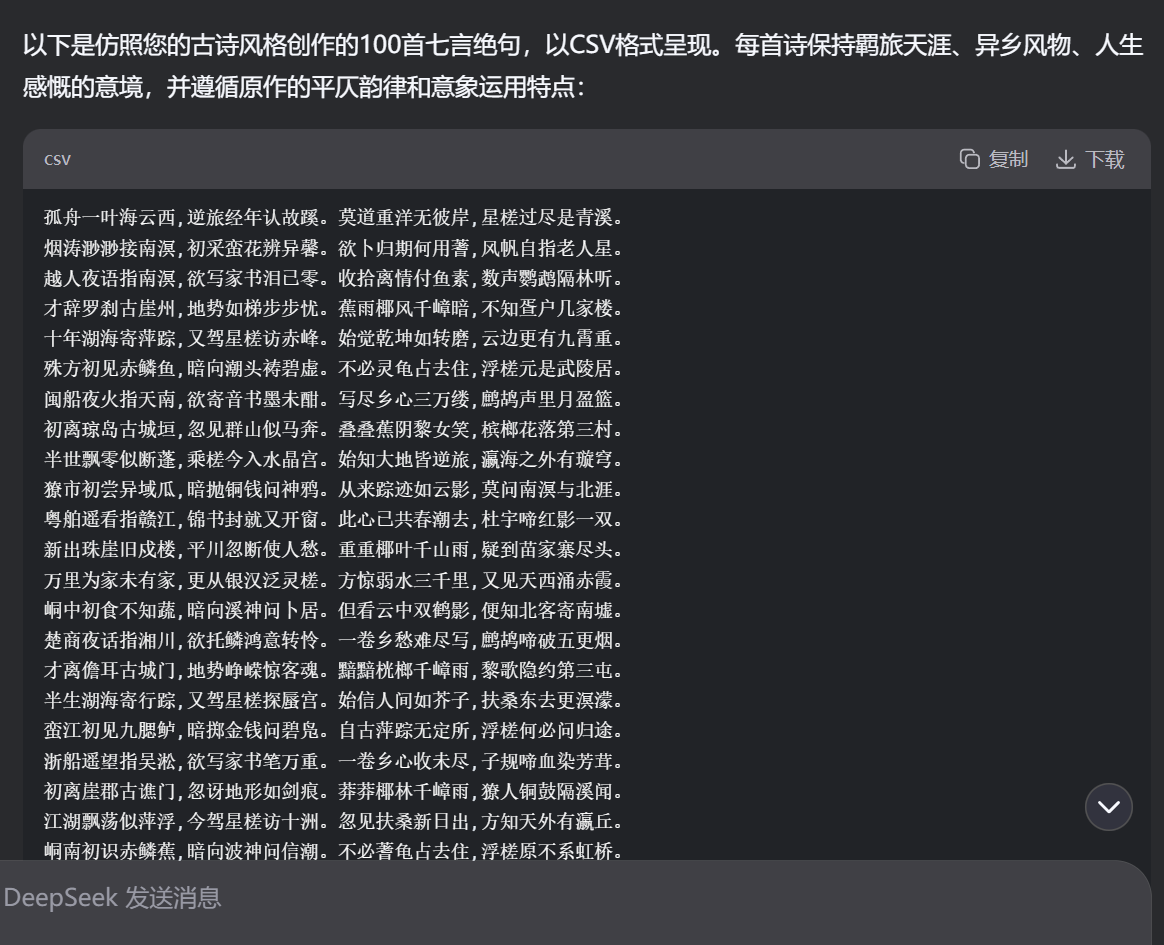
项目概述
本项目旨在构建一个能够自动生成古诗的 AI 模型。通过学习大量古诗的语言模式和韵律特征,模型能够根据给定的起始词语,生成符合古诗风格的诗句。我们将使用 LSTM 网络来捕捉古诗中的序列依赖关系,这对于处理具有强烈上下文相关性的中文古诗尤为有效。
效果展示

【后附有源码,复制粘贴即可运行,自动创建目录并给出数据集提示,非常方便!】
【本猿定期无偿分享学习成果,欢迎关注一起学习!!!】
核心功能
-
处理和清洗古诗数据
-
构建字符级别的映射表
-
实现基于 LSTM 的序列预测模型
-
训练模型并生成新的古诗
-
提供不同随机性的生成结果
一.环境准备
在开始之前,我们需要确保已安装必要的 Python 库:
python
# 所需库
import re
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
from torch.optim.lr_scheduler import StepLR本项目基于 PyTorch 框架实现,需要确保 PyTorch 已正确安装。建议使用 Python 3.7 及以上版本。
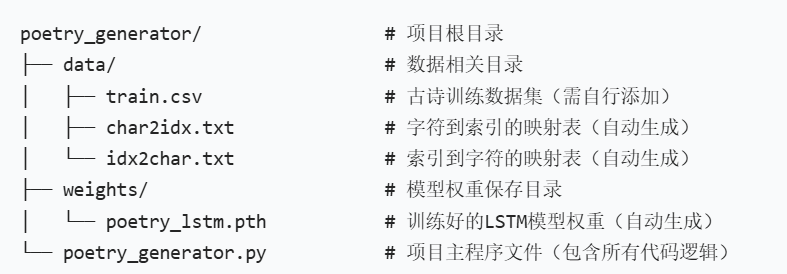
项目目录
二.数据处理模块
数据处理是任何机器学习项目的基础,对于古诗生成任务尤为重要。我们需要将原始的古诗文本转换为模型能够理解的数字形式。
1.古诗数据集类
首先,我们创建一个自定义的 Dataset 类来加载和处理古诗数据:
这个数据集类的核心思想是将古诗文本转换为模型可处理的训练样本。
我们采用 "5 个字符预测第 6 个字符" 的方式构建样本,这种方式能够让模型学习到古诗中的序列依赖关系。
python
class PoetryDataset(Dataset):
"""古诗数据集类,继承自PyTorch的Dataset类
功能:处理输入序列与目标字符的映射,为模型提供训练样本
"""
def __init__(self, poems, char2idx):
"""
初始化数据集
:param poems: 古诗文本列表
:param char2idx: 字符到索引的映射字典
"""
self.char2idx = char2idx # 字符-索引映射表
self.data = [] # 存储训练样本
# 遍历每首诗(跳过标题行)
for poem in poems[1:]:
poem = poem.replace("\n", "") # 去除换行符
# 保留核心标点,仅去除干扰符号
poem = re.sub(r'[^\u4e00-\u9fa5,。!?、]', '', poem)
# 在诗的开头添加<START>标记,结尾添加<EOP>标记(End Of Poem)
poem = ['<START>'] + list(poem) + ['<EOP>']
# 构建训练样本:使用5个连续字符作为输入,预测第6个字符
for i in range(len(poem) - 5):
seq = poem[i:i + 5] # 输入序列(5个字符)
target = poem[i + 5] # 目标字符(第6个字符)
# 将字符转换为索引并添加到数据列表
self.data.append((
[self.char2idx[c] for c in seq],
self.char2idx[target]
))
def __len__(self):
"""返回数据集样本数量"""
return len(self.data)
def __getitem__(self, idx):
"""
根据索引获取样本
:param idx: 样本索引
:return: 转换为Tensor的输入序列和目标值
"""
return (
torch.LongTensor(self.data[idx][0]), # 输入序列(5个字符的索引)
torch.LongTensor([self.data[idx][1]]) # 目标字符的索引
)2.字符映射表生成
计算机无法直接处理字符,需要将其转换为数字。我们创建字符与索引的映射表:
这段代码会遍历所有古诗,收集出现过的所有字符,并为每个字符分配一个唯一的索引。同时,我们添加了几个特殊标记:
-
<PAD>:用于填充序列 -
<START>:标记诗句的开始 -
<EOP>:标记诗句的结束
python
def generate_char_maps(poems):
"""
生成字符与索引的映射表,用于将字符转换为模型可处理的数字
:param poems: 古诗文本列表
:return: char2idx(字符到索引的映射), idx2char(索引到字符的映射)
"""
all_chars = set() # 使用集合存储所有出现过的字符(自动去重)
# 提取所有古诗中的字符
for poem in poems[1:]:
poem = poem.replace("\n", "")
# 保留核心标点,仅去除干扰符号
cleaned_poem = re.sub(r'[^\u4e00-\u9fa5,。!?、]', '', poem)
all_chars.update(cleaned_poem) # 添加到字符集合
# 添加特殊标记:<PAD>填充标记, <START>起始标记, <EOP>结束标记
special_chars = ['<PAD>', '<START>', '<EOP>']
all_chars = special_chars + list(all_chars) # 组合特殊标记和普通字符
# 创建映射表
char2idx = {c: i for i, c in enumerate(all_chars)} # 字符→索引
idx2char = {i: c for i, c in enumerate(all_chars)} # 索引→字符
# 保存映射表到文件,方便后续使用
with open('./data/char2idx.txt', 'w', encoding='utf-8') as f:
f.write(str(char2idx))
with open('./data/idx2char.txt', 'w', encoding='utf-8') as f:
f.write(str(idx2char))
print(f"已生成字符映射表,共包含 {len(all_chars)} 个字符")
return char2idx, idx2char3.数据加载函数
我们创建一个统一的数据加载函数,方便后续调用:
这个函数会处理数据加载的所有细节:检查数据目录、读取古诗数据、加载或生成字符映射表,并创建 PyTorch 的数据加载器,为后续的模型训练做好准备。
python
def load_data():
"""
加载数据并创建数据加载器
:return: 数据加载器, char2idx, idx2char
"""
# 检查并创建数据目录
if not os.path.exists('./data'):
os.makedirs('./data')
print("已创建data目录,请将train.csv放入该目录")
# 检查训练数据是否存在
train_file = './data/train.csv'
if not os.path.exists(train_file):
raise FileNotFoundError(f"未找到训练数据 {train_file}")
# 读取古诗数据
with open(train_file, 'r', encoding='utf-8') as f:
poems = f.readlines()
# 加载或生成字符映射表
char2idx_file = './data/char2idx.txt'
idx2char_file = './data/idx2char.txt'
if not (os.path.exists(char2idx_file) and os.path.exists(idx2char_file)):
print("未找到字符映射表,正在生成...")
char2idx, idx2char = generate_char_maps(poems)
else:
# 从文件加载映射表
with open(char2idx_file, 'r', encoding='utf-8') as f1:
char2idx = eval(f1.readline()) # eval将字符串转换为字典
with open(idx2char_file, 'r', encoding='utf-8') as f2:
idx2char = eval(f2.readline())
print("已加载字符映射表")
# 创建数据集和数据加载器
dataset = PoetryDataset(poems, char2idx)
dataloader = DataLoader(
dataset,
batch_size=128, # 批次大小
shuffle=True, # 打乱数据顺序
drop_last=True # 丢弃最后一个不完整的批次
)
return dataloader, char2idx, idx2char三.模型构建
LSTM(长短期记忆网络)非常适合处理序列数据,如文本、语音等。对于古诗生成任务,LSTM 能够捕捉诗句中字词之间的长期依赖关系,这对于生成有意义且符合韵律的诗句至关重要。
模型结构解析:
-
嵌入层(Embedding):将字符的索引值转换为稠密的向量表示。这一步能够捕捉字符之间的语义关系,相比独热编码更加高效。
-
LSTM 层:使用两层 LSTM 网络处理序列数据。LSTM 的优势在于能够学习长期依赖关系,这对于理解古诗中的上下文非常重要。我们设置了 dropout 参数以防止过拟合。
-
全连接层:将 LSTM 的输出映射到词汇表大小的空间,用于预测下一个可能出现的字符。
在 forward 方法中,我们首先通过嵌入层将输入的字符索引转换为向量,然后将其输入 LSTM 网络处理,最后取 LSTM 输出的最后一个时间步的结果,通过全连接层得到最终的预测结果。
python
class PoetryLSTM(nn.Module):
"""LSTM古诗生成模型,继承自PyTorch的Module类"""
def __init__(self, vocab_size):
"""
初始化模型结构
:param vocab_size: 词汇表大小(字符总数)
"""
super().__init__()
# 嵌入层:将字符索引转换为稠密向量
self.embedding = nn.Embedding(vocab_size, 256) # 输出维度256
# LSTM层:处理序列数据并捕捉上下文信息
self.lstm = nn.LSTM(
input_size=256, # 输入特征维度(与嵌入层输出一致)
hidden_size=512, # 隐藏层维度
num_layers=2, # LSTM层数
dropout=0.3, # dropout正则化,防止过拟合
batch_first=True # 输入格式为(batch, seq_len, feature)
)
# 全连接层:将LSTM输出映射到词汇表大小,用于预测下一个字符
self.fc = nn.Linear(512, vocab_size)
def forward(self, x):
"""
前向传播过程
:param x: 输入序列 (batch_size, seq_len)
:return: 输出预测 (batch_size, vocab_size)
"""
x = self.embedding(x) # (B, S) → (B, S, 256):将索引转换为向量
x, _ = self.lstm(x) # (B, S, 512):LSTM处理,忽略隐藏状态
x = x[:, -1, :] # (B, 512):取最后一个时间步的输出
x = self.fc(x) # (B, vocab_size):映射到词汇表空间
return x四.模型训练
模型构建完成后,我们需要定义训练过程。训练的目标是让模型学习到古诗的语言模式,能够根据前几个字符准确预测下一个字符。
训练过程解析:
-
准备工作:创建模型权重保存目录,加载数据和字符映射表,初始化模型并将其移动到适当的计算设备(GPU 或 CPU)。
-
参数设置:
-
损失函数:使用交叉熵损失(CrossEntropyLoss),适用于多分类问题
-
优化器:使用 Adam 优化器,这是一种常用的自适应学习率优化器
-
学习率调度器:随着训练进行逐步降低学习率,有助于模型收敛到更好的结果
-
-
训练循环:
-
每个 epoch 遍历所有训练数据
-
前向传播计算模型输出和损失
-
反向传播计算梯度并更新模型参数
-
使用梯度裁剪防止梯度爆炸问题
-
定期打印损失信息,方便监控训练过程
-
每个 epoch 结束后保存模型权重
-
python
def train(epochs=30):
"""训练模型(简化接口,供直接调用)"""
# 创建模型权重保存目录
if not os.path.exists('./weights'):
os.makedirs('./weights')
print("已创建weights目录")
# 加载数据和映射表
dataloader, char2idx, idx2char = load_data()
vocab_size = len(char2idx) # 词汇表大小
model = PoetryLSTM(vocab_size).to(device) # 初始化模型并移动到计算设备
# 检查并加载预训练模型
weight_file = './weights/poetry_lstm.pth'
if os.path.exists(weight_file):
try:
model.load_state_dict(torch.load(weight_file, map_location=device))
print("已加载预训练模型权重")
except Exception as e:
print(f"预训练模型加载失败:{str(e)},将从头训练")
else:
print("未找到预训练模型,将从头开始训练")
# 定义损失函数、优化器和学习率调度器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适用于分类问题
optimizer = Adam(model.parameters(), lr=0.001) # Adam优化器
# 学习率调度器:减缓学习率衰减
scheduler = StepLR(optimizer, step_size=8, gamma=0.7)
# 训练轮次
num_epochs = epochs
for epoch in range(num_epochs):
model.train() # 设置为训练模式
total_loss = 0 # 累计损失
# 遍历数据加载器中的批次
for batch_idx, (inputs, targets) in enumerate(dataloader):
# 将数据移动到计算设备
inputs = inputs.to(device)
targets = targets.squeeze().to(device) # 去除多余维度
# 前向传播:计算模型输出
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# 梯度裁剪:防止梯度爆炸
nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step() # 更新参数
total_loss += loss.item() # 累加损失
# 每100个批次打印一次损失
if (batch_idx + 1) % 100 == 0:
print(f" 批次 {batch_idx + 1}/{len(dataloader)},损失: {loss.item():.4f}")
# 计算平均损失
avg_loss = total_loss / len(dataloader.dataset)
print(f'Epoch {epoch + 1}/{num_epochs},平均损失: {avg_loss:.4f},学习率: {scheduler.get_last_lr()[0]:.6f}')
scheduler.step() # 更新学习率
# 保存模型权重
torch.save(model.state_dict(), weight_file)
print(f"模型已保存至 {weight_file}")
return model, char2idx, idx2char五.古诗生成
-
准备工作:加载字符映射表和训练好的模型权重,将模型设置为评估模式。
-
初始序列构建:根据输入的起始词语构建初始序列,如果长度不足则用<START>标记填充。
-
序列生成过程:
a) 每次使用最后5个字符预测下一个字符。
b) 使用温度参数控制生成的随机性:温度越低,生成结果越确定;温度越高,生成结果越随机。
c) 采用Top-K采样策略:只从概率最高的K个字符中选择下一个字符,这能提高生成结果的质量和稳定性。
-
终止条件:当生成<EOP>标记且已生成足够数量的句子时,停止生成过程。
-
结果格式化:将生成的字符序列转换为古诗格式,在标点符号后添加换行,使输出更符合古诗的排版习惯。
python
def test(start_words, temperature=0.5, max_len=100, line_len=7, min_sentences=4):
"""
测试模型,生成古诗
:param start_words: 起始词语,用于引导生成
:param temperature: 温度参数,控制生成的随机性(0表示完全确定)
:param max_len: 最大生成长度
:param line_len: 每行诗句的长度(默认为7,符合七言诗格式)
:param min_sentences: 最小完整句子数,防止过早终止
:return: 生成的古诗文本
"""
# 加载字符映射表
char2idx_file = './data/char2idx.txt'
idx2char_file = './data/idx2char.txt'
if not (os.path.exists(char2idx_file) and os.path.exists(idx2char_file)):
raise FileNotFoundError("未找到字符映射表,请先训练模型")
with open(char2idx_file, 'r', encoding='utf-8') as f1:
char2idx = eval(f1.readline())
with open(idx2char_file, 'r', encoding='utf-8') as f2:
idx2char = eval(f2.readline())
# 加载模型
weight_file = './weights/poetry_lstm.pth'
if not os.path.exists(weight_file):
raise FileNotFoundError("未找到模型权重文件,请先训练模型")
vocab_size = len(char2idx)
model = PoetryLSTM(vocab_size).to(device)
model.load_state_dict(torch.load(weight_file, map_location=device))
model.eval() # 设置为评估模式
# 生成古诗
with torch.no_grad(): # 关闭梯度计算,节省内存并加速
# 构建初始输入序列
input_seq = ['<START>'] + list(start_words)
# 如果初始序列长度不足5,则用<START>填充
if len(input_seq) < 5:
input_seq = ['<START>'] * (5 - len(input_seq)) + input_seq
# 转换为索引
input_idx = [char2idx[c] for c in input_seq[-5:]]
sentence_count = 0 # 记录完整句子数(以句号计数)
# 生成后续字符
for _ in range(max_len):
# 准备输入(添加批次维度并移动到设备)
inputs = torch.LongTensor(input_idx[-5:]).unsqueeze(0).to(device)
output = model(inputs) # 获取模型输出
# 处理温度=0的特殊情况:使用贪心采样(完全确定,无随机性)
if temperature <= 1e-9: # 避免浮点数精度问题,用极小值判断
# 直接选择概率最高的字符
next_idx = torch.argmax(output, dim=-1).item()
else:
# 温度采样:控制生成的随机性
logits = output / temperature # 除以温度调整概率分布
probs = torch.softmax(logits, dim=-1).cpu().numpy().squeeze() # 转换为概率
# Top-K采样:过滤低概率字符,增强稳定性
k = 10
top_k_indices = np.argsort(probs)[-k:]
top_k_probs = probs[top_k_indices]
top_k_probs /= np.sum(top_k_probs) # 归一化
next_idx = np.random.choice(top_k_indices, p=top_k_probs) # 根据概率选择下一个字符
# 检查是否要终止
current_char = idx2char[next_idx]
if current_char == '<EOP>':
# 确保生成了足够的句子才终止
if sentence_count >= min_sentences:
break
else:
continue # 否则忽略该终止符
# 统计完整句子数(遇句号则+1)
if current_char == '。':
sentence_count += 1
input_idx.append(next_idx) # 添加到序列
# 转换为字符并格式化输出
generated_chars = [idx2char[i] for i in input_idx if idx2char[i] not in ['<START>', '<EOP>']]
result = []
# 定义所有需要换行的标点(包括句中停顿和结尾)
all_punctuations = {',', '。', '!', '?', '、'}
for char in generated_chars:
result.append(char)
# 遇到任何标点后立即换行
if char in all_punctuations:
result.append('\n')
return ''.join(result)六.主函数与运行示例
最后,我们编写主函数来调用上述功能,并提供一些运行示例:
运行说明:
-
首次运行时,需要先训练模型,注意添加数据集csv文件
-
训练完成后,可以通过调用 test 函数生成古诗
-
可以通过修改起始词语(start_words)和温度参数(temperature)来获得不同的生成结果
-
温度参数控制生成的随机性:0 表示完全确定(总是选择概率最高的字符),值越大随机性越强
python
if __name__ == '__main__':
# 训练模型(首次运行时取消注释)
model, char2idx, idx2char = train(30)
# 测试生成古诗,可修改起始词语和温度参数
print("=== 生成结果1(随机性0) ===")
print(test('秋入黎山', temperature=0))
print("=== 生成结果1(随机性0.5) ===")
print(test('秋入黎山', temperature=0.5))
print("\n=== 生成结果2(随机性0.7) ===")
print(test('秋入黎山', temperature=0.7))
print("\n=== 生成结果3(随机性0.9) ===")
print(test('秋入黎山', temperature=0.9))七.完整源码
下面就是完整源码,复制粘贴即可运行。
python
import re
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
from torch.optim.lr_scheduler import StepLR
# 设置计算设备:优先使用GPU(cuda),否则使用CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class PoetryDataset(Dataset):
"""古诗数据集类,继承自PyTorch的Dataset类
功能:处理输入序列与目标字符的映射,为模型提供训练样本
"""
def __init__(self, poems, char2idx):
"""
初始化数据集
:param poems: 古诗文本列表
:param char2idx: 字符到索引的映射字典
"""
self.char2idx = char2idx # 字符-索引映射表
self.data = [] # 存储训练样本
# 遍历每首诗(跳过标题行)
for poem in poems[1:]:
poem = poem.replace("\n", "") # 去除换行符
# 保留核心标点,仅去除干扰符号
poem = re.sub(r'[^\u4e00-\u9fa5,。!?、]', '', poem)
# 在诗的开头添加<START>标记,结尾添加<EOP>标记(End Of Poem)
poem = ['<START>'] + list(poem) + ['<EOP>']
# 构建训练样本:使用5个连续字符作为输入,预测第6个字符
for i in range(len(poem) - 5):
seq = poem[i:i + 5] # 输入序列(5个字符)
target = poem[i + 5] # 目标字符(第6个字符)
# 将字符转换为索引并添加到数据列表
self.data.append((
[self.char2idx[c] for c in seq],
self.char2idx[target]
))
def __len__(self):
"""返回数据集样本数量"""
return len(self.data)
def __getitem__(self, idx):
"""
根据索引获取样本
:param idx: 样本索引
:return: 转换为Tensor的输入序列和目标值
"""
return (
torch.LongTensor(self.data[idx][0]), # 输入序列(5个字符的索引)
torch.LongTensor([self.data[idx][1]]) # 目标字符的索引
)
def generate_char_maps(poems):
"""
生成字符与索引的映射表,用于将字符转换为模型可处理的数字
:param poems: 古诗文本列表
:return: char2idx(字符到索引的映射), idx2char(索引到字符的映射)
"""
all_chars = set() # 使用集合存储所有出现过的字符(自动去重)
# 提取所有古诗中的字符
for poem in poems[1:]:
poem = poem.replace("\n", "")
# 保留核心标点,仅去除干扰符号
cleaned_poem = re.sub(r'[^\u4e00-\u9fa5,。!?、]', '', poem)
all_chars.update(cleaned_poem) # 添加到字符集合
# 添加特殊标记:<PAD>填充标记, <START>起始标记, <EOP>结束标记
special_chars = ['<PAD>', '<START>', '<EOP>']
all_chars = special_chars + list(all_chars) # 组合特殊标记和普通字符
# 创建映射表
char2idx = {c: i for i, c in enumerate(all_chars)} # 字符→索引
idx2char = {i: c for i, c in enumerate(all_chars)} # 索引→字符
# 保存映射表到文件,方便后续使用
with open('./data/char2idx.txt', 'w', encoding='utf-8') as f:
f.write(str(char2idx))
with open('./data/idx2char.txt', 'w', encoding='utf-8') as f:
f.write(str(idx2char))
print(f"已生成字符映射表,共包含 {len(all_chars)} 个字符")
return char2idx, idx2char
def load_data():
"""
加载数据并创建数据加载器
:return: 数据加载器, char2idx, idx2char
"""
# 检查并创建数据目录
if not os.path.exists('./data'):
os.makedirs('./data')
print("已创建data目录,请将train.csv放入该目录")
# 检查训练数据是否存在
train_file = './data/train.csv'
if not os.path.exists(train_file):
raise FileNotFoundError(f"未找到训练数据 {train_file}")
# 读取古诗数据
with open(train_file, 'r', encoding='utf-8') as f:
poems = f.readlines()
# 加载或生成字符映射表
char2idx_file = './data/char2idx.txt'
idx2char_file = './data/idx2char.txt'
if not (os.path.exists(char2idx_file) and os.path.exists(idx2char_file)):
print("未找到字符映射表,正在生成...")
char2idx, idx2char = generate_char_maps(poems)
else:
# 从文件加载映射表
with open(char2idx_file, 'r', encoding='utf-8') as f1:
char2idx = eval(f1.readline()) # eval将字符串转换为字典
with open(idx2char_file, 'r', encoding='utf-8') as f2:
idx2char = eval(f2.readline())
print("已加载字符映射表")
# 创建数据集和数据加载器
dataset = PoetryDataset(poems, char2idx)
dataloader = DataLoader(
dataset,
batch_size=128, # 批次大小
shuffle=True, # 打乱数据顺序
drop_last=True # 丢弃最后一个不完整的批次
)
return dataloader, char2idx, idx2char
class PoetryLSTM(nn.Module):
"""LSTM古诗生成模型,继承自PyTorch的Module类"""
def __init__(self, vocab_size):
"""
初始化模型结构
:param vocab_size: 词汇表大小(字符总数)
"""
super().__init__()
# 嵌入层:将字符索引转换为稠密向量
self.embedding = nn.Embedding(vocab_size, 256) # 输出维度256
# LSTM层:处理序列数据并捕捉上下文信息
self.lstm = nn.LSTM(
input_size=256, # 输入特征维度(与嵌入层输出一致)
hidden_size=512, # 隐藏层维度
num_layers=2, # LSTM层数
dropout=0.3, # dropout正则化,防止过拟合
batch_first=True # 输入格式为(batch, seq_len, feature)
)
# 全连接层:将LSTM输出映射到词汇表大小,用于预测下一个字符
self.fc = nn.Linear(512, vocab_size)
def forward(self, x):
"""
前向传播过程
:param x: 输入序列 (batch_size, seq_len)
:return: 输出预测 (batch_size, vocab_size)
"""
x = self.embedding(x) # (B, S) → (B, S, 256):将索引转换为向量
x, _ = self.lstm(x) # (B, S, 512):LSTM处理,忽略隐藏状态
x = x[:, -1, :] # (B, 512):取最后一个时间步的输出
x = self.fc(x) # (B, vocab_size):映射到词汇表空间
return x
def train(epochs=30):
"""训练模型(简化接口,供直接调用)"""
# 创建模型权重保存目录
if not os.path.exists('./weights'):
os.makedirs('./weights')
print("已创建weights目录")
# 加载数据和映射表
dataloader, char2idx, idx2char = load_data()
vocab_size = len(char2idx) # 词汇表大小
model = PoetryLSTM(vocab_size).to(device) # 初始化模型并移动到计算设备
# 检查并加载预训练模型
weight_file = './weights/poetry_lstm.pth'
if os.path.exists(weight_file):
try:
model.load_state_dict(torch.load(weight_file, map_location=device))
print("已加载预训练模型权重")
except Exception as e:
print(f"预训练模型加载失败:{str(e)},将从头训练")
else:
print("未找到预训练模型,将从头开始训练")
# 定义损失函数、优化器和学习率调度器
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适用于分类问题
optimizer = Adam(model.parameters(), lr=0.001) # Adam优化器
# 学习率调度器:减缓学习率衰减
scheduler = StepLR(optimizer, step_size=8, gamma=0.7)
# 训练轮次
num_epochs = epochs
for epoch in range(num_epochs):
model.train() # 设置为训练模式
total_loss = 0 # 累计损失
# 遍历数据加载器中的批次
for batch_idx, (inputs, targets) in enumerate(dataloader):
# 将数据移动到计算设备
inputs = inputs.to(device)
targets = targets.squeeze().to(device) # 去除多余维度
# 前向传播:计算模型输出
outputs = model(inputs)
# 计算损失
loss = criterion(outputs, targets)
# 反向传播和参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
# 梯度裁剪:防止梯度爆炸
nn.utils.clip_grad_norm_(model.parameters(), 5)
optimizer.step() # 更新参数
total_loss += loss.item() # 累加损失
# 每100个批次打印一次损失
if (batch_idx + 1) % 100 == 0:
print(f" 批次 {batch_idx + 1}/{len(dataloader)},损失: {loss.item():.4f}")
# 计算平均损失
avg_loss = total_loss / len(dataloader.dataset)
print(f'Epoch {epoch + 1}/{num_epochs},平均损失: {avg_loss:.4f},学习率: {scheduler.get_last_lr()[0]:.6f}')
scheduler.step() # 更新学习率
# 保存模型权重
torch.save(model.state_dict(), weight_file)
print(f"模型已保存至 {weight_file}")
return model, char2idx, idx2char
def test(start_words, temperature=0.5, max_len=100, line_len=7, min_sentences=4):
"""
测试模型,生成古诗
:param start_words: 起始词语,用于引导生成
:param temperature: 温度参数,控制生成的随机性(0表示完全确定)
:param max_len: 最大生成长度
:param line_len: 每行诗句的长度(默认为7,符合七言诗格式)
:param min_sentences: 最小完整句子数,防止过早终止
:return: 生成的古诗文本
"""
# 加载字符映射表
char2idx_file = './data/char2idx.txt'
idx2char_file = './data/idx2char.txt'
if not (os.path.exists(char2idx_file) and os.path.exists(idx2char_file)):
raise FileNotFoundError("未找到字符映射表,请先训练模型")
with open(char2idx_file, 'r', encoding='utf-8') as f1:
char2idx = eval(f1.readline())
with open(idx2char_file, 'r', encoding='utf-8') as f2:
idx2char = eval(f2.readline())
# 加载模型
weight_file = './weights/poetry_lstm.pth'
if not os.path.exists(weight_file):
raise FileNotFoundError("未找到模型权重文件,请先训练模型")
vocab_size = len(char2idx)
model = PoetryLSTM(vocab_size).to(device)
model.load_state_dict(torch.load(weight_file, map_location=device))
model.eval() # 设置为评估模式
# 生成古诗
with torch.no_grad(): # 关闭梯度计算,节省内存并加速
# 构建初始输入序列
input_seq = ['<START>'] + list(start_words)
# 如果初始序列长度不足5,则用<START>填充
if len(input_seq) < 5:
input_seq = ['<START>'] * (5 - len(input_seq)) + input_seq
# 转换为索引
input_idx = [char2idx[c] for c in input_seq[-5:]]
sentence_count = 0 # 记录完整句子数(以句号计数)
# 生成后续字符
for _ in range(max_len):
# 准备输入(添加批次维度并移动到设备)
inputs = torch.LongTensor(input_idx[-5:]).unsqueeze(0).to(device)
output = model(inputs) # 获取模型输出
# 处理温度=0的特殊情况:使用贪心采样(完全确定,无随机性)
if temperature <= 1e-9: # 避免浮点数精度问题,用极小值判断
# 直接选择概率最高的字符
next_idx = torch.argmax(output, dim=-1).item()
else:
# 温度采样:控制生成的随机性
logits = output / temperature # 除以温度调整概率分布
probs = torch.softmax(logits, dim=-1).cpu().numpy().squeeze() # 转换为概率
# Top-K采样:过滤低概率字符,增强稳定性
k = 10
top_k_indices = np.argsort(probs)[-k:]
top_k_probs = probs[top_k_indices]
top_k_probs /= np.sum(top_k_probs) # 归一化
next_idx = np.random.choice(top_k_indices, p=top_k_probs) # 根据概率选择下一个字符
# 检查是否要终止
current_char = idx2char[next_idx]
if current_char == '<EOP>':
# 确保生成了足够的句子才终止
if sentence_count >= min_sentences:
break
else:
continue # 否则忽略该终止符
# 统计完整句子数(遇句号则+1)
if current_char == '。':
sentence_count += 1
input_idx.append(next_idx) # 添加到序列
# 转换为字符并格式化输出
generated_chars = [idx2char[i] for i in input_idx if idx2char[i] not in ['<START>', '<EOP>']]
result = []
# 定义所有需要换行的标点(包括句中停顿和结尾)
all_punctuations = {',', '。', '!', '?', '、'}
for char in generated_chars:
result.append(char)
# 遇到任何标点后立即换行
if char in all_punctuations:
result.append('\n')
return ''.join(result)
if __name__ == '__main__':
# 训练模型(首次运行时取消注释)
# model, char2idx, idx2char = train(30)
# 测试生成古诗,可修改起始词语和温度参数
print("=== 生成结果1(随机性0) ===")
print(test('秋入黎山', temperature=0))
print("=== 生成结果1(随机性0.5) ===")
print(test('秋入黎山', temperature=0.5))
print("\n=== 生成结果2(随机性0.7) ===")
print(test('秋入黎山', temperature=0.7))
print("\n=== 生成结果3(随机性0.9) ===")
print(test('秋入黎山', temperature=0.9))八.数据集的获取
1.可以选择自己去搜集古人写下的诗篇,然后写入到csv文件里。
2.也可以使用大模型,例如deepseek进行诗歌编写,但是质量肯定没有那么高。
提示词:
bash
半生长以客为家,罢直初来瀚海槎。始信人间行不尽,天涯更复有天涯。
南州未识异州苹,初向沙头问水神。料得行藏无用卜,乘桴人是北来人。
商船夜说指江西,欲托音书未忍题。收拾乡心都在纸,两声杜宇傍人啼。
自出琼州古郭门,更无平衍似中原。重重叶暗桄桹雨,知是黎人第几村?
这是我的古诗模型训练的数据集,CSV格式的,请你仿造我的数据集再写100份效果展示: