Elasticsearch简述
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建,专为处理大规模数据设计
基本概念
| 概念 | 定义 | 核心作用 | 与传统数据库类比 | 关键特性 |
|---|---|---|---|---|
| 索引(Index) | 文档的逻辑集合,用于组织同类数据(如所有商品文档组成 products 索引)。 | 1. 数据隔离:不同业务数据独立存储 2.分布式管理:自动分片(Shard)与副本(Replica)实现高性能和高可用。 | 类似数据库中的表(Table) | 1. 可分片(横向扩展) 2.可配置副本(容灾) 3.支持生命周期策略(如日志滚动删除)。 |
| 映射(Mapping) | 定义索引中字段的结构和属性(如字段类型、分词规则)。 控制数据如何被索引和查询: | 1.指定字段类型(如 text 全文分词、keyword 精确匹配) 2.优化存储和检索效率。 | 类似表结构(Schema) | 显式定义(推荐)或动态推断-影响分词、排序、聚合行为 -决定是否支持模糊搜索等。 |
| 文档(Document) | Elasticsearch 中的最小数据单元,以 JSON 格式存储(如一条商品信息)。 | 存储实际数据内容,是搜索和分析的基本对象。 | 类似表中的一行记录(Row) | 1.唯一ID标识 2.支持动态结构(字段可动态添加 3.JSON 格式灵活存储半结构化数据。 |
文档 是数据载体(如一条JSON记录)。
多个 文档 逻辑聚合为一个 索引(如所有商品文档→products索引)。
映射 定义索引中所有文档的字段规则(如price字段必须是数值类型)。
演示环境
elasticsearch-9.0.4
Kibana
索引
创建索引
创建索引并指定映射,比如创建一个产品表,带名称和价格
json
PUT products //创建一个名为products的索引
{
"settings": { //设置参数
"number_of_shards": 2, // 主分片数(创建后不可修改)
"number_of_replicas": 1 // 每个主分片的副本数
},
"mappings": { //映射
"properties": { //设置字段
"product_name":{"type": "text"}, //产品名称为文本类型
"price":{"type": "float"} //价格为浮点型
}
}
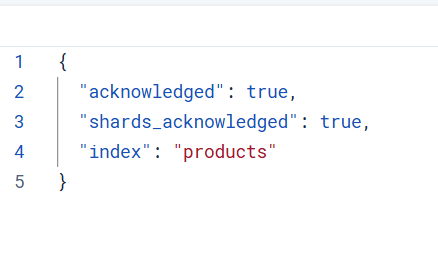
}创建成功返回信息
查询索引
json
GET products查询索引是否存在
json
HEAD products如果存在返回200,不存在返回404
修改索引配置
json
PUT products/_settings
{
"number_of_replicas": 2 // 每个主分片的副本数
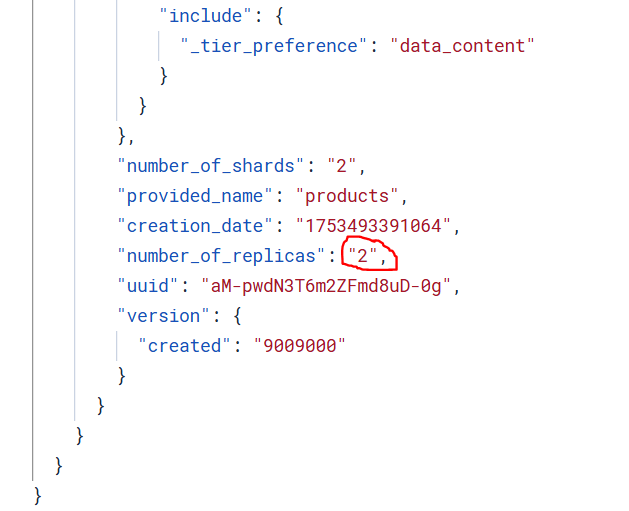
}查看索引信息,发现副本数已经修改为2
开启索引
json
POST products/_open关闭索引
json
POST products/_close删除索引
json
DELETE products索引别名
创建一个同类型的名为products_other索引
如果想查俩个不同的索引时可以将索引以(,)逗号隔开
json
GET products,products_other/_search但是这样很不方便,如果索引很多,连接的就很长
解决方法就是设置索引别名,将连个索引关联起来
json
POST _aliases
{
"actions": [
{
"add": {
"index": "products", //索引名
"alias": "product_index" //设置的别名
}
},
{
"add": {
"index": "products_other", //索引名
"alias": "product_index" //设置的别名
}
}
]
}这样搜索方法就直接用别名就可以了
json
GET product_index/_search补充:
删除索引后:
1.该索引的所有别名会自动被删除
2.别名不会独立存在,它只是指向索引的"指针"
3.删除索引后,指向它的所有别名都会失效并被移除
查询所有索引
json
GET /_cat/indices?v常见参数:
v - 显示列标题
h - 指定返回字段,如 h=index,docs.count,store.size
s - 排序字段,如 s=index:desc
format=json - 返回 JSON 格式
使用完整参数,看的更清晰
json
GET /_cat/indices?v&h=index,docs.count,store.size&s=index:asc查询结果,14行以上的都是系统索引,其它的都是我们自己创建的索引

映射
字段数据类型(Data Types)
| 类型 | 用途 | 示例 |
|---|---|---|
| text | 全文检索(分词处理) | 商品描述、文章内容 |
| keyword | 精确值匹配(不分词) | 订单状态、标签 |
| integer/long | 整数值 | 库存数量、用户年龄 |
| float/double | 浮点数 | 商品价格、评分 |
| date | 日期和时间 | 订单创建时间、日志时间戳 |
| boolean | 布尔值 | 是否上架、用户激活状态 |
| geo_point | 经纬度坐标 | 商家位置、配送地址 |
| nested | 存储对象数组(保留子文档独立性) | 订单中的商品列表 |
字段参数
1.索引控制
index:
true(默认) 字段可被搜索
false 字段不可搜索(节省磁盘,适用展示型字段)
doc_values:
true(默认) 启用列式存储,支持排序/聚合
false 禁用聚合能力(节省磁盘)
例子:
json
"name": { //字段名
"type": "text", //字段类型
"index": false // 禁止搜索
}2.分词优化
| 参数 | 说明 |
|---|---|
| analyzer | 索引时使用的分词器(如 ik_smart 中文智能切分) |
| search_analyzer | 搜索时使用的分词器(默认与 analyzer 一致) |
| ignore_above | 超过长度后忽略索引(keyword 字段专用,避免长文本浪费资源) |
设置中文分词例子:
json
"title": {
"type": "text",
"analyzer": "ik_max_word", // 索引时分词(细粒度)
"search_analyzer": "ik_smart"} // 搜索时分词(粗粒度,提升召回率)- 存储控制
| 参数 | 说明 |
|---|---|
| store | true:独立存储原始值(默认 false,从 _source 提取) |
| enabled | false:整个 JSON 对象不索引(仅存储,适用于二进制数据) |
创建映射
定义索引时指定,以上创建索引时已经用,在此不演示
更新映射
限制:已存在字段的类型不允许修改(需重建索引)
例如我现在要给products索引添加一个描述字段(description)
json
PUT products/_mapping
{
"properties": {
"description": {
"type": "text"
}
}
}查看映射,多了一个description字段

查看映射
json
GET /products/_mapping文档
动态创建:插入文档时若索引不存在,Elasticsearch 会自动创建索引(使用默认配置)
插入文档
手动输入ID插入
json
POST products/_doc/1
{
"product_name":"笔记本",
"description":"最新品笔记本",
"price": 6999
}自动ID插入
json
POST products/_doc
{
"product_name":"电脑",
"description":"最新品电脑",
"price": 9999
}查询文档
json
GET products/_search查看数据

更新文档
局部更新(未传字段保留原值)
将笔记本价格调整到12999元
json
POST /products/_update/1
{
"doc": { "price": 12999 } // 只修改价格
}全量替换(需传完整字段)
将电脑替换成冰箱
json
POST /products/_doc/0SKSRJgBSvl7mPAWpAaZ
{
"product_name":"冰箱",
"description":"最新品冰箱",
"price": 3000
}查询结果

删除文档
ID删除
json
DELETE products/_doc/0SKSRJgBSvl7mPAWpAaZ条件删除
删除名字为笔记本的产品
json
POST /products/_delete_by_query
{
"query": { "match":{"product_name":"笔记本"} }
}批量处理
批量索引
Bulk API 允许在单个请求中执行多个索引/删除操作:
批量创建索引必须带文档
_bulk API 不能 用于创建空索引(不包含文档的索引)
字段类型也不能指定,是自动创建的
json
POST _bulk
{ "create" : { "_index" : "users", "_id" : "1" } }{ "name" : "张三", "age" : 25, "email" : "zhangsan@example.com" }{
"create" : { "_index" : "users", "_id" : "2" } }{ "name" : "李四", "age" : 30, "email" : "lisi@example.com" }批量删除文档
删除以上的ID为1和2的用户
json
POST _bulk
{ "delete" : { "_index" : "users", "_id" : "1" } }{
"delete" : { "_index" : "users", "_id" : "2" } }批量插入
如果索引不存在,在第一次批量导入时,Elasticsearch会自动创建索引并推断字段类型。但自动推断可能不符合预期,因此建议预先定义映射。
用 index:
需要强制更新文档(无论是否存在)
例如:同步外部数据源时覆盖旧数据
用 create:
需要确保文档唯一性(避免重复插入)
json
POST _bulk
{ "index" : { "_index" : "user", "_id" : "101" } }{
"name" : "zs", "age" : 18 }{
"create" : { "_index" : "user", "_id" : "102" } }{
"name" : "ls", "age" : 20 }以上会自动创建索引
批量更新
将以上user索引数据ID 1和2的年龄改为22
json
POST _bulk
{ "update" : {"_id" : "101", "_index" : "user"} }{ "doc" : {"age" : "22"} }{
"update" : {"_id" : "102", "_index" : "user"} }{ "doc" : {"age" : "22"} }批量查询
json
GET _msearch
{"index" : "user"}{"query" : {"match_all" : {}}, "from" : 0, "size" : 10}{
"index" : "users"}{"query" : {"match_all" : {}}}关联关系
| 方案 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 冗余存储(宽表) | 将关联数据直接嵌入主文档 | 查询最快,无需额外操作 | 数据冗余,更新复杂 | 一对少,读多写少 |
| 嵌套类型(Nested) | 子文档独立存储,保留关联性 | 精准查询子文档 | 查询性能较低,更新成本高 | 一对少,需独立查询子文档 |
| 父子文档(Join) | 父/子文档分开存储,通过关系字段关联 | 支持一对多,更新灵活 | 查询性能差,内存消耗大 | 写多读少,层级关系复杂 |
| 应用层关联 | 多次查询,程序内存中拼接结果 | 灵活,无ES限制 | 网络开销大,延迟高 | 跨索引关联或复杂逻辑 |
1.冗余存储(宽表)
原理:将关联数据作为字段直接嵌入主文档(反范式化)。
示例:订单与订单商品
查询:直接检索主文档,无需额外操作。
适用:商品详情变化少的场景(如订单历史)
创建索引
json
PUT /orders
{
"mappings": {
"properties": {
"order_id": { "type": "keyword" },
"products": { // 商品数组直接嵌入
"type": "object",
"properties": {
"product_id": { "type": "keyword" },
"name": { "type": "text" }
}
}
}
}
}插入数据
json
POST /orders/_doc/1
{
"order_id": "O1001",
"products": [
{ "product_id": "P101", "name": "无线耳机" },
{ "product_id": "P102", "name": "手机壳" }
]
}以下数据将订单数据和产品数据融合在一起造成冗余

2.嵌套类型(Nested)
原理:子文档独立存储,避免对象数组的平铺问题。
示例:博客与评论
适用:子文档需独立查询(如评论搜索)。
创建索引
json
PUT /blogs
{
"mappings": {
"properties": {
"title": { "type": "text" },
"comments": {
"type": "nested", // 关键:声明为nested
"properties": {
"user": { "type": "keyword" },
"content": { "type": "text" }
}
}
}
}
}插入数据
json
POST /blogs/_doc/1
{
"title": "Elasticsearch指南",
"comments": [
{ "user": "Alice", "content": "非常实用!" },
{ "user": "Bob", "content": "缺少示例" }
]
}
POST /blogs/_doc/2
{
"title": "mysql指南",
"comments": [
{ "user": "Alice", "content": "非常不实用!" },
{ "user": "Bob", "content": "示例不好" }
]
}查询数据
json
GET /blogs/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{ "match": { "comments.user": "Alice" } },
{ "match": { "comments.content": "不" } }
]
}
}
}
}
}
3.父子文档(Join)
原理:通过 join 类型字段建立父子关系,分开存储。
示例:部门(父)与员工(子)
适用:层级关系复杂且需频繁更新的场景(如组织架构)。
创建索引
json
PUT /company
{
"mappings": {
"properties": {
"id": { "type": "keyword" },
"relation_type": { // 关键:声明join关系
"type": "join",
"relations": { "department": "employee" }
},
"name": { "type": "text" }
}
}
}插入数据
json
// 插入父文档(部门)
POST /company/_doc/1
{
"id": "D100",
"name": "研发部",
"relation_type": { "name": "department" }
}
// 插入子文档(员工)
POST /company/_doc/2?routing=D100 // 必须与父文档同分片
{
"id": "E101",
"name": "张三",
"relation_type": {
"name": "employee",
"parent": "D100" // 指向父文档ID
}
}查询数据
查找部门所有员工
json
GET /company/_search
{
"query": {
"parent_id": {
"type": "employee",
"id": "D100"
}
}
}4.应用层关联
原理:通过多次查询 + 程序内存中拼接结果。
示例:用户 + 订单(跨索引查询)
优化:使用 _mget 或 _search 的 terms 查询批量获取数据。
适用:ES无法直接处理的复杂关联(如多对多关系)。
技术选型
| 方案 | 写入性能 | 查询性能 | 数据一致性 | 开发复杂度 |
|---|---|---|---|---|
| 冗余存储 | 低 | 极高 | 难维护 | 低 |
| Nested | 中 | 中 | 强 | 中 |
| Join | 高 | 低 | 强 | 高 |
| 应用层关联 | 高 | 依赖实现 | 依赖实现 | 高 |
Object 优先考虑反范式,会将数组扁平化处理,对查询不友好
Nested 当数据包含多个数组对象,同时有查询需求
Join 关联文档更新频繁
避免过多字段
使用dynamic 限制动态字段创建
json
{
"mappings": {
"dynamic": "strict", // 或 "false"
"properties": {
// 明确定义允许的字段
}
}
}避免空值
空值(null或空数组/字符串)在Elasticsearch中会影响存储效率和查询性能
映射时设置默认值
使用null_value为字段指定默认值
json
{
"mappings": {
"properties": {
"price": {
"type": "float",
"null_value": 0.0
}
}
}
}DSL语法
Elasticsearch 的查询 DSL (Domain Specific Language) 是一种基于 JSON 的查询语言,用于构建复杂的查询和聚合操作
演示数据
json
// 创建索引即映射
PUT users
{
"mappings": {
"properties": {
"name":{"type": "keyword"},
"age":{"type": "long"},
"address":{"type": "text","analyzer": "ik_max_word", // 索引时分词(细粒度)
"search_analyzer": "ik_smart"} // 搜索时分词(粗粒度,提升召回率)
}
}
}
// 插入数据
POST _bulk
{"create":{"_index":"users","_id":1}}{"name":"张三","age":18,"address":"湖北省武汉市洪山区白云路"}{
"create":{"_index":"users","_id":2}}{"name":"李四","age":20,"address":"北京市东城区毛家湾胡同甲"}{
"create":{"_index":"users","_id":3}}{"name":"王五","age":19,"address":"上海市静安区秣陵路"}查询结构框架
json
{
"query": { ... }, // 查询条件
"aggs": { ... }, // 聚合分析
"from": 0, // 分页起始
"size": 10, // 返回数量
"sort": [ ... ], // 排序规则
"_source": [ ... ], // 返回字段控制
"highlight": { ... } // 高亮设置
}match_all 查询
match_all 查询是 Elasticsearch 中最简单的查询,它匹配索引中的每一个文档。当你需要返回所有文档,或者在没有指定查询条件时,可以使用它
获取全部文档
json
GET users/_search
{
"query": {
"match_all": {}
}
}默认查询:当未指定查询条件时,Elasticsearch 默认使用 match_all
分页
json
GET users/_search
{
"query": {
"match_all": {}
},
"from":0,
"size": 10
}from从第0个文档开始
size返回10个文档
在默认情况下match_all不会返回全部文档,而是返回10个文档
排序
将年龄以降序排序
json
GET users/_search
{
"query": {
"match_all": {}
},
"sort": [ //使用排序
{
"age": { //按年龄排序
"order": "desc" //以降序排序,asc为升序
}
}
]
}返回部分字段
只返回名字
json
GET users/_search
{
"query": {
"match_all": {}
},
"_source": ["name"] //设置返回名字,这是一个数组可以返回多个字段
}精确查询
精确查询是 Elasticsearch 中最核心的查询类型之一,用于对不分词的字段进行完全匹配,例如ID、年龄等...搜索
term(常用功能)
不要使用text类型字段进行搜索,可能会搜不到可以使用keyword类型的字段,keyword类型不会分词,text会分词,所以查不到,如果匹配数组只要满足其中一个就可以返回
搜索年龄为20岁的人
json
GET /users/_search
{
"query": {
"term": {
"age": { // 字段名
"value": "20" // 精确值
}
}
}
}结果

搜索叫张三的人,name字段是keyword类型所以可以搜到
json
GET users/_search
{
"query": {
"term": {
"name": {
"value": "张三"
}
}
}
}结果

搜索地址为上海市静安区秣陵路
json
GET users/_search
{
"query": {
"term": {
"address": {
"value": "上海市静安区秣陵路"
}
}
}
}结果

由于address字段是text类型所以搜不到,但是如果将搜索内容改为上海就可以搜索到了
json
GET users/_search
{
"query": {
"term": {
"address": {
"value": "上海"
}
}
}
}结果

term 查询是精确匹配,不会对查询内容进行分词,所以搜索内容改为上海了可以在分词里面找到文档就可以搜到了
避免算分
由于使用term查询,不做分词处理,所以不需要算分,提升性能
使用 constant_score 包装 term 查询,这会为所有匹配的文档赋予相同的固定分数(默认为1)
json
GET users/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"name": "王五"
}
}
}
}
}terms(常用功能)
terms 查询是 Elasticsearch 中用于多值精确匹配的查询方式,它允许您指定一个字段和多个值进行匹配
搜索张三和王五
json
GET users/_search
{
"query": {
"terms": {
"name": [
"张三",
"王五"
]
}
}
}结果

range(常用功能)
range 查询是 Elasticsearch 中用于范围匹配的查询方式,它允许您查找字段值在指定范围内的文档。
范围参数说明
| 参数 | 含义 | 示例 |
|---|---|---|
| gte | 大于或等于 (≥) | "gte": 100 |
| gt | 大于 (>) | "gt": 100 |
| lte | 小于或等于 (≤) | "lte": 200 |
| lt | 小于 (<) | "lt": 200 |
数值类型 (integer, long, float, double)
搜索19到20的人
json
GET users/_search
{
"query": {
"range": {
"age": {
"gte": 19,
"lte": 20
}
}
}
}结果

日期类型 (date)
高频使用场景速查表
| 场景 | 表达式 | 等效含义 |
|---|---|---|
| 最近24小时 | now-1d | 昨天此刻到现在 |
| 今日全天数据 | now/d | 今天00:00:00开始 |
| 本月数据 | now/M | 本月1日00:00:00开始 |
| 上周同期 | now-1w/w | 上周第一天00:00:00 |
| 整点查询 | now/h | 当前小时开始(如14:00:00) |
| 季度初至今 | now/3M | 当前季度第一天00:00:00 |
查询2023年的数据
json
GET /logs/_search
{
"query": {
"range": {
"timestamp": {
"gte": "2023-01-01",
"lte": "2023-12-31",
"format": "yyyy-MM-dd"
}
}
}
}日期的数学表达式
json
GET /logs/_search
{
"query": {
"range": {
"timestamp": {
"gte": "now-1d/d", // 昨天开始
"lt": "now/d" // 今天之前
}
}
}
}IP地址类型 (ip)
查询IP:192.168.1.1 至 192.168.1.254
json
GET /servers/_search
{
"query": {
"range": {
"ip_address": {
"gte": "192.168.1.1",
"lte": "192.168.1.254"
}
}
}
}exists
exists 查询用于查找包含指定字段的文档(无论字段值是什么),是检查字段是否存在的高效方式
json
GET users/_search
{
"query": {
"exists": {
"field": "name"
}
}
}查到就返回数据结果
ids
ids 查询是 Elasticsearch 中用于根据文档 ID 查找文档的高效查询方式,它可以直接通过文档的 _id 字段来检索文档。
搜索users索引ID为1和2的数据
json
GET users/_search
{
"query": {
"ids": {
"values": ["1", "2"]
}
}
}模糊匹配查询
| 查询类型 | 匹配方式 | 性能 | 典型用途 |
|---|---|---|---|
| prefix | 前缀匹配 | 高 | 分类编码、ID前缀 |
| wildcard | 通配符 | 中 | 复杂模式匹配 |
| regexp | 正则表达式 | 低 | 复杂模式 |
| fuzzy | 模糊匹配 | 中 | 容错搜索 |
prefix
prefix查询是 Elasticsearch 中用于查找以指定前缀开头的词项的查询方式,特别适合实现自动补全、分类筛选等功能。
json
GET users/_search
{
"query": {
"prefix": {
"name": {
"value": "王"
}
}
}
}对keyword类型高效,对text类型需谨慎
wildcard
wildcard 查询是 Elasticsearch 中支持通配符匹配的查询方式,它允许使用标准的通配符模式来查找文档,特别适合部分匹配、模糊查找等场景。
| 通配符 | 功能 | 示例 | 匹配示例 |
|---|---|---|---|
| * | 匹配0个或多个字符 | te*t | "test", "teast", "telt" |
| ? | 匹配任意单个字符 | te?t | "test", "teat" (不匹配"telt") |
| \ | 转义特殊字符 | te*st | 只匹配"te*st" |
最适合keyword类型字段
json
GET users/_search
{
"query": {
"wildcard": {
"name": {
"value": "张?"
}
}
}
}regexp
正则表达式查询(regexp)是Elasticsearch提供的强大模式匹配工具,允许使用正则表达式语法进行复杂的文本匹配。
核心参数说明
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| value | 字符串 | 必填 | 有效的正则表达式 |
| flags | 字符串 | "ALL" | 正则引擎标志 |
| max_determinized_states | 整数 | 10000 | 限制自动机状态数 |
基础元字符
| 语法 | 功能 | 示例 |
|---|---|---|
| . | 匹配任意字符 | a.c → "abc", "aac" |
| * | 前导字符0次或多次 | ab*c → "ac", "abbc" |
| + | 前导字符1次或多次 | ab+c → "abc", "abbc" |
| ? | 前导字符0或1次 | ab?c → "ac", "abc" |
| {n} | 精确匹配n次 | a{3} → "aaa" |
| abc | 字符集合 | abc → "ac", "bc" |
| \^abc | 否定字符集 | \^abc → "dc" (非"ac"/"bc") |
fuzzy
fuzzy 查询是 Elasticsearch 中用于处理拼写错误和近似匹配的强大工具,它基于编辑距离(Edit Distance)算法实现容错搜索。
核心参数解析
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| fuzziness | 字符串/整数 | "AUTO" | 允许的最大编辑距离 |
| max_expansions | 整数 | 50 | 生成的最大变体数 |
| prefix_length | 整数 | 0 | 不被模糊化的前缀长度 |
| transpositions | 布尔 | true | 是否允许相邻字符交换(ab→ba) |
由于输错将张三搜成了张四,依然可以搜到结果
json
GET users/_search
{
"query": {
"fuzzy": {
"name": {
"value":"张四",
"fuzziness":1
}
}
}
}补充:
terms_set 查询是 Elasticsearch 中一种特殊的术语查询,它允许您根据文档中字段包含的术语数量进行匹配。这种查询特别适合需要基于匹配术语数量的场景,如标签匹配、权限控制等。
核心参数
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| terms | 数组 | 是 | 要匹配的术语列表 |
| minimum_should_match_field | 字符串 | 可选 | 指定包含最小匹配数的字段名 |
| minimum_should_match_script | 对象 | 可选 | 脚本计算最小匹配数 |
| minimum_should_match | 数字/字符串 | 可选 | 固定最小匹配数 |
全文检索(Elasticsearch 核心功能)
全文检索是 Elasticsearch 最核心的功能之一,它允许对文本内容进行高效、灵活的搜索。
核心查询类型
| 查询类型 | 特点 | 适用场景 |
|---|---|---|
| match | 标准全文检索 | 常规内容搜索 |
| match_phrase | 短语匹配 | 精确短语搜索 |
| multi_match | 多字段检索 | 跨字段搜索 |
| query_string | 复杂查询语法 | 高级搜索框 |
match(常用功能)
核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| query | 字符串/数字 | 必填 | 要搜索的内容 |
| operator | 字符串 | "or" | 逻辑运算符(and/or) |
| minimum_should_match | 字符串/数字 | - | 最小匹配词项数 |
| fuzziness | 字符串/数字 | - | 模糊匹配容错度 |
| analyzer | 字符串 | 字段默认 | 指定分析器 |
| boost | 浮点数 | 1.0 | 权重提升值 |
找到名字为王五的人
json
GET users/_search
{
"query": {
"match": {
"name": "王五"
}
}
}multi_match(常用功能)
multi_match 查询是 Elasticsearch 中用于在多个字段上执行全文检索的查询类型,它扩展了基础的 match 查询功能,允许同时搜索多个字段
核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| query | 字符串 | 必填 | 要搜索的文本内容 |
| fields | 数组 | 必填 | 要搜索的字段列表,可用^n设置权重 |
| type | 字符串 | "best_fields" | 查询类型(见下文) |
| tie_breaker | 浮点数 | 0.0 | 次要字段得分权重系数 |
| minimum_should_match | 字符串 | - | 最小匹配词项数 |
json
GET users/_search
{
"query": {
"multi_match": {
"query": "湖北北京",
"fields": ["address"]
}
}
}match_phrase
match_phrase 查询是 Elasticsearch 中用于精确匹配短语的查询类型,它要求查询词项必须按照指定顺序完整出现,且位置相邻。
核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| query | 字符串 | 必填 | 要匹配的短语 |
| slop | 整数 | 0 | 允许的词项间隔数 |
| analyzer | 字符串 | 字段默认 | 指定分析器 |
查询湖北省某市的洪山区
json
GET users/_search
{
"query": {
"match_phrase": {
"address": {
"query": "湖北省洪山区", //查询内容
"slop": 5 //设置分词间隔距
}
}
}
}结果

query_string
query_string 查询是 Elasticsearch 提供的最灵活、最强大的查询类型之一,它支持完整的 Lucene 查询语法,适合实现高级搜索功能。
核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| query | 字符串 | 必填 | 查询表达式 |
| default_field | 字符串 | * | 默认搜索字段 |
| fields | 数组 | - | 多字段搜索 |
| default_operator | 字符串 | OR | 默认逻辑运算符 |
| analyzer | 字符串 | 字段默认 | 指定分析器 |
| allow_leading_wildcard | 布尔 | false | 允许前导通配符 |
| fuzziness | 字符串 | - | 模糊匹配设置 |
查询地址有山区和云路的
json
GET users/_search
{
"query": {
"query_string": {
"default_field": "address",
"query": "山区 AND 云路" //可以在里面添加一些逻辑,比如AND
}
}
}结果

json
GET users/_search
{
"query": {
"query_string": {
"query": "山区 OR 路" //可以在里面添加一些逻辑,比如AND
}
}
}结果搜出来2个

补充:
query_string查询提供了极大的灵活性,但也需要谨慎使用以避免性能问题和安全风险。对于用户输入的搜索内容,建议进行适当的验证和转义。
simple_query_string
simple_query_string 查询是 Elasticsearch 提供的比 query_string 更简单、更安全的查询类型,它支持有限的 Lucene 查询语法,更适合直接暴露给终端用户使用。
用法和query_string差不多
bool (常用功能)
bool 查询是 Elasticsearch 中最重要、最常用的复合查询,它允许将多个查询条件通过布尔逻辑组合在一起,实现复杂的搜索需求。
可以组合使用,嵌套使用
四个核心子句
| 子句 | 说明 | 贡献得分 | 缓存 |
|---|---|---|---|
| must | 必须匹配(AND) | 是 | 否 |
| filter | 必须匹配(AND) | 否 | 是 |
| should | 应该匹配(OR) | 是 | 否 |
| must_not | 必须不匹配(NOT) | 否 | 是 |
搜索地址为城区,不是21岁的人
json
GET users/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {"age": 21}
}
],
"must": [
{
"match": {
"address": "城区"
}
}
]
}
}
}结果

高亮显示(Highlighting)
高亮显示是搜索功能中的重要特性,它能够将搜索结果中匹配到的关键词进行特殊标记,提升用户体验。
核心配置参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| pre_tags | 数组 | <em> | 高亮开始标签 |
| post_tags | 数组 | </em> | 高亮结束标签 |
| fragment_size | 整数 | 100 | 每个片段字符数 |
| number_of_fragments | 整数 | 5 | 返回片段数 |
| no_match_size | 整数 | 0 | 无匹配时返回的文本长度 |
| require_field_match | 布尔 | true | 是否要求字段匹配 |
对搜索的北京市开启高亮显示
json
GET users/_search
{
"query": {
"match": { "address": "北京市" }
},
"highlight": {
"pre_tags":"<font color='red'>", //设置标签开头
"post_tags":"</font>", //设置标签结尾
"fields": { //"fields": {"*":{}} 对所有的字段高亮显示
"address": {} // 对address字段启用高亮
}
}
}结果

地理位置
Elasticsearch 提供了强大的地理位置数据处理和查询能力,支持多种地理空间查询类型和地理数据类型。
json
//创建索引
PUT areas
{
"mappings": {
"properties": {
"name":{"type": "text","analyzer":"ik_max_word"},
"position":{"type": "geo_point"}
}
}
}
//lon为经度 lat为维度
//插入数据
POST _bulk
{
"create":{"_index":"areas","_id":1}}{"name":"武汉博物馆","position":{"lon":114.26,"lat":30.62}}{
"create":{"_index":"areas","_id":2}}{"name":"武昌火车站","position":{"lon":114.32,"lat":30.53}}{
"create":{"_index":"areas","_id":3}}{"name":"黄鹤楼","position":{"lon":114.31,"lat":30.55}}百度地图
geo_distance
geo_distance 是 Elasticsearch 中用于查找指定距离范围内的地理点数据的查询方式。
核心参数
| 参数 | 类型 | 必填 | 说明 | 示例值 |
|---|---|---|---|---|
| distance | 字符串 | 是 | 搜索半径距离 | "2km", "1.5mi" |
| FIELD_NAME | geo_point | 是 | 地理点字段名 | "location" |
| lon | 浮点数 | 是 | 中心点经度 | 114.31 |
| lat | 浮点数 | 是 | 中心点纬度 | 30.55 |
| distance_type | 字符串 | 否 | 距离计算方式 | "arc"(默认), "plane" |
| validation_method | 字符串 | 否 | 坐标验证方式 | "STRICT", "IGNORE_MALFORMED" |
补充:
距离计算方式(distance_type)
- arc(默认)
最精确的计算方式
考虑地球曲率
计算开销较大 - plane
将地球视为平面
计算速度快
近距离时精度尚可(<100km)
距离单位支持
Elasticsearch 支持以下距离单位:
| 单位 | 描述 | 示例 |
|---|---|---|
| m | 米 | "1000m" |
| km | 千米 | "2km" |
| mi | 英里 | "5mi" |
| yd | 码 | "500yd" |
| ft | 英尺 | "1000ft" |
| in | 英寸 | "5000in" |
| nmi | 海里 | "1nmi" |
本人在黄鹤楼,查附近3km的地点
json
GET /areas/_search
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"geo_distance": {
"distance": "3km", //附近3km
"distance_type": "arc", //使用arc类型
"position": { // 本人坐标,假设在黄鹤楼
"lat": 30.55,
"lon": 114.31
}
}
}
}
}
}返回结果,3km内有武昌火车站和黄鹤楼
json
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "areas",
"_id": "2",
"_score": 1.0,
"_source": {
"name": "武昌火车站",
"position": {
"lon": 114.32,
"lat": 30.53
}
}
},
{
"_index": "areas",
"_id": "3",
"_score": 1.0,
"_source": {
"name": "黄鹤楼",
"position": {
"lon": 114.31,
"lat": 30.55
}
}
}
]
}
}向量检索
向量检索是 Elasticsearch 中用于处理高维向量数据的搜索技术,广泛应用于相似性搜索、推荐系统和语义搜索等场景。
创建向量检索和数据
json
//创建向量表
PUT image
{
"mappings": {
"properties": {
"title":{"type": "keyword"},
"image_vector":{"type": "dense_vector","dims": 3} //指定维度3
}
}
}
//批量创建数据
POST _bulk
{
"create":{"_index":"image","_id":1}}{"title":"苹果","image_vector":[0.9, 0.1, 0.8]}{
"create":{"_index":"image","_id":2}}{"title":"香蕉","image_vector":[0.6, 0.3, 0.7]}{
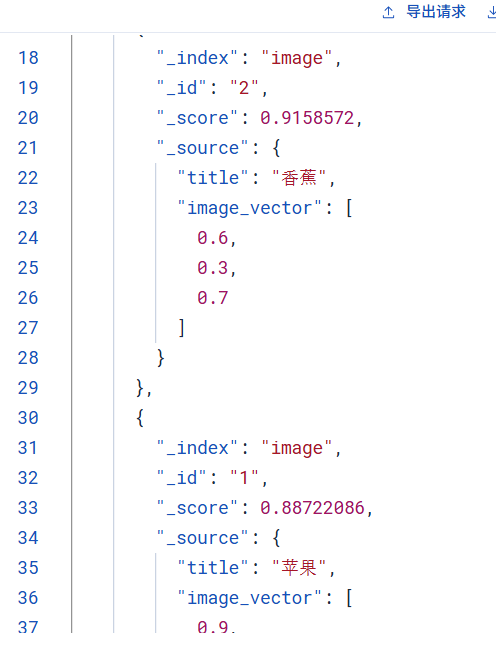
"create":{"_index":"image","_id":3}}{"title":"草莓","image_vector":[0.8, 0.5, 0.6]}查询与[0.1, 0.1, 0.8]相似的水果
json
GET /image/_search
{
"knn": {
"field": "image_vector",
"query_vector": [0.1, 0.1, 0.8], //值
"k": 2, //取最相似的数量
"num_candidates": 100 //候选向量数量
}
}查询结果:查看分数香蕉最相似
相关性评分机制
相关性评分(Relevance Scoring)是 Elasticsearch 搜索能力的核心,它决定了文档与查询条件的匹配程度,并按相关性高低排序返回结果。
TF-IDF 算法(Elasticsearch 5.x 之前默认)
BM25 (Best Matching 25) 是 Elasticsearch 5.0 及以后版本默认使用的相关性评分算法,它是在传统 TF-IDF 算法基础上优化而来的概率模型算法
相关性修改(常用功能)
字段权重提升 (Boost)
json
GET /products/_search
{
"query": {
"multi_match": {
"query": "智能手机",
"fields": ["title^3", "description^1.5", "tags^2"],
"type": "most_fields"
}
}
}title^3 表示 title 字段的权重是基准的 3 倍
适用于明确知道某些字段更重要的情况
降低相关性(常用功能)
使用负向 Boost
json
GET /products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "category": "电子产品" } }
],
"must_not": [ // 完全排除
{ "term": { "is_outdated": true } }
],
"should": [
{
"match": {
"name": {
"query": "手机",
"boost": 0.2 // 显著降低权重
}
}
}
]
}
}
}negative_boost
negative_boost 是一个用于调整查询相关性评分的参数,主要用于 boosting 查询(boosting query) 中。它的作用是降低某些文档的评分,而不是完全排除它们。
negative_boost 值:介于 0 和 1 之间,值越小,负面匹配的文档评分越低。
例子
json
GET products/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "apple"
}
},
"negative": {
"match": {
"title": "company"
}
},
"negative_boost": 0.2 // 匹配 negative 的文档评分 × 0.2
}
}
}匹配 title:apple 的文档会正常计算评分。
如果文档同时匹配 title:company,则其评分会乘以 0.2,从而降低排名。
自定义评分(常用功能)
自定义评分是 Elasticsearch 中强大的功能,允许您超越默认的相关性算法,根据业务需求定制评分逻辑。以下是实现自定义评分的全面方法。
结构
json
GET /products/_search
{
"query": {
"function_score": {
"query": { "match": { "name": "手机" } }, // 基础查询
"functions": [ // 评分函数列表
// 这里添加各种评分函数
],
"score_mode": "multiply", // 函数结果组合方式
"boost_mode": "multiply", // 与原始查询分数结合方式
"max_boost": 3.0 // 最大分数限制
}
}
}查询后二次打分(常用功能)
在 Elasticsearch 中实现查询后的二次打分(re-ranking)是提升搜索结果质量的高级技术。
json
GET /news/_search
{
"query": {
"match": {
"title": "世界杯"
}
},
"rescore": {
"window_size": 50, // 只对前50个结果重新打分
"query": {
"rescore_query": {
"function_score": {
"field_value_factor": {
"field": "view_count", // 根据浏览量提升
"factor": 0.1, // 调节因子
"modifier": "log1p" // 对数平滑
}
}
},
"query_weight": 1.0, // 原始查询权重
"rescore_query_weight": 0.5 // 二次打分权重
}
}
}多字段搜索场景优化
最佳字段类型处理
dis_max
json
GET /products/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "title": "apple phone" }},
{ "match": { "description": "apple phone" }}
],
"tie_breaker": 0.3
}
}
}工作原理:取所有字段匹配中的最高分
tie_breaker:为其他匹配字段添加部分分数(0-1)
0.0 = 仅取最高分(默认)
0.3 = 最高分 + 其他字段分×0.3
1.0 = 所有字段分求和
multi_match
json
GET /products/_search
{
"query": {
"multi_match": {
"query": "apple phone",
"type": "best_fields", // 默认类型
"fields": ["title", "description"],
"tie_breaker": 0.3
}
}
}等价于dis_max查询,但语法更简洁
多数字段类型处理(most_fields)
most_fields 是 Elasticsearch 多字段搜索的核心策略之一,特别适用于需要组合多个字段匹配结果的场景
关键参数
fields:指定搜索字段,可添加权重(如 title^3)
operator:and(必须包含所有词)或 or(包含任一词)
minimum_should_match:控制最少匹配词项比例
tie_breaker:调整最佳字段的权重(0.0-1.0)
json
GET /products/_search
{
"query": {
"multi_match": {
"query": "智能手机 5G",
"type": "most_fields",
"fields": ["title^2", "description", "specs", "tags"],
"operator": "or",
"minimum_should_match": "75%"
}
}
}混合字段类型处理
cross_fields 是 Elasticsearch 多字段搜索 (multi_match) 中的高级查询类型,用于解决搜索词分散在不同字段时的相关性计算问题,特别适合处理结构化数据(如人名、地址等分散在多个字段的数据)。
json
GET /articles/_search
{
"query": {
"multi_match": {
"query": "人工智能应用",
"fields": ["title", "content", "author"],
"type": "cross_fields", // 跨字段匹配
"operator": "and" // 必须包含所有词项
}
}
}聚合
演示数据
json
//创建索引
PUT employees
{
"mappings": {
"properties": {
"name":{"type": "keyword"},
"age":{"type":"integer"},
"gender":{"type": "keyword"},
"job":{"type": "text","analyzer":"ik_max_word"},
"salary":{"type": "integer"}
}
}
}
//数据
POST _bulk
{
"create":{"_index":"employees","_id":1}}{"name":"张三","age":18,"gender":"男","job":"运营","salary":1800}{
"create":{"_index":"employees","_id":2}}{"name":"李四","age":20,"gender":"男","job":"运维","salary":2800}{
"create":{"_index":"employees","_id":3}}{"name":"王五","age":22,"gender":"女","job":"前端开发","salary":3200}{
"create":{"_index":"employees","_id":4}}{"name":"赵六","age":19,"gender":"男","job":"软件开发","salary":4300}{
"create":{"_index":"employees","_id":5}}{"name":"孙七","age":19,"gender":"女","job":"前台","salary":4200}{
"create":{"_index":"employees","_id":6}}{"name":"周八","age":20,"gender":"男","job":"保安","salary":4800}指标聚合(Metrics)
指标聚合(Metrics Aggregations)是 Elasticsearch 中最常用的聚合类型,用于计算数值型字段的统计值。
基础指标聚合
平均值聚合 (Avg)
计算公司的平均工资
json
//平均数
GET employees/_search
{
"aggs": { //聚合操作
"my_avg_salary": { //返回结果的字段名,可自定义
"avg": { //搜索最小值
"field": "salary", //要搜索的字段
"missing": 0 // 搜不到默认0
}
}
}
}结果
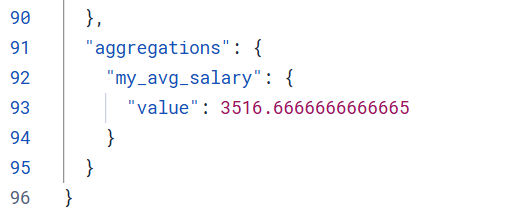
求和聚合 (Sum)
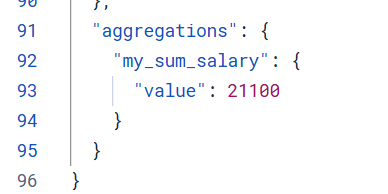
计算公司一个月要发的薪水
json
//总数
GET employees/_search
{
"aggs": { //聚合操作
"my_sum_salary": { //返回结果的字段名,可自定义
"sum": { //搜索最小值
"field": "salary", //要搜索的字段
"missing": 0 // 搜不到默认0
}
}
}
}结果
最小值/最大值聚合 (Min/Max)
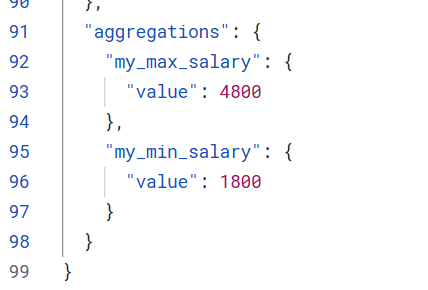
求薪水最大和最小
json
//求薪水最大和最小
GET employees/_search
{
"aggs": { //聚合操作
"my_max_salary": { //返回结果的字段名,可自定义
"max": { //搜索最小值
"field": "salary", //要搜索的字段
"missing": 0 // 搜不到默认0
}
},
"my_min_salary": { //返回结果的字段名,可自定义
"min": { //搜索最小值
"field": "salary", //要搜索的字段
"missing": 0 // 搜不到默认0
}
}
}
}结果
计数聚合 (Value Count)
默认不允许将text类型字段执行聚合,可以使用id号,由于我没有id好就用salary字段
json
GET employees/_search
{
"aggs": { //聚合操作
"my_count_salary": { //返回结果的字段名,可自定义
"value_count": { //计数
"field": "salary" //要搜索的字段
}
}
}
}结果

高级统计聚合
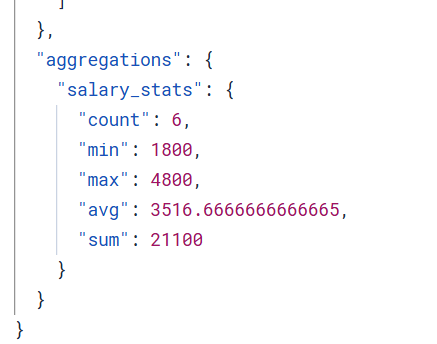
Stats
json
GET employees/_search
{
"aggs": {
"salary_stats": {
"stats": {
"field": "salary"
}
}
}
}结果
Extended Stats
json
GET employees/_search
{
"aggs": {
"salary_extended": {
"extended_stats": {
"field": "salary",
"sigma": 2 // 计算2个标准差范围
}
}
}
}去重
算不同年龄段的有几种
json
//算不同年龄段的有几种
GET /employees/_search
{
"size": 0,
"aggs": {
"unique_users": {
"cardinality": {
"field": "age",
"precision_threshold": 1000 // 精度控制(默认3000)
}
}
}
}
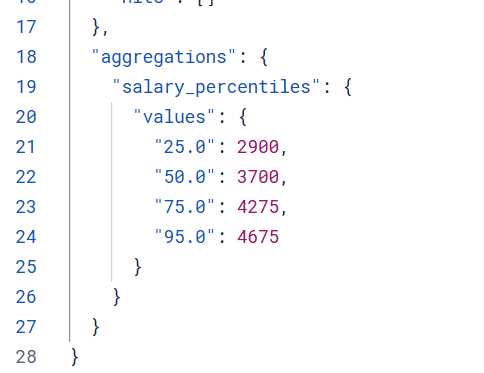
百分位数聚合
百分位聚合是一种统计聚合,用于计算数值字段的百分位数值,帮助你了解数据的分布情况。
json
GET /employees/_search
{
"size": 0,
"aggs": {
"salary_percentiles": {
"percentiles": {
"field": "salary",
"percents": [25, 50, 75, 95] // 可选,默认是[1,5,25,50,75,95,99]
}
}
}
}结果
桶聚合(Buckets)
桶聚合(Bucket Aggregations)是 Elasticsearch 中最强大的数据分析功能之一,它可以将文档分组到不同的"桶"中,类似于 SQL 中的 GROUP BY 操作。
词项聚合(Terms Aggregation)
参数说明:
size: 返回的桶数量
order: 排序方式(_count、_key 或子聚合)
min_doc_count: 最小文档数阈值
missing: 处理缺失值的桶
json
GET /employees/_search
{
"size": 0,
"aggs": {
"popular_age": {
"terms": {
"field": "age"
}
}
}
}结果

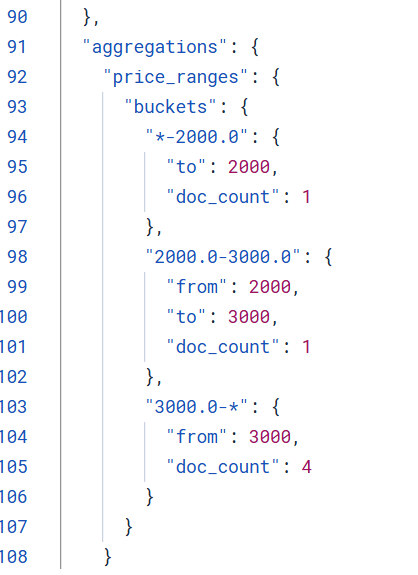
范围聚合(Range Aggregation)
json
GET /employees/_search
{
"aggs": {
"price_ranges": {
"range": {
"field": "salary",
"ranges": [
{ "to": 2000 },
{ "from": 2000, "to": 3000 },
{ "from": 3000 }
],
"keyed": true // 返回键值对形式
}
}
}
}结果
嵌套聚合(Nested Aggregations)
多级桶聚合
管道聚合(Pipelines)
管道聚合(Pipeline Aggregations)是 Elasticsearch 中一种特殊的聚合类型,它能够对其他聚合的结果进行二次处理。与指标聚合和桶聚合不同,管道聚合不直接处理文档数据,而是处理其他聚合的输出结果。
核心参数
-
buckets_path(必填参数)功能:指定要处理的聚合路径
格式:支持多级引用,如"
sales_per_month>sales" -
gap_policy(间隙策略)功能:处理缺失值或间隙数据的策略
可选值:
skip:跳过缺失的桶
insert_zeros:用0填充缺失值(默认)
-
format(格式设置)功能:格式化输出结果的key
找出所有年龄段中的最低薪资值
json
GET /employees/_search
{
"size": 0,
"aggs": {
"age_groups": {
"terms": {
"field": "age",
"size": 5,
"order": { "_count": "asc" } // 按照分组数量排序
},
"aggs": {
"min_salary": {
"min": { // 计算每个年龄段的最低薪资
"field": "salary"
}
}
}
},
"overall_min_salary": {
"min_bucket": { // 找出所有年龄段中的最低薪资值
"buckets_path": "age_groups>min_salary" // 注意这里的路径指向
}
}
}
}结果

*_bucket的前缀参数
- avg_bucket (桶平均值)
计算同级聚合的平均值 - sum_bucket (桶求和)
对多个桶的值求和 - min_bucket/max_bucket (桶最小/最大值)
找出极值桶 - percentiles_bucket (桶百分位)
计算百分位分布