主要内容:
-
了解深度学习如何改变我们在机器学习中所使用的方法。
-
了解为何
Pytorch适合深度学习。 -
了解要使用书中例子所需要的硬件配置。
1.1 深度学习革命
神经网络提取数据并根据实例提取有用表征的能力,正是深度学习如此强大的原因。
1.2 Pytorch 深度学习
Pytorch提供了一个核心数据结构 - 张量。
1.3 为什么用Pytorch
Pytorch 具备2个特性,使得它与深度学习关联紧密。
-
使用
GPU加速计算,通常比在CPU上执行相同的计算速度快50倍。 -
提供了支持通用数学表达式数值优化的工具,该工具用于训练深度学习模型。
1.4 Pytorch如何支持深度学习概述
Pytorch大部分是用 C++ 和 CUDA 编写的,CUDA 是一种来自英伟达的类 C++ 的语言,可以被编译并在 GPU 上以并行方式运行。
用于构建神经网络的 Pytorch 核心模块位于 torch.nn中,它提供了通用的神经网络层和其他架构组件。全连接层、卷积层、激活函数和损失函数都可以在这里找到。
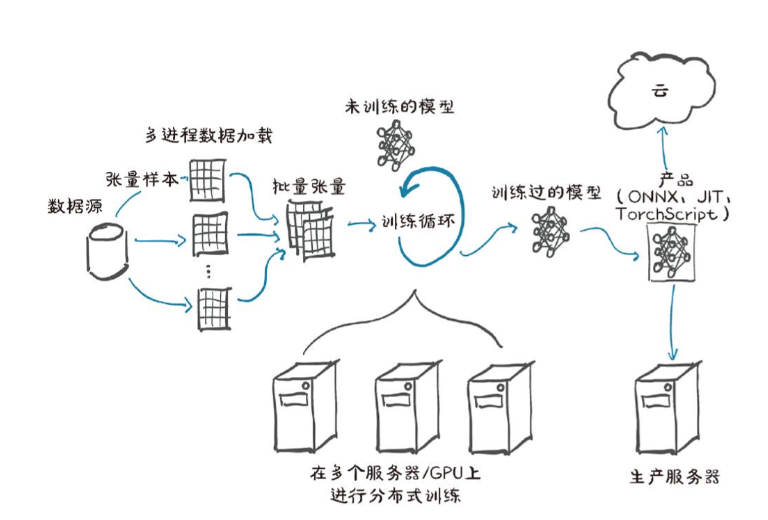
1.5 硬件要求和软件要求
硬件要求:NVIDIA GTX 1070或更高的配置。
软件要求:Jupyter Notebook、python3.6+。
1.6 代码
1_making_sure_things_work:
python
# 导入torch
import torch
# 查看torch的版本
torch.version.__version__
'2.6.0+cu126'
# 查看cuda是否可用
torch.cuda.is_available()
True
# 新建张量
a = torch.ones(3,3)
a
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
b = torch.ones(3,3)
b
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
# 张量相加
a + b
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
# 上面是张量在CPU上进行计算,将张量放在GPU上进行运算
a = a.to('cuda')
b = b.to('cuda')
a + b
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]], device='cuda:0')