最低要求 :参考指导书中直接映射写直达Cache 的实现,实现写回策略的Cache
此次实验大概分为以下几个步骤
- 首先,阅读实验环境介绍,明白 Cache 模块所处的位置与作用。
- 然后,阅读示例 Cache 实现过程,了解设计并实现 Cache 的主要步骤。其中类 sram 接口部分可以参考文档《A12_ 类 SRAM 接口说明》
- 接着,阅读 Cache 性能提升章节写回 Cache 内容 ,并参照示例代码,实现写回 Cache 。其中以下过程比较重要
- 分析写回 Cache 的流程图
- 分析写回 Cache 的状态机
- 分析写回 Cache 输入输出波形图
- 接着,阅读调试章节的内容,用自己实现的 Cache 模块,替换掉示例 Cache 模块,然后运行仿真程序,进行调试。
6 实验环境
当 MIPS core 向 Cache 模块请求指令和数据时,Cache 模块如果命中 ,则可以马上返回 数据,否则需要访问内存。而访问内存时 ,Cache 模块只需产生类 sram 信号,该类 sram 信号经过一个类sram-axi 转换桥后,会被转换成 axi 信号,因此 CPU 顶层对外接口为 axi 接口。
7 示例 Cache 的实现
7.1 直接映射 Cache 结构
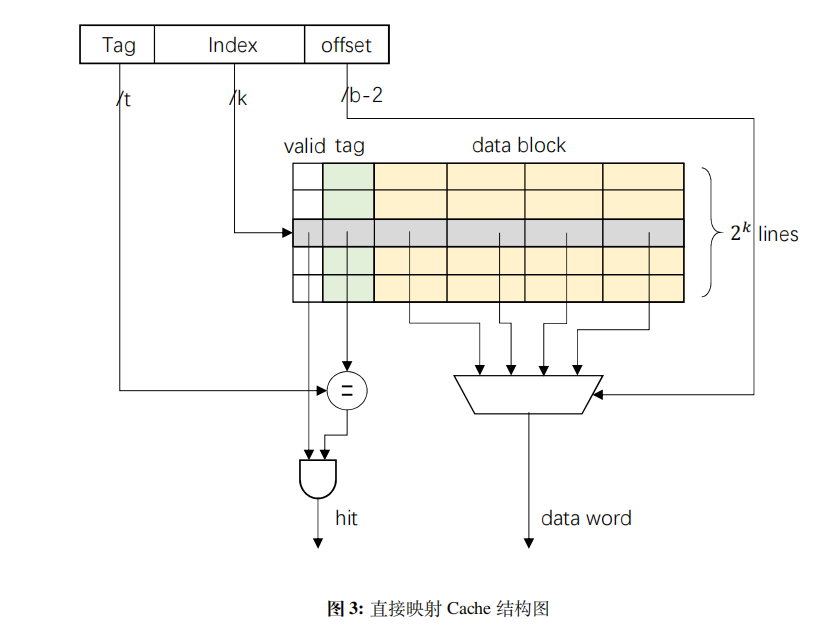
7.2 写直达-写不分配策略
当 CPU 执行 store 类指令时,对 Cache 应该如何操作呢?
- 当 Cache 命中时,最简单的想法是将数据同时写入到 Cache 和内存。
- 只写入 Cache,同时标记该 Cache line 为已修改,等到万不得已的时候(该 cache line 被替换时)再写入内存。
- 这两种策略分别为写直达 (Write Through) 和写回 (Write Back) 。本示例出于简单考虑,使用写直达策略。
当写缺失 时。针对是否将数据写入 Cache,可以分为写分配 (WriteAllocate) 和写不分配 (Non-Write Allocate)。
- 写直达通常结合写不分配 策略一起使用,即写缺失 时,直接写入内存,而不写入Cache。
- 而写回通常结合写分配 策略一起使用,即写缺失 时,只写入 Cache,而不写入内存。
示例使用写直达 策略、写不分配策略
7.3 状态机的设计
- 是读请求的话,判断是否命中。若命中了的话,便立刻返回数据。而如果缺失了,则需要从内存读取数据。再将数据写入 Cache,并返回数据给 CPU,这两个操作可以同时进行。
- 是写 请求的话,判断是否命中。如果缺失 的话,将数据写入内存 。如果命中 了的话,则既需要将数据写入内存 ,也需要写入 Cache。
IDLE 表示空闲状态也就是初始 状态,RM 表示读 取内存的状态,WM 代表写 内存的状态。以读为例,当读命中时,因为可以马上返回数据,因此仍然保持 IDLE 状态。当读缺失时,则进入 RM 状态,直到读取内存数据完成时(data_ok),Cache 返回数据给 CPU,写入 Cache,然后返回到 IDLE 状态。
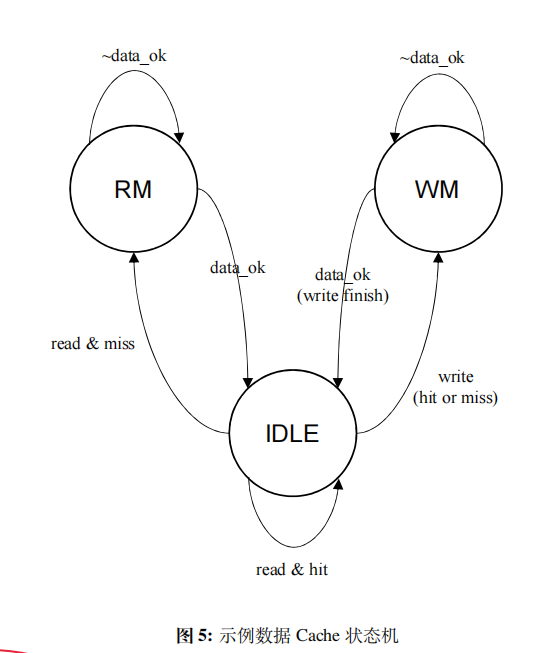
7.4 如何存储 Cache
7.4.1 使用 LUT(查找表)
verilog
//Cache配置
parameter INDEX_WIDTH = 10, OFFSET_WIDTH = 2;
localparam TAG_WIDTH = 32 - INDEX_WIDTH - OFFSET_WIDTH;
localparam CACHE_DEEPTH = 1 << INDEX_WIDTH;
//Cache存储单元
reg cache_valid [CACHE_DEEPTH - 1 : 0];
reg [TAG_WIDTH-1:0] cache_tag [CACHE_DEEPTH - 1 : 0];
reg [31:0] cache_block [CACHE_DEEPTH - 1 : 0];
//访问地址分解
wire [OFFSET_WIDTH-1:0] offset;
wire [INDEX_WIDTH-1:0] index;
wire [TAG_WIDTH-1:0] tag;
assign offset = cpu_data_addr[OFFSET_WIDTH - 1 : 0];
assign index = cpu_data_addr[INDEX_WIDTH + OFFSET_WIDTH - 1 : OFFSET_WIDTH];
assign tag = cpu_data_addr[31 : INDEX_WIDTH + OFFSET_WIDTH];
//访问Cache line
wire c_valid;
wire [TAG_WIDTH-1:0] c_tag;
wire [31:0] c_block;
assign c_valid = cache_valid[index];
assign c_tag = cache_tag [index];
assign c_block = cache_block[index];8.1 写回
写回--写分配策略、直接映射的 cache 的实现:
1 在读命中的情况下,CPU 直接读取对应的 cache line 的数据;
2 在读缺失的情况,如果索引到的 cache line 是干净的,那么发送读请求,从内存读取数据,然后返回给CPU,同时将数据写入到索引到的 cache line 中;如果索引到的 cache line 是脏的,那么首先要发送写请求,将这个 cache line 的脏数据写入到内存中。等待写请求处理完成后,再发送读请求,从内存中读取对应的数据,然后再把数据返回给 CPU,同时将数据写入到索引的 cache line 中。
3 在写命中 的情况下,如果索引到的 cache line 是干净 的,那么直接将数据写入到对应的 cache line 中,并且将 dirty 位置为 1;如果索引到的 cache line 是脏 的,直接把数据写入到 cache 中。
4 在写缺失的情况下,如果索引到的 cache line 是干净的,那么将数据写入到 cache line 中,覆盖掉原来的数据。如果索引到的 cache line 是脏的,那么首先发送写请求,将脏的 cache line 的数据更新到内存中;然后等待第一个写请求处理完成后,然后将数据写入到索引到的 cache line 中,并且将脏位标志位置为 1;
我们可能会多次将数据写入到某个相同的地址。针对这种情况,我们可以发现,写回策略仅需要在被替换出去的时候访问内存,而写通策略每次写操作都要访问内存。所以写回--写分配的策略有助于提升cache 性能。
调试过程
//存值,直接跳转
9fc003c8: afb10018 sw s1,24(sp)
9fc003cc: 25041590 addiu a0,t0,5520
9fc003d0: 3c11bfaf lui s1,0xbfaf
9fc003d4: afbf0024 sw ra,36(sp)
9fc003d8: afb30020 sw s3,32(sp)
9fc003dc: afb2001c sw s2,28(sp)
9fc003e0: 0ff004c2 jal 9fc01308
//
9fc003e4: afb00014 sw s0,20(sp)
9fc003e8: 3627e000 ori a3,s1,0xe000
9fc003ec: ace00000 sw zero,0(a3)
//进入函数
9fc01308 :
puts():
/home/rain/loongson/cache_lab/lib/puts.c:15
9fc01308: 27bdffe8 addiu sp,sp,-24
9fc0130c: afbf0014 sw ra,20(sp) //index == 464
//
/home/rain/loongson/cache_lab/lib/puts.c:16
9fc01310: 0ff004a0 jal 9fc01280
9fc01314: 00000000 nop
/home/rain/loongson/cache_lab/lib/puts.c:17
9fc01318: 0ff00495 jal 9fc01254
9fc0131c: 2404000d li a0,13
//...
9fc01284: afb10014 sw s1,20(sp)
9fc01288: afbf001c sw ra,28(sp)
9fc0128c: afb20018 sw s2,24(sp)
9fc01290: afb00010 sw s0,16(sp)
9fc0130c //sw未命中,直接在cache_block1d0即464中写入9fc003e8,且将dirty置为1,同时tag也改变
9fc01264 //lw读命中,直接读出cache_block中的值9fc012b4到cpu_data_rdata
9fc01258 //sw命中
命中后直接写入cache_block,此时dirty已为1不用改变
9fc00db0//lw读未命中,且dirty为1
进入WM状态,将cache_block中数据写入内存(cache_data_wdata),然后从内存加载lw需读的数据cache_data_rdata