eight categories. By comparing the CNN-LSTM and Attention-Enhanced CNN-LSTM models, this study offers comparative insights into modeling techniques, contributes to the development of more effective emotion recognition systems, and offers practical implications for real-time applications in healthcare and customer service.
Keywords:
speech emotion recognition; CNN-LSTM; attention mechanism; deep learning; audio processing; SER
1. Introduction
Speech signals are the most natural and practical form of human communication. They convey not only linguistic information but also a wealth of non-linguistic cues, including facial expressions and emotions. In the past decade, Speech Emotion Recognition (SER) has emerged as a promising research field, enabling computers to understand the emotional nuances in speech [1](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1"), [2](https://www.mdpi.com/2624-6120/6/2/22#B2-signals-06-00022 "2"). SER examines paralinguistic voice quality cues (paralinguistics refers to non-verbal elements of communication, such as tone, pitch, volume, and facial expressions, which convey meaning beyond words), such as pitch, intonation, rhythm, and speech rate, to understand speakers' emotional states. The applications of SER extend to healthcare and education, where systems can monitor emotional well-being and provide personalized support such as tailored therapy sessions or adaptive learning environments. As technology continues to evolve, SER holds the potential to enhance human--computer interaction (HCI) and deepen our understanding of human communication.
Recognizing emotions from speech signals is a complex task for several reasons. One of the main challenges is the lack of accurate and balanced speech emotion datasets, which restricts the development and evaluation of SER systems [2](https://www.mdpi.com/2624-6120/6/2/22#B2-signals-06-00022 "2"). Creating high-quality speech emotion databases requires significant effort and time, as they must include a wide range of speakers across different genders, ages, languages, cultures, and emotional expressions. Additionally, emotions are often conveyed through sentences rather than individual words, making it even harder to identify emotions from speech signals. These challenges are further complicated by the need to account for cultural and linguistic differences (e.g., variations in tone or expression across languages) in emotional expression, as well as the subjective nature of emotions (i.e., how individuals perceive and express feelings differently). All these factors play a crucial role in shaping the development and performance of SER systems [1](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1").
However, researchers are actively working to overcome these challenges, aiming to improve the accuracy and efficiency of emotion recognition from speech signals. Their efforts seek to enhance how machines understand the intricate emotional cues (e.g., subtle shifts in tone or pace) in spoken language. Beyond the words and information conveyed, the speech signal also carries the implicit emotional state (e.g., happiness or frustration) of the speaker [1](https://www.mdpi.com/2624-6120/6/2/22#B1-signals-06-00022 "1"). An efficient SER system, which effectively reflects the speaker's emotions by separating acoustic components, lays the foundation for more effective HCI. SER systems are not only essential but also hold significant scientific value in health, human--machine interactions, and various other areas like behavioral analysis and customer support. The potential of these systems in enhancing communication for individuals with speech impairments or in environments where non-verbal cues are crucial further highlights their importance in interpreting and facilitating emotional expression through alternative channels such as assistive technologies or virtual assistants.
The primary aims of this research are to develop and compare two deep learning models for SER, addressing the following research question: How do CNN-LSTM and Attention-Enhanced CNN-LSTM models differ in accuracy and generalization for emotion recognition? We developed these models to recognize emotions from the RAVDESS dataset [3](https://www.mdpi.com/2624-6120/6/2/22#B3-signals-06-00022 "3"). This study includes a brief literature review of SER. The main aim is to compare two different deep learning models: one using a 2D CNN with LSTM and the other incorporating a bidirectional LSTM and an attention layer. We detail the methodology for creating and using these models from scratch, including techniques for improving model generalization by adding AWGN. This paper contributes to the field by providing a comprehensive comparison of these advanced models, demonstrating their effectiveness in emotion recognition, and offering insights into their practical implementation and potential applications in real-world scenarios.
2. Literature Review
Traditionally, machine learning models in SER have relied on hand-crafted features such as signal energy, voice pitch, entropy, crossing rate, Mel-frequency cepstral coefficients (MFCC) [4](https://www.mdpi.com/2624-6120/6/2/22#B4-signals-06-00022 "4"), [5](https://www.mdpi.com/2624-6120/6/2/22#B5-signals-06-00022 "5"), [6](https://www.mdpi.com/2624-6120/6/2/22#B6-signals-06-00022 "6"), [7](https://www.mdpi.com/2624-6120/6/2/22#B7-signals-06-00022 "7"), and chroma-based features [8](https://www.mdpi.com/2624-6120/6/2/22#B8-signals-06-00022 "8"). However, the effectiveness of these models often depends on the specific features selected, leading to uncertainty in their performance (e.g., inconsistent accuracy across datasets). Ongoing research has explored new features and algorithms that aim to capture the complex dynamics of feature sequences reflecting human emotions. However, the challenge remains in identifying the attributes most closely connected to different emotions to facilitate accurate predictions.
Since 2015, significant advancements in deep learning techniques and increased processing capacity have led to the development of more efficient end-to-end SER systems. These systems can rapidly extract information from spectrograms or raw waveforms [9](https://www.mdpi.com/2624-6120/6/2/22#B9-signals-06-00022 "9"), [10](https://www.mdpi.com/2624-6120/6/2/22#B10-signals-06-00022 "10"), eliminating the need for manual feature extraction. Many studies suggest that employing deep learning (CNN and RNN) models based on spectrograms and raw waveforms can enhance SER performance [11](https://www.mdpi.com/2624-6120/6/2/22#B11-signals-06-00022 "11"), [12](https://www.mdpi.com/2624-6120/6/2/22#B12-signals-06-00022 "12"), [13](https://www.mdpi.com/2624-6120/6/2/22#B13-signals-06-00022 "13"). Tocoglu et al. (2019) analyzed 205,000 Turkish tweets using the Tweepy Python module, finding CNNs to achieve 87% accuracy [14](https://www.mdpi.com/2624-6120/6/2/22#B14-signals-06-00022 "14"). Kamyab et al. (2021) proposed an attention-based CNN and Bi-LSTM model for sentiment analysis, combining TF-IDF and GloVe word embeddings to achieve over 90% accuracy across multiple datasets [15](https://www.mdpi.com/2624-6120/6/2/22#B15-signals-06-00022 "15"). Previous work in audio emotion recognition achieved lower performance. Authors in [16](https://www.mdpi.com/2624-6120/6/2/22#B16-signals-06-00022 "16") proposed hybrid MFCCT-CNN features that demonstrate superior accuracy in recent studies. A multi-task deep neural network using ResNets and a gate mechanism showed potential in SER tasks with 64.68% accuracy on the RAVDESS dataset [17](https://www.mdpi.com/2624-6120/6/2/22#B17-signals-06-00022 "17"). Furthermore, Hidden Markov-based SER techniques were surveyed by [18](https://www.mdpi.com/2624-6120/6/2/22#B18-signals-06-00022 "18"), each addressing different challenges in emotion recognition. A hybrid model combining CNN with LSTM for sentiment analysis on RAVDESS achieved 90% accuracy [19](https://www.mdpi.com/2624-6120/6/2/22#B19-signals-06-00022 "19"), while BERT models [20](https://www.mdpi.com/2624-6120/6/2/22#B20-signals-06-00022 "20") excelled in emotion detection in text with 92% accuracy. Innovative approaches like combining DNN with GNN for audio signal emotion recognition and multimodal sentiment analysis were also explored [21](https://www.mdpi.com/2624-6120/6/2/22#B21-signals-06-00022 "21"). A lightweight neural network [22](https://www.mdpi.com/2624-6120/6/2/22#B22-signals-06-00022 "22"), optimized for real-time emotion recognition, achieved 80% accuracy. Several other studies [3](https://www.mdpi.com/2624-6120/6/2/22#B3-signals-06-00022 "3"), [23](https://www.mdpi.com/2624-6120/6/2/22#B23-signals-06-00022 "23"), [24](https://www.mdpi.com/2624-6120/6/2/22#B24-signals-06-00022 "24"), [25](https://www.mdpi.com/2624-6120/6/2/22#B25-signals-06-00022 "25"), [26](https://www.mdpi.com/2624-6120/6/2/22#B26-signals-06-00022 "26"), [27](https://www.mdpi.com/2624-6120/6/2/22#B27-signals-06-00022 "27"), [28](https://www.mdpi.com/2624-6120/6/2/22#B28-signals-06-00022 "28"), [29](https://www.mdpi.com/2624-6120/6/2/22#B29-signals-06-00022 "29"), [30](https://www.mdpi.com/2624-6120/6/2/22#B30-signals-06-00022 "30"), [31](https://www.mdpi.com/2624-6120/6/2/22#B31-signals-06-00022 "31") have also made significant contributions. However, these studies often lack direct comparisons on the same dataset or detailed ablation studies, limiting their insights into model generalization. Creating sophisticated SER systems is no small task, as it demands a considerable amount of labeled training data. Without enough data, models may fail to capture the nuances of speech emotions accurately, while a lack of data can result in models becoming too specialized, limiting their broader applicability.
The primary objective of this study is to train and evaluate two hybrid models using the RAVDESS dataset, focusing on achieving the highest possible accuracy while ensuring robust generalization across diverse conditions. Our major contribution lies in improving model generalization and increasing accuracy through novel architectures and noise augmentation. Additionally, we aim to conduct a comprehensive comparison of the models' performance across various training techniques and parameters to enrich insights into their efficacy and versatility, addressing a gap in prior work by validating generalization on RAVDESS and partially on SAVEE for cross-dataset insight and comparing with mainstream methods ( Table 1). This research seeks to enhance both models' optimization strategies and the broader understanding of SER systems. However, this research not only advances the technical aspects of SER but also explores the ethical implications and best practices for responsible technology use.
Table 1. Overview of significant studies in Speech Emotion Recognition (SER).

3. Methodology
This section explains the approach used in this study, including data collection, pre-processing, and model development. Each step details the research process to ensure the reliability of the findings.
3.1. Dataset
The publicly available Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) dataset was chosen for this research, as it provides a wide range of emotional expressions in both audio and video formats [3](https://www.mdpi.com/2624-6120/6/2/22#B3-signals-06-00022 "3"). RAVDESS, collected between 2015 and 2018, includes 1440 audio files from 24 professional actors (12 male and 12 female) expressing eight emotions: neutral, calm, happy, sad, angry, fearful, disgust, and surprise. Each emotion is recorded at two intensity levels (normal and strong), except for neutral, enhancing its suitability for SER. Its advantages include high-quality recordings and balanced gender representation, though it is limited to English and controlled settings, potentially reducing real-world variability. For this study, only audio data were used, which were extracted by isolating the speech component from the multimodal dataset, ignoring video elements. Figure 1 shows samples for each class.

Figure 1. RAVDESS dataset.
3.2. Pre-Processing
This subsection outlines the pre-processing steps to prepare RAVDESS audio data for SER models. Neural Networks yield efficient results in processing images, and CNN algorithms form the backbone of this research. While RAVDESS contains audio files, processing these audio files into images was mandatory to leverage CNN capabilities. Prior to giving the data directly to the models, the dataset is initially transformed into a form suitable for model processing. Pre-processing is a very important step because it transforms the data into a suitable format. Each audio signal is processed to create an image representation called the Mel spectrogram using mathematical transformations. To mitigate noise from multimodal data (e.g., background sounds or actor variability), audio was standardized to a 16 kHz sample rate, and silent segments were trimmed. First, the audio signal is divided into short overlapping segments using a process called windowing with a 25 ms window and 10 ms overlap. Each segment undergoes a Fourier Transform to convert it into the frequency domain, where it is represented as a spectrum of frequencies. These spectra are then transformed into a Mel scale, which approximates how humans perceive pitch. This transformation helps to emphasize perceptually relevant features in the audio. The resulting Mel spectrogram is essentially a 2D image, where time is represented on the horizontal axis and frequency on the vertical axis. Additionally, color intensities or brightness in the image correspond to the magnitude of each frequency component. Figure 2 shows a Mel spectrogram sample generated after preprocessing.
Figure 2. Mel Spectrogram Representation of the audio signal.
Converting Audio to Mel Spectrograms The mathematics of converting audio into spectrograms is mentioned below:
𝑥(𝑛)=∑𝑚=0𝑀−1𝑤(𝑚)·𝑠(𝑛+𝑚)x(n)=∑m=0M−1w(m)·s(n+m)
(1) where 𝑥(𝑛)x(n) is the windowed signal, 𝑤(𝑚)w(m) is the window function, and 𝑠(𝑛+𝑚)s(n+m) is the original signal.
Each windowed segment undergoes a Fourier Transform to convert it into the frequency domain:
𝑋(𝑘)=∑𝑛=0𝑁−1𝑥(𝑛)·𝑒−𝑗2𝜋𝑁𝑘𝑛X(k)=∑n=0N−1x(n)·e−j2πNkn
(2) where 𝑋(𝑘)X(k) is the frequency spectrum of the segment.
The frequencies are then mapped onto the Mel scale using the following formula:
𝑀(𝑓)=2595log10(1+𝑓700)M(f)=2595log101+f700
(3)
The pre-processing phase optimizes the data for SER models by adjusting sample rates and employing noise modulation techniques (detailed in Section 3.3) to ensure the proposed models are exposed to a realistic and challenging array of audio inputs, enhancing their ability to generalize and accurately identify emotions in varied conditions, such as noisy real-world environments.
3.3. Models Description
The proposed models integrate convolutions and recurrent neural networks to effectively process and classify emotions from audio data. Data were split into 80% training, 10% validation, and 10% testing sets with temporal separation (early recordings for training, later for testing) to avoid overfitting. Here is a comprehensive explanation of how both models work, supported by mathematical background and specific parameters, with their reproducibility ensured through shared configurations.
3.3.1. Time Distributed 2D CNN-LSTM Model
The following steps represent the structure of the first model. Stack time refers to the sequential processing of time-distributed data, such as Mel spectrogram chunks, to capture temporal dependencies [13](https://www.mdpi.com/2624-6120/6/2/22#B13-signals-06-00022 "13").
We designed the model as shown in Figure 3. This model starts with six time-distributed 2D CNN blocks that process segmented Mel spectrogram chunks, which are the spectra of the speech audio files obtained after pre-processing. The first two convolutional blocks apply a 5 × 5 kernel with a stride of 1 and padding of 2, while the remaining four use a 3 × 3 kernel with padding of 1. This configuration ensures that spatial dimensions are preserved throughout most convolutional operations. The initial convolution layers in each block extract local features from the input spectrograms. Batch normalization follows each convolution to stabilize and accelerate training, as described in Equation ( 4).
Figure 3. Model 1: Proposed system schema showing 2D CNN-LSTM architecture.
The activation function used throughout the model is ELU (Exponential Linear Unit), applied after normalization to introduce non-linearity and improve the learning of complex patterns (using Equation ( 5)). After each activation, max pooling is applied. The first three convolutional blocks use a 2 × 2 kernel with stride 2, while the latter three use a 4 × 4 kernel with stride 4 (Equation ( 6)). Dropout is applied after every pooling layer with a probability of 0.2 (Equation ( 7)) to prevent overfitting.
The convolutional blocks progressively increase the number of filters in the following sequence: 8, 16, 32, 64, 128, and 256. This enables the model to learn increasingly complex and abstract features from the Mel spectrograms, capturing variations relevant to different emotional expressions in speech.
After the convolutional layers, the output is flattened and passed to a fully connected dense layer. This dense layer acts as a dimensionality reducer and feature combiner before the features are forwarded to a final softmax classifier. The output layer uses a linear transformation (Equation ( 8)) followed by a softmax activation function (Equation ( 9)) to produce probabilities for each emotion class.
For example, consider a scenario in which there is an audio clip of someone speaking happily. This audio is first converted into a Mel spectrogram, highlighting the unique frequency and time characteristics of the speech. The time-distributed CNN layers analyze this spectrogram, extracting important features like intensity and pitch variations that signify happiness. These processed features are then passed through the dense layers to accurately classify the emotion as happy.
𝑋̂ =𝑋−𝜇𝜎X^=X−μσ
(4)
where 𝜇μ and 𝜎σ are the mean and standard deviation of the batch.
𝑓(𝑥)={𝑥𝛼(𝑒𝑥−1)if𝑥>0if𝑥≤0f(x)=xifx>0α(ex−1)ifx≤0
(5)
where 𝛼α is a small positive constant (typically 1.0).
𝑌𝑖,𝑗=max𝑚,𝑛𝑋𝑖+𝑚,𝑗+𝑛Yi,j=maxm,nXi+m,j+n
(6)
𝑦=𝑥·Bernoulli(𝑝)y=x·Bernoulli(p)
(7)
其中 p 是 dropout 概率 (0.2)。
𝑦=𝑊·x+by=W·x+b
(8)
softmax(𝑥我)=𝑒𝑥我∑𝑗𝑒𝑥𝑗softmax(x我)=ex我∑jexj
(9)
3.3.2. 堆叠时间分布 2D CNN------带注意力的双向 LSTM
第二个模型基于第一个模型 Section 3.3.1 构建,添加了一个 2D LSTM 和一个注意力层。主要增强功能是添加了双向 LSTM,它可以在正向和反向处理语音数据,使模型能够更深入地理解语音中的情绪( 架构如图 4 所示)。此外,还包括一个注意力机制来提高性能。这种机制侧重于语音中最关键的部分,为带有重要情感线索的部分分配权重。这种集中的方法有助于模型更准确地识别情绪信号,从而提高其情绪分类的准确性。双向 LSTM 层处理正向和反向的输入序列。这在数学上表示如下:
3.3.2. 堆叠时间分布 2D CNN------带注意力的双向 LSTM
第二个模型基于第一个模型 Section 3.3.1 构建,添加了一个 2D LSTM 和一个注意力层。主要增强功能是添加了双向 LSTM,它可以在正向和反向处理语音数据,使模型能够更深入地理解语音中的情绪(架构如图 4 所示)。此外,还包括一个注意力机制来提高性能。这种机制侧重于语音中最关键的部分,为带有重要情感线索的部分分配权重。这种集中的方法有助于模型更准确地识别情绪信号,从而提高其情绪分类的准确性。双向 LSTM 层处理正向和反向的输入序列。这在数学上表示如下:


**图 4.**模型 2:建议的系统架构显示 2D CNN-BiLSTM 架构。
这种双向处理使模型能够从过去和未来的上下文中捕获依赖关系,从而更全面地了解顺序数据。
此外,注意力机制被应用于双向 LSTM 的输出。注意力机制将上下文向量 c 计算为隐藏状态的加权和,其中权重α𝑡αt由每个隐藏状态的相关性决定:

在开发建议的模型时,观察到平衡数据导致过拟合,这意味着模型在训练数据上表现良好,但不能很好地推广到新的、看不见的数据(测试)。为了解决这个问题,我们在数据中引入了噪声,这是增强模型泛化能力的重要一步,这与 LIWC 等依赖于语言分类的简单方法 [32](https://www.mdpi.com/2624-6120/6/2/22#B32-signals-06-00022 "32") 不同。噪声是在数据增强阶段添加的。我们使用加性高斯白噪声 (AWGN) 和均匀噪声来增强训练数据,这与 Google 的注意力模型不同,它专注于序列加权而不进行噪声处理 [33](https://www.mdpi.com/2624-6120/6/2/22#B33-signals-06-00022 "33")。该过程包括生成高斯白噪声并将其添加到原始信号中。首先,对信号和生成的噪声进行归一化。规范化基于用于表示音频信号中每个样本的位数,对于高质量音频,通常为 16 位。在两个模型中,噪声的归一化和添加在数学上由以下公式给出:


此过程重复多次,以创建每个原始信号的多个增强版本,这与传统方法不同,传统方法可能无法解决噪声鲁棒性问题。然后将增强的信号添加到训练数据集中,有效地增加了其大小和多样性。这有助于防止模型过度拟合,确保模型在训练期间暴露于更广泛的数据中,从而提高从 RAVDESS 到潜在真实世界噪声条件的泛化能力。
3.4. 消融研究
为了验证关键架构组件的贡献,我们对两种模型进行了消融实验。在模型 2 中,删除 LSTM 层导致准确率从 98.1% 显着下降到 95%,突出了它在捕获时间依赖性方面的作用。此外,省略 dropout 层会导致过度拟合增加,验证损失增加 15% 就是证明。对于这两种型号。此外,排除双向 LSTM 将准确性降低到 89%,证实了它在增强上下文理解方面的价值。这些结果验证了每个组件实现高性能和强泛化的必要性。
4. 结果与讨论
本节使用损失、准确度、精度、召回率和 F1 分数等指标对模型的性能进行定性和定量评估。混淆矩阵用于有效地比较两种模型的分类能力。
在这项研究中,使用两种不同的技术将噪声增强应用于两个模型。模型 1 使用自定义均匀噪声注入方法将均匀分布的噪声添加到信号中进行训练,而模型 2 使用加性高斯白噪声 (AWGN) 进行增强,如提供的实现中所述。增强方法改进了泛化并减少过拟合,所有这些都无需修改底层模型架构。
为了确保公平评估并避免超时问题,在批量大小为 32 的 GPU (NVIDIA RTX 3080) 上进行了训练,在报告时间内完成了 564 个时期(表 2 )。有多种技术可用于改进泛化,例如正则化、提前停止以及通过删除层或块来简化模型。然而,在这项研究中,我们选择保持模型不变,使用简单的噪声增强来保持整体简单性。均匀噪声和 AWGN 都有助于显著降低验证损失,表明模型泛化程度有所提高。
Table 2. A comparison of the training epochs, time, and accuracy of both models.
| Models | Epochs | Training Time (Minutes) | Accuracy |
|---|---|---|---|
| Model 1 | 60 | 20 | 60% |
| 130 | 43 | 80% | |
| 200 | 71 | 96.5% | |
| Model 2 | 60 | 31 | 67% |
| 130 | 68 | 85% | |
| 200 | 103 | 98.1% |
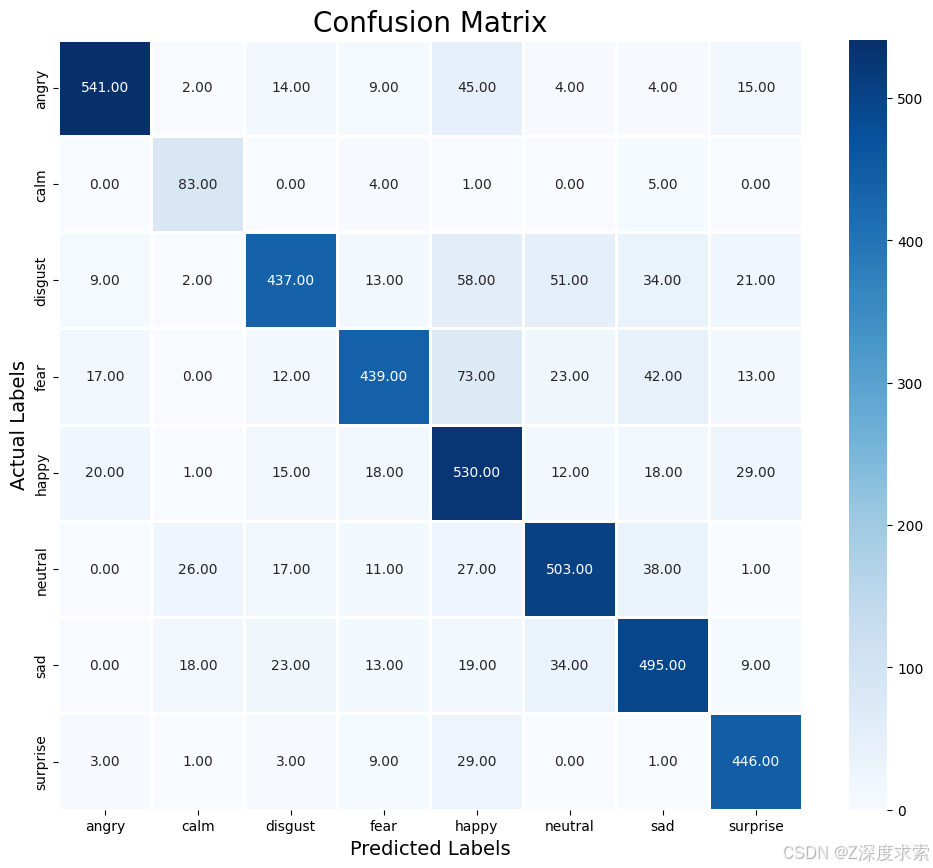
混淆矩阵对于评估分类任务至关重要。图 5 提供了两种模型在噪声增强前后的全面比较,以及它们的最终测试性能。图 5a、b 分别显示了添加均匀噪声之前和之后模型 1 的验证结果。最初,模型 1 很难区分情绪相似的类别,如悲伤和平静,如图 5a 所示。在均匀的噪声增强之后,图 5b 显示了大多数情绪的显著改善,尤其是在减少训练样本较少的中性错误分类方面。

图 5. 混淆矩阵显示了为两个模型应用均匀噪声之前和之后的性能,以及最终的测试集性能。每个子图都标有 (a ) 到 (f ) 以表示以下内容:(a ) 噪声前的模型 1 验证;(b ) 噪声后的模型 1 验证;(c ) 噪声前的模型 2 验证;(d ) 噪声后的模型 2 验证;(e ) 模型 1 的最终测试性能;(f) 模型 2 的最终测试性能。
图 5c、d 显示了模型 2 在应用加性高斯白噪声 (AWGN) 之前和之后的验证混淆矩阵。虽然图 5c 显示与模型 1 相比,初始性能相对较好,但惊讶 、恐惧 、厌恶 和平静 等类别之间仍然存在混淆。如图 5d 所示,应用 AWGN 后,模型 2 表现出更清晰的阶级界限,所有情绪状态的分类都有所提高。
图 5e,f 显示了两个模型的最终测试集混淆矩阵。模型 1(图 5e)使用均匀噪声进行训练,实现了 96.5% 的稳定准确率,正确预测了高兴 、愤怒 等 主导情绪。模型 2(图 5f)使用 AWGN 进行训练并通过注意力机制进行增强,达到了 98.1% 的峰值准确率,几乎没有错误分类,并且在整个情绪谱系中具有很强的泛化性。这些矩阵证实了均匀噪声和基于 AWGN 的增强以及架构设计对提高情感识别性能的贡献。

这些指标提供了有关分类模型性能的全面细节,有助于评估它们正确分类情绪和平衡精度和召回率的能力 [32](https://www.mdpi.com/2624-6120/6/2/22#B32-signals-06-00022 "32")。
混淆矩阵提供了对每个模型在各种情绪状态下的预测准确性的见解。模型 1 使用均匀噪声进行训练,准确率高达 96.5%,在识别快乐 、愤怒 等情绪 方面表现最高。模型 2 通过注意力层进一步增强并使用 AWGN 进行训练,准确率提高了 98.1%。它表现出更强的泛化性和更好的区分密切相关的情绪状态,例如中性和 平静性,同时在所有情绪类别中保持高准确性。
比较表 2 突出了不同时期的训练效率和准确性,展示了模型性能随着时间的推移而稳步提高和稳定。收敛率也非常高。性能指标表 3 显示,Model 2 在精度、召回率和 F1 分数方面实现了更好的平衡。这种改进是由于注意力机制能够突出显示数据中的重要特征。对这些指标的详细检查表明,虽然两个模型都表现良好,但在模型 2 中增加的注意力机制显着提高了性能,尤其是在准确分类细微的情绪表达方面。
**表 3.**比较两个模型的精确率、召回率和 F1 分数,以及总体准确率。
Table 3. Comparing precision, recall, and F1 score for both models, along with overall accuracy.
| Class | Precision || Recall || F1-Score || Accuracy (%) |
| Model 1 | Model 2 | Model 1 | Model 2 | Model 1 | Model 2 | ||
|---|---|---|---|---|---|---|---|
| Surprise | 1.00 | 1.00 | 1.00 | 0.95 | 1.00 | 0.97 | 96.5 (M1) 98.1 (M2) |
| Neutral | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 96.5 (M1) 98.1 (M2) |
| Calm | 0.90 | 0.95 | 0.95 | 1.00 | 0.92 | 0.97 | 96.5 (M1) 98.1 (M2) |
| Happy | 0.95 | 1.00 | 0.95 | 1.00 | 0.95 | 1.00 | 96.5 (M1) 98.1 (M2) |
| Sad | 0.95 | 1.00 | 0.95 | 1.00 | 0.95 | 1.00 | 96.5 (M1) 98.1 (M2) |
| Angry | 0.90 | 0.95 | 0.95 | 1.00 | 0.92 | 0.97 | 96.5 (M1) 98.1 (M2) |
| Fear | 1.00 | 0.95 | 1.00 | 1.00 | 1.00 | 0.97 | 96.5 (M1) 98.1 (M2) |
| Disgust | 1.00 | 0.95 | 0.95 | 0.90 | 0.97 | 0.92 | 96.5 (M1) 98.1 (M2) |
图 6 显示了模型 1 (a) 和模型 2 (b) 在添加噪声增强之前和之后的训练和验证损失。该图说明了引入 noise 前后训练和验证损失的显著对比。最初,两个模型都表现出较高的训练损失,并逐渐减少,表明通过学习稳定下来。然而,在几个 epoch 之后,两个模型的验证损失都增加了,表明可能存在过拟合。这里需要注意的一件重要事情是,与第一个模型相比,第二个模型的图形更平滑。此外,第二个模型在添加噪声之前表现出更高的验证损失。这表明该模型有效地记住了数据,但与基本模式作斗争。这种过度拟合可能归因于模型的复杂性,因为数据集非常平衡,数据不匹配不是主要原因。

图 6. 两种模型的训练和验证损失曲线。( a ) 模型 1 均匀噪声;( b) 型号 2 AWGN。
这项研究强调了 SER 深度学习模型中架构选择的重要性,使该领域超越了以前的工作( 表 1)。与 [17](https://www.mdpi.com/2624-6120/6/2/22#B17-signals-06-00022 "17") 相比(RAVDESS 为 64.68%),由于均匀的噪声、AWGN 和注意力增强,我们的模型实现了卓越的精度(96.5% 和 98.1%),这与缺乏噪声稳健性的 Google 模型不同 [33](https://www.mdpi.com/2624-6120/6/2/22#B33-signals-06-00022 "33")。网络中 CNN 和 LSTM 块的组织很重要,因为必须有效利用每一层的独特功能。CNN 层从频谱图中提取空间特征,而 LSTM 单元捕获对 SER 至关重要的时间依赖关系。这些模块之间的序列和交互决定了模型的整体学习效果和特征集成。此外,结合注意力机制可以提高网络的重点,从而对情绪线索进行更详细的分析。最终,网络架构的配置和组合在模型在 SER 任务中实现高精度的能力中起着关键作用。
文献综述部分的 表 1 展示了 SER 领域值得注意的先前工作。将我们的结果与这些研究进行比较表明,我们提出的模型,尤其是模型 2,在准确性和泛化性方面表现得非常出色。
例如,参考文献 [17](https://www.mdpi.com/2624-6120/6/2/22#B17-signals-06-00022 "17") 使用 ResNets,在 RAVDESS 上实现了 64.68% 的准确率。参考文献 [19](https://www.mdpi.com/2624-6120/6/2/22#B19-signals-06-00022 "19") 将 CNN-LSTM 应用于同一数据集,并报告了 90% 的准确率。同样,使用 CNN 的参考文献 [16](https://www.mdpi.com/2624-6120/6/2/22#B16-signals-06-00022 "16") 达到了 92%。其他最近的工作 [21,22](https://www.mdpi.com/2624-6120/6/2/22#B21-signals-06-00022 "21,22") 使用神经架构在不同的数据集上实现了 70% 到 80% 的水平。
相比之下,我们的模型 1 使用均匀噪声增强达到了 96.5% 的准确率,而模型 2 通过将 AWGN 与注意力机制相结合达到了 98.1% 的准确率。这些结果证实了我们的架构和增强策略的有效性,尤其是在像 RAVDESS 这样干净平衡的数据集上进行测试时。此外,对 SAVEE 数据集的初步测试表明,无需重新训练即可实现有希望的跨数据集泛化,突出了我们模型的稳健性。
从 表 1 中的几项研究比较中可以看出,许多研究都显示出积极的结果。然而,本研究中提出的模型因其独特的架构和泛化技术而脱颖而出。虽然以前的研究取得了良好的准确性,但本研究模型的表现始终更好。总体而言,模型不仅实现了更高的准确性,而且还显示出更好的泛化和抗过拟合的鲁棒性,这在前面提到的大多数研究中都没有得到突出解决。
5. 结论
我们通过创建两个混合模型来介绍 SER 的先进技术。尽管由于输入可变性,SER 系统存在挑战,但两种模型都表现良好。双向 LSTM 模型由于其双向学习和注意力机制而提供的准确性略高,尽管它提供的额外优势最小。第二个模型虽然更复杂且需要大量训练,但预测效果略好一些。这种精度可以归因于均衡的数据集、减少损失的战略数据增强以及对卷积块和层的仔细管理。此外,这些模型表现出高度的泛化性,即使在嘈杂的数据条件下也被证明是有效的。选择正确的超参数并使用 Mel Spectrogram 作为输入可以使模型获得出色的结果。
SER 对 AI 和研究至关重要,它专注于通过创建高级模型从语音信号中识别情绪。这项工作利用堆叠的 CNN 和 LSTM 层来分析 Mel 频谱图。第一个模型有效地利用了这些网络,而第二个模型则结合了带有注意力层的双向 LSTM 以增强特征检测。
两种模型都表现出较强的分类准确率,第一个模型达到 96.5%,第二个模型达到 98.1%。模型 2 的注意力机制提高了其预测性能,但与模型 1 相比,训练更加复杂且速度更慢。
这项研究证明了所提出的混合模型在 SER 应用中的巨大潜力,尽管仍然存在一些局限性。目前的评估主要是在 RAVDESS 数据集上进行的,该数据集以带有北美口音的英语语音为特色。为了进一步测试泛化性,我们还在 SAVEE [34](https://www.mdpi.com/2624-6120/6/2/22#B34-signals-06-00022 "34") 数据集上评估了该模型,这是另一个广泛使用的英语语音情感数据集。该模型正确分类了 7 个随机选择的情绪样本中的 5 个(使用我们的预训练模型进行测试,无需在 SAVEE 上重新训练),表明在类似的英语口音数据集中具有很好的泛化效果。然而,对非英语或多语言上下文的泛化性仍未得到验证。由于情感表达的语言和文化差异,需要对不同的数据集进行额外的测试,以实现更广泛的适用性。此外,本研究没有纳入多模态分析(例如,结合音频和视频);这可能会限制复杂方案中的实际适用性。尽管存在这些限制,但两种型号在受控环境中都表现出强大的能力。这种比较强调了深思熟虑的建筑设计的重要性。未来的工作将侧重于改进这些模型,试验高级特征提取技术,并扩大评估范围,以包括更大的多语言数据集和现实世界中嘈杂的多模式环境,包括客户服务和心理健康监测系统。
代码实现如下:Speech_Emotion_Recognition.ipynb
python
model = Sequential()
model.add(Conv1D(1024, kernel_size=5, strides=1, padding='same', activation='relu', input_shape=(X.shape[1], 1)))
model.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Conv1D(512, kernel_size=5, strides=1, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(Conv1D(256, kernel_size=5, strides=1, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2, strides = 2, padding = 'same'))
model.add(BatchNormalization())
model.add(Dropout(0.3))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(128))
model.add(Dropout(0.3))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(32, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(8, activation='softmax'))
model.summary()Model: "sequential_1"┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ conv1d_3 (Conv1D) │ (None, 162, 1024) │ 6,144 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling1d_3 (MaxPooling1D) │ (None, 81, 1024) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_3 │ (None, 81, 1024) │ 4,096 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_9 (Dropout) │ (None, 81, 1024) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv1d_4 (Conv1D) │ (None, 81, 512) │ 2,621,952 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling1d_4 (MaxPooling1D) │ (None, 41, 512) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_4 │ (None, 41, 512) │ 2,048 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_10 (Dropout) │ (None, 41, 512) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ conv1d_5 (Conv1D) │ (None, 41, 256) │ 655,616 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ max_pooling1d_5 (MaxPooling1D) │ (None, 21, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ batch_normalization_5 │ (None, 21, 256) │ 1,024 │
│ (BatchNormalization) │ │ │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_11 (Dropout) │ (None, 21, 256) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_3 (LSTM) │ (None, 21, 128) │ 197,120 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_12 (Dropout) │ (None, 21, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_4 (LSTM) │ (None, 21, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_13 (Dropout) │ (None, 21, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ lstm_5 (LSTM) │ (None, 128) │ 131,584 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_14 (Dropout) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_4 (Dense) │ (None, 128) │ 16,512 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_15 (Dropout) │ (None, 128) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_5 (Dense) │ (None, 64) │ 8,256 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_16 (Dropout) │ (None, 64) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_6 (Dense) │ (None, 32) │ 2,080 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dropout_17 (Dropout) │ (None, 32) │ 0 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_7 (Dense) │ (None, 8) │ 264 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘ Total params: 3,778,280 (14.41 MB) Trainable params: 3,774,696 (14.40 MB) Non-trainable params: 3,584 (14.00 KB)
python
Epoch 1/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m17s[0m 37ms/step - accuracy: 0.2153 - loss: 1.9636 - val_accuracy: 0.2426 - val_loss: 1.9693 - learning_rate: 0.0010
Epoch 2/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.3108 - loss: 1.6652 - val_accuracy: 0.3463 - val_loss: 1.5517 - learning_rate: 0.0010
Epoch 3/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 35ms/step - accuracy: 0.3883 - loss: 1.5169 - val_accuracy: 0.3664 - val_loss: 1.6439 - learning_rate: 0.0010
Epoch 4/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.4566 - loss: 1.4205 - val_accuracy: 0.5945 - val_loss: 1.1129 - learning_rate: 0.0010
Epoch 5/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 39ms/step - accuracy: 0.5555 - loss: 1.2191 - val_accuracy: 0.6353 - val_loss: 0.9806 - learning_rate: 0.0010
Epoch 6/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.6087 - loss: 1.1061 - val_accuracy: 0.5578 - val_loss: 1.2841 - learning_rate: 0.0010
Epoch 7/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.6493 - loss: 0.9911 - val_accuracy: 0.6758 - val_loss: 0.8649 - learning_rate: 0.0010
Epoch 8/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.6640 - loss: 0.9323 - val_accuracy: 0.6800 - val_loss: 0.8433 - learning_rate: 0.0010
Epoch 9/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.6765 - loss: 0.8867 - val_accuracy: 0.6717 - val_loss: 1.0084 - learning_rate: 0.0010
Epoch 10/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m22s[0m 39ms/step - accuracy: 0.6944 - loss: 0.8469 - val_accuracy: 0.6675 - val_loss: 0.8587 - learning_rate: 0.0010
Epoch 11/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.6899 - loss: 0.8328 - val_accuracy: 0.6892 - val_loss: 0.7895 - learning_rate: 0.0010
Epoch 12/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.6997 - loss: 0.8093 - val_accuracy: 0.7035 - val_loss: 0.7804 - learning_rate: 0.0010
Epoch 13/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.7010 - loss: 0.8087 - val_accuracy: 0.7247 - val_loss: 0.7322 - learning_rate: 0.0010
Epoch 14/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.7118 - loss: 0.7662 - val_accuracy: 0.7046 - val_loss: 0.7973 - learning_rate: 0.0010
Epoch 15/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7338 - loss: 0.7147 - val_accuracy: 0.7078 - val_loss: 0.7720 - learning_rate: 0.0010
Epoch 16/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 36ms/step - accuracy: 0.7229 - loss: 0.7290 - val_accuracy: 0.6889 - val_loss: 0.8257 - learning_rate: 0.0010
Epoch 17/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.7225 - loss: 0.7494 - val_accuracy: 0.6949 - val_loss: 0.8535 - learning_rate: 0.0010
Epoch 18/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.7355 - loss: 0.7058 - val_accuracy: 0.7194 - val_loss: 0.7390 - learning_rate: 0.0010
Epoch 19/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7411 - loss: 0.6920 - val_accuracy: 0.7376 - val_loss: 0.7078 - learning_rate: 0.0010
Epoch 20/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.7406 - loss: 0.6911 - val_accuracy: 0.7141 - val_loss: 0.7635 - learning_rate: 0.0010
Epoch 21/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.7450 - loss: 0.6977 - val_accuracy: 0.7265 - val_loss: 0.7643 - learning_rate: 0.0010
Epoch 22/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 39ms/step - accuracy: 0.7431 - loss: 0.6786 - val_accuracy: 0.7362 - val_loss: 0.7558 - learning_rate: 0.0010
Epoch 23/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m19s[0m 35ms/step - accuracy: 0.7346 - loss: 0.7241 - val_accuracy: 0.7348 - val_loss: 0.7062 - learning_rate: 0.0010
Epoch 24/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.7594 - loss: 0.6490 - val_accuracy: 0.7380 - val_loss: 0.6892 - learning_rate: 0.0010
Epoch 25/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 40ms/step - accuracy: 0.7486 - loss: 0.6795 - val_accuracy: 0.7286 - val_loss: 0.6955 - learning_rate: 0.0010
Epoch 26/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7423 - loss: 0.6799 - val_accuracy: 0.7389 - val_loss: 0.7198 - learning_rate: 0.0010
Epoch 27/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.7559 - loss: 0.6395 - val_accuracy: 0.7249 - val_loss: 0.7698 - learning_rate: 0.0010
Epoch 28/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 38ms/step - accuracy: 0.7583 - loss: 0.6320 - val_accuracy: 0.7429 - val_loss: 0.7185 - learning_rate: 0.0010
Epoch 29/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 35ms/step - accuracy: 0.7527 - loss: 0.6426 - val_accuracy: 0.7422 - val_loss: 0.6955 - learning_rate: 0.0010
Epoch 30/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7676 - loss: 0.6296 - val_accuracy: 0.7493 - val_loss: 0.6471 - learning_rate: 0.0010
Epoch 31/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7662 - loss: 0.6177 - val_accuracy: 0.7571 - val_loss: 0.6693 - learning_rate: 0.0010
Epoch 32/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7819 - loss: 0.6026 - val_accuracy: 0.7555 - val_loss: 0.6534 - learning_rate: 0.0010
Epoch 33/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.7768 - loss: 0.6018 - val_accuracy: 0.7544 - val_loss: 0.6464 - learning_rate: 0.0010
Epoch 34/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 35ms/step - accuracy: 0.7747 - loss: 0.6004 - val_accuracy: 0.7203 - val_loss: 0.7747 - learning_rate: 0.0010
Epoch 35/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.7768 - loss: 0.6081 - val_accuracy: 0.7461 - val_loss: 0.7599 - learning_rate: 0.0010
Epoch 36/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.7825 - loss: 0.5860 - val_accuracy: 0.7613 - val_loss: 0.6666 - learning_rate: 0.0010
Epoch 37/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.7836 - loss: 0.5870 - val_accuracy: 0.7622 - val_loss: 0.6769 - learning_rate: 0.0010
Epoch 38/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.7964 - loss: 0.5549 - val_accuracy: 0.7424 - val_loss: 0.6943 - learning_rate: 0.0010
Epoch 39/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.7884 - loss: 0.5751 - val_accuracy: 0.7611 - val_loss: 0.6916 - learning_rate: 0.0010
Epoch 40/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.7961 - loss: 0.5651 - val_accuracy: 0.7594 - val_loss: 0.7202 - learning_rate: 0.0010
Epoch 41/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.7930 - loss: 0.5558 - val_accuracy: 0.7574 - val_loss: 0.6860 - learning_rate: 0.0010
Epoch 42/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 35ms/step - accuracy: 0.7949 - loss: 0.5488 - val_accuracy: 0.7532 - val_loss: 0.6702 - learning_rate: 0.0010
Epoch 43/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.7946 - loss: 0.5478 - val_accuracy: 0.7491 - val_loss: 0.7065 - learning_rate: 0.0010
Epoch 44/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.7908 - loss: 0.5802 - val_accuracy: 0.7551 - val_loss: 0.7272 - learning_rate: 0.0010
Epoch 45/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8036 - loss: 0.5504 - val_accuracy: 0.7652 - val_loss: 0.6707 - learning_rate: 0.0010
Epoch 46/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 36ms/step - accuracy: 0.8009 - loss: 0.5405 - val_accuracy: 0.7689 - val_loss: 0.6954 - learning_rate: 0.0010
Epoch 47/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8067 - loss: 0.5342 - val_accuracy: 0.7774 - val_loss: 0.6802 - learning_rate: 0.0010
Epoch 48/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.8144 - loss: 0.5044 - val_accuracy: 0.7712 - val_loss: 0.6441 - learning_rate: 0.0010
Epoch 49/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8135 - loss: 0.5123 - val_accuracy: 0.7666 - val_loss: 0.7112 - learning_rate: 0.0010
Epoch 50/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.7987 - loss: 0.5400 - val_accuracy: 0.7661 - val_loss: 0.6949 - learning_rate: 0.0010
Epoch 51/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8163 - loss: 0.5119 - val_accuracy: 0.7696 - val_loss: 0.6756 - learning_rate: 0.0010
Epoch 52/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8204 - loss: 0.5084 - val_accuracy: 0.7578 - val_loss: 0.7212 - learning_rate: 0.0010
Epoch 53/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 36ms/step - accuracy: 0.8135 - loss: 0.5052 - val_accuracy: 0.7668 - val_loss: 0.6683 - learning_rate: 0.0010
Epoch 54/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8164 - loss: 0.5022 - val_accuracy: 0.7781 - val_loss: 0.6305 - learning_rate: 0.0010
Epoch 55/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m22s[0m 41ms/step - accuracy: 0.8148 - loss: 0.5150 - val_accuracy: 0.7737 - val_loss: 0.6815 - learning_rate: 0.0010
Epoch 56/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.8253 - loss: 0.4878 - val_accuracy: 0.7200 - val_loss: 0.9112 - learning_rate: 0.0010
Epoch 57/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 35ms/step - accuracy: 0.8114 - loss: 0.5258 - val_accuracy: 0.7703 - val_loss: 0.7413 - learning_rate: 0.0010
Epoch 58/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8100 - loss: 0.5143 - val_accuracy: 0.7832 - val_loss: 0.6766 - learning_rate: 0.0010
Epoch 59/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 36ms/step - accuracy: 0.8171 - loss: 0.5114 - val_accuracy: 0.7790 - val_loss: 0.6732 - learning_rate: 0.0010
Epoch 60/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8290 - loss: 0.4781 - val_accuracy: 0.7802 - val_loss: 0.6485 - learning_rate: 0.0010
Epoch 61/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8261 - loss: 0.4743 - val_accuracy: 0.7813 - val_loss: 0.6789 - learning_rate: 0.0010
Epoch 62/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8325 - loss: 0.4594 - val_accuracy: 0.7813 - val_loss: 0.6707 - learning_rate: 0.0010
Epoch 63/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8395 - loss: 0.4399 - val_accuracy: 0.7793 - val_loss: 0.6661 - learning_rate: 0.0010
Epoch 64/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8384 - loss: 0.4407 - val_accuracy: 0.7892 - val_loss: 0.6566 - learning_rate: 0.0010
Epoch 65/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 37ms/step - accuracy: 0.8408 - loss: 0.4469 - val_accuracy: 0.7657 - val_loss: 0.7264 - learning_rate: 0.0010
Epoch 66/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8357 - loss: 0.4654 - val_accuracy: 0.7717 - val_loss: 0.6659 - learning_rate: 0.0010
Epoch 67/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8366 - loss: 0.4634 - val_accuracy: 0.7823 - val_loss: 0.6298 - learning_rate: 0.0010
Epoch 68/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 35ms/step - accuracy: 0.8428 - loss: 0.4283 - val_accuracy: 0.7816 - val_loss: 0.6530 - learning_rate: 0.0010
Epoch 69/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8521 - loss: 0.4189 - val_accuracy: 0.7770 - val_loss: 0.6688 - learning_rate: 0.0010
Epoch 70/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8420 - loss: 0.4489 - val_accuracy: 0.7857 - val_loss: 0.6584 - learning_rate: 0.0010
Epoch 71/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8424 - loss: 0.4449 - val_accuracy: 0.7666 - val_loss: 0.7331 - learning_rate: 0.0010
Epoch 72/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 36ms/step - accuracy: 0.8456 - loss: 0.4312 - val_accuracy: 0.7878 - val_loss: 0.6981 - learning_rate: 0.0010
Epoch 73/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8492 - loss: 0.4324 - val_accuracy: 0.7878 - val_loss: 0.6661 - learning_rate: 0.0010
Epoch 74/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8401 - loss: 0.4341 - val_accuracy: 0.7855 - val_loss: 0.7077 - learning_rate: 0.0010
Epoch 75/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8461 - loss: 0.4273 - val_accuracy: 0.7857 - val_loss: 0.6850 - learning_rate: 0.0010
Epoch 76/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8463 - loss: 0.4318 - val_accuracy: 0.7906 - val_loss: 0.6968 - learning_rate: 0.0010
Epoch 77/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8548 - loss: 0.4133 - val_accuracy: 0.7882 - val_loss: 0.7185 - learning_rate: 0.0010
Epoch 78/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8409 - loss: 0.4635 - val_accuracy: 0.7825 - val_loss: 0.6842 - learning_rate: 0.0010
Epoch 79/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 35ms/step - accuracy: 0.8570 - loss: 0.4260 - val_accuracy: 0.7834 - val_loss: 0.6868 - learning_rate: 0.0010
Epoch 80/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8472 - loss: 0.4231 - val_accuracy: 0.7873 - val_loss: 0.6727 - learning_rate: 0.0010
Epoch 81/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8564 - loss: 0.4117 - val_accuracy: 0.7942 - val_loss: 0.6683 - learning_rate: 0.0010
Epoch 82/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8605 - loss: 0.3988 - val_accuracy: 0.7984 - val_loss: 0.7252 - learning_rate: 0.0010
Epoch 83/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.8571 - loss: 0.4182 - val_accuracy: 0.7968 - val_loss: 0.6476 - learning_rate: 0.0010
Epoch 84/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8532 - loss: 0.4352 - val_accuracy: 0.7982 - val_loss: 0.6890 - learning_rate: 0.0010
Epoch 85/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8636 - loss: 0.3951 - val_accuracy: 0.7813 - val_loss: 0.7375 - learning_rate: 0.0010
Epoch 86/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8647 - loss: 0.3963 - val_accuracy: 0.7919 - val_loss: 0.6307 - learning_rate: 0.0010
Epoch 87/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 37ms/step - accuracy: 0.8661 - loss: 0.3894 - val_accuracy: 0.7995 - val_loss: 0.6687 - learning_rate: 0.0010
Epoch 88/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8705 - loss: 0.3767 - val_accuracy: 0.7956 - val_loss: 0.6626 - learning_rate: 0.0010
Epoch 89/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8655 - loss: 0.3786 - val_accuracy: 0.7938 - val_loss: 0.7064 - learning_rate: 0.0010
Epoch 90/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 39ms/step - accuracy: 0.8708 - loss: 0.3785 - val_accuracy: 0.8000 - val_loss: 0.7013 - learning_rate: 0.0010
Epoch 91/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 35ms/step - accuracy: 0.8668 - loss: 0.3851 - val_accuracy: 0.7917 - val_loss: 0.6687 - learning_rate: 0.0010
Epoch 92/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 36ms/step - accuracy: 0.8640 - loss: 0.3867 - val_accuracy: 0.7988 - val_loss: 0.6336 - learning_rate: 0.0010
Epoch 93/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8602 - loss: 0.3998 - val_accuracy: 0.7795 - val_loss: 0.9010 - learning_rate: 0.0010
Epoch 94/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8661 - loss: 0.3733 - val_accuracy: 0.7984 - val_loss: 0.6607 - learning_rate: 0.0010
Epoch 95/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m11s[0m 36ms/step - accuracy: 0.8762 - loss: 0.3688 - val_accuracy: 0.7880 - val_loss: 0.7836 - learning_rate: 0.0010
Epoch 96/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m21s[0m 37ms/step - accuracy: 0.8844 - loss: 0.3356 - val_accuracy: 0.8092 - val_loss: 0.6792 - learning_rate: 0.0010
Epoch 97/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m12s[0m 38ms/step - accuracy: 0.8718 - loss: 0.3705 - val_accuracy: 0.8104 - val_loss: 0.6307 - learning_rate: 0.0010
Epoch 98/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m20s[0m 36ms/step - accuracy: 0.8714 - loss: 0.3702 - val_accuracy: 0.7763 - val_loss: 0.7733 - learning_rate: 0.0010
Epoch 99/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m22s[0m 41ms/step - accuracy: 0.8728 - loss: 0.3559 - val_accuracy: 0.7982 - val_loss: 0.6486 - learning_rate: 0.0010
Epoch 100/100
[1m317/317[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m19s[0m 35ms/step - accuracy: 0.8761 - loss: 0.3585 - val_accuracy: 0.8005 - val_loss: 0.6756 - learning_rate: 0.0010
53
precision recall f1-score support
angry 0.92 0.85 0.88 634
calm 0.62 0.89 0.73 93
disgust 0.84 0.70 0.76 625
fear 0.85 0.71 0.77 619
happy 0.68 0.82 0.74 643
neutral 0.80 0.81 0.80 623
sad 0.78 0.81 0.79 611
surprise 0.84 0.91 0.87 492
accuracy 0.80 4340
macro avg 0.79 0.81 0.80 4340
weighted avg 0.81 0.80 0.80 4340