本地部署Deepseek大模型
1、下载Ollama
去ollama官网https://ollama.com/ 下载可执行程序,可选macos、linux和Windows版本下载
下载之后如果点击直接安装(install)默认会安装在C盘.
在可执行程序目录级下打开终端窗口执行(这个是更改安装路径)
OllamaSetup.exe /DIR=D:\Ollama
##OllamaSetup.exe: 这是一个安装程序的执行文件,通常用于安装 Ollama 软件。
##/DIR=D:\Ollama: 这是命令行参数,告诉安装程序将 Ollama 安装到 D 盘的 Ollama 文件夹中。如果指定的目录不存在,安装程序通常会创建该文件夹安装成功显示
2、大模型下载和卸载
同样是在Ollama官网上选择Models
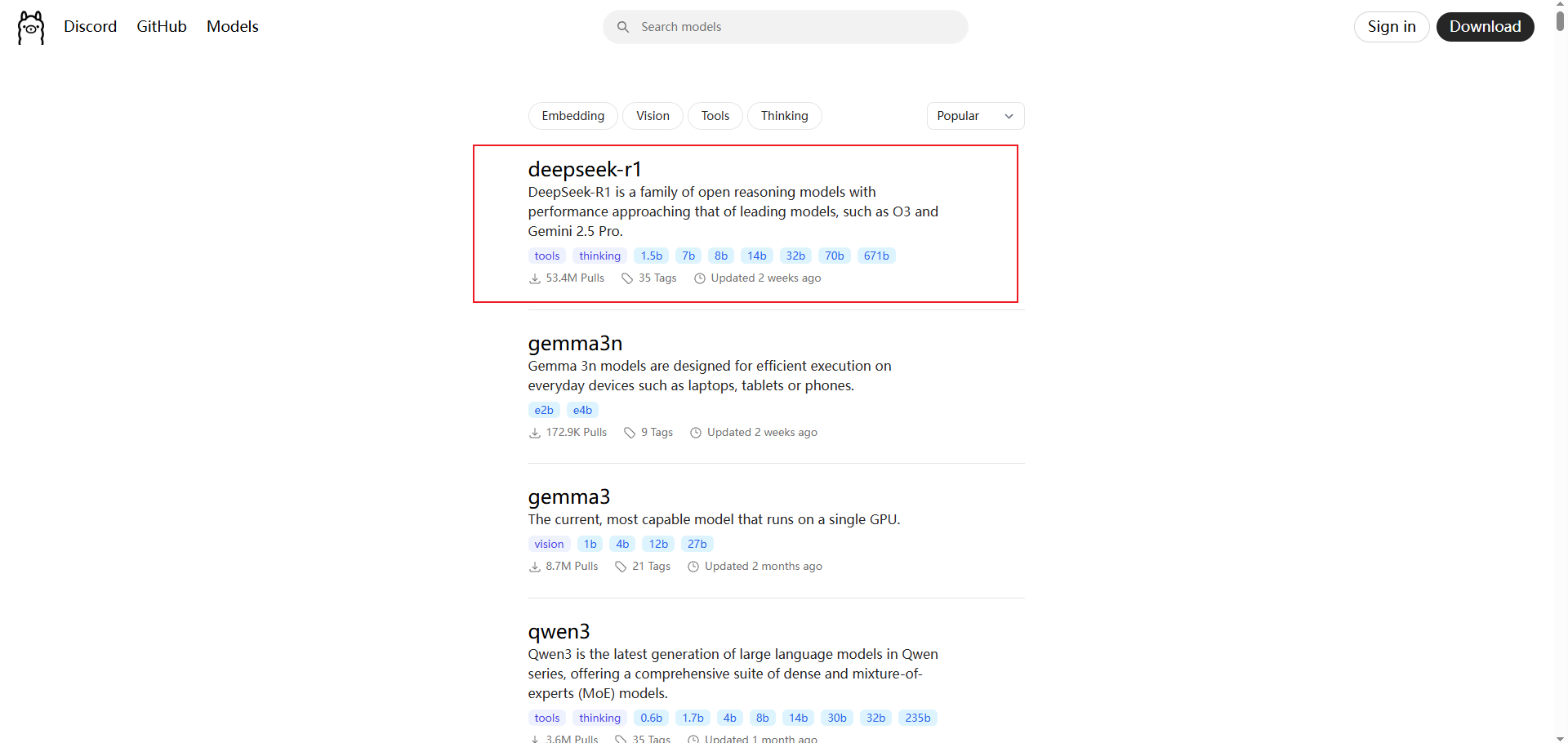
点击对应的Deepseek-r1可以看到对应版本的模型
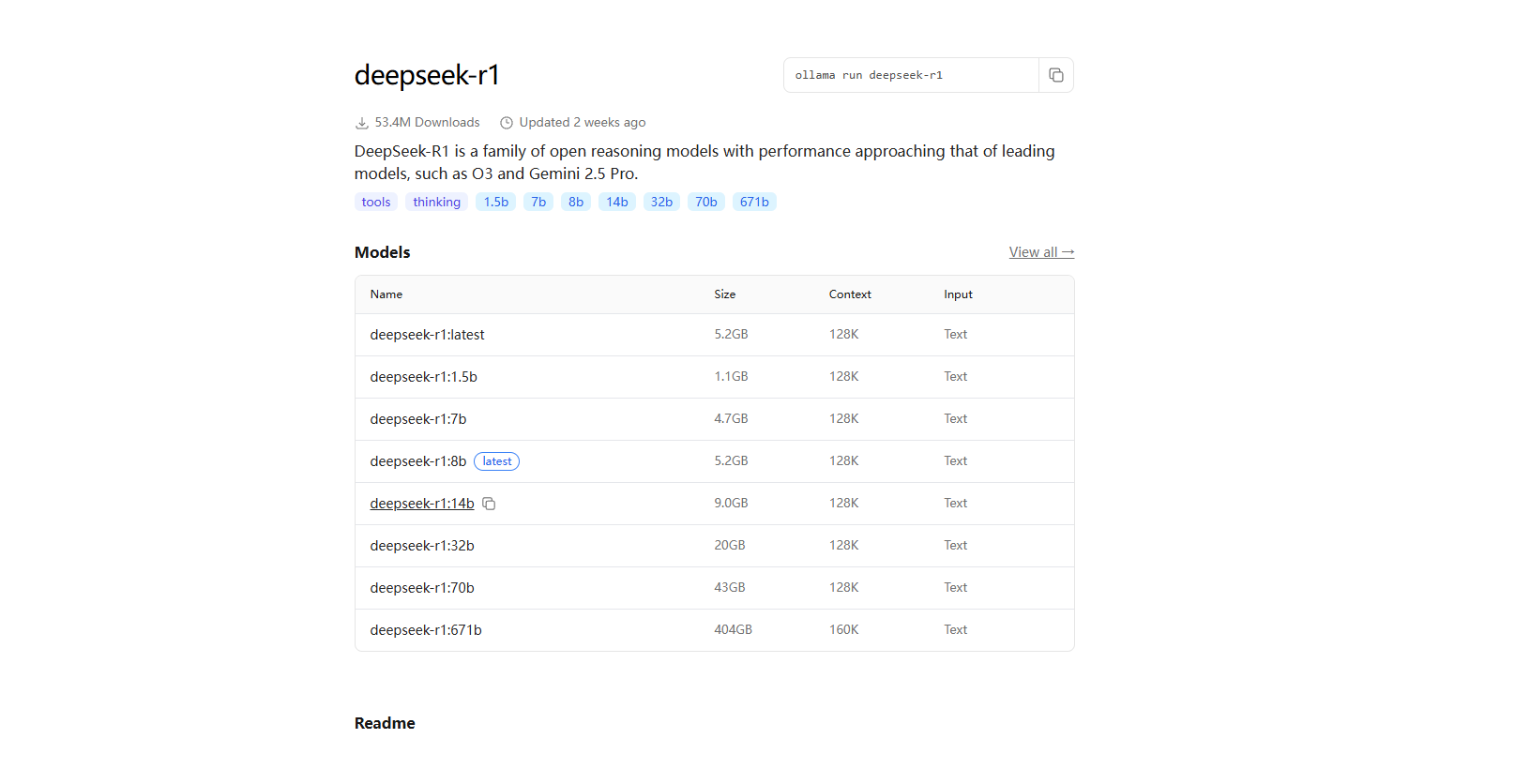
点击对应 模型,即可展示对应的部署命令
| 模型参数规模 | 典型用途 | CPU 建议 | GPU 建议 | 内存建议 (RAM) | 磁盘空间建议 | 适用场景 |
|---|---|---|---|---|---|---|
| 1.5b (15亿) | 小型推理、轻量级任务 | 4核以上 (Intel i5 / AMD Ryzen 5) | 可选,入门级 GPU (如 NVIDIA GTX 1650, 4GB 显存) | 8GB | 10GB 以上 SSD | 小型 NLP 任务、文本生成、简单分类 |
| 7b (70亿) | 中等推理、通用任务 | 6核以上 (Intel i7 / AMD Ryzen 7) | 中端 GPU (如 NVIDIA RTX 3060, 12GB 显存) | 16GB | 20GB 以上 SSD | 中等规模 NLP、对话系统、文本分析 |
| 14b (140亿) | 中大型推理、复杂任务 | 8核以上 (Intel i9 / AMD Ryzen 9) | 高端 GPU (如 NVIDIA RTX 3090, 24GB 显存) | 32GB | 50GB 以上 SSD | 复杂 NLP、多轮对话、知识问答 |
| 32b (320亿) | 大型推理、高性能任务 | 12核以上 (Intel Xeon / AMD Threadripper) | 高性能 GPU (如 NVIDIA A100, 40GB 显存) | 64GB | 100GB 以上 SSD | 大规模 NLP、多模态任务、研究用途 |
| 70b (700亿) | 超大规模推理、研究任务 | 16核以上 (服务器级 CPU) | 多 GPU 并行 (如 2x NVIDIA A100, 80GB 显存) | 128GB | 200GB 以上 SSD | 超大规模模型、研究、企业级应用 |
| 671b (6710亿) | 超大规模训练、企业级任务 | 服务器级 CPU (如 AMD EPYC / Intel Xeon) | 多 GPU 集群 (如 8x NVIDIA A100, 320GB 显存) | 256GB 或更高 | 1TB 以上 NVMe SSD | 超大规模训练、企业级 AI 平台 |
总结:配置越高,可部署的模型模型参数规模越大(通俗点讲就是硬件性能越好,问的问题可以更加复杂,回答的越精准)
在cmd命令行下复制前面的命令即可进行模型下载,如果下载速度慢,Ctrl + C,终止进程再次进行安装。
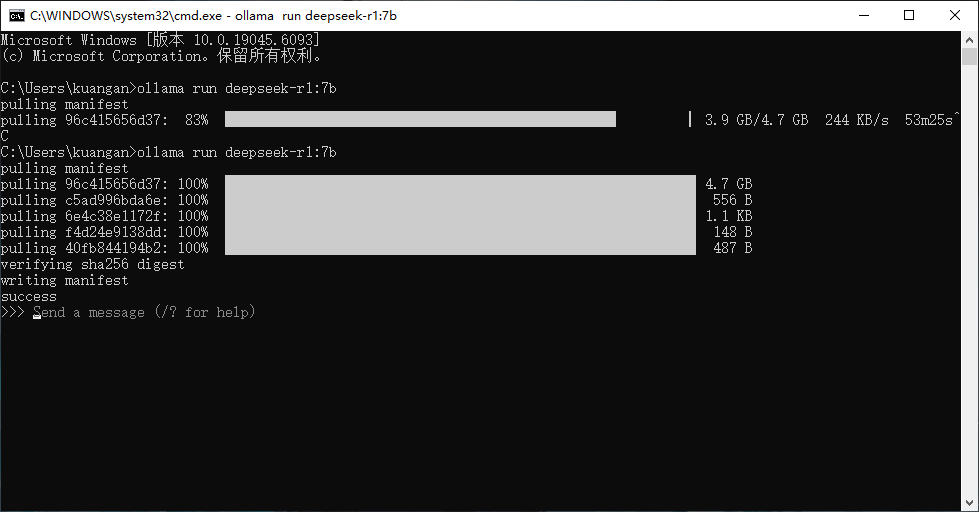
下载完之后就可以,进行模型使用了。
关于Ollama的使用,需要知道以下命令即可
ollama
## 安装模型/启动模型(后面就是模型名称)
ollama run deepseek-r1:7b
## 卸载模型
ollama rm deepseek-r1:7b
## 查看模型
ollama list拓展
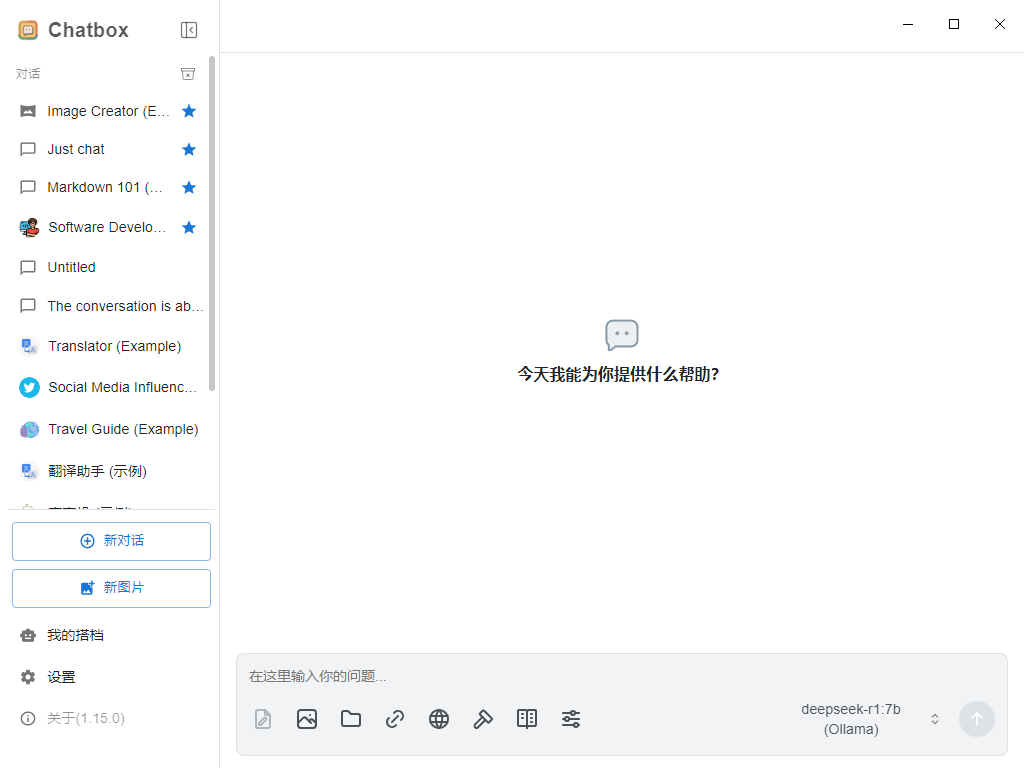
如果不喜欢上述命令行的提问方式,可以下载Chatbox AI 可视化工具https://chatboxai.app/zh
登录进来之后,软件会提示使用什么AI模型,这里选择使用自己的API Key 或本地模型 ,然后选择Ollama,点击获取即可得到本地部署模型
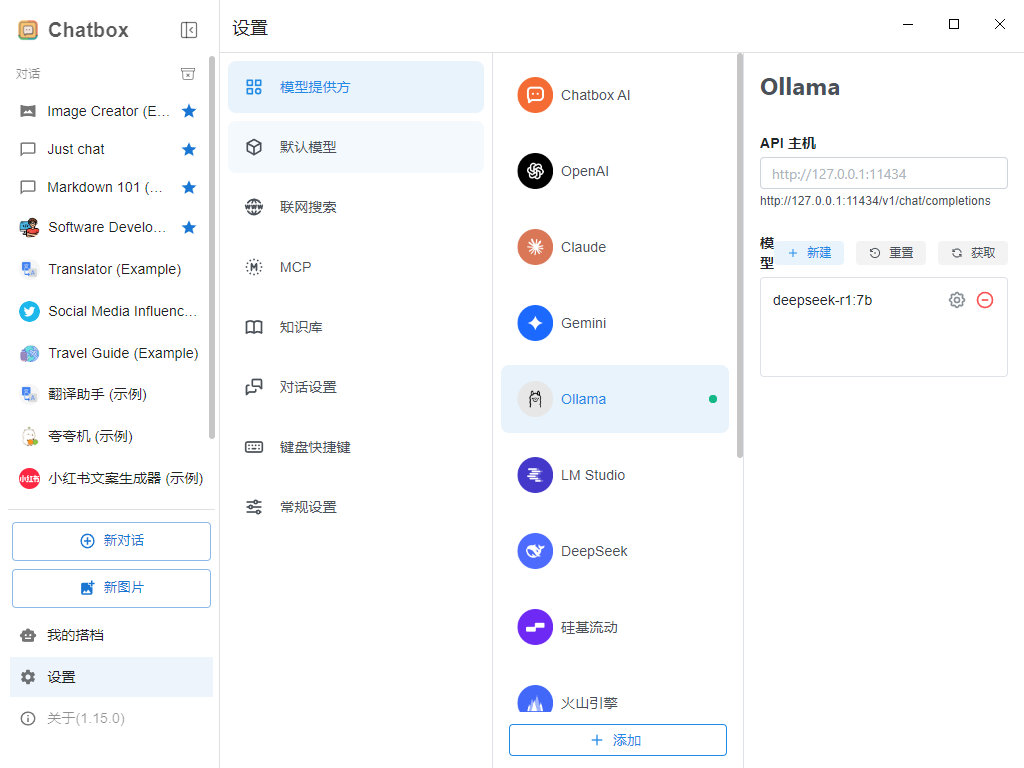
最终效果: