你可能会有这样的经历
作为一个golang后端工程师,维护着一套推荐/搜索/广告系统
明明用户只是对你的首页发起了一次请求,你的服务却召回了成千上万个item
为了性能考虑,这些item的正排/属性数据当然不能实时拉取,但是cache的选择却是一把辛酸泪
- 最开始的哥们直接用了map做缓存,上线不久就发现了问题:map本身没有过期时间的,运营同学数据都改半天了,转头一看banner还挂在首页呢
- 略一思索,哥们从map换成go-cahce,附赠value过期时间,一切都很完美,直到某次促销,服务器CPU超过了30%,接口响应时间一飞冲天。这时候你站了出来,先跑了下pprof,发现有20%的CPU耗在了GC scan object,终于破案:由于item数量太过庞大,go-cache已经存了几十万的数据,每次GC都会扫描KV和里面的所有指针,难怪性能上不去
- 顶着巨大的优化压力,你找到了解决方案---freecache or bigcache这类的0 gc cache,他们用自建索引+\[\]byte数据存储的办法规避了gc扫描问题,从此,item数量不再是问题,然而切换新cache后,CPU负载和接口时延却双双开始上涨:继续观察pprof,发现
*struct <-> []byte的编解码,甚至超过了GC的开销 - 虽然不敢相信这个来自protobuf的
*struct编解码性能如此差劲,但你还是找到了解决方案:golang官方的protobuf为了兼容性,大量使用了反射,导致编解码性能低下,切换到gogoproto后编解码性能暴涨70%
到目前为止,似乎gogoproto + freecache / bigcache似乎已经是多item cache的终极解决方案了
直到某次性能优化,你重新打开了pprof,看到了下面这张熟悉的图
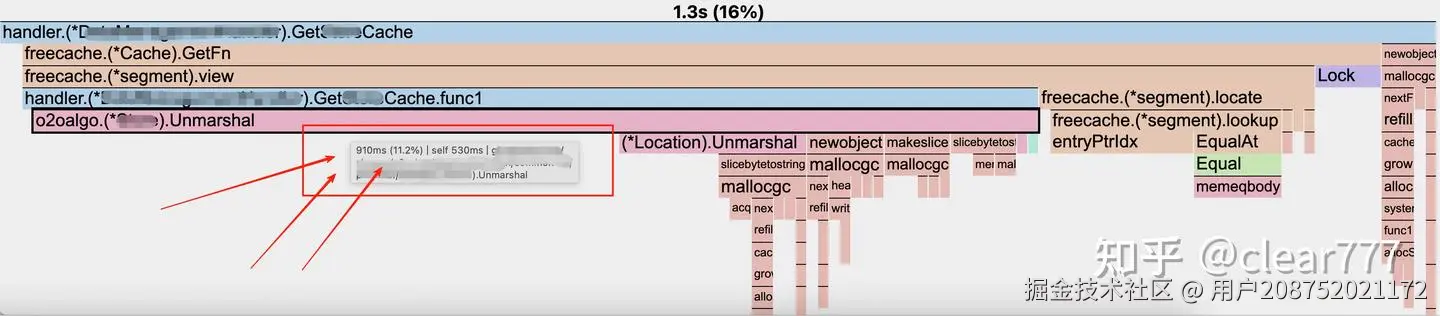
陷入沉思:10~15%的CPU花在了cache编解码上,这合理吗?
如果你也和我一样曾经或现在有这个疑问
那么,heyicache is all you need!
什么是heyicache?
heyicache代码:github.com/yuadsl3010/...
heyicache参考自的缓存结构设计,继承了freecache的许多优点的同时
将Get、Set的value对象从\[\]byte优化为struct指针,通过将struct指针内容指向提前申请好的\[\]byte内存,规避Get、Set前后编解码带来的性能损耗
性能对比
benchmark代码:github.com/yuadsl3010/...
100w item, 100 goroutine: 1 write, 99 read, after 99th read do a cache result check - 10s
bash
BenchmarkMap-10 6025 2195842 ns/op 1012247 B/op 42823 allocs/op
BenchmarkGoCache-10 4082 3160241 ns/op 999648 B/op 42456 allocs/op
BenchmarkFreeCache-10 2739 4742585 ns/op 35077612 B/op 616594 allocs/op
BenchmarkBigCache-10 2624 5127104 ns/op 35326953 B/op 626420 allocs/op
BBenchmarkHeyiCache-10 15436 799174 ns/op 1219251 B/op 44084 allocs/op
Read: success=59521064 miss=80582 missRate=0.14% // now we get some cache miss cause the eviction strategy
Write: success=1516698 fail=406 failRate=0.03%
Check: success=1528075 fail=0 failRate=0.00%业务实践
单机qps 1k以上,对业务无任何侵入改动,只是单纯将freecache替换为heyicache
平均cpu下降13%
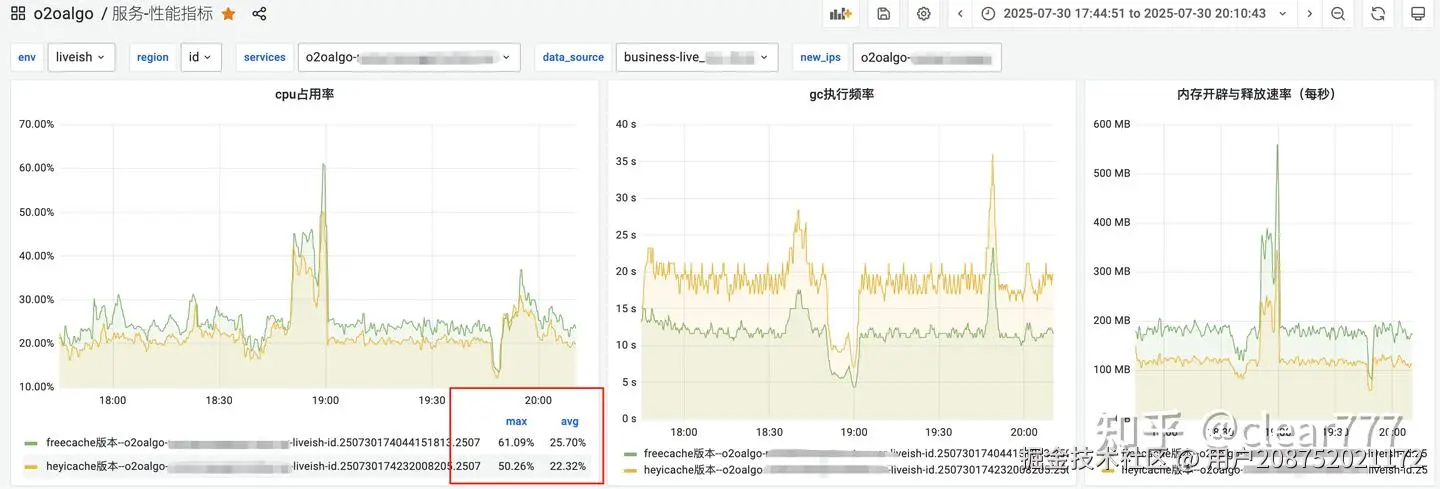
使用指引(详细原理和方案放在后面)
1. 准备好value结构体
假设value是TestCacheStruct
go
type TestCacheStruct struct {
id int
name string
}2. 为value结构体生成内存映射函数
推荐创建一个heyicache_fn_test.go文件,内容如下
go
package main
import (
"testing"
"github.com/yuadsl3010/heyicache"
)
func TestFnGenerateTool(t *testing.T) {
heyicache.GenCacheFn(TestCacheStruct{})
}执行后将得到一个go文件,里面包含HeyiCacheFnTestCacheStructIfc_实例
3. 使用cache进行读写
go
package main
import (
"context"
"fmt"
"unsafe"
"github.com/yuadsl3010/heyicache"
)
func main() {
cache, err := heyicache.NewCache(
heyicache.Config{
Name: "heyi_cache_test", // it should be unique
MaxSize: int32(100), // 100MB cache, the min size is 32MB
},
)
if err != nil {
panic(err)
}
key := "test_key"
value := &TestCacheStruct{
Id: 1,
Name: "foo string",
}
// set a value
err = cache.Set([]byte(key), value, HeyiCacheFnTestCacheStructIfc_, 60) // 60 seconds expiration
if err != nil {
fmt.Println("Error setting value:", err)
return
}
// get a vlue
ctx := heyicache.NewLeaseCtx(context.Background()) // init a new context with heyi cache lease
leaseCtx := heyicache.GetLeaseCtx(ctx)
leaseCache := leaseCtx.GetLease(cache)
data, err := cache.Get(leaseCache, []byte(key), HeyiCacheFnTestCacheStructIfc_)
if err != nil {
fmt.Println("Error getting value:", err)
return
}
testStruct, ok := data.(*TestCacheStruct)
if !ok {
fmt.Println("Error asserting cache value")
return
}
fmt.Println("Got value from cache:", testStruct)
heyicache.GetLeaseCtx(ctx).Done()
}内存映射实现原理
heyicache先从buffer中申请好指定长度\[\]byte,再将struct的空间内存,映射到这一段\[\]byte中
完成Set之后,Get就相对简单了,只需要将\[\]byte内存取出来,然后取前StructSize的\[\]byte强转成Struct指针就行
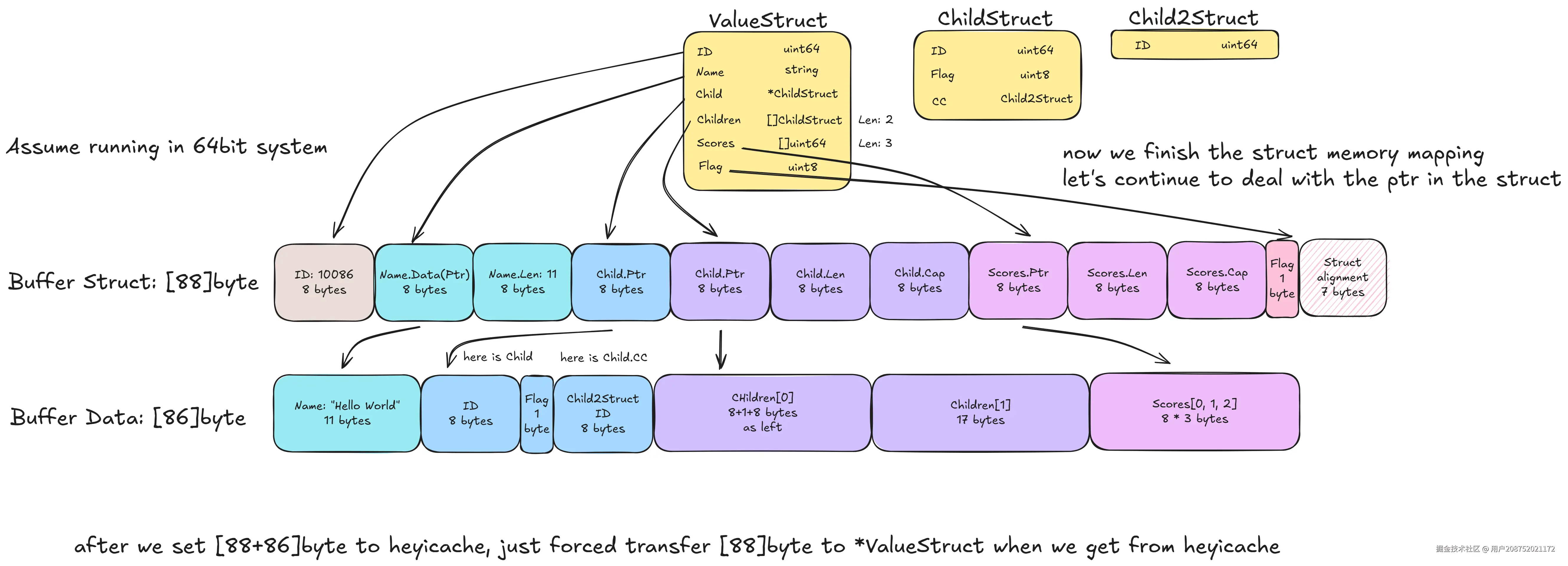
cache读写实现原理
heyicache会初始化256个segment,每个segment初始化10个buffer、1个entry数组、1个256长度的slotLen map
先介绍一下entry数组和slotLen(这里是完全复用的freecache的逻辑和实现):
entry数组长度总是256(slot个数) * 2的倍数,例如:如果entry长度是1024,那么0 \~ 3属于0号slot,4 \~ 7属于1号slot,如果我们锁定了1号slot,且slotLen1 = 3,则我们只需要对entry4 \~ 7中的4 \~ 6进行二分查找即可
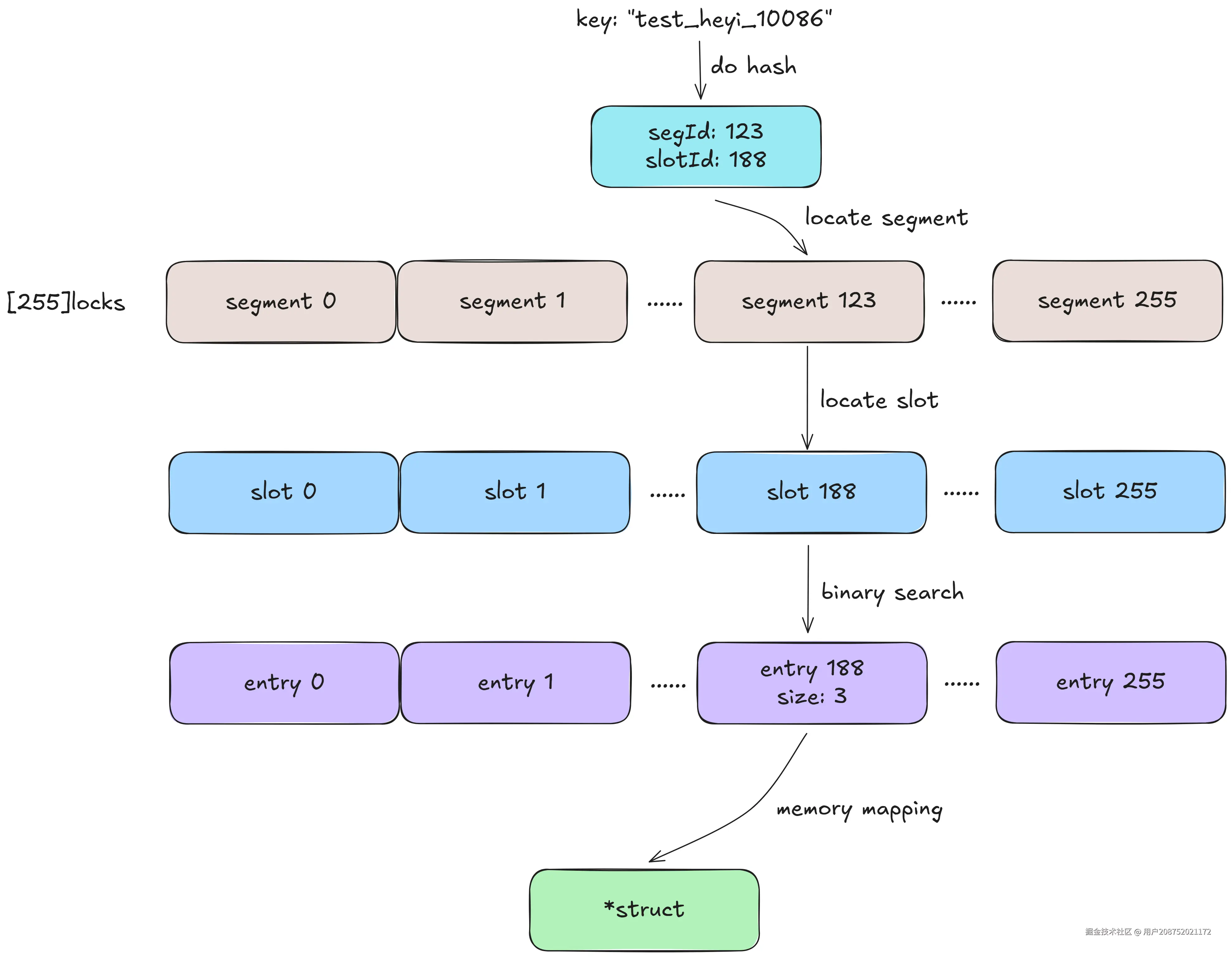
数据淘汰实现原理
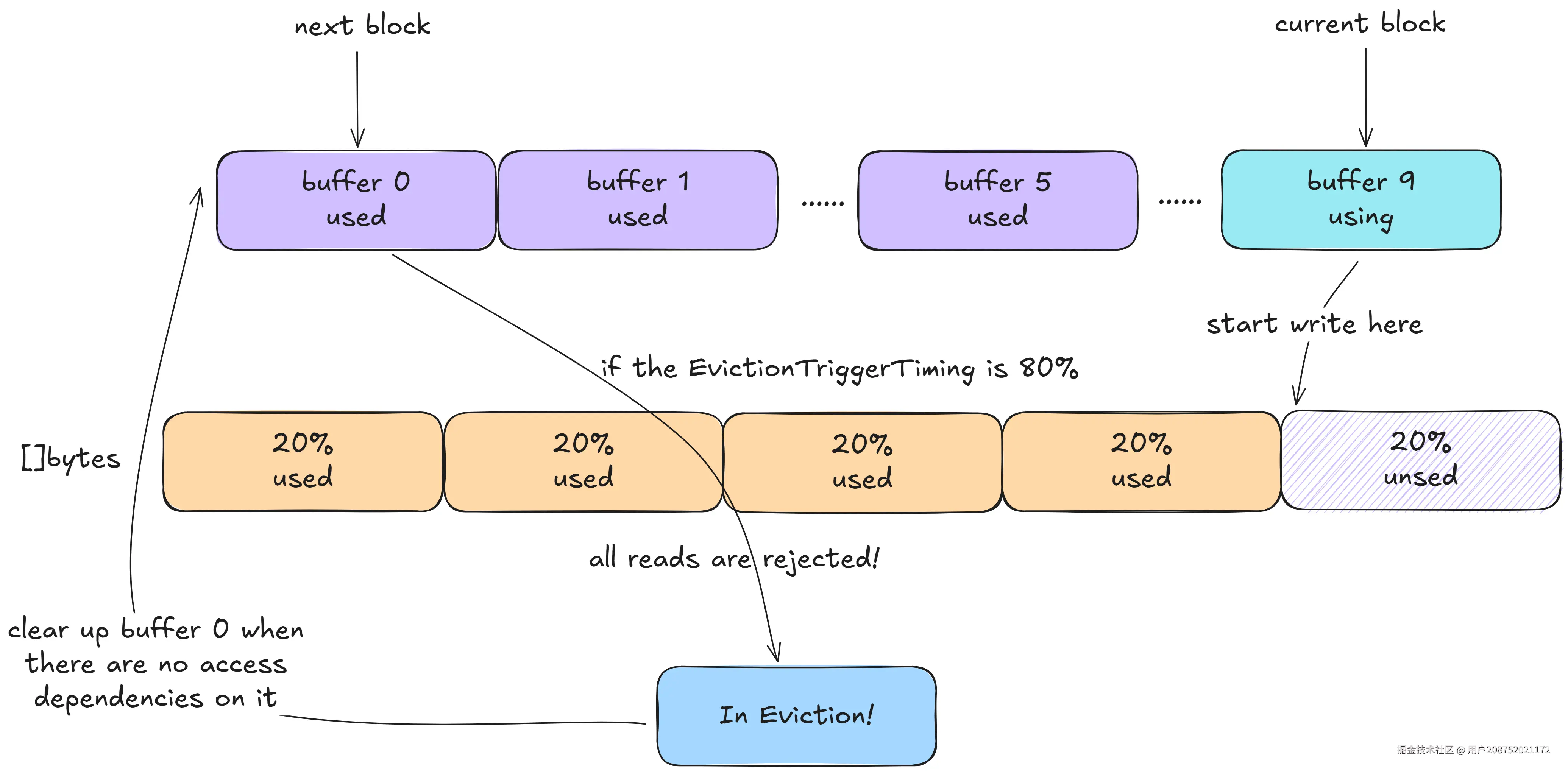
接下来说一下10个buffer的用法,首先每个buffer的size是相等的,他们相加等于一个segment,也就是总cache size的1/256
curBlock取值范围为0~9(也就是buffer数量),从0开始,写满buffer0后,curBlock改为1,继续写buffer1
nextBlock为curBlock的下一个取值,如果curBlock为9,则nextBlock为0
当curBlock写到超过EvictionTriggerTiming时(默认是50%),会开启nextBlock的eviction。此时nextBlock禁止读取,在确认nextBlock没有任何访问之后,对nextBlock的buffer和entry进行回收
一个直观的例子,EvictionTriggerTiming为80%时,cache size写入到98%时,开始eviction,确认next block没有访问依赖时会进行回收,cache size降为88%
lease实现原理
由于我们需要知道,一个block是否有访问依赖,所以引入lease机制
cache和任何一份lease都同时持有 segment countblock countint32 的数组
例如:
从segment 3的block 5中Get了一个对象,cache 和 lease中的35 都会+1
在ctx生命周期终止时,cache会减去lease,如果next block正好处于eviction且used = 0,则进行清理

使用限制
如此巨大的性能提升,but at what cost?
1. 作为value的struct有类型限制
value必须是*struct,且struct中的map成员无法被cache且会被强制指向nil
- 类型固定为*struct:更方便为其提供内存映射函数的代码(使用指引的第二节,可以为任意struct生成内存映射函数,无需人工干预)
- 不支持map成员:golang map所占用的内存并不连续,极其碎片化的分配方式导致无法用一段连续内存进行存储,推荐的实现方式是采用数组进行存储(如果有更好的内存管理方式,也欢迎一起探讨)
2. value是只读的
由于struct在内存映射后,所有的指针都指向那一段分配好的连续内存,所以哪怕是修改的string,也会导致下次get的string指向已被gc回收的内存,触发panic
所以value必须是只读的
tips: 我自己在业务实践的时候,也会去修改其中的某个静态变量(uint64、bool这种),因为这种变量存在在连续内存中,不会被gc回收,算是一个比较hack的使用方式。但用户在修改前,一定要清楚的知道自己在修改什么,否则会引发panic
3. 稍高的数据过期概率
由于内存映射的关系,heyicache的淘汰最小单位是一个segment中的一个buffer(与freecache一样,有256个segment,每个segment有10个buffer,例如cache总空间是256MB,那么一个segment就是1MB,一个buffer也就一次淘汰的内存就是100kb;与之相对的,freecache的会按照近似FIFO的方法淘汰一个)
因为无法知道这个segment上哪些数据正在被访问,所以当buffer写满的时候,只能新创建一个buffer,老buffer确认无法访问之后再回收
这样的特性导致:
内存写满时,数据过期概率相对freecache或者bigcache稍高一些
根据我自己的业务实践,相比性能的提升,cache率少许下降带来的损失可以忽略不计
4. 需要在get的数据不再访问后,主动进行lease的归还
如果你是grpc服务,那么最好增加一个中间件,确保respone已经封包后,调用heyicache.GetLeaseCtx(ctx).Done()进行归还(见使用指引第3部分)
否则heyicache无法判断buffer是否还在使用,在buffer写满的情况下就无法创建新的空间
使用建议
绝大部分场景按照接入指引可以进行快速接入,但建议定时增加heyicache的数据上报,可以帮助你快速分析是否应该增减内存或者调整数据访问方式
有任何疑问或者建议,也欢迎一起交流和讨论: yuadsl3010@gmail.com