本来是自己想了解下js中关于零拷贝的内容,顺藤摸瓜了解了下相关历史演进,便有了这篇文章。虽说是数据拷贝历,但其中也夹杂了大量关于Ajax和SPA的历史,也算是顺着拷贝这条藤摸到的瓜,所以有点跑题。希望大家能开心吃瓜,如果有任何纰漏和补充,请在评论区畅所欲言,我们一起完善这段有趣的历史。
一、为什么我们需要拷贝?
小明已经有了一个罗技G102鼠标,但是他又买了一个,请问为什么?答:因为怕第一个坏掉了(垃圾品控),或者...他想送给朋友。其实我们拷贝一份数据差不多也就这两个原因。
拷贝主要有以下两个用途:
- 保护原始值:想在一个数据的基础上做修改,但是又不想在他本体上动刀子,就可以复制一份出来。这样可以避免意外的副作用,特别是在异步和多线程的情况下,要是大家都在原始数据上修改,最终会完全无法预测这个数据的变化过程。不可变性也是纯函数的基石,对于函数式编程来说非常重要。
- 跨区传递数据 :浏览器特别是现代浏览器,为了安全等原因,对不同模块和上下文会做内存隔离。比如窗口之间,worker线程之间,主线程和其它IO之间。相互隔离的内存区域是无法直接访问对方的数据的。这时就需要调用系统提供的api,将数据拷贝过去。
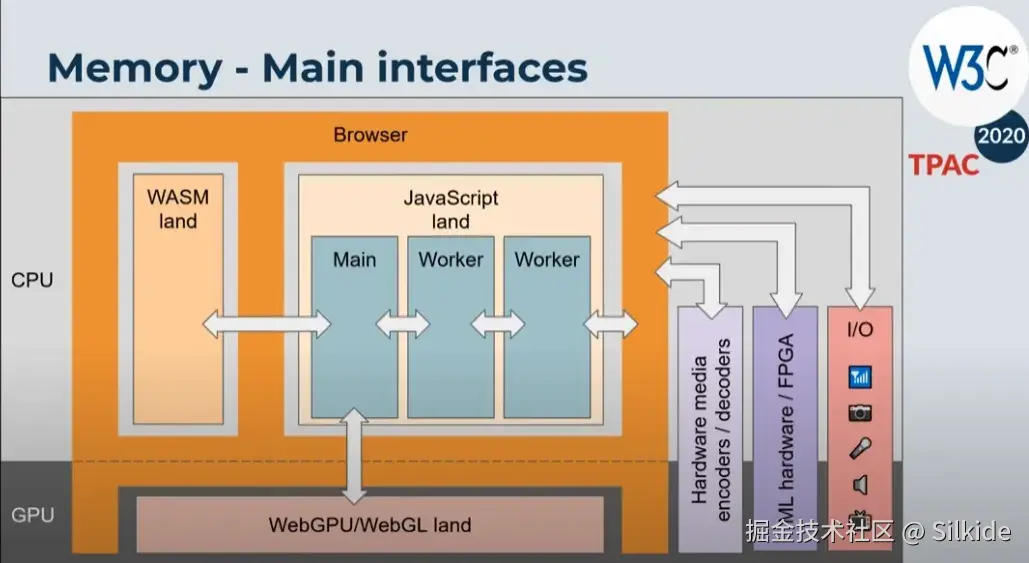
由于原始类型的数据具有不可变性 ,生来什么样到死就是什么样,所以拷贝原始类型数据非常简单粗暴,直接创建一个一模一样的副本。包括进行赋值、传参、运算等操作,都是进行的值拷贝。由于原始类型数据一般比较小,所以都放在栈中连续内存空间,因此拷贝速度非常快,不影响性能。
而JavaScript中的复杂数据拷贝,一直让前端开发者们如鲠在喉。拿对象来说,一个对象可以包含各种原始类型数据,也能包含其它引用类型的数据。这就让引用类型可以不停的套娃,对象套对象,对象套数组,数组套对象......无穷无尽。更可怕的是,引用类型的数据存储在堆中,其内存空间并不是像原始类型数据那样连续的!你不能像拷贝原始类型一样,一体化注塑,直接复制整块内存区域。你得像搜寻龙珠一样集齐所有的内存碎片才能召唤出一样的数据。还有js的原型链机制,引用类型上会有一大堆的隐式属性;还有可能A引用B,B引用A这样的循环引用。总之,拷贝复杂数据类型有一大堆的坑。
随着各种网络媒体的兴盛,二进制数据处理也成了重要的一环,因此对二进制数据的拷贝,也是一个需要解决的问题。而且二进制数据不仅会在js的上下文之间拷贝,还会涉及操作系统层面的,比如GPU,各种IO设备等等。
其实值拷贝也不单纯: 那些数字布尔值还好,顶天也就那么大点,但是字符串可以是个无底洞啊,理论上你空间足够,那字符串能一直长到长度突破数字的最大精度。难道一个超大的字符串,js引擎也要硬着头皮每次操作都拷贝一份?实际上js引擎并没有那么老实,比如v8引擎中就有各种不同优化的字符串类型,会动态的控制是否只引用字符串,比如使用 "+" 来拼接字符串,只在必要的时候才创建新的内存区域。详情可见:danbev的v8学习笔记。当然这些是js引擎底层偷偷做的优化,我们感知上依旧是每次创建新的不可变的字符串。
二、怎么才算深拷贝?
上面说了,引用类型的内存零散的分布在堆中,那如何才能集齐所有碎片克隆一个全新的数据呢?答案是递归,嵌套的对象,可以通过外层对象的引用,找到内层对象的引用,再根据内层对象的引用找到属于它的原始数据,也能找到它更内层的对象的引用,如此往复,像传教发展下线般一路找下去,直到没有新的引用类型。
但是js中的引用类型不只包含我们显示定义上去的数据,由于原型链机制,引用类型会继承许多js内建的东西。那么我们是否需要完整的把原型链也拷贝一份呢?通常来说不需要,我们看看MDN里对深拷贝的定义:
 也就是说,我们不需要真的去复制原型链,只需要保证原型链的结构等价。原型链结构等价就是要保证两个对象的继承路径一模一样,因此允许共享同一个原型,毕竟对于相同的原型,继承路径肯定是一样的。
也就是说,我们不需要真的去复制原型链,只需要保证原型链的结构等价。原型链结构等价就是要保证两个对象的继承路径一模一样,因此允许共享同一个原型,毕竟对于相同的原型,继承路径肯定是一样的。
我们来看一个拷贝案例
JavaScript
const a = {o: { data: 11}}
const b = {o: { data: 11}}现在我说,b是a的拷贝。没错,匠人风格的纯手工拷贝。但它确实符合深拷贝的定义,定义2的属性名和顺序肉眼可见的相同,然后我们先验证定义的1和4:
JavaScript
// 返回false,满足第一条不同对象
console.log(a === b);
// 返回true,毕竟字面量创建的对象都默认继承自Object.prototype,保证了它们的原型链结构等价
console.log(Object.getPrototypeOf(a) === Object.getPrototypeOf(b));第3条很有意思:它们的属性的值是彼此的深拷贝。
这在语义上就是一个递归的定义,因此我们再手动递归验证下b.o是a.o的深拷贝:
JavaScript
// 返回false
console.log(a.o === b.o);
// 返回true
console.log(Object.getPrototypeOf(a.o) === Object.getPrototypeOf(b.o));总结,MDN定义的深拷贝有两个关键点:
- 保证拷贝前后两个对象结构一致,这一部分靠递归实现。
- 保证对应的引用类型原型链结构等价,这一般是先判断引用类型的分类,是数组、对象、日期、Map、set、正则?然后调用js内建的构造函数new一个相同的容器,再复制数据。
当然,实际情况是灵活的,也许和定义略有不同。
首先是方法的拷贝:
想想我们拷贝的目的,其中之一就是创建一份独立的数据,我们修改这个数据不影响原本的数据。这里我们要建立一个数据(状态)和行为分离的思想,行为就是js中的方法。拷贝方法是复杂且没有必要的:
- 因为方法通常不包含任何数据(状态),而拷贝的核心恰恰是对数据的拷贝。
- 可能依赖于创建时的词法作用域。
- this指向也可能被改变。
- 难以序列化和反序列化,性能开销大。
- 安全问题。
- ......
由于困难重重,所以大多数的深拷贝库和api都放弃了方法的拷贝,默认认为方法不需要拷贝或由原型来管理。
其次是实用至上的拷贝哲学:
拷贝这份数据定是要拿来使用的,但通常情况下我们不会用到原本数据的全部,比如它原型继承的一些杂七杂八的方法属性,所以这些东西漏掉了似乎也没什么影响。因此我理解的深拷贝就是:递归的拷贝那些我们需要的东西。 后面我们能看到,很多深拷贝方案其实都是残缺的,但是不妨碍成为我们的好帮手。
三、上古时期:兼职的JSON和手搓的深拷贝
JSON起源
最早期浏览器和服务器之间传输复杂数据,使用的是XML,这种数据结构非常繁琐。当时的js对象是有字面量写法的,时任雅虎架构师的Douglas Crockford发现 eval() 可以直接将对象字面量字符串还原成数据:
JavaScript
// 服务端返回这样的字符串
const dataString = '{"name":"John", "age":30, "cities":["NY","LA"]}';
// eval()函数可以将字符串当作js代码执行,相当于一个小小的js解析器
// 这段字符串被当作 对象字面量语法,直接用这些数据创建了一个对象
const data = eval('(' + dataString + ')');
这是个革命性的发现,意味着服务端可以返回js对象字面量这样简洁优美的数据形式,浏览器也可以快速进行解析。 eval()是一个非常危险的函数,它会无差别的执行任何js代码,也包括恶意脚本,使用它很容易被跨站脚本攻击(XSS)。因此Crockford从js支持的数据类型中选出最安全最实用的那些,也对比了其它编程语言支持的类型,得到一个安全子集,并起名为JavaScript Object Notation,简称JSON。由此,纵横未来二十多年,还会继续流行下去的明星数据交换格式诞生了。
2002年,Crockford创建了json.org网站,在上面发布了自己对JSON概念的构思,将这个伟大的发明分享给了全世界。如下是JSON支持的类型:

JSON API的诞生
随着web2.0时代的兴起,简洁实用的JSON一炮而红。但JSON数据的解析一致依赖于 eval() 这个危险的函数,它经常被evil的人利用,用来执行恶意代码。社区开发出各种方法来保证仅仅解析JSON数据,而不执行代码。Crockford开发了一个名为 json2.js的库来解决这个问题,这个库提供了大家耳熟能详的JSON.parse()函数,通过严格的词法语法分析来合法的解析JSON数据。
2009年,ES5标准发布,JSON.parse()和JOSN.stringify()也响应开发者的需求,正式纳入标准,随后被各大浏览器实现。由于有浏览器的底层优化,所以性能比js库版本更好,从此我们便告别了危险的 eval() 函数。
JSON兼职深拷贝
从前文的历史可以看到,JSON本就脱胎于js对象,因此它被用于克隆对象也算是一种宿命。但这种技巧的局限也来自JSON本身,它受安全子集的约束,因此只能识别JSON规范规定的那寥寥几个基础的数据类型。不管什么复杂的数据结构,只要成功被JSON.stringify序列化,再用JSON.parse反序列化后,所有数据都会变成那几种基础的数据类型。更不用说实际复杂数据中,还有可能有很多无法被正确序列化的数据,还可能存在循环引用。JSON终究不是专业搞拷贝的,并没有为这些拷贝中的特殊情况作准备,就像一个算命先生因为会算数,被村里推举当了会计,不过这帐算错了,可不要推到JSON头上。具体JSON拷贝有哪些局限,问问万能的AI,这里不再赘述。
古时候的js通常只有一个主线程,因此拷贝通常也只发生在一个上下文内,数据的传输也主要面向网络IO。古代程序员喜欢用JSON的序列化和反序列化来深度拷贝js对象(当然现代程序员也喜欢,够用就用)。这其实是可以理解的,还记得我前面说过我对深拷贝的理解吗?------递归的拷贝我们需要的数据。由于前端要处理的数据,大部分来自网络传输,或者是为网络传输准备的。而网络数据的格式早已经是JSON的天下了,因此我们需要的数据往往是和JSON重合的!这也是使用JSON来深克隆数据的现实基础,只要JSON还统治互联网,那用JSON进行深克隆就会一直经久不衰。我们只有清楚的知道自己要拷贝的目标,才不会被JSON的局限性影响。
深拷贝的各种库实现
JSON到09年才成为事实标准,同年才首次加入主流浏览器,在这之前也存在深拷贝需求。并且虽然JSON进行简单的深拷贝很方便,但是我们总会遇到更复杂的数据。因此深拷贝最正统的做法,依旧是开发者自己手写深拷贝。
比如Date日期类型,日期数据继承自 Date.prototype ,原型上有很多日期相关的方法。很明显JSON中不存在Date这个类型,当我们 JSON.stringify(date) 的时候,会寻找date实例的 toJSON() 方法,而Date.pototype上正好有这个方法(实际上原生的也只有Date类型有这个方法),它返回一个 toISOString()返回的字符串,形如 YYYY-MM-DDTHH:mm:ss.sssZ 。到头来,date对象变成了一个字符串,使用JSON.parse反序列化也会将其当成普通字符串处理,最终克隆出来的date变成了字符串。
这只是JSON解析对象限制的典型个例之一,JSON还没法解析循环引用,只要遇到循环引用就会报错。
总之,将数据先JSON.stringify再JSON.parse,这套连招与其说是拷贝,不如说是一个漏斗,将JSON解析合法的数据给筛选出来。
为了实现更完善的深拷贝,大家只能自己手搓,各种流行库也实现了自己的深拷贝工具,比如jQuery、lodash。它们都是通过递归,或者迭代模拟的递归,逐渐构建拷贝对象。并且对特殊的js内建类型做判断,比如这里的Date,还有后来出现的Map、Set等作了判断,使用内建的构造方法生成同种容器,再拷贝数据。也会使用类似下面的代码,保证原型结构的等价:
JavaScript
// 用对象自己的原型,创建拷贝的对象
Object.create(Object.getPrototypeOf(src))这些库实现往往还给了开发者自定义的空间,比如lodash提供的 cloneDeepWith ,允许开发者自定义拷贝方式:
JavaScript
// 自定义的拷贝方式
const customizer = (value) => {
// 如果值有自定义的 .clone 方法,就用它!
if (typeof value?.clone === 'function') {
return value.clone();
}
// 对于其他任何值,让 Lodash 按默认方式处理
return undefined;
};
const clonedData = cloneDeepWith(data, customizer); 这又回到了前面说的,我们要拷贝的是我们需要的,而自定义的拷贝方式,就给了我们灵活筛选的空间。
四、HTML5时代:结构化克隆初具雏形
走出单一上下文
自1995年JavaScript诞生后,网页从静态走向动态,同时也给浏览器带来了许多新功能。比如弹窗,我们可以用window.open方法打开一个独立的新窗口。还有我们熟知的内联框架(iframe),允许页面内套一个页面,它拥有自己独立的文档环境。
随着开发者们对这些窗口的深度使用,窗口间通信的需求愈发广泛,比如大型门户网站不同子域名间的通信、身份验证窗口、同步支付窗口的状态等等。由于那时候没有一个规范的跨窗体数据传输方式,并且还有同源策略的阻碍,所以各种hack技巧百花齐放。比如修改document.domain、使用不会刷新页面的hash,甚至将要传输的数据存到window.name里面等等,甭管你厨子戏子痞子,只要能跑腿的,都被抓来报信了。
官方窗口通信问世
hack方法终究是旁门左道,各种安全问题、性能问题和限制层出不穷。因此WHATWG HTML5起草了官方的窗口间通信API。2005年Opera8率先实现了postMessage的原型,此事在这篇关于框架通信安全的论文里亦有记载,但和现在的postMessage不同的是它存在于document对象上。2008年Firefox3正式实现了我们熟知的window.postMessage,随后几年遍普及到了所有的主流浏览器。
最早的postMessage只能传输文本数据,因此想要在窗口之间传输复杂数据,就需要进行序列化和反序列化。后面出现的JSON api和postMessage一拍即合,成了跨窗口传递数据的好兄弟,先用JSON.stringify序列化成字符串传输到另一个窗口,另一个窗口再用JSON.parse将其还原成数据。
早期的postMessage还存在各种安全问题,并且字符串能承载的信息终究有限,那些超出JSON处理范围的数据,仍要依赖开发者手动处理,js急需一种原生的拷贝和传输对象的方式。
worker带着结构化克隆横空出世
实际上window.postMessage的使用者们并没有被折磨太久,因为有其他地方更加渴求原生的深拷贝方法,所以HTML5标准早早的就在筹备这一方法。
日趋复杂的网页建设需求,大规模计算的场景在网页端越来越常见,而单线程的js在进行长时间计算时,会阻塞UI渲染,导致页面卡顿。Web Worker便在这一背景下应运而生,前端走向了多线程时代,我们可以创建单独的线程来承载繁重的计算任务,让我们的主线程只管岁月静好,安心渲染页面。2009年,web worker在HTML5规范中正式被提出,同年便被主流浏览器实现。
大规模的运算任务往往伴随着大规模的数据,比如解析大量的JSON数据,进行复杂的图像算法。而将数据从主线程搬运到worker线程还用老一套的数据克隆方法就显得繁琐且不安全了。
由此,随着worker一起发布的还有结构化克隆算法,旨在安全的传递结构化数据。但是结构化克隆算法一开始并没有暴露给开发者,而是作为浏览器内建的基础设施,供其他功能模块使用。
结构化克隆算法带来新生态
结构化克隆算法总体也是采用递归+循环引用判断的方式来进行深拷贝,由于它由底层实现,因此不需要在js层面对对象做序列化和反序列化。并且在c++层面做了许多的优化,让它性能更优、安全性更好。
有了原生强大的深拷贝方法,那些急需这个功能的API便迫不及待拥抱上去。worker自诞生起便使用结构化克隆算法。worker也是使用一个叫postMessage的api传递数据,与window.postMessage不同,这个api底层调用结构化克隆方法来传输对象数据,免去了繁琐的序列化和反序列化过程,直接一个方法搞定。
和worker与结构化克隆一同推出的还有**indexDB**,一个运行在浏览器中的关系型数据库,其规范直接规定:任何由结构化克隆算法支持的对象都可以存储。
到2011年,Firefox引入快速发布流程,一年之内从4.0升级到9.0。它在4.0版本率先实现了indexDB,并在6.0版本将结构化克隆率先用于window.postMessage。随后postMessage的结构化克隆版本逐渐在所有的主流浏览器中普及,开发者们自此摆脱了传递数据前痛苦的序列化过程。
Ajax------微软的乌龙球
结构化克隆算法还被用于存储历史状态,这就涉及到ajax技术和SPA单页应用的崛起,这部分历史也蛮有趣,我决定跑个题讲一讲。
90s的早期网站,通过服务端脚本动态生成网站,每次请求都会导致页面刷新,用户体验非常差,这让业界一直在摸索更优雅的局部刷新网页的方式。早期人们通过插件的方式来解决这个问题,比如2000年左右微软推出的ActiveX控件,也是一种浏览器插件。这让网页可以只有一个文档,然后通过请求动态的更新内容,这时期便诞生了早期的SPA应用。
但微软的outlook团队希望在任何浏览器上可以直接使用outlook邮箱,就能达到和桌面应用差不多的体验,而不是还得先下个插件。因此他们开发了一种不刷新页面便发起http请求的技术,并命名为XMLHttpRequest,作为MSXML库的一部分发布。为啥叫这个名字呢,仅仅是因为XML火,想蹭,实际上和XML没啥关系,它是个通用的http请求工具(和JavaScript坐一桌很合适)。
1997年微软便开发出了动态HTML也就是DHTML技术,以DOM为核心,让js可以控制页面元素,让页面可以根据用户的操作做出变化。XMLHttp的问世,意味着在不刷新页面的情况下,请求网络数据改变页面内容成为可能,让web应用也能拥有接近桌面端的体验。
随后几年,主流浏览器也纷纷支持了XMLHttpRequest。由于种种原因,这项技术出现的前两年并没有溅起太大水花,而开发这门技术的outlook团队,发现即使支持了局部刷新页面,应用的体验依旧和桌面端天差地别,这也和当时浏览器性能和网速的限制有关。这时的微软也并没有重视这门技术,一边把java移植到IE浏览器中,试图在浏览器上运行java小程序(没错,正统的java),结果得罪了太阳微系统公司,在微软垄断案的大背景下惹了一身官司;另一边微软转头搞起了自己的技术标准,开发XAML和Avalon,后者最终变成了WPF。
这次引领时代的机会落到了谷歌手中。2004年,谷歌推出的gmail大量使用了这种动态加载的技术,其接近桌面应用的丝滑体验震惊世人,使其成为了SPA模式的里程碑产品。2005年谷歌继续发力,推出了谷歌地图,将这种技术的应用边界继续拓展,地图块动态的在页面上加载,用户可以进行无限的滚动,这在那个时代看来简直是进入了未来。谷歌地图发布到当年2月,科技作家Jesse James Garrett也被这两个现象级应用震撼,在洗澡的时候灵感爆发并给这种技术起了个名字,随后发表了一篇名为Ajax: A New Approach to Web Applications的文章,将这种技术命名为Ajax,并下了定义。如我们所知,Ajax就是Asynchronous JavaScript and XML的缩写,这个缩写恰到好处,大大提高了这项技术的传播度,使得本就如日中天的Ajax技术传播的更加广泛。
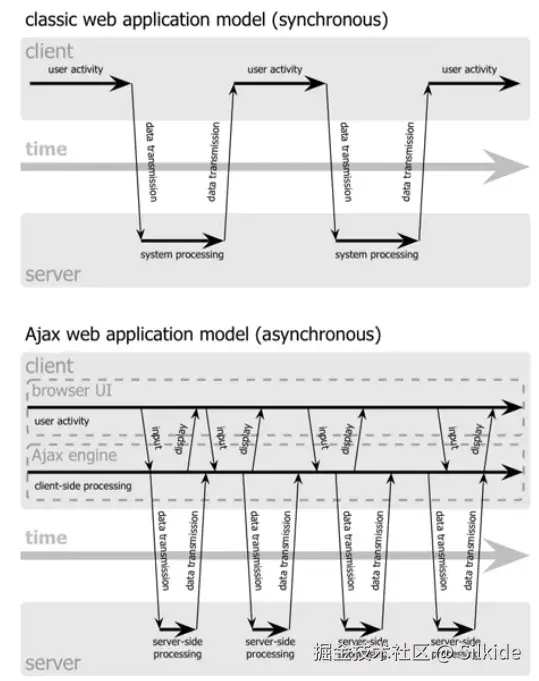
Ajax让web有了和桌面掰手腕的勇气,web应用的易用性和功能性进入了黄金分割点。在随后的日子里,web不断的蚕食桌面应用的市场。而桌面端正是微软的主战场,微软一手缔造了web应用的地基,却让别人筑起了高楼。当然,这是多方面因素导致的,路线的错误、技术营销的薄弱、对垄断的过度自信等等。
谷歌的早期格言"Don't be evil"的evil常常被认为是暗指微软,谷歌主张基于标准来行动,以此与任何意识形态划清界限,矛头直指试图围绕Windows平台建立自己标准的微软。这不禁让人联想到百度,百度的前瞻性始终让我印象深刻,从搜索引擎,云计算,到自动驾驶,再到AI大模型,百度无不走在最前列。但似乎最终这些关键词和百度的联系都会渐渐隐去,一波又一波的浪潮之后,百度成了觥筹交错的酒局里喝可乐的那位,虽然还在桌上,但早已不是大家的焦点。
关于XMLHttp的历史,可以参考XMLHttp的缔造者Alex Hopmann的一篇文章**The story of XMLHTTP**。里面记叙了XMLHttp的诞生过程,还有一些对微软错过这波浪潮的思考。另外还可以看看hacknews上这个讨论XMLHttp创造者的帖子。
不要刷新网页!
回归主题,SPA应用越来越流行,单个文档结合XMLHttp便可以满足千变万化的需求。新的痛点也随之到来,为了不让页面刷新,网页的url是不会改变的。由于网站只有一个url,所以url无法保存用户的状态。比如你开了一个url为www.example.com漫画网站,又打开了一卷漫画看到第42页,感觉很有意思想分享给好哥们。但是url只有孤零零的www.example.com,你把这个地址分享给好哥们后,还得给他说哪部漫画的第42页,他还得手动搜索这部漫画再翻到第42页。我相信你哥们会下楼旋三两重庆小面,然后悠哉游哉回家,敷衍的回你个------"真不戳👍🏽"。你以为他说的漫画,其实他在说面。
我们现在已经习以为常,翻到网站的哪一页,复制url再打开就是那一页,甚至还能保留里面的状态(不知道现在从小玩手机长大的小朋友,还会不会复制链接的操作)。此外还有一个类似的问题,当我们点击回退按钮时,由于没有存储状态,因此回退并不能返回上一个页面,这就是著名的后退按钮问题。
而这些状态必然需要让url来携带。那有什么办法可以让url携带一串数据,又不让页面跳转呢?通过前面的历史,我们可以发现程序员们非常擅长物尽其用。这次被迫搞副业的,就是哈希。
Hash路由模式的由来
hash自上古时期便存在了,可以追溯到1994年的RFC1738,它在规范中被称为Fragment Identifier(片段标识符)。"#" 符号是不安全字符,必须进行编码。到了2005年的RFC3986,URL通用语法标准正式定义了Fragment Identifier。
简单来说,hash就是用来做页面内的导航的。url后面跟一个 # 号,# 号后面跟个id名,用这个url就可以跳转到页面内对应id元素的位置。以掘金为例,我们点击旁边的目录,就会改变url的hash部分,跳转到页面对应的位置,掘金会自动在标题元素上加入heading-1之类的id:
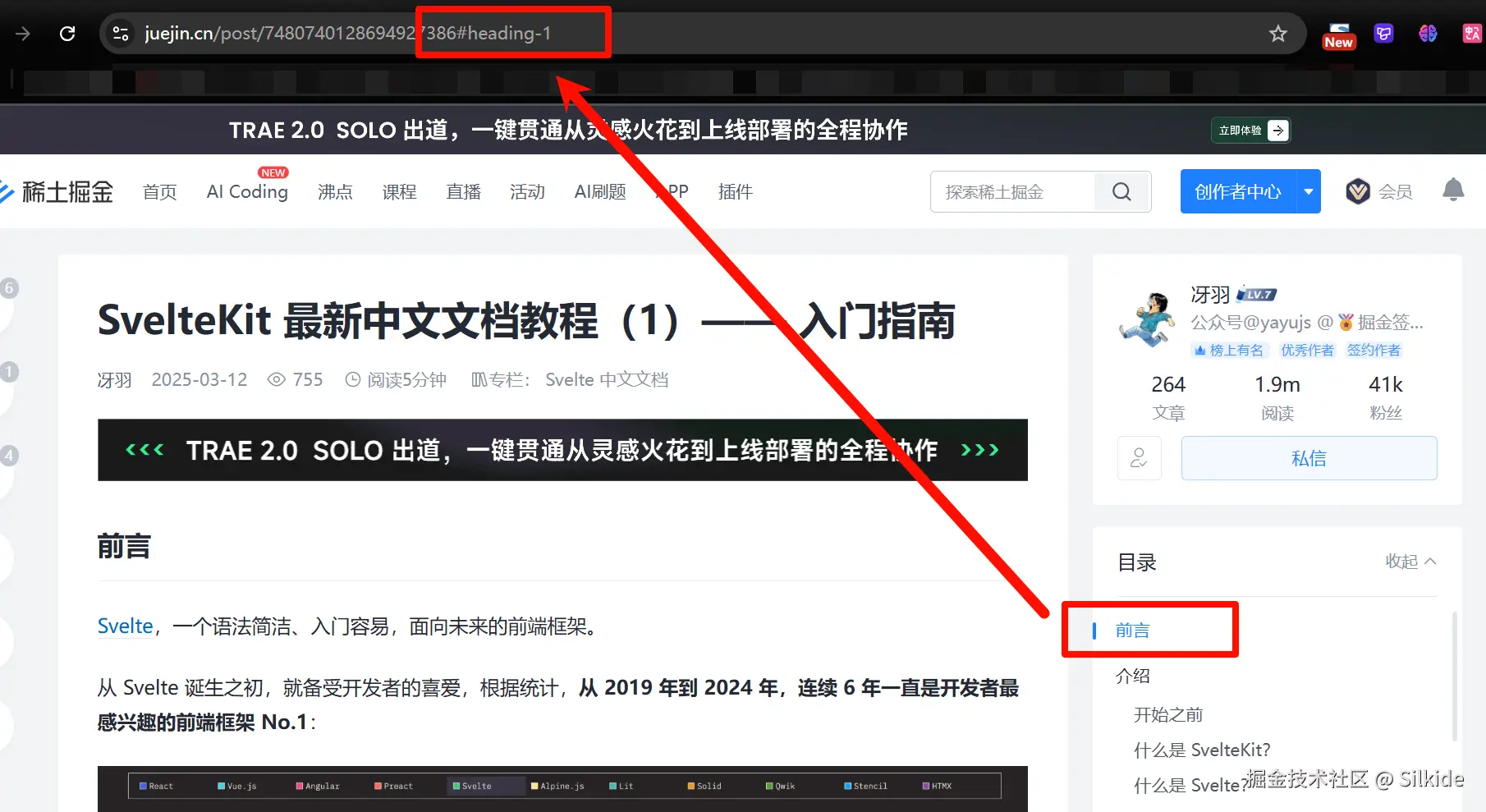
hash确实是用来导航的,只不过是页内导航,那它是怎么做到兼职页面之间的导航的呢?
我们在#后随便输入一个页面内肯定没有的id,敲击回车,此时页面没有任何反应,不会滚动也不会跳转。这不正好符合我们想要url携带信息,但是又不跳转的需求么?我们只需要监控url中hash部分的变化,就可以获取对应的页面状态。
我们都知道监听hashChange事件可以很方便的监听hash的变化,但是这里有个问题:SPA应用在2004年就开始大放异彩,而hashChange这个API实际上到了2009年才率先被IE8和Safari实现。这四年间人们要怎样去监听hash呢?
主流方法有两个,一个是用setInterval定时器轮询 ,不停监听url的变化。由于每次改变hash也算是一次新导航,因此都会加入浏览器历史记录,也就解决了后退按钮问题。jQuery的BBQ库就是用这种方式进行实现的。:
In browsers that support it, the native HTML5 window.onhashchange event is used, otherwise a polling loop is initialized, running every...
还有一种称为隐藏iframe的奇技淫巧,这个主要是用来处理后退按钮问题的。大概流程就是创建一个隐藏的iframe,每次页面状态改变就改变iframe的url(通常不是hash,而是真的改变了文档),以此触发浏览器的导航历史,解决了后退按钮问题,一些状态数据也可以存到iframe里。当然主页面的url是不会改变的,所以那时主流还是用定时器轮询的hash方案。
history路由模式的由来
由于SPA应用越来越流行,hash始终不是专为SPA而生的,传统方案有诸多性能和功能局限。因此开发者们非常需要一种原生的解决SPA路由的方案。
现在有两种方案,第一种就是让hash转正,设计一个原生的监听hash变化的机制。第二种就是设计一种url路径变化,也能控制它不刷新页面的方式,让url保持大众心中最初最完美的模样。后来我们都知道了,搞浏览器的大人们表示 我全都要!

hash转正后就是 hashChange事件,而后者就是2008年加入HTML5规范的 History API。由于这几年来hash模式在SPA领域已经深入码心,无论是从兼容性、web社区渐进增强的哲学角度,都应该将其保留下来。所以现在的一些路由库做兼容性处理时,会把hash路由从hashChange模式退回到定时器模式。
History API是一种面向未来的模式,美观的URL更符合我们的直觉,没有丑陋的#符号(或者说不会和作为页面锚点的#符号纠缠不清)。它很像是一种对隐藏iframe方案的原生改良,通过history.pushState()添加历史,在不触发重加载的情况下修改url。由于当时的主流依旧是hash模式,所以浏览器厂商们优先在2008年开始支持hashChange事件,到了2010年才开始着手实现history API。
然而History API有自己的特殊能力和特有的缺陷,所以它和hash模式不能完全互替,这也是经典面试题之------请说说hash路由和history路由的区别。
需要服务端的配合:由于SPA应用只有一个html文件,所以只更新url在运行中没有问题,但是一旦刷新当前页面,就会触发http请求。由于浏览器发起http请求,是不会携带#后的hash部分的,所以hash模式不管在哪个路由下发起http请求都是一样的,都能请求到同一个html文件。但是history模式不一样,不同路由的url,会发起不同路径的http请求,会向服务端请求不同路径下的html文档,如果不加配置就会找不到对应的文档,也就返回404了。从这方面来说,hash模式是纯前端的路由,稍微方便一点。
修改URL的时候可以添加数据:history.pushState()和history.replaceState() 的第一个参数,都可以传入一个数据。这个数据会保存到导航历史记录中,当我们从其它历史记录导航回来,可以通过 popstate 事件取回这个数据。而这个数据是存储在浏览器的session history中,其内部就用到了结构化克隆算法。包了这么大盘饺子,就为了这点醋,弯弯绕绕我们终于回到了主线。也就是说,导航记录中可以存储的数据,就是结构化克隆算法支持的数据。结构化克隆算法到了2009年才横空出世,是构成history API的重要基础,我猜想这也是History API比hashChange事件晚支持两年的一个原因。
五、结构化克隆算法的第一次大升级
2009年结构化克隆算法刚诞生时,只能克隆一些常见数据类型,比如基本数据类型、对象和数组。
2010年:支持稀疏表
JavaScript中的数组和我们上课时学习的数组很不一样,如果你是计算机相关专业或是学习过c、java等语言,一定知道通常说的数组有以下特点:
- 连续的内存
- 固定的长度
- 相同的数据类型
但我们知道,JavaScript中的数组可以加入不同的数据类型,还能动态的进行扩容。难道Javascript之父**Brendan Eich** 上课也在划水?大家应该都听说过Eich 十日造js的传说,js最初的使命是作为一种胶水语言来粘合网页元素和java小程序(1995年网景公司和太阳微系统公司合作,准备在自家浏览器中加入java applet,JavaScript这个名字也是这个背景下诞生的)。这种语言需要足够的灵活、动态和方便,还要基于原型和支持函数式编程,时间紧任务重,所以Eich最终多方权衡下,选择用哈希表来作为数组的基础。
哈希表(hash table),也就是散列表,是一种基于key来寻找数据的数据结构。也就是说js中的数组是根据索引这个key来找对应的value,这些value不必连续,可能分散在内存的各处。而散列表也给稀疏列表奠定了基础:数组的索引只是key的话,我们是可以不定义这些key的,也就是说索引可以不存在, 这就是所谓的空洞(hole) ,这种遍布空洞的哈希表就是稀疏表。(稀疏表的空洞表示这个位置真的什么都没有,如果有索引并且值是undefined,实际上也算是有值的)。
arduino
const arr = [1,,2,3]
console.log( 1 in arr ) // false
// 在arr中找不到 1 这个索引,就形成了一个空洞
// forEach、for in 等遍历方式会跳过空洞最早的结构化克隆算法对稀疏表支持不力,主要表现为会把空洞填充为undefined。从而稀疏数组就变成了密集数组,一方面丢失了稀疏数组的性能优势,另一方面克隆后数据结构被破坏,可能影响程序稳定。
因此2010年这个问题被修复,序列化时能精确的区分空洞和undefined。
我们之前说过现代浏览器并不老实,底层做了很多优化,数组的实现并不是完全的哈希表。毕竟在不同数据规模下,哈希表和传统数组的性能有所差别。以v8引擎为例,采取了快慢数组的方式,动态的选择两种模式,推荐这篇文章:探究JS V8引擎下的"数组"底层实现
2011年:真正支持复杂对象
前面说过,深拷贝的一个重点就是拷贝js内建的对象,需要使用内建方法重新new一个新容器,以此保证原型链一致性。而那个时代用的最多的内建对象便是Date和正则表达式,可最初的结构化克隆算法不支持,这在2011年得到了解决。
这一年还有一件大事,由于webgl需要频繁操作大规模的数据,js急需一种高效处理二进制数据的方式,ArrayBuffer和TypedArray便应运而生。至此,二进制数据也正式加入了JavaScript大家庭,所以结构化克隆算法也支持了ArrayBuffer和TypedArray。
有了这些升级,我们就可以在worker线程间通过postMeassage传递二进制数据,让多个线程处理webgl中用的大量数据提高性能。也可以将二进制数据存入indexDB、导航记录中...
总之结构化克隆之后的升级之路,都是为了匹配Javascript升级路上不断增多的数据类型。
真假拷贝:可转移对象和零拷贝
这里也是本篇文章诞生的缘由,之前搞threejs用到了可转移对象,以此为切入点深入,调查背后的历史,便有了这篇文章。
之前的结构化克隆算法,真的是老老实实在克隆。比如我们使用threejs,希望新开一个worker线程来处理一些纹理数据,从主线程中将纹理数据传输过去,就得把这份数据拷贝一份。这是物理上的主线程一份,worker线程一份,都在各自线程独立的内存空间中。然而现实情况中这些纹理、图像的二进制数据体积可能是很大的,这一拷贝操作会相当耗时,可以从谷歌的测试中看出,直接拷贝32MB的数据耗时可高达数百毫秒。
线程间的零拷贝:
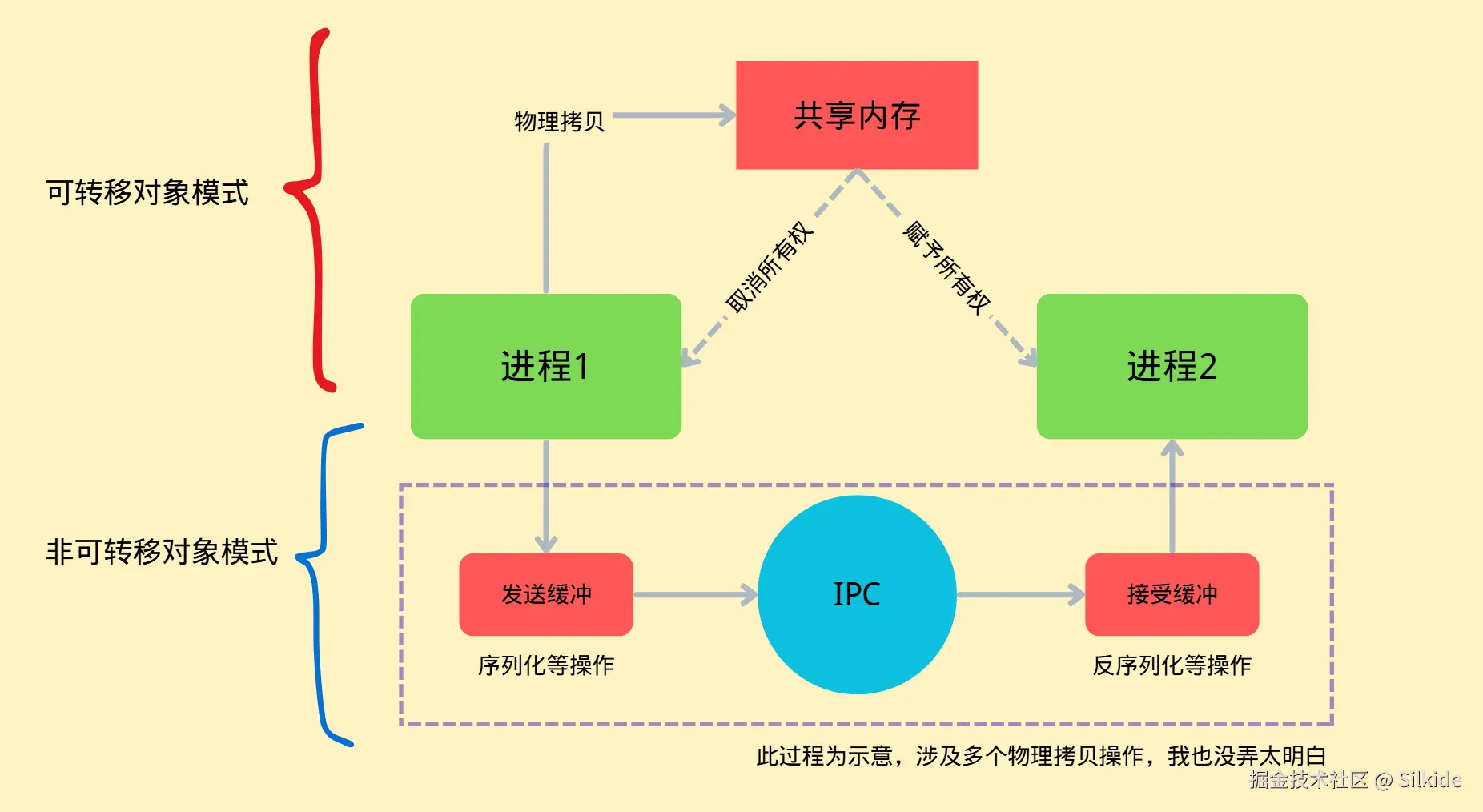
为了解决这一问题,可转移对象应运而生,ArrayBuffer被升级为了可转移对象。主线程和worker线程都在同一进程中,所以使用的是同一片虚拟内存空间,而线程之间的内存隔离是js引擎来主持的,相当于js引擎给这块内存里面的数据都颁发一个身份证,标记你属于哪个线程的,只有那个线程能用你。而可转移对象的原理,就是把这个数据的身份证给换了,也就是把所有权给移交了,数据本身还是躺在那片内存里。当然,所有权移交后,原本的线程就失去了对这个数据的访问权。
我们可以用如下方式使用可转移对象模式:
arduino
const buffer = new ArrayBuffer(1024)
const worker = new worker('xxx.js')
// 第三个参数就是可转移对象列表,代表buffer这儿数据会被作为可转移对象的方式传输
worker.postMessage(buffer, '*', [buffer])
console.log(buffer.byteLength); // 现在原本的数据就失效了这就叫零拷贝,并没有在物理上复制一份,而是转移所有权。(有点像引用类型的赋值)
进程间的零拷贝:
除了线程间通信,开发中还会设计跨窗口通信,而由于浏览器的站点隔离策略,不同窗口可能跑在不同的进程中。而不同进程间的内存隔离是操作系统层面的,相当严格,浏览器是没有操作的权限的,一个进程是绝对不允许访问另一个进程的数据的。
跨窗口通信的API也是postMessage 同样也支持可转移对象,那既然这么进程间的内存隔离这么严格,要怎么才能做到零拷贝呢?
事实上无法完全的做到零拷贝,浏览器会调用操作系统的API创造一片共享内存,共享内存是操作系统提供的一种可以让不同进程共享数据的机制,先把要转移的数据物理复制到共享内存中,再进行所有权的分配。只要数据不是原本就在共享内存中,至少得进行一次物理拷贝。
再回头看看非可转移对象模式在这种情况下的表现。进程间传递消息靠的的是IPC通信,如果你学过操作系统课程,应该会教你用管道来进行各种进程间的操作。以chrome为例,chromium团队将这个操作系统能力封装成了一个叫mojo的框架,用于更方便的进行进程间通信。非可转移对象的拷贝方法要进行数据传输,靠的就是IPC(当然可转移对象模式也需要IPC进行协调)。数据会先被拷贝到一个发送缓冲区,再发送到IPC缓冲区,再发送到读取缓冲区,最后进入目标进程,其中每一步都涉及真实的物理拷贝,因此开销巨大。当然这是一个简化的过程,实际过程复杂的多,我也没有能力完全搞懂。
这种OS层面的零拷贝方式其实更符合大家印象中的零拷贝,我们直接去搜零拷贝出来的多半也是这方面的知识。
2011年上线ArrayBuffer后,很快大家就发现了性能问题,可转移对象在2012年就得到了支持,也算响应的非常迅速了。
六、2012往后:不断进化的结构化克隆算法
随着js的发展,越来越多的新成员加入js大家庭,也随着大家的实践,社区对结构化克隆算法也有了更多的期盼。结构化克隆算法就这样不断的被完善、被扩充,下面就简要的概述一下:
支持getter/setter
2012年有一个很重要的更新,增加了对getter/setter的支持。以往的结构化克隆遇到getter属性,会忽略或者抛错,总之无法处理。而很多内建对象的对外暴露的字段,都是getter属性,机构化克隆后会造成相关字段丢失。特别是2012年普及开来的Map和Set,它们的size属性都是只读的getter。更新后的结构化克隆算法遇到getter属性会先调用一下,获取到它的值再克隆到新的数据中去。
Map和Set加入js了,getter也支持了,自然也支持克隆Map和Set了。还增加了对Error、Blob、ImageData等类型数据的支持。
命途多舛的SharedArrayBuffer
2016年-2017年,主流浏览器厂商是实现了SharedArrayBuffer,用于多个线程间共享内存。结构化克隆算法也增加了对SharedArrayBuffer的支持,SharedArrayBuffer不是一个可转移对象,因此经过结构化克隆后,目标线程中会有一个新的SharedArrayBuffer对象。你可能会问,内存不是共享的吗,为啥又真的复制了一份?你可以把SharedArrayBuffer对象看做是一个入口,我们复制的只是这个入口,两份SharedArrayBuffer对象指向的其实是同一块内存区域。
SharedArrayBuffer的发展也是一波三折,2018年1月研究人员发现了Spectre和Meltdown CPU漏洞SharedArrayBuffer成为了这些攻击的理想工具。因此各大浏览器紧急下线了SharedArrayBuffer,直到同年年中才恢复了部分功能,直到2020年才开始逐步的全面恢复。

Spectre和Meltdowm漏洞 :简单来说就是CPU厂商为了优化性能,开发出了分支预测功能,会提前执行分支中的内容并将数据准备到高速缓存中,若真的执行了这个分支就可以直接取缓存,若没有执行这个分支,那么扔掉即可。这个提前执行并没有考虑程序的内存边界,因为CPU认为程序真正执行到这里自会判断,要是越界了自会终止。并且若没有执行预测的分支,只会清理寄存器中的数据,而不会清理缓存的数据。这恰恰给了黑客机会,恶意程序可以诱导分支预测器缓存一个越界的数据,在真正执行时又不执行这个分支,而是用合法代码读取缓存中的值 。那要怎么知道哪个值是缓存的值呢,普通值读取在内存中,而缓存值在更快的高速缓存中。这就可以用到基于时间的侧信道攻击,我们计算哪个值访问的时间比别人快,就可以确定它是缓存的值。下面是网友对这个过程一个形象的描述:
一名常客经常点饭馆的炒饭 以后常客来的时候厨师想都不想就直接给做炒饭 \ 如果常客变了口味,厨师顶多不把炒饭给常客,就搁置在一边 然后接下来有个坏人,说随便点个吃的能饱流行,然后厨师把搁置的炒饭给他。 \ 坏人得到了信息: 常客喜欢吃炒饭。 \ 那如何治本呢?让厨师把搁置的炒饭扔掉。 那就浪费了做炒饭的时间了,这个期间做了毫无意义的事情。 \ 那厨师以后不要自作主张做炒饭了行不?当然可以,那厨师以后就得等常客点菜,假如一个这是个大饭馆,而且厨师只有一个,顾客还很多,那在常客想好要吃啥的时候,后面的顾客一直等。 \ 也就是cpu性能降低,所以这个预测执行,只要是个现代cpu都是标配
从上面描述可以看出,要进行Spectre和Meltdown攻击,需要对时间精度的要求很高,因为CPU高速缓存的存取都是纳秒级别的。浏览器原本有个能精准计时的API叫perform.now(),在漏洞爆出后精度被紧急改为5微秒甚至100微秒。同时SharedArrayBuffer也可以构建纳秒级别的计时器,其原理就是创建一块共享内存,让一个worker线程在里面疯狂计数。这个计数操作由于直接操作共享内存,所以速度非常快,可以达到纳秒级别,主线程只需要读取这个共享内存的计数,就可以获得当前的精准时刻。(当然其中有很多精度校准的细节)
修复:为了应对这两个漏洞,浏览器厂商在底层数据访问和SharedArrayBuffer上做了很多优化:
- v8加入了JIT毒化,破坏内存访问时间的精度
- 从CPU调度到操作系统层面来干扰时间精度
- 内存层面缓存污染、访问模式随机化
- 2020年后,解决方案标准化,SharedArrayBuffer只能在**跨源隔离**条件下使用,具体就是使用
'Cross-Origin-Opener-Policy': 'same-origin'和'Cross-Origin-Embedder-Policy': 'require-corp'两个响应头 - ...
更高性能的Canvas
canvas是浏览器提供的绘图API,可以高性能的实现复杂绘图。为了提高Canvas的渲染性能,也是为它量身打造了一些数据类型,这些数据类型也被加入到结构化克隆算法的菜单中。由于我的canvas使用经验不多,这里作简单的介绍。
ImageData :实际上结构化克隆诞生之初就支持了这种数据。如果你接触过一些图形学知识,应该能了解到,图像其实就是一个描述了每个像素色彩的矩阵。而做图像处理,就是对这个矩阵做一系列的数学变换。ImageData就是描述了这样一个矩阵的ArrayBuffer,可以通过 ctx.getImageData() 从canvas元素中取得这个矩阵,也可以通过 ctx.putImageData() 将一个矩阵数据赋予canvas元素。
值得注意的是,ImageData本身并非可转移对象,它的data属性是一个Uint8ClampedArray,这是能作为可转移对象的。
ImageBitmap :ImageData数据是用来给CPU操作的,如果用GPU绘制,需要读取到GPU中。随着GPU的普及,我们需要一个更高效渲染图像的方式。因此在2015到2016年,ImageBitmap被纳入HTML标准并被浏览器厂商实现。ImageBitmap持有一个对位图的引用,可以直接传递到GPU中渲染。ImageBitmap最大的特征是不可变,创建了就不能修改数据了,因此我们也不能对图像做各种数学变换。ImageBitmap还是可转移对象,因此在多线程情况下,有非常好的性能。比起ImageData只能从Canvas上下文获取,ImageBitmap可以从多种源中获取,比如:
- HTMLImageElement
- HTMLVideoElement
- HTMLCanvasElement
- ImageData
- Blob
- 其他ImageBitmap对象
总的来说,ImageBitmap提供了一种高性能的位图绘制方式。
关于上面两者的区别,可以看这个stackoverflow的讨论
OffscreenCanvas:我们知道操作Canvas需要获取Canvas元素的上下文,通过这个上下文来进行一系列的绘制动作和数据处理,最终渲染到页面上。虽然最终都需要在主线程中进行渲染,但数据处理和绘制动作的设定为何不放到一个新的线程中呢,等一切准备好再送回主线程渲染不就好了吗? OffscreenCanvas应运而生,顾名思义,离屏的Canvas,环境中不需要有Canvas元素就能进行绘制。我们可以通过如下方式创建一个离屏Canvas,并送到worker线程。这里就用到了postMessage和可转移对象,当然和结构化克隆算法脱不开关系。
JavaScript
const canvas = document.getElementById('myCanvas');
const offscreenCanvas = canvas.transferControlToOffscreen();
const worker = new Worker('canvas-worker.js');
worker.postMessage({
canvas: offscreenCanvas,
width: 800,
height: 600
}, [offscreenCanvas]);OffscreenCanvas在2016年左右加入规范,2017年后逐步被浏览器厂商实现,其中safari近几年才完整的支持。
像ImageBitmap和OffscreenCanvas这种新兴的API,基本诞生之初就考虑到了结构化克隆算法的支持,因此只要出来就加入了结构化克隆的菜单。
七、旧时王谢堂前燕:structuredClone API问世
2021年以前的时代,结构化克隆算法一直是个内部API,只有"内部人"才可以使用,比如在谁用postMessage API的时候,浏览器内部会自动调用结构化克隆算法来进行深拷贝,开发者是完全没有感知的。开发者要深拷贝自己的对象,还是得用前面说过的老法子。
深拷贝这么常用的功能,明明有这么高效的解决方案,居然藏着掖着不拿出来,属实说不过去。实际上这几年来,社区就已经对暴露这个API有山呼海啸的需求了:github.com/whatwg/html...。
终于到2021年,structuredClone()被正式添加到HTML标准中并完善,到2022年,主流浏览器基本都实现了这个API。由于是浏览器底层的实现,所以比纯JS方案的性能要优异很多。关于structuredClone() API的设计有两个有趣的地方:
采用同步设计
关于这个API是设计成同步还是异步,在上面那个issue中也有讨论,这里又充分体现出了web技术中权衡的艺术。
支持异步设计的一派可以看做是完美主义者,他们认为希望这个API能响应异步设计的哲学,就和fetch之类的API一样,避免克隆大数据阻塞主线程,还能降低内存峰值。
支持同步设计的一派则是实用主义至上,异步虽然能解决很多的性能问题,但是大大增加了代码的复杂度。并且就现实来讲,处理大数据的克隆总是少数情况,一般需要处理的数据都能在瞬间完成克隆。就算需要克隆大型数据,也有替代方案,原本worker线程间通信的postMessage API 不就天然实现了异步克隆吗。或者可以将大数据分片再加入事件循环中逐步克隆。
最终浏览器厂商也是走了实用主义路线,保证功能和易用性的平衡。
不支持原型链克隆
之前我们看到很多深度克隆的库,支持自定义的克隆规则,让我们可以为自定义的对象绑定自定义的原型链,从而达到全方位的原型链一致性。但是structureClone却不支持自定义扩展,甚至严格禁止原型链的克隆。这就意味着,我们自己定义的一些类的实例,无法保证原型链一致性!
浏览器为什么要在这里和我们使绊子,其实也很好理解,最主要的就是安全问题。structureClone本身是用于给 postMeassage、indexDB等API提供底层支持的,而暴露出的structureClone() API也是共用这个底层能力。而这些API通常需要跨realm传输数据(realm可以简单理解为js上下文,但指代更广)。我们设想一下,如果structureClone 支持自定义克隆规则,或者复制自定义原型链,意味着什么:
我们在另一个realm里,比如另一个worker线程中接受到了主线程过来的数据,其中就包含自定义的类实例。克隆时要想重建这些实例,就得调用它们的构造方法,这便是最危险的地方,得执行一个函数。我之前就解释过为什么要禁止克隆函数,因为这里面可以传递恶意代码,更别说这里直接就执行了。并且要从底层实现这个功能,肯定要加非常多的限制,让系统变得非常臃肿。因此直接禁止是一个比较划算的选择。
开发者要是需要克隆自定义的实例,可以使用structureCloneAPI后自己手动重建这些实例。
结构化克隆支持的列表
下面让AI总结了下结构化克隆算法目前支持的和不支持的数据类型,以供大家参考
支持的数据类型
| 类型分类 | 具体类型 | 说明 |
|---|---|---|
| 基本类型 | undefined |
原始值 |
null |
原始值 | |
Boolean |
原始布尔值和Boolean对象 | |
Number |
原始数字值和Number对象 | |
BigInt |
原始BigInt值和BigInt对象 | |
String |
原始字符串值和String对象 | |
| 内置对象 | Date |
日期对象 |
RegExp |
正则表达式对象 | |
| 集合类型 | Array |
数组(包括稀疏数组) |
Object |
普通对象 | |
Map |
Map集合对象 | |
Set |
Set集合对象 | |
| 二进制数据 | ArrayBuffer |
数组缓冲区 |
SharedArrayBuffer |
共享数组缓冲区 | |
Int8Array |
8位有符号整型数组 | |
Uint8Array |
8位无符号整型数组 | |
Uint8ClampedArray |
8位无符号夹紧整型数组 | |
Int16Array |
16位有符号整型数组 | |
Uint16Array |
16位无符号整型数组 | |
Int32Array |
32位有符号整型数组 | |
Uint32Array |
32位无符号整型数组 | |
Float32Array |
32位浮点数组 | |
Float64Array |
64位浮点数组 | |
BigInt64Array |
64位有符号BigInt数组 | |
BigUint64Array |
64位无符号BigInt数组 | |
DataView |
数据视图对象 | |
| 错误对象 | Error |
标准错误对象 |
EvalError |
Eval错误对象 | |
RangeError |
范围错误对象 | |
ReferenceError |
引用错误对象 | |
SyntaxError |
语法错误对象 | |
TypeError |
类型错误对象 | |
URIError |
URI错误对象 | |
| Web APIs | File |
文件对象 |
FileList |
文件列表对象 | |
Blob |
二进制大对象 | |
ImageData |
图像数据对象 | |
CryptoKey |
加密密钥对象 |
不支持的数据类型
| 类型分类 | 具体类型 | 错误类型 | 说明 |
|---|---|---|---|
| 函数 | Function |
DataCloneError |
所有函数类型都不支持 |
AsyncFunction |
DataCloneError |
异步函数 | |
GeneratorFunction |
DataCloneError |
生成器函数 | |
| DOM相关 | DOM节点 | DataCloneError |
所有DOM元素 |
HTMLElement |
DataCloneError |
HTML元素 | |
Event |
DataCloneError |
事件对象 | |
| 高级对象 | Symbol |
DataCloneError |
符号类型 |
WeakMap |
DataCloneError |
弱映射对象 | |
WeakSet |
DataCloneError |
弱集合对象 | |
Promise |
DataCloneError |
承诺对象 | |
Proxy |
DataCloneError |
代理对象 | |
| 特殊对象 | 原型链 | 被忽略 | 克隆后丢失原型链 |
| 类实例 | 变为普通对象 | 失去类的方法和原型 | |
| 已分离的缓冲区 | DataCloneError |
已被转移的ArrayBuffer |
后记
断断续续写了好久,终于完成了。学习前端也刚好一年半了,学习的时候一直有种掣肘难行的感觉,无数的API学了忘、忘了学,最后记住的也只有常用的那寥寥数个。每一句代码都好像是熟悉的陌生人,我写下它、使用它、运行它,但似乎总是隔着一层纱,让我有一种奇妙的疏离感。尤其是背八股文的时候,总觉得隔靴搔痒,那些答案往往都点到为止。直到有天看了一本书,叫做《前端跨界开发指南》,开头讲模块化的时候,讲了在那个没有现代模块化方案的年代,前辈们如何用尽已有的资源,开发出各种奇技淫巧来实现模块化,这时我才明白了import这短短六个字母的分量。
我似乎理解了这其中的隔阂,前端是一个历史包袱非常重的领域,我们现在用的很多API、工具、甚至代码约定,都有着复杂的历史变迁,规范和社区诉求你来我往,螺旋上升。我们用一个API时,它为什么这么用、为什么是这种写法、为什么是这种方式运作,背后可能经历了无数的拉扯。而了解背后的历史,能让我们知道来龙去脉,知道解决了什么问题,能让我们对代码有更多的共鸣。
另一方面前端的环境非常隔离,浏览器几乎完全隔离了开发者和操作系统的直接交互,工具封装程度很高(似乎现代化的工具都这样)。因此我们很难看到背后真正的运作过程,很多教程都是依据现象总结的经验性理论,工作中够用,但是感觉不真实。
好在前端方面的历史虽然散乱,但都在互联网上留了痕,各种issue和规范小组的讨论存档,都能在互联网的大海中捞到。前端也是开源最盛行的领域,上至UI框架,下至浏览器内核,他们的仓库都大门常开,各种标准和规范也是人人可查。这就给了我们从历史和底层两个方向深入学习的机会。
虽然这些东西好像对写业务没什么太多帮助,不过个人感觉还是蛮有趣的,作为一个记忆力奇差的人,也是一个加深记忆的好方式。最后感谢大家的观看,由于没有多少实际开发经验,因此文章中少不了各种疏漏,烦请各位大佬不吝赐教。
部分其它参考资源
- www.youtube.com/watch?v=lZW... TPAC 2020的分组会议,讨论cpu和gpu之间的内存复制问题对浏览器性能的影响
- github.com/danbev/lear... 一个大佬的v8学习笔记
- developer.mozilla.org/zh-CN/ MDN,无需多言
- www.json.org/json-zh.htm... JSON最早的布道网站
- caniuse.com/ 你可以在这里搜索每个API的普及情况,能方便的查看最早支持某个API的是哪个浏览器
- matrixlogs.bakkot.com/ 一个归档网站,记录了各种规范小组的群聊记录
- johnresig.com/ John Resig的博客,那个创造了jQuery的男人,有很多前端考古资料
- 影响全球的CPU漏洞深度解读:熔断与幽灵
- Fantastic Timers and Where to Find Them: High-Resolution Microarchitectural Attacks in JavaScript