数据分析(Numpy,Pandas,Matplotlib)
一、数分基础
1、基本流程
数据收集->数据清洗->数据分析->数据可视化
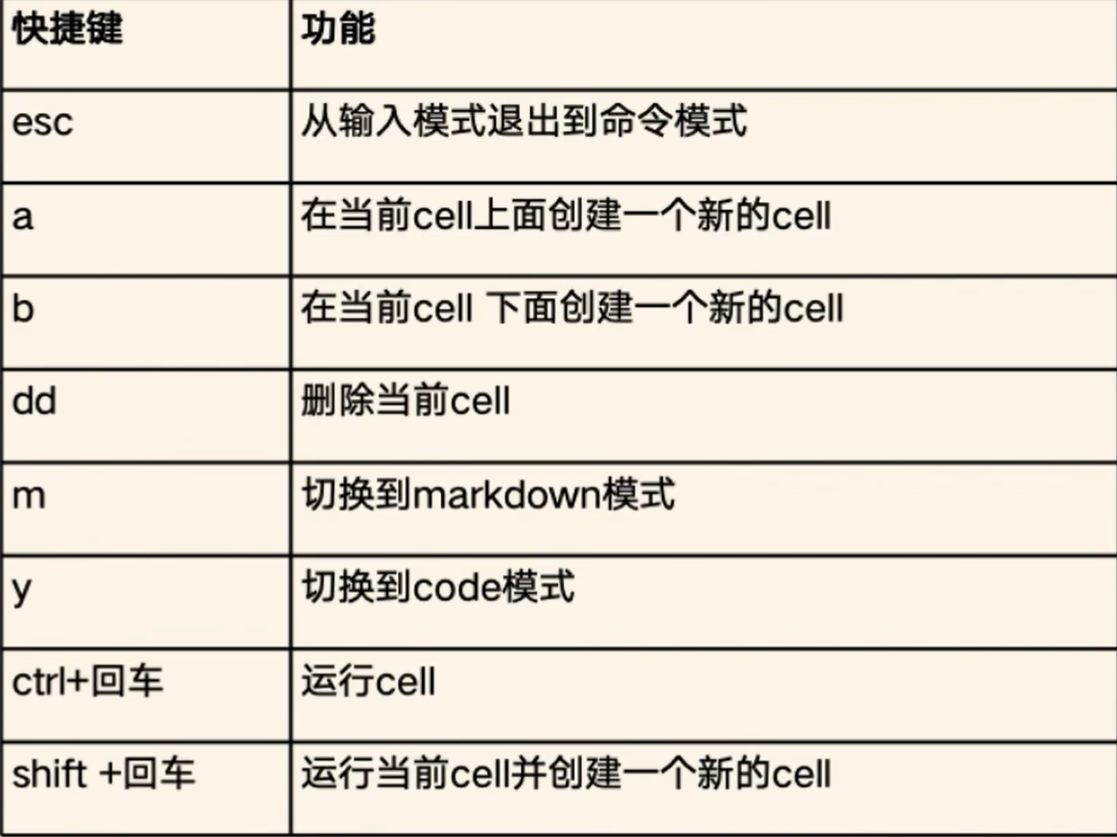
2、Jupyter Notebook
二、Numpy
1、ndarray的性质
特性:多维性、同质性、高效性
[1,'Hello'] # 这样得到的array里的 1 是字符串属性:


2、创建
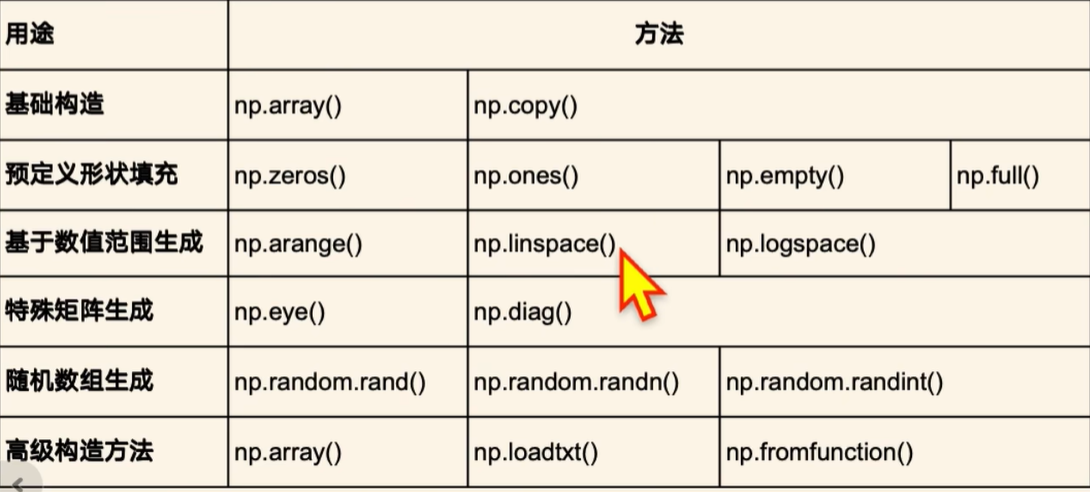
arr = np.array([1,2,3],dtype=float64) # 要求元素类型为浮点型
arr2 = np.copy(arr)
arr = np.zeros((2,3),dtype = int) # 创造一个2行3列的0矩阵
arr = np.zeros((200,),dtype = int) # 创造一个一维200个0的数组
arr = np.ones((2,3),dtype = int) # 创造一个2行3列的1矩阵
arr = np.empty((2,3)) # 创造一个2行3列的未定义矩阵
arr = np.full((2,3),2025) # 创造一个2行3列的元素全为2025的矩阵
arr2 = np.zeros_like(arr) # 创造与arr形状相同的0矩阵
arr2 = np.empty_like(arr) # 创造与arr形状相同的未定义矩阵
arr2 = np.ones_like(arr) # 创造与arr形状相同的1矩阵
arr2 = np.full_like(arr,2026) # 将arr元素全替换为2026高级
arr = np.arrange(1,10,1) # 从1到10 以步长为1的等差数列,左闭右开 1 ~ 9
arr = np.linspace(1,10,5 # 1 到 10之间等间隔地取5个数字
arr = np.logspace(0,4,2,2) # 从0 到 4等间隔取两个以2为底的数字 [1,16]
arr = np.logspace(0,4,3,2) # 从0 到 4等间隔取两个以2为底的数字 [1,4,16]特殊矩阵
arr = np.eye(3) # 生成一个秩为3的单位阵
arr = np.eye(3,4) # 生成一个三行四列的[E|0]
arr = np.diag([1,2,3]) # 生成特征值为1,2,3的对角阵
arr = np.random.rand(2,3) # 生成一个范围为0~1的2行3列的随机浮点数组
arr = np.random.uniform(3,6,(2,3)) # 生成一个指定范围为 3~6 的2行3列的随机浮点数组
arr = np.random.randint(3,6,(2,3)) # 生成一个指定范围为 3~6 的2行3列的随机整数数组
arr = np.random.randn(2,3) # 生成一个2行3列的正态分布数组
np.random.seed(20) # 设置种子可以保证下方的random生成的数组是固定的
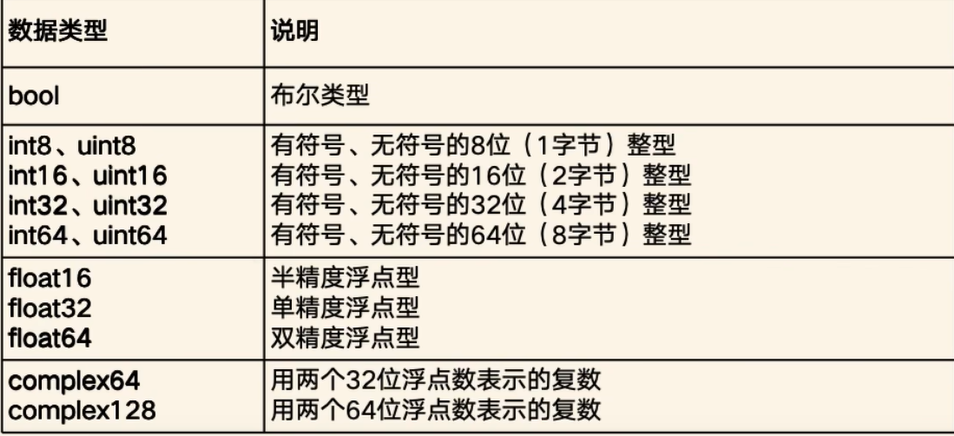
arr = np.random.randint(3,6,(2,3))3、数值类型
4、索引与切片

一维
arr = np.random.randint(1,100,20)
print(arr[10])
print(arr[:]) # 获取全部数据
print(arr[2:5]) # 获取下标为2~5的左闭右开的数据
print(arr[slice(2,15,3)]) # 与:等价 start,end,step
print(arr[(arr>10) | (arr < 70)]) # 获得所有大于10小于70的元素,通过布尔条件筛选满足条件的元素,支持逻辑运算符
二维
print(arr[1,3])
print(arr[:,:]) # 获得全部
print(arr[1,2:5]) # 取得第1行第2到4列 (都是下标)
print(arr[arr>50]) # 返回的是一维的
print(arr[2][arr[2] > 50])
print(arr[:,3]) # 取得第三列
print(arr[2,:]) # 取得第二行5、运算
a = np.array([1,2,3])
b = np.array([4,5,6])
print(a + b) # [5 7 9]
c = np.array([[1,2,3],[4,5,6]])
print ( c + 3 ) # 每个元素都加3# 广播机制
# 可广播条件:两个矩阵行和列分别看是否相同或是否含一个1
a = np.array([1,2,3]) # 1 * 3
b = np.array([[4],[5],[6]]) # 3 * 1

矩阵乘法运算
print(a @ b) # 矩阵乘法6、常用函数

(1)、数学函数
arr = np.array([1,2,3])
print(np.sqrt([1,4,9])) # 开平方根,返回浮点数
print(np.exp([1,2,3])) # 计算指数 e^x
print(np.log(2.71)) # 计算对数 lnx
print(np.sin(np.pi)) # sinx
print(np.abs(arr)) # 绝对值
print(np.power(arr,2)) # 幂
print(np.round([3.2,4,5])) # 四舍五入
print(np.ceil(arr)) # 向上取整
print(np.floor(arr)) # 向下取整
arr = ([1,2,3,np.nan])
print(np.isnan(arr)) # 检测缺失值,[False,False,False,True](2)、统计函数
arr = np.array([1,2,3,4,5])
print(np.sum(arr)) # 求和
print(np.mean(arr)) # 平均值
print(np.median(arr)) # 中位数,排序后
print(np.var(arr)) # 标准差
print(np.std(arr)) # 方差
print(np.max(arr)) # 最大值
print(np.min(arr)) # 最小值
print(np.percentile(arr,50)) # 分位数 , 取得50% 的数
print(np.cumsum(arr)) # [1,2,3]累和 [1,3,6]
print(np.cumprod(arr)) # 累积 [1,2,6](3)、比较函数
arr = np.array([1,2,3,4,5])
print(np.great(arr,4) # 是否大于
print(np.less(arr,4) # 是否小于
print(np.equal(arr,4) # 是否等于
print(np.equal(arr,arr) # 可以广播print(np.logical_and([1,0],[0,1])) # 与
print(np.logical_or([1,0],[0,1])) # 或
print(np.logical_not([1,0],[0,1])) # 非print(np.where(arr<3,arr,0)) # [1,2,0,0,0]
print(np.where(
score<60,'不及格',np.where(
score<80,'良好','优秀'
)
))(4)、排序函数
arr = np.array([1,2,3])
arr.sort()
print(arr)
print(np.sort(arr)) # 排序
print(np.argsort(arr)) # 打印出排序后的索引
print(np.unique(arr)) # 去重
print(np.concatenate((arr1,arr2))) # 数组拼接
print(np.split(arr,4)) # 数组分割(等分份数)
print(np.split(arr,[6,12,18])) # 给定分割位置,索引为6的元素前面切一刀
print(np.reshape(arr,[2,10])) # 调整数组形状三、Pandas
1、series

创建
import pandas as pd
s = pd.Series([1,2,3,4,5],index=['A','B','C','D','E'],name = '月份')
s = pd.Series({"a":1,"b":2,"c":3,"d":4,"e":5})属性
print(s.index)
print(s.values)
print(s.shape,s.ndim,s.size,s.dtype,s.name)
print(s.loc['a':'c']) # 显式索引,按标签索引或切片
print(s.iloc[1]) # 隐式索引,按位置索引或切片
print(s.at['a']) # 不可切片访问
print(s['a'])
print(s[s<3]) # 筛出元素小于3方法
print(s.head(3)) # 默认前五个,tail后五个
s.describe() # 查看所有的描述性信息
print(s.count()) # 元素个数
print(s.keys()) # s.index
print(s.isna()) # 判断是否为缺失值
print(s.isin(4,5)) # 判断是否含 4、5
s.quantile(0.25) # 分位数
print(s.mode()) # 众数
print(s.value_counts()) # 计算每一个元素频率
s.drop_duplicates() # 去重 ,得到series数据类型
s.unique() # 得到list类型
print(s.nunique()) # 去重后的元素个数
s.sort_values() # 排序 按values
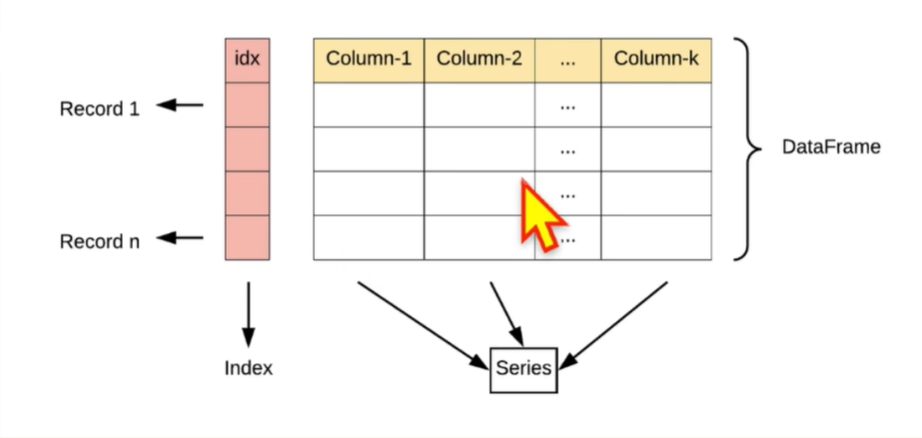
s.sort_index() # 排序 按index2、DataFrame
一列就是一个series,每一列数据类型相同,不同列可不同
创建
# 通过Series创建
s1 = pd.Series([1,2,3,4])
s2 = pd.Series([5,6,7,8])
df = pd.DataFrame({"第1列":s1,"第2列":s2})
# 通过字典创建
df = pd.DataFrame(
{
"id":[1,2,3,4,5],
"name":["tom","jack","rose","alice","kobe"],
"age":[15,16,18,24,0],
},index = [1,2,3,4,5],columns=["name","score","age"]
)属性
print(df.index,df.columns,df.values) # 行索引和列标签、值
print(df.T) # 转置
print(df.loc[4]) # 显式索引
print(df.iloc[3]) # 隐式索引
print(df.loc[:,'name'])
print(df.iloc[:,0])
print(df.at[3,'score'])
print(df.iat[2,1])访问
print(df['name','score'])
df[(df['score']>70) & (df.age<20)]
df.sample() # 随机抽样方法
print(df.isin(['jack',20])) # 是否存在
print(df.isna(['jack',20])) # 是否是缺失值
print(df['score'].sum())
print(df.value_counts()) # 每条信息出现的次数
print(df.drop_duplicates()) # 去重
print(df.duplicated(subset=['name'])) # 检查name列是否重复
print(df.replace(15,30)) # 替换
print(df.cumsum()) # 累和
print(df.cummax()) # 累积最大
print(df.sort_index(ascending=False)) # 按索引 ascending 是否升序,默认ascend
print(df.sort_values(by=['score','age'],ascending=[False,True])) # 按values排序,先降序score排序,再升序age排序
df.nlargest(2,columns=['score','age']) # 取成绩最高的两条数据
df.nsmallest(2,columns=['score','age'])四、数据分析
1、数据收集
df = pd.read_csv('data/employees.csv')
df
df.to_csv('new_profile.csv') # 导出
# pandas只能读取简单的json文件
import json
with open('data/test.json') as f:
data = json.load(f)
print(data['users'])
df = pd.DataFrame(data['users']) # 较为复杂的json格式是一个嵌套字典,将key传入可以分别得到users和用户的列表
print(type(df))
df2、数据清洗与分析
(1)、查找缺失值
s = pd.Series([1,2,None,pd.NA,np,nan])
df = pd.DataFrame([1,pd.NA,2][2,3,5][None,4,6])
print(s)
print(s.isma())
print(s.isnull)
print(df.isna())
print(df.isnull())
print(df.isna().sum(axis=1)) # 查看缺失值个数,默认按列索引,axis=1改为行索引
print(s.dropna()) # 删除缺失值,去除含有缺失值的整行
print(s.dropna(how = 'all')) # 如果所有的值为缺失值则删除该条数据
print(s.dropna(thresh=2)) # 至少有n个值不是缺失值就保留
print(s.dropna(axis=1)) # 剔除一整列,默认一行为一条数据,axis=1改为一列为一条数据
print(s.dropna(subset=['第1列'])) # 如果 '第1列' 列有缺失值则去掉整行数据以下分别是数据的格式和 isna() dropna() 的默认情况,也就是axis = 0



(2)、填充缺失值
print(df.fillna({'temp_max':20,'waind':2.5}))\
print(df.fillna(df[['wind']].mean()))
print(df.ffill()) # 使用缺失值前面的值填充
print(df.bfill()) # 使用缺失值后面的值填充为什么df\['wind'] 要加两个 \[\]?
df['wind'] → 返回一个 Series,
df[['wind']] → 返回一个 DataFrame
-
df[['wind']].mean()返回的是一个 DataFrame 的列向量(即单列 DataFrame), -
这样
.fillna()才能按列对齐地填充缺失值。
(3)、数据类型转换
df.duplicated() # 一整条记录都是一样的,标记为重复,返回为true
df.drop_duplicates(subset=['name']) # 根据指定的name列去重
df.drop_duplicates(subset=['name'],keep='last') # 保留最后出现的
df['age'] = df['age'].astype('int16') # 将age的int64变为int16
df['gender'] = df['gender'].astype('category') #将gender变为类别
df['is_male'] = df['gender'].map({'Male':True,'Female':False})(4)、数据变形
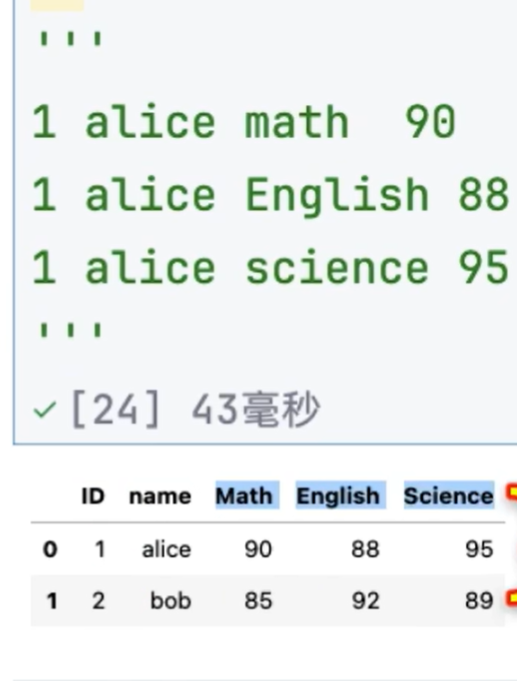
将下面的数据变形成上面的数据
# 宽表转长表
df2 = pd。melt(df,id_vars=['ID','name'],var_name='科目',value_name='成绩') # ID 和name不变 , var_name 为column名字,value_name 为value名字
df2.sort_values('name')
# 长表转宽表
pd。pivot(df2,index=['ID','name'],colunms='科目',values='成绩')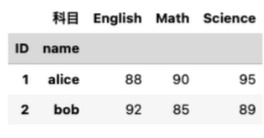
# 数据分裂,将姓名分开
df = pd.DataFrame(data)
df[['first','last']] = df['name'].str.split(" ",expand=True) # 这一步操作可以学到很多东西,将df的name列按空格分开,expand=True将分开后的列表拆开,df[[]] 将分开的两列分别作为series写入df(DataFrame)的两列
df[['high','low']] = df['blood_pressure'].str.split('/',expand=True)
df['high'] = df['high'].astype('int64') # 类型转换后注意都是字符型,如果需要对数据统计要转换成整形或浮点型 (5)、数据分箱
pd.cut(df1['salary'],bins=2) # cut将数据划分区间 bins=n,分成n段区间,起始值和结束值为最小和最大值
pd.cut(df1['salary'],bins=2).value_counts() # 统计
pd.cut(df1['salary'],bins=[0,10000,20000]).value_counts() # 指定区间
df1['收入范围'] = pd.cut(df1['salary'],bins=[0,10000,20000],lables=['低','中','高'])
pd.qcut(df['salary'],3) # 均分高低中收入人数# 睡眠数据
df = pd.read_csv('data/sleep.csv')
df1 = df.head(10)[['person_id','sleep_quality']]
df['睡眠质量'] = pd.cut(df['sleep_quality'],bins=3,labels=['差','中','优']) # 数值---》分箱---》统计
df['睡眠质量'].value_counts()
df['gender'] = df['gender'].astype('catogory') # 字符串---》类别---》统计
df['gender'].value_counts()(6)、其他操作
df = pd.DataFrame(
'name':['jack','rose'],
'age':['12','3'],
'gender':['male','female'],
)
df.set_index(name,inplece=True) # 将name变为索引,inplace在当前df上进行操作
df.reset_index(inplace=True) # 变回去
df.rename(columns={'age':'年龄'},index={0:4}) # 修改列名
df.index=[1,2,3,4] # 直接设置索引3、时间数据
(1)、基础操作
d = pd.Timestamp('2025-05-02 10:22')
print(d)
print(d.year,d.month,d.day,d.hour,d.minute,d.second,d.quarter,d.is_month_end) # quarter为季度,is_month_end 是否为月底
print(d.day_name) # day_name星期几
print(d.to_period('D')) # D转化为天 Q转化为季 Y转化为年 M转化为月 W转化为周# 数据类型转化为Timestamp
a = pd.to_datetime('2015-02-28 10:22') # 字符串类型转化为日期
df = pd.DataFrame({
'sales':[100,200,300],
'date':['20250601','20250602','20250603']
})
df['datetime'] = pd.to_datetime(df['date'])
df['week'] = df['datetime'].dt.day_time() # df['datetime'] 取出来的是Series,需要用.dt转化为DateTime数据类型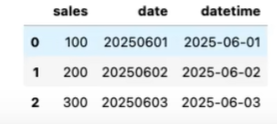
(2)、其他操作
df = pd.read_csv('data/weather.csv',parse_dates=['date']) # 把date这一列自动解析成日期类型# 其他操作
df.set_index('date',inplace=True) # 将日期设为索引
print(df.loc['2013-01':'2013-02']) # 取数据就很方便了
d1 = pd.Timestamp('2013-01-15')
d2 = pd.Timestamp('2023-01-15')\
d3 = d2 - d1 # 时间间隔
df['delta'] = df['date'] - df['date'][0] # 算出时间间隔
df.set_index('delta',inplace=True)
days = pd.date_range("2025-07-03","2026-02-09",freq="W") # 每周每年每季 DWYM 同上 YE年底 YS年初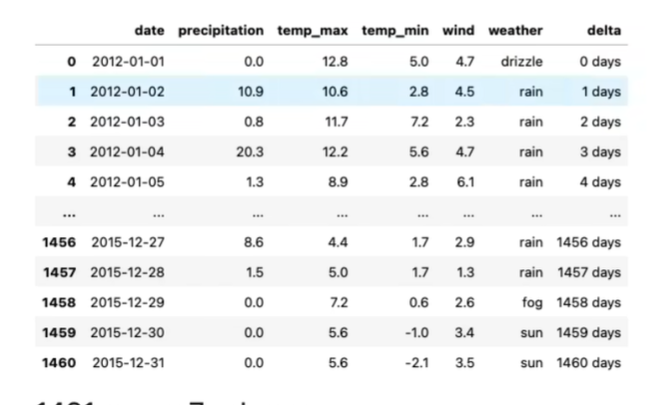
(3)、重新采样
df[["temp_max","temp_min"]].resample("YE").mean() # 重新采样,之前的数据是每天,将数据变为每周每月每年则为重新采样,可以看到 df[[]] 出来的就是一个新的dataframe df[] 就是增添新的column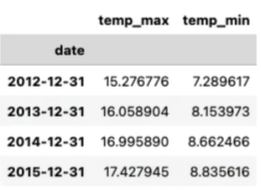
4、分组聚合
df.groupby('department_id').groups # 查看分组
df.groupby('department_id').get_group(10) # 得到department_id 为10的组
df2 = df.groupby('department_id')[['salary']],mean() # 以department_id分组,计算每组的salary平均值 (series很丑,用[[]])
df2['salary'] = df2['salary'].round(2) # 四舍五入
df2.reset_index(inplace=True)
df2.sort_values('salary',ascending=False)
df.groupby(['department_id','job_id']) # 每个部门每个岗位五、Matplotlib
1、折线图
import matplotlib.pyplot as plt
from matplotlib import rcParams # 字体
rcParams['font.family'] = 'SimHei'
plt.figure(figsize=(10,5)) # 设置纸张大小
month = ['1月','2月','3月','4月']
sales = [100,200,300,400]
plt.plot(month,sales,label='产品A') # 绘制折线图
plt.title('2025年销售趋势',color=red,fontsize=20) # 标题
plt.xlabel('月份',fontsize = 10) # 坐标轴标签
plt.ylabel('销售额(万元)',fontsize = 10)
plt.legend(loc = 'upper left') # 添加图例,左上角那个
plt.grid(True,alpha=0.5,color=blue,linestyle='--') # 背景添加网格线,True x y 两条轴都有 , alpha设置透明度 linestyle 设置线格式
plt.grid(axis='x') # 只有从x轴发出来的线
plt.xticks(rotation=0,fontsize=12) # 设置刻度大小 rotation 旋转角度
plt.xticks(rotation=0,fontsize=12)
plt.ylim(0,160) # 设置y轴范围
for x,y in zip(month,sales):
print(x,y)
plt.text(x,y+1,str(y),ha='center',va='bottom')# 在每个数据点上显示数值,ha水平方向,va竖直方向
plt.show() # 显示2、条形图
# 大部分步骤与折线图相同
subjects = ['语文','数学','英语']
scores = [54,78,89]
plt.bar(subjects,scores,lable = '小明') # 绘制柱状图
plt.barh(subjects,scores,lable = '小明') # 条形图3、饼图
subjects = ['语文','数学','英语']
times = [5,2,6]
explode=[0.1,0,0] # 让语文突出去
plt.pie(times,labels=subjects,autopct='%.1f',startangle=90,colors=['#66b3ff','#99ff99','#ffcc99'],wedgeprops={'width':0.6},pctdistance=0.6,explode=explode) # autopct 显示百分号保留一位小数startangle 起始角度 wedgeprops 设置圆环 pctdistance 百分比距离圆心距离 explode设置爆炸式饼图4、散点图
x=[]
y=[]
for i in range(1000):
tmp = random.uniform(0,10)
x.append(tmp)
y.append(2*tmp + random.gauss(0,2))
# 绘制
plt.scatter(hours.scores,s=20) # s设置原点大小