第二章:填充字符串
在第一章解析器中,我们学习了simdjson::dom::parser和simdjson::ondemand::parser作为可复用内存的JSON解析工具。
本章将深入解析JSON数据输入的核心要求------"填充字符串"。
为何需要填充?
simdjson通过SIMD(单指令多数据)指令实现高性能解析。
这些指令要求以固定字节块(如32或64字节)处理数据,可能越界访问内存。
若JSON数据位于内存末尾且未预留空间,将导致段错误。
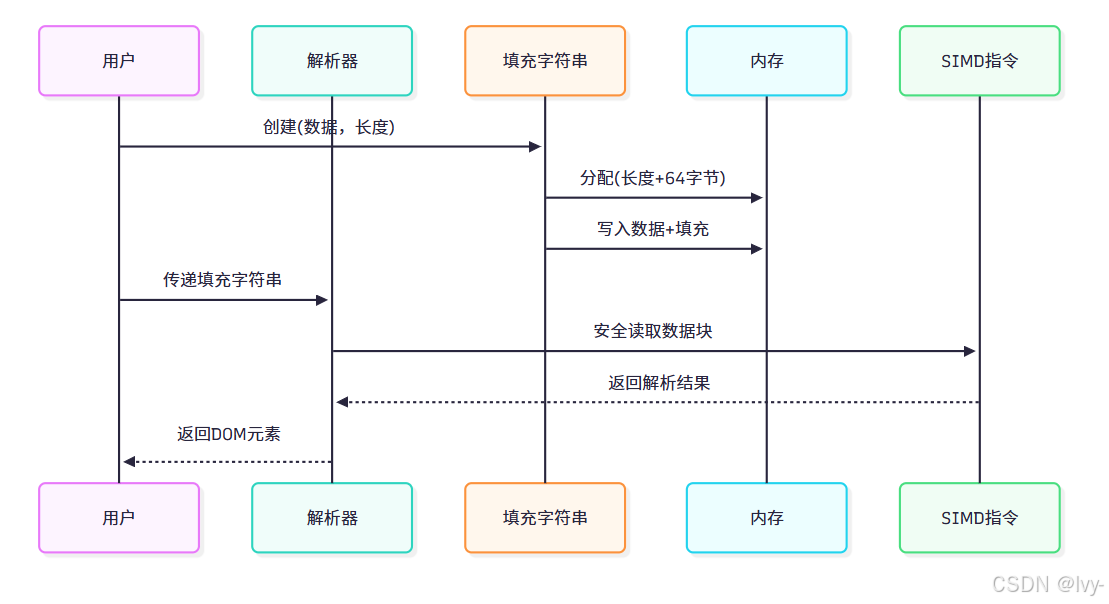
为此,simdjson要求输入数据必须包含SIMDJSON_PADDING(默认为64字节)的填充空间。
c++
// 来自include/simdjson/base.h
/**
* JSON解析所需的填充字节数
*/
constexpr size_t SIMDJSON_PADDING = 64;例如:100字节的JSON数据需要至少164字节的缓冲区,前100字节存储数据,后64字节为填充(通常置零)。
填充数据管理
simdjson提供两种核心类型处理填充:
1. simdjson::padded_string
内存自主管理型,保证数据尾部包含填充空间。创建时会自动分配新缓冲区并复制数据。
c++
#include <simdjson.h>
int main() {
// 从C风格字符串创建
const char* json_cstr = "{\"name\":\"simdjson\"}";
simdjson::padded_string s1(json_cstr, strlen(json_cstr));
// 从std::string创建
std::string json_std = "{\"count\":42}";
simdjson::padded_string s2(json_std);
// 使用_padded字面量(推荐)
auto s3 = R"({"active":true})"_padded;
// 数据访问
std::cout << "数据长度:" << s3.size() << std::endl; // 实际JSON长度
return 0;
}注意:
size()返回原始数据长度(不含填充)- 属于移动语义类型,不可复制
_padded字面量简化创建过程
2. simdjson::padded_string_view
非拥有型视图,适用于已有填充缓冲区的情况。需开发者保证缓冲区有效性。
c++
#include <simdjson.h>
#include <vector>
int main() {
// 手动创建填充缓冲区
std::string source = "{\"value\":99}";
std::vector<char> buffer(source.size() + SIMDJSON_PADDING, 0);
memcpy(buffer.data(), source.data(), source.size());
// 创建视图
simdjson::padded_string_view view(buffer.data(), source.size(), buffer.size());
// 使用pad()工具处理std::string
std::string dynamic_str = "{\"id\":123}";
auto padded_view = simdjson::pad(dynamic_str); // 修改原字符串容量
// 解析示例
simdjson::dom::parser parser;
auto doc = parser.parse(view);
return 0;
}注意:
pad()会修改原字符串,追加空格至满足填充要求- 必须确保底层缓冲区在视图使用期间有效
解析器集成
两种类型均可直接用于解析方法:
c++
// DOM解析示例
simdjson::dom::parser parser;
auto json = R"({"key":"value"})"_padded;
auto result = parser.parse(json);
// On-Demand解析(强制要求填充)
simdjson::ondemand::parser ondemand_parser;
auto doc = ondemand_parser.iterate(json);内存模型
类型对比指南
| 特性 | padded_string | padded_string_view |
|---|---|---|
| 内存所有权 | 自主管理 | 依赖外部缓冲区 |
| 填充保证 | 自动创建 |
需预先存在 |
| 适用场景 | 新数据创建 | 已有缓冲区复用 |
| 性能影响 | 可能内存拷贝 | 零拷贝 |
| 易用性 | 高(推荐新手) |
中(需内存管理经验) |
核心要点
- 安全第一 :SIMD指令越界访问可能引发段错误,填充是必须的
- 性能权衡 :padded_string简化开发但可能
内存拷贝,padded_string_view适合高性能场景 - 生命周期管理:解析结果依赖原始缓冲区,需确保数据持续有效
- 工具链整合 :
_padded字面量和pad()函数提升开发效率
掌握填充字符串机制是使用simdjson的关键下一步,我们将在第三章文档结构中学习如何访问解析后的数据。
第三章:文档(Document)
在前几章中,我们学习了用于解析 JSON 的核心工具:解析器(Parser),以及如何通过填充字符串(Padded String)格式准备 JSON 数据以实现安全快速处理。
现在我们已经准备好解析器并将 JSON 数据放入填充字符串中,执行解析操作会得到什么?在按需(On-Demand)API 中,这就是 simdjson::ondemand::document 的用武之地。
可以将 document 对象视为初始解析步骤(iterate 调用)的结果。
这是探索所提供 JSON 数据的入口点。
什么是按需模式中的文档?
与可能立即在内存中构建完整 JSON 文档树结构的传统 JSON 解析器不同,simdjson 按需 API 采用了不同的方法。
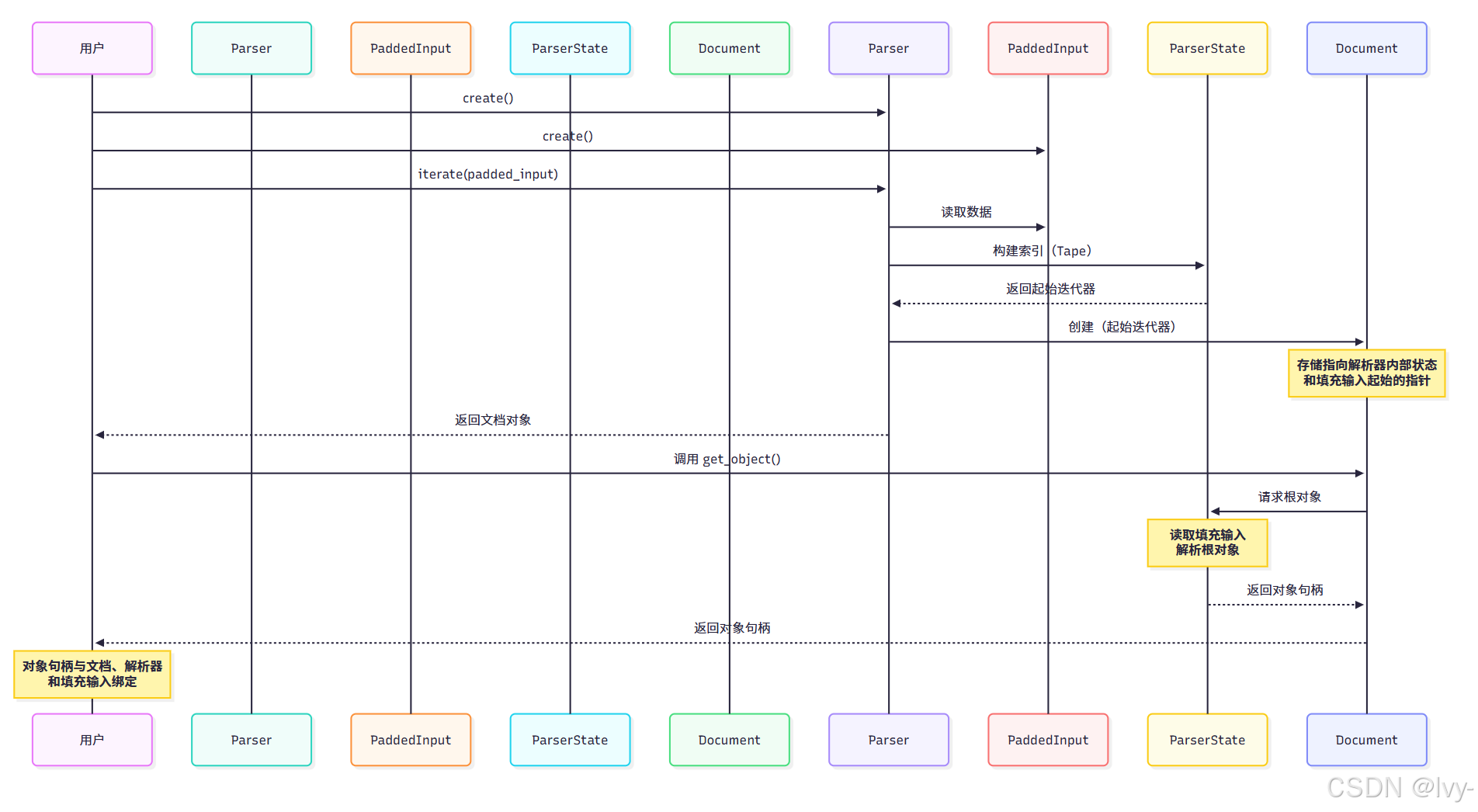
当调用 parser.iterate(padded_string) 时,我们得到的是 simdjson::ondemand::document 对象。
这个
document并非 整个 JSON 的完全解析表示,而更像是定位在 JSON 数据起始位置的智能迭代器 或游标 。它持有导航 JSON 结构和按需解析值所需的必要信息。
-
想象你的 JSON 数据是装满嵌套在盒子和袋子里的物品的大型宝箱。
document不是宝箱内所有内容的描述,而是打开宝箱的钥匙和指示第一个主容器(JSON 根值)位置的地图。 -
我们使用这张地图(
document的方法)找到第一个容器,然后通过进一步指令打开它并发现内部物品,仅在需要时挖掘宝物。
这种"按需挖掘"的特性使得按需 API 内存效率极高,尤其适用于只需少量数据的大型 JSON 文件。
获取第一个文档
让我们回顾前几章的简单示例,重点观察获得的 document 对象:
c++
#include <simdjson.h>
#include <iostream>
int main() {
// 1. 创建解析器实例(我们的工具)
simdjson::ondemand::parser parser;
// 2. 准备填充字符串格式的 JSON 数据(我们的原材料)
// 按需模式需要填充输入
simdjson::padded_string json_data = R"({"message": "hello world", "status": true})"_padded;
// 3. 使用解析器"遍历"填充数据
// 返回需要检查错误的结果对象
simdjson::simdjson_result<simdjson::ondemand::document> result = parser.iterate(json_data);
// 4. 检查遍历步骤是否成功
if (result.error()) {
std::cerr << "解析初始化失败: " << result.error() << std::endl;
return EXIT_FAILURE;
}
// 5. 从结果中获取文档对象
simdjson::ondemand::document doc = std::move(result.value()); // 使用 std::move 提高效率
std::cout << "成功获取文档对象!" << std::endl;
// 现在'doc'是我们进入 JSON 的入口
// 实际上还未真正*解析*内容,只是设置了迭代器
return EXIT_SUCCESS;
}代码解析:
parser.iterate(json_data)是关键函数调用,接收包含 JSON 的填充字符串- 返回
simdjson::simdjson_result<simdjson::ondemand::document>,这是 simdjson 处理潜在错误的方式 - 检查
result.error()确保文档迭代器设置成功,此步骤包括快速扫描 JSON 的基本结构有效性并构建内部索引(有时称为"tape") - 成功时通过
std::move(result.value())获取simdjson::ondemand::document对象
获得 doc 对象后,我们即可开始用它访问 JSON 数据。
探索文档根节点
document 对象表示 JSON 结构的根节点。JSON 文档的根可以是任意有效 JSON 值:对象 {}、数组 []、字符串 "abc"、数值 123、布尔值 true 或 null。
document 提供以下方法判断根值类型:
doc.type():返回根 JSON 值的类型(如json_type::object,json_type::array等)doc.get_object():尝试以 JSON 对象形式访问根节点doc.get_array():尝试以 JSON 数组形式访问根节点doc.get_string(),doc.get_int64(),doc.get_double(),doc.get_bool(),doc.is_null():尝试以标量值形式访问根节点
当调用这些 get_...() 方法时,simdjson 才会真正执行根节点的解析。让我们扩展示例来检查类型并访问根对象:
c++
#include <simdjson.h>
#include <iostream>
int main() {
simdjson::ondemand::parser parser;
simdjson::padded_string json_data = R"({"message": "hello world", "status": true})"_padded;
simdjson::simdjson_result<simdjson::ondemand::document> result = parser.iterate(json_data);
if (result.error()) {
std::cerr << "解析初始化失败: " << result.error() << std::endl;
return EXIT_FAILURE;
}
simdjson::ondemand::document doc = std::move(result.value());
// 6. 检查文档根节点类型
simdjson::simdjson_result<simdjson::ondemand::json_type> root_type_result = doc.type();
if (root_type_result.error()) {
std::cerr << "获取根类型错误: " << root_type_result.error() << std::endl;
return EXIT_FAILURE;
}
simdjson::ondemand::json_type root_type = root_type_result.value();
if (root_type == simdjson::ondemand::json_type::object) {
std::cout << "根节点是 JSON 对象。" << std::endl;
// 7. 以对象形式访问根节点
simdjson::simdjson_result<simdjson::ondemand::object> obj_result = doc.get_object();
if (obj_result.error()) {
std::cerr << "获取根对象错误: " << obj_result.error() << std::endl;
return EXIT_FAILURE;
}
simdjson::ondemand::object root_object = obj_result.value();
std::cout << "成功访问根对象。" << std::endl;
// 后续章节将学习如何使用此'root_object'
// 访问"message"和"status"等字段
} else {
std::cout << "根节点不是对象,类型代码: " << int(root_type) << std::endl;
}
// 重要提示:'doc'对象、解析器和 json_data 必须保持有效
// 只要仍在使用从'doc'派生的任何数据
return EXIT_SUCCESS;
}源码安装库文件:
css
git clone https://github.com/simdjson/simdjson.git
cd simdjson
mkdir build && cd build
cmake ..
make -j
sudo make install编译:
css
g++ -std=c++17 -o simdjson_test/test_simdjson simdjson_test/test_simdjson.cpp -lsimdjson输出结果:

此示例展示了如何获取文档、检查类型并以预期类型(本例为 object)访问根节点。获得的 simdjson::ondemand::object 是导航对象内部的入口点,我们将在第五章详细讲解。
注意:即使检查类型和访问根值也会返回 simdjson_result。在按需 API 中,验证和解析是渐进式进行的,在导航或提取数据的任何步骤都可能因 JSON 结构或值无效而产生错误。错误处理至关重要,后续将有专门章节讲解(错误处理)。
文档与依赖关系
必须牢记:simdjson::ondemand::document 对象并非已解析数据的独立副本,而是原始填充 JSON 字符串的视图,依赖解析器的内部状态(如 tape/索引)。
这意味着:
- 只要仍在使用从文档获得的任何
object、array、value或string_view实例,simdjson::ondemand::parser对象必须保持存活且未被修改 - 包含 JSON 数据的原始
simdjson::padded_string(或padded_string_view指向的缓冲区)必须保持有效且未被修改 - 每个解析器对象同一时间只能激活一个文档对象。若再次调用
parser.iterate(),新文档将使旧文档失效
实现原理(简化版)
调用 parser.iterate(padded_string) 时,解析器会进行初始化工作,主要包括识别大括号、中括号、逗号和引号等结构元素,并构建内部索引("tape")。此阶段不会完全解析字符串、数值或数组/对象的内容。
返回的 simdjson::ondemand::document 对象本质上是包装了解析器内部状态(特别是 json_iterator)和填充输入字符串起始位置的指针。
当调用 doc.get_object() 或 doc.type() 等方法时,document 对象使用存储的指针与解析器状态及原始 JSON 数据进行交互。它利用索引快速跳转到 JSON 的相关部分,并执行满足请求所需的最小解析(例如确认根节点是'{',并为对象字段设置迭代器)。
字符串的实际数据(std::string_view)和导航的结构(object、array、value)都是与原始填充字符串和解析器状态绑定的临时视图。
dom::document 与 ondemand::document 对比(简注)
在第一章中,我们简要展示了使用 dom::parser::parse 返回 dom::element 的 DOM 示例。虽然 simdjson 在内部确实有 dom::document 类型(simdjson::dom::parser 持有该类型),但 DOM API 中主要面向用户的结果通常是表示完全解析树节点的 dom::element。
相比之下,simdjson::ondemand::document 是按需 API 中的核心用户对象,是 iterate 调用的直接结果,也是惰性导航的起点。
它不持有完整的解析树,而是迭代解析过程的句柄。
对于使用按需模式(推荐方式)的初学者,初始阶段主要交互对象是 simdjson::ondemand::parser、simdjson::padded_string(或 padded_string_view)和 simdjson::ondemand::document。
流程图:
🎢初始阶段的on-demand 模式
simdjson 库在初始阶段聚焦于 simdjson::ondemand::parser、simdjson::padded_string 和 simdjson::ondemand::document 的设计,主要基于性能优化、内存安全性和接口简洁性的综合考量:
-
性能导向的解析器设计
ondemand::parser采用 SIMD 指令集加速 JSON 解析,直接操作原始数据而非预解析为 DOM 树。这种延迟加载(lazy parsing)策略避免一次性解析整个文档,仅当访问特定字段时才处理对应数据,极大减少内存占用和初始化开销。 -
内存安全的数据容器
padded_string或padded_string_view为 JSON 数据添加尾部填充(padding),确保 SIMD 指令能安全读取超出实际数据末尾的缓冲区。这种设计消除了边界检查开销,同时防止内存越界访问。 -
按需文档模型
ondemand::document作为轻量级视图,提供对 JSON 数据的惰性访问。它不持有数据所有权,而是基于解析器的内部状态动态生成字段值,避免了传统 DOM 模型的全量内存分配。
交互流程
解析流程通常遵循以下模式:
- 创建
parser实例并复用(避免重复分配资源) - 加载 JSON 数据到
padded_string(或直接映射为padded_string_view) - 通过
parser.iterate()生成document视图 - 在
document上执行具体字段访问
cpp
simdjson::ondemand::parser parser;
auto json = simdjson::padded_string::load("data.json");
auto doc = parser.iterate(json);
std::string_view title = doc["title"];与其他组件的对比
-
与 DOM API 的区别
传统 DOM 解析(如
simdjson::document)需完整解析整个 JSON 到内存树,而 on-demand 模式将解析延迟到字段访问时,更适合流式处理或大型文件。 -
与 SAX 模型的差异
SAX 需要实现回调函数处理事件,on-demand 则提供更直观的键值访问接口,同时保留相似的性能特性。
这种设计使初始阶段既能保持高性能,又能通过简洁的接口降低使用复杂度,符合现代 C++ 库零开销抽象的原则。
总结
simdjson::ondemand::document 是 parser.iterate() 的返回对象,代表按需 API 中 JSON 数据的根节点。
- 关键特性在于它并非完全解析的树结构,而是允许按需解析 JSON 值的迭代器。
我们使用 document 对象作为导航 JSON 数据的起点,通常通过检查其类型并调用 get_object() 或 get_array() 等方法来开始遍历结构。
请牢记依赖关系:文档对象、创建它的解析器以及原始填充字符串数据必须保持有效且在作用域内,才能安全使用从文档获得的任何数据。
现在我们已经掌握如何获取和访问 JSON 文档根节点,下一步是理解单个 JSON 值(如字符串、数值或嵌套对象/数组)的表示和访问方式,这将是下一章数值(Value)的主题。