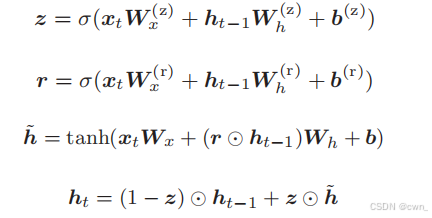Gated RNN & LSTM
-
简单RNN存在的问题
随着时间的回溯,简单RNN不能避免梯度消失或者梯度爆炸
-
梯度裁剪
用来解决梯度爆炸问题
code:
g:所有参数梯度的和;threshold:阈值
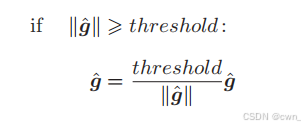
-
Gated RNN
用来解决梯度消失问题
Gated RNN框架下的两种结构:LSTM GRU
-
LSTM (Long Short-Term Memory:长短期记忆)长时间维持短期记忆
仅输出隐藏状态向量h,记忆单元c对外不可见
- ht = tanh(Ct)
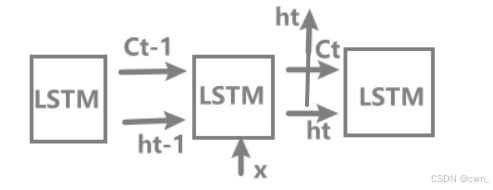
2. Gated 门:用来控制数据的流动,门的开合程度是自动从数据中学习到的,有专门的权重参数用于控制门的开合程度,这些权重参数也是通过学习被更新,sigmoid函数用于求门的开合程度-
输出门
对tanh(Ct)施加门,因为这个门管理下一个隐藏状态ht的输出,所以这个门称为输出门output gate
输出门的开合程度由xt和ht-1求出 sigmoid函数用于求门的开合程度:
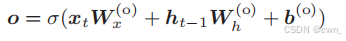
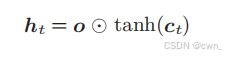
-
遗忘门
对记忆但会员Ct-1添加一个忘记不必要记忆的门,这个门称为遗忘门 forget gate
遗忘门的开合程度:
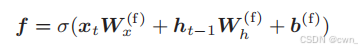
-
新的记忆单元
遗忘门从上一时刻的记忆单元删除了应该忘记的,现在我们还想向这个记忆单元添加一些应当记住的,为此我们添加新的tanh节点
g:向记忆单元添加的新信息
将g加到上一时刻的Ct-1上,从而形成新的记忆
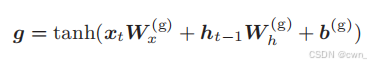
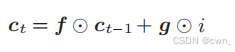
-
输入门
对这个新的记忆单元g添加门,这个门称为输入门 input gate
输入门的开合程度:
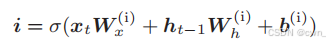
-
使用LSTM的语言模型
Embedding -> LSTM -> Affine -> Softmax with Loss
-
改进
-
LSTM的多层化
我们可以叠加多个LSTM层,从而学习更加复杂的模式(在PTB数据集上学习语言模型的情况下,LSTM的层数为2~4时,结果比较好)
-
Dropout抑制过拟合
常规Dropout:在深度方向(垂直方向)上插入Dropout层
变分Dropout:用在时间方向上
-
权重共享 weight tying
Embedding层和Affine层的权重共享,可以减少需要学习的参数数量
-
基于RNN生成文本
-
如何生成下一个新单词?
概率性的选择:根据概率分布进行选择,这样概率高的单词容易被选到,概率低的单词难以被选到。然后再把选中的词当作输入,再次选择下一个新的单词
-
seq2seq模型:Encoder-Decoder模型 编码器-解码器模型
编码器对输入数据进行编码,解码器对被编码的数据进行解码
编码:就是将任意长度的文本转换为一个固定长度的向量
seq2seq由两个LSTM层构成:编码器的LSTM和解码器的LSTM。LSTM层的隐藏状态是编码器和解码器的桥梁,在正向传播时,编码器的编码信息通过LSTM层的隐藏状态传递给解码器;反向传播时,解码器的梯度通过这个桥梁传递给编码器
-
seq2seq改进
-
反转输入数据 Reverse
反转输入数据的顺序,反转数据后梯度的传播可以更加平滑
-
偷窥 Peeky
将集中了重要信息的编码器的输出h分配给解码器的其他层
-
-
seq2seq的应用
-
聊天机器人 chatgpt
-
算法学习
-
自动图像描述
编码器从LSTM换成CNN
-
Attention 注意力机制
Attention从数据中学习两个时序数据之间的对应关系,计算向量之间的相似度,输出这个相似度的加权和向量
-
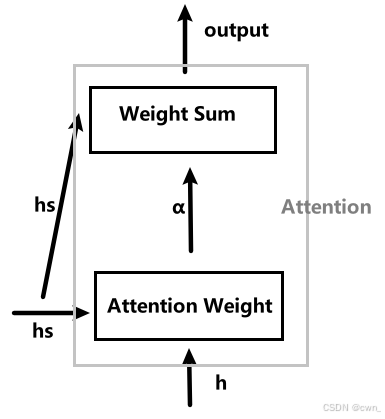
结构
Attention层放入LSTM和Affine层之间
hs:LSTM中各个时刻的隐藏状态向量被整合为hs
-
双向RNN
让LSTM从两个方向进行处理:双向LSTM
各个单词对应的隐藏状态向量可以从左右两个方向聚集信息,这些向量就编码了更均衡的信息
-
Attention层的不同使用
- Attention层放入LSTM和Affine层之间(垂直方向)
- Attention层放入上一时刻的LSTM层、Affine层和当前时刻的LSTM层之间(时间方向)
-
seq2seq的深层化 & skip connection
为了让带Attention的seq2seq具有更强的表现力,加深LSTM层
在加深层时使用到的一个技巧是残差连接(skip connection / residual connection / shortcut):是一种跨层连接的简单技巧
-
Attention应用
-
GNMT 谷歌神经机器翻译系统
-
Transformer
Attention is all you need
Transformer不用RNN,而用Attention进行处理:self-Attention
-
NTM Neural Turing Machine 神经图灵机
计算机的内存操作可以通过神经网络复现:
在rnn的外部配置一个存储信息的存储装置,使用Attention向这个存储装置读写必要的信息
-
GRU
GRU:Gated Recurrent Unit 门控循环单元
-
结构
GRU相比于LSTM的结构,取消了记忆单元的使用,只使用隐藏状态
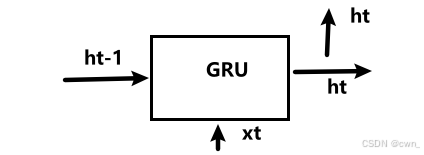
r:reset门:决定在多大程度上忽略过去的隐藏状态
h~:新的隐藏状态(下列第三个式子)
z:update门:更新隐藏状态
(1-z)· ht-1:forget门
z · h~:input门