目录
- 前言
- [什么是内存映射文件(Memory-Mapped File)](#什么是内存映射文件(Memory-Mapped File))
- [如何在 .NET 中使用 MMF](#如何在 .NET 中使用 MMF)
- 创建内存映射文件
- [使用 MemoryMappedViewAccessor 来直接读写结构体数据](#使用 MemoryMappedViewAccessor 来直接读写结构体数据)
- [使用 MemoryMappedViewStream 来读写数据](#使用 MemoryMappedViewStream 来读写数据)
- [使用 MMF 构建高性能的进程间通信队列](#使用 MMF 构建高性能的进程间通信队列)
- Benchmark
- 总结
前言
本文会先介绍内存映射文件(Memory-Mapped File)的基本概念,如何在 .NET 中使用,然后再介绍如何使用这两种实现来构建高性能的进程间通信队列。
文中的示例代码为了简化,是在单进程中进行的,但实际使用时可以在多个进程间共享内存映射文件。
笔者按使用场景的不同写了两套不一样的开源实现:
1. 只支持结构体序列化反序列化的内存映射文件队列:
Github:https://github.com/eventhorizon-cli/MappedFileQueues
nuget:https://www.nuget.org/packages/MappedFileQueues
该实现会直接将结构体的内存数据复制到 MMF 中,适用于需要高性能的场景,但因此不支持不定长的数据结构。
如果有和其他语言(如 C/C++)的交互需求,建议手动指定结构体的内存布局(使用 StructLayout 特性),以确保跨语言的兼容性。
可以参考我的这篇文章《理解 .NET 结构体字段的内存布局》来了解如何指定结构体的内存布局。
2. 支持任意类型序列化的内存映射文件队列:
Github:https://github.com/eventhorizon-cli/MappedFileQueues.Stream
nuget:https://www.nuget.org/packages/MappedFileQueues.Stream
该实现支持自定义类型的序列化,需要自己实现序列化和反序列化逻辑,性能上略低于第一种实现,但支持更复杂的数据结构。
什么是内存映射文件(Memory-Mapped File)
内存映射文件(Memory-Mapped File),下文简称 MMF,是一种将文件映射到进程的虚拟地址空间的技术。通过它可以实现高效的文件读写,且可以在多个进程间共享内存数据。
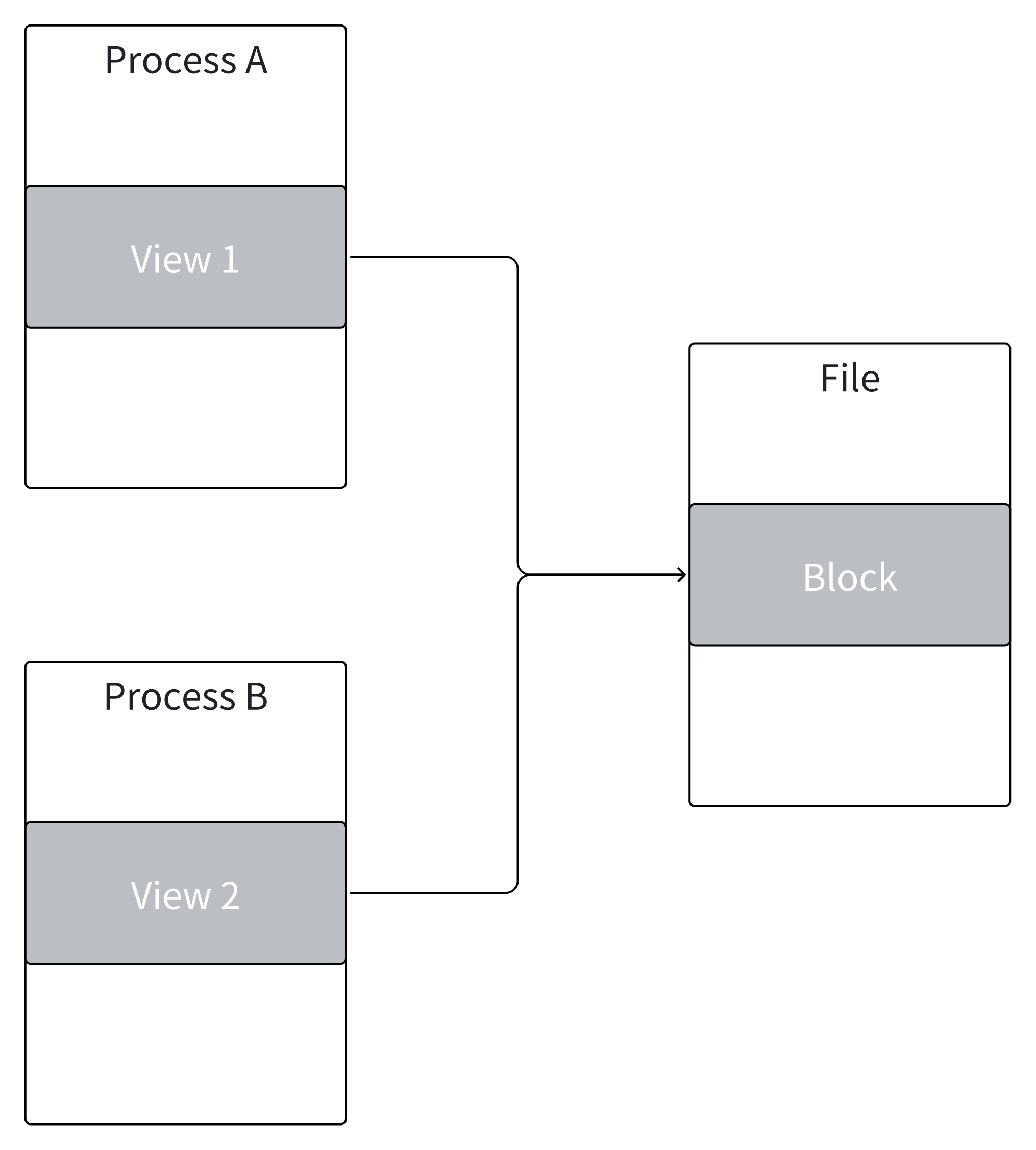
通过内存映射(例如 UNIX/Linux 的 mmap 系统调用),进程可以直接访问映射的内存区域,像操作普通内存一样操作文件内容。这种方式显著减少了内核与用户空间之间的数据拷贝,属于零拷贝(Zero-Copy)技术的一种。
在内存映射时,即使映射了一个文件,操作系统也不会立即将整个文件加载到内存中,而是根据需要按页(通常为 4KB)加载。这种按需加载的方式使得 MMF 在处理大文件时非常高效。
在一些消息队列的实现中,例如 Kafka、Rocket MQ 等,都使用了 MMF 来实现数据的高吞吐量传输。
如何在 .NET 中使用 MMF
创建内存映射文件
在 .NET 中,可以使用 System.IO.MemoryMappedFiles 命名空间提供的 MemoryMappedFile 类来创建和操作内存映射文件。
MemoryMappedFile 类提供了多种方法来创建内存映射文件,包括:
CreateNew:创建一个新的内存映射文件。CreateOrOpen:创建一个新的内存映射文件或打开一个已存在的内存映射文件。OpenExisting:打开一个已存在的内存映射文件。CreateFromFile:从一个文件创建内存映射文件。
其中 CreateFromFile 方法能够自定义的参数最多且各平台兼容性最好。本文将使用 CreateFromFile 方法来创建内存映射文件。
其方法签名如下:
csharp
public static MemoryMappedFile CreateFromFile(
FileStream fileStream,
string? mapName,
long capacity,
MemoryMappedFileAccess access,
HandleInheritability inheritability,
bool leaveOpen)各参数的含义如下:
fileStream:要映射的文件流。mapName:映射的名称,可以为null。在多个进程间共享内存映射文件时,可以指定一个名称来标识该映射。但在某些平台上可能不支持命名映射,例如 macOS。capacity:内存映射文件的最大容量,单位为字节。如果设置为 0,则表示取决于fileStream所指向的文件大小。access:映射的访问权限,使用MemoryMappedFileAccess枚举来指定。inheritability:句柄的继承性,使用HandleInheritability枚举来指定。leaveOpen:是否在创建后保持文件流打开。
我们使用下面这个构造函数来创建 FileStream:
csharp
public FileStream(string path, FileMode mode, FileAccess access, FileShare share)各参数的含义如下:
path:要映射的文件路径。mode:文件的打开模式,使用FileMode枚举来指定。如果文件不存在,可以使用FileMode.OpenOrCreate来创建新文件。access:文件的访问权限,使用FileAccess枚举来指定。例如FileAccess.ReadWrite表示允许读写该文件。share:文件的共享模式,使用FileShare枚举来指定。例如FileShare.ReadWrite表示允许其他进程同时读写该文件。
csharp
using System.IO.MemoryMappedFiles;
// 创建内存映射文件
var fileName = "example.mmf";
var fileStream = new FileStream(fileName, FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.ReadWrite);
var mmf = MemoryMappedFile.CreateFromFile(
fileStream,
mapName: null,
capacity: 1024 * 1024, // 1 MB
access: MemoryMappedFileAccess.ReadWrite,
inheritability: HandleInheritability.None,
leaveOpen: true);这边我们并不需要担心文件如果太大了会导致内存不足的问题,因为 MMF 是按需加载的,只有在实际访问时才会将数据加载到内存中。
下面我们有两种方式来读写 MMF 中的数据:
- 使用
MemoryMappedViewAccessor来直接读写结构体数据。 - 使用
MemoryMappedViewStream来读写数据。
使用 MemoryMappedViewAccessor 来直接读写结构体数据
MemoryMappedFile 类提供了 CreateViewAccessor 方法,可以创建一个视图访问器(MemoryMappedViewAccessor),用于直接读写内存映射文件中的数据。
csharp
public class MemoryMappedFile : IDisposable
{
public MemoryMappedViewAccessor CreateViewAccessor(
long offset,
long size,
MemoryMappedFileAccess access);
}CreateViewAccessor 方法的参数含义如下:
offset:视图的起始偏移量,单位为字节。size:视图的大小,单位为字节。如果设置为 0, 则表示视图会覆盖整个内存映射文件。access:视图的访问权限,使用MemoryMappedFileAccess枚举来指定。
MemoryMappedViewAccessor 类继承自 UnmanagedMemoryAccessor,提供了多种方法来读写值类型(BCL 中基础值类型和自定义结构体)的数据。
position 参数表示数据在内存映射文件中的偏移量,单位为字节。
csharp
public class UnmanagedMemoryAccessor
{
public bool ReadBoolean(long position);
public byte ReadByte(long position);
public char ReadChar(long position);
public void Read<T>(long position, out T structure) where T : struct;
public int ReadArray<T>(long position, T[] array, int offset, int count) where T : struct;
// 读取其他类型的方法...
public void Write(long position, bool value);
public void Write(long position, byte value);
public void Write(long position, char value);
public void Write<T>(long position, ref T structure) where T : struct;
public void WriteArray<T>(long position, T[] array, int offset, int count) where T : struct;
// 写入其他类型的方法...
}
public sealed class MemoryMappedViewAccessor : UnmanagedMemoryAccessor
{
// 继承自 UnmanagedMemoryAccessor 的方法
}下面是一个示例,展示如何使用 MemoryMappedViewAccessor 来读写结构体数据:
自定义一个结构体来存储数据:
csharp
public struct MyData
{
public int Id;
// 如果需要存储字符串,可以使用固定长度的字符数组
// 注意:固定长度的字符数组需要使用 unsafe 代码块来定义
public unsafe fixed char Value[20];
}
csharp
using System.IO.MemoryMappedFiles;
using System.Runtime.CompilerServices;
using System.Runtime.InteropServices;
// 创建内存映射文件
var fileName = "example.mmf";
var fileStream = new FileStream(fileName, FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.ReadWrite);
var mmf = MemoryMappedFile.CreateFromFile(
fileStream,
mapName: null,
capacity: 1024 * 1024, // 1 MB
access: MemoryMappedFileAccess.ReadWrite,
inheritability: HandleInheritability.None,
leaveOpen: true);
var sizeOfItem = Marshal.SizeOf<MyData>();
// 创建视图访问器
using var accessor = mmf.CreateViewAccessor(0, 1024 * 1024, MemoryMappedFileAccess.ReadWrite);
// 写入数据
for (int i = 0; i < 10; i++)
{
var data = new MyData { Id = i };
var managedString = "Value " + i;
// 需要通过下面的方式将字符串复制到固定长度的字符数组中
unsafe
{
fixed (char* fixedChar = managedString)
{
Unsafe.CopyBlock(data.Value, fixedChar, sizeof(char) * (uint)managedString.Length);
}
}
accessor.Write(i * sizeOfItem, ref data);
}
// 读取数据
for (int i = 0; i < 10; i++)
{
accessor.Read(i * Marshal.SizeOf<MyData>(), out MyData data);
var id = data.Id;
unsafe
{
string? managedString = ToManagedString(data.Value, 20);
Console.WriteLine($"Id: {id}, Value: {managedString}");
}
}
// 将固定长度的字符数组转换为托管字符串
unsafe string? ToManagedString(char* source, int maxLength)
{
if (source == null)
{
return null;
}
int length = 0;
while (length < maxLength && source[length] != '\0')
{
length++;
}
return new string(source, 0, length);
}使用 MemoryMappedViewStream 来读写数据
MemoryMappedFile 类还提供了 CreateViewStream 方法,可以创建一个视图流(MemoryMappedViewStream),用于读写内存映射文件中的数据。
MemoryMappedViewStream 类继承自 UnmanagedMemoryStream, UnmanagedMemoryStream 由继承自 Stream 类,提供了多种方法来读写字节数据。
下面列举了本文会用到的的方法:
csharp
public abstract class Stream
{
public void ReadExactly(Span<byte> buffer);
}
public class UnmanagedMemoryStream : Stream
{
public override unsafe void WriteByte(byte value);
public override void Write(ReadOnlySpan<byte> buffer);
public override long Seek(long offset, SeekOrigin loc);
}
public sealed class MemoryMappedViewStream : UnmanagedMemoryStream
{
// 继承自 UnmanagedMemoryStream 的方法
}与 MemoryMappedViewAccessor 最大一个不同点在于,在写入和读取数据时,MemoryMappedViewStream 不支持指定数据的偏移量,而是通过流的当前位置来进行读写操作。且在读取写入完成后,Stream 的位置会自动更新。如果我们需要重新读取或写入数据,需要手动调用 Seek 方法来调整流的位置。
下面是一个示例,展示如何使用 MemoryMappedViewStream 来读写数据:
自定义一个 class 来存储数据:
csharp
public class MyData
{
public int Id { get; set; }
public string Value { get; set; }
}创建内存映射文件,并使用 MemoryMappedViewStream 来读写数据:
csharp
using System.Buffers;
using System.IO.MemoryMappedFiles;
using System.Text.Json;
// 创建内存映射文件
var fileName = "example.mmf";
var fileStream = new FileStream(fileName, FileMode.OpenOrCreate, FileAccess.ReadWrite, FileShare.ReadWrite);
var mmf = MemoryMappedFile.CreateFromFile(
fileStream,
mapName: null,
capacity: 1024 * 1024, // 1 MB
access: MemoryMappedFileAccess.ReadWrite,
inheritability: HandleInheritability.None,
leaveOpen: true);
// 创建视图流
using var stream = mmf.CreateViewStream(0, 1024 * 1024, MemoryMappedFileAccess.ReadWrite);
// 写入数据
for (int i = 0; i < 10; i++)
{
var data = new MyData { Id = i, Value = "Value " + i };
// 使用 System.Text.Json 序列化数据为字节数组
var payload = JsonSerializer.SerializeToUtf8Bytes(data);
// 我们可以先写入数据的长度,然后再写入数据内容
var header = BitConverter.GetBytes(payload.Length);
stream.Write(header);
stream.Write(payload);
}
// 读取数据
stream.Seek(0, SeekOrigin.Begin); // 重置流的位置
// 使用 stackalloc 分配一个小的缓冲区来读取数据长度
Span<byte> headerBuffer = stackalloc byte[sizeof(int)];
for (int i = 0; i < 10; i++)
{
// 读取数据的长度
stream.ReadExactly(headerBuffer);
var length = BitConverter.ToInt32(headerBuffer);
if (length <= 0)
{
Console.WriteLine("No more data to read.");
break;
}
// 读取数据内容,可以通过 ArrayPool<byte> 来优化内存使用
var rentedBuffer = ArrayPool<byte>.Shared.Rent(length);
// 使用 ReadExactly 方法读取数据内容需明确指定 Span<byte> 的长度
var payloadBuffer = rentedBuffer.AsSpan(0, length);
stream.ReadExactly(payloadBuffer);
var data = JsonSerializer.Deserialize<MyData>(payloadBuffer);
Console.WriteLine($"Id: {data.Id}, Value: {data.Value}");
// 归还租用的缓冲区
ArrayPool<byte>.Shared.Return(rentedBuffer);
}使用 MMF 构建高性能的进程间通信队列
下面我们将基于上述两种方式来实现高性能的进程间通信队列,出于篇幅考虑,本文将只介绍整体的设计思路,具体的代码实现可以参考前面提到的开源项目。
仅支持结构体序列化反序列化的内存映射文件队列
Github:https://github.com/eventhorizon-cli/MappedFileQueues
nuget:https://www.nuget.org/packages/MappedFileQueues
设计概述
MappedFileQueues 通过内存映射文件来持久存储数据,整体结构分为若干个 Segment,每个 Segment 内又包含多个 Message。用户可以按需清理不需要的 Segment。
- Message:每个消息由 Payload 和 EndMarker(结束标记)组成。
- Segment:Segment 的大小可配置。系统会自动调整 Segment 的实际大小,使其不超过配置的 SegmentSize,并且能够容纳整数倍数量的 Message。
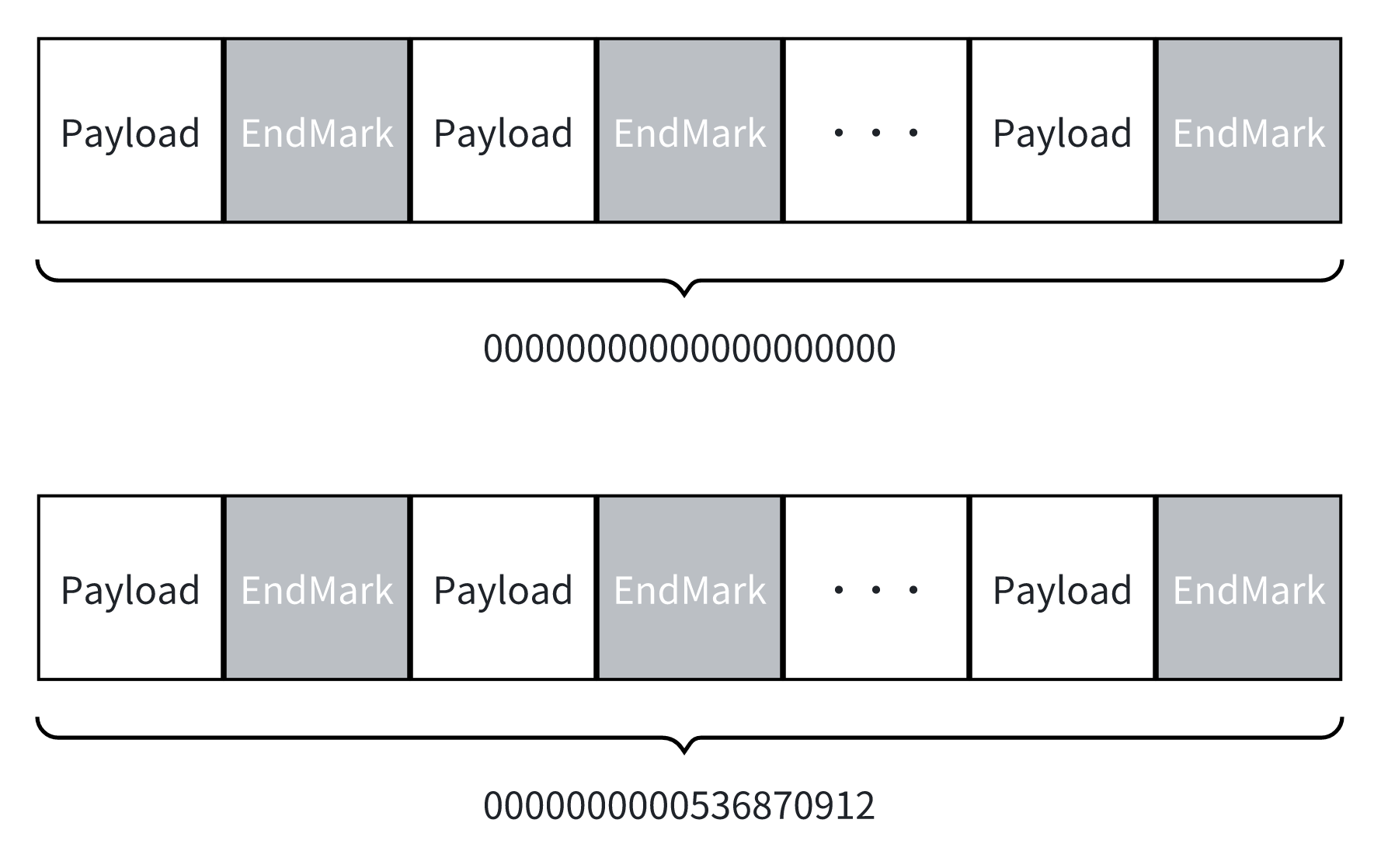
每个 Segment 的文件名为该段中第一个 Message 的 offset,并以 0 补足到 20 位。例如,0000000000536870912 表示该 Segment 从 offset 为 536870912 的位置开始。
- Message 的写入以 byte 为单位计数,每写入 1 byte,offset 加 1。
- 例如,offset 为 1024 时,表示之前已写入了 1024 字节的数据。
offset 使用 long 类型存储,支持的最大值为 2^63-1。
为简化设计,MappedFileQueues 并没有处理 offset 的溢出问题。理论允许写入的最大数据量为 2^63-1 字节(约 8 EB)。在实际应用中,通常不会达到这个极限。
如果确实需要处理比这个极限更大的数据量,可以考虑定期修改 StorePath(存储路径)或使用多个 MappedFileQueues 实例来分散数据。
为保证性能,当没有可消费数据时,Consumer 会先自旋等待,单次自旋等待的最长时间可通过配置项 ConsumerSpinWaitDuration 设置,默认值为 100 毫秒。若超时仍无数据,消费者将进入休眠状态,休眠时长由 ConsumerRetryInterval 控制,默认值为 1 秒。
存储目录
通过 StorePath 配置项指定的存储路径下,MappedFileQueues 会创建以下目录结构:
bash
├── commitlog
│ ├── 000000000000000000000
│ ├── 000000000000000001024
│ └── ...
├── offset
│ ├── producer.offset
│ └── consumer.offset其中:
-
commitlog目录存储实际的 Segment 文件。 -
offset目录存储生产者和消费者的偏移量文件,同样使用 MMF 存储。producer.offset:记录生产者的下一个可写入偏移量。consumer.offset:记录消费者的下一个需要消费的偏移量。
使用示例
配置选项(MappedFileQueueOptions)
-
StorePath:存储路径,必须是一个有效的文件夹路径。
-
SegmentSize:每个 Segment 的大小,系统会自动调整 Segment 的实际大小,使其不超过配置的 SegmentSize,并且能够容纳整数倍数量的 Message。
-
ConsumerRetryInterval:消费者在没有数据可消费时的重试间隔,默认为 1 秒。
-
ConsumerSpinWaitDuration:消费者单次自旋等待数据时的最大等待时间,默认为 100 毫秒。
生产和消费数据
MappedFileQueues 中的生产者和消费者接口如下所示:
csharp
public interface IMappedFileProducer<T> where T : struct
{
// 用于观察当前生产者的下一个可写入的偏移量
public long Offset { get; }
public void Produce(ref T message);
}
public interface IMappedFileConsumer<T> where T : struct
{
// 用于观察当前消费者的下一个需要消费的偏移量
public long Offset { get; }
// 调整当前消费者的偏移量
public void AdjustOffset(long offset);
public void Consume(out T message);
public void Commit();
}以下是一个简单的使用示例:
定义结构体:
csharp
public unsafe struct TestStruct
{
public int IntValue;
public long LongValue;
public double DoubleValue;
public fixed char StringValue[20]; // 最大支持20个字符
}创建 MappedFileQueues 实例获取单例的生产者和消费者,并进行数据的生产和消费:
csharp
var storePath = "test";
// 如果之前运行过测试,先删除之前的数据
if (Directory.Exists(storePath))
{
Directory.Delete(storePath, true);
}
var queue = MappedFileQueue.Create<TestStruct>(new MappedFileQueueOptions
{
StorePath = storePath, SegmentSize = 512 * 1024 * 1024 // 512 MB
});
var producer = queue.Producer;
var consumer = queue.Consumer;
var produceTask = Task.Run(() =>
{
for (var i = 1; i <= 100; i++)
{
var testStruct = new TestStruct { IntValue = i, LongValue = i * 10, DoubleValue = i / 2.0 };
// 如果你想在结构体中使用字符串,可以用下面的方法复制到固定数组
var testString = "TestString_" + i;
unsafe
{
fixed (char* fixedChar = testString)
{
Unsafe.CopyBlock(testStruct.StringValue, fixedChar, sizeof(char) * (uint)testString.Length);
}
}
producer.Produce(ref testStruct);
}
Console.WriteLine("Produced 100 items.");
});
var consumeTask = Task.Run(() =>
{
for (var i = 1; i <= 100; i++)
{
consumer.Consume(out var testStruct);
Console.WriteLine(
$"Consumed: IntValue={testStruct.IntValue}, LongValue={testStruct.LongValue}, DoubleValue={testStruct.DoubleValue}");
// 如果你想在结构体中使用字符串,可以像下面这样把固定数组转换回托管字符串
unsafe
{
string? managedString = ToManagedString(testStruct.StringValue, 20);
Console.WriteLine($"StringValue: {managedString}");
}
consumer.Commit();
}
Console.WriteLine("Consumed 100 items.");
});
await Task.WhenAll(produceTask, consumeTask);
// 如果你想在结构体中使用字符串,可以像下面这样把固定数组转换回托管字符串
unsafe string? ToManagedString(char* source, int maxLength)
{
if (source == null)
{
return null;
}
int length = 0;
while (length < maxLength && source[length] != '\0')
{
length++;
}
return new string(source, 0, length);
}支持任意类型序列化反序列化的内存映射文件队列
Github:https://github.com/eventhorizon-cli/MappedFileQueues.Stream
nuget:https://www.nuget.org/packages/MappedFileQueues.Stream
设计概述
MappedFileQueues.Stream 的整体设计与 MappedFileQueues 类似,但它支持任意类型的序列化和反序列化。用户需要实现自己的序列化和反序列化逻辑。且因为其数据是不定长的,所以每个 Message 都需要包含一个长度字段来标识数据的长度。
Message 由三部分组成:
- Header:记录了 Payload 的长度,其本身大小为 4 字节。
- Payload:实际存储的数据内容。
- EndMarker:用于标识 Message 的结束,大小为 1 字节,内容为 0xFF。
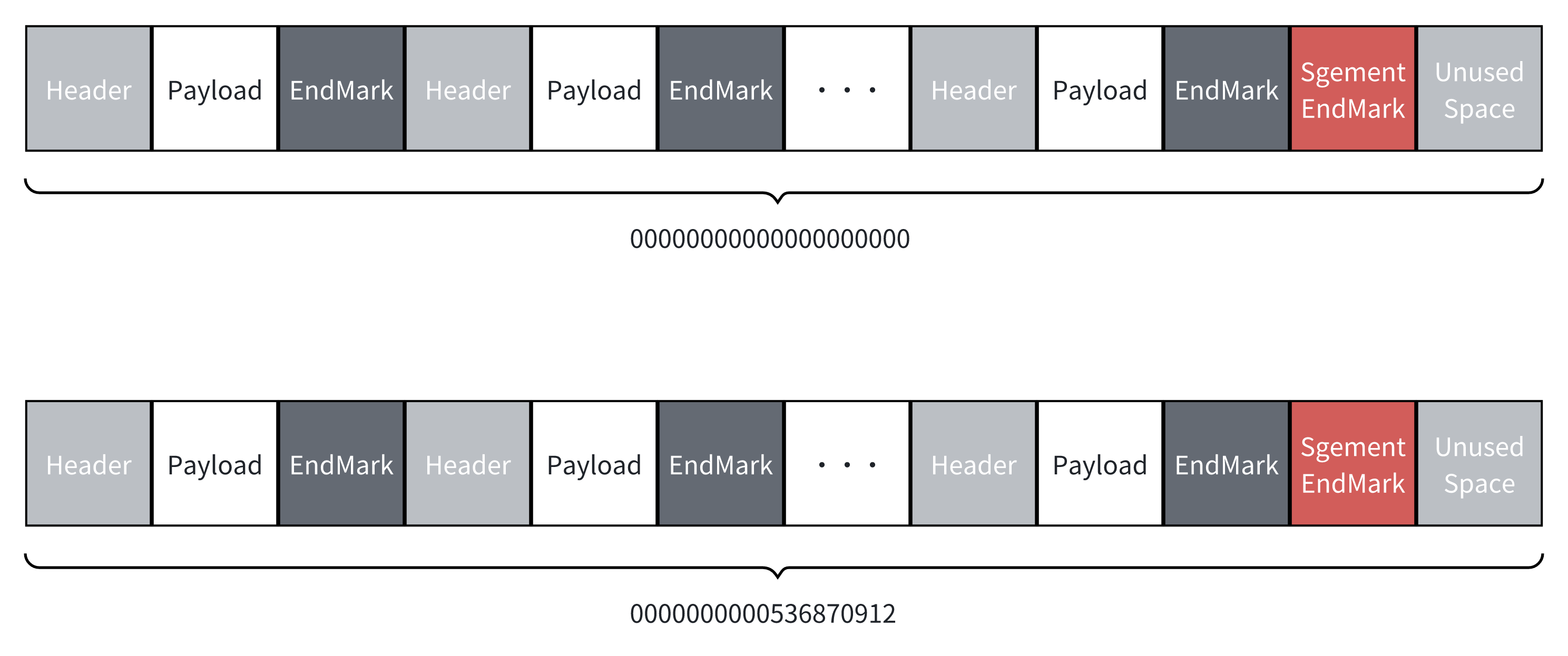
Segment 的设计如下:
- 每个 Segment 的文件名为该段中第一个 Message 的 offset,并以 0 补足到 20 位。例如,
0000000000536870912表示该 Segment 从 offset 为 536870912 的位置开始。 - 每个 Segment 的大小由配置项
SegmentSize决定,写入数据时如果末尾剩余的空间不足以容纳一个完整的 Message,会写入一个 Segment 的结束标记,并创建新的 Segment。 - Segment 结束标记的大小为 1 字节,内容为 0xEE,表示该 Segment 已经结束。此结束标志以及剩余的不被利用的空间不会纳入到 offset 的计算中。
- Message 的写入以 byte 为单位计数,每写入 1 byte,offset 加 1。
- 例如,offset 为 1024 时,表示之前已写入了 1024 字节的数据。
其余设计与 MappedFileQueues 一致,不再赘述。
使用示例
配置选项(MappedFileQueueOptions)
-
StorePath:存储路径,必须是一个有效的文件夹路径。
-
SegmentSize:每个 Segment 的大小。
-
ConsumerRetryInterval:消费者在没有数据可消费时的重试间隔,默认为 1 秒。
-
ConsumerSpinWaitDuration:消费者单次自旋等待数据时的最大等待时间,默认为 100 毫秒。
生产和消费数据
MappedFileQueues 中的生产者和消费者接口如下所示:
csharp
public interface IMappedFileProducer
{
/// <summary>
/// 下一个消息将被写入的偏移量。
/// </summary>
public long Offset { get; }
/// <summary>
/// 将消息写入到内存映射文件队列。
/// </summary>
/// <param name="buffer">包含要写入的消息的字节缓冲区。</param>
public void Produce(ReadOnlySpan<byte> buffer);
/// <summary>
/// Produces a message to the mapped file queue using the specified serializer.
/// 使用指定的序列化器将消息写入到内存映射文件队列。
/// </summary>
/// </summary>
/// <param name="message">待写入的消息。</param>
/// <param name="serializer">用于序列化消息的序列化器。</param>
/// <typeparam name="T">消息的类型。</typeparam>
public void Produce<T>(T message, IMessageSerializer<T> serializer);
}
public interface IMappedFileConsumer
{
/// <summary>
/// 下一个将被消费的消息的偏移量。
/// </summary>
public long Offset { get; }
/// <summary>
/// 调整当前消费者的偏移量。
/// </summary>
public void AdjustOffset(long offset);
/// <summary>
/// 从内存映射文件队列中消费一条消息。
/// </summary>
/// <remarks>请注意,在调用 Commit 后不要使用返回的 span。</remarks>
/// <returns>包含了消费的消息的 span。</returns>
public ReadOnlySpan<byte> Consume();
/// <summary>
/// 使用提供的反序列化器从内存映射文件队列中消费一条消息并进行反序列化。
/// </summary>
/// <param name="deserializer">用于反序列化消息的反序列化器。</param>
/// <typeparam name="T">消息的类型。</typeparam>
/// <returns>反序列化后的消息对象。</returns>
public T Consume<T>(IMessageDeserializer<T> deserializer);
/// <summary>
/// 提交当前消费的 offset。
/// <remarks>在调用此方法之前,请确保已经消费了消息。</remarks>
/// </summary>
void Commit();
}需要注意的是,在 Consumer 的实现中,为了优化性能,使用了 ArrayPool 来复用内存缓冲区。每次消费消息时,都会从 ArrayPool 中获取一个缓冲区,并在 Commit 后将其归还。这样可以减少内存分配的开销,提高性能。但这也意味必须在调用 Commit 之前处理掉返回的 span。如果使用的是 T Consume<T>(IMessageDeserializer<T> deserializer) 方法,则不需要考虑这点。
以下是一个简单的使用示例:
定义数据类型:
csharp
public class TestClass
{
public int IntValue { get; set; }
public long LongValue { get; set; }
public double DoubleValue { get; set; }
public string StringValue { get; set; }
}使用 System.Text.Json 定义序列化器和反序列化器:
csharp
public class TestMessageSerializer : IMessageSerializer<TestClass>
{
public ReadOnlySpan<byte> Serialize(TestClass message) => JsonSerializer.SerializeToUtf8Bytes(message);
}
public class TestMessageDeserializer : IMessageDeserializer<TestClass?>
{
public TestClass? Deserialize(ReadOnlySpan<byte> buffer) => JsonSerializer.Deserialize<TestClass>(buffer);
}创建 MappedFileQueues 实例获取单例的生产者和消费者,并进行数据的生产和消费:
csharp
var storePath = "test";
// 如果之前运行过测试,先删除之前的数据
if (Directory.Exists(storePath))
{
Directory.Delete(storePath, true);
}
var serializer = new TestMessageSerializer();
var deserializer = new TestMessageDeserializer();
var queue = MappedFileQueue.Create(new MappedFileQueueOptions
{
StorePath = storePath, SegmentSize = 512 * 1024 * 1024 // 512 MB
});
var producer = queue.Producer;
var consumer = queue.Consumer;
var produceTask = Task.Run(() =>
{
for (var i = 1; i <= 100; i++)
{
var testData = new TestClass
{
IntValue = i, LongValue = i * 10, DoubleValue = i / 2.0, StringValue = "TestString_" + i
};
producer.Produce(testData, serializer);
}
Console.WriteLine("Produced 100 items.");
});
var consumeTask = Task.Run(() =>
{
for (var i = 1; i <= 100; i++)
{
var testData = consumer.Consume<TestClass>(deserializer);
Console.WriteLine(
$"Consumed: IntValue={testData.IntValue}, LongValue={testData.LongValue}, DoubleValue={testData.DoubleValue}, StringValue={testData.StringValue}");
consumer.Commit();
}
Console.WriteLine("Consumed 100 items.");
});
await Task.WhenAll(produceTask, consumeTask);Benchmark
最后我们使用 BenchmarkDotNet 来对两种实现进行性能测试。
笔者选择了 macOS 和 Windows 11 两个平台进行测试,至于 Linux 平台,由于笔者没有直接安装在物理上的 Linux 系统,且使用 WSL2 或者 Docker 进行测试的结果并不具有参考价值,故没有列出,欢迎读者自行尝试。
- macOS:
- CPU:Apple M2 Max
- 硬盘:SSD
- Windows 11
- CPU:AMD Ryzen 5 9600X
- 硬盘:西数 SN850X 2TB NVMe SSD 以及 西数 WD40EZAZX 4TB HDD(带有 256MB 缓存)
测试代码的运行环境为 .NET 8.0。
测试读写的数量为 1000 万条数据。
MappedFileQueues.Stream 的序列化和反序列化除了使用 System.Text.Json 之外,同时也测试了 MessagePack,读者有兴趣也可以尝试其他的序列化库。
首先需要安装下面的 NuGet 包:
bash
dotnet add package BenchmarkDotNet
dotnet add package MappedFileQueues
dotnet add package MappedFileQueues.Stream
dotnet add package MessagePackMappedFileQueues 测试用的结构体为:
csharp
public struct TestStruct
{
public int IntValue;
public long LongValue;
public double DoubleValue;
public fixed char StringValue[20]; // 最大支持20个字符
}MappedFileQueues.Stream 测试用的类为:
csharp
[MessagePackObject]
public class TestClass
{
[Key(0)]
public int IntValue { get; set; }
[Key(1)]
public long LongValue { get; set; }
[Key(2)]
public double DoubleValue { get; set; }
[Key(3)]
public string StringValue { get; set; }
}序列化和反序列化的实现如下:
csharp
public class JsonMessageSerializer : IMessageSerializer<TestClass>
{
public ReadOnlySpan<byte> Serialize(TestClass message) => JsonSerializer.SerializeToUtf8Bytes(message);
}
public class JsonMessageDeserializer : IMessageDeserializer<TestClass?>
{
public TestClass? Deserialize(ReadOnlySpan<byte> buffer) => JsonSerializer.Deserialize<TestClass>(buffer);
}
public class MessagePackMessageSerializer: IMessageSerializer<TestClass>
{
public ReadOnlySpan<byte> Serialize(TestClass message) => MessagePackSerializer.Serialize(message);
}
public class MessagePackMessageDeserializer: IMessageDeserializer<TestClass?>
{
public TestClass Deserialize(ReadOnlySpan<byte> buffer)
{
// MessagePackSerializer 暂时不支持 ReadOnlySpan<byte>
// 需要转换为 byte[],再隐式转换为 ReadOnlyMemory<byte>
return MessagePackSerializer.Deserialize<TestClass>(buffer.ToArray());
}
}测试写入的Benchmark代码如下:
csharp
[IterationCount(3)]
public class WriteBenchmark
{
private const int ItemsCount = 1000_0000;
private const int SegmentSize = 512 * 1024 * 1024; // 512MB
private const string StorePath1 = "write_test1";
private const string StorePath2 = "write_test2";
private const string StorePath3 = "write_test3";
private MappedFileQueues.MappedFileQueue<TestStruct> _queue1;
// 使用 System.Text.Json
private MappedFileQueues.Stream.MappedFileQueue _queue2;
// 使用 MessagePack
private MappedFileQueues.Stream.MappedFileQueue _queue3;
private readonly JsonMessageSerializer _jsonSerializer = new();
private readonly MessagePackMessageSerializer _messagePackSerializer = new();
[GlobalSetup]
public void GlobalSetup()
{
// 清理旧数据
if (Directory.Exists(StorePath1))
{
Directory.Delete(StorePath1, true);
}
if (Directory.Exists(StorePath2))
{
Directory.Delete(StorePath2, true);
}
if (Directory.Exists(StorePath3))
{
Directory.Delete(StorePath3, true);
}
// 创建队列
_queue1 = new MappedFileQueues.MappedFileQueue<TestStruct>(
new MappedFileQueues.MappedFileQueueOptions
{
StorePath = StorePath1,
SegmentSize = SegmentSize
});
_queue2 = MappedFileQueues.Stream.MappedFileQueue.Create(
new MappedFileQueues.Stream.MappedFileQueueOptions
{
StorePath = StorePath2,
SegmentSize = SegmentSize
});
_queue3 = MappedFileQueues.Stream.MappedFileQueue.Create(
new MappedFileQueues.Stream.MappedFileQueueOptions
{
StorePath = StorePath3,
SegmentSize = SegmentSize
});
}
[GlobalCleanup]
public void GlobalCleanup()
{
_queue1.Dispose();
_queue2.Dispose();
_queue3.Dispose();
// 清理目录
if (Directory.Exists(StorePath1))
{
Directory.Delete(StorePath1, true);
}
if (Directory.Exists(StorePath2))
{
Directory.Delete(StorePath2, true);
}
if (Directory.Exists(StorePath3))
{
Directory.Delete(StorePath3, true);
}
}
[Benchmark]
public void WriteStruct()
{
var producer = _queue1.Producer;
for (var i = 0; i < ItemsCount; i++)
{
var testStruct = new TestStruct
{
IntValue = i,
LongValue = i * 10,
DoubleValue = i / 2.0
};
producer.Produce(ref testStruct);
}
}
[Benchmark]
public void WriteJson()
{
var producer = _queue2.Producer;
for (var i = 0; i < ItemsCount; i++)
{
var testStruct = new TestClass
{
IntValue = i,
LongValue = i * 10,
DoubleValue = i / 2.0
};
producer.Produce(testStruct, _jsonSerializer);
}
}
[Benchmark]
public void WriteMessagePack()
{
var producer = _queue3.Producer;
for (var i = 0; i < ItemsCount; i++)
{
var testStruct = new TestClass
{
IntValue = i,
LongValue = i * 10,
DoubleValue = i / 2.0,
StringValue = "TestString_" + i
};
producer.Produce(testStruct, _messagePackSerializer);
}
}
}测试读取的Benchmark代码如下:
csharp
[IterationCount(3)]
public class ReadBenchmark
{
private const int ItemsCount = 1000_0000;
private const int SegmentSize = 512 * 1024 * 1024; // 512MB
private const string StorePath1 = "read_test1";
private const string StorePath2 = "read_test2";
private const string StorePath3 = "read_test3";
private MappedFileQueues.MappedFileQueue<TestStruct> _queue1;
// 使用 System.Text.Json
private MappedFileQueues.Stream.MappedFileQueue _queue2;
// 使用 MessagePack
private MappedFileQueues.Stream.MappedFileQueue _queue3;
private readonly JsonMessageSerializer _jsonSerializer = new();
private readonly JsonMessageDeserializer _jsonDeserializer = new();
private readonly MessagePackMessageSerializer _messagePackSerializer = new();
private readonly MessagePackMessageDeserializer _messagePackDeserializer = new();
[GlobalSetup]
public void GlobalSetup()
{
CleanupStorePath();
InitializeQueues();
// 生产数据
for (var i = 0; i < ItemsCount; i++)
{
var testStruct = new TestStruct
{
IntValue = i,
LongValue = i * 10,
DoubleValue = i / 2.0
};
// 使用固定数组存储字符串
// testString 最大 19 个字符,20 个字符的固定数组足够存储
var testString = "TestString_" + i;
unsafe
{
fixed (char* fixedChar = testString)
{
Unsafe.CopyBlock(testStruct.StringValue, fixedChar, sizeof(char) * (uint)testString.Length);
}
}
_queue1.Producer.Produce(ref testStruct);
}
for (var i = 0; i < ItemsCount; i++)
{
var testData = new TestClass
{
IntValue = i,
LongValue = i * 10,
DoubleValue = i / 2.0,
StringValue = "TestString_" + i
};
_queue2.Producer.Produce(testData, _jsonSerializer);
_queue3.Producer.Produce(testData, _messagePackSerializer);
}
}
[GlobalCleanup]
public void GlobalCleanup()
{
// 清理队列和数据
_queue1.Dispose();
_queue2.Dispose();
_queue3.Dispose();
CleanupStorePath();
}
[IterationSetup]
public void IterationSetup()
{
// 每次迭代前重置消费者
RestQueues();
_queue1.Consumer.AdjustOffset(0);
_queue2.Consumer.AdjustOffset(0);
_queue3.Consumer.AdjustOffset(0);
}
[Benchmark]
public void ReadStruct()
{
var consumer = _queue1.Consumer;
for (var i = 0; i < ItemsCount; i++)
{
consumer.Consume(out var testStruct);
unsafe
{
// 为了尽量贴合实际,测试也加入字符串的从固定数组转换为托管字符串的代码
var managedString = ToManagedString(testStruct.StringValue, 20);
// Console.WriteLine($"StringValue: {managedString}");
}
consumer.Commit();
}
}
[Benchmark]
public void ReadJson()
{
var consumer = _queue2.Consumer;
for (var i = 0; i < ItemsCount; i++)
{
var testData = consumer.Consume<TestClass>(_jsonDeserializer);
// Console.WriteLine($"Consumed: IntValue={testData.IntValue}, LongValue={testData.LongValue}, DoubleValue={testData.DoubleValue}, StringValue={testData.StringValue}");
consumer.Commit();
}
}
[Benchmark]
public void ReadMessagePack()
{
var consumer = _queue3.Consumer;
for (var i = 0; i < ItemsCount; i++)
{
var testData = consumer.Consume<TestClass>(_messagePackDeserializer);
// Console.WriteLine($"Consumed: IntValue={testData.IntValue}, LongValue={testData.LongValue}, DoubleValue={testData.DoubleValue}, StringValue={testData.StringValue}");
consumer.Commit();
}
}
private void CleanupStorePath()
{
if (Directory.Exists(StorePath1))
{
Directory.Delete(StorePath1, true);
}
if (Directory.Exists(StorePath2))
{
Directory.Delete(StorePath2, true);
}
if (Directory.Exists(StorePath3))
{
Directory.Delete(StorePath3, true);
}
}
private void RestQueues()
{
// 重置队列
_queue1.Dispose();
_queue2.Dispose();
_queue3.Dispose();
InitializeQueues();
}
private void InitializeQueues()
{
_queue1 = MappedFileQueues.MappedFileQueue.Create<TestStruct>(new MappedFileQueues.MappedFileQueueOptions
{
StorePath = StorePath1,
SegmentSize = SegmentSize
});
_queue2 = MappedFileQueues.Stream.MappedFileQueue.Create(
new MappedFileQueues.Stream.MappedFileQueueOptions
{
StorePath = StorePath2,
SegmentSize = SegmentSize
});
_queue3 = MappedFileQueues.Stream.MappedFileQueue.Create(
new MappedFileQueues.Stream.MappedFileQueueOptions
{
StorePath = StorePath3,
SegmentSize = SegmentSize
});
}
private static unsafe string? ToManagedString(char* source, int maxLength)
{
if (source == null)
{
return null;
}
int length = 0;
while (length < maxLength && source[length] != '\0')
{
length++;
}
return new string(source, 0, length);
}
}各平台的测试结果如下:
macOS(SSD):
bash
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|----------------- |-----------:|-----------:|---------:|------------:|--------------:|
| WriteStruct | 714.9 ms | 1,239.1 ms | 67.92 ms | - | 2.65 KB |
| WriteJson | 2,721.9 ms | 1,383.1 ms | 75.81 ms | 190000.0000 | 1557820.17 KB |
| WriteMessagePack | 1,291.4 ms | 105.1 ms | 5.76 ms | 257000.0000 | 2100720.03 KB |
bash
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|---------------- |--------:|---------:|---------:|------------:|-----------:|
| ReadStruct | 1.716 s | 0.2851 s | 0.0156 s | 75000.0000 | 602.73 MB |
| ReadJson | 5.637 s | 0.3307 s | 0.0181 s | 132000.0000 | 1060.49 MB |
| ReadMessagePack | 2.396 s | 0.2737 s | 0.0150 s | 209000.0000 | 1670.79 MB |Windows 11(SSD):
bash
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|----------------- |-----------:|-----------:|----------:|------------:|--------------:|
| WriteStruct | 663.8 ms | 1,422.2 ms | 77.96 ms | - | 2.09 KB |
| WriteJson | 2,445.3 ms | 1,929.8 ms | 105.78 ms | 95000.0000 | 1557803.16 KB |
| WriteMessagePack | 1,298.8 ms | 381.4 ms | 20.90 ms | 128000.0000 | 2100719.89 KB |
bash
| Method | Mean | Error | StdDev | Gen0 | Gen1 | Allocated |
|---------------- |-----------:|---------:|---------:|------------:|----------:|-----------:|
| ReadStruct | 992.0 ms | 262.3 ms | 14.38 ms | 37000.0000 | - | 603.58 MB |
| ReadJson | 4,020.5 ms | 202.8 ms | 11.12 ms | 78000.0000 | 3000.0000 | 1249.09 MB |
| ReadMessagePack | 1,920.9 ms | 247.3 ms | 13.55 ms | 106000.0000 | - | 1705.85 MB |Windows 11(HDD):
bash
| Method | Mean | Error | StdDev | Median | Gen0 | Allocated |
|----------------- |---------:|----------:|---------:|---------:|------------:|--------------:|
| WriteStruct | 7.112 s | 54.1588 s | 2.9686 s | 5.481 s | - | 2.01 KB |
| WriteJson | 10.392 s | 52.4542 s | 2.8752 s | 12.029 s | 95000.0000 | 1557803.05 KB |
| WriteMessagePack | 5.949 s | 0.3359 s | 0.0184 s | 5.945 s | 128000.0000 | 2100719.89 KB |
bash
| Method | Mean | Error | StdDev | Gen0 | Allocated |
|---------------- |-----------:|----------:|---------:|------------:|-----------:|
| ReadStruct | 847.2 ms | 53.59 ms | 2.94 ms | 37000.0000 | 602.73 MB |
| ReadJson | 3,562.7 ms | 61.95 ms | 3.40 ms | 66000.0000 | 1060.49 MB |
| ReadMessagePack | 1,720.4 ms | 273.43 ms | 14.99 ms | 104000.0000 | 1670.79 MB |从上面的测试结果可以看出:
MappedFileQueues 的读写性能和内存消耗都明显优于 MappedFileQueues.Stream。尤其是内存消耗这一块,因为是直接将结构体的内存数据拷贝到 MMF 中,尽可能地减少了序列化和反序列化的开销。
MappedFileQueues.Stream 性能很大程度上取决于所使用的序列化库。
对比 HDD 和 SSD 的测试结果可以看出,SSD 的写入性能明显优于 HDD,读取性能差异不大,甚至 HDD 还略好于 SSD。但就算使用了 HDD,这两种实现的性能也都足以满足大多数应用场景。
总结
本文介绍了如何使用内存映射文件(MMF)来实现高性能的进程间通信队列。我们实现了两种不同的队列实现:一种仅支持结构体序列化反序列化的 MappedFileQueues,另一种支持任意类型序列化反序列化的 MappedFileQueues.Stream。前者性能更高,后者适用场景更广。