0. 前言
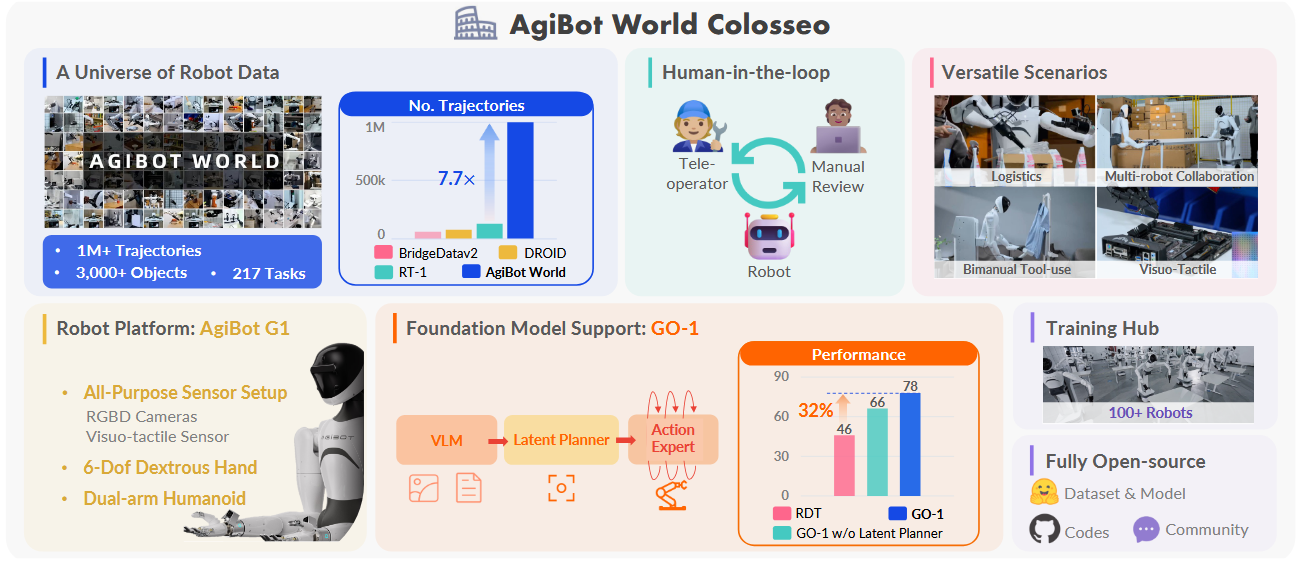
这是一个开源 的大规模操控平台 ,包含数据、模型、基准测试 和生态系统。与以往类似平台相比,AgiBot World 在规模和多样性上无可比拟。部署了 100 台双臂仿人机器人。
他们进一步提出了一个通用策略(GO‑1),并配备了潜在动作规划器。它在多样化的数据集上进行训练,与以往方法相比,实现了可扩展的 32% 性能提升。
1. 背景和相关工作
1.1 提出问题
操控(Manipulation)是机器人学的基石任务,使得机器人能够与物理世界互动并适应环境。虽然在通用基础模型(NLP 和计算机视觉)方面取得了显著进展,但机器人学由于高质量数据收集的难度,仍然落后。在受控实验室环境中,像"抓取并放置"这类简单任务已被深入研究。
然而在开放的真实世界中,从细致的物体交互、移动式操作到协同任务,都依然是巨大挑战。这些任务不仅需要身体上的灵巧,还要能在不同环境和场景中通用,这是目前机器人系统做不到的。
缺乏高质量数据是普遍认同的原因------与丰富且标准化的图像和文本不同,机器人数据因硬件多样和收集流程不一而零散不连贯,导致质量低且结果不一致。
本文提出问题:如何通过扩大 真实世界的机器人数据规模,有效解决现实复杂性?
最近的工作,如 Open X-Embodiment(OXE),通过汇总并标准化现有数据集来应对这一问题。尽管在大规模跨设备学习上有进展,但得到的策略仍局限于简单、短期任务,对新环境的泛化能力较弱。
DROID 通过众包方式,在各种真实场景中收集专家演示数据。由于缺乏质量审核(如人工反馈)且依赖固定单臂机器人,DROID 在真实应用和广泛效果上受限。
更近期,Lin 等人研究了影响同类物体和环境间泛化能力的规模定律,但仅限于少量简单的单步任务。这些工作在发展通用策略方面是重要进展,超越了传统在狭窄领域内的单任务学习。
然而,现有机器人学习数据集仍局限于 高度受控实验室中的短期任务 ,未能充分反映真实世界操作的复杂性和多样性。要实现通用机器智能,必须开发规模大、种类多的同时反映真实世界变化的数据集,并配合通用仿人机器人、标准化且有质量保证的数据收集流程,以及精心设计的任务来反映实际挑战。
1.2 解决问题
如图1所示,他们研究了如何利用可扩展的机器人数据 来应对通用机器人操作 的实际难题。引入 AgiBot World------一个在五种部署场景 下,包含超过 100 万条轨迹 、覆盖 217 项任务 的大规模平台;与现有数据集相比,数据规模提升了一个数量级。
借助带有人机交互审核的标准化数据收集流程,AgiBot World 保证了高质量且多样化的数据分布。它可以从简单的夹爪 扩展到灵巧的机械手和视触觉传感器,用于获取更细致的技能。
在数据基础上,推出了 Genie Operator-1(GO-1),高效衔接通用视觉语言模型(VLM)与机器人序列决策的新型通用策略。它利用潜在动作表示来最大化数据利用率,并展示了随着数据量增加可预测的性能提升。
在他们数据集上预训练 的策略,在同类任务和跨域任务中,平均比 在 Open X-Embodiment 上训练的策略提升了 30% 性能。值得一提的是,仅使用相当于 OXE 1/10 小时数据量的一小部分,我们的策略泛化能力就提升了 18%。
GO-1 在真实世界的灵巧操作 和长时序任务中表现优异,在复杂任务上成功率超过 60%,比之前的 RDT 方法高出 32%。
通过将数据集、工具和模型开源,他们旨在让更多人都能平等获取大规模、高质量的机器人数据,推动可扩展和通用智能的发展。
总之:
- 全栈平台:从硬件(带移动底座的仿人机器人、灵巧机械手、视触觉传感器)到软件再到数据与工具,一应俱全。
- 4000 平方米设施:家庭、零售、工业、餐饮和办公五大场景真实重现。
- 100 台机器人×100 万轨迹:前所未有的数据量与多样性。
- GO‑1 通用策略:基于潜在动作表示,训练于异构数据,性能随数据量稳定提升。
- 开源共享:数据、工具和模型免费放出,如同给机器人研究者发放"钥匙",让大家一起创新。
限制 :所有评估均在真实场景中进行。他们正在开发 与真实环境相匹配的仿真平台 ,旨在反映真实部署效果,从而实现快速且可重复的评估。
1.3 相关工作
机器人领域中的数据规模化
通过自动脚本或人类遥操作收集的机器人学习数据集推动了策略学习,早期工作如 RoboTurk 和 BridgeData 分别提供了约 2100 条和 7200 条轨迹的小规模数据集。
较大的数据集,如 RT-1(约 13 万条轨迹),虽然扩展了规模,但仍局限于少数环境和技能。Open X-Embodiment 将多个数据集整合为统一格式,轨迹总数超过 240 万;但因此在设备类型、视角和数据质量上差异巨大,降低了整体效果。
最近,DROID 通过众包演示来扩大场景多样性,但在数据规模和质量控制方面仍有不足。上述数据集普遍在数据量、任务实用性和场景自然度上有局限,再加上质量保证不足和硬件限制,阻碍了通用策略的训练。
如表 I 所示,他们的数据集充分弥补了这些空白。

搭建了一个覆盖五大场景的数据采集设施,以重现真实世界的多样性和真实性。由经验丰富的遥操作员通过严格审核协议采集的 100 万条轨迹,AgiBot World 使用配备视触觉传感器和灵巧机械手的仿人机器人进行多模态演示,区别于以往工作。
他们提出的是一个涵盖数据、模型、基准测试和生态系统 的全栈平台。
在吸收了近期多项创新思路的基础上,他们通过将带潜在动作的视觉语言模型应用于机器人控制,将网络级知识迁移过来,并结合人类视频与机器人数据进行可扩展训练,从而推动领域进步。
他们的工作展示了潜在动作规划器的整合如何提升长时序任务的执行,并使策略学习更高效,显著优于现有通用策略。
2. AGIBOT WORLD:平台和数据
AgiBot World 是一个全栈式、开源的具身智能生态系统。基于他们开发的硬件平台 AgiBot G1,构建了 AgiBot World------一个由 100 多台同质机器人采集的开源机器人操作数据集,为涵盖各种现实场景的高难度任务提供了高质量的数据。
最新版本包含 1,001,552 条轨迹,总时长 2976.4 小时,覆盖 217 个具体任务、87 种技能和 106 个场景。不仅限于实验室中的基础桌面任务(如抓取与放置);而是聚焦于包含双臂操作、灵巧手和协作任务的真实场景。
AgiBot World 致力于提供一个包容性的基准,以推动先进且鲁棒算法的未来发展。计划发布所有资源,供社区在此基础上进行构建。该数据集以及模型检查点和代码均在 CC BY-NC-SA 4.0 协议下提供。
2.1 硬件
硬件平台是 AgiBot World 的基石,决定了其质量下限。硬件标准化也是简化分布式数据收集与保证可复现结果的关键。为 AgiBot World 精心研发了一种新型硬件平台,其特点是配备视触一体传感器(visuo-tactile sensors)和具有类人配置的耐用 6 自由度(6-DoF)灵巧手。
如图 1 所示,机器人平台具有双 7 自由度(7-DoF)机械臂、移动底盘和可调节的腰部结构。末端执行器采用模块化设计,可根据任务需求选择标准夹爪或 6 自由度灵巧手。对于需要触觉反馈的任务,我们使用配备视触一体传感器的夹爪。
该机器人配备了 8 个摄像头:前方有一个 RGB-D 摄像头和三个鱼眼摄像头,每个末端执行器上还安装有 RGB-D 或鱼眼摄像头,此外在后方还有两个鱼眼摄像头。图像观测信息与本体状态(如关节位置和末端执行器位置)以 30Hz 的控制频率进行记录。
使用两种远程操控系统:VR 头显控制与全身动作捕捉控制。VR 控制器将手部姿态映射为末端执行器的平移与旋转,随后通过逆向运动学转换为关节角度。控制器上的摇杆和按键控制机器人底座与躯干运动,扳机键控制末端执行器动作。
然而,VR 控制器将灵巧手限制为仅能执行少量预定义手势。为了全面释放机器人的能力,采用动作捕捉系统记录人类关节(包括手指)的运动数据,并将其映射为机器人姿态,从而实现更细致的控制,例如单指动作、躯干姿态与头部方向。
该系统提供了完成复杂操作任务所需的姿态灵活性与执行精度。
2.2 数据收集
如图 2 所示,数据采集过程大致可分为三个阶段。
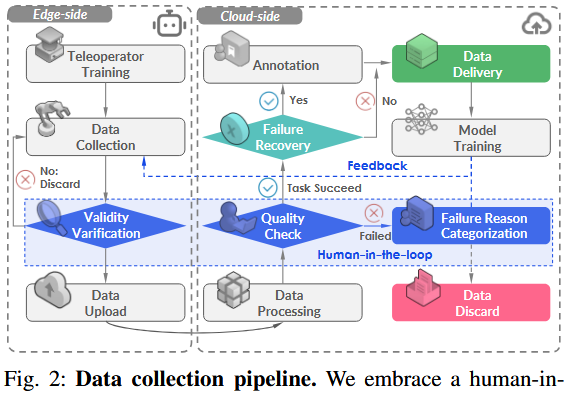
- 在正式开始数据采集之前,我们首先进行初步数据采集,以验证每项任务的可行性并制定相应的采集标准。
- 在验证可行性并审查采集标准后,由熟练的操控员布置初始场景,并根据既定标准正式开始数据采集。所有数据会在本地进行初步有效性验证,如检查是否存在缺失帧。一旦确认数据完整,即上传至云端进入下一阶段。
- 在后处理阶段,数据标注员会核查每条数据是否符合第一阶段制定的采集标准,并添加语言注释。
失败恢复
在数据采集过程中,操控员有时会出错,例如在操纵机械臂时不小心掉落物体。但他们通常可以从这些错误中恢复,并成功完成任务,而无需完全重新布置场景。
他们不会丢弃这些轨迹,而是保留它们,并手动标注失败原因和时间戳 。这些称为"故障恢复数据 "的轨迹约占数据集的 1%,我们认为它们对于实现策略对齐与失败反思极具价值,是推动下一代机器人基础模型发展的关键。
人类反馈机制
在收集标注员反馈的同时,采用"人类反馈"(human-in-the-loop)的方法来评估并优化数据质量。
该过程包含一个迭代循环:采集一小部分演示数据,训练策略模型,并部署该模型以评估数据的可用性。根据策略模型的表现,我们迭代优化数据采集流程,以弥补其中的缺陷或低效之处。
例如,在现实部署中,模型在动作开始时出现较长的停顿,与数据标注员指出的"动作衔接不连贯"和"空闲帧过多"的反馈一致。对此,我们修改了数据采集协议,并在后处理中增加了去除空闲帧的步骤,从而提高数据集在策略学习中的整体效用。
2.3 数据集统计和分析
AgiBot World 是在一个超过 4000 平方米的大型数据采集场地中开发的。该环境包含 3000 多个独特物体,分布在各种精心设计、贴近现实的场景中。数据集涵盖广泛的任务与环境布置,确保了数据在规模与多样性方面的兼顾,有助于学习可泛化的机器人策略。
AgiBot World 在五个关键领域中提供了广泛覆盖:家庭、零售、工业、餐饮与办公环境。在每个领域中,我们进一步定义了具体的场景类别。例如,家庭领域涵盖了卧室、厨房、客厅和阳台等环境;零售领域则包括货架区和生鲜区等具体区域。
数据集中包含 3000 多个独特物体,并在不同场景中进行系统分类。这些物体涵盖了各种日常用品,包括食物、家具、服装、电子设备等。
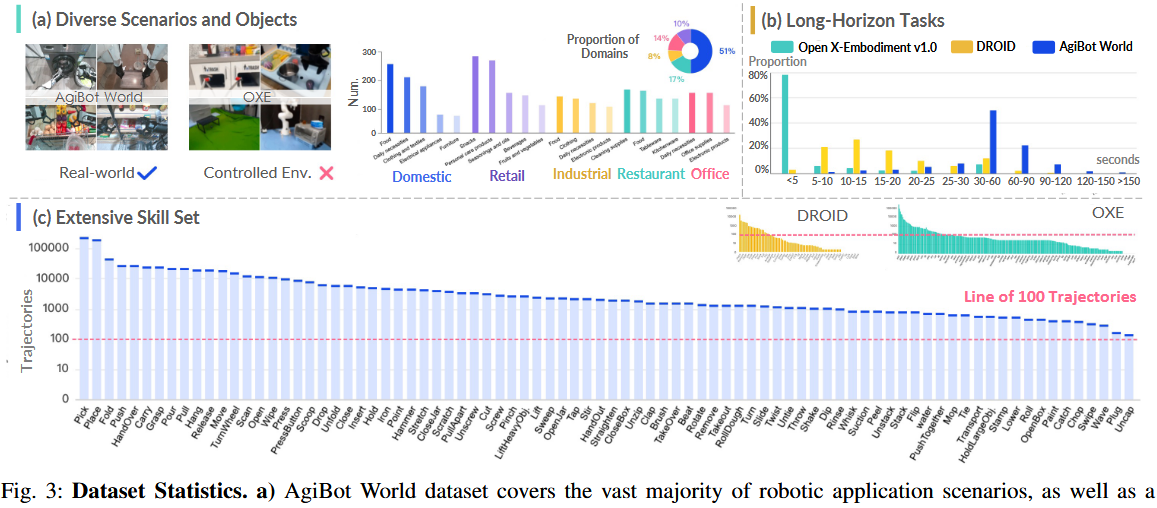
AgiBot World 数据集的一个显著特点是强调长时操作。如图 3(b) 所示,以往的数据集多集中于包含单一原子技能的任务,其轨迹大多不超过 5 秒。
相比之下,AgiBot World 建立在多个原子技能组成的连续完整任务之上,如"制作咖啡"。数据集中的轨迹平均时长约为 30 秒,部分超过 2 分钟。
虽然"抓取与放置"等通用原子技能仍占大多数,我们特别加入了一些强调"切菜"、"插电"等较少使用但价值极高的技能任务。这确保了数据集涵盖了广泛的技能类型,并为每种技能提供了足够数据支持稳健的策略学习。
3. AGIBOT WORLD: 模型
为充分利用高质量的 AgiBot World 数据集并提升策略的泛化能力,他们提出了一种分层的 视觉-语言-潜在动作(ViLLA )框架,如图 4 所示,分为三个阶段训练。
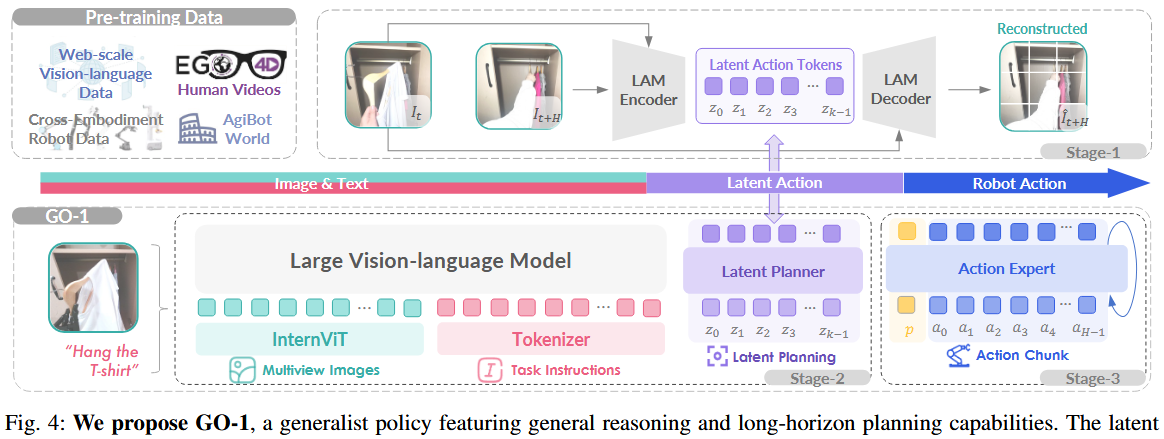
相较于传统视觉-语言-动作(VLA)模型直接预测动作,ViLLA 模型在此基础上引入了中间层的潜在动作 token 作为桥梁,从而提升对控制指令的建模能力。
尽管机器人示范数据日益丰富,但带有明确动作标签的数据在规模上仍远逊于互联网级别的数据集。为扩大数据来源,在第一阶段中引入"潜在动作"来建模连续帧之间的逆向动力学,从而使得无标签的人类视频与异构机器人的数据也能贡献于通用操控知识的学习。
为从视频帧 {It, It+H} 中提取潜在动作,构建了一个由逆动力学编码器 I(zt | It, It+H) 和正向动力学解码器 F(It+H | It, zt) 组成的潜在动作模型。
编码器采用时空 Transformer,并使用类似 Bruce 等人的因果时间掩码,解码器则为空间 Transformer,以初始图像帧和离散化后的潜在动作 token(zt = z0, ..., zk-1,k=4)为输入。token 经由 VQ-VAE(向量量化变分自编码器)进行量化,使用大小为 |C| 的码本。
为构建对场景、物体的理解基础与泛化推理能力,ViLLA 使用了在网络大规模视觉-语言数据上预训练的 VLM,并引入了潜在规划器,在潜在动作空间中实现"与具体机器人无关"的任务规划能力。
选用 InternVL2.5-2B 作为视觉语言模型的主干网络,因其强大的迁移学习能力。在初步实验与相关研究中,其 20 亿参数规模对机器人任务表现出良好效果。
多视角图像观测信息首先通过 InternViT 编码,并投射至语言空间。潜在规划器由 24 层 Transformer 组成,支持从 VLM 主干网络进行逐层调控,具备完整的双向注意力机制。
给定第 t 步的多视角图像输入 (来自头部、左手腕、右手腕)与语言指令,规划器将预测潜在动作 token,训练监督来自潜在动作模型对头视角的编码输出。由于潜在动作空间远小于离散的低层动作空间,这种方式也大幅提高了 VLM 向策略模型的迁移效率。
为实现高频率、灵巧的操作,第三阶段引入"动作专家"模块,通过扩散模型目标来拟合低层动作的连续分布。
虽然动作专家与潜在规划器在结构上相似,但目标不同 :前者通过迭代去噪回归具体动作,而后者通过掩码语言建模预测 token。两个专家模块均以分层方式接收前级模块信息,确保整个"双专家"体系结构内信息流的一致性与融合性。
动作专家解码动作序列 At = at , at+1, ..., at+H(H=30),输入为当前本体状态 pt。在推理阶段,VLM、潜在规划器与动作专家协同组成通用策略 GO-1:先预测 k 个潜在动作 token,再指导扩散过程生成最终控制指令。
4. 实验和分析
评估了在不同数据源(包括 AgiBot World 数据集)上预训练的策略在现实世界中的表现,展示 GO-1 模型在策略学习方面的有效性。
4.1 实验设置
从 AgiBot World 中选取了一组覆盖多维策略能力的代表性任务进行评估,包括:
工具使用(擦桌子 Wipe Table)、
可变形物体操作(叠短裤 Fold Shorts)、
人机交互(递瓶子 Handover Bottle)、
指令跟随(补货饮料 Restock Beverage)等。
此外,每个任务还设计了两个"未见场景",涵盖位置泛化、视觉干扰、语言泛化等因素,以全面评估策略的泛化能力。
示例任务:
- Restock Bag:从购物车中取出零食并放入超市货架
- Table Bussing:将桌面垃圾清理进垃圾桶
- Pour Water:抓住水壶把手并将水倒入杯中;
- Restock Beverage:取出饮料瓶并放入货架;
- Fold Shorts:将短裤对折两次;
- Wipe Table:用海绵擦去水渍。
评分标准:每个任务执行 10 次,得分为 0, 1,满分代表完全成功,部分成功有相应折算得分。最终结果为所有任务、场景、方法的平均归一化分数。
实施细节(Implementation Details)
AgiBot World alpha 是完整数据集 beta 的子集,约占 14%。GO-1 在完成三阶段预训练后,具有基本任务完成能力。除非另有说明,模型会在高质量、特定任务演示数据上微调。微调参数:学习率 2e-5,batch size 为 768,优化步数为 30,000。
4.2 AgiBot World 是否提升策略学习能力?
选用开源模型 RDT 评估 AgiBot World 数据集对策略学习的提升作用。
结果分析:
在任务 Table Bussing 中,使用 AgiBot World 预训练模型性能提升接近 3 倍。
平均完成度分数提升:
- 分布内任务 +0.30,
- 分布外任务 +0.29。
虽然 alpha 版含 236 小时数据,远少于 OXE 的 2000 小时,但表现更优,凸显其数据质量。
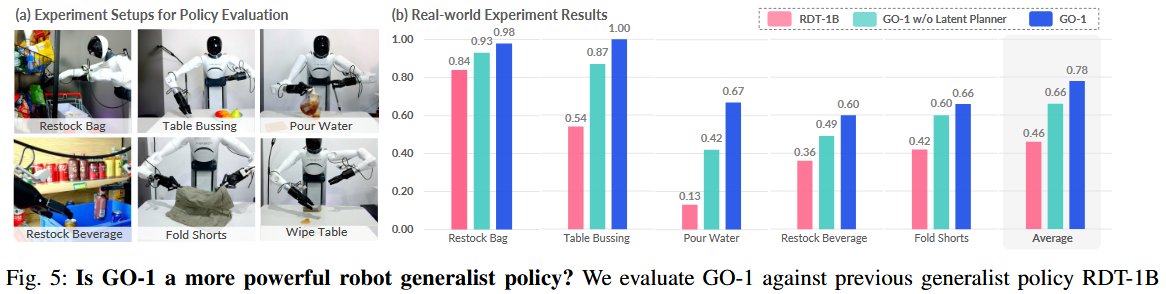
4.3 GO-1 是更强的通用策略吗?
在五个视觉复杂度与任务跨度不同的任务中评估 GO-1 表现。如图5
- 每个任务共评估 30 次(10 次 seen,20 次 unseen)。
- 在如 Pour Water(对位置鲁棒性要求高)与 Restock Beverage(需视觉与语言跟随能力)任务中,GO-1 明显优于
RDT - 加入 ViLLA 模型中的 Latent Planner 后,平均任务得分提升 0.12。
4.4 GO-1 的能力会随数据规模扩展吗?
通过使用不同规模数据子集(alpha 的 10%、100% 以及 beta 版)进行实验,分析策略性能是否与数据规模呈幂律关系。
- 训练数据规模从 9.2k 到 1M 条 trajectory。
- 在四个 seen task 上测试,结果如图 7(a)。
- 得分与数据量呈幂律关系,皮尔逊相关系数 r=0.97,支持数据规模 → 策略能力的可预测增长。
4.5 数据质量是否影响策略学习?
通过消融实验评估"人类在环"的数据质量审核机制对策略性能的影响。
对 Wipe Table 任务使用:
- 528 条人工验证轨迹
- 482 条未验证轨迹。
- 微调同一预训练 RDT 模型。
- 结果:验证数据虽少,但得分提升 +0.18。
- 说明:数量≠质量,高质量数据更关键。