当前文档为博主分析当前公司可观测性相关能力过程中痛点与架构的思考,希望能为广大博友带来一些架构帮助与借鉴
注: 为避免企业信息泄漏相关信息会进行脱敏,如后续公司均以fsdm来代替,相关平台与技术细节做模糊处理等
一、背景与目标
分析fsdm当前可观测性建设现状,识别核心痛点,并提出系统性的解决方案,使可观测性能力更有效地在业务中应用与落地,最终实现:
- 提升故障排查效率:缩短报警问题定位时间
- 优化排查体验:构建统一的可观测性平台,提升研发和运维团队的工作效率
- 增强业务保障能力:通过预测性监控进行提前预警
二、现状分析
2.1、已具备能力
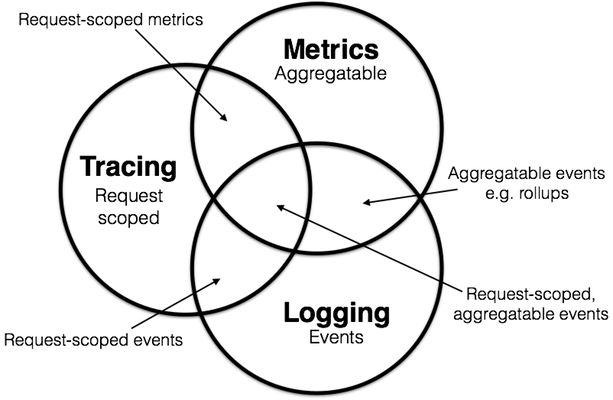
fsdm在可观测性建设方面已具备三大核心能力:
✅ 日志串联(Logging)
- 完成了分布式日志收集与聚合
- 支持链路trace的日志查询与分析
✅ 链路追踪(Tracing) - 利用Tracing相关平台
- 实现了分布式调用链跟踪
✅ 监控告警(Metrics) - 建立了基础监控指标体系
- 配置了关键业务告警规则
2.2、核心问题识别
基础设施相对完善,但存在以下关键问题:
🔥 业务利用率不足
- 研发团队仍主要依赖传统日志查看方式
- 可观测性工具在故障排查中的使用率不高
- 直接影响问题排查效率,平均定位时间较长
🔥 数据孤岛严重
- Metrics/Tracing/Logging三大能力相互分离
- 缺乏统一的关联分析能力
- 无法形成完整的问题排查闭环
🔥 平台体验割裂
- 告警通知与分析平台未打通
- 如:超时告警无法在Tracing平台直接关联分析
- 用户需要在多个平台间切换,操作复杂度高
以下为具体case抽样:
|----------|------------------------|------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------|
| case | 问题 | 关键问题 | 排查路径现状 | 期望排查路径 |
| 群内接口超时告警 | 无法准确定位当时链路,只能靠日志或人为分析 | 技术类告警未与trace关联 | 接到告警(1) -> 查询sls日志(2) -> 从日志中人为筛选出n条(3) -> 通过每条的traceid进行关联查询来源与参数(4) -> 打开Tracing平台查询链路,此时可能会没有(5) -> 打开监控平台查看当时请求波动(6) -> 通过sls或Tracing平台分析服务内部是否存在问题(7) -> 人为综合分析(8) | 接到告警(1) -> 一键跳转Tracing平台可直观看到来源、内部服务情况与请求波动(2) -> 可通过筛选某条日志的traceid进行日志查询(3) -> 人工分析 (长期可通过智能化手段进行"根因建议") (4) |
| 错误日志异常报警 | 仅靠日志排查或人为分析调用来源 | errlog未与trace关联(目前仅有Exception代入,但其实大多数Exception没有业务或参数关键信息,基本无效) | 接到告警(1) -> 查询sls日志(2) -> 从日志中人为筛选出n条(3) -> 通过每条的traceid进行关联查询来源与参数(4) -> 打开Tracing平台查询链路,此时可能会没有(5) -> 打开监控平台查看当时请求波动(6) -> 通过sls或Tracing平台分析服务内部是否存在问题(7) -> 人为综合分析(8) | 接到告警(1) -> 一键跳转Tracing平台可直观看到来源、内部服务情况与请求波动(2) -> 可通过筛选某条日志的traceid进行日志查询(3) -> 人工分析 (长期可通过智能化手段进行"根因建议") (4) |
| 业务告警 | 如某阶段业务指标徒增。需排查来源 | 业务指标与trace割裂 | 接到告警(1) -> 查询sls日志(2) -> 从日志中人为筛选出n条(3) -> 通过每条的traceid进行关联查询来源与参数(4) -> 打开Tracing平台查询链路,此时可能会没有(5) -> 打开监控平台查看当时请求波动(6) -> 通过sls或Tracing平台分析服务内部是否存在问题(7) -> 人为综合分析(8) | 接到告警(1) -> 一键跳转Tracing平台可直观看到来源、内部服务情况与请求波动(2) -> 可通过筛选某条日志的traceid进行日志查询(3) -> 人工分析 (长期可通过智能化手段进行"根因建议") (4) |
| 查询消息链路 | 单个traceid关联出全天数据 | 对于长链接等异步场景可能只存在问题(trace生命周期管理?) | 通过消息sid或消息内容排查,纯靠日志中准确打印内容,如某个节点未打印关键信息,需人工分析时间区间日志,推断当时节点情况 | 通过traceid一键关联 |
| 查询mq消息来源 | 能查出好多无关紧要的日志。需人为过滤无效信息 | 对于长链接等异步场景可能只存在问题(trace生命周期管理?) | 通过traceid关联日志 。人为过滤无关信息,需保证日志内容准确打印,不然可能存在过滤失误加大分析难度 | 通过traceid一键关联 |
三、根因分析
对当前情况调研与分析,可观测性利用率不高的根本原因可归纳为以下三个层面:
3.1、体验层面:不好用
- 工具链割裂:三大可观测性能力未深度集成,数据割裂并且缺乏统一入口
- 操作路径冗长:从告警到根因定位需要跨多个平台,操作复杂
3.2、能力层面:有问题
- Trace能力缺陷:对长链路、轮训线程、MQ等场景支持不友好
- 采样策略问题:动态采样机制存在缺陷,导致关键告警数据无法查到(可能,需排查)
- 数据准确性问题:如单个TraceID可能关联到全天数据,影响分析准确性
四、解决与演进方案
目前fsdm可观测性建设已具备良好基础,但需要系统性地解决当前的核心痛点。基于问题的紧急程度和影响范围采用分阶段解决策略,优先解决核心痛点,然后探索构建智能化体系,最终进行整体架构升级构建可观测性平台。
4.1、第一阶段:解决核心痛点,整合三大能力
4.1.1、修复关键技术问题
- 采样策略优化
- 排查并修复为何存在报警在Tracing平台无法查到问题
- 关键业务路径:强制采样?
- 数据准确性保障
- 异步场景支持优化
- TraceID生命周期管理?
- 服务流程自动化
- 服务自动录入,减少申请流程
4.1.2、完成三大能力深度集成
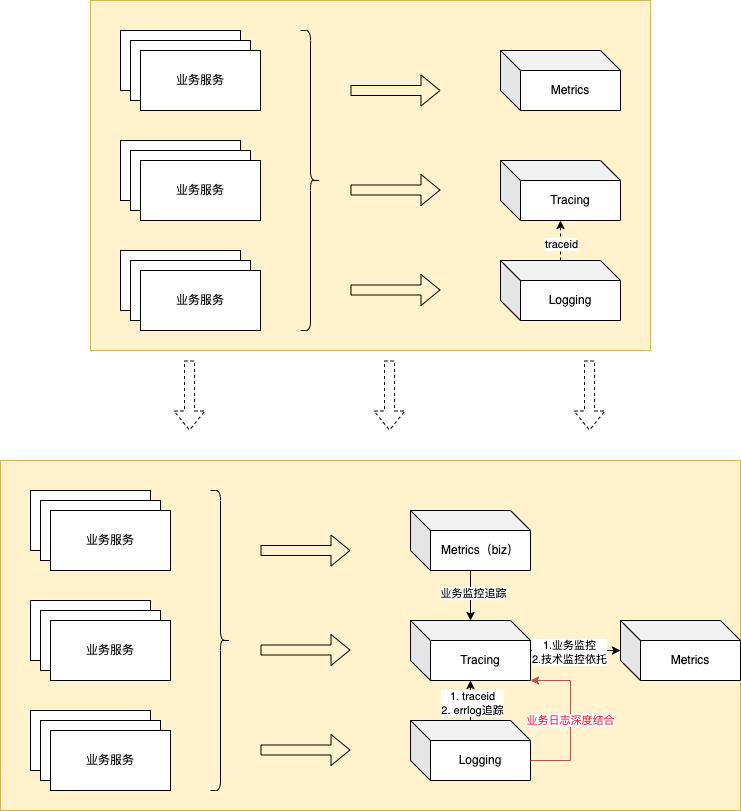
- 深度集成MTL三大套件 以Tracing为核心,实现三大数据源关联,提供关联分析能力
- Logging升级(原Logging仅支持到Trace Id埋入关联升级为)
- Trace Id埋入关联
- Tracing异常日志收集(使errlog具备一键链路追踪能力)
- 业务日志与Tracing深度结合
- Log -> span
- Metrics升级(原Metrics独立服务升级为)
- 技术监控与告警指标 ,依托Tracing进行处理(不再独立服务)
- 理论目前已有能力支撑
- 业务指标Tracing收集,支持关联链路(原Tracing收集百分比不变)
- 统一规范、统一数据(如转换为span)
- 技术监控与告警指标 ,依托Tracing进行处理(不再独立服务)
4.2、第二阶段:智能化升级与探索

4.2.1、短期智能化能力
- 接口/链路安全智能分析与预警
- 告警降噪
- 基于历史数据训练降噪模型
- 支持告警聚合和根因分析
- 智能排查建议
- API错误率上升 → 推荐查看网关日志+依赖服务状态
- 响应时间异常 → 自动分析数据库慢查询+缓存命中率
- 服务不可用 → 检查上下游服务拓扑+资源使用情况
4.2.2、长期AIOps构建
构建AIOps引擎(降低人为分析成本)降低人为分析成本:预测容量瓶颈、自动定位根因,异常传播分析
- 基于历史流量与资源指标,预警容量瓶颈
- 基于历史流量预测资源需求,提前1-2周预警容量瓶颈
- 整合拓扑关系+指标波动+日志异常,生成根因概率评分(如:MySQL慢查询导致API超时:置信度92%)
- 基于服务拓扑的异常传播路径识别,预测故障影响范围,自动生成应急响应建议
4.3、第三阶段:构建可观测性平台理想架构体系

- 采用存储与计算分离架构
- 通过存储与计算分离的架构体系,降低系统各模块之间的耦合度,从而显著提高服务的可用性和稳定性。
- 增强架构的扩展能力,能够灵活应对业务增长和数据量扩大的需求。
- 保证架构设计清晰,易于理解和维护,降低开发和运维成本。
- 数据采集与处理
- 数据采集与同步
- 利用OB Client对业务服务进行高效的数据采集,并将采集到的数据同步至OB数据中心。
- 数据同步模式可灵活选择为推送(Push)或拉取(Pull),具体实现细节待进一步确定。
- OB Client的能力提供方式可采用SDK或Agent的形式,具体实现方案需根据业务需求和技术可行性进行评估和选择。
- 数据清洗与存储
- 在OB数据中心对采集到的原始数据进行深度清洗,去除噪声数据和无效信息,确保数据质量。
- 将清洗后的数据按照统一的模型进行存储落地,为后续的数据分析和应用提供基础。
- 数据采集与同步
- 平台能力
- MTL可视化平台
- 依托OB数据中心强大的数据处理和存储能力,针对不同业务场景进行针对性的计算和分析。
- 仅是一种ui表现形式,可以是阿里云相关平台、开源系统自行部署等等
- AIOPS智能化插件
- 提供AIOPS智能化插件,增强平台的分析能力,提高运维效率和系统的稳定性。
- 如智能化分析、自动化故障检测、诊断和预测、接口/链路安全智能分析与预警
- MTL可视化平台
- 平台赋能与集成
- 发布平台集成
- 发布平台可进行能力集成,通过识别发布节点的链路情况,实现问题的快速识别和定位。
- 在发布过程中实时监控业务指标,及时发现潜在问题,保障发布过程的顺利。
- 自动化测试结果分析
- 自动化测试平台可进行能力集成,支持对自动化测试结果的链路分析,加快问题定位时间、降低人工分析成本
- 用户行为分析赋能
- 可为用户行为分析提供一定的数据基础
- 安全风控赋能
- 可为安全风控提供数据支持和决策依据。
- 发布平台集成
五、总结与思考
可观测性建设过程中的数据孤岛问题,其实在业界也是一个普遍性问题 。从该案例中可以发现,数据孤岛的形成往往是历史演进的结果,不同可观测性能力在不同阶段各自发展,后续数据未进行互联互通。
更进一步,从可观测性延伸看,当前的基础设施能力已相对完善 ,关键挑战在于能力的整合与打通 。后续架构分析与设计中,应着重考虑并解决这一问题。