**常见问题:**我们经常安装失败的原因是,esmfold需要3.7版本的python,1.0.0的openfold,11.3的CUDA,1.12的torch,0.13的torchvision,0.12的torchaudio......通常情况下会因为一个包的版本不匹配而造成安装的失败,安装教程如下:
一、安装esmfold的基础环境
1、将以下内容保存为esmfold_conda_environment.yml
bash
name: esmfold
channels:
- conda-forge
- bioconda
- pytorch
dependencies:
- conda-forge::python=3.7
- conda-forge::setuptools=59.5.0
- conda-forge::pip
- conda-forge::openmm=7.5.1
- conda-forge::pdbfixer
- conda-forge::cudatoolkit==11.3.*
- conda-forge::cudatoolkit-dev==11.3.*
- conda-forge::einops==0.6.1
- conda-forge::fairscale
- conda-forge::omegaconf
- conda-forge::hydra-core
- conda-forge::pandas
- conda-forge::pytest
- bioconda::hmmer==3.3.2
- bioconda::hhsuite==3.3.0
- bioconda::kalign2==2.04
- pytorch::pytorch=1.12.*2、创建esmfold的虚拟环境
bash
conda env create -f esmfold_conda_environment.yml安装结果如下:

可以检查安装的版本号是否对应:
bash
conda activate esmfold
conda list3、将以下内容保存为esmfold_pip_environment.yml
bash
biopython==1.79
deepspeed==0.5.9
dm-tree==0.1.6
ml-collections==0.1.0
numpy==1.21.2
PyYAML==5.4.1
requests==2.26.0
scipy==1.7.1
tqdm==4.62.2
typing-extensions==3.10.0.2
pytorch_lightning==1.5.10
wandb==0.12.21
biotite==0.39.0
matplotlib
joblib4、使用pip安装所需依赖
bash
pip install -r esmfold_pip_environment.yml安装结果如下:

二、esmfold的安装
**注意:**按照官网教程,目前还需要从Github下载并安装三个主要的包,分别为esm,dllogger,openfold。运行esmfold需要安装openfold 1.0.0,如果直接使用pip install openfold或者使用github作者给予的命令,会安装成2.0.0,会造成程序的错误,因此主要解决的一个问题就是需要手动安装1.0.0版本的openfold,过程中遇到的其他问题也会一一解决。
安装fair-esm、esmfold以及dllogger,这三个包是可以正常进行安装的,第一行和第二行都是安装esm包,可以二选一执行,推荐使用第二行的命令,因为第二行的指令是从 GitHub 仓库主分支安装 最新开发代码(也叫 bleeding edge),包含了最新的**CLI 工具(如 esm-fold)**及相关命令行入口;
bash
pip install fair-esm # latest release,OR
pip install git+https://github.com/facebookresearch/esm.git # bleeding edge, current repo main branch
pip install "fair-esm[esmfold]"
# OpenFold and its remaining dependency
pip install 'dllogger @ git+https://github.com/NVIDIA/dllogger.git'三、openfold的安装
1、首先按照esm官方提供的教程,我们应该执行以下命令进行安装,但是该命令会报错,不过报错信息中会有提示,如下图所示
bash
pip install 'openfold @ git+https://github.com/aqlaboratory/openfold.git@4b41059694619831a7db195b7e0988fc4ff3a307'
2、按照提示信息下载指定版本的openfold
bash
git clone --filter=blob:none --quiet https://github.com/aqlaboratory/openfold.git
cd ./openfold/
git rev-parse -q --verify 'sha^4b41059694619831a7db195b7e0988fc4ff3a307'
git fetch -q https://github.com/aqlaboratory/openfold.git 4b41059694619831a7db195b7e0988fc4ff3a307
git checkout -q 4b41059694619831a7db195b7e0988fc4ff3a307执行完上述操作后,我们可以使用nano或者vim文本编辑器去查看openfold/setup.py里的version由原来的2.0.0变成了1.0.0,说明指定版本openfold下载成功

3、pip以可编辑模式安装openfold包,安装过程也会遇到各种各样的问题,我们逐步解决
bash
pip install -e . (1)问题一:mkl版本问题,报错信息如下

解决方案:对mkl进行降级,首先卸载当前版本的mkl
bash
conda uninstall mkl注意:在卸载mkl的过程中会移除一些包,也会对一些包进行降级,尤其是这里把pytorch从GPU版本变成了CPU版本的了 ,所以后续还需要重新安装GPU版的pytorch!

然后在安装2018版的mkl,如果过程报类似这样的错误的话,"PackagesNotFoundError: The following packages are not available from current channels:" 需要对conda进行换源,可以参考其他博客:
bash
conda install mkl=2018 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/linux-64/
安装好之后可以再次尝试安装openfold,不出意外的话就会报第二个错误
bash
pip install -e . (2)问题二:No CUDA runtime is found

解决方案:需要安装cuda版本的torch,执行以下指令用pip或者conda进行安装,推荐pip安装,快速高效;
bash
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch安装好之后可以再次尝试安装openfold,这次应该可以安装成功,如果显示以下信息,说明安装成功。
bash
pip install -e . 
**注意:**使用上述指令是以"开发模式"(editable mode,即 pip install -e .)安装 openfold,它在环境中仅创建了一个指向源代码目录的链接(.egg-link 文件)。如果你是在系统root下的conda进行安装,并且源代码目录(例如 /root/openfold)对其他用户不可见或没有读取权限,那么当其他用户激活同一 conda 环境并运行 esm-fold 时,就会找不到 openfold 模块,从而报错 "No module named 'openfold'"。
**解决方法:**选择以普通的形式进行安装,这样 openfold 的包会被复制到 conda 环境的 site-packages 目录中,而不是仅仅建立一个链接,其他用户无需访问源代码目录。
bashpip install .
(3)问题三:g++版本过高
一般情况把问题二解决之后就可以成功安装了,但是如果系统的g++版本过高的话,可能还会遇到这个问题:
RuntimeError: The current installed version of g++ (11.4.0) is greater than the maximum required version by CUDA 11.3 (10.0.0). Please make sure to use an adequate version of g++ (>=5.0.0, <=10.0.0).
解决方案: 降低g++版本到9.5.0
bash
sudo apt install g++-9
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-9 100
sudo update-alternatives --config g++
g++ --version # 确保是 9.5.0g++版本成功降低后可以再次尝试安装openfold:
bash
pip install -e . (4)问题四: nvcc fatal : Unsupported gpu architecture 'compute_89'
这说明 nvcc(NVIDIA CUDA编译器)不支持你在编译参数里指定的 compute_89 架构。
 解决办法:将setup.py中"f'arch=compute_{major}{minor},code=sm_{major}{minor}',"改为"f'arch=compute_86,code=sm_86',"(备注:理论上替换成你的nvcc支持的compute构架就可以)
解决办法:将setup.py中"f'arch=compute_{major}{minor},code=sm_{major}{minor}',"改为"f'arch=compute_86,code=sm_86',"(备注:理论上替换成你的nvcc支持的compute构架就可以)
bash
nvcc --list-gpu-arch # 方法二:直接查看支持的compute构架nvcc --list-gpu-arch 这个指令的作用是:
列出当前 CUDA 编译器(nvcc)支持的所有 GPU 架构(compute capability)代码名称。
具体来说:
-
CUDA GPU 根据型号有不同的"计算能力"(compute capability),用数字表示,比如 6.1、7.5、8.6 等。
-
nvcc需要知道你的 GPU 架构,才能编译适合该架构的 CUDA 代码。 -
nvcc --list-gpu-arch会输出一组compute_xx标识符,表示它支持哪些架构代码,例如:
bash
compute_35
compute_50
compute_70
compute_86(5)问题五:gcc版本过高
error: #error -- unsupported GNU version! gcc versions later than 10 are not supported!
The nvcc flag '-allow-unsupported-compiler' can be used to override this version check; however, using an unsupported host compiler may cause compilation failure or incorrect run time execution.
解决方案:通过 conda 安装特定版本的 gcc/g++,然后建立软链接,确保系统或编译器调用的是符合兼容性的 gcc/g++,避免 nvcc 报"unsupported GNU version"的错误;
bash
# conda下载gcc和gxx
conda install -c moussi gcc_impl_linux-64=7.3.0
conda install -c moussi gxx_impl_linux-64=7.3.0
cd /home/username/miniconda3/envs/esmfold/bin # 进入自己esmfold的目录下
# 链接到gcc和gxx(进入自己的bin看叫gcc和gxx什么名字)
ln -s ./x86_64-conda_cos6-linux-gnu-gcc ./gcc
ln -s ./x86_64-conda_cos6-linux-gnu-g++ ./g++
# 设置环境变量指向软链接的gcc和g++
export CC=/home/username/miniconda3/envs/esmfold/bin/gcc
export CXX=/home/username/miniconda3/envs/esmfold/bin/g++注意:如果找不到某个库的话,可能需要一些软连接实现,参考如下(非必须项):
bash
sudo ln -s /usr/lib/x86_64-linux-gnu/libc.so.6 /lib/libc.so.6
sudo ln -s /usr/lib/x86_64-linux-gnu/ld-2.31.so /lib/ld-linux-x86-64.so.2
sudo ln -s /usr/lib/x86_64-linux-gnu/libc_nonshared.a /usr/lib/libc_nonshared.a
sudo ln -s /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2 /lib/ld-linux-x86-64.so.2四、运行测试
(一)通过代码进行结构预测
首先保证激活 esmfold 的虚拟环境,然后将以下内容保存为:reproduce.py,然后执行:python reproduce.py,会完成model下载,一个示例sequence的结构预测,保存为result.pdb。65个残基的蛋白,运行时间约25s。
python
import torch
import esm
model = esm.pretrained.esmfold_v1()
model = model.eval().cuda()
# Optionally, uncomment to set a chunk size for axial attention. This can help reduce memory.
# Lower sizes will have lower memory requirements at the cost of increased speed.
# model.set_chunk_size(128)
sequence = "MKTVRQERLKSIVRILERSKEPVSGAQLAEELSVSRQVIVQDIAYLRSLGYNIVATPRGYVLAGG"
# Multimer prediction can be done with chains separated by ':'
with torch.no_grad():
output = model.infer_pdb(sequence)
with open("result.pdb", "w") as f:
f.write(output)
import biotite.structure.io as bsio
struct = bsio.load_structure("result.pdb", extra_fields=["b_factor"])
print(struct.b_factor.mean()) # this will be the pLDDT
# 88.3预测的结构如下所示:
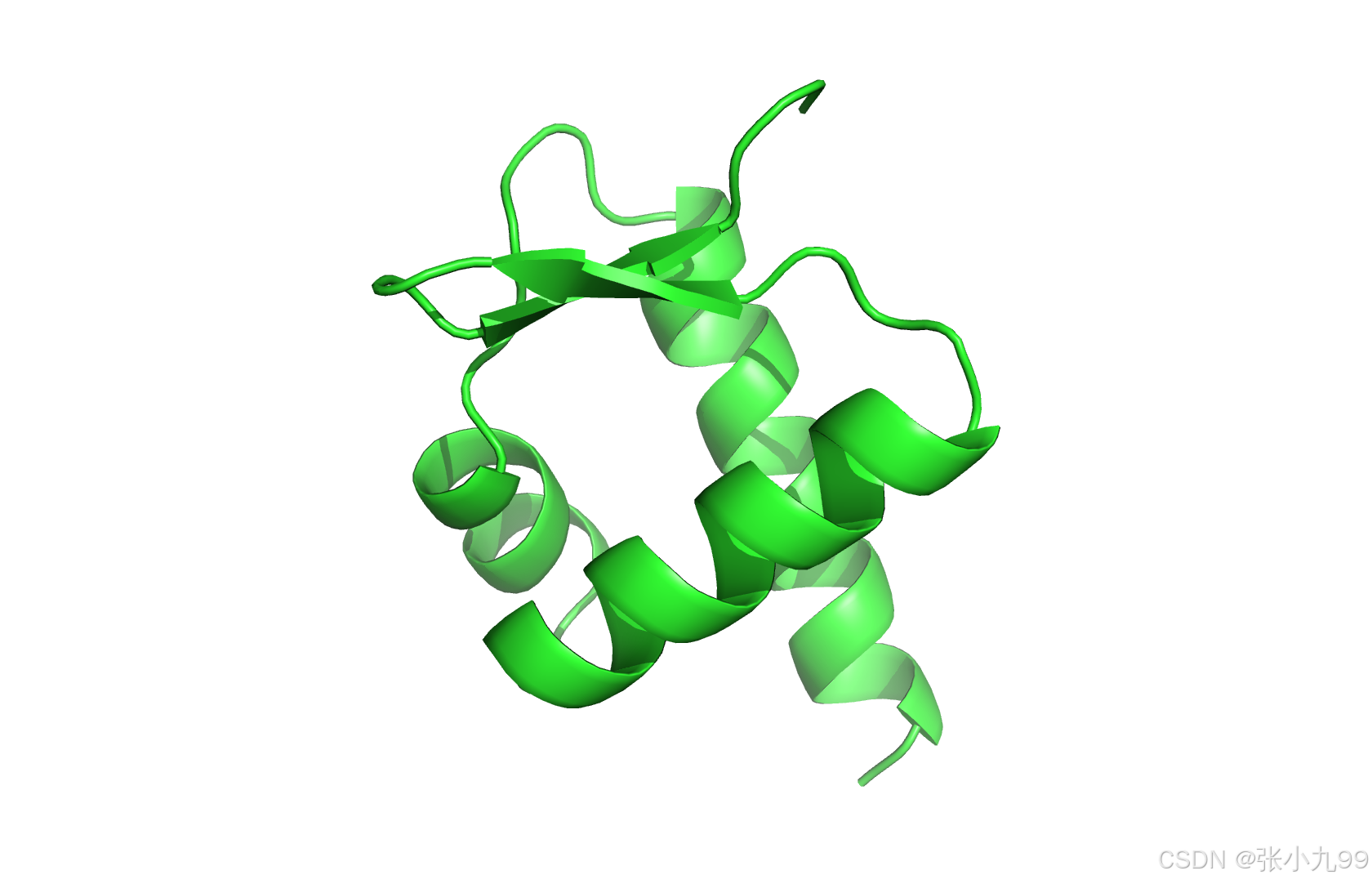
(二)通过CLI进行结构预测
CLI是 Command Line Interface 的缩写,中文叫做命令行界面。CLI 就是用命令行输入命令和程序交互的方式,是开发者和科研工作者常用的操作界面,尤其适用于批量、高效、远程的工作场景。
1、查看使用说明
bash
esm-fold -h
参数说明:
usage: esm-fold -h -i FASTA -o PDB -m MODEL_DIR
--num-recycles NUM_RECYCLES
--max-tokens-per-batch MAX_TOKENS_PER_BATCH
--chunk-size CHUNK_SIZE\] \[--cpu-only\] \[--cpu-offload
**-h, --help:**显示帮助信息并退出,列出所有可用参数及说明。
**-i FASTA, --fasta FASTA :**输入参数,指定要折叠的蛋白质序列所在的 FASTA 文件路径。
**-o PDB, --pdb PDB:**输出参数,指定折叠生成的 PDB 文件(结构文件)存放的目录。
**-m MODEL_DIR, --model-dir MODEL_DIR:**预训练模型数据目录的父路径。esm-fold 会在该目录下查找预训练的 ESM 模型文件。
**--num-recycles NUM_RECYCLES:**指定模型运行时进行"recycle"(循环迭代)的次数。默认值为训练时所用的次数(通常是 4 次)。循环迭代次数越多,理论上预测的结构可能更准确,但同时计算量也会增大。
**--max-tokens-per-batch MAX_TOKENS_PER_BATCH:**设定每个 GPU 前向传播中最大允许的 token 数量。这个参数用于将较短的序列组合到同一个 batch 中,便于批量预测。如果遇到内存不足问题,可以尝试降低该值以减少一次性计算的 token 数量。
**--chunk-size CHUNK_SIZE:**对轴向注意力计算进行分块处理,从而降低内存占用。默认注意力计算内存复杂度为 O(L²),使用 chunking 后可以降到 O(L)。chunk-size 越低,内存占用越少,但运行速度可能降低。常用的建议值为 128、64 或 32。如果不设置,则采用默认计算策略。
**--cpu-only:**指定仅使用 CPU 进行计算(不使用 GPU)。在没有 GPU 或需要调试 CPU 模式时使用。
**--cpu-offload:**启用 CPU offloading,即将部分计算或数据从 GPU 转移到 CPU,以减轻 GPU 内存压力。这在 GPU 内存不足时比较有用,但可能会导致速度变慢。
2、执行测试
(1)创建测试文件夹
bash
mkdir test(2)编辑fasta文件,写入测试序列
bash
vim test.fasta>test_0
MNKTRVAINGFGRIGRMVFRQAILDEQLEVVAINASYPAETLAHLIKYDSVHGIFDKEVKAVNEGIMISDKKIKLVNSRVPENLPWDELNIDIVIEATGKFKTKESAGGHIRAGAKKVVITAPGKEVDQTIVMGVNEGVYNPEKDDVISNASCTTNCLAPIVKIIDDHFSIENGLMTTVHAFTNDQKNIDNPHKDLRRARGCTQSIIPTSTGAAKALGEVIPHLNGRLHGMALRVPTPNVSLVDLVVDVKNSISVEEVNHIFKQAQETDFKGIVSYSEEPLVSIDYTTTDFSAVVDGLSTMVMDNHKVKVLAWYDNEWGYSKRVIDLTKYVGSYLYQKQAQIS
>test_1
MSVKVAINGFGRIGRMVFRRAISDGGLDIAAINASYPAETLAHLIKYDTTHGRFDGEVIPEDGSLIVNGKKILLLNSRDPKELPWGSLRIDIVIEATGKFNSRDRAAAHLEAGAAKVILTAPGKDEDITIVMGVNEERLDIDRHAIISNASCTTNCLAPVVKVLDEQFGIVNGLMTTVHSYTNDQRNIDNPHKDLRRARACAQSIIPTTTGAAKALSLVLPHLKGKLHGMALRVPTPNVSLVDLVADIHRDASVHEINEAFIAASQGNLAGILDFTSEPLVSADFNTNPHSAIIDGLSTMVMGRNKVKILAWYDNEWGYSSRVVDLTKLVAAEIHEKLRVKAV
>test_2
MKLKVLINGAGRIGKAVLKQLLNIEDFEIVSINDINPYIENIVYSINYDSTYGKFDDKFKIIDNNFIQNSKAKIKILNHNSLIDIDLKDIDIIIDASGKKEDIKLLEKLPVKAIFLTHPNRNAHINLVLGVNENKINPNIHKIISTSSCNATSLLPALKIIDDSKEILCGDIVTIHPLLNHQRVLDGNYVGSATRDVDLNFEFGRSSTQNIIPSHTTTIKACSYVLPKFNSELISSNSLRVPTDTVGAINVTLFTKQASNKDEIIDIFMNFEKNQKFPIVLNNFEPLVSSDFKKEKYTTIIDHRYLEVKNNMIKLLLWYDNEWGYASKVVETLRYYKSICSQI
(3)esm-fold进行结构预测
bash
# 使用esm-fold预测示例蛋白质序列的结构
esm-fold -i test.fasta -o test_output/ -m /public/esm --num-recycles 4输出结果如下,包括pLDDT信息和pTM的信息,以及每个结构建模的时间:

参考链接:
Ubuntu22.04+GPU4090 的 esmfold+openfold 安装全流程_openfold安装-CSDN博客