文章目录
前言
我们在上一篇文章中完成了ChatOpenAI实例的使用,接下来,我们将这个内容放入streamlit中,这样就可以实现一个简单的小产品了。
P.S.:本篇虽然包含实现过程,但是代码存在巨大缺陷,将在下一篇文章中修复。所以请不要太在意本文代码,请期待下一篇的正确代码。
所有的东西都放在了Github仓库中。
欢迎来玩。
前端基础页面
当然,因为一切从简,所以我这边采用的是streamlit。当然有些老哥喜欢用gradio,这都没问题。只是因为之前已经用streamlit做了一些,所以就不再考虑gradio了。欸嘿ᕕ( ᐛ )ᕗ
那我们先首先创立一个界面:
python
import streamlit as st
st.title("测试一下")这样大概就有个页面,然后运行只能采用这样的方法:
shell
$ streamlit run /path/to/file.py接收用户输入
其中,考虑到现在大模型主流页面都是将用户输入框固定在页面正下方,所以就干脆用streamlit内置的chat_input控件:
python
import streamlit as st
prompt = st.chat_input("请输入:")诶,你说,这个能不能再简单一点?当然,别忘了,咱还有海豹运算符::=,可以这样写:
python
import streamlit as st
if prompt := st.chat_input("请输入"):
result = do_something(prompt)加入大模型
当然,光有输入是不够的。我们需要额外的逻辑来处理输入,得到新的输出。
比如说,我们可以先有一个llm。这个我们就不再多说了,在之前的文章中已经说的够多的了:
python
llm: ChatOpenAI = DeepSeekFactory.get_instance(
base_url=st.secrets["deepseek_url"],
api_key=st.secrets["deepseek_api_key"],
_client = ClientFactory.get_instance(
base_url=st.secrets["deepseek_url"],
api_key=st.secrets["deepseek_api_key"],
timeout=st.secrets["deepseek_timeout"],
).client()
).build(
model="DeepSeek-70B",
temperature=0.7,
max_tokens=4096,
)输出信息
这个应该是一个比较关键的内容了。但是呢,在这个部分我需要分三个小节讲。
首先,我们先达成一个共识:我们能用的大概就是invoke和stream。
P.S.:
async方法我在后续肯定会补上的,所以,别急。
这俩返回值很不一样:
- 一个是
BaseMessage(主要是AssistantMessage); - 一个是
Iterator[BaseMessageChunk](主要是Iterator[AssistantMessageChunk]);
对于BaseMessage,我们只需要将content字段取出来,然后返回即可。
而对于Iterator[BaseMessageChunk],我们需要认识到,它本身是一个迭代器,所以我们需要使用for循环取出。
于是,我们就可以输出了:
python
response = llm.invoke(prompt)
assistant_response = response.content当然,你也可以使用stream方法:
python
assistant_response = ""
for chunk in llm.stream(prompt):
assistant_response += chunk.content看上去没啥问题。
信息处理
好了,接下来就是第二节,也就是我们应该怎么处理这些信息。
对于invoke其实很简单:
python
if prompt := st.chat_input("你想问点什么吗?"):
response = llm.invoke(prompt)
st.write(response.content)就这样。
但是对于stream呢?
在streamlit比较新的版本中,有一个新的方法:
python
if prompt := st.chat_input("你想问点什么吗?"):
response = llm.stream(prompt)
st.write_stream(response)看上去没啥问题。
完整项目
到这里,也就能够完成整个项目了。但是呢,接下来的代码并不是一个完整的代码,有很多莫名其妙的问题还没解决,所以就看个大概就行。
python
import streamlit as st
from factory.tongyi import TongyiFactory
st.session_state.dashscope = dict()
def write_message(
role: str,
message: Union[BaseMessage, Iterator[BaseMessageChunk]],
save: bool = True
):
# if save:
# if isinstance(message, BaseMessage):
# st.session_state.dashscope["messages"].append(
# {"role": role, "content": message}
# )
# elif isinstance(message, Iterator[BaseMessageChunk]):
# st.session_state.dashscope["messages"].append(
# {
# "role": role,
# "content": "".join(chunk.content for chunk in message)
# }
# )
###################################
# 这里上下两段代码只能选一个写上去 #
###################################
with st.chat_message(role):
if isinstance(message, BaseMessage):
st.markdown(message)
elif isinstance(message, Iterator[BaseMessageChunk]):
st.write_stream(message)
st.title("阿里千问")
llm = TongyiFactory().agent()
if "messages" not in st.session_state:
st.session_state.dashscope["messages"] = [{
"role": "assistant",
"content": "这只是一个基础测试页面,你不可以问一些奇怪的问题,不然的话我也会变得奇怪的இдஇ"
}]
for message in st.session_state.dashscope["messages"]:
write_message(message['role'], message['content'], save = False)
if user_input := st.chat_input("你得注意你的言行......求你了......(´;ω;`)"):
write_message("user", user_input)
response = llm.stream(user_input)
write_message("assistant", response)看上去没问题,但很有问题。
对话记录无法保存问题
python
st.session_state.dashscope = dict()这句话,看似平平无奇,实则大有问题。
我们都只知道,streamlit的运行是单线程的、不停循环的。从头到尾,然后又从头到尾。于是呢,我们第一次打开了页面,展示了一些信息,没问题。
用户提出了自己的问题,大模型做出了回答,没问题。
回答结束,第一次循环结束,从头开始进行第二遍循环,没问题。
但是第二遍开始就有问题了。
第二遍开始立即执行了这一行,瞬间将dashscope变量给清空了,原先保存在字典中的messages对话记录瞬间消失,每次见面都是第一次。
这可是严重的逻辑错误。
流式与记录二选一问题
出了对话记录无法保存,上面给出的代码中还有一段,注释中说上下两段代码只能选一个写上去,根本原因就是,迭代器只能使用一次。
当我们需要保持两个迭代过程的时候:
- 一个是在
stream执行过程中交给前端显示; - 一个是在彻底给出所有结果之后,将全部的内容拼起来给到存储桶中;
当在前端显示过程中,迭代器已经使用了,就彻底结束了,后续再想过一遍获得所有结果时,此时迭代器已经无法使用了。可以理解为指针已经指到最末尾了,再去访问迭代器中的元素时,只能获取到空字符串。
那,我们应该怎么做呢?
一种方法,就是放弃自行维护对话记录的过程。
其实langchain也不是没考虑这种场景,只是我们刻板印象就是用st.session_state自行维护一样。我们当然可以用ConversationBufferMemory来维护对话记录,唯一需要做的就是优化一下prompt,把ConversationBufferMemory的实例植入到prompt中,也就能够让大模型看到对话记录了。要取对话记录也是相当简单,直接获取ConversationBufferMemory实例中的chat_history属性即可。这个我们会在后面详细展开。
另一种方法,就是放弃流式显示了。你可能会问,如果放弃流式显示,会不会卡很长一段时间,让用户感觉像这个系统假死了一样?
没错,是会这样。
其实streamlit也不是没考虑这种场景,只是我们刻板印象就是用流式显示才叫大模型问答系统一样。实际上,我们只需要优化一下显示效果就好:
python
with st.spinner("正在思考..."):
do_something()就像这样:
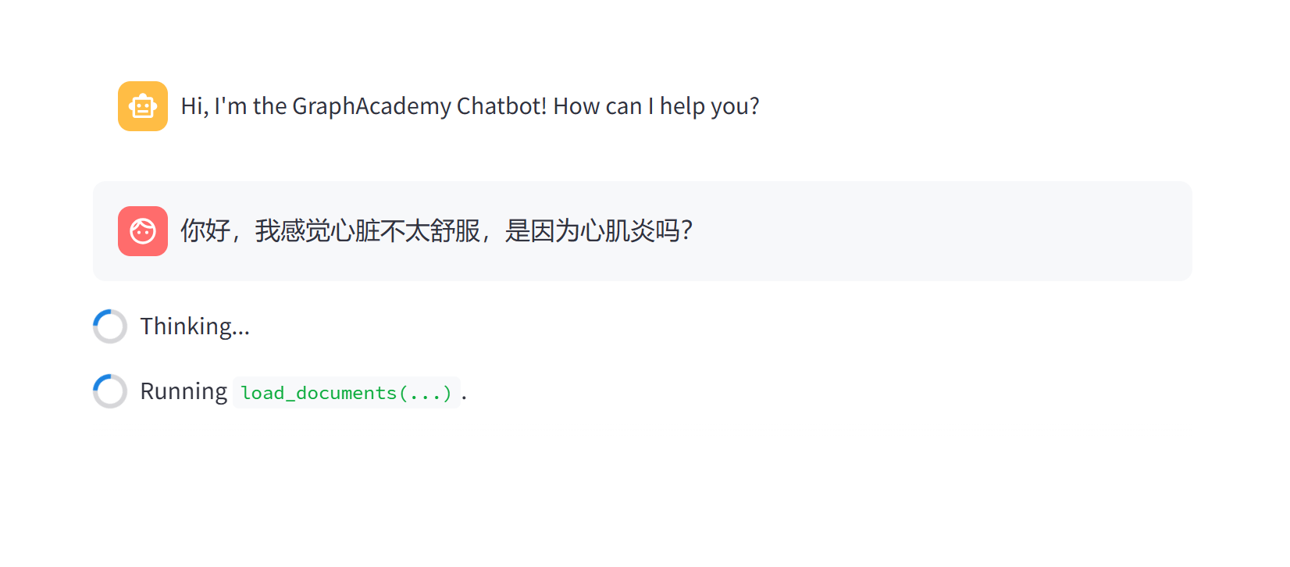
像这样,虽然后台已经卡的啥都看不到了,但是前台还是会出现一个思考中帮你圆场,就好像整个系统还在线一样。
解决方案
解决方案本质上来说,也就是单独构建一个st.expander和一个st.container,并手动维护其中显示的内容。也分主动模式和被动模式。
所谓的主动模式,也就是自定义一个Wrapper,然后在Wrapper类中自定义st.expander和st.container的内容。流式显示就解决了。
这个方法同时能解决对话记录的问题,其实也是因为Wrapper类中维护了一个全局缓冲区,从而在流式显示的过程中能够持续保存对话记录。
被动模式就相对来说运用了streamlit的callback机制。其中,在每次invoke和stream触发时,都能够通过传入callback的方式,在on_llm_new_token或者on_llm_end钩子函数触发的同时执行回调逻辑。
这也就是一种相对来说高级的模式了。
当然,这是两个大坑,也分为两篇文章详细展开。敬请期待。