1、基础架构
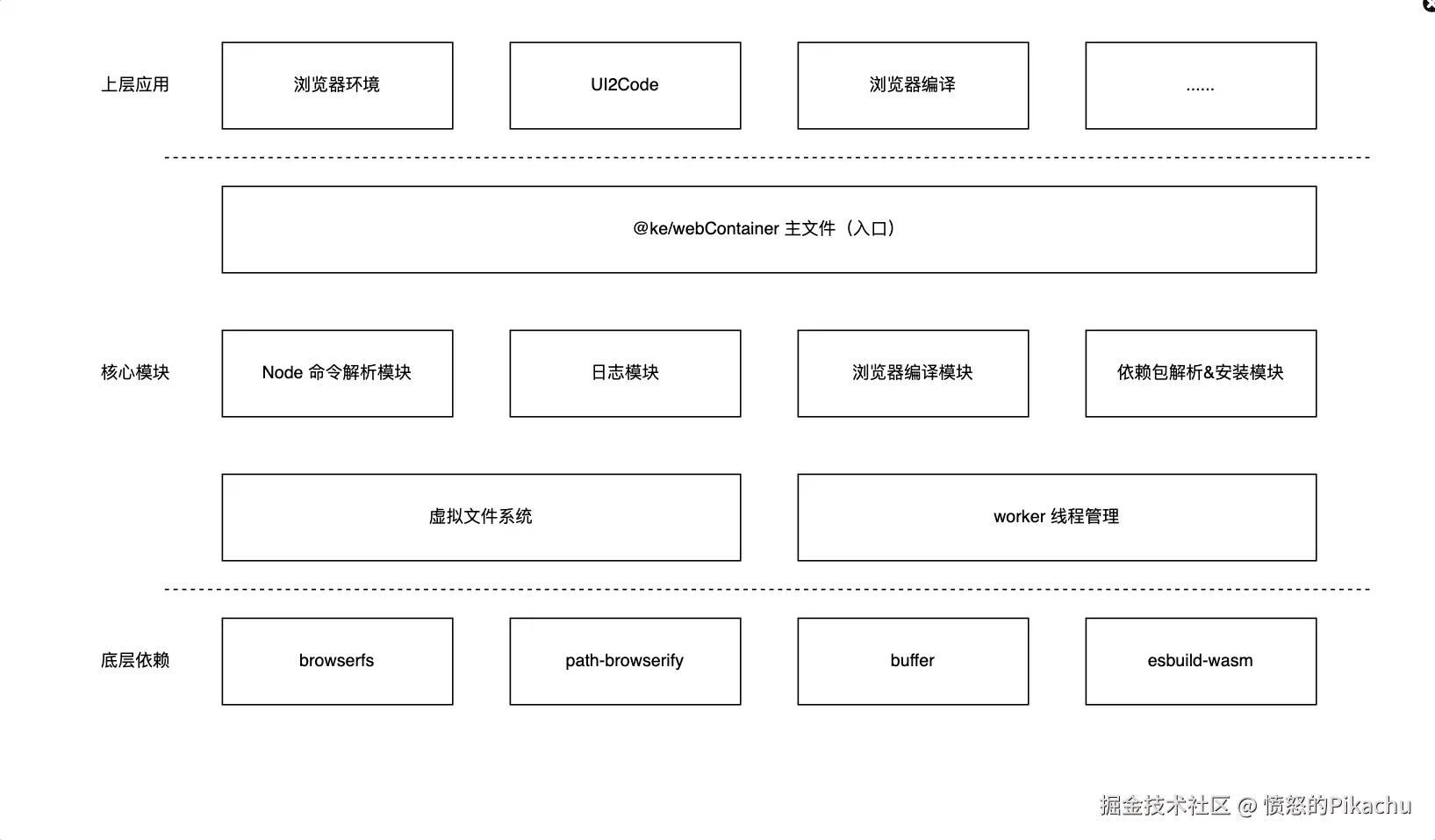
@ke/webContainer 的核心模块主要有:node 命令解析模块、浏览器编译模块、依赖包下载 & 安装模块、虚拟文件系统和 worker 线程管理模块。各个模块的主要功能如下:
- node 命令解析模块:用来解析 node 命令,比如:npm install、npm run build 等 npm 开头的相关命令。
- 浏览器编译模块:用于在浏览器环境编译前端项目,输出编译后的 .js、.css 等前端代码。
- 依赖包下载 & 安装模块:解析前端项目中的 package.json 文件,分析并下载项目依赖包。
- 虚拟文件系统:采用 browserfs 依赖包,模拟 node 环境中的 fs 模块,实现虚拟文件系统。
- worker 线程管理模块:管理 worker 多线程,给空闲线程分配相关任务。
1.1、虚拟文件系统
browserfs
官方文档: jvilk.com/browserfs/1...
简介: browserfs 是一个功能强大的文件系统库,旨在为浏览器提供类似于 node.js 的文件系统接口,并支持多种存储后端。
如果要实现浏览器编译,需要实现的核心模块之一就是 node 环境的文件系统(fs)模块。我们需要将前端项目按照特定的文件目录结构存储在内存、indexDB 或 localstorage 等空间中。市面上有很多很好的 fs 实现,比如:browserfs、browserify-fs 等依赖包,@ke/webContainer 的虚拟文件系统的底层就是采用 browserfs 依赖包。原因有以下两点:
- 考虑到文件信息需要在 worker 线程中共享,并且希望文件内容可以持久化存储,因此需要采用 indexDB 的存储模式,而 browserify-fs 仅支持内存存储。
- 虚拟文件系统需要模拟 node 环境的 fs 模块,文件相关 API 需要经可能的接近,因此需要采用 browserfs 依赖包。
有了虚拟文件系统后,我们可以将前端项目按照项目目录结构存储在浏览器中,并且也可以模拟安装 npm 依赖包以及将编译后的文件存储起来。为后续的依赖包下载 & 安装模块、浏览器编译模块提供了基础支持。
代码示例
typescript
import { BFSRequire, configure } from 'browserfs';
import path from 'path-browserify';
/**
* 虚拟文件系统类,用于在内存中模拟文件系统操作。
* 提供文件的读写、删除和存在性检查等功能。
*
* @example
* ```typescript
* const vfs = new VirtualFileSystem();
*
* // 写入文件
* await vfs.writeFile('/example.txt', 'Hello, World!');
*
* // 读取文件
* const content = await vfs.readFile('/example.txt');
* console.log(content); // 输出: Hello, World!
*
* // 检查文件是否存在
* const exists = await vfs.fileExists('/example.txt');
* console.log(exists); // 输出: true
*
* // 删除文件
* await vfs.deleteFile('/example.txt');
* ```
*/
export class VirtualFileSystem { // ... }1.2、worker 线程管理
node 的依赖下载 & 安装以及编译是一个十分消耗浏览器性能的操作,如果将依赖的下载 & 安装和编译放在主线程中执行,可能会导致页面卡顿。因此,我们需要将消耗性能的操作放在 worker 线程中运行,主线程只需要分配任务和调度 worker 线程即可(即:主从模式)。
当我们采用 worker 线程来执行消耗性能的任务时,会有以下两个问题:
- 开启几个 worker 线程合适呢?
- worker 线程之间如何通行呢?
1.2.1、开启几个 worker 线程合适呢?
我们可以通过 navigator.hardwareConcurrency 来获取用户设备的逻辑处理器数量,该 api 返回一个整数,表示设备的逻辑处理器数量(即 CPU 核心数 × 每核心的线程数)。这个整数就是浏览器可以开启的 worker 线程数量。
代码示例
typescript
const defaultMaxWorkers = navigator.hardwareConcurrency || MAX_WORKER_NUM;
this.maxWorkers = maxWorkers || defaultMaxWorkers;1.2.2、worker 线程之间如何通行呢?
首先,需要回答为什么 worker 线程之间需要通信?因为,各个 worker 之间的并行的,这会导致可能多个 worker 在执行相同的任务,导致性能浪费,比如:在做 npm 包依赖下载的时候,假设:A 依赖 a 和 b 两个包,B 依赖 a 和 c 两个包,我们开启两个 worker 线程分别时 worker1 和 worker2 对 A 和 B 依赖进行下载,当 worker1 解析到 A 发现有 a 和 b 两个包,于是开始分别下载 a 和 b,worker2 解析到 B 发现有 a 和 c 两个包,这时 a 包正在被 worker1 处理,worker2 应该跳过 a 包,去下载 c 包,这样才能更加高效的做依赖下载,因此,worker1 和 worker2 之间需要有个通信的机制。
在浏览器 web worker 线程之间可以通过 indexDB 、SharedArrayBuffer 和主从模式来实现信息的共享。
indexDB
可以在多个线程中实现信息共享,但是操作 indexDB 时异步操作,消息通信不够及时。
SharedArrayBuffer
SharedArrayBuffer 是 JavaScript 中用于在不同线程之间共享内存的对象,属于 Web 多线程编程的重要工具之一。它提供了一种在主线程与 Web Workers 或其他线程之间高效共享数据的机制,而无需复制数据。
基于这个特性我们可以将 npm 包名和版本号组成的字符串(如:react@16.14.0)映射成一个 hash 值,并将这个 hash 值映射成一个二维 hash map 的坐标(x,y),当其中一个 worker 在执行下载任务时,就在对应的 hash map 的坐标上打上标记,表明正在下载。其他的 worker 在执行下载依赖前先判断对应 hash map 中该依赖是否打过标,如果打过就跳过下载,反之打标并执行下载任务。
但是如果采用 SharedArrayBuffer 需要浏览器要求启用 Cross-Origin-Opener-Policy (COOP) 和 Cross-Origin-Embedder-Policy (COEP),这导致应用项目在接入 @ke/webContainer 的时候,需要配置额外的 header 才可以,使得 @ke/webContainer 接入成本升高。而且,有可能存在两个 worker 是同时执行下载相同任务的情况,这时也就无法判断出来是否正在下载依赖包。
主从模式
是一种常见的系统架构模式,广泛应用于分布式系统、数据库、并行计算等领域。它的核心思想是通过主节点(Master)和从节点(Slave)的分工协作,实现任务的高效处理、系统的扩展性以及可靠性。
我们可以将任务拆解成基本任务,比如:依赖下载这个任务,我们可以将其拆解成两个基本任务,一个是依赖分析,一个是依赖下载。依赖分析只获取对当前依赖包的 tarballUrl,以及对应的 dependencies 列表并返回,主线程在获取到多个 dependencies 列表后进行进行合并去重,然后继续分配依赖分析任务给空闲的 worker 线程,直到 dependencies 列表为空。依赖下载,就是将上一步依赖分析的结果,通过主线线程一个个分配给空闲的 worker 线程执行依赖包的下载和解压。
主从模式实现简单,且兼容性很好,因此,@ke/webContainer 采用主从模式来管理 worker 线程集。
代码示例
typescript
const run = async () => {
while (taskQueue.length > 0) {
const task = taskQueue.shift();
if (!task || 是否命中缓存) { continue; }
/** 获取空闲 Worker */
const worker = await this.getIdleWorker(workers);
const fn = async (id: string, worker: any, task: [string, string]) => {
try {
const response = await 执行任务()
/** 将结果写入任务列表中,并去重 */
taskQueue.push(...(response?.depList || []));
taskQueue = uniqBy(taskQueue, (item) => item[0]);
/** 删除当前任务 */
const index = findIndex(workerPromises, (item) => item.id === id);
workerPromises.splice(index, 1);
} catch (e) {} };
/** 执行任务 */
if (worker) {
workerPromises.push({ id: task[0], pro: fn(task[0], worker, task) });
}
const taskPromises: Promise<void>[] = workerPromises.map( (item) => item.pro );
/** 等待任务队列为空 */
if (workerPromises?.length === maxWorkers) {
await Promise.race(taskPromises);
}
} if (workerPromises?.length) {
await Promise.all(workerPromises.map((item) => item.pro));
} if (taskQueue?.length) {
await run();
}
};
await run();1.3、node 命令解析模块
该模块的主要任务就是解析输入的 npm 命令,比如:npm install ---registry=xxx.xxx 或 npm run build 等命令。解析出命令的目的和参数,同时调控 worker 线程去执行命令,比如:依赖安装命令,该模块会开启一定数量的 worker,并分步执行依赖分析和依赖安装两个任务;项目安装命令,该模块会开启一个独立 worker 单独执行编译任务。
代码示例
typescript
/**
* Spawn 类用于创建和管理 Worker 线程。
*/
export class SpawnManager {
private worker: any;
constructor(
private command: string,
private args: string[] = [],
private vfs: VirtualFileSystem,
private rootDir: string,
private maxWorkers: number
) { //... }
/**
* 启动管理方法,根据传入的配置和订阅函数执行相应的操作。
*
* @param config - 可选的配置对象,包含任意键值对。
* @param subscribe - 可选的订阅函数,用于接收日志信息。
* @returns 如果命令包含 'install',则启动工作器;如果命令为 'run build',则启动构建过程。
* @throws 如果执行过程中发生错误,则返回一个被拒绝的 Promise。
*/
async startManage(
config?: Record<string, any>,
subscribe?: (log: ILogItem) => void
) { //... }
/**
* 启动方法,执行一系列步骤来创建和管理 Worker。
*
* @param subscribe - 可选的日志订阅函数,用于接收日志信息。
*
* @throws 如果在任何步骤中发生错误,将会抛出异常。
*
* 步骤:
* 1. 创建 Worker 实例。
* 2. 初始化 Worker。
* 3. 订阅日志流(如果提供了 subscribe 函数)。
* 4. 执行命令。
* 5. 关闭 Worker。
*/
async startBuild(
config?: Record<string, any>,
subscribe?: (log: ILogItem) => void
) { //... }
/**
* 解析命令行参数并返回一个包含参数键值对的对象。
*
* @returns 一个包含参数键值对的对象。如果没有匹配到参数,则返回一个空对象。
*/
private getArgsObject() {
const match = this.args?.[1]?.match(/--([a-zA-Z-]+)=(.+)/);
const options = match ? { [match[1]]: match[2] } : {};
return options;
}
/**
* 批量安装依赖
* @param subscribe
*/
async startWorkers(subscribe?: (log: ILogItem) => void) { //... } /**
* 获取一个空闲的 worker。
*
* @param workers - 一个 worker 数组,默认为空数组。
* @returns 如果找到空闲的 worker,则返回该 worker;否则返回 null。
*/
private async getIdleWorker(workers: any = []) { //... }
/**
* 初始化工作线程。
*
* @param maxWorkers - 最大工作线程数。
* @param Worker - 工作线程类。
* @param subscribe - 可选的日志订阅函数。
* @returns 一个包含所有初始化工作线程的数组。
*/
private async initWorker(
maxWorkers: number,
Worker: any,
subscribe?: (log: ILogItem) => void
) { //... }
/**
* 停止所有传入的 worker 实例。
*
* @param workers - 要停止的 worker 实例数组,默认为空数组。
* @returns 一个 Promise,当所有 worker 都停止时解析。
*/
private async stopWorkers(workers: any[] = []) { //... } } 1.4、依赖包安装模块
上文已经简单的说过了,我将依赖包的安装拆解成了两个基础任务:依赖分析、依赖下载。
当 node 命令解析模块,解析命令,发现是依赖安装命令时,首先会根据当前 navigator.hardwareConcurrency 来确认开启几个 worker 线程合适,并初始化对应数量的 worker 线程,将命令中解析出来的参数(如:registry),传入 worker 线程中执行依赖分析和依赖下载两个任务。
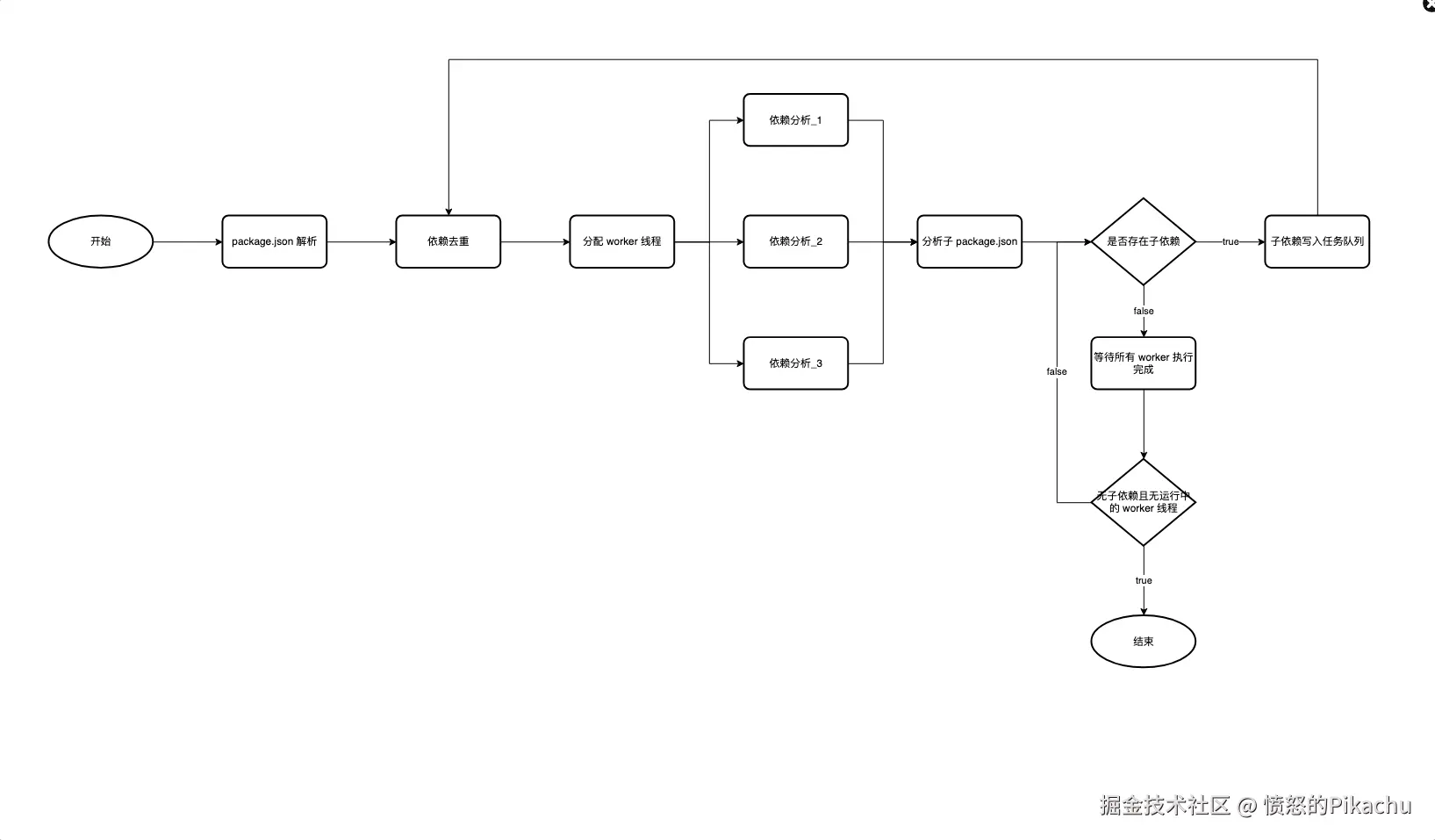
1.4.1、依赖分析
依赖分析就是对项目 package.json 中 dependencies 属性中的依赖包进行依赖分析,得出需要下载依赖包有哪些。举个例子:A@1.0.1 依赖 a@0.0.1 和 b@0.0.2,B@1.0.1 依赖 a@0.0.2 和 b@0.0.2,C@1.0.1 依赖 a@0.0.2 和 b@0.0.2 那么就需要下载 A@1.0.1、B@1.0.1、C@1.0.1、a@0.0.1、a@0.0.2 和 b@0.0.2 这 6 个包,并且,a@0.0.2 需要放到根目录的 node_modules 文件中,a@0.0.1 需要放到 A@1.0.1 包中的 node_modules 文件中。
因此,我们需要一个结构去解析和表达这个依赖结构,具体结构如下:
json
{
"root": [[A, 1.0.1, xxx.tgz], [B, 1.0.1, xxx.tgz], [C, 1.0.1, xxx.tgz], [a, 0.0.2, xxx.tgz], [b, 0.0.2, xxx.tgz]],
"B@1.0.1": [[a, 0.0.1, xxx.tgz]]
} 其中,root 字段标识安装在 node_modules 文件下的依赖包,包名, 版本, tarballUrl。B@1.0.1 属性下的依赖包安装在 B 包下的 node_modules 文件中。
依赖分析代码流程
代码示例
typescript
async dependenciesAnylysis(
pkgInfo: [string, string],
options?: Record<string, string>,
logStream?: Subject<ILogItem>
) {
const [pkgName, pkgVersion = 'latest'] = pkgInfo || [];
try {
if (this.cachePackages.has(pkgName)) {
return;
}
/** step1: 解析版本号 */
logStream && Logger.log(logStream, `开始分析: ${pkgName}`);
const mateData = await this.resolveDependencyVersion(
pkgName,
pkgVersion,
options
);
/** step2: 分析子依赖 */
const depNames = Object.keys(mateData?.dependencies || {});
logStream && Logger.log(logStream, `分析结束: ${pkgName}`);
return {
currentNpmInfo: [mateData.packageName, mateData.resolvedVersion, mateData.tarballUrl],
dependencies: depNames.map<[string, string]>((depName) => [
depName,
mateData?.dependencies?.[depName],
]),
};
} catch (e: any) {
throw new Error(`依赖分析失败:${e.message || e?.toString?.()}`);
}
} 1.4.2、依赖下载
依赖下载就是将依赖分析出来的结果,进行解析、下载、解压并通过虚拟文件系统写入浏览器中。
依赖下载流程
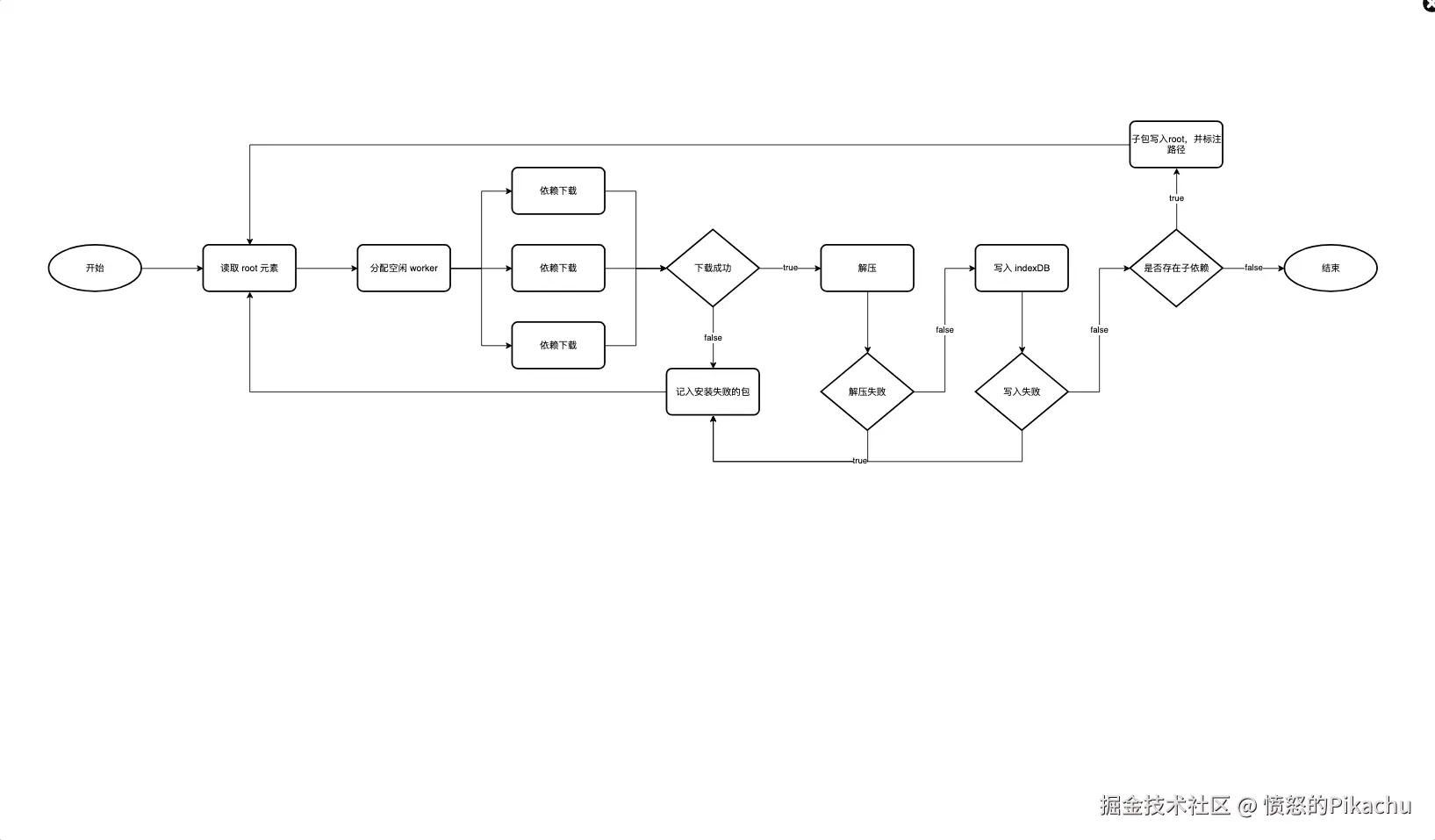
依赖下载也是多 worker 线程并行下载,因为,通过依赖分析,所以依赖下载流程就不需要考虑依赖包重复的问题,仅需要执行下载、解压和写入的逻辑即可。
代码示例
typescript
public async installPackage(
rootDir: string = ROOT_DIR,
packageInfo: [string, string, string],
options?: Record<string, string>,
logStream?: Subject<ILogItem>
): Promise<void | [string, string][]> {
const [pkgName, pkgVersion = 'latest', tarballUrl] = packageInfo;
try {
/** step1: 共享内存 */
const key = `${pkgName}@${pkgVersion}`;
/** step2: 检查依赖是否已安装 */
if (this.installedPackages.has(pkgName) || skipPackages.some((pkg) => pkgName.includes(pkg)) ) {
logStream && Logger.log(logStream, `hit cache ${key}`);
return;
}
/** step4: 标记为安装中 */
this.installedPackages.add(pkgName);
/** step5: 下载并解压依赖 */
const _talballUrl = tarballUrl || (await this.getPackageMetadata(pkgName, pkgVersion, options)).dist.tarball;
await this.downloadAndExtractTarball(rootDir, _talballUrl, pkgName);
logStream && Logger.log( logStream, `install npm done ${key}: ${pkgName}@${pkgVersion}`);
} catch (error: any) {
logStream && Logger.log( logStream, `安装失败:${pkgName}@${pkgVersion},错误信息:${error.message}`, 'error');
throw new Error(`安装失败:${pkgName}@${pkgVersion},${error.message}`);
}
} 图片文件处理逻辑
解压后如果遇见图片、字体等文件,需要将这些文件转成 buffer 对象,并通过虚拟文件系统存入 indexDB 中,因为,esbuild-wasm 本身就支持 base64 的 loader,而且,browserfs 支持将 buffer 格式的数据以 base64 格式转出,也就省略了图片格式转换的逻辑。
代码示例
typescript
/** 获取图片,字体等文件 */
let base64 = await vfs.readFile(args.path, 'base64');
/** 写入图片,字体等文件到虚拟文件系统中 */
if (this.isBinaryType(header.type, relativePath)) {
content = Buffer.from(merged);
isImage = true;
} 1.5、浏览器编译模块
WebAssembly(简称 Wasm)是一种可以在现代浏览器中运行的高效、低级别的二进制代码格式。它提供接近本地硬件的性能,同时具有与 JavaScript 无缝集成的能力。
其他说明:
webpack 并不能直接在浏览器中运行,因为它是一个为 Node.js 设计的工具链,依赖于文件系统、Node.js 模块解析机制等。然而,如果需要实现 Webpack 在浏览器中的运行,可以通过以下方法实现:
- 使用 webpack 的 WebAssembly (Wasm) 版本,目前,官方没有完整的 Wasm 版本。
- 构建 webpack 的轻量版本(codeBox 就是采用轻量版本的 webpack)。
其他编译工具,如:rollup、vite 和 parcel 等,目前都不支持在浏览器中运行,如果要这些工具在浏览器中运行的解决方案同上,实现起来比较复杂。还不如直接选择 esbuild-wasm 编译工具。
需要在浏览器中执行编译工作需要一个基于 WebAssembly (Wasm)的编译器或者工具链。目前支持浏览器编译的工具有 esbuild-wasm 和 Babel-standalone。
考虑到其他编译工具如果要实现浏览器编译的成本和编译速度相较于 esbuild-wasm 都要高。因此,@ke/webContainer 采用 esbuild-wasm 在浏览器中对项目进行编译。
在使用 esbuild-wasm 工具时,还需要考虑将路径解析改成从虚拟文件系统中获取。目前,市面上没有相关 loader,所以,需要自己实现一个代码路径解析 loader。
1.5.1、virtualFsLoader
该 Loader 主要功能就是将代码引用路径改成虚拟文件路径,并加载对应的 loader 解析代码,目前 esbuild 原本就支持 .ts、.tsx、.js、.jsx、.css、base64 等 loader,基本支持项目需要,但是,如:.less,.sass 等需要自己实现相关处理逻辑。
路径解析主要分为以下几种情况:
- 相对路径:路径上带有 .、./、../ 的引用,如:import Demo from './components/demo'。
- 绝对路径:非相对路径就是绝对路径,如:src/index.js 或 import React from 'react' 等。
- 缺失后缀的路径:路径上没有明确指出文件格式的路径,如:import Demo from './components/demo'。
路径解析的核心逻辑就是获取到具体的引用的文件的绝对路径。因此,路径解析的流程如下:
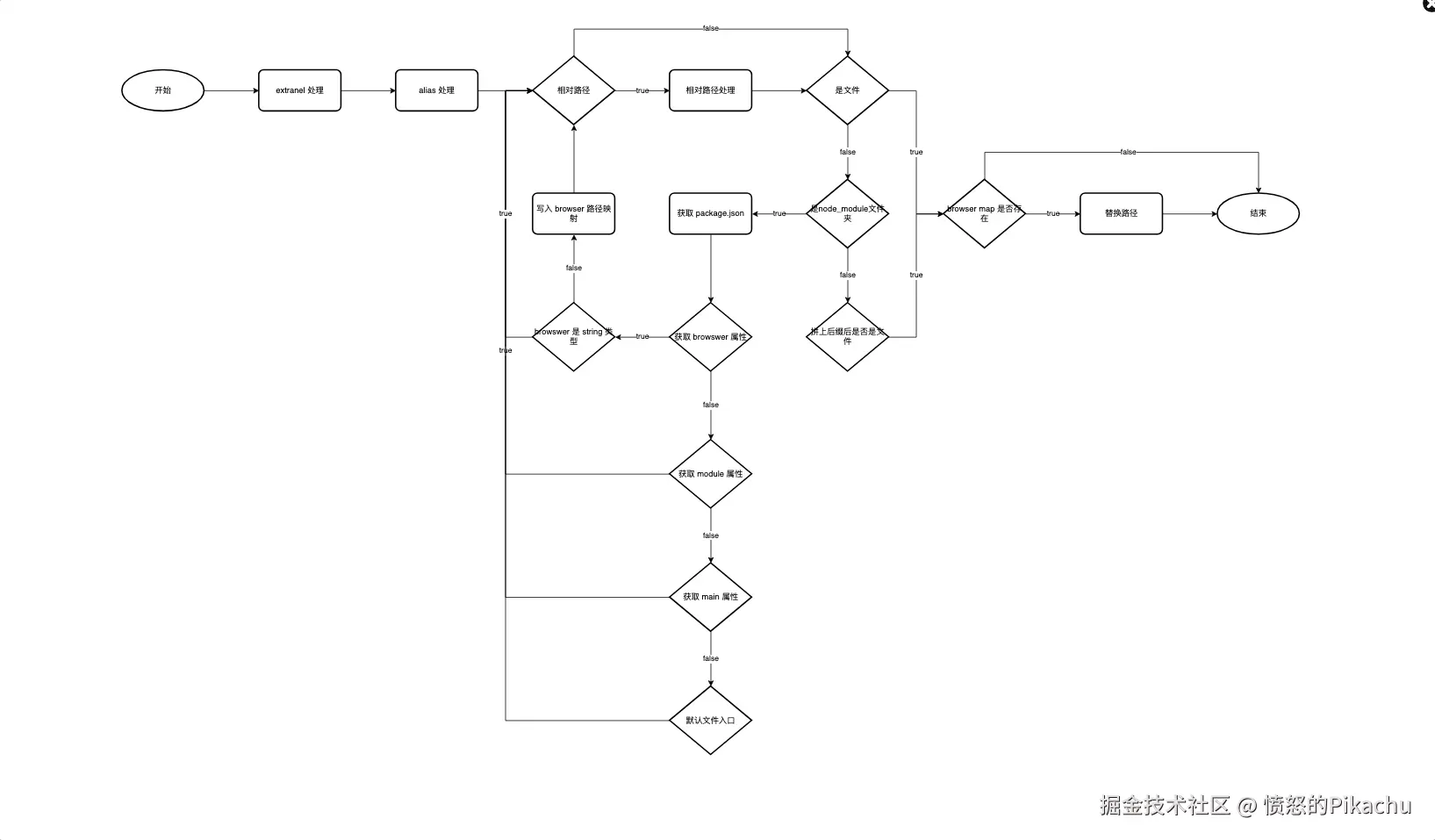
就不贴代码示例了,比较多 orz,详细代码参考:github.com/LemonsHi/we...