一、数据血缘背景&目标
随着业务数据持续涌入大数据平台,数据上下游依赖关系日益复杂,业务对报表数据溯源困难,传统的管理方式已难以满足追溯与治理需求。需要引入元数据血缘,实现对数据从源头到消费端的全链路追踪,精准刻画数据的生成、加工与流转过程。
个人对数据血缘、数据治理等概念了解比较浅薄,如有错漏欢迎大佬指正。
24年末,本着开箱即用的目标,开始调研相关元数据管理平台。先说结论,我们最后选用了 open_Metadata,整体数据架构如下图所示。
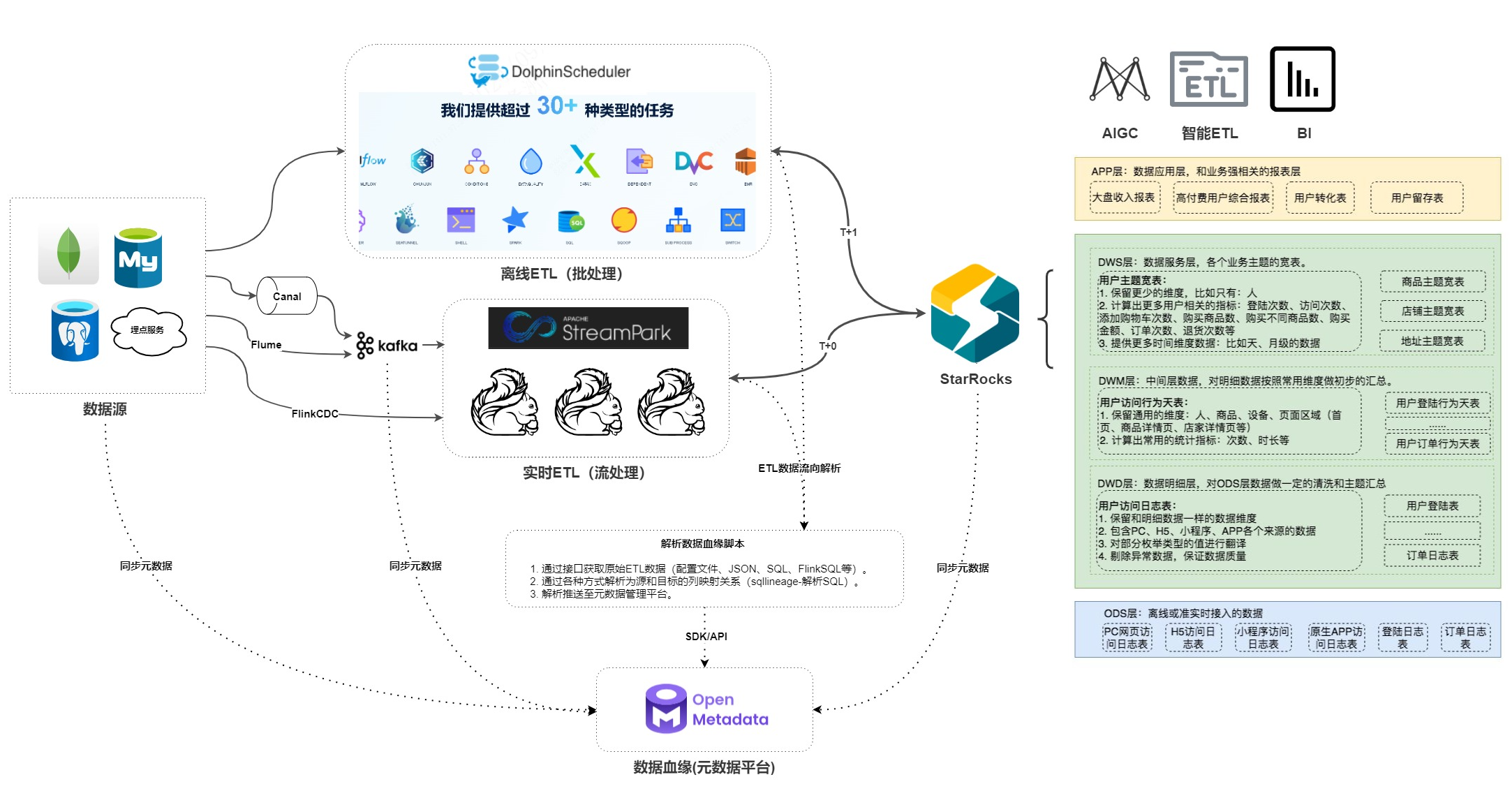
首先,数据从最左边的数据源(像 MySQL、PostgreSQL、MongoDB 数据库以及埋点服务这类地方)出发。
- 采集环节:通过 Canal(抓取 MySQL 等数据变更)、Flume(采集日志)、FlinkCDC(实时读库)这些工具把数据采集到 Kafka 消息队列里。
- 处理环节:一条 DolphinScheduler 做离线 ETL(批处理)。另一条数据从 Kafka 出来后到 StreamPark 结合 Flink 做实时 ETL(流处理)。
- 存储与应用环节:处理后的数据存到 StarRocks 里。然后基于 StarRocks 支撑起多层应用,从原始的 ODS 层,到清洗汇总的 DWD 层、初步汇总的 DWM 层、主题服务的 DWS 层,最后到业务报表的 APP 层。
- 数据血缘环节:整个过程中还会通过脚本解析数据血缘关系,通过 SDK/API 把血缘信息同步到 Open Metadata 元数据平台,方便了解数据的来龙去脉,进行数据治理。
我们目前只使用了数据库相关的功能,如果还需要应用、API等更丰富的,也可以自行研究,open_metadata也确实有接口。大厂应该不少都是自研的,但也可以参考参考,如b站:https://zhuanlan.zhihu.com/p/1931815312036196357
1. 开源元数据平台概览
| 序号 | 开源软件 | 基本情况 |
|---|---|---|
| 1 | Apache Atlas | Apache 顶级项目,起源于 Hadoop 生态(如 Hive、HBase、Storm),强调数据治理、安全与合规(如 GDPR、HIPAA)。支持分类(Classification)、策略(Policy)、数据血缘(Lineage)等功能。与 Ranger、Hive 等深度集成。但生态绑定过强,对非 Hadoop 技术栈(如 MySQL、PostgreSQL、Kafka)支持较弱,配置复杂,学习曲线陡峭。适合大型企业已有 Hadoop 架构的场景。 |
| 2 | DataHub | 由 LinkedIn 开源并捐赠给 LF AI & Data 基金会,是当前最活跃的元数据平台之一。采用现代微服务架构(Kafka + Elasticsearch + MySQL + GraphQL),支持实时元数据流、丰富语义模型(Entity、Aspect、Relationship)、强大的 API 和 SDK。支持列级血缘、数据质量、数据文档、权限管理、搜索推荐等。前端功能强大,社区活跃,文档完善。适合中大型企业构建统一元数据中枢。 |
| 3 | OpenMetadata | 由 OpenMetadata Inc(前 Acryl Data)主导开发,采用单体+微服务混合架构(基于 Flask/FastAPI + SQLAlchemy + MySQL/PostgreSQL + Airflow)。核心优势是开箱即用的功能完整性:内置数据发现、血缘、数据质量、数据剖析(Profiling)、告警、BI 集成、权限控制等。前端 UI 美观易用,API 和 SDK 非常丰富,支持 Python、Java、Airflow 插件等。社区增长迅速,定位为"一体化元数据平台"。 |
| 4 | Amundsen | 由 Lyft 开源,现属 LF AI & Data 基金会。严格来说它是一个数据发现与导航平台(Data Discovery & Navigation),而非完整元数据管理平台。核心功能是通过 Elasticsearch 构建数据搜索引擎,让用户快速找到所需表,并查看其描述、所有者、使用频率、模式信息等。血缘功能较弱(需 Marquez 集成),治理能力有限。优势是简单、快速部署、用户体验好。适合中小团队快速实现"找数难"问题。 |
🔔 说明:Amundsen 已于 2023 年进入"维护模式"(maintenance mode),官方推荐迁移到 DataHub。
2.关键疑问对比分析
| 序号 | 疑问 | OpenMetadata 确认情况 | DataHub 确认情况 |
|---|---|---|---|
| 1 | 库表展示方式?多环境支持? | ✅ 支持完整层级:Service Instance (e.g., MySQL) → Database → Schema → Table。 ✅ 支持多环境(prod/uat/fat)共存,通过"Environment"实体区分不同部署环境,避免元数据覆盖。 ✅ 可为同一数据库服务的不同实例创建独立的 Service,实现隔离。 |
⚠️ 展示层级简化为:Service Type → Database → Table,不保留实例名 。 ❌ 存在元数据覆盖风险 :若两个不同环境的 MySQL 实例同步同名 DB 和 Table,后同步者将覆盖前者。 ✅ 解决方案:可通过自定义 databaseServiceName 或使用命名空间(Namespace)变通处理,但非原生友好。 |
| 2 | 数据治理能力?性能影响? | ✅ 内置治理功能:支持数据所有者(Owner)、敏感字段标记(PII)、生命周期策略、审批流程(Beta)、数据质量测试集成。 ✅ 列级元数据同步性能良好,可按需开启。 ⚠️ 超大规模实例(>10万表)首次全量同步较慢,建议增量同步+分片采集。 | ❌ 原生 DataHub 不提供完整治理功能,需结合外部系统(如 IAM、Policy Engine)实现。 ✅ 支持 Owner、Tag、Glossary Term 等基础治理标签。 ✅ 列级同步性能良好,适合大规模部署。 ✅ 支持软删除、版本控制(via Kafka log compaction)。 |
| 3 | 前端功能 & API/SDK 支持? | ✅ 前端功能全面 :支持列级血缘可视化、数据质量结果展示、数据剖析图表、文档编辑、权限配置、通知中心等。 ✅ API & SDK 极其丰富:RESTful API 完整开放,Python SDK 支持 Ingestion、Lineage、Ownership 等操作,Airflow 集成完善。 | ✅ API/SDK 非常强大 :GraphQL + REST API,Java/Python SDK 成熟,支持自动化元数据写入。 ⚠️ 前端限制 :血缘仅支持表级展示,列级血缘需调用 API 查看或通过第三方插件展示。 ✅ 支持自定义前端插件(React)。 |
| 4 | 上手难度?中文支持? | ✅ 上手相对容易,文档清晰,Docker 部署一键启动。 ✅ 支持多语言:包括简体中文(前端界面、文档),国际化程度高。 | ⚠️ 上手有一定门槛,涉及多个组件(GMS、MAE、MCE、Kafka、ES 等)。 ❌ 官方前端无中文 ,但社区有翻译尝试。 📌 官方已合并 i18n PR,未来版本有望支持多语言。 |
| 5 | 团队协同?业务人员可用性? | ✅ 支持完整的组织架构模型:User、Team、Role、Policy。 ✅ 支持业务术语表(Glossary)、数据域(Domain)、文档中心(Knowledge Base)、评论功能。 ✅ 适合数据工程师、分析师、数据治理专员、业务人员协同使用。 | ✅ 支持 User、Group、Policy 权限模型。 ✅ 支持 Glossary、Domain、Custom Properties 扩展。 ✅ 支持数据文档、Owner 认领、关注(Follow)机制。 ✅ 适合技术+业务混合团队使用,但需一定培训。 |
| 6 | 二次开发难度?技术栈? | ✅ 后端:Python(FastAPI/Flask)+ SQLAlchemy + Alembic(Migration) ✅ 前端:React + Ant Design ✅ 元数据存储:MySQL/PostgreSQL(结构化) ✅ 插件机制良好,适合 Python 技术栈团队二次开发。 | ✅ 后端:Java(Spring Boot)为主,部分 Python(Ingestion Framework) ✅ 前端:React + TypeScript ✅ 元数据存储:Elasticsearch(索引)+ Kafka(事件流)+ MySQL(少量元数据) ✅ 架构灵活,适合 Java/React 技术栈团队扩展。 |
3. 综合对比维度补充
| 维度 | OpenMetadata | DataHub | 备注 |
|---|---|---|---|
| 部署复杂度 | 中等(单体+Airflow) | 高(多服务+Kafka+ES) | DataHub 组件更多,运维成本更高 |
| 社区活跃度 | 高(GitHub 7.5k+ stars) | 极高(GitHub 9.8k+ stars) | 目前(2025) OpenMetadata 产品更成熟,但 DataHub 社区更活跃 |
| 血缘能力 | 强(原生支持列级) | 强(需 Ingestion 配置) | 两者均支持自动/手动血缘 |
| 数据质量集成 | 内置 Great Expectations | 支持 Great Expectations / Soda | 均支持主流数据质量工具 |
| 中文支持 | ✅ 完整支持 | ❌ 仅英文(未来可能支持) | OpenMetadata 更适合中文团队 |
| 多环境支持 | ✅ 原生支持 | ⚠️ 需规避命名冲突 | OpenMetadata 更优 |
| 扩展性 | 高(插件化 Ingestion) | 极高(事件驱动 + SDK) | DataHub 更适合复杂架构 |
| 是否推荐生产使用 | ✅ 推荐 | ✅ 推荐 | 两者均已用于多家大厂 |
4. 选型调研建议与结论
| 软件 | 建议 | 适配团队特征 | 选型确定 |
|---|---|---|---|
| Apache Atlas | 不推荐新项目使用,除非强依赖 Hadoop 生态 | 已有 Hadoop 生态,合规要求高 | ×(非 Hadoop 体系) |
| DataHub | 适合技术能力强、已有 Kafka/ES 基础设施、追求高扩展性的团队 | 技术栈偏 Java,已有 Kafka/ES,追求高扩展性。 | ×(不保留实例名,不符合我司使用需求) |
| OpenMetadata | 适合希望快速落地、重视中文支持、需要开箱即用治理功能的团队 | 技术栈偏 Python,希望快速上线,重视中文和治理功能 | √ |
| Amundsen | 不推荐新项目使用 | 团队较小,只想解决"找数难"问题 可考虑 Amundsen(短期),长期建议迁移到 DataHub/OpenMetadata | ×(不维护了) |
二、元数据平台部署
1. Datahub docker-compose 部署
前置依赖 python
powershell
mkdir -pv /data/pkg
cd /data/pkg
wget https://www.python.org/ftp/python/3.12.5/Python-3.12.5.tgz
tar xvf Python-3.12.5.tgz
cd Python-3.12.5
# python 依赖
yum -y install gcc openssl-devel gcc-c++ compat-gcc-34 compat-gcc-34-c++ libffi-devel zlib zlib-devel bzip2-devel sqlite-devel
# 编译安装
./configure --enable-loadable-sqlite-extensions --prefix=/usr/local/python3.12.5
make && sudo make install
# 创建符号链接以便 python3 命令指向新版本
sudo rm /usr/bin/python3
sudo ln -s /usr/local/python3.12.5/bin/python3.12 /usr/bin/python3
vi /etc/profile
export PATH="/usr/local/python3.12.5/bin:$PATH"
source /etc/profile
pip3 --version安装DataHub CLI
powershell
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip install --upgrade acryl-datahub
datahub version启动停止
powershell
mkdir -pv /data/datahub
cd /data/datahub
wget -O docker-compose.yaml https://raw.githubusercontent.com/datahub-project/datahub/master/docker/quickstart/docker-compose-without-neo4j-m1.quickstart.yml
datahub docker quickstart --quickstart-compose-file docker-compose.yaml
datahub docker quickstart --stop --quickstart-compose-file docker-compose.yaml访问登录
- http://xxx.xxx.xxx.xxx:9002/
- username: datahub
- password: datahub
备份恢复
powershell
datahub docker quickstart --backup --backup-file <path to backup file>
datahub docker quickstart --restore --restore-file /home/my_user/datahub_backups/quickstart_backup_2002_22_01.sql2. Open_Metadata docker-compose 部署
powershell
#Docker (version 20.10.0 or greater)
docker --version
#Docker Compose (version v2.1.1 or greater)
docker compose version
#install openmetadata-docker
cd /data/
mkdir openmetadata && cd openmetadata
wget https://github.com/open-metadata/OpenMetadata/releases/download/1.8.7-release/docker-compose.yml
docker-compose up -d访问登录(官方文档给的默认账号有误,没有'-')
三、数据血缘解析
首先要知道,这些元数据管理平台本身能做的是:
- 录入数据库实例,并执行调度任务加载元数据(既库表结构等)
- UI展示血缘关系
录入实例信息在此不做赘述,可参考各自官方文档,稍加摸索便能上手,而且不止数据库还有各种类型的Connectors。
因此我们要自动化获取ETL内的血缘,就必须写代码去load,或者直接嵌入相关应用程序,再调用这些平台的API写入。
open_metadata 暂时不支持我们使用的数仓 starrocks 类型,目前使用mysql类型并修改部分源码临时替代
1. Datahub 数据血缘解析 Demo
sqllineage 分析再推送DataHUb
使用:sqllineage + DataHUb的API
借助第三方开源框架sqllineage去解析SQL;从SQL自动提炼出上游表和下游表关系;然后自动执行脚本创建。核心是先sqllineage分析血缘上下游;然后构建列级血缘,最有还有个优化就是筛选下游所有的表
2. Open_Metadata 数据血缘解析 Demo
注意 openmetadata-ingestion 包的版本要和应用程序对应
pip install openmetadata-ingestionOpenMetadata JWT 令牌
xxxxxxxxxxxxxxxxxxx创建连接并创建血缘关系
py
from metadata.ingestion.ometa.ometa_api import OpenMetadata
from metadata.generated.schema.entity.services.databaseService import DatabaseService
from metadata.generated.schema.entity.services.connections.metadata.openMetadataConnection import (
OpenMetadataConnection,
AuthProvider,
)
from metadata.generated.schema.security.client.openMetadataJWTClientConfig import (
OpenMetadataJWTClientConfig,
)
def add_lineage(metadata: OpenMetadata, service_name: str, sql : str):
database_service: DatabaseService = metadata.get_by_name(
entity=DatabaseService, fqn=service_name
)
if database_service is None :
return('service_name 名称有误:'+ service_name)
metadata.add_lineage_by_query(
database_service=database_service,
timeout=200, # timeout in seconds
sql=sql, # your sql query
)
return('血缘添加成功')
def open_metadata(hostPort: str, jwt_token: str):
server_config = OpenMetadataConnection(
hostPort=hostPort,
authProvider=AuthProvider.openmetadata,
securityConfig=OpenMetadataJWTClientConfig(jwtToken=jwt_token),
)
metadata = OpenMetadata(server_config)
return metadata
if __name__ == "__main__":
hostPort = "http://192.168.31.130:8585/api"
jwtToken: str = (
"xxxxxxxxxxxxxxxxxxx"
)
metadata = open_metadata(hostPort, jwtToken)
# check client health
health_check_result = metadata.health_check()
# return True if health
print("Health check result:", health_check_result)
sql = """
insert
into
my_test.fee_info(creator, tenant_id, updator)
select
A.creator,
B.tenant_id,
B.office_name
from
my_test.archive_ledger_relationship A
left join my_test.task_archive_borrowing B on
B.mid = A.archive_ledger_id
where
A.state_id = 1
"""
result = add_lineage(metadata,"个人博客",sql)
print(result)查看血缘:http://192.168.31.130:8585/table/个人博客.default.my_test.fee_info/lineage
3. Open_Metadata 数据血缘 ETL 实践
在自己的数据库上建表,open_metadata_url_service 用于存储 URL 与服务名称的映射关系
sql
CREATE TABLE open_metadata_url_service (
id INT AUTO_INCREMENT PRIMARY KEY,
url_pattern VARCHAR(255) NOT NULL,
service_name VARCHAR(255) NOT NULL,
UNIQUE INDEX idx_url_pattern (url_pattern)
);本目录下的脚本用于自动化提取和录入数据血缘信息,支持多种数据平台和ETL工具,包括 DolphinScheduler、StreamPark、Canal、FlinkSQL、DataX 等。血缘信息将自动同步到 OpenMetadata 元数据平台,便于数据治理和溯源。
- 同步 ETL平台 数据血缘至 元数据平台 的脚本程序还在优化中,当前支持类型如下:
| 序号 | 血缘来源 | 已支持 | 规划中 |
|---|---|---|---|
| 0 | 元数据同步(平台自带) | 视图血缘 | 无 |
| 1 | 离线ETL平台 DoplhinScheduler(海豚) | SQL、DATAX | shell、其他 |
| 2 | 实时ETL平台 StreamPark | FlinkSQL(starrocks、mongo-cdc、mysql-cdc、jdbc、kafka) | FlinkSQL(elasticsearch)、jar |
| 3 | Canal | mysql --> canal --> kafka | 无 |
依赖环境
-
Python 3.7+
-
依赖包安装:
bashpip install sqllineage openmetadata-ingestion pymysql requests django mirage-crypto
主要脚本说明
open_metadata_lineage.py
核心血缘提取与写入 OpenMetadata 的实现,支持 SQL、DataX、FlinkSQL、Canal 等多种方式。get_etl_add_lineage.py
各平台(DolphinScheduler、StreamPark、Canal)血缘提取入口,调用open_metadata_lineage.py。execute_demo.py
脚本入口,定时任务可直接调用,自动批量提取并写入血缘信息。open_metadata_db_info.py
数据库服务、域、标签等元数据的批量注册与同步脚本。
使用方法
-
配置数据库连接、OpenMetadata 地址和 Token(详见各脚本开头的配置)。
-
执行
execute_demo.py,即可自动批量提取并写入血缘信息。bashpython execute_demo.py -
可根据需要单独调用
get_etl_add_lineage.py中的各类 Demo 或平台方法。
注意事项
- 需提前在 OpenMetadata 平台配置好服务、域、标签等基础元数据。
- 数据库连接、平台 API Token 等敏感信息请妥善保管。
- 如需扩展支持新的数据源或血缘类型,可在
open_metadata_lineage.py中补充相应方法。
四、平台使用参考
用途:探索数据,查看数据血缘关系,了解数据来源及去向,方便数据治理。
1. 普通用户首次使用
- 访问 元数据平台 open_metadata,点击新建账号(Create Account)。
- 注册邮箱只要符合格式就行 。
- 登陆后界面右上角可以改为中文
2. 功能说明
2.1 搜索
- 顶部搜索栏可输入库表名称、字段名称、表备注等
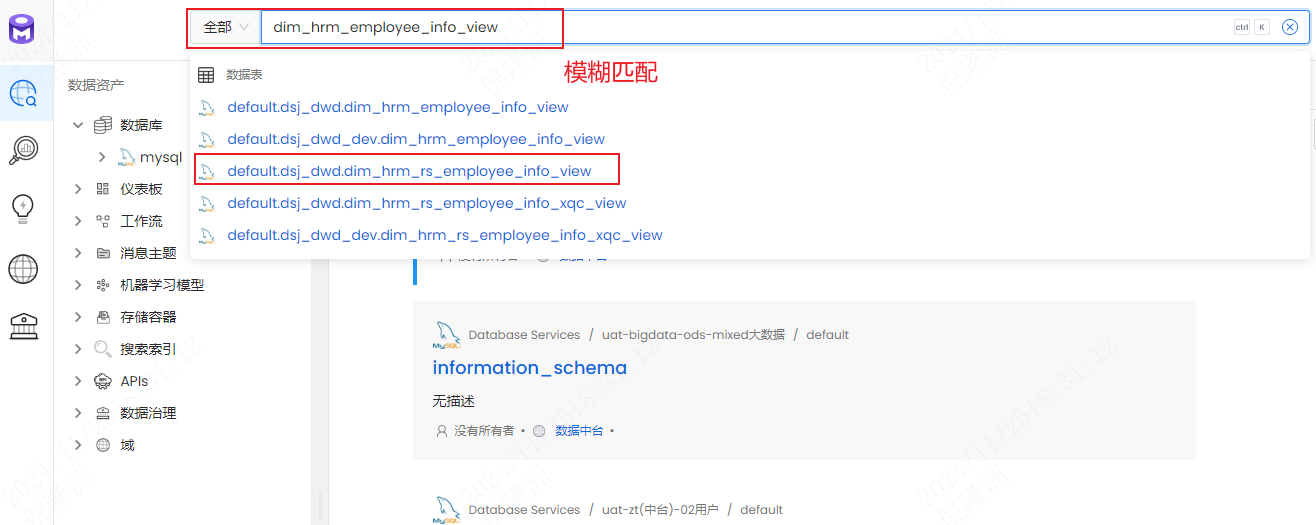
2.2 菜单
- 在左侧菜单栏中选择
探索->数据库->mysql->...
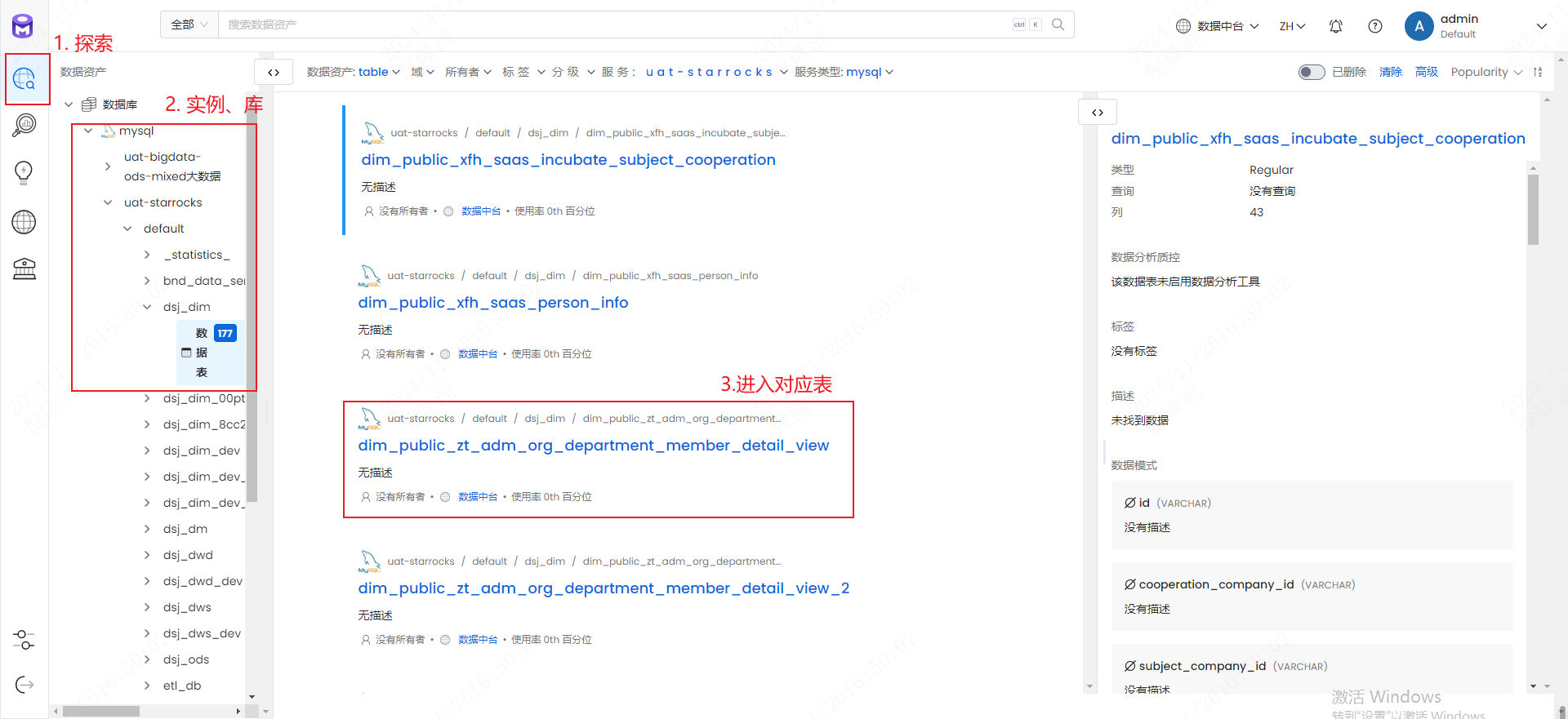
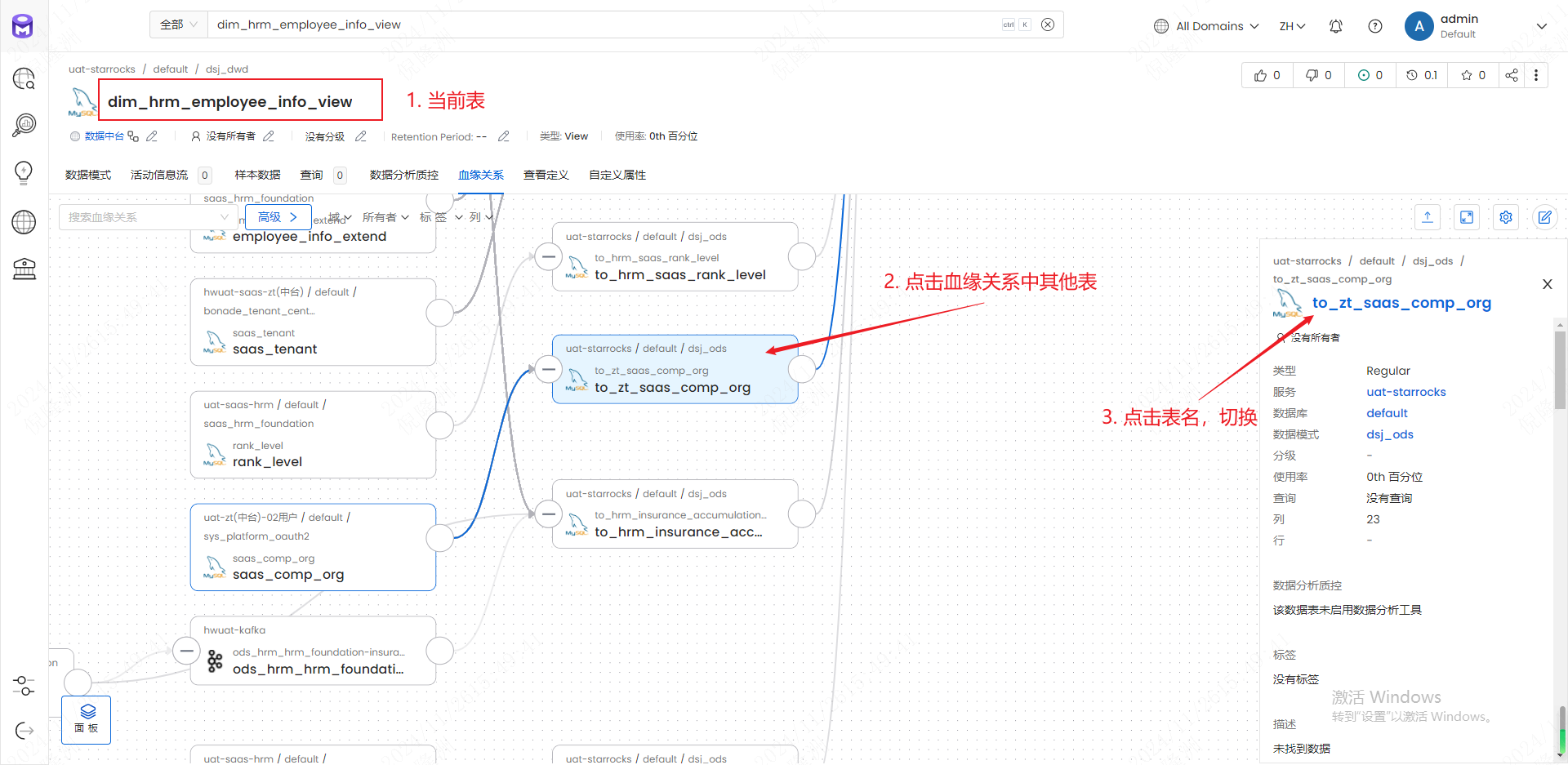
2.3 表血缘
- 选择血缘关系,点击连线
- 注意:如果血缘关系只有当前表,说明没有血缘关系或没有摄取到ETL平台的血缘数据(自己的脚本维护)。
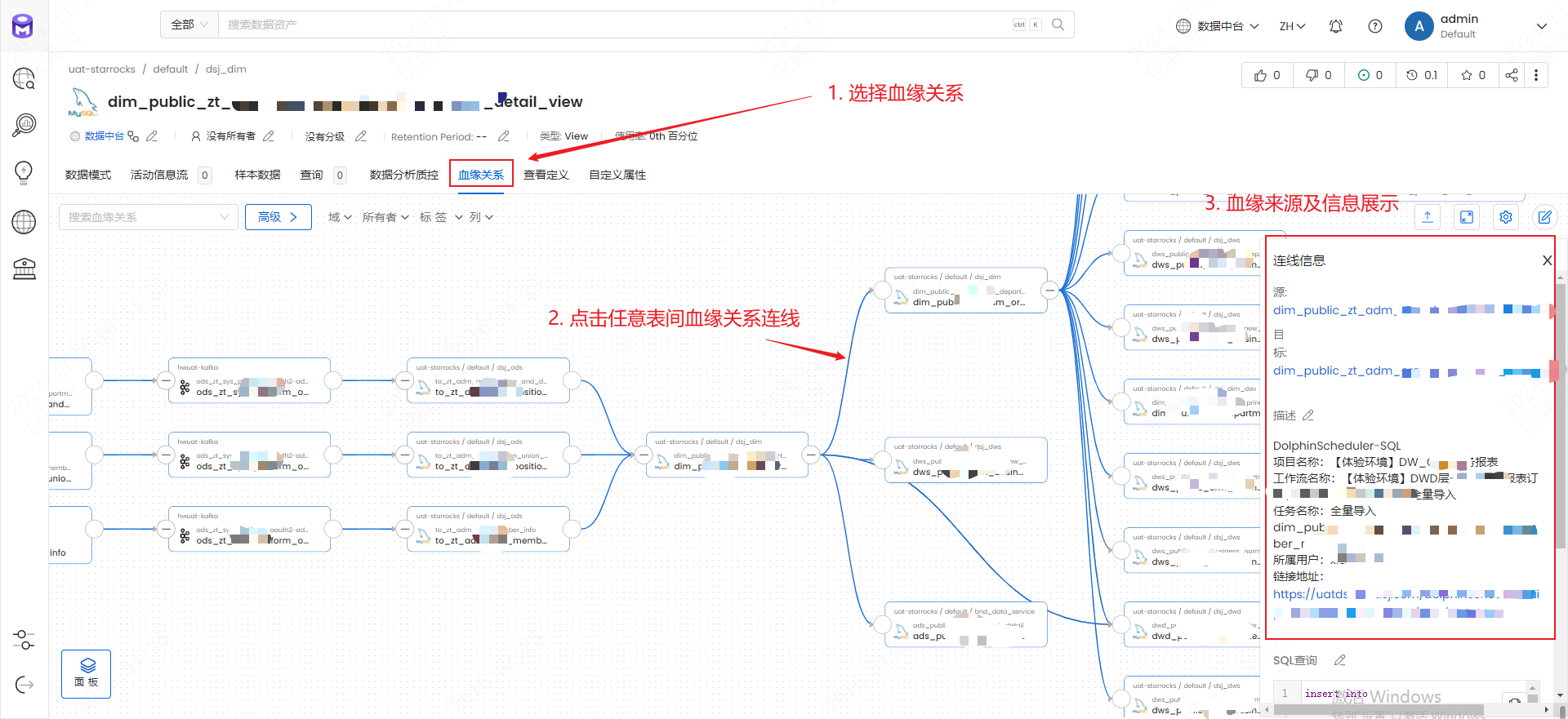
2.4 字段血缘
- 左下角选择面板-列
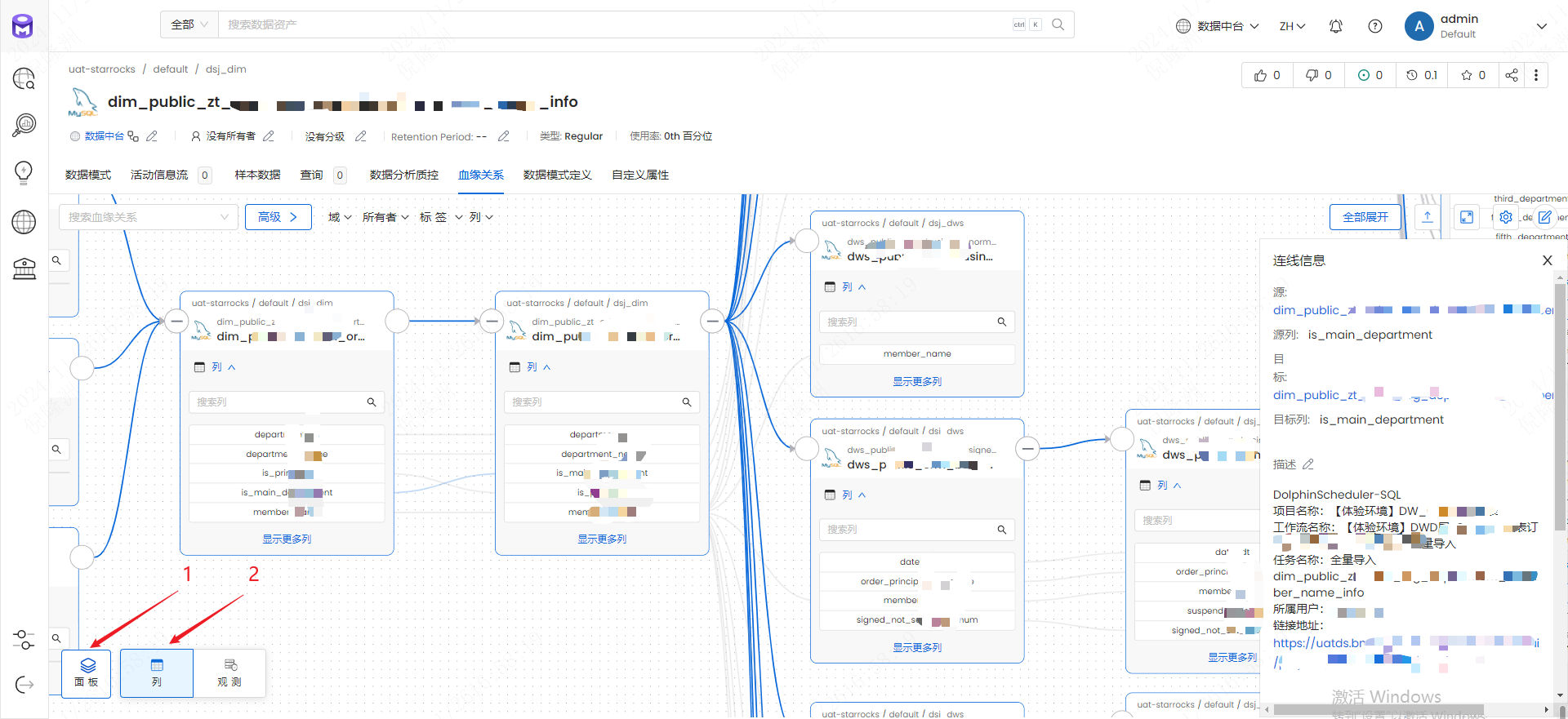
2.5 切换表
- 在血缘关系中点击其他表,点进右侧栏表名