第7章 流式重构
7.1 使用Lambda表达式的SOLID原则
SOLID 原则是设计面向对象程序时的一些基本原则。每种原则都对应着一系列潜在的代码异味,并为其提供了解决方案。有很多图书介绍这个主题,因此我不会详细讲解,而是关注如何在 Lambda 表达式的环境下应用其中的三条原则。在 Java 8 中,有些原则通过扩展,已经超出了原来的限制。
7.1.1 单一功能原则
程序中的类或方法只能有一个改变的理由。
计算质数个数,一个方法里塞进了多重职责
java
public long countPrimes(int upTo) {
long tally = 0;
for (int i = 1; i < upTo; i++) {
boolean isPrime = true;
for (int j = 2; j < i; j++) {
if (i % j == 0) {
isPrime = false;
}
}
if (isPrime) {
tally++;
}
}
return tally;
}将 isPrime 重构成另外一个方法后,计算质数个数的方法
java
public long countPrimes(int upTo) {
long tally = 0;
for (int i = 1; i < upTo; i++) {
if (isPrime(i)) {
tally++;
}
}
return tally;
}
private boolean isPrime(int number) {
for (int i = 2; i < number; i++) {
if (number % i == 0) {
return false;
}
}
return true;
}并行运行基于集合流的质数计数程序
java
public long countPrimes(int upTo) {
return IntStream.range(1, upTo)
.parallel()
.filter(this::isPrime)
.count();
}
private boolean isPrime(int number) {
return IntStream.range(2, number)
.allMatch(x -> (number % x) != 0);
}7.1.2 开闭原则
软件应该对扩展开放,对修改闭合。
MetricDataGraph 类的方法之一是将代理收集到的各项指标放入该类,API 如例
java
class MetricDataGraph {
public void updateUserTime(int value);
public void updateSystemTime(int value);
public void updateIoTime(int value);
}这样的设计意味着每次想往散点图中添加新的时间点,都要修改 MetricDataGraph 类。引入抽象可以解决这个问题,我们使用一个新类TimeSeries 来表示各种时间点。这时,MetricDataGraph 类的公开 API 就得以简化,不必依赖于某项具体指标。
每项具体指标现在可以实现 TimeSeries 接口,在需要时能直接插入。比如,我们可能会有 如 下 类:UserTimeSeries 、SystemTimeSeries 和 IoTimeSeries 。 如 果 要 添 加 新 的, 比如由于虚拟化所浪费的 CPU 时间,则可增加一个新的实现了 TimeSeries 接口的类:StealTimeSeries 。这样,就扩展了 MetricDataGraph 类,但并没有修改它。
java
class MetricDataGraph {
public void addTimeSeries(TimeSeries values);
}高阶函数也展示出了同样的特性:对扩展开放,对修改闭合。前面提到的 ThreadLocal 类就是一个很好的例子。ThreadLocal 有一个特殊的变量,每个线程都有一个该变量的副本并与之交互。该类的静态方法 withInitial 是一个高阶函数,传入一个负责生成初始值的Lambda 表达式。
java
// ThreadLocal 日期格式化器
// 实现
ThreadLocal<DateFormat> localFormatter
= ThreadLocal.withInitial(() -> new SimpleDateFormat());
// 使用
DateFormat formatter = localFormatter.get();
// ThreadLocal 标识符
// 或者这样实现
AtomicInteger threadId = new AtomicInteger();
ThreadLocal<Integer> localId
= ThreadLocal.withInitial(() -> threadId.getAndIncrement());
// 使用
int idForThisThread = localId.get();7.1.2 依赖反转原则
抽象不应依赖细节,细节应该依赖抽象。
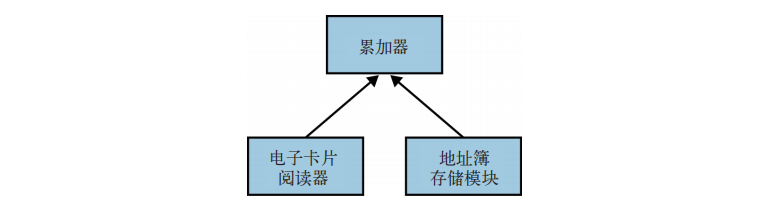
让我们看一个具体的、自动化构建地址簿的例子,实现时使用了依赖反转原则达到上层的解耦。该应用以电子卡片作为输入,使用某种存储机制编写地址簿。显然,可将代码分成如下三个基本模块:
- 一个能解析电子卡片格式的电子卡片阅读器;
- 能将地址存为文本文件的地址簿存储模块;
- 从电子卡片中获取有效信息并将其写入地址簿的编写模块。
依赖关系:
让我们看一段代码,该段代码从一种假想的标记语言中提取标题,其中标题以冒号( :)结尾。我们的方法先读取文件,逐行检查,滤出标题,然后关闭文件。
解析文件中的标题
但是代码将提取标题和资源管理、文件处理混在一起
java
public List<String> findHeadings(Reader input) {
try (BufferedReader reader = new BufferedReader(input)) {
return reader.lines()
.filter(line -> line.endsWith(":"))
.map(line -> line.substring(0, line.length() - 1))
.collect(toList());
} catch (IOException e) {
throw new HeadingLookupException(e);
}
}剥离了文件处理功能后的业务逻辑
java
public List<String> findHeadings(Reader input) {
return withLinesOf(input,
lines -> lines.filter(line -> line.endsWith(":"))
.map(line -> line.substring(0, line.length()-1))
.collect(toList()),
HeadingLookupException::new);
}
// withLinesOf方法 Reader参数处理文件,handler函数代表了执行的代码,参数error输入输出异常
private <T> T withLinesOf(Reader input,
Function<Stream<String>, T> handler,
Function<IOException, RuntimeException> error) {
try (BufferedReader reader = new BufferedReader(input)) {
return handler.apply(reader.lines());
} catch (IOException e) {
throw error.apply(e);
}
}7.2 使用Lambda表达式的一些重构技巧
7.2.1 不要重复你劳动
增加一个简单的 Order 类来计算用户购买专辑的一些有用属性,如计算音乐家人数、曲目和专辑时长。
Order 类的命令式实现
java
public long countRunningTime() {
long count = 0;
for (Album album : albums) {
for (Track track : album.getTrackList()) {
count += track.getLength();
}
}
return count;
}
public long countMusicians() {
long count = 0;
for (Album album : albums) {
count += album.getMusicianList().size();
}
return count;
}
public long countTracks() {
long count = 0;
for (Album album : albums) {
count += album.getTrackList().size();
}
return count;
}使用领域方法重构 Order 类
java
public long countFeature(ToLongFunction<Album> function) {
return albums.stream()
.mapToLong(function)
.sum();
}
public long countTracks() {
return countFeature(album -> album.getTracks().count());
}
public long countRunningTime() {
return countFeature(album -> album.getTracks()
.mapToLong(track -> track.getLength())
.sum());
}
public long countMusicians() {
return countFeature(album -> album.getMusicians().count());
}7.2.2 日志和打印消息
使用 peek 方法记录中间值
java
Set<String> nationalities
= album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.peek(nation -> System.out.println("Found nationality: " + nation))
.collect(Collectors.<String>toSet());7.2.3 合并集合操作
流的扁平化(flatMap)与连接(concat)处理集合
java
List<String> list1 = Arrays.asList("apple", "banana", "cherry", "date");
List<String> list2 = Arrays.asList("apple", "banana", "cherry", "date");
// 原始数据 - 嵌套列表
List<List<String>> nestedList = Arrays.asList(list1,list2);
// 扁平化操作 - 使用flatMap
List<String> flatMapped = nestedList.stream().flatMap(List::stream).collect(Collectors.toList());
// 合并集合 - 使用concat
List<String> concatResult = Stream.concat(list1.stream(), list2.stream()).collect(Collectors.toList());7.2.4 集合异步并行处理
CompletableFuture并行处理逻辑,提高处理速度
java
public void test() {
List<String> data1 = Arrays.asList("Alice", "Bob", "Charlie");
List<Integer> data2 = Arrays.asList(1, 2, 3);
// 并行处理1
CompletableFuture<?>[] futures1 = data1.stream().map(
name -> CompletableFuture.runAsync(() ->
cusService.queryCustomerAcquisitionDashboardUpdateTime()))
.toArray(CompletableFuture[]::new);
// 并行处理2
CompletableFuture<?>[] futures2 = data2.stream().map(
name -> CompletableFuture.runAsync(() ->
custService.queryCustomerAcquisitionDashboardUpdateTime()))
.toArray(CompletableFuture[]::new);
// 统一等待所有任务完成
CompletableFuture<Void> future1 = CompletableFuture.allOf(futures1);
CompletableFuture<Void> future2 = CompletableFuture.allOf(futures2);
CompletableFuture.allOf(future1, future2).join();
}