目录
[1.1 数据结构的概念](#1.1 数据结构的概念)
[1.2 数据结构的集合框架](#1.2 数据结构的集合框架)
[1.3 算法](#1.3 算法)
[1.3.1 时间复杂度](#1.3.1 时间复杂度)
[1.3.2 空间复杂度](#1.3.2 空间复杂度)
[2.1 为什么需要包装类?](#2.1 为什么需要包装类?)
[2.2 装箱和拆箱](#2.2 装箱和拆箱)
[3. 初识泛型](#3. 初识泛型)
[3.1 认识泛型](#3.1 认识泛型)
[3.2 泛型类的使用](#3.2 泛型类的使用)
[3.3 泛型的编译](#3.3 泛型的编译)
[3.4 通配符](#3.4 通配符)
[3.4.1 无界通配符](#3.4.1 无界通配符)
[3.4.2 上界通配符](#3.4.2 上界通配符)
[3.4.3 下界通配符](#3.4.3 下界通配符)
1.数据结构的概念和算法
1.1 数据结构的概念
数据结构是程序的骨架,算法是程序的灵魂。什么是数据结构?
在《大话数据结构》这本书中,作者指出:数据结构是相互之间存在一种或多种特定关系的数据元素的集合。也就是说,数据结构是计算机中存储、组织数据的方式。就像现实生活中我们使用文件夹整理文档、用书架分类书籍一样,程序也需要合理的方式管理数据。
1.2 数据结构的集合框架
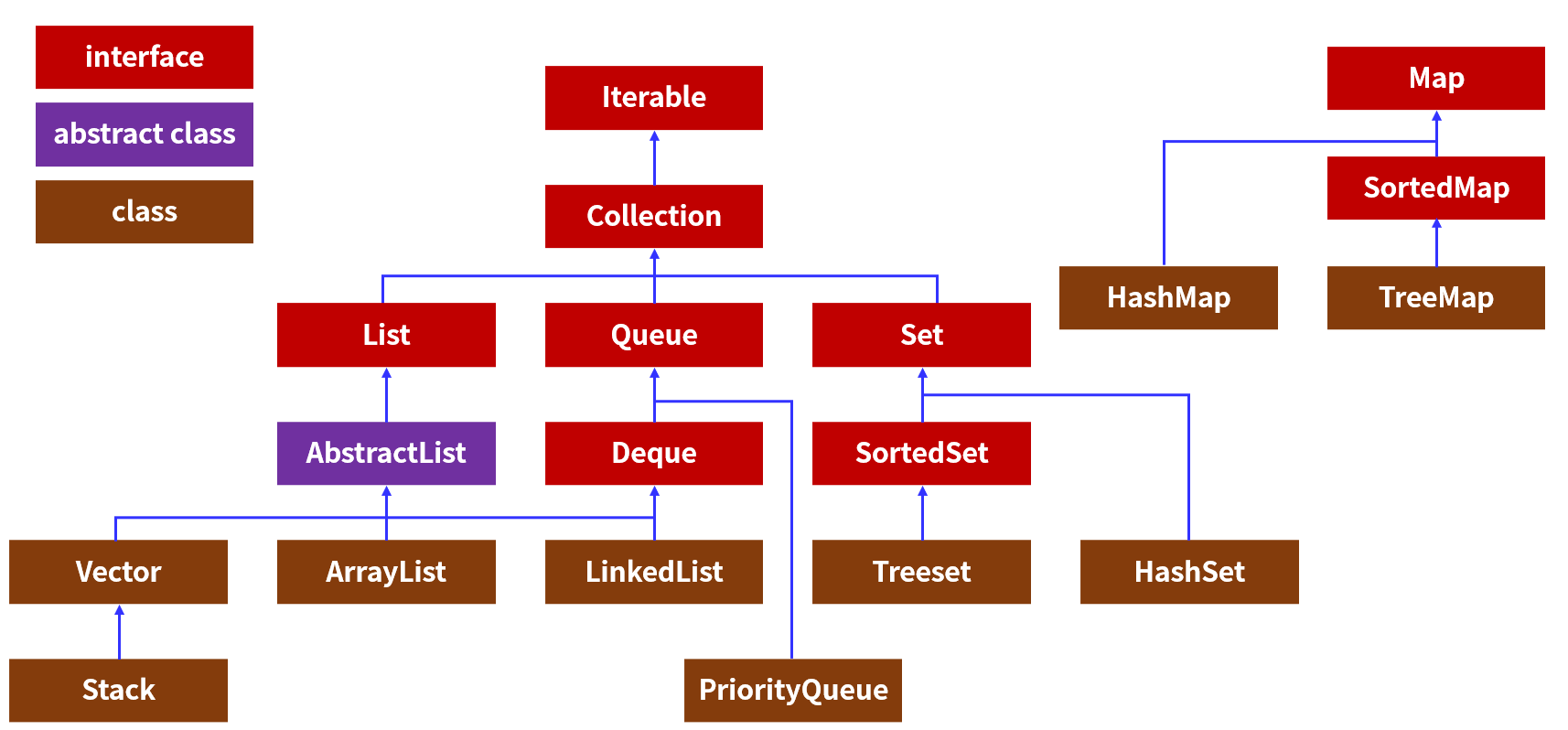
数据结构的主要集合框架为上图。
学习数据结构,就要了解以上集合框架图的关系和每个具体的类是什么样的数据结构。这个图做一个简单的了解即可,不必刻意深记,在后面的学习中都会详细介绍。
1.3 算法
算法是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
怎么衡量一个算法的好坏?这就要谈到算法的效率。算法的效率分为两种,一是时间效率,也称为时间复杂度,二是空间效率,也称为空间复杂度。二者通常用大O的渐进表示法来计算。
1.3.1 时间复杂度
时间复杂度(Time Complexity) 是衡量算法执行时间随输入规模增长的变化趋势的指标。它不计算具体的运行时间 ,而是描述算法在最坏或平均情况下执行基本操作的次数与输入规模 n 的关系,通常用 大O符号(Big-O Notation) 表示。
大O渐进法怎么表示?
- 用常数 1 代替运行时间中的所有加法常数
- 保留最高项,并且忽略最高项的系数
怎么理解大O渐进表示?
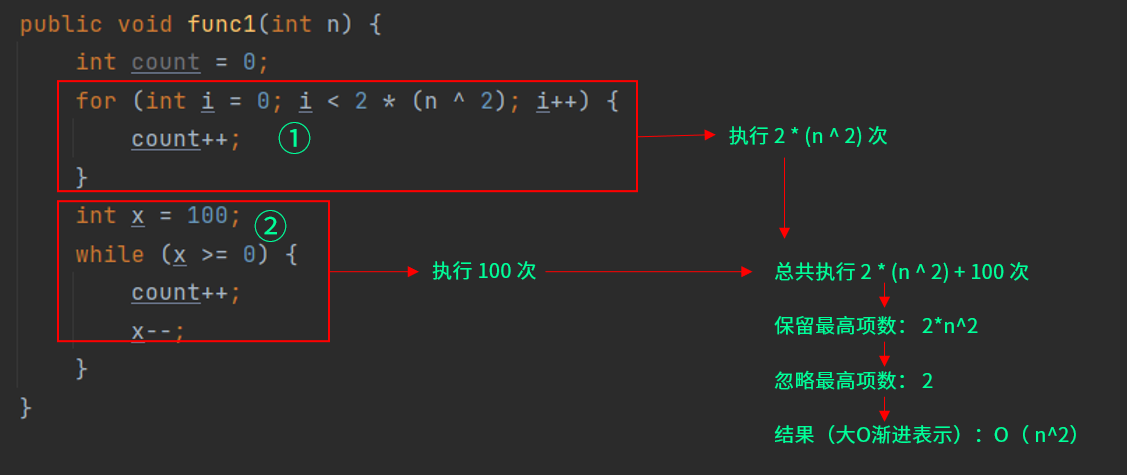
通常在衡量一个算法的效率时,都是根据最坏情况去衡量。当然会有一些算法存在平均情况和最后情况。
最坏情况:任意输入规模的最大允许次数
平均情况:任意输入规模的期望运行次数
最坏情况:任意输入规模的最小运行次数
比如在一个长度为n的整数 升序 数组中,查找数组中是否存在某一个值时,如果按照线性查找的方式(从前到后或者从后到前)查找,那么最坏的可能是最后一个数组元素才是需要查找的值,或者这个数组本身就没有这个值的时候,其时间复杂度便是达到 O(n) ,如果第一个元素就是要查找的值,这个时候就可以达到0(1) 。如果使用二分查找的方式(每次取这个数组的中间元素进行比较)进行查找,如果中间元素的值大于需要查找的值,则说明要查找的值在这个中间元素的左边,那么下次查找只需要在左边进行查找,依次类推,直到找到与需要查找的值相等或者最后一个元素为止, 这种方式时间复杂度最坏情况只有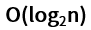 , 同理,如果第一个元素就是要查找的值,这个时候就可以达到0(1) 。
, 同理,如果第一个元素就是要查找的值,这个时候就可以达到0(1) 。
1.3.2 空间复杂度
空间复杂度(Space Complexity) 是衡量算法在运行过程中 临时占用的内存空间 随输入规模(n)增长的变化趋势。与时间复杂度类似,空间复杂度也用 大O表示法(Big-O Notation) 描述。
有一些说法是:空间复杂度就是计算变量的个数 。
这个说法并不完全正确,空间复杂度计算的是 算法运行过程中额外占用的内存空间,而不仅仅是变量的个数。变量个数是影响因素之一,还需考虑:
-
变量的规模 (如数组、链表、递归栈等占用的空间与输入规模
n相关)。 -
数据结构的内存占用 (如
HashMap比Array更占空间)。 -
递归调用的栈空间(每次递归都会占用额外的栈帧)。
比如曾经在递归的学习中,计算第 n 项的斐波那契数时,当项数达到一定值时,就会发生栈溢出。这是因为每一次递归时,都会产生一个临时的内存空间来存储参数和返回地址等。
2.包装类
2.1 为什么需要包装类?
在Java中,由于基本类型并不是继承Object 类,为了在泛型代码中可以支持基本类型,Java为8种基本数据类型 提供的对应的引用类型(对象类型),用于将基本类型"包装"成对象。其基本数据类型 的对应的包装类如下:
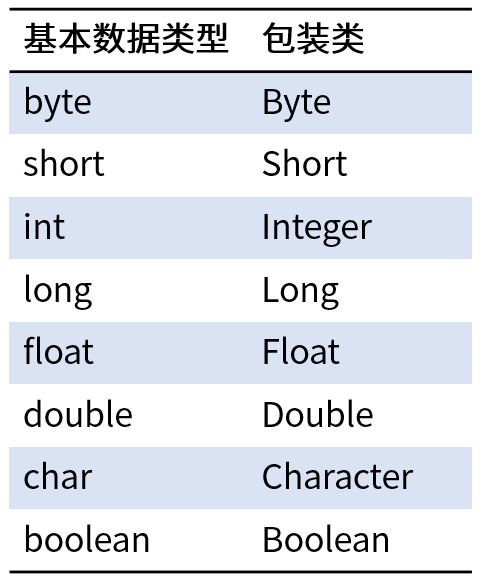
可以看出,出来int和char的包装类分别对应Integer和Character,其余的基本数据类型对应的包装类都是首字母大写。
那么,为什么需要包装类呢?
- Java是面向对象的语言,但是基本数据类型并不是对象。包装类的作用:
存储在集合中 :如
List<Integer>(集合只能存对象,不能存基本类型)调用对象方法 :如
Integer.parseInt(String s)支持泛型 :泛型类型必须为对象(如
ArrayList<Integer>),而 ArrayList<int> 是错误的如果没有包装类,就无法使用
ArrayList、HashMap等集合存储基本类型。2. 允许
null值基本类型不能为
null,但包装类可以表示数据缺失或未初始化。3. 提供丰富的工具方法
如Integer.toBinaryString(),可以把一个 int 类型的数据转为二进制字符串,Character.isLetter(),判断一个字符是否为字母等
4. 自动装箱和拆箱
2.2 装箱和拆箱
- 装箱(Boxing) :将基本数据类型 转换为对应的包装类对象 。分为手动装箱 和自动装箱。
java
public class Main {
public static void main(String[] args) {
int a = 10;
//装箱操作--手动装箱
Integer A11 = Integer.valueOf(a);
Integer A12 = new Integer(a);//这种创建新对象已经过时,但是可以用
//装箱操作--自动装箱
Integer A21 = a;
}
}- 拆箱(Unboxing) :将包装类对象 转换回基本数据类型 。分为手动拆箱 和自动拆箱。
java
public class Main {
public static void main(String[] args) {
Integer a = 10;
//拆箱操作--手动拆箱
int A = a.intValue();//
//拆箱操作--自动拆箱
int B = a;//编译器自动转换
}
}注意事项:
- 前面提到包装类允许有 null ,但是如果把包装类换成基本类型时,就会抛出异常NullPointerException 。
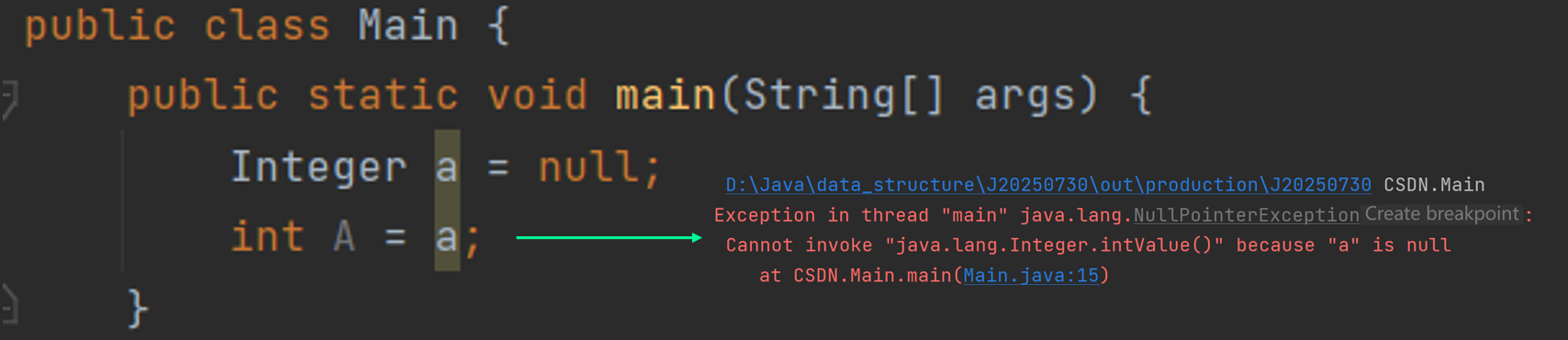
- 部分包装类(如
Integer)缓存-128 ~ 127的值,超出范围会新建对象:
观察以下代码:
java
public class Main {
public static void main(String[] args) {
Integer a = 100;
Integer b = 100;
Integer c = 200;
Integer d = 200;
System.out.println(a == b);//结果1:
System.out.println(c == d);//结果2:
System.out.println(a.equals(b));//结果3:
System.out.println(c.equals(d));//结果4:
}
}输出结果:
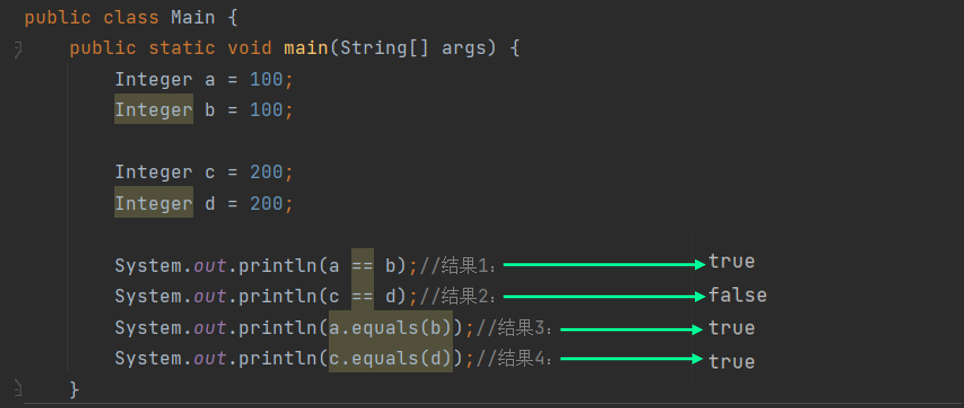
为什么 c 和 d 都等于200时,输出结果却是 false呢?这是因为Java 对 Integer 包装类设计了缓存机制 (范围默认是 -128~127 ),当超出这个范围后,就会new 一个新的对象,而对于对象的比较,不能用 == ,要用****equals() 或者对其拆箱再用 == 进行比较。
3. 初识泛型
3.1 认识泛型
关于泛型的概念,在《Java编程思想》中这样介绍:一般的类和方法,只能使用具体的类型,要么是基本类型,要么是自定义的类。如果要编写可以应用于多种类型的代码,这种刻板的限制对代码的束缚就会很大。也就是说,泛型的出现,是为了适用于许多种的类型。
当需要什么样的类型时,就传递什么类型即可,包括 Integer、Character 等,也可以是自定义的类,使用泛型,可以在编译时检查类型匹配,避免运行时发生异常ClassCastException
语法:
class 泛型名称 <类型形参列表> {
//使用的类型参数
}
比如在实现一个通用的哈希桶(在后面会学习到)时,就可以有以下代码:
java
public class HashBuck<K,V> {
static class Node<K, V> {
public K key;
public V val;
public Node<K, V> next;
public Node(K key , V val) {
this.key = key;
this.val = val;
}
}
//往后实现具体方法等....
}**泛型类用尖括号 <类型形参列表> 来表示,类型形参一般用大写字母表示,**常用的名称有:
- E:表示Element
- K:表示Key
- V:表示Value
- N:表示Number
- T:表示Type等
3.2 泛型类的使用
语法 :
泛型类<类型实参> 变量名;//定义一个泛型类引用
new 泛型类<类型实参>(构造方法实参);//实例化一个泛型类对象,实例化的泛型实参和构造方法可以没有
泛型类也是一个类,在使用泛型时要 new 一个新的对象。如
java
ArrayList<Integer> list = new ArrayList<>();3.3 泛型的编译
Java 泛型的核心在于编译时的类型检查 和运行时的类型擦除。
类型擦除的原则(和继承类似):
- 无边界类型参数
对于没有边界的泛型类(如<T>),在编译时都会默认上界是 Object 类,也就是上 T 全部变为Object ,因为 Object 类 是所有类的父类
- 有上界的类型参数
对于有上界的泛型类(如T extends Numbers),编译时 T 会替换成 Number。
- 泛型方法
编译后,方法签名中的
<T>被移除,参数和返回值的T替换为Object或上界。
java
// 源码(编译前)
public class Box<T> {
private T value;
public void set(T value) {
this.value = value;
}
public T get() {
return value;
}
}
// 字节码(编译后,等效代码)
public class Box {
private Object value; // T被擦除为Object
public void set(Object value) {
this.value = value;
}
public Object get() {
return value;
}
}因此,List<String>、<Integer>)将被替换为原始类型(Object 或指定的上界类型),运行时均为List.class。
3.4 通配符
通配符(?)是 Java 泛型中的一种特殊语法,用于增强泛型的灵活性,主要解决泛型类型在继承关系、未知类型、可以接收所有的泛型类型但又不希望他人随意修改场景下的匹配问题。
3.4.1 无界通配符<?>
表示未知类型,可以匹配任何的泛型类型,当方法需要接受任意类型的泛型对象但不关心具体类型时使用。
3.4.2 上界通配符 <? extends T>
表示**T 或其子类** ,用于放宽泛型的读取限制 ,当需要从泛型对象中安全读取数据 ,且数据是 T 的子类时使用。
3.4.3 下界通配符 <? super T>
表示**T 或其父类** ,用于放宽泛型的写入限制,当 需要向泛型对象中安全写入数据 ,且数据是 T 的父类。
何时使用上界/下界通配符?
需要读取数据时用
<? extends T>需要写入数据时用
<? super T>既读又写时用具体类型参数
<T>